
Abstract
It is difficult for underwater archaeologists to recover the fine details of a captured image on the seabed when the image quality worsens due to the presence of more noisy artefacts, a mismatched device colour map, and a blurry image. To resolve this problem, we present a machine learning-based image restoration model (ML-IRM) for improving the visual quality of underwater images that have been deteriorated. Using this model, a home-made bowl set-up is created in which a different liquid concentration is used to replicate seabed water variation, and an object is dipped, or a video is played behind the bowl to recognise the object texture captured image in high-resolution for training the image restoration model is proposed. Gaussian and bidirectional pre-processing filters are used to both the high and low frequency components of the training image, respectively. To improve the clarity of the high-frequency channel background, soft-thresholding decreases the presence of distracting artefacts. On the other hand, the ML-IRM model can effectively keep the object textures on a low frequency channel. Experiment findings show that the proposed ML-IRM model improves the quality of seabed images, eliminates colour mismatches, and allows for more detailed information extraction. Blue shadow, green shadow, hazy, and low light test samples are randomly selected from all five datasets including U45 [1], EUVP [2], DUIE [3], UIEB [4], UM-ImageNet [5], and the proposed model. Peak Signal to Noise Ratio (PSNR) and Structural Similarity Index (SSIM) are computed for each condition separately. We list the values of PSNR (at 16.99 dB, 15.96 dB, 18.09 dB, 15.67 dB, 9.39 dB, 17.98 dB, 19.32 dB, 14.27 dB, 12.07 dB, and 25.47 dB) and SSIM (at 0.52, 0.57, 0.33, 0.47, 0.44, and 0.23, respectively. Similarly, it demonstrates that the proposed ML-IRM achieves a satisfactory result in terms of colour correction and contrast adjustment when applied to the problem of improving underwater images captured in low light. To do so, high-resolution images were captured in two low-light conditions (after 6 p.m. and again at 6 a.m.) for the training image datasets, and the results of their observations were compared to those of other existing state-of-the-art-methods.
Keywords
Introduction
Ocean archaeologist investigates and observes most precious valuable objects present in the deep seabed surface which is periodically monitor with support of Autonomous Underwater Vehicles (AUVs) mounted by high-definition resolution cameras [1]. It is mainly used for several fields includes marine species migratory tracking, underwater cable and debris examination, underwater scene analysis, and human-robot collaboration [2]. However, AUVs suffers face a huge operating problem due to limited sight, light refraction, absorbent, and scattering properties despite the use of high-end cameras. The illustrative examples of visual actions include segmentation, classification, detection and tracking that are hampered by non-linear optical aberrations and distortions [3]. Real-time restoration of perceptual and statistical properties [15, 45] of distorted images is possible with fast and accurate image enhancement algorithms.
Unusual collections of non-linear light propagation variations exist in the underwater sea depth region, which causes visual distortions in the underwater sea depth region [4]. Because red wavelength is more absorbent in deeper water, the colour spectrum states that green or blue colour frequency has a higher degree of reflectivity than red wavelength [15]. In addition to this, images become low-contrast, hazy, and their colours get deteriorated when light scattering, and wavelength-dependent attenuation are present. Dehazing and colour correction models are well-structured to forecast features [5, 6], but it is extremely challenging to know the depth of the scene and maintain the visual quality of the underwater picture obtained in a variety of robotic applications.
An adequate approach uses a succession of bilateral and trilateral filters to minimise noisy artefacts and improve global contrast. No comprehensive research has been reported on large-scale unpaired underwater image training. To automatically filter out visual perception, a CNN-based model is preferable. A sequence of non-linear filters is learned using pairs of training data. Generative adversarial nets (GANs)-based models can train pixel-to-pixel mappings between distorted images and the enhanced images.
Challenges
There are many problems that can occur with an underwater image, such as colour casting issues, pixelated images, hazy effects on an image, shading and illuminance problems, and so on. This issue helps to improve the overall representation of the undersea environment. The purpose of image enhancement applied to an underwater scene is to restore the image’s quality, which has been diminished because of the dispersion of light. The surface reflects the sunlight, which is followed by reflections from the object to the camera. Because there is already light present, there is some light that is scattered. The quality of a photograph is diminished because of the way light scatters when it is captured underwater. When an image is captured in water, the light waves that propagate underwater are refracted and absorbed by the aquatic environment, which results in photos that have a hazy appearance. This is because water is a medium with a high density. Although there are many approaches like as colour correction, edge detection, and balancing of a white image, among others, it is still necessary to enhance an image of anything that is underwater.
Aim
To improve the visual quality of degraded underwater images by resolving issues that have accumulated in the image capture system, such as colour casting issues, pixelated images, hazy effects on an image, shading and illuminance issues.
Contributions
The following contributions are made as part of this work, and they are complemented by the proposed ML-IRM methods, which are listed below: The extract underwater seabed scenarios are recreated by the experimental set-up where four different colour shadows are observed by the self-made water tanks in which natural lighting is subjected to capture images of the four different light condition shadows such as blue, green, hazy, and low lighting. These extract underwater seabed scenarios are recreated by the experimental set-up where four different colour shadows are observed. In order to carry out appropriate colour correction as well as contrast modification across the entirety of the underwater images, the dilated RNN phase is extremely capable of retaining the best training samples. The separate channel is optimised for low frequency (LF) and high frequency (HF) to perform the denoising function with the assistance of two distinct filters, namely bilateral and gaussian, in that order. It has a strong potential to tolerate the noisy artefacts that are present in the acquired underwater images, and the creamily layers that are present in the dilated RNN promote the proper clearness of the noisy component in the LF and HF correspondingly. The textural details and contrast adjustment characteristic is readily recognised, and it is formulated to execute great colour correction, which is performed on the next coming image samples.
The rest of the sections of the paper’s structured as: Color correction and contrast adjustments have been viewed as key restrictions in recent work, and this is discussed in Section 2. Section 3 deals with the pipeline for preparing datasets; it mentions the need for publicly available datasets and provides a detailed description of the proposed methodology, which uses proper mathematical expressions to develop well-driven dilated RNN stages for textural and contrast adjustment characteristics. Using a variety of publicly available datasets and a performance evaluation of the proposed ML-IRM against existing state-of-the-art approaches for underwater image enhancement. Section 4 presents the experimental results that demonstrate the significant improvement that has been obtained. Section 5 concludes with a look ahead to what’s next.
Related works
Basics image enhancement approach
Fish species detection [7], historical item presence [8], and others, are some of the early methods that focus on improving the visual quality of an image. Image contrast, pixel intensity boosting, and saturation are used to enhance image quality, while a technique suggested by [9] is used to improve underwater images. Thus, numerous attempts to improve underwater images have been made. It is now possible to reduce image deterioration by combining colour correction and contrast adjustment to produce sharp, accurate, and color-balanced images with the use of frameworks mentioned in [10]. In addition to the development of numerous image pre-processing methods which mainly affect aerial dehazing principle to recover the deterioration of images, namely absorption and scattering features, which are derived from hazy images. This function is therefore re-created in the underwater captured image follows the calculation of detail and brightness as well as colour correction [11]. The development of [12] employing colour attenuation and various water models to extract more fine detail from a single degraded image. A simulation localization and mapping (SLAM)-based underwater degradation model was then proposed [13]. The dehazing approach of [14] can now be used in underwater settings because to its ability to handle two-color channels [15].
Aerial dehazing methods
Image dehazing methods try to restore a scene’s natural radiance intensity and rectify colour shifts produced by light scattering and absorption by water droplets and tiny particles [16, 17]. To begin the process of dehazing, multiple images are taken in various weather conditions and used as input to the picture pre-processing unit [18]. Dehazing was popularised by the introduction of the Dark Channel Prior (DCP), which can estimate a scene’s transmission map and atmospheric illumination, two essential qualities that are employed in the dehazing process, later on. According to several research [19, 20], this method is effective. Consequently, it is used in a wide range of undersea frameworks [21]. Recently, Convolution Neural Networks (CNNs) have been used to train systems that efficiently complete the dehazing/image recovery task [22–24]. These systems take a long time to tune, train, and evaluate the data they collect and the results they provide.
Visual perception and automatic color detection
An adequate approach [25, 26] uses a succession of bilateral and trilateral filters to minimise noisy artefacts and improve global contrast. The filtering process plays an important role in visual perception. Two methods have been developed [27] that integrates light propagation processes to minimise a specific distortion of underwater images in order to achieve better approximation. But before they can be employed effectively, these methods still require depth and optical measurements of the water body to be considered.
Many deep residual learning models for single picture enhancement have lately obtained outstanding results [28–30]. This can limit their ability to generalise, as they often use only distorted images for training pairs. In addition, no comprehensive research has been reported on large-scale unpaired underwater image training. For real-time visual augmentation, certain solutions failed to connect single-board robotic systems.
Single image enhancement has been exhausted, and a deep learning model with sufficient image datasets has now been developed. To automatically filter out visual perception, a CNN-based model is preferable [31]. A sequence of non-linear filters is learned using pairs of training data to surpass hand filtering in a reasonable number of cases.
Generative adversarial nets (GANs)-based models [32] have demonstrated tremendous success for style-transfer difficulties and for translating images one into the other [33]. Min-max strategy is employed in a two-player game in which the “generator” creates phoney images that appear to come from the genuine distribution to trick the “discriminator.” It works together to improve their ability to distinguish between real and bogus images simultaneously. For example, the earth-mover distance is used by Wasser stein GAN [34] to assess the distance between the data distribution and the model distribution. Later, energy based GANs [35] proposed to increase training stability by modelling the discriminator as an energy function, while a Least Squares GAN [36] tackles the issue of vanishing gradients by adopting a least square loss function for the discriminator. Conditions GANs [37] can train pixel-to-pixel mappings between distorted images and the enhanced images.
Low-light sensitive colour dispensing methods
As shown in the study [38], a black patch always emerges in low-light images that resembles haze when inverted. DCP-based dehazing is used to create haze-free image by examining the Laplacian distribution parameters in detail, as was explained earlier. As an alternative, [39] advocated for the use of a non-uniform lighting distribution model, which was then combined at many scales. According to [40], the highest local intensity in low-light images is solely dependent on the scene’s light source for maximum reflectance previously. The highest intensity in each colour channel is therefore estimated using an atmospheric lighting model and transmission map, which are both necessary prerequisites. Additional to this, the LIME framework for improving structural accuracy and smooth textural features is being created [41]. Using data-driven ways to improve low-light image quality has become increasingly common in recent years. Single-image low-light enhancement frameworks utilising CNNs were trained on composites of light/normal light pictures [42]. For this procedure, only the deteriorated photos are required.
Methodology
Preparation of high-resolution training dataset
The photos taken by the osteologists were captured with high-definition cameras that were coated with a double layer of glass to ensure their water resistance. The intensity of light propagation from the object is often modified by the presence of this double layer. Therefore, if an object is not clearly identifiable in the acquired image in order to uncover additional details, the image quality may be compromised. An abundance of online datasets makes it possible to explore scientific advancements in image enhancement in greater depth.
Specifically for the purpose of improving underwater images with colour correction and contrast adjustment, a dataset is constructed in this study and used to train our suggested methodology on these image samples. Three distinct liquid mixtures are used in the experimental setting to mimic the actual underwater image-capturing scenario. As a final step, an underwater video is placed behind the glass bowl to re-create the underwater bottom environment, and images are taken in the morning and evening at two precise times of the day. Because the colour space is 85% compatible with the public image dataset. Using this experimental set-up, we were able to collect additional information about the liquid characteristics, which we can use to better recognise the edges of objects and other moving object texture aspects.
As part of the process of capturing underwater images for the purposes of creating datasets and doing research, three different fish tanks are used to create three distinct colour shadows (blue, green, and hazy). The experiment is carried out in the morning and the evening to replicate the low-light scenario (6 a.m. and 6 p.m.).
According to the liquid colour shades in the fish tank, a week-long observation was made of the fishes’ activities and their interactions with each other. Using a high-definition camera and a video recorder, the photos are taken behind a glass bowl and used to construct a private image dataset. The captured images are replicate the image dataset available in public where they have used double protected underwater vehicle mounted HD cameras. Figure 1 depicts a selection of video clips from video records in which randomly choose 1 for experimental study.

Random colour shade videos play behind the bowl. (a) Blue shadow, (b) Green shadow, and (c) Hazy.
Using a Nikon D700 camera with a maximum resolution of 214 = 16384 pixels, a distinct database of high-definition image collections was constructed in this study. Extremely high pixel resolution can be achieved with a relatively small number of pixels. A low-light and a low-light scenario are both used to gather this dataset: one in typical low light (after 6 a.m. in the morning) and the other in low light (after 6 p.m. in the evening). In addition to the fact that three different liquid combinations are utilised to describe what it looks like when the colour degradation affects that are faced by underwater images are described. The target object is submerged in liquid mixtures in the crystalline glass bowl. We are interested in extracting object features’ textures without sacrificing their colour appearance or capacity to tell if an object is in motion or in standby mode. Using
In the dataset training and testing phases, the deep learning approach is fully deployed to remove dark and blurry effects from underwater images. For this purpose, we employ a dilated RNN network to find hidden information in the image’s textural features and then apply effective colour contrast adjustment in RBSC and GRU layers to enhance the image’s features. The dilated RNN network is trained using a labelled data set that includes the lhting conditions, colour class, and time stamp. Motion features are also incorporated so that the oect’s nature and texture can be discovered simultaneously.
Image datasets must be collected under two specific conditions: (i) all liquid mixtures must be captured without background motion and (ii) all liquid mixtures must be captured with background motion (Note: this includes both morning and evening sessions). By using a high-definition camera, the textural details are preserved despite the photographs having a low visual quality. Therefore, this dataset ensure that it contains images taken in various lighting environments.
Scattering in atmosphere
When a picture is taken in open space, the lightest is reflected to the camera, determining the brightness of the resulting image. Due to weather conditions and changes in light reflectance levels, some light samples could be scattered away. Mathematically, this phenomenon is handled [45] which is given by
Where, α is the attenuation co-efficient of the atmosphere and D x is the distance between object and camera.
Free space scattering mel is similar, but the key characteristic behaviour varies based on the light wavelength λ. The light is usually unable to reach the depths of the sea due to its great sensitivity in water. Using a camera flashlight to capture an image invariably results in a blurry or otherwise unsatisfactory image.a result, an image with a blue-green tint is captured [46].
Where, S λ (x, D x ) is the light strength after certain dtance isolation, S λ (x, 0) initial energy of the light source from its original position, and N λ (D x ) the normalized light energy.
To increase the overall visual quality of the image that w taken underwater, several image improvement techniques were applied to it. These approaches allowed for the extraction of more image detailing information, which was then used for in-depth research and observation. In recent times, automatic colour correction has been introduced with a reasonable minimization in the colour mismatch problem. It is rectified based on spatial and temporal space feature adjustment, which can support human visual perception for the purpose of better understanding t image detail. From [47] provides a description of the automatic colour equalisation (ACE) method, in which the required characteristic variation factor is extracted in detail, and the mhod mt be addressed through energy function correlation between the degraded image and the improving image. It can be described as
Where, I img (x) and I0 img (x) denotes the enhancing image and original degraded image, whose pixel coordinates are given as x and y, respectively. W is the weight function which is keep adjusting based on the relative distance changes exist between x and y. The intensity of subjected portion is formulated by the evaluating the slope function K slope .
On the other hand, the colour correction seems to have quite a few inconsistencies when applied to the underwater image. mainly because of the poor estimation of the colour correcting factor, which is generated from the local and global ACE characteristic. As a result, it possesses an adequate level of tolerance over the colour correction phenomena.
In this regard, a machine learning-based image restoration model (ML-IRM) is developed to boost visuality depth for more item detailing and to identify the textural era for future research. While estimating the degrading colour variation features, this mel does not make any physical assumptions. Textural features are seen in both the low- and high-frequency ranges of an object’s frequency range. Primitive channels for low and high frequency components should be separated initially in accordance with model ML-IRM. It is used to t Land HF channels, respectively, with gaussian and bidirectional filters. Allowing a soft thresholding on the HF component helps lessen the appearance of noisy artefacts in the edge and texture features of the underwater image. When the HF component is mixed with the LF component, it retains the necessary textural information. It’s also applied to the other LF component, and then colour correction is conducted to provide the guided image for proper RGB-to-HSI colour space transformation. Color adjustment in a target region is automatically resolved using a combination of gradient descent and pyramidal concepts.
The color adjustment is happened in the specific interval in the range (0,1) where actual energy function is modified which is given by
It is valid at the specific interval whose functional description is given as follows:
and I i img (x) = 0; if both s and i lies in the ierval less than 0, similarly, I s img (x) and I i img (x) = 1; if both s and i lies in the interval greater than 1, respectively.
Where, I g img (x) be the guided image representation f tolerating the RGB to HSI conversion image plane space. The soft thresholding is maintained individually for both the LF and HF channels to avoid the noisy bonding that created with the textural characteristic othe underwater image.
Mean and mean square error (MSE) are calculated for both LF and HF channels, respectively, in order to generate the guiding image. It is given in a mathematical form
Where, (f)
χ indicates the frequency of both LF and HF channels, χ
LF
and χ
HF
be the soft thresholding point is defined individually on the respective channels space. λ is the image dynamic factor is fixed to certain integer value say λ = 3. Therefore, guide image with proper color correction along the histogram equalization after soft thresholding is embedded in the LF and HF channels. The derived form of the color corrected guided image is computed as
After substation with Equation (5), positive and negative terms get adjusted toward the required color correction. That means, color variation factor is computed accordingly changes the color space of and I
i
img
(x)
from
The ML-IRM is used in conjunction with recurrent neural networks and an improved feature vectors for textural characteristic classifier to prevent these issues. It’s a method of deep learning that effectively retrieves spatial context. With different learning aorithms and skip connections, the new ML-IRM system is depicted in Fig. 2. RNN with residual block and dilation are the main components of this model. According to this, extract the local and global properties of the LF and HF channels. This feature is first used in an FC layer, then, it is sent into a softmax layer for further classification, where further classification is done based on the probability that each class will occur.
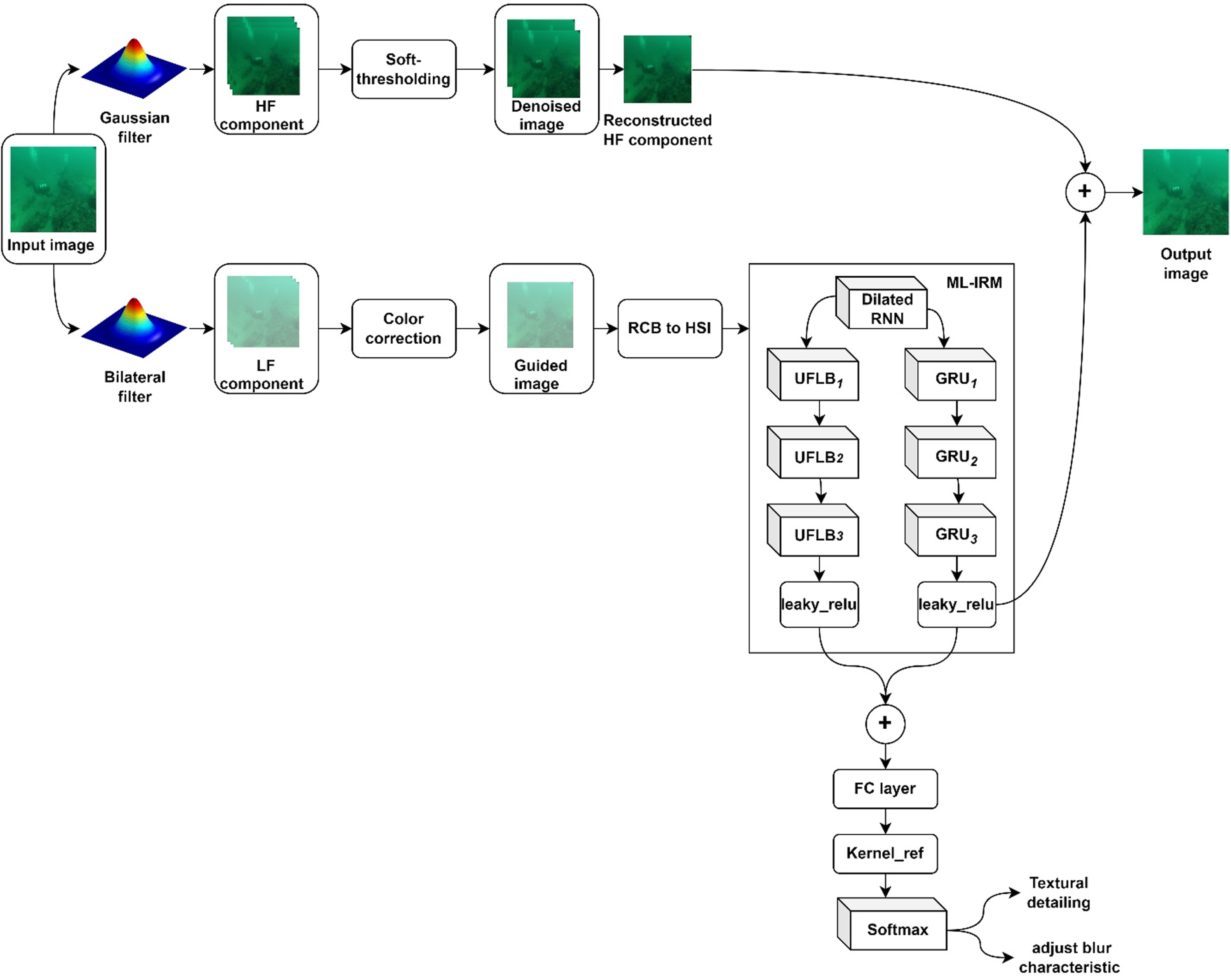
Operational flow of the proposed ML-IRM method.
Color correction factors, on the other hand, are always time-shifting in terms of their quantity. As a result of this change, a sequential module has been added that could potentially benefit from a network of gated recurrent units (GRUs). In the local and global mechanisms of the underwater photos, it is in charge of extracting the temporal information a improving the colour preservers. A multiple-learning (ML) technique is used to solve picture space interpretation, colour cues, and input correction by using the SC module in the residual block. Automatic learning of textural classification is supported by the fused layer, which is simply concentrate derived features. To confirm its accuracy in edge and textural colour cures and features, testing findings show that the proposed ML-IRM framework recognises these features with maximum accuracy.
All possible terms related to colour and contrast enhancement are included in S set ={ s1, s2, … , s t }, which is indicated as, which includes all possible terms related to colour and contrast enhancement for every pixel intendancy before the reconstructed image construction. After that, the GRUs uses a multiple learning (ML) strategy to extract spatial textural vectors by observing the weightage of each quantity for context-dependent characteristics. As a result, R out ={ r1, r2, … , r t } is used to signify UFLBs vectors after they have passed through the RBSC network and collected the sequential output. In the residual block of the ML approach, the skip connection (SC) module is used to compute space interpretation, colour cues, and input correction. After gathering data from both modules, a leaky_relu was used to ensure that the GRUs networks’ emotional cures were not possible. Softmax uses the fused layer to do self-learning by identifying diverse underwater objects based on simple concentration derived attributes.
Instead of standard CNNs, dilated RNNs are used in the proposed ML-IRM system. Feature extraction in a more thorough form necessitates a lot of repetition. RNN layers that have been dilated identify hidden textural feature information and so use effective colour contrast modification of the underwater image, which is further processed in both RBSCs and GRU layers to enhance features information. Thus, UFLBs are effectively utilised to enhance the LF component’s local features by inducing object recognition in order to extract accurate colour correction and distinguish object layer detailing that fits with the feature map. The enhanced feature set includes 3x3 dilation rates, as well as new weights and local networking. As a result, the leaky_relu activation function has more restored feature information, which may help prevent the vanishing gradient problem in the future. As a result, Eq. (6) estimates the RBSCs layer’s normalised feature extraction (1). There are three 3x3 RNN layers, followed by a normalised layer and the leaky_relu layer.
The ML learning mapping is denoted as I
g
: { x, z } → y, where x represents the original image domain, and z be the gaussian noise. The adverbial loss function in a condition [48] is given by
Where, G be the generator to tries minimum ψ χ LF (G, D) while the discriminator D tries to maximum it. Additionally, three more aspects of inclusion such as (i) global similarity, (ii) image content, and (iii) local texture information presents in the visually enhanced image quality for human perception.
To learn samples from the global similarity space, the objective formulation function includes an objective loss function that is essential [49, 50]. It is denoted as ψ1 which represents the blurring effects influence the color variation a contrast evolution on the object present in the underwater image.
The image enhancement is subjected with respect to similar content established over the required portion [51, 52]. The high-level fre extracted by the leaky_relu layer of the dilated RNN network. The content loss is formulated as
The Marko-patches are effectively adjusting the color correction over low and high frequency in the adversarial fashion [49].
RBSC configuration
The proposed ML-IRM architecture makes use of a single dilated RNN and a skip connection function to constantly extract features until the anticipated aim is achieved. Hidden feature information can be discovered accurately and without affecting the process of overlaying layers, according to this proposed paradigm. Because of this, it’s referred to as feature mapping. In the fusion state, learning remedies can be achieved by extracting the required feature from raw features. A few complexity inspections may be required; however, this is reduced using a skip connection between the input and residual unit which is given by
After that, the output of the RBSC is generated by making use of the Equation (15).
A layer of output and a layer of input are used to represent the dilated RNN features in the equations above. Where Φ denotes the ML-IRM framework’s activation function, and Bx,y be the associated bias reflects weights Wx,y values being updated. After the fusion process is completed, a features vector is generated and given to the FC layer for the purpose of accurately identifying the textures of objects.
Global feature vectors can be extracted using gated recurrent units in a separate module (GRUs). It uses a multiple learning (ML) approach to extract spatial contextual information vectors by observing long-term dependencies. In other words, GRUs uses limited memory space for weights updates in the enhanced underwater images and learns the feature from partial sequential data. When the candidate’s (H
x
) indication is activated and its prior function is interpolated, it is denoted as
As a weight update status, the activation in the gate is presented as
Finally, weight updating is used to compute the GRUs candidate activation following the changes as mentioned in Equation (18).
Where, r z is reset gate is multiplied by preceding agreed gate in element-wise multiplication in the above equation. So, it can change how features are extracted and how they are predicted. The formula below is a good fit for calculating the goal value. A new GRUs reset gate incorporates short-term GRUs layer dependencies into its design. Because of this, it can be used for a lengthy period.
Algorithm: 1 Pseudocode of proposed ML-IRM
The proposed ML-IRM outperforms existing approaches in terms of colour and contrast correction for the underwater images are tested. For the first time, self-teaching datasets for enhanced extraction of textural information from low-light underwater images have been created using this strategy. Because the developed image dataset s high similarity index to the publicly available image datasets, such as U45 [8], EUVP [16], DUIE [22], UIEB [26], and UM-ImageNet [28], in which the performance evaluation of the proposed ML-IRM is compared with existing datasets, it is necessary to ensure that the problem acute in low light imes iprecisely addressed. The following point related to dataset description are given as
Result and discussion
In this section, first address the denoising effects of the proposed ML-IRM by varying the characteristics factors. Then, focus on the qualitive as well as quantitative demonstration over the superiority of the proposed ML-IRM outcomes as compared with existing state-of-art-methods. Finally, we have tested the proposed ML-IRM performance on a variety of publicly available image datasets, including: U45 [8], EUVP [16], DUIE [22], UIEB [26], and UM-ImageNet [28], respectively.
ML-IRM performance evaluation
In this subsection, the denoising effects of the proposed ML-IRM is addressed by varying the characteristics factors of α, β, σ especially for the LF channels where actual object detailing is present. After converted into HIS color space, enhancement operation is directly influencing the α factor. That implies, whenever α varying form too low value into pre-defined maximum limit (i.e., 0.05 to 0.5). The image enhancement is significantly improving as linearly increases the α profile range. While doing this variation, other factors are remained fixed. Even, if the α is in too low value say 0.05, the contrast is maintained as maximum without losing its textural property. It is observed that the whenever α goes to high range, color enhancement is achieved but it seems to be unnatural. According to [12], α = 0.25 is the point where better image enhancement is obtained. But the proposed ML-IRM is reached reasonable image enhancement outcome even beyond the specified point. This is happened due to selection of best correlated features extracted from ery iteration of the image enhancement process.
Similarly, now, examine the unnatural color enhancement at high value of α range. This problem is resolved with help of β, since it is concentrating on increases the textural contrast ability up to certain point. The proposed ML-IRM is withstanding this ability as compared to [12], as a part of this, hazy effects are removed at maximum where the contrast factor is not disturbing the color enhancement at maximum value of α range. On the other hand, weight coefficient is sufficient to maintain global features which is highly reflected in the image enhancement. It is evidently shown in Table 1.
Evaluate the ML-IRM color adjustment with contrast maintained at high value of α > 0.25 by varying β and σ, respectively
Evaluate the ML-IRM color adjustment with contrast maintained at high value of α > 0.25 by varying β and σ, respectively

After evaluating the ML-IRM color adjustment with contrast preservation, now estimate the noise immunity profile. Typically, undesirable artefacts are removed in the denoising phase before the actual producer begins the ML-IRM process. LF and HF components are processed on distinct channels in our model. As a result, these two components display the edge details and original content information separately when capturing underwater image, the presence of a noisy occupant is always accompanied. HF component reconstruction is greatly aided by using gaussian filtering to improve the soft thresholding point. In the LF component, a bilateral filtering is used to enhance the image. To ensure that all textual information is preserved in this LF component, particular attention is paid to the LF component by ensuring that all noise is removed.
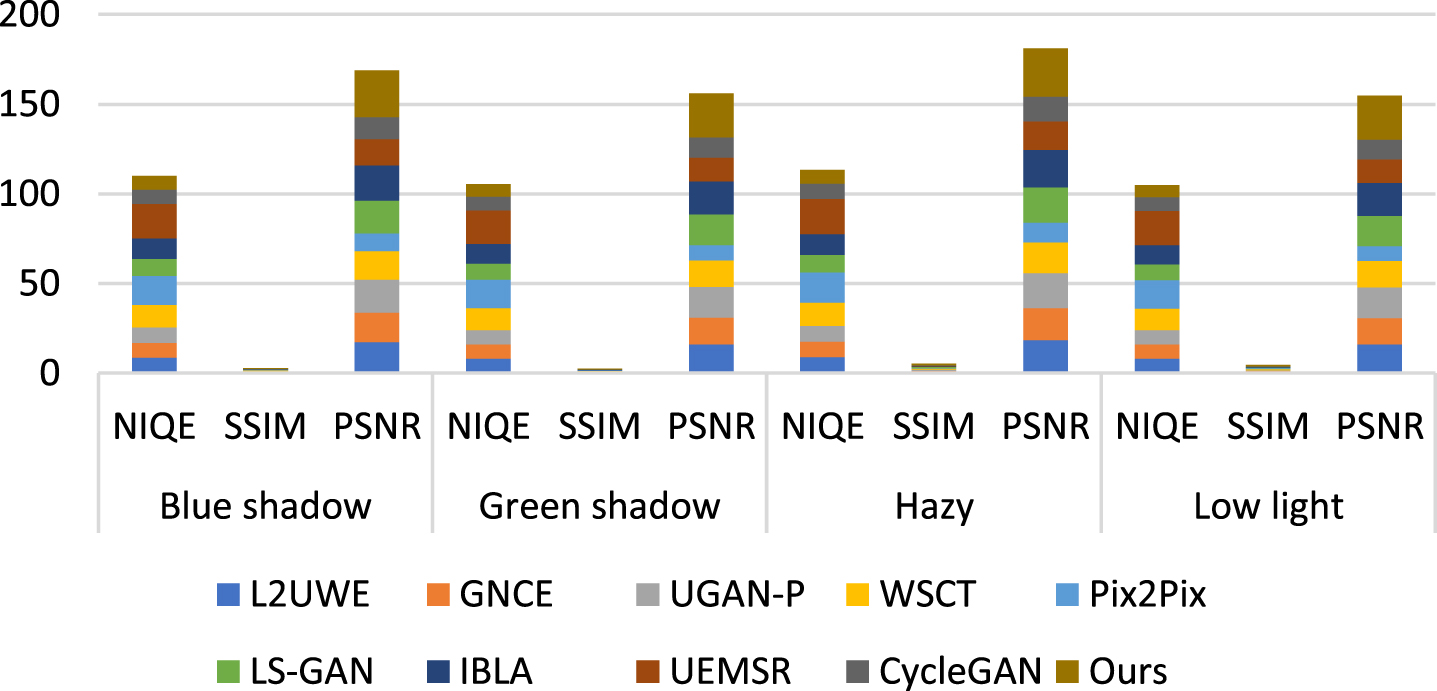
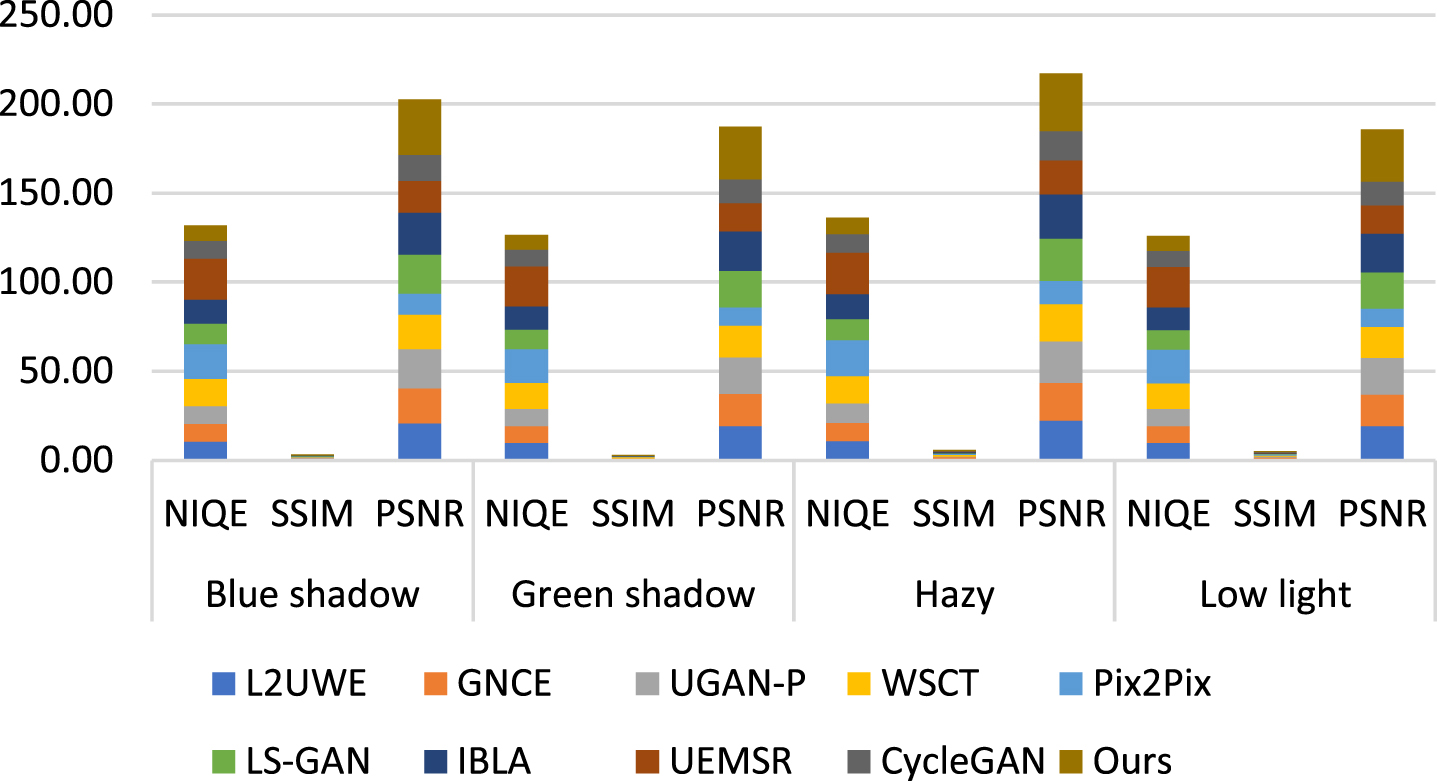
The proposed ML-IRM is influence the RGB to HSI conversion which is supported to create guided image for removing the artifices appear in the LF component. It achieved reasonable better outcome as compared to existing state-of-art-methods includes L2UWE [30], GNCE [40], UGAN-P [15], WSCT [7], Pix2Pix [25], LS-GAN [32], IBLA [20], UEMSR [33], and CycleGAN [6], respectively. Tables 2–5 clearly shows the textual perception accuracy of the proposed ML-IRM as compared other existing methods. Peak Signal to Noise Ratio (PSNR) and Structural Similarity Index (SSIM) are computed for blue shadow, green shadow, hazy and low light test samples respectively. It respective PSNR and SSIM are clearly given in the Tables 2–5 (a-i) for ensuring that the proposed ML-IRM achieved reasonable better results as compared to other methods.
The proposed ML-IRM edge perception profile compared to state-of-the-art over blue shadow image
The proposed ML-IRM edge perception profile compared to state-of-the-art over blue shadow image

The proposed ML-IRM edge perception profile compared to state-of-the-art over green shadow image

The proposed ML-IRM edge perception profile compared to state-of-the-art over Hazy image

The proposed ML-IRM edge perception profile compared to state-of-the-art over Low light image

The qualitative analysis of the proposed ML-IRM with various scenarios is investigated in this subsection. That is, three distinct fish tanks are used to create three distinct colour shadows (blue, green, and hazy) that simulate the colour fluctuation of the undersea seabed when photographing for dataset development and investigation. The experiment is carried out at 6 a.m. to simulate low light. and 6 p.m. Through its simulation results, we can see that the ML-IRM contributes significantly to colour correction and contrast adjustment. The progression of improvement in the image processing phases is depicted in Fig. 3. Infracts’ pre-processing filters are extremely effective at removing all external artefacts from underwater images. Color correction can be improved even further by addressing each colour channel space separately with two distinct channels. Color correction can be performed using the LF and HF channels, which have a high potential for preserving the ability to detect objects on the underwater image. The experimental setup mimics the undersea bottom environment. Because it is difficult to achieve more precise results in colour correction and contrast adjustment by training the model on an existing dataset. For the time being, we have a higher-resolution, more textured dataset with which to conduct additional colour space analysis and arrive at a workable solution via the extraction of an appropriate training sample.
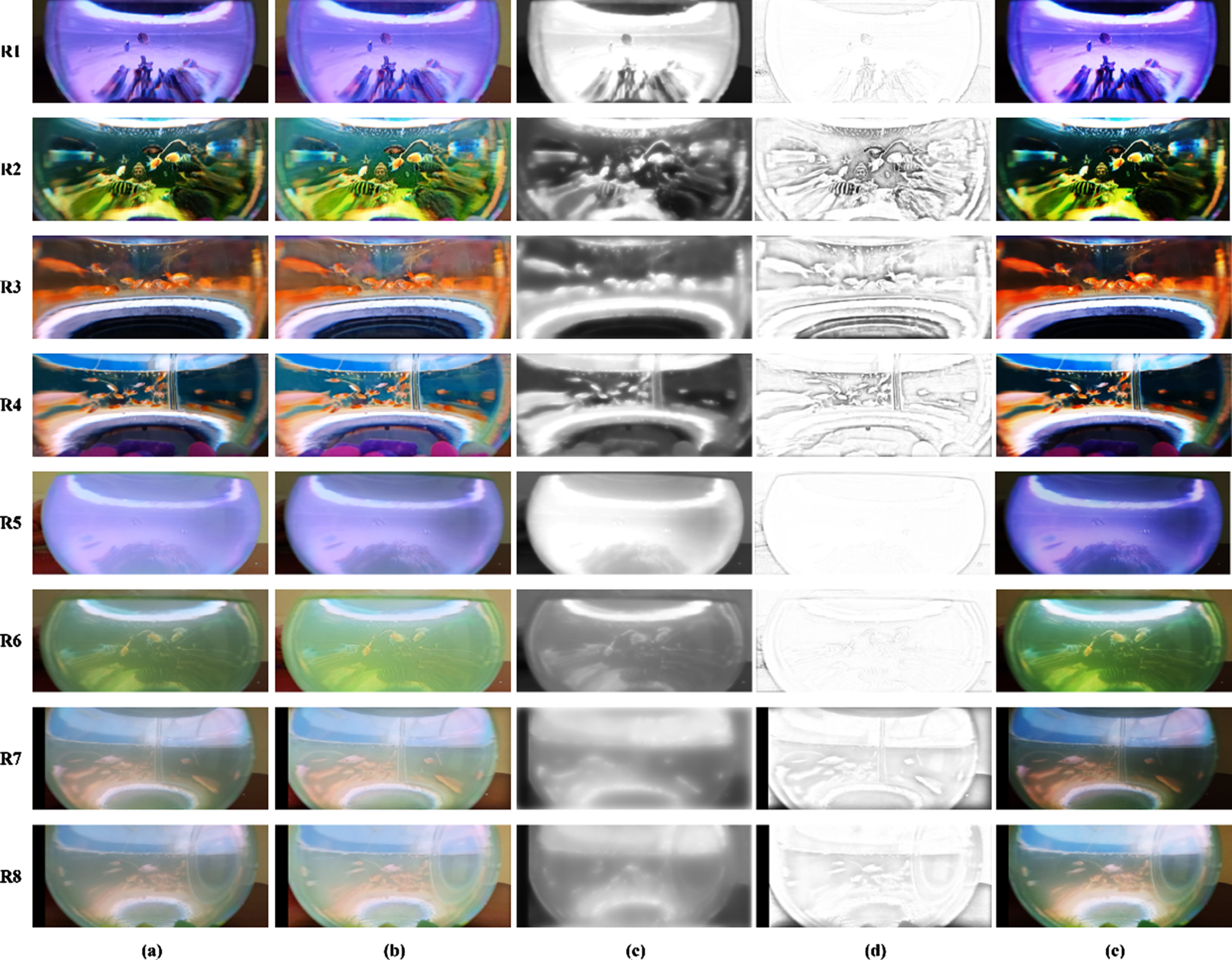
Image color correction and contrast enhancement of the proposed ML-IRM. (a) Original image, (b) Gaussian filtering, (c) HF component after soft thresholding, (d) LF component after influence the guided image (RGB to HSI space), and (e) Enhanced image. Note: (R1 to R4) represents the image captured after 6 a.m in morning where observe four different color shadows namely blue, green, hazy, and Low-light conditions. Similarly, (R5 to R8) represents the image captured after 6 p.m in evening where observe four different color shadows namely blue, green, hazy, and Low-light conditions.
The image in Fig. 3 (R1 to R4) and (R5 to R8) shows four different hue shadows: blue, green, hazy, and low-light circumstances can be observed after 6 a.m and 6 p.m, respectively which indicate the image captured pattern. Because the SSIM for the colour space is high, these datasets may yield a more realistic solution. Dilated RNNs are excellent at training features extracted from training photos to improve future images. Furthermore, you should determine why the extra artifice exists so that it can be removed in the next iteration. Finally, by extracting more textural details, the overall visibility of the image is improved. The qualitative analysis on different dataset images is available in public is tested with our proposed ML-IRM to show the better improvement is reached as compared with existing methods. Figure 4 shows the results of testing the proposed ML-IRM on several datasets. Using a random number generator, the odd rows (1, 3, 5, and 7 in the example above) are made up of test images with blue shadow, green shadow, haze, and low light. Furthermore, each of the even-numbered rows (2,4,6, and 8) is the enhanced image after correcting the colour and contrast of hazy and low-light test photographs.

Comparative test results of the proposed ML-IRM with respect to the different dataset. The odd number of rows (R1, R3, R5, and R7) be the random selection of blue shadow, green shadow, hazy, and low-light test images, respectively. Similarly, the even number of rows (R2, R4, R6, and R8) be the enhanced image after done the color and contrast correction of blue shadow, green shadow, hazy, and low-light test images, respectively. Note: (a) U45-dataset, (b) EUVP-dataset, (c) DUIE-dataset, (d) UIEB-dataset, and (e) UW-ImageNet-dataset.
The proposed ML-IRM is effectively retained the color correction factor which implies any additional artifices are not induced in the enhanced images. Because the textural features of both LF and HF are kept above the soft thresholding, the colour space characteristic is retained well across the distinct colour shadows. As a result, even after denoising, the colour space does not vary greatly, indicating that the enlarged image is visually good, and contrast adjustment provides clear vision of the object under observation and research. Tables 6–10 evidently proved that the proposed ML-IRM is reached reasonable result towards color correction and contrast adjustment over the low-light underwater image enhancement. That implies, the PSNR and SSIM are evaluated for randomly selected image from all five dataset includes U45 [1], EUVP [2], DUIE [3], UIEB [4], and UM-ImageNet [5], respectively.
U45-dataset comparisons (the best result is in bold) qualitatively
EUVP-dataset comparisons (the best result is in bold) qualitatively
DUIE-dataset comparisons (the best result is in bold) qualitatively
UIEB-dataset comparisons (the best result is in bold) qualitatively
UW-ImageNet-dataset comparisons (the best result is in bold) qualitatively
It is clearly given the PSNR and SSIM value individual for methods subjected for this study, whose state-of-art-methods such as L2UWE [30], GNCE [40], UGAN-P [15], WSCT [7], Pix2Pix [25], LS-GAN [32], IBLA [20], UEMSR [33], and CycleGAN [6], respectively. Color correction and contrast adjustment are clearly covered in the Figs. 5–9, respectively, for each of the methods.
IQA U45-dataset image colour correction and visual enhancement test results.
IQA EUVP- dataset image colour correction and visual enhancement test results.
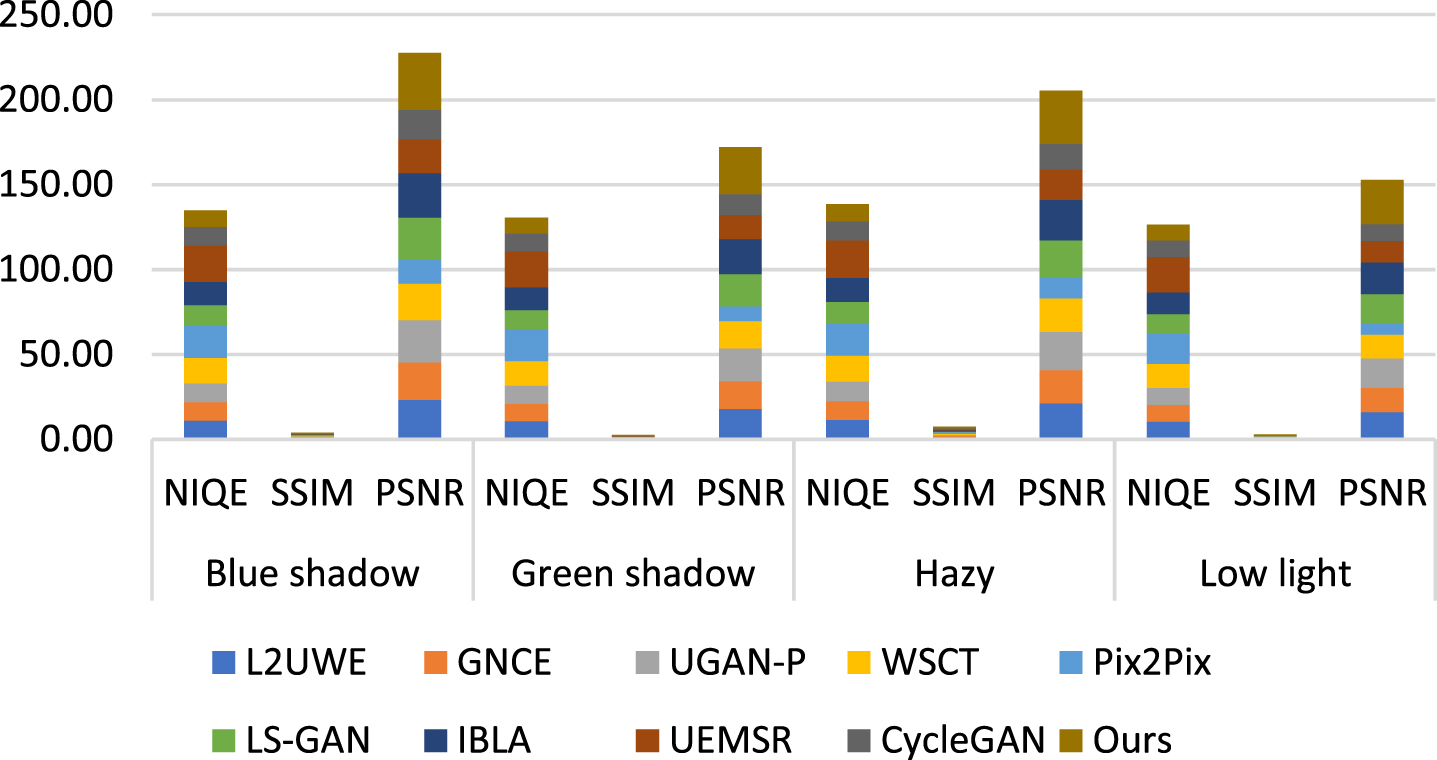
IQA DUIE-dataset image colour correction and visual enhancement test results.

IQA UIEB-dataset image colour correction and visual enhancement test results.
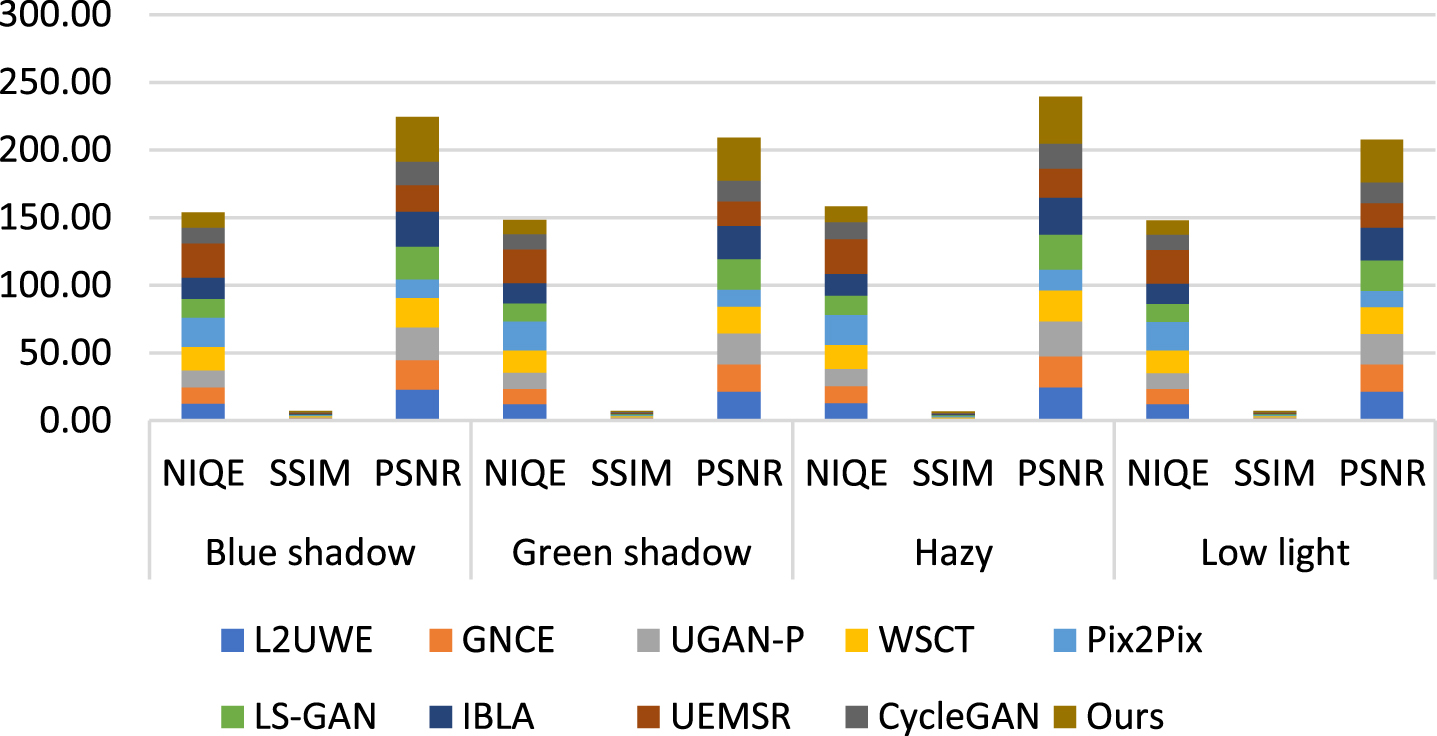
IQA UW-ImageNet-dataset image colour correction and visual enhancement test results.
Tables 11–15 show the evaluation results related with Fig. 10 Each row’s best score has been highlighted in bold. In most circumstances, our ML-IRM surpasses the competition. WSCT [7] and L2UWE [30] scores are both lesser than 0.65 for the various types of degraded photos are tested. The more steady and excellent scores of UEMSR [33] and Cycle GAN [6] did not change our method’s top ranking, however. In our subjective evaluation, we found that the suggested technique considerably enhances the contrast and visibility of the deteriorated image, while also restoring more vivid colour. [40, UGAN-P 15], LS-GAN [32], IBLA [20]. We conducted a larger test utilising 300 randomly selected degraded photos from the underwater benchmark dataset [42] to strengthen the validity of our initial findings. Our ML-IRM is shown in Tables 11–15, with average values of GNCE (40), IBLA (20), IBLA (32), and IBLA (40) for the five approaches examined.
ML-ideal IRM’s scores show that it is more robust than the other techniques, again proving its superiority. Our findings prove the proposed approach to be far superior.
U45-data comparisons (the best result is in bold) quantitatively
U45-data comparisons (the best result is in bold) quantitatively
EUVP-dataset comparisons (the best result is in bold) quantitatively
DUIE-dataset comparisons (the best result is in bold) quantitatively
UIEB-dataset comparisons (the best result is in bold) quantitatively
UW-ImageNet dataset comparisons (the best result is in bold) quantitatively
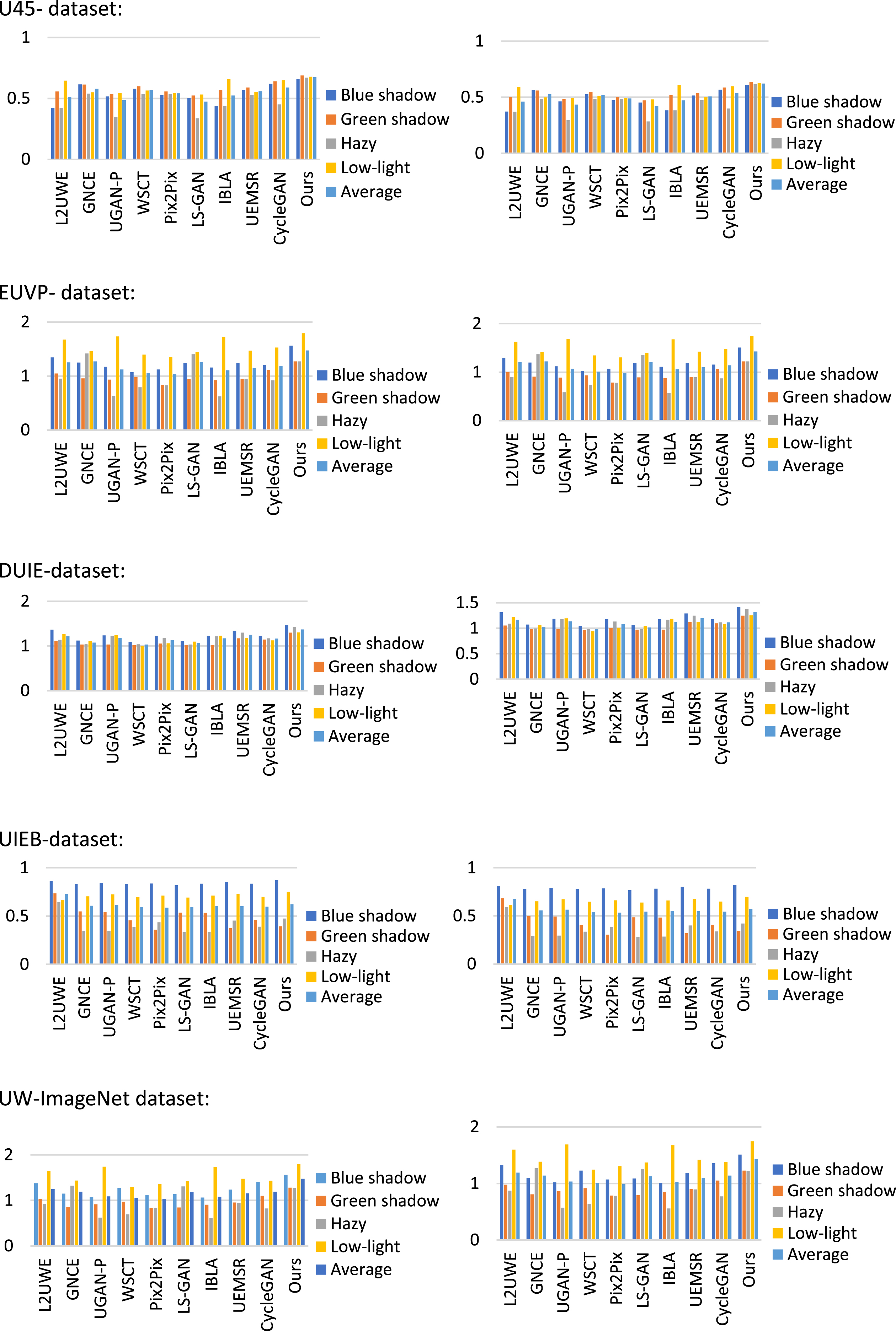
Performance evaluation of comparing image enhancement of proposed ML-IRM with other state-of-art-methods.
The ML-IRM approach for underwater image enhancement was introduced in this study, where the proper selection of behavioural factors is used to alter the underwater image’s characteristic qualities, such as colour correction and contrast adjustment. The experimental set-up has recreated underwater seabed settings by using self-made water tanks with natural illumination to capture photographs of blue, green, hazy, and low lighting shadows. To carry out appropriate colour correction as well as contrast modification across the entirety of the underwater images, the dilated RNN phase is extremely capable of retaining the best training samples. It has a strong potential to tolerate the noisy artefacts that are present in the acquired underwater images, and the creamily layers that are present in the dilated RNN promote the proper clearness of the noisy component in the LF and HF correspondingly. The textural details and contrast adjustment characteristic is readily recognised, and it is formulated to execute great colour correction, which is performed on the next coming image samples. The proposed ML-IRM is achieved reasonable better results as compared existing methods. Our ML-IRM scores are above 0.6 for damaged images as compared to L2UWE [30] and WSCT [7] respectively. Similar, our method is achieved the greatest score in UEMSR [33] and Cycle GAN [6] due to its stability and good scores. The best GNCE [40], UGAN-P [15], LS-GAN [32], and IBLA [20] demonstrate that the proposed technique may greatly increase contrast and visibility of degraded image, while recovering more vivid colour. To make our experimental results more believable, we have evaluated around 300 degraded underwater benchmark photographs from available datasets. The average GNCE [40], UGAN-P [15], LS-GAN [32], and IBLA [20] values of these five approaches are significantly lower than our ML-IRM. Again, ideal scores haven been proven the proposed ML-IRM method’s superiority. PSNR and SSIM were computed separately for blue shadow, green shadow, hazy, and low light test samples drawn at random from all five datasets, which include U45 [1], EUVP [2], DUIE [3], UIEB [4], UM-ImageNet [5], and proposed model. PSNR (16.99 dB, 15.96 dB, 18.09 dB, 15.67 dB, 9.39 dB, 17.98 dB, 19.32 dB, 14.27 dB, 12.07 dB, and 25.47 dB) and SSIM (0.52, 0.57, 0.33, 0.47, 0.44, 0.23, 0.28, 0.13, 0.16, and 0.75) are evaluated and the values are listed sequentially as per our reference order as L2UWE [30], GNCE [40], UGAN-P [15], WSCT [7], Pix2Pix [25], LS-GAN [32], IBLA [20], UEMSR [33], CycleGAN [6], and ML-IRM [proposed], respectively. Similarly, it was demonstrated that the proposed ML-IRM achieved a reasonable result for colour correction and contrast adjustment in low-light underwater image enhancement. For that, high-resolution images are taken in two different lighting scenarios: one in regular low light (after 6 p.m. in the evening) and another in low light (after 6 a.m. in the morning), and the observation results are compared with other existing state-of-the-art-methods.