
Abstract
In the past few years, due to the increased usage of internet, smartphones, sensors and digital cameras, more than a million images are generated and uploaded daily on social media platforms. The massive generation of such multimedia contents has resulted in an exponential growth in the stored and shared data. Certain ever-growing image repositories, consisting of medical images, satellites images, surveillance footages, military reconnaissance, fingerprints and scientific data etc., has increased the motivation for developing robust and efficient search methods for image retrieval as per user requirements. Hence, it is need of the hour to search and retrieve relevant images efficiently and with good accuracy. The current research focuses on Content-based Image Retrieval (CBIR) and explores well-known transfer learning-based classifiers such as VGG16, VGG19, EfficientNetB0, ResNet50 and their variants. These deep transfer leaners are trained on three benchmark image datasets i.e., CIFAR-10, CIFAR-100 and CINIC-10 containing 10, 100, and 10 classes respectively. In total 16 customized models are evaluated on these benchmark datasets and 96% accuracy is achieved for CIFAR-10 while 83% accuracy is achieved for CIFAR-100.
Introduction
Image retrieval is a well-researched problem of image matching where similar images are retrieved from a database as a result of some query image [1, 2]. With the development of the Internet era, image data is increasing, and image retrieval is widely used in the target recognition, photo filtering, and other scenarios. As the use of images has drastically increased in the last decade [1, 3–5], so more efficient and secured image retrieval models are required [2].
It is very important to improve the efficiency of image retrieval methods. It is estimated that over 380 billion photos were captured in the past 12 months, which is 10% of all the photos ever taken by humans. Data searching and content retrieval are major challenges from tremendous data collection [6]. content-based image retrieval (CBIR) has many applications in computer vision and artificial intelligence, it also plays a vital role in medical imaging. Different social network platforms use different methods for CBIR [6, 7]. In the field of content-based image retrieval “semantic gap” is considered a big challenge. It is the difference between the features extracted by the machines and features that humans can perceive [8].
The content-based image retrieval (CBIR) is also known as Query-based Image Retrieval (QBIR). This is a way of querying image databases. It uses the properties of the images as search terms to query the database and returns the images that share the same or similar visual properties. This method does not require the use of metadata associated with the image such as tags or descriptions. In general, the similarity of the query image’s representative features to those of the dataset photos is used to rank the retrieved [9]. Before CBIR, the only way to search the image databases was using text-based image retrieval [10]. In text-based image retrieval, the database contains photos that are annotated with a variety of descriptions and tags. So the user has to use those tags and descriptions to retrieve the photos that are similar to the search queries. This method has many limitations such as it being labor intensive and imprecise, the user has to know about exact tags [10].
Generally, there are two main methods that are used for efficient CBIR, one is using a hand-crafted feature vector descriptor and the second is based on distance metric learning [6, 11]. The performance of any CBIR approach is based on different attributes such as the similarity-based CBIR systems are highly dependent on the number of relevant images that are related to the content [12]. Deep learning models outperform other state-of-the-art image retrieval methods, they perform feature extraction implicitly in self-learning. CBIR systems based on deep learning methods have their own challenges and problems such as they are computationally very expensive, require domain expert persons, and a lot of annotated data is necessary to train the model [13, 14]. Transfer learning has been widely used to overcome the major issues in using deep learning models. Training and deep convolutional neural network (CNN) model from the scratch, transfer learning provides a good solution to using a pretrained model and only fine-tuning some upper layers for some new data [15–17].
The performance of a CBIR system mainly depends on the following two factors:
Test classification accuracy
CBIR models can be evaluated using the model’s calculated weights for the testing data and analyze the classification result using the test accuracy. After that these calculated weights are used to extract the features from images. Later the images are retrieved on the basis of the similarity between the features of the query images and the images of the database. So classification accuracy plays a very crucial role in deciding the retrieval results.
Speed of image retrieval
The efficiency of a CBIR also depends on the retrieval speed of the images. A system should immediately respond to a request and instantly retrieved the highly relevant images against a given query image.
The purpose of this research work is to analyze and assess state-of-the-art deep CNN models that are pretrained on some large datasets and could be used using transfer learning. In this research, different pretrained CNN models and their variants are used for Content-Based Image Retrieval. The effect of fine-tuning these deep CNN models using transfer learning has been extensively examined to infer useful findings for future research in the same area. Different models are used and many experiments are performed to deeply analyze the impact of changing layers and hyperparameters values on the performance of image retrieval. This research work will also provide an overview of the CBIR framework, current high-level feature extraction approaches, similarity measures, and a comparative analysis of different deep CNN models for efficient and accurate CBIR. This paper makes the following research contributions: Comparing and analyzing the performance of 16 variations of deep transfer learners for image retrieval using contents taken from images. Improving the accuracy of CBIR system up till 96.03% for 10 classes For multiclass classification, proposing a CBIR system that can classify 100 classes with 83.05% accuracy. Increasing the accuracy of CBIR system on two benchmark datasets i.e, CIFAR-10 and CIFAR-100 by 1.03% and 3.03% respectively. Training deep learners on an augmented unprecedented datasets i.e., CINIC-10 for CBIR system and achieving 96% accuracy. A deep insight into transfer learning-based CNN models for the Content-Based Image Retrieval systems. An analysis of efficient fine-tuning of the pretrained models, considering time complexity. Different experiments for avoiding the overfitting of models during training and analyzing the effect of preprocessing and augmentation techniques. A deep insight into the impact of hyperparameters over deep transfer learners.
The remaining paper is organized as follows: Section II describes the background and existing work done already in the same area. Section III of the paper, explains the methodology of the proposed method in detail and also explains the workflow of the CBIR system. In the next section IV, extensive experiments are performed to validate the results, and comparisons of different state-of-the-art deep CNN models are shown using transfer learning. Section V and VI describe the discussion and conclusion respectively.
Literature review
As image-based query searching is more efficient and convenient, a lot of research has been done in improving the performance of image retrieval from a database using different approaches [7, 10–12]. This section is worth mentioning previous work which is done in CBIR and it can be divided into machine learning, Deep CNN, and Transfer learning-based methods.
Machine learning methods
K-nearest neighbours (KNN) and BayesNet
In [18] a CBIR technique is proposed by Kumar et. al., they use two common methods named SIFT and ORB for the feature extraction. The SIFT method is used as a features recognizer and descriptor for an image. The technique of ORB uses the FAST and BRIEF as key points detector. For data analysis, K-means clustering is used, it generates the total number of clusters by utilizing a descriptor vector. The length of the feature vector is decreased to increase the performance and efficiency of the CBIR by deploying the Linear Programming Problems (LPP) technique. K-NN and BayesNet are used to perform the classification task. To evaluate the system performance the dataset named Wang is used during the experiments. The dataset contains 10 classes and each class has 100 images. There is a total of 1000 images in the dataset. The evaluation results show that the proposed image retrieval system has achieved a maximum precision of 0.889.
Deep CNN models
Deep learning methods are also used by different researchers [19, 20], to have more efficient and accurate CBIR systems. A few well-known CNN models are VGGNet [21], VGG16 [22], VGG19 [23], ResNet50 [24], ResNet18 [25], AlexNet [26], MobileNet [27], EfficientNet [28], Inception [29], and YOLO [30], and many more. These deep CNN models are used for efficient image retrieval [6, 7]. Different similarity measures have been used (cosine similarity, TD-IDF, and Euclidean distance) to measure the performance of those CBIR systems [31].
In [32] a TF-IDF-based methodology that utilized deep CNN architecture for the CBIR system was proposed in 2018 by Kondylidis et al. Term frequency and Inverse-document-frequency weighting scheme are introduced along with the CNN model. Initially VGG16 [22] based CNN model is used and then the concept of TF-IDF is introduced in this model. The trained filters of CNN are used as the visual detectors of the words. The filters of convolutional layers are used to activate the various visual patterns. The activations of all filters are used to get the information regarding the degree of existing visual patterns that filters received during the training process and these activations are considered as term frequency.
The technique named Pseudo Relevance Feedback is utilized for the purpose of query expansion. The proposed scheme [31] is tested using four different datasets named Oxford, Paris, Inria-holidays, and UkBench. During the training phase, the optimization problem is solved using gradient descent and regression using Euclidean loss. The bicubic interpolation method is used in the activation map resizing to increase the uniformity of the visual results. The experimental results show that the Paris-6k dataset produces the highest Mean Average Precision (MAP) of 0.9757.
In [33] the idea of a novel hybrid CBIR system is proposed by Jammula et al. in 2021. In this system visual contents of an image are used to find an image from a large dataset according to the user’s needs and interests. It is able to extract the important image features automatically. To resolve the problem of semantic gap in the images a machine learning-based method named Principal component analysis (PCA) is used. The CNN model is used for image retrieval. PCA is used for the salient feature extraction from the images. The Euclidean distance formula is used to measure the distance between the feature vectors of the query image and the images of the database. The Experimental results on various image categories show that the proposed methodology named DL-CNN-ML outperforms the previously published CBIR methodologies having machine learning and CNN in terms of mean average precision, mean average recall, and F-score values. The proposed model is able to achieve the mean average precision = 0.945, F1-score value = 0.9323, and mean average recall = 0.92.
In [34] a classification method for the diagnosis of pneumonia disease from the lungs using the chest X-ray images is proposed. They use a deep belief network for feature extraction. This method opens new directions in the field of CBIR. Similarly, another research is performed by Rajasenbagam et al. [35], they propose a pneumonia detection method using X-ray images. The size of the X-ray images in the dataset is limited. It contains a total of 12,000 photos of infected and healthy chest X-rays of people. During the training phase of the model total of 7000 images are utilized and the test set contained a total of 200 images. The method of data augmentation is used to enhance the size of the dataset by increasing the number of images in all categories. A pre-trained model named VGG19 is utilized for pneumonia infection detection with a few modifications. This technique used the metadata and contents of the images. A comparative analysis is performed to evaluate the proposed model named deep CNN with the other transfer learning-based models like VGG16, AlexNet, and Inception. This deep CNN model is able to attain superior accuracy of 99.34 in unseen testing X-ray images.
In [34] a novel method for CBIR using the deep belief network (DBN) is introduced by Saritha et al. It is used as a feature extractor and classifier. The DBN contains multilevel non-linear transformers like merging the multiple neural networks together. It can process the unsupervised data which can overcome the necessity of labeled data for the other deep learning-based model. The sole purpose of their methodology is to extract the important features at a high-level abstraction method. The DBN generates a large dataset for feature extraction and provides good classification results to get effective and smooth content extraction. The image dataset is preprocessed by selection removal and after extracting the features like image histogram, texture, edges, colors, etc, are stored as signature files. The experimental results show that the system has achieved an accuracy of 0.98 using a small dataset containing only 1000 images. For the large dataset containing images of more than 10,000, the accuracy is calculated as 0.96.
Transfer learning based models
Pretrained model VGG16
In [36] an efficient method of measuring the cosine similarity by using the L2 norm is presented by Tanioka et al. in 2021. In this research paper, a pretrained model VGG-16 [22] is used and evaluated using the ImageNet dataset. They compare the results of the proposed method based on cosine similarity calculations with different other image retrieval systems based on other similarity metrics. Results reveal that the Manhattan and Euclidean distance formulas give higher accuracy for the images with smaller dimensions. The results conclude that the use of an inverted index with cosine similarity can give good response time and high precision for a CBIR search engine.
In 2021, an efficient hybrid approach for CBIR is presented that is based on a Convolutional Neural Network and machine learning classifier by Desai et al. [37]. VGG16 [22] is used as a deep learning model and Support Vector Machine known (SVM) is used as a machine learning classifier. The key purpose of this method is to build an efficient model for fast image retrieval. The Corel dataset is used to evaluate this hybrid approach. The model VGG16 [22] is used for the feature extraction of important features from the images of the Corel dataset. The activation function used in the CNN model is ReLU. The purpose of using rectified linear activation function (ReLU) is to set the non-linearity in the proposed model because it gives the linear value for each positive point and gives zero to all negative points. The SVM model is used to calculate the distance between the important extracted features of the query images & the features of the images of the whole dataset. The retrieved images from the dataset per query image are displayed according to the similarity index with respect to the query image. The results demonstrate the robustness of the system. The comparison analysis shows that the Average precision of the VGG16 model is higher than HSV, this model gives average accuracy of 0.835%.
Pretrained model VGG16 and ResNet50
In [38] a multi-feature fusion and feature aggregation-based image retrieval methodology is proposed by Qi Wang et al. in 2018. The main idea is to represent an image by a feature vector taken from multi-feature fusion and feature aggregation. The deep learning models VGG16 [22] and ResNet50 [24] are used for feature extraction from the image and Cross-dimensional Weighting (CroW) is used to implement feature aggregation.
To enhance the model performance for image retrieval purposes, the concept of transfer learning is used to fine-tune the deep learning model VGG16 for the dataset named Perfect-500K. Before using the VGG16 for feature extraction, the model is first trained as a classifier on the image dataset because the Perfect-500K dataset is originally unclassified and it is hard to classify all images manually one by one. The dataset is divided into 28 classes and trained on the pre-trained weights of VGG16 that are initially trained on the ImageNet dataset. The training result gives the classification accuracy of 73% and 60% at the train and validation set respectively because the dataset is divided into different categories with respect to the tf statistics of text about the explanation of different kinds of beauty products.
First of all image preprocessing is done by resizing the images at the size of 224x224. Secondly, pre-trained models VGG16 [22] and ResNet50 [24] are used for the feature extraction from the preprocessed input images of the training data. Thirdly the Crow technique is used to aggregate the extracted features and to get the feature vectors of seven different sizes by applying the square root & L2 normalization. In the end, the output vector is obtained and every image in the dataset is represented by the output vector of the size (1, 3776).
ResNet50 (residual networks) has fifty layers and it has lesser computational cost as compared to the VGG16. But the research shows that VGG16 [22] gives better accuracy on many tasks. Crow is used to reducing the dimensions of input vectors without affecting the important information about different objects. The Spatial Weight is calculated by adding the entire available feature maps. While the Channel Weight is gained via obtaining the weight of entire channels consisting of inverse document frequency. The Channel Weight modifies the input feature’s weights, while the Spatial Weight, which functioned like a saliency map, keeps the information related to the objects while filtering out the unimportant background information.
In [39] a CNN model for the fine-grained CBIR known as CB-FGIR is introduced by Kumar et al. The type of CNN named ResNet18 [25] is utilized to get familiar with the spatial representations of the image dataset. To enhance the size of the dataset the number of images is increased using image augmentation. For distance calculation, the formula of Cosine distance is used to search the fine-grained images. To evaluate the proposed methodology the Oxford flower17 dataset is used. The dataset is divided into 5 splits. The preprocessing of the images is done in two parts. First, all the images are converted to 256x256 then the subsets of the smaller images are resized to 224x224.
A subset of the images from the dataset is randomly selected and given as the input to the ResNet18 [25]. The ResNet18 [25] is pretrained using the ImageNet dataset and then further fine-tuned using the Oxford flower-17 dataset. After fine-tuning the model the performance of the model is improved significantly as compared to the other state-of-the-art handcrafted methodologies. The pretrained model ResNet-18 achieves the Mean Average Precision of 0.80 after fine-tuning it. In the future, the investigation of the other versions of the ResNet will be done for the purpose of fine-grained image retrieval and to use the local sub-regions info to reduce the semantic gap.
Pretrained model VGG-19
In [40] an image retrieval system to retrieve the images of trademarks is invented by Perez et al. which is based on the combinations of the Deep CNNs. A well-known pretrained model VGG19 [23] is trained on the weights of the ImageNet dataset. The database consists of two parts. The one part of the database named DBv is made by downloading the trademark images from the WEB and arranged by experts from the IP office according to the visual similarities. The other part named DBc is made by taking the images of the trademark from US patents and from various trademark offices. There are two versions of the VGG19 model (VGG19v and VGG19c) using each database.
The VGG19v is trained on DBv which is arranged according to the visual similarities of the images. While VGG19c is trained on DBc which is arranged according to the Vienna conceptual similarities of the images. For the purpose of fine-tuning, the last fully connected layer of the VGG19 model is removed having 1000 neurons, and replaced with two new layers having 151 and 205 neurons. The sigmoid function is used as an activation function for both VGG19v and VGG19c. Both models are fine-tuned using both datasets and the gradient descent is used as an optimizer along with the Nesterov momentum. For the loss function, the formula of the cross-entropy function is implemented with a batch size of 32. The METU database is also used. The system is accessed at the normalized average rank of the testing dataset taken from the METU dataset and it consists of a total of 9,22,926 images of trademark logos.
The normalized average rank is calculated for VGG19v, VGG19c, and for the combination of both models. The purposed methodology attains better results using the METU dataset. The normalized average rank using the VGG19v model for the METU dataset is 0.066 and 0.063 for the VGG19c model. At the combination of both networks, the normalized average rank for the METU dataset is 0.047. The highest normalized average rank using the METU dataset as compared to the previously published ones is 0.062.
In [41] a CBIR system to retrieve the MRI images of brain tumors by using the concept of transfer learning is introduced by Swati et al. The major problem in the CBIR-based system for the MRI images is the occurrence of the semantic gap between the low-level visual features taken through the MRI machine and the high-level features viewed through human evaluation. Hence, a deep CNN model VGG19 [23] is used as a feature extractor. The approach of CFML is used to calculate the similarities query and the dataset images. Moreover, the concept of transfer learning is used which proposed a novel block-wise based technique to fine-tune the model to enhance the efficiency of the retrieval.
Another publicly accessible image dataset named CE-MRI is used to evaluate the proposed technique. This dataset contains three types of 3064 images (from 233 people) of brain tumors. These three types are glioma brain tumor, meningioma brain tumor, and pituitary brain tumor. For data normalization, the min-max technique is used.The proposed methodology required very little preprocessing and 5-fold cross-validation is used for validation. The proposed novel approach outperformed the previously proposed methodologies of CBIR using Mean Average Precision of 0.9613.
VGG16, VGG19, ResNet, MobileNet, EfficientNet, inception
In [42], a CBIR model using transfer learning for digital IP protection is published by Trappey et al. The concept of embedded learning along with the triplet loss is used to fine-tune a pretrained CNN model. A pretrained model VGG19 [23] from Keras applications. Training weights of the ImageNet dataset for the construction of the model LogoSimNet are used. Six well-known pretrained CNN-based models VGG16, VGG19, ResNet, Mobile, Inception, and Efficient Networks are trained. The models give better results after fine-tuning.
An image-based large-scale dataset consisting of logos (Logo-2K) is used and it is divided as 70% and 30% as the training and test sets. The dataset has a total of 10,846 logos and it consists of 195 company categories. The training set had a total of 7625 images of 140 companies that are used to fine-tune the proposed framework. The test set contained 3,221 images of a total of 55 companies that are used for the verification of model performance. Six pre-trained models are tested for selecting the best for the feature extraction of the image retrieval. The cropping method is used to resize the images from the original size of 255x255 to 244x244. Before the training process, all categories of logos are manually accessed to check them according to the human visualization and removed from the dataset if images are found very small and too blurry to see from a human eye.
Adam is implemented as the optimizer of the proposed model. After the process of fine-tuning last fully connected layers are removed and replaced with 3 new fully connected layers along with the implementation of the L2 normalization. The experimental verifications are demonstrated over Recall at 10 of the testing set. It reached 0.95 for VGG19 after adjusting it with transfer learning. The Mean Average Precision for pre-trained models VGG16 and VGG19 is 0.88.
Faster R-CNN, YOLOv2, VGG-16 and ResNet50
In [43] an image retrieval system to retrieve the signatures and logos from the scanned images of the documents is proposed by Nabin Sharma et al. The main objective of developing this system is signature and logo detection for the purpose of document retrieval. The Implementation of the traditional hand-crafted method for the feature extraction is very challenging because of the dataset with multiple categories of signatures and logos.
As a result, the deep learning-based models named Faster R-CNN [44] and YOLOv2 [45] are utilized as the object detectors for the automatic recognition of signatures and logos from scanned official documents. ZF [46], VGGM [47], VGG16 [22], and YOLOv2 [45] are used as the network models for comparative analysis for efficiency in the image retrieval for scanned documents. A publicly available dataset: Tobacco-800 is used for the experiments. The proposed methodology is able to recognize the Signatures and Logos at the same time. The experimental results are quite promising as compared to the existing methodologies.
For the experiments, Faster R-CNN [44] and YOLOv2 [45] are used with a deep learning library named Caffe. Caffe is used as a pre-trained model for object recognition. Since the size of the dataset is very small so transfer learning is used to fine tune the models. It helps in the better performance and fast convergence of the system. For the comparison analysis of the performance of the proposed system different models like VGG16, VGGM, ResNet50, and ZF are used. ZF model consists of 8 layers having 5 convolutional and 3 FC layers. While VGG16 has 16 layered architecture that contains 13 convolutional and 3 fully connected (FC) layers. YOLOv2 contains 5 pooling and 22 convolutional layers. The input images are resized to the size of 416 x 416 and fine-tuned at the weights of the pretrained model on ImageNet. The dataset contains a total of 1290 scanned official documents that are used for the experiments. The 0.896 Mean Average Precision is achieved with the newly proposed Deep CNN-based methodology.
Pretrained model AlexNet
In [48] a methodology that is based on a pretrained deep convolutional model called AlexNet having low computational complexity is introduced in 2019 by Abdel-Nabi et al. A subset of the ImageNet-2012 dataset is used as an image database. It contains 600 images having 20 different types of categories and each category consists of 30 images. Cosine similarity is used to calculate the similarities between the feature vector of the query image and the extracted features of the input images of the entire database. The purpose is to assess the overall performance of the proposed CBIR system. A set of 15 images is used as the query set to evaluate the efficiency of the model.
The system retrieves top 30 images against each query image. The experimental results achieve Mean Average Precision of 0.93 using the proposed approach. The ResNet outperforms the AlexNet by giving a lower error rate of 3.57% while AlexNet achieves an error rate of 15.3%. In the future, there is a plan to enhance the performance of the proposed model by fine-tuning the network, updating the last layers, and training the proposed model using a new dataset. Furthermore, an extra method for dimensionality reduction can be organized in the proposed methodology to decrease the size of extracted features.
A summary of related papers and their information are presented in Table 1.
Summary of literature review
Summary of literature review
In this research, four well-known transfer learning-based deep networks i.e., VGG16, VGG19, EfficientNetB0, ResNet50, and their variants are trained and evaluated for the performance evaluation of a content-based image retrieval system. These models have already been trained on the dataset of ImageNet and are considered pre-trained models. By employing the transfer learning technique, these models are further trained on the benchmark datasets i.e, CIFAR-10, CIFAR-100, and CINIC-10. Different experiments with different structures and hyperparameters are performed to further tune these models.
Dataset description
To train deep transfer learning CNN-based models and their variants, three image datasets named Cifar10 [8, 50], Cifar100 [50], and Cinic10 are used which contain 10, 100, and 10 classes respectively. The detailed description of these datasets and their statistics (metadata) are given in Table 2
Statistics of Datasets
Statistics of Datasets
The CIFAR-10 is a dataset of images that is very popular for the training of machine learning and computer vision models. It contains 60,000 coloured images of size 32 × 32. These images belong to 10 classes where each class contains 6,000 images. The dataset is split into 5 train batches and 1 test batch, each of which contains 1000 images. The test set batch comprises of exactly 1000 images per class, chosen randomly. The rest of the images are distributed randomly among the training batches. Each train set batch includes exactly 5,000 images from each class. Some sample images with their labels are illustrated in Fig. 1.

The CIFAR-100 contains 60,000 color images, having the size of 32 × 32, and is a part of the Tiny Images dataset. This dataset is similar to the CIFAR-10, however, it comprises 100 classes having 600 images per class. Each class has 500 trains and 100 test images. Some sample images are illustrated in Fig. 2 as thumbnails.

Sample images from CIFAR-100 Dataset [50].
The CINIC-10 dataset is very popular for image classification and is considered as a benchmark dataset. It contains a total of 270,000 images with size 32 × 32. this dataset is 4.5 times larger than the CIFAR-10 dataset. It is built from 2 distinct sources i.e., ImageNet and CIFAR-10. It is created specifically as a link between CIFAR-10 and ImageNet. This dataset is divided into 3 equal subsets i.e., training set, validation set, and testing set, each with 90,000 images. Some sample images with their labels are illustrated in Fig. 1.
Preprocessing and augmentation techniques
Before training the models, different kinds of preprocessing and augmentation techniques are applied to the three benchmark data-sets. Preprocessing includes re-scaling, normalization, feature-wise centering and dimensions expansion and reduction, etc. In augmentation, rotation, horizontal and vertical flip, shift, and elastic transformation are applied. For different models, different augmentations are applied, as can be seen in Table 3.
Image preprocessing and augmentation techniques
Image preprocessing and augmentation techniques
For a deep analysis of the effect of transfer learning on deep networks, 16 customized models are created by using base models. The variation which resulted in 16 models is named Custom CNN1, Custom CNN2, Custom CNN3, Custom CNN4, Custom CNN5, Custom CNN6, VGG16-A, VGG16-B, VGG16-C, VGG19-A, VGG19-B, VGG19-C, ResNet50-A, ResNet50-B, ResNet50-C, and EfficientNetB0. The structural details of these customized models are given in the subsequent sections while Table 4 provides a summary regarding layers and parameters.
Details of models
Details of models
The Custom CNN models CNN1, CNN2, and CNN3 share the same architectural details while CNN4, CNN5, and CNN6 are similar to each other as per their architecture.
3.3.1.1 Architectures of Custom CNN1, Custom CNN2, and Custom CNN3. The models named Custom CNN1, Custom CNN2, and Custom CNN3 have 4 different layers in their architecture consisting of 2 convolutional layers, 2 pooling layers, 1 flatten layer, and 2 dense layers. These models are not transfer learning-based models so the input layer is created and weights are randomly initialized. This model takes the input images of shape 224 × 224. The architecture of Custom CNN1, Custom CNN2, and Custom CNN3 along with their computable parameters is given in Fig. 3.
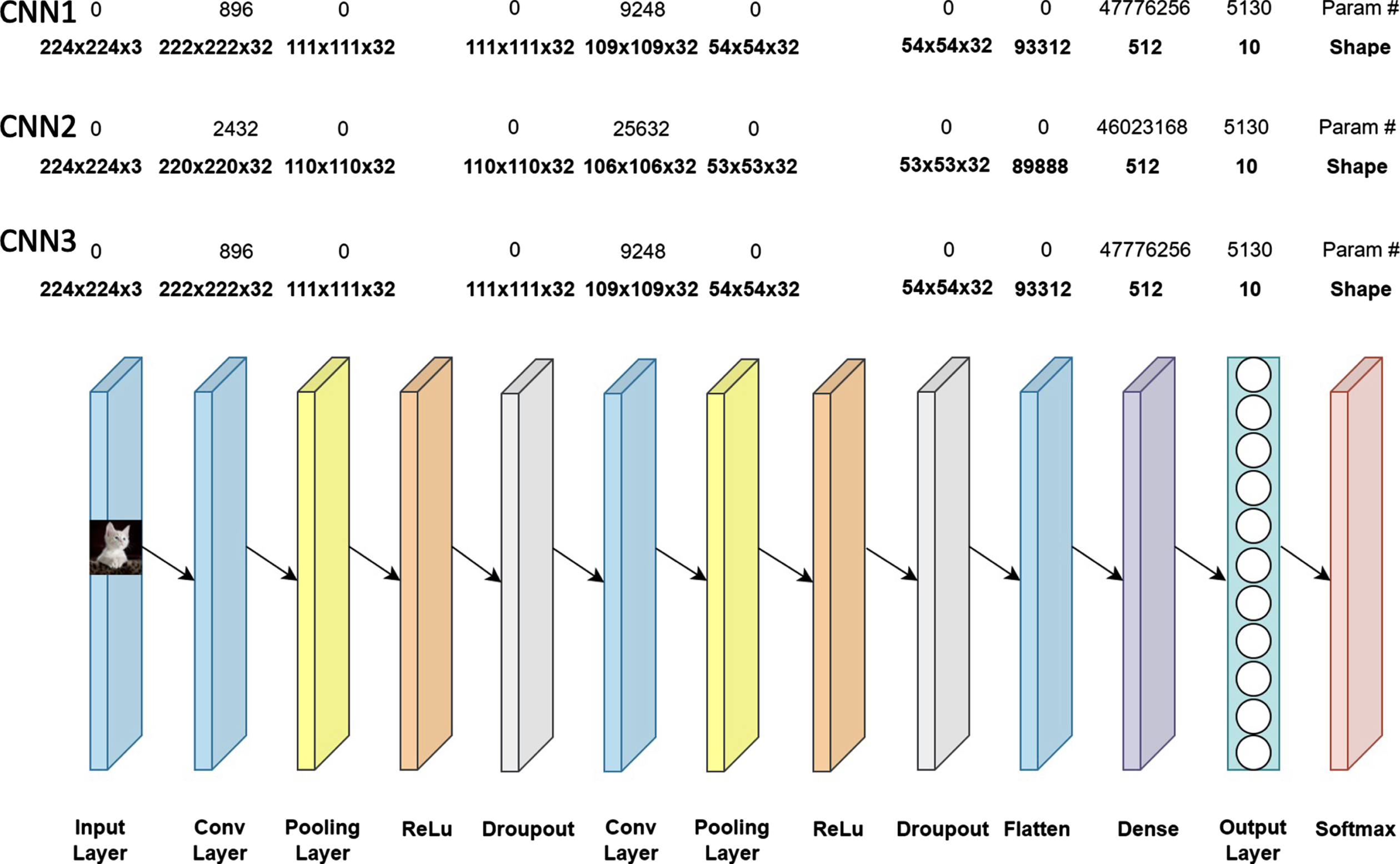
Architecture of Custom CNN1, Custom CNN2 and Custom CNN3 Models.
3.3.1.2 Architectures of Custom CNN4, Custom CNN5, and Custom CNN6. Custom CNN4, Custom CNN5, and Custom CNN6 models have 5 types of layers in their architecture comprising of 3 convolutional layers, 3 pooling layers, 1 flatten layer, and 2 dense layers. As these models are not transfer learning-based models so input layer is created for these models as well and weights are randomly initialized. This model takes the input images of size 224 × 224. The architectural details and their parameters are illustrated in Fig. 4.

Architecture of Custom CNN4, Custom CNN5 and Custom CNN6 Models.
The VGG16 architecture has 16 layers and for this research, three variants of VGG16 i.e., VGG16-A, VGG16-B, and VGG16-C are used. The number of layers and the number of parameters of each variant differentiate them from each other. An illustration of all the three architecture is given in Figs. 5–7. These models are pre-trained on the ImageNet database hence the pre-calculated weights from ImageNet are used as initial weights.

Architecture of VGG16-A.

Architecture of VGG16-B.

Architecture of VGG16-C.
3.3.2.1 Architecture of VGG16-A VGG16-A. model has 17 layers in its architecture including 13 convolutional layers, 5 pooling layers, 2 flatten layers, 3 fully-connected layers, 1 input layer, and 1 dense layer. It has in total 138,558,372 parameters out of which 126,203,492 are trainable and 12,354,880 are non-trainable. In this model, top layers are set as true and pre-calculated weights are used as initial weight. This model takes images as input with a size of 224 × 224. An overview of VGG16-A architecture is illustrated in Fig. 5.
3.3.2.2 Architecture of VGG16-B VGG16-B. model has 17 layers in its architecture with 13 convolutional layers, 5 pooling layers, 2 flatten layers, 3 fully-connected layers, and 1 input and dense layer. It has total 138,558,372 parameters out of which 4,297,828 are trainable and 134,260,544 are non-trainable. This model takes a fixed size of input images of shape 224 × 224. Figure 6 describes the layers of VGG16-B model.
3.3.2.3 Architecture of VGG16-C. The model VGG16-C has multiple layers in its architecture including 1 functional layer, 1 flatten layer, 2 fully-connected layers, and 1 input layer. The input layer takes images of size 32 × 32 as input. It has total 33,670,986 parameters out of which 33,654,602 are trainable and 16,384 are non-trainable. The architecture of VGG16-C is illustrated in Fig. 7.
The architecture of VGG19 has 19 layers. It is a transfer learning-based model which is trained on the ImageNet dataset. For this research, three variants VGG19-A, VGG19-B, and VGG19-C are used. The number of layers and number of parameters is different for each model. The architectural details of these three models are portrayed in Figs. 8–10.

Architecture of VGG19-A.

Architecture of VGG19-B.

Architecture of VGG19-C.
3.3.3.1 Architecture of VGG19-A. VGG19-A model has 20 layers in its architecture including 16 convolutional layers, 5 pooling layers, 2 flatten layers, 3 fully-connected layers, 1 input, and 1 dense layer. It has total 143,775,818 parameters out of which 126,111,242 are trainable and 17,664,576 are non-trainable. In this model, the top layers are trained and previously calculated weights, calculated from the ImageNet dataset are used as initial weights. This model takes a fixed size of input images of size 224 × 224.
3.3.3.2 Architecture of VGG19-B. The model named VGG19-B has 19 layers in its architecture, 16 convolutional layers, 5 pooling layers, 2 flatten layers, 3 fully-connected layers 1 input, and 1 dense layer. It has total 143,775,818 parameters out of which 38,964,298 are trainable and 139,570,240 are non-trainable. This model takes fixed-size of input images with size 224x224. Figure 9 portrays the architectural details of the VGG19-B model.
3.3.3.3 Architecture of VGG19-C. The model named VGG19-C has 4 layers in its architecture as described in Fig. 10. The layers include 1 functional layer, 1 flatten layer, 2 fully-connected layers, 1 input and 1 output layer. It has total 38,980,682 parameters out of which 33,654,602 are trainable and 16,348 are non-trainable. The model takes the input images of size 32 × 32.
The ResNet50 architecture has 50 layers and in this research, its three variants, ResNet50-A, ResNet50-B, and ResNet50-C are used for the CBIR system. The number of layers and the number of parameters of each variant differentiate them from each another. A brief description of the structure of all three frameworks is given in the subsequent sections while the overall architectural detail is illustrated in Fig. 11. ResNet50 is a transfer learning-based model, trained on the ImageNet database. In its variations, the top layers are trained and the previously calculated weights of the ImageNet are used for initial training.

Architecture of ResNet50C.
3.3.4.1 Architecture of ResNet50-A. ResNet50-A model has 54 layers including 48 convolutional layers, 2 pooling layers, 1 fully connected, and 1 dense layer. It has total 25,696,138 parameters out of which 3,164,170 are trainable and 22,531,968 are non-trainable. This model takes a fixed size of input images i.e., 224 × 224.
3.3.4.2 Architecture of ResNet50-B. The model named ResNet50-B has 50 layers in its architecture comprising 48 convolutional layers, 2 pooling layers, 1 fully connected, and 1 dense layer. It has total 25,696,138 parameters out of which 2,108,426 are trainable and 23,587,712 are non-trainable. ResNet50-B takes images as input with size 224 × 224.
3.3.4.3 Architecture of ResNet50-C. ResNet50-C has only 6 layers in its architecture including 1 functional layer, 1 flatten layer, and 5 dense layers. It has in total 26,376,202 parameters out of which 26,323,082 are trainable and 53,120 are non-trainable. The input images for this model are of size 32 × 32.
Another transfer learning-based model which is used for the CBIR system is EfficientNetB0 which has just 3 layers. One layer is the EfficientNet-B0-(Model) layer and the other is the pooling layer along with a dense layer as shown in the Fig. 12. It has a total of 4,062,374 parameters out of which 4,020,358 are trainable and 42,016 are non-trainable. Since it is a transfer learning-based who is trained on the ImageNet database so previously calculated weights from ImageNet are used as initial weights. This model takes the input images of size 32 × 32. As EfficientNetB0 is having memory bottlenecks associated with data movement, hence batch-normalization is performed to cater this overhead. Furthermore, Graphics Processing Unit (GPU) is used for training the model.

Architecture of efficientNetB0.
A step by step procedure of transfer learning for CBIR is explained in Algorithm I and II.
Input:
Output:
I train ← 70% of I
I validate ← 10% of I
I test ← 20% of I
E ← e // Number of epochs
B ← b // Batch size
T ← threshold
M ← LearningonI train
Wi,j ← ∀ i 1 ≤ i ≤ E, ∀ j 1 ≤ i ≤ B // Update weights
ta ← TrainingAccuracy ∀ i 1 ≤ i ≤ E
tl ← TrainingLoss ∀ i 1 ≤ i ≤ E
va ← ValidationAccuracy ∀ i 1 ≤ i ≤ E
vl ← ValidationLoss ∀ i 1 ≤ i ≤ E
FV ← ∀ image (x, y) ∈ I train // Feature vectors from image
QI ← ∀ image (x, y) ∈ I test // Query image
MF← Cosine similarity between FV and QI
G ← ∀ image (x, y) ∈ I train |MF > t // Retrieve the similar images against each query image
“Content-based Image Retrieval (CBIR)” algorithm explains, how images are retrieved using contents. At first, image dataset I is imported and divided into training I train , testing I test and validation I valid sets with a ratio of 70%, 20% and 10% respectively. Number of epochs E, Batch size B, Activation function F, threshold t and weights W are initialized. The model M is trained on I train and the weights are updated. For each epoch, training accuracy ta, training loss tl, validation accuracy va and validation loss vl are calculated. Finally feature vectors FV from I train and Query image QI are compared using a cosine similarity measure. Figure 13 portrays graphically how the CBIR system works.

Flowchart diagram of a CBIR system.
Input:
Output:
Algorithm II explains how transfer learning is applied to the proposed CBIR. With the help of a pre-trained model

Major steps of transfer learning technique.
The Table 5 shows the details of the parameters of each model including the model name, types of used weights, numbers of layers, total parameters, trainable parameters, and non-trainable parameters. The model named VGG16A has the largest number of trainable parameters (126,203,492), and ResNet50B has the smallest number of trainable parameters (2,108,426). ResNet50A and ResNet50B models have the highest number of layers (51), and the model EfficientNetB0 has the smallest number of layers (2).
Parameters of models
Parameters of models
Except EfficientNetB0, all the other models use Rectified Linear Unit (ReLU) as an activation function while EfficientNetB0 model uses Softmax activation function, given in Equations 2 respectively.
Sigmoid optimizer, given in Equation 3, is used as an optimizer in EfficientNetB0 and ResNet50-C while weights are updated using Equation 4.
The rest of the models use the Adam optimizer, given in Equation 5, which calculates the adaptive learning rate for every parameter by computing both x
t
and u
t
.
The learning rate η ranges from 0.1 to 0.6 for different models. All the models use Categorical Cross Entropy, Equation 6, as a loss function.
An in detail description of all the hyper parameters of the 16 models is given in Table 6.
Hyper parameters of models
For the content-based retrieval of images, the match between the contents (input image) and the required images is calculated via cosine similarity cos (θ), given in Equation 7.
Where X is the input image (contents) and Y is the target class (label).
In the custom CNN models to initialize the weights randomly, Glorot-uniform is used as the initializer to initialize the values of weights within a fixed negative and positive limit.
After training all the 16 models on three data-sets, the models are tested to evaluate the performance of transfer learning-based models. Among all the variations of Custom CNNs, CNN4 performs better than others for CIRAF-10 and CINIC-10 datasets with the accuracy of 63% and 53% respectively while for the CIFAR-100 dataset, CNN3 performs better. For VGG16-based models, VGG16-C performs better for all three datasets with an average accuracy of 73%. From the variations of VGG19 models, VGG19-A shows a better performance for CIFAR-100 and CINIC-10 with the accuracy of 42% and 68%. For the dataset CIFAR-10, VGG19-C achieves 86% accuracy which is far better than the other two VGG19 variations. Among ResNet50 variations, ResNet50-C beats all the others for all the three datasets by showing 52%, 84%, 69% accuracy for CIFAR-100, CIFAR-10, and CINIC-10 correspondingly. However, the best performance for each dataset is revealed by EfficientNetB0 which remains outstanding for all three datasets by showing 83.05$, 96.03% and 96% accuracy for CIFAR-100, CIFAR-10, and CINIC-10 respectively.
Considering the performance of models against different datasets, it is revealed that the average performance of all the models is better for CIFAR-10 which is 71% on average. While for CIFAR-100 and CINIC-10 the average performance of these models is 35% and 85% respectively. However, the maximum accuracy i.e., 96.03%, is achieved by EfficientNetB0 for the CIFAR-10 dataset. The transfer learning-based model EfficientNet50B has outperformed all the other models by achieving 92% accuracy, on average, for all three datasets. Table 7 describes all the details regarding the accuracy of each model for each dataset. Figure 15 provides a graphical depiction of the accuracy for all the 16 models which are computed via Equation 8.
Results of all the models for the three Benchmark Datasets
Results of all the models for the three Benchmark Datasets

Results of all models for three Benchmark Datasets.
In this research, 16 deep networks are trained to explore the effect of transfer learning for content-based image retrieval. On average, the maximum accuracy is achieved by EfficientNetB0 which is 92% for three different datasets, having 10 and 100 classes. Although VGG16 and VGG19 are considered very powerful pretrained deep learners their average performance remains 65.33% for VGG16 variations and 56.33% for VGG19 variations. The same is true for Custom CNNs and ResNEt50 which reveal average accuracy of 42.11% and 55.53% respectively. The analysis of results reveals certain factors behind the performance of these transfer learning-based deep learners such as overfitting, selection of hyperparameters, input variations, and the number of classes. The pretrained models VGG16A, VGG16B, VGG19A, VGG19B, ResNet50A, and ResNet50B perform very well in the training dataset but don’t give very good results in the testing dataset. It shows that the models are facing overfitting over training data.
At first, the Custom CNN models are used for the CBIR system. These models learn to fit the training set so well that they do not generalize to new data that is unseen as used as testing data. To analyze and overcome overfitting, VGG16C, VGG19C, ResNet50C, and EfficientNetB0 are introduced and certain steps are performed to reduce overfitting. To reduce the capacity of the model, a few layers are removed to decrease the number of neurons in the hidden layers. This results in an overall decrease in the number of training parameters. After that, the Dropout layers are added, which randomly remove a few features by assigning them zero value. These steps help the model in generalization.
Another technique that is used to remove the overfitting is, increasing the number of training samples. The amount of data can’t be increased further because models are already using the complete data collection. Hence, increasing the number of samples gives the classifier a larger range of samples and makes it less prone to overfit. It is predicted that when additional examples are added, the model would get more generic. Adjusting the images slightly such that the model does not focus on specific elements of each image further helped the models in generalization. This technique is known as image augmentation. So different image augmentation techniques are also used for effective generalization.
The effect of hyperparameters is also analyzed. Adam is used as an optimizer in the models VGG16A, VGG16B, VGG19A, VGG19B, ResNet50A, and ResNet50B cause these models have so many trainable parameters. So for efficient learning, Adam is used as it provides with fast training. In the models, ResNet50C and EfficientNetB0, the image augmentation techniques and SGD optimizer are used to facilitate better generalization.
Early Stopping is also employed to avoid overfitting of the models. In the EfficientNetB0 model, a call-back function early stopping is applied for monitoring the validation accuracy. The function waits for the 10 number of epochs before stopping the training. Another factor that is considered for avoiding overfitting is the decay rate. In the SGD optimizer decay rate is used which reduces the value learning rate from the previous epoch according to the fixed amount, and returns the updated value of the learning rate to the optimizer. In the models ResNet50C and EfficientNetB0, the call-back function reduce learning rate on plateau is also used for monitoring the validation accuracy and it changes the learning rate according to a fixed factor when the validation accuracy of the model does not increase further and becomes stagnates. A few important features of this function, which help in increasing the accuracy of the models are monitoring a matrix, considering a factor by which the learning rate will be reduced, and patience for a certain number of epochs without any improvement so that after that the learning rate can be reduced. By controlling these factors the accuracy of certain models is improved.
Due to the lack of high computational power the transfer learning-based models VGG16-A, VGG16-B, VGG19-A, VGG19-B, ResNet50-A, and ResNet50-B are having the weights of the ImageNet dataset and hence do not perform very well and give the accuracies between 50% to 80%.
The observations show that VGG16A and VGG19A take the longest training time due to the high number of trainable parameters. To reduce the space optimization and time optimization problem in the models VGG16-C, VGG19-C, ResNet50-C, and EfficientNetB0, The weights are initialized randomly. For further optimization by reducing the number of parameters and layers, the size of input images is reduced to 32 × 32. the rescaling of images causes poor resolution which resulted in a bad performance of feature extraction which eventually affected the efficiency of the retrieved images in a CBIR system.
Comparison with the State-of-the-Art techniques
The comparison between the state-of-the-art techniques and the models that are trained in this research, reveals that EfficientNet outperforms all the existing techniques for content-based image retrieval. The accuracy of different existing models for both CIFAR-10 and CIFAR-100 datasets is tested. The popular deep learners i.e., CNN, ResNet,VGG16, VGG19, AlexNet, GoogleNet, ResNet and machine learners GA, SVM, Adaboost, Bagging, PCA achieve accuracy from 36% to 95% for CIFAR-10 dataset while EfficeintNet that is trained in this reserch has achieved 96.03% accuracy for the same dataset. For CIFAR-100, the accuracy reported for the existing techniques reanges from 18.86% to 80%. The proposed trained EfficientNet is able to achieve 83.05% accuracy. In in depth comparison between these techniques is given in Tables 9.
Comparative analysis of the proposed technique with the State-of-the-Art for CIFAR-10
Comparative analysis of the proposed technique with the State-of-the-Art for CIFAR-10
Comparative analysis of the proposed technique with the State-of-the-Art for CIFAR-100
In this research work, the multi-class classification of four well-known transfer learning-based architectures VGG16, VGG19, EfficientNetB0, and ResNet50, and their variants are examined for the performance evaluation of a CBIR system. Eventually, in total 16 models are trained on CIFAR-10, CIFAR-100, and CINIC-10 image datasets which are benchmark datasets in the field of image classification. The article also discusses the statistics of datasets, experimental setup, hyperparameters, and the structural details of the models which affect the performance of models.
The research makes the following main contributions: Increasing the accuracy of CBIR system on two benchmark datasets i.e, CIFAR-10 and CIFAR-100 by 1.03% and 3.03% respectively, please refer to Figs. 17. Using augmented datasets CINIC-10 for CBIR system for the fisrt time and achieving 96% accuracy Comparing and analyzing the performance of 16 variations of deep transfer learners for image retrieval using contents taken from images. Improving the accuracy of CBIR system up till 96.03% for 10 classes For multiclass classification, proposing a CBIR system that can classify 100 classes with 83.05% accuracy. A deep insight into transfer learning-based CNN models for the Content-Based Image Retrieval systems. An analysis of efficient fine-tuning of the pretrained models, considering time complexity. Different experiments for avoiding the overfitting of models during training and analyzing the effect of preprocessing and augmentation techniques. A deep insight into the impact of hyperparameters over deep transfer learners.

A comparative analysis of the propsoed EfficientNet with the State-of-the-Art Techniques for CIFAR-10 Dataset.

A comparative analysis of the propsoed EfficientNet with the State-of-the-Art Techniques for CIFAR-100 Dataset.
For future work, the deep transfer learners can be explored for more optimization and robustness. Hyperparameters and factors like optimizers, pretrained weights, and input shapes can also be further analyzed. Other than CIFAR-100, CIFAR-10, and CINIC-10 more small-scale and large-scale datasets can also be used for a robust retrieval of images using contents. Small-scale datasets Fashion-Mnist-10 [60, 61], Emnist-10 [62], Mnist-10 [60], Kmnist-10 [63], Small-Norb-5 [64], and Rock-Paper-Scissors-3 [65] and the large-scale datasets Caltech-Birds-2010-200 [66], Caltech-Birds-2011-200 [66], Cars-196 [67], Stanford-Dogs-120 [68], and Food-101 [69] can be used to enhance the performance. Autoencoders can also be trained and their performance can be analyzed for a CBIR system.
Competing interests and funding
This paper will be of interest to the readership of this Journal. As the corresponding author and first author of the research work, we hereby confirm that the manuscript is entirely original, has not been copyrighted, published, submitted, or accepted for publication elsewhere.
Availability of supporting data
Three publicly available image datasets named CIFAR-10 [8, 50], CIFAR-100 [50], and CINIC-10 are used which contain 10, 100, and 10 classes respectively.
Competing interests
We assure that there is no conflict of interest with any organization.
Funding
We declare that we have no financial or other relationships that could be construed as a conflict of interest and that all sources of financial support for this study have been disclosed and are indicated in the acknowledgments.
Authors’ contributions
All authors have contributed equally in this research and writing and reviewing this manuscript.
Acknowledgments
We would like to acknowledge all data sources who made all datasets publicly available [8, 50]. In addition to availability of the dataset, all codes for deep CNN architectures are publicly available.