
Abstract
In the current market scenario, online customer reviews had a significant impact on boosting the sale of online products. Recently, there has been exponential growth in e-commerce industry owning to the online customer reviews. Over the years, researchers has observed the importance of online consumer reviews for purchasing online products. Hence, in this study, authors made an attempt to develop an efficient convolutional neural network (CNN) based classification model that aims to predict the usefulness of product reviews with higher accuracy on two different types of data sets (i.e., search product and experienced product). In our proposed study, to determine the usefulness of a review in terms of structural, linguistic, sentimental, lexical, and voting feature sets, we build a deep learning model to predict the review helpfulness as a binary classification problem. The performance of the proposed method is evaluated in terms of accuracy, precision, F1 score etc. and had been compared against the various leading machine learning (ML) state of art models viz., K-nearest neighbor (KNN), Linear regression (LR), Gaussian Naive Bays (GNB), Linear Discriminant Analysis (LDA) etc. The results demonstrate that CNN achieved better classification performance in comparison to other state of art models, with highest accuracy of 99.26% and 98.97%, precision of 99% and 99.01%, F1 score of 99% and 99.89%, AUC of 0.9999 and 0.9998, Average Precision (AP) of 0.9999 and 0.9997 and recall of 100% and 100% for two different amazon product datasets.
Keywords
Introduction
These days, number of social networking sites are working as independent organizations and helping customers to find better rated products online. Google is one such example. On the basis of large number of reviews and ratings obtained from multiple websites, including pbtech, eBay, Samsung, and others, Google tend to produce a cumulative rating of a product that had remarkable impact on boosting the online sale of product. One such rating for an electronic gadget can be seen in the Fig. 1.

Example of star rating by Google.
Nowadays, online Products are usually evaluated in term of quality by the online customers before buying it. This is done by reading the online reviews to get assistance in selecting the best product. In current scenario, e-commerce websites try to gauge the value of a product by taking online feedback from the customers whether their product was helpful to them or not. It has been general observation of Consumer psychologists that a helpful product review might significantly affects the consumers view point and decision-making in the online shopping [1, 2]. Current trends in shopping from online stores like Amazon, Flipkart, eBay etc., says that users most likely buy recommended products as compared to the non-recommended ones. It has direct impact on the finances of the company and plays a very vital role in overall business growth. Customer reviews are basically expression of sentiments of a customer after buying any product or service. This can easily be seen in the customer reviews as illustrated the Fig. 2.

Individual customer review (expression of sentiments) [10].
Millions of customer reviews on online review sites significantly influenced market trends as well as many potential consumers’ shopping decisions [3]. According to [4], it is reported that 86% of customers are in the practice of reading online reviews and around 91% out of them believe in those reviews. In general, customers have found helpful vote’s truly effective while selecting a particular product [7]. Despite of variations in review sites, similar concept of the helpfulness related to online reviews is observed everywhere in the current market scenario [8]. Challenges in front of customers and businesses are to how to control or get the benefit from such reviews which are voluminous, inconsistent and of varied nature. Online reviews, which are available as unstructured big data might have possibly both positive as well as adverse impacts on consumers. Helpfulness is preferred as key feature when several aspects of reviews are taken into account. Review helpfulness is computed as the ratio of the number of helpful votes and the total number of votes [10]. Thereafter, the reviews receiving the highest ratings are reorganized to the top of the web page so that customers can easily check them. Leading online retailers such as Amazon and Trip Advisor— also use this method to measure review helpfulness. Figure 3 demonstrate the procedure of how Amazon.com collected reviews helpful votes from their users [11].

An illustration of typical Amazon review, Source: Amazon, 2021.
Apart from prediction of helpfulness of user generated review, machine learning (ML) and deep learning (DL) algorithms had played a vital in different domains such as to detect the types of cancer [6, 28], intrusion detection [42, 43], classification and identification of unstructured road [5], fault detection in insulators [29].Besides these, ML and DL has also been utilized widely to solve the problem of the movement of a robot using path planning algorithms [9] in 2-dimensional search space.
The work flow of the proposed methodology was initially resumed with collection of datasets. To carry out the experiments, we initially collected two set of datasets from website https://jmcauley.ucsd.edu/data/amazon/. The procured datasets were based on experienced and search based product. The data initially being in the raw form underwent the rigorous preprocessing process to make it suitable for extraction of desired features and subsequently to be fed as an input to CNN and other ML algorithms. The subsequent step involves manual extraction of the characteristics from the dataset and categorizing them into five feature sets for reviews viz., structural, lexical, sentimental, linguistic, and voting. In next step, the dataset is divided into two halves that is utilized for training purposes (80%) and validation purposes (20%). 10 cross validation was used to assess the system performance. The training dataset was used to create five ML prediction models, including, K-nearest neighbor (KNN), Linear regression, second (LR), Gaussian-Naive Bays (GNB), linear discriminant analysis (LDA) and Convolutional neural networks (CNN). Finally, the model performance is evaluated based on accuracy, precision, recall, F1, AUC (area under curve), and AP (average precision).
The rest of the article is organized as follows: Section 2 describes Literature review, Section 3 presents the proposed methodology that is used in this paper for helpfulness prediction of online reviews. The section 4 describe the architecture of the CNN based classification model, while in section 5, we demonstrated and discussed experimental results. Section 6 discuss the conclusion and future scope of work.
Online product reviews attract interest from several academic disciplines, marketing is the main amongst them. Online product reviews are usually considered as one of the most valuable and promising tool to promote products. In addition, it also supports the collection of consumer feedback and boosting of product’s sale [12–14]. For example, online movie and book reviews might have a major impact on box office revenues [15], as well as on book sales [16]. However, online reviews gets impacted significantly by category, location, and other factors [17, 18] and hence heavily relies on these factors.
To forecast the significance of product reviews, authors in [19] developed a regression model. The authors used part-of-speech (POS)-based syntactic terms and lexical similarity as characteristics in these experiments [20]. Besides this, lexical subjectivity was also used as feature.
Review helpfulness assist in consumers’ information search process, and also perform other task like converting readers to buyers to increases the business [21, 22]. Over the past 20 years, the usefulness of reviews has been assessed using the star rating, reviewer’s credibility, price and categories of the products. [17, 23]. In this regard, numerous ANN based multilayer perceptron model has been developed by authors [24, 25] using product, review information, and review characteristics as common attributes. The prime objective of their work was to improve helpfulness prediction by employing neural network models instead of linear regression approaches [26].
Ref. [28] proposed a methodology for predicting the usefulness of travel-related websites. For the purpose of predicting helpfulness, they have combined reviewer and review features. More specifically, the authors developed a text regression model employing features including reviewer identity, reputation, competence, review valence, and readability in order to assess how helpful a review will be. They have used the reviews’ writing style, timeliness, and reviewer experience as features for the prediction the helpfulness of customer generated reviews. In [32], a new approach to calculating how useful reviews are, is provided. Instead of using a conventional review helpfulness problem, the authors calculate helpfulness using the confidence interval and the helpfulness distribution data. The key conclusions of many cutting-edge approaches about the worth of reviews are compiled in Table 1.
A summary of the recent works provided in the literature
A summary of the recent works provided in the literature
In Ref. [30] authors suggested a regression model that uses several variables based on semantic, structural, and meta-data to predict how useful online reviews will be. Along with other variables like review expertise, writing style, and timeliness, aspects like review feelings (valence), length, and unigrams are also recognized as significant predictors [33].
A unique suggestion about reviewer engagement (RFM) features was made in Ref. [34] in order to improve the effectiveness of the helpfulness prediction system. The authors stated that a hybrid model was made up of RFM and textual elements produced more accurate predictions. Subjectivity, readability, and meta-data aspects [30, 35], are also some important features that were excluded despite of being superior than other predictors. In Ref. [36], authors asserted a connection between valence consistency and review usefulness to track their impact on the outcome. As per study [37], in order to perform the review helpfulness, product reviews were divided into low, medium, high, and spam categories. Thereafter, a machine learning model was created utilizing the numerous parameters like readability, subjectivity, and information In order to categories poor and high quality reviews, Ref. [38] explored regression model to understand the significance of textual and non-textual elements in prediction of reviews helpfulness. As per the study, items were divided into two groups: experience-based products and search-based products. Extreme ratings of experiencing products have been found to be less helpful than moderate one.
In contrast to experience products, many evaluations of search products were more beneficial than moderate reviews. The review length is another important feature that has high impact on the prediction of reviews helpfulness, however, its influence rely upon the product category. For instance, in case of search product, review length affected the prediction result more positively as compared to experience products. The authors came to the conclusion that other aspects, such as star rating and review length, also have a higher influence on product categories based on the aforementioned findings.
In Ref., (Iwendi et al., 2022) [31] an item recommendation system based on pointer-based scheme was developed in the study as a modern machine learning attention model. All user reviews and comments are taken into consideration when recommending an item. With a Mean Absolute Error of 21%, 79% Precision, 80% Recall, and 79% F1-Score, the model was able to achieve 79% Accuracy on the Yelp dataset.
A recurrent convolutional neural network (RCNN) model was used by [45] to estimate the reviews’ helpfulness, and they came to the conclusion that semi-supervised learning performed better than supervised learning. In Ref. [46], Chau et al. proposed a model for retrieving useful reviews using the elastic net regularization and multiple linear regression algorithm based on reviews ranked lists. Furthermore, [47] Describes the development of a machine learning model to predict the usefulness of user evaluations based on the polarity, subjectivity, entropy, and readability textual properties of reviews. When compared to other machine learning-oriented methodologies, the Valence Aware Dictionary and Sentiment Reasoner (VADER) model [48] performs better for individual human raters in terms of F1 score and accuracy. Based on user-submitted evaluations, authors of study [49] developed a feature extraction approach to quantify and assess the helpfulness for each product. A methodology called Helpful Quality-related Review Mining (HQRM) was proposed by Jiang et al. in their study [50] to aid the multi-class classification problem pertaining to prediction of useful quality-related reviews. A descriptive and comparative analysis-based methodology was proposed in research [51] as a way to look into and report on changes in user preferences, corporate reputation, and rating behavior. Based on a prior study, authors of [52] proposed that the kind of product modifies the impact of emotions on perceived review usefulness.
In Ref. [11] authors used Yelp dataset’s review word count as a structural feature category to predict customer reviews’ helpfulness using B-GBT (Bagging Gradient-Boosted Trees) architecture, and they achieved accuracy of 95.3% with the highest area under curve (AUC) of 0.988. Based on the review rating and word count in structural features categories, authors in Ref. [12] achieved the confidence interval of 95% using SVR on Amazon dataset. Using Random Forest algorithm, authors [26] obtained the satisfactory performance with an accuracy of 81.33 percent based on the linguistic features viz., adjective and verb. In [38], authors employed DNN model on the Amazon dataset and achieved the maximum accuracy of 84.54 percent, on the search product by utilizing a hybrid features set (i.e. readability feature, sentimental feature, and linguistic features). For the classification of the review helpfulness prediction problem, Ref. [46] used a multiple linear regression model with the elastic net regularization method on the Amazon dataset to predict the outcome. The developed model achieved an accuracy of 83 percent using review length, character count, polarity feature, helpfulness vote feature, and readability features. In Ref. [47] the Gradient Boosting approach was developed based on ensemble learning by using sentimental feature (Polarity), linguistic feature (Noun, Adjective, Verb as), lexical feature (Flesch reading edge, Dale Chall RE), structural feature (Review length, Sentence Length, one letter words, two letter words, longer letter words, review rating), and voting feature (Helpful Ratio) to forecast the best mean square error (MSE) when the number of ensemble trees is 100 on the Amazon dataset. In Ref. [49], authors combined lexical (Flesch reading ease), structural (length of review, number of sentences, and character count), and semantic features to create hybrid features that were applied to the Amazon dataset and achieved an accuracy of 77.6 percent by decision tree classifier for classification of review helpfulness. A summary of current studies on how helpful reviews might be classified is shown in Table 2.
An overview of recent studies on the classification of reviews’ helpfulness
RC (Review Content), P (Product), R (Reviewer), ML (Machine Learning),C (Classification), REG (Regression), GBT((Gradient Boosted Tree), LNR (Linear Regression), RandF (Random Forest), SVR (Support Vector Regressor), M5P (M5 Model Trees), CART (Classification and Regression Tree), MARS (Multivariate Adaptive Regression Splines), GLM (Generalized Linear Model), GBT (Gradient-Boosted Trees), N.Net (Neutral Network), MLP (Multilayer Perceptron), MLP-BP(Multilayer Perceptron with back propagation), DNN (Deep Neural Network), NDCG (Normalized Discounted Cumulative Gain), LGR (Graphical model for Local Gaussian Regression), MAE (Mean Absolute Error), RMSE (Root Mean Square Error), MSE (Mean Squared Error), RAE (Relative Absolute Error), RSE (Relative Squared Error), RRSE (Root Relative Squared Error), R2 (R-squared), CC (Correlation Coefficient), KNN (K-nearest neighbor), LR (Linear Regression), GNB (Gaussian Naïve Bays), CNN(Convolution Neural Network).
In our study, we integrated various types of features to form five feature vectors. These features are taken from different studies [17, 49–52] based on their performance. In this study, we have selected those features only, which have been proven effective by the different authors based on the outcomes obtained in their previous studies. As of now, no study has been carried out on these features collectively as per the author’s knowledge, which motivated us to integrate and investigate these features (i.e., lexical [38], structural [46], linguistic [47], sentimental [17], and voting [26]) to build an effective classier using CNN for prediction of useful and unhelpful reviews.
The performance of suggested CNN model is compared against different current state-of-the-art models, including LR, KNN, GNB, etc. In the developed model, integrated features inherited the inherent quality of individual features like structural [10, 52], lexical [38, 49], linguistic [26, 50], sentimental [38, 51], and voting [11, 52], thereby enhancing the overall performance of the suggested model.
In this study, authors proposed a DNN model that was customized for an effective prediction of customer reviews based on the characteristics of customer evaluations. The major contributions of the proposed study are as follows: In this study, two different amazon datasets (i.e., one is based on search goods and other is based on experienced goods) were utilized to extract distinct features related to goods reviews and divided into five feature sets viz., voting, structural, lexical, sentimental, and linguistic features. The features extracted in step 1 were utilized as an input to train the DNN model, where the underlying model was customized and tuned to build an efficient and reliable prediction model for predicting the usefulness of customer generated review of a particular product. In the end, our suggested model’s performance was compared to other current-generation models in terms of sensitivity, precision, recall, F1 score, and area under curve (AUC).
In this section, we primarily focus on formulation and development of classification model that aims to predict review helpfulness of online products. The review helpfulness prediction model was built using five feature sets, wherein each feature set had varying number of parameters possessing different characteristics as illustrated in Fig. 5. In our study, we have utilized the most recent baseline attributes [5, 49–52] to create an effective CNN based prediction model.

Sample example of Review dataset (source amazon.com).
The framework proposed in this study comprises of phases, which is illustrated in Fig. 4.
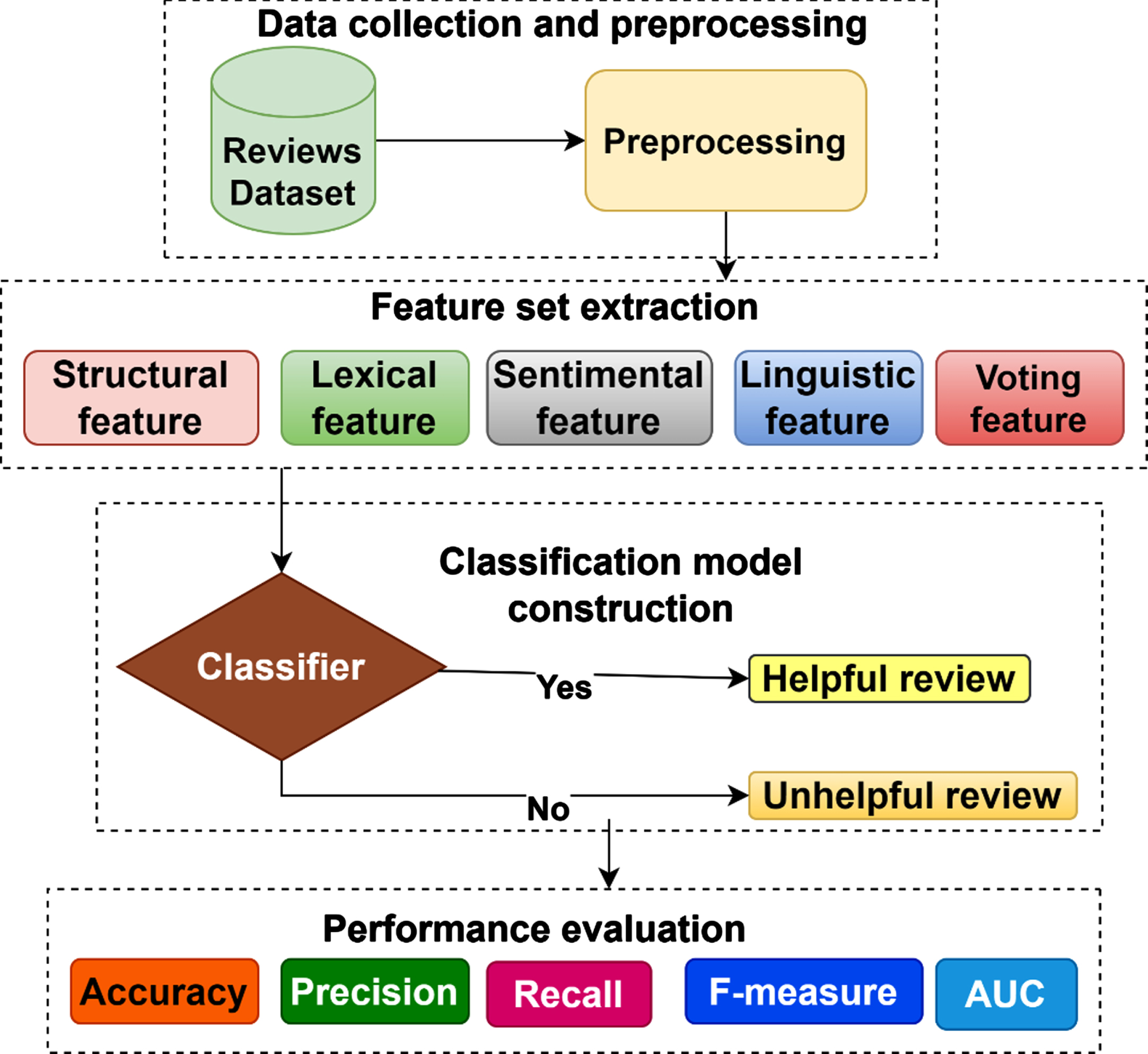
Framework of research methodology.
In the first phase, appropriate datasets were collected, followed by implantation of preprocessing step. The data initially being in the raw form underwent the rigorous preprocessing process to make it suitable for extraction of desired features and subsequently to be fed as an input to CNN and other ML algorithms. The subsequent step involves manual extraction of the characteristics from the dataset and categorizing them into five feature sets for reviews viz., structural, lexical, sentimental, linguistic, and voting. In next step, the dataset is divided into two halves that is utilized for training purposes (80%) and validation purposes (20%). 10 cross validation was used to assess the system performance. The training dataset was used to create five ML prediction models, including, K-nearest neighbor (KNN), Linear regression, second (LR), Gaussian-Naive Bays (GNB), linear discriminant analysis (LDA) and Convolutional neural networks (CNN). Finally, the model performance was evaluated based on accuracy, precision, recall, F1, AUC (area under curve), and AP (average precision).
The review information that has been utilized in our experiment has been taken from Amazon.com, which is freely available data source. This data source is made publically available especially to perform the experiment by researchers and scientific community. This dataset has three primary components such as reviews corpus, social information about those reviews, and reviewer data.
To conduct the experiments, we procured the data from Amazon.com. The data has sample helpfulness reviews collected between May 1996 and July 2014 [20, 44].
The data contains the review information about the two product categories, home and kitchen goods and cellphones and accessories. The former product category occupies the memory space of 138 MB, while later occupies the memory space of 411.5 MB, respectively. There are numerous items such as Phones and accessories, which are considered as a part of search goods category, while home and kitchen items are designated as experience products, making it challenging and expensive to learn about the quality of a product before using it [11].
Table 3 lists the various types of products along with the total number of reviews, goods, and reviewers (users) for each category. In dataset, there were nine column representing nine attributes such as reviewerID, asin, reviewerName, helpful, review Text, overall, summary, unixReviewTime, and reviewTime. The details of each attribute is explained as follows: reviewerID: it represents the alphanumeric code, which is given by Amazon to their reviewers asin: it is amazon standard identification Number(asin) that referred to as the alphanumeric product ID assigned to the products by Amazon. reviewerName: It demonstrates the name of reviewer that is present in the list of Amazon product review database. helpful: It indicates those cases of users for whom review was helpful. reviewText: it refers to the review contents submitted by the reviewer’s regarding a particular product. overall: it gives information about the star rating value of any product. summary: it provides the review’s summary of any goods which is available on website for sale. unixReviewTime: it refers as Unix time, when the review was published. reviewTime: it refers to the date and time, when the review was created.
Description of the dataset for Amazon reviews
Description of the dataset for Amazon reviews
An example Amazon.com review is given in Fig. 5.
DS1 and DS2 are two real-world review datasets, which have been utilized in this study to evaluate the performance of proposed methodology and other ML models under study for prediction of review helpfulness. A data cleaning process was used to eliminate unnecessary data with the aim of improving the qualitative features of the dataset. The applied cleaning method substantially improves the performance of the suggested mode [20, 38].
The various steps data cleaning approach can be summarized as follows: The first step plays very vital role in cleaning the data. It includes the process of identifying and eliminating the duplicate reviews from the datasets. In the second step, the redundant information such as blank text is eliminated from the dataset. In third step, Reviews with a large number of votes are taken out, which often produces better categorization outcomes.
Therefore, only evaluations with minimum 10 total votes are included. The number of reviews present in both datasets before preprocessing and after preprocessing are listed in Table 4.
Summary about the dataset1 (DS1) and dataset2 (DS2)
Summary about the dataset1 (DS1) and dataset2 (DS2)
This section primarily focus on classification problem and extraction of feature/characteristic set that is required to build an effective model. Let’s assume R = { αn, βn} where αn = { α1, α2, … … . .
αn } depicts the n-numbers of review features, while βn indicates the levels of helpfulness. βn ∈{0, 1} where ‘0’ and ‘1’ represents the review helpfulness and unhelpfulness, respectively. As we know that features plays crucial role in determining the performance of any classification model. Hence, feature set ought to be chosen wisely in order to ensure the better classification results. In this study, k number of features are used, where k ∈
In this experiment, we have used 22 reviews features, which have been derived from various studies based on their characteristics [26, 46]. These features have been grouped into different five disjoint feature sets based on their compatibility to each other. These feature can be well understood in the subsequent sections.
List of feature set used in previous studies
List of feature set used in previous studies
This feature set comprises of text reviews, which possess 11 structural characteristics to define it. In the review text specific words, phrases, and paragraphs are specified by structural components of structural feature set. Structural feature set (St) : {Char_Len, nWord, nSent, WPS, DFW, UW, Rating, Avg_W_Len, 1Word, 2Word, Long_Word} are used in our study. Each element of the feature are defined as follows: Char_Len: it alludes to the total amount of characters in the review’s content. nWord: it alludes to the total amount of words in a single review’s content. nSen: it alludes to the total amount of sentences in a review’s content. WPS: it represents the average numbers of word in a sentence. DFW: it represents the challenging words, which are part of review & is beyond the list of 3000 well-known words. UW: It represents the non-similar words in review. Avg_W_Len: it denotes the average number of character in a word of review content. 1Word: it alludes to the total amount of words in the review content that are of one length. 2Word: it represents the number of word, which have two length in review text conducted by company. Long_Word: it gives information about the presence of total number of word in text reivew, which have greater than two length.
Lexical feature set (Le)
Another crucial aspect of review content that might affect how beneficial a review is its readability. The readability of a review content tends to be directly correlated with the lexical feature set. The number of user votes for helpfulness might rise when a review is simple to read. In this study, we employed two readability measures that have been identified in the literature to calculate review readability [26, 47]. Flesch Reading Ease readability score (FRE) and Dale Chall readability score (DCR) are two such examples.
One of the most common and well-known readability metrics is the Flesch Reading Ease (FRE) score. The following is the formula for the FRE score [46]:
Where,
A = Average word length of a sentence
B = Average syllables per word
The formula of Dale-Chall Readability is given as [47]:
Where,
DCRI = Dale Chall Readability Index
A = Average word length of a sentence
C = Percentage of difficult words in a review text
In this work, sentimental feature set (Se) comprises of four review features viz., {Neg, Pos, Neu, Compound} Neg: Negative feature is assessed in the range of [–4,0]. Pos: Positive feature is evaluated in the range of [0,4]. Neu: Neutral sentiment is indicated ‘0’. Compound: It represents the normalized score of the sum of Neg, Pos and Neu that ranges between –1 to+1.
While performing the experiment, we performed vocabulary- and rule-based sentiment analysis using the Valence Aware Dictionary and Sentiment Reasoner (VADER) tool in order to generate of the polarity ratings in the form of numerical representations. [20, 48] using python library. Here VADER transformed the sentiment scores of lexical features into emotion scores.
Linguistic feature set (Li)
Linguistic feature set (
After the individual linguistic feature {Noun, Verb, Adj} extracted for
Pseudo Code of the scoring of linguistic feature set
Pseudo Code of the scoring of linguistic feature set
Voting feature set (V) comprises of three features that is mentioned as follows: Total: It represents all the votes that have been received. Vote: It represents all the votes, which are treated helpful. Helpfulness: It denote the fraction of the helpful votes and the total number of votes in [0, 1].
In literature [10, 37], the review helpfulness is categorized into two classes either as a ‘1’ or ‘0’ based some threshold value (Φ) as follows:
Here
Both the datasets (DS1, DS2) in Fig. 7 shows helpfulness scores (ratio) distribution (x-axis) versus frequency (y-axis). Helpfulness ratio (score) varies in the range of [0, 1].
In the Fig. 6, large amount of reviews in both datasets are distributed in the range of [0.9, 1], which point out to the density of helpfulness ratio lopsided towards the right.
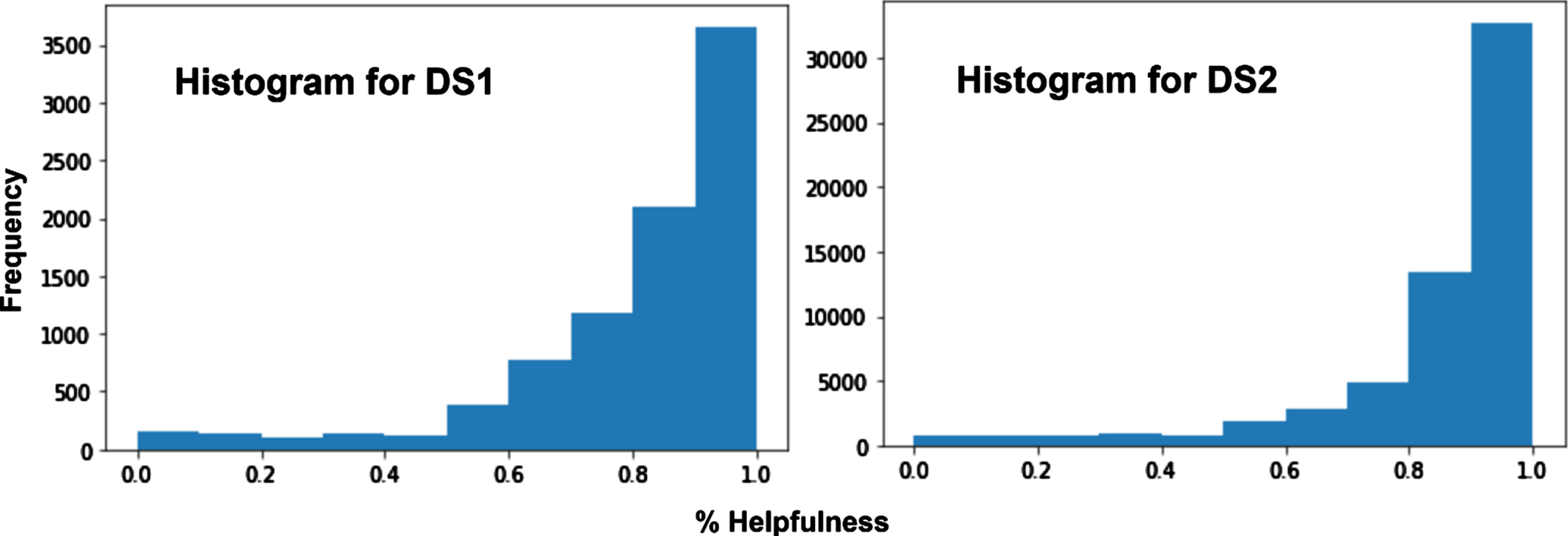
Helpfulness score distribution in DS1, DS2 datasets.
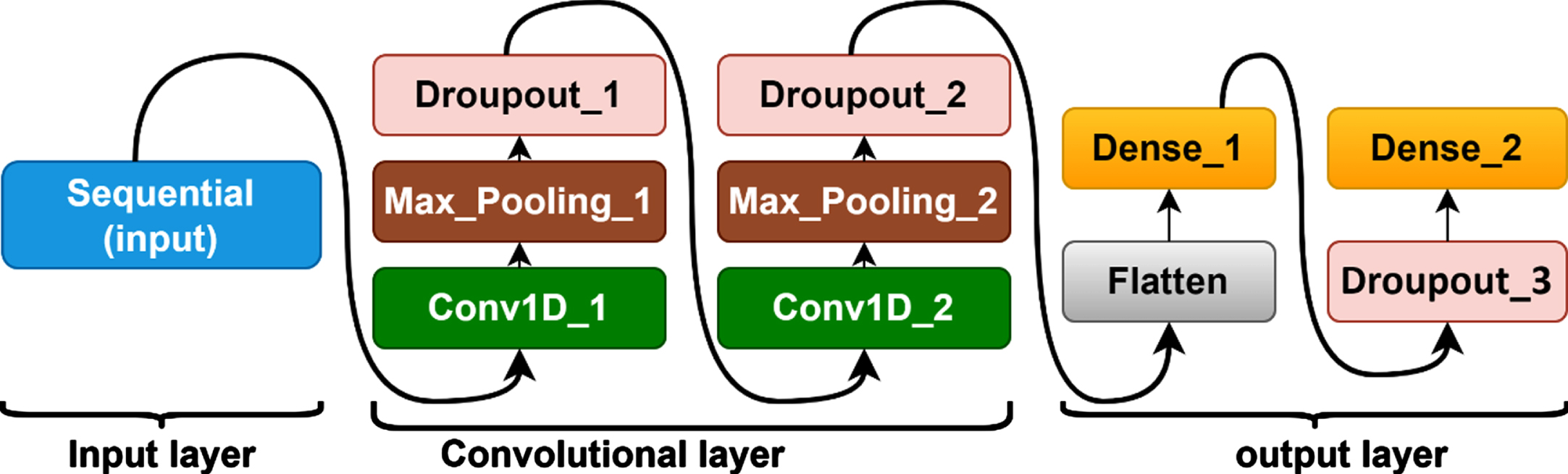
Structure of CNN model.
To build the CNN classifier, feature matrix of size N x F were used, where N & F denote the total number of reviews and total number of features used to train the model. Here, we set the value of F as 22. In this study, well-known machine learning algorithms such as Linear regression (LR), K-nearest neighbor (KNN), Gaussian Naive Bays (GNB), Linear Discriminant Analysis (LDA) were applied to classify the product reviews into helpful or unhelpful cases based on innovative feature sets. To build the classifier mode, both datasets (i.e., DS1 and DS2) were split into the ratio of 80 : 20 percent; wherein 80 percent of data was used for training purpose and remaining 20 percent was used to test the performance of the model. The proposed model was simulated using Python 3.7 and computed various performance measures like Precision, Recall, Accuracy, F1 Score, AP and AUC are some of the assess the performance of the developed system. The performance measures can mathematically be defined as [38, 42]
Where:
T
p
: True positive rate, T
n
: True negative rate, F
p
: False positive rate, F
n
: False negative rate
Where, Recall (n)=0, Precision (n)=1 and n is number of threshold
This section focus on the development of CNN based deep neural network model that aims to classify review data into binary category as helpfulness and non-helpfulness. Proposed model was constructed using Keras library in addition to Tensorflow which were served as a backend.
Figure 7 illustrate the basic structure of CNN model. Figure 8 shows that the proposed CNN model. The proposed model comprises of two 1-dimensional convolution layers (Conv1D). There are several parts to each Conv1D, including a pooling layer (Pool), batch normalization, and a rectified linear unit (ReLU) activation function. In addition, the developed model also comprise drop out layer, sigmoid function, fully connected (fc) layer, and binary classification output layers. In the output layer, we used binary cross entropy as the loss function. This model has 22 input neurons at the input layer in which feature information was passed sequentially. As stated above, feature vector matrix has the dimensions of N * 22 that represents five feature sets. Feature information from first convolution layer was passed on to second convolutional layer (Conv1D 2), which had 64 neurons. Single neuron was used to display the output as 0 or 1 at the output layer. 1 indicated the binary class as while 0 indicated the class as unhelpful.
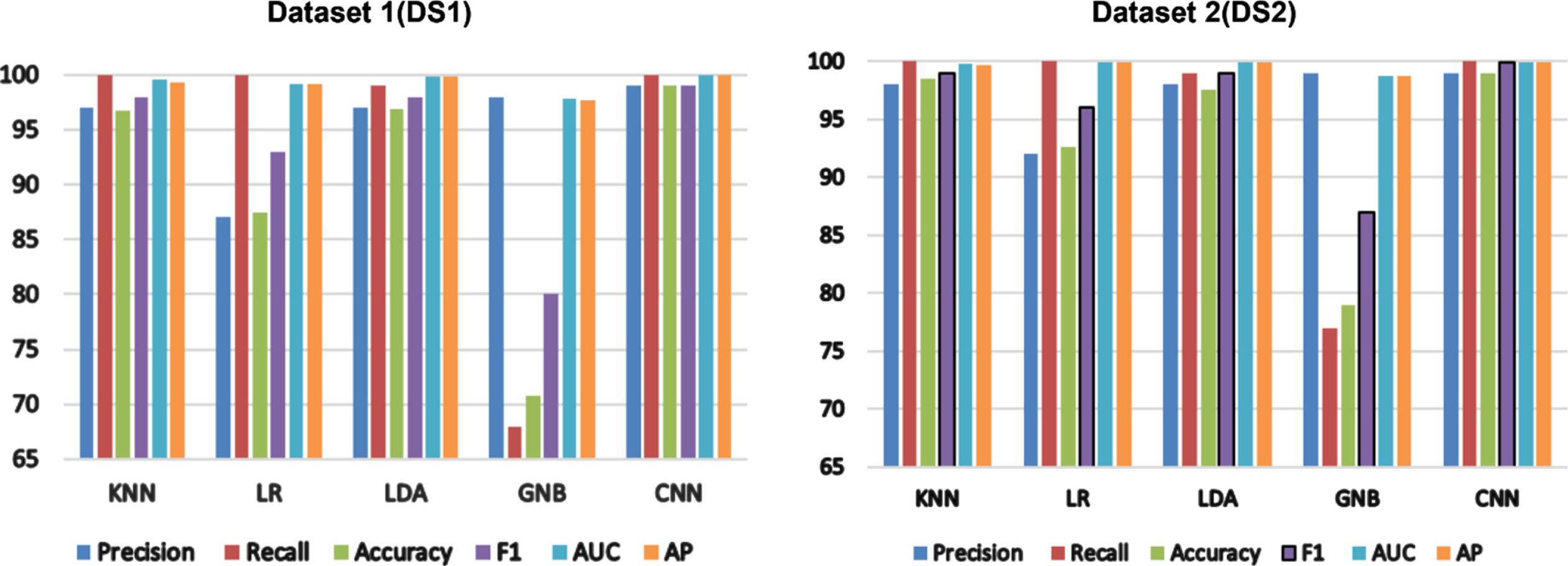
Predictive model performance in percentage (%) of ML algorithms for DS1 and DS2.
The various tuning parameters, which we used during building the model are listed out in Table 7.
Turing parameters of proposed model
This work illustrate the results of various experiments conducted with five machine learning algorithms using five sets of parameters. Subsequently the performance of all the algorithms understudy work evaluated and compared using the various performance matrices such as precision, recall, accuracy, AUC etc.
ML model performance evaluation
In this section, the performance analysis of various machine learning models for predicting reviews helpfulness is presented. The performance of all the underlying models (i.e., LR, LDA, KNN, GNB, and CNN) was validated using10-fold cross validation. In this experiment, using two datasets (DS1 and DS2), the significance and usefulness of suggested feature sets are also examined in terms of several performance metrics, including precision, recall, accuracy, F1 score, etc. Table 8 displays the performance of the predictive model using 10-fold cross-validation.
From the results given in Table 8, it can be observed that CNN method obtained better results than those of other competitive ML models for both the datasets. The proposed model obtained precision of 99.0% and 99.01% and accuracy of 99.00% and 98.97% for DS1 and for DS2, respectively. Similarly others parameters obtained highest result in proposed model in terms of recall, F1, AUC and AP i.e. 100%, 99%, 0.9999 and 0.9999 for DS1 and 100%, 99.89%, 0.9998 and 0.9997 for DS2 respectively. The results given in Table 7, demonstrate the superiority of CNN model with highest performance in terms of accuracy (98.99 for DS1, 78.67 for DS2), recall (100% for DS1, 100% for DS2), F1score (99% for DS1, 99.89% for DS2), AUC (0.9999 for DS1, 0.9998 for DS2) and AP (0.9999 for DS1, 0.9997 for DS2).
Predictive model performance using 10-fold cross-validation
Predictive model performance using 10-fold cross-validation
The performance of the Gaussian Naive Bays (GNB) classification model was the worst of all the models analyzed. (i.e., 70.83% 78.99% for DS1 and Ds2). Figure 8 shows comparative analysis of KNN, LR, LDA, GNB, and CNN models for both the datasets in terms of bar chart. In proposed model, dataset DS2 delivers relatively better performance than dataset DS1 in terms of precision and F1. The tests’ findings overwhelmingly support the usefulness of the proposed features for the review helpfulness prediction in terms of precision, recall, accuracy, f-measure, AUC and AP metrics.
From the above discussion, it can be concluded that CNN model produced superior results in comparison to other competitive ML based models.
Table 7 lists the results and outcomes of all the classifiers under study. Results shown in Table 7 declare the best predictive performance of CNN model for customer review helpfulness dataset. The various tuning parameters used in this study are given in Table 7. Both datasets (i.e., DS1 and DS2) were simulated for 10 epochs. Accuracy and loss curve yielded by CNN model for DS1 and DS2 are demonstrated in Fig. 9.

Accuracy and loss of CNN predictive model for DS1 and DS2.
The proposed model achieved an accuracy of 99.56% and 98.87% percent for DS2 dataset (shown in Fig. 9), while it achieved loss of 1.45 and 0.53 percent during training and validation phase Using hybrid feature sets as an input, our model obtained the good performance with precision, recall, accuracy, F1, and AP score of 99.7%, 100%, 99.26%, 99%, and 0.9999, respectively for dataset DS1.
On the DS2, CNN model achieved the Precision score of 99.01%, recall score of 100%, accuracy score of 98.97%, F1 score of 99.89%, and AP score of 0.9994 using the extracted features. For each datasets (DS1 and DS2), in the Fig. 10 precision recall curve demonstrates how these hybrid feature sets affect classification outcomes. In both precision & recall curve (DS1) and (DS2), violet color curve indicates the maximum area covered by the suggested model. The developed model gives an AUC value of 1for both datasets DS1 and DS2, respectively. LDA obtained second highest AUC value of 0.999 for both datasets.
Figure 11 uses a precision recall curve to offer a distinct view of performance in terms of average precision (AP) for all various ML methods. The CNN model scored the highest average precision (AP) value of in precision recall curve (DS1) and (DS2) for both the datasets DS1 and DS2 respectively. LDA obtained the second highest score with average precision value of 0.999 for DS1, while LR and LDA models secured 2nd highest score with average precision value of 0.999 for DS2, respectively. GNB ML model obtained the minimum with average precision value of 0.977 and 0.987 for dataset DS1 and DS2 respectively. As a part predictive model for the classification of experimentation we also computed the precision-recall curve for the both dataset and concluded that CNN is a powerful helpfulness of user-generated text reviews.
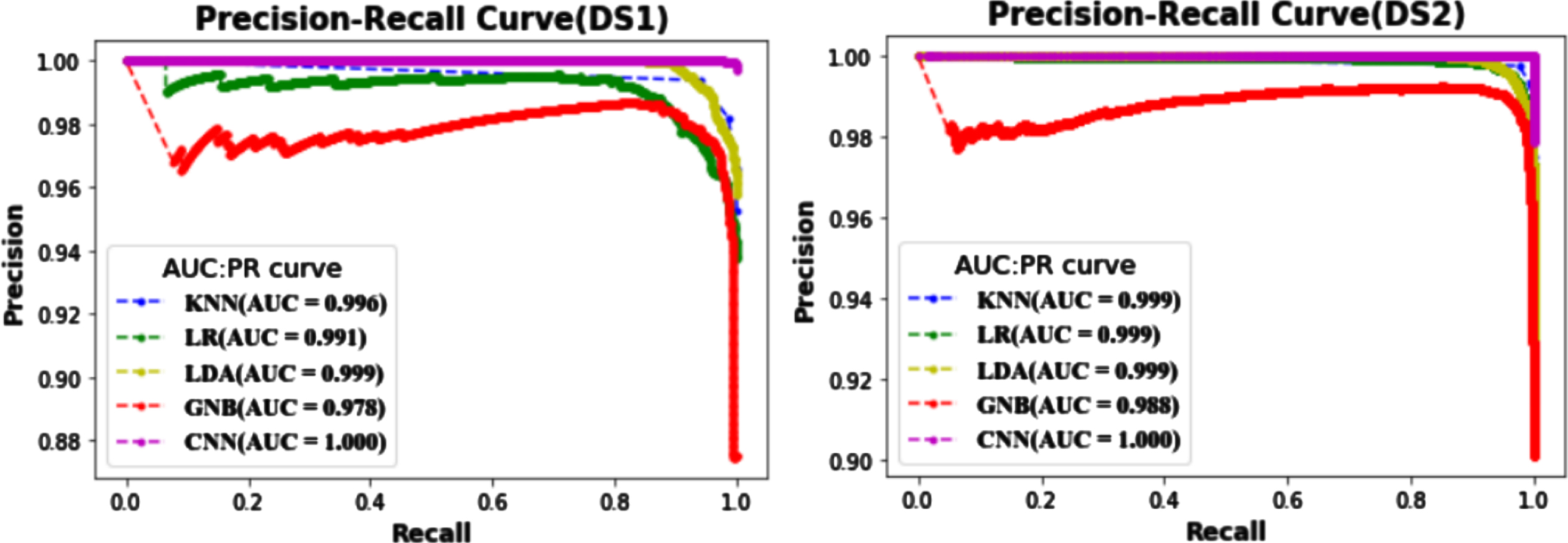
Precision recall curve for AUC for DS1 and DS2.

Precision recall curve for AP (Average Precision) for DS1 and DS2.
In this case also, GNB model yielded the poor performance.
In Table 9, the performance of our predictive model is evaluated and compared with current existing models contributed by other authors in recent years. The results presented in Table 8 demonstrate satisfactory performance of the proposed model in comparison to other models. The results presented in tabular form illustrate that CNN got improvement in precision by 29.79%, 15.01% and 16.4% with respect to [10, 50] methods, respectively. The developed approach achieved F1 score of 99.00 and 99.89 for searches and experience based products, respectively. We also evaluated the research’s findings in terms of average accuracy (AP) with the numerical score of 0.9997 for experienced product (EP) and 0.9999 for search products (SP).
Comparative analysis of the best earlier models
Comparative analysis of the best earlier models
B-GBT: Bagging Gradient Boosted Trees, HQRM: Helpful Quality-related Review Mining, S: Search Product(SP), E: Experience Product(EP), DNN: Deep Neural Network,
As is evident from the results, precision recall curve is near to 1 in our experiment. It indicate that CNN model has a powerful ability to classify the helpful and unhelpful problem. In [10] paper, authors used area under curve (AUC) to assess the predictive power of model and achieved the value of 0.773, although CNN model gives the score of 0.9999 and 0.9998 for the SP and EP datasets that seems to be better than the existing models. In addition CNN model produced the superior outcomes in terms of accuracy.
In this work, various competitive ML algorithms models CNN, KNN, LR, GNB, and LDA were developed in order to perform the classification of user generated text reviews dataset in terms of helpful and unhelpful reviews on two prominent Amazon datasets. In this study, models were trained using integrating the five set of features, which are known as voting, structural, lexical, sentimental, and linguistic characteristics. As discussed in above sections, features have limited scope and performance as an individual entity individual entity. Hence, in this study, we have integrated five set of features to analyze their classification performance in terms of various evaluation metrics such as precision, recall, AP, accuracy etc. To give better insight about the classifiers performance, the developed models generated a particular score. CNN achieved the accuracy of 99.26% and 98.97% for DS1 and DS2, respectively, while it achieved precision of 99% and 99.01% respectively for same datasets. The results produced by CNN model have consistently shown the superior performance over other state of art models, when these models were tested using different product categories available on Amazon. Based on the outcomes presented in results section, CNN model has proven its importance as a competitive classifier as compared to KNN, Linear regression LR, Gaussian Naive Bays GNB, and LDA for review helpfulness prediction problem.
The main limitation of the present work is that it requires manually generated feature set to solve classification problem. However, the present work can be further extended in near future to improve its scalability by using embedding and optimization techniques. The use of innovative features in related fields, such as ranking products based on helpful reviews and identifying prominent reviewers for their efficient ranking based on a hybrid set of attributes, is an additional promising study area.