
Abstract
The unintentional electromagnetic radiation of digital electronic devices during operation can cause information leakage and threaten the information security of the system. In order to explore the leakage level of important information, it is necessary to separate the electromagnetic leakage signal from the complex environmental electromagnetic wave, so the blind source separation technology is studied.Traditional blind source separation methods are mainly unsupervised learning methods, and their separation results are not as expected. In recent years, deep learning technology based on supervised learning has achieved good results in speech separation and other fields, indicating that it is a feasible method.In order to solve the problem of separating source signals from mixed electromagnetic radiation signals and reducing noise interference in electromagnetic safety detection. this paper proposes a Deep Focusing U-Net neural network, which makes the model pay more attention to the features at deeper layer. The network is applied to the blind separation of LCD electromagnetic leakage signals, and the good separation performance proves the effectiveness of this method.
Introduction
Digital electronic equipment sends electromagnetic signals during information processing [1]. For example, when the LCD screen is working, all data is processed and transmitted through the VGA bus, so the voltage in the bus is always changing [2]. The rise and fall of voltage will generate pulse current, generate electromagnetic wave and leak the information being processed. Therefore, in order to investigate the safety of electromagnetic signals of target equipment, it is necessary to conduct blind separation detection of mixed electromagnetic signals [3].
The purpose of blind source separation (BSS) is to estimate the source signal from the observed signal when prior knowledge such as source signal and mixing method is unknown [4]. According to the number of sources signal and the number of observations signal, blind source separation can be divided into three categories. When the number of sources is less than the number of observations, it is called over-determined blind source separation. When the number of source signals is equal to the number of observation signals, it is called positive definite blind source separation. When the number of source signals is greater than the number of observation signals, it is called under-determined blind source separation. Blind source separation technology has important applications in many fields, such as image processing, voice signal processing, and electromagnetic signal processing.
Traditional blind source separation techniques are mostly unsupervised learning methods, mainly including independent component analysis (ICA) [5], Nonnegative matrix factorization (NMF) [6] and sparse component analysis (SCA) [7].
ICA assumes that the source signals are independent of each other and that the mixing is converted to a linear combination of the source signals when the source signal and the mixing matrix are unknown [8]. Therefore, ICA algorithm can solve the problem of Electromagnetic Interference(EMI) signal separation, but it takes a long time. Therefore, Fast Independent Component Analysis(FastICA) [9] is proposed to separate EMI noise faster and more effectively. However, the above-mentioned ICA algorithm also has certain constraints. It is necessary to assume that the source signals are independent of each other and the number of source signals is known. In fact, the number of observed signals may often be less than the number of source signals, so the ICA algorithm cannot be used to solve the problem of under-determined blind source separation.
NMF is a method for matrix factorization, because of the introduction of non-negativity constraints, the decomposition results of NMF have a wide range of practical applications and better interpretability. NMF solves the problem of under-determined blind source separation by estimating covariance matrix and power spectral density. Mirzaei [10] proposed a new method to estimate the number of sources and source separation. The number of sources and the mixed parameters of the channel are estimated by using the peak position of the angular spectrum obtained by the generalized cross-correlation metric of the nonlinear phase transform. The preliminary estimation of the spectrum is obtained by using the estimated mixed parameters through the binary mask. Finally, the Bayesian NMF method is used to decompose each spectrum. Although NMF method has been applied to many practical tasks, it still faces some problems on dealing with noisy datasets. Because traditional NMF methods use mean square error to measure the reconstruction error of matrix factorization,the mean square error loss function forcibly fits outliers.
SCA assumes that the source signal allows sparse representation, and can estimate the mixed matrix and source signal. It uses the sparsity of the signal to estimate the source signal, so it can solve the signal separation problem of sparse representation in the time domain. Zayyani [11] proposed a Bayesian model to estimate the source signal.
With the development of deep learning, more and more scholars have adopted deep learning to solve the problem of blind source separation. Deep learning algorithm has been widely used in single-channel speech signal separation. Wang [12, 13] focuses on the target analysis of supervised speech separation, and compares some traditional methods such as non-negative matrix decomposition with supervised learning methods, indicating the obvious performance advantages of supervised speech separation. Han [14] uses a deep attract network to estimate the vector embedded in the mixed voice frame, and obtains the mask of each speaker to separate the mixed voice signal. Xu [15] applies DNN to speech separation, obtains the time-domain waveform signal of target speech through Inverse short time Fourier transform(ISTFT) [16], and learns the mapping function of speech amplitude spectrum.
In recent years, the application of deep learning technology in time-domain data separation has achieved good performance. Stoller [17] proposed the Wave-U-Net structure, which showed good separation performance. The characteristics of the same time scale are fused through the skip connection operation, which makes up for the lost details in the down-sampling process, and improves the learning performance of the model. It not only solves the problem of end-to-end separation, but also effectively realizes the function of blind source separation in time domain. Because the electromagnetic signal is similar to the audio signal and based on the good separation performance of Wave-U-Net in the audio field, Wave-U-Net is introduced into the electromagnetic signal processing field.
In this paper, in order to separate the source signal from the mixed electromagnetic leakage signal in a complex environment, We studied Wave-U-Net, optimized the weight of different layers, focused the model on deep pure features with less noise interference, and proposed a Deep Focusing U-Net to realize blind source separation of electromagnetic leakage signals. The experimental results show that this method can obtain good separation performance. The contributions of this paper are as follows. The characteristics of several blind source separation methods are briefly introduced. In order to solve the problem of electromagnetic wave separation, we introduce Wave-U-Net, which is due to its outstanding performance in music source separation. Attempt to improve some of the shortcomings of traditional Wave U Net. The traditional Wave-U-Net only connects the feature map of the same layer by skipping the connection operation, while ignoring the importance of the underlying pure feature. According to the concept of residual connection, the depth focus U-Net increases the skip connection between different layers, and increases the weight of the depth feature. Therefore, the deeper the layer, the greater the weight, and the more attention the model pays to the deep features. It not only reduces the error in the up-sampling recovery process, but also makes the model pay more attention to the characteristics of the bottom layer with minimum clutter. Find the best hyperparameter through experiment, it is found that the 5-layer Deep Focusing U-Net is the most suitable electromagnetic signal dataset for this experiment. The performance test of the activation function shows that when ELU activation function is used, the Deep Focusing U-NET obtains the best performance. Compare the separation performance of Deep Focusing U-Net with other network structures. Through comparison of Full-scale skip connection U-Net, U-Net3+, and Deep Focusing U-Net, the results show that Deep Focusing U-Net has the best separation performance in electromagnetic wave source separation.
Deep focusing U-Net
By applying prior knowledge to the preprocessing of mixed signals, we extract signal source 1 and signal source 2 as target signals. The mixed signal is used as the input, and the signal source 1 and signal source 2 are learned in the way of supervised learning through the Deep Focusing U-Net network. Encode, Decode and skip connection are used for feature extraction. The loss function of supervised learning is obtained by the sum of the mean square error of the output signal and the signal source. After network adjustment, judge whether the best separation result is obtained and terminate the separation training. The flow chart of the proposed system is shown in Fig.1.
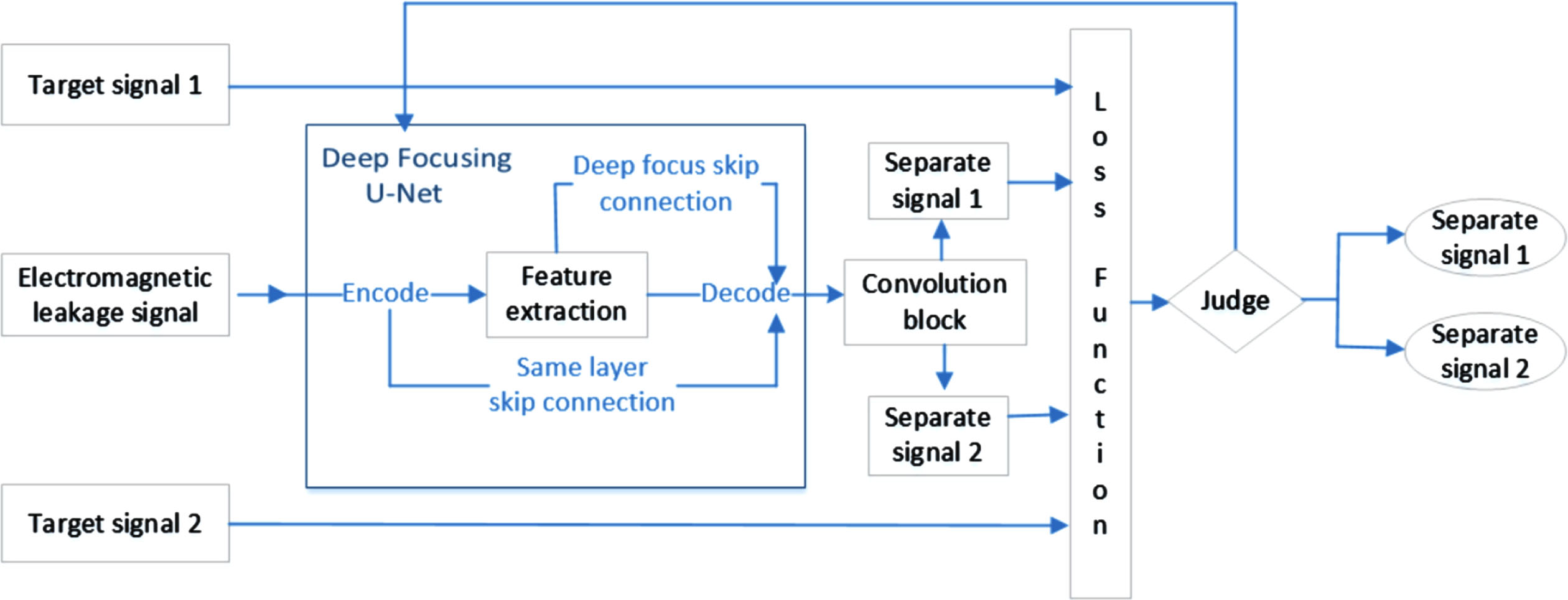
Flowchart of the proposed system.
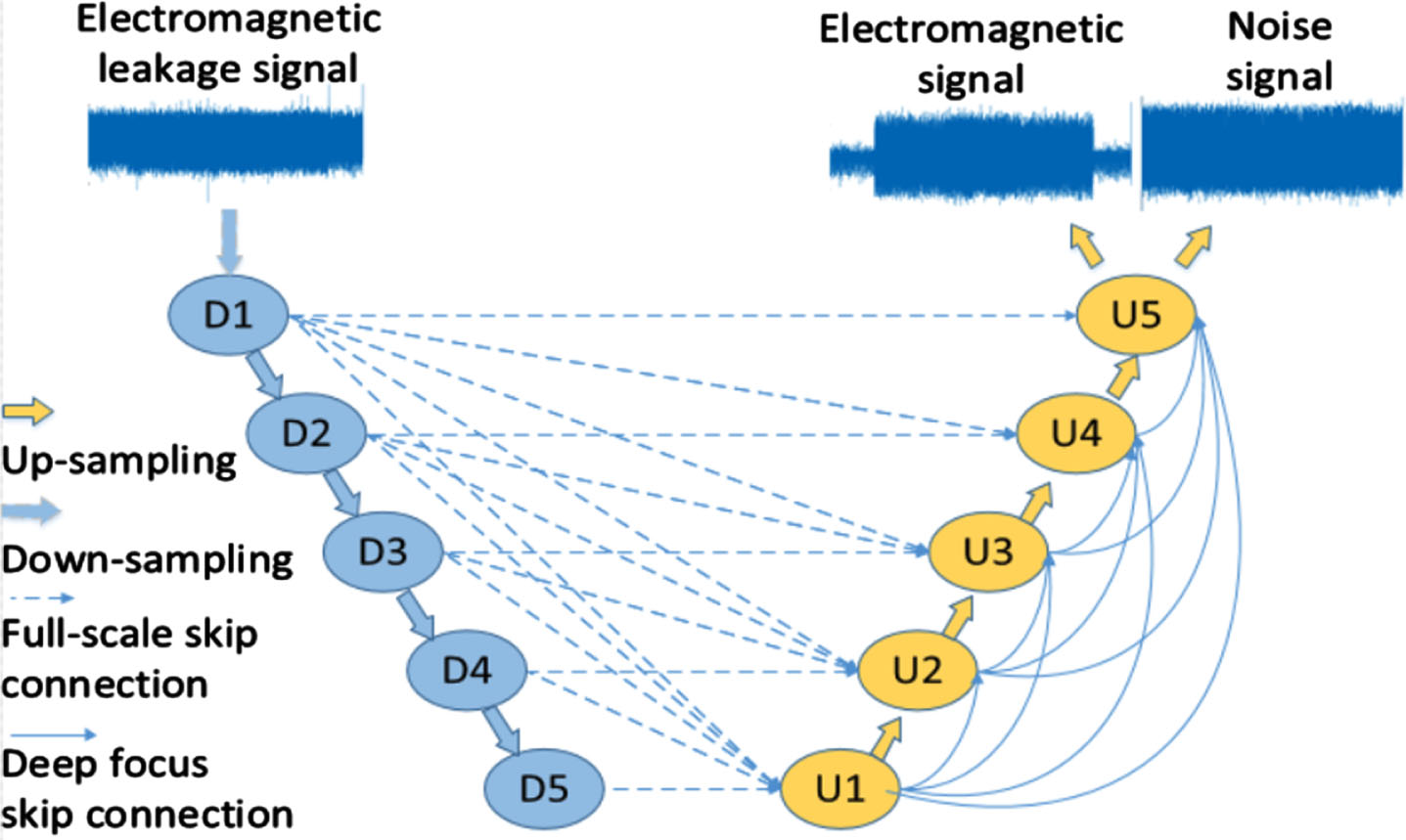
The Deep Focusing U-Net is composed of four parts: Down-sampling module, Up-sampling module, Same-layer hopping connection module and Deep-focus skip connection module. Deep Focusing U-Net flow chart is shown in Fig.2.
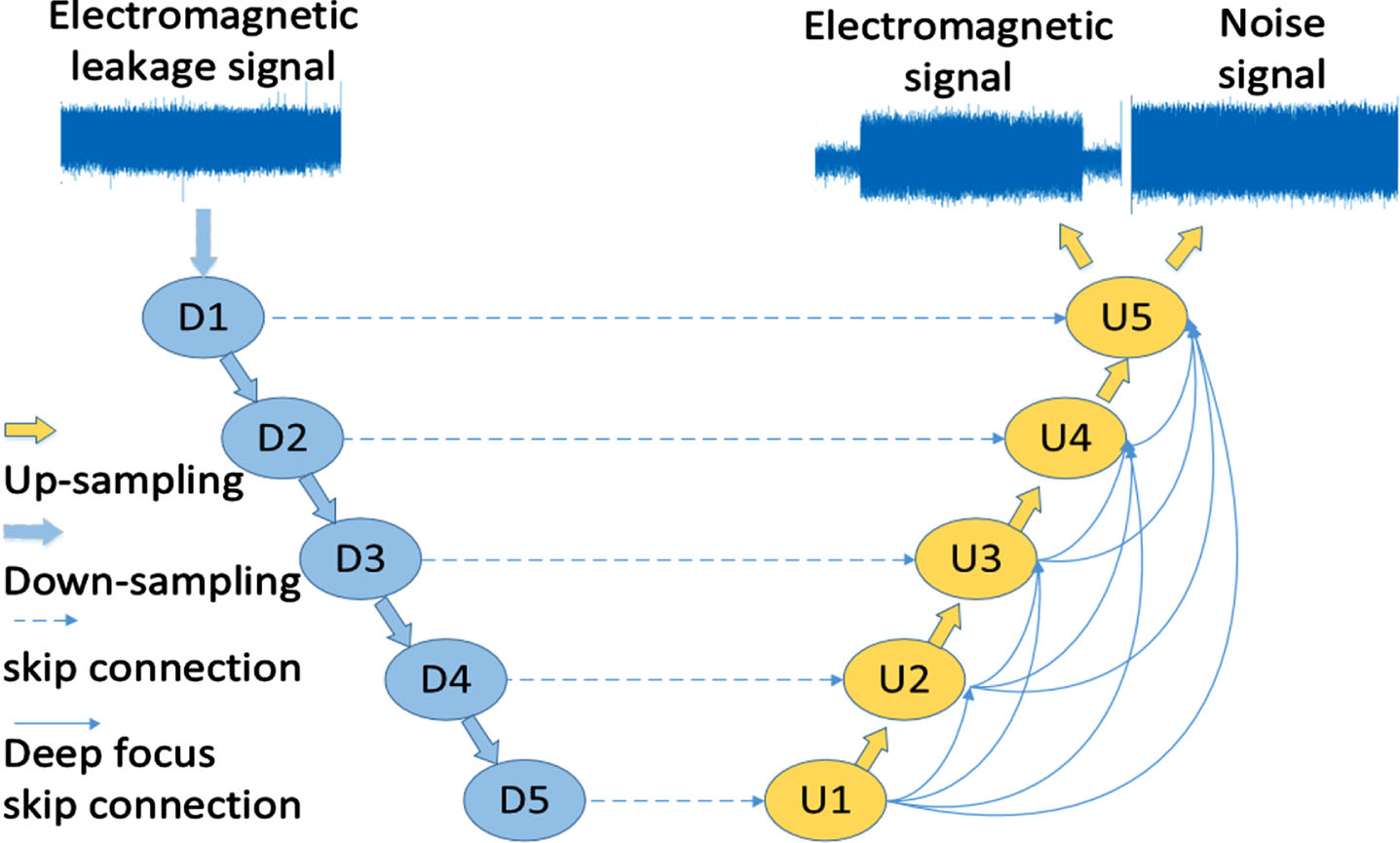
Deep Focusing U-Net.
Encoder is Down-sampling [18] operation, which obtains signal features of different depths through convolution and interval sampling. Decoder is Up-sampling operation [19], and gradually recovers the depth feature information obtained from the feature map through deconvolution and linear interpolation. Same layer skip connection [20] can connect the characteristics of the same layer encoder and decoder. Then, as the input of the next upper sampling block, the feature loss is compensated.
The Deep focus skip connection increases the weight of the depth feature map, making the model pay more attention to the depth feature during training. The depth focus skip connection first adjusts the feature map of different layers to the size of the target layer through convolution, and then extends the feature map of the target layer through connection. The characteristics of the bottom layer are connected to all the layers above by skipping the connection operation. The number of connections increases according to the depth of the layers. Therefore, the deeper the number of layers, the greater the weight in the final total characteristics.
The output of Deep Focusing U-Net is pure electromagnetic signal and noise signal. Each output is assigned an independent convolution separation module, and category labels are learned through the softmax layer. The loss function is obtained by the sum of the mean square error (MSE) of each output signal and target signal. Through multiple iterations of the back-propagation algorithm [21], update the weight parameters of the convolution layer, determine whether the loss value is relatively stable, and then terminate the training process.
Dataset
We collected the electromagnetic leakage signals of 46 LCD monitors in the laboratory as a data set, with more than 500 frames of data. One frame of data is collected from each computer at a speed of 250MHZ. The acquisition equipment is a Ni PXIE-5162 high-speed A/D card, which synchronously collects multiple signals from VGA cables [22], including horizontal synchronization signal, vertical synchronization signal, blue signal and electromagnetic leakage signal.The first three signals are collected through oscilloscope probes, and the electromagnetic leakage signal of VGA cables is collected through current probes. Signal probe device are shown in Fig.3.

Detection device.
Deep Focusing U-Net is supervised learning, so it needs to collect and classify learning samples. The dataset includes mixed electromagnetic leakage signal, RGB signal and horizontal synchronization signal. The mixed electromagnetic leakage signal is shown in Fig.4, the RGB signal is shown in Fig.5, and the horizontal synchronization signal is shown in Fig.6.

Mixed electromagnetic signals.

RGB signal.
Horizontal synchronization signal.
According to the working principle of the monitor [23] shown in Fig.7, in the preprocessing, the signal values at the beginning and end of each frame signal are very large, so the horizontal synchronization signal can be binarized to find out all the beginning and ending places. The result of binarization can be used to distinguish the beginning of the frame and the end of the frame through the difference operation. The RGB signal is subjected to a binary difference operation to obtain a signal mask. The pure electromagnetic signal is obtained by multiplying the mixed electromagnetic leakage signal and the signal mask. The noise sample is obtained by subtracting the pure electromagnetic signal from the mixed electromagnetic leakage signal. All learning samples are divided into training set and test set according to the ratio of 4:1.
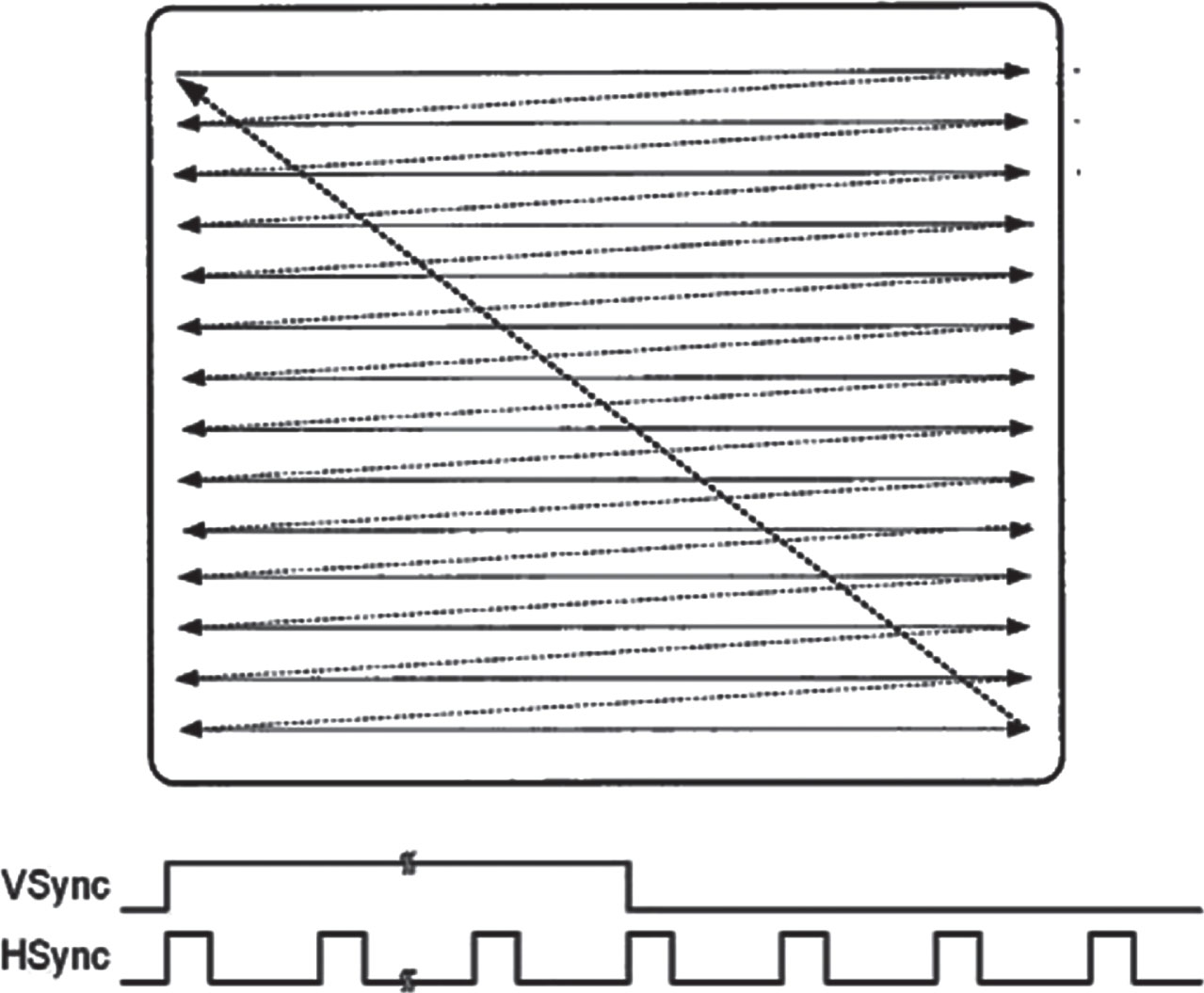
The principle of screen reproduction.
In the experiment, Mean Square Error [24] (MSE), Signal Noise Ratio [25] (SNR), and Pearson Correlation Coefficients [26] (PCCs) were used to measure the separation performance of the model for electromagnetic leakage signals.
Mean squared error
Mean squared error measures how different the separation result is from a pure electromagnetic signal. The smaller the MSE, the smaller the error and the better the separation effect. The mean squared error is defined as Equation 1.
Where n is the total length of the signal, x i is mixed electromagnetic leakage signal, f(x i ) is the separation result, and y i is the pure electromagnetic signal.
Signal-to-noise ratio (SNR) refers to the ratio of signal difference to noise difference. The signal difference is represented by the difference between the separated signal and the signal source, and the noise difference is represented by the difference between the mixed signal and the signal source. The SNR of this experimental design is shown in Equation 2.
Where S h is the collected mixed electromagnetic signal, S b is the pure electromagnetic signal, and S f is the electromagnetic signal after model separation. In the formula, the closer S f and Sb are, the smaller the molecule is. Because there is a negative sign in front of the formula, the closer the separation result is to the target, the greater the signal noise ratio, and the better the separation performance.
Pearson correlation coefficients (PCCs) measure the similarity of the two groups of data. The output range is - 1 to+1, where 0 represents no correlation, negative value represents negative correlation, and positive value represents positive correlation. The closer the value is to 1, the more similar the signal is, So it can show the similarity between the separation result and the signal source. PCCs are shown in Equation 3.
Where x is the separation result signal, y is the pure target electromagnetic signal, n is the length of the electromagnetic signal, cov is the covariance, E is the mean, and s is the standard deviation.
The number of layers affects the learning performance of U-Net [27]. Feature maps of different depths have different features for learning. The most suitable number of layers for the electromagnetic signal dataset is also to be investigated. Therefore, in order to find the most suitable number of layers for this experiment, Deep Focusing U-Net tests the separation performance of one to ten layers. The separation performance is shown in Fig.8, Fig.9, and Fig.10, and the specific values are shown in Table 1.
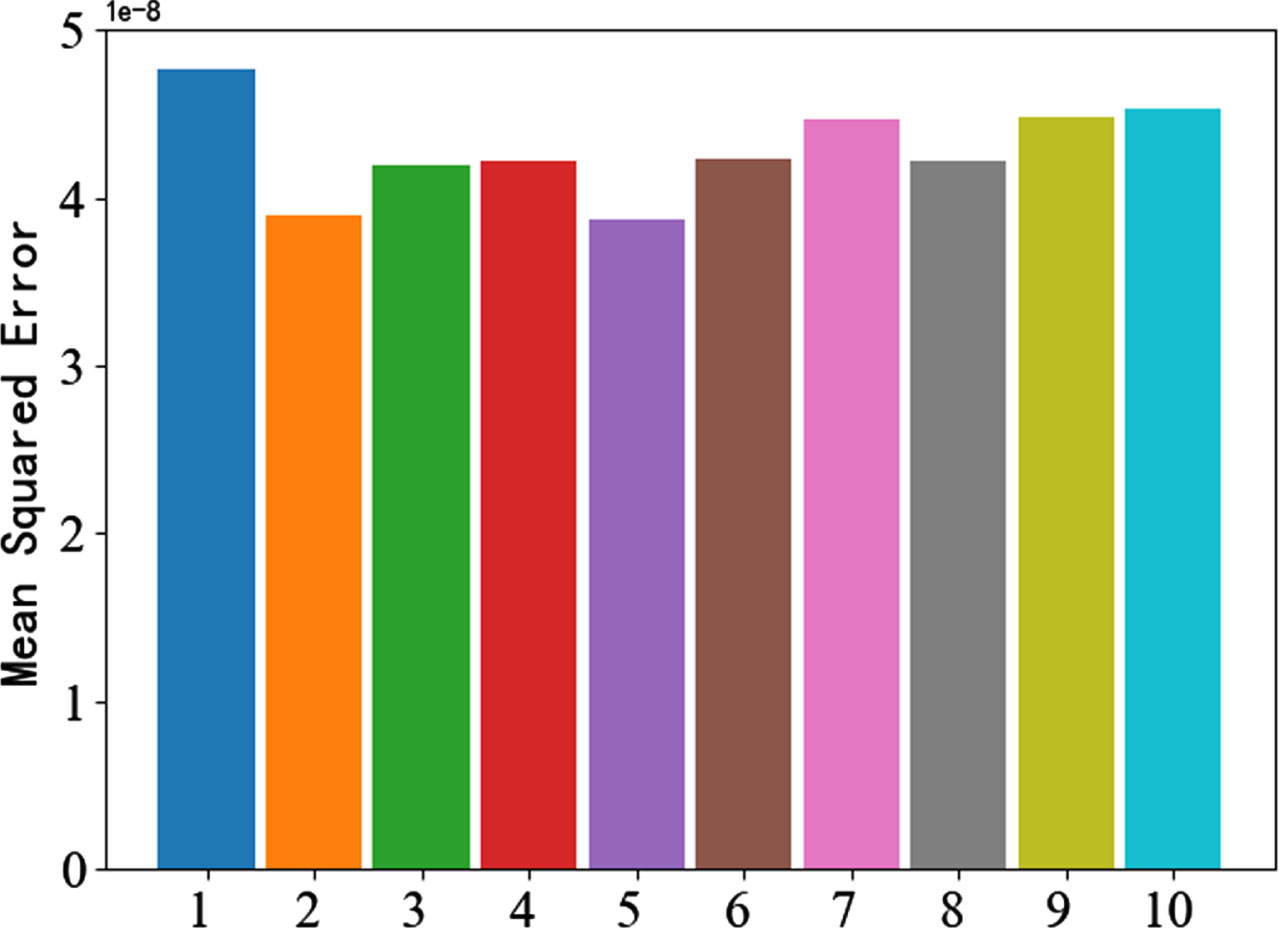
MSE of different layers.
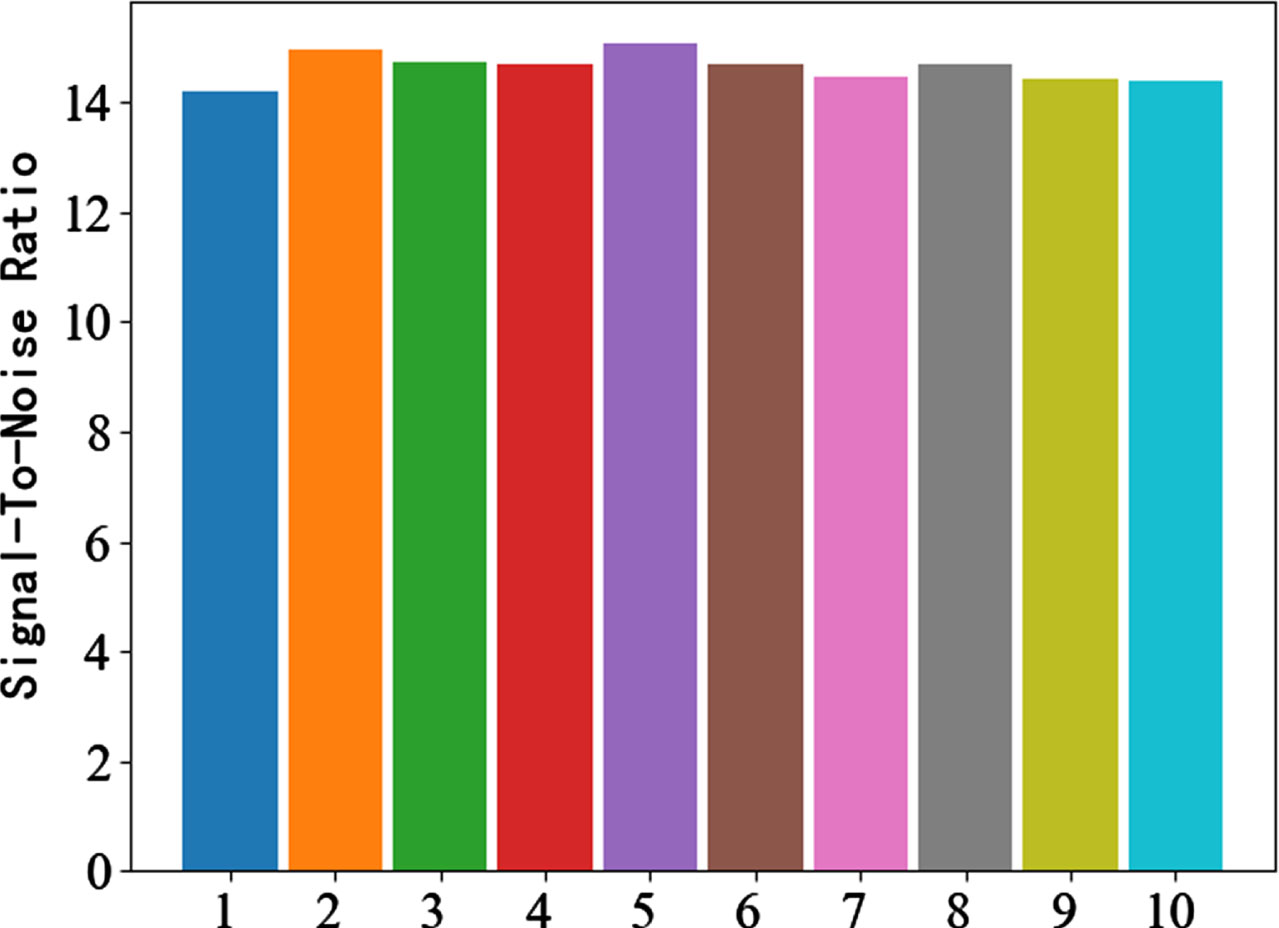
SNR of different layers.
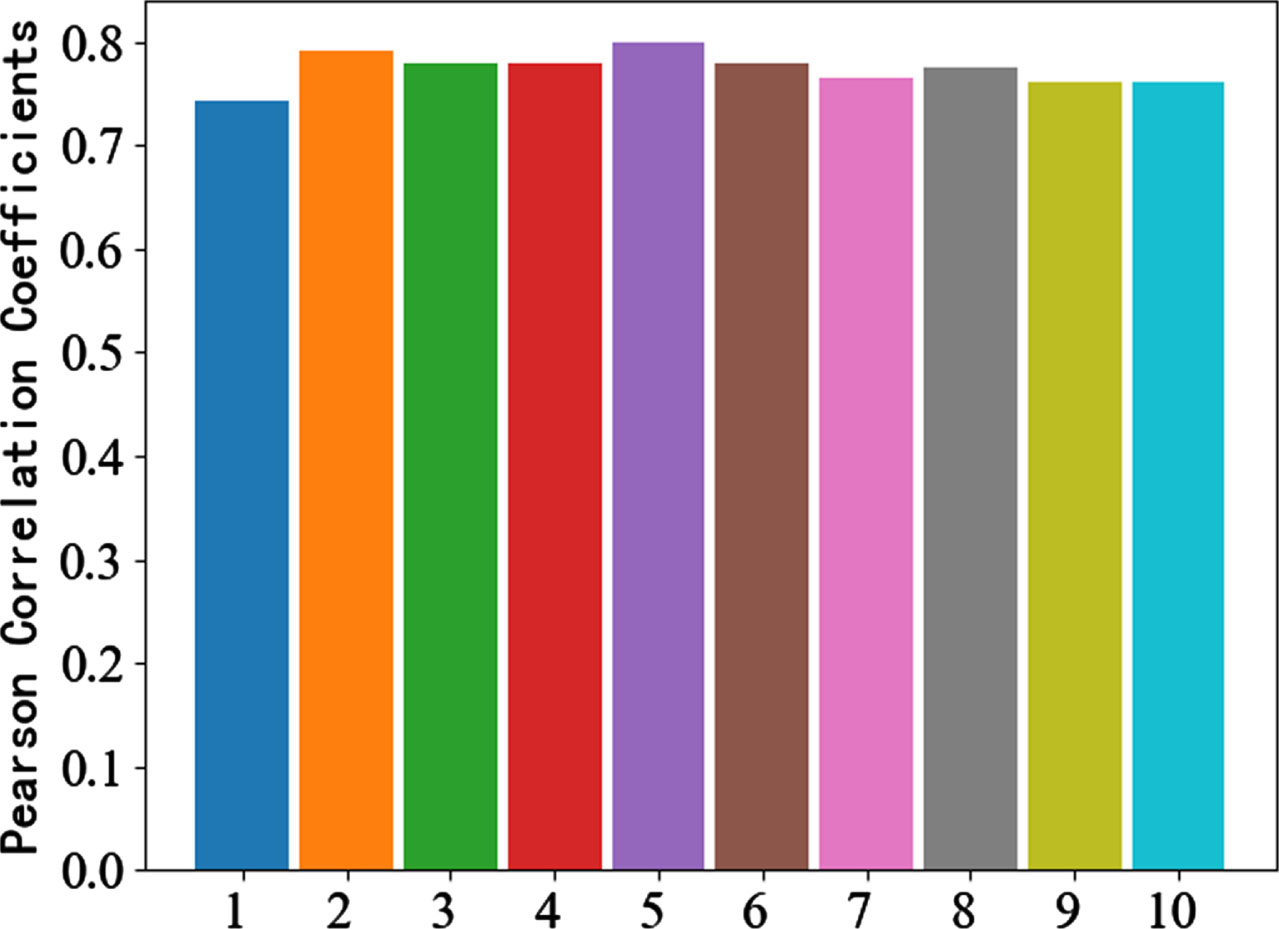
PCCs of different layers.
Separation performance of different layers in Deep Focusing U-Net
It can be seen from the Table 1 that the separation performance of the five-layer U-Net model is the best, not only the MSE is relatively small, but the SNR and PCCs are also relatively small and relatively high, so for this dataset, the five-layer Deep Focusing U-Net has the best separation performance.
Different activation functions will affect the separation performance of model [30]. Some commonly used activation functions are tested, such as tanh,Leaky relu,linear,ELU,Selu and swish activation functions. The performance evaluation results are shown in Figs. 11–13, and the performance values are shown in Table 2.
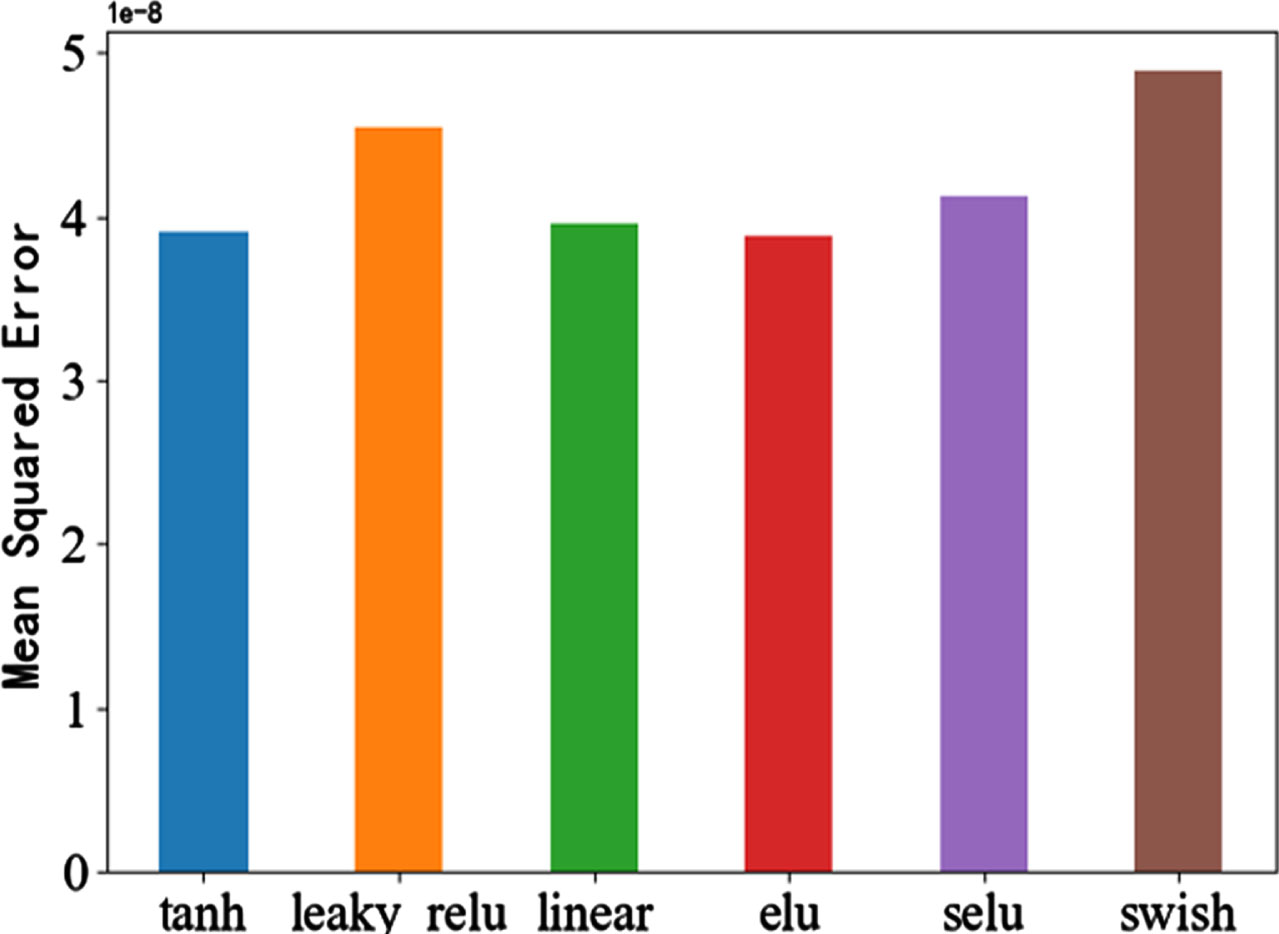
MSE of different activation functions.
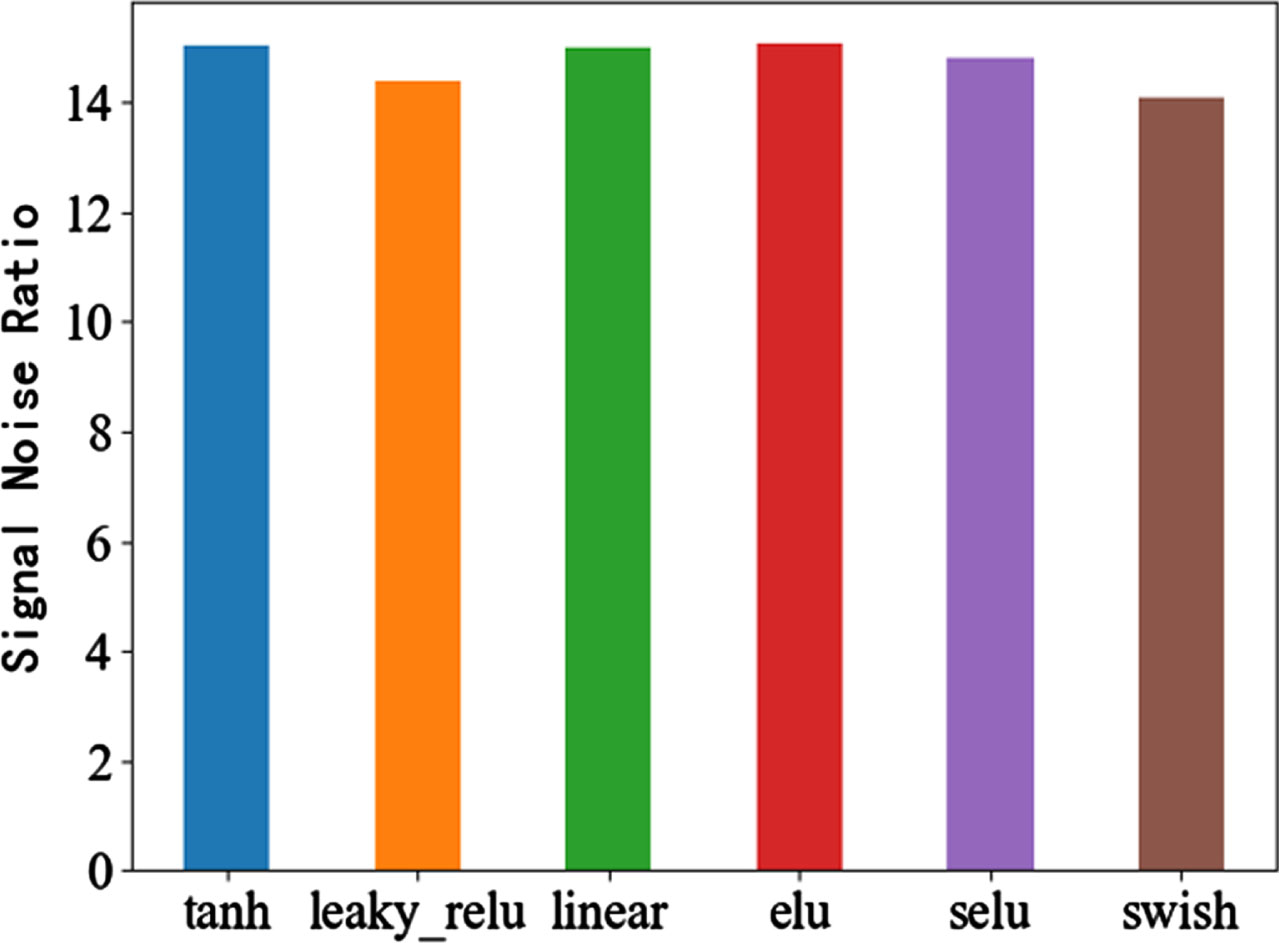
SNR of different activation functions.
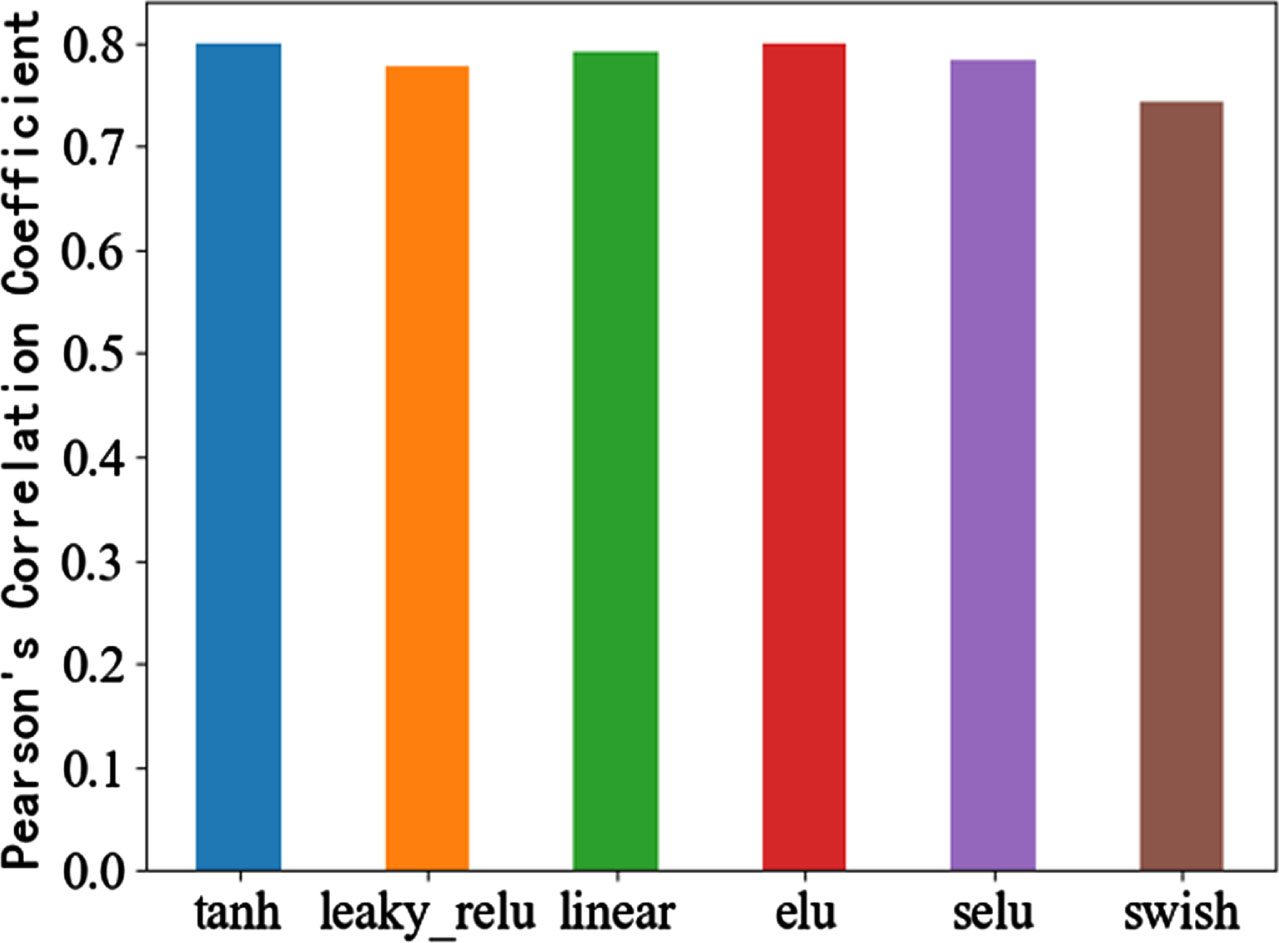
PCCs of different activation functions.
Separation performance of different activation functions
It can be seen from Table 2 that when using the Elu activation function, the MSE is the smallest, the SNR value is the largest, and the PCCs is the largest, so the most suitable activation function in this experiment is the Elu activation function.
The ELU activation function solves the problem of neuron death [31]. Exponential correction is performed on the negative part of the ReLU activation function to reduce the gradient difference and enhance the stability of the model. Similar to Leaky ReLU, ELU solves the problem of negative values, so the mean is close to zero and the learning speed is accelerated. The advantage of ELU is that it not only avoids neuron death, but also has some advantages of ReLU and Leaky ReLU functions, while the average output value is close to 0, which speeds up the convergence of the network.
Three variant U-Net models are used to compare the separation performance. Wave-U-Net, Full-scale skip connection U-Net and U-Net3+ all use the same 5-layer depth and ELU activation function as the Deep Focusing U-Net. Wave-U-Net is shown in Fig.14, Full-scale skip connection U-Net is shown in Fig.15, and U-Net3+ is shown in Fig.16.
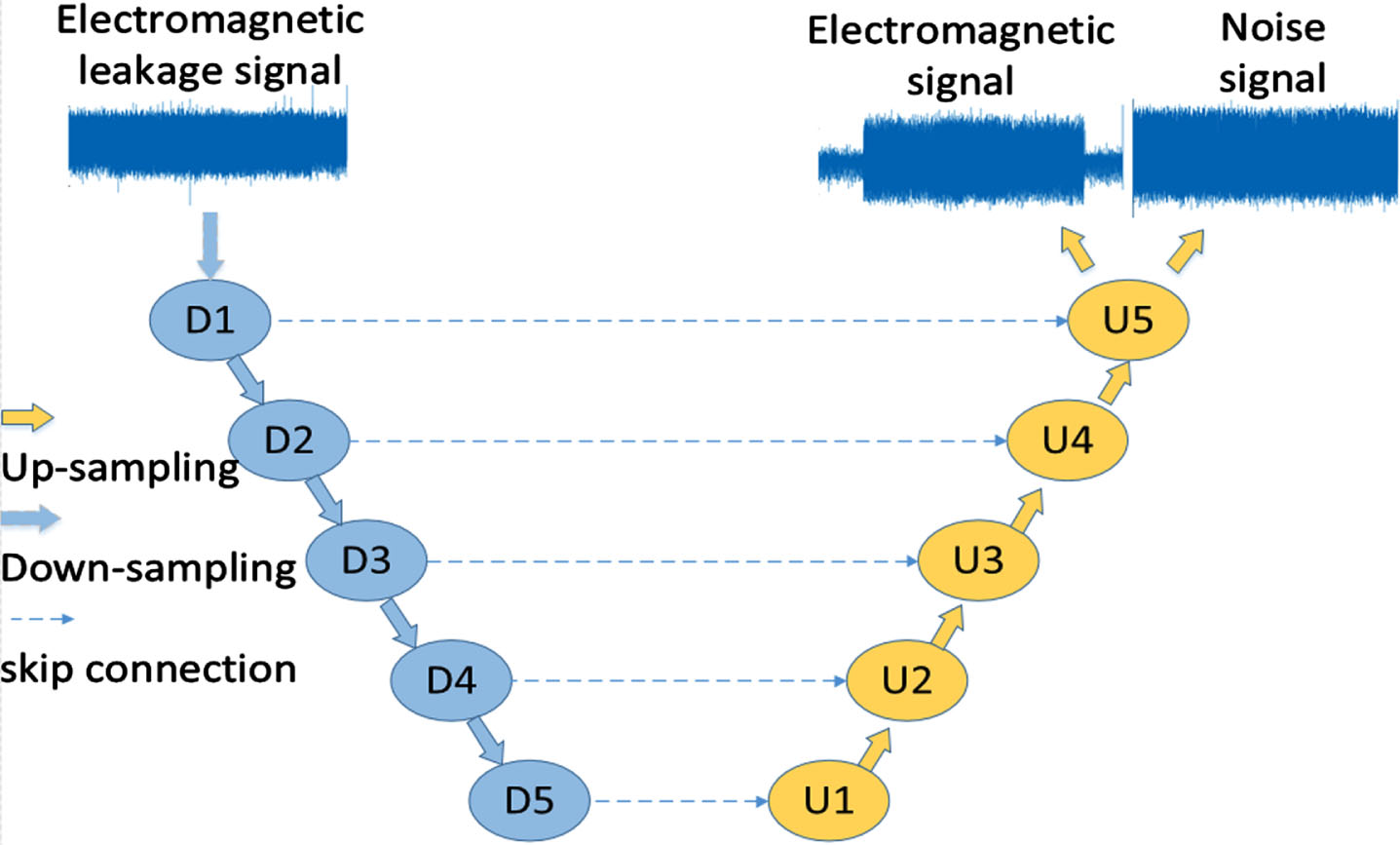
Wave-U-Net.
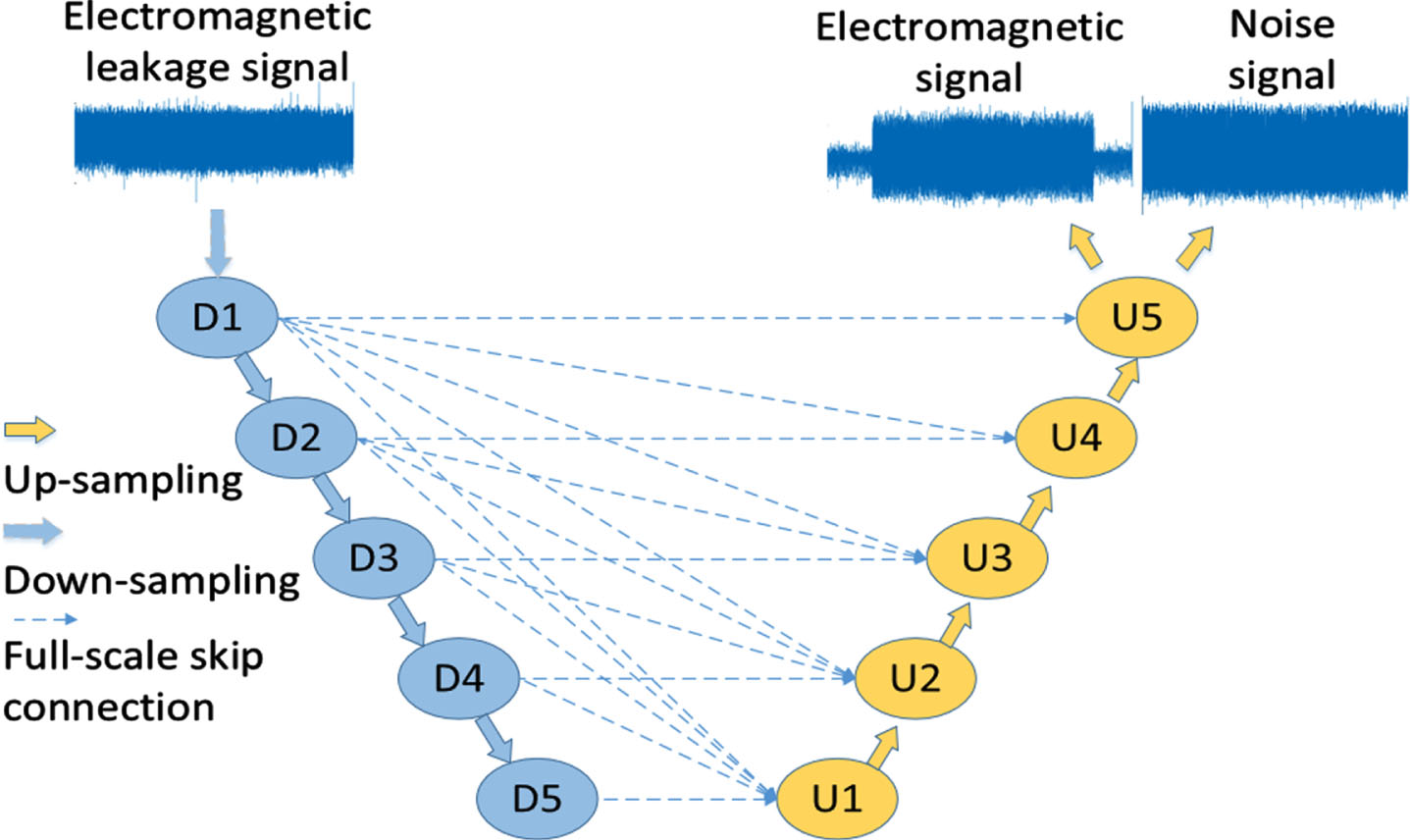
Full-scale skip connection U-Net.
U-Net3+.
As can be seen from the data in Table 3, the separation performance of Deep Focusing U-Net is improved compared to the Wave-U-Net structure, the Full-scale skip connection U-Net, and the U-Net3+. Deep Focusing U-Net has the smallest MSE and largest SNR. The U-Net3+ has the largest correlation coefficient. Because MSE and SNR are absolute metrics and PCC is a relative metric, the proposed Deep Focusing U-Net is the best model for this experiment.
Separation performance of U-Net variant models
The Deep Focusing U-Net, which has the best separation performance, was used to test the separation effect of the electromagnetic signal.According to the screen display principle, the image reconstructed from the mixed electromagnetic signal is shown in Fig.17, and the image reconstructed from the separated electromagnetic signal is shown in Fig.18. This group of reconstructed images is the situation before and after the separation when displaying Chinese. The latter two groups of reconstructed images are the situation of displaying only English letters and mixed Chinese and English characters, as shown in Fig.19 22. It can be seen that the model has good separation performance.

Image reconstructed from the mixed electromagnetic signal when displaying Chinese.

Image reconstructed from the separated electromagnetic signal when displaying Chinese.

Image reconstructed from the mixed electromagnetic signal when displaying English letters.

Image reconstructed from the separated electromagnetic signal when displaying English letters.

Image reconstructed from the mixed electromagnetic signal when displaying Chinese and English.

Image reconstructed from the separated electromagnetic signal when displaying Chinese and English.
In the detection of electromagnetic safety, it is necessary to solve the blind separation of mixed electromagnetic radiation signals, extract source signals and reduce noise interference. This paper proposes a Deep Focusing U-Net neural network. Due to the large noise interference of shallow layer features, we pay more attention to deeper layer features. Through Deep focus skip connection, let the model pay more attention to the pure characteristics of the deeper layer. In the blind separation of LCD electromagnetic leakage signals, the 5-layer Deep Focusing U-Net neural network with ELU activation function can separate electromagnetic signal from noise signal and work well under different conditions. The experimental results show that the proposed deep-focused U-Net network is superior to Wave-U-Net, U-Net3+and full-scale hop-connected U-Net networks, and achieves better separation performance.
In subsequent experiments, we will consider the addition of other frameworks to improve the separation effect, such as adding attention mechanism, GAN network and other structures, which may further improve the separation performance of the model.
Footnotes
Acknowledgments
This work was supported by Jimei University Doctoral Start-up Project Fund ZQ2021005.