
Abstract
Human faces have been naturally viewed as a central part in each image. One interesting task is to classify each face into different categories based on the emotion shown in the facial expression. In addition, an awareness of emotion during work on a project and how affective states are presented in the communication style might help system developers work more effectively, thus improving the performance of a collaborative team. Currently, the feasibility and portability of emotion recognition in the platform with Raspberry PI are insufficient. Hereby, a novel emotion recognition system in real time using the edge computing platform with deep learning has been implemented successfully. The feature values of objects are calculated by a high computing processor on the embedded platform. When an object with the matching features is detected, it is drawn as a rectangular bounding box and the results are displayed on the screen. In the proposed system, it first annotates the image datasets and saves them in the corresponding input data format for model training. Thus, the You Only Look Once (YOLOv5) model has been employed for training because it is a state-of-the-art object detection system. In other words, a fast and accurate emotion recognition is the main benefits of choosing YOLOv5 model. Then, the correctly trained YOLOv5 model file is loaded into an edge computing platform; and the feature values of objects are analyzed by a high computing processor. Finally, the experimental results show that the promising mean Average Precision (mAP), 92.6%, and recognition speed in Frames Per Second (FPS), 40, are obtained, which outperforms other existing systems.
Keywords
Introduction
Nowadays, there are lots of artificial intelligence (AI) techniques, in which machine learning and deep learning are used to enhance the scale of applications. The learning algorithms are executed on the architectural elements of neural networks so that computers with high performance can complete many things in a self-thinking mode like human beings [1]. Currently, the recognition technologies are widely employed and become more popular. For example, facial recognition is used as identity verification and people counting; and license plate recognition is used to recognize the car owner in the parking lot and applied for the road tracking [2]. Furthermore, the facial recognition can be applied for the basic emotional classification and the analysis of preference for certain things. It can even be equipped with a portable type of high-computing embedded platform for emotion recognition in real time, which might create more innovative applications [3].
In the recognition system, many training environments and equipment are used to execute the related programs through local high-performance computers, such as large-scale data collection and interpretation. It uses the Graphics Processing Unit (GPU) with a powerful and high-standard time-sharing feature to carry out the action such as data training [4]. Finally, it uses an industrial computer for the facial emotion recognition by the end devices, which can even be applied for portable and outdoor real-time image recognition [5]. Industrial computer is a special-purpose computer and more powerful than the general-purpose computer.
The image datasets are collected for annotation, labeling, training, and recognition, using the concept of time-sharing and industrial computer with a high-performance GPU as the data training environment. The more advanced YOLOv5 model aims to make the entire system more feasible [6]. YOLOv5 is the world’s most acceptable vision AI, representing Ultralytics open-source software, and incorporating lessons learned and best practices evolved over thousands of hours for research and development. To realize the portable and real-time image recognition, the trained model files are transplanted to an embedded platform. Therefore, the high computing processor, Kendryte K210, part of the MAIX platform, is used as a computing core to output the recognition results.
Problem statement: In the existing methods, the preprocessing of image datasets was not done well so that the goal of fast and accurate recognition of emotion category cannot be easily achieved due to their unstructured datasets [7]. Meanwhile, the feasibility and portability of emotion recognition are not good enough in the platform with Raspberry PI because of their insufficient functions [8]. Especially, it has poor capability to predict multiple objects and their locations at the same time [9]. Thus, it is the main reason to propose this edge computing system to solve the above problems.
The remainder of this paper is organized as follows: Section 2 discusses the literature review of emotion recognition systems. The system development with hardware structure and software tools are described in Section 3. The trained YOLO5 model with experimental results is presented in Section 4. The embedded platform with experimental results is presented in Section 5. Section 6 presents the detailed discussion on all experimental results. Finally, the conclusion is remarked in Section 7.
Literature review
This section presents the structure of model training, YOLO model, face recognition, edge computing platform, and related works.
Structure of model training
Convolutional neural network (CNN) is a feedforward neural network, which is formed from one or more convolutional layers and fully connected layers [10]. It consists of the numerical weights on pooling layers. This system takes advantage of the two-dimensional structure of the input data and related mathematical algorithms for computational analysis and learning. It has a good effect on large-scale image processing.
When computer and machine are expected to distinguish and recognize objects, it is necessary to train the datasets through the process of model training, and then the corresponding relationship between the features of an object to be identified is calculated and analyzed through the learning algorithm. Lastly, the bounding box of the recognized object will be drawn and displayed on the monitor.
YOLO model
You Only Look Once (YOLO) is the most advanced object detection system for real-time images, which applies the neural network algorithm [11]. The author, Joseph Redmon, used a small-scale structure to implement Darknet. The model structure has been applied to pedestrian recognition, industrial image recognition, and other application systems with the advantages of light weight, less dependence, and high-performance.
When using the YOLOv5 model to train, different versions have their own setting files, which need to be adjusted based on the relevant parameters, namely, batch, subdivisions, max batches, steps, object classes, as well as the parameters associated with YOLOv5 and hierarchical convolution structure [12]. Then, training and learning will be carried out with proper environment and equipment; and some relevant information such as current iteration, current loss, average loss, learning rate, total running time, and total image count is all displayed on the screen. Next, the model is gradually trained to complete and store a model file in the corresponding format. Finally, the model file can be applied for detection and recognition [13].
A face recognition system refers to the interpretation of two-dimensional image based on the faces in the datasets. It uses the training model to learn and analyze the relevant features, which can be divided into four steps to perform: the first step is to recognize the face for segmentation in the image background; the second step is to align the segmented face in the image, considering the face pose and size, and photographic attributes, such as light and darkness; the third step is the alignment process, which is the accurate positioning related to facial feature extraction such as eyebrows, eyes, nose, and mouth; and the fourth step is to analyze the established database with face featured values. Also, the related application systems include face positioning, identity confirmation, and identity search [14, 15].
Hardware and software development platform
This study adopts the edge computing platform, MAIX DOCK BEST KIT FRO RISC-V AIoT, produced by SiPEED company to realize the real-time image system [16]. This development board is equipped with Kendryte K210 Processor (i.e. KPU Neural Network Processor (NNP)) as the core of deep learning [17]. The development board of this MAIX series is mainly used for those image processing applications such as face recognition, object recognition, handwritten digit recognition, and 20 object classifications in YOLOv5-Tiny version. The MAIX series has complete hardware development modules, namely, image module, memory module, network module, bus module, camera, and LCD module, which are provided for the self-developing applications.
The software development platform, MaixPy, creates an easy-to-use software development kit (SDK) for image edge computing. It also makes AIoT program writing easier and better for development [18]. Based on the use of the Micropython program function library, it can run on the embedded platform with high computing power processor, Kendryte K210, and currently supports K210 processor with AI hardware accelerator as a carrier.
Preprocessing of image datasets
For machine learning in AI, supervised learning is a common and appropriate method. This step is to annotate the image datasets which need to be trained. In other words, each image needs to be labeled as a different class name, and to label the related image information of each object class. It consists of the stored path of image files, the name of each object class, and the coordinate parameters of the bounding box. The information is stored in the corresponding file of data formats, such as TXT, CSV, and XML, where the tools for annotating and labeling the images include computer vision annotation tool (CVAT), LabelImg, and visual object tagging tool (VoTT).
Input data format of a training model
A suitable model needs to be selected to train the image datasets, and before training, the datasets must be converted into an applicable file of the input data format. This step is required to convert the.xml file including plenty of information into five text files in.txt, which includes the object category index of the target bounding box in the image, namely, the ratio of central coordinates (x
center
and y
center
) of the normalized target bounding box to the width (w) and height (h) of the image (x
min
, x
max
; and y
min
, y
max
), and the ratio of the width (yolo
w
) and height (yolo
h
) coordinates of the normalized target bounding box to the width (w) and height (h) of the image. The calculation formula of the conversion process is denoted as Equations (1) to (4).
YOLOv5 was used to train and learn the features of the object class. The training process of this model is different from other model structures. Through the features in each image, cut it into S x S grids, then predict each bounding-box, and each grid will predict B bounding-box and reliability confidence scores. At this step, the probability of each object class in each bounding box can be calculated, and the confidence score is the confidence level of the object in the corresponding bounding box and the accuracy of the object in each bounding box, which is denoted as Equation (5) [19].
Each bounding box has five parameters: x and y denote the displacement of the center of the bounding-box in each grid, w and h denote the width and height of the bounding box, and confidence score represents the Intersection over Union (IOU) value, which is a standard to measure the accuracy of detecting the corresponding objects in a specific dataset. In addition, the conditional class probabilities of each object class corresponding to each grid are calculated and analyzed. In the test, the probability is multiplied by the reliability score in each bounding box, denoted as Equation (6).
Therefore, the reliability of the object class is calculated in each bounding box, and the image is divided into S x S grids, so that each grid can predict the probability of B bounding boxes and C classes. Moreover, the final Tensor dimension is S * S * (B * 5 + C), the result of this operation.
The YOLOv5 training process is based on the ImageNet datasets collected in 2015, which contains 1000 object classes, including the first 20 layers of convolutional layers, average pooling layers, and fully connected layers. It takes about a week of training time and the accuracy of the final top-5 can be up to 88%, in which both training and inference use the Darknet framework. And the training model adds a four-layer convolutional layer and a two-layer fully connected layer with random parameters, which can improve the detection performance of the model. In addition, the object detection requires more detailed feature values, so the original input size is increased from 224×224 to 448×448, and the final fully connected layer can simultaneously predict the probability of each class and the coordinate of the bounding box. Meanwhile, the width and height of a bounding box are normalized as 0 or 1 through the width and height of the image, and so do the other two parameters (x and y) for each grid. Linear activation is used in the last layer in the CNN model, and other neurons are conducted by the Leaky Rectified Linear Activation (Leaky ReLU), denoted as Equation (7) [20].
When the YOLOv5 model is selected for training, each version of the series has a setting file (.cfg) for the corresponding model. These files contain the framework of all layers of model structure in each version, as well as the parameters such as batch, subdivisions, image width and height, max batches, steps, and object classes, that need to be pre-set or adjusted in advance. The parameters to be adjusted are closely related to the image datasets and the training environment and equipment.
After the model training is finished and the files are stored in the related formats, the validation datasets can be used to assess the accuracy of the model. The assessment of the YOLOv5 model mainly adopts the common indices of object detection, such as IOU and mean Average Precision (mAP) values [19].
The first one is IOU value, which is an index used to assess and measure the accuracy of an object detector on a particular dataset [20]. Figure 1 depicts the intersection of two bounding boxes for calculating IOU value and how to calculate the IOU value [21]. Assume that bounding box 1 is denoted as [x1, y1, x2, y2], and bounding box 2 is denoted as [x3, y3, x4, y4]. Then the IOU values can be found, in which the most common standard for general prediction is.5 IOU value. It means that in a bounding box prediction, when the IOU value is larger than 0.5, the prediction is successful [22].
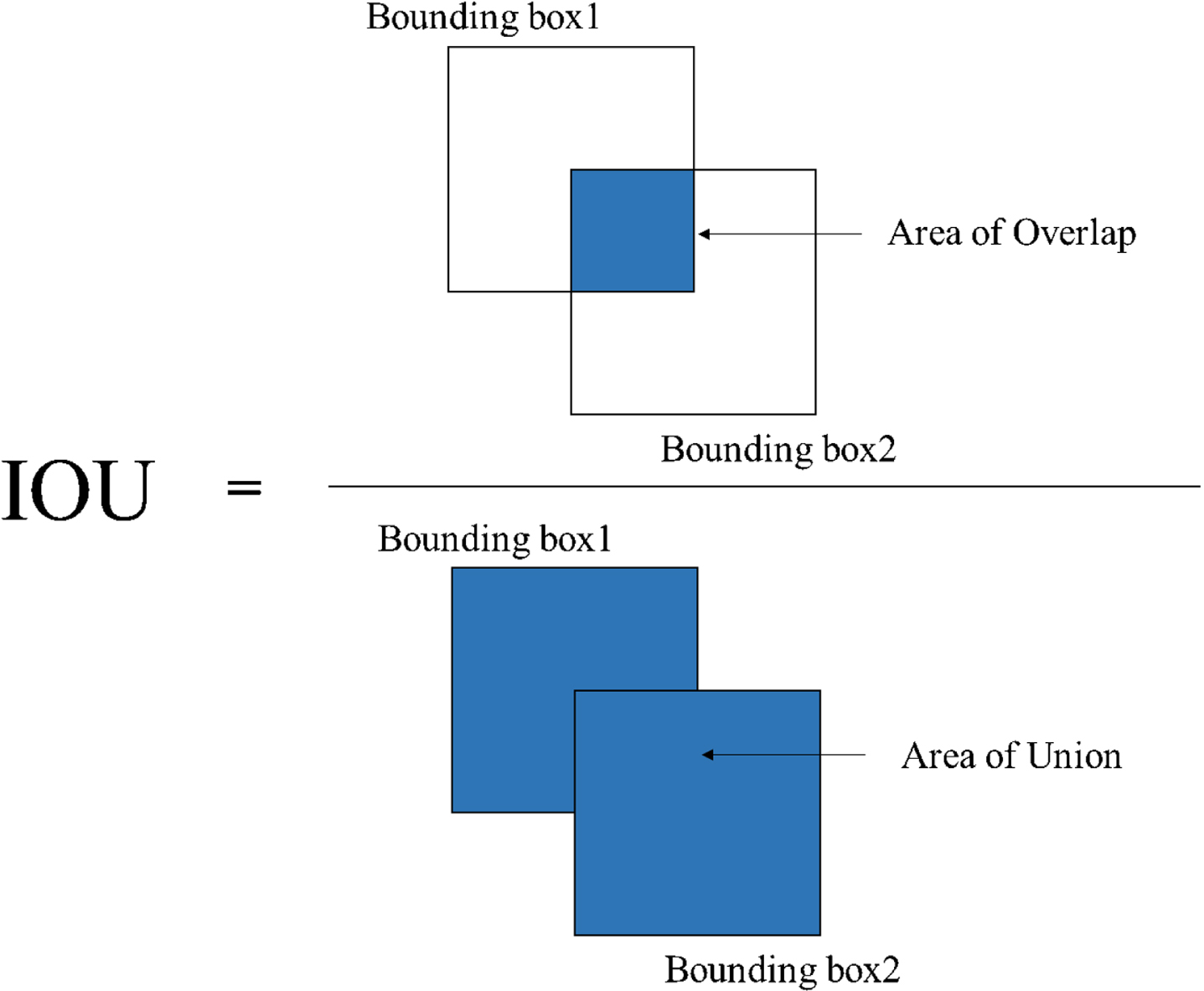
Calculation of IOU.
The second one is mAP value, which is an index to assess the good or bad positioning and classification in the object detection model [23]. Specifically, positioning is to make clear the actual target position, such as the coordinate of a bounding box, while classification is to identify the correct object class, such as human face and vehicle. The mAP value is calculated in the actual bounding box and the predicted bounding box, and the parameter returned as a reference is set between 0 and 1. Specifically, the higher the returned mAP value is, the more accurate the detection of the training model will be. Many object detection algorithms use this index for assessment, such as Faster R-CNN, MobileNet SSD, and YOLOv5.
Precision is also called the positive predictive value, which refers to the proportion of target object that is the actual target object when the target object is predicted. Recall is also called sensitivity, which refers to the proportion of the actual target object that is indeed predicted to be the target object. We can know that the ability of the model to identify the target object is listed in Table 1. It shows the relationship between the target object and the predicted object, which is the correlation of four parameters in the confusion matrix, including True Positive (TP), which is actually the target object and also correctly predicts the target object; True Negative (TN), which is not actually the target object, and it is also correctly predicted not to be the target object; False Positive (FP) is not actually the target object, but the wrong prediction of the target object; False Negative (FN) is the actual target object, but the wrong prediction of the target object (i.e. no prediction of positive samples). Equation (8) to Equation (10) denote the above parameters to calculate the precision, recall, and mAP for each object class [24].
Relationship between target object and predicted object
The preprocessed image with small sizes is sent to the edge server, which runs the CNN model and makes a decision on emotion. The decision is then transmitted back to the smartphones only with low mAP and recall values, 78.9% and 77.6%, respectively [1]. X. Liu et al. [24] presents a facial emotion recognition technique using two newly defined geometric features, landmark curvature and vectorized landmark, which are extracted from facial landmarks associated with individual components of facial muscle movements. Their proposed method combines the support vector machine (SVM) based classification with genetic algorithm (GA) for a multi-attribute optimization problem of feature and parameter selection, which results in more computation overhead and longer running time of 36.6 milliseconds. J. Redmon et al. [6] views object detection as a regression problem to spatially separated bounding boxes and associated class probabilities. A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation. But they did not yet address the facial emotion recognition. To improve convolutional neural network (CNN) recognition accuracy, A. Bochkovskiy et al. [12] assumes that the universal features include weighted-residual-connections (WRC), cross-stage-partial-connections (CSP), cross mini-batch normalization (CmBN), self-adversarial-training (SAT) and mesh-activation on large image datasets. However, they got poor results, namely, 43.5% mAP for the MS COCO datasets at a speed of 19 FPS on Tesla V100. In the work by H. Rezatofigh et al. [25], IOU denotes the most popular performance evaluation metric used in the object detection benchmarks. However, there is still a gap between optimizing the commonly used distance losses for regressing the parameters of a bounding box and maximizing this metric value.
Research methodology
In accordance with the operation process of the system, the proposed system structure, preprocessing of training model, training process, verification and fine-tuning, detection and recognition of the training model are presented in this section.
Proposed system structure
Figure 2 depicts the proposed system structure. In the data preprocessing, first annotate and label the emotional image datasets by using software tools and save them in the corresponding input data format for model training [21]. Then, the YOLOv5 model has been employed as a state-of-the-art and real-time object detection system. Next, assess and analyze the trained model files. Finally, detect and recognize the training model.

Proposed system structure.
This study is based on the YOLOv5 training model. Therefore, the following statement illustrates the entire training process.
— Fine-tuning of the training model
Through the assessment and analysis methods discussed in the previous section, the relevant information and parameters of the training model can be obtained, such as precision, recall, and IOU values. Then, whether to adjust the model structure can be considered. The following steps may be needed. There are two ways to handle the datasets. The first one is data augmentation [26], which is a technology enabling the limited or insufficient datasets to produce more equivalent information that can manually augment the training datasets of a suite, such as crop, exposure, flip, Gaussian noise, hue, and rotation. Besides, the image information without any object class is added to the datasets for training, which means the negative training samples are added.
In addition, there are some other ways to improve the highest resolution of the model structure, such as 608 or greater than 322, or to use the clustering method to recalculate the anchors box, which uses the k-means method to select a suitable anchor bounding box from the training set. And the parameters in the setting file (.cfg) in the relevant version can even be adjusted.
— Detection and recognition of a training model
The last step is to use the model files for detection and recognition after training, assessing, analyzing, and fine-tuning improvement. At this step, it is to analyze and calculate the feature values of processors and hardware devices with high computing power, such as graphics processor unit (GPU) in the industrial computer. The results of drawing the bounding box by calculating and extracting the image or video from the corresponding object classes are also displayed on the screen of the device.
System design flow chart
First, the collected emotion image datasets are annotated and labeled according to the class it belongs to and then stored as training datasets. Next, to use the YOLO model for dataset training, it is necessary to convert all datasets into the corresponding input file of data format (such as text file) programmatically [26]. After adjusting the parameters in the setting file of the model in one version, the emotional classifier can be trained. When the training step is completed, the weight file (.weight) of the model is stored and identified after loading. The image or video is then input for calculation and analysis, and the bounding box of the corresponding object class is drawn. If the emotional feature value is not met in the detection, the calculation and analysis will be repeated; and the detection results will be finally displayed on the screen. Figure 3 depicts the system design flow chart.

System design flow chart.
This section realizes the recognition system of facial emotion. Because the final implementation needs to be operated on an embedded platform, to improve the efficiency and quality of training image datasets and to avoid spending a lot of development time, this system is developed with deep learning-related hardware and software components. And the training environment in industrial computer is used to realize the feasibility of the developing concept.
Image datasets
The training image datasets have different categories of facial emotion, and the emotions expressed by faces are generally divided into seven categories, including angry, disgust, fearful, happy, neutral, sad, and surprised. Among them, it is difficult to set a consistent standard for image annotation and labeling for the angry and disgust emotions. Moreover, it is also difficult to collect a high-sized and large number of images for the fearful and sad emotions. Therefore, the experimental datasets conclude the following four categories of facial emotion to detect and recognize, which are angry, happy, neutral, and surprised emotions.
In addition, this study has employed the YOLOv5 model as the structure of the training datasets [21], which is one type of deep learning. The YOLOv5 model has multi-level convolutional operations and other algorithms to learn and analyze, resulting in the images at the input to have some restrictions and requirements on the size. For example, the input image size is 416×416, and the maximum resolution is 608×608, or any value more than 322. Consequently, this study adopts another 3,000 image datasets, where the images with a size of more than 1,000 pixels were selected as the training datasets.
Experimental results by YOLOv5 model
For briefly discussing YOLOv5 algorithm [26], the required operation procedure is presented as follows:
Step 1: Use the LabelImg to annotate images.
Step 2: Display the name of the labeled emotion category.
Step 3: Match the input data format of the YOLOv5 model.
Step 4: Adjust the parameters in the setting file of the corresponding version in the model structure.
Step 5: Adopt the Darknet environment for model training.
Step 6: Display all training information.
Step 7: Fine-tune the training model if necessary.
Step 8: The end.
The YOLOv5 model can store the weight files every 1,000 batches during the training process. In this experiment, the last batch of training is ended in the 8,000th one. So, there are many weight files in the related path folder. For example, there are 10 files. The parameters of the two assessment and analysis indices provided by the YOLOv5 model are used. Because of the learning process in the early and middle stages of model training, the feature values of the object classes do not yet obtain good recognition results. Therefore, the weight files are stored in the 7,000th, 8,000th, and the last batches are used for assessment and analysis.
To build the model weight files, the commands of the mean Average Precision (mAP) and assessment indices provided by the Darknet environment are adopted for analysis. The execution order is the Darknet executable file (darknet.exe), the detector and its mAP, the location of the emotional data file (data∖emotion.data), the model version setting file (yolov5-tiny-obj_maix.cfg), and the location of the model weight file (backup∖yolov5-tiny-obj_maix_7000.weights). With the model assessment and analysis of the 7,000th batch, the 8,000th batch, and the last batch, it can be observed that after the successful loading, the feature values of four facial emotion categories are analyzed with the image datasets. At this moment, the relevant parameters are calculated, including true positive (TP) and false positive (FP) values of various categories, as well as mAP. In addition, the precision and recall values of the model are employed to calculate the average IOU values. Finally, the mAP is obtained by reviewing the above values, and then the model needs to be fine-tuned and improved for further analysis. Thus, this experiment selects the last model of weight files for object detection and recognition after comparing the model assessment and analysis results of all batches of weights, as shown in Fig. 4.
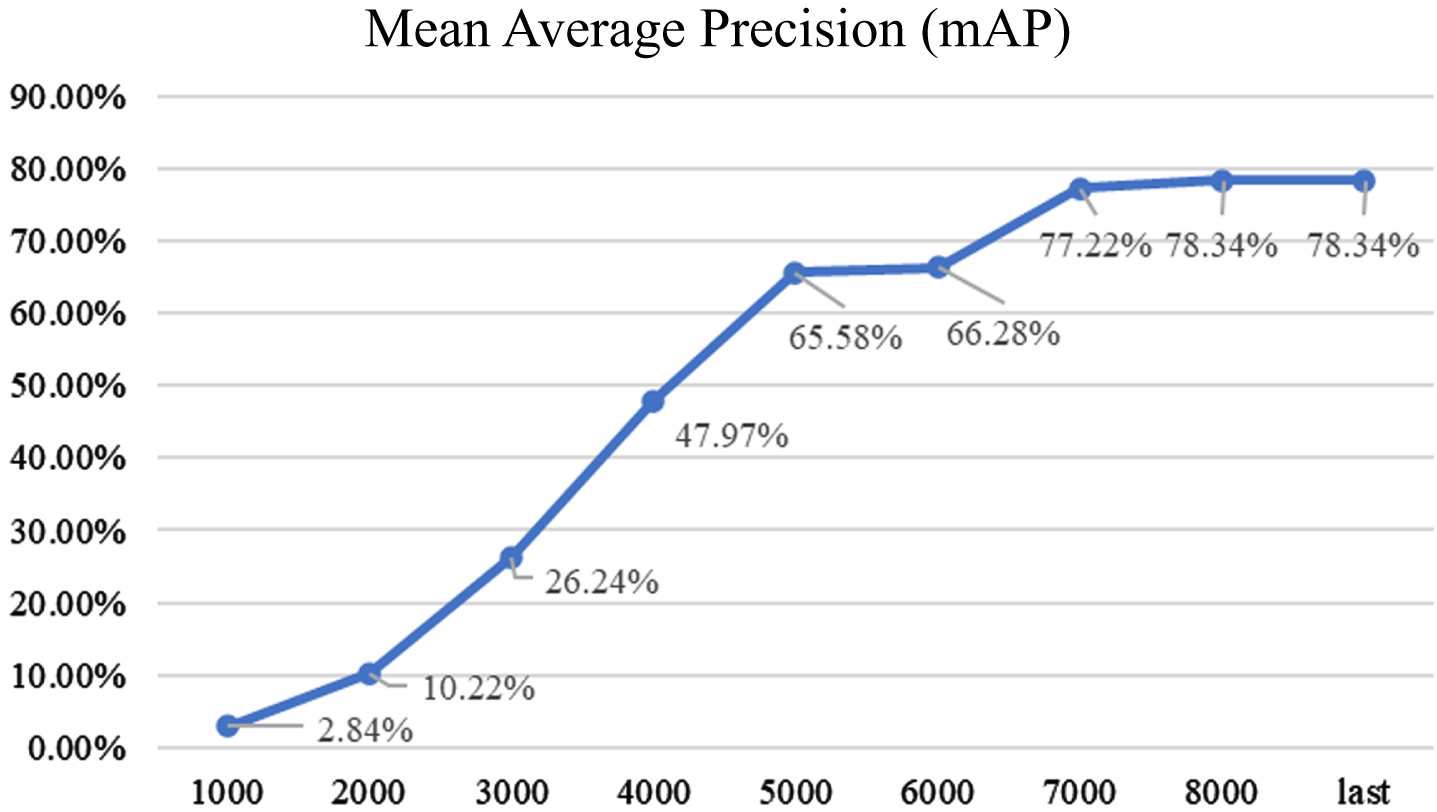
Model evaluation curves of all batches of weights.
Next, the test instructions provided by the Darknet environment are adopted to detect and recognize the facial emotions in the images and videos with the model weight files. Then, all the detected emotions are drawn as bounding boxes, remarking with the emotional category and displaying on the screen.
First, the image is detected and recognized, including the Darknet executable file (Darknet.exe), detector and its tests, location of emotional data file (emotion.data), model weight file (yolov5-tiny-obj_maix_last.weights), and location of an image file to be calculated and recognized (emotion.jpg). Then, the model weight files are loaded, and the feature values are calculated and recognized. If the matching emotional feature values are detected, the detected emotional category and recognition precision are all displayed on the command window, which is open to present the resulting bounding box and emotion category.
The other scenario is to detect and recognize the video, including the Darknet executable file (darknet.exe), the detector and its presentation (demo), the location of the emotional data file (data∖emotion.data), the model weights file (yolov5-tiny-obj_maix_last.weights), and the location of video file (data∖emotion.mp4). As shown in Figs. 5 to 9, the angry, happy, neutral, surprised, and multi-person’s emotions are all shown in the bounding box, respectively. If the emotion that conforms to the feature values is detected in one bounding box, the emotion category with the recognition precision and FPS values is shown on the left window. If the emotion that conforms to the feature values is continuously detected, all related information is displayed in order on the screen.
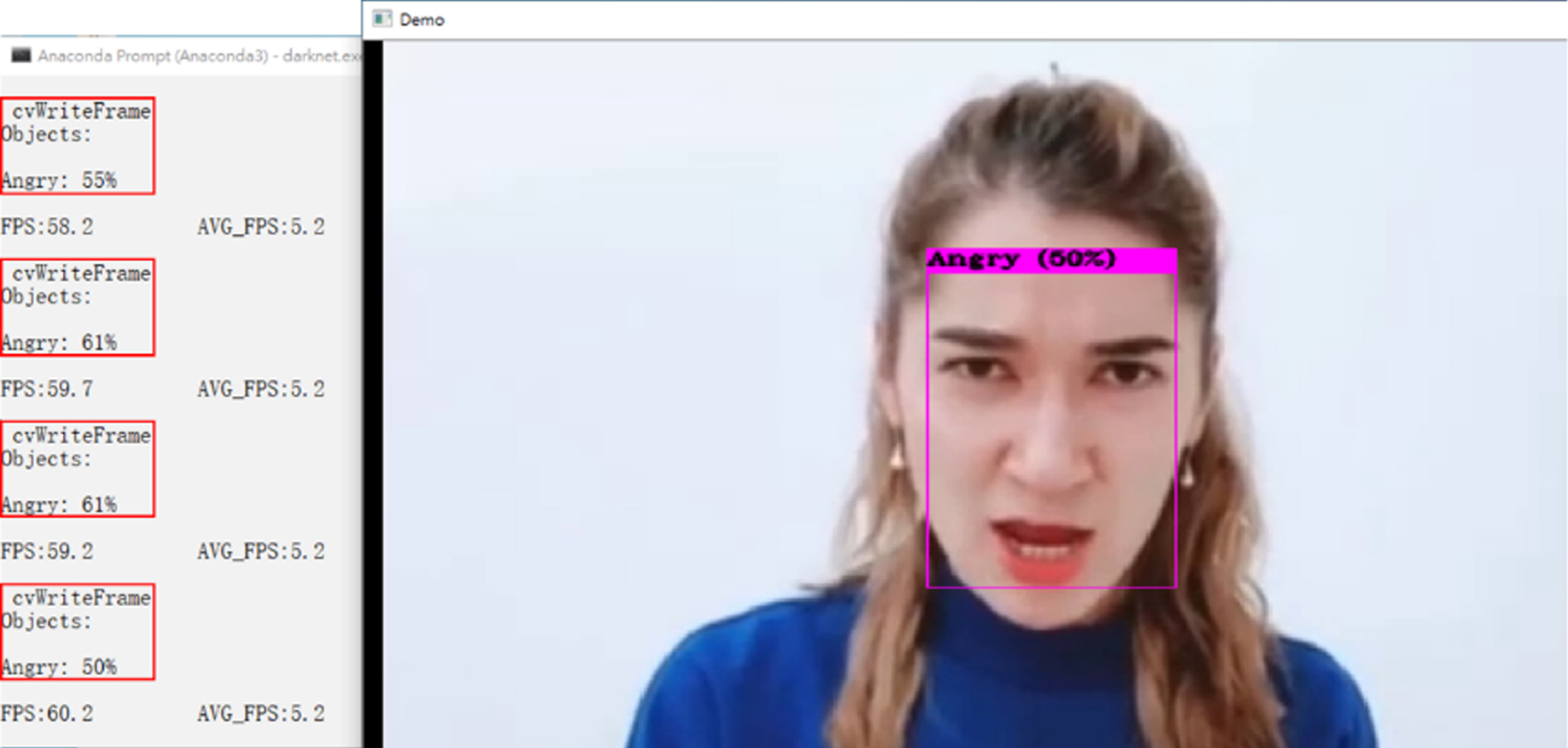
Facial image recognition of angry emotion.
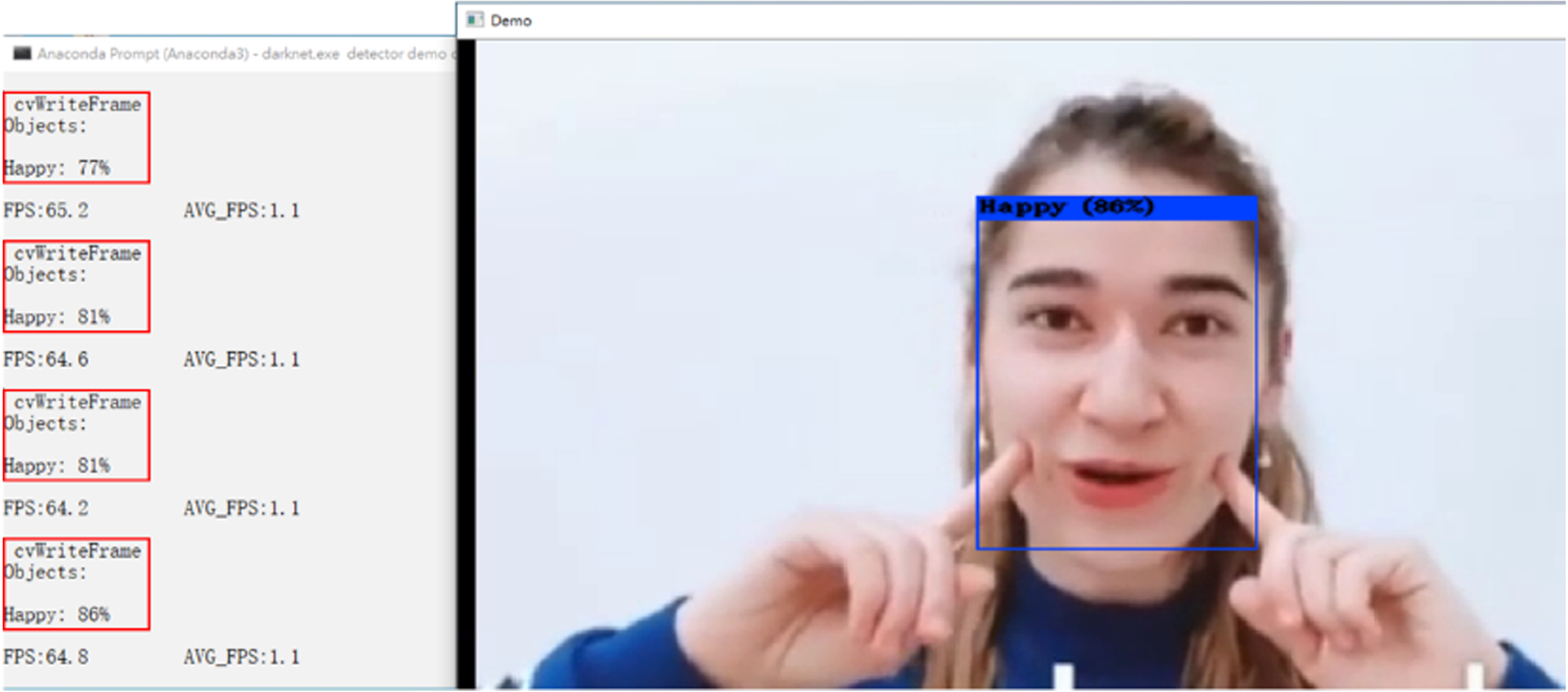
Facial image recognition of happy emotion.
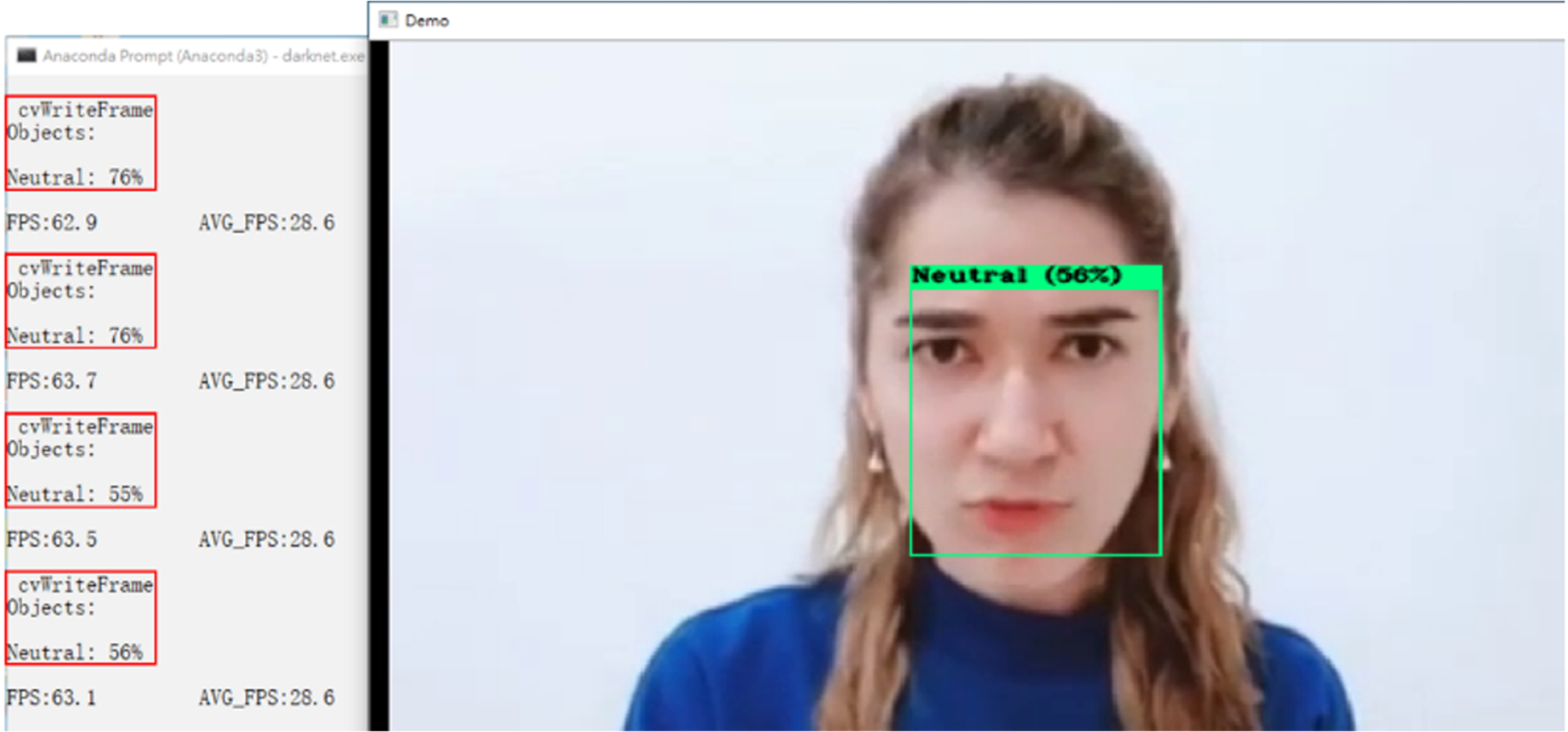
Facial image recognition of neutral emotion.
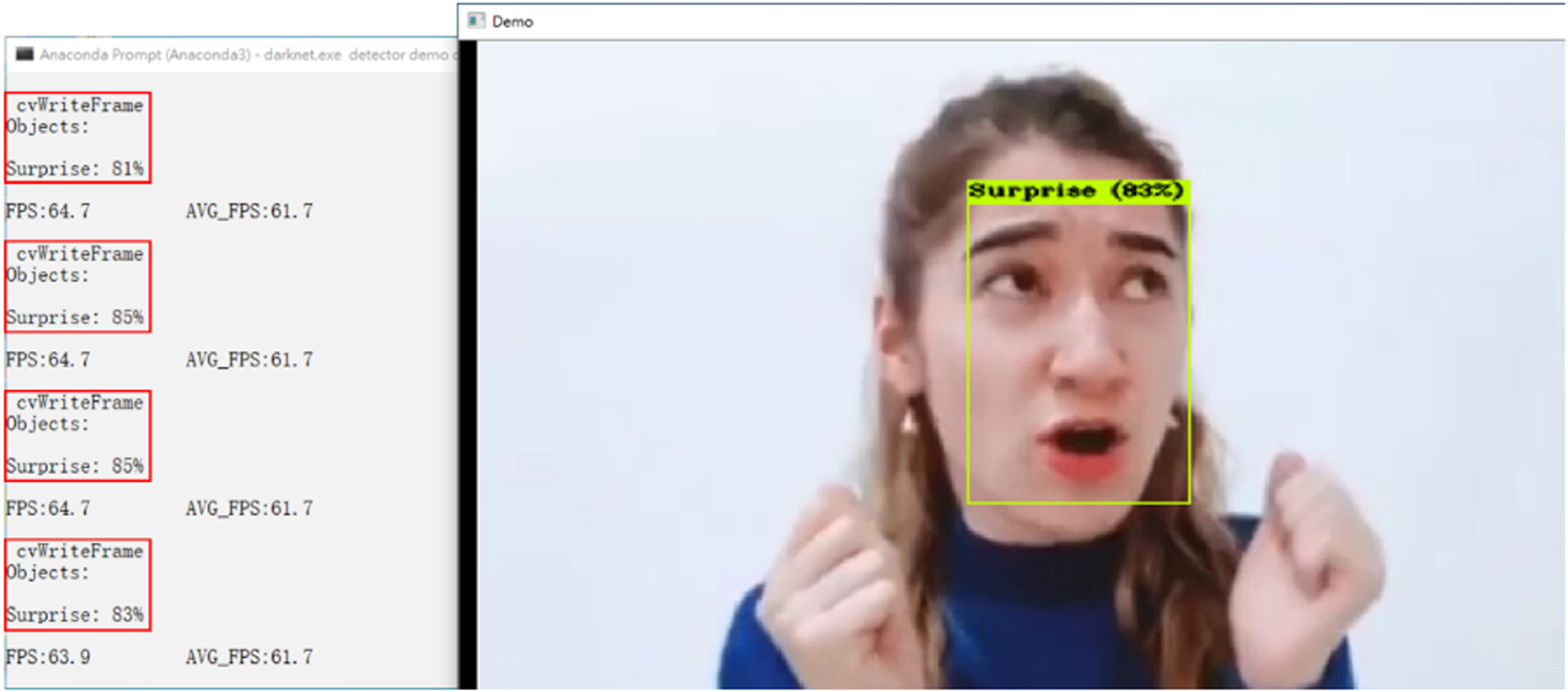
Facial image recognition of surprised emotion.

Image recognition of multi-person’s emotions.
In this section, the hardware and software development platforms, the implementation environment, and the experimental results are presented.
Implementation environment
The structure of hardware platform is shown in Fig. 10. MAIX DOCK development board is set up at first, and the program is developed by connecting with a computer. The development board of this MAIX series is mainly used for those image processing applications such as facial recognition, object recognition, and handwritten digit recognition. It has complete hardware development modules, such as image module, memory module, network module, bus module, camera, and LCD module, which are provided for self-developing applications by users. The hardware components of the MAIX DOCK development board are illustrated with English symbols showing different functions.
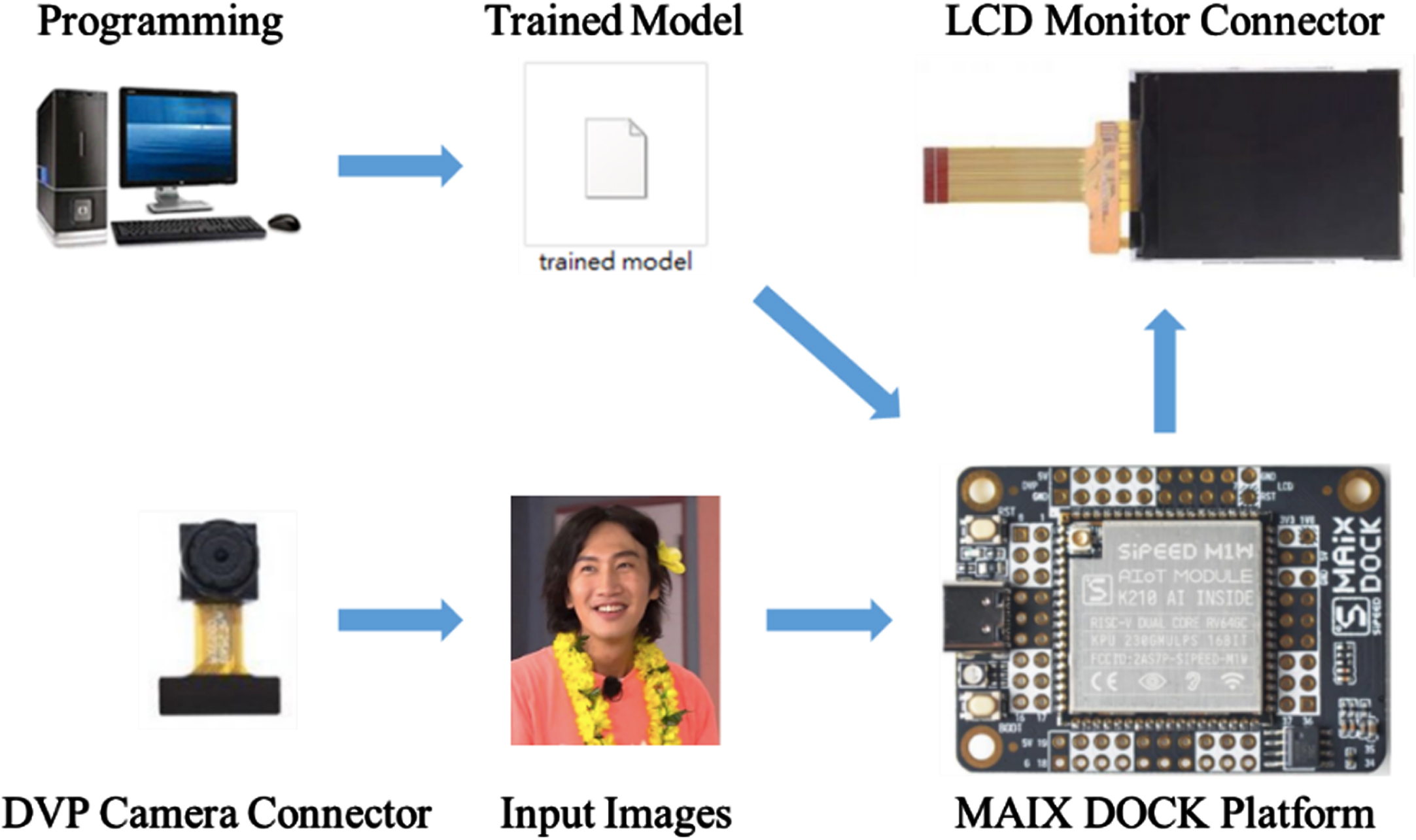
Structure of MAIX DOCK platform.
The MaixPy software interface applicable to AIoT and Kendryte K210 processor is adopted, and the model files applicable to the MAIX DOCK platform (such as Kmodel) are input. The images are input by connecting the ones captured by a camera with the development board. Through the loaded model files, the facial emotion classification is carried out, and the Kendryte K210 processor is employed to accelerate the detection and recognition. If a matching facial emotion is detected, the region is drawn as a bounding box, remarking with the emotional category and recognition rate of the face, and displaying on the screen.
After the training of YOLOv5 model is completed, the model file is stored in the weight format (.weight). Before loading into the MAIX DOCK development board for recognition, the model file must be converted into a file of data format suitable for this platform. Therefore, this study explains three steps for the conversion file of feature data in sequence.
First, the weight file (.weight) is converted into a PureBasic file (PureBasic/.pb). This part refers to the weight file that is trained through TensorFlow to re-train and fine-tune the action, in which the constant graph is output to the mobile devices. The conversion process is based on the usage of the Darflow environment and runs in Python executor. Second, both parts 2 and 3 are required to use Maix Toolbox provided by the SiPEED R&D team for file conversion, which is a set of model tool scripts. The executable file (pb2tflite. sh) uses the pure basic file to convert the TensorFlow file in light version (.tflite). Third, the instructions in sequence are the executable conversion file (pb2tflite.sh) and the location of the pure basic file is to be converted. The instructions are listed in order, the executable conversion file (tflite2kModel.sh) and the location of TensorFlow file in lightweight version.
Experimental results on the embedded system
After converting the file format, the uPyLoader burning software is used to load the Kendryte model and the files of the completed program (such as Python) into the storage on MAIX DOCK. Finally, the virtual terminal (such as PuTTY) is used for file transplanting and communication with the development board [26].
As the MAIX DOCK development board is connected to a computer system and starts standby, it must be successfully connected before uPyLoader burning software is used to transplant. Using the power input port (USB Type C) as the connection interface, one of the Baud Rates is set as 115200. Hence, a suitable driver’s executable file (such as maixpy_v0.4.0_88. bin) and files of complete
executable Python programs (such as emotion.py) are selected, transplanted, and burned into the MAIX DOCK development board.
Before the MAIX DOCK development board can communicate with the transplanted files, the PuTTY transmission communication software must be set up. It also uses power input port (USB Type C) as a connection interface. The baud rate must be set as 115200 before the transmission and communication are carried out. Once the related instructions are executed, the complete program is running. It includes loading the files of the Kendryte model. Then, the input image and video are analyzed and classified according to the feature values of facial emotion learnt from the model. After that, the bounding box is drawn for the feature values consistent with a facial emotion. The name of facial emotion detection and recognition speed are also displayed on the LCD screen connected to the output port of MAIX DOCK development board, as shown in Figs. 11 to 15. The angry, happy, neutral, surprised, and multi-person’s emotions are shown in the white bounding box, respectively. The recognition precision and speed are also shown on the screen.

MAIX DOCK recognizing the angry emotion.

MAIX DOCK recognizing the happy emotion.

MAIX DOCK recognizing the neutral emotion.

MAIX DOCK recognizing the surprised emotion.

MAIX DOCK recognizing multi-person’s emotions.
As presented in the reference [11], the sub-classes of CNN model include Fast R-CNN, Faster R-CNN VGG-16, and Faster R-CNN ResNet, and other related models such as SSD300 and SSD500. The more the mAP values are, the less the FPS values will become because of more computation costs required for the images with higher resolution.
Meanwhile, YOLO can just reach a speed of 30 FPS and 63.4 mAP on Titan X GPU. However, YOLOv5 has improved the recognition speed in FPS and the recognition precision in mAP if compared with the previous versions of YOLO. In addition, it has good compatibility with different file sizes. Obviously, YOLOv5 is suitable for real-time operations on images and its mAP values perform well in many deep learning models. In the experiments, the training datasets contain PASCAL VOC2007 (Visual Object Classes) and VOC2012. In a classifier with high resolution, after being trained by 288×288 images, YOLOv5 also uses 544×544 images for fine-tuning the classification network for 20 epochs on ImageNet with the best results, 92.6 mAP and 40 FPS.
Furthermore, mAP and FPS values of the YOLOv5 model and others are compared with each other. All models are trained and analyzed by using PASCAL VOC datasets. Thus, the performance of YOLOv5 has been improved, including batch normalization and anchor box at algorithmic level, which have better recognition speed and precision. It also has good compatibility with different image sizes, providing a good balance between the recognition process and the accurate results.
In addition, the mAP values obtained by using the YOLOv5 model is slightly higher than those (90.34%) obtained by using the YOLOv5-Tiny model with fewer structural levels because there are only four emotional types for training. Although the features of datasets are different, YOLOv5 has better recognition speed and precision than the previous YOLO versions.
The results of the functional comparison with each other among the systems by G. Muhammad and M. S. Hossain [1], N. Novielli and A. Serebrenik [5], A. Bochkovskiy, et al. [13], and our proposed one are all listed in Table 2. According to the analysis results, it can be observed that the Raspberry PI platform is more suitable for basic development applications, whereas the MAIX platform can be developed as the core module of AI operations such as deep learning [8]. Moreover, the accelerated processors with deep learning (e.g. Darknet, Keras, Paddle, and TensorFlow) allow users to easily extend AI functionality to object recognition. Thus, the performance metrics of our proposed system are superior to others.
Results of functional comparison among four systems
Results of functional comparison among four systems
Research Limitation: Since the image datasets with high resolution and more layers of CNN model are required for training, the previous version of software tools and the lower level of hardware components than ever may not work well. Meanwhile, the image datasets with proper resolution and the suitable training model must be selected to obtain better mAP and FPS values.
This study has successfully built a complete process of emotion recognition, which adopts the edge computing platform, MAIX DOCK BEST KIT FRO RISC-V AIoT, produced by SiPEED company to realize the real-time image processing system. The development board is equipped with Kendryte K210 Processor as the core of deep learning. The experiments were finally carried out on an industrial computer with high performance hardware and transplanted to the MAIX DOCK development board, acting as a small and portable emotion recognition system.
Contributions of the proposed emotion recognition system on the edge computing platform are made as follows: The powerful analysis capabilities of deep learning are employed. There are some preparation tasks required for the entire process. Then, how to tune and apply the trained model is a key action. The YOLOv5 model, which is more advanced for real-time image detection, is adopted for training. This study has formally verified the feasibility and portability of emotion recognition transplanted into the MAIX platform. Moreover, the MAIX DOCK development board has a Kendryte K210 processor, acting as a key part of deep learning to accelerate computation. By using a camera on the embedded platform, it is a portable recognition system that analyzes the image datasets in real time. Also, it can predict multiple objects and their locations at the same time. Based on the computational analysis results and capability of this recognition system, its recognition results are more accurate and faster than other systems. So, it can be employed in many fields.
In the future, when a large amount of information is input and the deep learning algorithm is analyzed continuously, it must become time-consuming. Since NVIDIA’s lightweight and low-power devices have high computing power and simultaneously execute multiple neural networks, these characters will improve the emotion recognition precision and speed.
Footnotes
Acknowledgments
The authors are grateful to the anonymous reviewers for their constructive comments which have improved the quality of this paper. Also, this work was supported by the Ministry of Science and Technology, Taiwan, under grants MOST 110-2637-E-131-005-, MOST 110-2221-E-845-002- and MOST 111-2221-E-845-003-.
Declaration
No conflict of interests is reported by the author(s).