
Abstract
Throughout history, cholera has posed a public health risk, impacting vulnerable populations living in areas with contaminated water and poor sanitation. Many studies have found a high correlation between the occurrence of cholera and environmental issues such as geographical location and climate change. Developing a cholera forecasting model might be possible if a relationship exists between the cholera epidemic and meteorological elements. Given the auto-regressive character of cholera as well as its seasonal patterns, a seasonal-auto-regressive-integrated-moving-average (SARIMA) model was utilized for time-series study from 2017 to 2022 cholera datasets obtained from the NCDC. Cholera incidence correlates positively to humidity, precipitation, minimum temperature, and maximum temperature with r = 0.1045, r = 0.0175, r = 0.0666, and r = 0.0182 respectively. Improving a SARIMA model, autoregressive integrated moving average (ARIMA), and Long short-term memory (LSTM) with the k-means clustering and discrete wavelet transform (DWT) for feature selection, the improved model is known as MODIFIED SARIMA Outperforms the LSTM, ARIMA, and SARIMA and also outperformed both the modified LSTM and ARIMA with an RSS = 0.502 and an accuracy = 97%.
Introduction
Cholera, which is caused by the microorganisms Vibrio cholerae 01 or 0139, manifests as watery diarrhea and severe intestinal illness [1–3]. The exotoxin produced by Vibrio can cause serious symptoms such as electrolyte imbalance, dehydration, and circulatory failure [4]. If the chain reaction is allowed to continue without appropriate medical intervention, consequences like myocarditis, acidosis, tubular necrosis, heart failure, and death may occur [5].
The fecal-oral pathway is the most prevalent way for cholera to spread, and it is brought on by tainted food and beverages caused by a lack of basic hygiene [1, 6]. In developed nations, consuming contaminated food is the main means of cholera infection transmission. On the other hand, cholera is typically spread through contaminated water in undeveloped countries [7].
Worldwide, 28 to 150 thousand cholera deaths and 3 to 5 million cholera illnesses are estimated and recorded each year. Yet, the occurrence is more common in undeveloped countries with significant levels of human poverty in the tropical and subtropical areas [2, 8]. The authors in [3] claims that there have been seven cholera pandemics since 1817, with the seventh pandemic causing the majority of the world’s infections. In the majority of African countries, cholera has spread to be an endemic illness in less than five years [9].
In 2012, 86% of cholera deaths and 71% of all reported cases were found in Sub-Saharan Africa [5]. Although 129,064 cases and 2102 deaths were reported in 2013 by 47 nations, the World Health Organization (WHO) indicated that the exact disease epidemic is just 5–10% of the cases that are officially reported. The disparity between reported data and the estimated illness burden might be attributed to inadequate monitoring and laboratory systems. A total of 52812 (83%) of the 63658 cholera deaths documented by the WHO between 2000 and 2015 were in sub-Saharan Africa, but this figure is likely an underestimate. The number of nations reporting indigenous cases of cholera has increased from 24 in 1971 to 30 in 1998 and 36 in 2008, and decreased to 27 in 2011 [6, 10, 11]. Sub-Saharan Africa accounted for 1,080,778 of the 4,426,844 (24%) cholera cases reported to the WHO between 2010 and 2019 from 34 countries [12, 13].
The first cholera cases in Nigeria were discovered in a community close to Lagos State in 1970, with an unknown total of cases and a case fatality rate (CFR) [14]. This outbreak resulted in 22,931 cases, 2,945 fatalities, and a CFR of 12.8% in a population of 1,477,000 in 1971 [15]. The latest 2018 cholera epidemic in Nigeria, which resulted in over 45,000 cases and a 1.9% CFR, shows the country’s high cholera burden [15].
Furthermore, except for Liberia, which reported just two cases, it was only Nigeria that recorded cholera cases in 2021 in the West African sub-region, with 93,362 cholera incidents reported and 3,283 cholera-related deaths resulting in a CFR of 3.5%; 32% of the Federal Capital Territory (FCT) had the most cholera cases [16]. In line with global epidemiology, the primary indicators of cholera spread is the unavailability of clean drinking water and unhygienic situations [17]. Several variables are potential aids in the transmission of cholera in Nigeria, including lack of safe drinking water, unclean surroundings, natural disasters, illiteracy, and internal conflicts that cause people to flee to internally displaced people (IDP) camps [18].
Water is likely a major factor in cholera epidemics in Africa [19]. Floods, which are caused mainly by high rainfall, enhance the spread of water-borne illnesses by hindering access to safe drinking water, contaminating safe water sources, causing sanitary issues, and restricting access to essential health services [20]. Water becomes easily contaminated during and after rains due to the washing of open-air defecation grounds or spills from pit toilets, both of which contribute to a worsening of sanitary conditions and an increased risk of cholera transmission. It is also observed another contributing reason has been discovered: a lack of efficient sewage disposal, because of the contamination of the food and water in the area from individuals buying and selling food close to trash bins, the cholera pandemic may happen if people ingest contaminated food and water [3].
Another enabling factor that enhances cholera transmission is increasing the pressure on already congested sanitation facilities; a densely populated area with informal and low-quality housing also impacts cholera occurrence and epidemic intensification. In Harare, cholera attack rates in 2008–2009 varied from 1.2 cases per 1,000 persons in a less dense residential areas to 90.3 cases per 1,000 in an overpopulated environs, with Ghana and Uganda showing similar trends [1]. According to a research in Kenya and Yemen, rising violent conflicts can have a global impact on recurrent cholera transmission [21].
Climate conditions, particularly tropical rain, have a well-established relationship with cholera outbreaks as significant climatic elements that aid to the spread of cholera in Nigeria [22]. According to [22], the Southern Oscillation Index (SOI) and Sea Surface Temperature (SST) also aid in the spread of cholera in Africa. A detailed analysis of the relationship between cholera incidence and climate factors using various statistical techniques in various parts of the world has been done [23].
According to the review, there is a statistically significant correlation between the prevalence of cholera in different nations and climate factors including Nigeria’s average temperature, relative humidity and precipitation [22]; The authors used generalized additive modeling (GAM) and multiple linear regression (MLR) and found that the temperature and rainfall have a dynamics in the spread of cholera disease.
In another study conducted by [24], strong coherence was found between cholera epidemic resurgences in Ghana and climatic/environmental characteristics. After cross-correlation analysis, rainfall and SOI correlate with the number of cholera incidences. A strong correlation also exist between rainfall and cholera cases in Senegal after a Cross-correlation analysis [24].
In order to evaluate the relationship between the rise in number of incidence weekly and the mean of the daily maximum temperature and rainfall on a weekly basis, a Poisson autoregressive model for trend control was designed in Zambia, there has been a 2.5% rise in the number of cholera cases with a 50 mm rise in rain 3 weeks earlier and a 5.2% increase in cholera incidence with a 1 °C rise in temperature 6 weeks prior [25].
In addition, cholera cases increased 2 times with a 1°C temperature RISE and a 4-month delay, but only by 1.6 times with a 200 mm increase in rainfall and a 2-month delay. At a 1-month lag, Zanzibar’s temperature and rainfall increased, producing a positive association (P = 0.04) [26].
A Poisson regression model was employed in southeastern African nations to examine the probable relationship between cholera incidence rates and yearly variations of temperature and sea surface temperature (SST) [27]. During the research period, the results showed that cholera rates in individuals had significantly increased and the analysis of the annual average air temperature and the SST revealed a significant relationship between these variables and cholera occurrences [27].
The WHO-led Global Task Force on Cholera Control (GTFCC) released their “Roadmap to End Cholera by 2030” in 2017. Rapid response to outbreaks is a key part of the road map. This objective would be greatly facilitated by a low-cost, reliable rapid diagnostic test (RDT). There are a number of commercial RDTs that are being used for surveillance or during outbreaks. These tests are portable and suitable for almost any setting [28]. However, the accuracy and dependability of the tests that are currently available can vary depending on the user and the circumstances. Public health experts have been reluctant to declare an epidemic based only on the results of an RDT because they have little confidence in the existing cholera RDTs. This may lengthen the time it takes to respond to an outbreak [4, 29].
A form of artificial intelligence uses algorithms to find patterns in data called Machine Learning (ML), are used to create a data model that can make predictions that are more accurate [30]. Machine learning has been employed in a number of ways to predict, identify, and prevent the development of severe infectious disease epidemics [31]. In recent decades, there have been numerous research and significant advances in the development of commonly used models and methodologies for precise cholera prognosis and forecasting.
In Hanoi, three distinct forecasting models called the complete (CP), the weather-independent (WI), and the geographically independent (GI) were developed. The weather and prior cholera cases from the entire region are used as supplementary predictors for each model’s lagged parameter (l), measured in days. The RF regression technique was used to develop a machine learning (ML) model. With the CP model being the best model, the adj-R2 measure was reduced with 0.0076, and the 95% confidence interval is [0.0095, 0.0057] if all other variables are held constant and the forecasting duration is increased by a day [32].
The author in [33] proposed a new method to enhance the accuracy of cholera cases prediction in Hanoi, Vietnam, by using solar terms, which is an ancient Chinese idea that signifies an exact point of season change in lunisolar calendars; and the training data being resampled. Results from the research validate the research, by combining solar nomenclature with random oversampling example and random forest obtaining an area under the curve (AUC)=0.84 and very strong sensitivity and specificity [33].
In order to predict the prevalence rate of the most recent cholera outbreaks in a Yemeni governorate, the authors in [34] proposed the cholera artificial learning model, which is made up of four (4) extreme gradient-boosting machine learning proto-types. Using previous cholera data, fatality rates, civil war casualties, and interconnections across governorates depicted over many years, CALM is a revolutionary ML approach.
In another research, the authors in [35] proposes ML methods the adaptive synthetic sampling approach (ADASYN) with principal component analysis (PCA) methods are used for dealing with the imbalanced dataset problem and restoring the dimensionality of the dataset’s sample balance. The researchers also compared other ML approaches and discovered that the XGBoost algorithm performed better than the RF classifier for predicting cholera cases in Tanzania, with a sensitivity of 0.805 and 0.645, respectively. The XGBoost was selected as the best model for the study on the basis of the model’s characteristics [35].
The cholera pandemic has been predicted in previous research using key climate factors from satellites, such as atmospheric, terrestrial, and oceanic data. The authors [36] used a novel approach to test if a machine learning system could predict an environmental cholera pandemic. 89.5% of outbreaks were classified by the RF classifier as having accuracy = 0.89, sensitivity = 0.89, and F1 scores = 0.942 [36].
The cholera forecast model employed simple stochastic time-series SARIMA. The temporal clustering of cholera at lags of 1 month and 12 months were detected by the SARIMA model. Their research indicates that a minimum temperature change of 100°C causes a 6% increase in cholera infections during this time of year. When the sea surface temperature (SST) rises by 10°C, cholera incidence increase by 18% and 25%, respectively, in the present month and after two months. Over the research period, rainfall had no impact on the incidence of cholera. The model did reasonably well in forecasting the variability in cholera cases, with a root mean square error (RMSE)=0.108. Therefore, the ambient and SST-based models can be utilized to forecast cholera epidemics [37].
A correlation between climatic factors and cholera cases was found in [23]. According to their research, the two factors that affect cholera prevalence the most are rainfall and maximum temperature. A cholera incidence time series study was conducted from 2000 to 2013 using a SARIMA technique because of the auto-regressive and the seasonal behavioral pattern of the illness. Models A, B, C, and D were created as single variables SARIMA models (SVM) and multiple variables SARIMA models (MVM). These models were then compared and their relationship to cholera outbreaks was assessed. An Akaike information criterion (AIC)=21 and Bayesian information criterion (BIC)=39 was obtained, where the MVM outperformed the SVM with RMSE = 16.2 and MAE = 13.2, with RMSE = 14.7 and Mean Absolute Error (MAE)=11, respectively. In addition, it had BIC = 36 and AIC = 15.
The method’s drawback is that feature extraction and selection were not used, which is thought to increase the accuracy of the outcome and bring the error rate of the model down to a minimum [23]. In order to use SARIMA for cholera forecasting, the proposed research will thus employ a unique method that combines the DWT as a feature selection method and outlier detection using the K-means clustering. The aim of this research was to develop a Modified SARIMA model with the following objectives: To determine whether incorporating DWT will improve the performance of the model? To determine whether the detection and removal of outliers in the data using K-means clustering will have an effect on the performance of the model? Establishing a link between cholera incidence and climate factors. To compare different time series models and select the best fit.
Materials and methods
DWT and time series forecasting were used to build the proposed model. According to [38], DWT can quickly identify abrupt signal changes and minimizes noise as well as reducing the size of the data and its dimensionality. The modified SARIMA, ARIMA, and LSTM models were built after applying the feature extraction in order to narrow the selection so that only relevant features were used before the outcome are analyzed and evaluated.
Data collection
The dataset utilized and its source are described in this section. The dataset used in this study is a cross-sectional data set that spans the months of January 2017 and May 2022 and contains monthly cholera cases and climatic factors.
Cholera cases
The weekly epidemiological reports made accessible to the public in portable document format (PDF) from January 2017 to May 2022 obtained from the Nigerian Center for Disease Control (NCDC) contained information on cholera outbreaks at the state level in Nigeria. Each report offers thorough details on the illness including the states, the number of cases recorded, CFR, number of deaths, culture, and rapid diagnostic test (RDT). Over the years 2017 through 2021, there were 172135 reported cases in total, with 2021 having the most cases. A Microsoft Excel (.xls) file was created from the whole dataset. Figure 1 shows the reported cholera cases to the NCDC.

Time series pot for reported cholera cases.
The source of all climatic data is the European Center for Medium-Range Weather Forecasting (ECMWF). The systems’ resolution ranges from 0.1 to 0.25, and it has over 1.8 temperature billion data points. Data on precipitation, temperature, humidity, and Sun hours were collected for many countries between 1991 and 2021 using daily, weekly, monthly, and yearly records which are calculated for each state in Nigeria as well as the Federal Capital Territory (FCT) using the monthly average for each state. In Figs. 2–4, the maximum monthly average temperature (0°C), total accumulated rainfall (mm), and relative humidity (%) are all displayed.
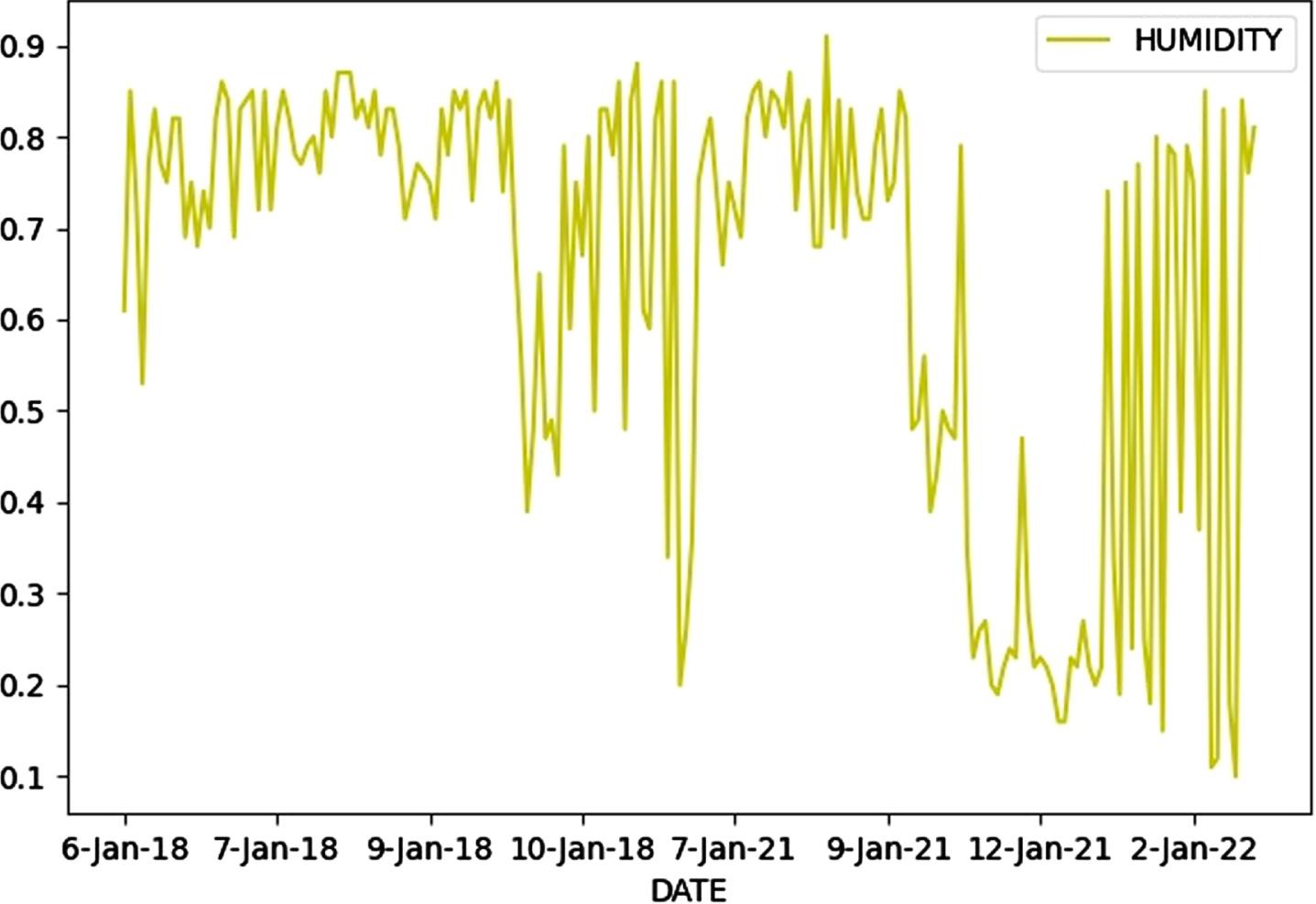
Time series plot relative humidity (%).

Time series plot maximum temperature (°C).

Time series plot for minimum temperature (°C).
Anaconda 3, an open-source program that is compatible with Python 3.8 was used to implement the proposed model (Modified SARIMA) on a Windows 8 PC with 16 GB RAM and a core i5 CPU. The steps were used in building the forecasting model are discussed in the subsections below.
Data preprocessing
It the process of cleaning, incorporating, choosing, modifying, normalizing, and extracting features [39]. Everyday data is typically inadequate, unclean, inconsistent, and untrustworthy. The efficacy, correctness and accuracy are boosted if any data irregularities are identified, repaired, and rectified at an initial stage of data pre-processing, which result in a very effective and reliable decision-making process. Data quality is vital for ML-based sickness prediction. To improve the usability and application of the first dataset for cholera forecasting, the two data acquired were integrated, and multiple preprocessing procedures were used.
Feature extraction using DWT
Feature extraction is defined as process of generating a significant sets of attributes from real time-series dataset and removing unnecessary variables. Feature vectors are another name for this collection of features [40].
Because DWT samples’ wavelets are at distinct intervals, it is often used for feature extraction and functions as an effective feature extractor [41]. Simply by discretizing the scaling variables logarithmically and coupling them to the step size implemented between the translational variable values (t), the insertion of discrete scale and translation variables values during wavelet transformation enable it to reduce the redundant signal data [42]. This exhibits how hidden frequencies can be processed to produce extremely distinctive, useful attribute for classification, regression, pattern recognition, and other ML algorithms that evaluates discrete signal time frequency. The method also approximates and details original signals using low- and high-frequency filters [43]. Equation (1) defines DWT using wavelets and scaling for a certain k-level DWT function and an f(r) signal.
Where bJ, defines the Jth scaling coefficient, cj, defines the jth coefficient of the wavelet, Ψ(t) defines the wavelet function, φ(t) defines a scaling function, t defines the time, and J define the largest level of WT. A wavelet function and a scaling function are used in a multi resolution decomposition to separate the sign at different resolution levels. Wavelet function details, the filter coefficients, and the scaling function technique are shown in Equations (2) and (3).
This is a clustering approach based on partitioning that makes use of the quick and effective unsupervised classification method [44, 45].
By using clustering, a significant number of datasets are divided into distinct groups based on their proximity to one another. This is accomplished by computing and comparing their distances. Outliers are identified using k-means clustering, and then the dataset is cleaned in the manner described below.
Step 1: Initially, kis declared to be k = 5. To determine the similarity measure to identify the closest k given input data the Manhattan distance was utilized.
Step 2: Recalculating the average for all the assigned values in the cluster to update the centroid. Steps 1 and 2 are continued until the cluster’s mean value converges.
Step 3: Outliers are removed from the results, and new data is built.
ARIMA model
ARIMA a Box-Jenkins model, is developed to evaluate events which happens across given time-frame which is used to interpret past data or predict future trend in data. It is used when data is at regular intervals, such as every few seconds or minutes, or once a day, once a week, or once a month [46].
It is defined as a “ARIMA(p,d,q)” model, whereby p denoting the autoregressive components, d denoting non-seasonal differences required for model stationarity, and q denoting the delays in the prediction error equation [47]. It is built by combining autoregressive (AR) and moving average (MA) functions, and ARMA model [46] expressed mathematically in Equation (4) below:
The model is recognized for its forecasting reliability and adaptability under different time-series conditions [47]. Being a basic equation, ARIMA is constrained in its capacity to address nonlinear problems like predicting which is projected to perform better at short-term period as opposed to long-term [48, 49].
This is another ARIMA variation that obviously tackles seasonality issues in time series using data that are univariate. ARIMA (p, d, q)(P,D,Q)s are often used to represent the SARIMA model. The non-seasonal moving-average process is denoted by the letters q, whereas non-seasonal autoregressive elements are represented by the letters p, d, and differencing. P stands for the order of the seasonal autoregressive component, D for the order of seasonal differencing, Q for the order of the seasonal moving average process, and s for the duration of the seasonal cycle [50]. SARIMA is mathematically defined in Equation (7).
With φ (B) defines the non-seasonal autoregressive polynomial, yt represent the time-series that are non-stationary, wt denotes Gaussian white noise, θ (B) denotes non-seasonal moving average polynomial and S denotes the seasonal differencing term [51].
The sequential relationship in a time series dataset is captured using the LSTM method which was initially proposed by Hochreiter [52]. The unique architecture of recurrent neural networks (RNN) created to better accurately illustrate orders and their distant links than ordinary RNNs. The recurrent hidden layer is made of memory blocks. This blocks are dedicated units containing self-connecting memory blocks that houses the gates. In addition to the self-connecting memory cells that store the network’s temporal state with each memory block, there is also an input gate and an output gate [49]. The input gate delays the transfer of input activation and the output cell controls how cell activations moves from the cell to the rest of the network. The forget gate is designed to overcome the issue with the method that prohibit the processing of continuous input streams that have not been separated into smaller sequences [53]. In order to obtain precise output timing, the modern LSTM design has peephole connections that is between the gates and the internal cells in the same cell [47, 52]. An LSTM cell’s architecture is seen in Fig. 6. A sequence of Equations (8)–(12) define the LSTM computation:

Time series plot for precipitation (mm).

LSTM Architecture.
The input, output, forget gates, and cell are denoted by i,o,f, and c, respectively, while the logistic sig-moid activation function is denoted by c. The b terms denote bias vectors (bi is the input gate bias vector), and W stands for weight matrices, and the diagonal weight matrices for peep-hole connections are W ci , W hc , W co , W cf , and W xi [53].
Various evaluation techniques were used to measure the performance of all the methods used as discussed in sections 2.3, 2.4, and 2.5. The SARIMA, ARIMA, and LSTM are compared to the Modified SARIMA, Modified ARIMA, and Modified LSTM: Accuracy (%), Mean Absolute Percentage Error (MAPE), Mean Absolute Error (MAE), Residual Sum of Squares (RSS) and Root Mean Square Error (RMSE), and are all measures of precision. Where n number of dataset, A
r
is the real value, F
r
is the forecasted value,
Mean absolute percentage error
The mean absolute percentage error (MAPE) is a metric used to assess the precision of a forecasting system. It is the mean or average of the absolute percentage errors of forecasts as defined in Equation (13).
RMSE is the residuals’ standard deviation (prediction errors). In other words, it tells how closely the data clusters around the line of best fit. RMSE is commonly used to confirm experimental results in regression analysis and forecasting. RMSE is mathematically defined in Equation (14).
MAE is a statistic used to measure a regression model’s performance. It is defined as the average the difference between the predicted values and the data’s true values. Equation (15) mathematically defines MAE.
R-squared is a statistical measure that measures a regression model’s goodness of fit. It is a metric that indicates the closeness of the data points to the fitted line. It is mathematically defined in Equation (16):
Is a statistical measure of the variation of a dependent variable that is explained by an independent variable (Equation (17) defines the
The RSS is a statistical method for calculating the proportion of a data set’s variance that is not explained for by the regression model itself. Instead, it calculates the error term’s or residuals’ variance. Equation (18) defines RSS mathematically.
Accuracy is defined as the ratio of correct predictions to total predictions made using the false positives (FP) are actual negatives incorrectly categorized as positives; True Positives (TP) are the number of actual positives accurately identified as positives. The number of actual negatives correctly categorized as negatives is known as true negative (TN), while the number of actual positives wrongly classified as negatives is known as FN (false negative). Equation (19) provides a mathematical representation of the accuracy.
The accuracy metrics were used to evaluate the model’s prediction ability, which took into consideration all components.
Summarization of the outcomes of the research is explained in this section. After modifying the model with DWT and k-means clustering, outliers were found and deleted from the dataset at a rate of 0.062%.
A lower value for MAE, MAPE, and RSME indicates a regression model that is more accurate [55]. A number of 0 indicates that the model fits the data precisely, and a lower RSS value indicates how well the model matches the data. However, a higher adj R2 demonstrates how well the model matches the data. If the answer is 1, the model fits perfectly [56].
The logarithmic adjustments was required to stabilize the variation in cholera incidence when plotting the mean-range for each seasonal period (12 months) (Figs. 7–9). The logarithmically scaled cholera case data was used in all statistical analyses.

Non-transformed data.
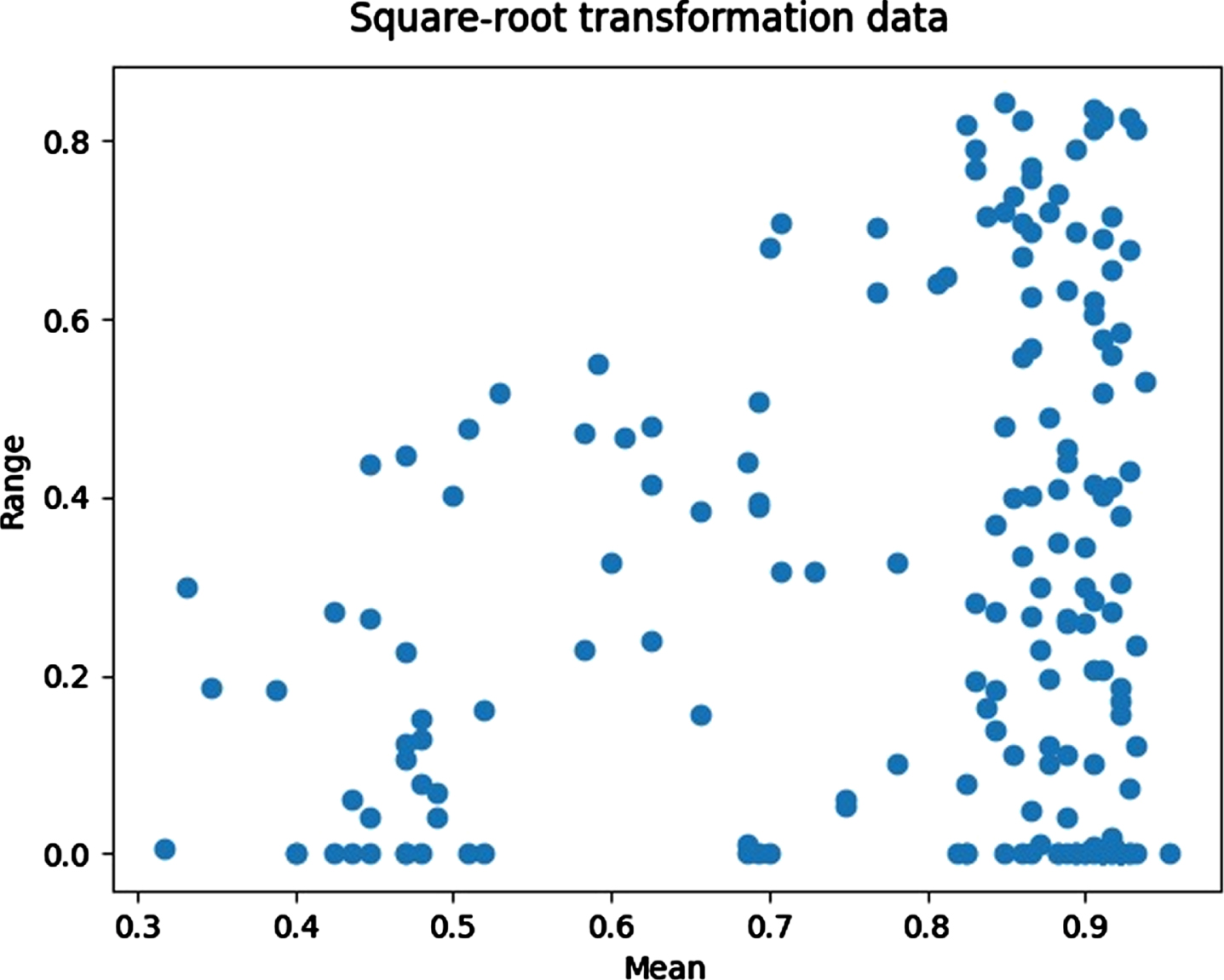
Square root transformed data.
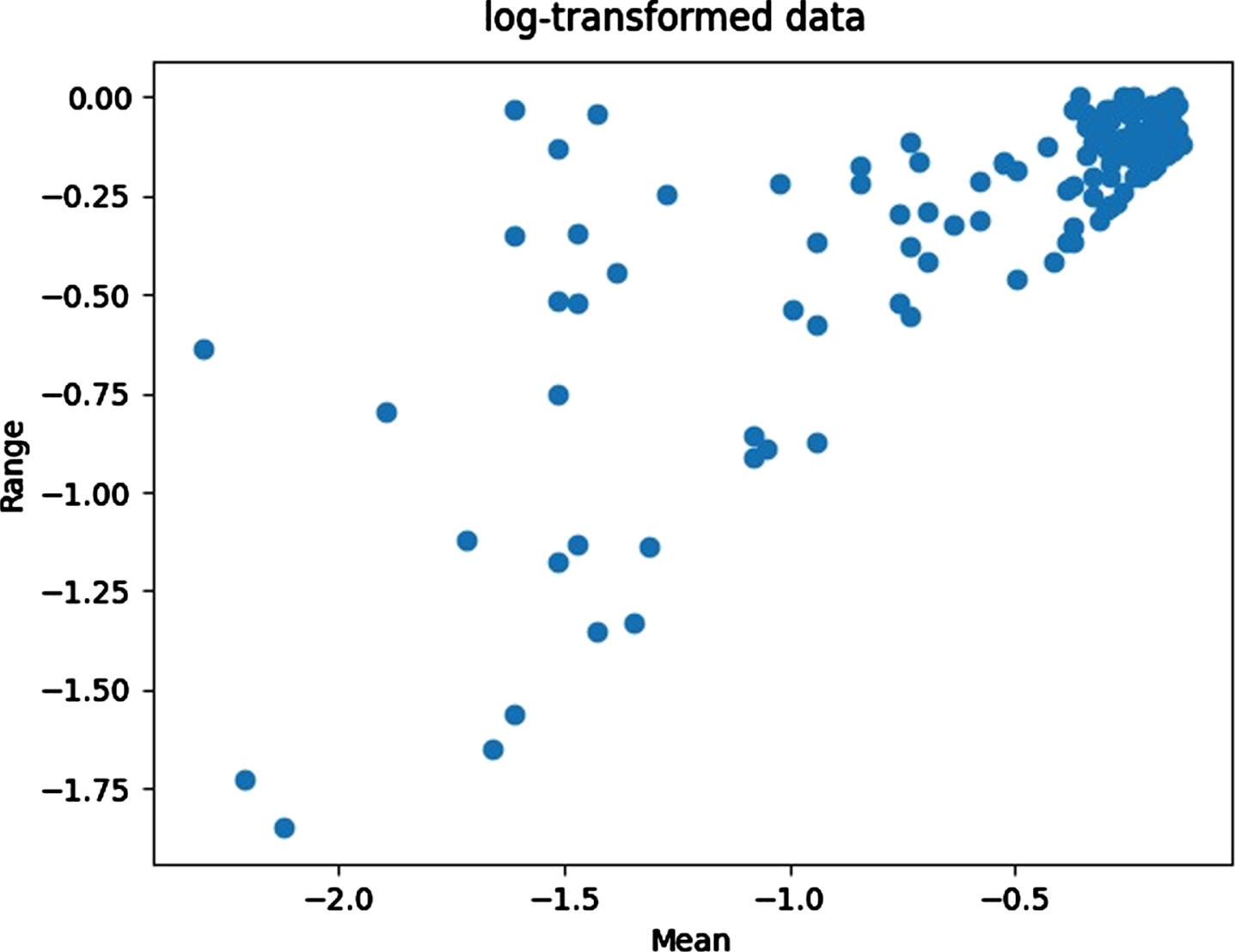
Log transformed data.
It is discovered that the data required 1-month non-seasonal differencing and 12-month seasonal differencing to achieve stationarity using the Augmented Dickey-Fuller Unit Root Test (test statistic=–7.14, and critical values at 0.01=–3.46, 0.05=–2.87, 0.1=–2.57) and evaluating ACF and PACF (Figs. 10, 11) [57]. Eventually, the SARIMA (0, 1, 2) (0, 1, 1)12 model was chosen to be the best fitted for the data used with the lowest AIC = 1526.2759.
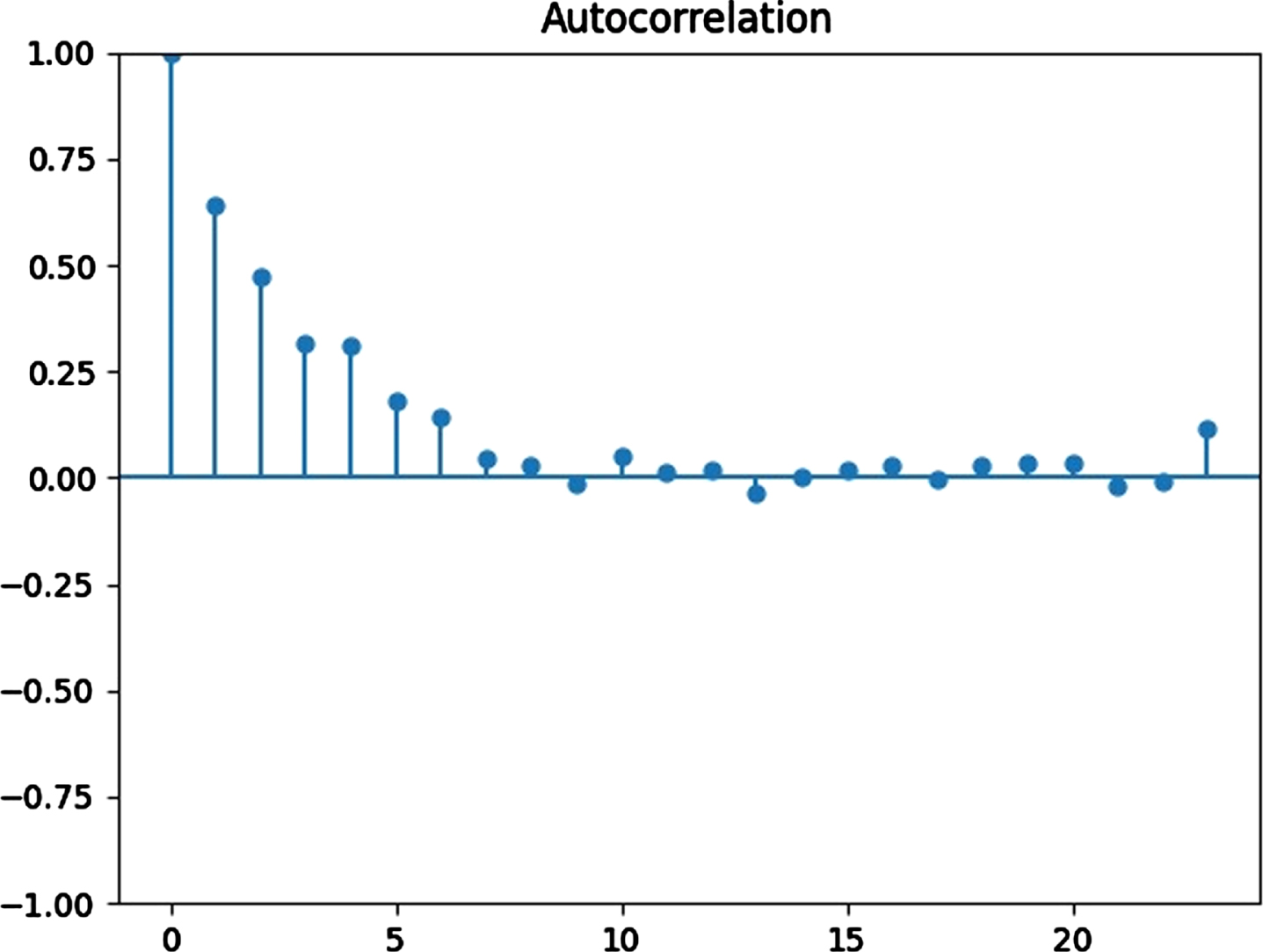
Autocorrelation function plots.
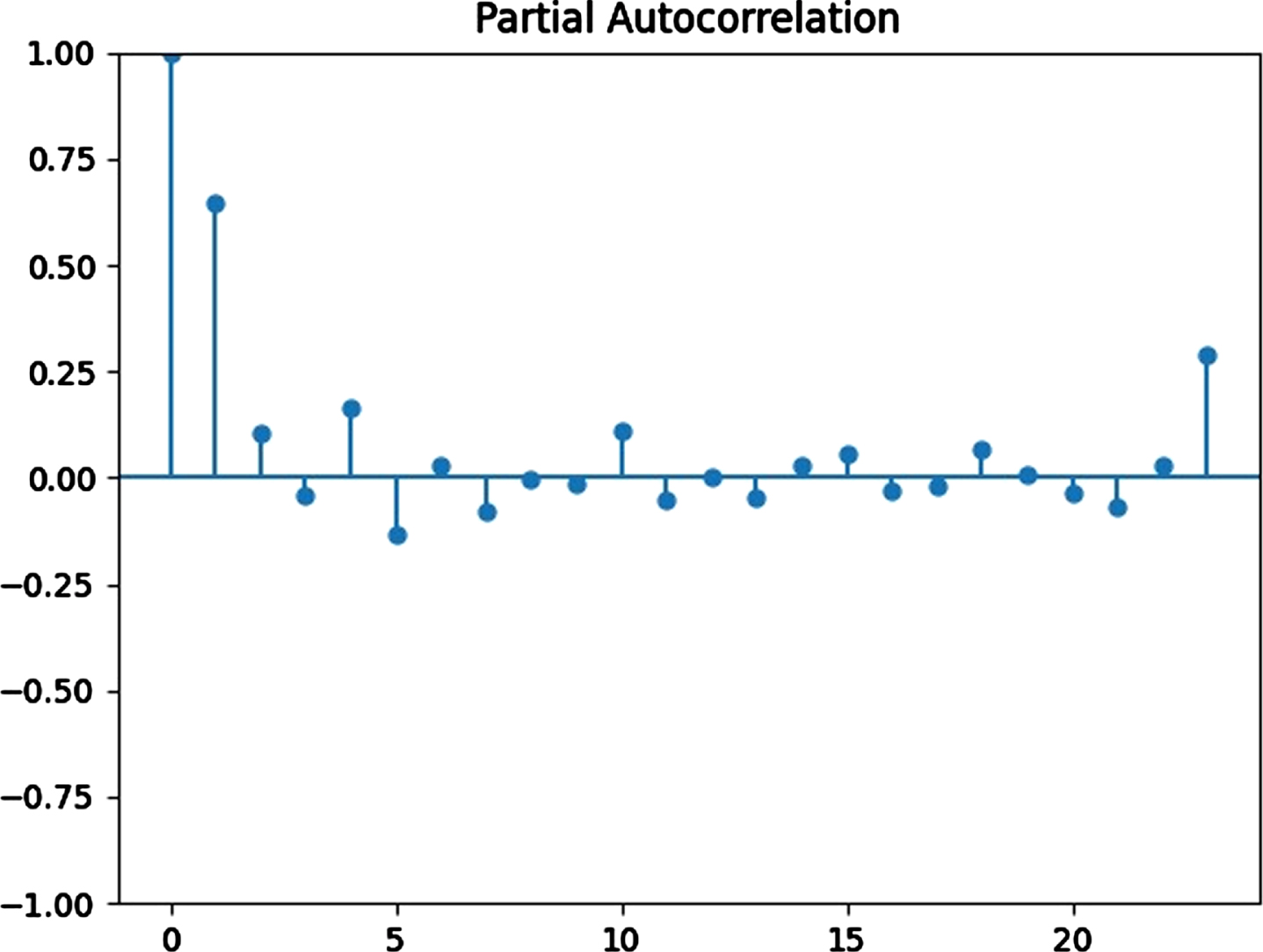
Partial autocorrelation function plots.
Using Pearson’s correlation coefficient, the cross correlation among the independent variables shows that all the variables correlated significantly with each other. The minimum and maximum temperatures were significantly associated with each other, with r = 0.2679. Precipitation and humidity were significantly and negatively correlated with maximum temperature with r = -0.7797 and r = -0.7035 respectively. The results of the cross-correlations also shows that precipitation and humidity correlate positively with r = 0.8159. r = 0.1045, r = 0.0175, r = 0.0666, and r = 0.0182 respectively. Ljung Box Q statistics was 39.67 (p = 0.635), this signifies the regression model is acceptable.
After implementing the forecasting methods described in Sections 2.3, 2.4, and 2.5, time series models SARIMA, ARIMA, and LSTM have RSS values 0.60, 0.91, and 0.72 respectively. This demonstrates that the SARIMA model, as opposed to the ARIMA and LSTM, fits the cholera and climate data the best. In comparison to Modified ARIMA and Modified LSTM, the Modified SARIMA model outperformed all other methods with an RSS = 0.502, making it the model that fits the dataset used the best. The Modified SARIMA makes use of SARIMA because it is more effective at forecasting complicated data with seasonality as a measure because cholera outbreak is a seasonal illness.
Performance metrics score
The time series model on Cholera namely ARIMA, SARIMA, and LSTM were evaluated by using the performance metrics given in Section 3.1, and the results are presented in Table 1. It is evident that the LSTM model an accuracy = 93% and a MAPE = 0.074, outperforming other models with the best accuracy and the lowest MAPE. When feature extraction using DWT was implemented in all of the methods, the performance of all the models increased. The modified model is termed as Modified LSTM, Modified ARIMA and Modified SARIMA. According to Table 2, MODIFIED SARIMA is more accurate and has a lower error rate than LSTM. With accuracy = 97%, a MAPE = 0.0300, ME = 0.235, MAE = 0.321, and an RMSE = 0.19, the Modified SARIMA model has the least amount of error among all modified models. As a consequence, it was determined that the Modified SARIMA approach is the best way under time series methods for cholera forecasting. Finally, the related parameters are plugged into Equation 7 above and the fitted model SARIMA (0, 1, 2) (0, 1, 1)12 could be written as Equation 20:
Comparison of the performance of the models
Comparison of the performance of the modified models
Quantile-quantile plots (Q-Q plots) and formal normality tests have historically been two popular methods for testing the normality assumption [58]. A common and useful visualization technique for comparing the empirical probability distribution of a random variable to any proposed theoretical distribution is the Q-Q plot. The residuals are approximately normally distributed, according to the Q-Q plot in Fig. 12, since they lie along the 450 line. For the formal normality test, the Shapiro-Wilk test which evaluates the combined hypothesis that the data are independent and identically distributed and normal [59] was used to test for normality. The result shows that the residuals were distributed normally (p = 0.164).
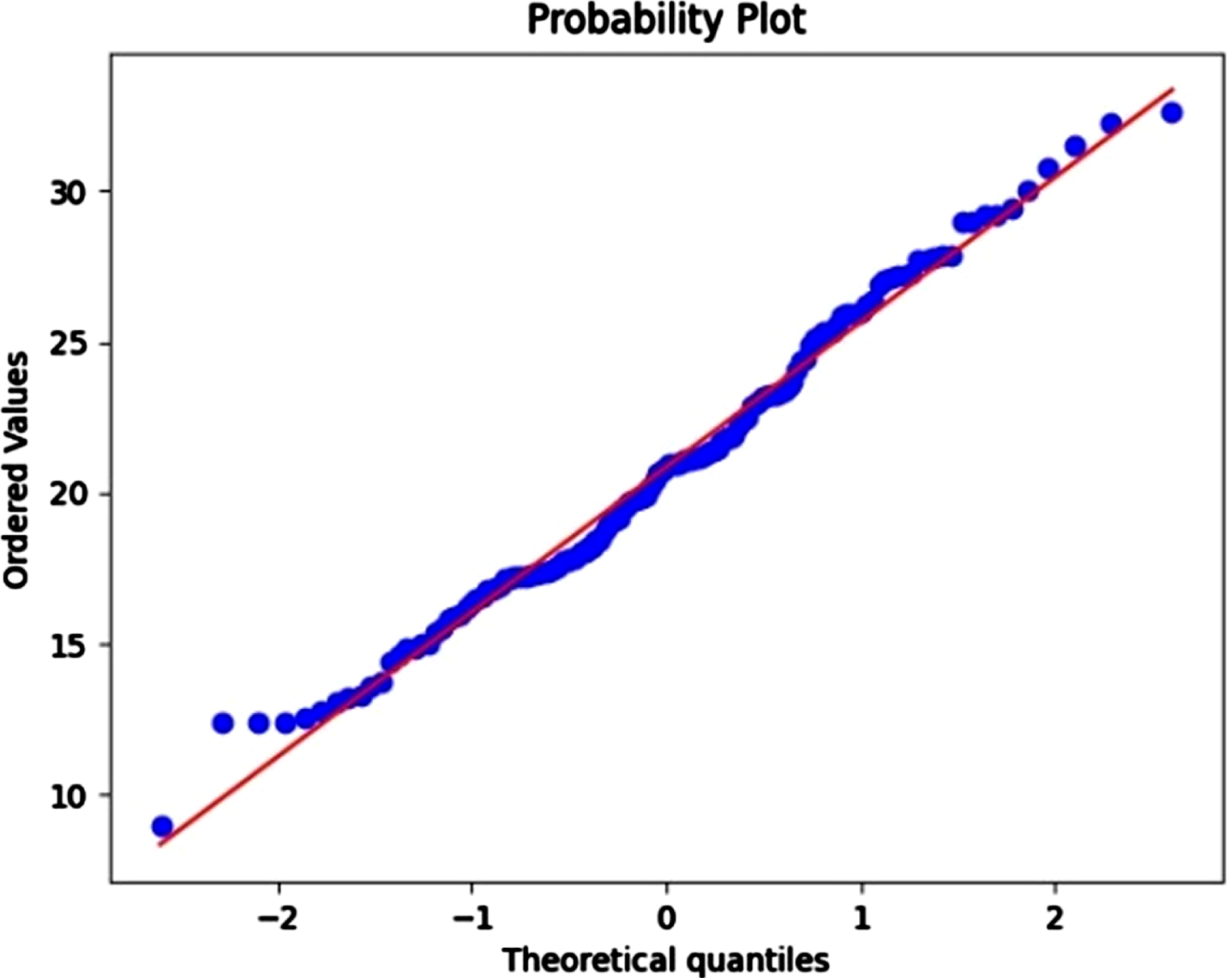
The residual plot of the fitted model and the resulting Q–Q plot.
Three time series models, ARIMA, SARIMA, and the LSTM, have employed and assessed. Later, the methods were improved using the DWT in order to have a higher forecasting accuracy and little error. The modified models shown greater promise by offering more precise findings and low error rates. Because it has been improved using DWT, which eliminates duplicated data, and k-means clustering, used to finds and discard outliers that may impair the performance of the model, Modified SARIMA was better than the SARIMA.
The study advises the use of various clustering methods for efficient outlier detection and the addition of socioeconomic data for improved outcome predictions because these factors also affect cholera epidemics and further the disease’s spread.
The result of this research will be important to epidemiologists and health professionals interested in the curtailing of cholera cases by preparing and creating Response Plans. Health professionals can prepare potential coping and adaptation strategies for potential health risks associated with climate change in Nigeria which will aid in fulfilling the Global Taskforce on Cholera Control (GTFCC) 2030 mandate on cholera “Roadmap to End Cholera by 2030”.
Footnotes
Funding and conflicts of interests
This research is not funded by any agency. The authors declare no conflict of inter.