
Abstract
Over the past ten years, deep learning has enabled significant advancements in the improvement of noisy speech. Due to the short time stability of speech signal, previous speech enhancement (SE) methods concentrated only on magnitude estimation, and these methods added a phase of the mixture in reconstructing the speech. The performance is limited in these approaches since the phase will also carry some of the speech information. Some of the speech enhancement approaches were developed later to jointly estimate both magnitudes as well as phases. Recently, complex-valued models, like deep complex convolution recurrent network (DCCRN), are proposed, but the computation of the model is very huge. In this work, we propose a Discrete Cosine Transform-based Densely Connected Convolutional Gated Recurrent Unit (DCTDCCGRU) model using dilated dense block and stacked GRU. The dense connectivity strengthens the gradient propagation by concatenating features from previous layers at the input. The advantage of the dense block is that at various resolutions, the dilated convolutions aid with context aggregation, and the dense connectivity provides a feature map with more precise target information by passing through multiple layers. To represent the correlation between neighboring noisy speech frames, a two Layer GRU is added in the bottleneck of U-Net. The experimental findings demonstrate that the proposed model outperformed the other existing models in terms of STOI (short-time objective intelligibility), PESQ (perceptual evaluation of the speech quality), and output SNR (signal-to-noise ratio).
Introduction
Speech Enhancement (SE) is a critical topic in the area of signal processing. The goal is to extract target speech from the noise environments to improve intelligibility and perceptual quality. Traditional techniques can deal with stationary noise correctly; however, they are powerless against non-stationary noise, such as the Wiener filter method [28]. Deep learning (DL) based methods make up for the above shortcomings as they regard SE as supervised learning trouble in the time-frequency (T-F) or the time domain. Common TF domain speech enhancement techniques most effectively enhance the magnitude spectrum and use the noisy phase to reconstruct clean speech [39]. This is because there may be no clear structure in the phase spectrogram, which makes it difficult to estimate the clean phase from the noisy phase. These techniques may be divided into two classes: mapping and mask-primarily based strategies. The mapping techniques use a deep neural network (DNN) to learn the mapping characteristic between the noisy phase spectrum and its corresponding target speech magnitude spectrum. The mask-based techniques estimate a mask that classifies each part of the signal, either speech or noise, after which the enhanced signal may be generated by using weighting or filtering the noisy speech with this mask. Some of the common masks are the ideal binary mask (IBM) [8], ideal ratio mask (IRM) [30], and spectral magnitude mask (SMM) [36], which show better performance than direct spectral mapping. Currently, a few researchers have proven the significance of the phase for spectrograms to be resynthesized again into time-domain waveforms [20]. Phase-sensitive masks (PSM) [5] changed into the first one that uses the latest phase data showing the feasibility phase estimation. Later, the complex ratio mask (CRM) [37] and complex spectral mapping (CSM) [32] were proposed, which may reconstruct clean speech. In 2017, Chiheb et al. proposed a deep complex network (DCN) [33], which performs better than real-valued networks. After that, deep complex u-net (DCUNET) [3] mixed the benefits of DCN and UNET [27] to address the complex-valued spectrogram. It was recently reported that a deep complex convolution recurrent network (DCCRN) [9] was developed based on both DCN and CRN, which gave a state-of-the-art performance in the T-F domain. DCCRN won the championship on the real-time track at Inter Speech 2020 in the deep noise suppression (DNS) challenge. Some other popular approach is to form an end-to-end in the time domain. In 2019, Luo et al. proposed Conv-Tas-Net, an encoder-decoder structure [16]. It uses an encoder layer to extract the input features and multiple temporal convolutional networks (TCN) as the processing modules followed by a decoder layer to reconstruct the target speech. Although producing a fine performance, a lot of 1-dimensional convolutional layers are followed to extract context data that ends in large time delay and computational complexity, which limits its practical usage in delay-sensitive applications. Recently a DCTCRN model [13] is proposed for SE based on discrete cosine transform to overcome the difficulties associated with SE approaches based on only magnitude spectrum enhancement and joint estimation of both magnitudes as well as phase.
In 2019, Li Y et al. [14] proposed T-F dilated convolution-based SE method, which overcomes the vanishing gradient problem by dense connectivity and yields better performance than the EHNET model where bidirectional RNN (LSTM) is used in the bottleneck [40]. Both the models [14, 40] used the magnitude spectrum of the clean speech as the input and reprocess phase of the noise during resynthesis, which is improbable and a valid STFT. Later some studies revealed that joint enhancement of magnitude as well as phase shows improved performance [38] but suffers from memory overhead and requires much more computation. Later, to overcome this, the short-time discrete cosine transform (STDCT) [1] is used as the input feature in the DCT-U-NET model [6] and DCTCRN model [13], which has been proven helpful to improve the performance by reducing calculations. It also circumvents the problem caused by using the phase of noisy speech at the reconstruction stage. The LSTMs are used in DCTCRN [13] and DCT-U-NET [6] models to learn long-term dependencies between speech signals in order to enhance U-Net’s performance. Pascual et al. proposed a speech enhancement technique (SEGAN) in the time domain where stridden convolutions are used in the generator and discriminator [23]. In [10], a SE model with basic U-Net architecture in the magnitude domain with 2D ordinary convolution layers in the encoder and a decoder with a 2D convolution as a bottleneck was proposed. A time domain Wave-U-Net [17] SE model was proposed with basic U-Net architecture with 1D ordinary convolution layers in the encoder and decoder with a 1D convolution as a bottleneck. A 2-stage SE model was presented in [7], where, in the first stage, the binary mask was predicted to eliminate noise dominant frequency bins, and the second stage recovers the spectrogram that was removed in the first stage by utilizing the output of the first stage.
The existing baseline models, such as the DCT-U-NET [6], SEGAN [23], U-Net [10], Wave-U-Net [17], and masking model [7], are built using convolution layers only. It is difficult for CNN alone to correctly model the long-range dependencies of speech signals. The local receptive field of the convolution limits the model’s ability to capture long-range dependencies across input sequences. To deal with the long-range dependency of speech, some models [6, 40] incorporated LSTMs in the bottleneck. Even though the performance of models [6, 40] is better, the LSTMs are easily prone to the problem of overfitting, and it also requires a long time to train. LSTM requires 4 linear layers (MLP layer) per cell to run at each time step. Linear layers require large amounts of memory bandwidth to be computed.
To overcome the above drawbacks in the proposed model, dilated dense blocks and GRUs are introduced. First, the advantage of dilated convolutions in the receptive field increases with increasing dilation rates, which are used to capture long-range speech contexts. And the dense connectivity provides a feature map with more precise target information by passing through multiple layers. Second, to represent the correlation between neighboring noisy speech frames, a two Layer GRU is added in the bottleneck of U-Net, which has the advantage of increased training speed because of its simpler architecture. GRU captures the long-range dependencies across input sequences. The vanishing gradient problem is solved by GRUs using update gates and reset gates. The flow of information into and out of memory is controlled by the update and reset gates, respectively. The advantage of GRU is that it is easier to modify and doesn’t require memory units, which means it can train faster than LSTM and also give performance results as fast as LSTM. Moreover, the proposed model is a real-valued network, which is simpler and requires less computation and memory than the complex-valued network. Hence, the performance of the model is enhanced compared to existing models, such as DCT-U-NET [6], SEGAN [23], U-Net [10], Wave-U-Net [17], and masking model [7].
The proposed DCTDCCGRU consists of an encoder, decoder, and stacked GRUs in the bottleneck part and dense layer. Each layer in the encoder and decoder comprises a convolution layer, batch normalization, PReLU, and dense layer. The proposed networks perform better due to the powerful feature self-learning ability of the CNN model and the excellent performance of the RNN network (stacked GRU layer) in processing time series data. Because the feature detection layer of CNN learns through training data, it avoids explicit feature extraction when using CNN and can learn implicitly from training data. In addition, because the weights of neurons on the same feature map are the same, the network can learn parallelly, which is also a major advantage of a convolution network compared with a network of interconnected neurons. CNN has unique advantages in speech recognition and image processing because of its special structure of local weight sharing; weight sharing reduces the number of parameters and the complexity of the network greatly. In addition to this, the proposed method has the advantage of dilated convolutions aiding context aggregation at various resolutions, and the dense connectivity provides a feature map with more precise target information by passing through multiple layers. Since information from future frames is prevented through the use of causal convolutions, the network is ideal for real-time applications.
First, in the dense block, the input of the next layer is the output of the concatenation of all the previous layers. This creates a dense connectivity pattern between layers, allowing the network to efficiently propagate information and gradients through the network. The advantage of the dense block is that the disappearing gradient issue is avoided by the dense connection to all the preceding layers. Second, the advantage of dilated convolutional layers in the dense block is that at various resolutions, the dilated convolutions aid context aggregation, and the dense connectivity provides a feature map with more precise target information by passing the input through the multiple dilated convolutional layers in the dense block. Also, one more advantage is that the information from future frames is prevented through the use of causal convolutions, and the network is ideal for real-time applications. Third, the advantage of combining CNNs with GRUs is that it can effectively capture both spatial and temporal dependencies in the input signal, which can help improve the performance of speech enhancement systems. Specifically, CNN is used to extract local frequency features from the input spectrogram, while the GRU component is used to model the temporal evolution of these features over time. Finally, the DCT is a powerful tool in signal processing, as it allows signals to be efficiently represented in a lossless manner with implicit phase information. Its real-valued coefficients also make it easier to implement than the complex-valued DFT, which requires twice as many coefficients to represent the same signal.
The paper is organized as follows: Section 2 discusses the proposed DCTDCCGRU model architecture, stacked GRU, dense layer, input feature, and loss function. In section 3, experimental results are analyzed and discussed. Concluding remarks are given in section 4.
The proposed DCTDCCGRU model
Architecture of encoder-decoder
The architecture of a basic encoder and decoder (ED) consists of three main blocks. They are the encoder, processor, and decoder. The encoder is used to extract high-level information from the input, which causes a reduction in complexity and is helpful for reduction model training. These high-level features are used to learn temporal dependencies as well as performance enhancement. Decoder reconstructs low-resolution features to the original size and predicts the output targets. For the information to flow smoothly and without any hurdle, we use skip connection which connects each of the layers of output layers of the encoder to each of the layers of input layers of the decoder. Convolution Recurrent Unit is the finest ED architecture [31]. This method is designed such that it uses multi-convolutional layers at the input, LSTM as a processor, and the transposed convolutional layers at the decoder. The Encoder-Decoder LSTM is a recurrent neural network designed to address sequence-to-sequence problems. This implementation is challenging as it induces many inputs and outputs whose number is not the same. As noticed, CGRU gives much more robust speech intelligibility than LSTM. The conclusion is that the usage of convolutional layers and transposing convolutional layers makes the trainable parameters much fewer and is not confirmed in the complex CRN model. In real-time applications, solving the complex layers becomes a huge task, which is a challenge to the device. Currently, there is no necessity for the real and imaginary parts of the short-time Fourier transform to be correlated. The complex layer designed for the operation of complex values may not be suitable.
Deep complex convolution recurrent network (DCCRN), where both CNN and RNN structures can handle complex-valued operations, is a method that has a few drawbacks. To overcome them, we proposed a Discrete Cosine Transform-based Densely Connected Convolutional Gated Recurrent Unit (DCTDCCGRU), which replaces STFT with STDCT and ISTFT with ISTDCT and uses a real-valued network layer to predict the mask. STFT has an explicit phase, while STDCT includes an implicit phase that can be utilized to train a real-valued network without designing the complex layers manually. The DCTDCCGRU model architecture is shown in Fig.1.
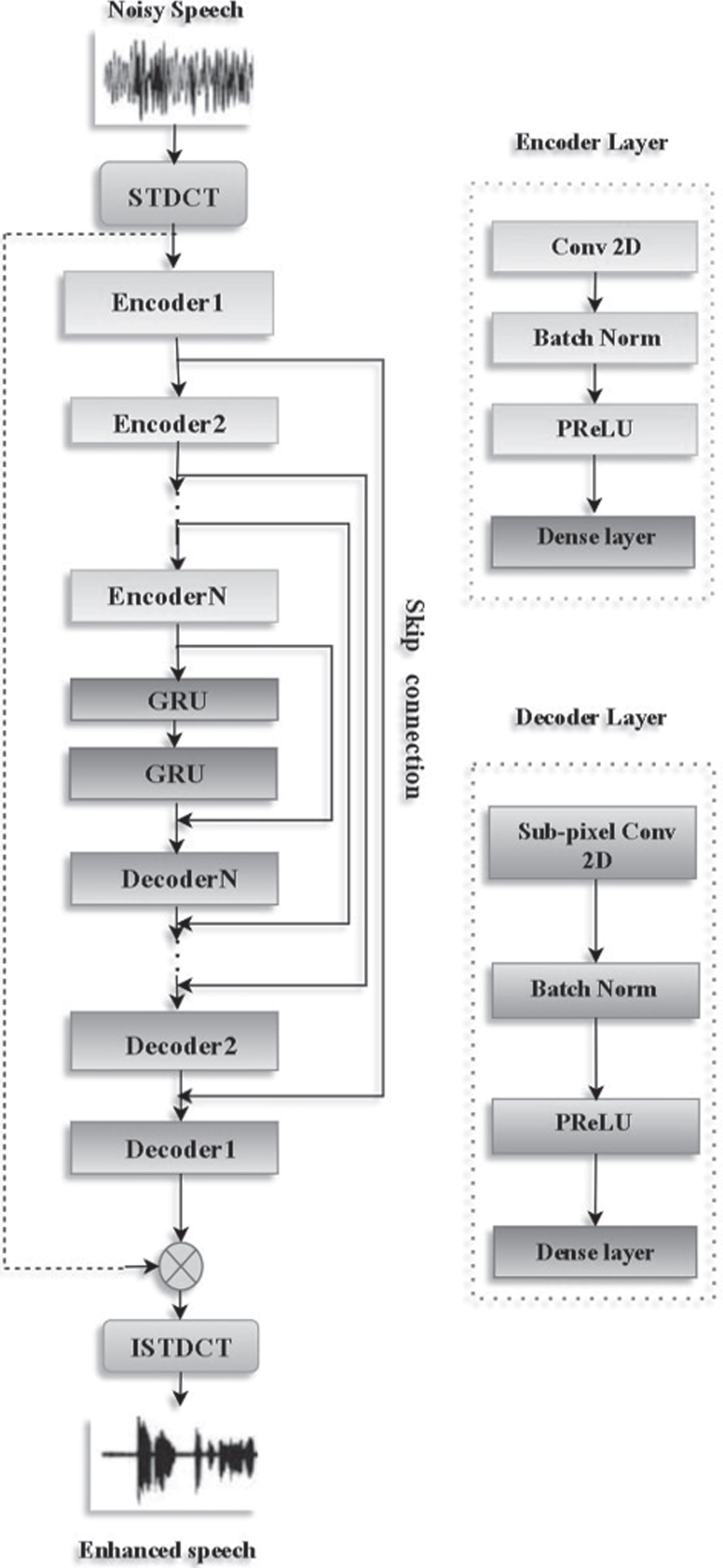
Proposed DCTDCCGRU model architecture.
In the proposed work to eliminate checkerboard artifacts [19], we use subpixel convolution (SP Conv) instead of transposed convolution (Trans-Conv). A transposed convolution initially upsamples an input signal by implanting zeros between successive samples, accompanied by a convolutional layer to produce a signal with non-zero entries. If the filter stride is not divisible by the filter length, this results in an asymmetric configuration, resulting in checkerboard artifacts [19]. A subpixel convolution [21] consists of two steps: general convolution and pixel rearranging. The subpixel convolution process uses (n * m) convolutions to obtain (n * m) signals of the same size as the input at an upsampling rate (n, m). In SP Conv, the convolution operation is performed without implanting zeros in the original signal, and the output number of channels is increased by a multiplicative factor of the upsampling rate. To achieve the desired upsampled signal, the extra channels are reshaped. The subpixel convolution with rate of (2,3) for up sampling is shown in Fig.2.
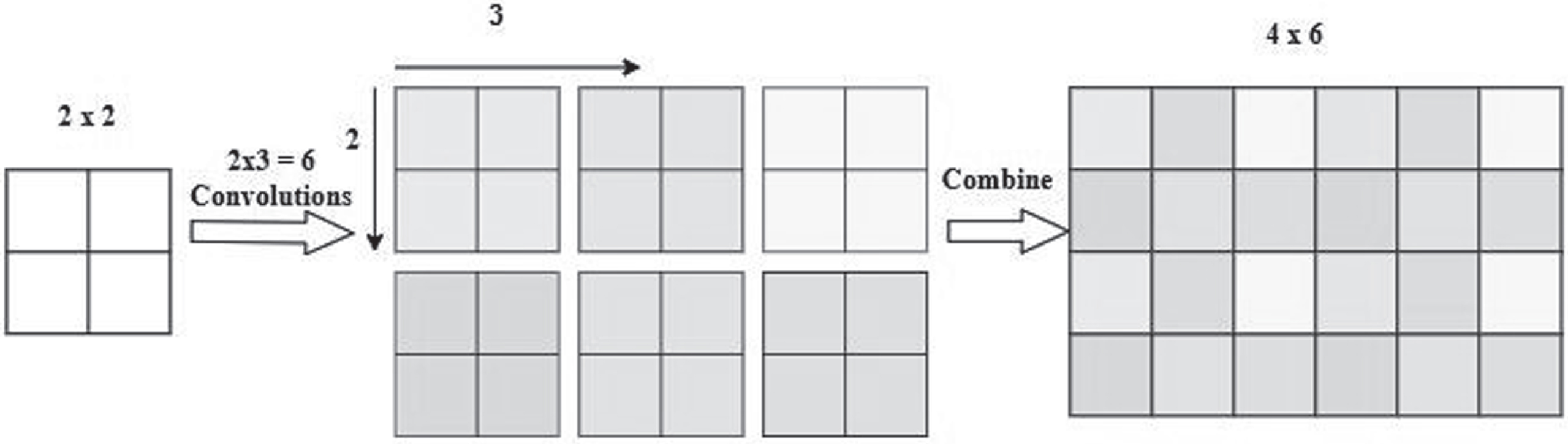
The subpixel convolution with rate of (2,3) for upsampling.
Convolutions in a sub-pixel convolution are as follows:
Convolutional neural networks often enhance contextual information by expanding the receptive fields. Although the network depth can be increased, doing so reduces computational efficiency and frequently leads to disappearing gradients [35]. Dilated convolutions for multi-scale context aggregation in picture segmentation were the first solution suggested by Yu and Koltun [22] to address this issue. Their research is predicated on the ability of dilated convolutions to dramatically increase receptive fields while maintaining resolution and coverage. In the proposed work, we employ dilated convolutions as an alternative to LSTM models to leverage long-range dependency of speech signals. The dilation is increased exponentially to have a large receptive field in the network, and it is grown from d = 1 to 16 1,2,4,8,16. The dense layer in our network is made up of dilated as well as causal convolutions to make the network suitable for real-time applications with no information leakage from future frames. The Structure of dense layer with dilated convolutions is shown in Fig. 3.

Structure of dense layer with dilated convolutions
Recently, in [26], densely connected networks (DCN) were proposed. In a DCN, the outputs from every layer before the current layer are concatenated to provide the inputs to that layer. There are two main benefits to this strategy. First, the disappearing gradient issue is avoided by the dense connection to all the preceding layers. Second, a narrower dense network is discovered to perform better than a normal wider network, increasing the network’s parameter efficiency. We suggest using a dilated dense block after each layer in both the encoder and decoder of our model. Five layers of two-dimensional convolutions make up each dense block. Convolutions between frames are causal. The causal convolutions ensure that the suggested method is appropriate for real-time application.
The input features of the SE model are classified into two categories: the time domain feature and the transform domain feature. In the time domain, speech has low dimensional spatial features. Since it is difficult to deal with complex speech in low-dimensional space, the complexity of the network must be increased. Most commonly used transform domain feature is discrete Fourier transform (DFT). The DFT converts the time domain to the frequency domain, and there will not be any information loss in the transformation. As the value of DFT data is complex, operating both the real and imaginary parts simultaneously is also complex. So, some researchers considered STFT amplitude or energy spectrum [4]. This will increase the amplitude spectrum without the estimation of a clean phase which would limit the performance of enhancement. Discrete Cosine Transform is a transformation that is real-valued without loss of information and holds an implicit phase. This overcomes the problem of designing a complex network manually to estimate the explicit phase. As discussed above, the calculation time is increased in the time domain feature. To reduce this, an input feature of a real-valued network is highly recommended.
DCT is mentioned as:
And the inverse of DCT is
Where
g (k)→ time-domain vector.
M→ vector length.
Here both DCT and IDCT functions in real domain.
An ideal cosine mask (ICM) is estimated during the training stage by using the signal approx-imation method of DCTDCCGRU. It can be defined as:
Y → STDCT data of mixture
Since the PReLU is of range (- ∞ , ∞), post-processing is used to reconstruct
With the use of add & overlap operations and ISTDCT time domain speech can be evaluated.
Scale-invariant signal noise ratio (SI-SNR) is a most commonly used as evaluation metric, which has been used as the loss function for the optimization of the model in the work [11, 29].
SI-SNR [12] is given as:
s→ clean time-domain speech
〈· , · 〉 → dot product between two vectors
∥· ∥ 2 → Euclidean norm
Datasets
The model training is done using the ICASSP2021 DNS challenge dataset [24]. This training set consists of the clean speech of 760.53 hours; read speech of 562.72 hours; singing voice of 8.80 hours; emotion data of 3.6 hours, and Chinese mandarin data of 185.41 hours. The details of noisy and clean datasets are in [25]. During this training, some noisy clips are generated to ensure the complete use of this data. During every training period, we convolve both the speech and noise with discrete room impulse response (RIR) at random, which is selected from the Domain Name System-room impulse response (DNS-RIR) dataset. After that, the simulation of noisy data is done dynamically by mixing reverb speech and noise at a particular signal-to-noise ratio (SNR). The SNR is selected in the range of -10dB to 20dB at random. For selecting the finest performed model, we use a development test set in the Domain Name System (DNS).
To generate 10000 room impulse responses (RIR) as the test room impulse response set, the image method [18] is used during the test phase. We set the room parameters to 5m×4m×3.5m size and 0.1:0.1:0.5 T60 range. The speaker and microphones are placed in the room at random with a height between 1m to 1.5m. We arrange both the speaker and mic in such a way that the distance between them should be in the range of 0.2m to 3m. We selected the TIMIT Acoustic-Phonetic Continuous Speech Corpus [2] as the clean speech for testing NOISEX-92 [34], and the real-life noise set is selected as the test noise. Real-life noise datasets include wind, songs, background music, an office, the inside of a train, and a cafeteria. Here, two types of test sets are generated; one is a reverberant test set, and the other is a non-reverberant test set. In the reverberant test set, we convolve each speech remark with room impulse responses (RIR) set. And then, we have to combine the non-reverberant and reverberant speech with a noise corresponding to each signal-to-noise ratio.
The current study also used GPU technology. The model was trained with Google Colab. However, larger datasets could not be trained due to memory constraints. Hence, GPU technology was used on a desktop (without Google Colab). The NVIDIA 2080Ti GPU was also utilized in training the model, which improved the processing power. The time taken for each epoch for training was reduced after using the above-mentioned GPU.
Model setup and baseline
Here, every waveform is resampled to 16Khz. We are using the Hanning window of size 512, and the hop time is set to 8ms and set the learning rate to 0.001 for the first 100 epochs. This will decay by 0.5 when the validation loss is increased. The number of epochs should be set to 300. For selecting the finest models, we would use early stopping.
The proposed model, DCTDCCGRU, is compared with a deep complex convolution recurrent unit (DCCRN-E). The setups of the DCCRN-E are similar to [9]. The frame after the short-time Fourier transform (STFT) is a 512-dimensional conjugate symmetric complex vector. In the DCCRN-E model, the last 256 points are used as input after deleting the direct present component. The number of encoder layer channels of DCTDCCGRU is [8, 16, 32, 64, 128, 128, 256], and the number of decoder layer channels is [128, 128, 64, 32, 16, 8, 1]. The kernel parameters, such as size, are set to 5,1, and the stride is set to 2,1 for all the layers. Every layer of encoder and decoder is followed by a dense layer. The dense layer is aided with contextual aggregation at various resolutions. To represent the correlation between neighboring noisy speech frames, a two-layer GRU is added in the bottleneck of the encoder-decoder. The number of two-layered GRU nodes should be set to 256. In this model, a causal system is also implemented to meet the requirements of the ICASSP2021 domain name system challenge. In the beginning, we had one zero frame before every convolution-encoded layer at the time domain. Lastly, we had to remove the final frame at every sub-pixel convolution decoder. Here, a frame length (32ms) with a stride (8ms) is used, resulting in a delay of 40ms to fulfill the requirements and limitations of the domain name system challenge within the time limit of 40ms.
Experimental results
The short-time objective intelligibility, the perceptual evaluation of speech quality, and the signal-to-noise ratio (SNR) are used as the objective metrics and are compared. The tables (Table-1, Table-2, Table-3) show the results of the non-reverberant test set, and the tables (Table-4, Table-5, Table-6) show the results of the reverberant test set. The experiment results are compared with the existing techniques, such as Wiener [28], DCT-U-NET [6], SEGAN [23], U-Net [10], Wave-U-Net [17], and masking model [7].
In the proposed DCTDCCGRU, the dense block of the dilated as well as causal convolutions follow the layers in the encoder and decoder. At various resolutions, the dilated convolutions aid context aggregation, and the dense connectivity provides a feature map with more precise target information by passing through multiple layers. In this work, the experiment was conducted without a dense layer named DCTDCCGRU-X-w/o-dense, DCTDCCGRU-Y-w/o-dense, and DCTDCCGRU-Z-w/o-dense and tested the performance.
Next, we included a dense layer in the encoder-decoder architecture named DCTDCCGRU-X-with-dense, DCTDCCGRU-Y-with-dense, and DCTDCCGRU-Z-with-dense. Then we compare the performance between these two DCTDCCGRUs with and without dense layers and the other existing methods. Table 1 shows PESQ values for non-reverberation Test sets. For DCT-U-NET [6] method, at -6dB and 3dB the PESQ values are 2.09 and 2.85 respectively. The PESQ values at -3dB and 3dB input test SNRs for DCCRN-E are 2.54 and 3.06 respectively. The PESQ values at 0dB and 3dB input test SNRs for DCTDCCGRU-X-w/o-dense are 2.88 and 3.12 respectively. The PESQ values at 3dB and 6dB input test SNRs for DCTDCCGRU-Y-w/o-dense are 3.19 and 3.29 respectively. The PESQ values at 3dB and 6dB input test SNRs for DCTDCCGRU-Z-w/o-dense are 3.12 and 3.37 respectively. The PESQ values at -6dB and 3dB input test SNRs for DCTDCCGRU-Z-with-dense are 2.46 and 3.23 respectively. As compared to DCT-U-NET [6] the proposed method DCTDCCGRU-X-with-dense performs better with PESQ score of 2.42 and 3.42 respectively at -6dB and 3dB input test SNRs. The PESQ score for Masking [7] is 1.99 and 2.50 respectively at -6dB and 0dB input test SNRs. The PESQ values at -6dB and 3dB input test SNRs for DCTDCCGRU-X-w/o-dense are 2.35 and 3.12 respectively. The models from DCTDCCGRU-X-w/o-dense to DCTDCCGRU-Z-with-dense substantially the PESQ score is increased. The proposed models DCTDCCGRU with and without dense yields high PESQ scores at all input SNR conditions as compared to all the existing methods.
PESQ on the non-reverberation test sets
PESQ on the non-reverberation test sets
Table 2 shows STOI values for non-reverberation Test sets. For Wave-U-Net [17] method, at -6dB and 6dB input SNRs the STOI values are 67.65% and 90.5% respectively. The STOI values at -6dB and 0dB input test SNRs for Masking [7] are 69.7% and 83.1% respectively. The STOI values at -6dB and -3dB input test SNRs for DCCRN-E are 76.9% and 83.5% respectively. The STOI values at -3dB and 3dB input test SNRs for DCTCDCGRU-X-w/o-dense are 84.9% and 92.9% respectively. The STOI values at -6dB and 6dB input test SNRs for DCTCDCGRU-Y-w/o-dense are 77.5% and 96.6% respectively. The STOI values at -6dB and 0dB input test SNRs for DCTCDCGRU-Z-w/o-dense are 77.9% and 89.1% respectively. The STOI values at -6dB and 6dB input test SNRs for DCTDCCGRU-X-with-dense are 78.9% and 96.2% respectively. The STOI values at -6dB and 6dB input test SNRs for DCTDCCGRU-Y-with-dense are 77.8% and 94.9% respectively. The DCTDCCGRU-Z-with-dense have the STOI score of 93.1% and 96.2% respectively at 3dB and 6dB input SNRs. The models from DCTDCCGRU-X-w/o-dense to DCTDCCGRU-X-with-dense yields high STOI scores compared to existing methods. As compared to all the existing methods listed in above table the proposed method DCTDCCGRU-X-with-dense performs better in all the test conditions. The proposed models DCTDCCGRU with and without dense yields high STOI scores at all input SNR conditions as compared to all the existing methods.
STOI (in %) on the non-reverberation test sets
Table 3 shows SNR values for non-reverberation test sets. For the U-NET [10] method, at -6dB and 6dB input SNRs, the output SNR values are -2.10 and 7.83, respectively. The output SNR values at -6dB and 0dB input test SNRs for Masking [7] are 0.17 and 5.82, respectively. The output SNR values at 0dB and 3dB input test SNRs for DCCRN-E are 9.92 and 12.08, respectively. The output SNR values at 0dB and 3dB input test SNRs for DCTDCCGRU-X-w/o-dense are 11.70 and 13.94, respectively. The output SNR values at 0dB and 3dB input test SNRs for DCTDCCGRU-Y-w/o-dense are 11.20 and 13.38, respectively. The output SNR values at 0dB and 3dB input test SNRs for DCTDCCGRU-Z-w/o-dense are 11.51 and 13.81, respectively. The output SNR values at -3dB and 6dB input test SNRs for DCTDCCGRU-X-with-dense are 10.19 and 16.97, respectively. The output SNR values at 0dB and 3dB input test SNRs for DCTDCCGRU-Y-with-dense are 11.97 and 13.57, respectively. The DCTDCCGRU-Z-with-dense have output SNR scores of 14.06 and 16.87, respectively, at 3dB and 6dB input SNRs. The models from DCTDCCGRU-X-w/o-dense to DCTDCCGRU-X-with-dense yields high output SNR scores compared to existing methods.
SNR on the non-reverberation test sets
Compared to all the existing methods listed in the above table, the proposed method DCTDCCGRU-X-with-dense performs better in all the test conditions. The proposed models DCTDCCGRU with and without dense yield high output SNR scores at all input SNR conditions compared to all the existing methods. From non-reverberant sets, DCTDCCGRU-X and DCTDCCGRU-Z methods, with and without dense, outperform DCCRN-E. In both cases, DCTDCCGRU with and without dense, the DCTDCCGRU-X achieves better performance. The range of the Parametric Rectified Linear Unit is near the value of Image Colour Matching so that the network can estimate the mask more accurately. In order to obtain better performance in speech enhancement, the ICM value should be more.
In speech enhancement, the ideal cosine mask is a commonly used method for estimating the clean speech signal from a noisy observation. The ideal cosine mask is computed as the ratio of the clean speech signal’s magnitude spectrum to the noisy observation’s magnitude spectrum. It represents the ideal amplitude gain that should be applied to each frequency bin of the noisy observation to obtain the corresponding frequency bin of the clean speech signal.
The ideal cosine mask value ranges from 0 to 1, with 1 indicating that the amplitude of the clean speech signal at a particular frequency bin is equal to the amplitude of the noisy observation at that frequency bin. As the ideal cosine mask value increases, the amplitude gain applied to each frequency bin of the noisy observation also increases, resulting in a higher estimated amplitude of the clean speech signal.
A higher ideal cosine mask value leads to better speech enhancement for several reasons. Firstly, a higher ideal cosine mask value means that the estimated clean speech signal has a higher amplitude, which can improve the signal-to-noise ratio and increase speech quality and intelligibility. Secondly, a higher ideal cosine mask value means that more of the clean speech signal’s energy is preserved in the estimated signal, which can result in less distortion and fewer artifacts in the reconstructed signal. Finally, a higher ideal cosine mask value can result in a better spectral shape of the estimated speech signal, which can improve the perceptual quality of the reconstructed signal.
Table 4 shows PESQ values for reverberation Test sets. For SEGAN [23] method, at -6dB and 3dB the PESQ values are 1.64 and 2.22 respectively. The PESQ values at -6dB and 3dB input test SNRs for Wave-U-NET [17] are 1.67 and 2.31 respectively. The PESQ score for Masking [7] is 1.78 and 2.39 respectively at -6dB and 0dB input test SNRs. The PESQ values at -6dB and 3dB input test SNRs for DCCRN-E are 1.95 and 2.53 respectively. The PESQ values at 0dB and 3dB input test SNRs for DCTDCCGRU-X-w/o-dense are 2.70 and 2.84 respectively. The PESQ values at 3dB and 6dB input test SNRs for DCTDCCGRU-Y-w/o-dense are 2.76 and 2.99 respectively. The PESQ values at 3dB and 6dB input test SNRs for DCTDCCGRU-Z-w/o-dense are 2.91 and 3.21 respectively. The PESQ values at 3dB and 6dB input test SNRs for DCTDCCGRU-X-with-dense are 2.90 and 3.26 respectively. The PESQ values at 0dB and 3dB input test SNRs for DCTDCCGRU-Y-with-dense are 2.67 and 2.82 respectively. The proposed method DCTDCCGRU-Z-with-dense performs better with PESQ score of 2.34 and 3.12 respectively at -6dB and 3dB input test SNRs as compared to existing methods. The models from DCTDCCGRU-X-w/o-dense to DCTDCCGRU-Z-with-dense substantially the PESQ score is increased. The proposed models DCTDCCGRU with and without dense yields high PESQ scores at all input SNR conditions as compared to all the existing methods.
PESQ on the reverberation test sets
Table 5 shows STOI values for reverberation Test sets. For DCT-U-NET [6] method, at -6dB and 6dB input SNRs the STOI values are 60.5% and 83.0% respectively. The STOI values at -6dB and 0dB input test SNRs for Masking [7] are 58.2% and 73.2% respectively. The STOI values at -6dB and -3dB input test SNRs for DCCRN-E are 64.8% and 71.7% respectively. The STOI values at -3dB and 3dB input test SNRs for DCTCDCGRU-X-w/o-dense are 73.7% and 84.9% respectively. The STOI values at -6dB and 6dB input test SNRs for DCTCDCGRU-Y-w/o-dense are 65.9% and 88.2% respectively. The STOI values at -6dB and 0dB input test SNRs for DCTCDCGRU-Z-w/o-dense are 66.9% and 80.7% respectively. The STOI values at -6dB and 6dB input test SNRs for DCTDCCGRU-X-with-dense are 67.4% and 89.9% respectively. The STOI values at -3dB and 3dB input test SNRs for DCTDCCGRU-Y-with-dense are 73.2% and 85.8% respectively. The STOI values at -6dB and 6dB input test SNRs for DCTDCCGRU-X-with-dense are 67.4% and 89.9% respectively. The DCTDCCGRU-Z-with-dense have the STOI score of 86.7% and 90.1% respectively at 3dB and 6dB input SNRs. The models from DCTDCCGRU-X-w/o-dense to DCTDCCGRU-X-with-dense yields high STOI scores compared to existing methods. As compared to all the existing methods listed in above table the proposed method DCTDCCGRU-X-with-dense performs better in all the test conditions. The proposed models DCTDCCGRU with and without dense yields high STOI scores at all input SNR conditions as compared to all the existing methods.
STOI (in %) on the reverberation test sets
Table 6 shows SNR values for reverberation Test sets. For Wiener [28] method, at -6dB and 6dB input SNRs the output SNR values are -5.12 and 6.18 respectively. The output SNR values at -6dB and 0dB input test SNRs for Masking [7] are -2.45 and 2.56 respectively. The output SNR values at 0dB and 3dB input test SNRs for DCCRN-E are 5.49 and 6.95 respectively. The output SNR values at 0dB and 3dB input test SNRs for DCTDCCGRU-X-w/o-dense are 7.99 and 10.09 respectively. The output SNR values at 0dB and 3dB input test SNRs for DCTDCCGRU-Y-w/o-dense are 7.57 and 9.98 respectively. The output SNR values at 0dB and 3dB input test SNRs for DCTDCCGRU-Z-w/o-dense are 8.24 and 10.88 respectively. The output SNR values at 0dB and 3dB input test SNRs for DCTDCCGRU-Y-with-dense are 7.85 and 10.01 respectively. The output SNR values at -3dB and 6dB input test SNRs for DCTDCCGRU-Z-with-dense are 5.75 and 12.94 respectively. The DCTDCCGRU-X-with-dense have the output SNR score of 5.99 and 12.88 respectively at 3dB and 6dB input SNRs. The models from DCTDCCGRU-X-w/o-dense to DCTDCCGRU-X-with-dense yields high output SNR scores compared to existing methods. As compared to all the existing methods listed in above table the proposed method DCTDCCGRU-X-with-dense performs better in all the test conditions. The proposed models DCTDCCGRU with and without dense yields high STOI scores at all input SNR conditions as compared to all the existing methods. Compared to the existing methods listed in the above table, the proposed method DCTDCCGRU-Z-with-dense performs better in all the test conditions. DCTDCCGRU-Z-with-dense yields better results in the case of the reverberant test case in all conditions. In the case of reverberant, it is difficult to learn ICM because the mask range is limited (-1, 1) due to Tanh activation. Tables 6 confirm that the proposed DCTDCCGRU model is much better than deep complex convolution recurrent network (DCCRN-E), DCT-U-NET [6], and the other existing methods on both non-reverberation and reverberation test sets.
SNR on the reverberation test sets
The present study proposes a robust discrete cosine transform-based densely connected convolutional gated recurrent unit network for real-time speech enhancement. The proposed model has the advantage of combining CNNs with GRUs to effectively capture both spatial and temporal dependencies in the input signal, which can help improve the performance of speech enhancement systems. Additionally, the proposed model has the advantage that the dilated convolutions aid context aggregation at various resolutions and the dense connectivity provides a feature map with more precise target information by passing through multiple layers. Since information from future frames is prevented through the use of causal convolutions, the network is ideal for real-time applications and performs better when compared to existing methods in terms of PESQ, STOI, and SNR. The results from the experiment show that DCTDCCGRU achieves both objective and subjective metrics of state-of-the-art performance. Further, we evaluate a scenario in which a speech signal is corrupted with different sounds. And the outcome demonstrates that our model is unable to filter the noise at the point where different noise types switch over. In the future, we will investigate the speech enhancement issue with noise tracking.