
Abstract
The energy consumption prediction of the chiller is an important means to reduce the energy consumption of buildings. Therefore, a novel energy consumption prediction model for chillers based on an improved support vector machine (ICA-DE-SVM) is proposed. The imperialist competitive algorithm (ICA) is used to optimize the penalty coefficient and kernel function width of SVM, greatly improving the generalization ability and prediction accuracy of the SVM model. The assimilation process is very important in ICA. Colonies of empires move randomly toward imperialists during the assimilation process in ICA, which decreases population diversity and can lead to premature convergence. Therefore, to create more new locations for colonies and increase population diversity, the idea of differential mutation proposed by differential evolution (DE) was applied to ICA. The established model was experimentally verified in an actual multi-chiller system in a building, and the results showed that the ICA-DE-SVM model could obtain good prediction results. Finally, the proposed model was compared with SVM model, PSO-SVM model, GA-SVM model, WOA-SVM model, and ICA-SVM model. With an MAPE of 0.6%, an MSE of 2.3, and an R2 of 0.9998, the findings demonstrate that the ICA-DE-SVM model has a greater prediction accuracy than the other models.
Keywords
Introduction
Achieving carbon peak and carbon neutrality is a broad and profound socio-economic transformation. The proposed “double carbon” goal has elevated the green development path to a new height. Energy consumption is the key to achieving “double carbon” [1].
The central air-conditioning system of the whole building is the highest energy consuming facility, and its power consumption accounts for a large part of the total power consumption of the building. The cold source system is one of the main components of the central air conditioner, and it consumes a lot of energy. Therefore, the energy consumption optimization of the cold source system is an important means to reduce the energy consumption of buildings. However, due to the nonlinear, hysteretic, complex operating, time-varying and strong coupling conditions of the cold source system, its actual energy consumption optimization is costly and time-consuming. Therefore, establishing the model of energy consumption prediction of the cooling source system and realizing the energy consumption prediction under different working conditions is one of the important ways to achieve energy conservation in buildings [2, 3].
The energy consumption prediction method of the cold source system is separated into 3 main categories. The first category is a physical model based on thermodynamic mechanisms, the second category is a gray box model using mechanism information modeling, and the third category is a data-driven black box model [4]. The physical model requires a lot of information, which results in the establishment of its thermodynamic model. The physical model is usually reliable and reflects the operation of the device. However, the establishment of a physical model requires knowledge of a large amount of information and consumes a lot of human and material resources. The gray box model consists of building the structure of the model by analyzing the information of the device and then identifying the parameters of the model through operation data of equipment [5]. Afram A et al. [6] identified the parameters of the energy consumption model of chillers through the experimental data. Janabi-Sharifi F et al. [7] established the grey box model of the cooling tower, and verified the usefulness and adaptability of the grey box model through experiments. The grey box model is more accurate than the physical model, but it needs to keep a lot of information of the machine operation yet.
In the past, regression models were mainly used to forecast energy consumption by scholars [8–12]. Due to the rapid development of machine learning, it is more and more widely used in the field. Kim J-H et al. [13] established the energy consumption prediction model of the cold source system by using multilayer perceptron (MLP), and verified the effectiveness of the model. Li et al. [14] proposed a new neural network structure with an attention mechanism based on building energy consumption prediction of the RNN model. Wang et al. [15] established the power consumption prediction method by using the extreme value gradient lifting, and carried out a comparative test between the models established.
Su et al. [16] suggest a unique capacity prediction approach for SOH estimates based on deep learning, transfer learning, and the battery equivalent circuit model. Su et al. [17] provide a capacity estimation approach for an adaptive boosting charging strategy that is utilized for state estimation and adaptive charging strategy modification during the charging and discharging cycle process. Black-box data-driven models have been utilized extensively, but their precision is primarily dependent on the caliber and number of learning samples. The sample data in the actual field are frequently accompanied by noise, which has a negative impact on the data-driven model. In addition, many essential data describing the operating characteristics of the object are difficult to gather directly in the actual process. The generalization capacity of the model decreases dramatically when the system’s operational conditions change or the learning samples’ coverage is limited [18].
Due to the nonlinear, hysteretic, complex operating, time-varying, and strong coupling conditions of the cold source system, its actual energy consumption optimization is costly and time-consuming. These conclusions motivated us to investigate more effective machine learning techniques. In the rest of this paper, we present our method as well as a reference implementation for dealing with energy consumption prediction for chillers.
Support vector machine (SVM) is based on kernel function theory, which maps samples to high dimensional space and has unique advantages in dealing with small samples, high-dimensional, nonlinear problems. Zhao et al. [19] compared the SVR model with the ANN model and GPR model, and verified the usefulness and adaptability of the SVR method through experiments. Tang et al. [20] established an SVR model according to the selected input variables. They then used the office building’s data set to confirm the model’s efficacy. The SVM approach was used by Paudel et al. [21] to forecast how much energy a university would use. The choice of the penalty parameters and kernel function parameters, however, has a significant impact on the prediction performance of an SVM model in practice. Many swarm intelligence optimization algorithms, such as the genetic algorithm, particle swarm optimization, cuckoo search algorithm (CSA), and others, have been applied to SVM parameter optimization. Jing W et al. [22] proposed a energy-saving diagnosis method based on an enhanced PSO-SVM model. Ding Y et al. [23] established prediction models for office buildings based on the GA-SVR and GA-WD-SVR algorithms. However, these optimization algorithms have some flaws, such as being prone to local optimums, taking a long time to run, providing insufficient feedback information, and failing to achieve optimal prediction performance.
The imperialist competitive algorithm (ICA) proposed by Atashpaz Gargari and Lucas in 2007 [24], is a socially inspired randomized and optimized search method. Currently, ICA has been effectively used to solve a variety of optimization issues such as scheduling, classification and mechanical design [25, 26]. In an experimental comparison of published literature, when compared to other algorithms, ICA has better local and global search capabilities, faster convergence speed, and tolerable calculation times (e.g., GA, PSO, etc.) [27, 28]. In ICA, the differential mutation idea of DE algorithm is used to improve the assimilation process of ICA in order to improve the diversity of solutions generated in the assimilation process and increase the probability of jumping out of the local optimal solution. The new algorithm is called ICA-DE.
The ICA-DE is used to optimize the penalty coefficient and kernel function width of SVM and establish an energy consumption prediction model for chillers based on the ICA-DE-SVM model. The proposed model is experimentally verified in an actual building. The experimental results show that the ICA-DE-SVM model has a better effect than the other methods. The overall idea of this article is shown in Fig. 1. The main innovations are as follows: A novel energy consumption prediction method for chillers based on ICA-DE-SVM is proposed. The established model was experimentally verified in the actual building, and the results showed that the ICA-DE-SVM method could obtain good prediction results; The proposed ICA-DE differs from the original ICA in that it allows colonies to learn not only from their corresponding imperialists but also from other colonies in the empire. This decreases the possibility of trapping in the local optimum and increases the chance of finding a better position; Apply the differential mutation idea that was proposed by differential evolution (DE) to ICA. In ICA-DE, the mutation rate and crossover ratio are not always constant but vary with the evolution process, which can improve the convergence speed of the algorithm.
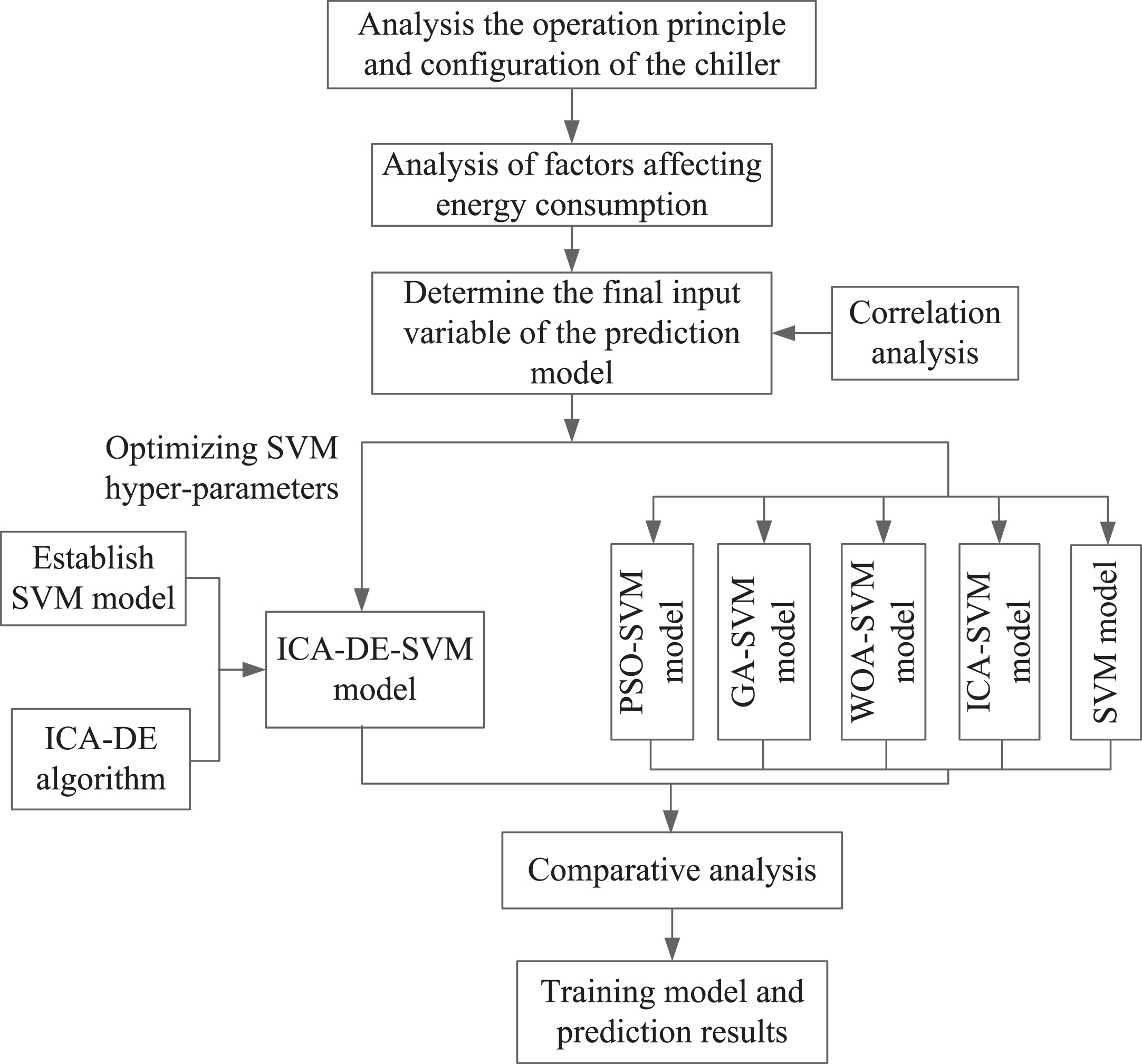
The flow chart of overall thought.
The paper is arranged as follows: Section 2 introduces the composition and working principle of the cold source system, and analyzes the main factors that affect the energy consumption of chillers. In Section 3, the ICA-DE-SVM model is constructed, and the process of using the model to predict energy consumption is introduced. Section 4 experimentally verifies the usefulness and adaptability of the model proposed in this article and compares it with other methods. Section 5 gives the conclusion and an outlook for future work.
The operation principle and configuration of the chiller
As shown in Fig. 2, the chiller is mainly composed of four parts, namely compressor, expansion valve, evaporator and condenser.
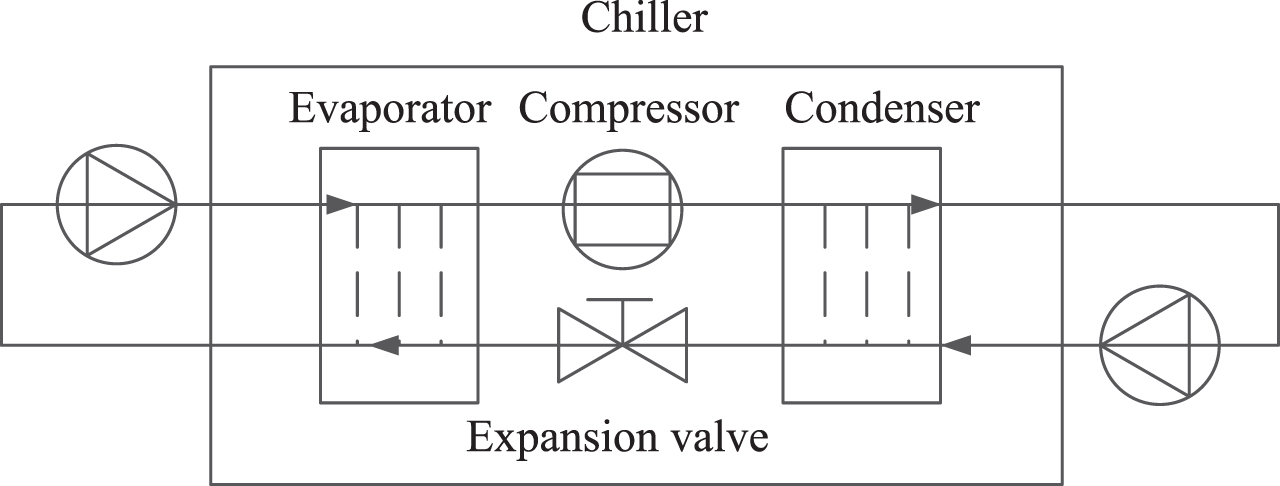
The configuration of chillers.
As shown in Fig. 3, the three primary cycles in the cold source system are the refrigerant cycle, the chilled water cycle, and the cooling water cycle. The purpose of the refrigerant cycle is to complete the heat transfer from chilled water to cooling water. In the refrigerant cycle’s evaporator, the refrigerant evaporates, absorbs heat, and then releases heat from the chilled water. A significant amount of heat is released into the cooling water as the refrigerant condenses in the condenser, and this heat is then carried by the cooling tower to the outside air. The compressor converts low temperature, low pressure gas refrigerant into high temperature, high pressure gas refrigerant. In the expansion valve, the high-temperature, high-pressure liquid refrigerant is changed into a low-temperature, low-pressure refrigerant. In addition to completing interior temperature and humidity adjustments, chilled water circulation serves to remove heat generated in the space and maintain a cool environment. Through terminal devices like fan coil units, the low-temperature chilled water transfers heat to the indoor air and removes it. The purpose of cooling water circulation is to dissipate heat into the atmosphere, bringing down the temperature of the cooling water. High-temperature cooling water enters the cooling tower, where it exchanges heat with the ambient air to transform into low-temperature cooling water. Returning to the condenser, the low-temperature cooling water continues to collect heat and transforms into high-temperature cooling water.

The operation principle of chillers.
The factors affecting the energy consumption of chillers are very complex, which are not only affected by each facility, but also by working environment. Based on a review of the cold source system’s operating mechanism, the main factors affecting the energy consumption of chillers can be preliminary determined, as shown in Fig. 4 and Table 1.

Influencing factors: (a) influencing factors in chilled water cycle and (b) influencing factors in cooling water cycle.
Variables affecting energy consumption
As shown in Table 1, the Th1, Th2, Qch, Qcl, Tc1, Tc2, COP, W, PLR, T0, Thu, and Twb are used as input variables to establish a model for predicting the energy consumption of chillers.
To better understand the ICA-DE-SVM model, in Section 3.1, the basics of ICA are introduced. In Section 3.2, the ICA-DE method is introduced, and then the ICA-DE-SVM model is detailed in Section 3.3.
ICA
(a) Initialization
In ICA, each individual is referred to as a country. In solving the optimization problem, each group of solutions is called a country. Each element in a country corresponds to each variable of the optimization problem. For a D-dimensional optimization problem, the i-th country can be expressed as follows:
The power of a country is expressed as a cost function, and the cost of the i-th country is expressed as:
N countries are randomly generated, and the elements of each country are generated as:
The cost of the randomly generated N countries is calculated and then the first N
imp
countries that are powerful are chosen as imperialist and the rest of the N
col
countries as colonies. The colonies are distributed according to the size of the imperialist power. The greater the power, the more colonies are distributed, and the smaller the power, the fewer colonies are distributed. The number of colonies owned by each imperialist is calculated as follows [27]:

The empire.
(b) Assimilation
In the process of assimilation, all colonies of the empire shifted to imperialism. The inclination between the moving direction and the connecting direction of the colony and imperialist is θ, as shown in Fig. 6. θ is a uniformly distributed random number, which can be expressed as [30]:
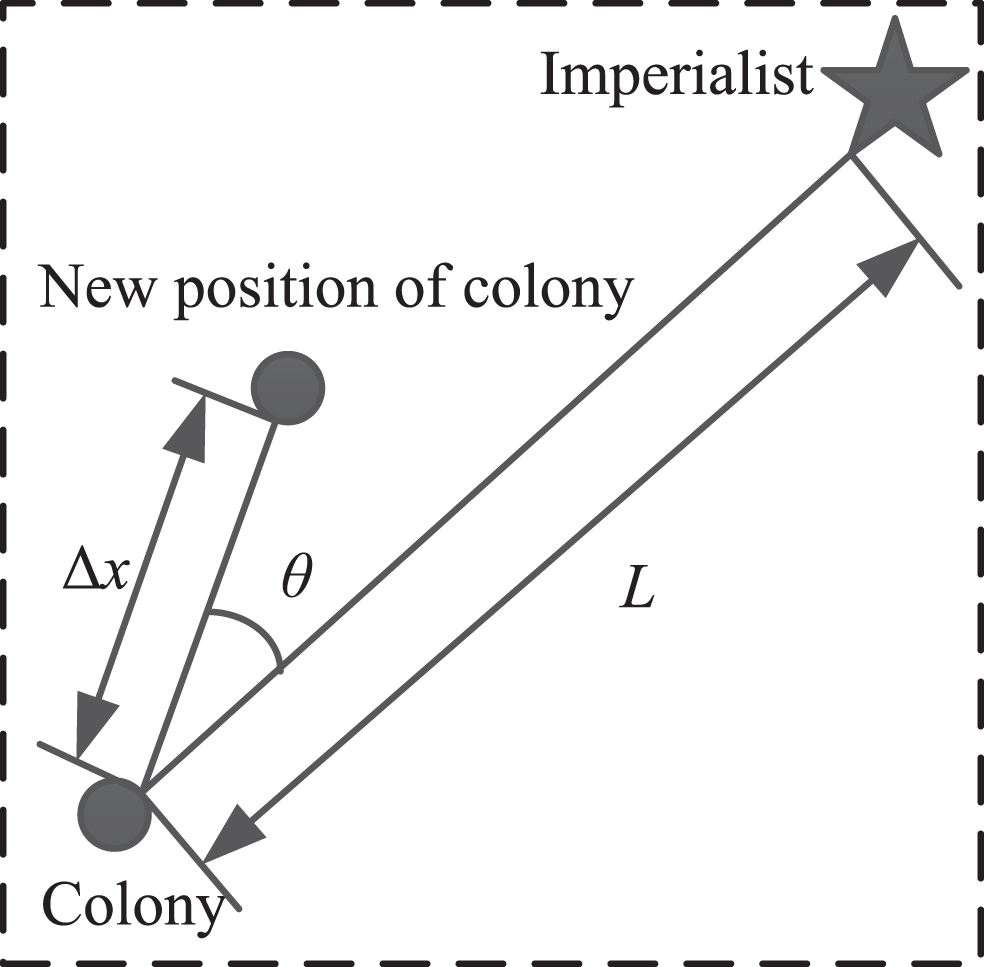
The process of assimilation.
The current position of the i-th colony is X
i
, and the new position after moving can be expressed as:
In the assimilation process, when a colony moves to a new position, if its cost is less than the imperialist to which it belongs, that is, if its power is greater than that of the imperialist to which it belongs, the positions between the colony and its imperialist should be exchanged; in other words, the colony becomes an imperialist in the empire, while the original imperialist becomes a colony [31], as shown in Fig. 7.

Exchange positions between colony and imperialist.
(c) Imperialistic competition
Empire competition is the process by which the stronger empire occupies the colony of the weaker empire [32]. The first step is to calculate the total cost of empire, that is, the size of empire power. Imperialist has a great influence on the whole empire, while the influence of colonies is very small. Therefore, ICA calculates the total cost of the n-th empire using the following formula:

Competitive process.
(d) Elimination of powerless imperialists
By occupying the colonies of other empires, powerful empires became increasingly powerful, while the number of colonies of the weaker empire declined. If an empire loses every colony, that empire is wiped out [33]. With the elimination of empires, one empire is finally left. At this time, the algorithm terminates.
In ICA, the assimilation process is very important. It explores the optimal solution to the optimization problem. In each empire, colonies move in order to create a better position and thus increase the total power of the empire. However, the movement of colonies to imperialist in the assimilation process of ICA is random, which reduces the diversity of the population and can lead to premature convergence. Therefore, in order to create more new locations for colonies and increase population diversity, the idea of differential mutation proposed by differential evolution was introduced into ICA. The new algorithm is called ICA-DE. The assimilation process of the new algorithm is shown in Fig. 9.

The process of mutation and crossover.
The colony X
coli
in an empire generates a mutation position, which is expressed as:
The F and CR can improve the exploration ability of the new algorithm, but the capacity for exploitation will decline in tandem. Two iterative indicators I1 and I2 are set to regulate when the mutation and crossover alter adaptively in order to achieve a better balance between exploration and exploitation. Algorithm 1 illustrates the new assimilation process.
The prediction impact of SVM is superior to the present ELM and BP neural networks, whose energy consumption is influenced by too many parameters. As a result, the SVM is employed to create an energy consumption prediction model for chillers.
A set of input and output data sets, it can be represented as:
It is necessary to solve for the coefficients ω and b in order to obtain the nonlinear fitting function depicted in Equation (22). By including relaxation variables ξ
i
(
By introducing the Lagrange operators η
i
and
The penalty coefficient c and the kernel function width parameter g are crucial for creating an appropriate model, according to the support vector machine theory [37]. In order to increase the effectiveness and accuracy of parameter optimization and remove the influence of random error of sample data on the accuracy of the regression model, the parameters c and g are optimized using ICA-DE with the aim of minimizing the mean square error (MSE). The ideal values of the optimized parameters c and g are used to create the ICA-DE-SVM-based energy consumption prediction model. Figure 10 Depicts the ICA-DE-SVM model’s flowchart.
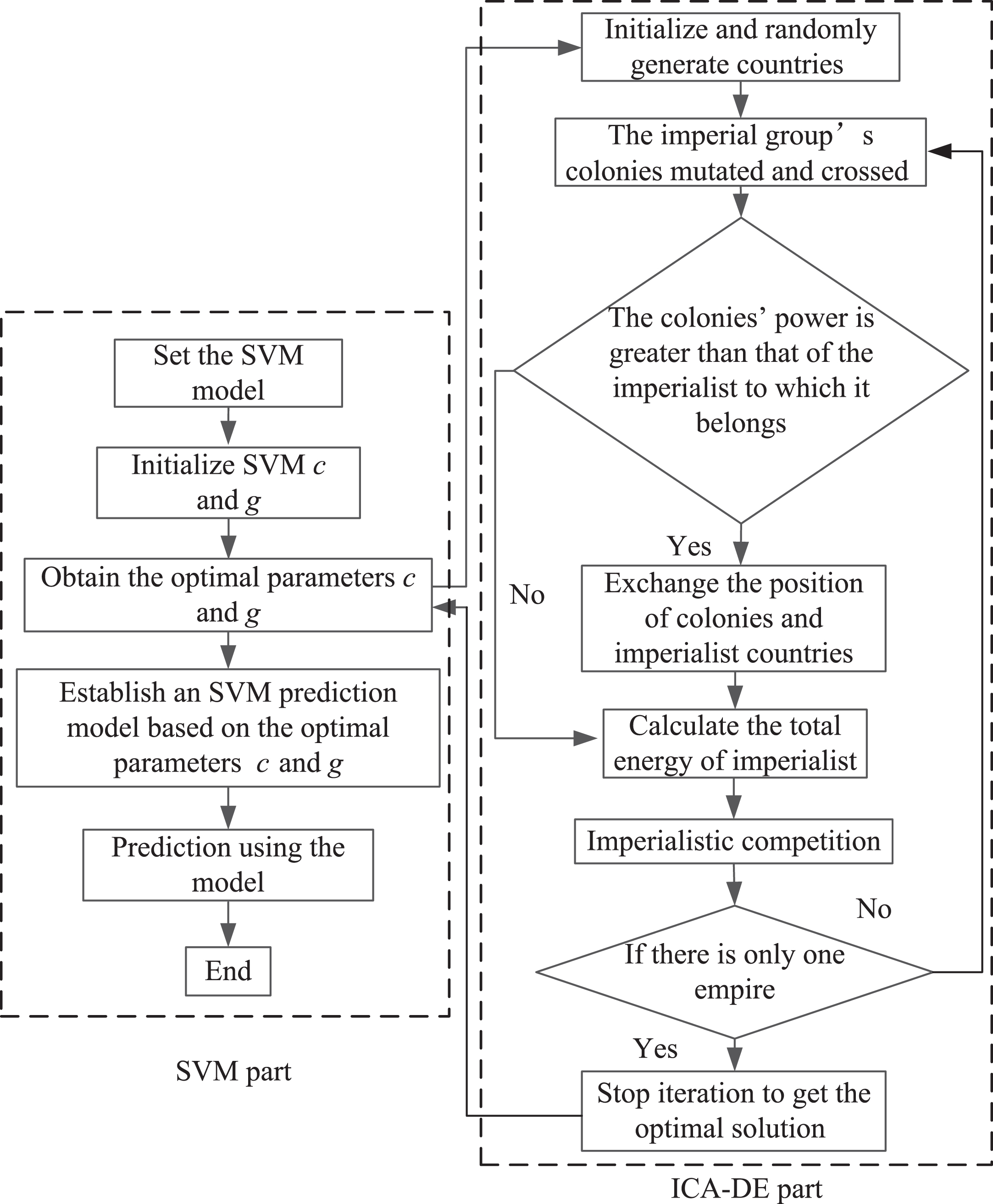
The framework of the ICA-DE-SVM model.
The flow chart of energy consumption prediction method for chillers based on ICA-DE-SVM is shown in Fig. 11. The steps are as follows:
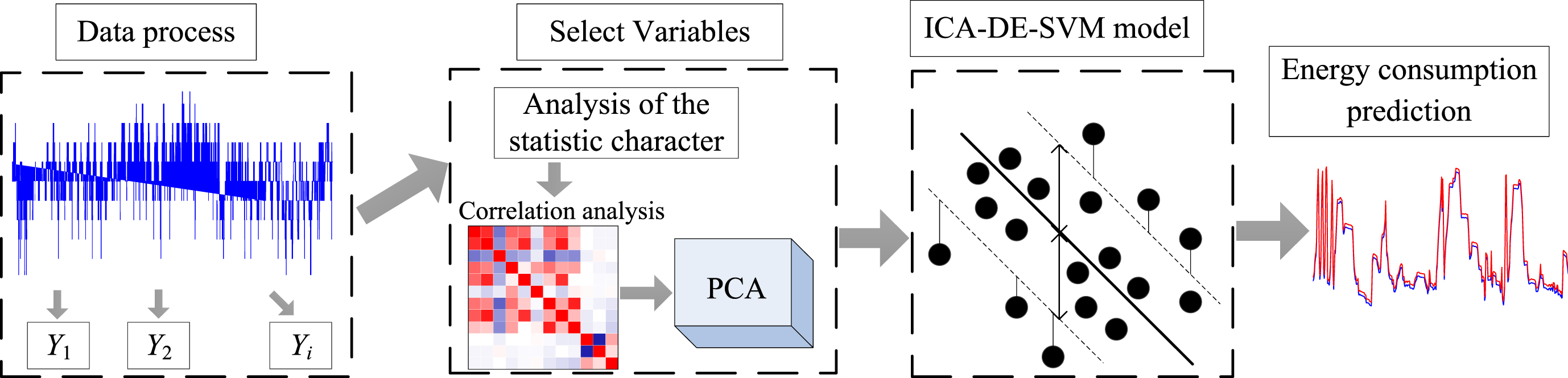
The flow chart of the proposed model for chillers.
Collect operation data set of multi chiller system: Y
i
= { yi1, yi2, ⋯ , y
in
} ∈ Rm×n. n is the number of variables, m is the number of samples; Statistical analysis of collected data, as well as variable correlation analysis, to eliminate variables with high correlation. The eliminated variables are then fed into the network model via principal component analysis; Input data into the ICA-DE-SVM model to predict energy consumption.
In the experiment, it is assumed that the chillers can work normally and that their performance is not affected by the increased operation time. Moreover, the failure rate of the chillers will not change with the extension of the operation time.
Collection of experimental data
The operation data set of the chiller is used to confirm the availability of the proposed model, The dataset used in this experiment is collected from the operational datasets of an actual chiller in a building in Panyu District, Guangzhou, China. The building’s area is 5372 m2, and the total construction area is 111000 m2. The ground area of the building is 48 floors, with 3 floors on the ground and a building height of 178 m. The central air-conditioning refrigeration station of the building mainly includes four chillers, four cooling water pumps, eight cooling towers, four chilled water pumps, and the total cooling capacity of the cold source system is rated at 8440 kW, as shown in Fig. 12. and Table 2. The building monitors and stores the operation data of the chiller in real time through the IBMS.

Refrigeration station.
The building type
Operational data was collected from July to August, 2022 using sensors that were installed. The variables for data collection include Th1, Th2, Qch, Qcl, Tc1, Tc2, COP, W, PLR, T0, Thu, and Twb. A total of 12000 sets of data were collected through the sensors that were installed. Part of the operational data collected is shown in Table 3. The sample data for Th1, Th2, Tc1, and Tc2 are shown in Fig. 8. Figure 13 shows that the working conditions of the central air conditioning cold source system parameters are always changing, and these four variables show periodic changes.
Part of operation data
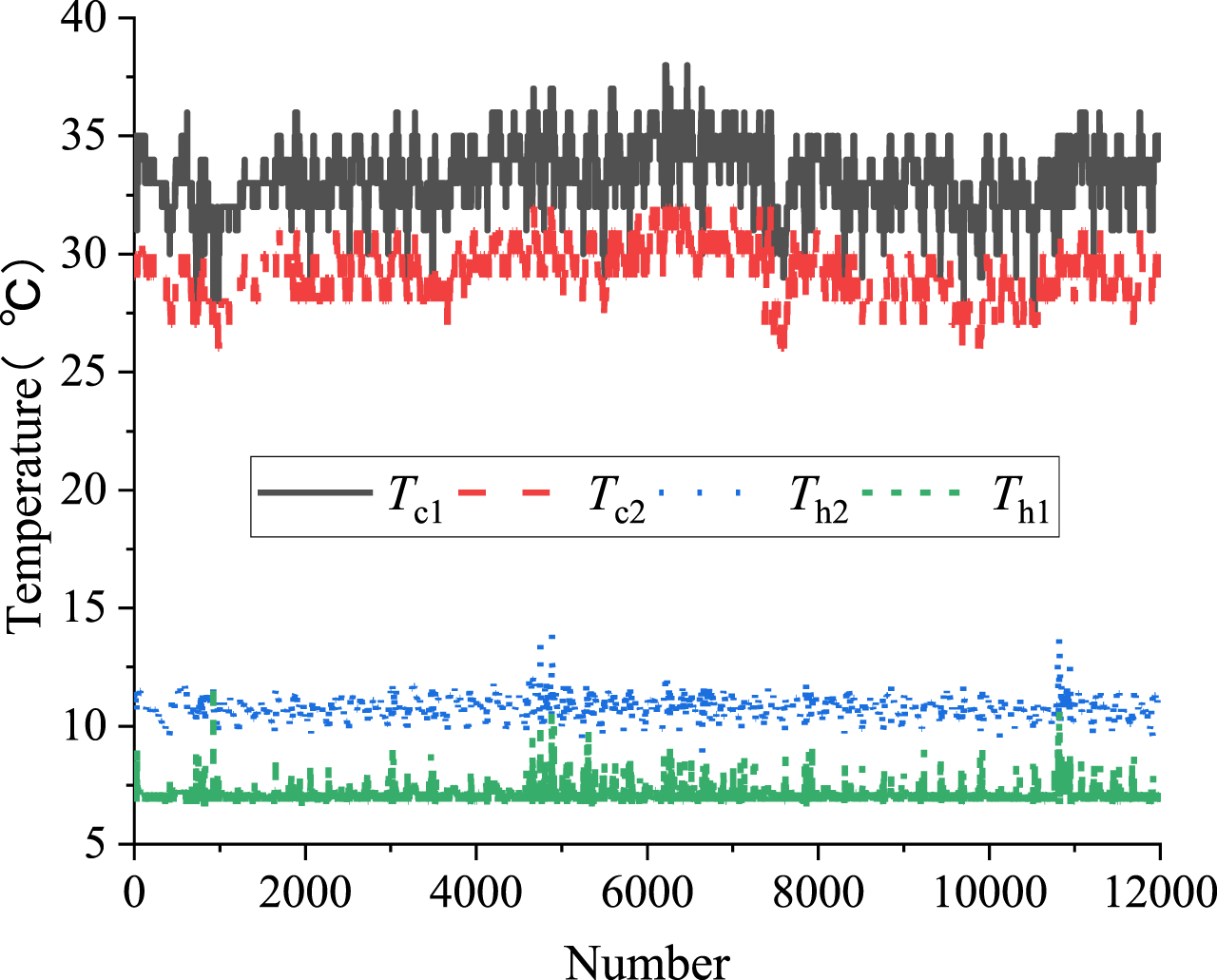
The sample data of some variables.
The violin diagram of 12000 sample datasets for each variable is shown in Fig. 14. The distribution of the variables in the sample data, including the maximum, minimum, median, and mean values of each variable, is shown in the box in the center of each violin diagram. The sample datasets for each variable are distributed within a particular range, and there are individual extreme values, as shown in Fig. 14. A normal distribution trend may be seen in the sample data distribution.
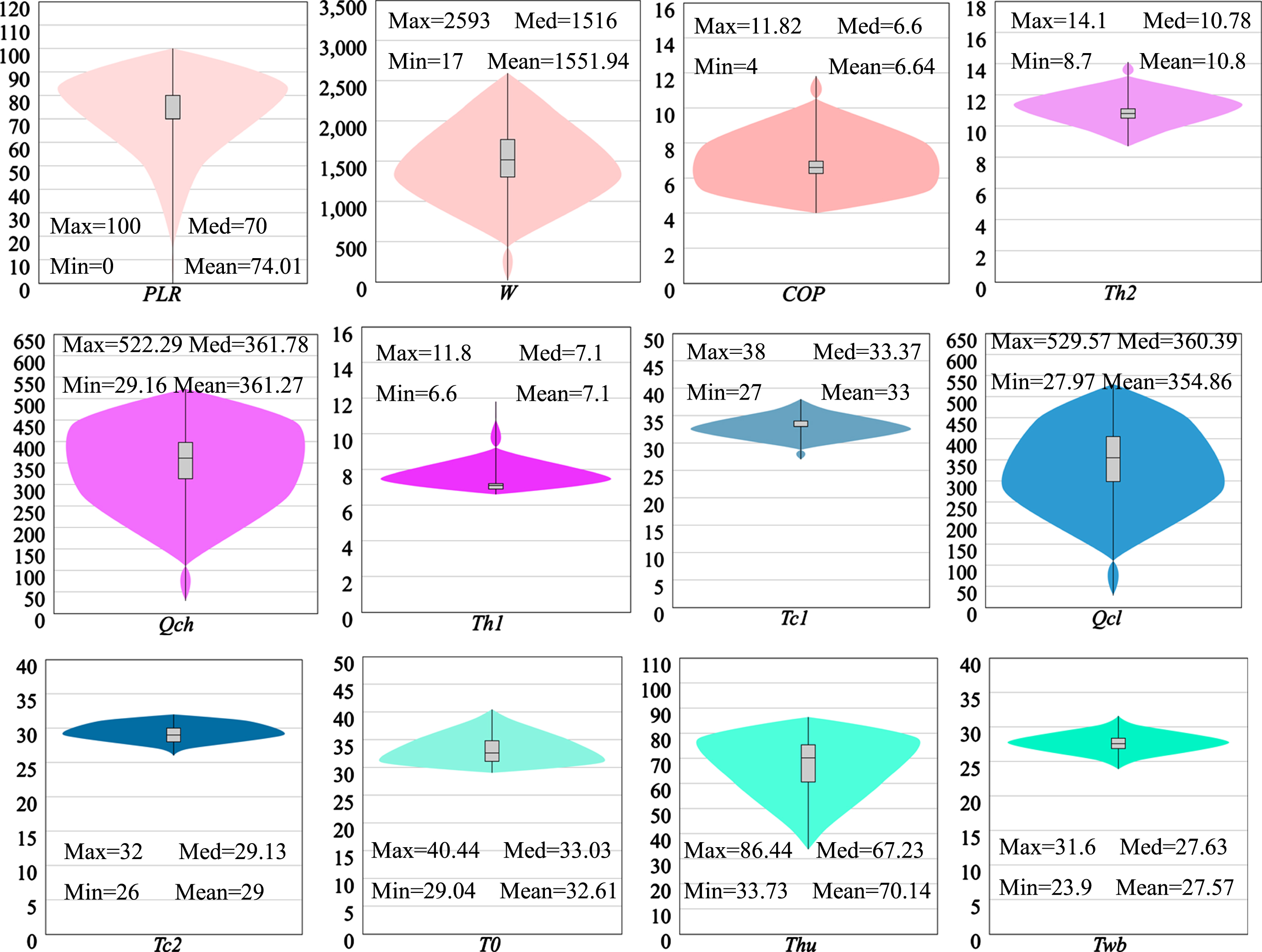
Violin chart of 12 variables.
In order to improve the accuracy of the established ICA-DE-SVM model, it is necessary to carry out correlation analysis among variables in order to eliminate variables with high correlation. If not, the accuracy of the resulting model may be compromised. Therefore, the correlation between each variable is evaluated using the Pearson correlation coefficient [38]. Figure 15 displays the heat map of the Pearson correlation coefficient between variables. Figure 10 shows that there is a strong association between the two variables, PLR and W. PLR and W are eliminated, and then the eliminated variables are input through principal component analysis processing into the network model.

The correlation heat map.
To evaluate the usefulness and adaptability of the established ICA-DE-SVM model, then conduct 9 experiments with different training sets. The training set is randomly generated. The number of training datasets was N, which was set to 2000, 2500, 3000, 3500, 4000, 4500, 5000, 5500, and 6000, respectively. Then the ICA-DE-SVM energy consumption prediction model was established. To evaluate the accuracy of the ICA-DE-SVM method, the absolute relative errors (ARE), mean absolute percentage error (MAPE), mean square error (MSE), and coefficient of determination (R2) were used as the evaluation criteria of the ICA-DE-SVM model. The smaller ARE and MAPE, the higher model accuracy. The closer R2 is to 1, the higher model accuracy.
The equations are as follows:
MAPE (%), MSE, and R2 of the ICA-DE-SVM model
Table 4 shows that when the training set number are 2000, the MAPE, MSE, and R2 of the ICA-DE-SVM model are 0.91, 8.4357, and 0.9844, respectively; when the training set number are 2500, the MAPE, MSE, and R2 of the ICA-DE-SVM model are 0.78, 7.3, and 0.9868, respectively; when the training set number are 3000, the MAPE, MSE, and R2 of the ICA-DE-SVM model are 0.7, 6.2, and 0.9981, respectively; when the training set number are 3500, the MAPE, MSE, and R2 of the ICA-DE-SVM model are 0.66, 5.6574, and 0.9983, respectively; when the training set number are 4000, the MAPE, MSE, and R2 of the ICA-DE-SVM model are 0.55, 5.5475, and 0.9984, respectively; when the training set number are 4500, the MAPE, MSE, and R2 of the ICA-DE-SVM model are 0.5, 5.4469, and 0.9986, respectively; when the training set number are 5000, the MAPE, MSE, and R2 of the ICA-DE-SVM model are 0.47, 2.9112, and 0.9993, respectively; when the training set number are 5500, the MAPE, MSE, and R2 of the ICA-DE-SVM model are 0.44, 2.17, and 0.9994, respectively; when the training set number are 6000, the MAPE, MSE, and R2 of the ICA-DE-SVM model are 0.42, 1.69, and 0.9995, respectively. It is not difficult to see that as the quantity of training samples increases, the value of MAPE decreases, the value of MSE also decreases, and the value of R2 is closer to 1. Due to the nonlinear, hysteretic, complex operating, time-varying, and strong coupling conditions of the cold source system, its actual energy consumption optimization is costly and time-consuming. The above experiments fully verify the effectiveness of the ICA-DE-SVM model, especially when the number of training datasets is large. It has obvious advantages. When dealing with the energy consumption prediction problem for chillers, the ICA-DE-SVM model could obtain good prediction results.
The ARE of the ICA-DE-SVM model for training sets, which was set to 2000, and testing sets, which was set to 500, are shown in Fig. 16. Most error using ARE of the ICA-DE-SVM model is less than 5%, which can satisfy the demand. Table 4 and Fig. 16 show that the established ICA-DE-SVM energy consumption prediction model for chillers meets the requirements, and the larger the number of training sets, the better the accuracy of the model.
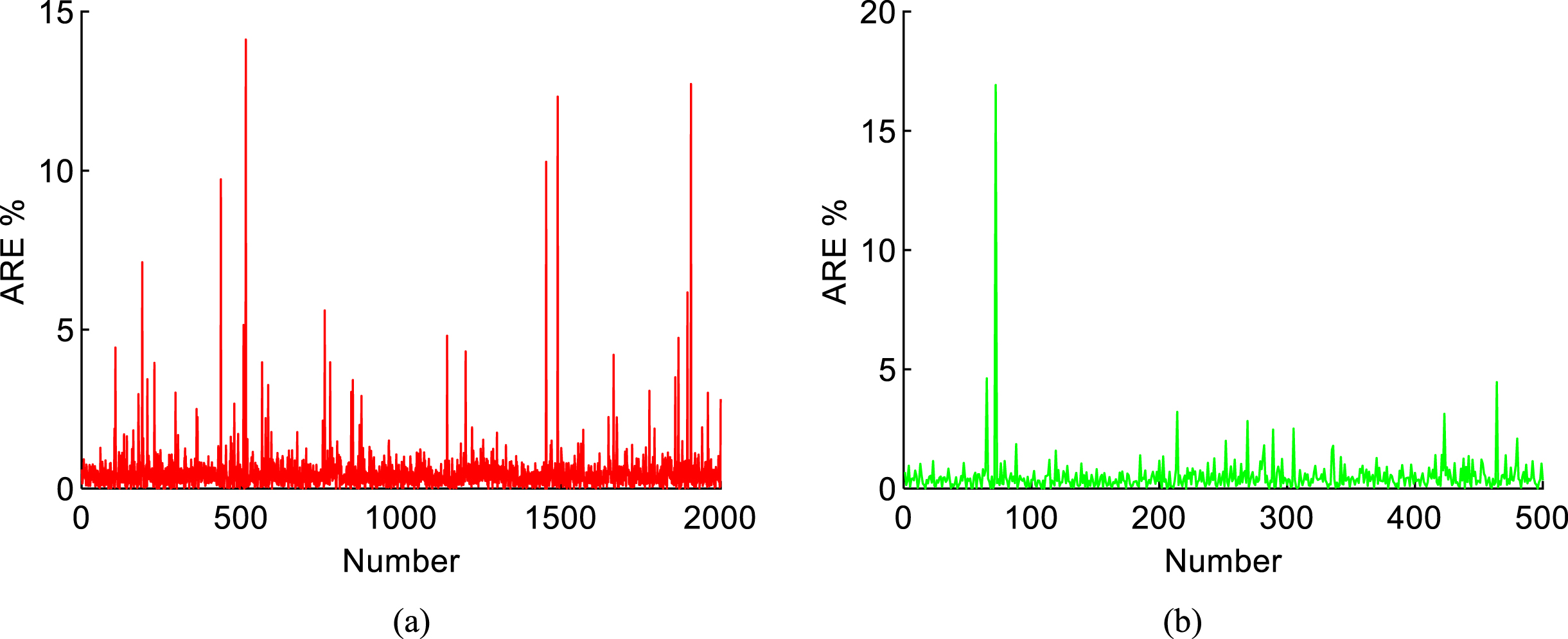
ARE of the proposed model: (a) using testing data, and (b) using training data.
To further verify the accuracy of the proposed model, the energy consumption values corresponding to 2000 sets of training datasets and 500 sets of testing datasets were calculated using the ICA-DE-SVM model and compared with the actual values. The results are shown in Fig. 17. Figure 17 shows that the predicted energy consumption value is relatively close to the actual value, which further illustrates the validity of the established model.
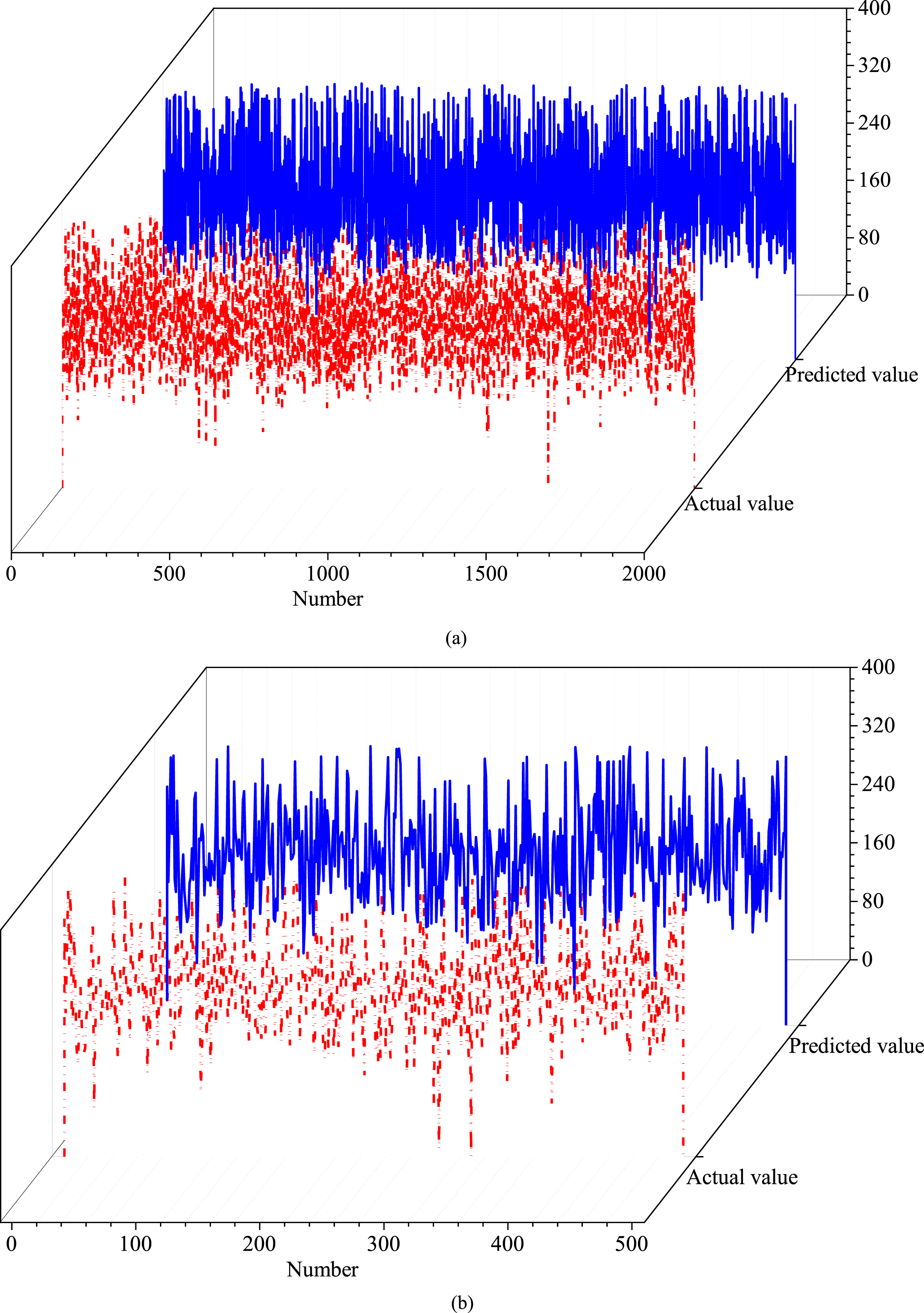
The actual value and predicted value of energy consumption: (a) using training data, (b) using testing data.
In this section, several sets of comparative experiments were designed. The SVM model, PSO-SVM model, GA-SVM model, WOA-SVM model, and ICA-SVM model were compared with the ICA-DE-SVM model, respectively. To facilitate a comprehensive comparison of the performance of each model, we conducted 10 experiments with training sets of the same number. The training set is randomly generated. In 10 trials, set the training set to 6000. The MAPE, MSE, and R2 for each model can be calculated via Equations (26) –(29). The box plots of three evaluation indexes, MAPE, MSE, and R2, are shown in Fig. 18.
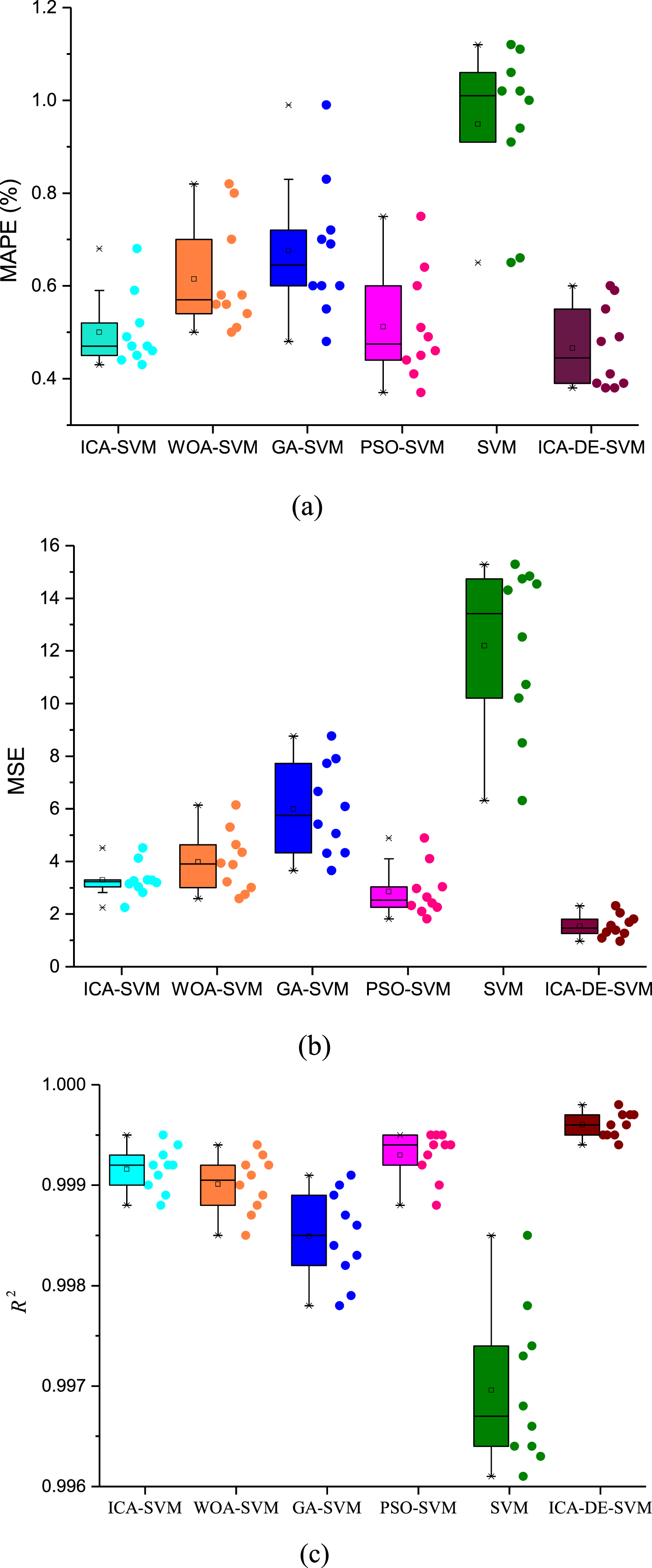
Box plot conducting 10 experiments: (a) box plot of MAPE, (b) box plot of MSE, (c) box plot of R2.
Figure 18 depicts the maximum, minimum, and median values of the three performance indicators MAPE, MSE, and R2 for the six energy prediction models. Figure 18 shows that the maximum and minimum MAPE values of the ICA-DE-SVM model are 0.60 and 0.38, respectively, the maximum and minimum MSE values are 2.3 and 0.9645, which are smaller than those of other models, and the maximum and minimum R2 values are 0.9998 and 0.9994, which are larger than those of other models. This demonstrates that the ICA-DE-SVM model outperforms other models.
The MAPE, MSE, and R2 values of the ICA-SVM model and the PSO-SVM model differ by only a small amount, indicating that they perform similarly when it comes to predicting energy consumption. The SVM model has the lowest accuracy. The GA-SVM model has higher precision than SVM but lower precision than other models.
In order to predict the energy consumption of the chiller, a method based on ICA-DE-SVM is proposed. To further improve the usefulness and adaptability of the proposed model, the Pearson correlation coefficient was used to analyze the correlation between each variable and then to eliminate variables with high correlation. Then the eliminated variables are input through principal component analysis processing into the network model.
The usefulness and adaptability of the ICA-DE-SVM model were verified on the actual cold source system. The results show that as the quantity of sample datasets increases, the value of MAPE decreases, the value of MSE also decreases, and the value of R2 is closer to 1. However, the training time also increases. To select the optimal population numbers, it is necessary to consider both the training time and the values of the evaluation indices at the same time. And from Table 4, the optimal population numbers of the proposed model can be seen clearly is 5000 (MAPE = 0.47, MSE = 2.9112, R2 = 0.9993). This can be a good reference in an actual multi-chiller system in a building. Finally, the ICA-DE-SVM method was compared with the SVM model, PSO-SVM model, GA-SVM model, WOA-SVM model, and ICA-SVM model, respectively, and the results show a better performance of this proposed method.
In reality, as the amount of running time increases, the cold water host’s performance will suffer. With longer operating times, the failure rate of the chiller will rise. The model’s prediction error would progressively rise in the latter stage when it was trained on the earlier running data. Therefore, in future work, focus our attention on the following two aspects: (1) Due to the complexity and variability of the operating environment of the chiller, more input variables need to be considered. (2) The performance of the equipment needs to be considered.
Declaration of competing interest
The authors declare that they have no conflict of interest.
Acknowledgment
This research has received funding from the National Natural Science Foundation of China under Grant U1501248 and Grant 51905109, the Foshan Key Field Project of Science and Technology under Grant No. 2020001006509.