
Abstract
The research aims to provide network security so that it can be protected from several attacks, especially DoS (Denial-of-Service) or DDoS (Distributed Denial-of-Service) attacks that could at some point render the server inoperable. Security is one of the main obstacles. There are a lot of network risks and attacks available today. One of the most common and disruptive attacks is a DDoS attack. In this study, upgraded deep learning Elephant Herd Optimization with random forest classifier is employed for early DDos attack detection. The DDoS dataset’s number of characteristics is decreased by the proposed IDN-EHO method for classifying data learning that works with a lot of data. In the feature extraction stage, deep neural networks (DNN) approach is used, and the classified data packages are compared to return the DDoS attack traffic characteristics with a significant percentage. In the classification stage, the proposed deep learning Elephant Herd Optimization with random forest classifier used to classify the data learning which deal with a huge amount of data and minimise the number of features of the DDoS dataset. During the detection step, when the extracted features are used as input features, the attack detection model is trained using the improved deep learning Elephant Herd Optimization. The proposed framework has the potential to be a promising method for identifying unidentified DDoS attacks, according to experiments. 99% recall, precision, and accuracy can be attained using the suggested strategy, according on the findings of the experiments.
Introduction
Information security reports suggest that distributed denial-of-service (DDoS) attacks have recently cost business and governments considerable sums of money. These records are consistent with the rise of Internet-connected devices, which is primarily being driven by the acceptance of ubiquitous computing, which is realised through the Internet of Things (IoT) paradigm and is characterised by the idea of linking anything, anywhere, at any time. The majority of Internet situations include devices interacting with apps that are operated remotely on the network, which makes it possible for rogue agents to take over equipment. To exploit and defend the system, respectively, the attackers and defenders are constantly engaged in conflict. In order to take advantage of the system, attackers search for flaws. Defenders, on the other hand, work to stop that exploitation and offer a solution. One of the most well-known attacks, called distributed denial of service (DDoS), aims to block access to a system, service, or resource by authorised users. DDoS involves a distributed intrusion on the system. The attackers carry out DDoS using both conventional and modern methods. A programme or system known as an intrusion detection system (IDS) is frequently used to examine and monitor the activity of the target system and to sound an alarm as soon as it detects any suspicious activity. Depending on how the system defines architecture, it can be put either inside or outside the network perimeter.
The Internet has been at risk from DDOS assaults, and many security measures have been proposed to mitigate such issues. While the researchers continually improving their systems to thwart this attack, the hackers never stop looking for new ways to get past the security systems. The DDoS, a phenomena with a rising number of attacks, quickly transforms into a complex environment. The known attacks have now made it more challenging to understand and tackle this issue. At the same time, a variety of defence techniques have been developed in response to the current defence systems. Additionally, this makes it challenging to evaluate efficacy in relation to other comparisons and for decision-making.
The target server will unavoidably receive a lot of data in a short amount of time during a DDoS assault. Data packets made up of this information are divided up, and even if they don’t exactly match, they will at least have a few common features in common. It can be time-consuming to spot them as a component of a hostile network by looking at each of these packages independently. These prebuilt packages are designed not to significantly stray from the no harmful packets standard. However, if we simply view each packet as a component of a longer sequence that spans time, we are able to study them all at once and determine their true meaning. Simply said, arranging data into time sequences enables us to step back and see the “big picture,” which makes it more obvious if a server is under assault or not. We draw the conclusion that it is always advisable to take into account the time period in which each data set component is situated in a piece of crucial information.
Our research aims to create an accurate deep learning model. In traditional Deep learning, key input features are manually created, and the algorithm automatically figures out how to translate the characteristics to an output. There are numerous degrees of features in deep learning. These characteristics are automatically identified, and they are combined to produce outputs with high levels of exclusivity. Each stage identifies the current summary capabilities that are a direct result of the patterns established inside the stage before. For the purpose of early DDoS attack detection, we have improved deep learning Elephant Herd Optimization with random forest classifier. The feature extraction stage makes use of deep neural networks (DNN), and the data packages that have been classified are compared to determine which DDoS attack traffic characteristics have the highest percentage. A hybrid model was used to classify DDoS attacks after developing an x2 test for feature selection. The x2 test was used to find highly rated traits that significantly help predict court case verdicts. Such highly rated features were extracted using DNN. The suggested deep learning Elephant Herd Optimization with random forest classifier was used to classify the learning data that dealt with a lot of data and reduced the number of features in the DDoS dataset during the classification stage. After the extracted features are used as input features in deep learning during the detection stage, the attack detection model is trained using the upgraded Elephant Herd Optimization.
Related work
It is widely acknowledged that intrusion detection systems (IDS) and intrusion prevention systems work. IDS. For the purpose of detecting DoS attacks in IoT networks, the use of a novel intrusion detection system (IDS) based on long short-term memory deep learning techniques is advised. [1] Benchmark datasets such as CICIDS-2017 and NSL-KDS were used to test the model. The datasets underwent three pre-processing steps: dimensionality reduction, normalisation, and encoding. [2] a gated recurrent unit in an LSTM (long short-term memory). The effectiveness of the suggested approach is evaluated using a combined DDoS dataset consisting of the CIC DoS, CI-CIDS 2017, and CSE-CIC-IDS 2018, as well as a dataset for vehicle hacking. [3] a denial of service (DoS) attack-specific DL-based intrusion model. The dataset that is most frequently used for assessing intrusion detection systems is the KDD CUP 1999 dataset (KDD), which we use for the intrusion dataset. [4] To solve the problem of class imbalance, a novel intrusion detection system based on deep learning and machine learning models was developed using the Bot-IoT dataset. We used three different feature sets for binary to examine how the record timestamps impact the predictions. As a result, we were able to get an average accuracy of > 99% and remove feature dependencies that the Argus flow data generator had provided. [5] The Banking Dataset can be used to identify distributed denial-of-service (DDOS) attacks on financial institutions. In this study, we employed a variety of classification models to foresee DDOS attacks. The SVM has a 99.5% accuracy rate for detecting (DDoS) attacks, compared to 97.5% and 98.74% for the KNN and RF.
The Naive Bayes (NB), Support Vector Machine (SVM), Random Forest (RF), k-Nearest Neighbor (KNN), and Logistic Regression (LR) classifiers are used to build a model for identifying DDoS attacks using training and testing environment-specific datasets. The experimental results show that the proposed framework performs better than the existing one. [6]. There is also coverage of the Mutual Information (MI) and Random Forest Feature Importance (RFFI) techniques in [7]. Gradient Boosting, Logistic Regression, Random Forest, Weighted Voting Ensemble, and K Nearest Neighbor are used to process some features. Using 19 characteristics, the experimental results show that RF, GB, WVE, and KNN are accurate to 0.99. [8] A cutting-edge deep learning approach to image identification for network intrusion detection. A trained version of the ResNet50 deep learning model. [9] Convolutional, deep, and recurrent neural networks are used in an intrusion detection system for DDoS attacks based on deep learning. Using two brand-new real traffic datasets that include various DDoS attacks, the effectiveness of each model is evaluated within two classification classes. [10] The development of the Vehicular Ad-hoc Network (VANET) aims to facilitate efficient vehicle communication and the transmission of traffic-related data. IDS performance will be improved using a machine learning model that uses Random Forest and posterior detection based on core sets. This model tries to increase detection accuracy and efficiency.
The customised SDN-based dataset consists of the normal and attack TCP, UDP, and ICMP traffics. Statistical information including byte count, time sec, packet rate, and packet per flow are present in the dataset, with the exception of features that specify the source and target devices. [11] The results of the experiments show that DT outperforms the other algorithms with 100% accuracy. In order to develop detection and classification models for DDoS attacks, four different types of DDoS attacks were submitted to machine learning techniques using real network traffic data. 96.2% accuracy and 0.12 s of prediction time were shown by the developed model in tests using the UNSW-NB15 dataset. [13] For the networking domain to transition from the conventional networking domain to an automated network, software defined networking will be a crucial component. After the dataset has undergone pre-processing, the traffic is classified into one of the classifications. We were able to achieve an accuracy rating of 99.75% thanks to the Stacked Auto-Encoder Multi-layer Perceptron (SAE-MLP), which is discussed in the paper. [14] Distributed denial of service (DDos) attacks are essentially a classification problem in machine learning. The problem of DDoS attack detection in a cloud environment is addressed by this study’s multiple regression analysis, which builds a machine learning model that anticipates DDoS and bot attacks using the most popular CICIDS 2017 benchmark dataset. [15] Deep learning and information entropy should be used to detect DDoS attacks. By identifying information entropy, the controller can examine suspicious communications. This technology, which according to experiments has an accuracy rate of 98.98%, enables the accurate identification of DDoS attack traffic in an SDN environment.
Attacks that cause distributed denial-of-service on the software-defined network are possible. [6] The use of static thresholds and their reliance on dated data from earlier eras increase the time needed to detect attacks and decrease their ability to adapt to new attacks. DDoS assaults are found in SDN using a new approach. This approach is divided into three parts: classification, entropy-based, and collector. [17] A special traffic pre-processing approach is used to submit network traffic to the CNN model for online DDoS attack detection while taking into account how data flows across network devices. According to the findings of our evaluation, LUCID operates at a level that is currently on par with the state-of-the-art. But unlike other research, we offer consistent detection results across a variety of datasets, proving the strength of our strategy. [18] To enable early detection for distributed denial-of-service (DDoS) attacks planned by a botnet that commands rogue devices, a consolidated framework utilising deep convolutional neural networks (CNNs) and actual network data has been created. In order to launch a cell-wide DDoS attack that can obstruct CPS operations, these puppet devices each initiate a DDoS attack against a call, the Internet, an SMS service, or a combination of these services. [19] We detect DDoS attacks using a classification based on machine learning (ML), which is acknowledged as the major methodology for anomaly detection. The classification accuracy and train/test times of various ML algorithms are compared. Additionally, using state-full data planes with ML and P4 capabilities, we create a real-time DDoS attack detection module and assess its latency requirements. [20] For detecting botnet DDoS, we investigated machine learning techniques. The USML, NB, ANN, DT, and SVM algorithms were evaluated. The datasets UNBS-NB 15 and KDD 99 were used for the evaluation; these datasets are well-known for their use in the detection of botnet DDoS attacks. It has been demonstrated that in terms of accuracy, false alarm rate (FAR), sensitivity, and specificity, false positive rate (FPR), AUC, and MCC, USML outperforms other methods when attempting to distinguish between Botnet and regular network traffic.
The remaining sections are arranged as follows: In Section II, we go over the current status of recent DDoS assaults that employ ensemble learning and how our contribution is superior to their methods. In Section III, we suggest a framework for DDoS attacks; in Section IV, our experiments and findings are presented. After careful observation and verification, we employ the NSL-KDD dataset. We examine the advantages and disadvantages of our approach in Section V, where we also summarise the findings and suggest a course for further research.
Proposed method
The system’s development for detecting DDoS. The initial step of the process, which is shown below, entails looking through a useful DDoS dataset that has recently been created by a number of research projects. To select the most important characteristics, the dataset must be pre-processed in the second stage using feature extraction techniques. The performance of the constructed deep learning system will then be tested using a number of deep learning models, and after the training and testing processes have been completed, the model’s accuracy will be determined.
In deep learning, crucial input features are manually created, and the algorithm automatically figures out how to translate the characteristics to an output. These characteristics are automatically identified, and they are then brought together to produce outputs at various levels. Each level shows newly discovered abstract features derived from those seen in the previous level. With an input layer, two hidden layers, and an output layer, a straightforward deep neural network was built for our study. Figure 1 illustrates the structure of this network.

Deep learning network.
This study develops an improved elephant herd optimization with a random forest classifier to identify DDoS attacks. The advantages of fine-tuning learning through pre-training and a multi-layer structure make deep learning networks superior to machine learning networks. The deep learning approach, which is used to extract the deep properties from the training data, was made possible thanks to these benefits. A security technique for identifying DDoS attacks is suggested in this study. This algorithm uses four key phases: database training, data pre-processing, feature selection, and classification. Step by step procedure is shown in Fig. 2.
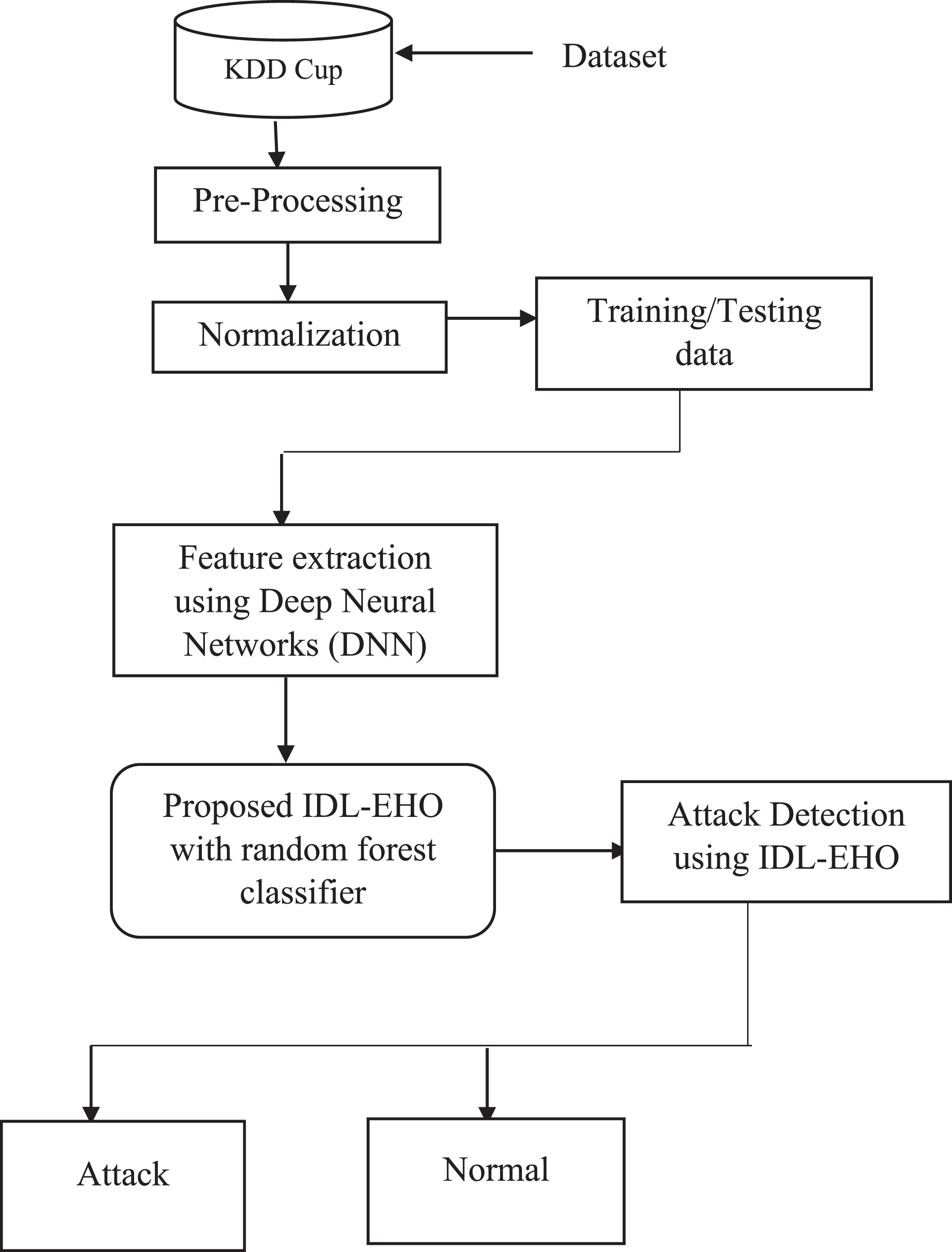
Proposed DDoS attack block diagram.
Pre-processing is the initial process that uses IP traffic data as input and produces cleansed data as an output. Data pre-processing is regarded as a crucial step in machine learning since it can greatly increase the effectiveness and efficiency of the training procedure. It includes several essential operations, including the eradication of superfluous data, handling of missing values, label conversion, categorization, and data normalization. Pre-processing the dataset to make it more suitable for training and reduce over fitting is always the first step before deep learning models are trained. Pre-processing is carried out in the following ways:
The removal of unnecessary components is the first stage of pre-processing. Unnamed: 0, Flow ID, and Inbound features don’t provide any information that is relevant to the current problem. If the model has features connected to an IP socket or feature ID, such as “Timestamp” IP address and port number information, it might be too well suited. As a result, we manually remove any unnecessary features and keep only the vital ones. The objective in the pre-processing stage after determining pertinent features is to deal with the missing values.
Normalization
The min-max normalisation approach is used in this study to normalise the traffic data in order to reduce the issue of inconsistent impact weights between different dimensions of the data. Applying a linear transformation to the baseline data is intended to produce results that fall between [0, 1]. The min-max normalisation method’s conversion function is as follows:
The minimal value of all the sample data is represented by one of them, X min . All of the sample data’s greatest value is represented by X max . X stands for the initial sample data prior to conversion. X+ is the data that has undergone converted.
The dataset’s continuous values contain a wide range of possible values, which causes more unpredictable predictions. The model can converge more quickly because to dataset normalisation, which considerably lowers classification errors. The standardisation method (z-score) was applied by scaling the features to have a mean of 0 and a standard deviation of eqn 2. The model is less susceptible to outliers thanks to this method. Standardization is provided by
The σ is represented by where stands for standard deviation, x
i
for the feature value, N for the number of training samples, μ and is given by (eqn 3)
The encoder process is initially developed, which serves as pre-training for the Deep Learning network model. The input layer of the first hidden layer of the DLN network is thought to be the encoder neural network of the first auto encoding process for the input signal x
v
. Reconstruction error is decreased by initial auto encoder training. Using the first trained parameter of the encoder neural network, the first hidden layer of the DLN process is initialized.
The input data already makes up the encoder vector. The second auto encoder’s encoder neural network is built using the first and second hidden layers of the DLN. Using the second learned auto encoder, the second hidden layer of the DLN network is initialised. The aforementioned process is continued until the DLN model’s last hidden layer. The final encoder vector’s generalised form is provided in the paragraphs that follow.
The encoder neural network’s Nth trained parameter is indicated by the symbol θ
N
. The N-stacked encoder procedure pre-trains the hidden layer of the DLN. The generalisation aspect is enhanced by this pre-trained process, which also avoids local minima. The following are used to calculate the DLN model’s output.
The output layer’s trained parameter is indicated by the symbol θN+1. The back propagation algorithm is used to lower the output error.
Deep neural network (DNN) models can be learned and used effectively by using a technique called feature selection. Accuracy is increased while reducing over fitting and learning time. The value of y determines whether feature selection is unsupervised or supervised (label). The filter, wrapper, and embedding technique subcategories of supervised feature selection are the three primary categories. These techniques select features based on the label. The feature selection stage is where the features are actually chosen after the pre-processed data has been presented. To make the framework less complex and easier to understand, the feature selection procedure must be carried out. The statistical data of the features is used to pick features using deep neural networks. The main advantage of using deep neural networks is that it enables users to recognise the appropriate qualities based on class data. Three categories—foundational features, content-based features, and traffic-based features—are used to categorise the selected features. Deep neural networks are used to select the features, which aims to improve upon the shortcomings of the global features by identifying more beneficial characteristics utilising the class data that has previously been collected. Deep neural networks are used to pick the important properties.
To identify DDoS attacks, the DNN has one Random Forest layer and two RBM layers, as specified in the design. Neurons used for output computation vary depending on the layer. The initial RBM layer input neurons, denoted by the expression eqn, get direct feeding of the features chosen for training (7).
Consider a DDoS query as a collection since tags are produced as qi. Q ={ q1, q2, …… , q
k
}, where k is the desired number of Tags for DDoS sets. ={ xi1, xi2, …… , xi
k
} Indicate the features that were found for qi. The best choice is made when Y2 ={ 0, 1, 2 …… . }, etc. and each feature is chosen as the maximum relevance measure for retainedY. Denote the feature set with F ={ f1, f2, …, f
n
}. “n” stands for the entire amount of features, and “m” stands for the selective tags feature that should be chosen by the emotions. S stands for the collection of DDoS tags. The following equation to determine the maximum features,
Where the class label M is used. The algorithm chooses one attribute for each iteration that maximises the aforementioned equation.
To determine the self-reliability between two qualities, the chi-squared test is a predictive test that is utilised. It determines the discrepancy between the observed value and what was anticipated. This study employed a x2 test to rank and choose traits, and the findings were favourable. A x2 test determines whether the frequencies of specific classes and attributes depend on the correlation between predictor and target variables or are independent of it. The following calculation method was used.
Additionally, the deep neural networks are calculated using the equation as follows:
The three variables Ai, Bi and C each represent a projected observation in the ith class, a degree of freedom, and an observed value. The x2 test was applied to the original data set to identify the features that were most significant and had a direct connection to the target variables. The Select K Best score and the Chi2 function were used to combine the key characteristics that deep neural networks had selected. Stronger correlations exist between the aim attribute and more optimal features.
To find the DDoS assault in the vast data, the Improved Deep Learning Elephant Herd Optimization with Random Forest Classifier is proposed. When the training process is based on EHO, the proposed IDN-EHO classifier is used to perform classification. A more advanced deep learning Elephant Herd Optimization with random forest classifier model is suggested for DDoS attack detection. The system tracks traffic and categorises it into two groups: “normal,” which is given to activity that adheres to norms, and “anomaly,” which is given to behaviour that deviates from norms.
The basic idea behind the random forest classifier is to create multilayer neural networks by increasing the number of hidden layer layers in the network. The one-way multilayer design of the model ensures that there is only one path for transmission from input to output. The nonlinear model consists of the input layer, the hidden layer, and the output layer. Due to its nonlinear mapping and potent self-learning abilities, the multilayer perceptron has been widely used as an efficient classifier in a variety of areas. The output of the multilayer perceptron is divided into six groups: normal traffic that hasn’t been subjected to DDoS attacks, five different types of abnormal traffic that has, and normal traffic that hasn’t.
The output of the random forest classifier, which takes as an input the estimated likelihood of the DDoS attack for the input sample, is the label of the type of network traffic assault. The output layer separates DDoS attacks from harmful traffic.
(i) Input layer: The input gate, which is also a sigmoid layer, determines how much information will be used to alter the cell state as stated in Eq(9) by contrasting the current input Ct-1 with the previous hidden state ht-1. Furthermore, the tanh layer, which is defined by Eq. 4, compresses values between -1 and 1, where C is a median value. The new cell state is created by equation 5.
(ii) Forgot layer: The input sequence is denoted by the letters xt, the previous block output is denoted by ht–1,the previous LSTM block memory is denoted by Ct–1), and the bias vector is denoted by bf. W denotes the logistic sigmoid function and denotes particular weight vectors for each input, where is the input
(iii) Output layer: It consists of m nodes, each of which computes the estimated probability of the type of DDoS traffic attack, which is the actual output of the neural network. Using the inputs Ct-1 and the prior hidden state ht-1 to produce the output O
t
. The following hidden state, ht, is obtained by multiplying output O
t
by the outcome of the tanh operation performed on cell state C
t
t, as shown in equations 12.
The test sample x reaches a certain leaf node through each tree once the RFC model training is finished, and then the probability that the sample x belongs to c is as indicated in equation (13).
T is the total number of random trees in the forest. The selection of category x is then displayed in equation (14): P
t
((c|x)) is the category distribution of the leaf node.
The Random Forest model’s classification procedure uses a majority vote. Establish the test sample set E = (e1, … . , e m ). The decision trees’ training set is DT ={ dt1, … dt n }. CIR [n] Is a subscript array that stores the categorization outcomes of each decision tree. C = (c1, … . , c n ) is the category. The categorization result set is represented as CR = (CR1, … . , CR m ).
The IDN-EHO approach successfully incorporates the deep neural network (DNN) algorithm feature to carry out detection. Therefore, levy flying, photo toxic, and more moth flight finding ability improve the functionality of the assault detection. The elephant’s herding behaviour is also paired with the best moth fly for DDoS detection. The appropriate features are picked, and the suggested improved deep learning algorithm is then given them. To find DDoS attacks, one uses Elephant Herd Optimization. The appropriate weights were picked using the suggested optimization technique. Deep learning algorithms outperform traditional neural networks because of the benefits of pre-training using the fine-tuning learning technique and a multi-layer structure. The deep properties can be extracted from the training data using deep learning thanks to these prerequisites.
Deep learning elephant heard optimization algorithm
The elephants live in social groups called clans, and the matriarch, the female elephant leader, stays with each clan. The adult male elephant does not live in groups with the females. According to how physically fit each individual is, the elephant population is formed at random and divided among many clans. The IDN-EHO algorithm contains three main rules.
R b Denotes the sites of the seagull search agent in Equation (15). The behaviour B is randomised and steered R l in the direction of the most appropriate search agent PR best in order to correctly balance exploitation and exploration (i.e., fittest seagull). R l Denotes the location of the search agent at the moment.
The minimum boundaries for a single elephant are shown here by the symbol Rmin. RWorst,h Denotes the worst elephant members of clan ci, and the rand value is determined using a Chebyshev chaotic map. From 0 to 1, the value is available.
The Random Forest algorithm’s moth flying component is provided to the IDN-EHO approach to effectively detect attacks. Levy flying, additionally, the best moth fly and the elephant’s natural skills for herding are merged to detect cyber-attacks. This is how the moth flew during its whole flight:
Change the scaling factor σ from to χ in Equation (18)
Where the acceleration factor is represented by υ. The elephant in the clan with the highest value for fitness is updated using the phrase,
In this example, 1 ⩽ n ⩽ D stands for the nth dimension, j sk for the number of elephants in the clan sk, hsk,l, n n for the nth individual elephant in hsk,l, and N for the overall dimension. Equation is used to calculate the clan centre for hcntr,sk (21).
To improve deep learning Elephant Herd Optimization, the Taylor series is added to the current approach for choosing the optimum weights and biases for the Random classifier. IDN-EHO is among the best strategies for discovering a global optimization solution. In finding the best answers to a variety of optimisation benchmark problems and real-world applications, IDN-EHO has shown encouraging results. Because IDN-EHO uses no relaxations of any kind, it outperforms state-of-the-art optimisation techniques. Thus, the proposed deep learning Elephant Herd Optimization more precisely detects DDoS attacks.
We compare the appropriateness of our suggested design to already-used methods using several performance criteria. A common metric for assessing the efficacy of an IDS is the confusion matrix. Other important evaluation criteria are deduced from it. We also debate the performance of our model in comparison to other ML-based DDoS detection schemes using metrics like precision, accuracy, recall, and F1-Score.
KDD dataset
The global highest data mining competition is the KDD Cup. To address several built-in issues with the KDD Cup 1999 Dataset, a solution was offered. It is still a useful benchmark for comparing IDS models even if it is relatively outdated and not a precise representation of real-world networks. There are considerable performance measurement findings for comparison because it has previously been utilised by numerous researchers to assess IDS performance. Only 22,554 network traffic samples are present in the KDD Cup 1999 Dataset, whereas 125,973 network traffic samples are present in the KDD Cup 1999 Train+Dataset. Each traffic sample contains a total of 41 features that are divided into three categories: basic features, content-based features, and traffic-based features.
Performance metrics
The following descriptions of precision, recall, F1-score, and confusion matrix table metrics are used to rate the effectiveness of the classifiers.
True Positive (TP) is the percentage of sample cases that were correctly categorised as attacks, or as attack traffic. The number of sample cases that were accurately identified as legitimate traffic, or the TN (True Negative). False Positive (FP) refers to the number of positive sample instances that were incorrectly labelled as genuine traffic rather than attack traffic, and False Negative (FN) refers to the number of negative sample cases that were incorrectly labelled as attack traffic rather than legitimate traffic. The harmonic mean of recall and precision is used to calculate the F1-score. Instead of focusing only on accuracy or recall, this average measure provides a more complete picture of the classifier’s performance. These standards are employed to categorise the sophisticated assaults taken into account in this work and to assess the effectiveness of the suggested defences.
The accuracy score calculates the proportion of real predicted labels to all labels. Our Dataset might not be balanced, thus relying solely on the Accuracy Score is not a wise move. The following is a list of the Accuracy Score formula:
The KDD Cup 1999 Dataset and our experimental model are used to compare different algorithms in this section, and the results are presented and discussed. According to Table 1, XGBoost and AdaBoost are the most precise algorithms, each having 100% accuracy and an F1-Score of 1. AdaBoost and XGBoost both recorded marginally faster Training Times. With F1-Scores of 0.9942, 0.9936, and 0.9306, respectively, Random Forest and KNN also demonstrated respectable accuracy of 98.94%, 99.94%, and 99.35%. When compared to the results of previous experiments, our experiment’s Nave Bayes model’s F1-Score and accuracy of 98.21% are insufficient. This makes it seem like a poor algorithm for DDoS detection.
Detection evaluation results
The confusion matrix identifies the correct and incorrect predictions. Table 2 shows that our model has a detection rate for both attack and normal categories of 0.95.
Based on a suggested technique for four unique occurrences, the confusion matrix
Figure 3 displays the classification of the dataset using the Chi-square, IG, and F-test feature selection techniques.

The classification of the dataset.
Table 3 displays the overall effectiveness of the Improved Deep Learning Elephant Herd Optimization Model. Despite having a stated accuracy of 0.9541, the traditional LSTM model performs poorly in terms of genuine negative class identification when compared to hybrid models. Performance is improved more than with the traditional LSTM technique by feeding the model with a PSO-based feature selection strategy.
Performance of the proposed improved deep learning elephant herd optimization model
After putting the IDN-EHO technique into work, the true negative and true positive situations are better when compared to PSO. A hybrid feature selection technique is employed to feed the model, and its performance against the outputs of the other two algorithms is examined. False negative cases have significantly decreased, which has improved performance. The importance of the Improved Deep Learning Elephant Herd Optimization Model strategy in improving the deep-learning model’s performance is illustrated in Fig. 4 of the report.
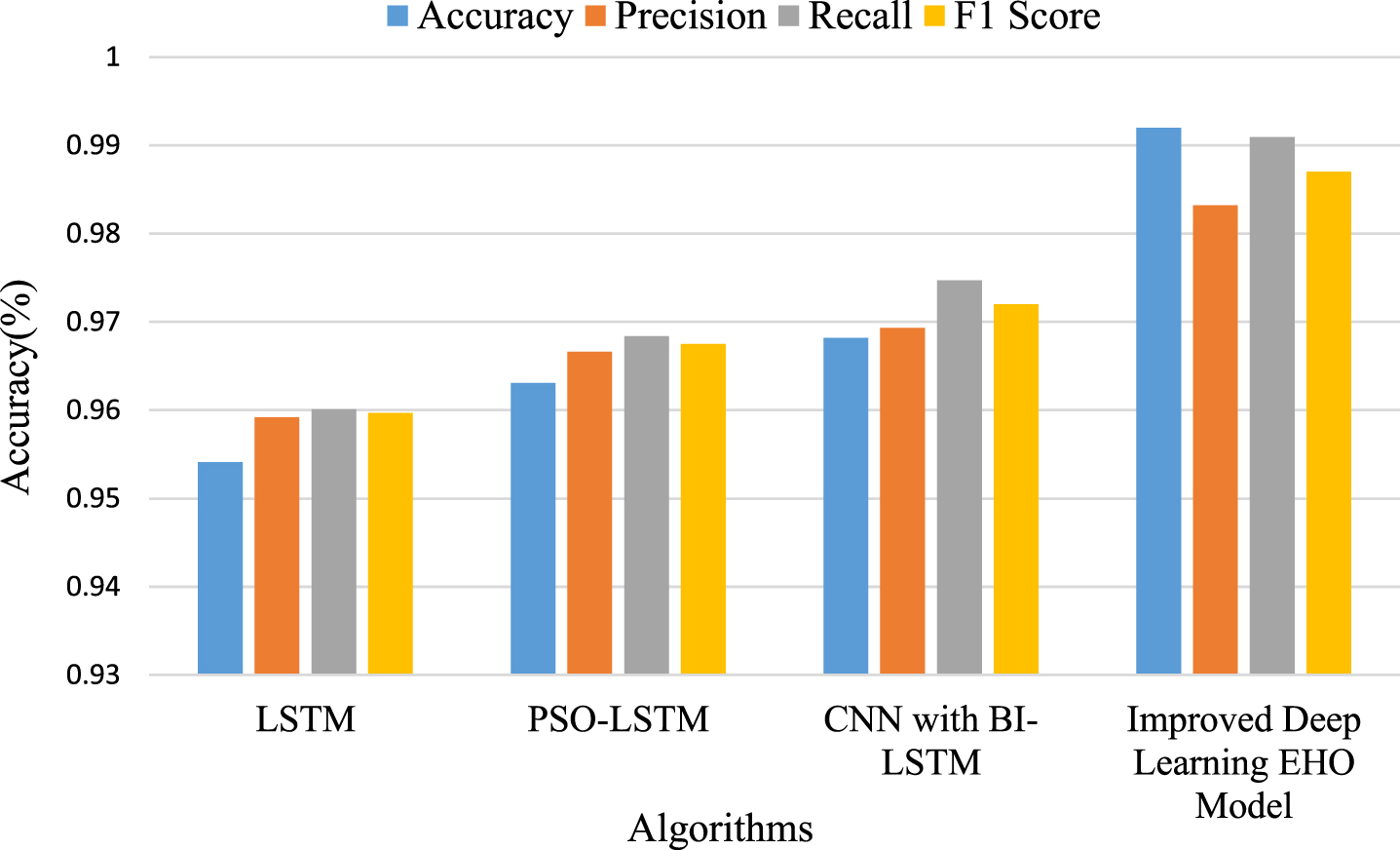
Compared proposed Improved Deep Learning EHO Model to existing algorithm.
The performance of the model’s response time was assessed using the DDoS dataset. 20% of the dataset’s preprocessed data were used to test the model. Three models—the PSO-LSTM, CNN with BI-LSTM, LSTM, and the proposed Improved Deep Learning EHO Model—were also subjected to time testing. The entire DDoS dataset, consisting of 79,668 batches of size 32, was used to test the proposed model on 2,549,370 instances. Figure 5 shows that the total testing time was 692 s, and each batch of 32 instances had a response time of 0.27 ms and a completion time of 8.7 ms. For the same instances, the overall testing times for LSTM, PSO-LSTM, and CNN with BI-LSTM were 1307.33 and 1116 s, respectively. The proposed model is quicker than the current algorithm, according to the testing response time.
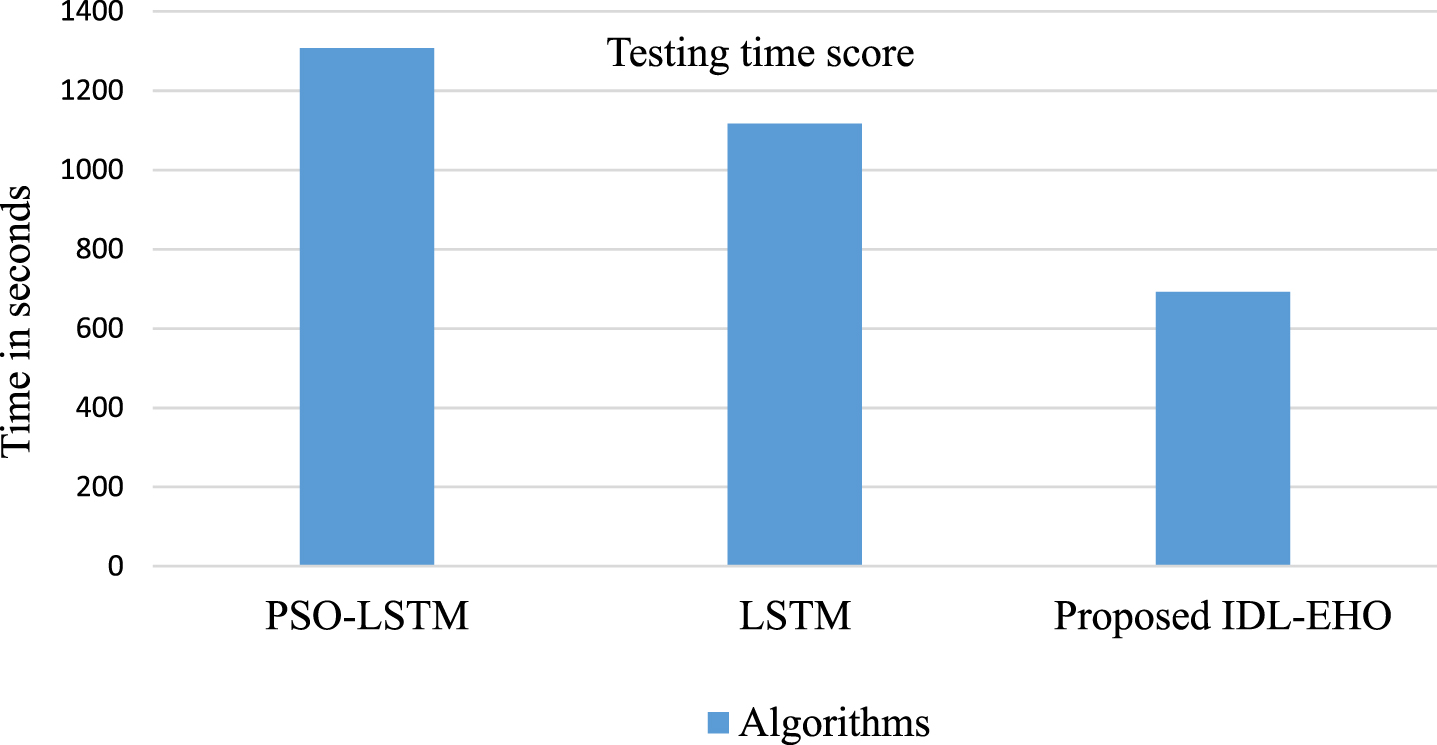
Testing Time on the DDoS dataset.
In this study, early DDos attack detection is accomplished using deep learning Elephant Herd Optimization and a random forest classifier. The proposed IDN-EHO approach to categorise data learning minimises the number of characteristics in the DDoS dataset and works with large amounts of data. The feature extraction stage uses the Deep Neural Networks (DNN) technology, and the DDoS attack traffic characteristics are recovered by comparing the classified data packages. Reduce the number of features in the DDoS dataset when classifying learning that deals with a lot of data using the suggested deep learning Elephant Herd Optimization with random forest classifier. When the extracted features are used as input features in the detection stage, the attack detection model is trained using the upgraded deep learning Elephant Herd Optimization. According to the experimental findings, the accuracy rate of a random forest classifier and IDN-EHO is higher than that of other algorithms. The results of the experiments indicate that the proposed strategy can achieve 99% recall, precision, and accuracy. To obtain performance in terms of accuracy and detection rate with reduced computational expense, the immediate future scope is to investigate the possibilities of inventing new optimization algorithms.