
Abstract
In the E-commerce environment, conversations between customers and businesses contain lots of useful information about customer sentiment. By mining that information, customer sentiment can be validly identified, which is helpful in accurately identifying customer needs and improving customer satisfaction. For conversational sentiment analysis, most existing approaches take contextual information into account. On this basis, we focus on the degree of association between utterances, which can more effectively capture overall and useful sentiment information in conversation. For this purpose, we propose a hybrid model to recognize customer sentiment in conversation. The model obtains utterance vectors with sentiment information through Sentiment Knowledge Enhanced Pre-training (SKEP), then uses the bidirectional long short-term memory network (BiLSTM) to generate contextual semantic information, and further obtains customer sentiment information by applying the self-attention mechanism to focus on the degree of association between utterances. The experimental results on the JD Dialog dataset show that our model can more accurately recognize customer sentiment than other baseline models in customer service conversation.
Keywords
Introduction
Recently, with the development of artificial intelligence, conversation systems are gradually moving towards practical application. Thereinto, customer service chatbot is widely used in online business environments, such as Amazon’s Alexa [1], JD.com’s JIMI [2], and Alibaba’s AliMe [3]. The customer service chatbot content usually comes from a corpus of web-based knowledge [4], which can answer accurately enough and save the company’s labor costs. But its emotional intelligence is still a short board. Emotion is indispensable key element in human communication. For customer consults, the customer service chatbot sometimes fails to accurately identify customer sentiment, which may result in low customer satisfaction and negative reviews. Then, it will lead to a decline in corporate performance. Consequently, accurately recognizing customer sentiment in conversations has become a vital way to shape a positive corporate image and improve the competitiveness of enterprises.
Recognizing customer sentiment in conversations needs to consider an essential aspect, i.e., the contextual information, which can enhance, weaken, or reverse the original sentiment of the current utterance [5]. Take the conversation in Fig. 1 as an example, if only considering the sentiment of the current utterance, the fourth utterance expresses the neutral sentiment. However, the fourth utterance expresses the negative sentiment if considering the contextual information of the conversation, which is inferred by the third sentence indicating that the order was placed for a long time. For considering contextual information in the conversational sentiment analysis, most researchers mainly utilized the recurrent neural networks (RNN) [6] or long short-term memory (LSTM) [7] method. Although these two methods can effectively capture contextual semantic information, they can only capture contextual semantic information in the forward direction, which cannot identify more fine-grained sentiment classification, such as the five-category task that used in this paper (very negative, negative, neutral, positive, and very positive). For accurately identifying the more fine-grained sentiment classification, it is essential to capture the bidirectional semantic information [8] of the research subjects, understanding more thoroughly the interaction between the contextual sentiment words, degree words, and negative words. In addition, the degree of association between utterances is ignored by these existing studies. Focusing on the degree of association between utterances is helpful for accurately detecting customer sentiment in conversations because the previous utterances have different degrees of influence on the sentiment tendency of the current utterance. For instance, compared with the first three sentences, the content of the fourth to sixth sentences has a greater impact on the sentiment of the seventh utterance. Thus, analyzing the sentiment of the seventh utterance should pay attention to the important association between the fourth to sixth and the seventh utterance.
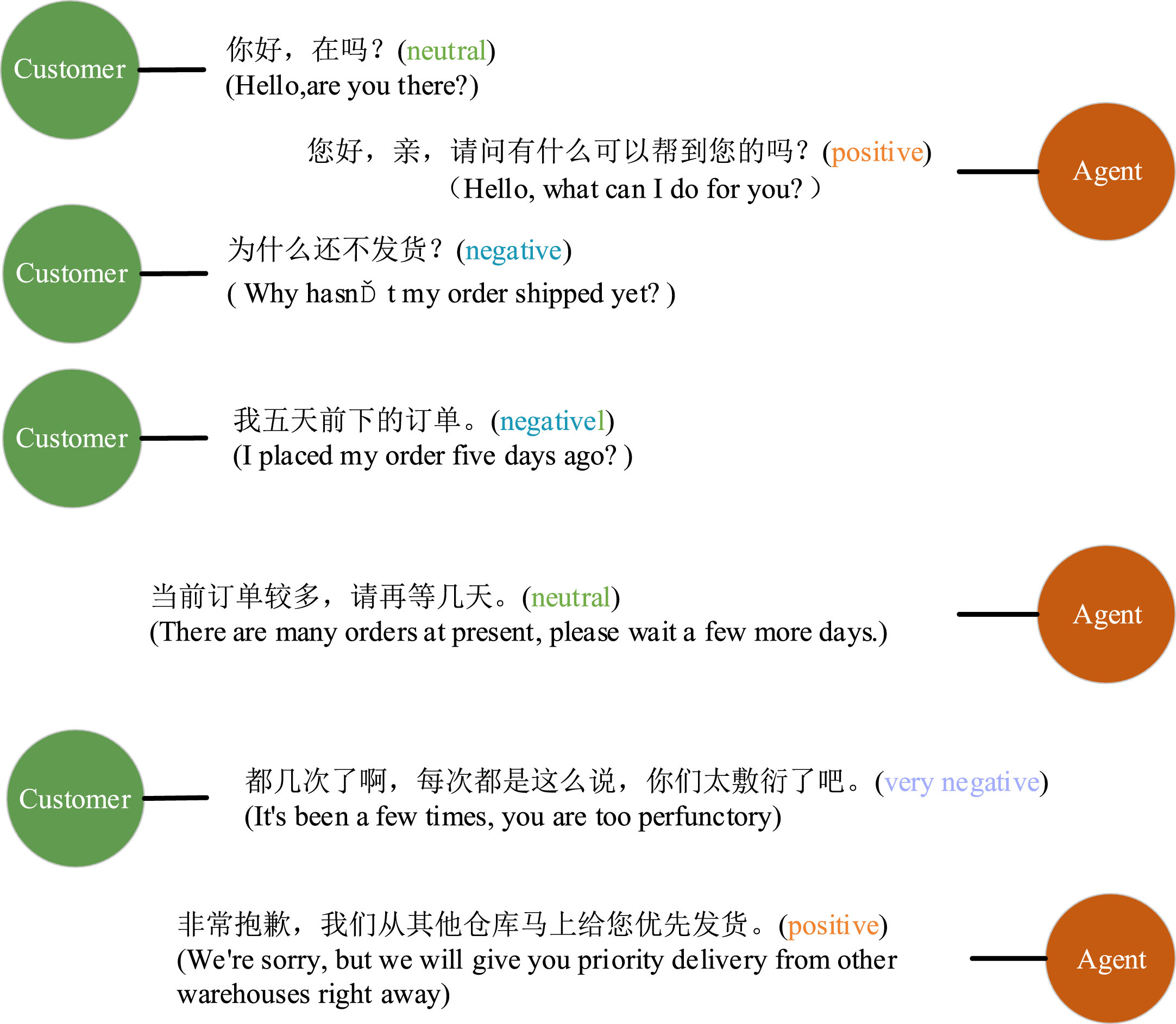
Illustration of a customer service conversation.
Conversation sentiment analysis is different from single-sentence sentiment analysis, which not only needs to consider the context information of the current utterance, but also considers the degree of influence of historical utterance on the emotion of the current utterance. Current models for analyzing the sentiment of single-sentence utterances, such as SVM [9] and Random Forest [10], fail to pay attention to contextual information and the degree of impact. Recent research on sentiment analysis of customer service conversations focuses on sentiment analysis by modeling speaker, contextual information, or multimodal aspects such as: DSAGCN [11], BiERU [12], Affect-GCN [13]. In addition, most dialogue sentiment analysis models use BERT pre-training models, which cannot extract rich emotional information such as aspect-sentiment pair, sentiment word, word polarity, which will affect the accuracy of the emotion recognition model. Because it is a challenging task to extract sentiment knowledge in the pre-training process, the main objective of our study is to design a sentiment analysis model that extracts sentiment knowledge, contextual information, and the degree of correlation between utterance.
In this paper, to accurately recognize customer sentiment in customer service conversations by capturing context information from two directions and focusing on the degree of association between utterances, we propose a sentiment analysis approach based on the self-attention mechanism and bidirectional long short-term memory network (BiLSTM). As the first step of the method, we use a pre-training model to encode each utterance in conversations and extract the sentiment feature from utterances. After contextual sentiment information and bidirectional semantic dependencies between utterances are captured by BiLSTM, we apply the self-attention mechanism to discover the degree of association between utterances in conversations.
The main contributions of this paper can be concluded as follows. We propose a self-attention-based BiLSTM model to recognize customer sentiment in conversation, which can effectively combine contextual information and the degree of association between utterances. The SKEP model is used to generate the utterance representations with sentiment information. The experiment results demonstrate that the performance of our model is superior to the baseline models for sentiment analysis of the JD Dialog dataset.
The remainder of this paper is organized as follows: Section 2 introduces the related work from both conversational sentiment analysis and Sentiment Analysis with Self-attention based BiLSTM model. Section 3 presents the proposed model. Section 4 is the comparative experiment and results analysis. Finally, the conclusion and future prospects are presented in Section 5.
The related work mainly consists of conversational sentiment analysis and Sentiment Analysis with Self-attention based BiLSTM model, which will be described as follows:
Conversational sentiment analysis
Sentiment analysis is one of the most meaningful tasks in the field of NLP and has attracted great attention from the academia [12]. Sentiment analysis is also known as sentiment recognition [14], sentiment classification[15, 16]. In the extant literature, conversational sentiment analysis research has mainly focused on speech sentiment recognition [17], textual sentiment analysis [18], image sentiment analysis [19], and multimodal sentiment analysis [20]. Recently, some deep learning technologies were applied to sentiment recognition like capsule networks, convolutional neural network (CNN), graph convolutional networks (GCN), and recurrent neural network (RNN). Singh et al. [21] proposed a capsule network based novel approach to analyze textual conversational sentiment. Sun et al. [4]proposed a hybrid model to detect abnormal sentiment in conversation in which the CNN-LSTM method is used to identify users’ emotions. Ghosal et al. [22] proposed Dialogue Graph Convolutional Network to model inter and self-party dependency to improve context understanding for utterance-level emotion detection in conversations. Huddar et al. [23]utilized the RNN to capture the interlocutor state and contextual state between the utterances. Another research method is to combine bidirectional LSTM for text sentiment analysis, which is related to our work. Bidirectional long short-term memory (BiLSTM) can gain contextual sentimental sequences by combining forward and backward hidden layers, and capture the connections between sentimental aspect words and their context words [16]. However, the bidirectional LSTM was rarely applied to conversational sentiment analysis, which was mainly introduced to Community reviews [24].
Sentiment analysis with self-attention based BiLSTM model
For the research of sentiment analysis, many researchers utilized deep learning to capture contextual information, which can improve the accuracy of sentiment recognition. Majumder et al. [20] proposed multimodal sentiment analysis method using context modeling, which mainly uses recurrent neural network (RNN) to extract context-aware utterance features at three modalities feature. Shenoy and Sardana [25] proposed an end-to-end RNN architecture to model four factors that affect the sentiment of an utterance, i.e., the context of the conversation, interlocutor state, interlocutor intent, and previous interlocutor states and emotions of a particular participant in the conversation. In addition, LSTM-based model also can extract contextual features from the utterances [7]. Yang et al. [26]proposed a method to model context, entity, and aspect memory for sentiment analysis of posts on social media platforms in which the contextual information is captured by LSTM model. However, long short-term memory fails to analyze the sentiment due to the existence of multiple types of contexts. To solve this problem, Keramatfar et al. [27] proposed a multithread hierarchical long short-term memory network to extract different context types of tweep, which helps recognize its sentiment polarity. Tang et al. [28] proposed a method about target-dependent sentiment classification, which mainly uses target-dependent long short-term memory to capture contextual information and model the relatedness of a target word with its context words. Unidirectional LSTM only can capture the contextual information in the forward direction, but bidirectional long short-term memory can obtain the contextual information in the forward and backward direction. Basiri et al. [29] utilized two independent bidirectional LSTM and GRU layers to extract both past and future contexts by combining the forward and backward hidden layers, and then used the attention mechanism to focus on important parts, at last performed sentiment analysis in the output of the convolutional and pooling layer that decreases the dimensionality of the feature space. Lv et al. [30] applied bidirectional long-short memory network to extract the context, then used the self-attention mechanism and the encoder-decoder attention mechanism to capture the correlation between context words and the correlation between context word and aspect word, respectively.
In addition, attention mechanisms often are regarded as an effective way to accurately recognize sentiment by focusing on important information. Bahdanau et al. [31]was the first to apply attention mechanisms to the NLP field. Huddar et al. [32]proposed a novel method for multi-modal sentiment analysis in conversation, which mainly uses RNN to capture the interlocutor state and contextual state between the utterances, then utilizes the pair-wise attention mechanism to focus on the important information of modalities before fusion. Huang et al. [32]proposed a model about integrating emotional intelligence and attention mechanism for sentiment analysis, which first uses utilizing EI to improve the feature learning ability of LSTM network, and then apply attention mechanism based on high-level abstraction to adaptively adjust the weight of text hidden representation. Huddar et al. [33] proposed a model to solve feature alignment between the modalities in the sentiment analysis, which uses BiLSTM to capture the contextual information among the words of an utterance and between the nearby utterances, and then applied the attention model based on weighted pooling to select the important features within the modalities and importance of each modality. However, the attention-based deep learning approach ignores the influence of each utterance on the entire text. To solve this problem, Wang et al. [34]proposed a sentence-to-sentence attention network based on multi-head self-attention, which can focus on the importance of each sentence to the complete text. Gan et al. [35]proposed a sentiment analysis method that considers multi-channel features, which uses local attention and global attention to weight the output features of each channel and the fused features of all channels, respectively.
Inspired by but differs from the aforementioned studies, this paper proposes a conversational sentiment analysis method based on self-attention mechanism and BiLSTM. The novelty of this approach is that it takes into account both contextual information and the degree of association between utterances. Specifically, BiLSTM is used to extract contextual semantic features from the current utterance, and the self-attention mechanism is applied to set different weight according to the degree of influence between utterances.
Methodology
The architecture of our model is shown in Fig. 2. The model mainly contains three steps. Firstly, we regard each utterance in the dialogue dataset as the basic unit to form a sequence of utterance. The sentiment features are extracted from dialogue text based on SKEP method. Each utterance vector with sentiment features is then used as the input of BiLSTM. Secondly, BiLSTM processes the utterance vector by combining forward and backward LSTM to capture bidirectional semantic dependencies, and extract the hidden information in different aspects of the utterance. Finally, self-attention mechanism is applied to extract the dependence of all utterances in the conversation. The softmax classifier is then applied on the output of self-attention layer to classify the corresponding dialogue emotion, which result in five sentiment classes i.e., negative, very negative, neutral, positive, and very positive. The proposed model is described from three sections i.e., SKEP pre-training model, BiLSTM, and self-attention mechanism.
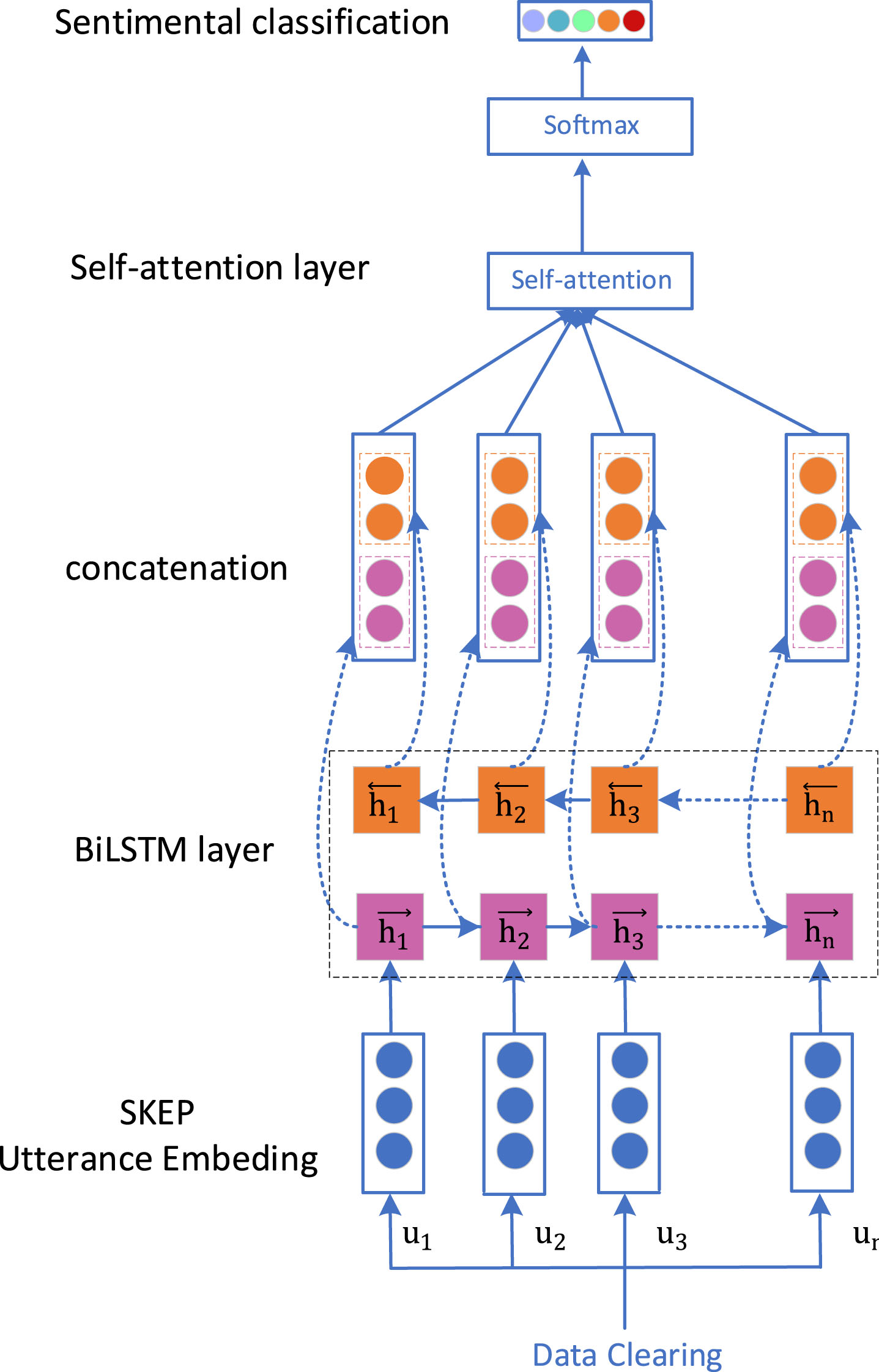
The framework of BiLSTM with self-attention model.
Existing conversational sentiment analysis work ignores emotional knowledge, i.e., affective words and aspect-affective pairs during pre-training. The importance of sentiment knowledge has been verified by different tasks, i.e., sentence-level sentiment classification, aspect-level sentiment classification, and opinion extraction. Sentiment words play a key role in sentiment analysis, and many studies on sentiment analysis have focused on extracting sentiment words. In addition, these studies also focus on analyzing word polarity, such as traditional dictionary-based models that use word polarity to analyze the sentiment of text. Aspect-sentiment pairs reveal more information than sentiment words, which can clearly indicate the emotion corresponding to the thing. Therefore, we use SKEP to extract emotional words, word polarity, and aspect-sentiment pair, which generate utterance representation that will be more suitable for customer sentiment analysis in conversations.
Furthermore, sentiment word is recognized by Pointwise Mutual Information (PMI) method and sentiment seed words; After mining the sentiment word, the aspect-sentiment pair is extracted by simple constraints. Aspect-sentiment pairs refer to an aspect and its corresponding sentiment word. Therefore, the sentiment word with the closest noun will be considered an aspect-sentiment pair. The aspect-sentiment pairs are recognized by the constraint

Example of SKEP model.
SKEP masks a sequence by three masking strategies: Aspect-sentiment Pair Masking. In a sentence, there are no more than two pairs are selected to mask, and they are random. Sentiment Word Masking. The number of tokens that are MASK cannot exceed 10% of the total number of tokens in the current sentence. Common Token Masking. If the proportion of tokens accounted for by emotional words in the second step is not 10%, the number of MASK is only to supplement the remaining number of 10% in the second step.
SKEP uses the sentiment masking mechanism to recognize the sentiment information of input texts, and generate a corrupted version by masking this information [36]; then, the SKEP recovers the sentiment information with three sentiment objectives, i.e., Sentiment Word prediction L sw , Word Polarity prediction L wp , and Aspect-sentiment Pair prediction L ap . These sentiment objectives can be calculated as follows.
The objective optimization function L
m
of the SKEP model is as follows:
The L
sw
is calculated as follows:
where W and b are the parameters in the pre-training process;
we use the SKEP to obtain emotional information of conversations and provide it to whole models in the form of emotional context vectors. Finally, the SKEP generates the utterance representations with sentiment information as the input vectors to BiLSTM.
BiLSTM is an improvement of LSTM that effectively solves some problems of RNN, such as the long-term distance dependence, gradient disappearance and gradient explosion. It is composed of forward LSTM and backward LSTM; hence, BiLSTM can more precisely capture contextual semantic information. LSTM consists of the input gate, the forget gate f, the output gate o, and cell memory state C. These modules can be computed as follows.
where h t is the output vector of hidden layer at position t; σ is the sigmoid function; x t is the input vector of LSTM; W i , W f , and W o ∈ Rd h ×d k are the weight matrices; b i , b f , b o , and b c ∈ R d h are the biases.
Traditional LSTM models can capture the semantic information in the forward direction but ignore the backward context information [24]. Therefore, we utilize the BiLSTM model to consider contextual information to capture bidirectional semantic dependencies. By combining forward and backward LSTM, BiLSTM build contextual sentimental sequences based on features recognition of utterance vectors from the JD Dialog dataset. The two LSTMs are calculated as follows:
Where C
t
and h
t
consider forward and backward context. At the tth position, the output is
Although BSTM can build contextual sentimental sequences from conversations, it cannot extract the important information in the context. To improve the accuracy of sentiment analysis, the self-attention mechanism is introduced to set the different weight of the degree of association between utterances according to the degree of influence of each utterance on other utterances and focus on the sentiment features in the utterance [37]. The self-attention mechanism can be formally expressed as follows:
Finally, a softmax layer is utilized to classify the result:
Dataset and parameter settings
Our experiments are conducted on the JD Dialog dataset which is obtained from JD Dialogue Challenge 1 . To the best of my knowledge, the JD dialog dataset in the field of e -commerce is rarely used to analyze customers’ sentiment in conversation. We first process the dataset by cleaning, deleting, removing noise and irrelevant content. Each utterance is then annotated with one of five sentiment labels, which are very negative, negative, neutral, positive, and very positive.
The specifications in the annotation process are as follows:
If the sentence contains very obvious negative emotional words, or contains two or more negative emotional words, the emotional tendency of the sentence is marked as very negative, as in Example 1:
Customer: It’s been several times, you are too perfunctory. (very negative)
If the statement expresses dissatisfaction with the goods or services without significant negative emotions, the emotional tendency of the statement is marked as negative, as in Example 2:
Customer: Why hasn’t my order shipped yet? (negative)
If the statement is just a simple consultation without any emotional color, mark it as neutral, such as Example 3:
Customer: Hello, are you there? (neutral)
If the sentence expresses gratitude or contains one or two positive emotional words, label the emotional tendency of the sentence as positive, as in Example 4:
Agent: Hello, thank you for coming, how can I help you? (positive)
If the sentence contains obvious positive emotional words, or contains two or more positive emotional words, the emotional content of the sentence is labeled as very positive, as in Example 5:
Customer: The quality of the goods is good, I will give you good reviews. (very positive)
When manually annotating each sentence in a dialogue, three annotators are assigned to independently label their emotional tendencies. If two of them do not agree on their emotional labeling, an expert makes the final decision. The data annotation results show that the consistency of the two is above 89%, and the consistency of the three is above 83%. The Kappa coefficient was calculated between each two labeled personnel, and the mean value of the Kappa coefficient was greater than 0.75 after consistency analysis. Based on the results of the above related indicators, the data annotation of this topic has good consistency, and the quality of the data annotation meets the experimental standards.
In this paper, after labeling the dialogue emotional tendency of the dataset, the dataset is divided into training set, verification set and test set according to the ratio of 7 : 2:1, and the dataset is statistically analyzed. Table 1 shows the distribution of five types of affective tendency labels on the dataset. From the statistical results in Table 1, it can be seen that the neutral and positive emotions in the data set account for a relatively large proportion of words, and the negative emotions are less. The main reason why neutral emotions account for a large proportion is that the content related to consultation in the conversation accounts for more, and the reason why positive emotions account for a large proportion is that positive emotions account for a large proportion in the words of customer service, which is consistent with the actual situation in our daily communication. In addition, the proportion of dialogue sentences with very negative emotional tendency and very positive emotional tendency in the whole sample was 2.13% and 1.46%, respectively, which brought label imbalance to the sentiment analysis task in the customer service dialogue scenario. In addition, the dataset includes a total of 70616 conversation sentences, of which the average conversation length of each sentence of customer service is 20.65, and the average length of customer conversation per sentence is 11.61.
Information of the dataset
Information of the dataset
In this experiment, the maximum utterance length of the JD Dialog dataset is set to 196. We set up different epochs to observe the loss value, this result is shown in Fig. 4. When epoch is executed after 16, the loss value has not improved significantly. Thus, the epoch parameter value is set to 16. In addition, the size of the LSTM cell state is 128, the dropout rate is 0.5, the learning rate is e-3, and the batch size is 8. The optimization function of the model is Adam, considering that the emotional tendency classification in this experiment belongs to a multi-classification scenario and there is an unbalanced distribution, the training loss function is selected as the cross-entropy loss function.
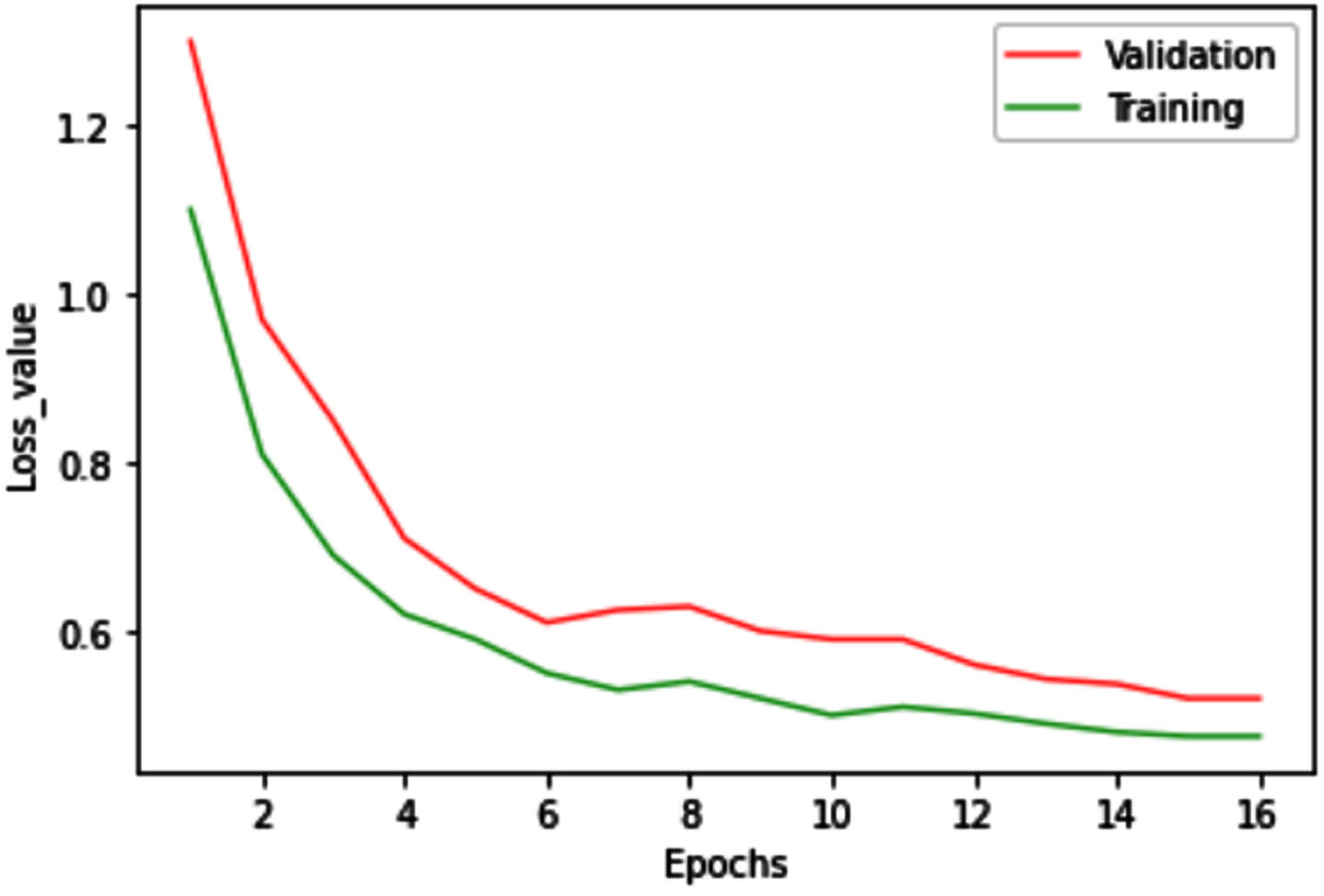
The loss value of training and validation.
This paper uses Precision(Pr), Recall(Re), F1-measure(F1), and Marco-F1 to evaluate the performance of the model. These standards are widely used in sentiment analysis tasks. These criteria are calculated as follows:
Marco-F1 is obtained by averaging the F1 values of all classes and is used to evaluate the overall performance of the model.
To evaluate the performance of our model, we implement following baseline models to sentiment recognition in conversation. BERT [39],where a BERT model is used to construct the utterance representations. SKEP [36], where the SKEP model embeds sentiment information into pre-trained utterance representations which combines sentiment words, word polarity and aspect-sentiment pair. BERT-BiLSTM [40], in English Textual Dialogue, the model extracts BERT embeddings then feed them into BiLSTM layer. After that, the output from BiLSTM layer is used for sentiment classification. SKEP-BiLSTM, where BERT is replaced with SKEP in BERT-BiLSTM. BiERU [12], where use LSTM and CNN to extract context information. DSAGCN [11], where employs a self-attention mechanism to capture the most effective words in the dialogue context emotional semantics, construct multimodal sentiment relationship graphs based on speaker relationships,
Experimental results and discussions
We compare the performance of our model with baselines on the JD Dialog dataset. Each model is run five times and recorded the average scores of evaluate metrics. From Table 2, we can see that the performance of our model is superior to the baseline models, which demonstrates our model can better recognize sentiment by considering the contextual information and the degree of association between utterances.
Comparison of our model and other baseline models
Comparison of our model and other baseline models
The performance of the pre-trained models, the SKEP-BiLSTM model performs better than the BERT- BiLSTM model on the sentiment recognition of conversation, which indicates the effectiveness of using SKEP to encode each utterance in the conversation. In addition, BERT-BiLSTM and SKEP-BiLSTM are all superior to a single BERT and SKEP model, which indicates that conversation is a continuous process and the sentiment recognition of the current utterance depends on the historical conversation. Furthermore, the F1 values of the negative and positive labels increased much more than that of other sentiment labels after considering the context features, which conform to the actual situation, i.e., when there is no contextual information, the utterance with the very negative or the very positive sentiment have obvious sentiment features, which is easier to recognize than the utterance with the negative or positive sentiment. Thus, for the utterance with negative or positive sentiment, when considering the context of which, the performance of BERT-BiLSTM and SKEP-BiLSTM models has more obviously improved in recognizing negative and positive sentiment.
To find out whether paying attention to the degree of association between utterances is beneficial for analyzing sentiment in the conversation, we compared our model with the SKEP-BiLSTM model. The results show that the macro-F1 value of our model is 2.15 higher than that of the SKEP-BiLSTM model, which indicates the effectiveness of using the self-attention mechanism to focus on the degree of association between utterances based on the contextual information.
The performance of our model is better than that of existing models i.e., BiERU and DSAGCN, which shows the importance of models considering sentiment knowledge, context information and the degree of association between utterances.
To further evaluate the performance of our proposed model in recognizing the conversational sentiment, we select two cases for analysis. Figure 5 illustrates two dialogue examples predicted by SKEP, SKEP-BiLSTM, and our model. We can see from this figure that: 1) For example 1 about “refund”, we find that both SKEP-BiLSTM and our model give correct predictions, while SKEP give wrong prediction. This is because both SKEP-BiLSTM and our model can capture contextual information, while SKEP focuses only on the current utterance. 2) For example 2 about the exchange of goods, the last utterance expresses dissatisfaction with the quality of the goods after the exchange. Both the predictions of SKEP and SKEP-BiLSTM aren’t negative, while our model still predicts accurately. The main reason for this is that our model not only captures contextual information but also focuses on the degree of association between utterances. Specifically, compared with the twelfth and thirteenth utterances, the content of the eleventh utterance has a greater impact on the sentiment of the last utterance. The relation between the eleventh and last utterances is set to a larger weight by self-attention mechanism. Hence, our model can recognize sentiment more accurately than SKEP and SKEP-BiLSTM. Experimental results show the necessity of SKEP, BiLSTM and Self-attention, and they give full play to their respective advantages, that is, extracting sentiment knowledge, context information and the degree of association between utterances that is conducive to dialogue sentiment analysis.

Illustration of examples from the JD Dialog dataset with their sentiment predicted by different approaches.
In this paper, we proposed an efficient model to accurately recognize customer sentiment in customer service conversations. The model consists of SKEP, Bidirectional LSTM, and self-attention mechanism. Firstly, the SKEP is used to generate the utterance representations by embedding sentiment information. Then, we use BiLSTM to capture contextual information on the utterance representations. Finally, the self-attention mechanism is applied to focus on the degree of association between utterances. To verify the performance of our model, we select four baseline models for the same task. Altogether 6305 customer service conversations (i.e., 70616 utterances) in the JD Dialog dataset are used to evaluate the performance of our proposed approach. Experimental results on the JD Dialog dataset show that our model has better performance than other baseline models in terms of recognizing customer sentiment.
For future work, the following two research directions merit exploration: 1) considering more factors that affect the accuracy of sentiment recognition in conversations, such as topics, commonsense knowledge, interactions between interlocutors, etc. 2) extending our experiments on additional application domains and language datasets, which is used to verify the effectiveness of our model.