
Abstract
The process of associating words with their relevant parts of speech is known as part-of-speech (POS) tagging. It takes a substantial amount of well-organized data or corpora and significant target language research to obtain good performance for a tagger. Mizo is a language that needs more research attention in computational linguistics due to its under-resourced nature. The limited availability of corpora and relevant literature adds complexity to the task of assigning POS labels to Mizo text. This paper explores two methods to potentially improve the Hidden Markov Model (HMM)-based POS tagger for the Mizo language. The proposed taggers are compared with the baseline HMM tagger and the N-gram taggers on the designed Mizo corpus, which consists of 72,077 manually tagged tokens. The experimental results proved that the two proposed taggers enhanced the HMM-based Mizo POS tagger, achieving 81.52% and 84.29% accuracy, respectively. Moreover, a comprehensive analysis of the performance of the suggested hybrid tagger was conducted, yielding a weighted average precision, recall, and F1-score of 83.09%, 77.88%, and 79.64% respectively.
Introduction
Part-of-speech (POS) tagging is the process of assigning a meaningful description to each individual word in a sentence [1]. The description is referred to as a “tag,” and it represents one of the language’s elements of speech. POS tagging assists in corpus parsing, which is an essential stage in language processing. It is an important step because it addresses ambiguous words in a phrase by giving each word a specific POS label based on the text.
POS tagging has gained importance in various natural language processing (NLP) applications, including information extraction, parsing, chunking, machine translation, question answering, semantic processing, and disambiguation of word sense. The development of POS taggers can be accomplished in a number of ways. Rule-based, statistical, and neural network-based methods are the most often adopted techniques for POS tagging. The language’s characters and structures are taken into account while developing rules in the rule-based method. Conditional Random Field-based, Hidden Markov Model, Maximum Entropy-based, and Support vector machine-based are the most commonly used statistical approaches. The primary issue with POS tagging is ambiguity and dealing with unfamiliar words [2]. Occasionally, a word might have different meanings with distinct parts of speech depending on the circumstances in which the term is used. A POS tagger’s objective is to address this ambiguity based on the context in which it is used. Several POS taggers have been developed in a variety of languages using various approaches.
The Mizo language is the language that is spoken mainly by the Mizo people who live in the state of Mizoram as their first language. Mizoram, one of the Indian states, shares international borders with Myanmar and Bangladesh, as well as domestic borders with Tripura, Manipur, and Assam. The nomenclature’ Mizo’ is used interchangeably to refer to both the people of Mizoram and the language they speak. The Mizo language belongs to the Tibeto-Burman language family, and there are approximately 8.3 lakh speakers in the country [3].
The Mizo language is currently under-resourced and still in its early stages of development. As a result, there is a scarcity of publicly available resources for computational linguistics pertaining to this language. Numerous studies in language processing have been conducted for various Indian languages, English, and many European languages. However, there have been a limited number of research studies focusing on computational linguistics in the Mizo language. Furthermore, the United Nations Education, Scientific and Cultural Organisation (UNESCO) has recognized the Mizo language as an endangered language [4]. In such circumstances, it is necessary to give a great deal of research attention to the language. The main goal of this study is to help move the Mizo language forward in the field of computational linguistics.
This study introduces a novel approach for part-of-speech tagging in the Mizo language, combining the HMM-based, N-gram, and rule-based models. The primary contributions of this study encompass two key aspects: Firstly, the development of tailored regular expressions designed specifically for the intricacies of the Mizo language. Secondly, the enhancement of an HMM-based Mizo POS tagger through two innovative strategies. The first strategy involves optimizing the decoder utilized in the process, resulting in improved performance. The second strategy involves the integration of three distinct models, leading to the creation of a highly robust and reliable Mizo POS tagger that can handle a wide range of linguistic variations and complexities.
Related works
Several academics have already begun working on building POS taggers, employing a variety of algorithmic approaches. In recent years, considerable effort has been expended on the POS tagging of Indian languages as well. Some of the POS tagging works done for various Indian languages are highlighted below.
One of the earliest articles on POS taggers for the Hindi language was published by Ranjan et al. [5]. It was based on the lexical tags of words. Many new approaches have emerged since the works were first published. A statistical POS tagger for Bengali using the Maximum Entropy (ME) model was presented by Ekbal et al. [6]. On a testing dataset of 20,000 words, the POS tagger was trained with 72,341 words and obtained an overall accuracy of 88.2%. Experiments have shown that the different word suffixes, named entity recognizer, and lexicon can help with unknown word difficulties and considerably enhance the POS tagger’s accuracy significantly.
Applying Artificial Neural Networks, Narayan et al. [7] built a POS tagging system for Hindi. The proposed model was compared to other strategies, such as Maximum Entropy-based, Rule-based, and CRF-based taggers. The experimental findings demonstrated that the proposed tagger outperformed all of them. Jahara et al. [8] presented the results of an empirical study of various POS tagging approaches for the Bengali language. Brill combined with the CRF had the highest accuracy of 91.83% of all tagging approaches.
Sharma et al. [9] proposed a bigram HMM-based POS tagger for the Punjabi language. The model was put through its paces on a corpus of 26,479 tokens. This procedure yielded an accuracy of 90.11%. A POS tagger for the Maithili language based on the CRF model was proposed by Priyadarshi et al. [10]. They built a corpus containing around 52K words, manually annotated with the designed tagset. They have experimented with various orthography features in the model and achieved an accuracy of 82.67%.
Jobanputra et al. [11] introduced the use of Long-Short-Term Memory (LSTM) for developing a part-of-speech (POS) tagger for the Gujarati language. They reported achieving an accuracy of 95.34% with their proposed approach. Tailor et al. [12] proposed a hybrid technique for Gujarati POS tagging that combines computational linguistic rules and LSTM-based POS tagging. The experimental outcome indicated that adopting language-specific rules improved the statistical tagger. The review paper by Gamit et al. [13] presented various methods of POS tagging in the Gujarati language.
Modi et al. [14] developed a hybrid Hindi POS tagger with 88.15% accuracy using rule-based and probability-based models. Mundotiya et al. [15] introduced an attention-based model for Hindi POS tagging, achieving 98.36% accuracy on the Hindi disease dataset. Dalal et al. [16] created a Hindi POS tagger based on Maximum Entropy Markov Model with 88.4% average accuracy. Swamy et al. [17] designed a Kannada POS tagger using CRF with F1-score, recall, and precision values of 91.4%, 91.6%, and 91.3% respectively.
Daimary et al. [18] introduced an HMM-based Assamese POS tagger with 89.21% accuracy, using a corpus of 2,71,890 words. Pathak et al. [19] presented another Assamese POS tagger based on deep learning, achieving 86.52% accuracy. Singh et al. [20] developed Manipuri POS taggers using CRF and SVC, obtaining accuracies of 72.04% and 74.38%, respectively, with 39,449 training tokens and 8,672 testing tokens. Tham [21] proposed a hybrid POS tagger for Khasi, combining HMM and CRF with 95.29% accuracy. Additionally, Warjri et al. [22] presented a Khasi POS tagger using BiLSTM-CRF and character-based models, achieving a maximum accuracy of 96.98% based on testing data. Vaishali et al. [23] presented a Marathi POS tagging system using a rule-based technique. The experimental result demonstrated an accuracy of 97.56%.
Many more diverse POS tagging works have been highlighted in these papers [24–26]. In conclusion, various approaches, such as rule-based, machine learning, and deep learning techniques, have been extensively employed in POS tagging for Indian languages. As documented in this review, the most notable achievement in terms of accuracy stands at 98.36% [15]. Moreover, publicly available POS tagged corpora for several Indian languages have been published [27].
System description
This section discusses the dataset, the tagset, the details of the baseline Hidden Markov Model-based tagger, and the architecture of the two proposed systems for improving the baseline Hidden Markov Model-based tagger.
Dataset and tagset
The selection of appropriate lexical categories is critical to the development of a tagging system. According to Zikpuia [28], the Mizo language contains 60 different parts of speech, which include subcategories of the major parts of speech. Nevertheless, these parts of speech cannot all be included in their original form in the parts of speech tagging system because the language has many compound phrases that can be classified as a single part of the speech element. For instance,
Compound noun: Biak in (church), vawk sa (pork), ar tui (egg)
Nounal Adjective: Bawng sa (Pork)
Verbal adjective: Naupang mu (sleeping baby), bawng thlun (tied cow) We combined certain fine-grained tags in this research to improve efficiency and accuracy. This merging process reduces the number of tags while preserving essential linguistic information, enhancing both processing speed and accuracy. For example, material nouns, countable nouns, common nouns, and concrete nouns are classified under the category of Common Nouns. Based on an analysis of the Mizo language’s morphological structure and considering various factors, a comprehensive tag set of 48 tags (as shown in Table 1) has been designed to encompass all grammatical categories in the Mizo corpus. The process involved following the Part-of-Speech Tagging Guidelines for the Penn Treebank Project [29] as a starting point for creating POS tags. These initial tags were then refined by taking into account the specific morphological characteristics of the Mizo language, resulting in the final set of 48 POS tags.
List of proposed Mizo tagsets and each tag’s frequency in the corpus
List of proposed Mizo tagsets and each tag’s frequency in the corpus
As far as we know, the Mizo language lacks a properly classified corpus, and the dearth of reliable free corpora for the Mizo language necessitated the manual creation of a tagged corpus. From a wide variety of web sources, raw digital texts have been gathered that cover a wide range of topics like sports, music, current events, and articles. With the assistance of linguistic experts, the required pre-processing tasks were meticulously performed. These tasks encompassed activities such as rectifying spelling errors, standardizing the writing styles of the collected phrases, and eliminating undesired symbols. The thorough execution of these pre-processing tasks ensures the quality and consistency of the data used in the research. It is then tokenized into words and manually annotated with the proposed tagset. Table 2 displays statistics of the designed Mizo corpus consisting of 72,077 tokens (The training and testing data are provided in a ratio of 90:10 for statistics.)
Corpus Statistics
A Hidden Markov Model (HMM) is a statistical model that depicts probability distributions over a sequence of observed events [2]. It assumes that the system being described is a Markov process with hidden states. To model a problem using a hidden Markov model, both observation sequences and a set of possible states must be available.
In the part-of-speech tagging problem, observations are the tokens in the string, and hidden states are the POS tags for the words. The HMM tagger selects the tag sequence for a particular sentence so that it optimizes the probability value and uses historical occurrences to assign a probability to a current word. The main goal of the HMM is to find the most likely tag sequence
Transition probability: The likelihood of occurrence of a specific tag in a sequence given the preceding tag is referred to as Transition probability. The transition probabilities can be calculated using the following equation:
Emission Probability: The emission probability determines the most appropriate tag for the specific word based on the number of occurrences of the word. These can be calculated using the following equation:
This baseline HMM model has been utilized for the Mizo POS tagging system that generates a sequence of tags for a particular sentence. With this model, 81.13% accuracy has been obtained on the designed Mizo corpus.
This section outlines our first technique for improving an HMM-based tagger for the Mizo language by modifying the decoder.
The Hidden Markov Model (HMM) finds the most probable tag sequence, but the time required to solve the problem grows exponentially. So, we used the Viterbi method to optimize the HMM, the most commonly used decoding algorithm for HMM in part-of-speech tagging. It is a dynamic programming technique with the objective of determining the most probable series of hidden or unobservable states, referred to as the path of Viterbi, which will result in a series of observed events. The Viterbi algorithm takes a set of observations, W = (w1w2w3w4 . . . w n ) as an input and returns the most likely state sequence, S = (s1s2s3s4 . . . s n ) with its probability.
The Viterbi algorithm creates two probability metrics, one for the transition and one for the emission. This Viterbi decoding algorithm (utilized during the testing phase) uses a matrix of tag transition probabilities and a matrix of emission probabilities to calculate the most probable sequence of tags for each phrase in the input corpus.
In this work, the baseline version of the Viterbi algorithm is modified to handle unknown terms in the corpus, resulting in improved performance of the HMM-based tagger. As mentioned earlier, the Viterbi algorithm utilizes both emission probabilities and transition probabilities to determine the most probable tag sequences. However, if a word is not found in the training data (meaning it is an unknown word), its emission probability becomes zero, resulting in a state probability of zero. In such cases, when the algorithm encounters an unseen word during training, it exclusively relies on the transition probability to calculate the state probability, disregarding the emission probability. Thus, the algorithm operates in the following manner:
State _ prob = Trans _ prob
State _ prob = Trans _ prob * Emi _ prob
The algorithm mentioned above can be interpreted as follows: If a word is not present in the vocabulary, then the state probability is equal to the transition probability; otherwise, the state probability equals the product of the transition probability and the emission probability.
With this simple method, the baseline version of the HMM-based tagger for the Mizo language has been improved, allowing it to produce better results.
Proposed method II: Hybrid Mizo POS tagger
This section describes another proposed method for enhancing the HMM-based POS tagger for the Mizo language by integrating the Hidden Markov Model (HMM) with the N-gram bigram tagger from the NLTK package and the rule-based tagger.
The N-gram model is one of the most straightforward language models for assigning probabilities to phrases and word sequences. The tagger first creates a context for the token before deciding which tag should be assigned. This context is made up of the type of the token and the part-of-speech tags of the n tags that came before it. The N-gram POS taggers select tags based on the word string and the tags of the n-words that precede it. Figure 1depicts an example of an N-gram tagger with n=3, where the context for determining the tag t n is tinted gray that includes tn - 2, tn - 1, and w n .
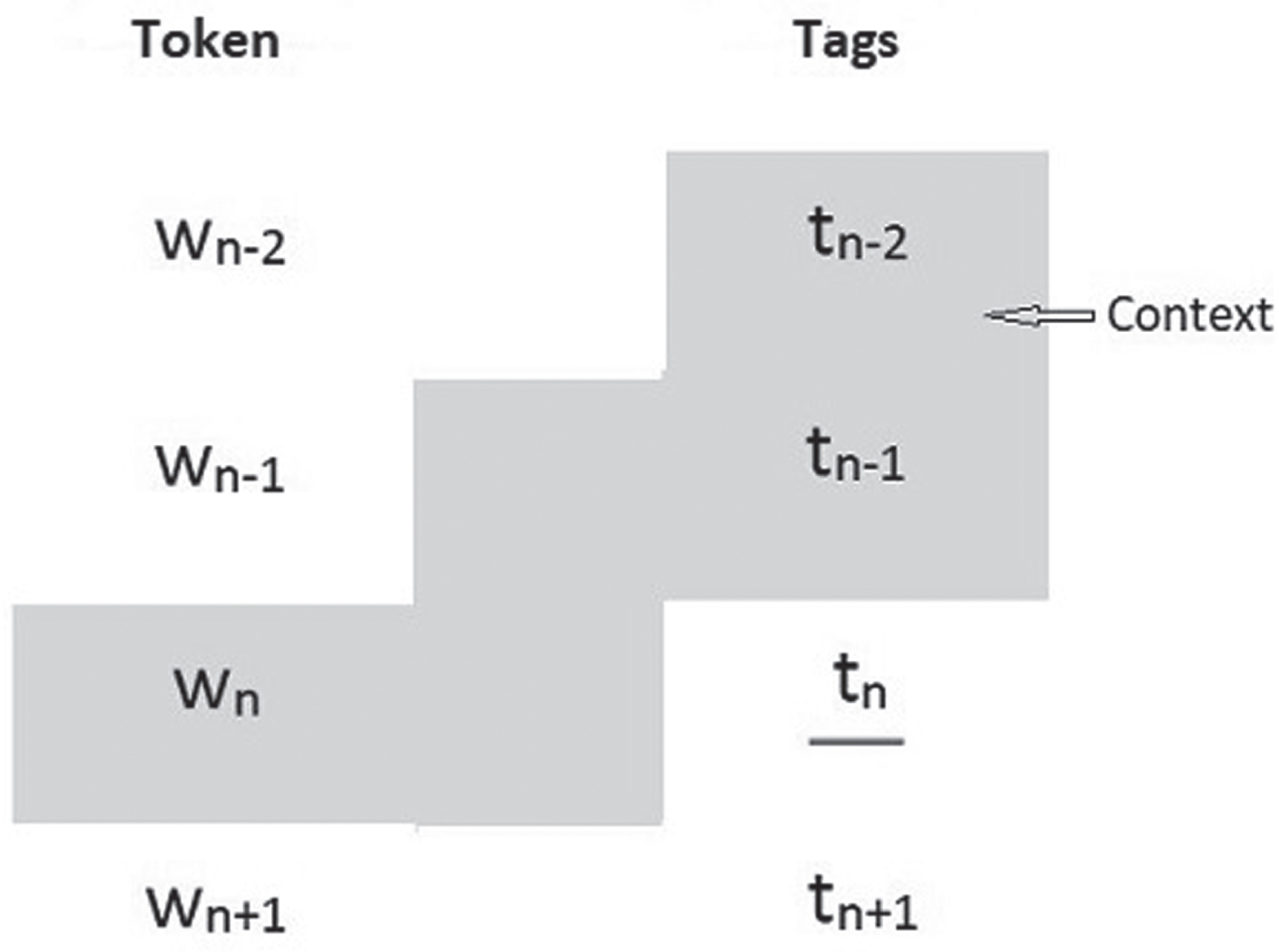
Context of the N-gram model.
In order to handle unknown terms, a number of regular expressions for analyzing the Mizo language have been designed. The rules have to be carefully crafted because the Mizo language is sophisticated and morphologically complex. Based on examining and analyzing the morphologically rich Mizo language’s structure via the language experts and the authoritative Mizo grammar publications [28, 30], The designed regular expression tagger, in this work, provides a word-level analysis of tokens in the string. In addition to the trivial tagging such as symbols, conjunctions, articles, and personal pronouns, the analysis and the clues are provided below:
- Foreign Word(FW):
If a word contains characters that are not available in Mizo alphabets, such as Q(q), X(x), Y(y)
If a word contains W(w) but not prefixed by A(a)
If a word contains a character H(c), but not followed by H(h)
If a word contains a character G(g), but not prefix by N(n)
- Proper Noun(PPN):
If a word starts with a capital letter and ends with ‘i’ or ‘a’
If all letters of a word are capital
If a word ends with ‘-in’
- Abstract Noun(ABN):
If a word ends with ‘na’
- Common Noun(CMN):
if a word ends with ’te’ or ’ten’
if a word ends with ’ho’
if a word ends with ’pui’
if a word ends with ’tu’
if a word ends with ’in’
-Demonstrative Pronoun(MP)
If a word ends with ‘ngte’
- Adverb of Place (RBP)
If a word consists of characters only and ends with ‘-ah’ or ‘-a’
If a word ends with ‘ah’
- Adverb of Time (RBT)
If a word consists of digits only and ends with ‘ah’ ‘-a’
-Verb base form (VB)
if a word starts with ’In’ or ’IN’
if a word ends with ’san’
if a word ends with ’tir’
-Date (ET)
if a word is a month or day of the week
-Adjective base form (JJ)
if a word ends with ’zia’
-Default tag: VB
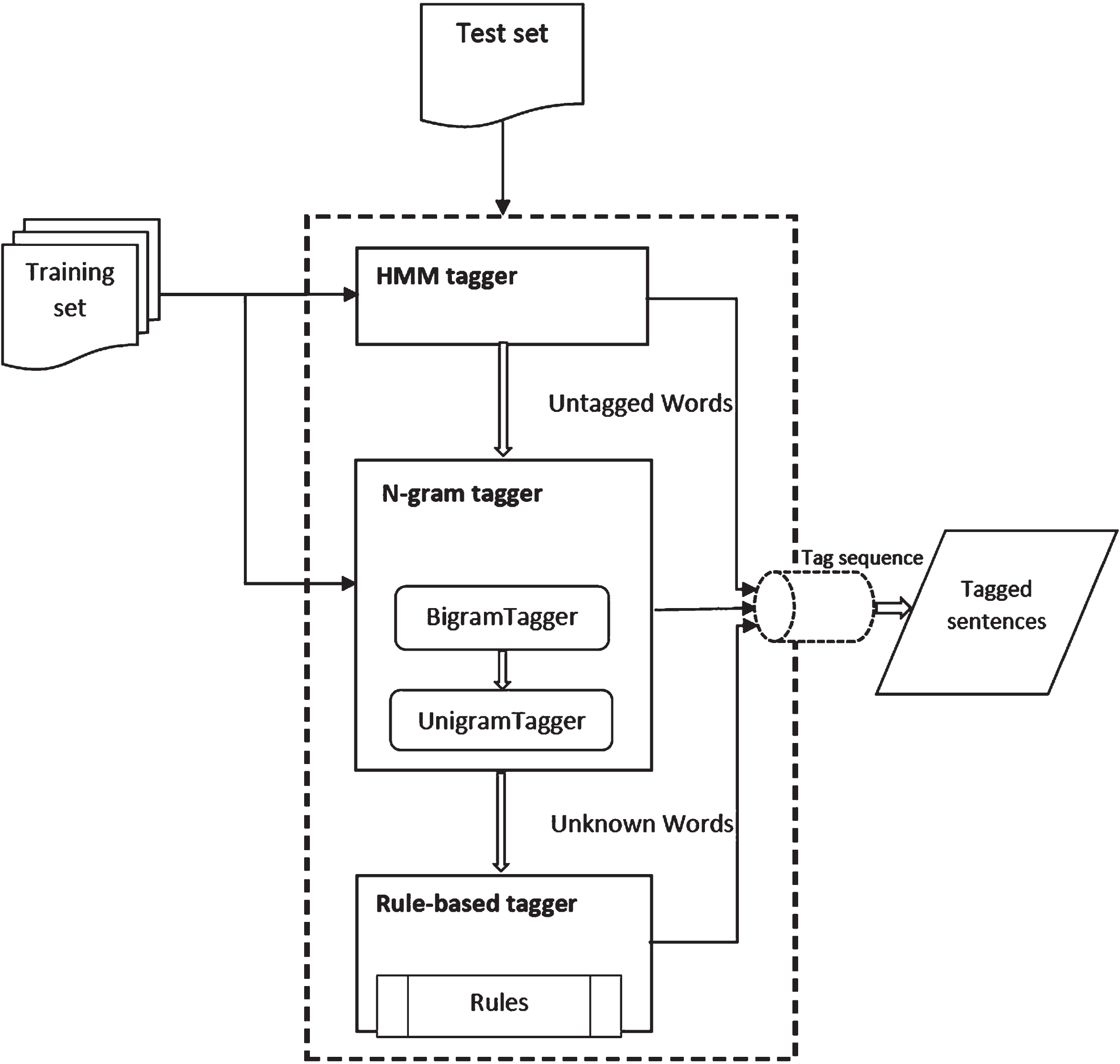
The overall architecture.
Figure 2 depicts the overall architecture of the proposed tagger. The HMM tagger and the N-gram model bigram tagger are trained with the training data. During the process of determining the tag sequence that is most likely to be used for the sentence, the HMM-based tagger will initially assign tags to the tokens that have a high probability of being used. The responsibility of tagging any tokens with a probability less than the threshold values will be passed on to the N-gram bigram backoff tagger. The bigram tagger performs a lookup for a tuple that contains the previous tag and the current word in the context to find the appropriate tag for a given word. If the bigram fails to identify a suitable tag for the provided word, the duty is handed off to the unigram tagger.
The unigram tagger employs a basic statistical technique to tag a token by selecting the most frequently encountered tag associated with that token in the annotated training text corpus. The unigram tagger will not be able to label words that are not found in its vocabulary, commonly known as out-of-vocabulary words (or unknown words). These words are then forwarded to the rule-based tagger. Subsequently, the rule-based tagger analyzes these unknown words and attempts to assign them appropriate tags based on the predefined rules. Since VB (Verb) is the most prevalent tag in the corpus used in this study, it has been chosen as the default tag. So, if the rule-based tagger cannot find a suitable rule for tagging a token, the token will be given the default tag "VB (Verb)."
The designed Mizo-specific regular expressions play a crucial role in the success of this hybrid technique, enabling it to capture unknown words in Mizo text. Although computationally more time-consuming, this approach yields substantial improvements in accuracy.
Implementation and result comparison
This section covers the detailed experimental setup, results obtained from different methods, and conclusions drawn from the findings.
We tested and compared the accuracy of the baseline HMM tagger and our proposed taggers on the designed Mizo corpus of 72,077 tokens. Two data sets of varying sizes are employed to compare the performance of the taggers. Set 1 (95:5) has 68,474 words in the training set and 3,603 words in the test set, whereas Set 2 (90:10) has 64,869 words in the training set and 7,208 words in the test set. For comparison purposes, we also evaluated the performance of the NLTK unigram tagger, the NLTK bigram tagger, and the NLTK trigram tagger on the same dataset. The outcomes of the various taggers we have examined are summarized in Table 3.
Comparison of accuracy
Comparison of accuracy
Input Features: Based on the various possible combinations of the word and tag context, the primary input features for the POS tagging task have been identified. In order to find plausible tags, the model utilized in this study employs two types of probabilities: transition probabilities and emission probabilities, as well as word-level analyses. The main input features identified for known and unknown words are given in Table 4.
Input features
As a result of the findings of our experiment, which showed that the NLTK bigram tagger performed marginally better than the NLTK trigram tagger, the bigram tagger was selected to be integrated into the proposed hybrid method, which also included the HMM-base method and the rule-based tagger. It is observed from Table 3 that the baseline HMM tagger has been improved with the proposed method one by approximately 1%, and the proposed hybrid approach improves it by around 4%. It is worth noting that as the data set grows in size, performance improves significantly, and a significant improvement has been achieved with these two proposed techniques, with our proposed hybrid approach producing the best results (84.29% accuracy).
We assessed the performance of our hybrid POS tagger by evaluating precision, recall, and F1-score for each tag. The results, presented in Table 5, show promising performance. Table 6 displays the macro and weighted averages for these metrics. The macro average precision, recall, and F1-score were determined to be 78.87%, 76.25%, and 75.95%, respectively. Moreover, the weighted average precision, recall, and F1-score were calculated at 83.09%, 77.88%, and 79.64%, respectively, showcasing its effective handling of class imbalance. Upon analysis of the results, it can be concluded that the tagger demonstrated a balanced performance across all tags, as evidenced by the macro average scores. The weighted average scores effectively addressed the class imbalance issue and displayed good overall performance.
Precision, recall, and F1-score for each tag
This section presents the performance analysis of the baseline HMM model and the proposed hybrid HMM-based tagger. The experimental results unveiled that, while both taggers correctly tagged a considerable number of words, there were instances where they mislabeled certain words. Table 7 showcases some examples of such cases, providing insight into the performance of both taggers on the designed corpus.
When the baseline HMM tagger encounters a word that is not in the vocabulary, it will tag the word as "None." It has been observed that certain words in the corpus are annotated with multiple tags due to variations in their contextual usage. For example, consider the word, "sawrkar" in the corpus. Based on the context, this word has been assigned both CMN and VBN tags. However, the baseline HMM tagger assigns the CMN tag to all occurrences of the word, regardless of context. On the other hand, the proposed hybrid tagger utilizes the relevant context and correctly assigns both CMN and VBN tags to different instances of the word.
Let us consider another example, the term, "boxer." As per the rules defined in the proposed tagger, it should be tagged as FW. However, due to the probabilistic nature of determining the most probable tag, both the baseline HMM tagger and the proposed hybrid tagger incorrectly assign the tag CMN to this term.
The number of incorrect predictions made by both the baseline HMM tagger and the proposed hybrid tagger is illustrated in labeled bar graphs in Figures 3 and 4, respectively. A comparison of these two graphs reveals a significant difference in the number of inaccurate predictions. The baseline HMM tagger demonstrates a considerably higher number of incorrect predictions (over 300 counts), while the proposed hybrid tagger shows a lower number (fewer than 150 counts). Figure 3 demonstrates that the error rate is largely influenced by the RBP, which has been reduced in Figure 4. In Figure 4, the distribution of errors across various tags is not heavily biased towards a single tag. However, it is worth noting that the default tag exhibits a slightly higher number of incorrect predictions compared to the other tags.
Macro average and Weighted average
Macro average and Weighted average
Comparing word tagging by baseline HMM tagger and hybrid tagger
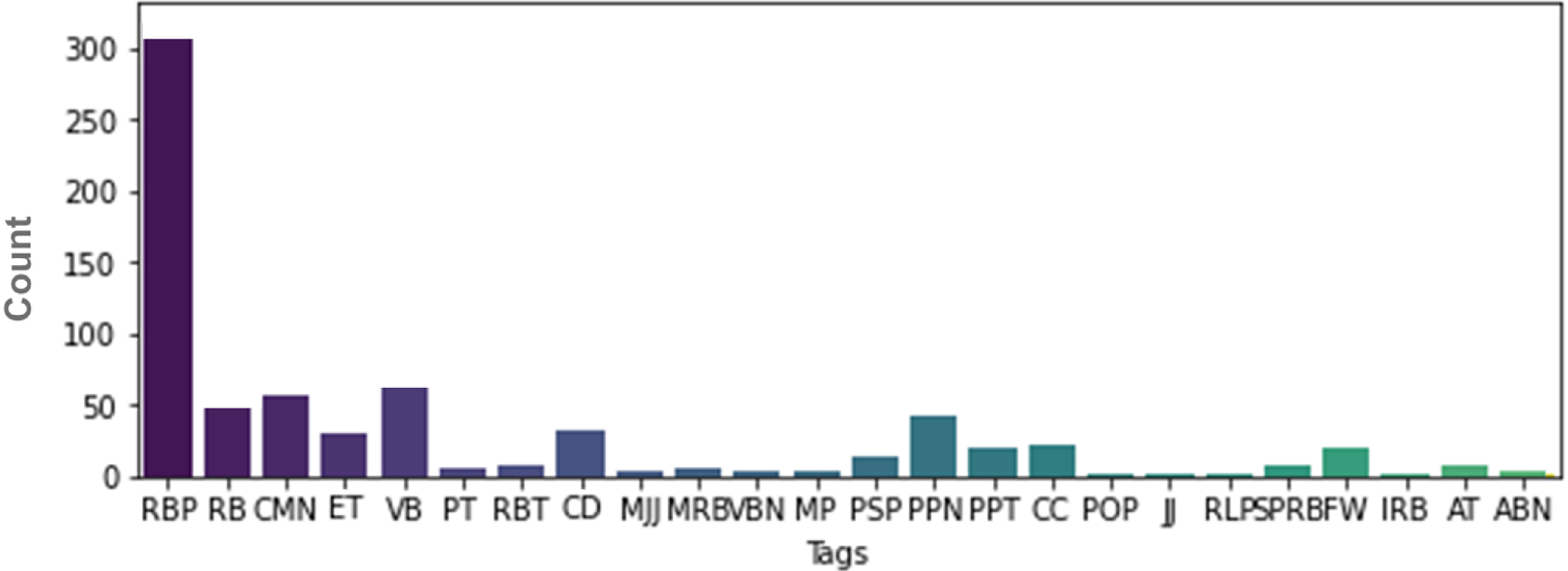
Number of incorrect predictions by baseline HMM tagger.
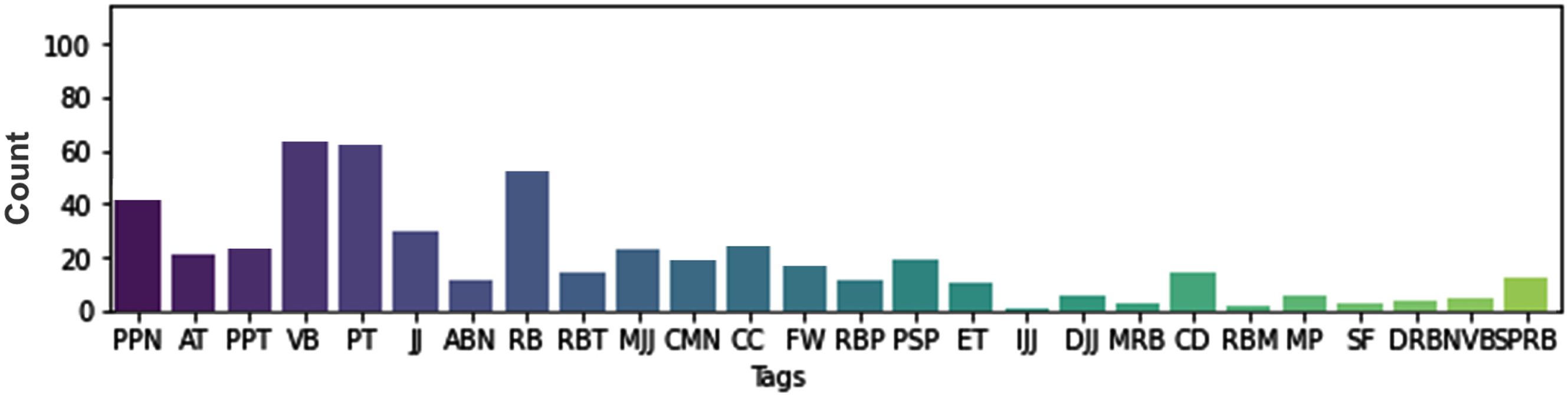
Number of incorrect predictions by the proposed hybrid tagger.
In addition, to evaluate the performance of the two taggers, we conducted a comparison using external test data. We selected three simple sentences that consist of both known and unknown words. These sentences were inputted into the system to analyze how the taggers assign tags to each token.
Input text 1: "Aizawlah ka bazar dawn"
Input text 2: "Dintharah ka hau dawn"
Performance on external test data 1
Performance on external test data 2
The two taggers handle the above two simple sentences quite well, as shown in Table 8. In the training corpus, the word bazar has been assigned three different tags, such as CMN, VBN, and PPN. When this sample Input text 1 is fed to the system, the baseline HMM and our proposed tagger successfully identify the word bazar as VBN. The term hau, that appears in Input text 2 is an unknown word. The baseline HMM tagger wrongly tags the word as "ABN," whereas the proposed tagger correctly tags it as VB.
Input text 3: "Bombay-ah Mawia remhriatna avangin WPO buatsaih X-ray chungchang seminar-ah ka tel ve."
The third statement in the input text is a little more complicated than the previous two input samples. Table 9 provides a detailed analysis.
The proposed hybrid tagger performs well on this specific sample input. Apart from the word "seminar-ah," which has an incorrect RBP tag, the proposed method accurately assigns tags to each word. Integrating the rule-based tagger in the proposed system enables the effective handling of unknown terms.
This study describes a Hidden Markov Model-based tagging technique for the Mizo language. Two methods have been proposed to increase the performance of the baseline model. The first proposed model yielded 81.52% accuracy, which is higher than the baseline HMM model. The highest accuracy, 84.29%, is obtained with the second proposed hybrid tagger, which is 3.85% higher than the baseline HMM model.
The effectiveness of the proposed hybrid POS tagger has also been assessed by determining the value of precision, recall, and F1-score for each tag. The overall performance of our model is illustrated through the macro average and weighted average for each metric, indicating satisfactory results.
We have also analyzed the Mizo language and its grammatical structure, which has helped us come up with morphological clues for identifying the corresponding tag for a particular word. The experiments show that our methods substantially improve the accuracy and overall performance of the tagger for both known and unknown words. It is anticipated that this effort will, at least, serve as a primary foundation or groundwork for subsequent research in the language.
The contributions and results obtained with our proposed approaches are quite satisfactory, considering that Mizo is a low-resource language. We believe that there is room for improvement in the taggers’ performance by increasing the corpus’s size and developing more precise regular expressions tailored to the language. In our future research, we intend to explore the application of diverse deep-learning architectures to further enhance the accuracy of the Mizo tagger. Moreover, future studies could also consider incorporating the Kappa score, a metric for evaluating inter-rater agreement. This inclusion would provide a comprehensive understanding of result reliability and strengthen the overall robustness of the study.
Footnotes
Acknowledgment
The authors would like to express their gratitude to Mr. Mika Lalngaihtuaha, and Mr. Lallawmsanga for their assistance in developing the Mizo corpus. They also thank the Department of IT, Mizoram University and the Department of CSE, NIT Silchar for supporting this research work.