
Abstract
Selecting appropriate Cluster Heads (CHs) can significantly enhance the lifetime of the wireless sensor networks (WSNs). Fuzzy logic is an effective approach for CH election. However, existing fuzzy-logic-based CH election methods usually require a large number of fuzzy rules, making the CH election procedure inefficiency. In this study, a data-driven CH election method is proposed based on a compact set of fuzzy rules, which are learned by group sparse Takagi-Sugeno-Kang (GS-TSK) fuzzy system. Specifically, five linguistic variables were first used as features to describe the status of sensor nodes. After that, a compact set of fuzzy rules were learned by GS-TSK, and they were then used to predict the chance of each sensor node becoming a CH. Based on the selected CHs, the clusters are generated. Simulation results show that the GS-TSK can select CHs with fewer rules more accurately. Besides, by using the proposed DD-FLC, an average improvement of WSN was shown in terms of first node dead (FND), 10% of nodes dead (10PND), quarter of nodes dead (QND), half of nodes dead (HND).
Introduction
Wireless sensor networks (WSNs) have been successfully applied in many fields including healthcare, environmental sensing and industrial monitoring [2–5]. A WSN usually includes a base station (BS) and a lot of distributed sensors. The BS receives, processes, and provides data to the end user, while the sensors collaboratively collect, process and transmit the information in the network coverage area, and ultimately send the information to the network owner.
WSNs usually include a large number of stationary or moving sensors in a self-organizing manner. The sensors rely on their on-board batteries, which are limited, non-rechargeable and non-replaceable. Due to the limited storage, memory, and CPU processing capabilities of sensors [6], energy-efficient routing protocols is crucial in energy consumption and network life cycle [7–10]. In the WSN environment, sending data over multiple short phases consumes less energy than directly transmitting information to BS over the same total distance. Grouping sensor nodes into clusters is an effective low-cost communication strategy. Specifically, the sensor nodes in the WSN are grouped into several clusters. In each cluster, one sensor node is selected as the cluster head (CH), and other sensor nodes in the cluster transmit data to the CH. The CH then assembles the data and transmit them to the BS.
Selecting appropriate CHs can significantly extend the lifetime of the WSN. However, it is a challenging task because it is affected by multiple factors. Energy conservation is a main concern in CH selection. Besides, location suitability, and distribution of surrounding nodes should also be fully considered [6].
In order to select appropriate CHs based on these factors, fuzzy logic has been adopted [11] to estimate the chance to be a CH of each sensor node. In literature, Rajeswari et al. proposed a trusted energy-aware cluster based routing protocol based on fuzzy logic [12]. Wu et al. proposed strategies of attack-defense game for wireless sensor networks considering the effect of confidence level in fuzzy environment [13, 14]. Abdulmughni et al. proposed a fuzzy-based centralized clustering technology for efficient routing protocols for wireless sensor networks [6]. Gamal [15] et al. enhanced the lifetime of WSNs by fuzzy logic LEACH-based particle swarm optimization. However, these methods used a large number of fuzzy rules, resulting in inefficiency CH election, especially in the dynamic WSN environment where network conditions change frequently.
Learning a compact set of fuzzy rules is an effective solution to this issue. In literature, data-driven fuzzy systems have been fully investigated. It can automatically learn a compact set of fuzzy rules from the training data and has been successfully applied in various fields such as disease diagnosis [35], fault diagnosis [16], and so on. However, there is no work reported on its application in CH selection for WSNs.
To this end, this paper proposes a novel CH election method for WSN using data-driven TSK fuzzy systems. It automatically learns a compact set of fuzzy rules in a data-driven manner and estimate the chance of each senor node being a CH by using a group sparse Takagi-Sugeno-Kang (TSK) fuzzy system, making the CH election procedure more efficient. Besides, it uses residual energy, distance from BS, location suitability, and distribution of surrounding nodes to compute the chance to be a CH, making the prediction more accurate. We also develop a data-driven fuzzy-logic based clustering method DD-FLC based on the proposed CH election method to accomplish optimal clustering in WSN.
The contributions of the paper are summarized as follows: We propose a novel CH election method for WSNs. Different from classical methods that always used a large number of fuzzy rules, it adaptively learns a compact set of fuzzy rules, making the CH election procedure more efficient. To the best of our knowledge, this is the first attempt that used data-driven fuzzy systems in CH selection for WSNs. We propose a group-sparse TSK fuzzy system called GS-TSK to adaptively learns a compact set of fuzzy rules. It integrates the group sparse regularization in the learning criterion to find the compact set of contributive fuzzy rules. An Alternating Direction Multiplier method is developed to find the optimal solution of GS-TSK. We develop an efficient data-driven fuzzy-logic clustering method DD-FLC to accomplish optimal clustering in WSN.
The rest of this paper is organized as follows: Section 1 introduces the background of our work; Section 2 proposes GS-TSK for CH election and further proposes a data-driven fuzzy logic-based clustering algorithm DD-FLC. Section 3 reports the experimental results. In Section 4, some conclusions are drawn.
Related works
The energy consumption is the most imperative resource in the WSN design. Developing the clustering-based routing protocol is an effective way to deal with this issue. Many clustering algorithms are proposed in the literature [14, 17–19]. LEACH [20] is the first dynamic clustering protocol for hierarchal sensor networks. It used randomized rotation of CHs to evenly distribute the energy load among the sensors in the WSN. Afterwards, LEACH-C (LEACH-Centralized) [21] is proposed for centralized networks. In LEAH-C, the BS controls the procedures of CH selection using the simulated annealing strategy, and the global knowledge of the network helps the BS to form better clusters.
The environmental factors always have uncertainty properties, and it is usually difficult to accurately identify their values. To handle the uncertainty properties of the environmental factors in CH selection, fuzzy logic is introduced in literature. For example, Mao et al. proposed an improved fuzzy unequal clustering method IFUC [22] that created the fuzzy rule base using the energy, BS distance, and density of the nodes; Bagci et al. proposed a distributed competitive unequal clustering algorithm EAUCF [23] that estimated the competition radius and selected CHs using fuzzy logic; Logambiga et al. proposed FBUC [24], which was an enhanced version of EAUCF that introduced node degree in computing the competitive radius; Gajjar et al. proposed a fuzzy based unequal clustering protocol FUCP [25] that used energy, node centerness, and link quality for the CH selection. Baranidharan et al.proposed DUCF [26] that computed both chance and size for CH nomination using fuzzy system using energy, BS distance, and node degree as the inputs to the fuzzy system. Lipare et al. [27] proposed an energy-efficient two-phase fuzzy logic approach EETPF to associate clustering and routing algorithm based on the residual energy of sensor nodes, distance of sensor nodes from the BS and the number of nodes in the communication range. Sert et al. [28] extended the idea of CLONALG technique and proposed a CLONALG-M for rule-based CH selection. Gamal et al. [15] enhanced the lifetime of wireless sensor networks by combing fuzzy logic and Particle Swarm Optimization.
The above methods were developed based on Type-1 fuzzy logic. Since type-2 fuzzy logic can handle the uncertainty more accurately than Type-1 fuzzy models, Nayak et al. introduced type-2 fuzzy logic to into clustering nodes in WSNs and proposed T2FL [29]. The CH was nominated based on the inputs (energy, concentration, and BS distance) for the CH competition. Due to the utilization of type-2 fuzzy logic, the fuzzy system provided a confidence factor value for the nodes to participate in the CH competition. The network is shaped in a layered structure in which the CHs are arranged in a chain arrangement and the data travels through the chain to reach the BS.
The following Table 1 presents the input and output variables, and compares the contributions of these works.
Comparison of clustering algorithms for WSNs based on fuzzy-logic
Comparison of clustering algorithms for WSNs based on fuzzy-logic
Although these methods introduced fuzzy logic to handle the uncertainty issue in CH selection, they were develop based on fuzzy systems with a large number of fuzzy rules, resulting in inefficiency in CH election. This is not suitable for the dynamic WSN environment where network conditions frequently change.
In this sect
Pipeline
Figure 1 shows the pipeline of the proposed method. It mainly includes three steps, i.e. feature extraction, chance estimation using GS-TSK, and node clustering based on chance estimation using GS-TSK. In the first step of feature extraction, five linguistic variables (i.e. variables whose values are words or sentences in a natural or artificial language [30]) such as residual energy, distance from BS, location suitability, density of surrounding nodes, and compression of surrounding nodes are extracted as features to describe the status of each sensor node. In the second step of chance estimation using GS-TSK, the chance of each sensor node becoming a CH is estimated by a GS-TSK fuzzy system using a compact set of fuzzy rules. Finally, the nodes with the largest chance predicted by GS-TSK are selected as CHs and clusters are formed based on the elected CHs.
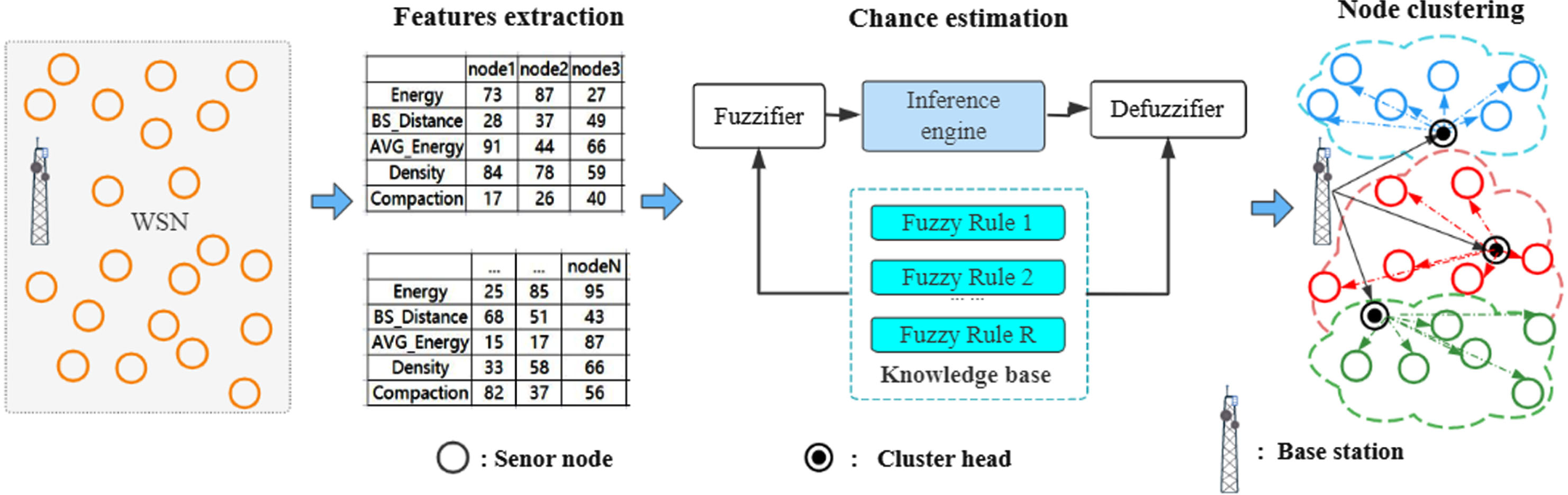
Pipeline of the proposed method.
We use five linguistic variables i.e. energy, AVG_Energy, density, compaction, and distance from the BS, to describe the sensor status. Residual energy (Energy): This variable refers to the residual energy of the sensor node. By selecting sensors with higher energy as CHs, and balancing energy consumption through WSN nodes, which can increase the life of the network. Distance to BS (BS_Distance): This variable refers to the distance between CHs and BS. The shorter the distance, the lower the energy consumption. BS_Distance is normalized to a percentage value. The sensors closer to the BS are more likely to become CHs, and the nodes farther away from the BS are more likely to become CHs. Location suitability (AVG_Energy): This variable measures the suitability of a node’s position as a CH relative to surrounding nodes within a predefined range. For a CH node, a more appropriate position is the one with lower total communication energy. The location suitability of any node is thus measured by averaging the local energy consumption of the sensors around the current node within a predefined range. Density of surrounding nodes (Density): The nodes with more surrounding neighbors are more likely to be selected as CHs, which helps to reduce the local energy consumption of group members. Given a sensor node, its Density is computed based on the number of surrounding nodes within a predefined range. Compaction of surrounding nodes (Compact): Nodes surrounded by more neighboring nodes are considered to have a higher compaction degree. Selecting nodes with a higher compaction degree can minimize the total energy consumption. It is computed as the ratio of the number of nodes located within the first vicinity region to those located within the second vicinity region. This criterion helps to distinguish candidate nodes surrounded by sensors of the same density.
Chance estimation using data-driven fuzzy inference system GS-TSK
The fuzzy logic has been widely used in CH election to handle the uncertainty issues [31]. The fuzzy system is always used in this procedure. Specifically, it first accepts the input data and transfer them to the linguistic variables. After that, the inference module employed in the fuzzy system uses the fuzzy rules to produce the fuzzy output, which indicates the chance of a node becoming a CH. However, existing fuzzy-logic based methods for CH election uses a rule base that contains a large number of rules, making the CH election process inefficiency. Therefore, it is significant to automatically learn a compact set of fuzzy rules by proposing a novel fuzzy-logic based method. In this section, we first introduce the basics on TSK fuzzy systems. Then, we propose Group-Sparse TSK fuzzy system that can learn a compact set of fuzzy rules.
TSK fuzzy system overview
The TSK fuzzy system was proposed by Takagi and Sugeno [32]. The core idea of TSK fuzzy system is to divide the input and output training data into several groups, extract the IF-THEN fuzzy rules, and then learn the corresponding parameters to find the mapping between the input and output data.
The TSK fuzzy system mainly includes multiple fuzzy rules in the form of “IF-THEN”. Let P be the feature number of the input data, and R be the rule number. Given any P-dimensional input vector
We denote
(5) can be reformulated as:
To obtain a compact set of fuzzy rules, we proposed a novel TSK fuzzy system called group sparse TSK (GS-TSK) fuzzy system. Considering the consequent parameters in the redundant fuzzy rules should be assigned zero values, we introduced group sparse in the GS-TSK. Specifically, a regularization term
We use the Alternating Direction Multiplier Method (ADMM) to solve the optimization problem. We reformulate (11) as the following optimization problem:
Minimizing (11) can be rewritten as:
Using the augmented Lagrangian, we have the following solution:
1. Solve for
Taking derivation of L
ρ (
Let
We have
Let
We have the solution of (19) as:
2. Solve for
The above procedure is described as follows:
The training procedure of GS-TSK includes both FCM that partition the training data into R partitions (rules), and an ADMM procedure that finds the optimal solution of
Although training GS-TSK introduces additional computation, it is an offline procedure. Moreover, the rule number is greatly reduced, which accelerate the procedure of estimating the chance of each node becoming a CH, and further improves the efficiency of CH election.
We use Algorithm 2 for node clustering on WSN. To ensure a minimum separation distance between CHs, the overall WSN area is divided into several identical rectangles, each of which only has one CH. This strategy can keep the node clusters compact. After that, the chance of each node becoming a CH is estimated by the proposed GS-TSK and CHs are elected based on the minimum separation distance. The clusters are formed by assigning each node to the nearest CH. In practice, the number of CHs and the coverage area should be determined according to the practical requirement.
Experiments
In this section, we report the experimental results of our proposed method. We first introduce the simulation settings used in our experiments in Section 4.1. After that, we report the results of GS-TSK in chance estimation in Section 4.2. In Section 4.3, we report the lifetime achieved by DD-FLC on the WSNs with different number of sensor nodes.
Simulation settings
Our experiments were conducted on the MATLAB 2022 platform. We randomly generated a simulated WSN including 300 sensors within an area of 500×500 meters, and the BS was in the center of the WSN. The residual energy of each node was assigned by a randomly generated value, and other four linguistic features including distance to BS, location suitability, density and compaction of surrounding nodes were computed for each sensor node. Each sensor communicated with the BS through the CH if the CH was determined. We assumed that all sensors had the same battery, radio, sensing, and storage capabilities. They were also homogeneous in terms of processing and communication capabilities. We also assume that BS is able to estimate the locations of the sensors by using localization techniques such as GPS or weighted centroid localization method based on the received signal strength.
In our experiments, the energy consumption of sending and receiving a k-bit message over a distance d is calculated as follows:
Parameters in simulation
In this subsection, we conduct the experiments to show the effectiveness of GS-TSK in chance estimation of each node becoming a CH. To train the GS-TSK to learn a compact fuzzy rule set, we randomly generate a training set, and used the fuzzy rules in [6] to compute the chance of each sensor node becoming a CH according to the linguistic features. These chance values were considered as the labels in training GS-TSK. After that, a GS-TSK was trained using Algorithm 1 and a compact fuzzy rule set was thus generated. In the testing procedure, the GS-TSK predict the chance of becoming a CH for each sensor node in the simulated WSN. Finally, the sensors were grouped into clusters based on the selected CHs using Algorithm 2.
The following Table 4 shows the compact rule set learned by GS-TSK on the training data, which was generated based on the 72 fuzzy rules in [6]. From the table, we observe that the number of fuzzy rules was greatly reduced compared with the original rules.
Fuzzy Rules in GS-TSK system for WSN
Fuzzy Rules in GS-TSK system for WSN
In the second part of the experiment, we evaluated the accuracy of GS-TSK in estimating the chances. We compared the prediction results of GS-TSK with SVR, ELM, OP-ELM and RBF in RRSE, which is computed as
Parameter settings of compared algorithms
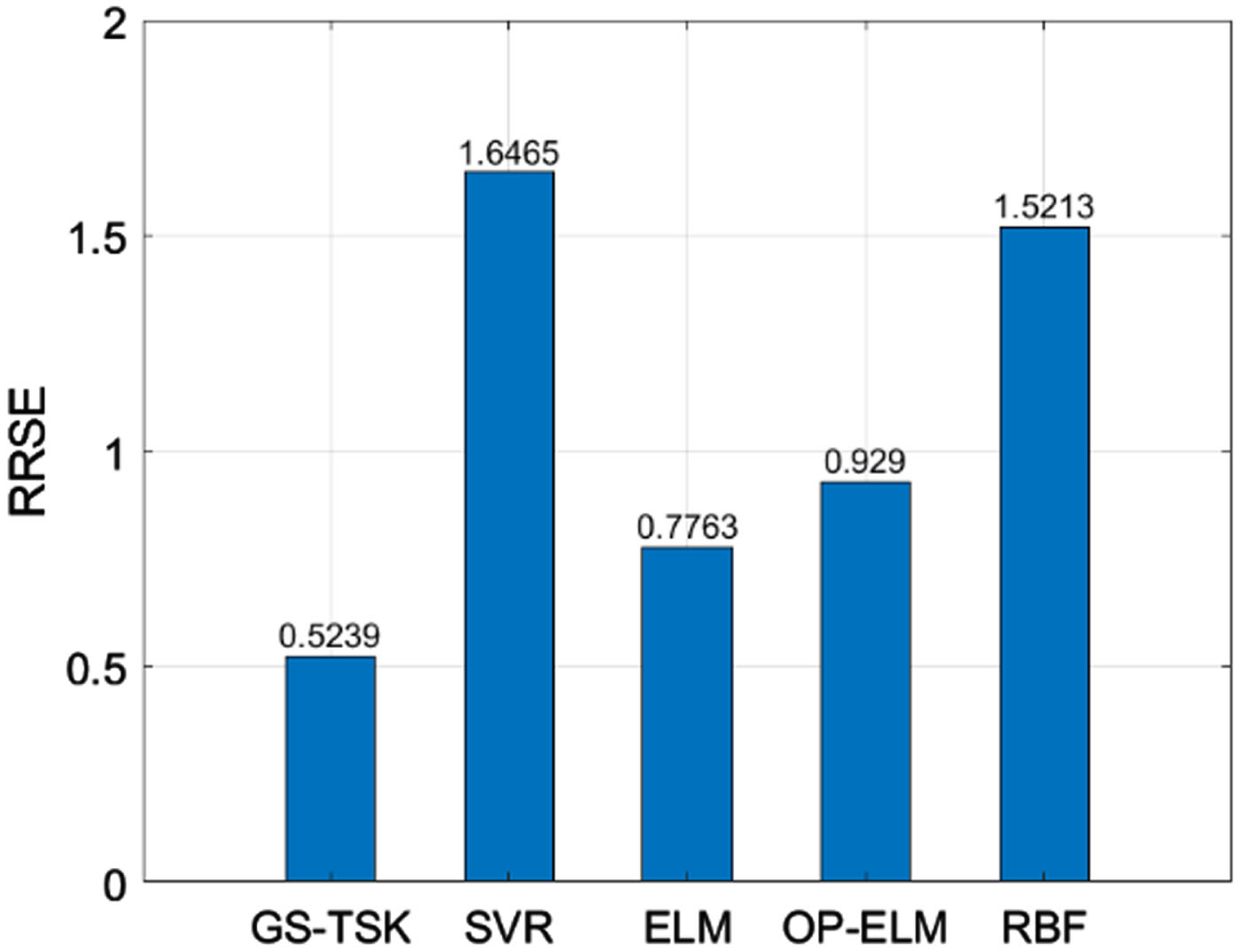
Comparison results of all algorithms.
From the results in Fig. 2, one may observe that the chances estimated by GS-TSK are more accurate than those obtained by other methods.
We further use Algorithm 2 to elect the CHs in the WSN area by using the compact rule set learned by GS-TSK. Figure 3 shows the elected CHs and Fig. 4 further shows the clustering results of DD-FLC. From Fig. 3, one may observe that all the sensor nodes are grouped into nine rectangle regions of the same sizes. The GS-TSK is performed on the sensor nodes in each region, and the nodes with the largest chance is elected as the CH of that region.
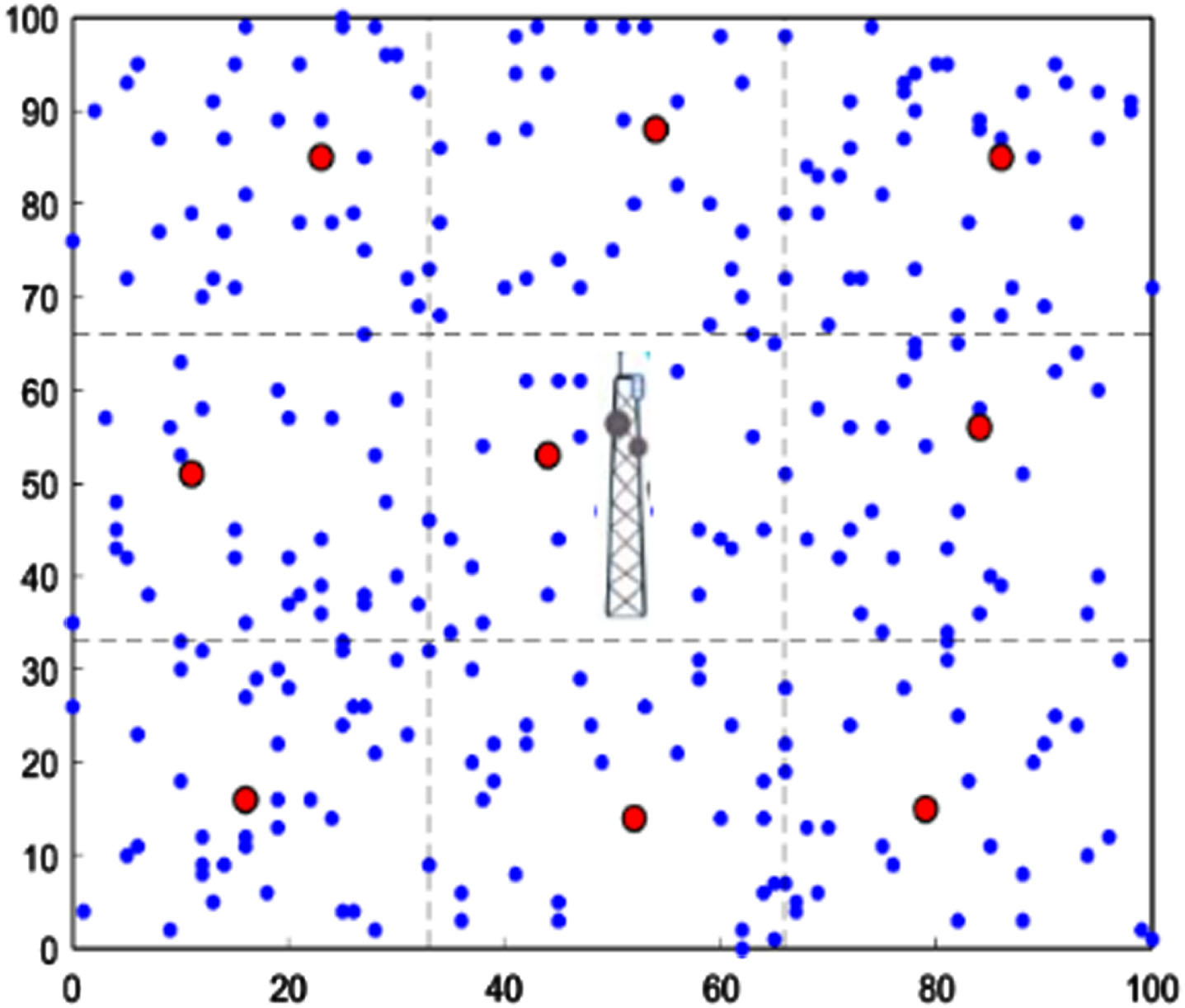
Visualization of CHs selected by GS-TSK. There are 300 sensors in WSN area. The sensors selected to be CHs are marked in red.
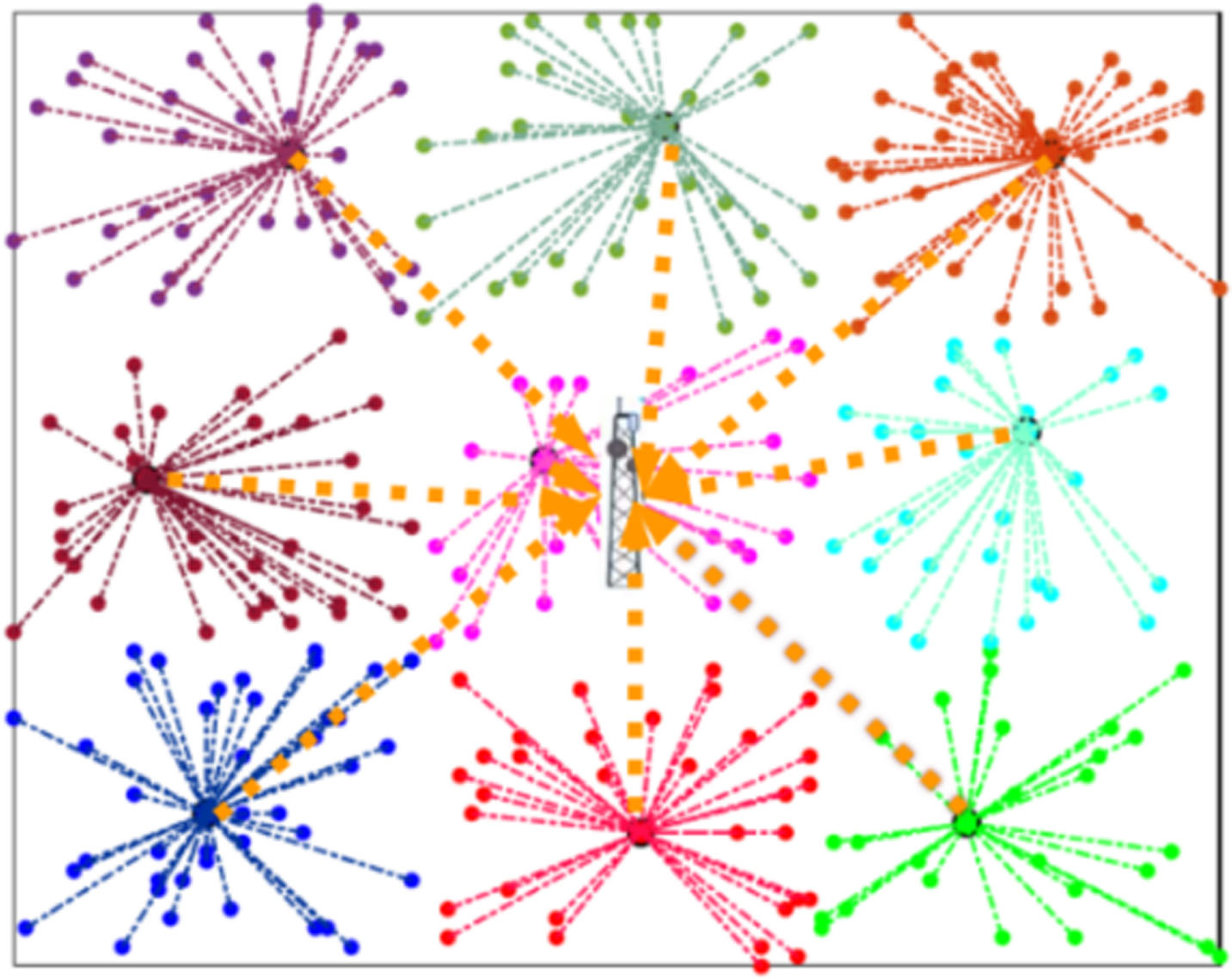
Clustering results by DD-FLC.
To verify the advantage of our method, we implemented the DD-FLC algorithm to simulate the life cycle in WSN scenarios with different number of sensors, and compared the results with classical WSN clustering algorithms LEACH [9], K-means-LEACH [33], FSEP-E [31], Leach-MF [11], and Shurman’s Approach [34]. The first dead node (FND), 10% dead node (10PND), Quarter of Nodes Dead (QND), and Half of Nodes Dead (HND) were used as the metrics to evaluate the energy balancing and network lifetime of different algorithms. Figures 5–8 presents the best results of average lifespan achieved by these methods with different number of sensor nodes.
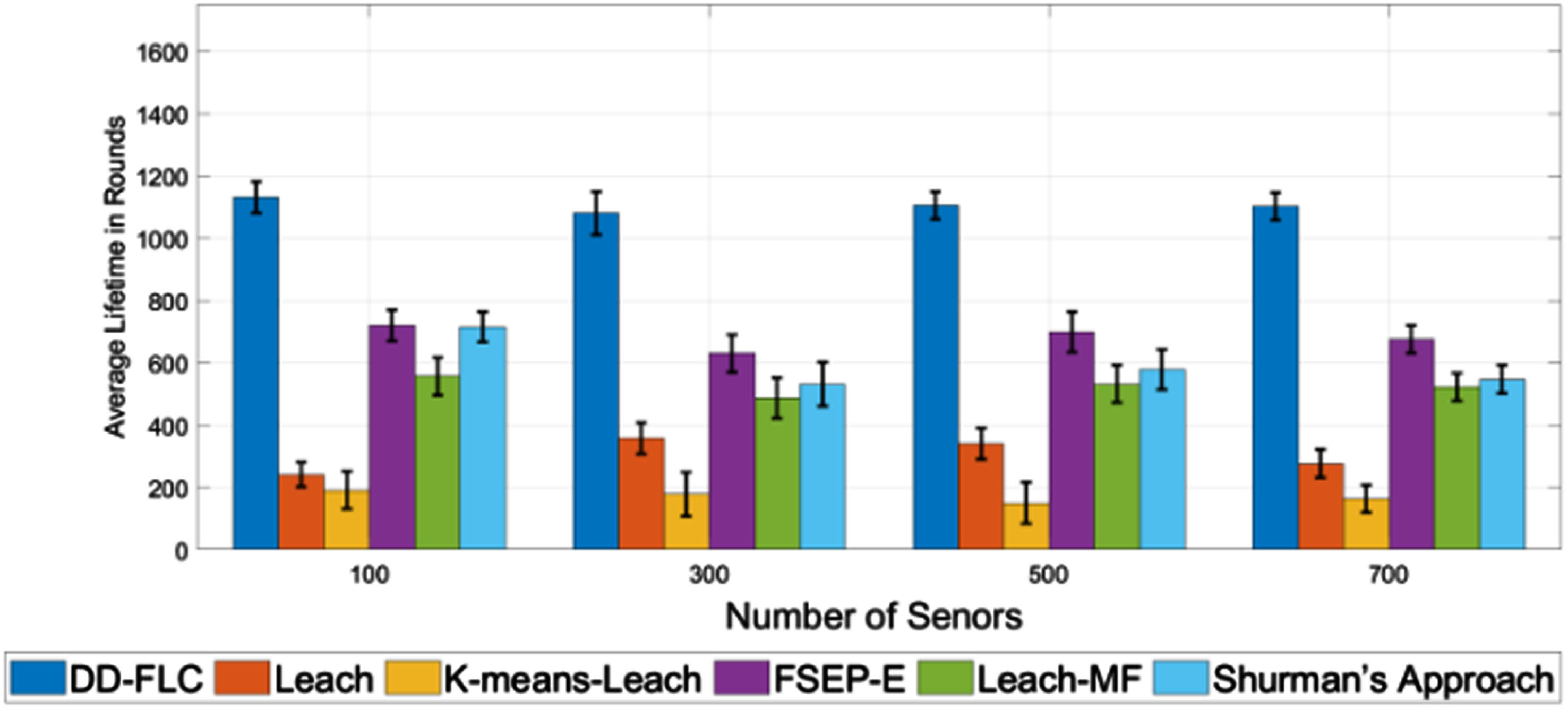
FND of DD-FLC against LEACH, K-means-LEACH (BS at the center of WSN).

10PND of DD-FLC against LEACH, K-means-LEACH (BS at the center of WSN).
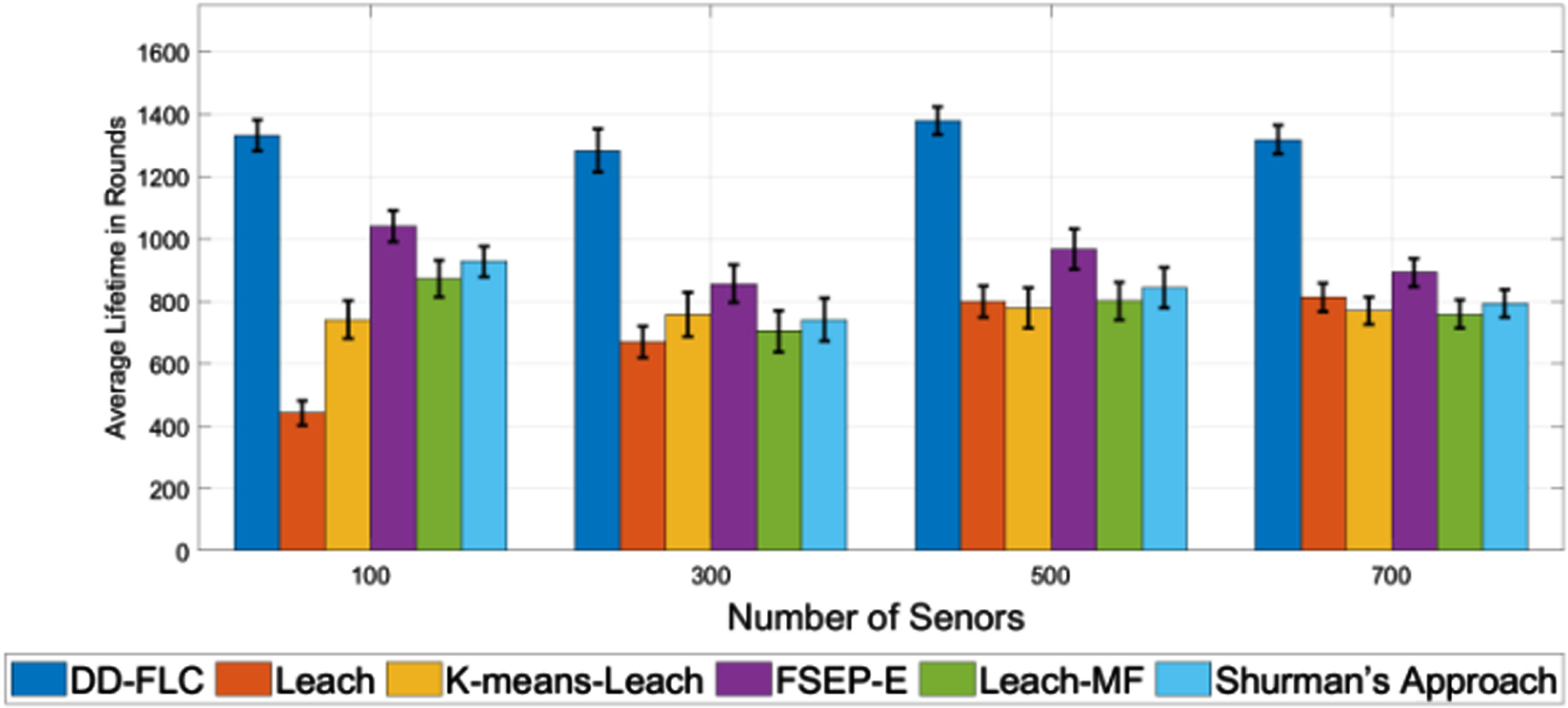
QND of DD-FLC against LEACH, K-means-LEACH (BS at the center of WSN).
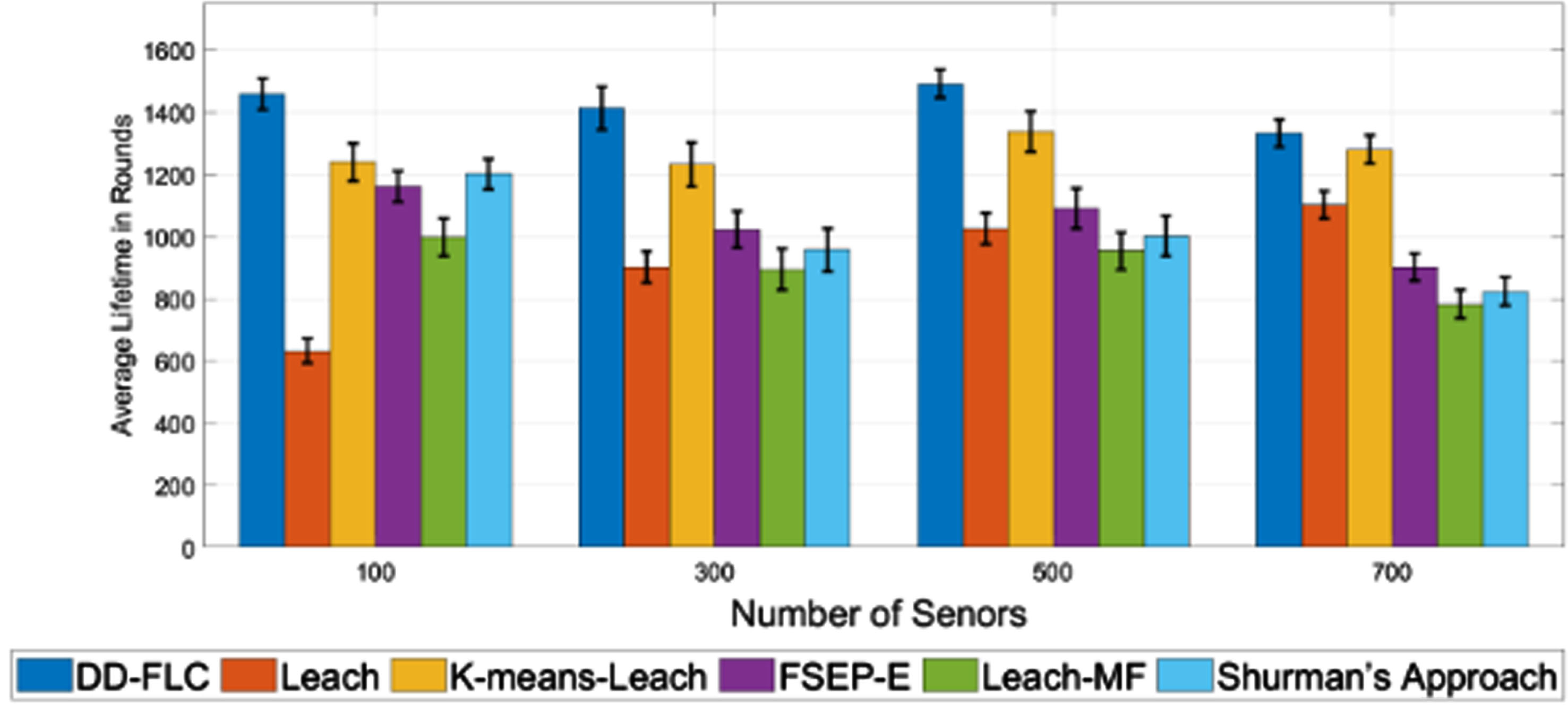
HND of DD-FLC against LEACH, K-means-LEACH (BS at the center of WSN).
From Figs. 5–8, one may observe that the proposed DD-FLC achieves a longer average network lifespan for all network sizes in terms of FND, 10PND, QND and HND. As shown in Figs. 5–8, the network lifetime achieved by DD-FLC in terms of the FND of a 100-node network is approximately 4.68 times the average value achieved by LEACH and 5.9 times the average value achieved by the K-means-LEACH. Similar observations can also be found on other metrics. Meanwhile, the proposed DD-FLC overcomes the disadvantage that most sensors die early in the life cycle. The proposed DD-FLC used remaining energy, distance to BS, density, etc. to describe each sensor node, and adopted a data-driven method to learn a compact fuzzy rule set, helping us estimate the chances of each sensor node of becoming a CH and select the most suitable CHs with fewer fuzzy rules. This modification makes the life cycle of WSN longer than those of WSNs constructed by traditional fuzzy-logic-based algorithms.
CH election plays an important role in prolonging the life cycle of the WSN. According to the attributes of sensors,fuzzy-logic can help to select nodes that are more suitable for CHs. However, most of existing fuzzy-logic-based methods were developed based on a large number of rules in rule base, leading to low-efficiency in CH election. To this end, this paper proposes an efficient CH election method based on GS-TSK. It not only reduces the number of required rules, but also obtains a high accuracy in estimating the chance of each node becoming the CH. We also develop a senor node clustering method DD-FLC based on the proposed CH election method. Experiments show that the proposed CH election method is effective. Moreover, the senor node clustering methods DD-FLC is significantly better than existing senor node clustering methods in terms of network life cycle. According to the results in Figs. 5–8, the network lifetime achieved by DD-FLC was improved by more than 40% with respect to FND, 10PND, QND and HND on a 300-node network. It not only guarantees a satisfactory accuracy of selecting CHs, but also reduces the energy consumption, which effectively solves the problems of high energy consumption and short WSN life cycle existing in traditional models.
This study aims to reduce the number of required rules in rule base using GS-TSK, which is developed based on classical TSK fuzzy systems. According to our experiments, only 7 fuzzy rules were learned by GS-TSK. This is number is much smaller than the number of the original fuzzy rules, i.e. 72 fuzzy rules in [6]. Although it may introduce extra computation overhead in learning a compact rule set, it is executed offline. Besides, the generated fuzzy rules are compact, making it more efficiency in estimating the chance of a sensor node being CH. The efficiency of the whole clustering procedure thus improves.
Although the proposed method demonstrates effectiveness in experiments, it still has some limitations. For example, the proposed method in this paper only considers WSNs in static environments, and does not consider the re-election of CHs and the charging of sensors in dynamic scenarios. Besides, this work does not consider the control packets used for the duty cycling schemes. In the case of synchronous mechanism, more control packets are required to synchronize the clock of each node. In the case of asynchronous mechanism, retransmitting packets are also required. In our future work, we will report our latest progress as soon as possible.
It is worth noting that, although the proposed GS-TSK is developed based on classical TSK fuzzy systems, this is the first trial that adaptively learns a compact set of fuzzy rules using TSK fuzzy systems for CH election in WSNs. In our future work, more advanced fuzzy systems can be developed for this task.
Footnotes
Acknowledgments
This research was supported by the State Key Laboratory of Rail Transit Engineering Informatization (FSDI) (SKLK20-10), Guangdong Basic and Applied Basic Research Foundation, Science and Technology Projects in Guangzhou.