
Abstract
This paper presents a novel decision-making method for face recognition where the features were extracted from the original image fused with its corresponding true and partial diagonal images. To extract features, we adopted the generalized two-dimensional FLD (G2DFLD) feature extraction technique. The feature vectors from a test image are given as input to neural network-based classifier. It is trained with the feature vectors of original image and diagonally fused images and thereby the merit weights with respect to different classes were generated. To address the factors that affect the face recognition accuracy and uncertainty related to raw biometric data, a fuzzy score for each of the classes is generated by treating a type-2 fuzzy set. This type-2 fuzzy set is formed by the feature vectors of both the diagonally fused training samples and the test image of the respective classes. A concluding score for each of the classes under consideration is computed by fusing complemented merit weight with the complemented fuzzy score. These class-wise concluding scores are considered in the face recognition process. In this study, the well-known face databases (AT&T, UMIST and CMU-PIE) are used to evaluate the performance of the proposed method. The experimental results illustrate the fact that the proposed method has exhibited superior classification precision as compared with other state-of-art methods. Our T2FMFImgF method achieves highest face recognition accuracies of 99.41%, 98.36% and 89.80% in case of AT&T, UMIST and CMU-PIE (with expression), respectively while for CMU-PIE (with Light) the highest recognition accuracy is 97.957%. In addition to it, the presented method is quite successful in fusing and classifying textural information from the original and partial diagonal images by integrating them with type-2 fuzzy set-based treatment.
Introduction
In most of the recent security-based application, the multi-biometric systems dominate the unimodal systems. However, the multi-biometric systems have some limitations in terms of storage, implementation cost and requirement for computation resources. Furthermore, inappropriate selection of fusion methods while amalgamating evidences from multiple biometric sensors might affect the accuracy of the multi-biometric system. Multi-biometric systems are categorized into five forms [1–5] corresponding to the nature of the source of biometric information. Multi-sensor biometric system uses more than one sensors to capture single biometric trait of an individual. The use of multiple sensors enables the acquisition of complementary information to augment the recognition accuracy. Multi-sample system counts on multiple samples educed from the same biometric acquired by a single sensor. Various samples of the same biometric trait account for the disparities that can transpire in the trait, or to reveal a more complete representation of the underlying trait. The individual results are coalesced to derive the final recognition score. The performance of the multi-sensor system relies on determining the number of samples to be acquired with variability and typicality of the individual’s biometric data. Multi-algorithm system consolidates and evaluates the outputs of various algorithms for the same biometrics data. The auxiliary information resulting from more than one algorithm helps to improve the performance. These systems are less costly as no new sensor is required but are more expensive in terms of computational time due to engagement of multiple algorithms such as feature extraction or/and classification algorithms. Multi-instance system make use of the biometric information sublimated from the multiple instances of the same body traits, for instance, the left and right index finger and iris of individuals. Multi-modal system aggregates more than one evidence of different biometric traits to resolve the identity and to improve the performance of the system. These different biometric traits can originate from a variety of modalities. These systems are reliable due to the presence of multiple independent biometric. At the same time, cost of deploying such systems is substantial because of the requirement of many sensors.
In case of biometric systems, Modak et al. [2] discuss of multi-classifiers into three types, which can further be broaden into four. Type 1: Classifier is trained by means of various training set for the patterns. Type 2: Classifier is trained by means of various feature set (e.g. Random Forest); Type 3: Classifier has multiple values for its parameters or several types of classifiers are combined. Type 4: Classifier is trained from data acquired by multiple sensors.
In the multimodal biometric system [1–3], combining the different modalities, which have been taken into consideration, is the most crucial stage. Fusion strategy can be classified into different levels depending on the type of the information meant to be fused together. It is important to decide whether the fusion should be carried out before or after the classification process. The levels included in fusion prior to classification are fusion at the sensor level and fusion at the feature level. The fusion before classification is more challenging compared to fusion after classification. Post-classification fusion scheme can be achieved either at score level or at rank level or at decision level. The simplicity of processing the match scores, ranks and individual decisions make post-classification fusions as most exploited strategies among the technical community. Because of noisy or redundant data may creep in with the raw biometric data accumulated through the sensors and extracted features may be of incompatible representation and dimension in which case its fusion might turn out to be inefficient, less sturdy [4, 5]. From the related literature study, it is evident that if the feature space is having high dimensionality then it cannot make out the distance between the pair of objects in the space. As a result, it limits the efficacy of the classifier.
Deep learning [6–11] has given a new dimension in various fields of computer vision because of the fact that it can extract distinctive features from data and has the ability to model complex relationship among data. It has been utilized in different image fusions such as pixel level image fusion [6], Face and Finger Vein fusion [7], multi-focus image fusion [8], full-resolution training framework [9]. Liu et al. demonstrated the use of convolutional neural network in addressing activity level measurement and weight assignment in infrared and visible image fusion [10]., Mustafa et al. [11] presented a multi-focus image level combination algorithm. A multi-focus color image fusion algorithm proposed by Liu et al. based on low vision image reconstruction which was focused feature extraction [12]. Sing et al. proposed Generalized Diagonal 2D FLDA for Efficient Face Recognition [13]. Ma et al. [14] suggested a two-scale multi-focus image fusion algorithm based on an enhanced random walk procedure. The convolutional sparse representation for image fusion; using Taylor Expansion is established by Xing et al. [15]. A comprehensive performance analysis of different image fusion techniques in face recognition is demonstrated by Dey et al. [16]. In [17], Aymaz et al. primarily presented the image super-resolution procedure into multi-focus image fusion. The descriptive techniques is image combination/fusion based on wavelet transform with genetic algorithm [18], 3D transform domain [19], and so on. Spatial domain-recognized techniques include image fusion built on: multi-lvel multi modal feature fusion [20], max-min filtering in high quality multi-focus image fusion [21], remote sensing image fusion [22], and multi-feature fusion procedures created on mean shift [23].
The past established works puts forth the minimum endeavour to scrutinise the concluded performance of a biometric system by operating the significant information delivered using numerous feature extraction techniques along with different fusion techniques. In this paper, we put forward an ideal methodology based on fuzzy type 2 evidence theory based decision fusion. Different feature extraction methods are employed to spawn feature vectors equivalent to a face image which are then fed to different neural network based classification. The outputs of such neural networks are considered to be as different belief factors.
In the present work, we have employed the proposed fusion method on face recognition. The proposed method is evaluated with two different classifiers –radial basis function (RBF) neural network, and support vector machines (SVM). There are 4 major steps, involved in the present research:– The aforementioned feature extraction techniques were used to obtain three feature vectors per class (subjects) from the multiple sensor data. These feature vectors are given as input to the classifiers to obtain the weights corresponding to the classes. These weights are the confidence factors with respect to each class while using a particular feature extraction technique. These confidence factors are used in rank level fusion. Corresponding to a particular feature extraction technique, the feature vectors of the top ordered classes with respect to the descending order of the confidence factors are selected from the test image. These vectors and the respective feature vectors from all training samples, yielded from the same feature extraction technique are employed to find out the Euclidian distances corresponding to each of the top ordered classes. The normalized values of the Euclidian distances are, in turn, shaped into type-2 fuzzy membership values. By applying vertical slice centroid type reduction (VSCTR), the type-reduced sets of classes are produced along with its fuzzy ranks by using Gaussian density function. For a test image under consideration, corresponding to top ordered classes, there are at most 3 sets of confidence factors and fuzzy ranks with respect to three feature extraction techniques. The top ordered classes may vary from the classifier outputs based on different feature extraction techniques. By imposing penalty in case of absence of a class in a set but present in other set(s), confidence factor sum and fuzzy rank sums are calculated for final multi-sensor multi-classifier rank level fusion. Based on the fused score, final class of the test image is selected. The workflow diagram of proposed T2FMFImgF methods discussed in Fig. 2.
Remaining part of this paper is organised as follows. Review of fuzzy type 2 and the detailed framework for proposed Type 2 fuzzy induced multi-fused facial image fusion (T2FMFI mg F) is described in Section 3. The empirical outcomes and discussion are offered in Section 4. Finally, based on the discussions, a conclusion is drawn in Section 5.

Workflow of proposed T2FMFImgF methods for face recognition.
Recently, Type-2 fuzzy logic (FL) [24–32] has been used extensively in different applications due to its phenomenal success in handling higher degrees of uncertainty. This section is dedicated to showcase the state-of-the-art applications of type-2 fuzzy logic in the area of pattern recognition. In this section we have described the advancements and precedence of type-2 over type-1 fuzzy logic from past to present [25]. The difference between the structures of type-1 over type2 lies in the form of the membership functions, which for type-2 have the FOU. Typically, the human recognition system uses three biometric measures like iris, ear and voice as inputs to make a decision on the identity of a person [26]. This problem can be viewed as decision making problem. We exploit the advantage of type-2 fuzzy logic over type-1 which can efficiently handle the inherent uncertainty due to noise, dynamic changes in the environment and imprecision in the models in recognition problem [27]. In the following we outline some of the existing works on using type-2 fuzzy logic in pattern recognition.
In recent years, fuzzy logic theory is extensively applied in the field of image processing [28, 29]. Recently, type-2 FL is applied in achieving dynamic parameter adaption in nature-inspired metaheuristics, such as in the bee colony optimization [30]. Type-2 FL can be applied to wide range of rev by determining amount of ground water and industrial and manufacturing applications [31]. Type-2 FL can be applied to many other areas, which include: monitoring, diagnosis, industrial and manufacturing operations, like control of mobile robots, induction motor working and control, engine management, turbine inlet temperature prediction, water management by determining amount of ground water [33], scheduling, segmentation, filtering and so on. On the other hand, in connection with metaheuristics, recently there have been interesting works on applying type-2 fuzzy logic in achieving dynamic parameter adaptation in nature-inspired metaheuristics, such as in the gravitational search algorithm, bee colony optimization, ant colony optimization, particle swarm optimization, and others [34, 35].
Due to their ability to handling uncertainty, fuzzy logic-based image fusion methods usually yield better performance than classical image fusion methods. The optimal membership function and fuzzy set selection is an open problem in image fusion. The effects of feature processing and analysis can be improved by combining fuzzy logic and multifarious analysis approaches. There has been increasing interest in higher order forms of fuzzy logic; in particular, the application of type-2 fuzzy logic techniques in the past two decades. For example, type-2 fuzzy logic has been successfully applied to interpolation function [32], and face recognition method based on Type 2 blurry [33]. However, they are seldom used for image fusion. Compared with traditional fuzzy logic, the membership functions in type-2 fuzzy logic are also fuzzy, and this extra degree of fuzziness allows better management of higher degrees ofuncertainty.
Material and method
This section deals with the development procedures of the proposed Type 2 Fuzzy induced multi- fused facial image fusion (T2FMFI mg F) method. Whenever we take classifiers outputs from feature vectors using different feature extraction techniques the result is found to be correct in most of the case. But when we consider more than two classifier output from the feature vector from using different feature extraction techniques, then it does not always give the expected results in all cases. That’s why we proposed our algorithm.
Main objective is to generate confidence factors of a neural network and then to apply T2FMFImgF theory obtained from two (RBFNN and SVM) neural networks, trained by different feature vectors, to get classification and recognition. In this study, we have used one feature extraction approaches generalized two-dimensional LDA (G-2DLDA) [34, 35], for facial feature extraction from face images. The G-2DLDA method maximizes class separability from both (x- and y-) directions simultaneously and found to be superior to the contemporary methods [34, 35]. We have used neural networks (radial basis function neural network (RBFNN), and support vector machines (SVM)
Review of Type 2 fuzzy sets
The fuzzy logic has already proven to be a powerful tool in business knowledge-based systems and decision support systems. The fuzzy logic systems use type-1 fuzzy sets (T1FS), which represent imprecision with numerical values in the range [0, 1]. However, the type-1 approach is not able to directly model all uncertainties and minimize their effects. Type-2 FSs was developed by Zadeh in 1975 as an extension of Type-1 FSs [24]. The main difference of Type-2 fuzzy systems (T2FS) with respect to Type-1 is the use of membership functions in which the membership is fuzzy instead of crisp.
A T2FS
which is often referred to as the point-valued representation of a T2FS [25]. The function
The ∂
x
(u)/x is the vertical slices of
Type-2 fuzzy sets are usually divided into interval type-2 fuzzy logic systems (IT2 FS) and generalized type-2 fuzzy logic systems (GT2 FLS) fuzzy sets. There are different membership functions to represent IT2 and GT2 FS; e.g., triangular, Gaussian, trapezoidal, etc. The GT2 membership function represented in 3D and this additional DOF (degree of freedom) is powerful to cope with high-level of uncertainty levels which enables to bring-out more information and provides many advantages over IT2 FS. However, The computational cost and complexity of the inference system for a GT2 FLS is high due to the defuzzification process. Vertical Slice Centroid Type-Reduction (VSCTR) is a highly intuitive method presented by Chen [26]. Mittal et al. [29] show that the type-2 fuzzy set is cut into vertical slices, each of which is defuzzified as a type-1 fuzzy set.
This section, elucidates the problems associated with the image fusion methods and represent a comprehensive performance study of three image fusion methods and its application to face recognition. Image fusion is performed among the original face image and its true/partial diagonal face images. The fundamental idea is that the human cognition process can identify a face by viewing into the horizontal, vertical and also diagonal vectors of the face image matrix. To explain the fact, three image fusion methods between the original and three diagonal (true and partial) images are discussed in [16]. Figure 1 illustrates the schematic diagram and essential stages of our method. Training images are diagonalized to obtain their true and partial diagonal images. The original and diagonal face images are combined in the forms of given below:

Case study and outcomes of Generation of five type fused image: [16].
(i) one-over-another using original and true diagonal images and (ii) one-over-another using original and partial diagonal images and (iii) side-by-side and up-and-down using original and partial diagonal images.
1) one-over-another: original image with its true diagonal image fusion
This method fuses the original and its true diagonal image as illustrated in Fig. 1 to obtain the texture information from both the original and diagonal images. However, in this process the pixel intensity values may exceed beyond the permissible limit, hence reducing the contrast of the fused image. To enhance the contrast of fused image, we adopted the method used in [16]. The resolution of horizontally and vertically fused face image are
2) one-over-another: original image with its partial (horizontal and vertical) diagonal image are fused together
The original image is fused with the horizontal partial diagonal and vertical partial diagonal image. The step-by-step procedure are illustrated in Fig. 1.
3) side-by-side and up-and-down: original image with its partial (horizontal and vertical) diagonal image fusion
Our main endavour is to obtain the textural information from the original and partial diagonal images one after another which augments the information in the original image with that of the partial diagonal image.
Figure 1 Generation of five type fused image (a): original image; (b): true diagonal image; (f): resized the true diagonal image into the size of original image; (g): resultant superimposed fused image; (h): resultant contrast enhanced superimposed fused image; (i): intermediate image; (c), (d), (e): horizontal partial diagonal image, horizontally fused image, and superimposed image respectively; (f), (g), (l): vertical partial diagonal image vertically fused image, and superimposed image respectively.
To characterize the aforementioned fact, the horizontal partial diagonal face image matrix is concatenated at the right side of the original image matrix. Likewise, the vertical partial diagonal face image matrix is concatenated at the bottom of the original image matrix, as shown in Fig. 1. The resolutions of horizontally and vertically fused face image are
This section emphasizes the step-wise description of the proposed Type 2 Fuzzy Set induced diagonally-fused facial image fusion (T2FMFImgF). The G-2DLDA technique is used to generate the feature vectors corresponding to the fused version of the original image with its true/partial diagonal images. Researchers in [34, 35] argued with the fact that efficiency of the G-2DLDA method is better than that of the contemporary methods. Two classifiers, radial basis function neural network (RBFNN), and support vector machines (SVM), are trained with the feature vectors of the merged image training sets. The workflow of proposed T2FMFImgF methods for face recognition is describes inFig. 2.
Let T and X be the feature vectors of training set and test set respectively. xi,c, c = 1, 2, 3, …… . C and ti,c, c = 1, 2, 3, …… . C, denote the feature vectors of i th test image and i th training image. For a test image x i ∈ X, the feature vectors, xi,c, j = 1, 2, 3, …… . C, are given as input to a classifier and the merit weights with respect to C classes under consideration are generated. The merit weights are denoted by ωi,c, c = 1, 2, 3, …… . C where C is the number of classes under consideration. Top u classes are selected based on the merit weights.
The merit weights of these u classes are normalised by satisfying the condition as below.
Fuzzy score corresponding to each of the classes, c ∈ u, of the test image x i are compute as follows –
There are S training samples corresponding to the class c ∈ u. The Euclidian distances, between feature vector of the class c and that of each of the training samples corresponding to class c are calculated as:
where, c ∈ u, r = 1, 2, … S
The values of
As the test image x i ∈ X is the candidate here, the merit weight of the classes may further be replaced with only ω c .
Considering the test image x
i
∈ X, a type-2 fuzzy set,
where,
It is expedient to further express
For a particular c, the 2D plane whose axes are m and
For each of the class c ∈ u of the test image x
i
, the crisp value of ∅
c
is considered as the fuzzy score, the complemented merit weight (ω
c
) is multiplied with the complemented fuzzy score (∅
c
) to yield the concluding score of the respective class.
The class with minimum fused score is considered as the class of the input image x
i
.
The performance of our decision-level fusion technique is validated by means of four publicly available face databases namely, AT&T [38], UMIST [39], and CMU PIE [40]. The AT&T database is focuses on minor variations of pose and scaling. The UMIST database provides face images with larger variation in pose. This procedure is implemented in C on the Linux operating system installed in computer with Intel Core i5 (2.4 GHz) processor and 64 GB DDR3 RAM. We have compared the performance of the proposed method using diagonal feature extraction techniques based on FLD method Dia FLD [20, 54], G-Dia2DFLD [54] and two different neural networks (RBFNN [34, 35], and SVM [36, 37]). In addition to it, we have compared our method with the recent state-of-the-art fusion methods such as, (i) Partial diagonal image superimposed with original image [16] (ii) Partial diagonal image placed horizontal and vertical with original image [16] (iii) True diagonal image superimposed with originalimage [16].
In
Summarization of recently proposed multi-modalities feature-level fusion techniques
Summarization of recently proposed multi-modalities feature-level fusion techniques
Figure 3 shows an example for an image of class 18 where the feature vectors are extracted by means of G-2DLDA method and classification is done by RBFNN. We considered top k (k = 5) ranks in case of G-2DLDA based feature vectors. The score of “Class 12” for the proposed method, the class wise weight using T2FS is 0.726 and the normalized confidence factor (CF) is 0.372 and fused score is 0.270 whereas the calculations for the score of “Class 18” for the proposed method the class wise weight using T2FS is 0.744 and the normalized confidence factor (CF) is 0.368 and fused score is 0.274, whereas if we consider only output value then class 12 is selected. The T2FS based fused score outcomes show in the proposed method correctly recognizes the image; as it truly recognizes it as “class 18”.
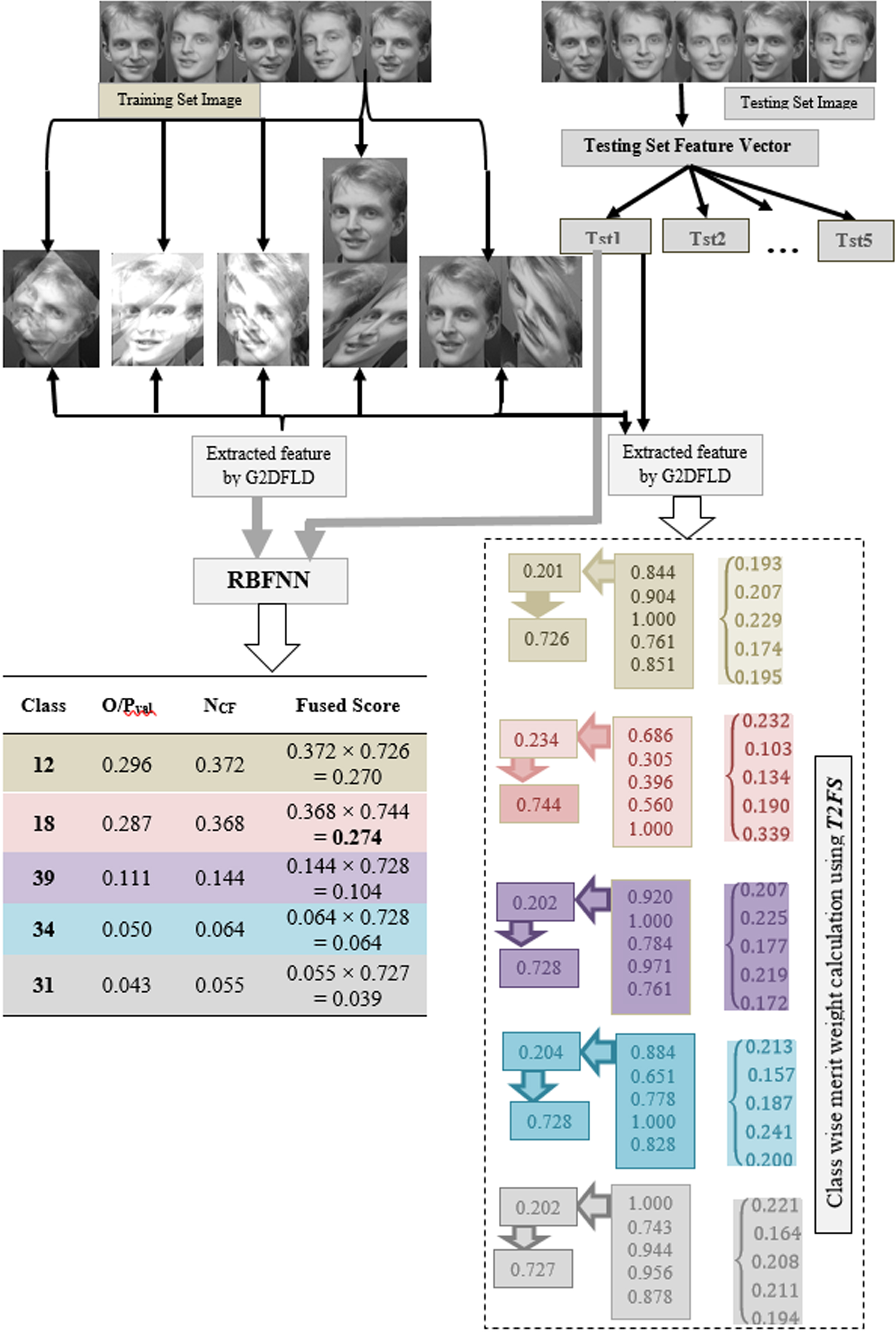
Case study and outcomes of proposed T2FMFI mg F methods for face recognition.
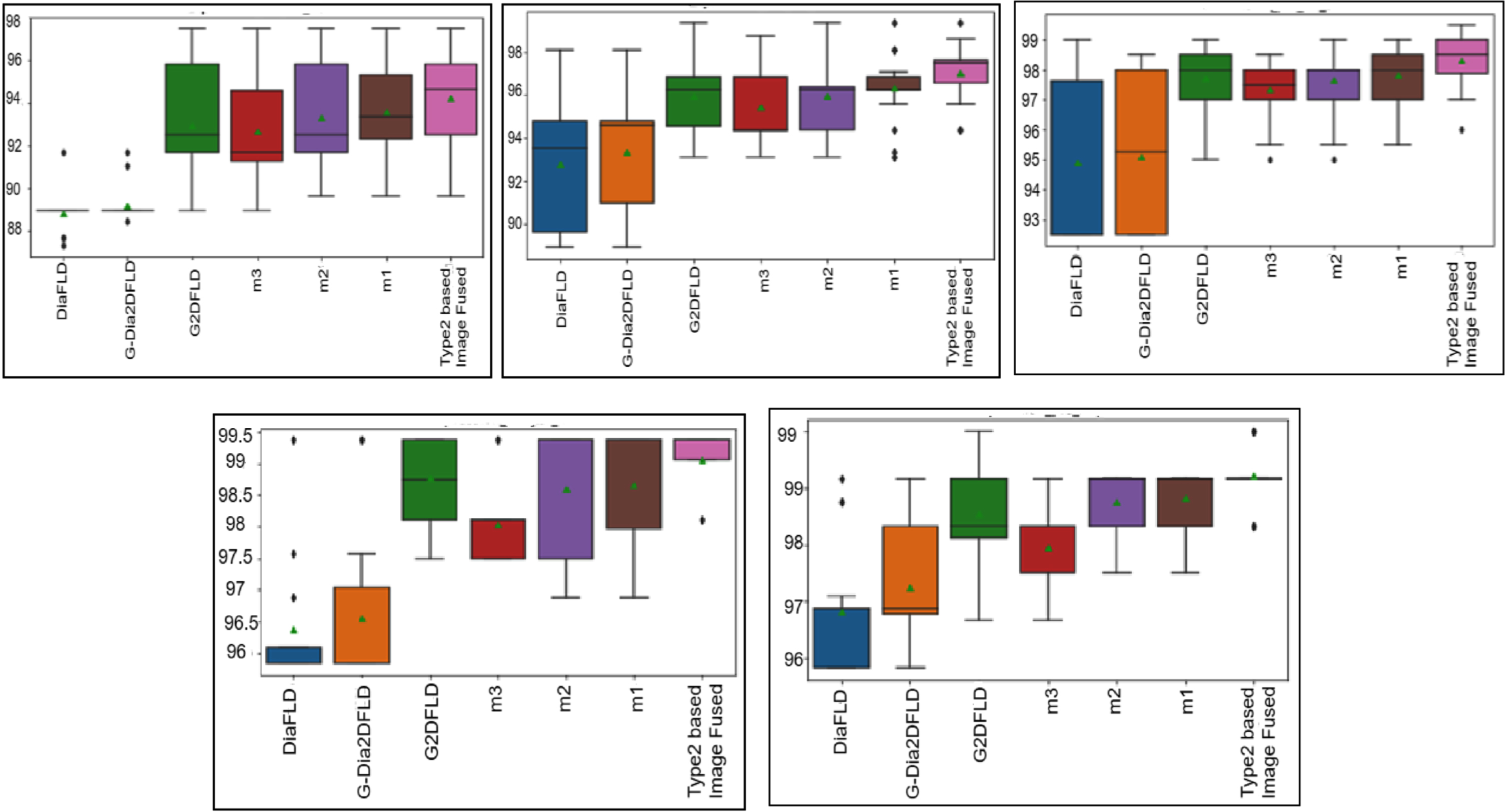
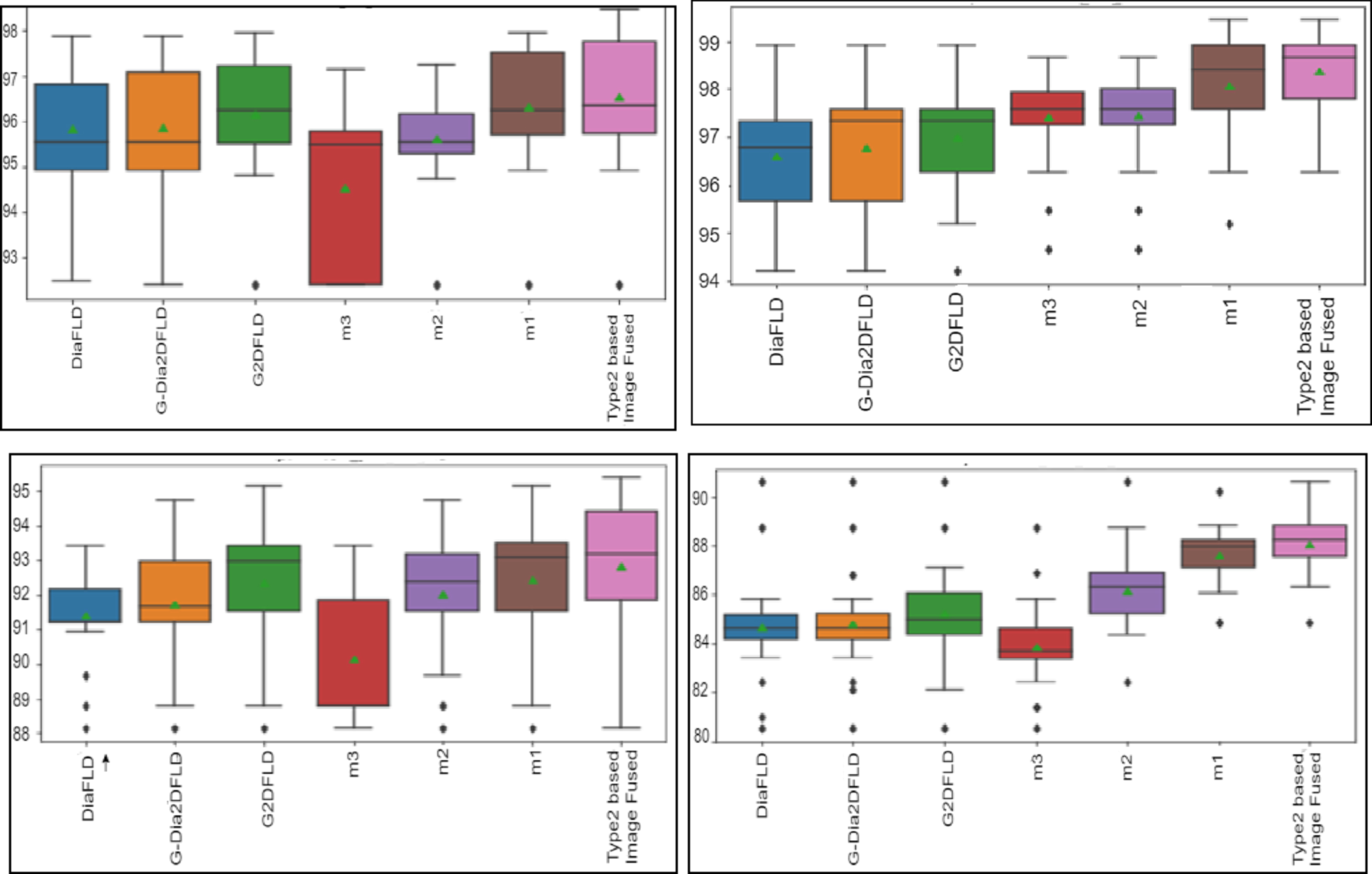
To validate the performance and capability of T2FMFImgF method, we have performed statistical significance test by calculating paired t-test (one tailed method) between T2FMFImgF method and all other related competitive methods in terms of p-value on all the datasets presented above. In this context, the null hypothesis (H0) is defined as: ‘the average recognition rate of our T2FMFImgF method is same as the compared method’ against the alternative hypothesis (H1) as: ‘the average recognition rate of T2FMFImgF method is higher than the related method’. The relative box plots were shown in Figs. 4–11 to understand the spread and skewness of the data.
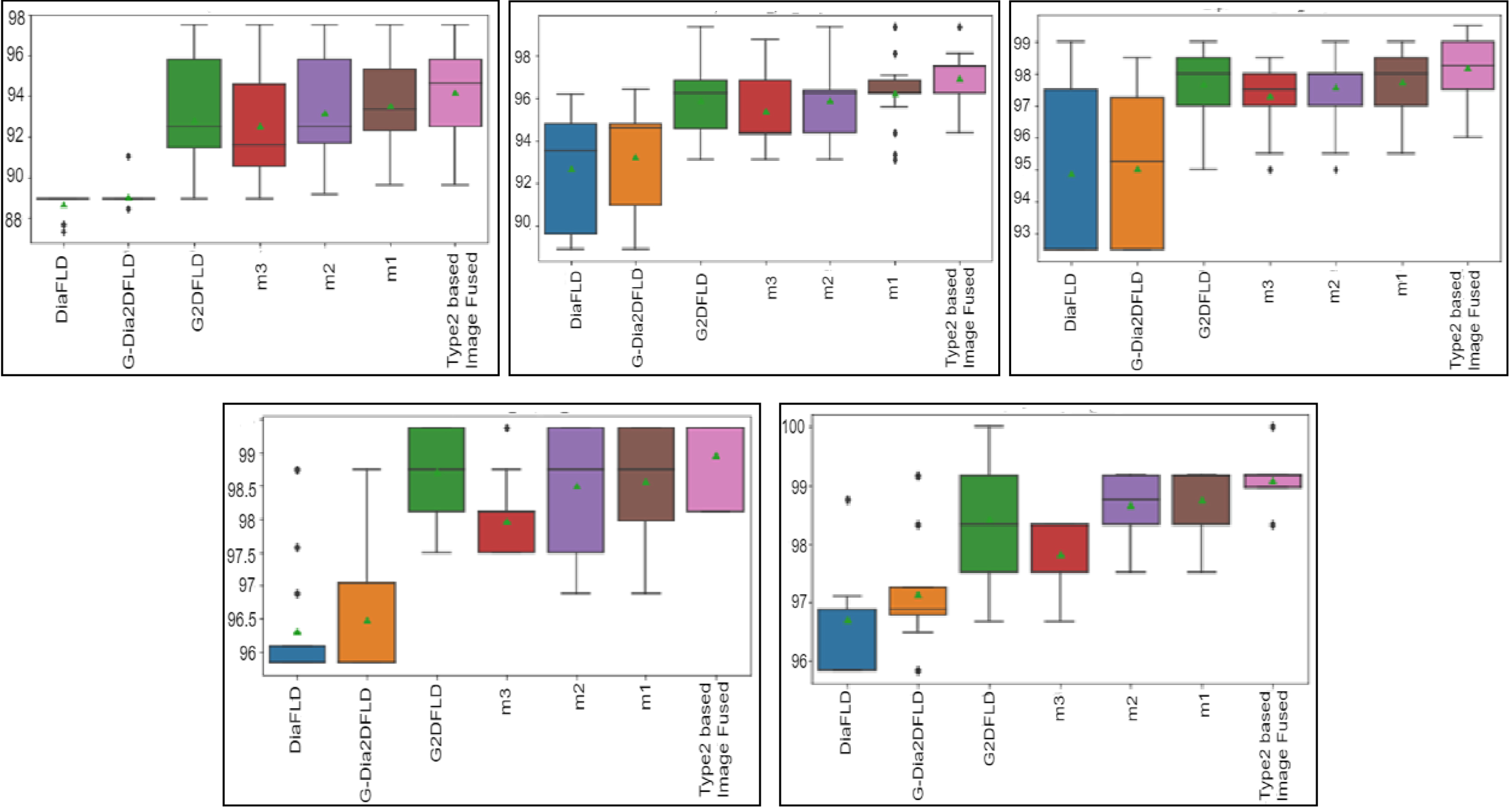
Box plots displaying range of face recognition scores T2FMFImgF other state-of-the-art methods using RBFNN classifier on the AT&T face dataset (Boxes signify interquartile range (IQR) and whiskers describe maximum and minimum values).
Box plots displaying range of face recognition scores T2FMFImgF other state-of-the-art methods using SVM classifier on the AT&T face dataset (Boxes signify interquartile range (IQR) and whiskers describe maximum and minimum values).

Box plots displaying range of face recognition scores T2FMFImgF other state-of-the-art methods using RBFNN classifier on the UMIST face dataset (Boxes signify interquartile range (IQR) and whiskers describe maximum and minimum values).
Box plots displaying range of face recognition scores T2FMFImgF other state-of-the-art methods using SVM classifier on the UMIST face dataset (Boxes signify interquartile range (IQR) and whiskers describe maximum and minimum values).

Box plots displaying range of face recognition scores T2FMFImgF other state-of-the-art methods using SVM classifier on the CMU-PIE-Expression face dataset (Boxes signify interquartile range (IQR) and whiskers describe maximum and minimum values).

Box plots displaying range of face recognition scores T2FMFImgF other state-of-the-art methods using RBFNN classifier on the CMU-PIE-Expression face dataset (Boxes signify interquartile range (IQR) and whiskers describe maximum and minimum values).

Box plots displaying range of face recognition scores T2FMFImgF other state-of-the-art methods using RBFNN classifier on the CMU-PIE-Light face dataset (Boxes signify interquartile range (IQR) and whiskers describe maximum and minimum values).

Box plots displaying range of face recognition scores T2FMFImgF other state-of-the-art methods using SVM classifier on the CMU-PIE-Light face dataset (Boxes signify interquartile range (IQR) and whiskers describe maximum and minimum values).
To evaluate the performance of the suggested technique, we have compared the outcomes with state-of arts methods on three face databases in Tables 2 (AT&T), 3 (UMIST), 4 and 5 (CMU-PIE). The empirical outcome stated in the table represents the average of the 20 replication runs for each value of p (total of individuals in the training set). In this environment, we can achieve that the suggested method has the highest average recognition rates in all the cases. Moreover, the results reported in Tables 2, 3, 4 and 5 clarifies that the T2FMFImgF technique outperforms the classical methods in all cases. We can conclude from the results reported in aforementioned tables that T2FMFImgF with SVM yields better performance across databases for all sets (p). More precisely, our method achieved highest recognition accuracies of 99.41% (p = 7), 98.36% (p = 10) and 89.80% (p = 20) in case of AT&T, UMIST and CMU-PIE (with expression), respectively while for CMU-PIE (with Light) the highest recognition accuracy is 97.957% (p = 20). The results are reported in Table 2(AT&T), 3 (UMIST), 4 and 5 (CMU-PIE) which validates that our T2FMFImgF method is statistically significant over the state-of-arts methods at p < 0.05 (5% level of significance). We are extending this work which will allow us to recognize face from video sequences.
Performance evaluation of contemporary methods on the AT&T face database
Performance evaluation of contemporary methods on the UMIST face database
Case Study of state of art methods on the CMU-PIE (with expression) face database
Case Study of state of art methods on the CMU-PIE (with Light) face database
In the proposed method, T2FMFImgF, multiple fused face image with one feature extraction technique, G2DFLD [34], along with two neural network RBFNN [34, 35], SVM [36, 37] are employed. Faces from well-known face databases (AT&T, UMIST, CMU-PIE) are used to evaluate our model against individual feature extraction methods and interrelated fusion methods. It has been observed that the proposed method, T2FMFImgF achieved supremacy in terms of accuracy and stability of the image-level fusion. More specifically the following conclusions may be drawn from the results reported in this manuscript: The prediction results from the T2FMFImgF, model is quite successful to exhibit the classification precision despite of the variations in pose, occlusion and illumination. By employing a type-2 fuzzy set based treatment, T2FMFImgF is effective to deal with the uncertainty and variability caused by the factors that pretend the face recognition accuracy. It has the ability to synthesize highly conflicted classification results in fusing and classifying textural evidence from the original and partial diagonal facial images integrated with type-2 fuzzy set based treatment.
Indeed, there is a scope of improvement to explore the predictive effect of multi-fused image in real situation with true labels. In that case, type-2 fuzzy logic system can be applied to greater extent in order to deal with the factors that pretend the face recognition.
Conflict of interest
The authors declare that they have no conflict of interest.
Data availability
All data analysed are included in this paper.