
Abstract
Self-driving cars are expected to replace human drivers shortly, bringing significant benefits to society. However, they have faced opposition from various organizations that argue it is challenging to respond to instances involving unavoidable personal injury. In situations involving deadly collisions, self-driving cars must make decisions that balance life and death. This paper investigates the ethical and moral decision-making challenges for self-driving cars from an algorithmic perspective. To address this issue, we introduce the accident-prioritized replay mechanism to the Deep Q-Networks (DQN) algorithm based on early humanities research. The mechanism quantifies a reward function that takes priority into account. RGB (red, green, blue) images obtained by the camera installed in front of the self-driving cars are fed into the Xception network for training. To evaluate our approach, we compare it to the conventional DQN algorithm. The simulation results indicate that the Rawlsian DQN algorithm has superior stability and interpretability in decision-making. Furthermore, the majority of respondents to our survey accept the final decision made by our algorithm. Our experiment demonstrates that it is possible to incorporate ethical considerations into self-driving car decision-making, providing a solution for rational decision-making in emergency and dilemma circumstances.
Keywords
Introduction
With the rapid development of automatic control, artificial intelligence (AI), computer vision, wireless communication, and many other technologies, self-driving cars have been feasible from an engineering perspective [1]. The potential benefits of self-driving cars are immense, including improved road efficiency, reduced traffic accidents, increased productivity, and minimized environmental impact. Given these advantages, various studies have estimated that the market demand for self-driving cars is expected to grow at a compound annual rate of 53.6% from 2022 to 2030 [2]. This projected growth is driving companies to expand the production of self-driving cars by utilizing technological improvements, such as adaptive algorithms, sensor processing, high-definition mapping, and enhanced infrastructure.
Current research primarily focuses on advanced decision-making and perception systems technology. Hsu and Chen proposed a dynamic vehicle prediction system that comprises a sensor fusion system and a vehicle recognition system [3]. Goodall presented a three-stage algorithm to enhance the collision algorithm [4]. Meanwhile, Liu et al. suggested a perception system for self-driving cars based on a 3D projection model [5]. Additionally, Lefebvre and Ambellouis introduced a primitive joint obstacle detection and tracking method that uses a mean shift algorithm and a semi-dense disparity map [6].
Self-driving technology has brought about significant progress, yet there are still dilemmas associated with its development. These dilemmas primarily include cognitive and ethical concerns. A survey conducted by Kyriakidis revealed that users express heightened apprehension regarding safety, economy, and legal issues concerning self-driving cars [7]. In the present scenario, only about 40% of users are willing to invest in self-driving cars [8]. Hence, it is essential to resolve conflicts when self-driving cars face different dilemma scenarios. In that case, the moral decision-making problem has to be considered for the further prosperity of the self-driving industry.
One solution to the ethical dilemma in self-driving cars is to use machine learning for intelligent decision-making and driving behavior planning. Machine learning has a wide range of applications in various fields, including image recognition [9], path-tracking [10], talent growth [11], disease treatment[12], drug development [13], etc. The ethical decision-making schemes for self-driving cars must comply with popular perceptions to encourage widespread acceptance of these cars [14]. However, most of the existing studies only propose ethical decision theories and give less consideration to the implementation of decision schemes. Furthermore, many of the decision theories have inherent flaws. In this paper, we have chosen the Rawlsian maximin principle for designing reward functions and have combined it with the empirical preferential replay theory. Moreover, we developed the Rawlsian Deep Q-Network(DQN) algorithm for simulation and compared the simulated decision outcomes with publicly acceptable results to validate the feasibility of the proposed scheme. The main study framework of this paper is shown in Fig. 1.
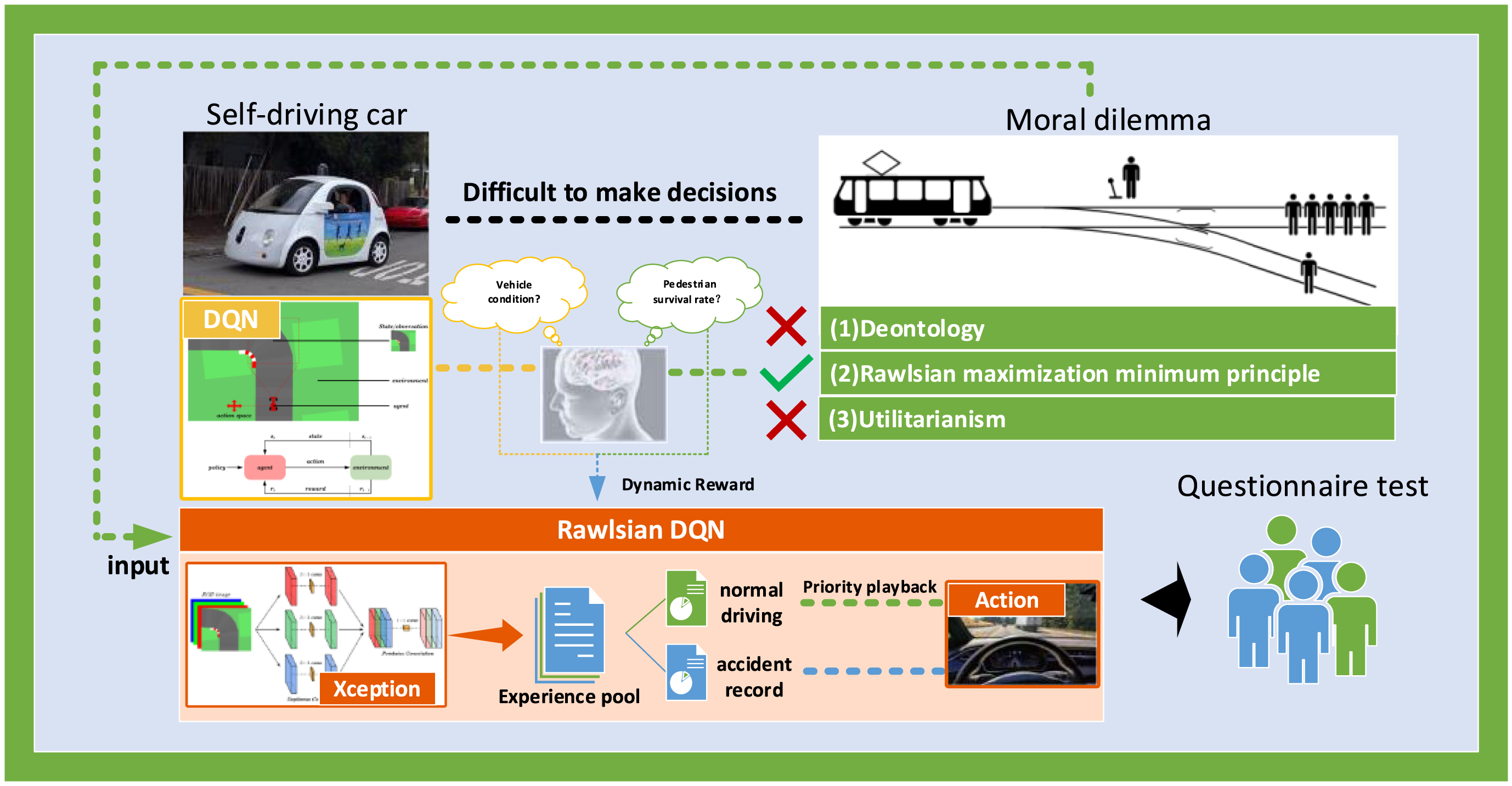
The study idea and technical framework of this paper.
The primary contributions of this paper are summarized as follows: We propose a unique combination of deep reinforcement learning with moral and ethical decision-making. This approach combines the Rawlsian maximin principle with the DQN algorithm to avoid the moral issue of deontology, which tends to prioritize strict adherence to specific rules over the complexity of the situation. Furthermore, it overcomes the problem of unfairness that utilitarianism creates. The validity of the questionnaire analysis was made and the corresponding results were cross-validated with the outcomes of self-driving decision-making under deep reinforcement learning. This approach confirms the credibility of our novel ethical decision-making solution for self-driving cars.
The paper is organized as follows: Section 2 presents a review of the relevant literature, while Section 3 provides a detailed problem description. Section 4 states the details of our Rawlsian DQN algorithm. And the performance of the proposed algorithm through computational experiments is validated in Section 5. Furthermore, Section 6 details a real-world questionnaire test for cross-validating our algorithm. Finally, a summary of our findings and potential future research directions were made in Section 7.
With the development of society and self-driving car technology, the safety of self-driving technology has now surpassed that of manual driving. However, it still faces ethical decision problems [15], such as the decision choice in the face of the trolley dilemma. Making self-driving cars the subject of decision-making is more acceptable to the public [16]. The moral decision problem can be solved by using scenario planning, which helps developers build moral decision mechanisms for self-driving cars. The mainstream approach is to integrate philosophy and technology to study the moral decision problem of self-driving cars [17].
Table 1 conducts a comparative analysis of the existing decision-making approaches with machine learning. Here are three main academic theories of ethical decision-making: deontology, utilitarianism, and the Rawlsian maximin principle. From a deontological perspective, self-driving cars follow previously established “specific rules” to confront decision problems under moral dilemmas, which emphasizes the rule of reason. The “specific rules” method is technically easy to implement, but it cannot capture the complexity of real moral dilemmas, which can result in irrational behavior. From a utilitarian perspective, the decision-making of self-driving cars is aligned with the direction of the optimal outcome. Although this theory ensures the maximization of group interests, it may also lead to behaviors that sacrifice fairness [4]. The Rawlsian maximin principle makes decisions by maximizing the worst possible outcome [18], which promotes both parties to reach the Pareto optimal state. From a practical perspective, it considers the complexity of the environment without sacrificing fairness. However, this theory requires evaluating the payoffs under various mechanisms, which makes it more difficult to implement [19].
Comparison of the existing methods related to ethical decision-making
Comparison of the existing methods related to ethical decision-making
Deontology adopts an ethical knob with two sides representing “egoism” and “altruism”, respectively, allowing the individual to decide on the decision option [20]. Utilitarianism uses dynamics to evaluate the loss of multiple options for the self-driving car in the current situation to generate a decision [21], represented by the “dynamics algorithm”. Nevertheless, the complexity of the decision scenarios, the incompatibility of egoism and altruism, and the differences in ethical concepts make it impossible to obtain a uniform ethical decision solution.
The Rawlsian maximin principle stands out among current ethical decision-making theories due to its approach of maximizing the worst gain, which takes into account the complexity of moral-ethical dilemmas and promotes both survival rate and fairness to reach the Pareto optimal state. However, it is important to clarify how different actions are evaluated when applying this principle [22]. Additionally, Chandak et al. proposed a two-stage algorithm to address ethical and moral issues in self-driving cars, highlighting the potential use of deep reinforcement learning as a technical means to tackle the ethical decision problem [23]. Despite these efforts, the complexity of decision scenarios, the incompatibility of egoism and altruism, and differences in ethical concepts still make it challenging to find a uniform ethical decision solution.
Previously, deep reinforcement learning-based self-driving car research mainly focused on designing reward values based on rational judgments, without integrating ethical decision-making issues with the technology. However, in recent years, there has been a growing interest in the humanities of self-driving cars, and researchers have started to consider the rationality of the technology’s actions during training [17]. On one hand, researchers have been working on newer and faster neural network algorithms to improve the safety and comfort of self-driving cars. For instance, Du et al. proposed a vehicle control algorithm based on safety constraints to make decision-making more stable by applying reasonable constraints during training [24]. Cervera-Uribe used code-decode networks in deep learning to improve in-vehicle systems’ reaction to the driving environment and possible collisions between the driver and obstacles, increasing the speed of vehicle recognition of road conditions [25]. On the other hand, researchers have been exploring better road condition capture technology to enable self-driving cars to analyze road conditions as humans do. Additionally, they have been delving deeper into the connection between manual driving and self-driving. Duan et al. used a hierarchical reinforcement learning approach to study lane change and approach strategies for self-driving cars, demonstrating that deep reinforcement learning can achieve smooth and safe decision-making [26]. Maqueda et al. combined event cameras with deep reinforcement learning to achieve smooth steering prediction of self-driving cars, showing that deep convolutional neural networks can enable the prediction and control of vehicle motion parameters [27]. Kim and Canny introduced attention models into convolutional neural networks to produce a more concise visual interpretation and more accurate exposure of the network’s behavior, providing causal cues between neural networks and human driving for various features [28].
Currently, researchers are exploring models that combine global optimization of the road with local vehicle decision-making. In this regard, Chen et al. proposed a self-driving obstacle avoidance strategy that combines path planning and reinforcement learning [29]. The strategy involves first planning the global optimal path using global information and then combining the globally optimal path and vehicle information as input into a reinforcement learning neural network. The output of the network is a vehicle control signal that follows the optimal path while avoiding obstacles. This approach shows promise in achieving both safe and efficient self-driving.
However, the guidelines for training in these works are often based solely on the rational judgment of the researcher and lack integration with socio-ethical knowledge. As a result, there is a need to develop reasonable criteria for training ethical decision-making in self-driving cars from a social human ethics perspective and to subject the results to testing by the public. This paper proposes the use of the Rawlsian maximin principle as a decision theory for driverless cars. The feasibility of this principle is verified by combining it with the kinetic principle to design the agent’s reward function in deep reinforcement learning. To train the agent, an accident priority replay mechanism is used, and the decision results of self-driving cars in different ethical and moral environments are obtained.
This paper considers how to make a reasonable decision in the face of a dilemma that a self-driving car may encounter when it is out of control. From an ethical perspective, we explore the crisis decision of whether to crash into a passerby and save the owner or take other actions based on deep reinforcement learning. To study its decisions, we constructed a local environment, as shown in Fig. 2.
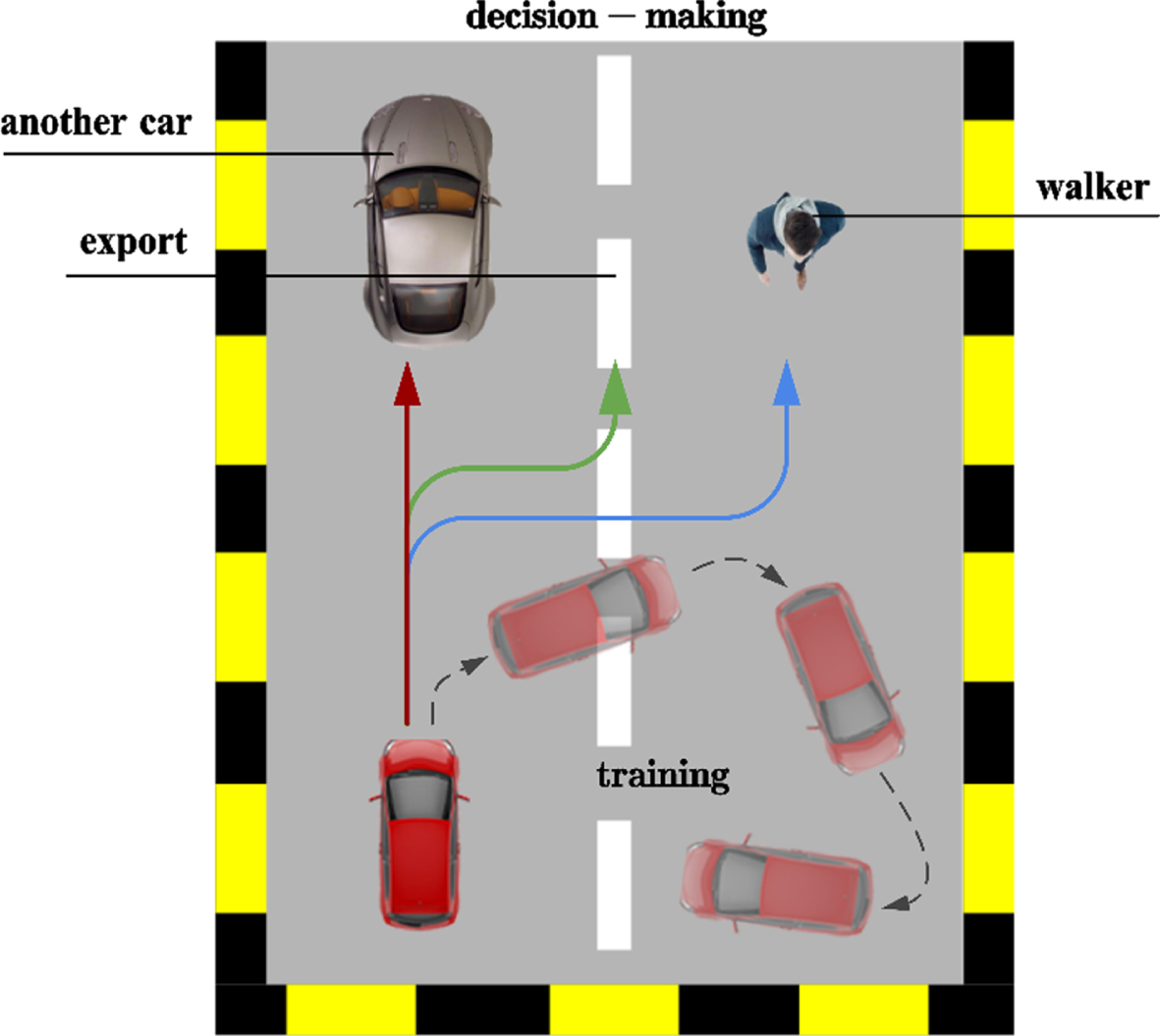
Local environment for self-driving car.
In the local environment previously mentioned, a simulated “junction” setting is used to test self-driving cars’ decision-making abilities. This scenario requires the car to choose between hitting a person or a car while traveling a certain distance. To make an informed decision, self-driving cars must consider both external environmental factors, such as speed and distance, and internal moral factors. Balancing the importance of these factors is crucial to prevent moral dilemmas, such as sacrificing an innocent person to save a group of criminals. The paper aims to determine how self-driving cars can make decisions that promote both fairness and survival rates, achieving the Pareto optimal state. Ultimately, the study aims to determine whether a self-driving car with ethical considerations can produce a “satisfactory solution” accepted by society. The final decision solution is compared with social statistics, and its applicability to other environments is evaluated.
Markov decision-making process
Here, we abstract the out-of-control car as an agent and study its decision-making process in the face of ethical dilemmas. The decision of the car can be regarded as a Markov decision process, where the quintuple < S,A,P,R,γ>is used to represent the state space, action space, transition probabilities, reward function, and discount factor, respectively. These elements are explained in detail in Table 2.
The elements of the Markov process
The elements of the Markov process
The Markov decision model employed in this study is depicted in Fig. 3, which outlines the potential state transitions of a self-driving car as it navigates its motion space. Under normal conditions, the car’s state can take on nearly infinite possible values, represented by the blue circle in the Fig. 3. However, in the event of a traffic accident, the model designates it as an absorbing state, requiring the self-driving car to learn from the collision with another object. By utilizing this Markov decision model, the self-driving car can make informed decisions based on its current state and the potential future states it may transition to, enabling it to navigate complex environments and handle unexpected scenarios.
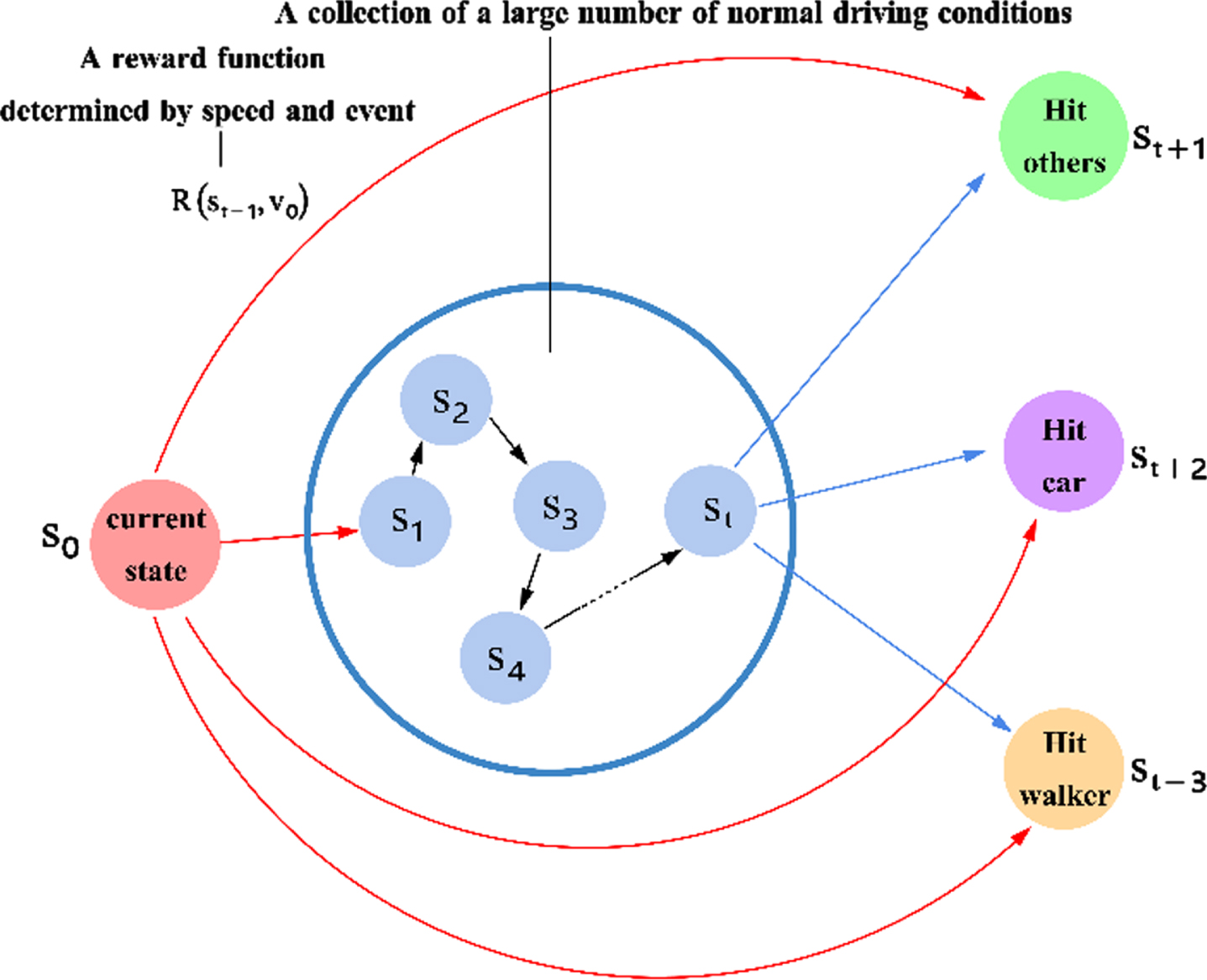
Markov decision model for self-driving cars.
Unlike conventional deep reinforcement learning methods, the control of self-driving cars involves continuous and real-time decision-making. To achieve this in our study, we make use of the “throttle” and “steer” functions within the Carla environment, ensuring that the model can make decisions in real time and avoiding instances where it defers decision-making, which could negatively impact convergence. To represent the car’s actions, we encode them as 0, 1, or 2, corresponding to the “throttle,” “steer left,” and “steer right” functions, respectively. This approach allows for precise adjustments to the car’s speed and direction, enabling it to navigate complex environments. We represent the Markov decision action space of the out-of-control vehicle using Equation (1).
The parameter “steer” controls the driving direction within the environment, allowing for the continuous control of the self-driving car’s movements in a single training cycle.
Reinforcement learning is centered on discovering the optimal solution without receiving explicit feedback on the correctness of each action until the end. The objective of an agent in reinforcement learning is to maximize the cumulative reward in each epoch through continuous exploration. In our study, we implement reinforcement learning for the self-driving car, as depicted in Fig. 4. This enables the car to learn from its actions and modify its behavior accordingly. By maximizing the cumulative reward over time, the car can make informed decisions that strike a balance between safety and efficiency.
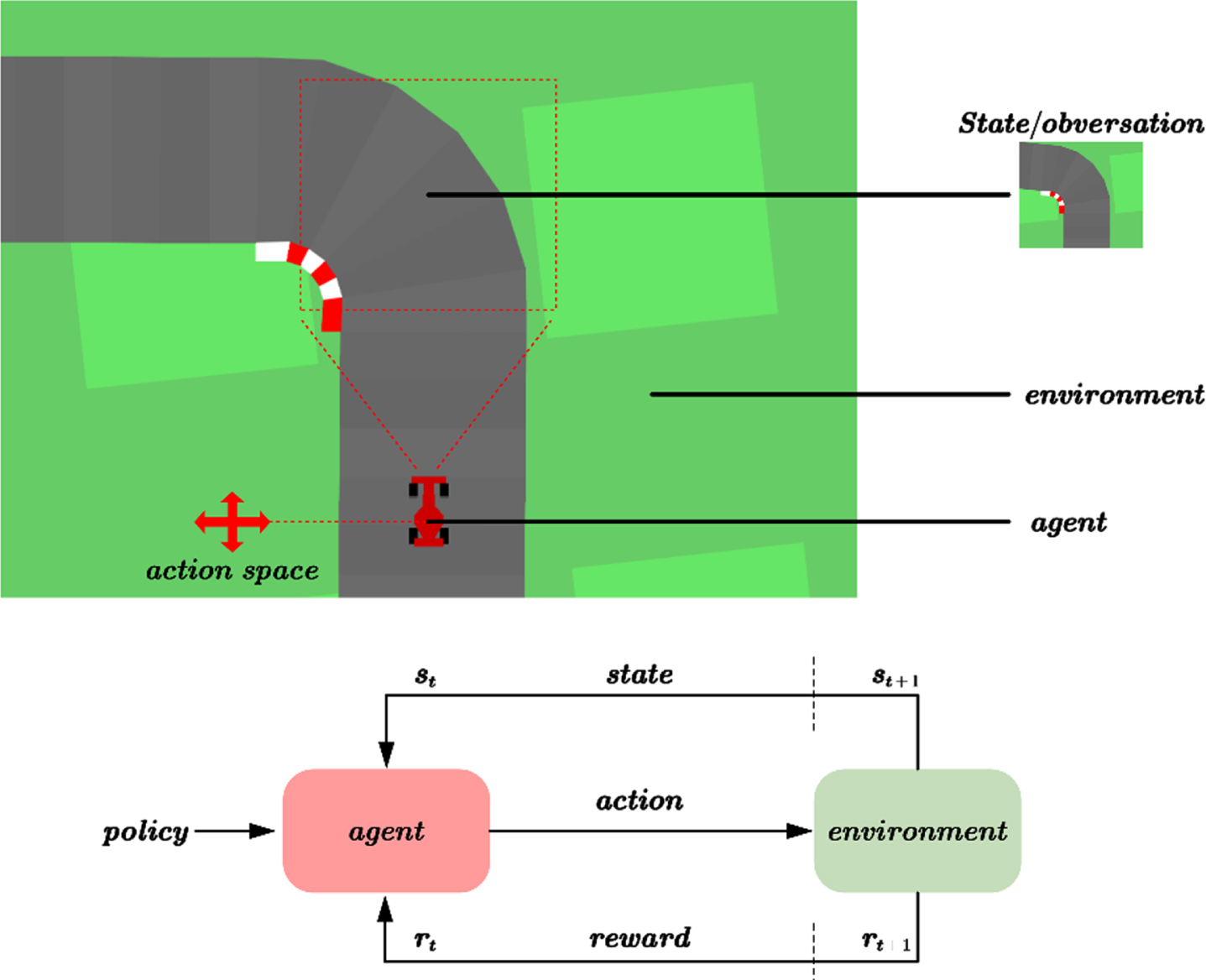
Self-driving car reinforcement learning architecture.
The Q-learning algorithm in reinforcement learning takes into account all possible behavioral pathways. In the self-driving car, the “speed” and “direction” features are used to define the decision-making model for the out-of-control vehicle in critical moments. The speed state is kept constant, and the action can be obtained directly through DQN. The updated form of the DQN algorithm used in our study is single-step Q-learning, which is defined as Equation (2).
In our experiment, we utilized Xception for detecting traffic conditions ahead of the vehicle, ensuring that the model meets both accuracy and speed requirements. The main concept behind Xception is depth-wise separable convolution: each feature channel of an RGB image is first convolved individually with a 3×3 convolution kernel and then convolved across channels with a 1×1 convolution kernel [30]. It works as shown in Fig. 5 below.
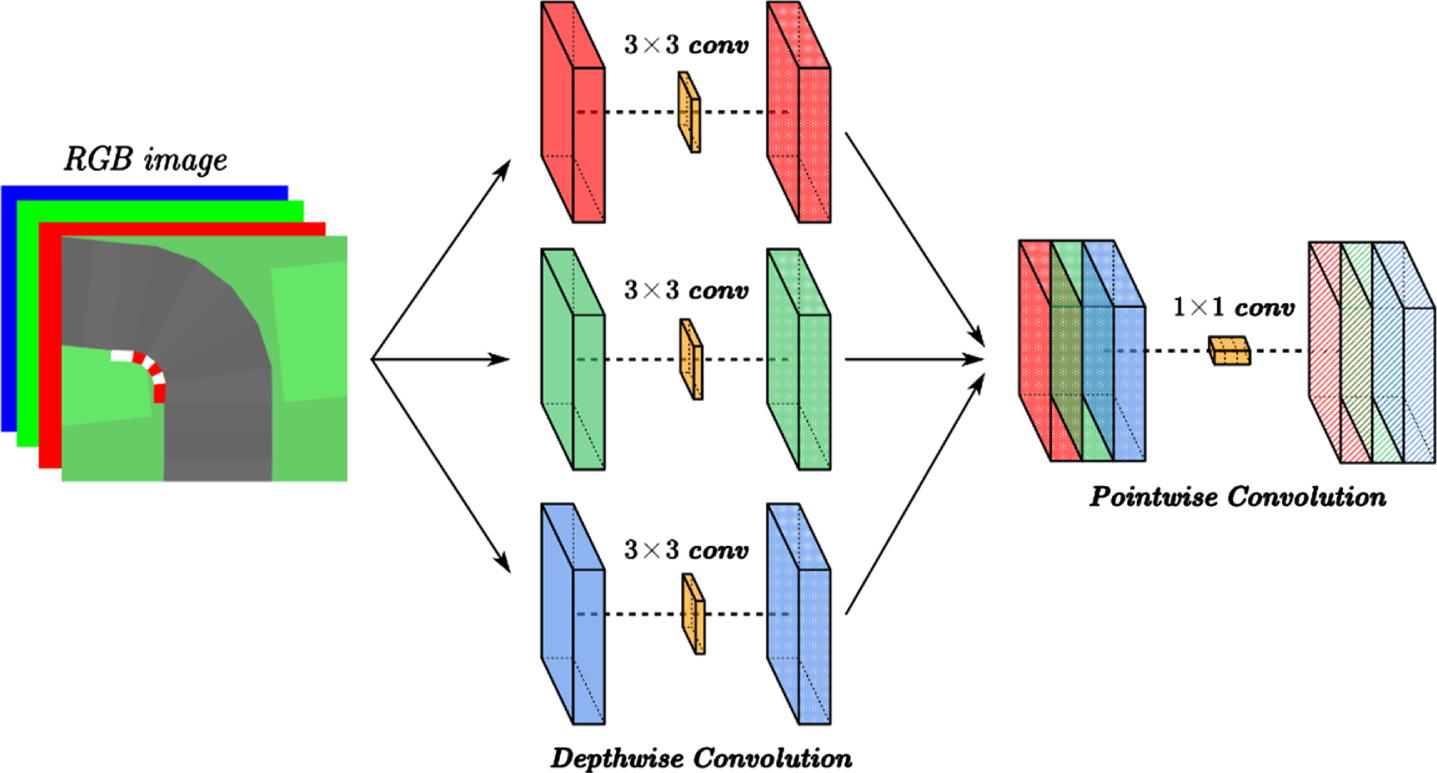
Xception network structure.
Table 3 shows that Xception, a lightweight neural network structure [31], has the highest prediction accuracy on the ImageNet dataset compared to Resnet-152 [32], VGG-16 [33], and Inception V3 [34]. The Xception architecture has shown significant performance improvement on ImageNet datasets, making it an ideal choice for our experiment. It is capable of meeting the requirements for training accuracy and speed, allowing us to efficiently detect traffic conditions ahead of the self-driving car.
Classification performance comparison on ImageNet
The reward function is a critical factor in guiding the decision-making of self-driving cars when faced with ethical dilemmas. This paper uses the Rawlsian maximin principle as the design criterion for the rewards, taking into account the complexity of the decision-making environment and ensuring fairness. The paper focuses on the collision selection problem in car ethical dilemmas and uses the kinetic theory in car collision theory to determine the reward function in reinforcement learning. This approach allows for the measurement of the accident subject and survival rate under different scenarios.
The simulation environment used in this study is based in an urban setting, with the intention of emulating real-world scenarios. Therefore, the self-driving car’s speed is limited to no more than 60km/h (50km/h) when driving on city roads. However, it is also taken into account that, in real-world driving situations, the vehicle’s speed should not be less than 20km/h. It is important to note that driving at excessive speeds can result in greater harm than driving at a slower pace. The reward for the speed aspect is determined using Equation (3).
In real-life situations, car collisions typically result in inelastic collisions, which are classified as either elastic or fully inelastic collisions. For the purposes of this study, the fully inelastic collision type is considered based on the Rawlsian maximin principle, which results in the highest energy loss. The mass and velocity of the objects involved in the collision can vary in real-world scenarios, but for the purposes of the reward design in this paper, a high level of precision is not required. The specific values of the parameters used in the study are presented in Table 4.
Parameter description of the collision object
The reward function for collisions is derived from collision dynamics and the Rawlsian maximin principle, and is represented by Equation (4), which can be found in the appendix.
It is evident that the speed aspect and collision aspect are relatively independent and have little influence on each other. Thus, the total reward is the sum of the rewards from the speed and collision aspects, following the summation principle, and can be computed using Equation (5).
Equation (6) presents the obtained reward function for various behaviors in different states.
The complexity of self-driving cars’ behavior and the diversity of states they encounter present challenges in adopting Q-learning. The storage space required to store reward values can increase significantly, leading to memory constraints. To address this issue, this paper introduces the convolutional neural network (CNN) as an approximation method for estimating Q-values. The CNN-based Q-function approximator reduces storage requirements and improves the learning efficiency of the Q-learning algorithm. To speed up the training efficiency, a small batch half-gradient descent strategy for Rawlsian DQN is adopted. The decision of the self-driving car is evaluated using MSE [35] (as shown in Equation (8)) as a loss function.
Algorithm 1 outlines the procedure for implementing the DQN algorithm used to train the self-driving car in our experiment.
In contrast to the conventional collision recognition Q-function, collision recognition is incorporated into the training process, and distinct reward values are assigned to different collision objects based on their priority. This paper presents a departure from previous qualitative humanistic research in favor of quantitative calculations, resulting in the development of a reward function that takes priority into account. This approach enables the agent to develop a greater awareness of the incidents it causes during training, which facilitates more effective learning. Additionally, Prioritized Accident Replay is introduced, which differs from the conventional preferential replay mechanism that utilizes high-quality samples to increase training speed. In this study, we propose prioritizing the replay of low-quality samples in order to reduce the number of incidents that occur during subsequent training. This approach seeks to improve the robustness of the self-driving system by emphasizing the importance of unfavorable learning experiences.
To evaluate the efficacy of the proposed method, we used the PythonAPI to control the Carla Simulation in order to construct an environment for reinforcement learning. This simulation-based evaluation framework permits us to examine the agent’s performance in a variety of complex scenarios and simulate real-world driving situations.
Hardware and software configuration
Carla is an open-source self-driving simulator that enables the construction of self-driving simulation environments and the algorithmic incorporation of deep reinforcement learning via Python API [36]. This simulation software primarily supports the construction of the learning environment for deep reinforcement learning, the acquisition of image data used for training, agent control methods, the discrimination of the nature of collision events, and diverse dynamical programming for the experiments conducted in this paper.
A relatively even and well-coordinated town (Town02_0pt) was chosen as our experimental scene to facilitate the experimentation process and reduce collision conflicts during environment construction. We generated a training vehicle at a random location within the town and positioned 15 non-player character (NPC) vehicles and 25 NPC pedestrians within the environment. Figure 6 depicts the resulting environment.

Experimental environment.
The environment and system configuration for the experiments are as follows: the operating system is Windows 10, the CPU is Intel(R) Xeon(R) Gold 5218R CPU @ 2.10GHz 2.10 GHz, the graphics card configuration is 24 GB memory NVIDIA GeForce RTX 3090. Python version is 3.7, Tensorflow version is 1.13.1, Keras version is 2.2.4, and Carla simulator version is 0.9.13. The data and source code are available at https://github.com/newsigema/Ethical-and-moral-decision-making-for-self-driving-cars-based-on-deep-reinforcement-learning.
The experiments are accelerated via GPU, and the RGB images captured by the front camera of the self-driving car are used as training data. The real-time images are fed into the Xception network model, and tensorboard is applied for curve output. In terms of experimental design, we will compare the performance of both Rawlsian DQN and DQN. The main difference between the two is that Rawlsian DQN uses a reward function based on the dynamic change of vehicle state, taking into account the priority. And an accident priority replay mechanism has been introduced to circumvent the worst solution. The experimental group would adopt Rawlsian DQN while the control group adopts DQN with “experience random replay” and “0-1 reward function”.
Before beginning the formal experiment, we conducted 100 pre-training iterations to fine-tune the relevant parameters in order to improve the experiment’s outcomes. Given that the RGB images used for training are acquired in real-time, we use the mini-batch technique to train the model using 4, 8, and 12 batches, as shown in Fig. 7.
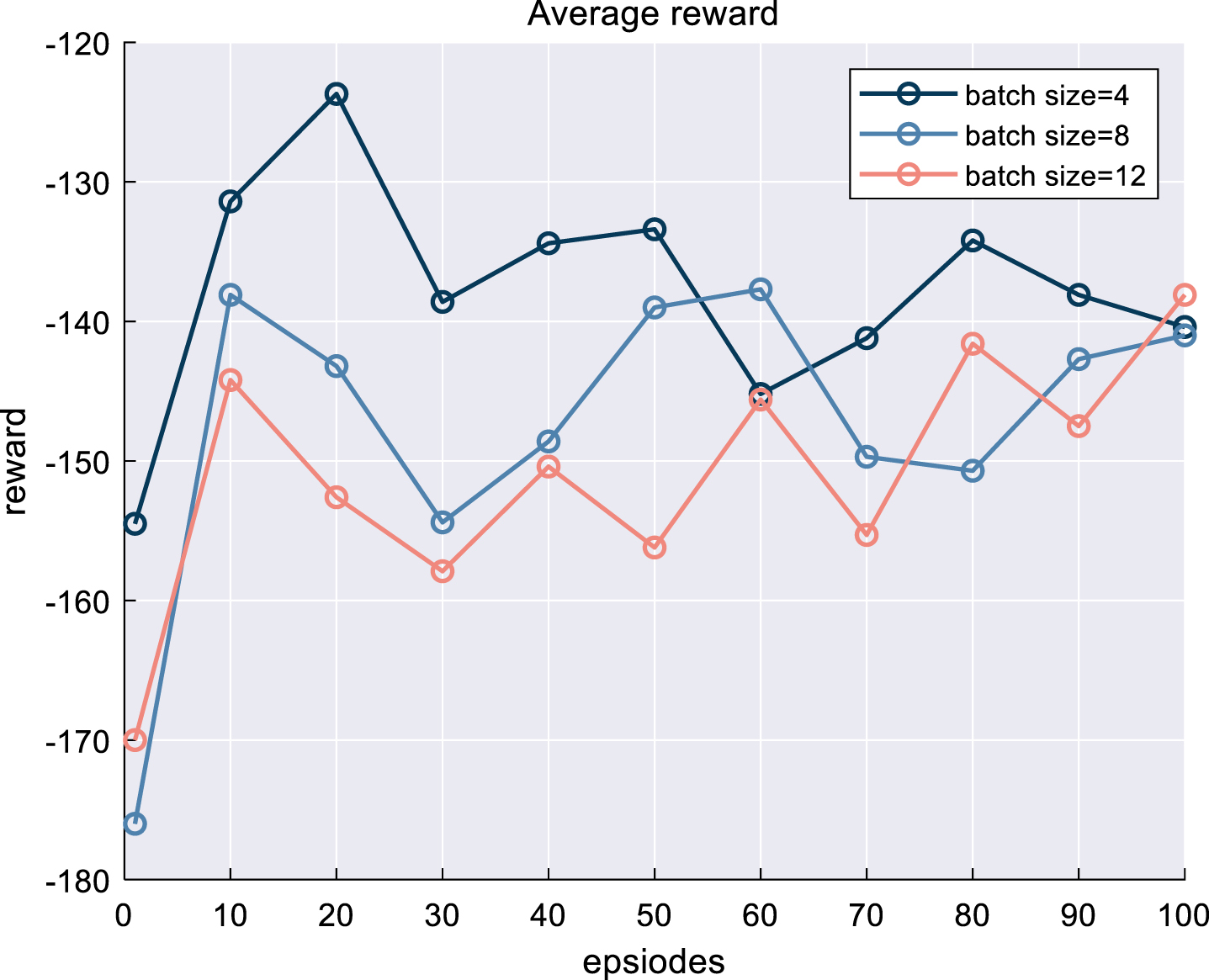
Comparison of different batch sizes.
Regarding the learning rate, the initial learning rate is set as 1 to avoid fast convergence. Meanwhile, the pre-training results with the Learning rate decay of 0.975, 0.9975, and 0.99975 are compared (as shown in Fig. 8).
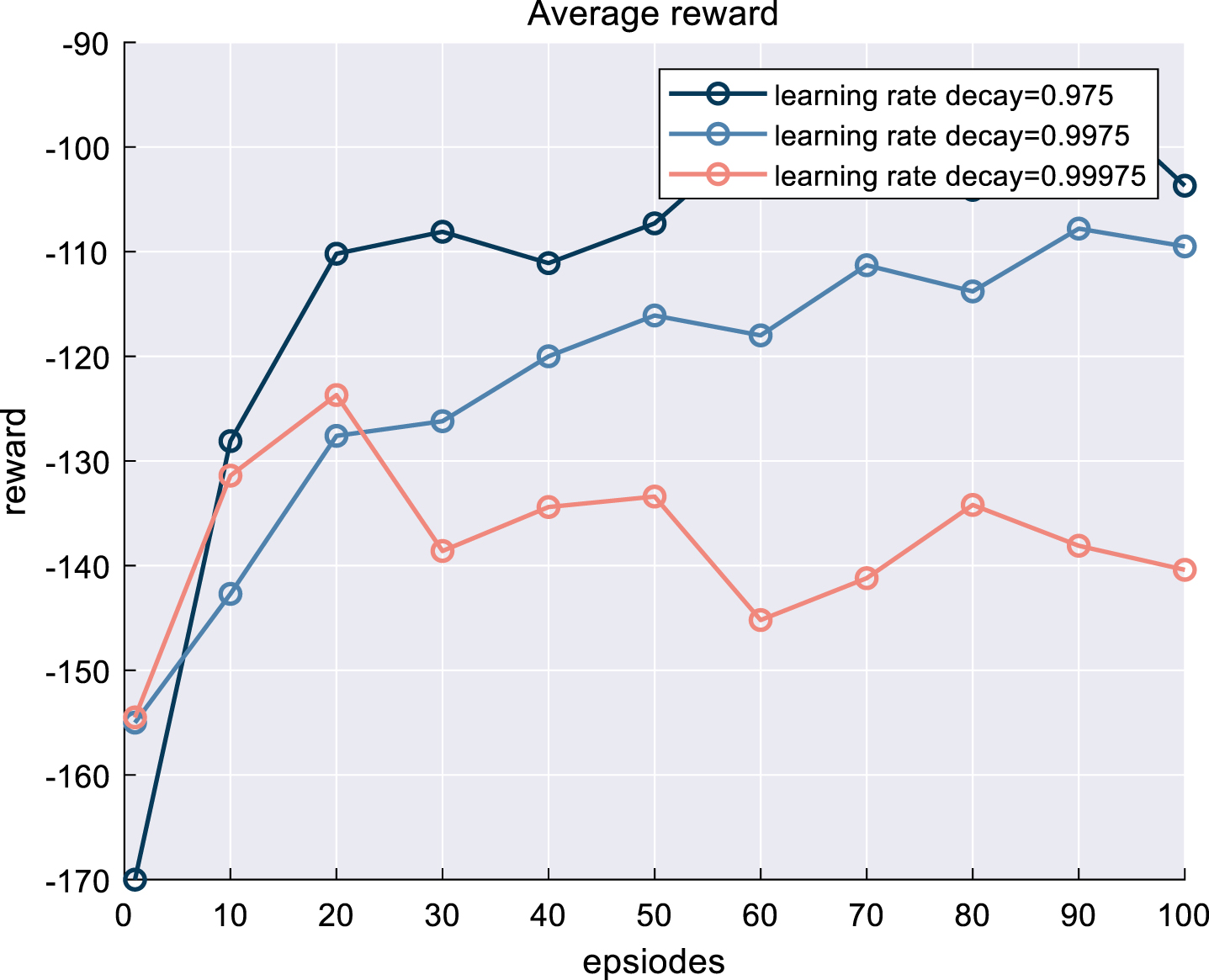
Comparison of different learning rate decay.
Due to the Carla emulator’s large consumption of computer memory in this experiment, this paper chooses the Adam optimizer with high computational efficiency and low memory requirements. In summary, the related parameters are set in Table 5.
Related parameter settings
The observation input for the self-driving car is the road conditions ahead of it. The training image dataset employed in this study was obtained from the front-facing RGB camera, which captures 640×480-pixel three-channel images. The specific camera structure is depicted in Fig. 9.
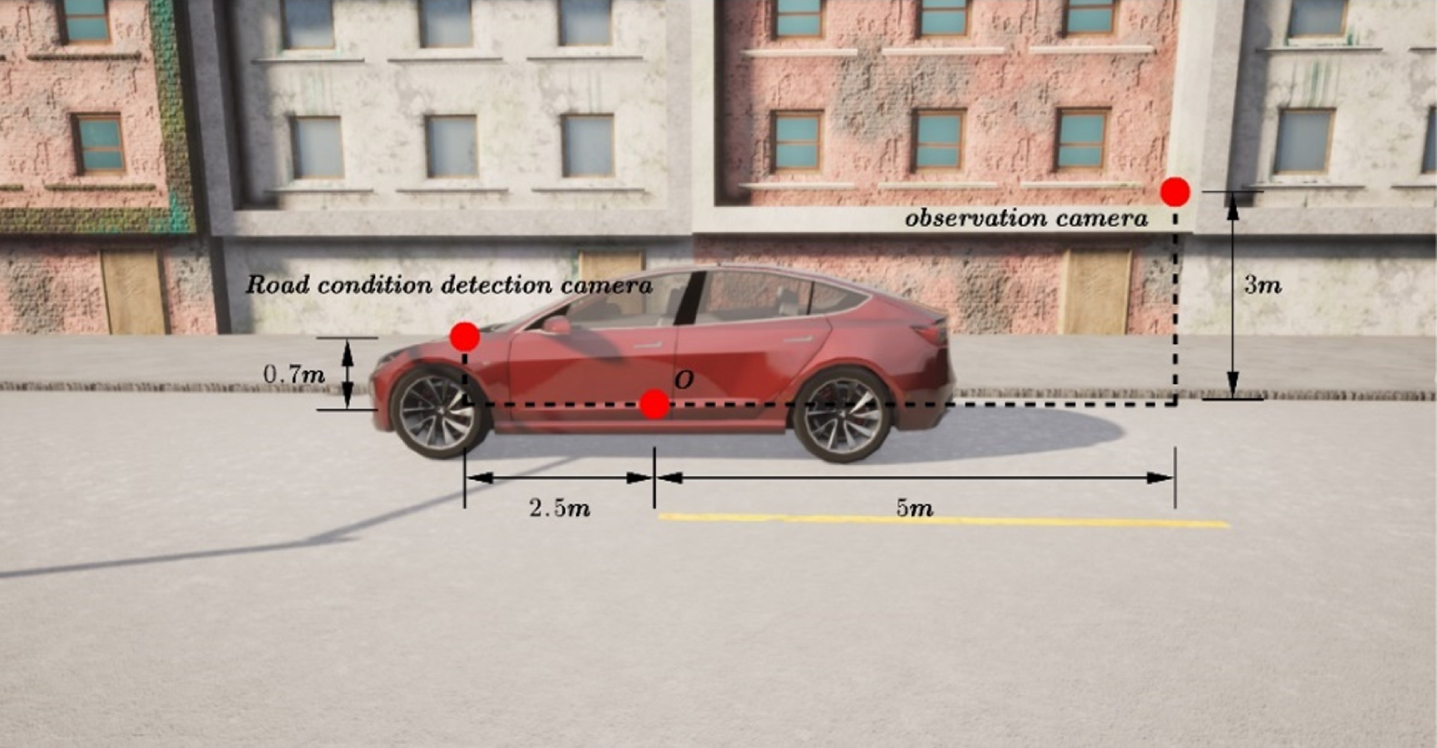
Camera position setting.
This paper also added the observation camera in the rear of the car to make the presentation more intuitive. Here are the images captured by the two cameras. Figure 10 shows the training perspective and observation perspective.

The picture two cameras captured.
In this study, a training cycle for the self-driving car is defined as the period from its inception until a collision occurs. Within the Python API of the Carla simulator, the collision object’s type (e.g., “vehicle,” “walker,” “barrier”) can be printed using the “isinstance” function in Python.
Figure 11 depicts the reward curve for the environment depicted in Fig. 2 which was trained using the DQN algorithm that integrates ethical prioritization. Since the ultimate goal of self-driving car research is to minimize collisions with pedestrians under the most adverse conditions, this study focuses predominantly on the average and minimum rewards received during training.
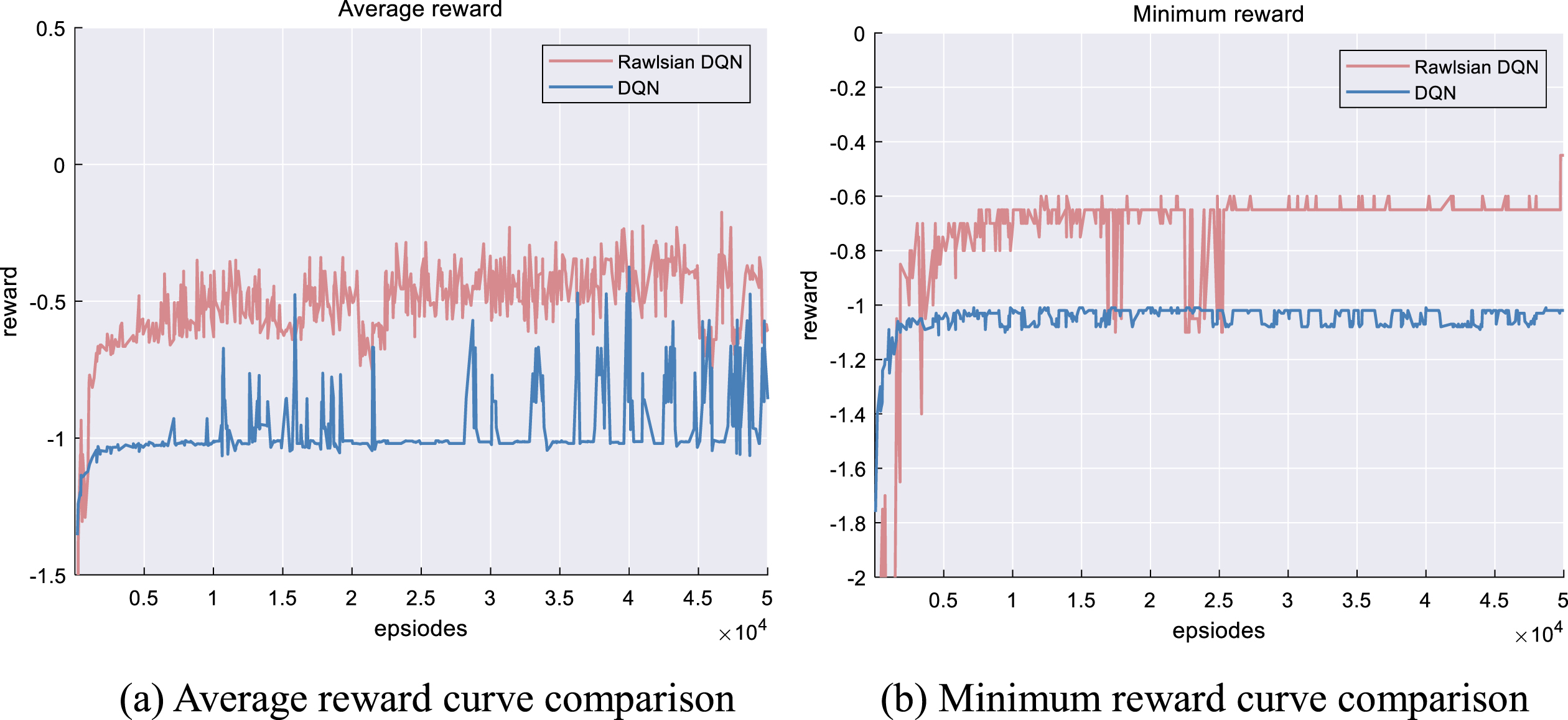
Reward curve of Rawlsian DQN and DQN.
Observing the training outcomes of the experimental group, two significant decreases in reward were observed between 15,000 and 20,000 steps (as depicted in Fig. 11 (b)). Further investigation revealed that these decreases were the result of collisions with pedestrians, resulting in a significant penalty factor that negatively impacted network performance (as illustrated in Fig. 12). This finding was reflected in the replication of the script.

Footage captured by the camera before colliding with passers-by.
The minimum reward’s convergence was more notable than that of the average reward. Priority allowed the minimum reward to converge to approximately -0.65 between 20,000 and 45,000 steps, with only minimal fluctuations attributable to changes in speed. The control group’s training curves indicate that although the vehicle attempted to avoid collisions, it was unable to evaluate the ethical and moral implications of the various individuals involved in the scenario. As a consequence, the direction of the training process was unclear, and the responses exhibited persistent jumps in the curve, making it impossible to draw meaningful conclusions. This had a substantial effect on the convergence of the results.
Due to variations in environmental parameters during training and the number of training sessions, training outcomes may vary depending on the training situation. We conducted 10 training sessions and recorded the data of the DQN algorithm and the Rawlsian DQN algorithm for the minimal reward curve in order to quantify this uncertainty. Calculating the mean value and standard deviation of the minimum reward for 10 repeated experiments yielded the results shown in Table 6.
Reward statistics
The results demonstrated that the standard deviation of the Rawlsian DQN algorithm was greater than that of the DQN algorithm. This is because the Rawlsian DQN algorithm takes into account realistically complex factors such as collision objects and speed. Nevertheless, the standard deviation of both algorithms is extremely low (10 - 2), so the algorithm’s stability is acceptable.
Based on the calculated standard deviation, it is evident that the proposed model is stable for the locally determined environmental model. After approximately 50,000 training steps, however, the experimental group’s reward trajectory began to fluctuate once more. Further analysis of the model file revealed that the fluctuations in Fig. 13’s reward curve were the result of a successful departure from the local decision environment and subsequent training in the new environment. The standard deviation results also indicate that when the local environment alters, the optimal decision-making model requires additional training time. Therefore, environmental ambiguity has a significant impact on the algorithm’s performance, which represents its limitation.
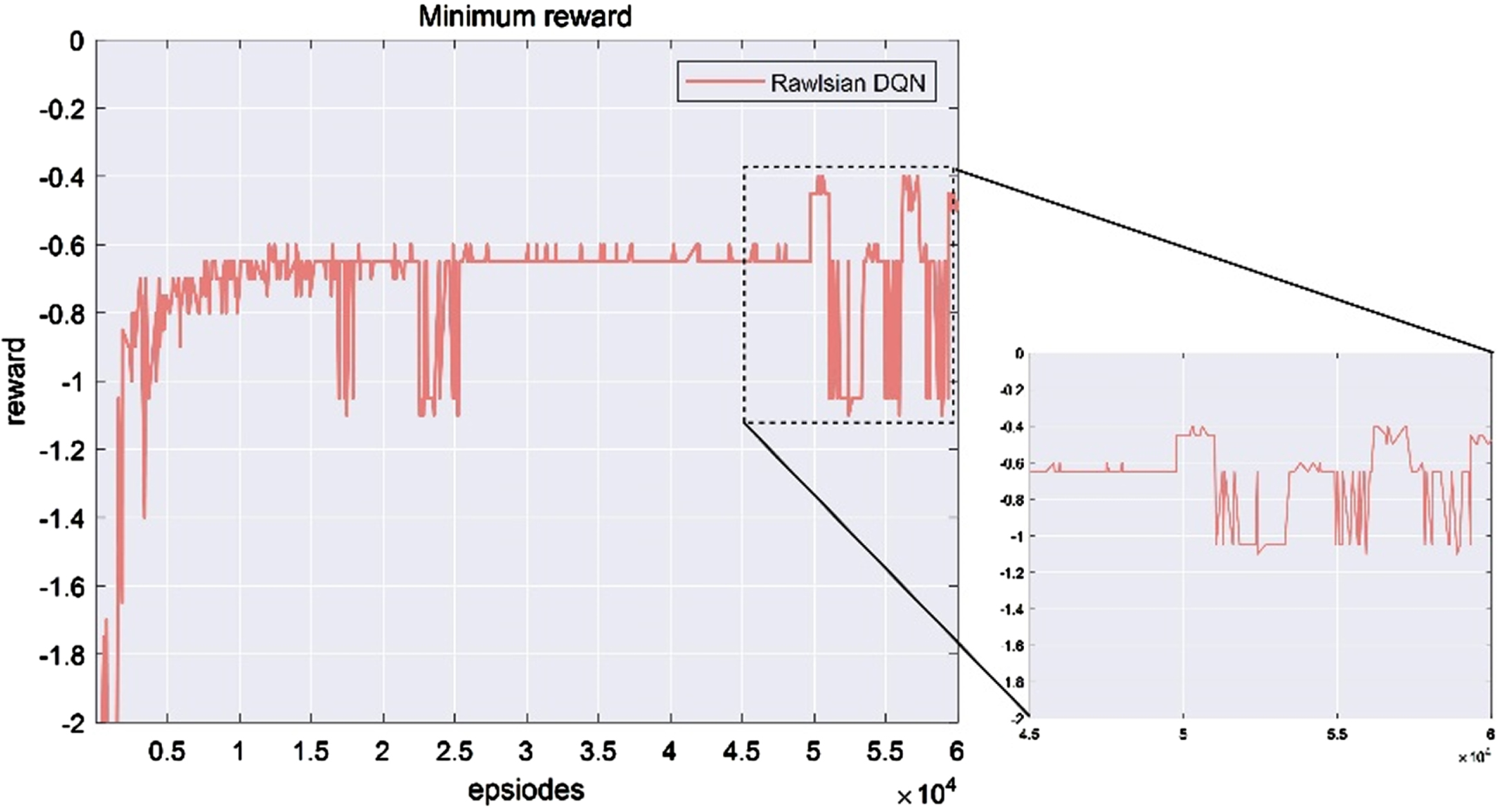
The fluctuation of a curve after leaving the given environment.
Finally, we performed a questionnaire to determine whether the Rawlsian DQN algorithm’s ethical decision-making in this scenario was acceptable to the general public. The questionnaire was conducted online, and seventy valid responses were collected. It was a two-tiered survey, with the first tier collecting basic information and the second tier concentrating on intentions regarding ethical decision-making. The two-tiered approach helped participants differentiate the focus of the survey sections.
In the basic information survey, there was a comparatively balanced gender ratio, with 51.43 percent of respondents being male and 48.57 percent being female. The ratio of drivers with licenses to those without licenses was close to 1 : 1, at 47.14 percent to 52.8 percent. This allowed for a more objective evaluation of the decision-making intentions of self-driving cars. 71.43% of respondents answered in the affirmative to the question of whether the public is willing to own a self-driving car, indicating a greater willingness to embrace self-driving cars. The second level of questions was also predicated on the assumption that the general public was more willing to own self-driving cars. The questionnaire for the scenarios depicted in Fig. 2 yielded the data shown in Fig. 14.
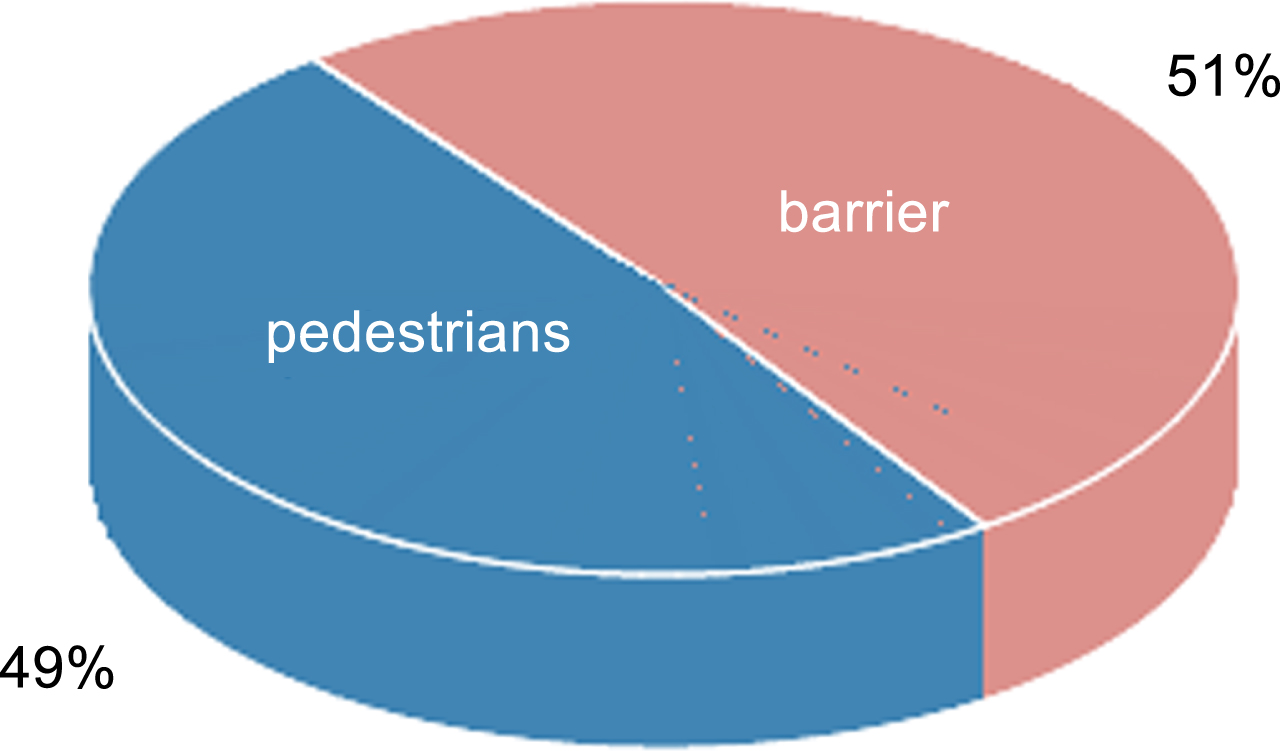
Questionnaire results.
Even at the risk of their own lives, more individuals continue to choose to collide with the barrier. The convergence of the reinforcement learning algorithm’s reward curve to -0.65 results in “striking the barrier at a slower speed.” The fact that the data is consistent with the research findings and is even superior to the optimal solution envisioned by the team demonstrates that the Rawlsian DQN algorithm is capable of making rational decisions in the given environment.
Furthermore, This paper also expands the scenario, and separate questionnaires were administered in Table 7.
Decision-making scenarios
According to the training approach adopted in this paper, the deep reinforcement learning training scheme for the above scenario is described in Table 8.
Training program changes
This paper proposes an ethical decision-making scheme for self-driving cars based on deep reinforcement learning. The Rawlsian maximin principle is utilized to develop the reward function and to incorporate insights from humanities research. In order to prevent accidents and other undesirable outcomes during the training process, a prioritized accident replay mechanism is also implemented. The experiment demonstrates that this approach is more effective for addressing the ethical decision-making challenges posed by self-driving cars. In addition, the paper presents the results of a survey of seventy participants, which corroborate that the subjects’ decision-making tendencies align with the simulation outcomes, thereby validating the enhanced efficacy and rationality of the Rawlsian maximin principle.
Nevertheless, our long-term investigation reveals that despite this algorithm’s success in local decision-making, its performance fluctuates once it leaves the established decision-making environment. Therefore, the algorithm’s present application is relatively limited. We propose two future research directions. Inspired by DDQN [11], we will first investigate the combination of Rawlsian decision theory with more advanced reinforcement learning algorithms and further evaluate its performance. s, e, s’;>can also be used to expand the decision-making scope in future work. Then, DDQN can be used to simulate the autonomous simulation process with greater precision. Second, we intend to investigate how to implement the knowledge gained from local decision-making to automatic driving in the real world. To accomplish this, we should consider how to speed up training in a simulation environment and reduce computational complexity.
Footnotes
Acknowledgments
The research of this paper is supported by the Sichuan Science and Technology Program (No. 2022NSFSC0459) and the Fundamental Research Funds for the Central Universities (No. 202210613020).
Appendix
In elastic collisions, since there is no loss of kinetic energy, so get Equation (1).
In a perfectly inelastic collision, the loss of kinetic energy is most significant, i.e., the two objects move together after the collision, so Equation (1) can be changed to Equation (2).
In the actual situation, the collision involved in the car is often very complex, and this article uses an entirely inelastic collision to facilitate the calculation.
Since the velocity is a two-dimensional vector, the velocity can be expressed by Equation (3).
Thus obtain Equation (4).
The amount of change in momentum is calculated by Equation (5).
However, since the change in momentum in a single direction (x-direction or y-direction) can qualitatively measure the change in momentum on the combined momentum. Thus, when only the momentum in the x-direction is considered, the amount of change in momentum is obtained when the car hits different objects in Table 9.
Thus obtain Equation (6).
A check of the data shows the collision time for the different collision types(as shown in Table 10).
Combine the momentum theorem expressed by Equation (7).
Therefore, the force per unit time generated by the collision is shown in Equation (8).
Considering the buffering capacity of different objects, Equation (9) is then obtained.
According to The Rawlsian maximin principle, i.e. finding the optimal object in the set of minimum values under different measures.
From Fig. 15, the car-car collision occurs only when v > 40. What’s more, the priority in the driving process is determined according to the magnitude of the values of different curves, so get Equation (10).
So, according to the worst results under different crash types and according to the Rawlsian maximin principle, the rewards are set as follows in Equation (11).