
Abstract
Preserving the integrity of log data and using the same for forensic analysis is one of the prime concerns of cloud-oriented applications. Since log data collates sensitive information, providing confidentiality and privacy is of at most importance. For data auditors, maintaining the integrity of the log data is a prime concern. Existing models focus on providing models and frameworks that relies on any third-party entity or the cloud service provider (CSP) to handle the logs, which lacks in securing the integrity due to the presence of the external entities. Sole dependence on CSP is a major flaw together with a drawback, since the CSP itself is prone to data theft alliance. In this paper, we instantiate a mechanism which maintains the integrity of the log without compromising the performance efficiency of the system. The influence of machine learning classification techniques is leveraged in order to efficiently classify the log data before it is processed. Progressively the log data integrity is maintained through the proposed Propagated Chain of Log Blocks (PCLB), the Hybrid Vector Committed BST (HVCBST) and lightweight Multikey Hybrid Storage (MKHS) structures. The results of the implemented systems have proven to be efficient and tamper proof compared to the existing systems and can be easily rendered in any private or public cloud deployments.
Introduction
Creating a hyper environment with shared set of various resources is always the objective behind the technology cloud computing. Provisioning of resources has been a prime outcome of cloud services. The NIST model suggests that cloud computing provides large-scale ubiquitous model for easy and feasible sharing of resources, which can be accessed through the internet based on the demand and requirement whenever needed. This in turn can be provisioned rapidly and of course with very negligible effort in managing the resources. The next evolutionary step in the deployment and delivery of IT services has been supplied by cloud computing. Virtualization is a key enabler for achieving delivery of on-demand service, having more reliable data, worth mentioning the multi-tenancy aspect along with the characteristics of scalability and the nature of elasticity.
Some of the major issues in implementing this cloud computing framework in any work environment is directly related to the data availability, data integrity, authentication, management of resources and protocols, and so on [3]. Data leakage has been addressed by a wide range of computer community as the most serous problem in the cloud era. This can be closely understood with the kind of updates received by the cloud computing framework in its evolution. Every model that is implemented by organizations and applications around the globe rely on the security updates released by the computing community, which acts as a bridge between efficient applications and research towards these concerns.
Logs are commonly used to track and record the current and previous state of a computer system. As a result, the most basic digital forensic tool for ensuring security and reliability in modern distributed computing systems is logging. In the past, a logging mechanism was used to keep track of malicious activities in the system. Logs inside any computing system is of greater advantage due to the fact that they can be utilized for software troubleshooting and debugging, managing the issues related to the model’s performance and so on. The audit log trails are of more importance and it is a known fact that these logs are prime targets for attackers to insist on. Apart from attacking the systems, the attackers are focused more on removing the trails created by them in the process of attacking the systems [8]. There exist many applications which leverage the advantages of these system logs in their application layer. These applications may be based on detecting the intrusions, systems based on mobile environment, systems which are partially trusted by other third-party entities and internetworked systems. Since many organizations and application have stared to adopt vibrant network infrastructures, the continuous and rapid increase in the intrusions, threats and harm towards data security have also increased multifold. Hence there lies a need for securing this log management and processing mechanism. The challenging task here is to maintain the confidentiality and the integrity of these log files. Tampering these properties will be the prime focus of the attackers since those logs can act as proof of integrity. Achieving these objectives especially maintaining the integrity and confidentiality is not as simple as the data resides in the cloud environment where it is prone to modification without being sensed by the auditing tool. Anyhow, the log data should be secured from being tampered, so that the applications which make use of these logs can be more reliable and stable.
Technically the previously mentioned problems could be resolved using the advancements in Blockchain technology [6]. The unique qualities and characteristics of customizable blockchain could serve the purpose. The inception of crypto based currencies has increased the application ladders of this blockchain technology. Some of the major advantages of this blockchain technology is that it could be considered as a total trustworthy as well as distributed system. The classical model of transaction system includes an intermediary like banker which comes in the form of additional fee that the user or the client has to commit, whereas this technology doesn’t include intermediaries, hence reduction in process cost but with increased reliability. Stability is increased through higher retention rate of their services. As the data is stored in digital distributed ledger, it’s very complex in reality to delete or modify the data, thereby making the processes much stronger than the latter. The system is void of tedious documentation process and various transactions are executed with almost nil errors making it more trustworthy. Any technology of this many advantages always comes with a lag with respect to some system attributes. The main concern with this technology is the private and the public credential keys to be confidentially maintained by the users in order to leverage the use of this technology. The public key is shared with all the participants of the chain and the private keys are to be maintained secretly by the individual participants. If it is lost, then there is a major concern in retrieving the stored data from the chain. Another important issue that are faced is related to scalability and volatility of the technology. Volatility occurs in the form of unpredictable nature of the technology and since the transactions are heavily loaded, completing them in prompt timing is a challenging task for the implementers.
Our proposed system embraces the advantages of all the techniques and technologies discussed above and at the same time ensures to overcome the challenges faced in order to dominantly solve the major issues discussed herein. Our proposed model processes the system and related logs from the sources and secures the integrity of the logs. This is done using the above-discussed technologies by customizing the architecture and methodology to our needs. Initially the logs are collected and classified based on their priority. Once classification is completed, the segregated classified logs are then sent to the Type Specific Hash Gen Unit where the integrity of the log hashes is protected with the support from our uniquely modelled propagated chain of log blocks. Further, the classified data can be securely stored in our extremely strong multi key hybrid secure storage system. The integrity of the classified logs can be further examined and verified by acknowledging their hashed data using consensus mechanisms in the PCLB as per the data owners need. The implementation and modelling are further discussed in the upcoming chapters.
Literature survey
Abid et al. [1] introduces secure log as a service using reversible watermarking (SecLaaS-RW) scheme. This contextual reversible method is a variant of limitless fragile watermarking, which is deployed for data content authentication. These are the outsourced logs to which the technique is applied. Of course, the methodology does not involve testing of the system with a multi attack environment and protocols to prove the efficiency of the proposed model.
The application programming interface (API) can be utilized to acquire the log data as per the discussions done by Birk et al. [3]. The API can be made read only access so that the data cannot be disturbed by the forensic team. Having a trust enabled third party for collecting the logs is now resolved by this API solution providing frequent sync between the customers and their respective log data. Still, the reliance on the cloud service provider is at concern. The proposed model also suggests to provide an encryption layer before the data reaches the APIs.
A unified, distributed and secure system with deep learning enabled frameworks was studied and implemented in the research works of [2, 4–6, 10, 15, 20]. The implemented models provide a value enabled and data driven and incentive-based mechanisms using block chain technology which fuels the security of the processed and stored data packets. They guarantee privacy of data packets, but still the reliability on the third-party enablers and CSPs cannot be revoked as it forms an integral part of their implementation ecosystem. Ray et al. [7] used a reliable delivery mechanism of the user log records from a system of log generators attached to the logging client systems with some cryptographically strong data digests and end point authentic communication protocols. But this model lacks tight coupling with the operating system-based logging methodology. There is always multiple scope for a variant of encryption techniques to be tested with the same architecture.
Using the infrastructure as a service model for cloud management was justified by Dykstra and Sherman [8]. The data required for processing has to be obtained from the trust management layer by the users in their system. This methodology in the cloud is very complex, even though it extenuates the users’ reliance on the cloud service provider.
Reliance on the CSP was further broken into simplicity by Dykstra et al. [9] through a 6-layer trust enabled model. The data log collectors once again have to rely on the resultant trust layers which benefits only the IaaS architecture. In turn, concerns about the individual planes and the PaaS remain unaddressed. Edington et al. [11], highlights the various challenges and complexities faced by the data investigators in the cloud. It overcomes the limitations faced by the data users depending on the service providers by implementing a centralized forensic layer and a data monitoring plane. But the model validates the security with a very limited set of parameters, with very less influence on a full-fledged attack environment. Kobayashi et al. [12], establishes an approach to automatically detect the systems operational history through the log processing architecture. The data model designed can also be utilized for visualization. The unformatted log records and the low-level event track records are processed through log abstraction and event mapping functionality using the cross-cloud reference data. The correctness of the mapping factors has to be improvised in order to get an efficient system.
In order to diagnose user and system related issues in the cloud, it is at most necessary to strongly evaluate the machine generated or extracted log files. Due to the nature of the cloud, the absolute number of files existing in the cloud can be numerous. Lemoudden et al. [13] studied the micro challenges of implementing cloud log management solutions in a cloud computing environment. They have tried to unlock the hidden metadata available within the context of those log files. A new methodology was proposed by them through different phases of log retention and transfer along with incorporating filters through text analytics and text error correction tools. The purpose is to structure the data in a considerable format for further analytics. But the solution does not fit itself in an automated category and the reporting segment is not in correlation with the management technique used.
Sandikkaya and Harmanci [14] explores the possibility of analyzing the various security factors and is particularly focused on the Platform as a Service clouds. The consideration is given multiple perspectives, which latently includes controlling user and system access, the data and log privacy and the continuous service rendered by the CSP to the cloud users. The plane architecture followed in their model doesn’t address the real pull factor which affects the access control, instead focuses on the variant factors involving user attributes. The solution intends better PaaS designs for achieving spontaneous data security. Pichan et al. [16], proposed a cloud forensic logging framework, a CFLog application in which they employ a two-component architecture. The framework is worth enough to recreate and trace a chain of events, even though it can be easily attributed to a cloud service providers’ task. But then, speeding up the forensic analysis process through this methodology is very unrealistic, since the involvement of CSP is proxied by the components administrator in this model, thereby slowly degenerating the efficiency of the whole system.
Gathering the log from the servers at times becomes more complex than expected. This is partially resolved by the work done by Marty R [17], where guidelines were proposed to retrieve the log data through a business-oriented logging framework through a SaaS architecture. The outer delivery layer is a serious security concern in this model, yet the solution is adaptable.
Presentation of interactive evidence through proper visualization can be done without the support of the cloud service provider was elaborated by Wolthusen et al. [18]. But the data collection is still dependent on the CSP who provides access for the same. This mechanism works perfectly for Software as a Service and Platform as a service but not much for other services that exist in the cloud platforms.
Sandikkaya et al. [19] deploy an open live bulletin board whose uptime is always high and at the same time is used as a write-only database for the user and system log data. When there is conflict of opinion and data, this board can serve the purpose. A fair privacy preserving logging mechanism is proposed. One of the major disadvantages of their model is that it’s very hard to obtain the timely recording of log entries. The channel experiences a delay through which the log data is being captured, which may lead to inefficient capture.
Pourmajidi et al. [21] proposed a blockchain oriented architecture to ensure transparency of the log processing environment and to enhance the trust between the existing participants in the cloud. This architecture is claimed to be tamper proof. The model closely depends on the architecture strength of Ethereum which is a public chain network and involves the support of CSP and administrator to manage the whole life cycle of this model. The ideology can be extended to the private cloud and tested for its efficiency.
A more suitable model to extract log data from the cloud premises using the IaaS model was proposed by Zafarullah et al. [22]. Extraction involves Operating System logs and security file logs. This proposed system was less efficient due to the fact that the sample attack scenarios created by them were inside the eucalyptus emulation module which in turn depends on the generation capacity of the CSP, since it is extracted within the cloud environment. Therein, the CSP’s have to adopt new techniques in order to provide integrity to the log data.
System architecture and proposed methodology
In the forthcoming sections, we will be practically explaining our proposed framework. The whole model goes through a sequence of processes, where the final outcomes are extracted by tactical means and then compared with the existing architectures. Based on the comparison results, proper validation is performed on our model for perpetual analysis.
The objective of our proposed framework is to efficiently secure the data logs that are obtained from the cloud server through different sources. Securing the log data from the external influences has always been a core objective in many of the research works. But, in almost every methodology, the model is reliant on the cloud service provider (CSP) [6] to provide this security. Sole dependence on the CSP could be a major flaw cum drawback in the system, since the CSP itself is prone to data theft alliance and the data analyzers, like the forensic analysts need the support of CSP to get reliable log data. Our model mitigates this issue by securing the data and maintaining them in an Adaptable Assembled Log Chain (AALC), so that even a slight modification by any entity, including the CSP can be identified.
Phase 1: Log data extraction from cloud service
In order to arrive at our objective, the very first phase in our proposed framework is log data extraction. The cloud infrastructure, by definition provides a variety of services such as Infrastructure (IaaS), platform (PaaS) and software as a service (SaaS). All these services, irrespective of how they are implemented, generates a massive amount of log data. Log data consists of details corresponding to every activity that happens in the cloud system. These activities could be user-initiated or system-initiated.
The attributes that form the log data could be date, time, source address, destination address, location, type of resource, time to live, access policy attached to it and so on. There cannot be a standard format for all typical log data available in the cloud servers. Each service gather data based on the profile in which it is available and that is the main reason why we cannot have unique formats for log data. Extraction of these log data from the cloud servers is hence a tedious process.
The overall architecture is depicted in Fig. 1. Let the proposed cloud system has ‘k’ servers, CLD = {cs1, cs2, cs3, … ., csk}.

Overall system architecture.
The attributes that form the log data could be date, time, source address, destination address, location, type of resource, time to live, access policy attached to it and so on. There cannot be a standard format for all typical log data available in the cloud servers. Each service gather data based on the profile in which it is available and that is the main reason why we cannot have unique formats for log data. Extraction of these log data from the cloud servers is hence a tedious process.
The overall architecture is depicted in Fig. 3.1. Let the proposed cloud system has ‘k’ servers, CLD = {cs1, cs2, cs3, … ., csk}. Based on the system architecture, let’s assume there are ‘p’ users per cloud server, UCSi = {u1, u2, u3, … , up}, where UCSi is the users’ per cloud server ‘i’. If the log data generated per user in the cloud server is denoted by LDp, where p is the number of users, then the total log data generated per user is given by, ULD = {LD1(data), LD2(data), LD3(data), … ..., LDi(data)}. The accumulated log data can be aggregated as
Where, n is the total number of connected cloud server systems, p is the total number of users per cloud server system and i is the aggregated log per user in a cloud server system.
It is a good practice [4] to separate the log data from the cloud users, so that the data can be processed in such a way that the cloud users do not have the access control to it, thereby obtaining no or very minimal knowledge about the respective data. This superior way of segregating the log data upsurges the integrity value of the data as well as its trust factor. A better approach could be to isolate the logging layer to the hypervisor so that it is totally detached from the cloud user’s control. Still, it could be under the control of the cloud service provider (CSP). Since one of our objectives is to secure the integrity of the log data even from the CSP’s obstructions, it would be better if the data is directly moved to the next phase in our architecture without the consent of the CSP. This should be applicable only for log data and not on any other category of data for that matter.
Since our focus is on securing the data rather than extracting it, we adapt the existing the data extraction mechanism [6] for our model. The system captures the log data based on the existing attributes of the cloud system user and processes it to the next phase for classification. In real time implementation, this could be performed using API functionality available as a part of the cloud services.
Since the data arrives at our model from various sources of services, it is always a better idea to classify and prioritize the log data according to our requirement. This prioritization is done based on the requirements of the cluster of domain users who would like to implement the system in their premises. The list of log data that is obtained from different sources of services will be of multiple attributes which has to be classified into some categories. These categories of classes will help the analysts and the users of the system to understand the complexity of the data that is currently been handled. At the same time, this classification process supports the users to understand the complexity of the confidentiality to be maintained for different set of data elements.
The prioritization model of log data can be strictly based on the classified classes. The different class of log data could be Resource access logs (Open, edit and read) Network access logs Logs that are user written Audit logs security logs Admin audit logs Policy based logs System event logs and others
The priority of these classes of logs can vary based on the different users of the system. The priority model can be depicted as,
The Accumulated log data is given by
Table 3.1 describes the dataset utilized in our model with their respective category and priority. In fact, the prioritization is done after the classification and clustering is completed in this phase. Classification goes by the process of predetermining the class category of a given set of data points. We can also refer classes as targets or labels or categories of data elements. Classification predictive modelling is nothing but the job of approximating a mapping function (MF) from the given input variables (I) to the set of discrete output variables (O).
Sample dataset with their respective category and user priority
The classifier is the component that utilizes some training data to clearly understand how the given input variables relate themselves to the class that is to be classified. The process of classification pertains to the category of supervised learning where the target data is also provided along with the input data. A vibrant variety of applications is available for classification in multiple domains. A stream of various classification algorithms is available in the current situation, but identifying the best one among them is not viable since it depends on the application and nature of available set of data. Majority of the learners are divided into two categories, Lazy and Eager Learners. The conceptual distinction between the former and later learners is based on the time moment, when the algorithm abstracts from the data. In order to better understand the difference between lazy and eager learning, the difficulty lies in conceptualizing what the “abstraction” refers to between the two. A lazy learner model delays abstracting from the data until it is asked to make a prediction while an eager learner model abstracts itself away from the data during training and makes use of this abstraction to make predictions rather than directly comparing the queries with instances in the dataset. When comparing both in terms of accuracy, the lazy learner method effectively uses a highly rich and concentrated hypothesis space because it utilizes many local linear functions to create the implicit global approximation to the required target function, whereas, the eager learner method must bind to an individual single hypothesis, which covers the complete instance space.
Since we focus on effectively classifying our log data, we do not shift our research scope into dealing more about the various classification techniques available. Instead, we focus on utilizing the best available algorithm, which can satisfy our requirement based on some constraints and criteria. In that case, lazy learner would be apt solution to our model, where they simply save the training data and wait until a testing data appear on the result set. When that happens, the classification is conducted based on the most associated data in the saved training data. Compared to eager learners, lazy learners have less training time but they spend more time in predicting the values for our model.
In order to get a better efficacy of the afore mentioned classification to our log data, we use k-nearest neighbor algorithm which best comes in the class of Lazy Learners classification models. We have taken a sample of dataset from the Apache server log suspicious archive and IEEE access log of apache web app servers for testing our models [4]. We utilize the hold out method for properly test our model. This has proven to give the expected results and the classification is based on our requirement of classes.
Table 3.2 discusses the details of the various datasets taken into consideration in our proposed model of implementation. The dataset is categorized based on the discussed categories such as {1}, {2} and so on based on the metadata of the respective dataset.
Dataset details
By implementing the K-NN algorithm with the discussed datasets, we have obtained the various success rate percentages of the classification algorithms based on the lazy and eager methodologies. Table 3.3 lists the success percentage of both the methodologies. It is imminent that lazy classification methodology wins over eager methodologies in most of the cases and that is the main reason to include this method in our proposed model thereby claiming more effectiveness during the testing phase, which is the prominent role of the lazy classifiers.
Success % of lazy and eager classification methodologies on our dataset using K-NN
Figure 3.2 shows the variation in the success rate percentages of the eager and lazy classifier methodologies through Naïve Bayes model. As depicted in the graph it’s clear that the K-NN algorithm of lazy classifiers wins over the Naïve Bayes model of both lazy and eager classifier methodologies. This stands the main reason for incorporating lazy methodologies through K-NN in our proposed implementation. We expect them to be a provable and strong system that adds up to the overall efficiency of our integrity protection model.
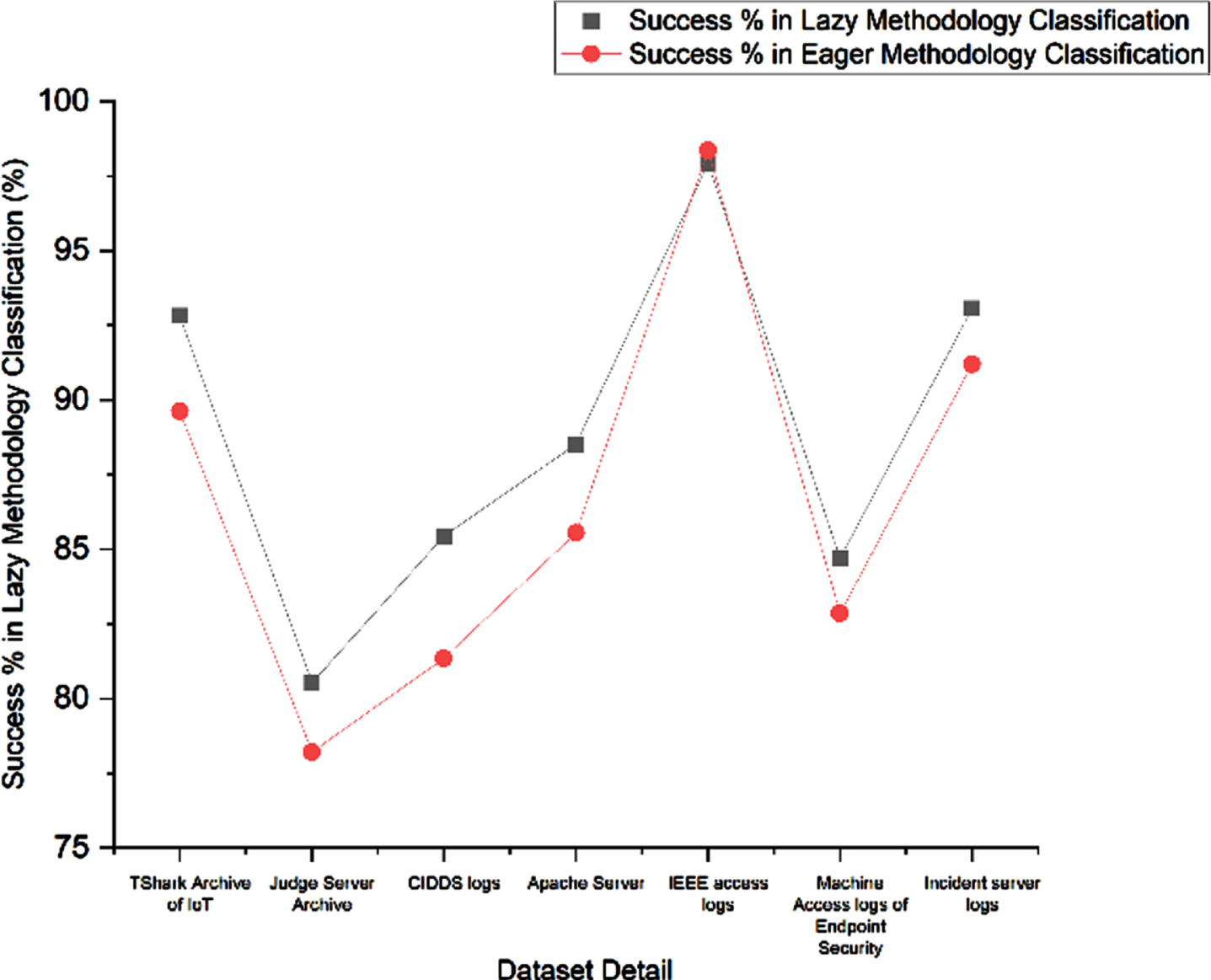
Success % of lazy and eager classification methodologies using Naïve Bayes.
Based on the above classification, we formulate the data as variant clusters so that, as mentioned above, it will ease the process of prioritizing the log data as per the user’s priority requirements. Hence at the end point of this phase, the log data set that is circulated through many of the cloud services will go through the different phases in order to reach an intermittent level, where it is categorized, classified and then prioritized. Now the user has an ample set of clear log data which is of course prioritized based on the user’s opinion. This data can be further sent to other phases for processing as mentioned in the introduction.
Once the classification is completed, the set of classified log data along with the classes will be moved to the phase 3 where the type specific data is being hashed using specific hash functions. This phase, hashes the incoming data first, once the hash is generated, a confirmation signal is retrieved back, based on which, the data hash is sent to the next phase: Propagated Chain of Log Blocks (PCLB). The log data is then sent for secured storage, which will be discussed in the later phases. The algorithm used for developing the data hash is discussed below.
Algorithm 3.1: Creation of Log data hash and Signaling.
One of the major objectives of our work is integrity of log data. However, storing all the log data as it is, in a block chained structure of any type would not be a feasible solution. The main reason behind those statements is, as the size and quantity of log data increases, the length of the chain increases, which would be difficult to manage in a practical scenario and at the same time, it would not be a practical cost-effective solution. Instead, our proposal includes a system that hashes the log data and then the hashed data is being processed further. In this way, the impractical issue of increase in data size and the length can be controlled and the storage of these hash data in a blocked manner seems feasible.
Phase 4: Propagated chain of Log Blocks (PCLB)
Once the log data blocks are hashed, they are arranged according to their classes and priorities into different categories. This categorization is an important aspect in our work, since the length and the horizontal growth of the chain depends on the priorities and the class categories obtained from the previous phase. Our main PCLB architecture as depicted in Fig. 3.3 has two divisions. The master chain and the associate chain. Most of the blockchain consensus mechanisms that are available in the present scenarios requires that each item of the network to process every other item of the blockchain, thereby creating a huge series of calculations that limit our application to less scalable category. We designed our architecture to override this constraint by sectoring a portion of the chain and capturing it in a higher level of chain, thereby creating a ladder of data chains, which is Propagated Chain of Log Blocks (PCLB). As picturized in the Fig. 3.3, if the integrity of the main block is validated, that leads to the consensus, which confirms the validity of the associate blocks. This specific modification to the chain finally reduces the total validation to be done in terms of the number of operations performed per validation.
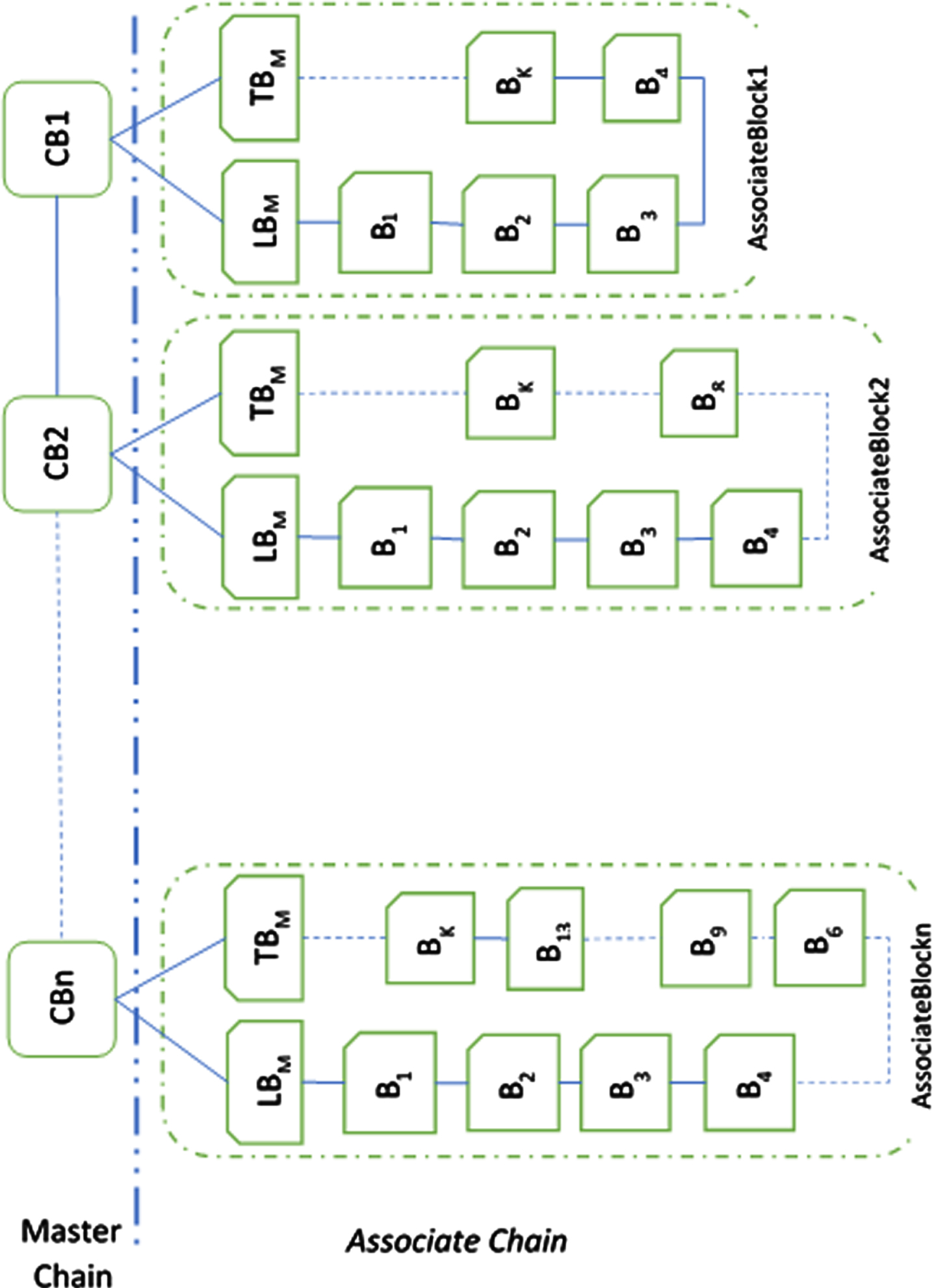
PCLB architecture.
The master chain consists of p number of candidate blocks, where p depends on the categories of prioritized log data that is received from various sources. Every candidate block is in turn developed further.
Total loaded blocks are given by:
As depicted in the Fig. 3.4, the block id (BiD) is prefixed with ‘cb’, ‘lb’, ‘tb’, ‘b’ based on its location. The BiD is the block ID which is a unique identifier to identify the block individually, ‘N’ is the nonce which utilizes customized proof of stake algorithms to mine the blocks, ‘LD’ is the exact log data (hashed), ‘PrH’ is the previous hash, ‘CrH’ is the Current Hash, ‘TSP’ is the Timestamp, ‘NSB’ refers to the number of sub blocks in every candidate block, ‘TBF’ is the TrailBlock Flag, ‘LBH’ is the LeadBlock Hash and ‘TBH’ is the TrailBlock Hash. The Associate Chain consists on ‘n’ number of associate blocks based on the number of Candidate Blocks the system holds. Every associate block is internally looped so that it serves the purpose of the validation limitation that is previous mentioned. Every associate block consists of a LeadBlock (LB) and a TrailBlock (TB) and a series of data blocks called as LogBlock (B). The number of LogBlocks (k) in the series is optionally selected by the analyzer or by the system when the chain is created. Hence, the number of LogBlocks per associate block varies throughout the associate chain as depicted in the Fig. 3.3. The TrailBlock Flag (TBH) is activated only for the TrailBlocks (TBs) and remains nil for all other blocks in consideration.

Block Structure of the Log Data.
Based on the number of LogBlocks in every associate block, it is partitioned into ‘q’ parts. The value of ‘q’ is determined similar to the value of ‘k’. The value of q can also be random but with the restriction that it is maintained less than k. Usually, q is maintained at a value of 2, for feasible transactions. The previous hash (PrH) of every LeadBlock is maintained nil whereas the FirstPartHash (FPH) of every lead block is determined by calculating the hash of data of first k/q parts, i.e., the data of the first k/q LogBlocks. When generating the TrailBlock (TB), the NextPartHash is determined by calculating the hash of the remaining LogBlocks, i.e., hash of the remaining k (q-1)/q blocks. This process is done in order to reduce the overhead of validating all the blocks and instead validate the Lead and Trail Blocks for maintaining the integrity of data. The log index submodule will take care of generating the block ids based on the constraint requirements and the location of the blocks.
The regular implementations of any block chain include Merkle Trees. However, since our focus is on reduced use of storage to attain maximum efficiency, customizing the data structure that fits our requirement is the real need of the hour. In this aspect, our proposed model includes an efficient and customized alternative to the existing sources through a hybrid vector commitments and BST. This hybrid model brings up the efficacy multifold. This efficacy is attributed to the bandwidth consumed by the executed protocol. Actually, the Merkle Trees are instantly deployed in an assorted set of diverse applications in which proof of memberships are distributed transversely through a network, including the vibrant consensus protocol, public and private key enabled directories and cryptocurrencies. This instance of the Merkle Tree with x leaves as shown in Fig. 3.5 has a complexity of O (log2 x). This complexity can be related to the proof of work that is sent through the network.
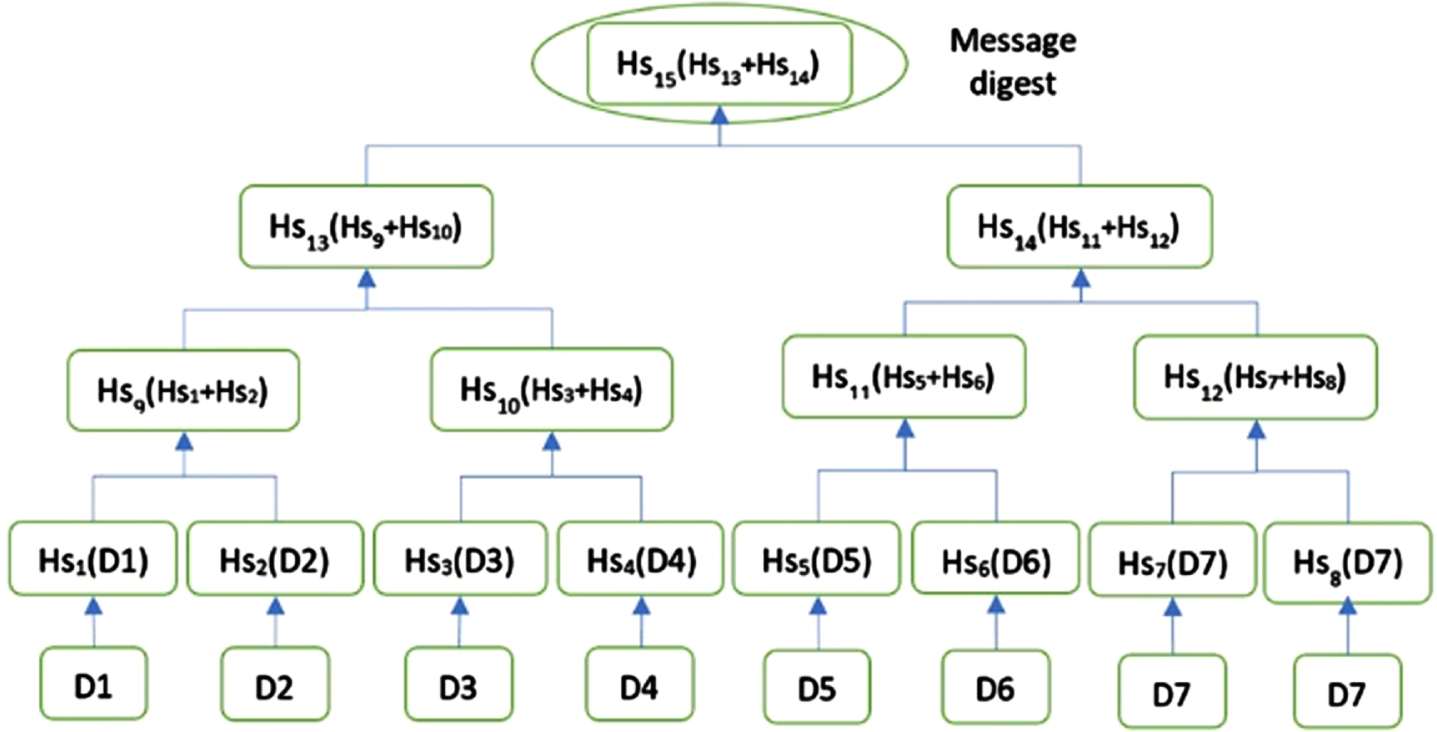
Binary merkle tree construct.
When the size of the tree increases, becomes large, transmission of these proof of work could consume a wide range of bandwidth.
Alternatively, we can consider Vector Commitments, which has more potential compared to the Merkle Trees. To thwart our contribution, we have noticed that, the construction time is very unfortunate and is equivalent to O (x2), that is certainly too large for several processes or applications. Hence, we intend to present a modified vector construct, which is built analogous to Merkle Tree substituting vector commitments rather than the classically used hash functions. The traditional Merkle Tree has the hash of its children being held on a parent node, whereas our new construct will have the Vector Commitment of its children nodes on the parent node. Branching factor plays a very vital role in this aspect as given in the Fig. 3.6, which has N-ary construct, where a branching factor of ‘m’ provides a competitive exchange between the bandwidth of the system and the computing health in terms of power. Reducing the bandwidth solely depends on the branching factor and not on the height of the tree. Our successful experimentation model shows a reduction factor of almost 7 to 9 compared to the existing Merkle Tree models.

N-ary merkle tree construct.
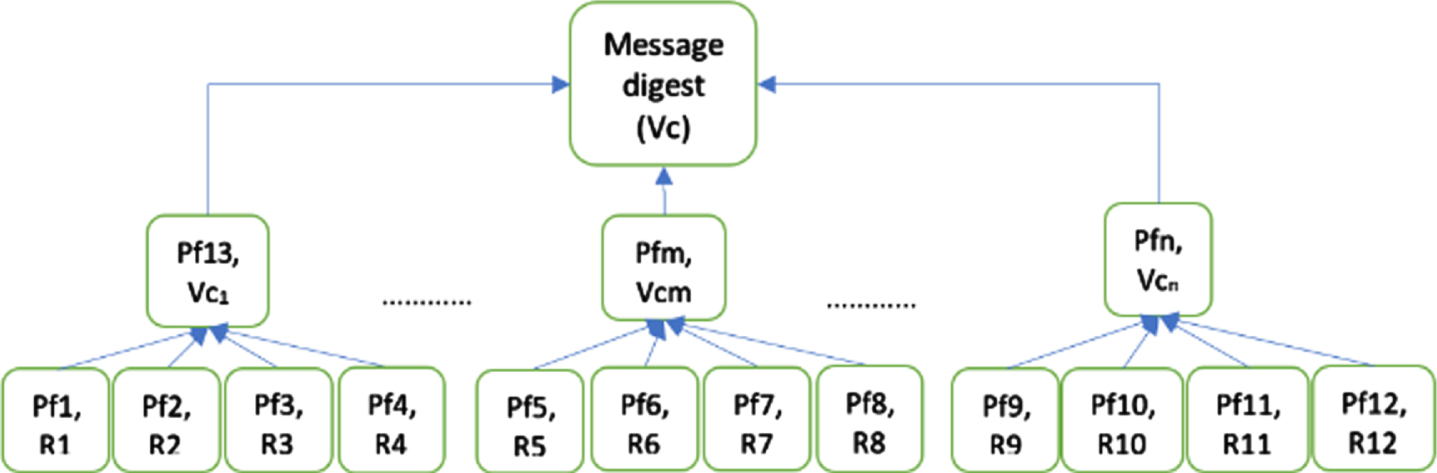
Our computation typically follows a fusion of various methods. As shown in Fig. 3.7, let’s have R1, R2, R3, … ., Rn are the files over which the computation has to happen. The vector commitment VC is calculated over R1, R2,..., Rn in addition to the proof of membership Pf1, Pf2,..., Pfn for each file R1, R2,...Rn respectively with respect to the VC. Hence, VC hierarchically is derived to be the digest of the commitment. Instantly, we utilize the vector commitment model promoted by Fiore et al., which incorporates the concepts of Computational Diffie-Hellman properties and total bilinear groups. Implementation of these hard-ended properties are out of our scope. Suggestively, the size of every proof of membership is found to be constant, in spite of the number of files that are held in the vector commitment. Even though it takes O (x2) to build a commitment including the O(x) proof of memberships, the fact that the size of proof stays constant is highly commendable.
Verkle Tree of Key Size - KS4.
As mentioned in the Fig. 3.8, the Hybrid Vector Committed BST (HVCBST) is an efficient data structure, which provides incomparable efficient search time; addition and updating of ordered data nodes inclusive of the proof of works. The hash value of every node is calculated as
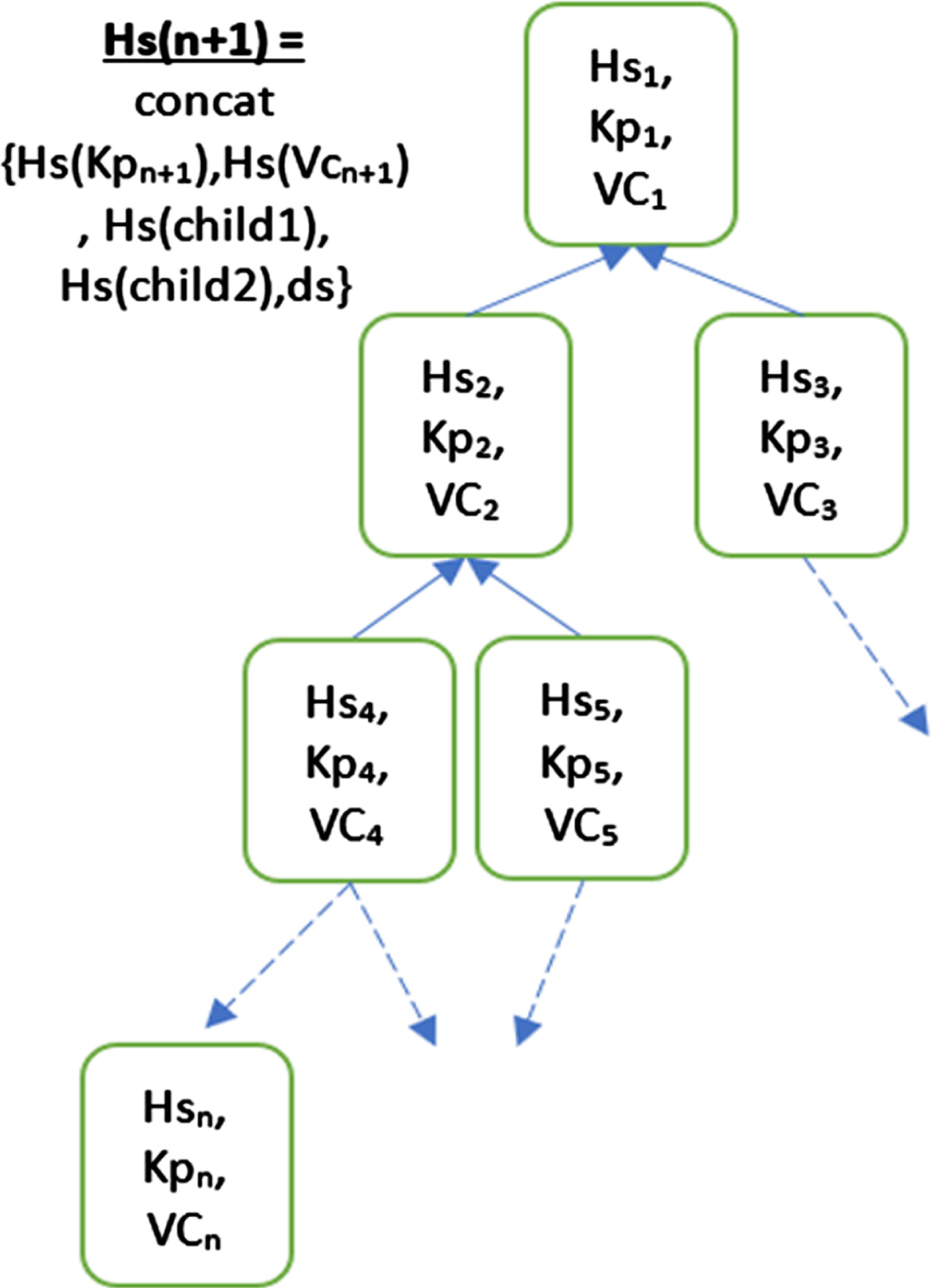
Hybrid Vector Committed BST (HVCBST).
Hs(child1), Hs(child2),ds}, where ds is the unit which separates the domain, Hs is the hashing segment of the control packets, Vc is the vector commitment, Kp is the search key. Like in a BST, our model accumulates the key entries in all the nodes of the tree and creates a traditional-similar hash structure for the purpose of authentication. This hybrid model is useful since it supports in providing a better way of reusing huge sets of key-value pairs across the various nodes in the distributed environment.
Implementation Algorithms:
Algorithm 3.2: Initialize (D, HF)
In order to create a new node in this implementation, we utilize the common method available in all the block chain data structures, Create Node (Ds, Key, Value) which incorporates the various intrinsic algorithms such as InsertNodeR(Ds, Key, Value), UpdateNodeR((Ds, Key, Value), SearchNodeR((Ds, Key, Value), GetFingerPrintR((Ds), GetProofR(Ds, Key) and VerifyProofR(MemP, F, KeyHash, H, ValueFP). Then we define the exact correctness properties of our associated data structures with that of the required membership proofs.
Algorithm 3.3: Block Structure
The above algorithm explains the basis of the block design. Initially the memory is checked to be empty or not. If not, then block index assigned to the created block and the previous hash along with the timestamp is embedded to the same structure. Finally, the hash of the current block is computed and then the block is returned. In case the block memory is not empty initially then null value is returned out of this method.
Algorithm 3.4: New Block Creation
Algorithm 3.5: Create Head Block
In order to create new block every time a new data log comes in for the chain entry, the above two algorithms are utilized. Initially, the request for the new block creation is validated. Once the validation is proven true, the details of the last block is obtained and the new block index for the currently processed block is instantiated. The timestamp is generated with the current date and time. With all these data upstream, then hashGen method created the hashed new block encoding the details along with the sent data. If the block is requested to be created as head, then the header hardcoded hash value is tagged along with this newly created block.
Algorithm 3.6: Validating the blocks
Validation is done through the proof of concept abstracted by the individual participating nodes in the network. The index of the received block is initially verified, further which the hash values of the previous block and the value inside the currently accessed block is verified to be valid. Once it has been proven then the current block’s hash value is validated against the hash that is calculated currently based on the data obtained, which gives the final validity status of the processed block.
Once the classified log data passes the type specific hash generation unit, it has to store in a secure storage system. Comparing the importance of log data with that of the user files or related data, the log data lags behind the regular user data or files. Therefore, a lighter algorithm satisfies the basic requirement to secure the log data. This creates a possible root to devise a low latency yet affordably secure algorithm in order to store the log data. Hence, the proposed simple encryption and decryption methodology – Multikey Hybrid Storage system (MKHS) is designed in a homomorphic way. It consists of three major phases. The key creation phase, followed by the encryption and decryption phases. All the three phases are discussed below as algorithms.
Procedure 3.7: MKHS Key Creation Select two unique prime numbers p1 and p2 Calculate q = pr1pr2, is the product of both the prime numbers, where pr1 is given by 1 + 2p1 and pr2 is given by 1 + 2p2. Pick a random value hr which belongs to ZQ*, and calculate h = hr2 mod q, where h belongs to Qq. Here Qq is given by the subgroup of squares in ZQ* which is the multiplicative group modulus Q. Also, q and h are released in public community, deleting pr2 and keeping pr1 safe and secure. The server S, then selects another unique prime number pr3, where pr3 < pr1 and keeps pr1 and pr3 secure. In order to create a private key for any user, the server identifies two random numbers, a and b and instantiates the following key, K = (pr3 x a + pr1 x b) mod q, where K is the respective user’s private key.
Procedure 3.8: MKHS Encryption Assume every data element is of length L. The user U, generates a random number Ur, which is of ‘x’ bits known privately. Then the user calculates the value of E. A = 2Lmax+[log n]. Ur+data, where Lmax is the maximum length of the data item ‘data’ and Ur is the random value chosen by the user in the earlier stages, number of users de noted by n. This indicates that the maximum bit size of A should be less than 2Lmax. In order to generate the encrypted text, the following calculation is done. E = (A + c. K) mod q, where c is a random chosen number by the user ‘U’ and A is the value calculated at step 4 and K is the calculated private key of the user. The encrypted text is given by the value of E.
Once the data is encrypted based on the above procedures, the encrypted data is sent to the storage service for permanent storage where it is kept intact. The decryption could be done as described in the next algorithm.
Procedure 3.9: MKHS Decryption The decryption starts by identifying the value of E by using the keys pr1 and pr3. E can be calculated as E = (A mod pr1) mod pr3 Once the value of E is identified, then the Decryption can be done with the attributes Lmax and n D = E mod 2Lmax+[log n], where the equation related to E can be referred from the previous algorithm and Lmax gives the maxi mum bit length followed by the number of users n. The value of D is the plaintext obtained. This can be generated by only authenticated users in the cloud service.
All the three algorithms namely, encryption, decryption and key creation are designed in such a way that the working complexity nature of the algorithm is reduced but the efficiency is increased. This algorithm is used to store the log data in a secured fashion; hence, it should be light weighted but at the same time, it cannot compromise on the traditional qualities of any encryption and decryption cryptographic algorithm.
Attack state and validation model
It is proposed to evaluate our implemented model through the classical evaluation [4] techniques which describes the role and the state of every attribute during evaluation. According to this model, the attack personnel is capable of apprehending any data that is sent and received over the network, probably the internet. In this way, the attacking entity is able to alter and resend the data to both the communicating entities in discussion. This attacking entity can also act as a legal system user pretending to be valid network systems. The attacking entity can also support in compromising the entire logging mechanism by altering the log data. By means of impersonation, the attacking entity can spoil the privacy of the server. It is also capable of copying the data from any illegal outside source and database into the working systems.
Performance evaluation and result discussions
The implementation part includes a proof-of-concept solution for the proposed work. The implementation is done with two pathways. The first prototype is implemented through creation of log clients (computers from which the logs are gathered), the system the monitors the logs and its semantics, and the repository with cloud log infrastructure with Java, its core and supporting packages. The second prototype has been developed through Ethereum.
Since Ethereum has gained more popularity in recent years for blockchain implementation, we have utilized the same for our proposed model implementation of Propagated Chain of Log Blocks (PCLB). This PCLB is layered on the top of available private blockchain. In order to make it public, we have built a fused structure where we deploy both our private framework with Ethereum blockchain network. The financial economics of Ethereum are managed through fees such a Gas. This gas is executed and paid through Ether, which is the official currency of Ethereum, and the gas is used to measure the total energy required to process the complete and related transactions.
In our model evaluation of the implemented system, the core analysis is based on a) the extent to which the insertion and processing of the log records in our Propagated block chain structure affects the performance of the solution and b) the extent to which the communication and processing of the logs for validation for integrity affects the performance of the system. Based on the above two essential factors the performance of the overall implemented system is captured and evaluated.
The basic experimental setup variables are shown in Table 4, which depicts the factors involved in the setup.
Implementation setup features
Implementation setup features
The overhead experienced with respect to the number of log messages processed is studied and the results are analyzed in Figs. 4.1, 4.2 and 4.3. The analysis is done in three different aspects such as a) the overhead versus the number of log messages when there is no security model enabled, b) the overhead versus the number of log messages when the security model is partially enabled, and finally c) the overhead versus the number of log messages when the security model is fully enabled. It is clearly seen that the overhead in milliseconds gradually increases as the number of log messages increase and it is a huge variation for the overhead when the log messages are processed using our security constraints which proves the efficacy of our implemented model.
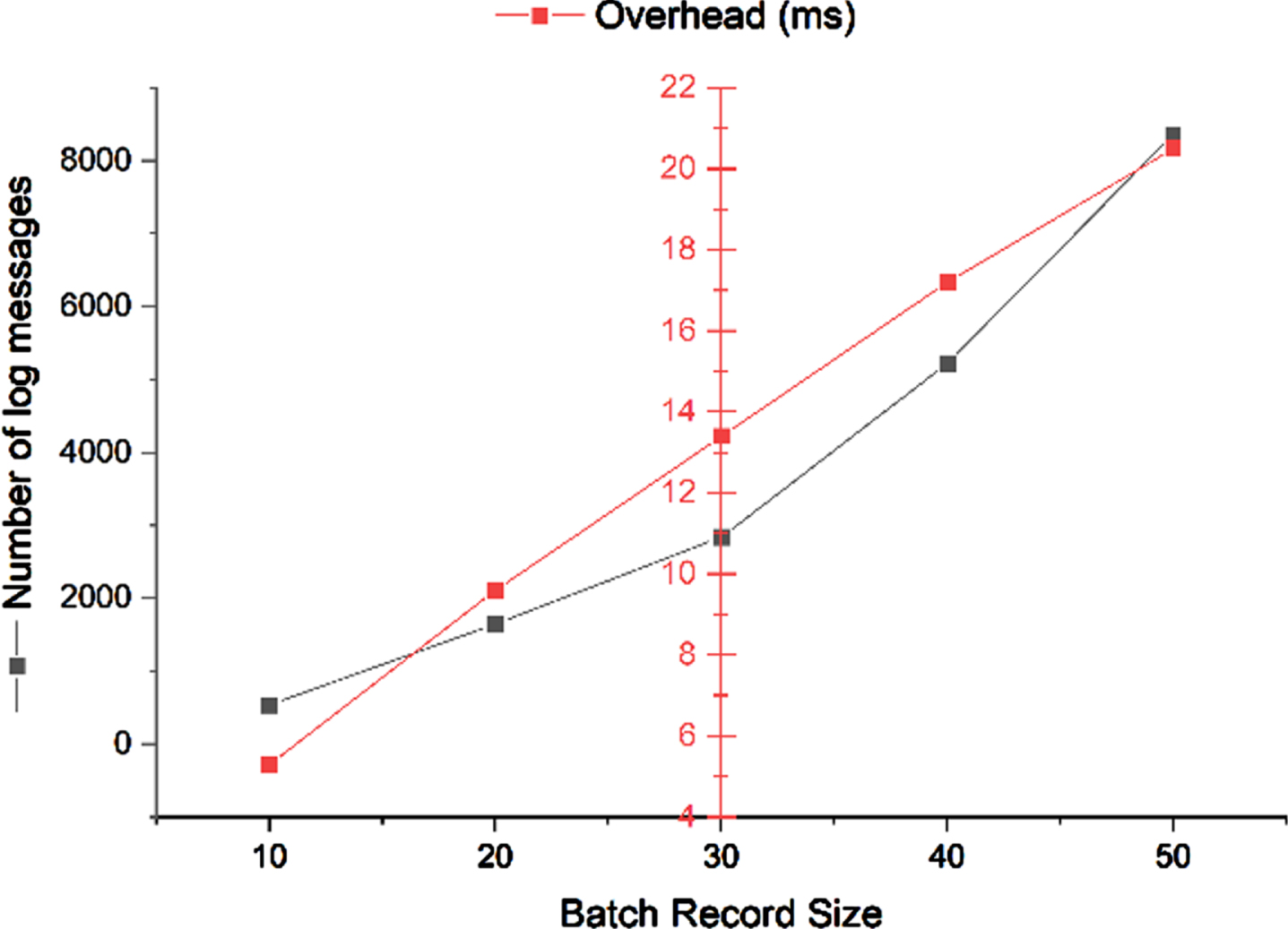
Overhead with no enabled security constraints.

Overhead with partially enabled security constraints.

Overhead with fully enabled security constraints.
The memory required in the form of storage overhead is analyzed in Table 4.1. It shows the variation in the memory utilized when the log messages are processed in queues. For simplicity and better comprehensibility, we have the log messages grouped into batches as per the classification made in the initial stages of our work.
Storage overhead
Storage overhead
The storages requirement doubles as we move from 1K to 5K and further which further extends the case that message batch ranging within 1K have a better memory utilization and prone to less memory leaks.
False positive is the attribute that gives information about the number of messages that has been wrongly identified as model failure when there is none in reality. It gives the percentage (%) of erroneous data identified when there is no such error in the implemented model. As shown in Table 4.2, the false positive ratio percentage decreases, the storage memory gained increases gradually. This can be interpreted as the storage savings increases with lower false positive index which proves the strength of the implemented model in memory saving. Through Table 4.3, it is understood that during validation of the block data, as the number of log messages or batch of messages increase, the false positive rate gradually decreases which highlights the validation economy obtained by the proposed model.
False positive ratio vs storage savings
False positive ratio vs storage savings
False positives with respect to logs (Integrity validation)
Time complexity of the built data structure has a huge impact in determining the complexity and efficiency of the overall system. Table 4.4 compares the time complexities of the existing tree structures such as Merkle tree, Committed Vector tree, Verkle formatted tree with respect to the proposed HVCBST model. The proposed HVCBST has better complexity in terms of time and nominal complexity in terms of space, which directly relates to the overall efficiency of the implemented model.
Time complexity comparison
Time complexity comparison
Fragmentation and Defragmentation is the process of modularizing the incoming data in order to have an ease in processing and reducing the load in the processing element. Since our model is based on log of block chains, fragmentation and defragmentation computation time plays a very vital role in deciding the efficiency of the implemented proposed system. As we see in the Figs. 4.4 and 4.5, the computation cost for the fragmentation and defragmentation is improvised and is nominal for range of data between 64 Mb and 512 Mb, which seems to be a normalized and optimal threshold for our model.
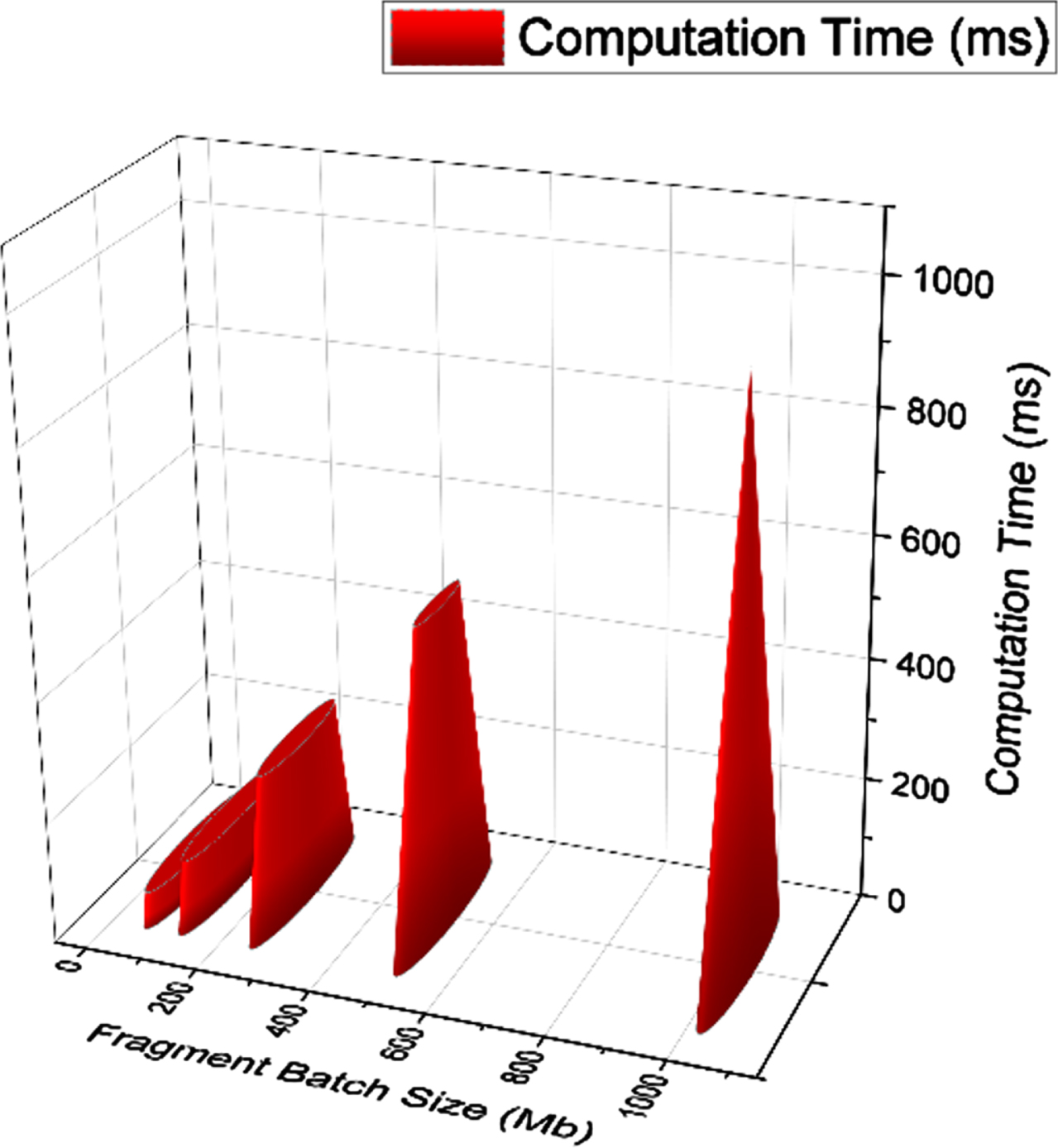
Computation time for batch fragmentation.
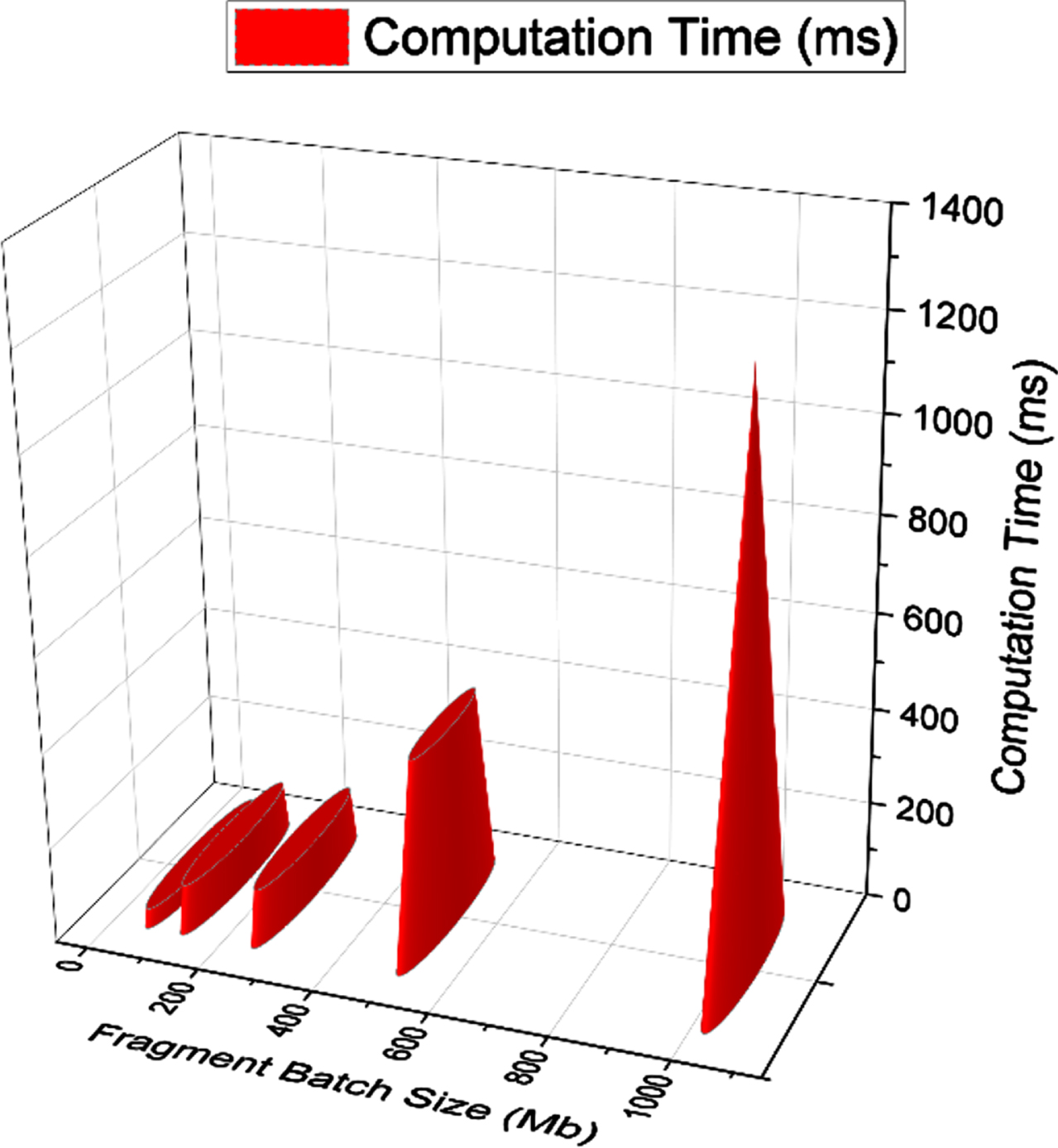
Computation time for batch defragmentation.
The successful attack probability depicts the number or percentage of nodes that are to be compromised in order to evade the overall system for any outside or third party hacker entity. This factor shows the efficiency of the implemented system through the validation process. It can be clearly witnessed from the Table 4.5, that the successful attack probability ratio is very less (0.055) and it gradually aiming to reach nil as the number of participating nodes in our block chain network increases.
Percentage of nodes to compromise vs successful probability
Percentage of nodes to compromise vs successful probability
The total number of bytes transferred per second can we witnessed through the Table 4.6 as the compared to the communication overhead. The cost of communication can be obtained through the communication overhead and the increase in the communication bits per second is minimal with respect to the increase in the number of logs. It is clearly shown that the threshold for the communication cost is comparatively low making the proposed model an efficient one.
Communication overhead
Communication overhead
The encryption process plays a vital role in the proposed model. The time taken for encrypting the textual data with that of the size of the data packets are compared in Fig. 4.6. As depicted in the figure, the proposed MKHS algorithm gives optimal efficiency compared to the algorithms of similar family until a slight variance witnessed around 2000 kb of data packet size. This might be marginal and can be presumed to be the optimal threshold for our data processing system. Similar to encryption, the decryption process also plays a vital role in the proposed model. The time taken for decrypting the textual data with that of the size of the data packets are compared in Fig. 4.7. As depicted in the figure, the proposed MKHS algorithm gives optimal efficiency compared to the algorithms of similar family until a slight variance witnessed around 1000 kb to 2000 kb of data packet size.
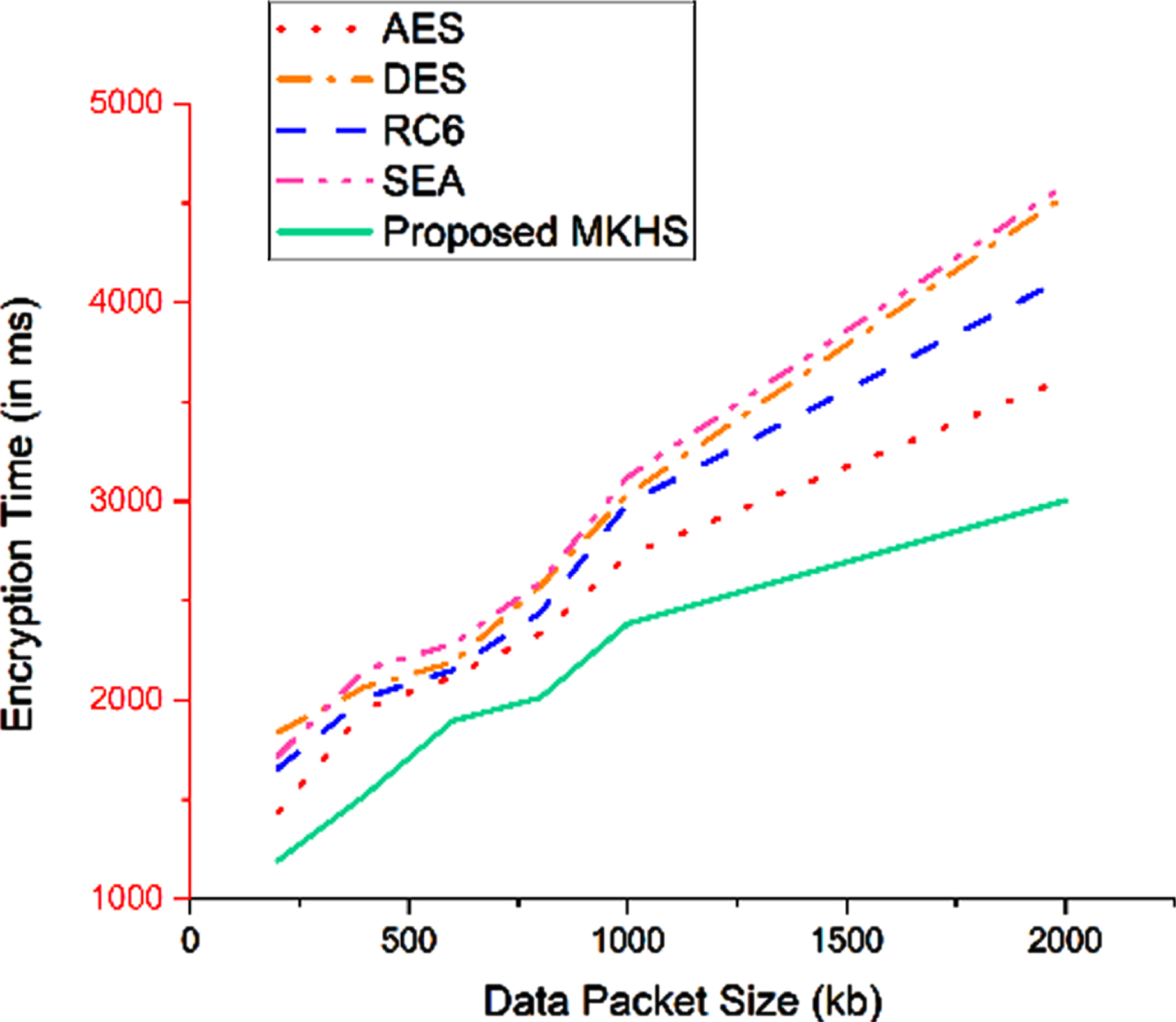
Processing time comparison for textual data encryption.
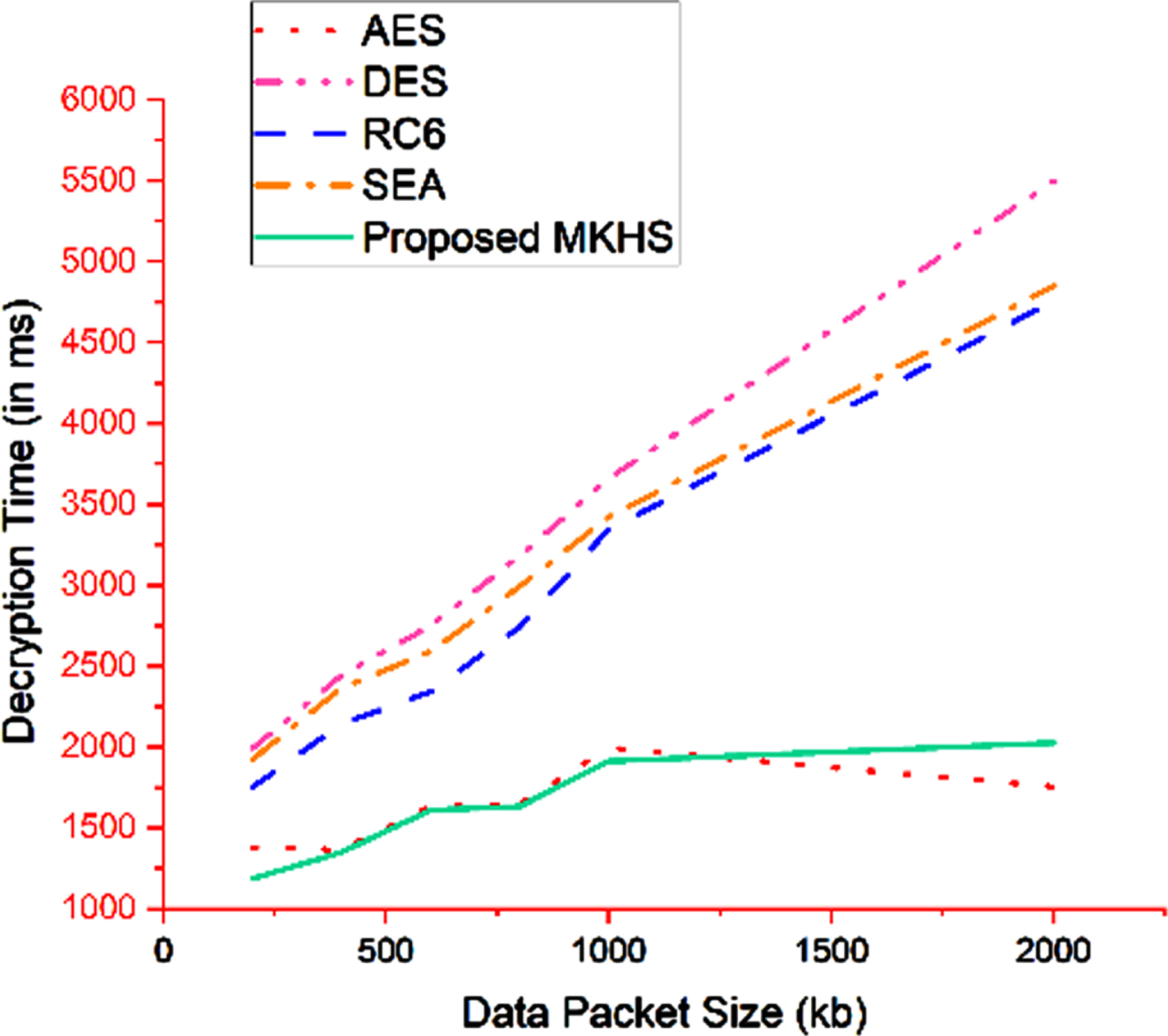
Processing time comparison for textual data decryption.
This might be marginal and can be presumed to be the optimal threshold for our data processing system.
Correlation is an effective method to evaluate out how strong a cryptographic algorithm works and retains the security attribute to its core efficiency. In this study, the connection between the encrypted data and the original data is evaluated. An effective encryption approach will ideally result in encrypted data with 0% overlap. The analysis of correlations seen during the image data sequencing is shown in Table 4.7.
Correlation in image data encryption
Correlation in image data encryption
The throughput rate can be used to evaluate the algorithm’s effectiveness. The algorithm’s throughput is directly related to its performance; the higher the performance/the higher the throughput as given in the Fig. 4.8. The formula for calculating the transfer rate of encoder technology is as follows.
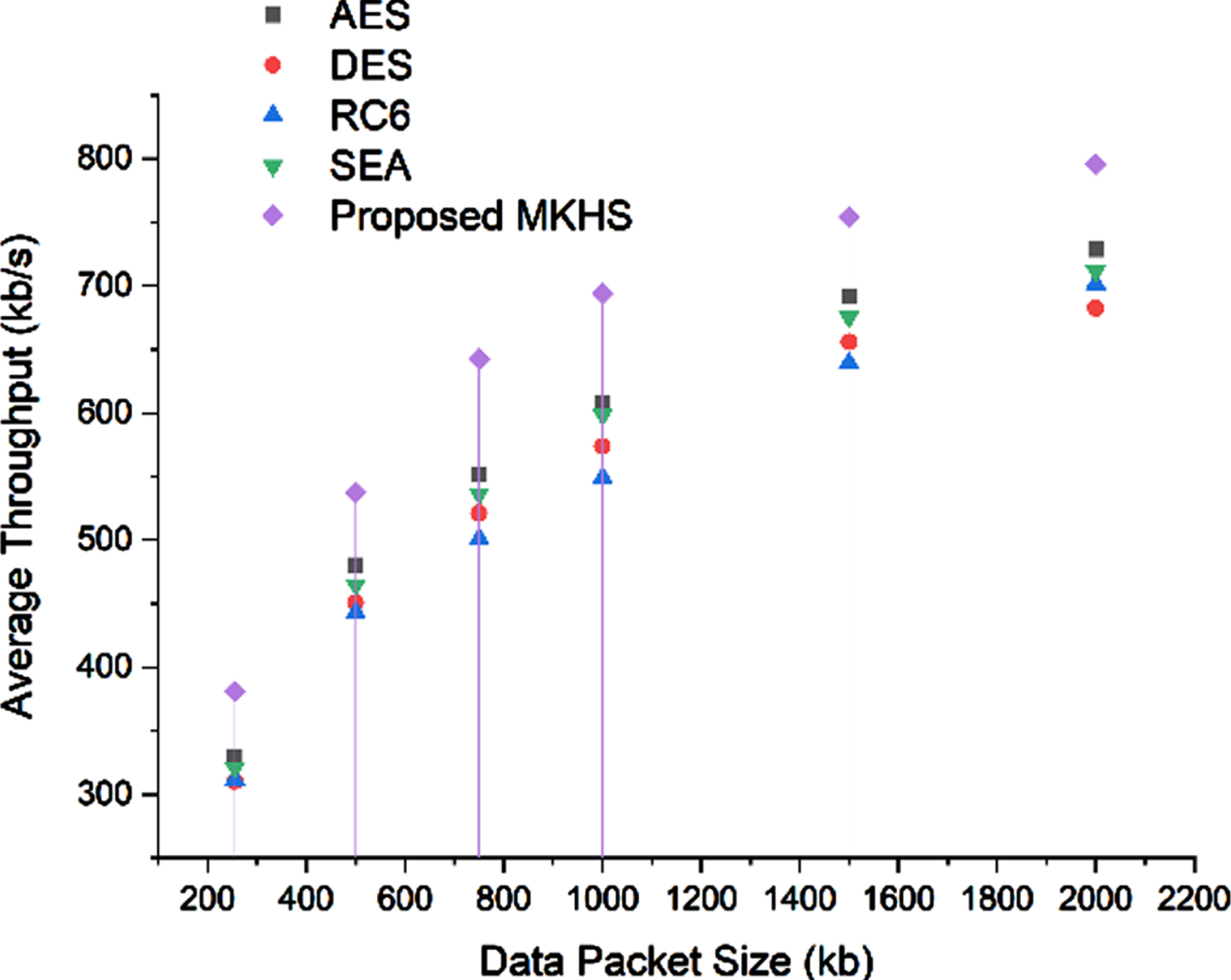
Average throughput comparison for the proposed MKHS.
Throughput = PlainTextSize/Encoding (enc/dec) Time
Tables 4.8 and 4.9 shows the overall amount of memory utilized for execution of the encryption and decryption modules of the MKHS algorithm. As witnessed the total memory required in megabytes are comparatively low with respect to other counterparts, which proves the efficiency of the implemented model.
Encryption memory utilization comparison
Encryption memory utilization comparison
Decryption memory utilization comparison
The memory occupancy witness wide variation as the data packet size lies within the threshold of 2000 kb and more which can be a key consideration when processing the blocks of data in the proposed mechanism.
This paper proposes a framework to maintain the integrity of the log data. Initially it captures the data from the log generation processing and migration unit, which in turn is sent to the classification unit for further classification based on the user priority. Integrity of log data is maintained through the propagated chain of log blocks and the Hybrid Vector Committed BST (HVCBST) methods. Further, the log data is secured using the lightweight multikey hybrid storage structures. The implementation is done using Ethereum, self-coded platforms, and the results are compared and validated. The results of the implemented systems have proven to be much more efficient and tamper proof compared to the existing frameworks and methodologies. One of the limitations experienced is the implementation space and time required for the hybrid vector committed BST gradually increases as the data threshold goes beyond 3000kb per packet, which has a wide scope for improvisations in future implementations. In future, the classification of the log records can be improvised further by studying dimensionality reduction and better data splitting techniques, so that better processing efficiency can be obtained.