
Abstract
Optimal allocation of production resources is an urgent need for the development of industrialization. Reasonable production scheduling algorithm and excellent scheduling scheme can efficiently plan production resources, reduce production costs and shorten order completion time. Genetic algorithm has become one of the most popular algorithms for solving job shop scheduling problem because of its simplicity, versatility and good robustness. However, the genetic algorithm for solving NP-hard problems such as job shop scheduling has the problem of falling into local optimum, which leads to the decrease of solution accuracy. This study focused on the problem and proposed a generic enhanced search framework based on genetic algorithm, which named niche adaptive genetic algorithm. The niche selection mechanism and adaptive genetic operators were used to enrich the diversity of population, balance the genetic probability and enhance the global search performance of the algorithm. The working mechanism of this algorithm is analysed by testing data, and the proposed algorithm was tested on job-shop scheduling problem instances. The results show that the performance of the proposed method is 0.79 percentage points higher than that of the standard genetic algorithm, and it has the ability to search for the global optimum.
Introduction
Production scheduling problem is a key problem in manufacturing field. Production scheduling technology is an important technology in manufacturing system and enterprise management, and it is also one of the key technologies to realize intelligent production. Since Johnson first proposed the optimization method of the flow shop scheduling problem processed by two machines in sequence, researchers all over the world have carried out in-depth research on this problem. Most of the scheduling problems at this stage are small-scale, and generally use Branch and Bound, Dynamic Programming [1–4] and other enumeration methods for solving.
Since the emergence of large-scale flow shop scheduling problem, the heuristic constructive approximation method is used to solve it due to the high computational time cost of the exact algorithm [5–7]. However, although heuristic rules can meet the requirements of industrial production to obtain the approximate solution quickly, when the scheduling scale increases again, the solution time will also increase geometrically. The emergence of metaheuristic algorithms provides a more efficient way to solve NP-hard problems, such as Genetic algorithm [8], Particle swarm optimization [9], Ant colony optimization [10], Differential evolution algorithm [11]. These algorithms have in common that they all require separate encoding and decoding processes, and differ in the rules for updating the population. Reeves [12] first proved that genetic algorithm can be used to solve flow shop scheduling problem. Since then, genetic algorithm has become one of the most popular algorithms for solving job shop scheduling problems due to its simplicity, versatility and good robustness. Banu Cali et al. [13] counted the algorithms adopted by researchers in job-shop scheduling solutions from 1997 to 2012, among which genetic algorithm ranked first with 26.4% of applications.
In the practical application of genetic algorithm, due to the shortcomings of the algorithm itself and the characteristics of the problem, some defects are common and need to be solved. A typical one is easy to fall into local optimum, which affects the accuracy of the solution [14–16]. The researchers theoretically analysed the reasons for the problem. The population individuals processed by genetic algorithm are limited, so there are random errors, mainly including sample errors and selection errors. The limited individuals in the selected population cannot represent the whole population, which will cause sample error. The sample error of a small population will hinder the forward transfer of the search process and hinder the appearance of the expected performance. The sample cannot reflect the required proportion with arbitrary accuracy, and the randomness of selection will lead to a large gap between the sample and the theoretical prediction. As a result, population diversity and effective features are lost early in the middle of the iteration, and the search performance is reduced.
The single algorithm cannot satisfy the application of the current scheduling problem model, so most of them use the strategy of mixing with other algorithms to enhance the search performance of the hybrid algorithm by using the advantages of a variety of algorithms. The literature [17] utilizes Refraction Learning (RL), which is a special type of opposition learning, to generate a diverse initial population of solutions and uses three mutation methods to explore the search space of a problem. In literature [18], subpopulations are divided and multiple mutation methods are used to enhance the search ability of the algorithm. In literature [19], the information of the current solution and its neighbors are utilized and shared reasonably with a cooperative search by utilizing the history information in the previous iteration and collaborative selection strategies based on feedback to explore the solution space efficiently. In literature [20], the population is initialized by using two heuristics based on problem-specific knowledge and a random heuristic and two knowledge-based local search operators are proposed to enhance the exploitation. In literature [21], variable neighborhood search based on the reinforcement learning is introduced to balance the exploration and exploitation, and further to generate the current optimal. In literature [22], Q-learning is employed to select an appropriate low-level heuristic from a predesigned set according to historical information fed back by low-level heuristic. Through the study, it is found that the improvement of the algorithm can be roughly divided into three aspects: hybrid local search, optimizing the initial population and optimizing the population update strategy. The literatures [23–26] introduces algorithms with local search capability such as tabu search and simulated annealing algorithm to improve the local search capability. The literature [26–29] has designed and introduced heuristic rules to optimize the initial population. Regarding the population updating strategy, more attention is paid to the construction of effective neighborhood structures to produce better quality solutions [31, 32].
Most of the above methods are designed according to the characteristics of the problem, and are targeted to solve a certain kind of problem. Crossover probability and mutation probability are two key control parameters in genetic algorithm. Reasonable parameter setting can improve the search performance and convergence performance of genetic algorithm. Selecting dynamic genetic probability is a general way to improve genetic algorithm. The larger the crossover probability is, the larger the proportion of individuals in the population is theoretically updated. Especially in the early stage of iterative search, the higher the individual diversity is, the wider the global search scope of the algorithm is. However, the crossover operation with high probability also has disadvantages. Even the excellent individual has a higher probability of being destroyed. At the later stage of iteration, the crossover operation will lose the ability to update the population individuals because the population tends to converge, so the crossover probability value has little effect on the performance of the algorithm at this time. On the other hand, if the value of crossover probability is too small, the iterative process will be difficult to generate new individuals, which will lead to the stagnation of population evolution. Mutation operation in standard genetic algorithm is the only effective means to make the search escape from the local optimum. If the mutation probability is too large, although it can play the role of updating individuals to enrich the diversity of the population, it will also make each mutation operation update a large proportion of individuals in the population, resulting in the algorithm becomes a random search and lose the search direction. On the other hand, if the value of mutation probability is too small, the iterative process will be difficult to generate new individuals, which will lead to the stagnation of population evolution [32–34]. To play the important role in the genetic operation of crossover probability and mutation probability, dynamic adaptive operator is designed by researchers to perform dynamic genetic operation [36–39].
In this paper, an effective improvement scheme with generic enhanced search framework based on genetic algorithm is addressed. The niched selection mechanism and adaptive mechanism help to balance the relationship between population diversity and convergence. In order to verify the performance of the proposed NAGA algorithm, the job shop scheduling problem instances are solved, and the effectiveness of the proposed method is proved by comparing with the standard genetic algorithm and other improved algorithms.
The remainder of the paper is organized as follows. Section 2 proposes the method. Section 3 shows the mathematical mode of job shop scheduling problem and the solution flow of genetic algorithm for job shop scheduling problem. Section 4 gives the experimental results. Section 5 provides the conclusion.
Method
By comprehensively analysing the problems encountered in the application of genetic algorithm, a generic enhanced search framework based on genetic algorithm is designed, and it is embedded into the genetic algorithm to form a niche adaptive genetic algorithm. The flow chart of the algorithm is shown in Fig. 1.
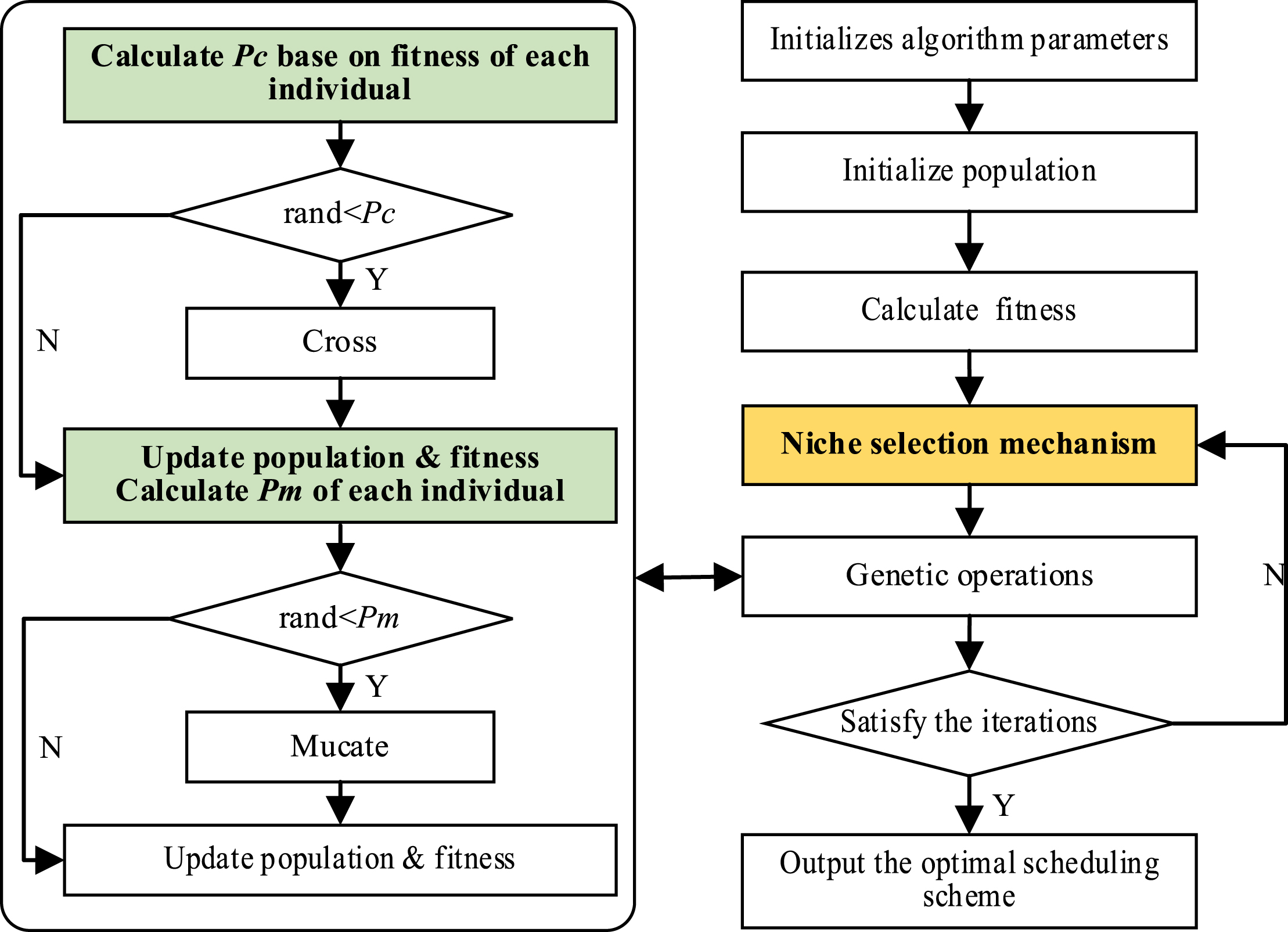
Flow chart of niched adaptive genetic algorithm.
The genetic framework uses niche selection mechanism to create a niche according to the fitness distribution of individuals in the population, and punishes the suboptimal individuals in the niche. At the same time, the genetic probability of individuals is dynamically adjusted by an adaptive function, so as to achieve the purpose of balancing the diversity of individuals and the retention of excellent individuals.
The basic idea of selection is the survival of the fittest, and the individual with low fitness is not completely eliminated. Assuming that the population size is M and the fitness value of individual i is f
i
, the individual probability can be calculated by Equation (1).
The commonly used selection operators are:
(1) Roulette wheel selection operator
The roulette wheel selection operator is the most commonly used selection operator in GA. Its essence is proportional selection, and the basic idea is that the probability of an individual being selected is proportional to the size of the individual fitness. Specifically, the fitness is ranked from small to large, and the cumulative probability of each individual is calculated according to this ranking as follows:
Then generate a random number r in the interval [0,1], search for individua k, such that P k - 1 < r≤P ki , then select individual k to enter the next generation. A new random number is generated again and the above process is repeated until the offspring population size reaches M.
(2) Tournament selection operator
Select k individuals from the population randomly, and determine the optimal individual among the k individuals across their fitness, then put the first λth optimal into the offspring population. As an extension of this selection operator, the size k of the tournament and the number of advanced individuals can be adjusted as needed. The advantage of this selection operator is that it does not need to convert the fitness calculation, and can be achieved by comparing the value of the objective function. The principle of the tournament selection operator is shown in Fig. 2.
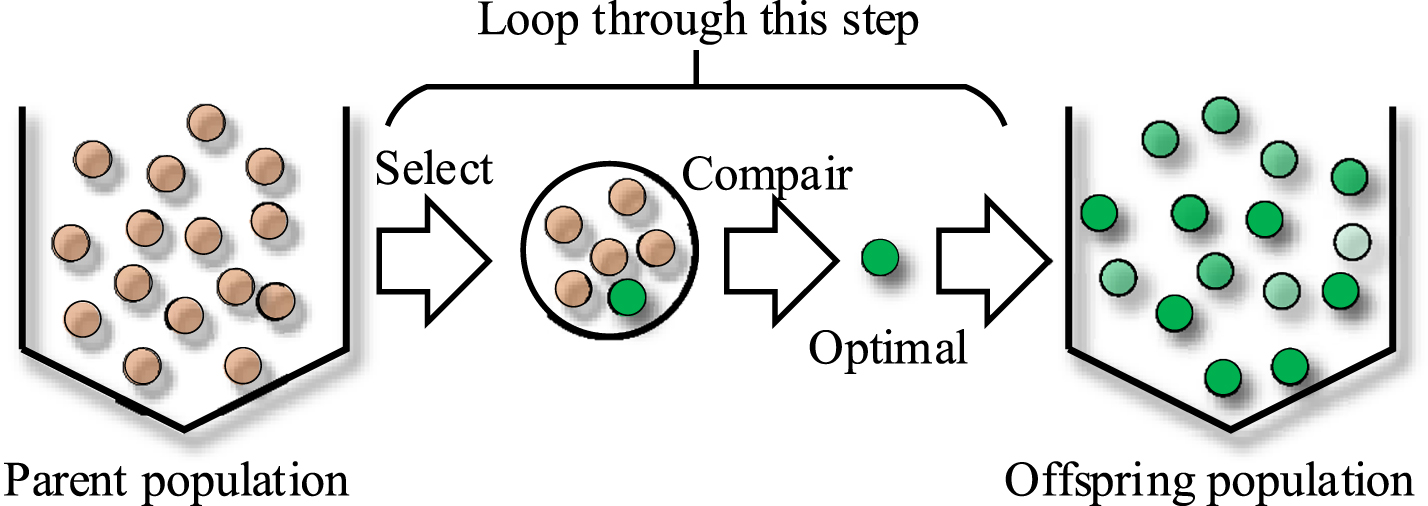
Tournament selection operator.
(3) The optimal saving strategy
The idea of the optimal preservation strategy is to keep individuals with higher fitness to the next generation as much as possible. From the 1st generation, the best and worst individual fitness individuals in the contemporary population are found, and the best individual is recorded as the best individual so far. From the 2nd generation, the best individual so far is updated, and the worst individual in the current population is replaced by this individual. As an extension of this selection operator, the number of recorded individuals and the number of substitutions can be adjusted as needed.
The above 3 selection operators can be considered as greedy mechanism selection strategies to some extent, which have the advantage of simple operation, but for multimodal optimization problems, individual aggregation is easy to fall into local optimum. In order to make up for the defects of the common selection operator, the concept of niche from biology is introduced. In the process of biological evolution, biological individuals usually live together with their own species and reproduce together, thus constituting a specific living environment. Improve this idea and apply it to the genetic algorithm selection mechanism: when the Hamming distance of two individuals is less than a predetermined value (or niche distance), the individual with the smaller fitness will be punished. Figure 3 shows the principle of the niche selection mechanism.
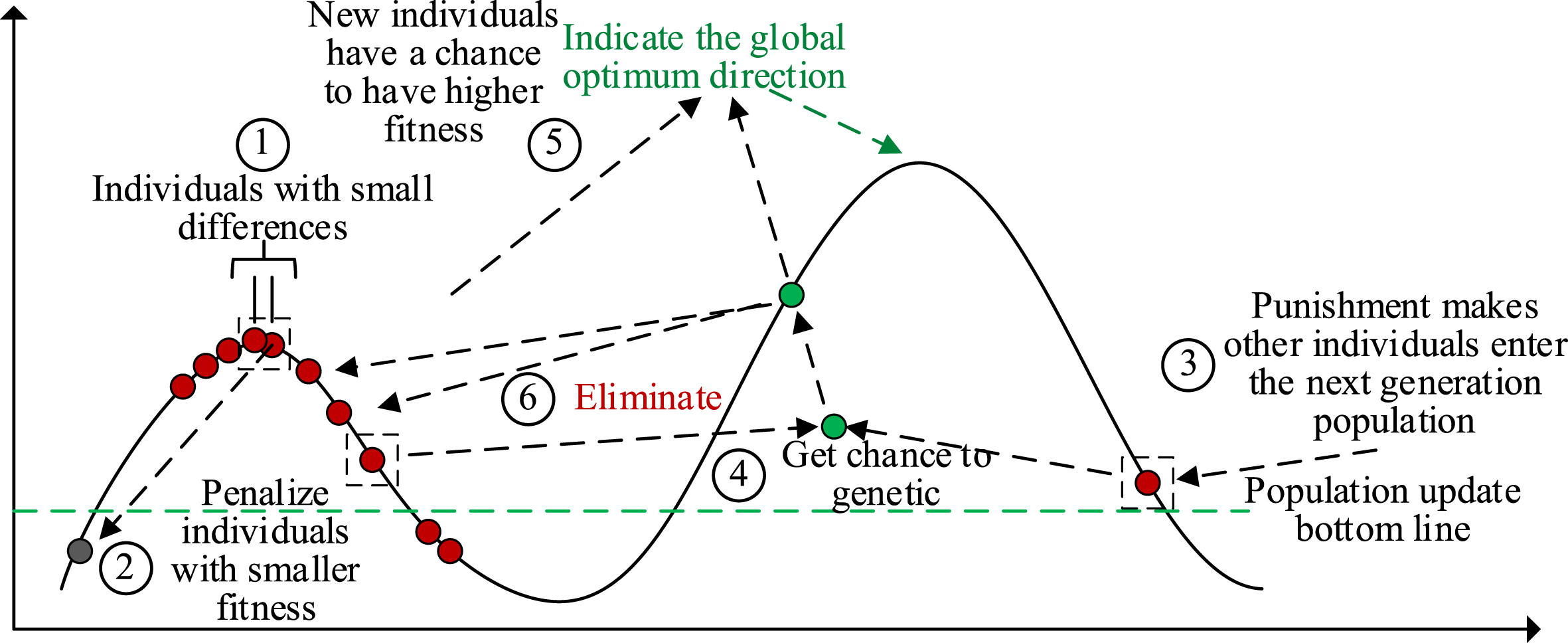
Principles of niched selection mechanisms.
The idea of the niche selection mechanism proposed in this paper is as follows: First, pairwise comparisons of Hamming distances between individuals in the population are performed. If the obtained Hamming distance is less than a pre-set value L, their fitness is compared and a strong penalty function is imposed on the individual with lower fitness, which reduces its fitness. In this way, for two individuals in the same peak range, after the penalty function, the fitness of the worse individual becomes worse, and its probability of being eliminated in the subsequent evolution process increases. In other words, there is only one individual with high fitness in a single peak range, so that the population of the same generation not only maintains the diversity of individuals, but also maintains a certain distance between individuals, and improves the ability of global search. This allows individuals to be more dispersed in the whole solution space, achieving niche states. The specific steps are as follows:
Step 1: Randomly generate u individuals {x1, x2, …, x u }, to form the initial population P, and calculate the fitness F(x) of each individual.
Step 2: Sort individuals in descending order according to their fitness, and record the first v (v < u) individuals in filial population Q.
Step 3: Perform selection, crossover and mutation to population P according to rules and get the updated P.
Step 4: Merge P and Q, and then calculate the Hamming distance H(xi, xj) between these u+v individuals. If H(xi, xj) < L, then min(F(xi), F(xj)) = Penalty, where Penalty = Avg(P).
Step 5: Update the fitness of these u + v individuals and sort them in descending order. Then select the first u individuals to form new P.
Step 6: If the termination condition is not satisfied, then turn Step 2. Otherwise, end loop.
Crossover probability Pc and mutation probability Pm are two key control parameters in GA. Reasonable parameter settings can improve the search performance and convergence performance of genetic algorithm, so that ideal results can be obtained in optimization applications.
The crossover probability Pc determines the ability of the population to maintain diversity among individuals during evolution. The larger the Pc is, the larger the proportion of individual updates in the population is theoretically. Especially in the early stage of iterative search, the higher the individual diversity is, the wider the global search scope of the algorithm is. However, the crossover operation with high probability also has disadvantages. Even the excellent individual has a higher probability of being destroyed. At the later stage of iteration, the crossover operation will lose the ability to update the population individuals because the population tends to converge, so the crossover probability value has little effect on the performance of the algorithm at this time. On the other hand, if the value of Pc is too small, it will be difficult for the iterative process to generate new individuals, which will lead to the stagnation of the population evolution.
The mutation probability Pm has the ability of updating individuals and maintaining the diversity of population in the whole search cycle of standard genetic algorithm, and the level of this ability does not change with the process of iteration. The most important function of Pm is that in the later iteration, when the population tends to converge and the crossover operation cannot update the individuals, the mutation operation is carried out according to its pre-set probability to update part of the individuals in the population. Mutation operation in standard genetic algorithm is the only effective means to make the search escape from the local optimum. If Pm is too large, although it can play the role of updating individuals to enrich the diversity of the population, it will also make each mutation operation update a large proportion of individuals in the population, resulting in the algorithm becomes a random search and lose the search direction. On the other hand, if the value of Pm is too small, it will be difficult for the iterative process to generate new individuals, which will lead to the stagnation of the population evolution.
In summary, the performance of standard GA can be theoretically improved by using dynamic strategies to change the crossover probability and mutation probability, so that GA can exert its search advantages in optimization applications.
Theoretical analysis of dynamic adaptive operators
(1) AGA-1
Srinivas et al. [37] proposed an adaptive operator, and this is also an early adaptive operator. As shown in Equations (4).
It can be seen from the above equation that when f’ is larger than favg, the value of Pc and Pm are adjusted linearly and adaptively. On the contrary, when f ’ is smaller than favg, then a large fixed value k2 and k4 is given. This method allows individuals with poor fitness to evolve quickly, but sometimes individuals with poor fitness also carry some good genes. However, the larger the fixed values of k2 and k4 are, the higher the probability of losing these high-quality genes carried by poor individuals is, thus destroying the diversity of population individuals to a certain extent and increasing the possibility of the algorithm falling into local extremum.
(2) AGA-2
Guo et al. [36] proposed an adaptive operator and it is shown in Equations (6).
From the above equation, it can be seen that this method ensures that all individuals in the population have a large probability of crossover and mutation in the early stage of iterative evolution. With the increase of the number of iterations, the value of (tmax-t)/tmax will approach 0, so that the values of Pc and Pm become smaller and smaller, which makes the population stop updating and achieves the effect of convergence. This gives the algorithm a forced convergence effect. The setting of constants pc1 and pm1 has the same effect as the setting of Equations (4), which is the same in search performance.
(3) AGA-3
Yan et al. [38] proposed an adaptive operator, and it can adjust the order of crossover operation and mutation operation in genetic algorithm according to the relationship between average fitness and maximum fitness of population individual. As shown in Equations (8).
where fmax represents the maximum fitness value of all individuals in the population, favg represents the average fitness value of individuals in the contemporary population, kc and km are two constant coefficients of crossover probability and mutation probability respectively.
As can be seen from the above equation, favg/fmax = 1/2 is taken as the cut-off point to judge the dispersion and concentration of individuals within the population. With the change of favg caused by iterative evolution, the response speed of arcsin(favg/fmax) will be different, which makes the standard of judging the concentration and dispersion state of individuals in the population will be different. A characteristic of this adaptive method is that the so-called adaptive adjustment is population specific, that is, within the population of the same generation, all individuals adopt the same Pc and Pm values. However, the previous two methods are for individuals, and the Pc and Pm values of each individual can be different in theory.
Sigmoid function is the most commonly used function to construct neuronal activation functions, which can show a good balance between linear and nonlinear behavior. The Sigmoid function is defined by Equation (9).
The Sigmoid function has a smooth top and bottom and its image is symmetric about the centre of the point (0,0.5). As x tends to –6, S(x)tends to 0. As x tends to 6, S(x)tends to 1. According to this feature, this paper proposes an adaptive operator based on Sigmoid function, denoted as AGA-S, which calculates the crossover probability and mutation probability of individuals according to the different fitness of individuals in the population, so that the probability value has the characteristics of Sigmoid function, that is, the top and bottom positions realize absolute crossover, no-crossover, mutation and no-mutation strategies. The intermediate group performs probability crossover and mutation operation according to its fitness in the population. As shown in Equations (11).
where the parameter meaning is exactly the same as in AGA-2. From Equations (11), it can be seen that Pc and Pm can be nonlinearly adjusted according to the relationship between favg and fmax. When most individuals in the population have considerable fitness, that is, when fmax is close to favg, Pc and Pm will increase. At the same time, individuals with fitness near fmax will get a smaller Pc and Pm, whose value is infinitely close to pc2 and pm2, which will be beneficial to retain good genes.
Problem description
There are n jobs {J1, J2, …, J n } are required to process on m unrelated machines {M1, M2, …, M m }, and job J i contains m operations {Oi1, Oi2, …, O im }. Each operation of each job specifies a fixed processing machine and the processing time is determined. Different operations are located in different processing machines. It is required to find out the processing sequence of different jobs that meets the requirements of the operation sequence to meet the objective function optimization. Figure 4 shows the schematic diagram of job shop scheduling problem.
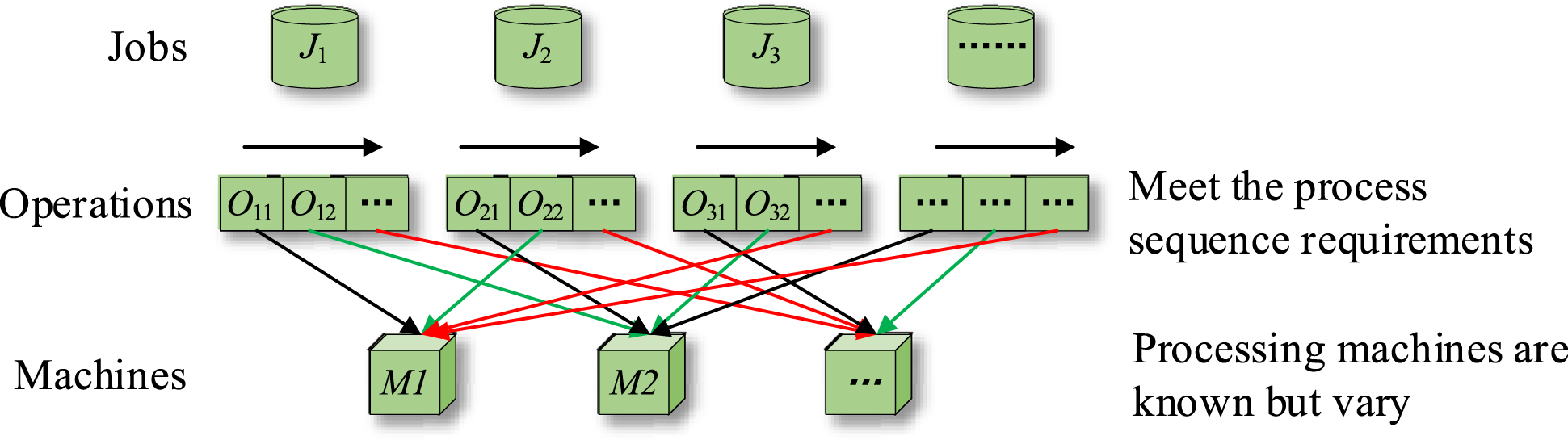
Schematic diagram of job shop scheduling problem.
When the makespan is taken as the objective function, the objective function of the scheduling with respect to the minimum makespan can be expressed as Equation (12), in which C
ij
presents the complete time of operation O
ij
.
s.t.
The size of the job shop scheduling problem can be simply calculated as n×m, where n is the number of jobs and m is the number of machines. Each job owns the same number of operations, denoted as o, and o = m in general. Then, for a job shop scheduling problem of size n×m, the number of all its solutions is (n×m)!/(o!) n . Table 1 shows an instance of job shop scheduling problem of size 6×6, and its name is Ft06. The data in the table represent the processing time on the machine where the relevant operation is located.

Coding rules based on operations.
Instance of job shop scheduling problem
Chromosome encoding is used to represent the solution of the problem in the form of a chromosome. A good encoding method can ensure that the individuals generated in the subsequent genetic operations are feasible solutions, so as to improve the execution efficiency. In this paper, coding rules based on operations are used for encoding. As shown in Fig. 5, The chromosome length is equal to the total number of all operations, and the numerical value of each gene is directly equal to the job number in which the operation at that position is located, and the order in which the job number appears represents the corresponding operation within the job. In other words, the chromosome is coded from left to right, and the job number i of the jth occurrence, denotes the jth operation of J i , and it’s called O ij .
Then, according to the coding rules, considering the number of decoded operations on the machine and in the job, the start processing time of the current operation to be decoded is calculated. The decoding flow chart is shown in Fig. 6.

Coding rules based on operations.
In this paper, POX (precedence preserving order-based crossover) operator is used to produce progeny individuals, and multi-point greedy mutation operator is used to generate mutated individuals. They have been explained in the literature and will not be explained here.
Niche adaptation mechanism testing and mechanism analysis
Through data testing, the changes of individual distribution before and after niche selection mechanism are compared, and the changes of genetic probability in the process of population evolution under the influence of adaptive operators are studied, so as to verify the effectiveness of the two operators respectively.
Niche selection mechanism testing and mechanism analysis
In the test of the niche selection mechanism, the initial data is generated by random initialization of the “Rec” instances, and the makespan after chromosome decoding is used as the fitness value of a single individual, where the “optimal” refers to the minimum value in the contemporary population. The test comparison was divided into 16 groups with population sizes ranging from 20 to 200, and the data were compared with the tournament selection. Parameter settings for selection operators are shown in Table 2 and the test results are shown in Table 3.
Parameter settings for selection operators
Parameter settings for selection operators
Comparison of data before and after selecting mechanisms
Through the two selection mechanisms, the best individuals of the current population are selected into the parents of the next generation. The difference is that the number of selected individuals in the niche selection mechanism is significantly less than that in the tournament selection mechanism. In terms of average and variance, the data after the two selection mechanisms are lower than those before the selection, and the average and variance of the niche selection mechanism are slightly larger than that of the tournament selection mechanism.
Figure 7 shows the probability distribution of population individuals before and after data selection for groups 6, 10, 13, and 16 in Table 2, whose population numbers are 50, 100, 150, and 200, respectively. It can be seen from the figure that after selection, the main body of the distribution curve moves to the left along the X-axis direction, which comes from the fact that the optimization goal is to solve the minimum value, which is in line with the general trend of the average decreasing in Table 2. The left end of the distribution curve, from height to bottom, is tournament selection, niche selection, initial population. The right end of the distribution curve, from high to low, is initial population, niche selection, tournament selection. This performance is consistent with the variation of the number and variance of the optimal individuals in Table 2.
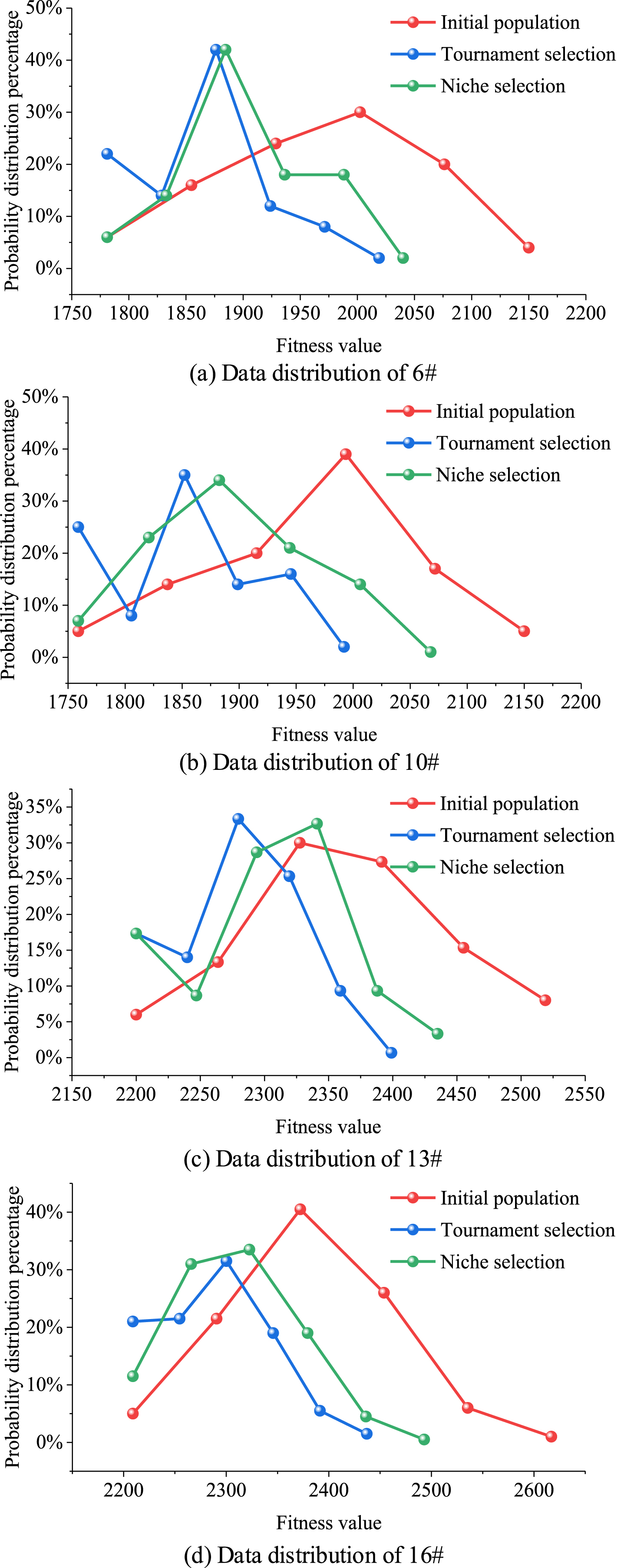
Comparison of data distribution before and after selecting mechanism.
The principle of selection mechanism is that the fittest survive and the unfit are eliminated. Excessive selection will lead to the destruction of population diversity, and effective genes in inferior individuals cannot be preserved and transmitted. Therefore, the goal of niche selection mechanism is to balance the diversity of individuals in the population. The test result shows the following effect: the population does not agglomerate excessively after selection, which can avoid falling into local optimum in a sense. The retention of a large number of medium quality individuals and the existence of poor-quality individuals can also generate new individuals during the subsequent execution of genetic operations, so as to improve the global search performance of the algorithm.
In order to observe the change of genetic probability in population evolution, this section solves the “la06” instance and records the individual fitness value of population evolution convergence, which is used as a set of test data for discrete convergence, and the population size is 50. Since the subsequent iterations enter the state of full convergence, only the population individuals of the first 15 generations and the initial population individuals of the 0 generation are recorded here. The individual distribution is shown in Fig. 8, and the individual probability density distribution curve is shown in Fig. 9.
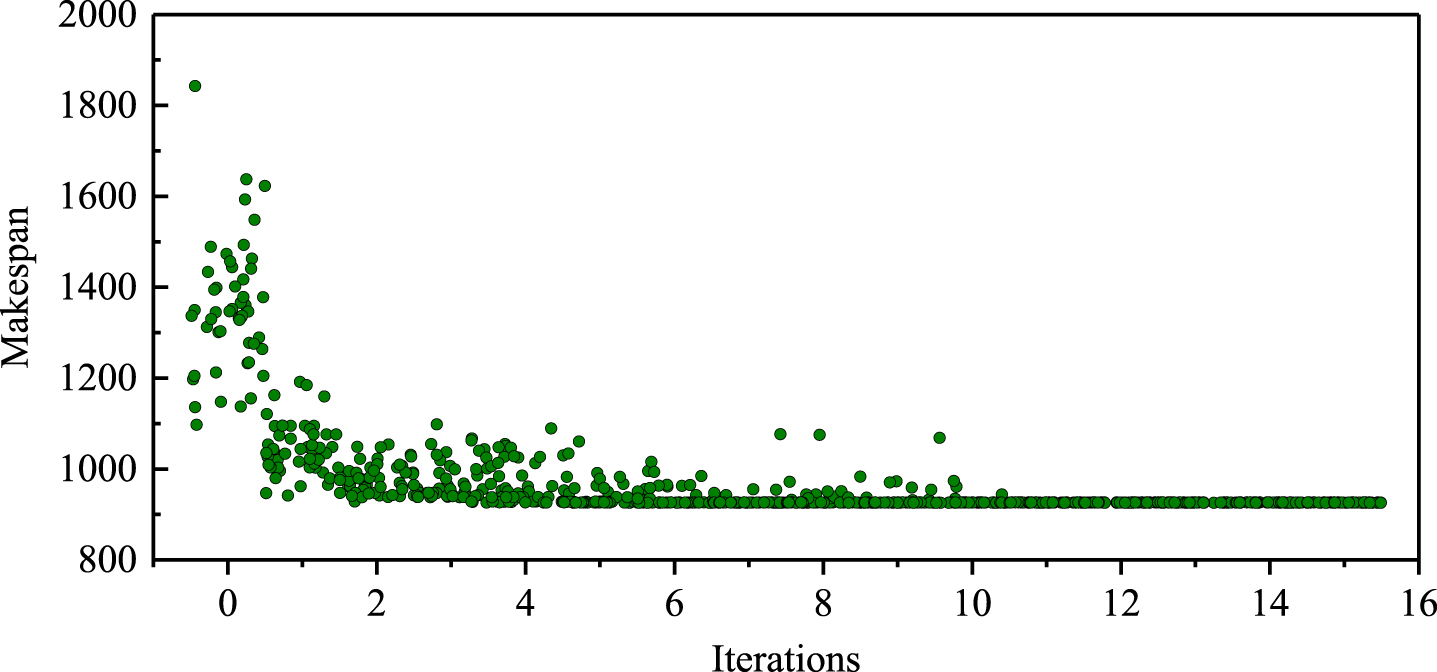
Discrete convergent population distribution diagram.
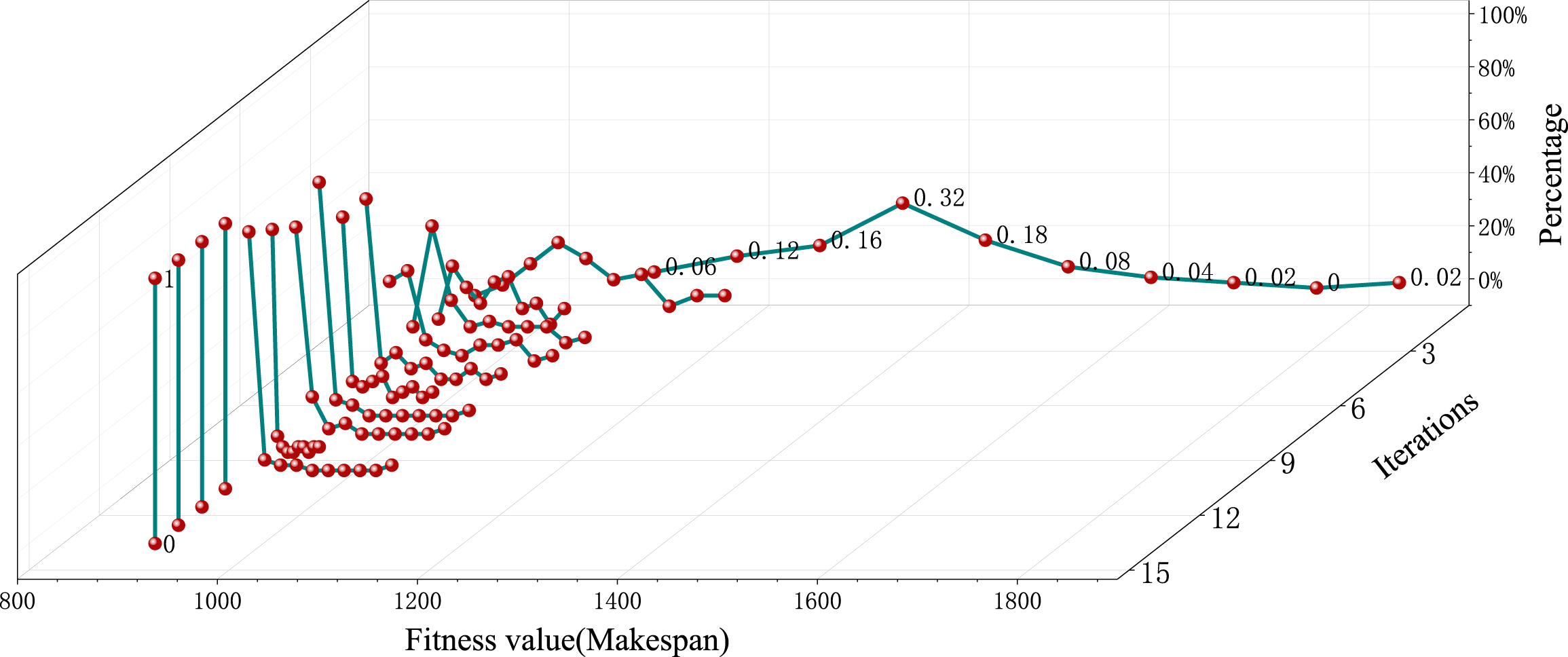
Discrete convergent population individual distribution probability density curve.
The test sample data began to converge from the 11th generation to the 15th generation, which showed that the peak of the probability density curve gradually moved to the left in the direction of the X-axis, and the peak became steeper and steeper, and finally became a vertical line with height 1 at the optimal solution. Table 4 shows the adaptive operator parameter settings.
Parameter settings for adaptive operators
Figure 10 illustrates the adjustment curves of the three adaptive operators in this set of data. It should be noted that this only represents a single genetic test carried out on the same population. When different adaptive operators are used to solve the problem, the population individuals have been different from the second generation, so it is not suitable for the comparison of the whole iteration. It can be seen that AGA-1 and AGA-2 are both based on individual linear adjustment. As the iteration goes on, the slope of the linear part of the adjustment curve of AGA-2 becomes slower because the iteration number of AGA-2 participates in the coefficient calculation in the operator calculation formula. For AGA-3, it can be seen that the adjustment of the probability value is population specific, that is, the same genetic probability is used in the same generation, and the genetic probability is recalculated according to the population situation at each iteration. The AGA-S proposed in this paper can calculate the genetic probability value according to the individual, and can have a more obvious “S” classification effect in both large and small population dispersion.
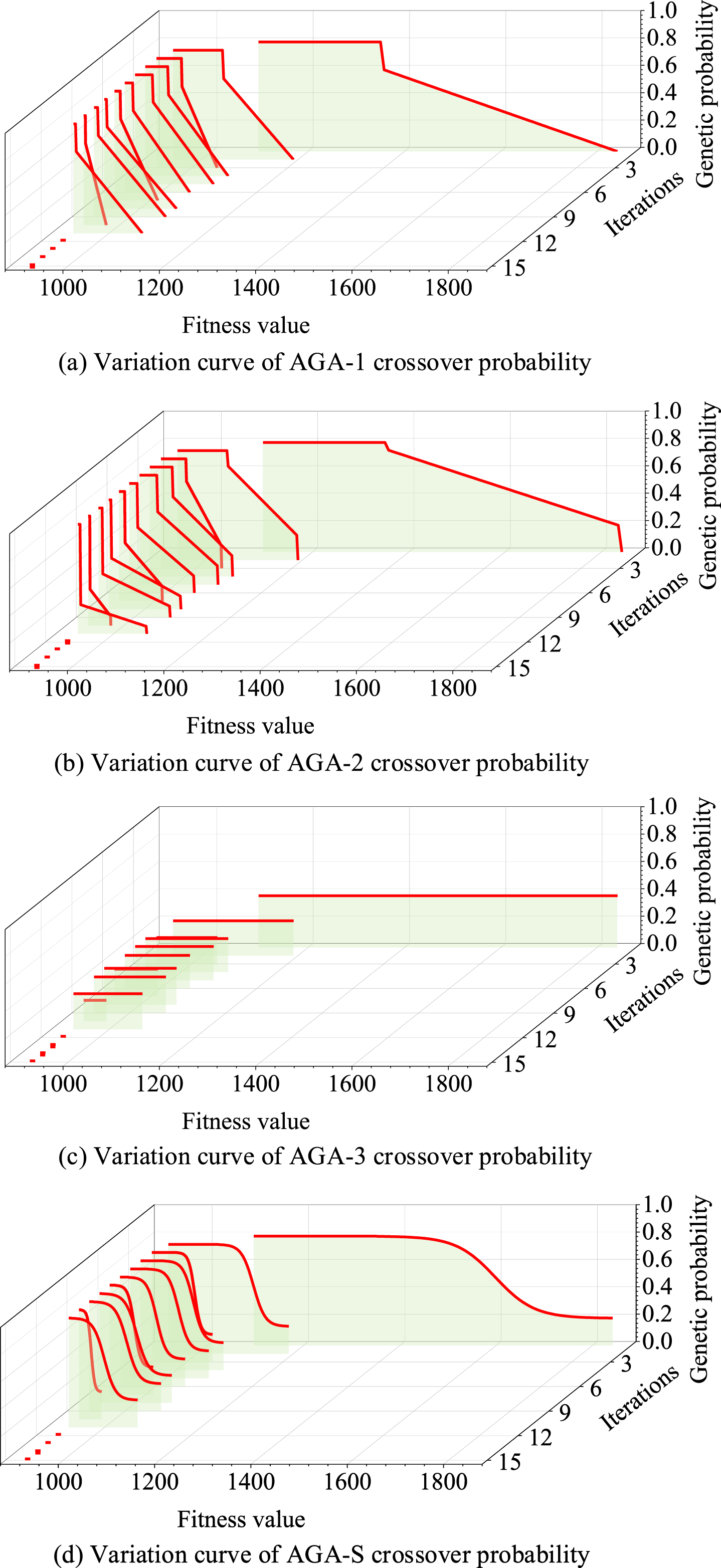
Adaptive adjustment curve comparison of Pc.
In order to test the performance of the algorithm, considering the complexity of the job shop scheduling problem, this paper selected 15 general scale job shop scheduling instances to solve and test. Each instance was solved 10 times by standard genetic algorithm (SGA), adaptive genetic algorithm mentioned in 2.2.1 (AGA-1, AGA-2, AGA-3) and the niche adaptive genetic algorithm (NAGA) proposed in this paper. Then calculate the average of the obtained optimal solutions and mark the best optimal solution among them, and the results are shown in Table 5.
Comparison of solution results
Comparison of solution results
As shown in Table 5, NAGA has found the optimal solution in all the 15 instances. For small scale instance such as ft06, all algorithms can easily search for the optimal solution. Differences appear in the solution of general medium-scale instances.
The raw date for Avg values in Table 5 are applied Friedman’s test and we reported the results of Friedman’s test in Table 6 which presents the statistical information about the ranks of SGA, AGA-1, AGA-2, AGA-3 and NAGA. It is clearly shown that NAGA is followed by AGA-2, then AGA-3 provides the best average of mean ranks. The average of mean ranks of AGA-2 is better than SGA.
Results of Friedman’s test
Figure 11 shows the comparison of the average solutions. The order of solution accuracy from high to low is NAGA (98.95%), AGA-1 (98.72%), AGA-3 (98.67%), AGA-2 (98.24%), SGA (98.16%). In the solution of some instances, AGA-2 shows reverse optimization compared with SGA, the main reason is that the number of iterations participates in the calculation of genetic probability factors and plays a dominant role. Although the average performance of NAGA is 0.79 percentage points higher than that of SGA, NAGA can search the optimal solution in a limited number of solving times, which is very significant. In other words, it also means that NAGA has the ability to jump out of local optima and has a stronger global search ability. Figure 12. shows Gantt charts of partial representative with different scale instances solved by proposed NAGA. Each rectangle corresponds to an operation, and same colour represents same job. From the Gantt chart, we can see that the resulted solution is feasible and efficient.
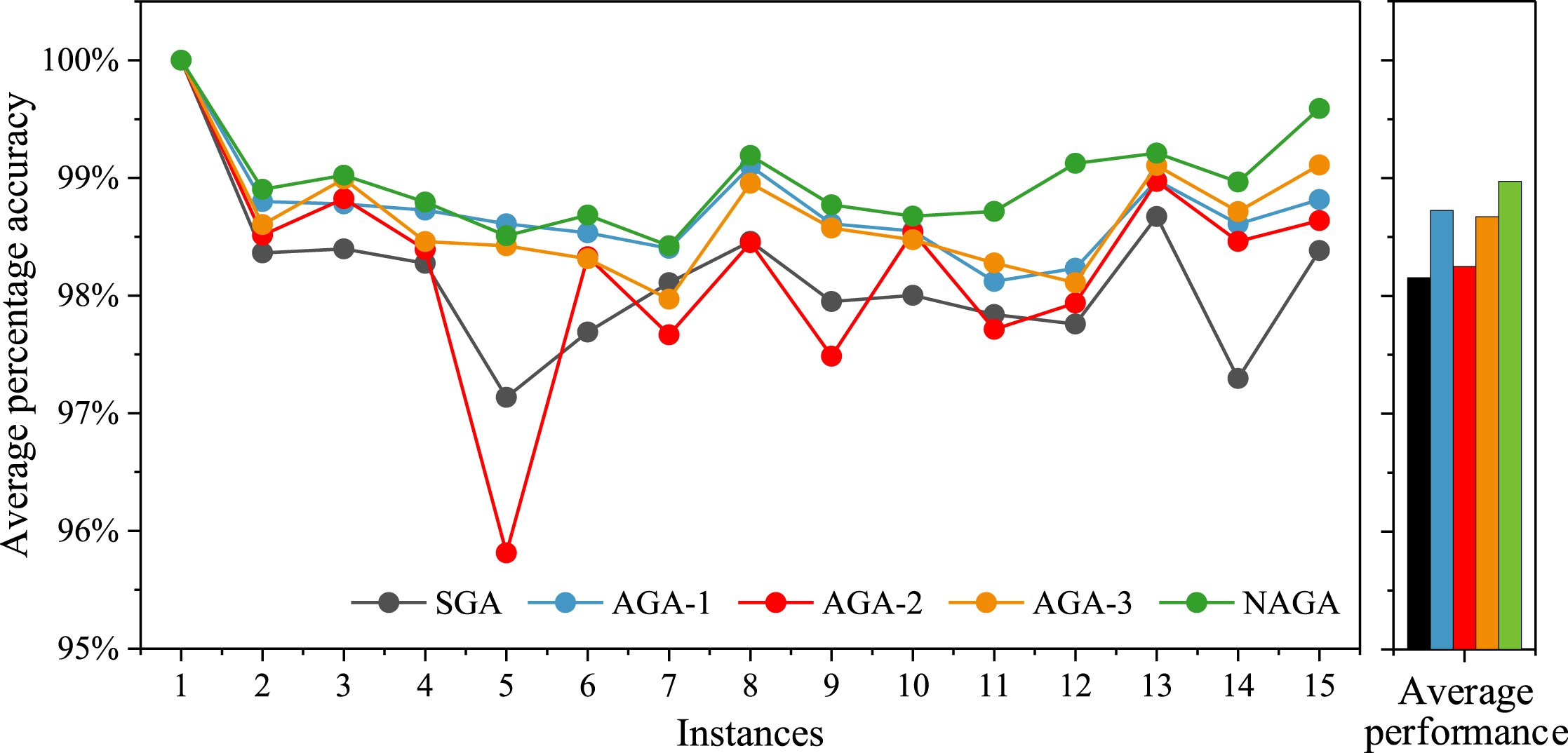
Comparison of average solutions.
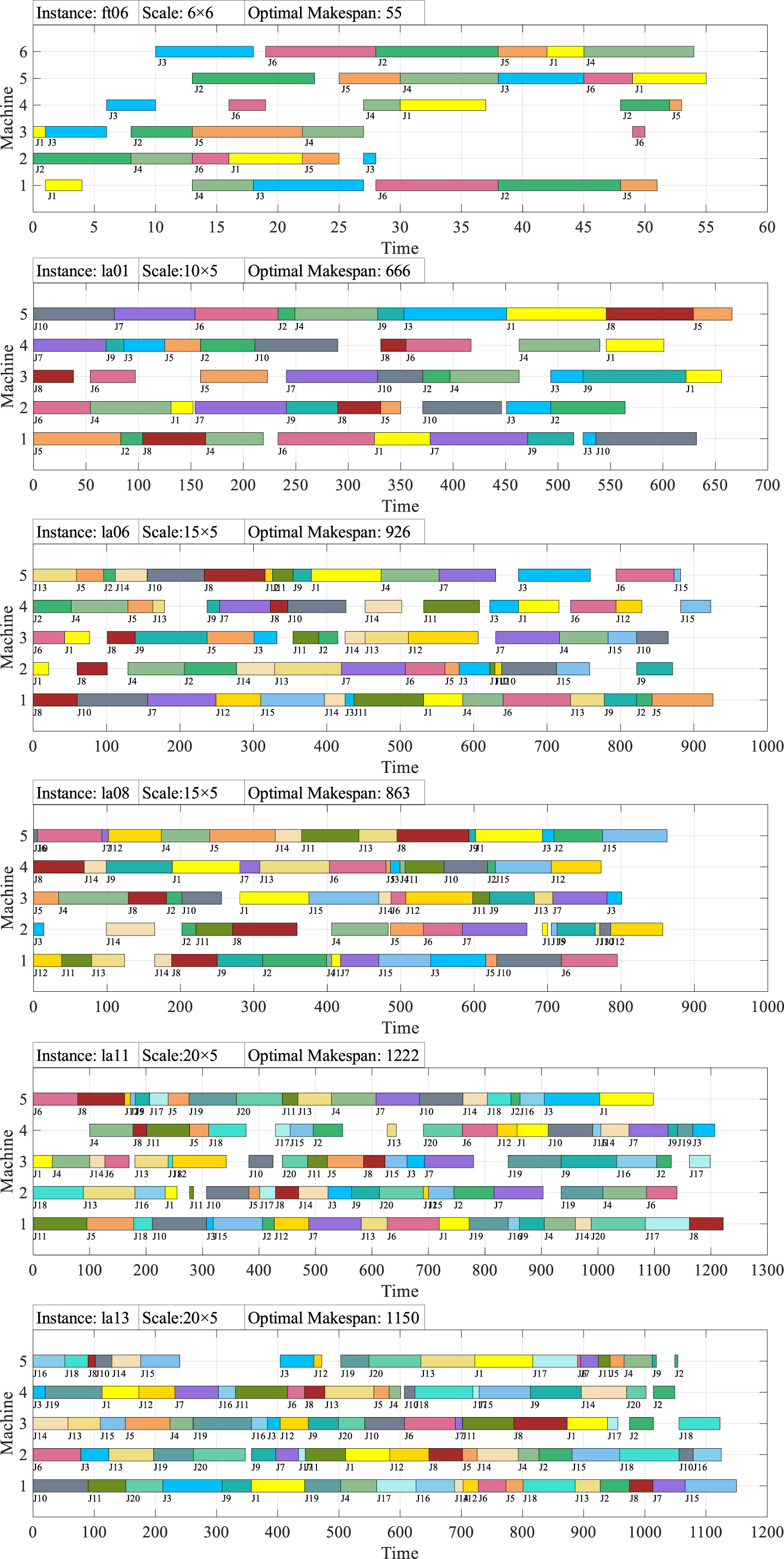
Gantt charts of partial instances solved by NAGA.
Figure 13 shows the comparison of the solution process convergence curve of the instance in Fig. 12. As can be seen from the figure, in the iterative process, all curves have a certain degree of horizontal state, which represents a certain degree of prematurity in the solution. However, this state did not last long and continued to decline after two or three generations of iterations, which means that each algorithm has the ability to jump out of the local optimal. However, after convergence, the NAGA curve has the lowest position, which means that it has the highest solution accuracy.
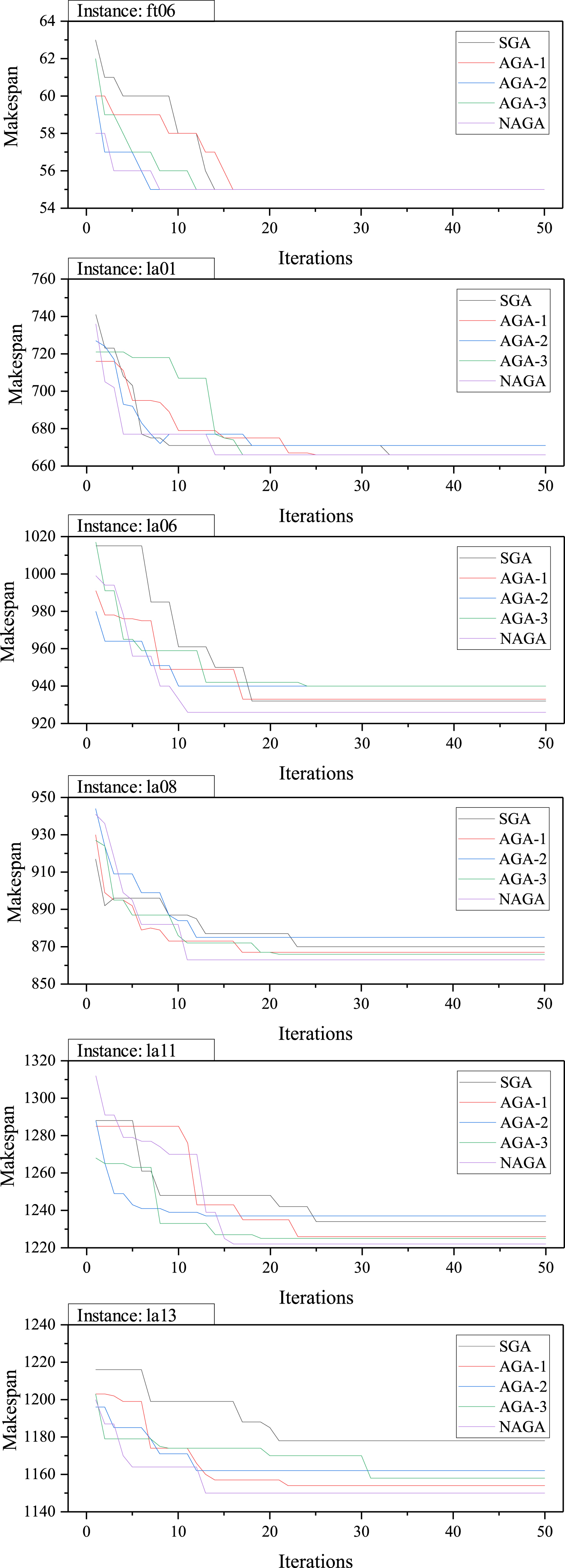
Comparison of solution process convergence curve.
In this paper, an effective improvement scheme with generic enhanced search framework based on genetic algorithm is addressed and the performance of the proposed NAGA algorithm in solving job shop scheduling problem is studied. The contributions of our research are summarized as follows:
The niched selection mechanism creates niches according to the fitness value of the population individuals and the hamming distance encoded by the chromosome. By punishing the suboptimal individuals in the niches, the population diversity is enriched and the global search performance is improved. The adaptive mechanism is based on the classification characteristics of sigmoid function, and adaptively adjusts the genetic probability according to the discrete degree of individual fitness value, so as to balance the relationship between population diversity and convergence. The results show that the niched adaptive genetic algorithm improves the search performance of small and medium-sized scheduling problems, and can jump out of the local optimum in multi-peak space.
The advantage of this algorithm is that it is not sensitive to the characteristics of the problem and has robustness and universality. However, the limitation of NAGA application is that it is effective to solve the precocious problem in the process of solving small and medium-sized scheduling problems, while the solution of large-scale scheduling problems still has the problem of insufficient precision. On the basis of this research, it will be the future research work to design a local search method according to the characteristics of the specific scheduling problem model, such as introducing heuristic rules to construct the neighborhood structure of the optimization direction.
Footnotes
Acknowledgments
This work was supported by Natural Science Foundation of Shandong Province (ZR202103070107).