
Abstract
Visual question Answering (VQA) is a computer vision task that requires a system to infer an answer to a text-based question about an image. Prior approaches did not take into account an image’s positional information or the questions’ grammatical and semantic relationships during image and question processing. Featurization, which leads to the false answering of the question. Hence to overcome this issue CNN –Graph based LSTM with optimized BP Featurization technique is introduced for feature extraction of image as well as question. The position of the subjects in the image has been determined using CNN with a dropout layer and the optimized momentum backpropagation during the extraction of image features without losing any image data. Then, using a graph-based LSTM with loopy backpropagation, the questions’ syntactic and semantic dependencies are retrieved. However, due to their lack of external knowledge about the input image, the existing approaches are unable to respond to common sense knowledge-based questions (open domain). As a result, the proposed Spatial GCNN knowledge retrieval with PDB Model and Spatial Graph Convolutional Neural Network, which recovers external data from Wikidata, have been used to address the open domain problems. Then the Probabilistic Discriminative Bayesian model, based Attention mechanism predicts the answer by referring to all concepts in question. Thus, the proposed method answers the open domain question with high accuracy of 88.30%.
Keywords
Nomenclature
Input image
Number of pixels
Image feature extracted by CNN
Number of pixel matrix generated
Expected value
Predicted value
The image data
The textual data
Initial weight
Mean
Covariance
The posterior probability of y
Conditional probability
The prior probability of y
The prior probability of x
Weight matrix
Bias vector
image feature
Query feature
Answer
I th element of α(t)
Contextual vector
Parameters to optimize.
Introduction
In recent years, both computer vision and natural language processing groups have paid close attention to VQA, which is considered an essential attempt at Artificial Intelligence for heterogeneous data interpretation and reasoning. These techniques employ two strategies to incorporate outside knowledge: i) They make use of the accompanying facts that are provided for each question in the VQA databases. ii) They compile potential search terms for each question-image combination and employ a search API to obtain the solutions. Data augmentation has been extensively used in numerous computer vision jobs as one of the key DNN methods. There are, however, few studies focused on the data augmentation issue for VQA, and none of the image-based augmentation techniques currently in use (such as rotation and flipping) can be directly applied to VQA due to its semantic structure, which requires that an accurate image, question, and answer triplet be maintained VQA can help image and video databases improve their search capabilities. Users can search for relevant visual content by asking queries about certain features or objects in photographs or videos [1, 2]. The VQA job involves both visual and language knowledge to answer a question given an image and a related question. Utilizing visual components of the image and inference drawn from textual questions, the VQA system attempts to determine the right response. The most difficult aspects of VQA were extracting the visual representation of images and embedding the textual sentences of questions, as well as bridging the semantic gap between image and question representations. The answer might take the shape of a word, a sentence, a binary answer, a multiple-choice answer, or a fill-in-the-blank response. Deep learning breakthroughs have undoubtedly aided in the development of systems for the purpose of Visual Question Answering. While most research on inferring model behavior has focused on indirect strategies such as estimating prediction uncertainties and visualizing model support in the input image space, the ability to explicitly query a prediction model about its image content provides a more direct way to determine the behavior of trained models [3–6].
To complete VQA tasks, the responder must be able to comprehend the question’s intent, reason about the visual features of the image, and occasionally have general knowledge of the world. Based on the recent success of deep learning, most current approaches tackle Visual Question Answering by concurrently learning interactions and conducting inference over the question and image contents, which may be further enhanced by incorporating attention mechanisms. However, the majority of questions in the current VQA dataset are straightforward and can be answered simply by examining the question and image [7–10]. It is debatable whether the system can answer queries that need previous knowledge ranging from common sense to subject-specific and expert-level information [11]. It’s appealing to build ways for deeper image understanding by addressing open-domain queries, but this necessitates the system’s ability to combine VQA with structured information. Although some efforts have been made in this area, the majority of them can only handle a small number of specified sorts of inquiries. In contrast to the text-based QA challenge, conducting open-domain VQA based on knowledge-based reasoning is unfavorable since it is invariably inadequate to describe an image with structural forms [12–16].
Some seminal efforts are also made to implement VQA based on dynamic memory networks a visual knowledge memory network (VKMN), which seamlessly mixes structured human knowledge and deep visual features into memory networks in an end-to-end learning framework. [17, 18], however, because it lacks the mechanism to absorb outside knowledge, it is unable to respond to open-domain visual questions and is unable to express its responses in intelligible sentences as a result of improper use of reasoning and attention mechanisms. The feature extraction process for both the image and the question presents several challenges for the current VQA methodologies. Therefore, a creative solution must be created to address the aforementioned problems while addressing open-domain complicated questions utilizing VQA. The main contribution of this paper is as follows, In image and question featurization, using CNN with a dropout layer, which avoids several layers of the neural network and by optimized momentum backpropagation, features were recovered from the image content. This eliminates overfitting of information from an image. Additionally, by identifying the question’s syntactic and discourse dependencies, graph-based LSTM determines the type of query. In cyclic probabilistic graphical LSTM model, information is transferred from each node (neuron) to all nodes that rely on it until convergence occurs. The CNN enhanced BP decreases information loss caused by the existence of a dropout layer and overfitting by identifying the spatial details of picture data. To answer open domain questions, Spatial Graph Convolutional Neural Network gets information from Wikidata and analyses keywords relating to visual features and attention mechanisms in the Probabilistic Discriminative Bayesian model uses the attributes of an image to determine the response to knowledge-based questions.
The content of the paper is organized as follows: Section 2 presents the literature survey; the novel solutions are presented in section 3; the implementation results and their comparison and conclusion are in sections 4 and section 5 respectively.
Literature survey
Saqur et al. [19] presented to address this problem in this research by using neural factor graphs to create a stronger link between concepts in different modalities (e.g. images and text). Inherently compositional, graph representations allow us to encapsulate entities, characteristics, and relations in a scalable manner. This methodology generates a multimodal graph, runs it through a graph neural network to get a factor correspondence matrix, and then generates a symbolic program to predict responses to questions. However, this technique is incapable of answering open-domain complex questions.
Ren et al. [20] presented the CGMVQA model, which includes categorization and answer generation capabilities to break down this big problem into several basic questions. On images, use data augmentation, and on words, use tokenization. To deal with texts, utilize pre-trained ResNet152 to extract picture characteristics and combine three types of embedding. To lower the computational cost, reduce the parameters of the multi-head self-attention transformer. However, this technique is not providing an answer in a complete sentence.
Gupta et al. [21] presented a hierarchical deep multi-modal network that evaluates and categorizes end-user questions/questions before incorporating a query-specific strategy for response prediction. This HQS-VQA (Hierarchical Question Segregation-based Visual Question Answering) is a question segregation (QS) approach for VQAMed and then integrates the QS model with the hierarchical deep multi-modal neural network to create appropriate replies to medical image inquiries. However, this technique is not providing any external knowledge to answer the commonsense questions.
Xi et al. [22] presented a VQA model based on the identification of multi-objective visual relationships. The appearance feature is first utilized to substitute image characteristics from the original item, and the appearance model is then expanded using the notion of word vector similarity. After that, the appearance characteristics and relationship predicates are fed into the word vector space and represented by a fixed-length vector. Finally, components from the picture feature and the question vector are concatenated and fed into the classifier to get an output answer. However, this technique focuses only on reasoning and not on efficient feature extraction.
Guo et al. [23] presented a re-attention framework for the VQA challenge by computing the similarity of each object-word combination in the feature space to link the image with the query. The learned model then re-attends the matching visual objects in pictures and reconstructs the initial attention map depending on the answer to generate consistent results. The question may be better comprehended and a good answer can be developed using the re-attention technique. However, there is a need to improve the image featurization and question featurization to avoid the loss of information.
Himanshu Sharma et al. [24] proposed a semantic textual information, which the present visual question answering (VQA) models do not utilize, can be highly valuable for better understanding of images. However, the existence of this textual information in photographs can heavily guide the VQA work. This paper addresses the task of visual question answering by combining textual signals with visual material to improve the accuracy of VQA models. A unique VQA model based on the PHOC and fisher vector representation However, instead of assuming answer prediction as a classification task, a sequence of decoding steps for answer generation
Shengyan et al. [25] proposed Bi-branched model based Parallel networks and Image retrieval for Medical Visual Question Answering (BPI-MVQA). They used first branch of BPI-MVQA for image sequence feature and spatial feature extraction. Also, multi-modal features are extracted by using the multi-head self-attention mechanism. The second branch was retrieving the similarity of image features generated by the VGG16 network to obtain similar text descriptions as labels. Even though they obtained best result for close domain question answer, it is not capable to answer open domain questions.
Lobry et al. [26] presented a novel dataset for visual question answering using remote sensing images: This massive open access dataset extracts image/question/answer pairs. Triplets from the BigEarthNet dataset which contains nearly 15 million samples was used in this approach. The characteristics and preliminary findings were obtained with a deep-learning-based methodology in the dataset construction approach. These preliminary findings demonstrated that visual question answering was difficult and opened up new research opportunities at the intersection of remote sensing and natural language processing. However, this model is incapable of dealing with the dataset’s massive imbalance and sophisticated, logical questions.
Narayanan et al. [27] presented a Research have shown a great deal of interest in Visual Question Answering (VQA), which involves training neural models for jointly analyzing, grounding, and reasoning over the multi-modal space of image visual context and natural language in order to respond to questions in natural language about the contents of the images. But even while cutting-edge models for answering questions that can be answered by relying only on the visual context of the image have seen substantial improvements recently, leveraging state-of-the-art deep learning techniques for reasoning and inferring answers to free form questions. However, depending on the quantity of facts and captions present, the inference time may vary from case to case.
Lezama-Sánchez et al. [28] proposed evaluation of semantic links in embedding models for text categorization. Three embedding models are presented and compared to existing word-based models. This method takes into account the following relationships: synonymy, hyponymy, and hyperonymy they were considered because earlier research has proven that they give semantic knowledge. On the basis of two corpora, evaluations of the suggested relationship embedding configurations and the current word-based models were conducted. However, the results are not the best in comparison with GloVe and FasText, the approach can be helpful for data analysts.
From the literature Survey Table 1, [19] is incapable of answering open-domain complex questions and [20] is not providing an answer in a sentence. [21], no external knowledge is provided to answer the commonsense questions. [22] focuses only on accuracy and reasoning and not on efficient feature extraction. In [23] there is a need to improve the image featurization and question featurization to avoid the loss of information. [24] not capable of dealing with imbalance dataset [25] time may vary from case to case [26]. In comparison to GloVe and FasText, the outcomes are not the best. [27] incapable of proceeding the current condition of images. [28] does not capable of answering open-domain question. Hence to overcome the above-mentioned problems, a novel technique has been developed which is explained in next section.
Survey on visual question technique
Survey on visual question technique
The visual question-answer system must be able to answer any inquiries that people may have about the image. The development of artificial intelligence would help to develop a system that could correctly answer questions. However, the existing techniques have given the inappropriate answer for the question because of the localization of image content as well as the syntactic and disclosure dependencies of the question properly during a featurization process. Hence to find the correct answer, a novel

Proposed visual question answering method architecture.
The features from the input image were extracted by Convolutional neural network (CNN) with dropout and optimized momentum back propagation. Also, the features from the questions were extracted by using Graph-based LSTM with loopy backpropagation. Convolutional features are used by the Graph LSTM to create adaptively specified node update sequences for each input phrase. The aggregated contextual information is then effectively propagated towards all nodes to improve feature extraction and produce improved parsing outcomes. Then the extracted features are combined with joint embedding and the noun-verb linking algorithm used to provide the answer in a sentence. To answer the open domain questions, the keywords were extracted from the questions and using Wikidata, the external knowledge was retrieved by a Spatial Graph Convolutional Neural Network. The obtained knowledge is provided in a standard SVO (subject-verb-object) sentence by utilizing structure preserved sentence embedding. Then it is given to an improved dynamic memory network to answer the common sense question where the Probabilistic Discriminative Bayesian model-based Attention mechanism predicts the type of question by referring to all concepts in question. The answer is displayed in a proper sentence format by a noun-verb linking algorithm. The feature extraction and the answering of closed domain questions were discussed in the next section.
The CNN and the graph-based LSTM were used to extract the features from the image as well as the question. Convolutional neural network is utilized with dropout and optimized backpropagation to extract the feature from the image with positional details of subjects in the image as well as reduce the overfitting error. A Graph-based LSTM is used in the architecture as the query processing module. The graph-based LSTM enhances this capability by including graph structures that record the relationships between the words in the question. Traditional LSTMs process sequential input. The model’s comprehension of the question’s semantics and contextual dependencies is improved by this method. The architecture provides an improved backpropagation method known as the optimized backpropagation (BP) Featurization approach, which is probably a modification of the original backpropagation algorithm. Faster convergence and more effective learning are made possible by this technique’s efficient computation and updating of the gradients during the training phase. The total training effectiveness and precision of the VQA model are enhanced by the optimized BP Featurization approach. The loopy backpropagation uses Image Featurization and Question Featurization which are explained in the following subsections.
Image Featurization
To answer the open and closed domain questions, the features of the image are extracted by a convolutional neural network optimized momentum backpropagation. For the image feature extraction task of VQA, CNN defines the problem as follows in Equation (1) [29]
In Equation (1)
I is input image
M is number of pixels
The presence of dropout layer in CNN helps to minimize overfitting by setting input units to 0 with a frequency of rate at each step during training time. Non-zero inputs are scaled up by 1/(1 - rate) so that the sum of all inputs remains unchanged. This dropout layer only applies when training is set to true such that no values are dropped during inference. CNN with optimized momentum backpropagation is presented in Fig. 2.
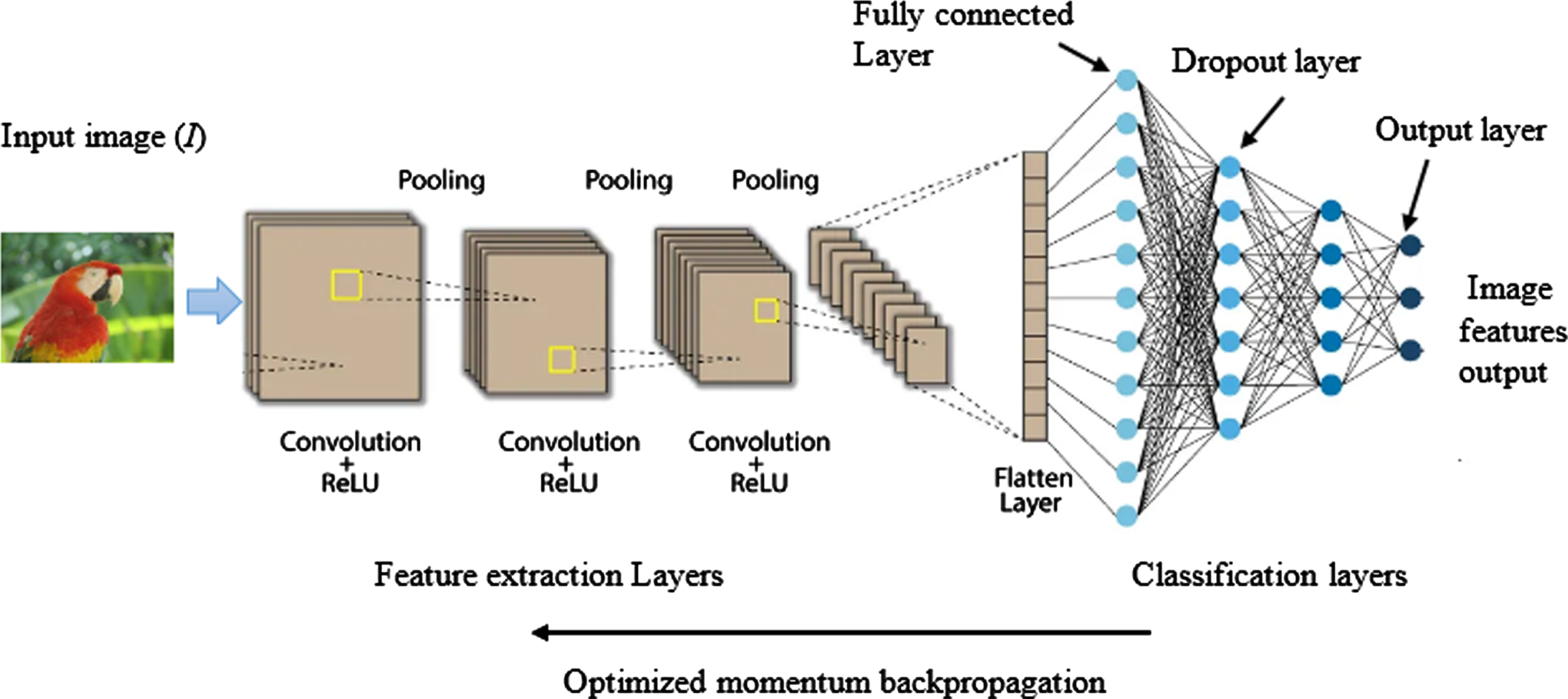
Convolutional neural network with dropout and optimized momentum backpropagation.
The input image given to the convolutional neural network has been passed through several hidden layers of convolution and pooling layers where the convolution layer identifies and extract best features/patterns from input image and preserves the generic information into a matrix. The pooling layer operates on each feature map independently which reduces resolution of the feature map by reducing height and width of features maps, but retains features of the map required for classification. The convolution layer in the CNN convolves the pixel matrix generated for the given image to produce an activation map for the given image thereby identifies the localization of subjects in image. After convolution pooling according to the input image I, the image feature set is as follows in Equation (2).
In Equation (2)
f x is image feature extracted by CNN
n is number of pixel matrix generated
The output from the hidden layers were given to fully connected layer to classify image after training. Each layer connected to every activation layers of next unit makes overfitting issue so the dropout layer omits random node during training process to avoid overfitting. Different versions of an image are generated by dropout to identify the various position of the image. The convoluted model is also trained with optimized momentum backpropagation in order to reduce the loss of image information in each layer. Rather than number of input parameters no additional parameters required in optimized momentum backpropagation so, that the proposed model minimized information loss. The loss of information extracted from the image is estimated by the following equation (3).
In Equation (3)
x i is expected value
Then, features from the questions were extracted using Graph based LSTM with loopy back propagation which is explained in the following sub-section.
In question featurization, the Graph LSTM takes the convolutional features in which the adaptively specified node updating sequence for each input sentence were formed and then efficiently propagates the aggregated contextual information towards all nodes enhance the feature extraction and better parsing results. The output gate in the LSTM decides the features of question which want to carry to next layer of featurization. The residual connections between layers after one Graph LSTM layer to generate the input features of the next Graph LSTM layer extracts the semantic and disclosure dependencies in question. The loopy backpropagation is reminiscent of a cyclic probabilistic graphical LSTM model. For such instances, a popular class of inference techniques is loopy belief propagation information is passed from each node (neuron) to all those nodes dependent on them until convergence comes. Unrolling is seen as a variant of loopy belief propagation with a specified order of message passing and a fixed number of iterations. This loopy backpropagation is parallelized in each layer and even each filter, lending the possibility of speed up model learning performance significantly. The loopy backpropagation with Graph based LSTM is shown in Fig. 3.

Graph-based LSTM with loopy backpropagation.
The graph-based LSTM considered the syntactic dependencies of the question because of loopy back propagation which reduce the error for Featurization. The loopy backpropagation in LSTM is formed by the chain rule as follows in equation (4).
In Equation (4),
y i is propagates via n variances
Then the extracted features from the image using CNN with dropout and question features from graph-based LSTM with loopy backpropagation are concatenated by joint embedding by considering the similarity of the image and text. The similarity function is shown in equation (5).
In Equation (5),
x is the image data
y is the textual data
Then it answers the given question related to the image content. By embedded features of image and questions through joint embedding. Even though, if the question is an open domain question then it is not possible to answer the question based on image content. So that the spatial GCNN knowledge retrieval with probabilistic discriminative Bayesian model-based attention mechanism is utilized to answer the common sense questions related to the image were discussed in the next section.
Spatial GCNN knowledge retrieval with a Probabilistic discriminative Bayesian model-based attention mechanism introduced to answer the complex open domain question in a standard SVO triples sentence format. The PDB model makes a structure for expressing and evaluating uncertain or probabilistic beliefs. The PDB model enables the architecture to handle uncertainty and probabilistic reasoning in the retrieved knowledge, enabling more reliable and complex responses to queries. Spatial GCNN is used to retrieve external knowledge from the Wikidata and the keywords from the questions were represented in graphical structure to encode the relationships between objects. Wikidata information are preprocessed before feeding into the neural network. During the preprocessing of data, the punctuations and stop words are avoided, also the words that are present more than once in a sentence are omitted. Also, the upper case is changed to the lower case to make it easy for machine interpretation. Then, the preprocessed sentence was given to a neural network. The proposed spatial GCNN architecture is shown in Fig. 4.

Spatial graph convolutional neural network.
The GCNN extracts candidate nodes in Wikidata by assessing significant visual items in images and textual terms in order to recover the most valuable knowledge. Both pieces of information are stored in a first-order graph, which includes all edges that link to at least one candidate node to reduce redundancy. By minimizing redundancy, the subgraph comprises the most important information, which is adequate to answer queries. The resultant first-order knowledge subgraph is denoted as G. Then the most relevant information subgraph is found out by scoring through assigning weights to each sub graph. The importance score of each node in G by traversing each edge and propagating node weights to their neighbors with a decay factor r ∈ (0,1) as in Equation (6) and importance of the edge wa,b is in Equation (7) [29].
In Equation (6),
w a is initial weight
Then the retrieved structured knowledge is represented as a triple with subject and object being two entities or concepts, and relation corresponding to the specific relationship between them. The external knowledge is mined from Wikidata, an open multilingual knowledge graph containing common-sense relationships between daily words, to aid the reasoning of open-domain VQA. The image information integrated with the retrieved data from Wikidata in improved dynamic memory. Structure-preserved sentence embedding in the memory finds the symmetries information in the Graph for memory update. Structure preserve embedding represent each node into Gaussian distribution with the learning function as follows in Equation (8) [29]
In Equation (7)
The query vector and the visual information from the dynamic memory is given to the Probabilistic Discriminative Bayesian model that capture question-answer context information as given in Equation (9) [29].
In Equation (9),
W1 is weight matrix
b1 is bias vector
f x is image feature
f y is query feature
f a is answer
Probabilistic discriminative Bayesian model creates new instances using probability to estimate the type of question. Discriminative classifiers model the posterior p (y | x) directly inputs x to the class labels which does not assume anything related to the independence of features. Therefore, Bayes’ theorem calculates P (y|x) in terms of P (A|E
i
), as expressed in Equation (10) [30].
In Equation (10),
P (y|x) is the posterior probability of y
P (x|y) is conditional probability
P (y) is the prior probability of y
P (x) is the prior probability of x
The type of question was identified and the improved dynamic memory provides a mechanism to address the problem by modeling interactions among multiple data channels. In dynamic memory a memory vector is formed and updated during an iterative attention process, which memorizes the most useful information for question answering. The dynamic memory gradually refines the episodic memory m until the maximum number of iterations steps T is reached. By the T
th
iteration, the episodic memory m (T) memorize useful visual and external information to answer the question. At the T
th
iteration, knowledge embedding M
i
with last iteration episodic memory m(t-1) and query vector q as per Equation (11) [31].
C t is contextual vector
Thus the probabilistic discriminative Bayesian model predicts the type of question and the attention mechanism focus on the part of an image that contains the answer by referring to all concept in question. Attention mechanism focus on temporal dimensions, spatial dimensions or different features of an input image and it relates with each part of the input in direct and symmetric way to predict the answer. The obtained contextual vector C
t
captures useful external knowledge for updating memory m(t-1) and providing the supporting facts to answer the open-domain questions. The memory update mechanism update the dynamic memory as follows in Equation (12) [31].
In Equation (12),
W i & b i are parameters to optimized.
Then the noun-verb linking algorithm is used to show the results in the SVO pattern by adding the subject and verb to the keyword. The algorithm for providing the answer in a sentence is as follows.
The noun-verb linking algorithm along with reasoning provides the answer in a meaningful sentence and the memory update takes place in the improved dynamic memory network. The noun verb linking algorithm link the answer with the subject and verb to make a meaning full sentence.
Overall, the proposed Visual Question Answering method outperforms by utilizing CNN with dropout and optimized momentum backpropagation to avoid information loss from the image. The Graph based LSTM with loopy backpropagation reduces the loss by considering the syntactic and discourse dependencies of the questions. Further spatial GCNN utilize the knowledge from Wikidata and is represented with their concept and relation in graph nodes. Additionally, the Probabilistic Discriminative Bayesian model-based Attention mechanism has been included in the improved dynamic memory network to refer all concepts in the Spatial GCNN and provide the answer for the open domain questions related to the input image. The result obtained from the proposed model has been described in section 4.
This segment provides a detailed description of the implementation results as well as the performance of the proposed system and a comparison section to ensure that the proposed method performs valuably.
Experimental setup
The following system specification was used to implement this study on the Python working platform and the simulation results are given below.
Dataset description
In this work, the VQA dataset is used to train the proposed model by extracting features from an image as well as questions. The VQA dataset containing open-ended questions about images. These questions require an understanding of vision, language and commonsense knowledge to answer. It has 265,016 images and at least 3 questions (5.4 questions on average) per image as well as 10 ground truth answers per question. VQA dataset was split into a training set and a test set, the proposed model used the training set to train the proposed model in which 80% of the dataset was assigned to the training set while 20% of the dataset was assigned a test set.
Simulation results of knowledge incorporated VQA method
This section contains the simulation results sample input image and answer predicted by the proposed model. Also this section provides the knowledge retrieved from the Wikidata results.
Figure 5 shows the output of the closed domain questions where the answer to the question is directly available in the image itself. Thus the system identifies the answer by extracting features using dropout layered CNN and LSTM with loppy backpropagation which combines the features of the image with a question to predict the answer.

Output of the proposed method.
From Fig. 6 the system creates the id for the image and question to relate the question with the corresponding image. Also, it indicates the type of question as well as the accuracy of the answer. The answers are provided in a single word by refers the question type which is yes or no based question else the question is in other types.

Simulation view of proposed VQA method.
The Fig. 7 is the input image for open domain question which has been taken in proposed method. The input image has river surrounded by forest. Here the keyword taken as river and the data reterived from wikidata based on the keyword.

Input image for open-domain question.
The information retrieval for answering the knowledge-based question from the wiki data is shown in Fig. 8. The information extracted from the question and image is correlated with wiki data and retrieves the relevant keywords. Then the keywords are tokenized to find the exact match to the query.

Information retrieval from Wikidata.
Figure 9 shows the keyword extraction from the query and identifies the most related by fining the weightage of the keyword. Here the image is related to a river specifically an amazon river so the system found the matching score by cosine similarity is 4.6 and for the Anadyr river the matching score is 2.2. Also, the query matching found by the system for amazon river is 1.0 and the other words matching is 0.

Keyword extraction from the query.
Figure 10 shows set of input image from VQA dataset and corresponding answer in SVO pattern. Here all the answers are exactly identified by proposed model because the proposed system has the external knowledge about input. Also the answers are in SVO sentence pattern form due to the presence of noun verb linking algorithm in the dynamic memory. The proposed method does not only answer for ‘Yes’ or ‘No’ question it also able to answer any type of questions.

VQA answering in SVO triple sentence.
The performance of the proposed method evaluated by various performance matrices such as accuracy, recall, precision, f1-score, sensitivity.
Accuracy
The accuracy gained by the proposed system is shown in Fig. 11. The accuracy for a six epoch is 87.45%. For 8 epochs, the accuracy is 87.4 %. For 10 epochs, the value of accuracy is 87.54%. Then the accuracy increased to 87.63% at 12 epochs. Finally, the accuracy of the proposed system reaches the maximum value of 88.30 at 16 epochs. The presence of a dropout layer and optimized backpropagation in the proposed network make this high accuracy possible. This dropout layer increases the accuracy of training with the reduction of overfitting. The proposed system uses optimized momentum backpropagation that increase the accuracy by eliminating overfitting issues of information.
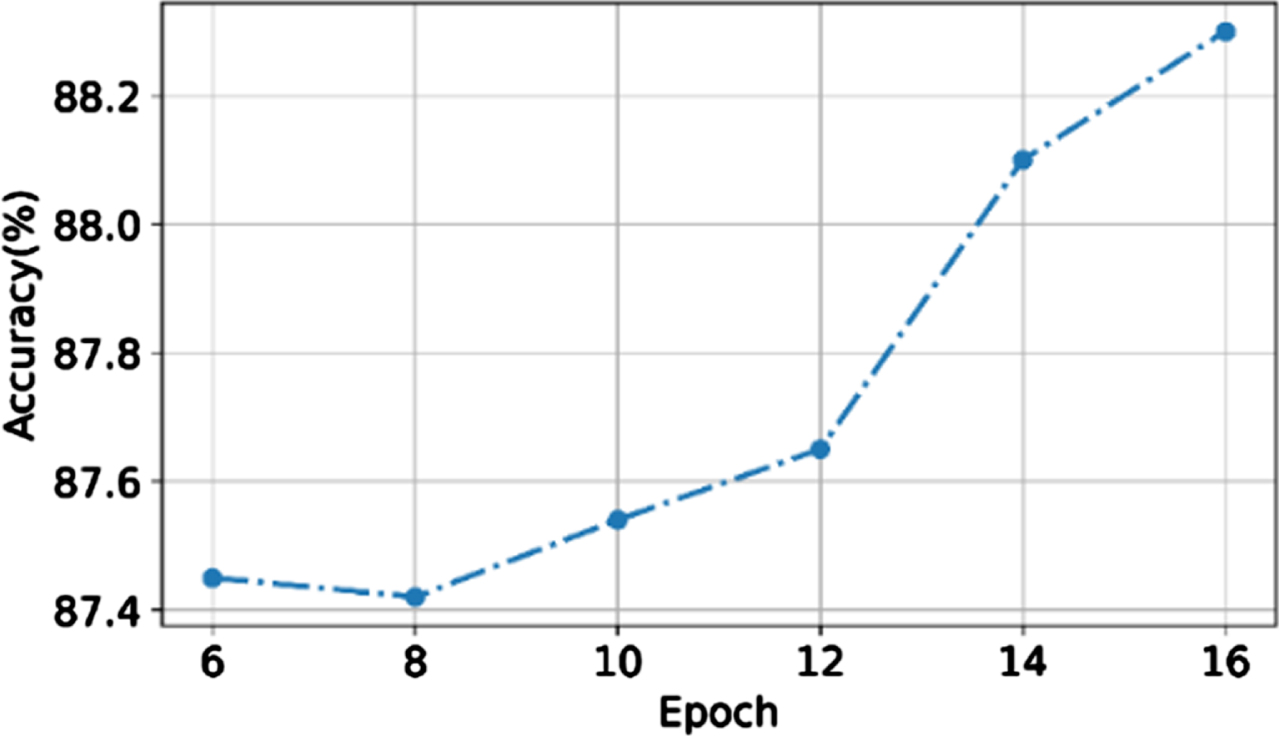
Accuracy of the proposed system.
Figure 12 concludes that the proposed method reaches maximum recall value of 88% at 16 epochs. When 6 epochs of training the proposed method has the recall value of 87.1% and recall increased in corresponding with the number of epoch increases. At the point of 16 epochs the recall is the maximum value of 88%. In proposed system LSTM reduces the loss by considering the syntactic and discourse dependencies of the questions thereby increase recall.

Recall value of the proposed system.
The precision of the proposed system is shown in Fig. 13. It shows the precision of the proposed system is increased when the number of epoch increases. When the number of epochs is 6, 8, 10, 12, 14 and 16 then the corresponding precision values are 83.9%, 84.13%, 84.24%, 84.3%, 84.35% and 84.5% respectively. Spatial GCNN used in the proposed method increase the precision by extracting knowledge from the Wikidata by keywords from the question based on the input image feature. The precision is increased in the proposed system using optimized momentum backpropagation by identifying the spatial details of image features and also eliminates overfitting with high precision.
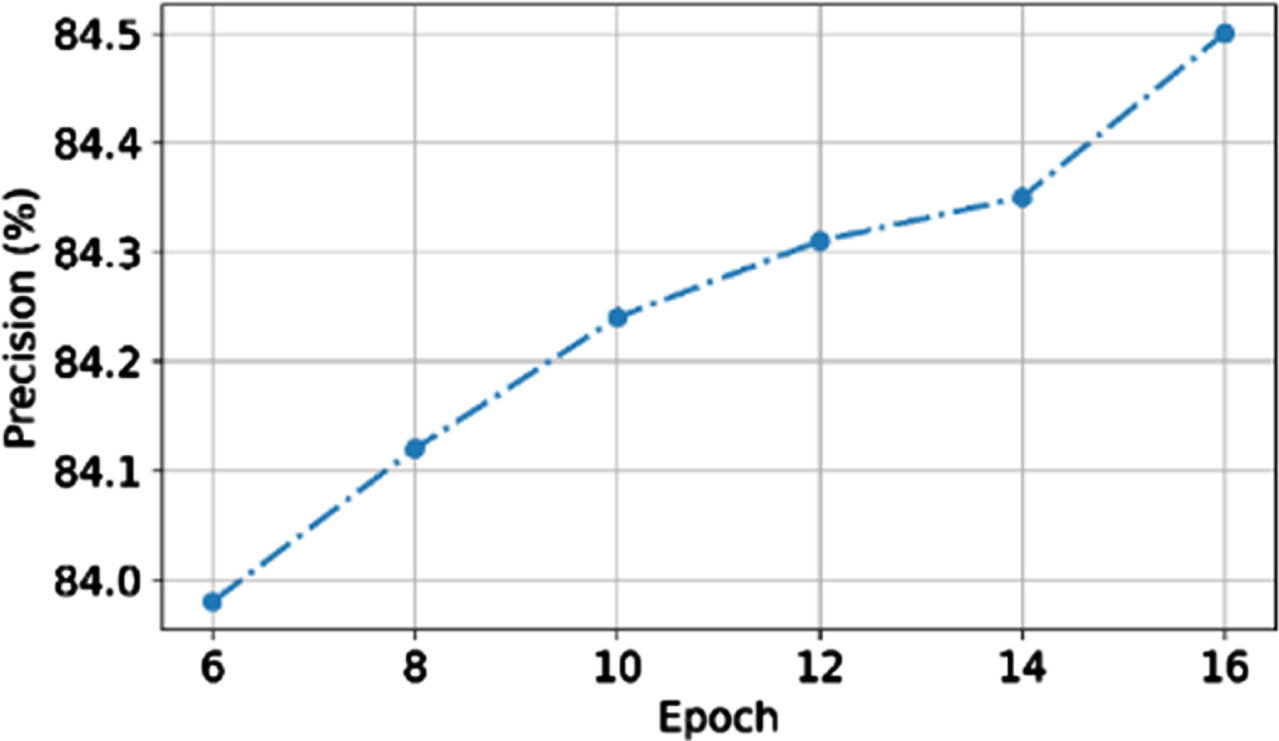
Precision value of proposed method.
From the Fig. 14, F1-score has increased from 85.4% to 86% when the number of epochs increases from 6 to 16. The proposed method reaches maximum of 86% in 16 epochs due to the presence of optimum momentum back propagation in the network layer which increase the F1-score by identifying the positional details of image and sematic features of the input question. In proposed system image feature extracted in CNN considers the positional change of the content in the image. So that the accurate features of the image are extracted and using CNN increases the F1 score by without loss of image information
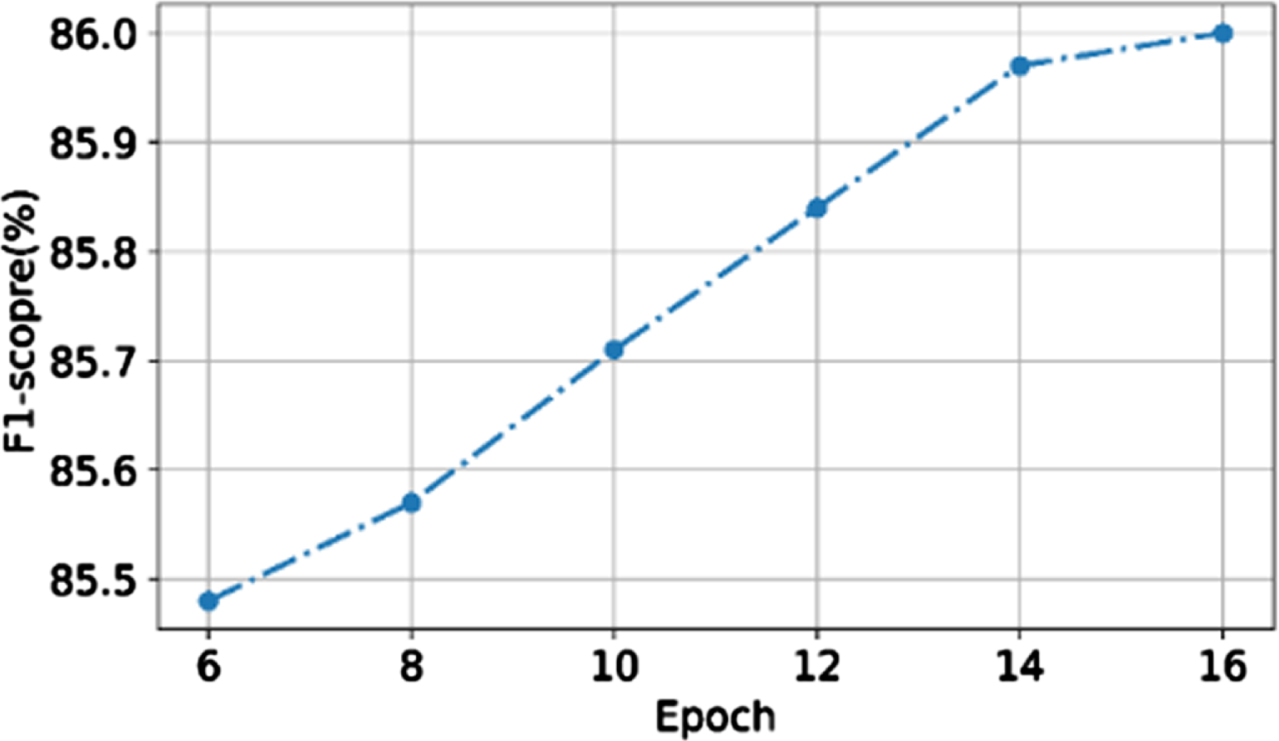
F1 score of the proposed system.
Figure 15 shows the sensitivity of the proposed system. The proposed method sensitivity has reached maximum of 89% in 16 epochs. The suggested technique achieves great sensitivity through the use of a probabilistic discriminative Bayesian model, in which the response to the input question is determined based on the type by referring to picture content via an attention mechanism. The suggested model has an 88.08% sensitivity rate after 6 training epochs. The sensitivity of the proposed model increases for each epoch and it reaches maximum sensitivity within 15 epochs. The proposed system uses LSTM with loopy backpropagation will enhance the sensitivity in different epochs training, LSTM reduces the loss by considering the syntactic and discourse dependencies of the questions.
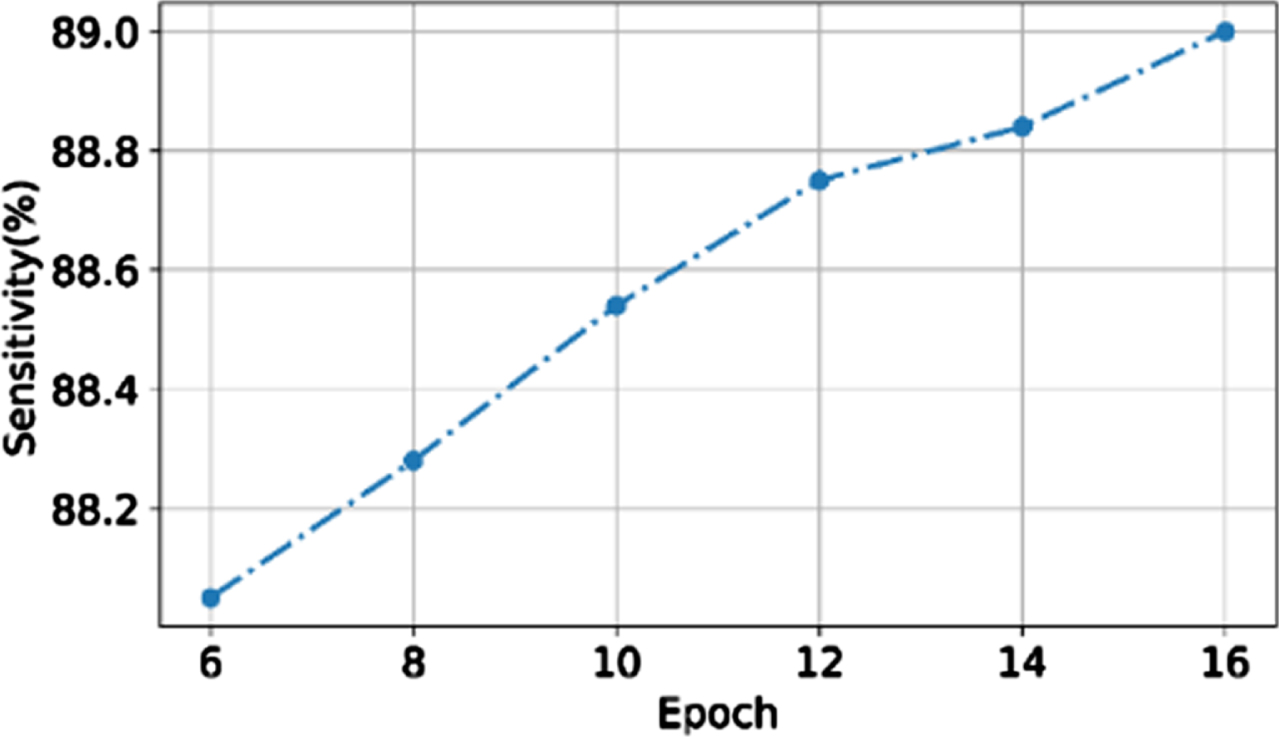
Sensitivity of the proposed system.
Overall performance achieved in the proposed method is shown in Fig. 16. The proposed model reached maximum accuracy of 88.30% by reducing error and loss of information when extracting image and question features. Also has 88% of recall and precision value of 84.5% due to the adaption of attention mechanism in proposed answering system. The proposed method has high sensitivity of 89% and F1-Score of 86%. Thus the proposed method has achieved better performance in terms of accuracy, precision, recall, F1-score, sensitivity.
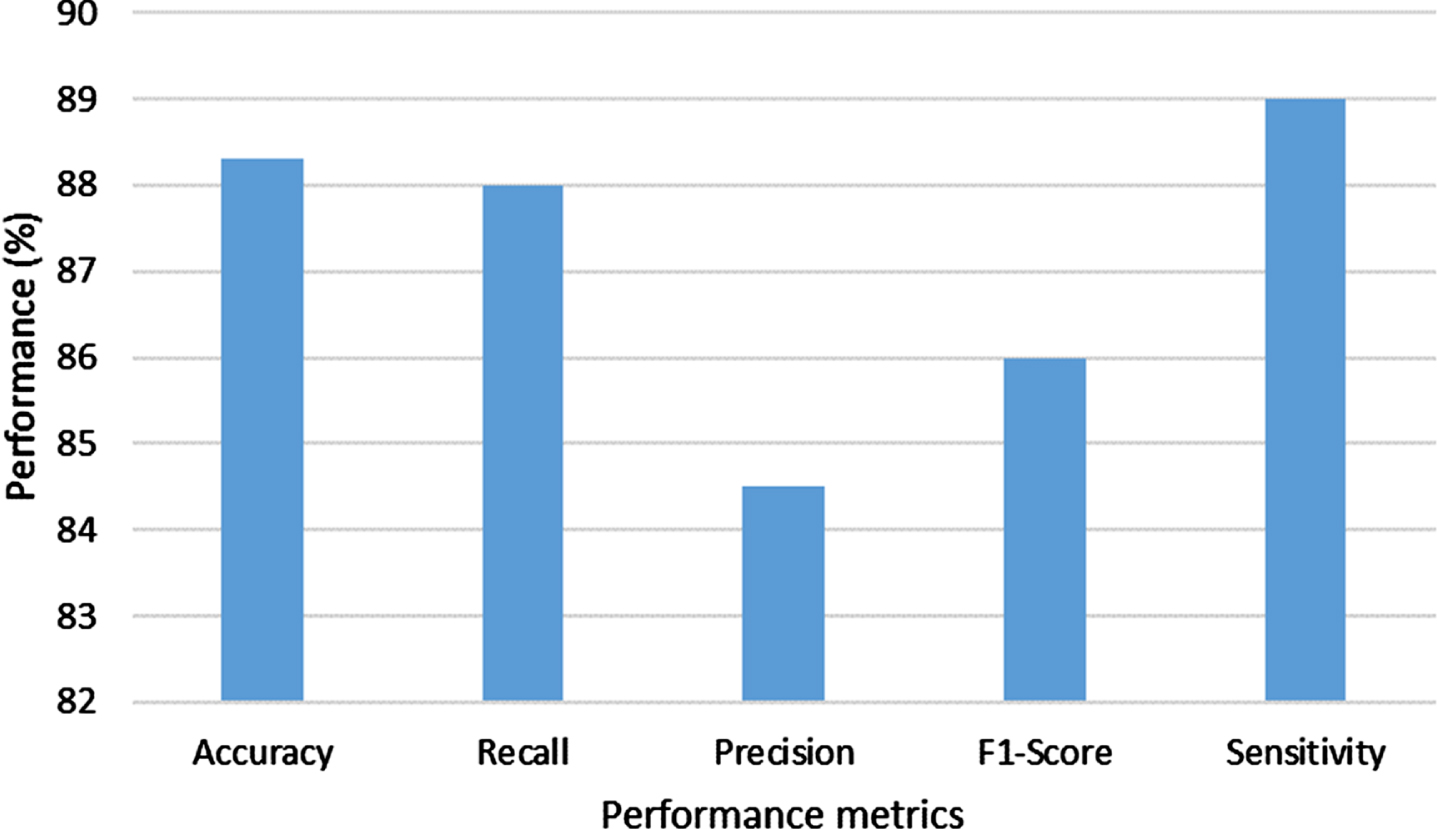
Overall performance of proposed method.
This section describes the various performances of the proposed method compared with the results of previous methodologies like convolutional neural network with Long Short-Term Memory (CNN-LSTM), Memory Attention and Composition (MAC) [32], Language-conditioned graph networks (LCGN) [33], and Reasoning-Aware Graph Convolutional Network (RA-GCN) [34].
Figure 17 shows the accuracy of our proposed system is 88.30% which is higher than the other methods that are taken for comparison. The accuracy of CNN-LSTM, MAC, LCGN, RA-GCN are 49.8%, 57.03%, 63.7%, 62.4% respectively. The proposed method reaches the maximum accuracy of 88.30% which is greater than the other existing methods. The image features are extracted in the proposed model uses dropout layer and optimized momentum backpropagation increase the accuracy by eliminating overfitting issues of information.
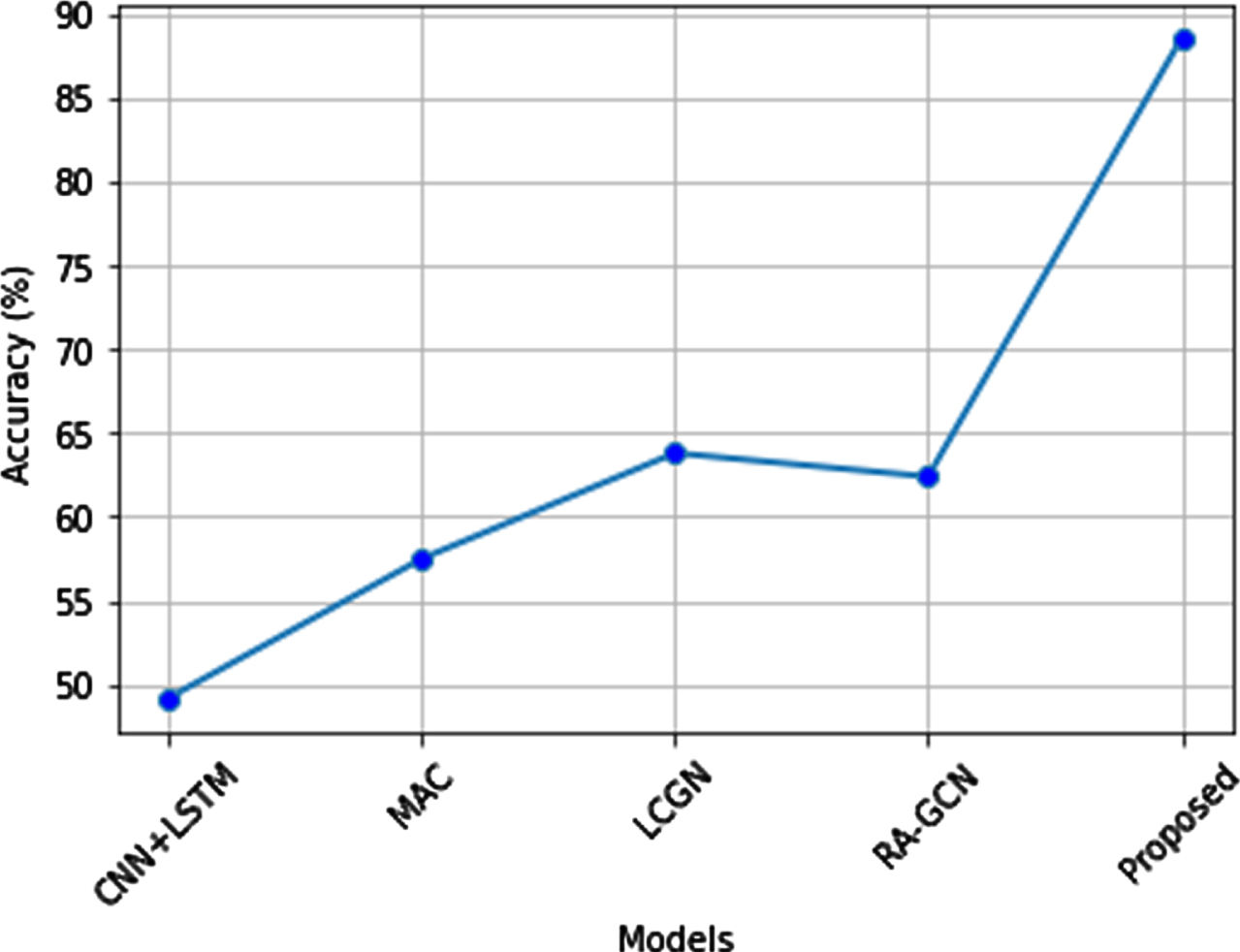
Accuracy comparison of the proposed method.
Precision comparison of the proposed system is shown in Fig. 18. The precision value of CNN-LSTM is 45%, the precision value of the MAC model is 56%, the precision value of LCGN is 63%, and the precision value of RA-GCN is 61%. When it comes to the proposed system precision value reaches a maximum of 88%. This shows that the proposed method performed better compared to other methods because the proposed method extracts the features by using optimum momentum backpropagation.
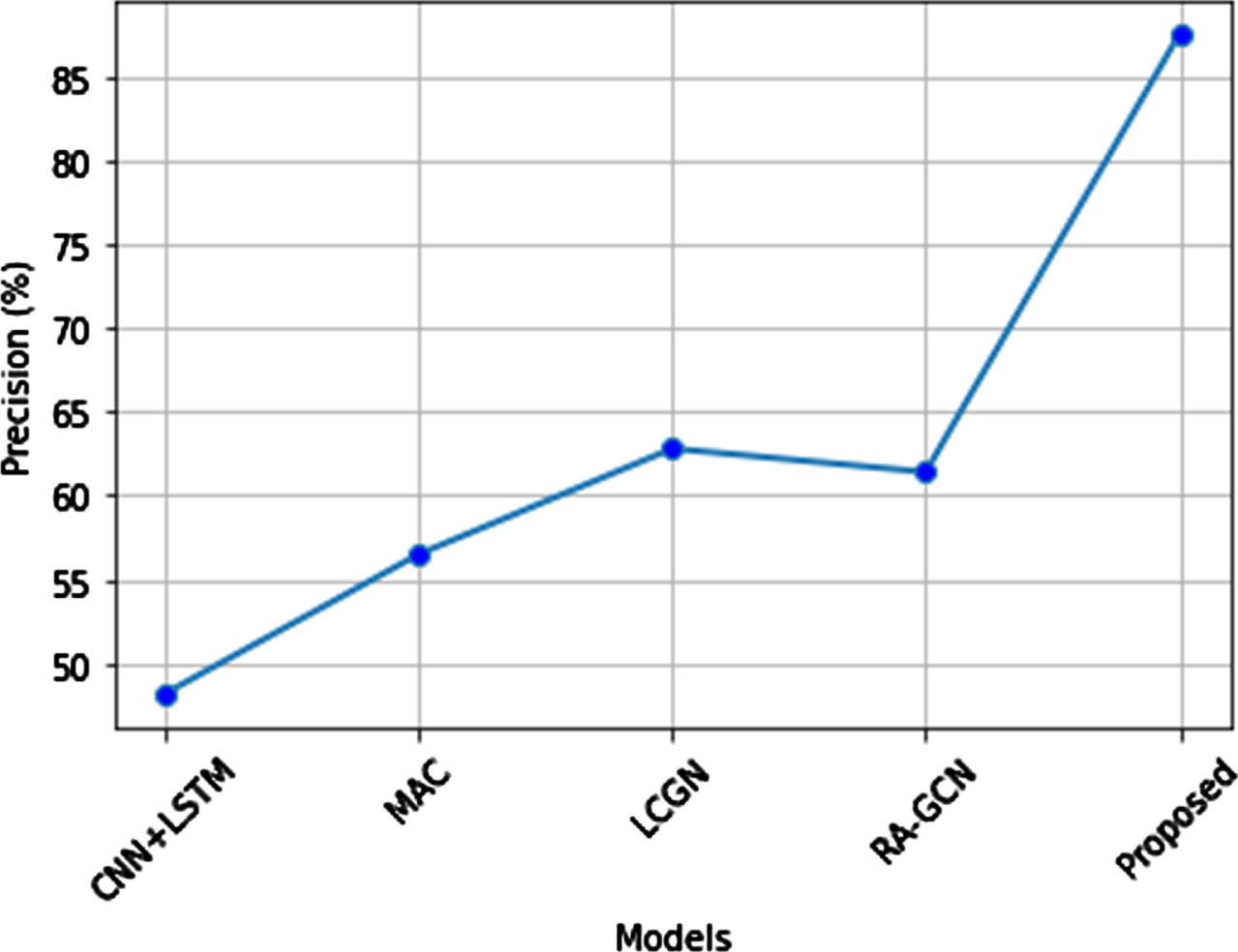
Precision comparison of the proposed method.
When a recall is compared to the existing systems such as CNN-LSTM, MAC, LCGN, and RA-GCN the proposed system recall is higher than the existing systems as shown in Fig. 19. The proposed recall is 84.5% highest when compared with the recall of other existing techniques. Recall percentage of existing systems like CNN-LSTM, MAC, LCGN, and RA-GCN are 57.5%, 56%, 51.5%, and 60.10%. Hence the proposed system has a higher value than other methods because the proposed method uses the LSTM with loopy backpropagation, which identify the semantic dependencies of the questions.
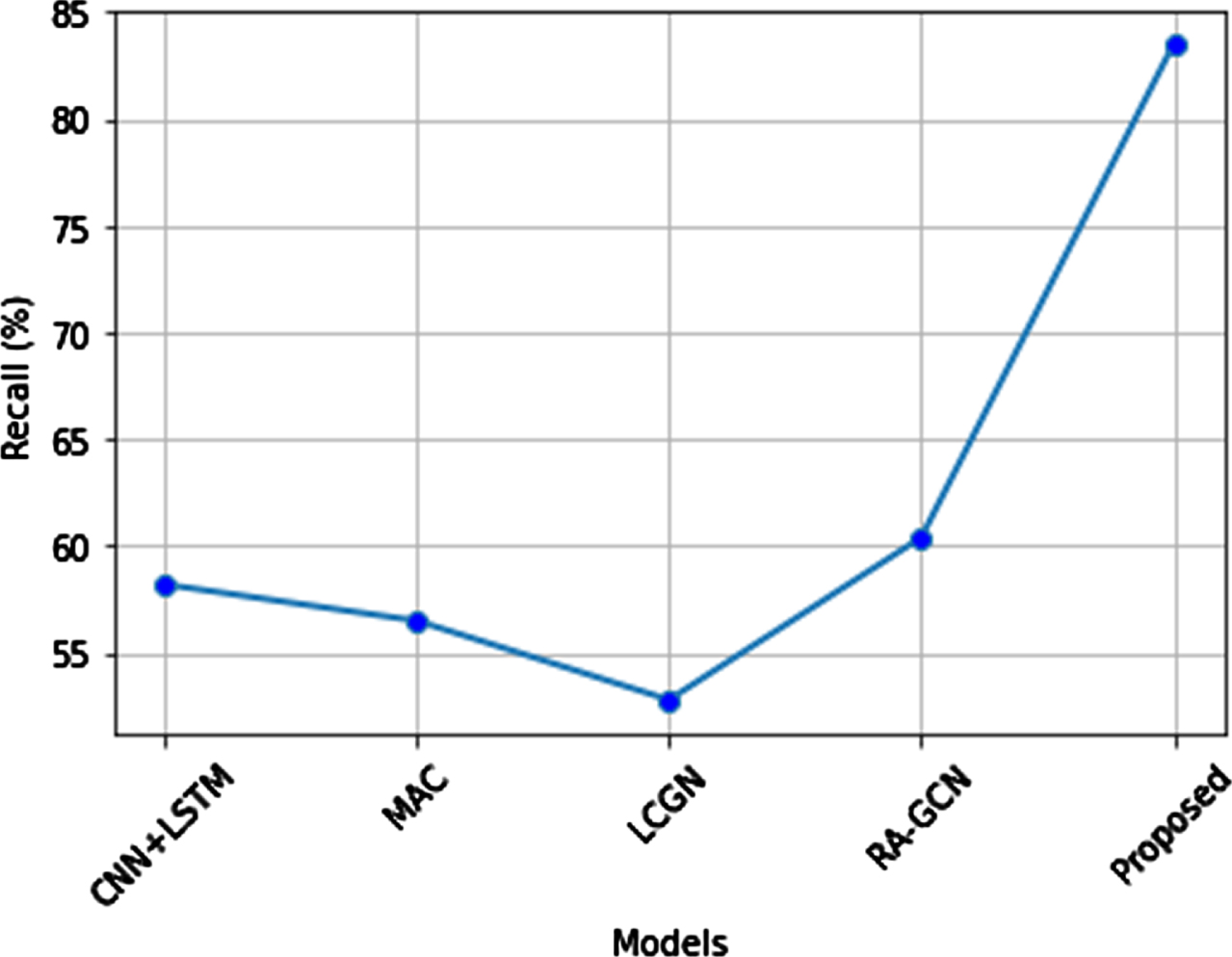
Recall comparison of the proposed method.
Figure 20 shows the F1-score comparison of the proposed system. When a proposed method has a value of 86%, other comparison methods have the lowest value than the proposed system. The previous methods such as CNN-LSTM, MAC, LCGN, and RA-GCN has recall value of 56%, 57%, 60% and 61%, respectively. These values are lower than the proposed value of 86%. This proves that the proposed system has better performance due to the knowledge extraction about the image from Wikidata using spatial GCNN.
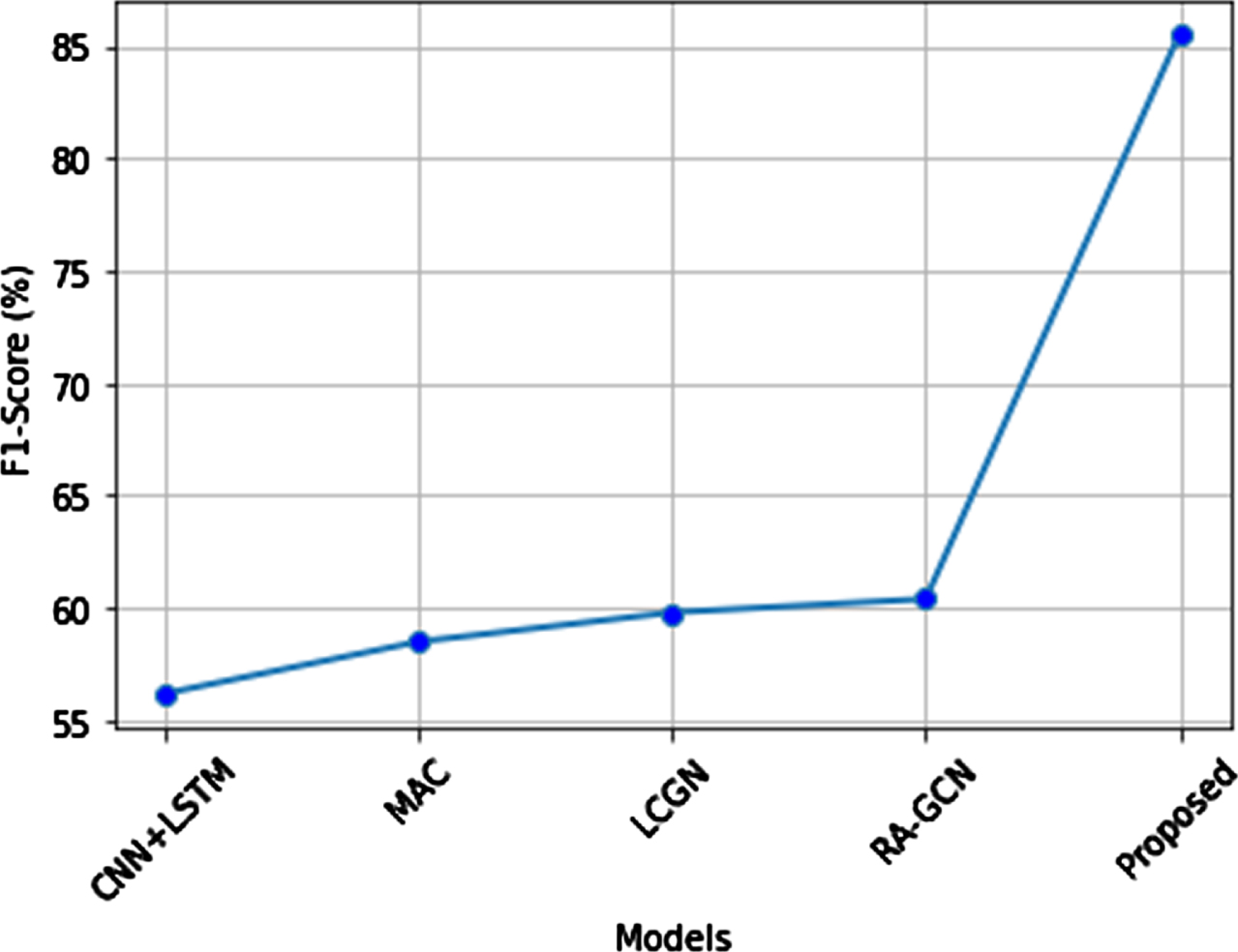
F1-score comparison of the proposed method.
When sensitivity is compared to the existing systems such as CNN-LSTM, MAC, LCGN, and RA-GCN the proposed system sensitivity is higher than the existing systems as shown in Fig. 21. The proposed sensitivity is 89% highest when compared with the sensitivity of other existing techniques. The sensitivity percentage of the CNN-LSTM method is 87%, the sensitivity of the MAC method is 77%, the LCGN method has a very low sensitivity of 73% and the RA-GCN has a sensitivity of 80.10%. The proposed sensitivity is increased by attention mechanism in the Probabilistic Discriminative Bayesian model.
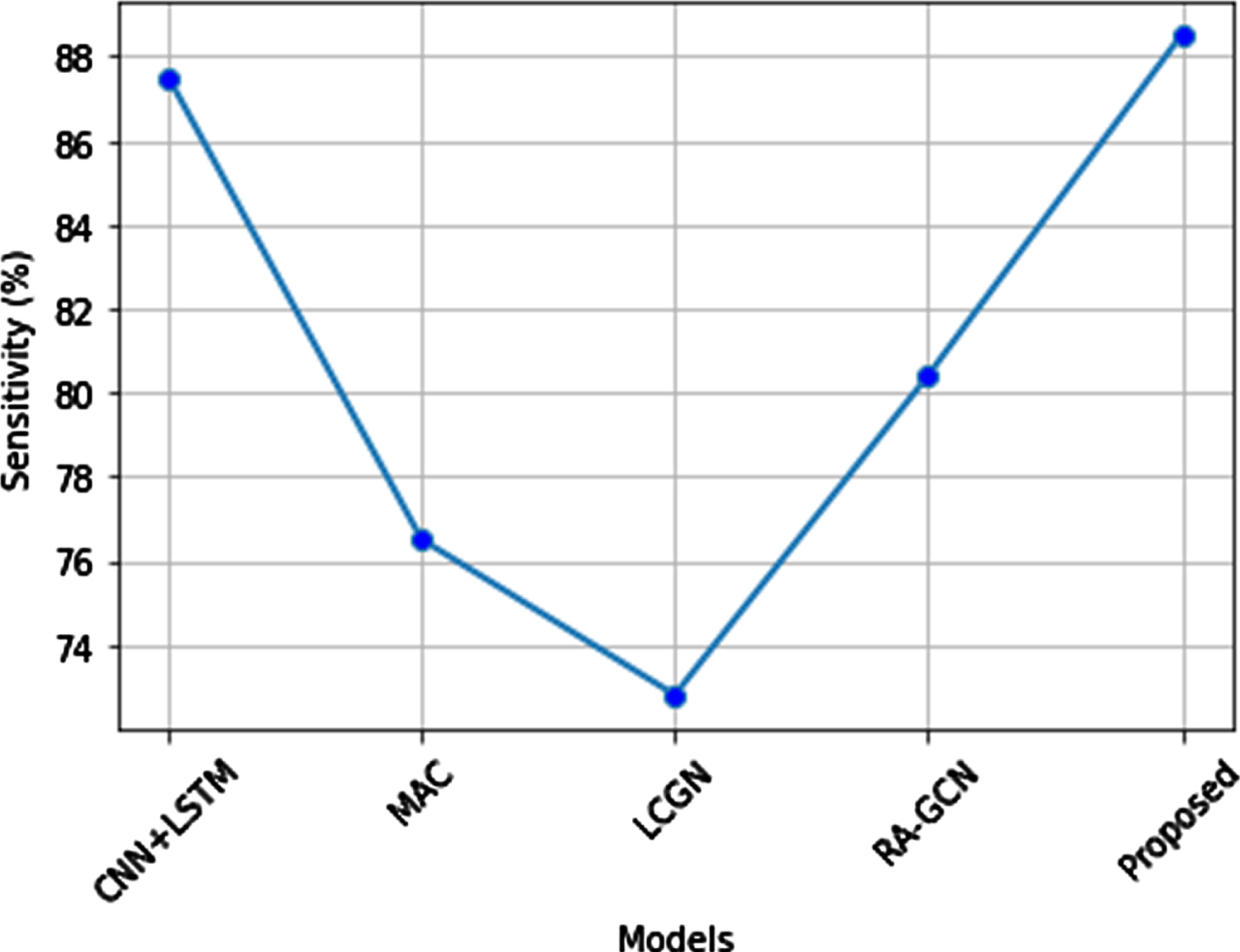
Sensitivity comparison of the proposed method.
Table 2 shows the accuracy of the proposed system for answering knowledge base question. Knowledge-incorporated dynamic memory network framework (KDMN) without knowledge has a low accuracy of 45.1%. Further KDMN without memory has an accuracy of 51.9%, and KDMN has achieved up to 57.8%. Answer with ensemble method obtained 60.9% accuracy. But the proposed method has high accuracy of 88.3%. The maximum accuracy in the proposed method is achieved by external knowledge retrieval using Spatial GCNN.
Accuracy in open domain question answering
Overall, the proposed Visual Question Answering system outperforms existing methods like CNN-LSTM, MAC, LCGN, and RA-GCN. As the proposed technique used CNN with optimum momentum backpropagation has been used for feature extraction from image and LSTM with loopy backpropagation for question feature extraction therefore proposed method achieved an accuracy of 88.30% using a dropout layer with optimized momentum backpropagation and the Graph-based LSTM-based loopy backpropagation by eliminating overfitting error and loss of information.
In the Visual Question Answering system, the previous works are incapable of answering the knowledge-based open-domain critical questions. Hence, the proposed work uses CNN with dropout and Graph-based LSTM for featurization, which recognizes the spatial specifics of picture characteristics also gets rid of overfitting and lessens information loss brought on by the existence of a dropout layer. Also, the spatial graph convolutional network nodes are linked based on the image content and question keyword. Moreover, to provide the information in a standard SVO triples sentence it retrieves the knowledge from wiki data as keywords related to the query. Then the Probabilistic Discriminative Bayesian model-based Attention mechanism predicts the answer by focusing on the part of the image which contains the answer by referring to the content of the image. Further, to generate the answer in sentence format the noun-verb linking algorithm is used which creates the SVO sentence pattern to answer the question in a meaningful sentence. The answer predicted by the proposed system is 88.30% accurate and with a system precision of 88%. The recall of the approach is increased by 84.5%, with an 80.10% sensitivity, and also depicted enhanced performances comparatively with other existing approaches. In future, the research has been enhanced by adding transformer-based models and feature fusion networks.