
Abstract
The Dunhuang murals, notably the paintings on the interior walls of China’s Dunhuang Grottoes, are considered international cultural treasure. The Dunhuang murals were ruined to varied degrees after a lengthy period of erosion. Deep learning networks were utilized to reconstruct broken parts of murals in order to better preserve their important historical and cultural values. Due to the presence of various damages, such as large peeling, mold and scratches, and multi-scale objects in the mural, a simple porting of existing working methods is suboptimal. In this paper, we propose a progressive Dunhuang murals inpainting (PDMI) based on recurrent feature reasoning network to progressively infer the pixel values of hole centers by a progressive approach, aiming to obtain visually reasonable and semantically consistent inpainted results. PDMI consists mainly of the FFC-based recurrent feature reasoning (RFR) module and Multi-scale Knowledge Consistent Attention (MKCA) module. The RFR module first fills in the feature value at the feature map’s hole border, then utilizes the obtained feature value as a clue for further inference. The module steadily improved the limitation of hole centers, making the inpainted results more explicit; MKCA enables feature maps in RFR to handle richer background information from distant location information in a flexible manner while preventing misuse. After several round-robin inferences provide multiple feature maps, these feature maps are fused using an adaptive feature weighted fusion mechanism, then the fused feature maps decode back to RGB image. Experiments on a publicly available dataset and a self-made Dunhuang mural dataset reveal that the proposed method outperforms the comparison algorithm in both qualitative and quantitative aspects.
Introduction
The Mogao Grottoes in Dunhuang are the largest and most abundant treasure house of Buddhist grotto murals in the world. The murals and scriptures stored in them have precious research value. However, due to the damage of natural weathering and the influence of human factors, the murals in the caves have suffered serious disasters such as falling off, scratches, fading, cracks [1], which need to be protected urgently. Therefore, it is extremely important to study the restoration of the damaged Dunhuang murals. Traditional mural restoration methods rely on manual restoration, which has the risk of irreversibility. Therefore, there is a growing interest in using digital restoration techniques for the protection and preservation of ancient murals, which has become a hot research topic in recent years [2–8].
Image inpainting as a way of mural conservation can be divided into traditional methods and learning-based methods. Traditional exemplar-based image inpainting methods [9–11] usually through copy-and-paste or information propagation for inpainting. These methods can complete images with small broken areas or repetitive patterns to some extent, but they often do not perform satisfactorily enough for images with large broken areas or complex structures. This is mainly because these methods focus only on the low-level features of the image and are not able to understand the semantic information of the image, which makes it difficult to produce reasonable inpainted results.
In recent years, deep learning-based methods for image inpainting have made significant progress. These methods can be broadly classified into two categories: one-stage methods and two-stage methods. One-stage methods, such as those described in [12–15], aim to synthesize both reasonable semantic contents and fine details in a single network. On the other hand, two-stage methods use two serial networks, a coarse network and a refinement network, to deal with coarse and fine contents separately. Two-stage methods have explored the use of coarse-to-fine inpainting models in various ways. For example, they may use a coarse network to generate intermediate outputs such as edges [16], structural information [17], segmentation maps [18], which are then used as guidance for filling in the missing details in the refinement network. Although these methods have achieved better results than before, they apply an encoder-decoder architecture, assuming that once a damaged image is encoded, it should contain enough information for reconstruction and can be inpainted in a one-shot. For minor damage, this assumption is reasonable since pixels in a local area may have significant association, and hence pixels can be inferred from the surrounding environment. However, as the damaged region of the image grows larger, the distance between the known and unknown pixels increases, the correlation between the hole center and the hole boundary decreases, and the constraint of the hole center lessens. In this situation, it is impossible to efficiently recover the pixel at the center of the hole from the information in the known area, resulting in semantic ambiguity in the network.
To tackle the aforementioned limitation, Li et al. [19] proposed the Recurrent Feature Reasoning network (RFR-Net), which employs a progressive inpainting strategy to gradually reinforce the constraints on the hole centers. The RFR-Net network is composed of two key components: the Recurrent Feature Reasoning (RFR) Module and the Knowledge Consistent Attention (KCA). The RFR Module recurrently predicts the hole boundaries of the feature maps and utilizes them as guidelines for further inference. As the RFR Module advances, it progressively intensifies the constraints on the hole center, leading to more explicit and accurate inpainted results. To capture information from remote areas in the feature map for RFR, the KCA is integrated into the RFR network, which enhances the network’s ability to reason over the entire feature space and to maintain coherence in the inpainting process.
Inspired by the RFR-Net, we designed a progressive Dunhuang murals inpainting (PDMI) based on recurrent feature reasoning network to address various possible damages in mural images (such as large peeling, scratches, and mold), as well as multi-scale objects that may have different scales of the same or similar objects in the mural. Compared to RFR-Net, our main differences are as follows. First, the RFR Module we designed is based on Fast Fourier Convolution (FFC) [20]. FFC has a global receptive field, which can better obtain global information. Secondly, we designed a multi-scale knowledge consistency attention module, and compared with a single scale KCA, our MKCA can better capture multi-scale information. Finally, we designed a weighted adaptive fusion module for fusing multiple feature maps, while using an average approach in RFR ignores the importance of feature maps generated at different stages. In summary, the following are the main contributions of our work: Multi-scale Knowledge Consistency Attention (MKCA) module is proposed to flexibly borrow background information, avoid misuse of background information, and ensure the consistency of patch exchange process between recursions. Based on FFC framework, the RFR module is designed to enhance reasoning efficiency. It enables integration of multi-scale mural information from preliminary layers, thereby improving the efficiency of detailed complex representations. An adaptive weighted fusion mechanism is designed to fuse feature maps generated at different inference stages to obtain more refined results.
Related work
There are two types of traditional inpainting methods: geometry-based approaches and patch-based methods. The geometry-based approaches work by using partial differential equations to propagate the local structure from the outside to the interior of the hole. Patch-based approaches pick comparable patches from a database or an undamaged environment and paste them into damaged parts based on patch distance measurements (e.g. euclidean distance, screening distance [21], etc.). PatchMatch stands up among other previous traditional approaches [9]. PatchMatch fills holes faster than other traditional approaches, however the inpainting will be poor if no matching texture is identified in the image. Patch-based image inpainting approaches can yield precise results that resemble the backdrop. Patch-based approaches, on the other hand, struggle to yield semantically appropriate results due to their incapacity to capture the global semantics of images. There are three main problems with all traditional methods. First, they fail to capture global structure and image semantics. Second, they cannot fill complex holes [9, 13]. Finally, the time cost of completing a large hole is high.
To produce semantically consistent and visually reasonable results, most learning-based methods rely on a CNN or a GAN [22, 23]. Pathak et al. [12] proposed Context Encoders, the first attempt to inpaint images with large damaged areas effectively. To ensure global and local consistency of foreground and background, Iizuka et al. [13] introduced a double discriminator, but post-processing need to use Poisson blending to reduce artifacts [24]. Yu et al. [25] proposed a framework for coarse to fine image inpainting that includes context attention modules. The convolution layer was modified to handle irregular masks by Liu et al. [14] and Yu et al. [26]. However, in the case of a large broken area, these methods cannot restore semantically reasonable results.
Recent research has focused on progressive image inpainting. To ensure structural consistency, Xiong et al. [27] and Nazeri et al. [16] driven image completion by contour/edge constraints. Xu et al. [28] presented a three-stage progressive inpainting network. To complete end-to-end progressive inpainting, Li et al. [29] incorporated a gradually reconstructed structural map as an extra training target. The approaches presented above attempt to tackle the inpainting challenge by applying structural prior restrictions, however they lack the information in the backbone to recover the deeper pixels in the hole. Zhang et al. [30] filled the image step by step using cascaded generators. Guo et al. [31 directly inpainted images of original size using a single-stage feed-forward network. 32] employed the Onion-peel approach to progressively restore the video data with the aid of the reference frame content, achieving accurate content borrowing. However, these approaches are typically constrained by traditional progressive inpainting or multi-stage procedures.
Proposed method
In this section, we will introduce the PDMI network in detail. The PDMI network takes the masked image as input and first maps it through the Mapping module to obtain the feature map F in . The RFR module then identifies the area to be inferred in F in , progressively fills in the missing regions, and generates a feature map at each stage. The feature merge operator is used to fuse the feature maps generated by each stage, and the final feature map is fed into the decoder to obtain the inapinted image. To establish long-term dependencies on the pixels in the feature map, the MKCA module is utilized to assist the RFR module. The complete network architecture can be observed in Fig. 1, which provides a better understanding of the entire image inpainting process.
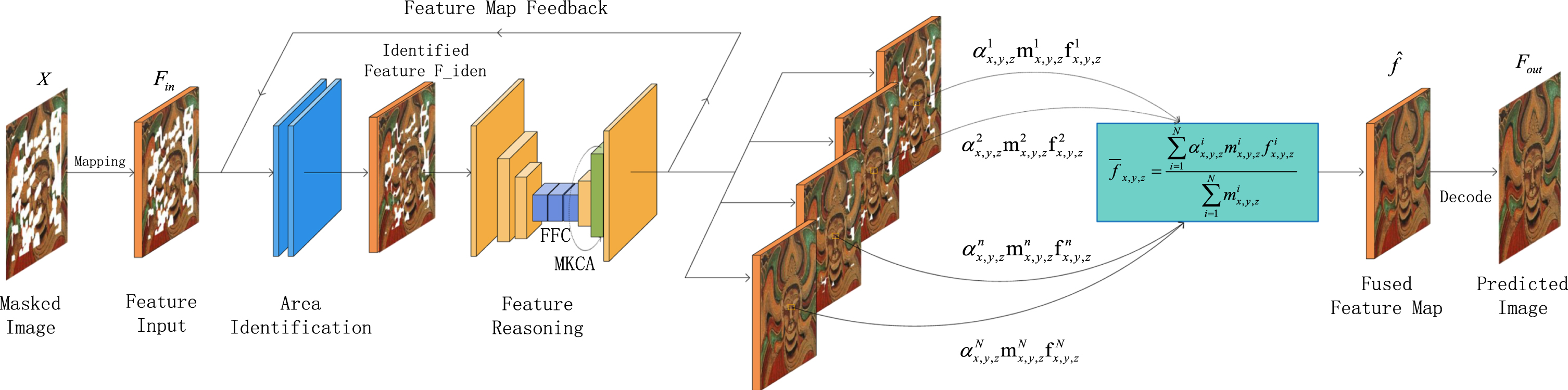
Network architecture. The network takes the masked image as input and maps it through the mapping module to obtain the feature map F in . The RFR module progressively infers the missing area in F in and generates a feature map at each stage. The feature maps are fused using the feature merge operator, and the final feature map is decoded to obtain the inpainted image.
The mapping module, which consists of a downsampling convolution and three vanilla convolutions, transforms the masked image X into the convolutional feature space, generating the feature input F in for the feature inference module. This can be mathematically expressed as:
The recurrent feature reasoning module contains three modules: 1) an area identification module to identify the area to be filled in the current recursion; 2) a feature reasoning module to infer the content in the identified region; and 3) the feature merge module to fuse intermediate feature maps. The module alternates between area identification and feature reasoning. After filling the holes, the feature maps generated during inference are combined to form a fixed-channel feature map.
Area identification
Partial convolution [14] can be used to identify the area to be updated in each recursion. However, the mask obtained through partial convolution layer is not learnable, making the network difficult to train. Therefore, LAM in LBAM is used to replace partial convolution, and the difference between the updated mask and the input mask is defined as the area to be inferred in current recursion [33]. After convolution computation, LAM layers update masks and renormalize feature maps. A LAM layer is described formally as follows. Let F* denote the feature maps produced by LAM layers.
We cascade two LAM layers as the area identification module. After passing through the area identification module, the feature maps are fed to the feature reasoning module after being processed by the normalization layer and activation function. Note that the holes in the mask remain unchanged during the current recursion.
After obtaining the region to be inferred, the feature reasoning module estimates the feature value of the region. Continuously estimating the feature value of the region to be inferred at the feature map level helps to obtain high-quality feature value, which high-quality features can make the restoration effect more in line with human visual perception and facilitate subsequent reasoning. To obtain high-quality feature value, we design an FFC-based network architecture. FFC has a receptive field that covers the entire image, allowing the use of global context at early layers. High receptive field is essential in image inpainting, allowing the network to utilize more valid information. FFC are split into local ones encoded by vanilla convolutions and global ones encoded by the spectral transform. The spectral transform is consisted of Fast Fourier Transform (FFT), Conv → BatchNorm → ReLu, and the inverse FFT. And both the real and imaginary parts are confirmed in the Conv2D after FFT. After the inverse FFT, local and global features are combined as the final output. The illustration of FFC is available in Fig. 2.

The schematic illustration of the Fast Fourier convolution (FFC).
Let F i denote the i th recursive input feature map. As shown in Fig. 3, we initiatively divide F i into multi-scale patches of size 1 × 1 and 3 × 3 and compute the inter-patch normalized inner product:
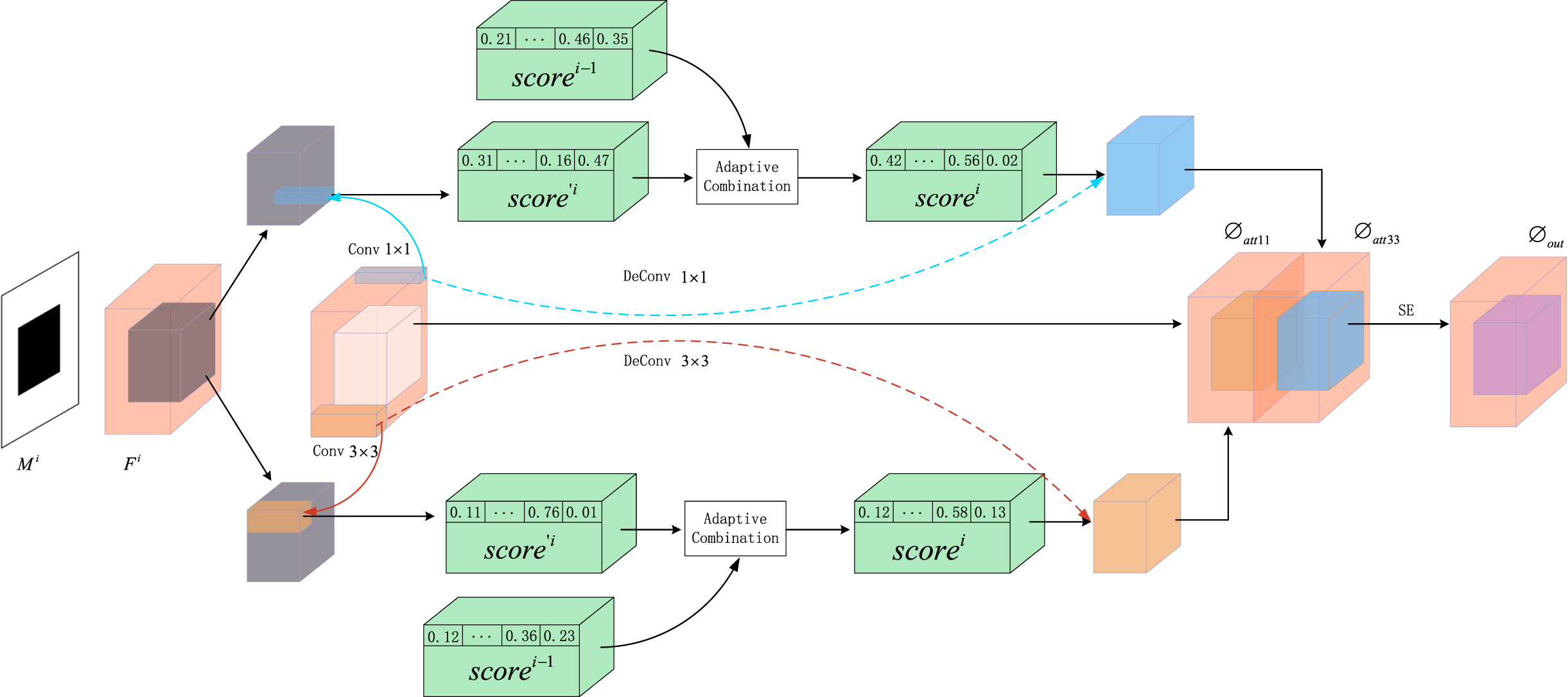
The schematic illustration of the multi-scale knowledge consistent attention (MKCA) module.
Then, apply softmax function along p′ - q′ dimension to normalize inter-patch similarity. The produced score map is marked score′. We follow the operation in [19] to calculate the attention score in score
i
for a pixel: if the pixel is valid, its attention score in the current recursion is the weighted sum of the attention scores of the current recursion and the previous recursion. Specifically, if the pixel at position (p, q) is a valid pixel in the previous recursion (i.e., the mask value
If the pixel was invalid in the previous recursion, no additional operations are performed, and the final attention score for the pixel in the current recursion is calculated as follows:
Then, the attention score is used to reconstruct the feature map. Formally, the reconstruction feature map at position (p, q) is calculated as follows:
Finally, concatenate the generated feature maps, denoted by <φatt11, φatt33>. then feature maps fed into a squeeze-and-excitation (SE) to decide which level of detail is the most important one on current image [35]. The final output of the module could be denoted as:
When the feature map passes through the feature reasoning module several times until it is completely filled, directly using the last feature map to generate the output, gradient vanishing may occur and it will corrupt the signal generated in the previous recursion. RFR-Net uses an adaptive merging scheme to solve this problem. The difference is that we use the adaptive weighting scheme to fuse the feature maps generated in different recursion, and the adaptive learning of the respective weights of the feature value fusion, rather than treating all the feature values equally [36]. Similarly, the values in the output feature map are only based on the features that have filled the corresponding positions.
Formally, we define F
i
as the i
th
feature map generated by the feature reasoning module, and fx,y,z as the values at positions x, y, z in the feature map F. M
i
is the binary mask of the feature map F
i
. The value at the output feature map
The decode module, consisting of one upsampling operation and three vanilla convolutions, generates the inpainted image in the RGB image space from the fused feature map. This can be expressed as:
The decode module is responsible for generating the final inpainted image from the fused feature map.
The loss functions used in this paper mainly include perceptual loss, style loss, multi-scale edge loss, hole loss, and valid loss.
The perceptual loss and style loss compare the semantic difference between the generated image and the ground truth [37]. To extract semantic features, a VGG19 network pre-trained on the ImageNet database is used [38, 39]. A loss function of this type can effectively teach the model the structural and textural information of an image. The following is a representation of these loss functions. The feature map of the i th pooling layer in fixed VGG-16 is denoted by φ pool i . The size of φ pool i is represented by H i × W i × C i . The perceptual loss can then be written as:
Again, the style loss is calculated as follows:
We use a multi-scale edge loss to guide structure generation, forcing the model to pay more attention to the structure of the generated image, thereby implicitly encouraging the generator to leverage relevant structural knowledge when inpainting.
The adversarial loss (L adv ) quantifies the inpainting verisimilitude. In addition, L valid and L hole are also used in the model, which calculate the L1 difference in unmasked and masked regions, respectively. So the total loss function is:
In this section, experiments on the Dunhuang mural dataset were conducted out, and the visualization results and index comparison were displayed. In addition, to further validate the algorithm’s effectiveness, we ran experiments on the public dataset Paris StreetView Dataset. Our computing device is equipped with a 2.1GHz Intel(R) Xeon(R) CPU and a 12GB NVIDIA Titan Xp GPU. Our programming environment is PyTorch v1.1, which is running on the Ubuntu 18.04 operating system.
Datasets
Dunhuang Mural Dataset: As the dataset source, choose 3000 different Dunhuang mural images, primarily Tang Dynasty murals, and expand the dataset to obtain 12,000 mural datasets, 10,000 mural images in the training dataset and 2,000 mural images in the test dataset. The mask dataset is from [14], and it contains 12000 sheets.
Paris StreetView Dataset [40]: The dataset contains 14,900 training images and 100 test images, primarily of real-world street scenes, such as buildings, trees, streets, and sky.
Inpainting of Dunhuang mural dataset
We conducted extensive experiments on the Dunhuang mural dataset to further validate the effectiveness of the proposed method. The experiment is evaluated in comparison to other advanced image inpainting methods. So that the benefits of this method can be demonstrated intuitively. We demonstrated the visualization and numerical comparison of partial inpainting results of Dunhuang murals in Fig. 4 and Table 1. The results of Pconv restore are prone to color artifacts, as shown in Fig. 4, whereas Rethink, RFR, and CTSDG all show varying degrees of structural distortion in the first image, and we successfully obtain more reasonable visual results on all images.

Numerical comparison on Dunhuang Mural Dataset
We further evaluate the inpainting results in Fig. 4 using PSNR and SSIM index, as shown in Table 1. PSNR and SSIM are important quantitative evaluation index to measure image quality. The larger the PSNR value, the less distortion, that is, the better the restoration effect; SSIM is an index to measure the similarity of two images, the higher the value, the better the recovery effect, and the smaller the image distortion. From Table 1, it can be found that the proposed algorithm is superior to other comparative algorithms in PSNR and SSIM, indicating that the proposed method has better repair quality, which verifies the effectiveness of the proposed method for the repair of artificially damaged murals.
The inpainting results in Fig. 4 are further evaluated using the PSNR and SSIM indexes, as shown in Table 1. PSNR and SSIM are important quantitative image quality evaluation index. The greater the PSNR value, the less distortion, and thus the better the restoration effect; SSIM is an index that measures the similarity of two images; the greater the value, the better the recovery effect and the less image distortion. According to Table 1, the proposed algorithm outperforms other comparative algorithms in PSNR and SSIM, indicating that the proposed method has better inpainting quality, confirming the proposed method’s effectiveness for the inpainting of artificially damaged murals.

Numerical comparison on Paris StreetView Dataset
In this part, we validate the effectiveness of the multi-scale knowledge-consistent attention module on the Paris Street View dataset, and as a control group, we kept the same settings and use single-scale knowledge-consistent attention instead of multi-scale knowledge-consistent attention. The experimental results are shown in Fig. 6. As can be seen from Fig. 6, multi-scale attention can make better use of contextual information, and our multi-scale attention can mine more information than single-scale attention to guide the inpainting process in the face of larger breakage.
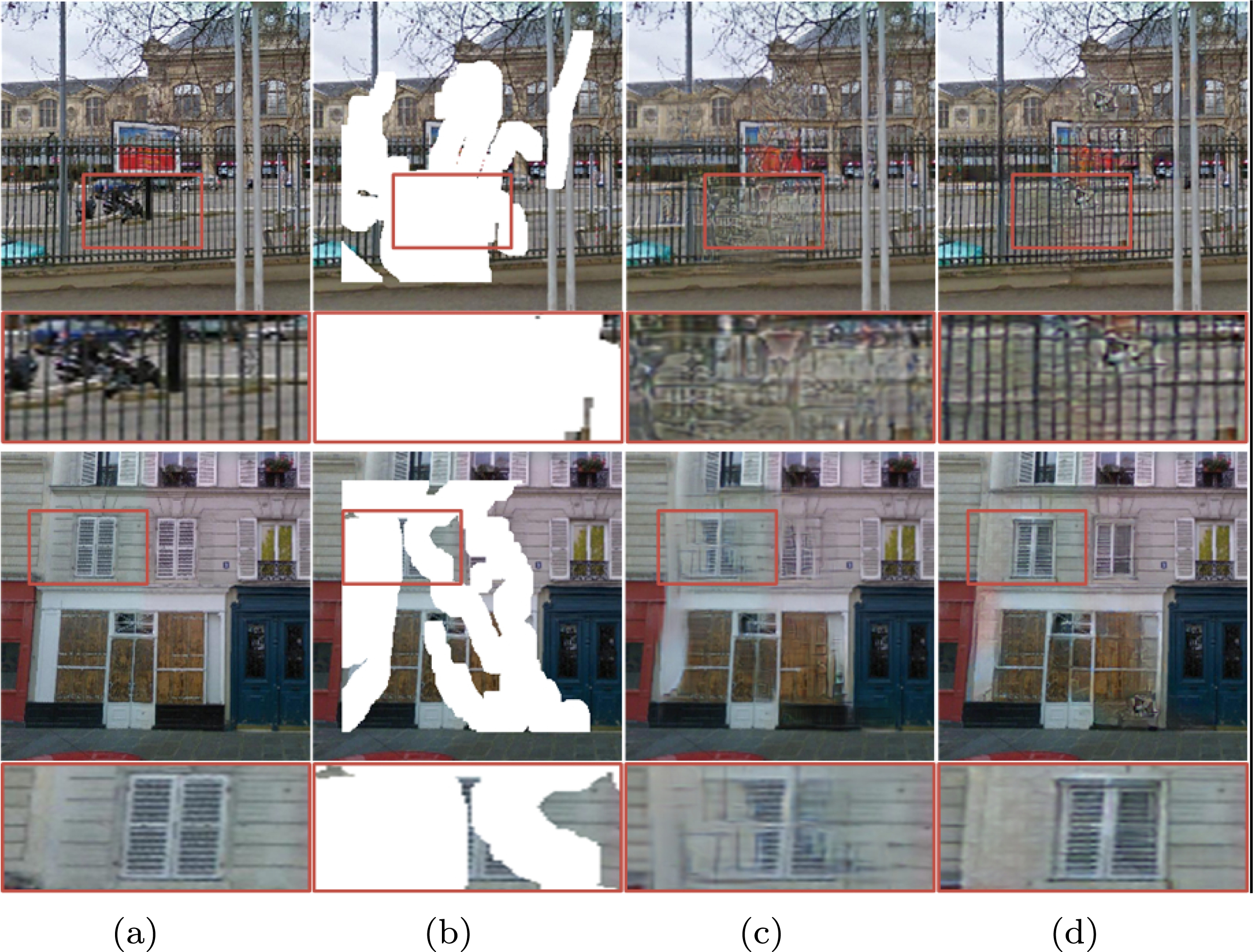
Qualitative comparisons of MKCA module. From left to right are: (a) GT, (b) Input, (c) the control group: keep the same settings, use single-scale KCA to replace MKCA, (d) Ours.
In this paper, a progressive mural inpainting method based on recurrent feature reasoning is proposed. To begin, it infers the area to be inferred on the feature level repeatedly until the hole is completely filled or the specified number of inferences are reached. After obtaining several inferred feature maps, the adaptive weighted fusion mechanism is used to fuse them, and the fusion map is decoded to obtain the final prediction map. This recursive design can gradually enrich the information of the mask area and produce an inpainting result with clear semantics. Compared with comparison algorithms, our method has achieved competitive results both qualitatively and quantitatively. This shows that the algorithm is effective for inpainting complex Dunhuang murals with large damage. Although our method achieves certain results, there are still some limitations, such as our model does not take into account the color consistency of the mural. In the future, we will further design the loss function and model architecture for the characteristics of the mural.
Footnotes
Acknowledgment
This work was supported in part by the Gansu Provincial Department of Education University Teachers Innovation Fund Project (No.2023B-056), the Fundamental Research Funds for the Central Universities (No. 31920230137, 31920230030, 31920220130), the Gansu Provincial First-class Discipline Program of Northwest Minzu University (No.11080305), the Leading Talent of National Ethnic Affairs Commission (NEAC), and the Young Talent of NEAC, and the Innovative Research Team of NEAC (2018) 98.