
Abstract
In image processing, segmentation is a fundamental problem but an important step for advanced image processing problems. When dealing with hyperspectral image data, the task becomes much more challenging due to the large number of features (dimension), higher nonlinearity, and greater capacity of the data. This paper proposes a solution of features reduction collaborative fuzzy c-means clustering (FR-CFCM) for hyperspectral remote sensing image analysis using random projection. The dimensional reduction technique is based on the Johnson Lindenstrauss lemma algorithm, preserving the relative distance between data samples. This can make clustering easier without affecting the clustering results. Moreover, by reducing dimensionality and sharing information among sub-data in collaborative clustering, it is possible to improve the performance and accuracy of hyperspectral remote sensing image analysis results. The experiments conducted on two hyperspectral image data sets with five validity indexes show that the proposed methods perform better compared with the other methods.
Introduction
Hyperspectral imaging (HSI), which acquires hundreds of individualized reflectance or fluorescence spectrum for each pixel, is applied in various fields and is one of the most comprehensive applications in earth observation [1]. HSI has huge numbers of narrow and contiguous bands that involves high computation complexity in processing and analyzing the image. Hence dimensionality reduction is applied as an essential pre-processing step for HSI data.
HSI is a technology that can accurately identify and characterize any material by measuring the radiation that reaches the sensor with high spectral resolution across a wide range of spectral bands. This allows for the differentiation of various land-cover classes such as water, soil, forestry, crops, and urban areas [2]. When analyzing images, image segmentation is a crucial but difficult step, especially when dealing with the complex task of processing HSI data [3]. There are several factors that contribute to the complexities of the situation. These include a limited number of training samples, the curse of dimensionality, the variability of hyperspectral signals across different land-cover classes, and the impacts of the atmosphere [4].
In recent years, various methods have been suggested to address the challenge of dealing with a vast number of spectral bands, which is known as the curse of dimensionality. This issue has a significant impact on hyperspectral image segmentation. In data analysis, a feature refers to an attribute or dimension that impacts the problem at hand. It is essential to select the most significant features for a model to ensure its effectiveness [5]. Reducing the dimensions of HSI can serve as a necessary preparation for segmentation, helping to eliminate unnecessary components and simplify the computational process.
Two common dimensionality reduction methods are feature selection [6, 7] and feature extraction [8]. Both feature selection and feature extraction are used for dimensionality reduction which is key to reducing model complexity and overfitting. Although feature selection and extraction processes may have the same objective, both are completely different from each other. The main difference between them is that feature selection is about selecting the subset of the original feature set, whereas feature extraction creates new features [9]. Feature selection identifies the "important features" in the high-dimensional data sets to understand the underlying phenomena of interest [10].
In contrast, feature extraction builds derived features from initial features of data sets intended to be informative and non-redundant. Most dimensionality reduction processes are based on multivariate analysis: projecting data onto a subspace that maximizes explained variance and minimizes correlation. The primary goal of dimensionality reduction techniques is to decrease the number of dimensions without losing the structural details of the data [11, 12].
Accordingly, it can be considered that principal component analysis (PCA) is a form of feature extraction algorithm, which creates new features from features. PCA is one of the most used algorithms because it is simple and fast. However, this algorithm has limitations such as only working with numeric data, being sensitive to outlier/extreme points, and not being suitable for nonlinear models, because PCA is completely based on linear transformations. In the paper [5], a new semi-supervised dimensionality reduction (DR) method, termed geodesic-based manifold joint hypergraphs (GMJHs), is proposed for HSI.
Dealing with the spectral variability and nonlinearity of HSI is a challenge for many existing classification methods [13]. To solve these problems, Feng al et. proposed a simple spectral hierarchical feature fusion and selection network (HFFSNet) [14]. Specifically, the paper applies 1-D grouped convolution for dimensionality reduction and multilevel feature extraction. The multilevel features are fused to assist the adaptive feature selection of different layer features via the soft attention mechanism, and finally, the selected features are fused to further enhance the feature representation. Extensive experimental results on HSI datasets demonstrate the effectiveness of the proposed network. In the paper [15], an unsupervised dimensionality reduction (DR) method termed Laplacian regularized collaborative representation projection (LRCRP) is proposed, where Laplacian regularization and local enhancement are introduced into collaborative representation (CR) to construct an adjacent graph and then to reduce the spectral dimension in graph embedding framework [16].
Much related work has recently been carried out to solve the HSI segmentation problems. In general, there are three approaches to HIS segmentation: the first is based on unsupervised learning techniques; the second is based on supervised learning techniques, such as support vector machine (SVM) [8, 17], and the third is based on semi-supervised learning techniques. In fact, many datasets have little or no sample data, so supervised learning algorithms cannot be applied.
Due to the lack of data samples, clustering is one of the most commonly applied techniques for segmenting images [6, 18]. Some hybrid techniques have also been proposed by many researchers and produce good results, such as using kernel methods [3, 19–21]; applying evolutionary algorithms to increase cluster accuracy [22, 23]. Moreover, most clustering algorithms use a combination of spectral information and spatial information to optimize segmentation results [24]. However, when working with data with a large number of attributes like HSI, besides accuracy, computational complexity also needs to be considered [25].
The purpose of clustering methods is to identify patterns in data sets. This helps group objects together that share similarities and are positioned within the same cluster [26, 27]. Clustering was briefly associated with data mining techniques, which include machine learning and knowledge discovery [28]. Various algorithms have been implemented for various applications and industries. Clustering methods have led to a notable improvement with regards to k-means and their advancement [29, 30] and a family of Fuzzy C-Mean (FCM) methods [31–33].
A particular type of FCM, collaborative fuzzy clustering, was developed in [34, 35] as an approach to detect a pattern and reveal similarity on many data sets [36]. The collaborative clustering technique is adopted to enhance the ability to recognize the intrinsic structure of clusters [37, 38]. In which, each cluster will adjust the clustering results against all other groups according to the collaborative parameter until all clusters are optimized [39]. With the above advantages, the collaborative fuzzy clustering method has been studied by many scientists [40]. However, there are not many studies on collaborative fuzzy clustering in hyperspectral remote sensing image data analysis problems because of their difficulties [41].
When processing HSI data, there are two main challenges to overcome: the high dimensionality of the data and the large number of instances. With the goal of HSI segmentation, we present a solution that involves reducing dimensionality through random projection. Next, the data is divided into smaller data sets, or data sites, and locally clustered. Finally, collaborative clustering is performed to complete the process. The objective of this approach is to decrease computation time while still benefiting from the advantages of the collaborative fuzzy clustering algorithm. The dimensionality reduction method in the paper is based on the Johnson Lindenstrauss lemma algorithm, which also preserves the relative distance between data samples. These can help reduce the computation time for the proposed algorithm and also improve the accuracy of the image segmentation results.
The paper is organized as follows: Section II offers a brief introduction to random projection dimensionality reduction, FCM, and collaborative clustering; Section III proposes a novel method for HSI segmentation; Section IV shows the experimental results; The conclusion and future studies are covered in Section V.
Background
Random projection features reduction
Formally, a dimensionality reduction technique can be defined as follows. Given a dataset of d-dimensions, we find a function such that f : R d → R k , with k < d. The function f projects the original d-dimensional data to k - dimensional data with the constraint k < d. Most dimensionality techniques share two common properties [42] but the ensemble of these two properties in a dimensionality reduction method would produce a state-of-the-art technique for reducing high dimensional data.
The dimensionality reduction used in this paper is a random projection. The main idea behind this random projection is from a popular lemma named Johnson Lindenstrauss (JL) lemma [43].
The lemma states: given a finite set X ⊂ R d of size |X| = K, there exists a linear map f : R d → R k with k = O (ɛ-2 * log K) such that:
(1 - ɛ) ‖ x - y ‖ 2 ≤ ‖ f (x - y) ‖ 2 ≤ (1 + ɛ)‖x - y ‖ 2, for all x, y ∈ R d .
This means that when we have a set of points that are of high dimensionality in Euclidean space, it can be linearly embedded into a space of lower dimensions. The projection also preserves the distance between points. It does not specify a method for identifying the value of k, rather it merely states that such a dimension does exist. The reduced data are obtained by multiplying the vector of the original data with a random matrix: X d × R to produce a new vector Y with the new reduced dimensions.
Fuzzy c-Means clustering (FCM)
The fuzzy c-means [31] is a scheme to partition data set X into a predefined number of clusters taking into account the uncertainty of cluster assignment. It produces a fuzzy partition of X that allows the sharing of objects between clusters as a matrix U. In the FCM, each cluster is represented by a cluster center. Let v
i
be the prototype of cluster c
i
and let V be the set of all C cluster centers. The objective of the FCM is to minimize the following criterion function:
Suppose there are P data sites D [1] , D [2] , . . . , D [P], which comprises of N [1] , N [2] , . . . , N [P] patterns (data) defined in the same feature space X. For each data site, all patterns are grouped into C clusters. Data at each site exhibits a relationship with others, but because of technical constraints such as transmission bandwidth, performance, privacy, and security constraints, the data cannot be shared and clustered in a centralized manner. Instead, clustering is done locally but in the clustering process conducted at a certain data site, one is provided with the structure obtained at other data sites. The structural information is conveyed in terms of the prototypes obtained for other data sites. This collaboration process is referred to as collaborative clustering.

To accommodate the collaboration effect in the optimization process, the objective function in [34] becomes:
The parameter β describes the collaborative level between the data sites. The higher the value of β the stronger the collaborative level among the corresponding sites and vice versa. Details of the steps to implement the CFCM algorithm are described in algorithm 2.

In this section, we propose a general algorithmic model for the problem of hyperspectral image segmentation. First, the data is preprocessed and reduced in dimension using a dimensionality reduction algorithm that utilizes random projection. Afterward, the data is separated into individual data sites and local clustering is performed on each site. For the final step, collaborative clustering will be performed between the data sites to obtain the ultimate segmentation outcome at the output.
To perform data dimensionality reduction, it is necessary to find the mapping function f. In the study [44], the initial method of using the random matrix is improved with each entry R
ij
to be an independent identically distributed variable, by introducing two sparse matrixes:
Fix x ∈ R
d
, and s < k ∈ N, there exists a linear map distribution ψ
s
: R
d
→ R
k
in which, with a probability exceeding 1 - 2de-ɛ2k/s, (0.63 - ɛ) ‖ x ‖ 1,2,s ≤ ‖ ψ
s
(x) ‖ 1 ≤ (1.63 + ɛ) ‖ x ‖ 1,2,s, where ψ
s
is a random matrix with
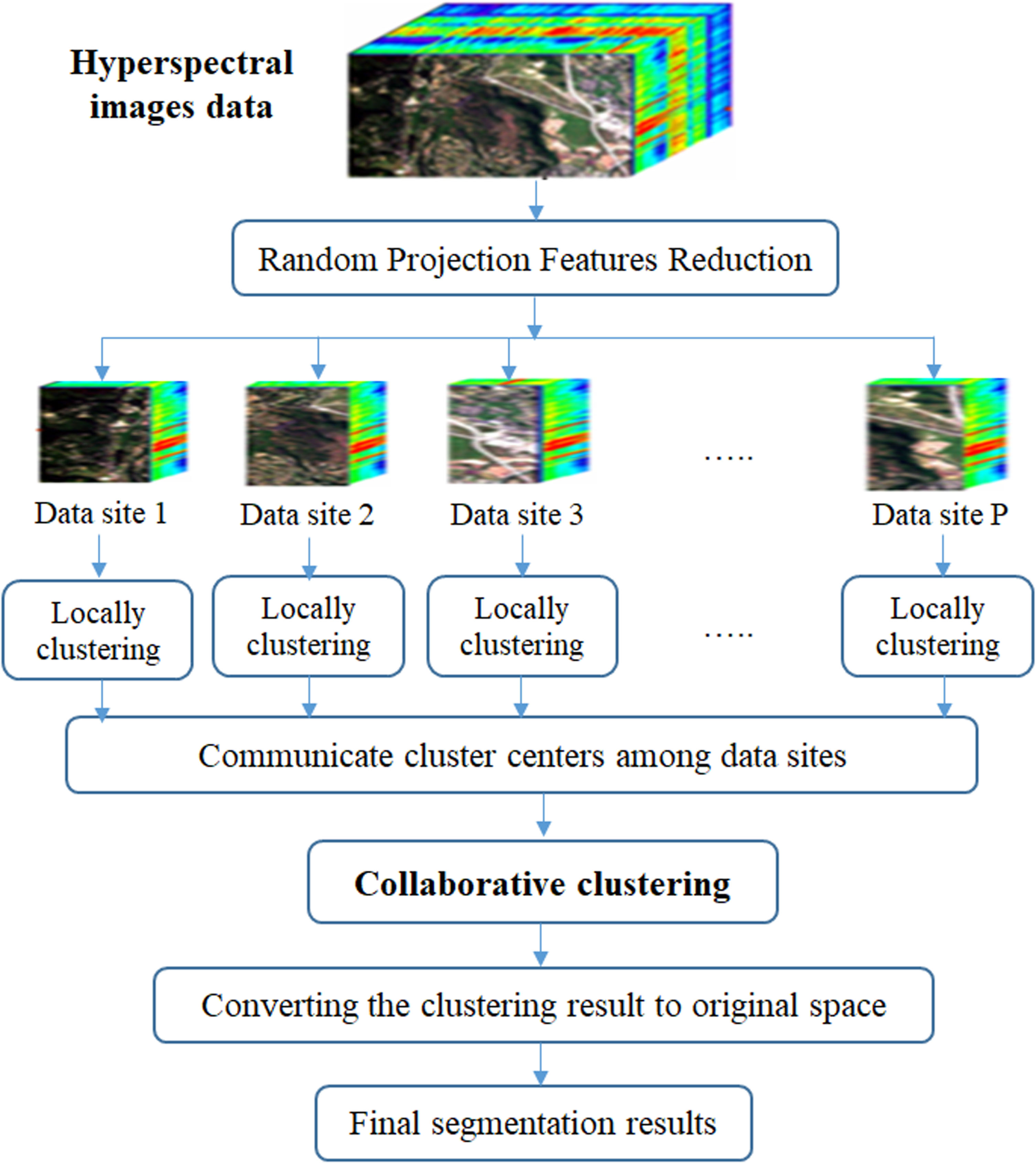
HSI segmentation diagram.
Algorithm 3 describes the steps to perform dimensionality reduction based on random projection. With input data is the HSI dataset X, the parameters epsilon ɛ, and sparsity level s. The output is the data set in a space with a smaller number of dimensions.
Step 1: Compute the value of the new dimension k.
Step 2: Find the Gaussian matrix G with (k, s).
Step 3: Find a random matrix A with 0′s and 1′s.
Step 4: Compute the Hadamard product of A, G, Φ s .
Step 5: Calculate the random matrix
Step 6: Calculate the output data as a product of X and Ψ s .
Figure 3 shows how the hyperspectral remote sensing image data is processed to select important components for segmentation and minimize calculation time issues. This involves pre-processing steps such as geometry correction, image quality enhancement, and noise filtering, followed by dimensional reduction. The resulting data is then divided into P data sites. Perform local clustering using Algorithm 1 on the data sites to obtain the local centroid and membership function values of each site. These results will be used to calculate the global cluster centers for all data sites. Finally, implement a collaborative clustering algorithm on the data sites to produce the data clusters.
Run
1. Divide HSI data to P sub data sets.
2. Run
1. Run
2. Give the clustered data as an output result.
3. Converting the clustered data to the original space as a final result.
The proposed method is described in detail in Algorithm 4, whereby the proposed algorithm includes three phases: Reduce dimensions, divide data, and local clustering and collaborative clustering.
Computational complexity : The computational complexity of the proposed algorithm includes the computational complexity in three phases corresponding to three algorithms 1, 2, and 3. For the first phase, the computational complexity of the algorithm reduces the feature dimension. depends mainly on matrix computation with a computational complexity of O (ndkt max ). For the second phase, the computational complexity is algorithm 1, namely the FCM algorithm. The computational complexity of the second phase is O (c . n . k . P . t max ). For the third phase, the computational complexity is a collaborative clustering algorithm, which includes a computational complexity of O ((c2 . n . k + c2 . n . P + cnkP) * (T max . P . t pmax )) and the communication complexity between data sites is O (cdPT max ). Where, t max is the maximum number of iterations on algorithms 1 and 3, T max is the maximum number of iterations of algorithm 2, and t pmax is the maximum number of iterations when executing local clustering on data sites where P are the number of data sites on algorithm 2, C is the number of clusters, n is the total number of pixels, d is the number of data dimensions before reduction and k is the number of data dimensions after reduce.
In this section, the proposed method is evaluated by the experiments on two real HSI datasets. For collaborative clustering, after dimensionality reduction, the data sets are divided into some sub-datasets. The Xie-Beni (XB) and Partition Coefficient (PC) validity index [20] are used to compare the performance of the clustering result of the fuzzy c-means clustering algorithm (FCM) [31], the collaborative fuzzy c-means clustering algorithm (CFCM) [34], the interval type-2 fuzzy c-means clustering algorithm (IT2FCM) [46], the improved interval type-2 fuzzy c-means clustering algorithm (IT2FCM*) [47]. The method with a greater Partition Coefficient and smaller Xie-Beni values would be the optimal solution. The PC index measures the fuzzy membership degree of final divided clusters by means of the fuzzy partition matrix, and the larger its value, the better the partition result:
+ TP (True Positive): Total number of cases where the classification matches Positive.
+ TN (True Negative): Total number of cases where the classification matches Negative.
+ FP (False Positive): The total number of cases that classify the labels of the Negative label as Positive.
+ FN (False Negative): The total number of cases that classify labels belonging to the Positive label to Negative.
The algorithms are tested on the computer Intel(R) Core(TM) i5-4210U CPU @ 1.70GHz 4 processors and a hard disk of 500Gb, Windows 10 64bit operating system, 16Gb RAM, NVIDIA 2Gb graphics card. The program is written in the latest released Python language to simulate the algorithms.
In this experiment 1, the HSI data is the Indian Pines dataset in the North-western Indiana area. The image data has a size of 145x145 with 200 spectral reflectance bands in the wavelength range 0.4μm - 2.4μm. The number of pixels labeled is 10, 201 pixels. The Indian Pines dataset consists of 14 land-covers including classes Alfalfa, Corn-notill, Corn-mintill, Corn, Grass-pasture, Grass-trees, Hay-windrowed, Soybean-notill, Soybean-mintill, Soybean-clean, Wheat, Woods, Building-Grass-Trees-Drives, Stone-Steel-Towers. Detailed information about the dataset and the number of pixels labeled for each layer is shown in Table 1.
Groundtruth classes for the Indian Pines scene and their respective samples number
Groundtruth classes for the Indian Pines scene and their respective samples number
For collaborative clustering, after feature reduction, we split data into four sub-datasets (data site 1, data site 2, data site 3, and data site 4). When changing the value of epsilon, the number of dimensions of the data set will change, leading to a change in the accuracy of the proposed algorithm. In the experimental part, the authors tested the proposed algorithm at different values of epsilon to find the optimal value for each data set.
Based on formula 10, we can determine the relationship between the value of epsilon and the dimension after reduction in Table 2. To find the optimal epsilon value for the proposed algorithm, we set the epsilon value to increase from 0.1 to 0.9. Based on the accuracy obtained with each epsilon value, the epsilon value at 0.3 gives the highest accuracy. Note that accuracy is obtained on the entire data set. Figure 2 shows the landcover classification results from Indian Pines image data by the algorithms FCM, CFCM, IT2FCM, IT2FCM*, and FR-CFCM. It can be seen that the FCM algorithm produces the poorest results with a lot of noise in land cover. Other algorithms produce clearer results.
he epsilon value and their effect on the FR-CFCM algorithm for Indian Pines dataset
Table 2 shows the value ϵ and the number of new dimensions of the data, their influence on the execution time, and the accuracy of the proposed FR-CFCM algorithm. The value ϵ is set from small to large, including the values 0.1, 02,....., 0.8, and 0.9; At values ϵ, the number of original data dimensions is 200 bands, the new data dimensions are 130, 58, 26, 14, 9, 6, 5, 4, and 3, respectively. Performing the FR-CFCM algorithm after reducing the data dimension shows that the accuracy (Accuracy Index) reaches the maximum value of 97.66% at the value ϵ = 0.3 and the new dimension is 26. When the ϵ values are 0.1 and 0.2, the accuracy is 96.18% and 96.89% respectively. As ϵ increases, the number of data dimensions decreases and the accuracy of the FR-CFCM algorithm also decreases. The accuracy is lowest at ϵ = 0.9 with an Accuracy index of 81.11%.
In Table 2, the execution time of the FR-CFCM algorithm decreases as the value of ϵ increases. At ϵ = 0.1, the new dimension is 130, and the execution time is 51.89s; the time is reduced to 14.76s when ϵ = 0.2 and the new dimension is 58. At ϵ = 0.3, the FR-CFCM algorithm achieved the greatest accuracy and the execution time was 3.65s, about 16 times less than when ϵ = 0.1 and about 4 times less than when ϵ = 0.2; When ϵ increases from 0.3 to 0.9, the execution time of the FR-CFCM algorithm decreases but not significantly. Because there is no significant change in data dimensionality after dimensionality reduction.
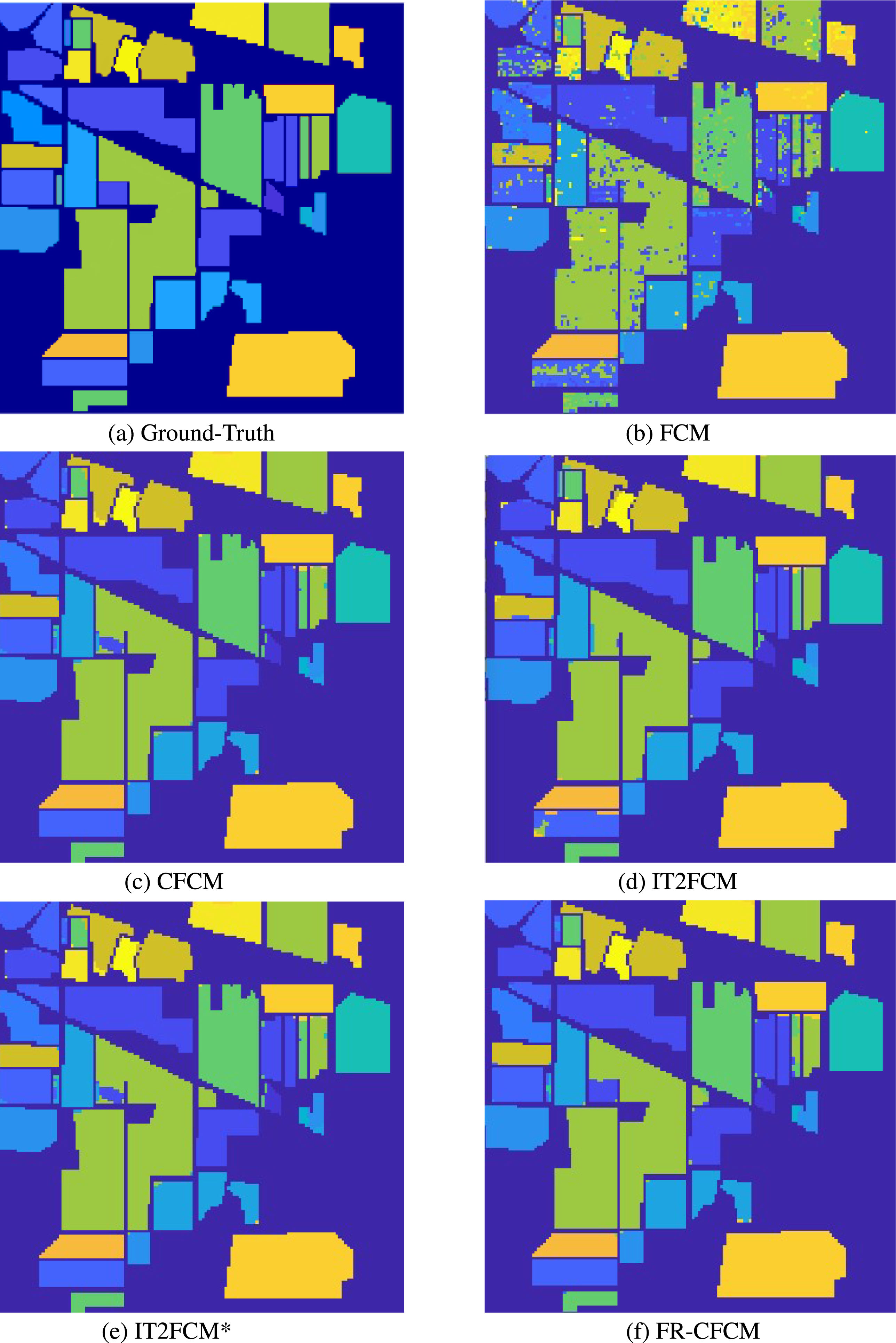
Ground-Truth and landcover classification results.
Table 3 shows the clustering quality by PC, XB, TPR, FPR, Accuracy indexes, and the execution time of the algorithms FCM, CFCM, IT2FCM, IT2FCM*, FR-CFCM. Overall, it can be seen that the FCM algorithm gives the results with the lowest accuracy. For PC and XB indexes, which are cluster quality metrics, the PC index is best at 0.456 with the IT2FCM algorithm, while the XB index achieved the best clustering result at 0.659 with the IT2FCM* algorithm. Although the FR-CFCM algorithm has PC and XB index values of 0.453 and 0.698, respectively, lower than those of IT2FCM and IT2FCM*, the difference is insignificant. This may be due to the effect of data dimensionality reduction. PC and XB indexes on FCM and CFCM algorithms give the worst results.
Landcover classification results on Indian Pines dataset
For TPR indexes, the IT2FCM* algorithm gave the highest accuracy with 98.35%, the FR-CFCM algorithm reached 98.34%, only 0.01% lower, followed by the IT2FCM algorithm with a TPR index of 98.04%. FCM and CFCM algorithms give much lower accuracy than other algorithms. While the FPR index of the FR-CFCM algorithm has the least misclassification rate with only 1.63%. Especially the Accuracy index, the FR-CFCM algorithm gives the classification results with the highest accuracy rate of 97.66%, while the IT2FCM*, IT2FCM, CFCM, and FCM algorithms are 97.45%, 97.43%, 94.12%, and 86.34%, respectively.
Regarding the execution time of the algorithms, it can be seen that FR-CFCM has the fastest execution time with 3.65s compared to 6.18s for CFM, 7.69s for FCM, 16.87s for IT2FCM and 18.74s for IT2FCM*.
In general, with the Accuracy index FR-CFCM algorithm gives the best results, while the PC and XB indices of IT2FCM, IT2FCM*, and FR-CFCM algorithms are higher than those of FCM and CFCM algorithms. This can be explained that the data dimensionality reduction method in the FR-CFCM algorithm can keep quite well the basic characteristics of the data, helping the FR-CFCM algorithm achieve much higher accuracy than CFCM. While the data representation based on the interval type 2 fuzzy set in the IT2FCM and IT2FCM* algorithms can help improve the accuracy. However, the execution time of the IT2FCM and IT2FCM* algorithms is about 6 times slower than that of the FR-CFCM algorithm, and the execution time of the FCM and CFCM algorithms is about 2 times slower than that of FR-CFCM.

Ground-Truth and landcover classification results.
The data used in experiment 2 is the Pavia University dataset. These are the scenes acquired by the ROSIS sensor during a flight campaign over Pavia, northern Italy. This dataset has 103 spectral bands with an image size of 610x610 and a spatial resolution of 1.3 meters. The data is classified into nine different classes including Asphalt, Meadows, Gravel, Trees, Painted metal sheets, Bare Soil, Bitumen, Self-Blocking Bricks, and Shadows. The number of sample data is 42, 776 pixels. Detailed information on the number of samples for each class is shown in Table 5.
For collaborative clustering, after feature reduction, we also split data into four sub-datasets (data site 1, data site 2, data site 3, and data site 4). Based on formula 10, we determine the relationship between the value of epsilon and the dimension after reduction in Table 4. For the Pavia University dataset, the accuracy of the proposed algorithm reaches the optimal value at epsilon equal to 0.4. Note that accuracy is obtained on the entire data set.
The epsilon value and their effect on the FR-CFCM algorithm for Pavia University dataset
From the original data’s dimensionality of 103, after dimensionality reduction, the dimensionality is reduced to 101 (at ϵ = 0.1), 50 (at ϵ = 0.2), and so on. Table 4 shows that when the number of dimensions is greater than 8, the accuracy of the FR-CFCM algorithm is quite high, about 96%. Meanwhile, when the number of dimensions is less than 8, the accuracy drops sharply from 94.32% to 79.28%. The FR-CFCM algorithm achieves the largest Accuracy index of 96.41% at ϵ = 0.4 and the new dimension is 13.
Table 4 also shows that the execution time of the algorithm is proportional to the dimensionality of the data. When the data dimension is 101, the execution time of the FR-CFCM algorithm is 286.33s and decreases to 110.38s when the data dimension is 50. When the number of dimensions is 2, the execution time of the FR-CFCM algorithm is reduced to as low as 7.74s.
Table 5 shows the land cover of different colors. The classification results are shown in Figure 3 with image data and results from 5 different algorithms including FCM, CFCM, IT2FCM, IT2FCM*, and FR-CFCM.
Groundtruth classes for the Pavia University scene and their respective samples number
In Table 6, the FR-CFCM algorithm gives the best classification results in most indicators, followed by the IT2FCM and IT2FCM* algorithms, while the FCM and CFCM algorithms give the worst results. Specifically, the FR-CFCM algorithm gives the best classification results in TPR, FPR, Accuracy, and Running time indexes. With the PC index, the FR-CFCM algorithm reached 0.653 compared to 0.674 of the IT2FCM* algorithm and 0.672 of the IT2FCM algorithm. While the two algorithms FCM and CFCM have PC index values of 0.481 and 0.583, respectively. Similar to the XB index, the FR-CFCM algorithm reached 0.677 higher than the IT2FCM and IT2FCM* algorithms, but the difference was not significant. The FCM and CFCM algorithms gave the worst classification results with the XB index of 0.895 and 0.799, respectively.
Landcover classification results on Pavia University dataset
For TPR, FPR, and Accuracy indexes, the FR-CFCM algorithm gives the best results with the highest correct classification rate of 96.89% and the smallest false classification rate of 1.88%. Overall accuracy also reached the highest at 96.41% with the FR-CFCM algorithm. Meanwhile, these values are lowest with the FCM algorithm, followed by CFM, IT2FCM, and IT2FCM* algorithms.
Regarding the execution time of the algorithms, the FR-CFCM algorithm has the fastest execution time with 27.47s, while the IT2FCM* algorithm has the slowest with 219.81s. The algorithms IT2FCM and IT2FCM* based on interval type 2 fuzzy set give higher accuracy than algorithms FCM and CFCM, but the computation time is quite slow.
From the results in Tables 2 and 4, it can be concluded that the computation time is proportional to the number of dimensions of the data because the larger the number of dimensions, the greater the computational complexity. In addition, the use of multiple data dimensions does not guarantee the highest accuracy, this is because HSI data has many spectral channels, spectral channels are received by different bands of electromagnetic waves and are therefore useful for different problems. The dimensional transformation not only reduces the computation time but also preserves the important characteristics of the data, thereby not reducing the accuracy of the classification results.
With both Tables 3 and 6, it can be seen that the FR-CFCM algorithm has the highest classification accuracy among the five experimental algorithms, and the computation time is also the fastest. Meanwhile, PC and XB cluster quality index values are nearly equivalent to IT2FCM, IT2FCM* and much better than FCM, and CFCM.
The above experiments show that the epsilon value will be adjusted for each dataset. Due to the complexities of hyperspectral image data, it is difficult to give a specific optimal epsilon value for all data sets. In this study, we recommend that when using the algorithm, experiment on different epsilon values to find the best value for each data set.
This study focuses on the challenges of HSI segmentation, which includes the high number of dimensions and data instances. The paper proposes a new method to tackle these issues by utilizing collaborative clustering and reducing data dimensions based on the JL lemma. We believe this approach will be effective in HSI segmentation. The experiments subsequently indicate that the proposed method produces better results with regard to validity indexes and running time. The experimental results on 02 datasets of hyperspectral remote sensing images show that the proposed algorithm FR-CFCM gives better results than the algorithms FCM, CFCM, IT2FCM, and IT2FCM*.
In future research, we aim to propose an algorithm to automatically find the optimal epsilon value on each data set. Moreover, we will develop algorithms based on parallel computing models to improve algorithm performance when working with large data sets.
Footnotes
Declarations
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Author Contribution Statement
The authors confirm their contribution to the paper as follows: study conception and design: Trong Hop Dang, Viet Duc Do, Dinh Sinh Mai; data collection: Viet Duc Do, Le Hung Trinh; analysis and interpretation of results: Viet Duc Do, Dinh Sinh Mai, Trong Hop Dang, Long Thanh Ngo, Le Hung Trinh; draft manuscript preparation: Viet Duc Do, Dinh Sinh Mai, Le Hung Trinh. All authors reviewed the results and approved the final version of the manuscript.