
Abstract
Power system load forecasting is a method that uses historical load data to predict electricity load data for a future time period. Aiming at the problems of general prediction accuracy and slow prediction speed in using typical machine learning methods, an improved fuzzy support vector regression machine method is proposed for power load forecasting. In this method, the boundary vector extraction technique is employed in the design of the membership function for fuzzy support vectors to differentiate the importance of different samples in the regression process. This method utilizes a membership function based on boundary vectors to assign differential weights to different sample points that used to differentiate the importance of different types of samples in the regression analysis process in order to improve the accuracy of electricity load prediction. The key parameters of the fuzzy support vector regression model are optimized, further enhancing the precision of the forecasting results. Simulation experiments are conducted using real power load data sets, and the experimental results demonstrate the effectiveness of the proposed method in terms of accuracy and speed in predicting power load data compared to other prediction models. This method can be widely applied in real power production and scheduling processes.
Keywords
Introduction
Power load forecasting refers to the use of historical load data to predict the load values for a future time period. It has become an important component of achieving modernization in power system management. It finds wide-ranging applications in formulating generator unit combinations, inter-regional power transmission schemes, and load dispatching plans within the power system. Improving the accuracy of load forecasting effectively contributes to the economic and secure operation of the power system and serves as a vital basis for rational power system scheduling, planning, electricity distribution, and development [1].
With the emergence and rapid development of machine learning and artificial intelligence models, related theories and methods have been widely used to solve complex problems in engineering applications and scientific fields. Khalid Elbaz et al. proposed a new model to estimate the disc cutter life that used in shield tunnel by integrating a group method of data handling (GMDH)-type neural network (NN) with a genetic algorithm (GA), and the research results are helpful to the rational planning of shield tunnel [2]. Wafaa Shaban used the salp swarm algorithm (SSA) with the differential evolution technique (DE) via a multi-objective fitness function to predict the compressive strength of the volcanic ash material (RAC). It provides an effective method for predicting the physical properties of RAC [3]. Tao Yan et al. utilized the Bayesian optimization machine-learning algorithm to forecast the long-term trend of water quality changes. The research findings offer valuable technical support for emergency water pollution control [4]. Yu-Lin Chen et al. used the estuarine trophic state assessment method (ASSETS) and Monte Carlo simulation method (MCS) to predict the risk level of red tide in the coastal area, which can provide an effective risk assessment scheme for red tide management [5].
Machine learning algorithms have strong data mining and fitting capabilities, which can better deal with strong randomness problems and provide new ideas for power load forecasting. With the emergence of the Artificial Neural Network (ANN) model, researchers have applied its adaptive function to a large number of non-structural and imprecise rules for power load prediction. However, as the research has progressed, the final convergence of artificial neural networks heavily depends on the initial set point, resulting in slow convergence, local extreme value problems, and weak autonomous learning ability due to algorithmic defects. These limitations prevent breakthroughs in existing research results, and only local improvements or combinations with other methods have achieved better convergence in load prediction [6]. The Artificial Bee Colony (ABC) algorithm is also commonly applied in electricity load forecasting. The ABC method has a relatively large number of load forecasting parameters, but its setting is simple. It excels at processing noisy data and exhibits strong robustness. However, its implementation method is complex. Because of the characteristics of random search data set, the convergence speed of ABC is slow and it is easy to generate local optimal solution, which leads to low prediction accuracy.
Support vector machine (SVM) [7] is a prediction method based on statistical theory. Because of its good nonlinear data processing ability and be used to deal with power load forecasting problems. SVM is essentially a classical quadratic programming problem. Compared with ANN and ABC, SVM has faster convergence speed and effectively avoids local optimal solutions, and it can use many mature algorithms in optimization theory. However, it is sensitive to noise data, which makes its prediction accuracy not significantly improved compared with ANN and ABC.
Compared with Support Vector Machines (SVM), Support Vector Regression Machine (SVRM) uses more appropriate loss functions and kernel functions. It combines membership functions to reflect the importance of data samples to the regression plane, determining the weights of data samples in the load forecasting process. This helps to mitigate the impact of noisy data on the load forecasting process and improve its predictive performance. Because of these advantages, SVRM is widely used in power load forecasting.
Recently, scholars have done a lot of work on power load forecasting using SVRM method. In 2021, Fan Guo-Feng et al. proposed a hybrid short-term load forecasting model based on support vector regression (SVR) and random forest (RF). The experimental results show that this model has high prediction accuracy for power load forecasting [8]. In 2022, Wang Rui et al. proposed a fuzzy support vector machine based on geometric algebra, named Clifford fuzzy support vector machine for regression (CFSVR). The weights of different input points are determined by fuzzy membership degree with respect to the optimal regression hyperplane. The experimental results show that CFSVR can improve the accuracy of power load forecasting and realize multi-step forecasting [9]. Zhang Weiguo et al. proposed a hybrid model that combines logarithmic spiral, firefly algorithm and support vector regression (LS-FA-SVR). Compared with the benchmark model, the LS-FA-SVR hybrid model has higher prediction accuracy [10]. Luo Jian et al. proposed a robust support vector regression (RSVR) model to realize the power load forecasting model in 2023. By introducing a weight function to calculate the relative weight of each observed value in the load history, a weighted quadric surface SVR model is constructed. This method improves the prediction accuracy of the RSVR model [11].
SVRM has good predictive ability. It can approach nonlinear functions with arbitrary precision, and has the advantages of global minimum points, fast Rate of convergence. SVRM has good prediction ability. It can approximate nonlinear functions with arbitrary precision, and has the advantages of global minimum point and fast convergence speed [12]. It also has the problem of rapid decline in training speed and accuracy due to the large increase in the number of training samples. The main reason is that the classical membership function determines the membership degree by the distance between the sample data and the regression plane, and the membership degree of the data far away is small. Some noise data are close to the regression plane, but far away from most data samples. This kind of noise data is also called outliers have a great influence on training accuracy and speed.
In order to solve the above problems, the authors propose a fuzzy SVR algorithm based on boundary vector extraction (BVE-FSVR). BVE-FSVR algorithm is to find the minimum hypersphere that can contain the effective sample points in the feature space to replace the regression plane which used by the traditional membership function. BVE-FSVRM algorithm is to use the distance between the sample point and the center of the hypersphere as the membership value of the sample data instead of using the distance between the sample point and the regression plane. BVE-FSVRM algorithm can more effectively distinguish the importance of different samples in the training process, greatly reduce the influence of noise data to improve the training accuracy, and reduce the number of training samples to improve the training speed [13].
Support vector repressor machine and the training algorithm
The classical SVM algorithm is an important machine learning method proposed by Vapnik, SVM aims to minimize the upper limit of the generalization error by maximizing the margin between separating the hyperplane and the data, providing a basis for the structural risk minimization principle [14]. Support vector regression for SVR is an important branch of application in SVM. The difference between SVR regression and SVM classification is that the SVR finally has only one class, and the optimal superplane it seeks is not to “maximize” the distance between two or more class samples as the SVM does, but to “minimize” all sample points from the superplane [15].
Loss function
SVR can be used in functional regression analysis, and the accuracy of the estimation process is estimated by constructing the appropriate loss function. The loss function is used to evaluate the degree to which the predicted value and the true value differ, and the selection of the loss function usually determines the model performance [16]. The loss function is divided into the empirical risk loss function and the structural risk loss function. The empirical risk loss function refers to the difference between the predicted results and the actual results, and the structural risk loss function refers to the empirical risk loss function plus a regular term. Several common loss functions are used as follows.
(1) 0-1 loss function: 0-1 loss function is the earliest loss function proposed by Cortes and Vapnik et al. [7]. It is discontinuous at t = 0, and is a non-convex continuous bounded function. This discontinuity makes it unsuitable for traditional optimization theories and methods.
(2) Hinge loss function: Hinge loss function is also proposed by Cortes and Vapnik et al. [7]. The hinge loss function is the best convex approximation of the 0-1 loss function. If t≤0, the loss value is 0, indicating that it has no loss to the correctly divided samples and has good sparsity. If t > 0, the loss value is t, indicating that it has a large contribution weight to the SVM objective function and affects the solution of the optimal hyperplane.
(3) Logarithmic loss function: Wahba introduced the logarithmic loss function into SVM in 1998 [17]. Different from the hinge loss function, it gives the logarithmic loss to all samples, and this characteristic makes it not sparse and sensitive to outliers.
(4) Pinball loss function: In 2013, Jumutc et al. proposed the pinball loss function [18]. If τ= 0, it degenerates into the hinge loss function. The loss value is – τ. when t≤0, so it does not have sparsity and sensitive to outliers.
(5) ɛ-insensitive pinball loss function: In order to overcome the shortcomings of the pinball loss function that is not sparse, Xiaolin Huang et al. proposed the ɛ-insensitive pinball loss function (ɛ-i PLF) in 2014 [19]. Different from the pinball loss function, the ɛ-insensitive pinball loss function sets different values through different ranges of parameter t to ensure sparsity and reduce its outlier sensitivity. The ɛ-i PLF is used in the method proposed by the author.
Considering the training sample data set (x1, y1) , (x2, y2) , . . . , (x
n
, y
n
), if the input data sample is linearly separable, then the hyperplane can be represented as w × x + b = 0, and a function of the sample point x
i
can be obtained:
The ɛ-i PLF is introduced, and rewritten it into an equation form suitable for linear regression, as shown in Equation (7).
In the above equation, ɛ is a positive value taken in advance. The ɛ-i PLF shows that when the difference between the observed value y and the predicted value of the point f (x) does not exceed the previously determined value ɛ, then the predicted value at the point f (x) is considered as no loss.
Finding parameter pairs (ω, b) makes a small possible deviation between the function f (x) and the actual acquisition target y
i
, while also making it as smooth as possible. To maximize the remainder in the linearly separable case, and as shown in Equation (8).
w is the weight vector, and b is the amount of deviation. For linear inseparability, all constraints are impossible to meet in Equation (8), then the violation of constraints measured using relaxation variables ɛ
i
, i ∈ (1, 2, . . . . . . , l), Equation (8) can be converted into Equation (9).
In the Equation (9), C is a constant, the larger the value of C, the less the training misclassification of SVM, the smaller the marginal value; on the contrary, the decrease of C will cause the SVM to ignore more training points, resulting in the swing amplitude of the convergence result is more [20].
To facilitate the calculations, Lagrangian is introduced and simultaneously simplified by the corresponding saddle point conditions:
Where
The regression function of the available SVM is:
Nonlinear regression usually uses a nonlinear transformation φ to transform the input space into a high-dimensional feature space to solve the optimal regression function. The calculation of φ and the regression function involved in the feature space is expressed in the form of the inner product of φ, and the kernel function K (x, x
i
) = (φ (x) , φ (x
i
)) is introduced to replace the inner product operation of φ, as shown in Equations (13) to (15):
The kernel function K (x, x i ) is an important part of SVR, which allows SVR to efficiently handle high-dimensional problems with finite samples. The reference kernel function can transform the non-linear no separable data sample into the linear separable data sample in high-dimensional space, which effectively solves the problem of large mathematical operations in high-dimensional space.
Set the attribute quantity of the kernel function σ, the kernel function can be defined using Equation (16)
Fuzzy support vector regressive machine algorithm
The concept of Fuzzy SVM (FSVM) was proposed by Lin C F in 2002 [22], the FSVM makes different input sample points contribute differently to the decision plane, and the proposed method improves the SVM ability against noise and is especially suitable for not fully revealing the input sample features. Despite its good learning performance and generalization ability, the SVM is sensitive to noise, causing model overfitting, and for specific sequences, each sample makes different contributions to the hyperplane. Therefore, the fuzzy support vector regression (FSVR) machine method is introduced to effectively distinguish the noise and the effective samples by constructing the FSVR, in order to improve the accuracy of the model and minimize the error.
Ideally, the selection of parameters based on minimizing the generalization error of the learning machine, while in practice, the generalization error of the learning machine is impossible when the distribution function is unknown, so the generalization error is estimated. The estimation of the generalization error is the basis of model selection as well as parameter optimization [10].
For the given training data (x1, y1) , (x2, y2) , ·· · , (x
i
, y
i
) ∈ R
n
× R, the training sample x
i
can be mapped to the Hilbert feature space through the nonlinear mapping φ, and the unknown function is estimated in the feature space with the linear function f (x) = (w × φ (x)) + b, then the Equation (17) can be used to solve the optimization problem:
The corresponding decision function can solve using the following functions.
The function K (x
i
, x) in Equation (18) is the inner product of the vectors (φ (x) · φ (x′)) in the feature space. Set T′ = {(x1, y1, u1) , (x2, y2, u2) , . . . , (x
i
, y
i
, u
i
)} for the training, the regression problem of the FSVR can be equivalent to the quadratic programming solution problem as shown in the Equation (19).
The value of C · u i in the Equation (19) determines the importance of the corresponding sample in the optimization problem [23].
This optimization problem can be solved by using the Lagrangian equation as follows.
α, β are the non-negative Lagrange multiplier in Equation (20).
Taking the partial derivative of L and setting it to zero, the solution of the dual problem of Equation (20) can be converted into the solution of Equation (21).
Classical membership function design method
The membership function must be able to reflect the importance of samples for the regression plane objectively and accurately, but there is no accepted and observable guideline at present. When dealing with the actual situation, it is also necessary to determine the reasonable membership function for specific problems combined with experience. Although the support vector classification and regression problems are different, the design idea of the fuzzy membership function, is consistent, namely, sample points that are important for classification or regression obtain large membership, while relatively unimportant sample points obtain small membership [24].
Membership function μ (x
i
) = f (μ
d
(x
i
) ,
The operation f of the representation μ
d
(x
i
) and
In Fig. 1, the distance between the sample to the class center is equal, only based on the distance between the sample center and the center of the sample membership is not only related to the distance of the design membership function is not accurate, need to improve the design of the membership function [26]. Combined with the above situation, the membership function is composed of two parts, which represent the distance from the sample to the class center and the relationship between each sample.

Schematic diagram of the tightness difference between the data samples.
The general idea of using the boundary vector extraction method to improve the membership function is to find two minimum hyperspheres in the feature space that can separately package the two types of sample points respectively, and choose the boundary vector that may become the support vector as the new sample, reducing the number of samples involved in the training, and thus improving the training speed [26].
Assuming the training sample set is {x1, x2, . . . , x m } , x i ∈ R n , the purpose of setting up a support vector domain is to find the minimum hypersphere that contains the data from this training set and provide a description. When the sample set does not contain noisy samples, the goal is to find and determine a minimum ball that contains all the samples. On the other hand, if there are a few samples outside the ball, it is acceptable to exclude outlier points from the ball. Find and determine a minimum ball containing all samples with no noise or field value samples in the sample set; otherwise, a small number of samples can be allowed to be outside the sphere and exclude the isolated point from the sphere.
A mapping ψ : R
n
→ F is introduced when the sample distribution in the input space is not spherical, and the input space sample is also mapped to a high-dimensional space F and minimized, and the volume of the hypersphere is transformed into the quadratic programming problem shown in Equation (23).
Where the radius of the minimal hypersphere is R, the sphere center is a, and the regularization parameter is C. The solution to the optimization problem is obtained from the Lagrangian formulation below:
β
i
⩾ 0 and γ
i
⩾ 0 is a Lagrange multiplier, and R, a, ξ
i
the partial derivative are equal to zero:
Substituting Equation (25) into Equation (24) yields the solution to the dual problem, as shown in Equation (26):
The data domain description in the feature space F is obtained through the value of its optimal solution β
i
. In the feature space F, the distance ψ (x
i
) to the minimum containing the center of the supersphere.
In feature space, the distance from the positive or negative sample points to the center of the minimum hypersphere is
If the boundary vector x
i
is outside the hypersphere, it increases with the increase of p and
FSVR can be obtained by introducing the concept of fuzzy membership u
i
into SVR. Input sample data set (x1, y1,u1) , (x2, y2, u2) , . . . , (x
i
, y
i
, u
i
), x
i
∈ R
n
, y
i
∈ R, and fuzzy membership function u
i
= αw1i + βw2i, α + β = 1, parameter w1i represents the distance weight value based on the current sample’s distance from the hypersphere center. Parameter w2i is the influence factor of the input parameters, which is determined by load parameters such as load trend, temperature and holidays, Parameter α, β is the fuzzy parameter in FSVR that determines the fuzzy interval range of the sample and affects the model parameter estimation and prediction performance of FSVR and it can be converted into Equation (30):
The ∈ loss function |ξ|ɛ is described as Equations (31):
Introduce the Lagrangian coefficient α, α*, η, η* to construct Lagrangian functions, the bivariate in Equation (32) are subject to constraints αα*, η, η* ⩾ 0:
Seek partial derivative for the original variable (w, b, ξ, ξ*) and indicate optimality to 0 and obtain equality Equation (33):
The dual optimization problem can be obtained by substituting equation (33) into equation (32), as shown in Equation (34).
For nonlinear regression, nonlinear mapping φ is used to map the data to a high-dimensional feature space, and then perform linear regression in the high-dimensional feature space, finally obtaining BVE-FSVR as shown in Equation (35).
Membership function is k (x i , x) = φ (s i ) T φ (s j ) in Equation (35).
Experimental data and preprocessing
Data set analysis
To validate the performance of the load prediction model based on the FSVR algorithm with the boundary membership function, the authors select a reliable professional benchmark data pool for power load forecasting provided by IEEE Working Group on Energy Forecasting (WGEF) for researchers. Because this power load forecasting data set is used for Global Energy Forecasting Competition in 2012, it is also called the GEFCom2012 data set. The data set collects the historical power load data and related parameters of each hour in a certain area of the United States from 2004 to 2007 and the first half of 2008 that released by American industrial units [27]. In the experiment, the power load data from 2004 to 2007 in the GEFCom2012 data set are used, and the power load data are distributed according to the date as shown in Fig. 2.
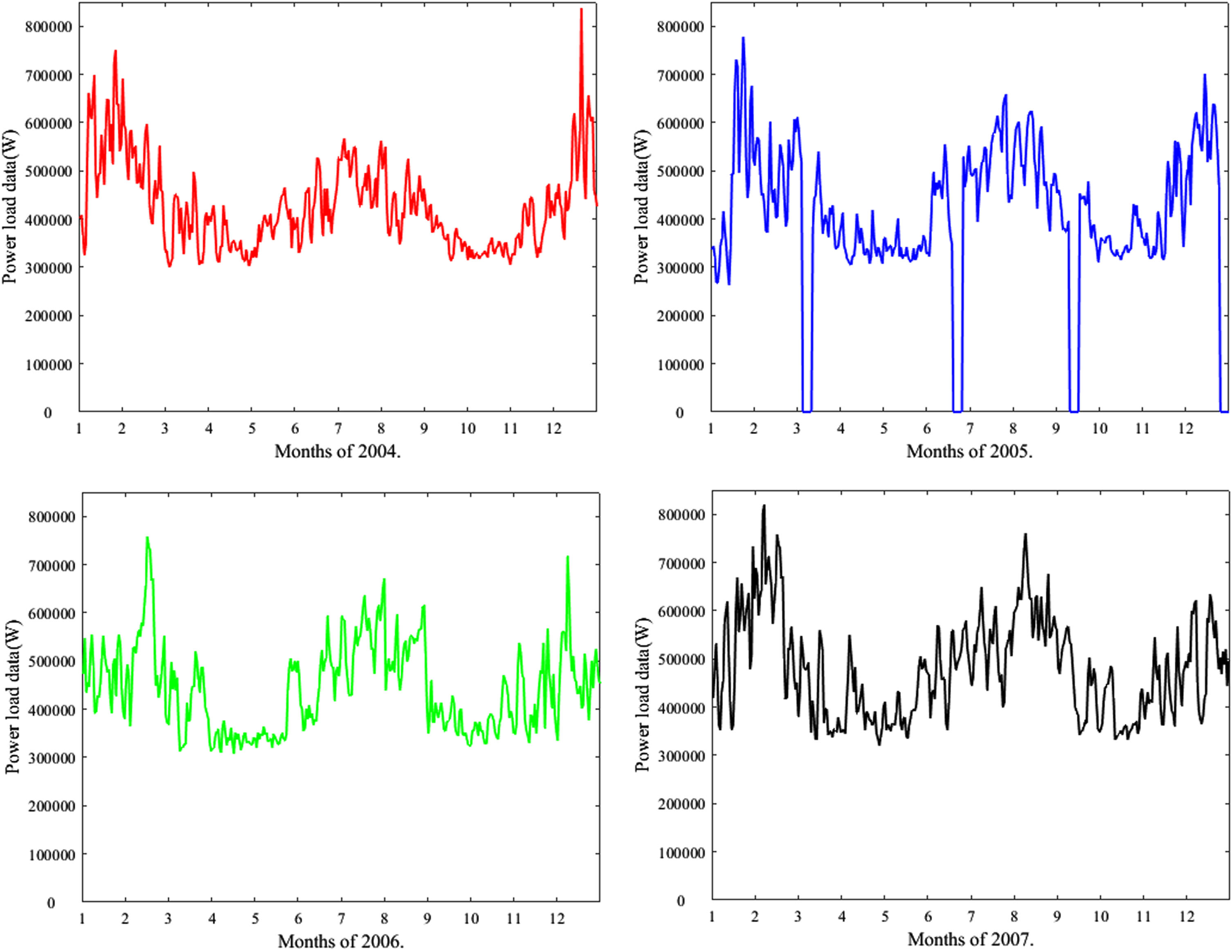
Statistical charts for GEFCom2012 data set.
As shown in Fig. 2, in the GEFCom2012 data set, there is no lack of load data in 2004 and 2007. The load data values of some dates in 2005 and 2006 are 0, and some data show extreme conditions that deviate significantly from other observations. If using this kind of abnormal directly during the experiment, it may have a negative impact on the analysis results, interpretation ability and subsequent prediction results. It is necessary to use data preprocessing and cleaning methods to further process such data to ensure its statistical characteristics and meet the requirements of subsequent load forecasting experiments.
To test the predictive performance of the model, the Mean Absolute Percentage Error (MAPE) and the Mean Absolute Standard Error (MASE) are used in the predictors [28]. The MAPE used to compare the percentage error between the true values and the predicted values, and the smaller the MAPE, the closer the prediction value is to the true value [29]. MASE is a measure of prediction accuracy, whose values range between 0 and 1, and a smaller value of MASE indicates higher prediction accuracy.
The MAPE calculation formula is as follows:
The MASE calculation formula is as follows:
The predicted value of sample i is yt+i, and the real value of sample is
In order to illustrate the statistical characteristics of the electricity load data provided by the GEFCom2012 data set, descriptive statistics including the mean, standard deviation, maximum value, median, and minimum value were calculated for hourly, daily, and monthly intervals, as shown in Table 1.
Statistical features of the GEFCom2012 data set
In order to avoid the impact of missing data on the data analysis process and results, data preprocessing is required before the experiment. Some data have ultra-low values or missing data in the GEFCom2012 data set. If these abnormal data do not have any abnormal description, then such data can be identified as noise data. The generation of such noise data may be due to the planned shutdown of power generation enterprises for maintenance or abnormal external environment, such as extreme natural factors or non-man-made controllable equipment failures, and these noise data must be preprocessed to avoid affecting the results of data analysis and prediction. The data cleaning method for noise data is based on the outlier cleaning method proposed in reference [30], which is improved according to the characteristics of GEFCom2012 data set.
The basic process is as follows, set values that meet the criteria for noisy data as outliers, and replace the outlier values with data generated by specific rules to avoid affecting the experimental results by deleting noisy data directly. The specific method is as follows. Firstly, the original data set is divided into several sub-datasets according to year and month.
The specific method is as follows: first, divide the data set to be analyzed into several subsets based on the same year and month. For example, divide the load data for the year 2004 into 12 subsets according to the months. The subsequent cleaning process will be based on these subsets and remove the data with a load value of 0 in each subset.
Then calculate the average load value for each hour within each subset. Any data within a subset that is less than 1/4 of the average load value will be considered as an outlier.
Afterwards, calculate the weighted average load value for each hour, excluding the outliers. The absolute percentage error (APE) between the hourly load values and the weighted average value is computed. If the calculated APE exceeds 50%, the data point is considered an outlier. Once all the outliers are identified within each subset, the mean interpolation method is used to replace the load data points of these outliers. Specifically, the load data value for an outlier is estimated by taking the weighted average of the corresponding time point for the 7 days before and after the outlier occurrence.
The parameter t in Equation (38) represents the time of the outliers.
The statistical charts of GEFCom2012 data set after data preprocessing and outlier cleaning are shown in Fig. 3.
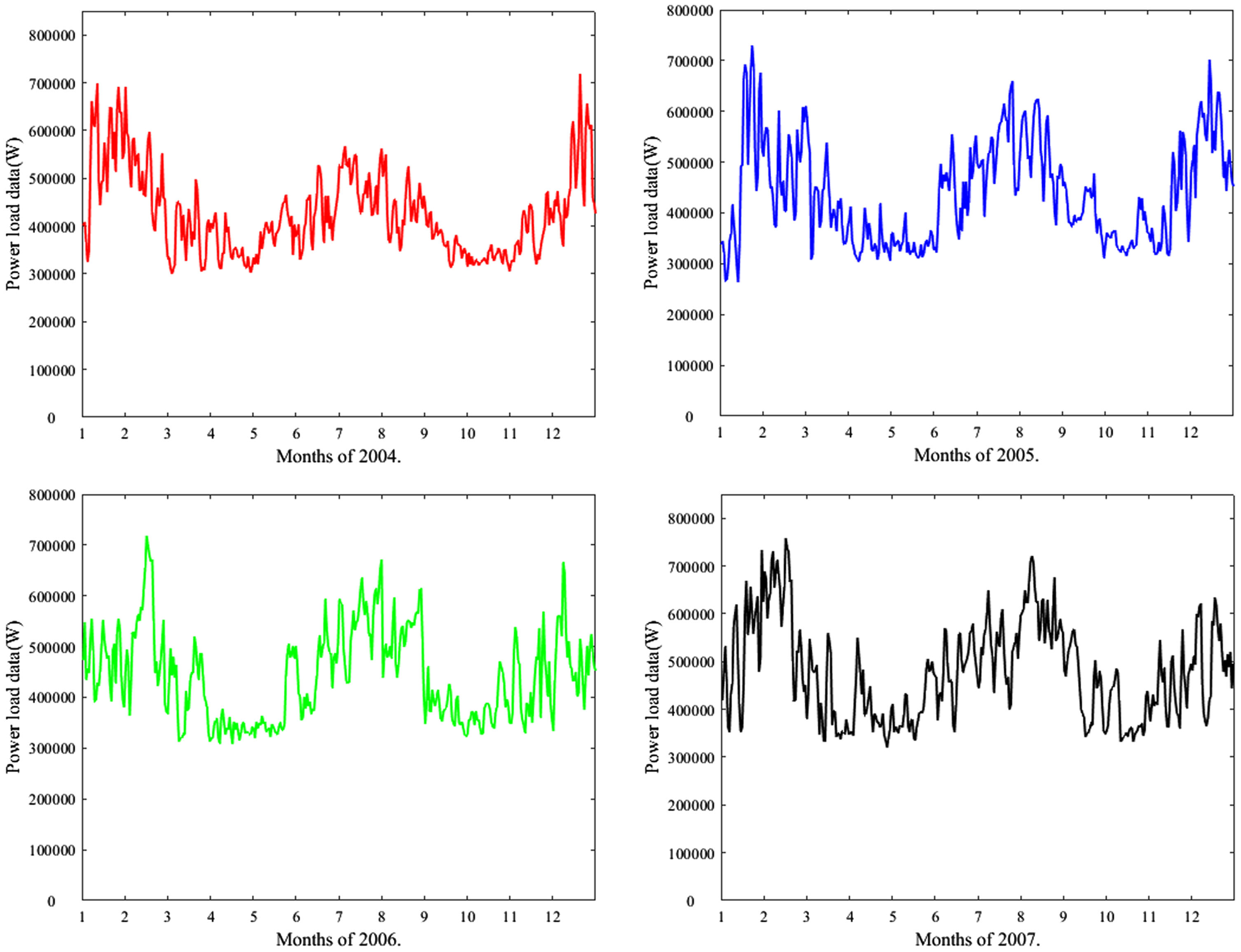
Statistical charts of GEFCom2012 data set after data preprocessing and outlier cleaning.
To avoid overfitting, k-fold cross-validation is used in the experimental process, which can effectively solve the overfitting issue and evaluate the model’s generalization ability, while avoiding uneven division of the training and validation sets. The basic method is to divide the data set into K subsets, select one subset as the validation set each time, and use the remaining K-1 subsets as the training set. Repeat the process K times for cross-validation, and finally use the average of the K metrics as the final model performance measurement. Multiple cross-validations can reduce the impact of randomness on model performance evaluation, make the evaluation results more reliable and stable, and also effectively reduce the risk of model overfitting to training data, while improving the model’s generalization ability and robustness, thus obtaining better performance and predictive power.
After data preprocessing, the data set contains a total of 1,600 records stored on a daily basis from January 1, 2004, to June 29, 2008. Each record consists of 24 hourly power load values, resulting in a total of 38,400 load values. Specifically, there are 362 records for the entire year of 2007, totaling 8,688 load values. The characteristics of the time series and k-fold cross-validation method used in the experiment with the GEFCom2012 data set are not followed according to the common practice of setting the value of k and the number of cross-validation iterations. In the experiment, the data set consisting of 26,016 load values from 2004 to 2006 is used as both the training and validation sets.
After data preprocessing, the GEFCom2012 data set contains a total of 1,600 records stored on a daily basis from January 1, 2004, to June 29, 2008. Each record consists of 24 power load values sampled hourly, resulting in a total of 38,400 load values within these 1,600 records. Specifically, the dataset includes 1,084 records from 2004 to 2006, totaling 26,016 load values used for training and validation. The dataset also includes 362 records from the entire year of 2007, amounting to 8,688 load values used for testing. Due to incomplete data, the 154 records available for the year 2008 are not used in this study.
Each year’s load data is divided into 12 subsets based on the months, and randomly selecting 10 subsets as the training set and the remaining 2 subsets as the validation set. This process will be repeated 10 times for each year to perform cross-validation. For testing purposes, use the load data from the entire year of 2007 consisted of 8,688 load values as the test set.
In addition to providing actual electricity load data, the GEFCom2012 data set also includes relevant parameters that influence the electricity load. These parameters primarily consist of load trend variation, temperature data corresponding to time, and holiday data provided according to dates. Considering the impact of temperature and holiday factors on electricity load, these data contribute to constructing more accurate load forecasting models.
Based on the relevant parameters provided by the GEFCom2012 data set, the authors adopt the methodology used in reference [31] with modifications to select input load parameter and conduct sensitivity analysis.
In Table 2, the load parameters combined with their sensitivity weights to obtain the input factors can be used as the calculation parameters of the fuzzy membership function s (x i ), as shown in Equation (39).
Load parameters for input factor
Load parameters for input factor
The coefficients θ1, θ2, θ3 and η1, η2, η3, η4 of the influencing factors have different sensitivities to the load parameters for different values.
According to the analysis in reference [31], it is observed that the trend value coefficient θ1 should have the highest weight, typically ranging from 0.7 to 0.8, the temperature coefficient θ2 has a weight range of 0.1 to 0.2, and the holiday coefficient θ3 is generally set at 0.1. By following the recommendations in references [31], the values will be set as follows: η1 = 0.05, η2 = 0.7, η3 = 0.15, η4 = 0.1.
Using the historical load data from January to March of 2004 and considering the coefficient ranges and recommended values mentioned earlier, calculate the average MAPE for each day within the monthly range. The result can assess the sensitivity of the parameters θ1 and θ2, as shown in Table 3.
MAPE values of prediction result
Based on the sensitivity analysis of the relevant parameters shown in Table 3, it is observed that a smaller MAPE is achieved when θ1 = 0.75, θ2 = 0.15. Based on the analysis process, the coefficient values will be used as θ1 = 0.75, θ2 = 0.15, θ3 = 0.1 and η1 = 0.05, η2 = 0.7, η3 = 0.15, η4 = 0.1 in Equation (39). In the subsequent experimental process, the input factors determined by multiple load forecasting parameters are calculated using Equation (39). The input factors that affect load forecasting will be introduced into the prediction model through fuzzy membership functions, represented as s (x i ).
Parameter optimization
In the subsequent experimental verification process of the fuzzy support vector regression machine based on boundary vectors, the main optimization parameters include the fuzzy parameter σ, the penalty factor C, and the membership function u i .
Fuzzy parameter: Control the degree of ambiguity in the fuzzy sample set. In the method proposed in this paper, two parameters of α, β are used to determine the fuzzy parameter.
Penalty factor C: Penalty factor is a parameter that measures the importance of the training model samples. It is used to control the complexity of the model and the degree of fit to the training data.
Membership function u i : The function of membership function is to evaluate the importance of the sample to the regression plane. The method proposed in this paper does not use the traditional regression plane equation, but uses the minimum hypersphere in the high-dimensional space to determine the membership value of the sample.
In the specific experimental process, it is important to try different combinations of optimization parameters (σ, C and u i ) to find the best configuration, to obtain the best performance and generalization ability of fuzzy support vector regression machine.
As indicated by Equation (19), the product of the penalty factor C and the membership function u i determines the importance of the sample in the prediction process. The fuzzy parameter σ is determined by α, β. The main optimization parameters selected in the experiment are α, β and C · u i , and the prediction effect is measured by different optimization combinations of these three parameters.
Experimental procedures
The steps of the power load prediction algorithm based on BVE-FSVR model are as follows:
Step1: Input the data and calculate the values for initial boundary membership function.
Input variables x i , i = 1, 2, . . . , n of the initial data set and calculate the boundary membership function u (x i ) , i = 1, 2, . . . , n for x i .
Step2: Calculate fuzzy input variables: Calculate fuzzy input variable m (x i ) and fuzzy membership function s (x i ) = u (m (x i )) , i = 1, 2, . . . , n using initial data x i and boundary membership function u (x i ).
Step3: Calculate the fuzzy output variable: Calculate the fuzzy output y i = f (s (x i )) , i = 1, 2, . . . , n of x i based on the calculated m (x i ) and s (x i ).
Step4: Calculate the fuzzy SVR: Train an fuzzy SVR model between the fuzzy input variable m (x
i
) and the fuzzy output variable y
i
, and obtain the weighting w and bias b based on the training to calculate the SVR fuzzy output
Step5: Repeat Step 1 to Step 4 until all the input variables x i are computed to obtain y i .
Step6: Defuzzification: Form a set of fuzzy output variables
The specific method is as follows:
Step7: Output the Result: Output the obtained actual output variable y as the prediction result.
Take the steps as the basic process, the program flowchart for implementing electricity load forecasting using BVE-FSVR model is shown in Fig. 4.
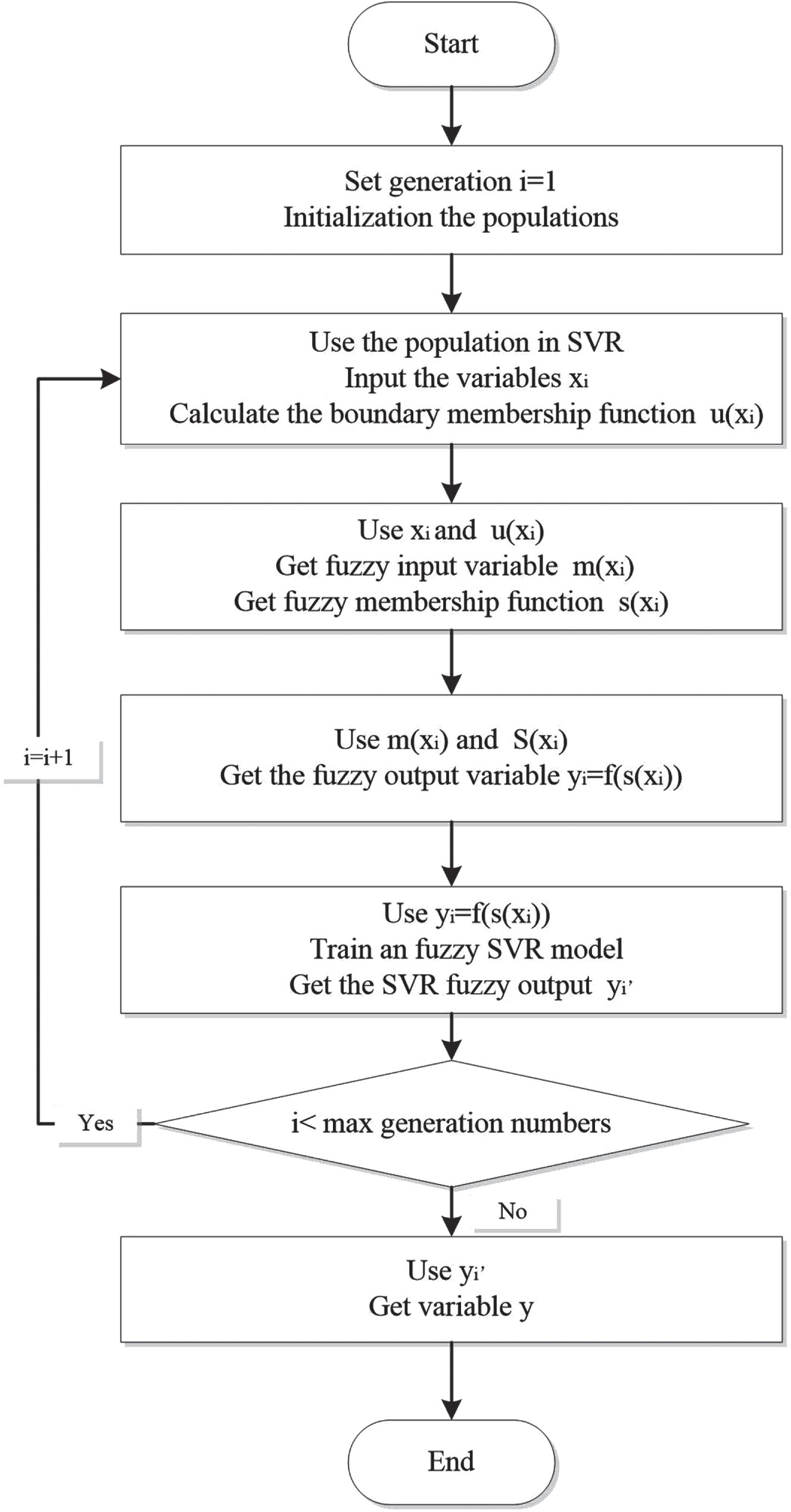
Program flowchart of BVE-FSVR model.
Experimental process
The experiment use the power load data provided by GEFCom2012 data set as the training set from the year 2004 to 2006. Using the k-fold validation method divides the load data monthly into 12 subsets for each year, selected 10 random subsets as the training set, and the remaining two subsets are used as the validation set, completed 10 rounds of prediction process and evaluated the prediction results by the values of MAPE and MASE using Equations (36) and (37).
Under the conditions of α+β= 1, experiment select α= 1, β= 0; α= 0.8, β= 0.2; α= 0.6, β= 0.4; α= 0.4, β= 0.6; α= 0.2, β= 0.8; α= 0, β= 1,combined C · u i = 1, 2, 5 as parameters for training sets. The test data set undergoes 10 rounds of cross-validation using different parameter combinations for each year.
Table 4 and Fig. 5 show the predicted data and schematic diagram obtained for 2004, with different parameters for α, β, C · u i .
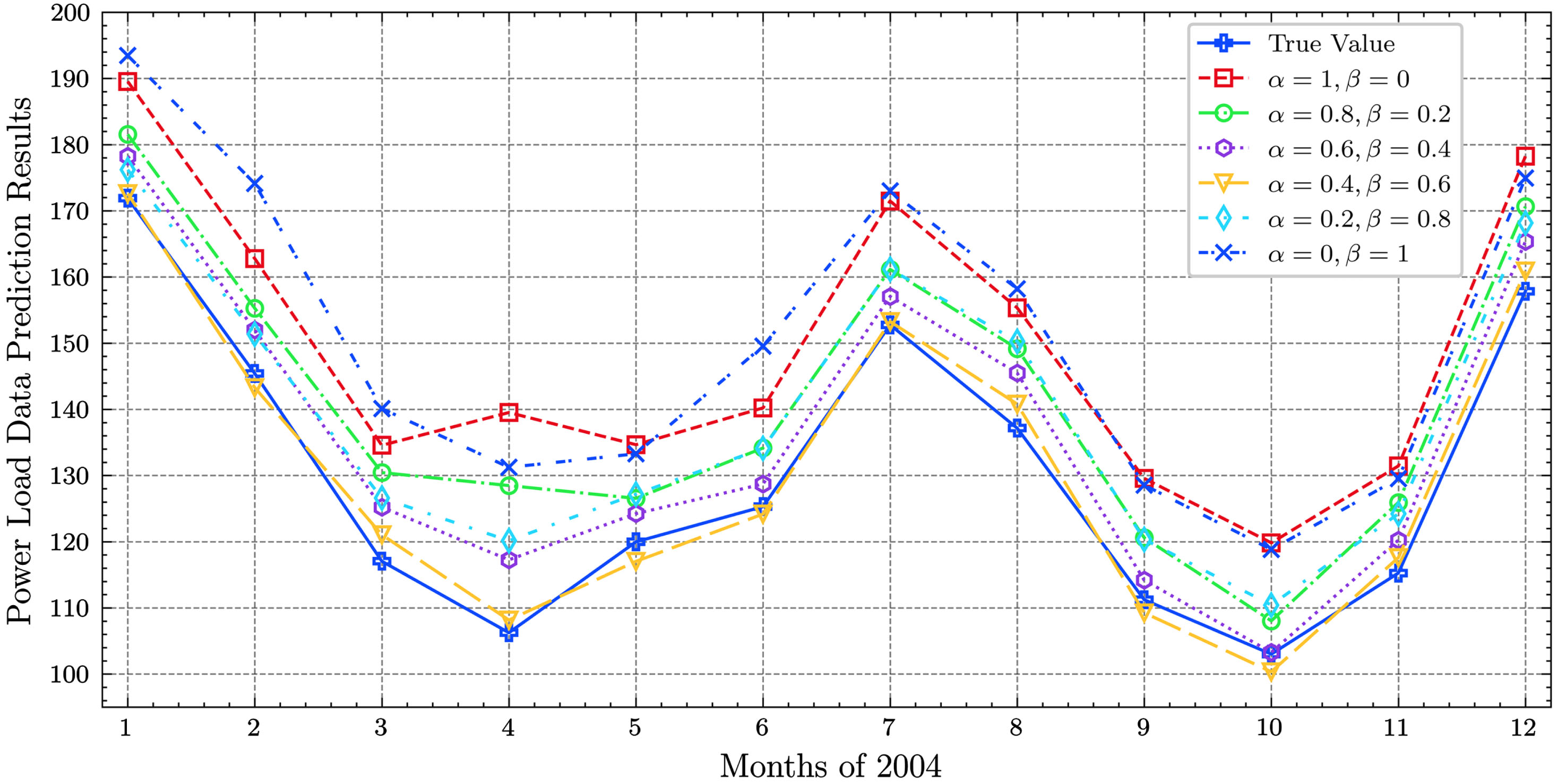
Prediction results used parameters in Table 4.
Prediction results with different parameters for 2004
Table 5 and Fig. 6 show the predicted data and schematic diagram obtained for 2005, with different parameters for α, β, C · u i .

Prediction results used parameters in Table 5.
Prediction results with different parameters for 2005
Table 6 and Fig. 7 show the predicted data and schematic diagram obtained for 2006, with different parameters for α, β, C · u i .
Prediction results with different parameters for 2006

Prediction results used parameters in Table 6.
Based on the experimental process and results obtained in this section, the values of MAPE and MASE have been calculated using Equations (36) and (37) that as shown in Table 7. Based on the analysis of Table 4, it can be observed that when α= 0.4, β= 0.6 and C · u i = 1 or C · u i = 2, the values of MAPE and MASE for prediction results from 2004 to 2006 are smallest among all parameter combinations. This analysis result indicates that choosing this parameter combination can achieve higher prediction accuracy, and the subsequent parameter optimization process will focus on the range of parameter values around combination.
Values of MAPE and MASE for different parameter combinations
Considering the experimental results in section 4.3.1, when α= 0.4, β= 0.6, and the value of C · u i is around 1 or 2, the prediction accuracy is relatively higher. Based on the research findings, the K-fold cross-validation method will be used to perform parameter optimization again for load forecasting from 2004 to 2006. Five sets of parameters are selected: α= 0.6, β= 0.4; α= 0.5, β= 0.5; α= 0.4, β= 0.6; α= 0.3, β= 0.7; α= 0.2, β= 0.8. The parameter value for C · u i is chosen as 1, 1.5, and 2. The existing prediction results obtained using the same parameters will be preserved, and the new parameter combinations will undergo 10 rounds of training and validation to obtain the average results for load prediction.
Table 8 and Fig. 8 show the predicted data and schematic diagram obtained for 2004 with different parameters for α, β, C · u i .
Prediction results with different parameters for 2004
Prediction results with different parameters for 2004

Prediction results used parameters in Table 8.
Table 9 and Fig. 9 show the predicted data and schematic diagram obtained for 2005 with different parameters for α, β, C · u i .
Prediction results with different parameters for 2005

Prediction results used parameters in Table 9.
Table 10 and Fig. 10 show the predicted data and schematic diagram obtained for 2006 with different parameters for α, β, C · u i .
Prediction results with different parameters for 2006

Prediction results used parameters in Table 10.
Based on the completed parameter optimization process, it is evident that when using the parameter combination α= 0.3, β= 0.7and C · u i = 1.5, the predicted values obtained from the BVE-FSVR model are closest to the actual load values. By calculating the MAPE and MASE values from 2004 to 2006 as evaluation metrics for prediction accuracy, it can be concluded that the parameter combination α= 0.3, β= 0.7and C · u i = 1.5 achieves the highest prediction accuracy. Therefore, this parameter combination will be used in the subsequent prediction process on the test set. The specific prediction accuracy indicators are shown in Table 11.
Values of MAPE and MASE for different parameter combinations

Comparison of power load data prediction results obtained using different machine learning models.
To evaluate the performance of BVE-FSVR method in power load forecasting, in conjunction with the results obtained in the previous experimental process, the BVE-FSVR method selects α= 0.3, β= 0.7, and C · u i = 1.5 as the parameters for the test set. The electricity load data for the 12 months of the year 2007 from the GEFCom2012 data set is used as the test set. In order to compare the differences between the proposed FSVR method and other machine learning models, several machine learning models commonly used for power load forecasting, including SVM, SVR, BPNN, and ABC are implemented for load prediction.
The experimental parameters for each method in the experiment process were referenced from recent relevant literature for the basic methods and parameter values [32–35], as shown in Table 12, and the specific prediction results are shown in Table 13 and Fig. 10.
Parameter values used different prediction models
Parameter values used different prediction models
Prediction results using different machine learning models
In Table 14, the values of MAPE and MASE are recorded for the different prediction models using the electricity load data of 2007 that provided by the GEFCom2012 data set.
Values of MAPE and MASE for different prediction models
Based on the comparison of the predicted results and the MAPE and MASE values, it can be concluded that when comparing the SVM, SVR, BPNN, ABC, and BVE-FSVR methods as load forecasting models, the BVE-FSVR method demonstrates significantly higher predictive accuracy and result stability than the BPNN and ABC methods, and slightly higher than the SVR and SVM methods.
Based on the above analysis results and considering the design principles and methods commonly used in machine learning models for electricity load forecasting, an analysis result can be obtained through comparison and summarization of these methods. SVM can handle high-dimensional and nonlinear data, has good generalization ability, and is robust in handling outliers. However, its predictive results may not be highly interpretable. SVR can handle nonlinear relationships and high-dimensional data, has good generalization ability and robustness, but is sensitive to hyperparameter selection. BPNN can capture nonlinear relationships in the data, has good adaptability and generalization ability, but it is prone to being trapped in local optima and requires significant computational resources during training. ABC has the ability for global search and can avoid being stuck in local optima, but its performance significantly declines when dealing with high-dimensional problems. Compared to these methods, the proposed approach in this paper demonstrates higher prediction accuracy and stability in power load forecasting. It is suitable for handling nonlinear relationships and high-dimensional data, shows good robustness against outliers, and has the ability to provide real-time predictions with integration capabilities for big data analysis.
In this paper, the authors proposed an improved fuzzy support vector regression (FSVR) algorithm to enhance the accuracy of power load forecasting. Authors applied the boundary membership function to the typical FSVR algorithm and incorporated boundary and distance factors into the design of the membership function. The proposed method has been using GEFCom2012 data set, and trained and validated the algorithm model using a subset of the prediction data set, obtaining the optimal parameter combination. The predicted results compared with algorithm models generated by commonly used methods such as BP Neural Network, Artificial Bee Colony, SVR, and SVM. The prediction results demonstrated that the BVE-FSVR method outperformed the BP Neural Network and Artificial Bee Colony models significantly and slightly outperformed the SVR and SVM models in terms of prediction accuracy.
The power load forecasting method proposed in this paper has wide applications in power enterprises, including the combination strategy of power generation units, design of power transmission schemes between different regions, and power load scheduling and operation. This method can effectively improve the operational economy of the power system, and the predicted results can serve as important reference for power system dispatch, production planning, and electricity planning and design.
In the future, the development of power load forecasting will trend towards more prediction that is refined, real-time interaction, and integration with big data analysis and processing. BVE-FSVR method proposed in this paper demonstrates high levels of prediction accuracy and stability. Therefore, transforming the method proposed in this paper into a program model suitable for typical real-time big data analysis platforms will be the direction for future development and research.
Footnotes
Acknowledgments
This work was supported by Applied Basic Research Program of Liaoning Province, China.
Grant: [2022JH2/101300134], [2023JH2/101300065].