
Abstract
Assembly flow shop scheduling problem (AFSP) in a single factory has attracted widespread attention over the past decades; however, the distributed AFSP with DPm → 1 layout considering uncertainty is seldom investigated. In this study, a distributed assembly flow shop scheduling problem with fuzzy makespan minimization (FDAFSP) is considered, and an efficient artificial bee colony algorithm (EABC) is proposed. In EABC, an adaptive population division method based on evolutionary quality of subpopulation is presented; a competitive employed bee phase and a novel onlooker bee phase are constructed, in which diversified combinations of global search and multiple neighborhood search are executed; the historical optimization data set and a new scout bee phase are adopted. The proposed EABC is verified on 50 instances from the literature and compared with some state-of-the-art algorithms. Computational results demonstrate that EABC performs better than the comparative algorithms on over 74% instances.
Keywords
Introduction
Assembly shop scheduling problem plays an essential role in balancing batch production and production flexibility. It has been widely used in many manufacturing industries such as fire engine [1], computer [2], clothes [3] and automobiles [4]. Facing the competitive market, research on assembly shop scheduling can assist managers to choose an efficient scheduling plan and help enterprises produce more products in the shortest time. Relevant problems have been considered and a large number of results have been obtained since the pioneering work of Lee et al. [1]. After that, a unified definition method and a full review of assembly scheduling problems were displayed by Framinan et al. [5] and Komaki et al. [6].
As a frequently investigated problem, AFSP has been successfully studied, and most works are about AFSP with DPm → 1 layout, which consists of m dedicated parallel machines and an assembly machine. For AFSP in a single factory, various meta-heuristics have been the main optimization method. Allahverdi and Al-Anzi [7] first introduced tabu search and particle swarm optimization(PSO) algorithm to handle AFSP with makespan criterion in 2006. Wu et al. [8] studied the problem through a branch-and-bound algorithm and six hybrid PSO algorithms. Shokrollahpour et al. [9] presented an imperialist competitive algorithm (ICA) to minimize the weighted sum of mean completion time and makespan in AFSP. Kazemi et al. [10] developed a hybrid ICA incorporating a dominant relation for AFSP with batching and delivery. Considering setup times, Mozdgir et al. [11] proposed three meta-heuristics: differential evolution algorithm, genetic algorithm(GA) and population-based variable neighborhood search algorithm to minimize makespan in no-wait AFSP. Jung et al. [12] provided three versions of genetic algorithm (GA) to obtain minimum makespan in AFSP with dynamic component-sizes. Basir et al. [13] also applied a bi-level GA to the problem with batch delivery systems. Afterward, Komaki et al. [14] proved the effectiveness of a discrete cuckoo optimization algorithm in solving the three-stage AFSP with makespan minimization. In addition, Azzouz et al. [15] devised a hybrid greedy iterative algorithm on AFSP with small and big size jobs. More detailed meta-heuristic algorithms on AFSP can be found in [16].
The above works on AFSP are all accomplished in a single factory. Nowadays, production and scheduling are gradually transforming from a single factory to multiple factories to respond quickly to the changes in market demand. Different from AFSP in a single factory, distributed assembly flow shop scheduling problem (DAFSP) reveals more sub-problems and more complex interrelationships among subproblems.
Regarding DAFSP with DPm → 1 layout in each factory, Xiong et al. [17] established a variable neighborhood search algorithm (VNS) and a hybrid variable neighborhood search algorithm combined with reduced variable neighborhood search (GA-RVNS) to minimize the time-related objective. Deng et al. [18] applied a competitive memetic algorithm (CMA) to solve the problem with makespan optimization. Lei et al. [19] provided a cooperated teaching-learning-based optimization algorithm to investigate the problem with makespan criterion. Li et al. [20] developed an imperialist competitive algorithm with empire cooperation (ECICA) to minimize the fuzzy makespan.
Besides that, other types of DAFSP are also considered. For DAFSP consisting of F manufacturing factories and one assembly factory, Hatami et al. [21] designed a variable neighborhood descent algorithm to minimize makespan. Wang et al. [22] proposed a novel memetic algorithm to optimize the maximum completion time. Lin et al. [23] presented a backtracking search hyper-heuristic algorithm to obtain the minimum makespan. Sang et al.[24] provided an effective invasive weed optimization algorithm to optimize total flow time. Huang et al. [25] reported an iterated greedy algorithm for the same problem. Zhao et al. [26] also investigated a self-learning hyper-her-heuristic to minimize the total flow time. Wang et al. [27] presented a cooperative memetic algorithm with feedback to minimize total tardiness and energy consumption. Zhang et al. [28] proposed a matrix cube-based estimation of distribution algorithm to minimize the makespan and total carbon emission. For DAFSP with F factories containing a flow shop and an assembly line in each factory, Pan et al. [29] utilized three heuristics, two VNS and an iterated greedy algorithm to minimize makespan.
As stated above, FDAFSP has attracted much attention. However, research on DAFSP with DPm → 1 layout is limited, and DAFSP with uncertainty is seldom investigated. Moreover, various uncertain factors extensively exist in the actual processing environment, and the negligence of uncertainty may invalidate the original scheduling plan. In recent years, the fuzzy set theory [30] has been widely used to solve fuzzy scheduling problems [31–37]. According to the definition of fuzzy dimension [38, 39], the fuzzy dimension of FDAFSP is decided by the number of processed jobs, and operations on fuzzy numbers also can be applied to the research of FDAFSP. Therefore, it is significant to investigate FDAFSP.
Various meta-heuristic algorithms [15–18, 41] own excellent optimization performance and have been used to deal with multi-domain problems including AFSP and DAFSP. Compared with other meta-heuristics, artificial bee colony algorithm (ABC) [42, 43] has certain characteristics, such as simple algorithm structure, fast convergence speed and effective global search ability [44–46]; on the other hand, ABC shows excellent abilities and advantages in solving production scheduling in a single factory [47–50] and multiple factories [51–53]. However, ABC has not been applied to cope with DAFSP, let alone FDAFSP. Thus, we are motivated to improve ABC for solving FDAFSP.
The contributions of this study can be concluded as follows: (1) FDAFSP with DPm → 1 layout in each factory is considered and a novel algorithm called EABC is proposed to minimize fuzzy makespan. (2) In EABC, an adaptive population division procedure based on evolutionary quality of subpopulation is implemented; the newly designed employed bee phase and onlooker bee phase are performed by utilizing a diversified combinations of global search and multiple neighborhood search; historical data set and a novel scout bee phase are constructed. (3)A number of comparative experiments are conducted to test the performance of EABC on the considered FDAFSP. Computational results demonstrate that EABC holds more advantages than other algorithms on over 74% instances.
The rest of this article is structured as follows. Fuzzy operations are shown in Section 2, and the problem description is given in Section 3. Section 4 reports EABC for FDAFSP and is followed by the computational results in Section 5. Conclusions and future research topics are summarized in the final section.
Operations on fuzzy processing time
Due to its convenience, triangular fuzzy number(TFN) is often adopted to describe fuzzy processing time in shop scheduling problem [31–37]. A TFN can be expressed as
In this article, the fuzzy processing, setup and assembly time are all expressed as TFNs. Three operators, including addition, ranking and max, are provided to build a scheduling. Addition is applied to compute the completion time of jobs. Ranking is used to make a comparison between fuzzy objectives. Max is utilized to calculate the fuzzy beginning time of jobs.
For TFNs
For
Ranking
If
Max operation is implemented in terms of
FDAFSP consists of n jobs {J1, J2, ⋯ , J n } and f homogeneous factories {F1, F2, ⋯ , F f } distributed in different sites. Each factory f possesses m dedicated parallel machines Mf1, Mf2, ⋯ , M fm at the fabrication stage and one assembly machine AM f at the assembly stage. Each job is composed of m components, which are first processed on m manufacturing machines, then transported to AM f and assembled together into a final product. Figure 1 shows an illustration of FDAFSP.
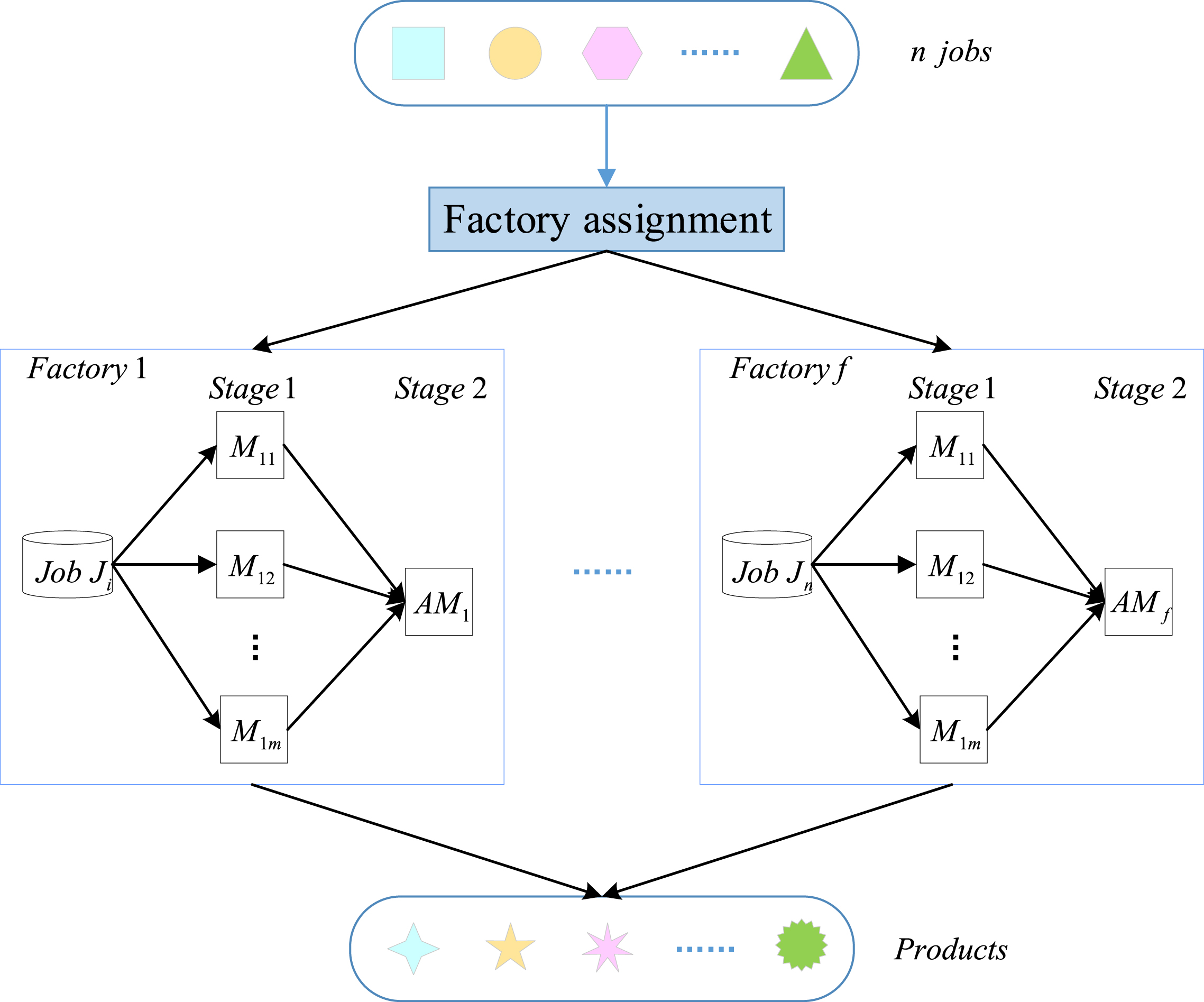
an illustration of FDAFSP.
Jobs in each factory have same setup, processing and assembly time. At fabrication stage, fuzzy setup and processing time of job J
i
on machine M
fk
are
The assumptions on jobs and machines in this study are as follows:
(1) No machine can process or assemble more than one job at a time.
(2) At most, one job can be manufactured or assembled on one machine at a time.
(3) Interruption or preemption is not considered.
(4) Setup time is considered and transportation time is ignored.
(5) Once a job is allocated into a factory, it cannot be transferred to another.
(6) Machines and jobs are continuously available throughout production and assembly process.
FDAFSP consists of factory assignment and scheduling subproblems. Strong coupled relations can be found between two subproblems [22]. Changes in factory assignment will directly affect the scheduling sequences and the final scheme, so the two subproblems should be optimized simultaneously.
There are some challenges in solving FDAFSP. Since AFSP in a single factory is NP-hard [1], FDAFSP deals with AFSP in multiple factories and uncertain environments, which means more sub-problems and more complex interrelationships. Thus, FDAFSP is also NP-hard.
In FDAFSP, fuzzy completion time of job J
i
is represented by TFN
An illustrative example of FDAFSP is given in Table 1, which contains eight jobs and two identical factories. For each factory, there are two parallel machines at fabrication stage and one assembly machine at assembly stage.
An illustrative example of FDAFSP
ABC was first proposed by Karaboga et al. [42, 43] and composed of initial population, employed bee phase, onlooker bee phase and scout bee phase. In ABC, a food source represents a feasible solution, and the fitness value corresponds to quality of the food source. Employed bees seek to search for food sources, and onlooker bees wait for a food source to follow. The scout bee is used to abandon a hopeless solution.
The initial population P with N solutions is randomly generated by
In employed bee phase, for each solution x
i
, a new solution
The greedy selection is used to update solution x
i
. If fitness (x′
i
) < fitness (x
i
), then
Thus, the bigger the fitness value is, the better the solution is.
For each onlooker bee, roulette selection is applied to select food source to follow, and the selection probability is calculated by
Once an onlooker bee chooses a food source x
i
to follow, a new solution
For each solution x i , trail i is used to record the number of consecutive trials. If trail i > Limit and a solution x i has not been updated, the corresponding employed bee will become a scout bee, where Limit indicates a threshold of trail i . The scout bee randomly generates a new solution according to equation(4).
The basic framework of ABC is described in Algorithm 1.
The basic framework of ABC
1: Initialization
2:
3: employed bee phase: search for improvements around the neighborhood
4: onlooker bee phase: seek new solutions around the chosen solutions
4: scout bee phase: randomly generate a new solution after Limit trials
6:
output the elite solution
In previous ABCs [47–53], multi-population division procedure is seldom involved, employed bees and onlooker bees often lead a similar way to generate new solutions. On the other hand, the frequent utilization of some worst solutions may waste computing resources. In this study, an adaptive multi-population division method is constructed; diversified search approaches are executed in employed bee phase and onlooker bee phase, historical optimization data of subpopulations and a novel scout bee phase are obtained.
Representation and initialization
A solution representation method in [18] is adapted for FDAFSP. The encoding string is expressed as follows:
where γ g ∈ { n + 1, n + 2, ⋯ , n + F - 1 }, h f is the total number of jobs
allocated into factory f,
Decoding procedure is described as follows. First, divide encoding string into F segments for F factories. Second, for each factory, start with job Jπ φf-1+1, allocate its m components to m fabrication machines sequentially and then send them to assembly machine to be assembled into the final product. An example of the encoding string and the corresponding Gantt chart are illustrated in Fig. 2.
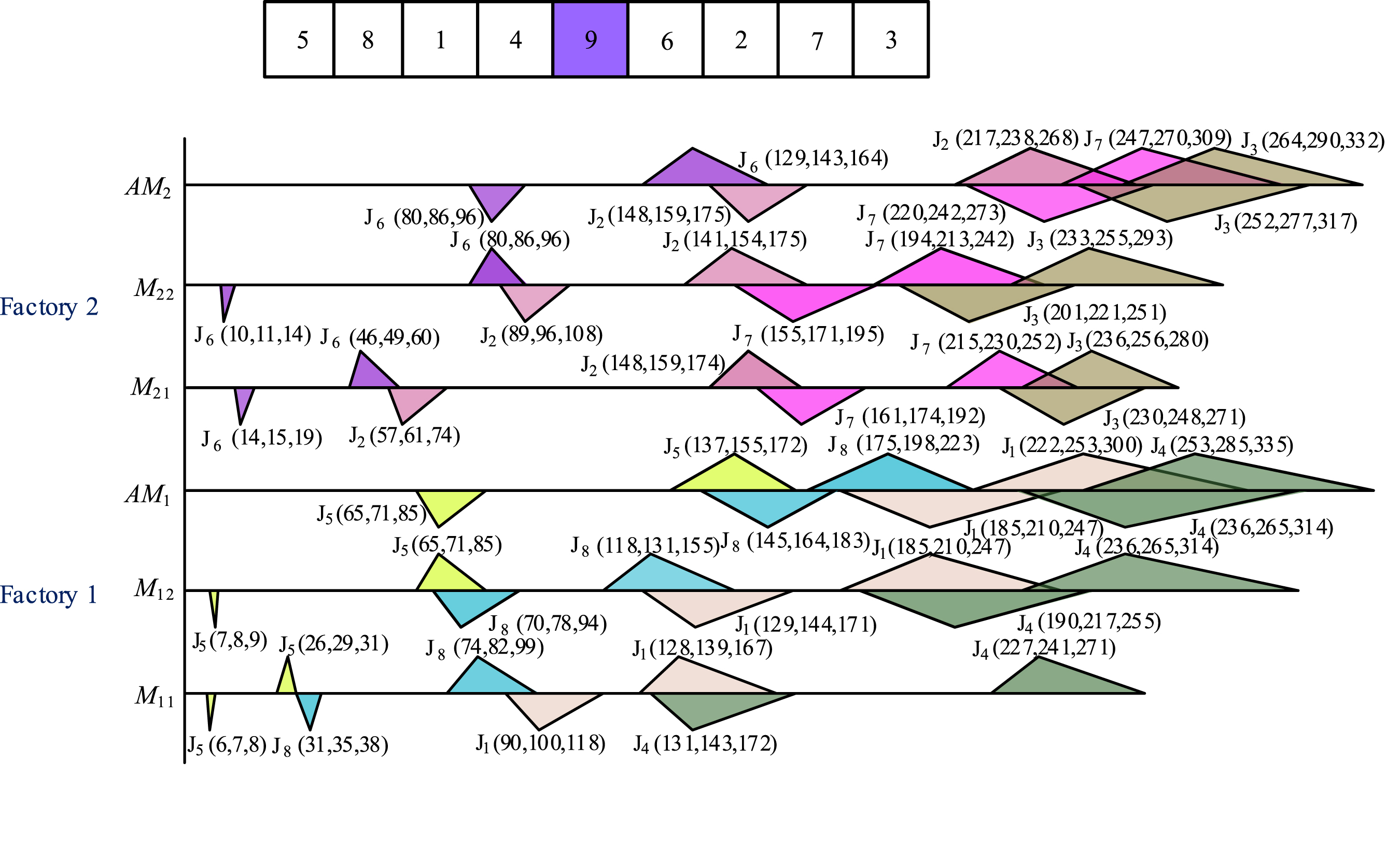
Gantt chart of example.
The population P is initialized by randomly generating N solutions.
After the initial population is constructed, directly sort all solutions of P in a ascending order of fitness f
i
, where
If
If
where
For sub
i
, its quality M
i
is evaluated by
Sort M
i
in descending order, suppose that M1 > ⋯ > M
j
> ⋯ > M
s
. Calculate average quality
Employed bees compete to get the chance of generating new solutions. The detailed search process is described in Algorithm 2, where λ best is the best solution of EB i .
In Algorithm 2, both global search(GS) and multiple neighborhood search(NS) are executed on the winner between x and y, so the excellent computing resource in each subpopulation is utilized by the stronger to improve search efficiency. That is, employed bees obtain computing resources and generate new solutions by competing.
Employed bee phase
Employed bee phase
2:
3: stochastically choose y ∈ EB t (t ≠ i) and the best solution λ best in EB i
4:
5: perform GS (x, λ best , x, t) on x and λ best
6: conduct NS (x, x, t) on x
7:
8: conduct GS (y, λ best , x, t) on y and λ best
9: apply NS (x, x, t) to x
10:
11:
12: randomly select y ∈ EB i (x ≠ y)
13: obtain the winner z by competing between x and y
14: conduct GS (z, λ best , x, t) and NS (z, z, t) on z
15:
16: update Ω t and Num x
17:
Order-based crossover(OBX) operator is designed for GS. For OBX between x and y, randomly choose g elements from x and delete these picked elements from y. Then generate x new by filling in the blanks in y with the chosen elements in the order that they appeared in x. g is set to be 8 by experiments. The process of OBX is shown in Fig. 3.

Order-based crossover
GS (x, y, z, t) is described below. Generate a new solution x new by performing OBX between x and y, compare it with z. If x new is better than z, renew the history data set Ω t with z and update z with x new ; otherwise, renew Ω t with x new .
Ω t is especially designed to record the historical optimization data for sub t . Its update process is as follows: The initial Ω t is empty. If z is allowed to update Ω t , we directly add solution z to Ω t until |Ω t | exceeds |Ω t |max. To guarantee |Ω t | is no more than |Ω t |max, we calculate the fitness value f i of all solutions and delete the worst solutions to keep |Ω t |max solutions left in Ω t . |Ω t |max = 15 by many experiments.
Three neighborhood structures including exter-factory insert N1, exter-factory swap N2 and inter-factory swap N3 [18] are adopted to implement NS, which are shown in Fig. 4.
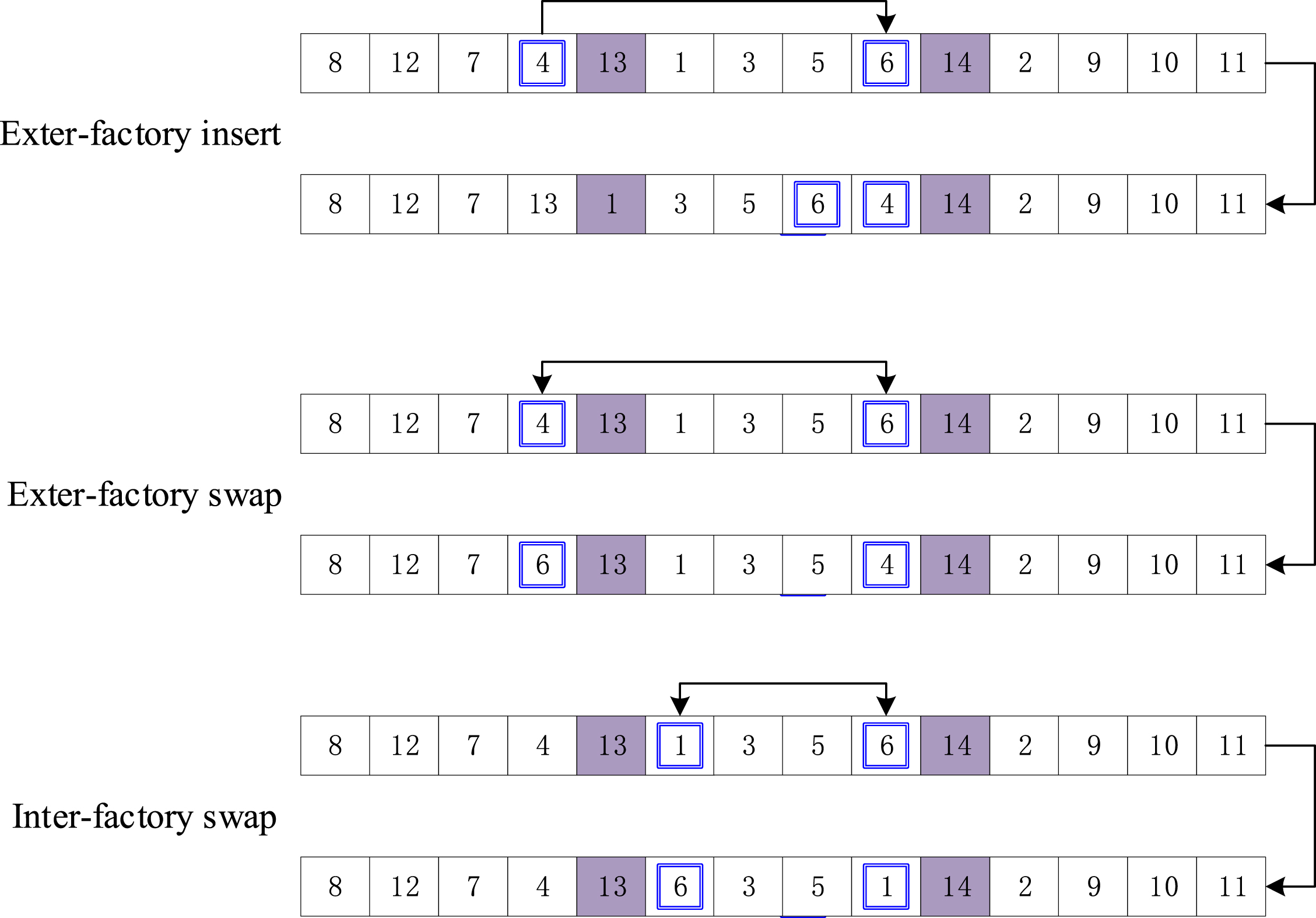
Multiple neighbour structures
NS (x, y, t) is displayed below. For a solution x, set l = 1, w = 1, and repeat the following steps R times: if l = 1, N1 is performed on x; if l = 2, N2 is used on x and if l = 3, N3 is applied. After that, a new solution x new ∈ N l (x) is produced. If x new is better than y, then renew Ω t with y and substitute y with x new ; else update Ω t with x new , l = l + 1 and let l = 1 if l = 4. Where N l (x) is a set of neighborhood solutions generated by N l on x and R is an integer.
Onlooker bees follow and learn from the elite solutions in employed bee subpopulation. They track the good performance of employed bees through global search and multiple neighborhood search. The detailed search procedure is shown in Algorithm 3, where rand is a rand number in [0,1] and φ is the neighborhood search probability, |φ| = 0.3 and |Φ| = 10 according to lots of experiments.
Onlooker bee phase
Onlooker bee phase
1: choose several elite solutions from the employed bee subpopulation to construct Φ
2:
3:
4: randomly select a solution y from Φ
5: execute GS (x, y, x, t) between x and y
6:
7: execute NS (x, x, t) on x
8:
9:
10:
In Algorithm 3, all onlooker bees follow a part of excellent employed bees and conduct the neighborhood search in a small probability to increase the population diversity.
In basic ABC, scout bee phase is used to substitute for a hopeless solution by generating a random one. However, this method is characterized by strong randomness and low efficiency. In this article, the scout bee x is updated as follows: First, select a random employed bee subpopulation EB k and obtain the best solution y from EB k , then conduct global search GS (y, z, x, k) on y and a random solution z from Ω k , and execute neighborhood search NS (x, x, k) on x. After that, the substitution rules are performed to update x and Ω k . The novel scout bee phase is beneficial to avoid early convergence. The main steps of modified scout bee phase are displayed in Algorithm 4, where trial i indicates the number of trials for x.
Scout bee phase
Scout bee phase
1:
2:
3: randomly select an employed bee subpopulation EB k , 1 ≤ k ≤ m
4: choose the best solution y of EB k and a random solution z in Ω k
5: perform GS (y, z, x, k) and NS (x, x, k)
6: update x and Ω k according to the substitution rules
7:
8:
For sub t , the poor solutions are exchanged with the ones in Ω t , which can avoid wasting computing resources. The detailed exchange process is below. First, put all the solutions in Ω t into sub t and calculate the fitness value for all, then exclude the worst ones to keep the number of sub t unchanged. In this way, the population is updated, and the computing resources are fully utilized.
When the above phases are finished, the population is recombined and regrouped, which is the same as the division of the initial population.
The detailed procedure of EABC is shown in Algorithm 5.
EABC
EABC
1: Initialize the population P and parameters
2: Divide P into s subpopulations, construct initial EB and OB
3:
4: employed bee phase: compete with other solutions and generate new solutions
5: onlooker bee phase: construct a set of elite employed bees Φ and track the excellent performance in Φ
6: scout bee phase
7: update Ω t and exchange the worst solutions in sub t with Ω t
8: redivide the population P into EB and OB
9:
The time complexity of EABC for FDAFSP is O (Gmax × N × (n - F + 1) × R), where F is the number of factories, n indicates the number of jobs, Gmax represents the maximum number of generations.
There are some features in EABC: (1) A novel subpopulation division method combining the characteristics of the problem is constructed. (2) A competitive search strategy is applied in employed bee phase, and a tracking search strategy is used for onlooker bees to improve search efficiency. (3)The historical optimization data set and a novel scout bee phase are developed. These features can take advantage of computing resources and void premature. As a result, the search efficiency and effectiveness are greatly improved.
A series of experiments are conducted to verify the performance of EABC for FDAFSP and compiled in Microsoft Visual C++ 2015 and run on 4.0G RAM 2.00GHz CPU PC.
Test instances and comparative algorithms
Since there are no test instances on FDAFSP, we adopt 50 instances from [17], which are extended by adding fuzzy processing information. TFN
To verify the performance of EABC, several comparative algorithms are chosen, including ECICA [20], GA-RVNS [17], VNS [17], CMA [18] and DIWO [24].
GA-RVNS and VNS are both used to minimize the weighted sum of mean completion time and makespan of FDAFSP. They can be utilized to solve FDAFSP by setting the mean completion time to zero.
CMA is proposed to solve DAFSP with makespan minimization, which can be directly used to compare with EABC for FDAFSP by simply adding fuzzy information into CMA.
DIWO is developed for DAFSP with total flowtime minimization. By adapting the related objective function, DIWO can be applied to FDAFSP.
ECICA is presented for FDAFSP, in which an adaptive imperialist cooperation between the strongest empire and the weakest empire is performed. Thus, these algorithms are selected to conduct the comparison experiments.
Parameter settings
In this study, the termination condition is determined by CPU time. We found by experiments that EABC can converge well on all instances when 0.2 × n CPU time reaches; moreover, all selected comparative algorithms also converge fully under this stopping condition. Therefore, we set 0.2 × n as the termination condition for all algorithms.
There are four main parameters in EABC: N, s, Limit, R. Taguchi method is adopted to determine the settings for four parameters. The levels of each parameter are shown in Table 2, and the orthogonal array L16 (44) is given in Table 3.
Parameters and their levels
Parameters and their levels
The orthogonal array L16 (44)
EABC with each combination independently runs 20 times for instance 6 × 20 × 8. The response variable value is denoted as
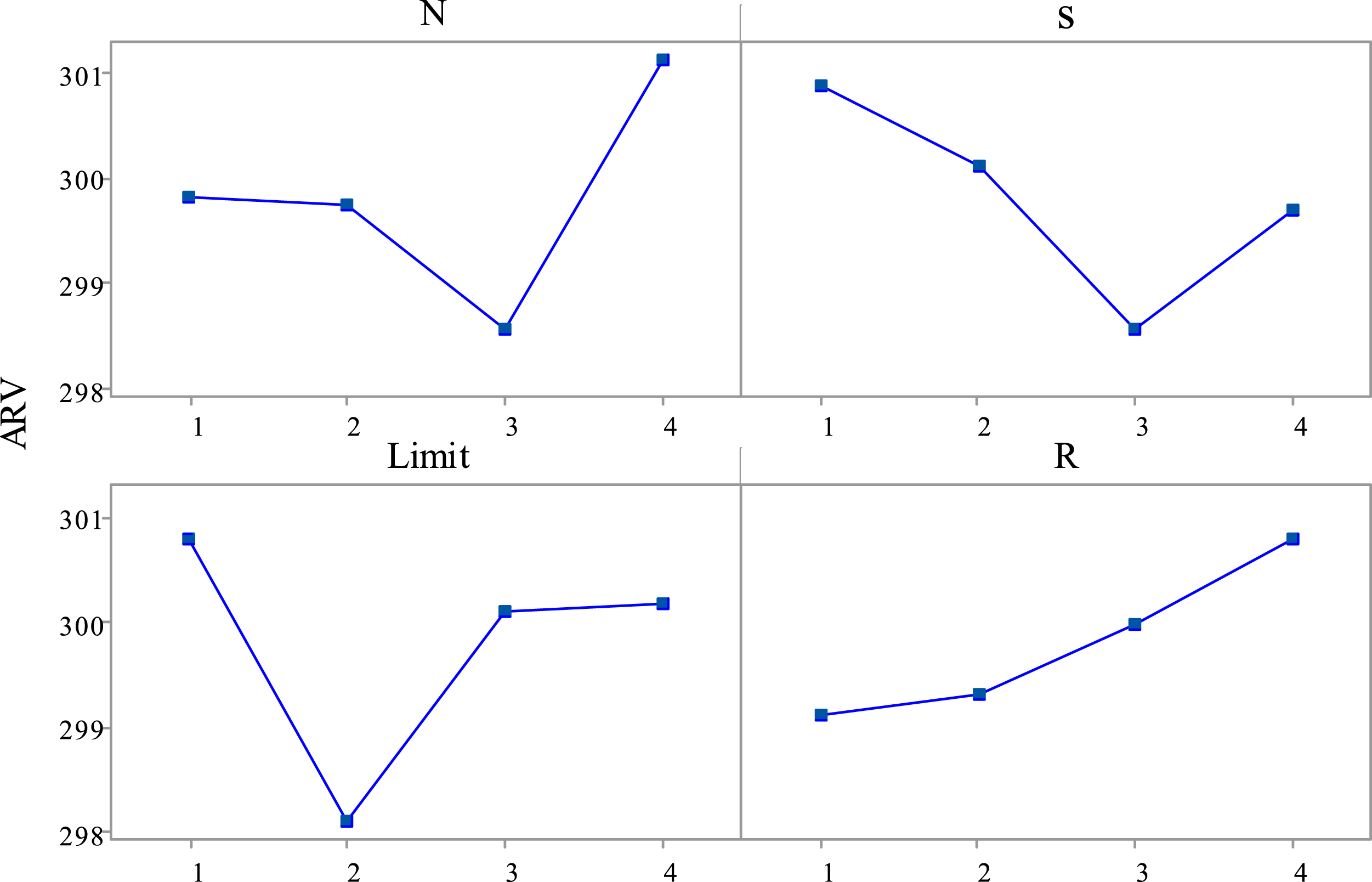
The mean ARV.
Response value and rank of each parameter
As shown in Tables 2–4 and Fig. 5, when the levels of N, s, Limit and R are 3,3,2,1, EABC can produce smaller ARV than EABC with other parameter levels, so we decide that the best settings of parameters in EABC are N = 80, s = 5, Limit = 6 and R = 8.
Meanwhile, it is found by experiments that the original parameter settings of comparative algorithms can result in better performance than other settings, so we directly select the parameters of ECICA, GA-RVNS, VNS, CMA and DIWO from literatures.
To test the impact of new strategies of EABC, we construct two variants of EABC, namely EABC1 and EABC2. In EABC1, the subpopulation division process is deleted, so there are no multiple subpopulations. The search process of each phase is identical to that of EABC. The comparison between EABC and EABC1 is used to reveal the impact of the multi-subpopulation division method. In EABC2, the multi-subpopulation division process is preserved, and the search process of each phase is conducted as the general ABC. The contrast between EABC2 and EABC is adopted to show the influence of the novel diversified search process in each phase.
Three algorithms independently run 20 times for each instance. Tables 5–7 report the comparative results of new strategies on Min, Average and Max, where Min is the minimum solution gained in 20 runs, Max denotes the maximum one obtained in 20 runs, Average indicates the average value of 20 runs.
Comparative results of new strategies on Min
Comparative results of new strategies on Min
Comparative results of new strategies on Average
Comparative results of new strategies on Max
To make the results statistically convincing, the paired-sample t-test is conducted. The p-value results of t-test are shown in Table 8. The term t-test(A,B) means that a paired t-test is done to judge whether B produces a better sample mean than A. The significance level of 0.05 is assumed, which means that there is a significant difference between A and B in the statistical sense if the p-value is less than 0.05.
Results of paired sample t-test
As stated in Tables 5–7, EABC provides better results than EABC1 and EABC2 on three metrics. Min of EABC is smaller than that of EABC1 on 42 of 50 instances; Average of EABC is superior to that of EABC1 on 43 of 50 instances; moreover, Max of EABC is better than that of EABC1 on 41 of 50 instances. Compared with EABC2, EABC provides a better Min on 44 of 50 instances and a smaller Average on 44 of 50 instances; moreover, Max of EABC2 is inferior to that of EABC on 40 of 50 instances. The performance differences between EABC and the two variants can also be found in Table 8. Therefore, the new strategies really improve the performance of EABC.
For each instance, EABC and five comparative algorithms independently run 20 times. Tables 9–11 list the results of comparative algorithms on Min, Average and Max. Figures 6–8 display the box plot of six algorithms on Min, Average and Max, in which Z1 (Min), Z1 (Average) and Z1 (Max) are applied.
Result of the comparative algorithms on Min
Result of the comparative algorithms on Min
Results of the comparative algorithms on Average
Results of the comparative algorithms on Max
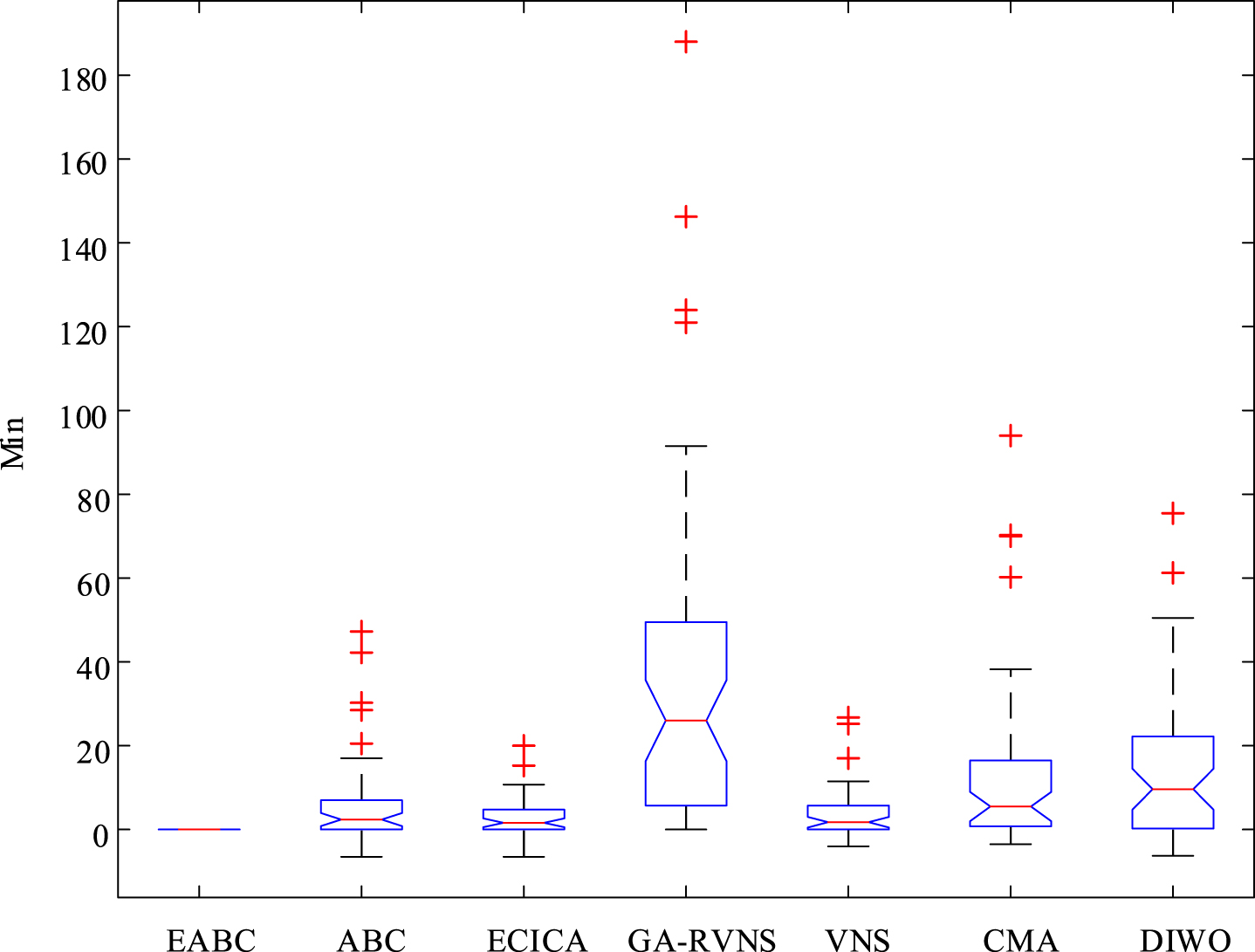
Box plot of all algorithms on Min.
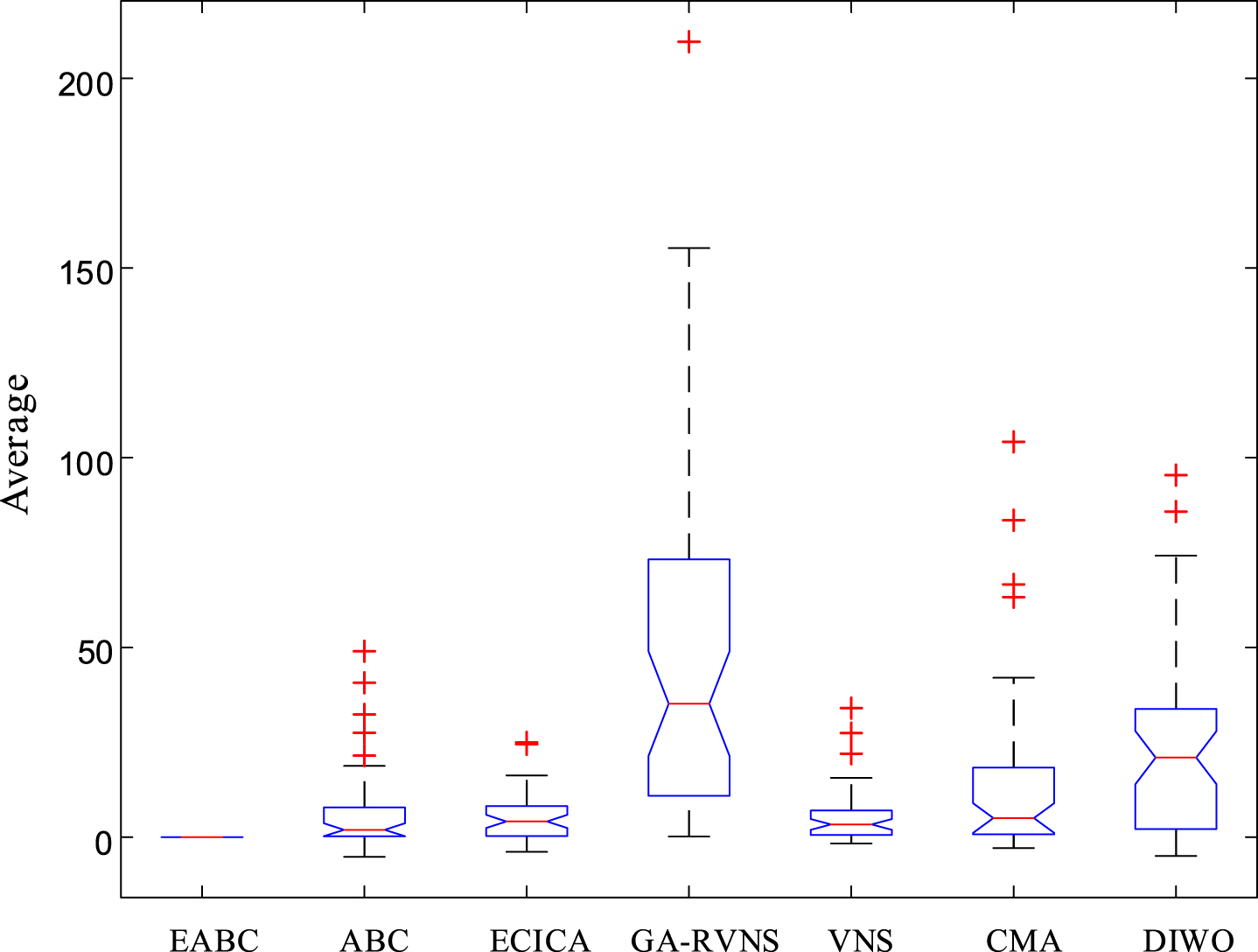
Box plot of all algorithms on Average.
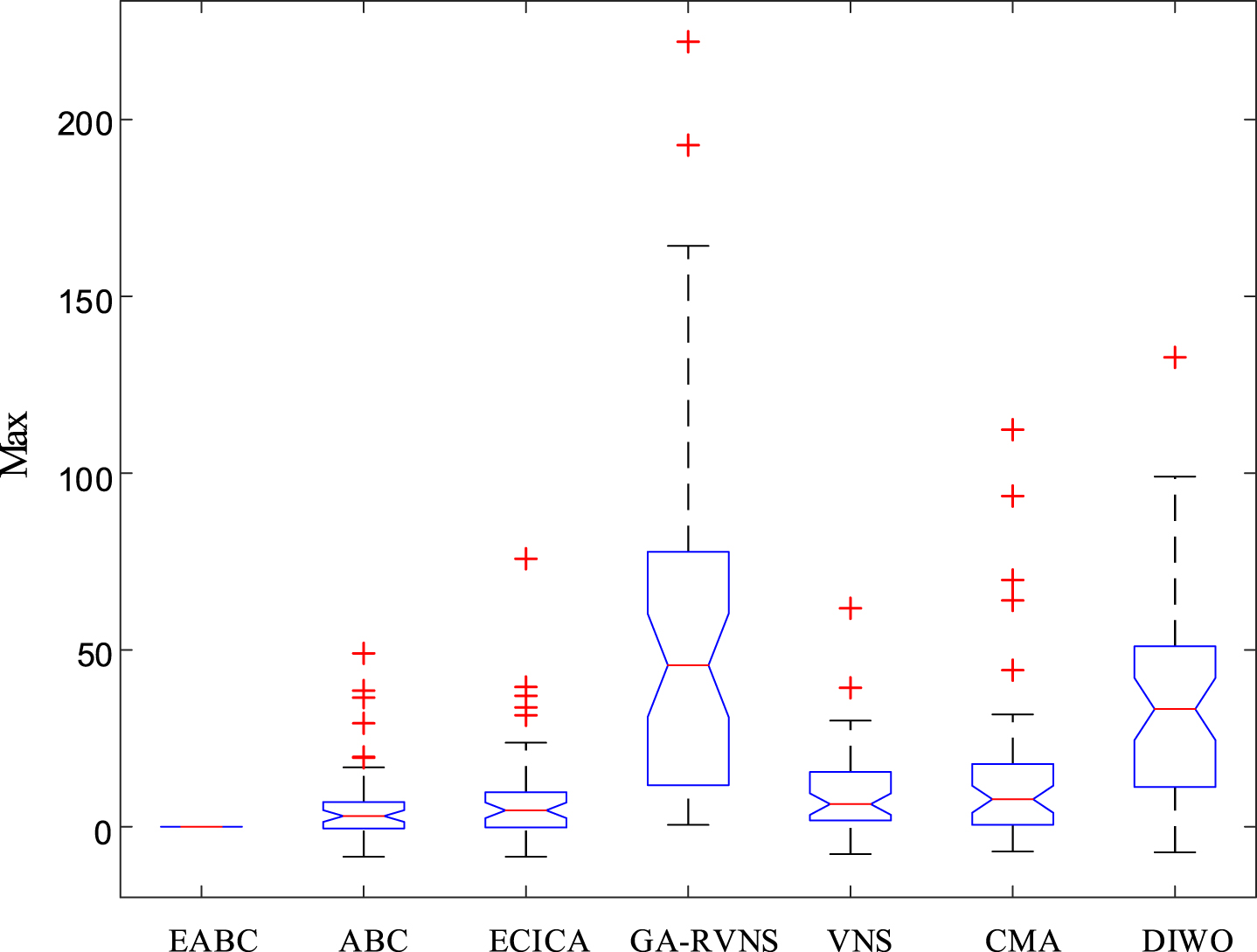
Box plot of all algorithms on Max
As stated in Tables 9–11, EABC generates better results than the comparative algorithms on Min, Average and Max. Min of EABC is less or identical than that of ECICA, GA-RVNS, VNS, CMA and DIWO on 44, 50, 44, 48 and 46 instances, Average of EABC exceeds that of ECICA, GA-RVNS, VNS, CMA and DIWO on 40, 50, 41, 43 and 41 instances, and smaller Max is possessed than that of ECICA, GA-RVNS, VNS, CMA and DIWO on 37, 50, 45, 40 and 44 instances. That’s to say, EABC performs better than the comparative algorithms on over 74% instances. Meanwhile, it is found from Table 8 that there are significant differences between EABC and its comparative algorithms. This conclusion can also be drawn from Figs. 6–8. Thus, EABC outperforms the comparative algorithms on metrics.
The above results and comparative analysis reveal the superior performance of EABC on FDAFSP. The excellent performance mainly depends on the usage of a novel subpopulation division method, diversified search strategies implemented in different search phases, and the adoption of a historical optimization data set. These features can effectively improve search efficiency and make a balance between global search and local search. Thus, EABC exhibits excellent capabilities in solving FDAFSP.
AFSP in a single factory has been well investigated, but the fuzzy AFSP in multi-factories is seldom studied. In this study, a novel algorithm called EABC is put forward to minimize the fuzzy makespan in FDAFSP with DPm → 1. In EABC, an adaptive subpopulation division method depending on the features of the problem is proposed; a competitive employed bee phase and a novel onlooker bee phase are designed based on the diversified combinations of global search and neighborhood search operators. The historical data set and a novel scout bee phase are also utilized. The effective performance of EABC in solving FDAFSP is verified by a series of comparative experiments.
FDAFSP widely exists in modern manufacturing environments. The research of EABC on FDAFSP also reveals some management implications: the selection of the optimal scheduling scheme will guide the managers to make the smartest production decision and achieve the highest production efficiency. However, there are still some limitations in this research. For example, this paper mainly focuses on the design of the optimization method rather than the improvements of the problem model; moreover, some practical constraints and multi-objective optimization problems are not considered in this study, which are more realistic and challenging. Accordingly, the extension of this problem will be our future research topics, such as multi-constraint, multi-objective, energy-related distributed assembly flow shop scheduling problems. Meanwhile, some new strategies can be adopted to improve search quality and efficiency in shop scheduling, such as the dynamic combination of decision makers’ preferences and the reasonable coordination of pre-event, in-event and post-event decisions.
Footnotes
Acknowledgment
This work is supported by the National Natural Science Foundation of China (62176147).