
Abstract
A framework for spatial crowdsourcing task allocation based on centralized differential privacy is proposed for addressing the problem of worker’s location privacy leakage. Firstly, by combining two stages of differential privacy noise addition and clustering matching, a spatial crowdsourcing worker dataset with high differential privacy protection can be obtained; Secondly, the dynamic problem of spatial crowdsourcing task allocation is transformed into a static combinatorial optimization problem by dividing the spatiotemporal units and the “delay matching” strategy; Finally, the improved discrete glowworm swarm optimization algorithm is used to calculate the results of spatial crowdsourcing task allocation. It has been demonstrated that, compared to the direct differential privacy noise-adding assignment method and the discrete glowworm swarm optimization assignment method, the proposed method achieves better task assignment results, with the total travel distance reduced by 12.42% and 3.56%, respectively, and the task assignment success rate increased by 11.75% and 3.34%, respectively.
Keywords
Introduction
With the rapid development of the Internet and intelligent terminal devices, many Location Based Services (LBS) and applications have emerged [1]. These services and applications usually require users to continuously provide the dynamic location and related information, leading to a higher risk of user privacy exposure and posing serious security threats. For example, Strava publishes a heat map of user activities, and web users mine base locations, personal addresses, etc. [2]. The HMM models can identify the most anonymous users in the Gowalla dataset [3]. The literature [4] documents that 15 out of 30 LBS applications [5] leak the user’s location. How to ensure the normal operation efficiency of LBS applications under the premise of improving privacy protection is an important direction faced and researched by the IT and e-commerce industries. As one of the maincategories of LBS applications, spatial crowdsourcing refers to a newly developed type of crowdsourcing in which users publish customized tasks according to their needs. In the platform, the user’s needs are matched with the worker’s skills and location distance, and the worker is arranged to arrive at the specified location to complete the task, such as Meituan takeout and Didi taxi. At present, the task distribution of space crowdsourcing is mainly based on the platform server, users need to upload location and related information when posting tasks, and workers need to dynamically upload real-time location in order to receive orders, while the security performance of the space crowdsourcing platform server is generally not well guaranteed at present.
The most common technique for location privacy preservation is K-anonymity, which achieves indistinguishable K objects by generalization. Even though K-anonymity gives rise to a privacy-preserving method, it lacks rigorous mathematical proof. A worker’s security depends on their background knowledge, and an increase in K results in a longer invisible area, which is significantly prolonged by the server when the information is processed [6, 7]. According to the literature [8], a selection scheme based on maximum-minimum false locations makes it difficult for an attacker to distinguish between filtering false locations and providing privacy protection. Literature [9] achieves privacy protection by fuzzy periods and fuzzy space to encrypt the time and the region where the worker works and protects by increasing the number of regions and the range of periods where the worker submits after completing the task, which increases the spatiotemporal range when the worker completes the task. The location is too fuzzy to be used for assigning tasks. The above method is based on the study of the adversary without the user’s background information. However, these methods fail or decrease their effectiveness when the adversary has the user’s background information. Differential Privacy (DP), proposed by Dwork [10], has rigorous mathematical proof by adding random noise to the original query results, so an attacker cannot recognize the impact of adding or removing a record even if he has some background knowledge. Usually, the original data is first pre-processed with conversion, compression, and other pre-processing before adding noise to release. This method is beneficial to improve data availability. Common methods include clustering, hierarchical tree, Fourier transform, etc., where the accuracy and time complexity of clustering is excellent [11]. In addition to being one of the most widely used clustering algorithms, the k-means algorithm provides high-speed clustering and has a more straightforward implementation. Literature [12] proposed a differential privacy k-means method, but the availability of clustering results is not robust; literature [13] proposed another differential privacy k-means method based on initial centers, using k-means clustering to promote differential privacy, and proved the effectiveness with experiments; literature [14] proposed a differential privacy k-means method that eliminates anomalies and then selects initial centroids according to the data distribution and adds noise, but it has not been proved to be suitable for privacy protection of large-scale datasets; Literature [15] divides tasks by region. Based on the research methods in reference[15], literature [16] improved the traditional method by obtaining initial centroids after dividing the dataset into multiple subsets randomly under the condition of differential privacy protection, but the shortcoming is that the number of subsets of the dataset division is difficult to determine and affects the stability of the results. In addition, literature [17] introduces PPTA which take advantage of only lightweight cryptography (such as additive secret sharing and secure shuffle), is available but has low computational efficiency. Combining k-means with DP can improve the performance of noise addition in applications based on the above analysis.
Task allocation of space crowdsourcing (TSC, Task allocation of space crowdsourcing) is the problem of solving the optimal solution of different combinations of workers and users in the corresponding spatiotemporal range [18, 19]. In recent years, swarm intelligence optimization algorithms have been used as a common algorithm to compute optimal solutions or near-optimal solutions for various combinations of problems such as scheduling and TSP. Common algorithms include the particle swarm algorithm [20, 21], artificial fish swarm algorithm [22], and Glowworm Swarm Optimization Algorithm [23, 24], etc. The particle swarm algorithm has high search efficiency but easily falls into local optimality for higher dimensional data search. The artificial fish swarm algorithm is robust, and the initial parameters do not have much influence, but the convergence speed is slow. The Glowworm Swarm Optimization Algorithm (GSO) is fast and has good search capability in multi-dimensional space. Domestic and foreign scholars optimize the algorithm from initialization, variable step size, discretization, change of movement strategy, and other methods [24–28]. In this paper, we will combine the practical application of spatial crowdsourcing task assignment for effective coding and use the IDGSO algorithm to compute task assignment ground efficiently.
Only a few studies have examined how spatial crowdsourcing can enhance privacy protection through task assignments. Due to the uneven distribution of spatial crowdsourcing spatiotemporal data, it produces results on task assignment results. In particular, noise is added directly to the location information of workers and users before distribution, resulting in low usability of task assignment results. Three main aspects are addressed in this paper to address the existing research deficiencies. When spatial crowdsourcing tasks are assigned, both workers and tasks appear in real-time at any location in space. It is difficult to achieve high allocation efficiency if the real-time allocation is performed. The “delayed matching” [29] strategy can better improve allocation efficiency and benefit. By matching tasks with online workers in a spatiotemporal unit, the dynamic problem of spatial crowdsourcing task allocation is transformed into a static combinatorial optimization problem to achieve a more effective allocation. An application framework of TDPKC (Two-stage differential privacy based on k-means clustering algorithm) for spatial crowdsourcing task assignment based on centralized differential privacy is designed on this basis. It is theoretically proved that the framework is consistent with differential privacy. To fully characterize the spatiotemporal unit data distribution based on workers and tasks, a two-stage differential privacy plus noise approach is combined with cluster matching as part of TDPKC, an application framework for spatial crowdsourcing task assignment based on centralized differential privacy. This will ensure that task assignment results are readily available for the spatial crowdsourcing worker dataset while retaining differential privacy protection. The IGSO algorithm is used to calculate the assignment results for spatial crowdsourcing tasks. The IGSOTSC is consistently effective regardless of the experimental validation on small or larger datasets. Compared with the method of direct differential privacy noise and the allocation method based on the discrete glowworm swarm optimization algorithm, the success rate of task allocation and the travel cost of task allocation is improved under the condition of satisfying the same budget noise of differential privacy.
Task assignment framework for clustered collaborative differential privacy TDPKC
Differential privacy mainly includes two types of differential privacy, localized differential privacy and centralized differential privacy. A trusted server is assumed to exist in the centralized differential privacy model. It is necessary to upload the dynamic trajectory of the worker in real-time since the worker’s location changes in real-time, and the spatial crowdsourcing server is constantly calling the worker’s location for the assignment of tasks. This poses a significant risk to the protection of the worker’s privacy. Users need to upload their real location when using the APP to post tasks to get the corresponding services, and they can protect the real-time location by turning off location sharing after getting the services. Since the spatial locations of users and workers are the same after the meeting, protecting the location privacy of workers means protecting users’ location privacy. Therefore, TDPKC is valuable for protecting the location privacy of both workers and users.
Differential privacy protection based on two phases
As shown in Fig. 1, the specific working steps in this framework are as follows. After obtaining a collection of tasks, the space crowdsourcing server uploads a request to a trusted server using a space-time unit as the space-time unit. The trusted server first extracts the worker dataset based on the corresponding spatiotemporal unit information, clusters it is using the k-means method, and generates different clustering results (K1 set, center-of-mass set C1, cluster N1) by adding differential privacy as noise. The spatial crowdsourcing server synchronously performs clustering analysis on the task set. It matches the clustering results (K2, C2) with the former, selects the matching parameters (K1 best, Cbest), and uploads them to the trusted server. Based on the clustering results corresponding to the parameters, the trusted server performs noise addition, generates snapshots by differential privacy, and transmits the results back to the spatial crowdsourcing server again. Using the improved glowworm swarm optimization, the spatial crowdsourcing server matches task datasets and worker datasets of the same spatiotemporal unit to generate a task assignment scheme.
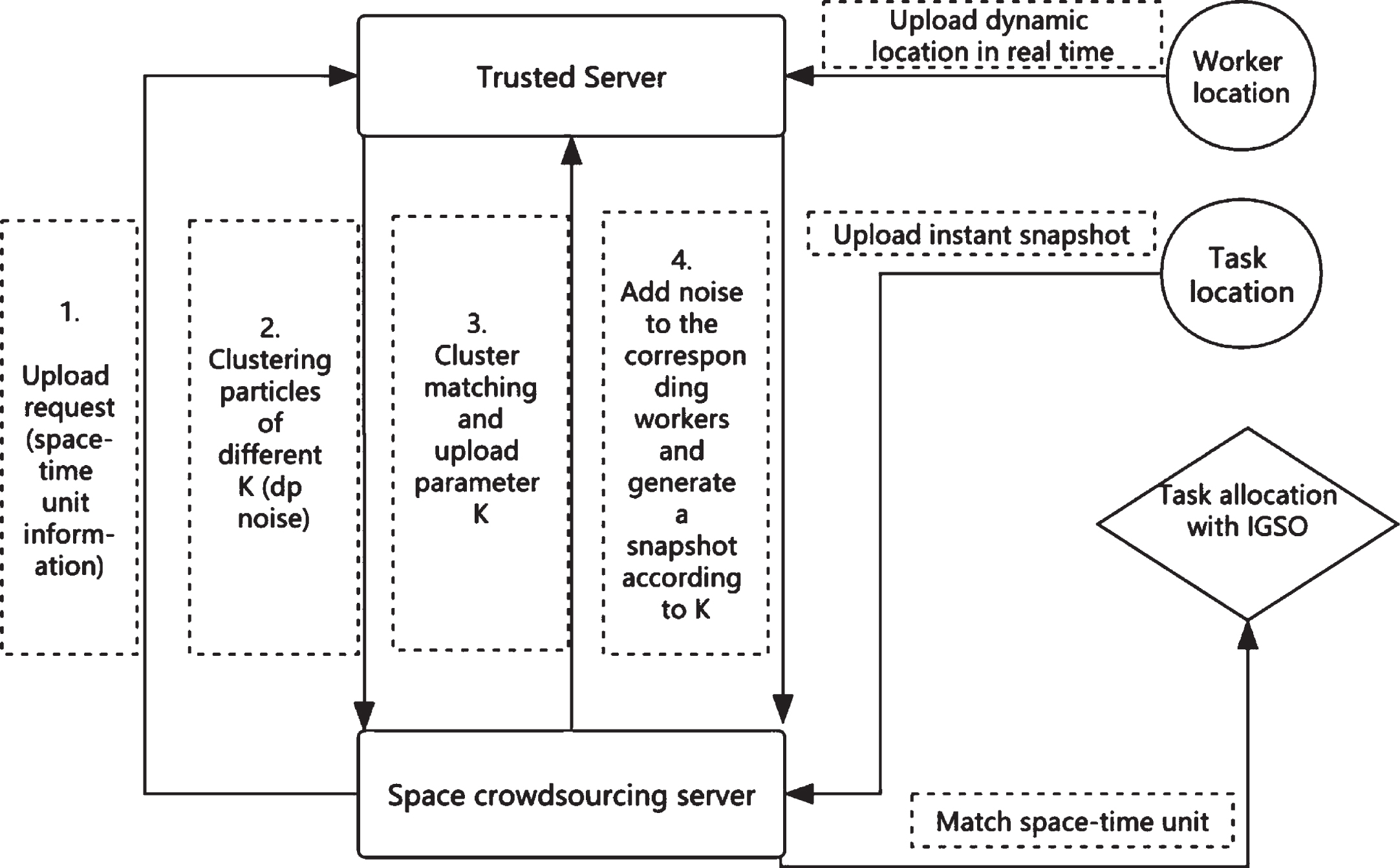
Encryption process of task assignment.
The trusted server passes data to the spatial crowdsourcing server twice at each task assignment. The first time is the clustering result of the set of workers corresponding to the spatiotemporal unit, and the second time is the noise-added location data after the clustering match of the set of workers matching the set of tasks. According to the definition of sequence combination of differential privacy 3, to ensure compliance with differential privacy protection, differential privacy protection shall be performed in both step 2 and step 4, and the privacy budget is the sum of the two times.
When spatial crowdsourcing tasks are allocated, the k-means mean clustering is performed on location data where k clusters are present. Among them, when the cluster is k, the set of centroids obtained by the worker location data clustering is C1, and the number of workers in the corresponding cluster is N1. When the cluster of spatial crowdsourced task location data is k2, the group of centroids obtained by clustering is C2, and the number of tasks of the corresponding cluster is N2. TC represents the matching of clustering results, such as Equation (1), which considers the distance between centroids and the weight of the elements in the corresponding cluster. A smaller TC value indicates a higher degree of matching of clustering results and vice versa.
(1) The basic properties of differential privacy
Differential privacy is specified as defined 1 [30], and the main properties include global sensitivity [31], sequence combinatoriality [31], parallel combinatoriality [32], Laplace noise mechanism [33], exponential noise mechanism [34], etc. In this paper, some of the relevant properties are described as follows.
The Laplace noise mechanism is one of the noise mechanisms for differential privacy, adding random noise to the returned result that conforms to the Laplace function distribution. The Laplace function is Equation (4).
In differential privacy, usually let μ = 0, b = Δf/ɛ, when the function Laplace function is noted as Equation (5).
Lap (Δf/ɛ) is the added Laplace noise, which is proportional to the global sensitivity and inversely proportional to ɛ
(2) TDPKC complies with differential privacy
Let the spatial crowdsourcing dataset LW be
According to the sequence combinatoriality of DP,
Therefore.
Testimonial Bi.
Model definition
The study scenario assumes that the model meets the following preconditions.
(1) workers can receive task allocation only if their online status and location are uploaded to the central server in real-time; (2) workers cannot receive new tasks while they are in the process of completing them; (3) task postings are automatically canceled when they reach the deadline, and the user performs a re-posting as a new task.
The model-related concepts are defined as follows.
Evaluation indicators
Space crowdsourcing task assignments are evaluated based on total travel distance, total waiting time, and success rate [34]. The total travel distance and waiting time are equivalent when the effect of the worker’s speed is not considered. In this paper, total travel distance and the assignment success rate are chosen as evaluation metrics without considering the factor of worker’s speed. The total travel distance measures the total efficiency of the assignment. The smaller the total travel distance, the greater the total allocation efficiency, and the larger the total travel cost, the lower the allocation efficiency. The allocation success rate is usually related to the user waiting time and the expected return of the task. If the posted task reaches the deadline and still no corresponding worker is scheduled, it will lead to order failure.
(1) Glowworm swarm optimization GSO
As the fluorescein of the glowworm corresponds to the target function, the brighter the glowworm is, the stronger the attraction, and the attraction capacity decreases with distance. GSO has a total of stages of fluorescein update, selection of moving direction, position update, and decision domain update, and the specific steps are as follows.
(2) Discrete glowworm swarm optimization DGSO
Based on the coding rules, an initial solution is generated at random, the subscripts of the dimensions indicate the worker numbers, the numbers on the dimensions indicate the user numbers, and the number b on the a th position represents the combination of user b and worker a. Glowworm i and glowworm j use the Hemming distance, and the sum of the distances on each dimension of each glowworm is the actual distance between the two fireflies, as detailed in Equations (14) and (15), where g ∈ [1, m].
(3) Improved glowworm swarm optimization IGSO
In the iteration of the discrete firefly algorithm DGSO, five new mobile strategies (5NMS, five new mobile strategies) are introduced with mutation factor p to improve the optimization efficiency and obtain IGSO. These five moving strategies can ensure that the solution after moving is still feasible, including inner inversion [31] (0 < rand ⩽ 0.2), outer inversion (0.2 < rand ⩽ 0.4), left inversion (0.4 < rand ⩽ 0.6), right inversion (0.6 < rand ⩽ 0.8), and queue jumping (0.8 < rand ⩽ 1). See Table 1 for details.
Glowworm’s mobile strategy
(1) Specific steps
If m workers and n tasks are in a spatiotemporal cell Q (assume m ⩽ n), each assignment forms a combination of
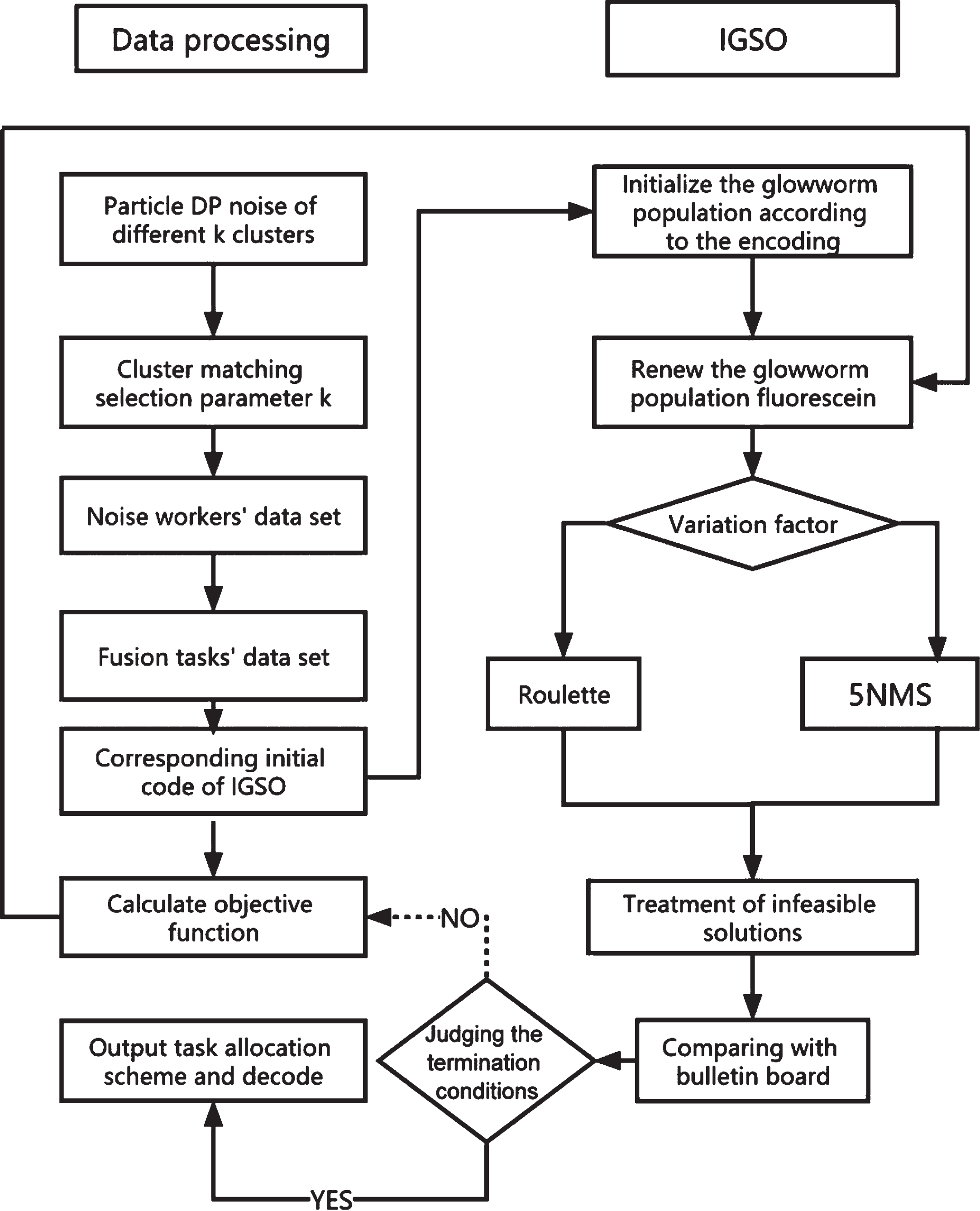
Specific steps of task assignment.
Step 1: Pre-process spatial crowdsourcing data to form the initial dataset for spatial crowdsourcing task assignment by cluster matching, differential privacy noise addition, and fusion of datasets.
Step 2: Initialization of the IGSO algorithm’s parameters, the codes’ initialization, and corresponding task allocation.
Step 3: Constantly updating the glowworm fluorescein by roulette or inverse, reciprocal, and other moving strategies under adaptive factor adjustment and calculating the corresponding objective function.
Step 4: Check and address infeasible solutions.
Step 5: Compare bulletin boards and replace them if they are better than bulletin boards.
Step 6: Output the task assignment scheme and decode it when the number of iterations is reached.
(2) Objective function setting
The objective function is shown in Equation (16), respectively. The total travel distance LUW is as small as possible, and the assignment success rate SUCUW is as large as possible, so the objective function F solves for the minimum value. Where in the objective function, coefficients c1 and c2 separate the two parts of data into uniform measures. I and J
I
denote the set of tasks and the corresponding set of workers assigned to the tasks by the spatial crowdsourcing server.
1) for j = 1 to k
2)
3) end
4) for j = 1 to m
6) LW′ (j) = LW (j) + Lap (Δf/ɛ1)
7) end
1) while t ⩽ tmax do
2) for i = 1 to m
3) if rand <p
4) glowworm (sei) → roulette move
5) else if p <rand < =1
6) glowworm (sei) → 5NMS
7) end if
8) if f (sei) max
9) se max = se i ; Update bulletin board
10) end if
// Decode and generate releases according to se max DT′
11) end for
Experiment and analysis
Experimental environment and data description
The experiments were done in Matlab R2016a with PC parameters: system Windows 7, RAM (8 G), CPU Intel(R) Core(TM) i5-4460 (3.2 GHz). Parameters selection and justification of the IGSO and DGSO algorithms are specified in the literature [26].
The location data were downloaded from the Dataju website (http://dataju.cn) at [35], and the 3000 geolocation coordinates required for the experiment were obtained by removing duplicate location information. Scaled mapping to the interval [0,200], other data were generated by experiment, synthesis, and the specific relevant data and the range of values are shown in Table 1. e denotes the privacy budget, and k represents the number of clustering clusters. The small-scale dataset SD contains 6 scale sub-datasets sd1 sd6, and the larger-scale dataset BD contains a total of 6 scale sub-datasets bd1 bd6. Each dataset contains the spatial location information of workers and users at corresponding times l u , l w .
A total of four methods, OR-DGSOTSC, DP-DGSOTSC, TDPKC-DGSOTSC, and TDPKC-IGSOTSC, are experimentally compared for task assignment performance. A spatial crowdsourcing task assignment using DGSO on the original dataset, differential privacy direct noise addition dataset, and differential privacy two-stage noise addition dataset utilizing k-means clustering is depicted by OR-DGSOTSC, DP-DGSOTSC, and TDPKC-DGSOTSC, respectively. In order to assign spatial crowdsourcing tasks, TDPKC-IGSOTSC utilizes IGSO to cluster differential privacy two-stage noise-added datasets based on k means clustering.
Experiments on small-scale data sets
(1) Total travel distance analysis
Based on the results of the 20 experiments on SD, Fig. 3 shows the average results of the total travel distance. On the six sub-datasets of SD, the total travel distance obtained from TDPKC-DGSOTSC is always smaller than that of DP-DGSOTSC, decreasing by 4.62%, 9.87%, 6.14%, 4.20%, 6.26%, and 4.08%, respectively, indicating that DGSOTSC in TDPKC mode can effectively reduce the total travel distance. On each sub-dataset, the total travel distance calculated by all three methods keeps increasing as the differential privacy budget decreases and the noise increases. Despite an increase in data size for sd1-sd6, the rate of decline in total travel distance does not seem to be significantly correlated with the dataset size because the spatial distribution of the worker and user datasets has randomness. The spatial distribution characteristics affect the worker’s travel distance, which can affect the effect of cluster matching, so the performance of TDPKC-DGSOTSC on SD different-size datasets varies. Still, the average decrease is 5.86% compared with DP-DGSOTSC, so TDPKC-DGSOTSC can get a better task assignment scheme.
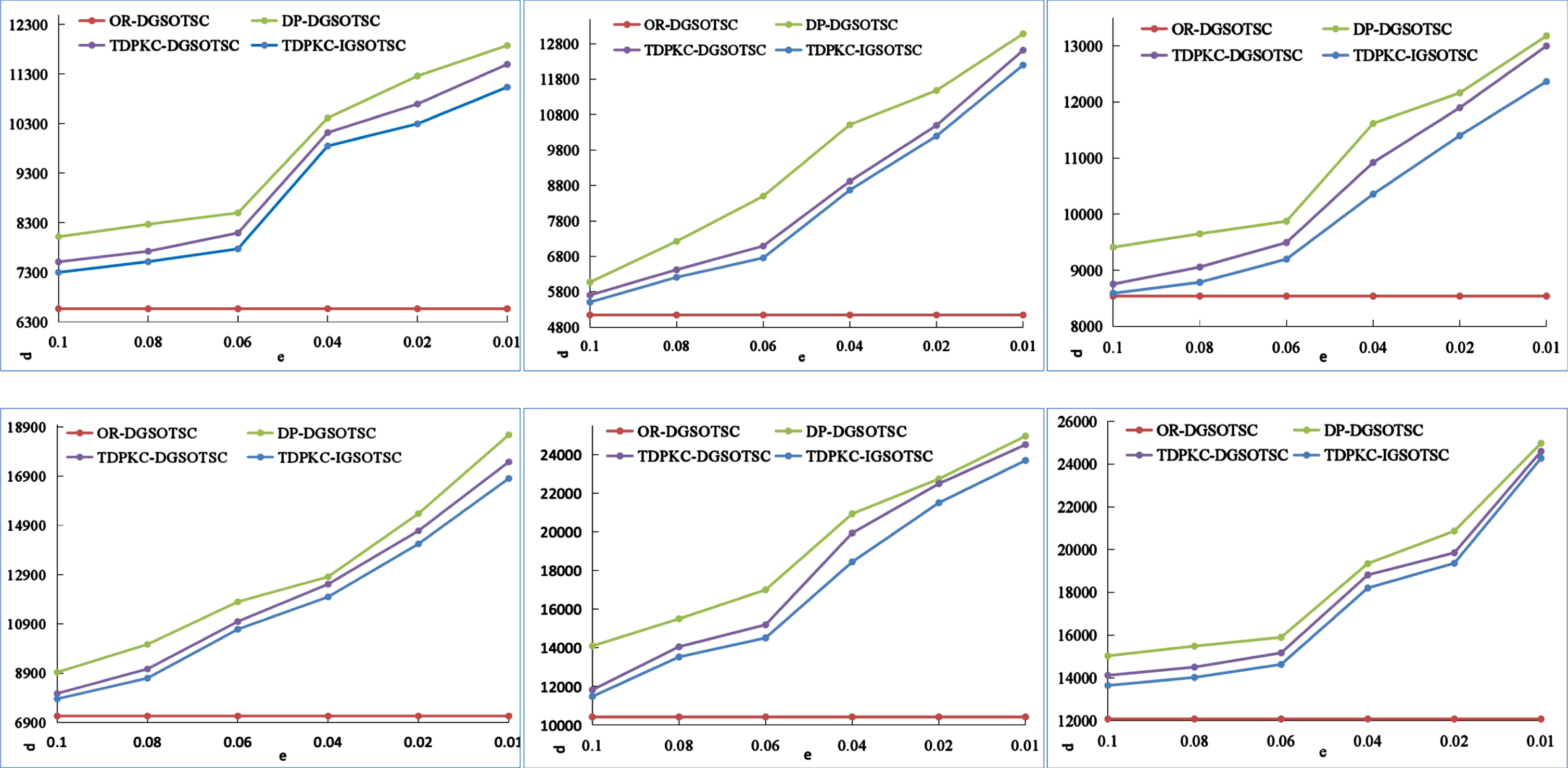
Total travel distance for different methods.
In TDPKC mode, the total travel distance obtained by IGSOTSC is all smaller than that of DGSOTSC, decreasing by 3.36%, 3.35%, 3.61%, 3.84%, 4.49%, and 2.72%, respectively, with an average decrease of 3.56%, indicating that IGSO has a better ability to search for optimal solutions than DGSO, improving the performance of task assignment. TDPKC-IGSOTSC decreases by 12.42% on average compared to DP-DGSOTSC. Combined with the above analysis, TDPKC-IGSOTSC can obtain a better task assignment solution under compliance with differential privacy.
(2) Analysis of distribution success rate
The average results of task assignment success rates obtained from 20 experiments on SD are shown in Fig. 4. On the six sub-datasets of SD, the success rate of TDPKC-DGSOTSC is consistently greater than that of DP-DGSOTSC, increasing by 6.57%, 15.95%, 10.06%, 4.62%, 6.67%, and 6.59%, respectively, indicating that DGSOTSC in TDPKC mode effectively improves the allocation success rate. The success rate calculated by the three methods decreases as the differential privacy budget decreases and the noise increases on each sub-dataset. sd1 sd6 datasets are increasing in size, but the task assignment success rate does not show a significant linear relationship with larger data sizes because the datasets’ spatial distribution is random. Compared with DP-DGSOTSC, the average improvement is 8.41% so TDPKC-DGSOTSC can obtain a better task assignment scheme. With a TDPKC mode assignment success rate of 1.70 percent, 5.27%, 4.16 percent, 2.91%, 3.21%, and 2.82 percent, respectively, IGSOTSC obtains a higher assignment success rate than DGSOTSC. The average improvement is 3.34%, which indicates that IGSO is better at solving search problems than DGSO and performs better on task assignments. TDPKC-IGSOTSC performs better than DP-DGSOTSC on average by 11.75%. Combined with the above analysis, TDPKC-IGSOTSC can obtain a better task assignment scheme under compliance with differential privacy.
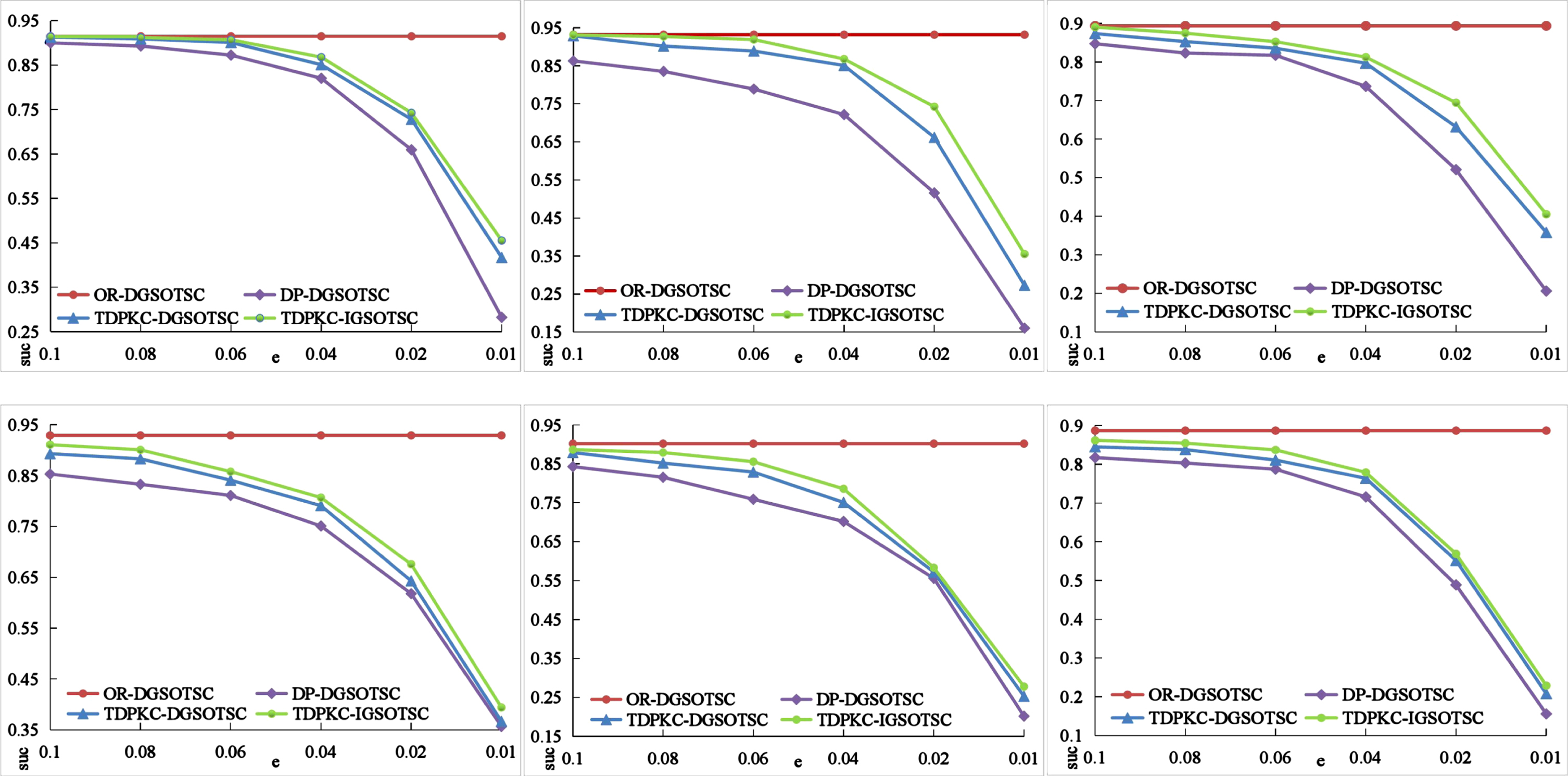
Assignment success rate of different methods.
(3) Parameter analysis
Description of experimental data
Privacy budget e allocation and K are important parameters that affect the TDPKC-IGSOTSC method. The sd3 dataset was selected for 20 experiments to take the average results detailed in Tables 3 and 4. Table 3 shows the average results of the experiments of the two methods when the total privacy budget ɛ = 0.1, and the clustering clusters k = 3. In the TDPKC mode, the total travel distance of IGSOTSC is always more extensive than that of DGSOTSC, indicating that IGSO improves the performance of searching the solution space. As the privacy budget allocated in the first stage decreases, the matching rate of 20 clusters decreases from 100% to 35%, and the total travel distance first decreases and then increases. Although the clustering matching rate decreases, the elevated privacy budget allocated in the second stage improves the accuracy of each spatial crowdsourcing task assignment. The experiments yielded the best solution for task assignment when the first and second-stage privacy budgets ɛ1 = ɛ2 = 0.05.
Total travel distance corresponding to different privacy budgets
Total travel distance corresponding to different K
Table 4 shows the average results of the 20 experiments corresponding to different values of the clustering clusters K when the total privacy budget ɛ = 0.1 and ɛ1 = ɛ2 = 0.05 is taken. As K increases, the total travel distance derived from both methods first decreases and then increases. When k = 3 or k = 4 is used to calculate the task assignment with DGSOTSC, the total travel distance of TDPKC is smaller than DP, and when K takes 1, 2, and 5, the travel distance of TDPKC is larger than DP, proving that TDPKC-DGSOTSC is not always valid. This is related to the parameter K.
In the case that K is too small, clustering and dimensionality reduction cannot be fully exploited, and when K is too large, workers and tasks are decomposed into too many clusters, and the number of wrapped workers and tasks within each cluster is too small. This affects the effectiveness of the first stage of cluster matching as well as the second stage of task assignment for spatial crowdsourcing. At any time K increases, the computation consumes more and more time. In summary, the TDPKC-DGSOTSC calculation results are optimal when the parameter k is taken as 3. The total travel distance of IGSOTSC is always larger than that of DGSOTSC when k takes different values in the TDPKC mode, indicating that IGSO improves the performance of searching the solution space.
When conducting experiments on larger datasets, each dataset is still decomposed into several sub-datasets according to the specifics of spatiotemporal units, and the results are obtained based on cumulative calculations.
Table 5 defines the relevant experiments as the average results of 20 experiments. The experimental results on bd1 bd6 datasets show that the total travel distance calculated by TDPKC-DGSOTSC and TDPKC-IGSOTSC is always between OR-DGSOTSC and DP-DGSOTSC, indicating that the TDPKC-DGSOTSC and TDPKC-IGSOTSC methods are still effective on larger data sets. Additionally, the TDPKC-IGSOTSC results are always better than the TDPKC-DGSOTSC results, which further verifies that IGSO has better performance in finding the optimal solution than DGSO.
Total travel distance for different methods
Total travel distance for different methods
When conducting task assignment experiments for larger datasets, each dataset is decomposed into several sub-datasets according to the specifics of the spatiotemporal unit, and the results are obtained based on the average value. The relevant experiments were taken as the average results of 20 experiments, as detailed in Table 6.
Success rate of different methods
The experimental results on bd1 bd6 datasets show that the task assignment success rates calculated by TDPKC-DGSOTSC and TDPKC-IGSOTSC are always between OR-DGSOTSC and DP-DGSOTSC, which indicates that the TDPKC-DGSOTSC and TDPKC-IGSOTSC methods on larger datasets are still valid. The results of TDPKC-IGSOTSC always outperform the results of TDPKC-DGSOTSC, which further verifies that IGSO has better performance in finding the optimal solution compared with DGSO.
In this paper, using centralized differential privacy protection as a basis for spatial crowdsourcing task allocation, we develop a framework for addressing the issue of worker location privacy leakage in spatial crowdsourcing task allocation. The framework is theoretically consistent with differential privacy and is effective. By dividing spatiotemporal units and applying a “delayed matching” strategy, the dynamic problem of spatial crowdsourcing task assignment is transformed into a static combinatorial optimization problem. We combine two-stage differential privacy noise addition with cluster matching to obtain a dataset of spatial crowdsourcing workers with high usability protected by differential privacy. Using an improved glowworm swarm optimization algorithm, we compute the spatial crowdsourcing task assignment results after noise addition with different methods. Experiments on several datasets show that the results of task assignment obtained by the method in this paper are better compared with the method of direct differential privacy noise addition and the method based on discrete glowworm swarm optimization assignment.This method is based on two-stage centralized differential privacy denoising, which will reduce efficiency when the number of tasks is large. In the next step, we will continue to improve and enhance the performance of the glowworm swarm optimization algorithm, and study task allocation based on localized differential privacy and personalized privacy budget.
Footnotes
Acknowledgments
This work was supported by the Anhui Provincial Natural Science Foundation under Grant (No. 1908085QG298), the National Nature Science Foundation of China under Grant (No. 71521001), and the Open Research Fund Program of Key Laboratory of Process Optimization and Intelligent Decision-making (Hefei University of Technology), Ministry of Education.