
Abstract
In recent years, contrastive learning has been very successful in unsupervised tasks of representation learning and has received a lot of attention in supervised tasks. In supervised tasks, the discrete nature of natural language makes the construction of sample pairs difficult and the models are poorly robust to adversarial samples, so it remains a challenge to make contrastive learning effective for text classification tasks and to guarantee the robustness of the models. This paper presents a contrastive adversarial learning framework built using data augmentation with labeled insertion data. Specifically,By adding perturbation to the word-embedding matrix, adversarial samples are generated as positive examples of contrastive learning, and external semantic information is introduced to construct negative examples. Contrastive learning is used to improve the sensitivity and generalization ability of the model, and adversarial training is used to improve robustness, thereby improving the classification accuracy. In addition, the momentum contrast from unsupervised tasks is also introduced into the text classification task to increase the number of sample pairs. Experimental results on several datasets show that the proposed approach outperforms the baseline comparison approach, and in addition some experiments are conducted to verify the effectiveness of the proposed framework under low-resource conditions.
Introduction
Pre-trained models, such as Bert [1] and Roberta [2] have shown a very important role in natural language processing tasks, such as text classification, machine translation, etc. While well-designed tasks such as (Masked Language Model) MLM and (Next Sentence Prediction) NSP enable pre-trained models to effectively capture semantic features in text, pre-trained models cannot directly learn and provide a good and useful representation of text for downstream tasks, so fine-tuning pre-trained language models with labeled data in downstream training sets is a common approach to build better representations.
Contrastive learning [3] has been shown to be an efficient method for obtaining generic representations for downstream tasks. In short, Contrastive learning is widely used for tasks such as text representation [4–6], employing a loss function that forces samples and their augmented samples closer to each other and keeps different examples away from each other, as a way to learn a good representation space, while in supervised tasks, using contrastive learning allows the model to be more sensitive to semantic changes in the samples. Wang et al. [7] demonstrate that the effectiveness of contrastive learning is actually achieving “alignment” and “uniformity” at the same time. Nowadays, most of the attention is focused on the generation of positive samples, and the construction of effective sample pairs is more conducive to the implementation of contrastive learning. For example, in computer vision there is SimCLR [8], who compared various image processing methods to generate positive samples with success; He et al. [9] proposed the use of a queueing approach to further improve the effectiveness of contrastive learning in unsupervised tasks. As for the field of natural language processing, due to the uniqueness of language, changes in sentences can easily make the semantics of sentences change; Qu [10] et al. compared several methods for data augmentation at the sentence level and found that using paraphrasing could preserve the semantics of sentences to the greatest extent; while Yan [11] et al. proposed adding perturbations to the Word-Embedding layer to further narrow down the changes to semantics; while Gao et al. [4] propose to use the model itself to construct positive examples to make contrastive learning more effective in unsupervised tasks. Therefore how to generate sample pairs is still a major research hotspot. In this work, one of the objectives is to find a way to efficiently construct sample pairs.
Adversarial training was first proposed by Goodfellow [12] in computer vision, and some researchers have extended it to the text domain with good results. Adversarial training improves the robustness of a model by generating perturbations that interfere with the model. In recent years, many people have proposed adversarial training methods such as (Fast Gradient Sign Method) FGSM [12], (Fast Gradient Method) FGM [13], (Free Large-Batch) Freelb [14], (SMoothness-inducing Adversarial Regularization) SMART [15] etc. Although adversarial training has become an important method to improve the robustness of models in text classification tasks, the models after adversarial training lack sensitivity to the semantic changes of sentences.In this work, FGM [13], a simple and efficient adversarial training method, has been used. Our main contributions are as follows. A contrastive adversarial learning framework for text classification tasks is proposed. Perturbations are added to the word-embedding matrix to generate adversarial samples as positive samples, external knowledge is introduced to generate hard negative samples, and momentum contrast is introduced to the text classification task.
Contrastive learning has been shown to have superior performance in unsupervised tasks. In this work, The goal is to find an effective method to generate meaningful positive and negative samples to make the model have good representation, and then use contrastive learning to improve the classification accuracy of the pre-trained model in text classification tasks, Specifically, this study constructs a contrastive adversarial learning framework for the text classification task to obtain a good representation of the text. Also, the use of an adversarial training strategy helps to increase the difficulty of contrastive learning, and finally the sensitivity and generalization of adversarial training are improved using contrastive learning, and the robustness of contrastive learning is improved using adversarial training.
This paper is structured as follows: Section 2 introduces the current research status of text classification, adversarial training, and contrastive learning in recent years; Section 3 discusses the theoretical part of CTAL; Section 4 describes the experimental details and main experimental results in the paper; in Section 5, an ablation experiment is set to verify the effectiveness of CTAL; Section 6 is the conclusion section.
Related works
Text classification
Text classification task is the process of automatically mapping text to one or more pre-given topic categories, mainly including sentiment classification, (Question-Answering) QA, etc. The main goal of text classification tasks is to give a predictive label to the text content, and these tasks include binary classification, ternary classification, etc. The discrete nature of the text itself makes it not easy to extract features from the text. Recently, Transformer-based [16] pre-trained language model Bert has recently achieved better results in various tasks, and some variants of Bert, such as Nezha [17], XlNet [18], Albert [19] etc. these improved Bert-based models achieve high performance mostly from the results of training on a large corpus. Meanwhile, researchers in TextGCN [20] proposed the use of graph convolutional neural networks for text classification; Zhang et al. [21] constructed a hierarchical attention-based framework with a concept-based classifier for each layer; and Hu et al. [22] introduce Prompt Learning, which extends the linguistic expression using external knowledge and performs very well in short text classification tasks. The approach of this paper is to combine adversarial training and contrastive learning to improve the classification accuracy of pre-trained models.
Adversarial sample and adversarial training
In natural language processing, adversarial sample refers to adding an imperceptible perturbation to a sample so that the model recognizes it incorrectly and leads to false predictions. This process of adding a perturbation and making the model predictions incorrect is called adversarial attack, for example, in spam detection, an attacker can evade the detection system by making subtle modifications. Adversarial training (AT) refers to training the network with clean and adversarial samples to resist attacks and improve the robustness of the network, which has been applied to many supervised scenarios, such as target detection [23], image classification [24] etc. Currently, researchers have proposed much adversarial training and adversarial attack approaches. Word-level replacement and sentence-level rewording are typical ways of adversarial sample generation. Goodfellow et al. proposed FGSM [12] to generate adversarial samples, while in FGM [13] in which the adversarial was extended to the textual domain, after which many adversarial training methods were proposed, Chen et al. [14] proposed FreeLB, which reduces the training period while updating the gradient of model parameters; Najibi et al. [25] proposed (Free Adversarial Training) FreeAT, which further accumulates the gradients. In this work, The simpler FGM method is used to generate adversarial perturbations, which are added to the word-embedding matrix to generate adversarial samples, and used with clean examples for contrastive learning, which in turn improves the robustness of the model.
Contrastive learning
Recently, self-supervised contrastive learning has made great progress, and its main idea is to reduce the distance between samples and positive samples and increase the distance between samples and negative samples in order to learn a good semantic representation space that allows the model to recognize similar samples and distinguish different samples. Contrastive learning first appeared in computer vision, and the focus of contrastive learning is to use data augmentation to generate positive samples, which in computer vision is usually done by cropping, color change, etc. Researchers have also extended contrastive learning to the textual domain, and Wang et al. [26] proposed an unsupervised way to construct positive and negative samples, which effectively improves the classification accuracy; meanwhile, SimCSE [4] has made a huge improvement in unsupervised text tasks. On the contrary, the application of contrastive learning in supervised tasks is still rare, and Zhang et al. [27] proposed Dual contrastive learning, which effectively improved the effectiveness of pre-trained models in text classification tasks; Miao et al. [28]and Pan et al. [29] proposed two different adversarial learning framework for supervised tasks, which introduced contrastive learning into adversarial training; Zhang et al. [30] introduced contrastive learning into clustering, which effectively improved the purity of clustering. The key to contrastive learning is how to generate positive pairs, and it is very difficult to generate effective positive pairs in natural language, Qu et al. [10] explored word-level and sentence-level data augmentation and found that the translation approach is better; unlike them, Yan et al. [11] proposed a Word-Embedding layer data enhancement approach, which further reduces the changes to the semantics of utterances; Wang [31] et al. argue that the quality of positive and negative samples has a significant impact on contrastive learning, and therefore propose a method to construct positive samples to offset the intrinsic bias.
In this work, The data augmentation by inserting labels in the data proposed by Yin et al. [32] was used to construct the framework and to perform data augmentation on all samples of the input, not limited to positive samples. The key issue of contrastive learning is how to generate positive and negative samples. Adversarial samples are used as positive samples for contrastive learning, and for some classification tasks, an external knowledge Wordnet lexicon for antonym replacement is introduced to generate hard negative samples for contrastive learning.
Methodology
Sample generation
Goodfellow proposed FGM to generate adversarial samples, and also applied it to (Natural Language Processing) NLP to do adversarial training as a way to improve the robustness of the model, and adversarial training can also be seen as a process to find the best defense parameters. Using the generated adversarial sample as a positive sample for contrastive learning, and the process of generating adversarial samples is as follows: for the training dataset D = {X, Y}, X = (x1, x2, . . . , x n ) is the input sample, Y is the real label corresponding to X, n is the number of samples, the samples are sent to the encoder, and the generated features are denoted h i , and the perturbation generation is achieved by minimizing the cross-entropy loss as follows.
Then for the input data the gradient is
Generation of adversarial perturbations.
Finally, unlike images, the input of text is usually discrete. To use adversarial samples in contrastive learning, the generated perturbation is added to the word-embedding matrix of batch data to generate adversarial samples, as shown in Equation (4).
The final adversarial sample
In addition, most existing work uses data augmentation to generate positive samples for contrastive learning, while little attention has been paid to the generation of negative samples. In this work, Not only introduce adversarial into contrastive learning to improve the robustness of the model, but also lexicalize sentences using Spacy and use external knowledge Wordnet lexicon to generate hard negative samples by antonym substitution of adjectives and verbs etc. in the sentences, and examples of generating hard negative samples are shown in Table 4. For a given sentence, substitute the antonyms “lack”, “accelerate”, and “dishonor” for “features”, “slow”, and “rewarding” to generate hard negative samples that are opposite to the original sample label. These samples are used as negative samples for contrastive learning together with samples in the dataset that are different from the original sample category.
Based on this, a contrastive adversarial learning framework for simultaneously learning sample-sample and sample-category feature information is proposed. First, the sample-sample contrastive learning is performed by using the adversarial samples generated after adding perturbations as positive samples for contrastive learning, and the samples generated by antonym replacement using Wordnet lexicon for some tasks as negative samples for contrastive learning. The contrast loss used is shown in Equation (5).
where N is the number of samples, z i is the original sample; the positive sample z p consists of two parts, one is the adversarial sample generated by z i by adding perturbation, and the other is the sample of the same category as z i in the input sample; z j is the negative sample, also consists of two parts, one is the hard negative sample generated by z i by antonym replacement, and the other is the sample of a different category than z i in the input sample; p is the sample z i and z p of true labels, p i is the index set of positive samples, ∣pi∣ is the cardinality of p i , and τ is the temperature super-parameter. The use of supervised contrastive learning allows using of both the samples of the same batch with the same class as the original samples and the generated adversarial samples as positive samples for contrastive learning, instead of being limited to using only one augmented sample of the original samples as positive samples, to enhance the gain effect of contrastive learning for text classification tasks by increasing the number of positive and negative samples in each training batch.
Data augmentation is to increase the diversity of training samples. Data augmentation is widely used in the image field, such as cropping, rotation, etc., but in NLP due to semantics, etc., slight changes can affect the semantics of sentences, so it is necessary to find a simple and effective way to use data augmentation. The data augmentation methods used are as follows. First, all the labels after randomly disordering are inserted together in front of the data, separated from the data using a separator, and the inserted labeled data are input to the model, for the samples input to the model is equivalent to the augmented samples with label information injected in the feature space.
By using the data augmentation method of inserting labels to build a CTAL framework, on the other hand, it is hoped that the model will have better classification results. For each input sample X i the feature representation z i and its true class θ p , Replace one sample feature in the supervised contrast loss with a category feature, making each input sample as close to its true category as possible, and keeping samples of different categories as far away from that category as possible, and let the samples of different classes are as far away from that category as possible so that the sample-categories contrastive learning is performed, so that the representation learning under the supervised task can be regarded as generating (z i , θ p ), which in turn allows the model to learn a good categorical representation, as shown in Equation (6):
where M is the index set of negative samples, due to the incorporation of momentum contrast and adversarial samples, L θ can not only discriminate the true category of the original samples, but also achieve the purpose of identifying the true category of adversarial samples and hard negative samples, and finally the Argmax result of the input sample X i is output as the prediction result of the model.
Figure 1 illustrates the framework for contrastive adversarial learning, where h is the feature representation of the sample, Class is the feature representation of the category, h
i
is the original sample,

Framework for Contrastive Adversarial Learning (CTAL) + Hard Negative Samples. The dashed box part of the figure shows the hard negative samples for generating semantic inversion using the Wordnet lexicon for antonym replacement.
The cross-entropy loss is used to accurately classify the input samples as well as the adversarial samples. The sample-category loss (L θ) allows the model to learn a good classification representation. The pre-trained encoder generates a linear categorical representation for the input samples, while the encoder clusters all samples with the same categorical representation around it, thus achieving accurate classification of the input samples, The objectives of CTAL are shown in Figure 2. Triangles and inverted triangles are input samples with different categories, circles are categorical representations of input samples, and squares are adversarial samples generated from the original samples (triangles). The large ellipse is the representation space of the encoder output, and the goal of CTAL is to keep the input samples close to their true class and away from samples that are different from their class. In addition, we also want to improve the robustness of the model by closing the distance between the adversarial samples and the input samples, and the model learns directly an encoder that can output a robust semantic representation, even if the input sentence is an adversarial sample, the representation will not be significantly affected.
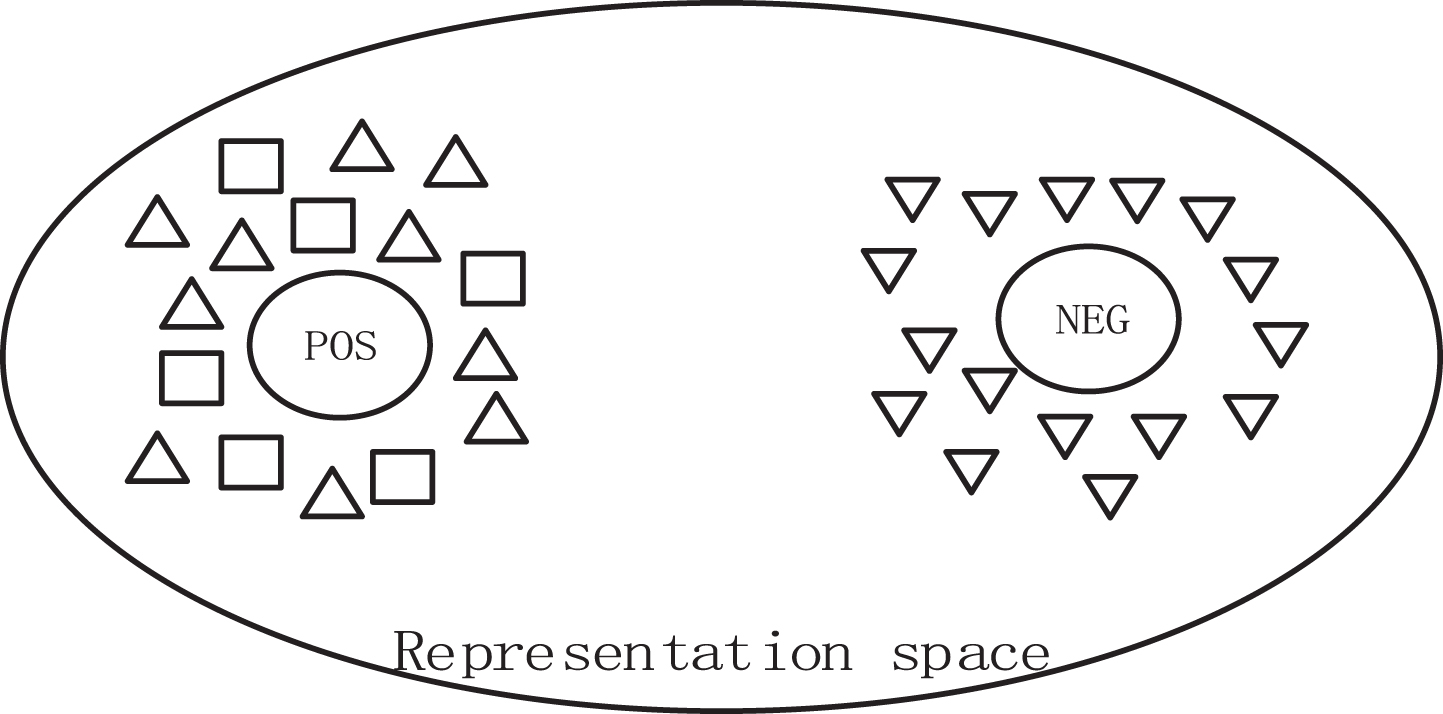
The goal of CTAL is to keep both the adversarial samples and the clean samples in the dataset close to their true classes.
Momentum Contrast is mainly done by maintaining a queue of fixed size to reuse sentence embeddings from the previous training batch, and if the queue is saturated before the current batch of sentences is fed into the model, then the oldest “old” sentences in the queue are deleted one by one and the “new” data into the queue. The purpose of using the queue is to reuse all the samples from the previous batch, and in turn, supervised contrast loss can further increase the number of positive and negative samples in each training batch, encouraging the model to move towards greater refinement. Specifically, we generate sentence embeddings for the samples in the queue using an additional dynamically updated encoder with parameters θ q for the momentum update encoder, θ e for the model encoder, and λ for the update parameter λ ∈ [0, 1). θ q is not involved in back-propagation updates, and update θ q in the following way, as shown in Equation (9).
Datasets
Six tasks were tested in the GLUE benchmark, including textual entailment (RTE), paraphrasing (MRPC), grammatical correctness task (COLA), sentiment analysis (SST-2), question answering/entailment task (QNLI), and question interpretation task (QQP). The statistical information of the six GLUE tasks is summarized as in Table 1.The proposed framework is also evaluated on six data sets.
Summary information of some GLUE test sets
Summary information of some GLUE test sets
IMDB: is a sentiment analysis dataset with the task of predicting the sentiment (positive or negative) of movie reviews.
AG: is a sentence-level classification on four news topics. Includes four categories: world, sports, business and science/technology.
MR: is a dataset of sentence-level sentiment classification of positive and negative movie reviews.
SUBJ: is a comment dataset where sentences are marked as subjective or objective.
CR: A dataset of customer reviews, where each sample is marked as positive or negative.
PC: is a binary sentiment classification dataset, which includes both pros and cons data.
In order to better utilize the existing knowledge of the pre-training model, the official Bert_base and the Roberta_base models were directly used.The Bert_base model consists of a multi-layer bidirectional Transformer encoder, consisting of 12 layers, 768 hidden cells, 12 heads, and a total number of 110M parameters, about 115 million parameters. Roberta_base model provides a larger number of parameters and can be seen as an enhanced version of bert. Use the AdamW [33] optimizer to fine-tune the model, set the weight to 0.01. The specific parameter settings are shown in Table 2.
Hyperparameter setting in this paper
Hyperparameter setting in this paper
This work sets the same parameters with supervised contrastive learning baseline (SCL) [34] and Dual contrastive learning (DUAL) [27] on four datasets and the results are compared as shown in Table 3.The classification accuracy of the model on the test set using 10% and 100% training data is also compared.
Accuracy rates on the test set
Accuracy rates on the test set
As can be seen from the results, better results were achieved on all four data sets. The average improvement of fine-tuning the Bert and Roberta models using the full data is 0.67% and 0.76% relative to using only SCL, and 0.40% and 0.50% relative to DUAL on average. Also, when using only 10% of the data, our method achieved better results, with an average improvement of 0.75% relative to SCL and 0.35% relative to DUAL on the Bert model, and 0.51% relative to SCL and 0.46% relative to DUAL on the Roberta model. We believe this is due to the inclusion of adversarial samples that increase the diversity of the data, and the contrast loss that allows the model to have a good classification representation, which in turn improves the classification accuracy.
In addition, Classification accuracies are also compared on test sets of three datasets (SST-2, AG, PC) after fine-tuning the bert model using three different contrastive adversarial training methods, CTAL(ours), SCAL [28], and (AT+CTR) [29]. The results are shown in Figure 3. From the results, it can be seen that CTAL has achieved good results, which better reflects the advantages of the CTAL method.
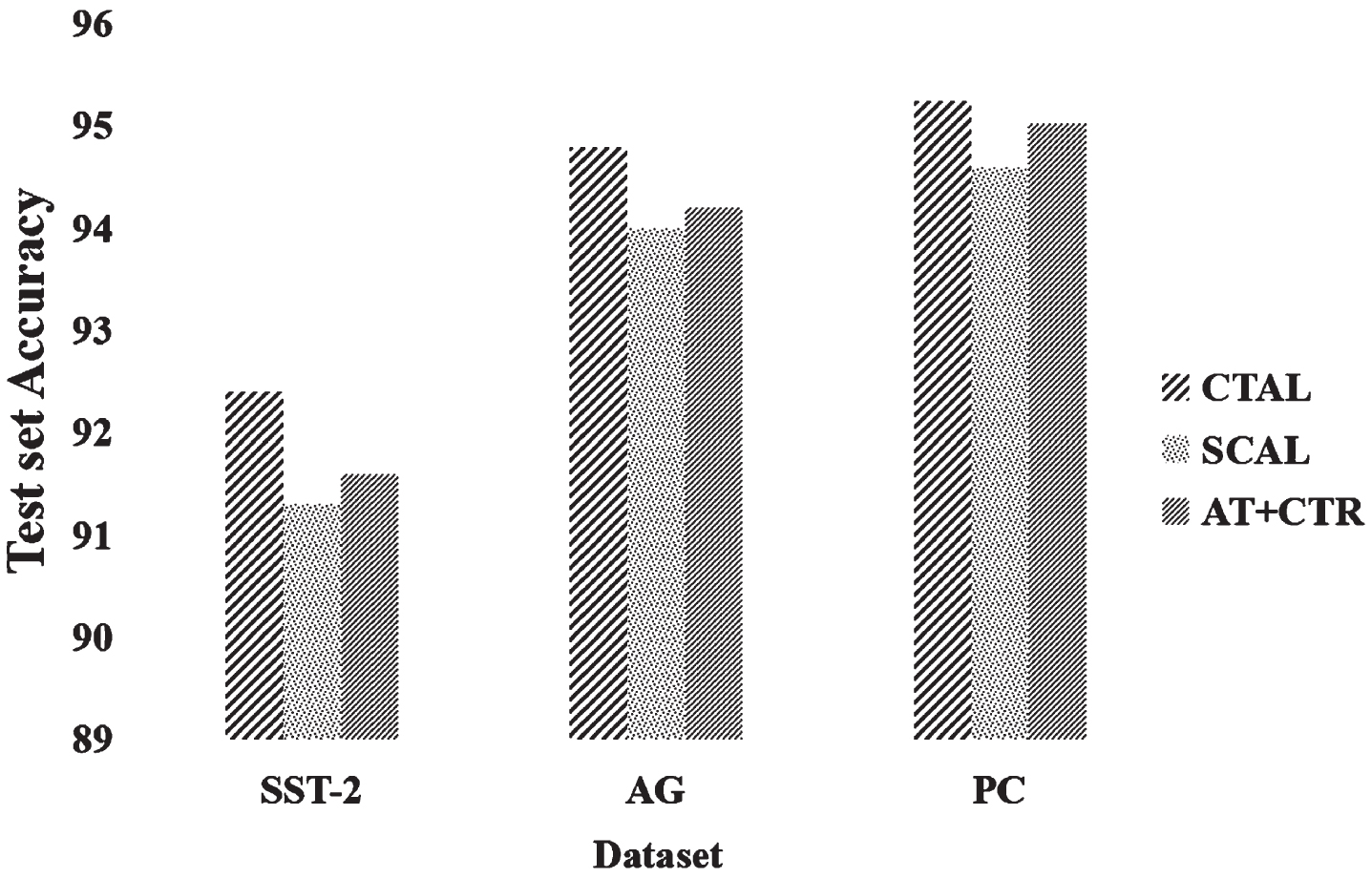
Compare the classification accuracy of CTAL, SCAL, and (AT+CTR) on the test set of the three datasets.
In six GLUE benchmark tasks, CTAL was used to fine-tune the Bert_base and compare it with the Bert_base baseline. In the Bert_base baseline, training sets were used to train for 10 epochs, with all other parameters unchanged. For the QQP dataset, 100,000 data are used to fine-tune the model, the Matthews correlation coefficient (MCC) is used for COLA evaluation, and accuracy (ACC) is used for all others, and the statistical information of the six datasets is shown in Table 1.
Results on the GLUE development set
Results on the GLUE development set
The results of the development set are given in Table 4. Clearly, in the Bert_base model, CTAL shows some improvement on most of the datasets, and for all tasks, the fine-tuned CTAL shows an average improvement of 0.30% compared to the traditional Bert_base model, which further proves the effectiveness of CTAL.
To verify the robustness of CTAL, using three datasets IMDB, SST-2, and MR combined with cross entropy (CE), supervised contrastive learning (SCL),Dual contrastive learning (DUAL), Adversarial Training (FGM), and (CTAL) to fine-tune the Bert_base model, and for the IMDB dataset use ten percent of the data to fine-tune the Bert_base model. Instead of using adversarial attacks to directly attack the model, using TextFooler [35] combined with the Hownet lexicon to generate adversarial samples after fine-tuning the model using the corresponding dataset to test the classification accuracy of the model on the adversarial samples. The word-level adversarial attack method TextFooler first identifies words in the text, filters out the important words, and then replaces the important words with the most similar and grammatically correct words according to priority. Using Textfooler to generate 200 adversarial samples on each of the three datasets for testing the robustness of the model. Examples of the generated adversarial samples are shown in Table 5, and the robustness test results are shown in Table 6.
The results show that the model after fine-tuning using CTAL is relatively better than the model using only cross-entropy loss, supervised contrastive learning, Dual contrastive learning, and adversarial training methods have high robustness and are able to classify most of the adversarial samples correctly.
The original sample in the table is taken from one data in the IMDB dataset; the adversarial sample is generated using the Textfooler adversarial attack algorithm for testing the robustness of the model; the hard negative sample is generated after antonym replacement using the Wordnet lexicon
The original sample in the table is taken from one data in the IMDB dataset; the adversarial sample is generated using the Textfooler adversarial attack algorithm for testing the robustness of the model; the hard negative sample is generated after antonym replacement using the Wordnet lexicon
To further explore the effectiveness of our method in low-resource scenarios, Using N samples from the SST-2 dataset in fine-tuning the Roberta_base model using SCL, DUAL, and CTAL methods to test the accuracy on the full test set. Here, batch_size = 4, epoch = 20, N ∈ {10, 20, 30, 40, 50, 60, 70, 80, 90, 100}, and the rest of the parameters remain unchanged, and the results are shown in Figure 4.
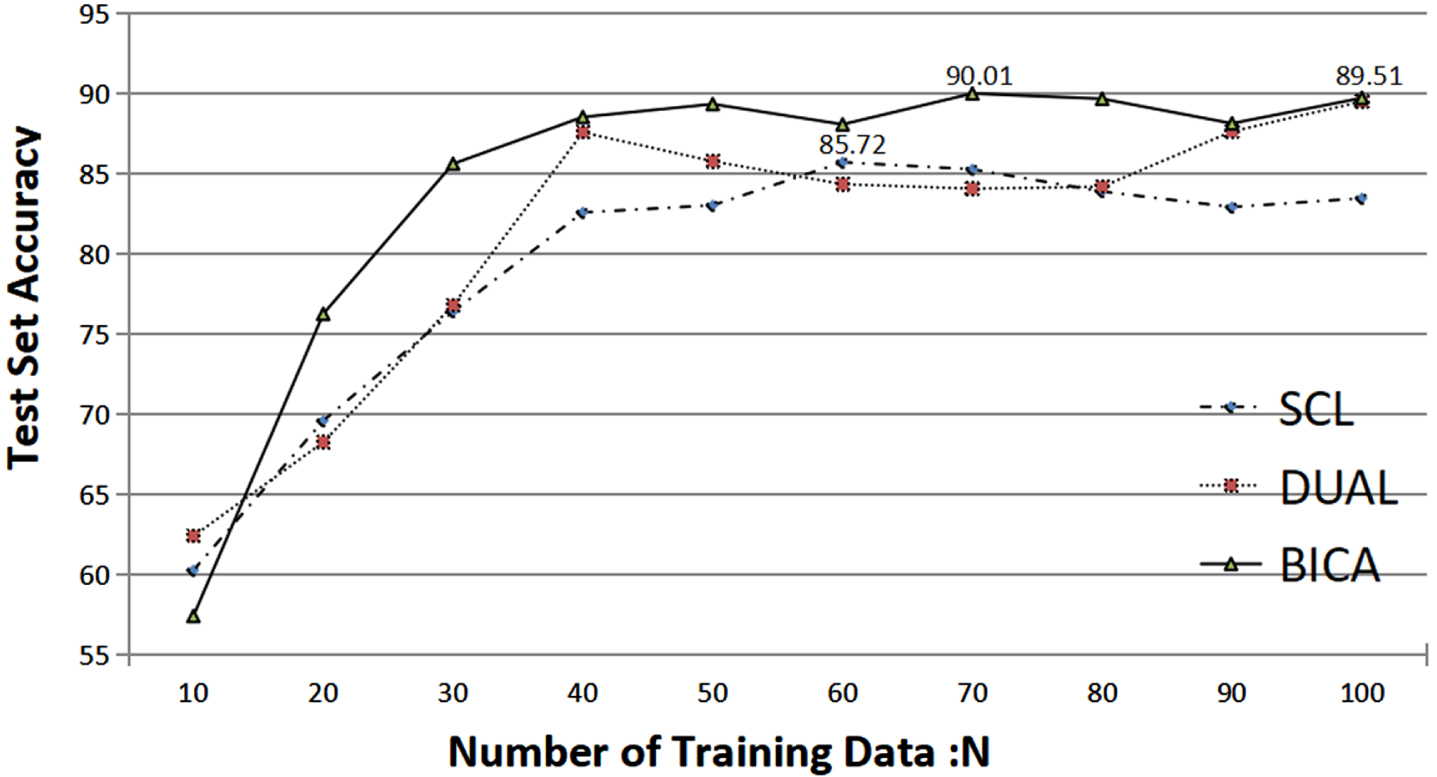
Comparison of SCL, DUAL, and CTAL for fine-tuning the Bert model under low-resource conditions to verify the accuracy (%) on the test set, with the numerical labels in the figure showing the maximum classification accuracy for the whole process.
Accuracy on the set of adversarial samples
As can be seen in Figure 4, CTAL outperforms SCL and DUAL methods for the Roberta_base model with low resources. With only 30 training data, CTAL achieves a 9.23% improvement over SCL and an 8.82% improvement over DUAL, while our method achieves an accuracy of 90.01% with only 70 data, which proves the superiority of CTAL under low-resource conditions.
Effectiveness of CTAL
In this section, experiments are designed to demonstrate the advantages of CTAL over four data sets.The results are shown in Table 7. It can be seen that our method improves 0.91% on average relative to Bert_base using only supervised contrastive learning (SCL) and 1.38% on average relative to the adversarial training (AT) only method, while momentum contrast(MC) also improves 0.43 % on average for classification accuracy, CTAL also has some improvement when using only SCL and AT without momentum contrast, thus demonstrating the effectiveness of CTAL.
Accuracy in the test set. The results are compared after training using the Bert_base model combined with supervised contrastive learning (CL), adversarial training (AT), CTAL without added momentum contrast, and contrastive adversarial learning (CTAL)
Accuracy in the test set. The results are compared after training using the Bert_base model combined with supervised contrastive learning (CL), adversarial training (AT), CTAL without added momentum contrast, and contrastive adversarial learning (CTAL)
In this section, ablation experiments are used to verify the gain effect of adding hard negative samples. The Spacy tool has been used to classify sentences by vocabulary, and a Wordnet lexicon has been introduced to generate hard negative samples by replacing verbs and adjectives in sentences with antonyms. The generated hard negative samples are shown in Table 5.The datasets used in this part are IMDB, AG, and MR, and the comparison baseline is cross-entropy loss (CE), and the results are shown in Table 8.
Accuracy rates on the test set. Demonstrate the effectiveness of adding hard negative samples
Accuracy rates on the test set. Demonstrate the effectiveness of adding hard negative samples
From the results, it can be seen that increasing hard-negative samples can increase the amount of data, encourage the development of models in a more refined direction, improve sensitivity to small semantic changes, and thereby improve classification accuracy.
The impact of different ways of generating disturbances on training results is discussed, including the use of cross-entropy loss, the improved cross-entropy loss D-CE generation perturbation mentioned in DUAL [27]added to the word-embedding matrix to generate adversarial samples for contrastive learning, and the results are shown in Table 9. In the Bert_base and Roberta_base models, better results were achieved using the original cross-entropy loss, so the traditional cross-entropy loss was used in this study to generate perturbations to generate adversarial samples.
Generating perturbation fine-tuning models using different cross-entropy losses and comparing the accuracy of the models in the SST2, CR test sets
Generating perturbation fine-tuning models using different cross-entropy losses and comparing the accuracy of the models in the SST2, CR test sets
The queue size in the momentum contrast directly affects the size of the loss function, so the Bert_base model was fine-tuned using the SUBJ dataset without considering the time cost, and the classification accuracy was verified for the SUBJ test set with different queue_size and batch_size under the same conditions of other parameters, as shown in Table 10.
Accuracy on the test set. Effect of momentum contrast queue size on the SUBJ test set
Accuracy on the test set. Effect of momentum contrast queue size on the SUBJ test set
It can be seen that with the same parameter settings, the classification accuracy reaches the highest when batch_size=32 and queue_size=1.0*batch_size, while it gradually decreases when the queue_size continues to increase. For this result, we believe that using supervised contrastive learning in text classification tasks and introducing momentum contrast as a way to increase the number of positive and negative samples will motivate the model to learn more information in each training batch. However, too large queues can further increase the loss and training time. Therefore, a larger queue is not necessarily better. And in this paper, due to the large average number of words in the data of some datasets, and considering the time cost for other reasons, we set batch_size=16 and take the queue size as 1.5*batch_size.
To verify whether CTAL can effectively identify semantic changes and accurately recognize important information in the sentences, the [CLS] token and the attention score of each word in the sentence were first calculated. We fine-tuned the Roberta_base model using the IMDB dataset beforehand, and then validated it with the example sentences in Table 4, and the results are shown in Figure 5. From the results, it can be seen that CTAL pays more attention to words such as “rewarding” “features” that express positive emotion in the sentence. In contrast, the cross-entropy loss (CE) does not pay much attention to this information. It can be demonstrated that CTAL and the addition of hard negative samples allow the model to detect small semantic changes and focus on critical information with a higher degree of attention.
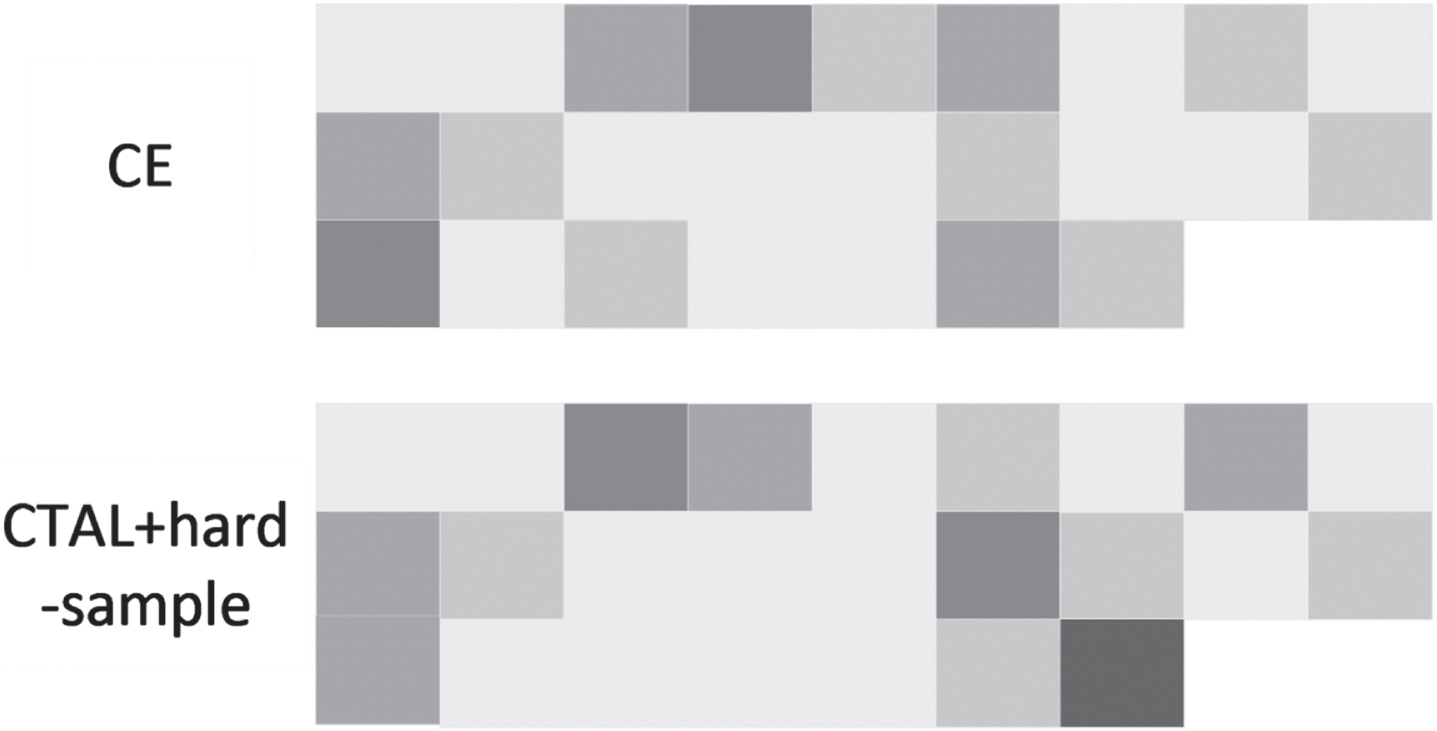
Attention map visualization for CE and CTAL. The darker parts represent higher attention scores.
In this work, a simple text classification task based on a contrastive adversarial learning framework is proposed. Specifically first the framework is constructed using a data augmentation method with inserted labels, adding perturbation to the word-embedding matrix using adversarial training, generating adversarial samples as positive examples for contrastive learning, and performing antonym replacement on clean samples to generate hard negative samples to improve the accuracy and robustness of the pre-trained model in the text classification task through adversarial training and contrastive learning. In addition, to further improve the gaining effect of supervised contrastive learning on the model,momentum contrast is introduced to reuse the training data from the previous batch. It is experimentally demonstrated that using CTAL improves the accuracy of the pre-trained model in the text classification task and makes the model robust.
We believe that contrastive adversarial learning is always beneficial to enhance the robustness and generalization of the model, so we will continue to investigate the use of knowledge graphs to generate adversarial samples and complement sentence-level contrastive learning in order to extend our approach to more natural language processing tasks.
Footnotes
Acknowledgments
This work was supported by the Natural Science Foundation of China under Grant 61562065 and the Inner Mongolia Natural Science Foundation Project under Grant 2019MS06001.