
Abstract
Traditional collaborative filtering algorithms use user history rating information to predict movie ratings Other information, such as plot and director, which could provide potential connections are not fully mined. To address this issue, a collaborative filtering recommendation algorithm named a movie recommendation method based on knowledge graph and time series is proposed, in which the knowledge graph and time series features are effectively integrated. Firstly, the knowledge graph gains a deep relationship between users and movies. Secondly, the time series could extract user features and then calculates user similarity. Finally, collaborative filtering of ratings can calculate the user similarity and predicts ratings more precisely by utilizing the first two phases’ outcomes. The experiment results show that the A Movie Recommendation Method Fusing Knowledge Graph and Time Series can reduce the MAE and RMSE of user-based collaborative filtering and Item-based collaborative filtering by 0.06,0.1 and 0.07,0.09 respectively, and also enhance the interpretability of the model.
Introduction
Recommendation System(RS) [1, 2] can quickly and accurately recommend items of interest to users in massive amounts of data. RS has been widely applied in various fields [3–6]: e-commerce, music, books, movies, news, etc. Through the recommendation algorithm [7], the sales volume, click rate, etc. have been increased. In common, RS is a method for analyzing user interests based on users’ historical behavior and making personalized recommendations for users.RS is mainly divided into a collaborative filtering algorithm, content-based filtering algorithm, and hybrid recommendation algorithm [8–10]. Among them, the recommendation algorithm based on collaborative filtering is the most widely used. The collaborative filtering algorithm analyzes the historical ratings of items by users to make personalized recommendations for users. But at the same time, collaborative filtering algorithms also have many deficiencies, such as cold start and low recommendation accuracy due to data sparseness. Cold start means that when a new item is added to the recommendation system, how to recommend items for such users because the user has not yet produced historical behavior? Some researchers [11] use users’ historical behavior to calculate similar items of historical items, or similar users, predict which items users may be interested in, and make recommendations. Data sparseness means that there are few user rating data, and the large rating matrix leads to high time complexity. How to make recommendations for such users? Some researchers [12, 13] use the method of probability matrix decomposition to make up for the problem of insufficient information. Compared with the collaborative filtering method, both have been improved.
As deep learning [14–16] has made significant progress in the fields of image processing, natural language understanding, and speech recognition, it has become a popular tool in the field of intelligent information processing, and it also brings opportunities for recommendation systems. With the help of deep learning, on the one hand, user historical data can be used to mine deeper features and improve recommendation performance; on the other hand, it can reduce the time consumption of manually constructing features.
Another defect of collaborative filtering is that it cannot deeply mine the characteristics of users and items, and it does not consider that users’ interests will change over time. Deep learning model Long Short Term Memory (LSTM) is a model that can learn and predict long-term series data. LSTM can deeply mine the characteristics of user interests over time. Some researchers [17–19] these papers use LSTM for in-depth exploration in the field of recommendation systems, such as learning path recommendation, energy management, news recommendation, and movie classification. The use of deep learning technologies such as LSTM can effectively solve the modeling problem of sequential data (such as the historical behavior records of users on items) and improve the recommendation effect.LSTM can solve the deep mining of time series features, but there is no deep mining of hidden relationships between users and users, between users and items, and between items and items.
In recent years, Knowledge Graph (KG) has made great progress in the fields of intelligent dialogue and natural language processing [20, 21]. KG adopts the representation method of triples, that is,
At the same time, recommendation systems based on knowledge graph [22] have also received extensive attention. KG can express the relationship between entities in a structured and formal way, improve the cold start and data sparse problems in the recommendation method based on collaborative filtering, and improve the recommendation accuracy.
To improve the accuracy of movie recommendation methods, we design a Movie Recommendation Method Fusing Knowledge Graph and Time Series. The main contributions of this paper are as follows: Construct a triple knowledge graph with three relations of user-rating-movie, user-plot-movie, and user-director-movie. The triples are encoded by a graph embedding model (transH), and the encoded triples are used as the input of a long short-term memory network (LSTM), through the LSTM, the user feature vector is obtained and the similarity between users is calculated. The user-rating matrix is constructed by using the user’s historical behavior data and the user similarity is calculated. The similarity is used as the input of collaborative filtering and the score is predicted.
The experimental results show that the recommendation algorithm integrating knowledge graph and time series features for scoring prediction improves the prediction accuracy and makes the recommendation results interpretable.
Our major contributions are summarized as follows: We constructed the knowledge graph of the three relations of user-rating-movie, user-plot-movie, and user-director-movie, and used transH to encode the semantic relationship of the triplet, learning more users and movies. semantic relationship. We encode the knowledge graph through LSTM to learn the time-series-based semantic features of users, and calculate the similarity between users with time-series features. We combine similarity with time-series semantic features with a user-based collaborative filtering method for the recommendation.
Related work
Knowledge graph
Knowledge Graph (KG) [23] is a semantic network composed of entities and relations, which contains a large amount of semantic knowledge. It is mainly constructed in the form of triples and searches for relationships based on the knowledge graph to obtain hidden relationships. The triples [24] are represented by the relationship as follows {(
Taking movie data as an example, extract the knowledge graph, as shown in Fig. 1, and make recommendations based on the historical behavior records of users Alice and William. First, organize entities and relationships from the original data, and then use the knowledge graph to display various entities and relationships in the data to obtain the relationship between users and movies such as (Alice, Adventure and Cloud Map). (Alice, Howard, The Da Vinci Code) represent (user-plot-movie) and (user-director-movie) respectively. Recommendation algorithm based on knowledge graph mainly use the triple information of knowledge graph to train the intrinsic relationship between users and movies, provide users with more accurate recommendation results, and at the same time make the recommendation results interpretable.

Movie relationship based on knowledge graph.
In recent years, knowledge representation learning based on knowledge graph has attracted people’s attention, mainly including distance-based models, translation models, and neural network models [25], The knowledge graph represented by the translation model has become one of the research hotspots, including the TransE model, the TransH model and the TransD model [26] and so on.
The triples in the knowledge graph are usually represented by (

TransE model.
The same entity encoding is the same in the TransE algorithm, so it is impossible to solve the encoding of one-to-many or many-to-many models. To solve this problem, Wang [28] et al. proposed the TransH model in 2014, as shown in Fig. 3:

TransH model.
As shown in Fig. 3, TransH defines a hyperplane and a relation vector
Among them,
TransH can encode the entities and relations in the knowledge map into low-dimensional distributed vectors, which is convenient for calculation and reasoning.
In this paper, the loss values of TransE, TransR and TransH are compared, and TransH with the lowest loss value is selected to encode the knowledge map triplet. This is described in detail in the experimental section that follows.
In the neural network, each input is an independent node, and the previous input is unrelated to the next input. However, when dealing with some tasks with sequence information, the input information has a sequence relationship, and this traditional network cannot handle it. To solve this problem, researchers proposed a Long Short Term Memory (LSTM) deep learning network structure [29].
LSTM is a special kind of RNN, but there are four states inside each recurrent structure (aka cell) of LSTM. In addition, in some tasks, only a short period of historical information is needed to obtain better output, and too much historical information will cause noise interference. For such cases, the LSTM recurrent structure can maintain a cell state. In contrast to an RNN, LSTM can decide what information to discard and pass down. The internal structure of LSTM is shown in Fig. 4:

LSTM internal structure diagram.
Since users watch movies in chronological order, this paper processes the movies watched by users into data with time-series features. LSTM is suitable for ordered data, mining the time-series information in the data and extracting user features.
User-based collaborative filtering algorithm (UserCF) [30] mainly considers the degree of correlation between users and users, and recommends users with similar hobbies to users or products that users may like to them.
The calculation of similarity mainly includes cosine similarity and Jaccard similarity. This paper uses cosine similarity to calculate student similarity. As shown in formula (2), (3):
Among them,
Among them,
Construction of knowledge graph
This paper solves the MovieLens dataset. The dataset contains two entities, user and movie, by cleaning the data, and taking movie category, user rating and director as the relationship between entities, three triples of user-rating-movie, user-plot-movie and user-director-movie are established, and the triples are represented as knowledge graphs. The knowledge graph based on the user-rate-movie triple is shown in Fig. 6, the knowledge graph based on the user-plot-movie triple is shown in Fig. 6, and the knowledge graph based on the user-direct-movie triple is shown in Fig. 7 shows:
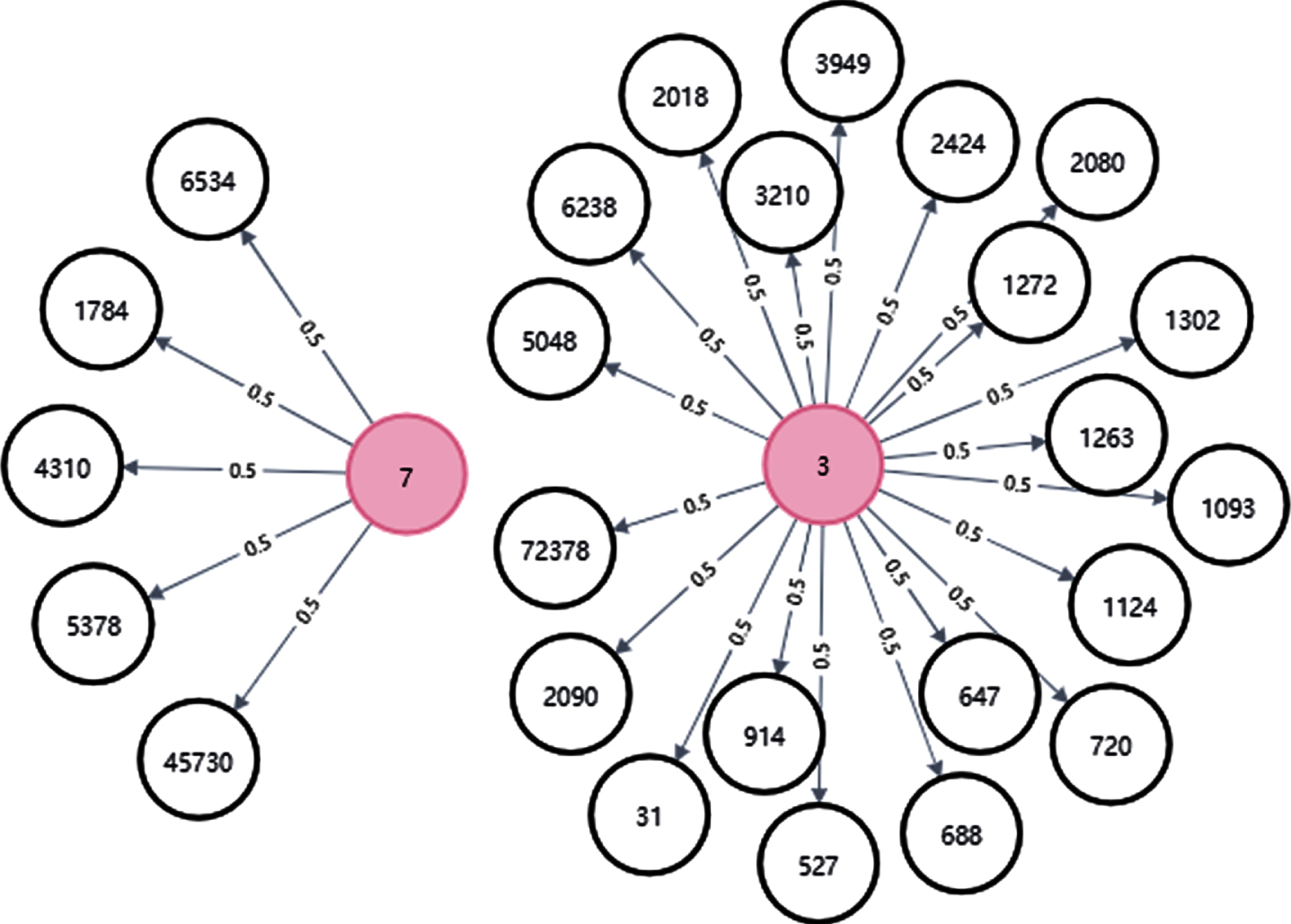
User-rate-movie.

User-plot-movie.
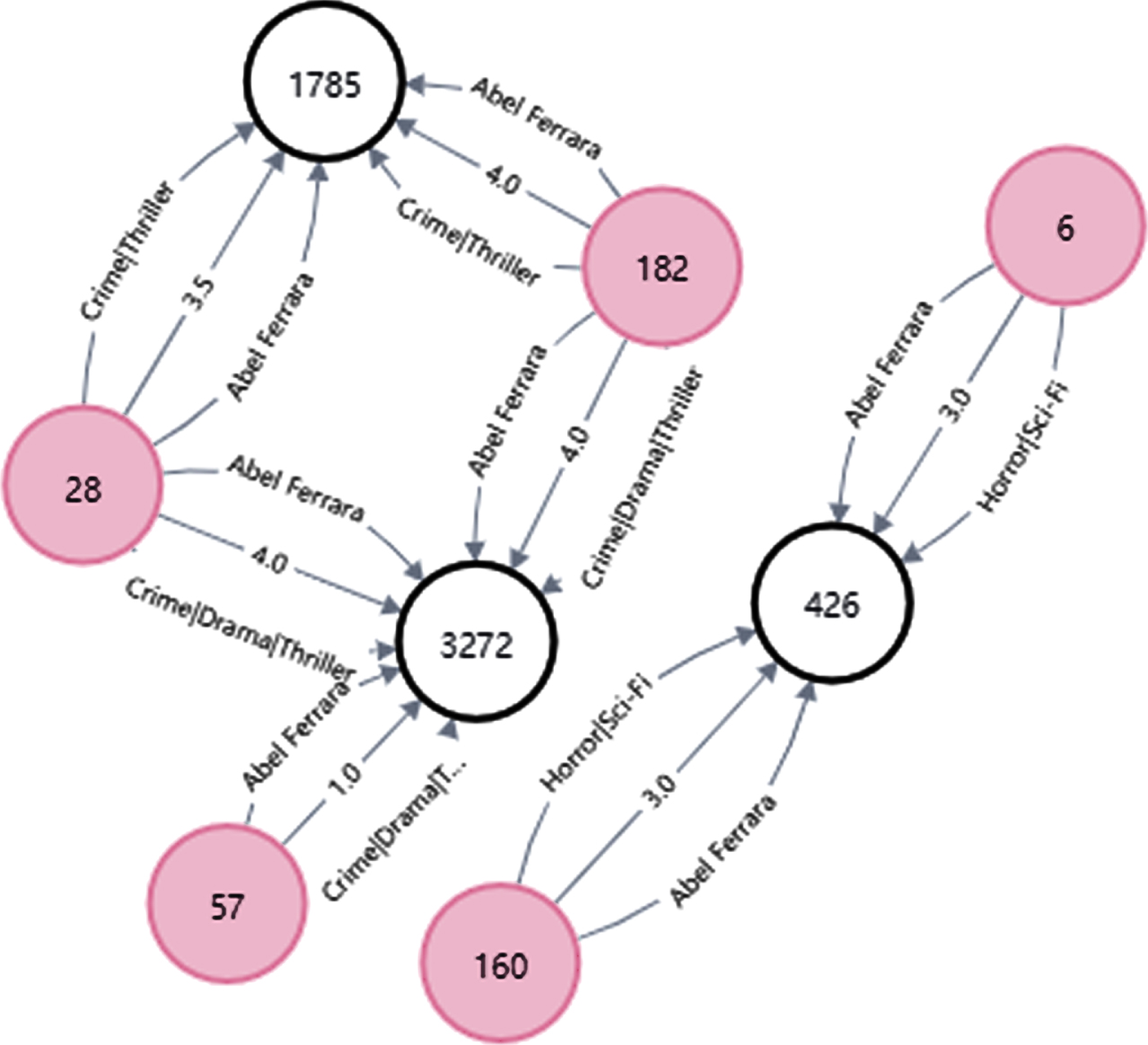
User-direct-movie.
Among them, white circles are movies, dark circles are users, and edges are relationships between entities.
Use user-rate-movie to calculate the similarity between users, find the most similar N users for each user, then predict the ratings of the movies that the target user has not watched, and recommend the highest-rated movies to the user. According to formulas (2) and (3), the similarity between users is calculated and the union is obtained, and the top N users with the highest similarity are selected as the most similar user set of the target user, and then the movie ratings that the target user has not seen are predicted. The calculation formula is shown in formula (4).
Among them, Pu,i is the predicted score of user
The recommendation method integrating knowledge graph and time series features calculates the similarity of users in two parts. First, the knowledge graph is constructed and encoded with transH. The data of users watching movies are time series, the encoded triples are put into LSTM to obtain the user feature vector and calculate the user similarity, and then use the user-based collaborative filtering algorithm to calculate the similarity of users. Take the union of degrees, make rating predictions and recommend. The algorithm frame diagram is shown in Fig. 8.

Model frame diagram.
Dataset
The experiment uses the MovieLens 100k dataset [31], which includes users, movies, movie ratings, movie genres, and directors. The movie rating value is between 0.5 and 5. The size of the rating value indicates the user’s degree of liking for the movie, and the score is positively correlated with the degree of liking. Movie plots are divided into 18 types, such as action, romance and comedy and so on. The dataset is shown in Table 1.
Details of the datasets used for evaluation
Details of the datasets used for evaluation
Data preprocessing includes the following steps.
Step 1: Manually encode users and movies. Uniquely identify users and movies with numbers.
Step 2: Code the director. Each film may have more than one director. For films with multiple directors, encode all directors as a whole.
Step 3: There are 18 kinds of plots corresponding to movies, and each movie has more than one plot. For movies with multiple plots, all plots are regarded as one type of overall coding.
Step 4: Arrange all the codes in Step 1, 2, and 3 into triples, which are user-rate-movie, user-plot-movie, and user-direct-movie triplet.
In this paper, root mean square error (RMSE) and mean absolute deviation (MAE) [32] are used as evaluation indicators in this experiment. If the values of MAE and RMSE are smaller, the error is smaller, that is, the accuracy of the prediction is higher.
RMSE is defined as formula (5):
In formulas (5) and (6),
The experiment is divided into three parts. In the first part, compare the three models of TransE, TransH, and TransR, observe which one has the best effect through the loss value, and make a choice. The second part is to train the parameter learning rate (LR) in LSTM, and select the optimal parameters for experiments. In the third part, collaborative filtering (KG-LSTM-UserCF) that combines the knowledge map and LSTM is used for score prediction.
(1) The graph of loss result of the experimental dataset trained in three Trans models: TransE, TransH and TransR encoding, as shown in Fig. 9:
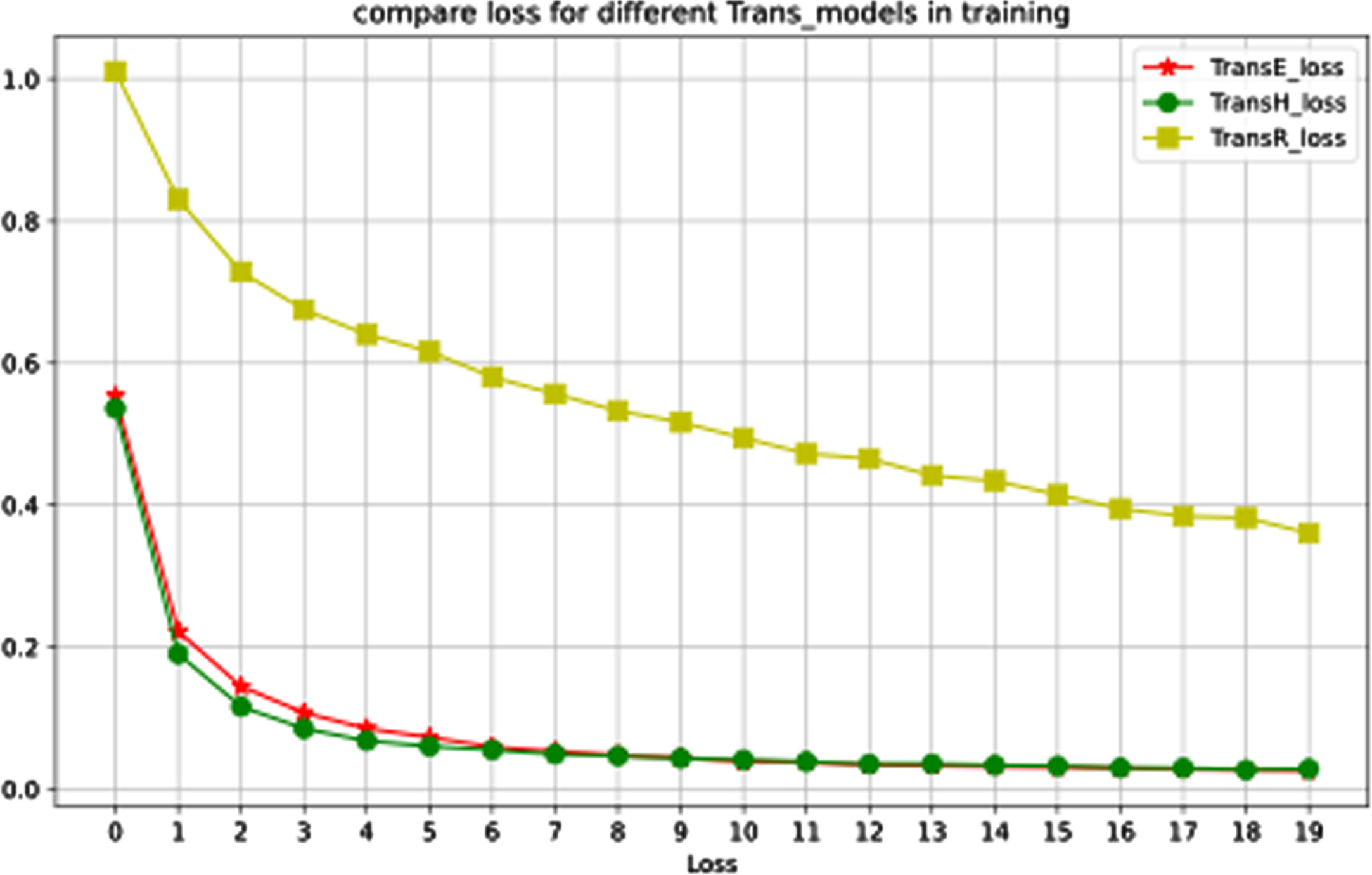
Loss comparison of Train_models.
It can be seen from Fig. 9 that the loss value of TransH is the smallest, so this paper uses TransH to encode triples.
(2) The value of the learning rate (LR) in the training LSTM, when the fixed dropout is 0.5 and the batch_size is 100, the parameter when the training effect is optimal. The training results are shown in Fig. 10:

The training process of the learning rate.
It can be clearly seen from Fig. 10 that when the learning rate is selected as 0.13, the error value is the smallest, so the value of LR in the experiment is 0.13.
(3) The data set is randomly divided into training dataset and test dataset according to 8 : 2 for 5-cross-validation, by comparing the values of MAE and RMSE of the four algorithms mentioned in this paper.
The comparison results of MAE value and RMSE value are shown in Figs. 11 and 12:

MAE comparison results.

RMSE comparison results.
As shown in Figs. 11 and 12, the recommendation methods that add knowledge graphs are better than the baseline methods ItemCF and UserCF. The KG-LSTM-UserCF proposed in this paper works best. It shows that the knowledge map learns more relationships between users and items, and LSTM deeply mines the temporal characteristics of users and items.
The proposed method is also compared with some main methods and state-of-the-art methods. The main methods are User-based Collaborative Filtering recommendation method. An item-based collaborative filtering recommendation method [33]. Genetic Algorithm and Gravitational Emulation [34], Noise Correction Based RS [35], Slop One [36], Regularized SVD [37], Improved Regularized SVD [37], Non-Negative Matrix Factorization [38]. The proposed method improves on the best RMSE results on Movielens 1M with the best performance. The comparison is shown in Table 2.
Comparison with other methods
As can be seen from Table 2, our proposed KG-LSTM-UserC method outperforms some baseline methods and advanced methods on the RMSE metric. It shows that using the knowledge graph method can learn more internal connections between users and items, and users’ interests have certain temporal characteristics.
This paper uses a recommendation algorithm that fuses knowledge graphs and time series features for movie scoring prediction. Since the knowledge graph contains the rating of the movie, the plot of the movie and the director corresponding to the movie, the potential relationship between the user and the movie can be learned, and the model can be better explained. The long short-term memory network can capture the sequence features between the user and the movie, which can improve the prediction performance of the algorithm. The experimental results show that the recommendation algorithm integrating knowledge graph and time series features has the highest accuracy.
There are still some deficiencies in the experiment, due to the large-scale establishment of triples, and some users, movies and interaction data are not used, there is still room for improvement in accuracy. In the follow-up research, other data should be added, such as the basic information of users, the time when users submit evaluations and the title of the movie, etc. To further reduce the error and enhance the interpretability of the model. At the same time, optimize the data, reduce the data scale, and reduce the time complexity while ensuring accuracy.
Footnotes
Acknowledgment
This research is supported by the Natural Science Foundation of Anhui Provincial Education Department (KJ2020A0784, KJ2021A1159).