
Abstract
Pre-trained Visual Language Models (VLMs) like CLIP have shown great potential in the multimodal domain. Among this, using different modal contexts and interaction features to construct prompt can stimulate the model’s prior knowledge circuit more accurately, thus generating better outputs. However, in CLIP, the formal mismatch of textual descriptions between the pre-training and inference phases results in a suboptimal representation ability of prompt, which is detrimental to model alignment learning. Therefore,
Introduction
Recently, a growing number of researches about Pre-trained Vision-Language Models (VLMs) have shown that VLMs learned from image and text knowledge jointly can achieve a striking performance in downstream tasks, which demonstrates a great potential in the field of visual-language learning [1–4]. For example, CLIP [5] and ALIGN [2] are pre-trained on millions of image-text data pairs to align the vision and language modalities in the embedding space, and the resulting models obtain impressive performances on downstream tasks in a zero-shot manner.
Various works such as CLIP [5] transform a discrete category label into a complete sentence using manual-designed prompts such as “a photo of a {CLASS}” to make better use of the encoder’s prior knowledge. However, manual-designed prompts such as “a photo of a {CLASS}” are highly time-consuming and inefficient, because they must be based on trial and error, which cannot guarantee an optimal prompt. In addition, the currently popular Large Language Models (LLMs) also rely heavily on prompt engineering. a well-designed prompt can fully stimulate prior knowledge circuits in LLMs and enable them to generate output in a more precise and controlled manner. Therefore, how to construct prompt to efficiently mine the prior knowledge of models is an important research direction [6, 7]
To automate prompt engineering Zhou et al. [8] have recently introduced prompt learning, a recent trend in NLP, into VLMs [9–13] and propose CoOp. It introduces a set of learnable vectors to replace the manual prompt to adapt specific downstream tasks, and it turns out that CoOp achieves better performance with few training parameters. CoCoOp [14] adds an image-conditional token into learnable context vectors and shifts the focus from text-only learning to image-text learning, which can improve CoOp’s generalizability.
It can be concluded that the textual formal mismatch between the pre-trained data and downstream data results in a suboptimal representation ability of prompt, resulting in a suboptimal representation ability of prompt. The text description used by CLIP [5] in the pre-training phase is corresponding to the image, which is often a semantically rich and complete sentence. For example, in the pre-training stage “Pepper the aussie pup” is the text description corresponding to the image "dog", but when inferencing on image classification tasks, a manually designed template “a photo of a {CLASS}” is used where "dog" is filled into {CLASS} as a text description. This is detrimental to CLIP’s alignment learning because using a fixed template to construct prompt cannot fully exploit the prior knowledge in CLIP, thus compromising classification accuracy.
One wise way to address the problem above is to use image-based features to construct prompt. This prompting method is able to enrich text representation to approach the text description semantically and formally in the pre-training process, thus benefiting CLIP’s alignment learning. Considering that CLIP learns to match a whole image with the corresponding text description instead of regions in the image, CLIP ignores learning a more fine-grained alignment representation [15]. The image-text level alignment capability of CLIP should be extended to the region-text level by introducing region features into the prompt.
Therefore, Region-Attention Prompt (RAP) is proposed in this paper to serve as a more region-level and category-sensitive prompt, thus modeling a more fine-grained region-text joint embedding learning. RAP is essentially an instance-level and category-sensitive prompt, which enhances the attention weights of regions that are more relevant to the category in the vector space. Therefore, RAP can further enrich the semantic representation of the text description to make it more sensitive to important regions, thus improving the alignment ability of CLIP.
Our contributions are summarized as follows: c(1) We point out that the representation ability of prompt is crucial for the downstream task performance of Pre-trained Visual Language Models (VLMs). Meanwhile, we propose a paradigm for constructing prompts using image-based features, called
(2) Semantic Interaction Network (SINet) is proposed to generate RAP, which includes: (a) Transformer Decoder Module, which uses the Cross-Attention mechanism for image and text to obtain region-attention features. (b) Projector Module, a lightweight neural network, which gets the projected representation of region-attention features.
(3) CLIP is equipped with RAP (called RA-CLIP) to improve image classification performance in generalization scenarios. Concretely, RA-CLIP’s generalization performance is evaluated on 7 image classification datasets, and it turns out that RA-CLIP on average outperforms 6.77%, 7.21%, and 3.52% than CLIP, CoOp, and CoCoOp respectively on harmonic-mean performance (among which, it outperforms the three by 0.64%, 10.86%, and 3.7% on new classes). In addition, we demonstrate that concentrating on category-related regions to construct prompts can further improve the model’s alignment ability.
Related work
Theoretical development
Those developments in image-text joint learning are largely driven by advances in the following three areas: (1) text representation learning with Transformers [21], (2) large-minibatch contrastive representation learning, and (3) web-scale training datasets [2, 22].
A representative approach is CLIP [5], which trains two neural network-based encoders using a contrastive loss to match pairs of images and texts. After consuming 400 million data pairs, CLIP shows competitive performance in various downstream tasks such as image recognition, objective detection, and dense prediction. Moreover, CLIP shows an impressive transferable ability to other datasets. Inspired by CLIP [5], several follow-ups have been proposed to improve the training strategy (e.g., CoOp [8], CLIP-Adapter [23], Tip-adapter [24], CoCoOp [14]) or apply CLIP to other domains (e.g., ActionCLIP [25]). Our work is built on CLIP, aiming to construct a more instructive and region-sensitive prompt to model more fine-grained region-text learning.
Motivated by the achieved prompt learning in NLP, several works have adapted prompt learning into VLMs. CoOp [8] replaces the manual prompt used in CLIP with a set of learnable vectors. Despite demonstrating outstanding performance, interpreting the results of CoOp, like other continuous prompt learning methods in natural language processing (NLP), poses a significant challenge. Furthermore, the conducted experiments indicate that CoOp is highly susceptible to the presence of noisy labels. Moreover, the learned context prompt is not generalizable to wider unseen classes within the same dataset,
Based on CoOp, prompt tuning methods for complex tasks have also been proposed, such as open-vocabulary object detection [30, 31], zero-shot semantic segmentation [32], continual learning [33], and multi-label image classification [34]. CoCoOp [14] extends CoOp by further learning a lightweight neural network to generate for each image an input-conditional token(vector). Although CoCoOp introduces instance-level image features for context prompt, it assigns the same image features to each category to construct prompt. Based on this, the model still fails to recognize the intrinsic semantic associations of different classes of text and images, resulting in semantic ambiguity and inaccuracy of prompt.
Our work aims to explore the use of image information to build a category-sensitive prompt, which we hope can adaptively focus on different regions in the image according to different category descriptions, so we call it Region Attention Prompt.
The most common approach to ZSL is to learn a semantic space based on auxiliary information such as attributes or word embedding. Different from existing ZSL methods, our work addresses the above problem by using image-based information to construct an instance-level prompt called
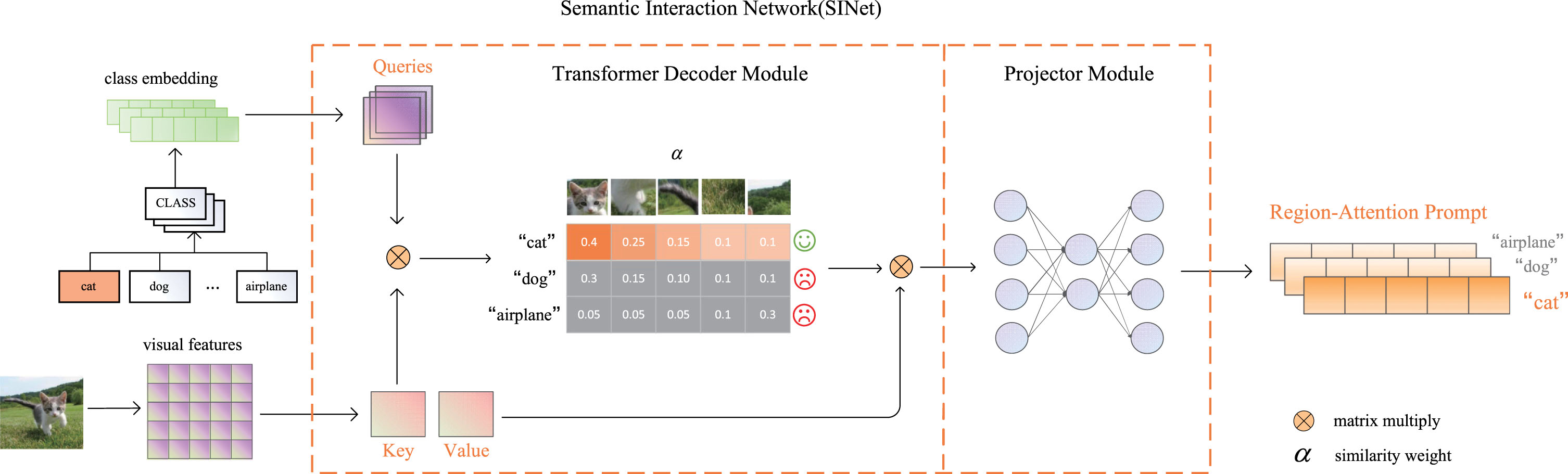
Semantic Interaction Network(SINet), which makes prompt focus on those category-related regions (cat’s head, tail, paw). SINet can assign a higher attention weight to prompt, while a lower one to background regions (grass and trees).
Method
Region features analysis
A good prompt in CLIP should be instructive and precise, thus helping alignment learning more adapt to downstream tasks. For image classification tasks, the information in different regions of the image does not have the same relevance to the category. Moreover, assuming that the classification object in the image is not obvious, or there are other focal parts in the image irrelevant to the classification, then simply making the whole image interact with category text to construct the prompt may be harmful to CLIP’s alignment ability. It can be found that category texts provide conceptual-level semantic descriptions and regions offer the more precise and instance-level ones, so refining the image features with category features can obtain more instructive and fine-grained region information.
Therefore, in constructing the prompt for image classification tasks, it is necessary to pay more attention to regions that contribute more to the category texts, which makes prompt more sensitive and precise to important regions. This prompting method can enrich the semantic representation of text descriptions, thus improving CLIP’s image-text level alignment capabilities.
To illustrate that focusing on category-related regions is beneficial for better alignment in CLIP, the region-text similarity experiments are conducted on OxfordPets dataset. We split a complete image into 4 regions (region 1 - 4) and additionally extract the classification object region (region*) from the image, then the similarity between classes and regions/region* is calculated by the dot-product operation. Greater similarity indicates better alignment.
Table 1 shows that for a cat image, region* (which is more relevant to the class “cat”) achieves the highest similarity score 0.942 than the other regions and full image. It indicates that it is beneficial for CLIP’s alignment to use category-related regions to construct the prompt. Moreover, those regions that are not relevant to the “cat” (region1, region3) may further be classified into the wrong category (such as “dog” or “lion”) thus hurting CLIP’s alignment ability.
Region-category similarity experiments
Region-category similarity experiments






In general, an instance-level prompt called
SINet is built to generate RAP, which uses the Cross-Attention mechanism to make every category interact with the image to assign greater attention weight to the region with higher semantical relevance to the category. In this process, all category texts act as queries while images serve as keys/values. SINet allows each category text to obtain unique region-attention features that make prompt more instructive and precise to important regions. Also, benefiting from the properties of the Cross-Attention mechanism, SINet can maximize the use of semantic information from both modalities. Specifically, SINet consists of two modules:
In general, CLIP is equipped with RAP (called RA-CLIP), the framework of RA-CLIP is shown in Fig. 2, which mainly includes the following parts:
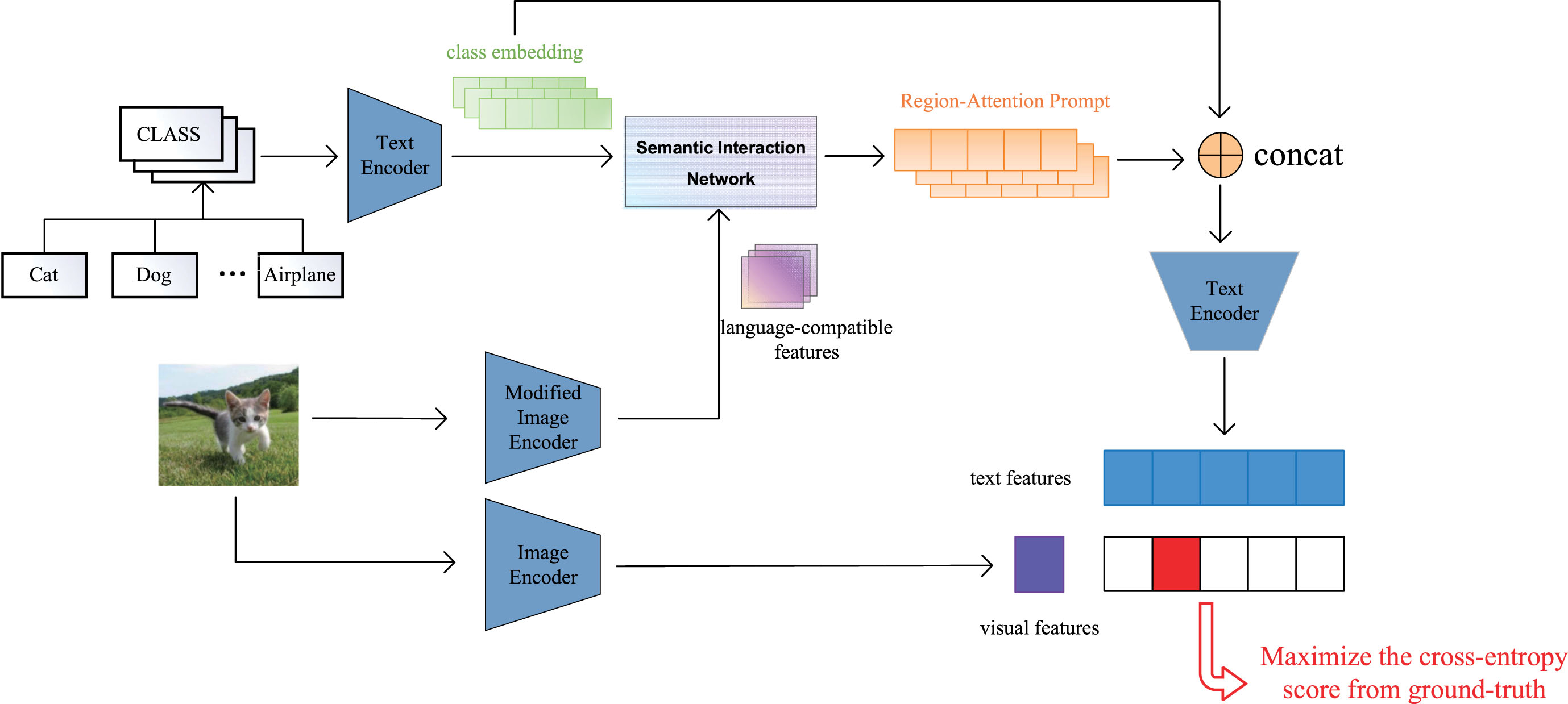
Framework of RA-CLIP, where both text encoders are original CLIP text encoders and share the same pre-training parameters. "concat" means that RAPs are concatenated with class embedding as inputs to the right text encoder(the number of RAPs is always equal to the number of classes). Meanwhile, in order to maintain the consistency of the text encoder, we pad the token length of the concatenated vectors to 77.
Language-compatible features contain sufficient image space features while being well aligned with text features. Eq. (3) can be used to obtain the language-compatible features:
And RAP can be denoted by Eq. (6):
Let’s assume a dataset τ with training data
Then the K classes features are prepended after RAP to get the input of the second text encoder:
For example, the input of the second text encoder for the i
th
category now becomes:
Specifically, the cross-entropy loss is adopted as our loss function to maximize the score from the ground-truth, which can be denoted by Eq. (10):
During training, only the parameters of SINet are updated, both text encoders and image encoders are frozen.
In this work, the Transformer Decoder Module is built on six-layer Transformer Decoder Blocks with eight heads, and the Projector Module is built with a two-layer bottleneck structure (Linear-ReLU-Linear), with the hidden layer reducing to 64 dimensions.
Datasets Statistics
Training Settings
Training Settings
Comparison of CLIP, CoOp, CoCoOp, and RA-CLIP in the base-to-new generalization setting
RA-CLIP is evaluated over 7 datasets in the base-to-new generalization setting, the results are averaged over three runs. CoOp [8], CoCoOp [14], and RA-CLIP are learning-based methods, CLIP [5] is the zero-shot prompt. The detailed results are shown in Table 3, which strongly justifies the strong generalization performance of RA-CLIP.

Comparisons of RA-CLIP and CLIP in the base-to-new generalization setting.
For base classes, RA-CLIP outperforms CLIP by a large margin on all 7 datasets (up to 33.59%, least to 0.64%). This indicates that learning-based prompt methods can more effectively adapt training data, thus providing better semantic representation for base classes. Moreover, RA-CLIP’s gains in base classes far outweigh its losses in new classes than CLIP, thus achieving better harmonic performance, e.g., on DTD dataset in base classes is +27.94% while its losses in base classes are -3.06% or RAP’s gains on FGVCAircraft dataset in base classes are +9.63% while its losses in new classes are just -2.18%.
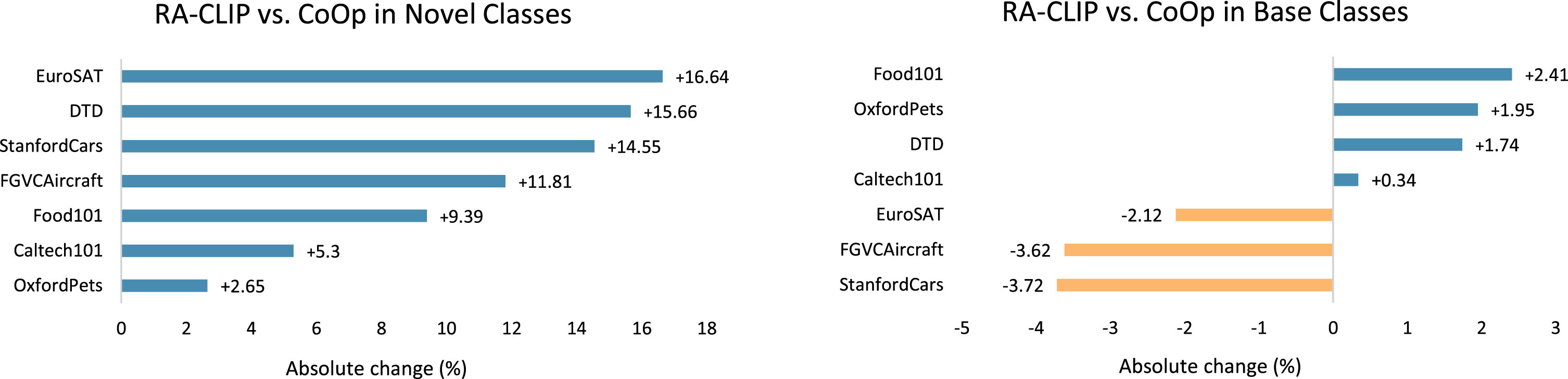
Comparisons of RA-CLIP and CoOp in the base-to-new generalization setting.
But it is worth noting that although RA-CLIP’s base accuracy drops below CoOp on 3 of 7 datasets (range from -2.12% to -3.72%), RA-CLIP’s gains in new classes are significantly larger than its losses, which is enough to turn the averages improvement into positives, e.g., StanfordCars sees the worst base accuracy drop of -3.72% but obtains accuracy gain of +14.55% in new classes, which together bring a 10.83% positive improvement for RA-CLIP, or StanfordCars sees the base accuracy drop of -2.12% but also obtains accuracy gain of +16.64% in new classes, which together bring a 14.52% positive harmonic improvement for RA-CLIP.
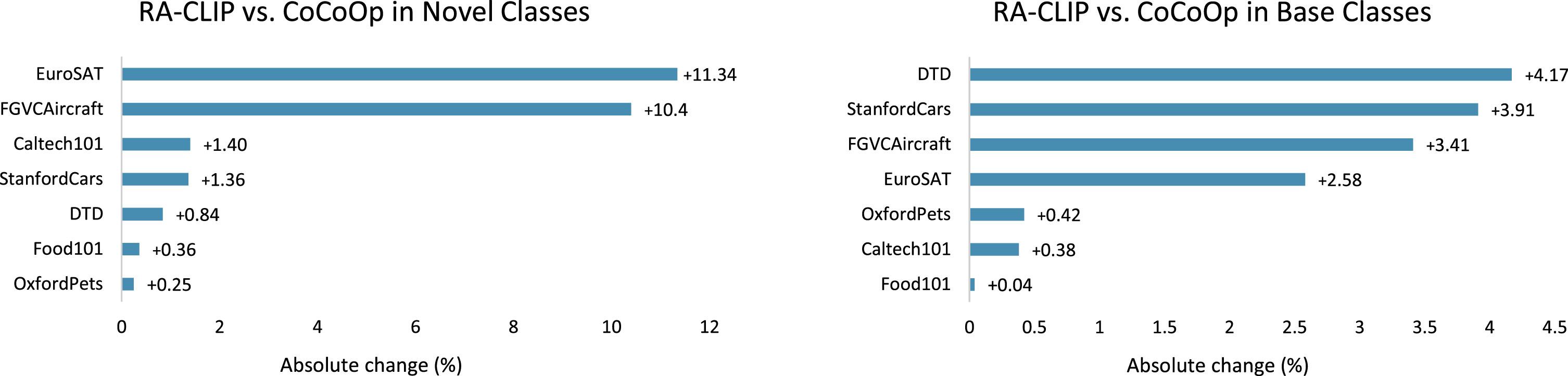
Comparisons of RA-CLIP and CoCoOp in the base-to-new generalization setting.
For base classes, RAP still outperforms CoCoOp on all datasets, (specifically on DTD, StanfordCars, FGVCAircraft, and EuroSAT). In general, compared to CoCoOp (which adopts the image-condition features to construct prompt), RAP is more competitive in both base and new classes. It suggests that using region-attention features to construct prompt can provide a more precise and instructive semantic representation for text description.
To understand the working mechanism of RAP and explore how RAP improves image classification performance, we visualized the attention weights of RAP on oxfordPets and Food101 datasets. In our experiments, we visualized RAP’s attentional weights on the base class and the new class, respectively, and for each image, we sampled the attention feature maps corresponding to the three classes (only one of which is GroundTruth).
The detailed results are shown in Table 5 and Table 6, it can be inferred that regardless of whether it is on base classes or new classes, Ground-Truth-RAP always focuses on the correct regions in the image, and assigns higher attention weights to these regions. Meanwhile, the rest of the RAPs still maintain lower attention weights overall. This suggests that RA-CLIP is conditioned on each input instance, it always focuses on regions that are semantically similar to category and assigns high attention weights. Meanwhile, RAP can be optimized to characterize each instance, so it is more robust to class shift. In other words, RA-CLIP learns a pattern of extracting region-level features, when comes to the generalization scenario the learned extraction pattern helps RA-CLIP obtains the instance-level region features.
RAP attention weight visualization on OxfordPets dataset, where "GT" represents Ground Truth
RAP attention weight visualization on OxfordPets dataset, where "GT" represents Ground Truth
RAP attention weight visualization on Food101 dataset, where "GT" represents Ground Truth
Moreover, to explore the advantages of this regional attention feature in model alignment learning, we further measured the cosine similarity between the Ground-Truth-RAP and the image on OxfordPets dataset(see Table 7). The larger the η, the closer the semantic distance between Ground-Truth-RAP and the image, which indicates stronger alignment ability. The results in Table 7 demonstrate that RAP - the prompting approach that utilizes the Cross-Attention mechanism to acquire region features - is able to bring images and classes closer in the vector space, thus improving the model’s alignment ability (image classification performance).
Similarity experiments between RAP and image on OxfordPets dataset
The results in Table 7 show that the larger η (RA-CLIP) helps to improve generalizability. It indicates that RAP has a more similar semantic representation to image features in vector space, thus enhancing the alignment ability. Moreover, RA-CLIP also improves base accuracy, which means RA-CLIP can reduce the generalizability trade-off between base classes and new classes (increase the harmonic performance).
Comparison experiments over 7 datasets are shown in Fig. 6. The result shows that RA-CLIP outperforms CLIP with IT-Prompt on both base classes and new classes by 1.7% approximately, suggesting the key to enhancing alignment capability is using region features to construct prompt.
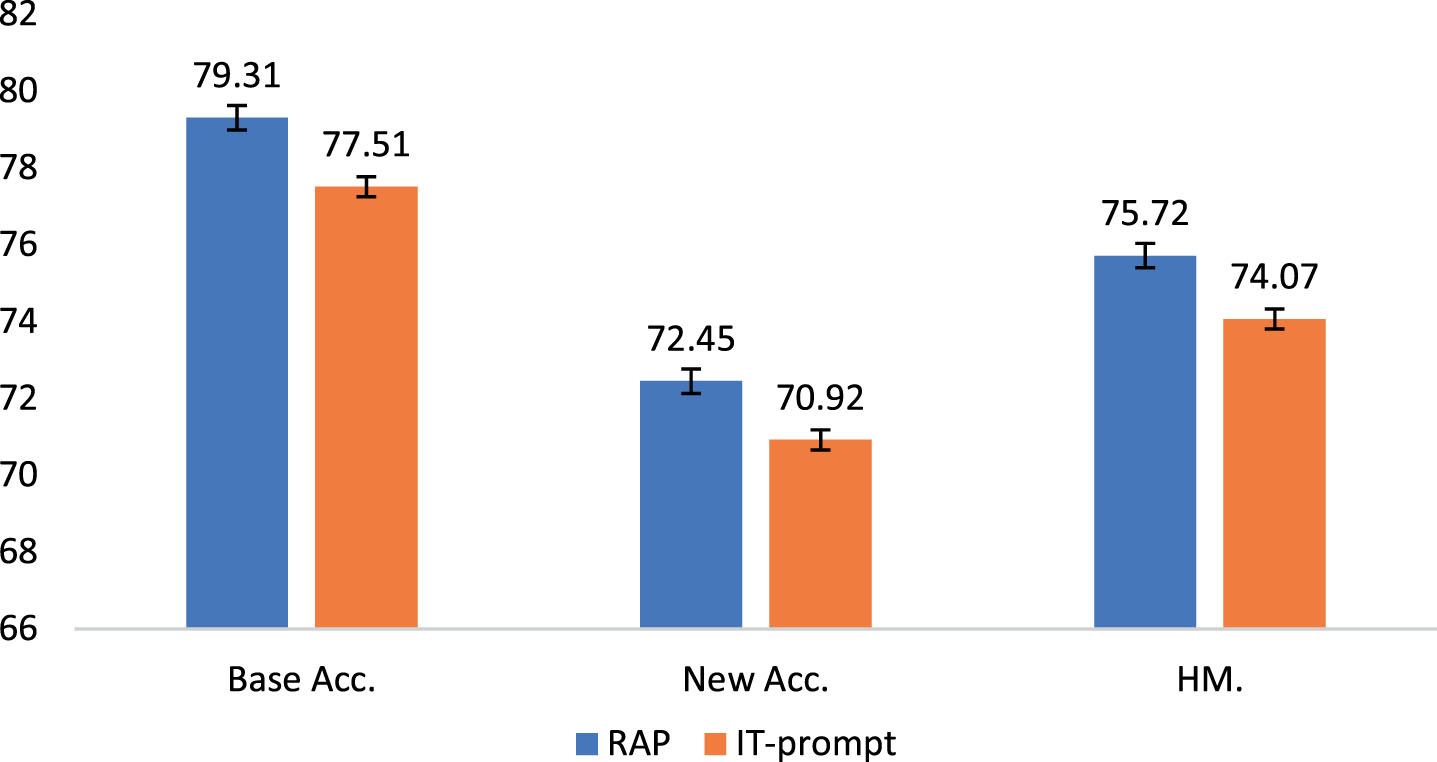
RAP vs. IT-prompt.
The Projector Module plays a crucial role in extracting higher-level abstract features through additional nonlinear transformations and mappings. By removing the Projector Module, the model loses the ability to fully leverage the output of the Transform Decoder Module, leading to incomplete feature representations and consequently impacting performance.
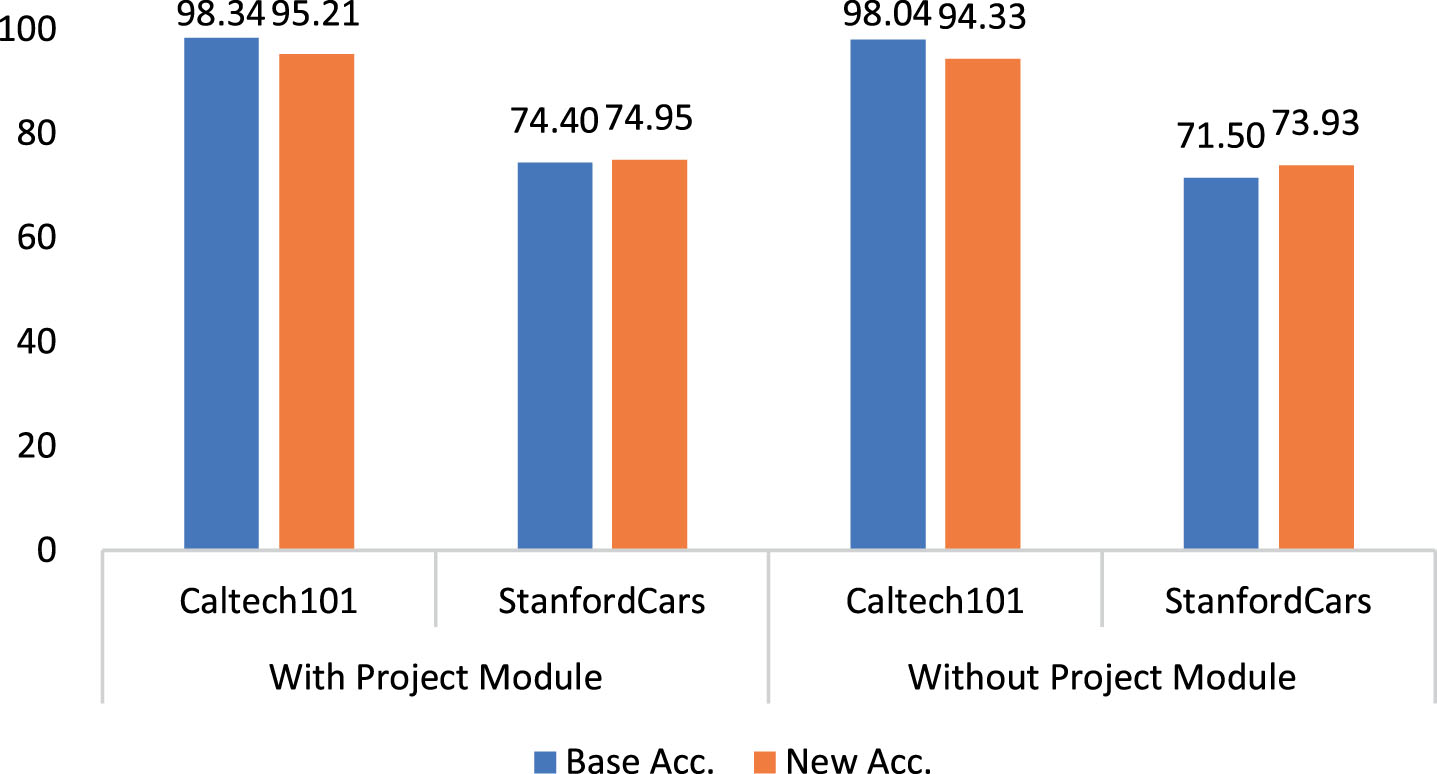
SINet vs. SINet without Projector Module on Caltech101 and StanfordCars datasets.
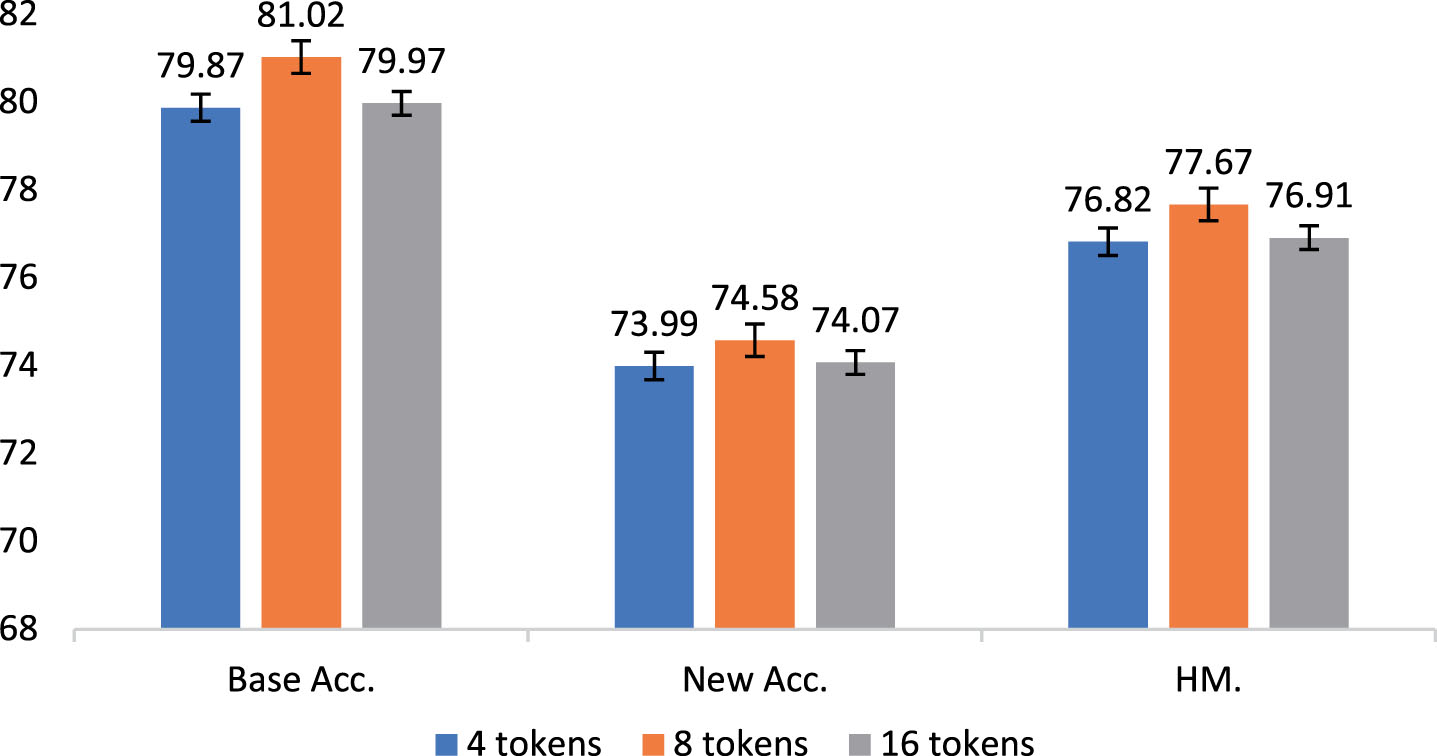
Study on the length of RAP over 7 datasets.
This indicates that a suitable length of RAP (which is 8 token lengths in this work from our experience) has contain the most precise region features (semantic representation), which can maximize the model’s alignment ability. On the contrary, RAP with longer length may suffer from information redundancy and ambiguous referents, while RAP with shorter length may suffer from information missing for important regions, both cases will result in inadequate representation ability of prompt.
Table 8 demonstrates that as the scale increases RA-CLIP also gains a slight performance improvement, but the increase in performance slows down significantly. However, it is important to note that the model also runs the risk of increased computational cost and overfitting as the size increases. Moreover, SINet-small can still achieve better performance on both the new classes and the base classes than CoCoOp. It indicates that region features adopted in RAP are the key to guaranteeing the alignment ability, rather than the training parameters of SINet.
Average results of scale experiments on 7 datasets
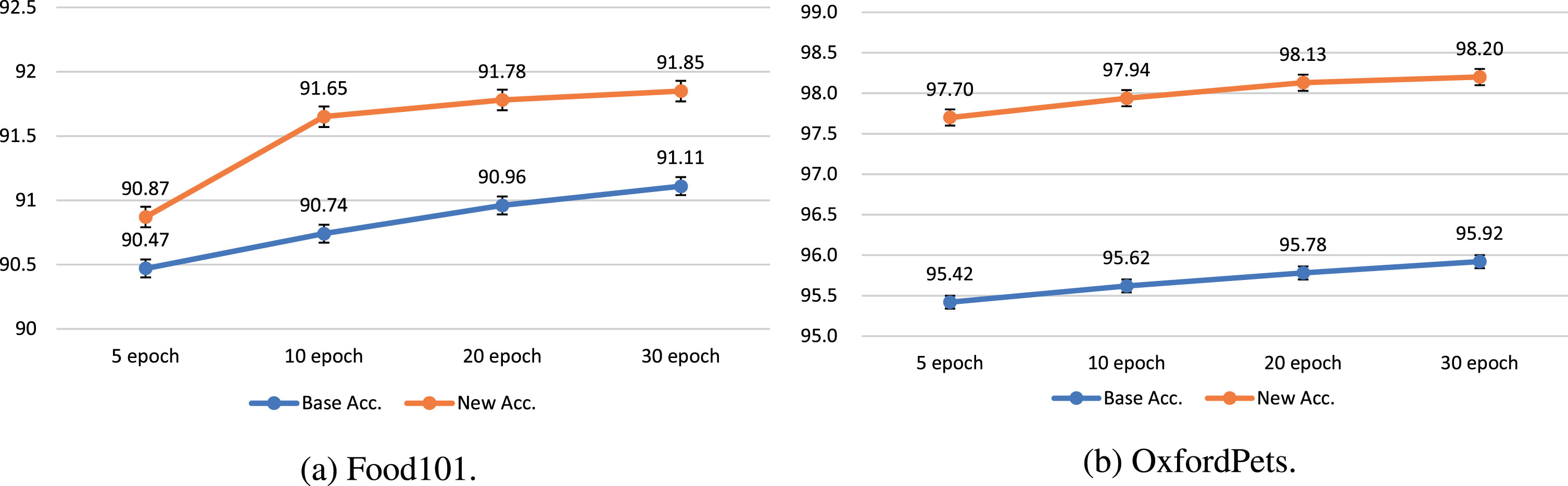
Training epoch experiments.
To understand the use of templated category descriptions (like CLIP) affects the RA-CLIPs’ performance, an experiment is conducted over 7 datasets. In the experiment, a template is adopted to expand the classes into one sentence as the input of SINet, following CLIP [5], we use "a photo of a CLASS" as a template to compare with the non-templated RA-CLIP. The detailed results are shown in Fig. 10.
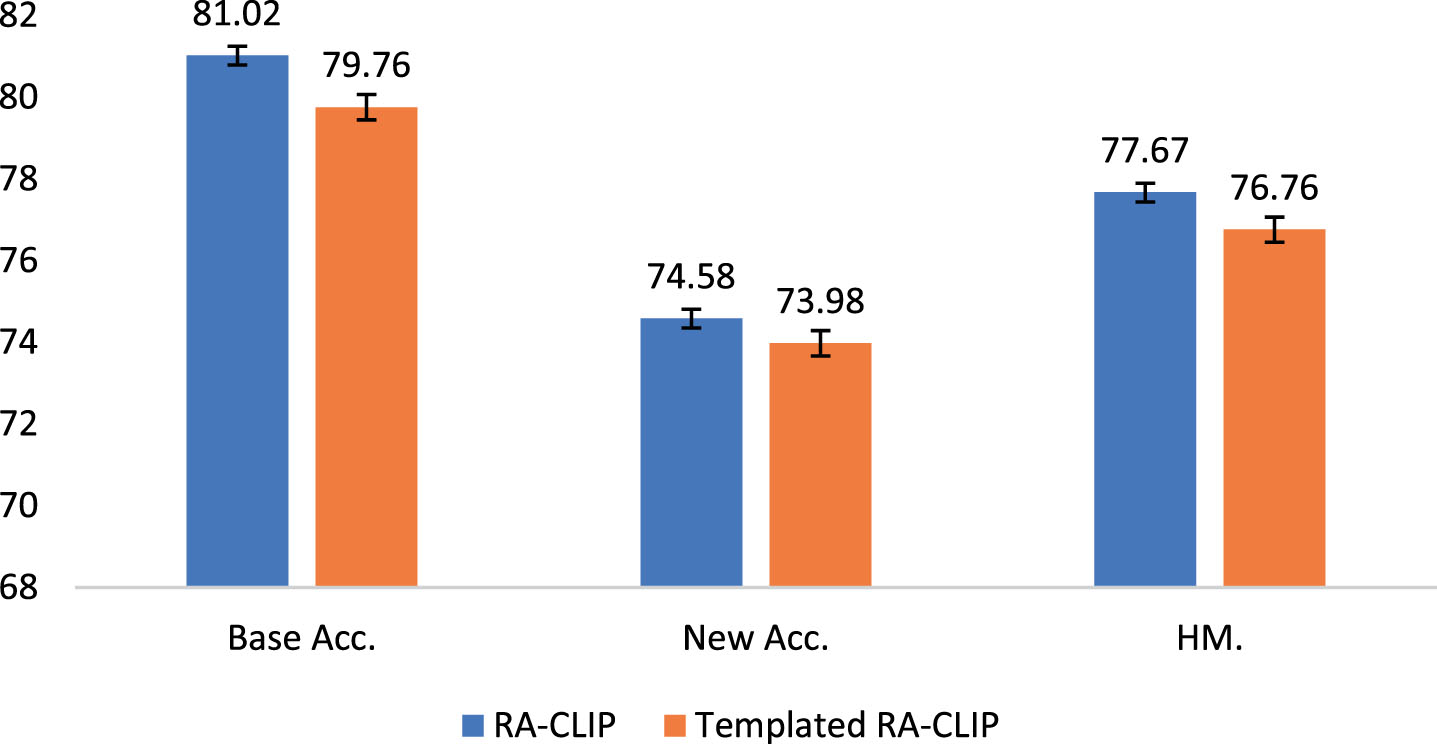
Template experiments over 7 datasets.
Fig. 10 shows that templated RA-CLIP has a certain degree of regression on both base classes and new classes (from 1.26% and 0.60% drops compared to the original RAP). This illustrates the original RA-CLIP already contains enough conceptual-level semantic representation to guide the image in extracting important region features. On the contrary, using additional templates for classes may complicate the text semantics and thus be detrimental to the generation of RAP.
In order to analyze the computational resource cost as well as the scalability of RA-CLIP, we conduct comparison experiments with 7 datasets (see Table 9) on each of the three computing platforms(Nvidia 3090, Nvidia 3080Ti, Nvidia Tesla T4). Meanwhile, we introduce CoCoOp on Nvidia 3090 computing platform as a baseline to explore the trade-off between performance improvement and computational cost.
Computational cost analysis over 7 datasets
Computational cost analysis over 7 datasets
Table 9 shows that on the Nvidia Tesla T4 platform, RA-CLIP’s training/inference times and GPU memory consumption are marginally longer than CoCoOp. This is likely due to the increased complexity and parameters of RA-CLIP, which necessitates more computational time. However, given the enhanced performance of RA-CLIP, this increase in computation time is acceptable. Besides, RA-CLIP exhibits robust scalability across a diverse range of datasets. It delivers stable and reliable performance on datasets of various scales, from those requiring fewer computational resources such as OxfordPets, to those imposing higher ones like StanfordCars. This illustrates the model’s capability to effectively scale across datasets of various types and magnitudes. Furthermore, RA-CLIP’s memory usage and GPU memory utilization remain relatively consistent across all platforms and datasets. This stability underlines the model’s proficient resource management, demonstrating its ability to maintain an efficient balance between computational resource expenditure and performance outcomes.
The first limitation pertains to the training process’s efficiency. RA-CLIP was found to be notably slow during its training phase, exhibiting a high consumption of GPU memory. Our runtime analysis indicates that when the batch size exceeds 4, it becomes untenable for standard civilian-grade GPUs. This is primarily attributed to the proposed SINET, which necessitates independent forward and backward propagation for each image in the minibatch during training to construct an instance-level Region Attention Prompt. This is markedly less efficient than both CLIP and CoOp, which require only a single forward and backward propagation through the text encoder for the entire minibatch, irrespective of its size.
The second limitation emerges in the detailed performance analysis. Despite RA-CLIP demonstrating the best overall performance across all 7 datasets, it does not consistently yield the most optimal results in either the base or new classes. Specifically, it failed to provide the top performance for base category recognition on 3 datasets and new category recognition on 2 datasets. This underscores the necessity for a substantial community effort in the pursuit of fully bridging or even reversing the gap between manually-designed prompts and learning-based prompts.
Conclusion
An instance-level and category-sensitive prompt called