
Abstract
In recent years, it has been shown that deep learning methods have excellent performance in establishing spatio-temporal correlations for traffic speed prediction. However, due to the complexity of deep learning models, most of them use only short-term historical data in the time dimension, which limits their effectiveness in handling long-term information. We propose a new model, the Multi-feature Two-stage Attention Convolution Network (MTA-CN), to address this issue. The MTA-CN intercepts longer single-feature historical data, converts them into shorter multi-feature data with multiple time period features, and uses the most recent past point as the main feature. Furthermore, two-stage attention mechanisms are introduced to capture the importance of different time period features and time steps, and a Temporal Graph Convolutional Network (T-GCN) is used instead of traditional recurrent neural networks. Experimental results on both the Los Angeles Expressway (Los-loop) and Shen-zhen Luohu District Taxi (Sz-taxi) datasets demonstrate that the proposed model outperforms several baseline models in terms of prediction accuracy.
Keywords
Introduction
With the development of technology, the increase in vehicle ownership per capita inevitably leads to many transportation problems, for example, congestion on transportation networks is a long-standing, hot topic [1–5], and these problems can have some impact on people’s livelihood and social economy [6–8]. In order to solve these traffic problems, it is particularly important to develop intelligent transportation systems [9], which have become the future direction of transportation systems. Traffic speed prediction is an extremely important part of the intelligent transportation system. By accurately predicting the traffic flow, we can effectively analyze the road conditions and avoid the possible future risks in time. It can not only help traffic managers to dispatch and control the traffic system in a timely manner, but also improve the operation efficiency of the traffic network by planning appropriate travel routes in advance for people who travel. However, due to the complex spatial correlation and temporal correlation of traffic data, it has been a challenging task for traffic speed prediction to make suitable models to improve the accuracy of prediction by adequately considering both factors.
In the spatial dimension, traffic data exhibits spatial dependency [10]. The traffic flow of a certain road section is greatly related to the topology of the traffic system of the entire city, the traffic flow between multiple road sections affects each other, and the correlation between different road sections affects the traffic status of the road. While some researchers use Convolutional Neural Networks (CNN) for spatial modeling, it is only applicable to Euclidean spatial structures and cannot be applied to complex topological models like traffic roads. In the time dimension, the traffic data also changes dynamically over time, with the current traffic flow being influenced by the previous or earlier traffic flow. Therefore, accurate traffic speed prediction requires us to pay attention not only to the influence of correlations between time series in different spaces but also to fully consider the long-term temporal patterns.
After observing sufficiently long time series, we found that the computational complexity of the model usually increases with the length of the time series, and deep learning models do not easily scale to long historical time series as the length of the time series increases. Cho et al. [11] pointed out that the performance of the model decreases as the sequence length increases. Most deep learning models typically use shorter historical data to make predictions, such as the past hour, but traffic flow at earlier moments is also closely related to the current traffic flow. For example, people go to work during the morning peak period and leave work during the evening peak period, and the traffic flow during the evening peak period depends largely on the traffic flow during the morning peak period. It is impossible to learn these time patterns from long-term information by selecting only short historical data. The prediction of traffic data requires the observation of long-term data, but for models, long-term data can lead to a loss of accuracy. This contradictory issue requires the model to address the conflict between the lack of long-term data and the decrease in accuracy caused by long-term data in traffic prediction.
To address this problem, Guo et al. [12] intercepted three time series segments along the time axis, representing the most recent, daily, and weekly features, as in Fig. 1. In this way, the model can use shorter historical data while taking into account the long-term information of the time series. However, the intercept positions of these three time series segments are artificially set, and the daily feature with the greatest causal relationship with Tp may not be Td but Td1, and the weekly feature with the greatest causal relationship may not be Tw but Tw1. Existing models often manually segment time series data, such as dividing them into days, weeks, or distinguishing between holiday and non-holiday periods. However, in some cases, important features may not be captured by such segmentations, and significant temporal patterns need to be discovered by the model rather than determined by human intuition. How can the model adaptively capture the most important features rather than by artificially selecting specific time series? For this problem we propose a new model Multi-feature Two-stage Attention Convolution Network (MTA-CN). It imports a continuous period of long-term historical data, represents the long-term historical time series fragmentarily into multiple time period features, and learns the temporal correlation of these fragments through an attention mechanism. By using this approach, the model can adaptively capture significant temporal patterns instead of relying on manual segmentation, thereby enabling it to learn temporal patterns from long-term historical data.

Input of Time Series Segments (Suppose the time step is set to one hour, Tw1, Tw, Td1, Td, Th, Tp are equal in length).
The main contributions of this paper are summarized in the following: Our model is built by inputting long-term historical data and dividing it into multiple time periods equally, taking the most recent time period as the main feature and the rest as time period features. The model can fully take into account the causality in the time dimension and does not degrade the prediction accuracy due to the long time step. The model uses a two-stage attention to learn temporal correlation, where time period attention to extract the importance of different time period features, adaptive extraction of relevant driving sequences for each time period features, and temporal attention to select relevant encoder hidden states in the time step. In the spatial dimension, we use the Graph Convolutional Neural Network (GCN) for extracting spatial features of traffic data, which can extract non-Euclidean spatial structures. The data passes through the GCN and enters the Gated Recurrent Unit (GRU), which is then combined with the attention mechanism as the encoder and decoder of the model.
The rest of the paper is organized as follows. In Section 2, we survey several works related to the traffic speed prediction. In Section 3, we define the model notations and derive the formulations used in the present model. In Section 4, we present a two-stage convolution network algorithm based on multi-feature attention mechanisms. Our experimental results will be conducted in Section 5, and the data analysis will also be presented. Finally, we summarize the conclusions and future research directions of this paper in Section 6.
Statistical method model
Statistical method models used for traffic speed prediction include the Historical Average model (HA) [13], which has a simple algorithm and can solve the traffic speed prediction problem at different times to some extent. But this model can only be used for static prediction and cannot overcome the influence of disturbing factors. The Autoregressive Integrated Moving Average model (ARIMA) [14] regards the prediction subject as a random time series, converts the non-stationary sequence into a stationary sequence, and then uses a mathematical model to approximate the description of the random sequence. The Vector Autoregressive model (VAR) [15] can better reflect the fluctuation of traffic flow in real time and reduce the uncertainty in the prediction process as much as possible, but it needs to estimate too many parameters. Although these above models can capture the temporal correlation in traffic data, they cannot describe the spatial correlation in road traffic network.
Machine learning
While the statistical method models have a simple and easy-to-calculate algorithm, they can only be applied to a static model. However, traffic data is often nonlinear and uncertain, and there are random events such as traffic accidents that these models cannot account for. In contrast, traditional machine learning models only need enough data to learn these regularities. Among them, the K-Nearest Neighbor model is one of the most commonly used non-parametric regression models. It can filter historical data and find the nearest neighbors that match the current real-time observation data based on relevant elements from historical data. The function of support vector regression (SVR) is to collect some parameters of the previous period at a certain time as input and output the traffic of the corresponding period. Then it selects the kernel function to train the support vector machine to predict the next stage of data. There are also some classic models such as Bayesian Network (BN) [17] and Kalman Filtering (KF) [18]. However, these models are still unable to describe the spatial correlation of road network topology.
Deep learning
Compared with machine learning models, deep learning can achieve higher prediction accuracy as the amount of data increases [19]. In the time dimension, because the back propagation neural network has a very good effect in fitting nonlinear data, some researchers use it in traffic speed prediction, but the back propagation neural network also has many shortcomings, such as gradient disappearance and gradient explosion. Some variants of Recurrent Neural Networks (RNN) such as Long Short-Term Memory (LSTM) [20], Sequence to Sequence (Seq2Seq) [21] help to solve this problem. These networks are suitable for many time series prediction problems such as stock price prediction [22], traffic speed prediction [23], and they can overcome the error decay problem of back-propagation to capture long-term dependencies in time series.
Liu et al. [24] proposed an end-to-end deep learning architecture that uses convolution and LSTM combined into a Conv-LSTM module and a bidirectional LSTM to extract the periodic characteristics of traffic flow. Zhang et al. [25] proposed a multi-task learning framework (MDL) for predicting the flow of nodes and edges respectively, which models the correlation between the two types of flows through the regularization of the loss function, which strengthens the prediction for each type of flow. Chen et al. [26] used three deep residual neural networks to simulate the trend properties of time, cycle and traffic flow and proposed a prediction algorithm DeepTFP, which can optimize the parameters of the time series prediction model.
In the spatial dimension, the model Conv-LSTM proposed by Liu et al. [24] uses convolution operations to capture the spatial correlation of the road network. Ranjan et al. [27] proposed a symmetrical U-shaped structure called PredNet, which has CNN blocks at the input and output ends. The performance of this model is stable. Compared with Conv-LSTM, it has higher accuracy and faster training speed. Cheng et al. [28] proposed an end-to-end framework DeepTransport, which uses CNN and RNN and attention mechanism, and the model is used to capture complex relationships in the spatio-temporal domain. Wang et al. [29] used Gaussian regularized residual learning and proposed a new convolutional neural network, which is a Gaussian noise residual network. Chai et al. [30] proposed a new multi-graph convolutional neural network to capture the spatial relationship between different sites, and each graph is learned by a CNN individually. The above methods essentially use CNN to extract the spatial features of traditional Euclidean space, but the traffic road network itself is a complex topology, and CNN cannot be applied to this irregular non-Euclidean space.
ethispage2pt
In recent years, with the development of graph neural networks, some researchers have found that it is very suitable for traffic speed prediction problems, because it can capture the non-Euclidean spatial structure of road networks. Li et al. [31] proposed a new model, Diffused Convolutional Recurrent Neural Network (DCRNN), which captures spatial correlation through bidirectional random walks on the graph. Zhao et al. [32] used GCN [33] to extract non-Euclidean space, in this model, GCN is used as a feature extractor before inputting GRU. Yu et al. [34] also used graph convolutional neural networks to extract spatial features. In addition, the attention mechanism [35] is also used to extract spatio-temporal correlations in traffic speed prediction. Zheng et al. [36, 37] used the attention mechanism to extract the spatio-temporal correlation of the traffic road network, and Abdelraouf et al. [38] combined the attention mechanism with the encoder-decoder architecture.
Some models also incorporate other types of temporal periodicity in addition to recent time series. Guo et al. [12] considered two new time patterns in their model, namely, daily cycle and weekly cycle. Shao et al. [39] considered long-term historical data, while Lu et al. [40] used time-aware convolutional contextual blocks to enhance the network’s ability to capture more distinguishable temporal features. Pan et al. [41] divided time into two categories, weekdays and weekends.
Problem formulation
Problem definition
In this paper, the traffic road network is defined as an undirected graph G = (V, E, A), where the notation V = (v1, v2, …, v N ) represents a node in the road network corresponding to N sensors, the notation E denotes a set of edges representing node connections, while the notation A ∈ RN×N represents the adjacency matrix of the network.Note that the notation A ∈ RN×N is used to represent the connection between nodes. If nodes i and j are connected, and the graph is a weighted graph, then Ai,j is the proximity between two nodes, otherwise it is 1. If the nodes i and j are not connected to each other, Ai,j = 0.
Summary of notation
Summary of notation
The symbol X ∈ RN×C represents the characteristic matrix of the road network, traffic speed is regarded as the attribute of the node, and the symbol C represents the number of attribute features of the node. Let Xt denote the observation of the road network at time step t. Our problem is defined as: Given the historical time step T observations of all nodes χ = (Xt+1, Xt+2, …, Xt+T) ∈ RT×N×C, predict the traffic situation of all nodes in the time series of the next time step τ. We use (Xt+T+1, …, Xt+T+τ) ∈ RT×N×C to represent the future length as τ The traffic situation of the time series, as shown in Equation (1):
When dealing with spatial structures in the past, the road network is usually divided into several grids equally, and then the CNN is used to extract the local spatial structure features, but this method only uses the grid structure with the structural norms. This method is not suitable for the non-Euclidean spatial structure of the traffic road network. Therefore, the GCN, which can extend the convolution operation to any graph structure, has received extensive attention in recent years, and it can be better applied to the extraction of spatial structure features of traffic road networks. GCN ingeniously designed a method to extract features from graph data. It uses spectral graph theory to realize convolution operations on topological graphs. Specifically, it maps graph signals to the frequency domain and then performs convolution operations. As shown in Fig. 2, the red node represents the target node to be aggregated, and the blue node represents the node adjacent to the red node. GCN can extract the topological relationship between the target node and the adjacent nodes. We define L = D - A as the Laplacian matrix of a graph, where D represents the degree matrix and A is the adjacency matrix of the graph. The Laplacian matrix reflects the cumulative gain generated when the current node disturbs the surrounding nodes, which can describe the degree of change in the graph. The formula of GCN is as follows:
Red nodes represent target nodes. (a) The blue part represents the aggregated other node information. (b) Obtain the topological relationship of the target node and the adjacent blue nodes.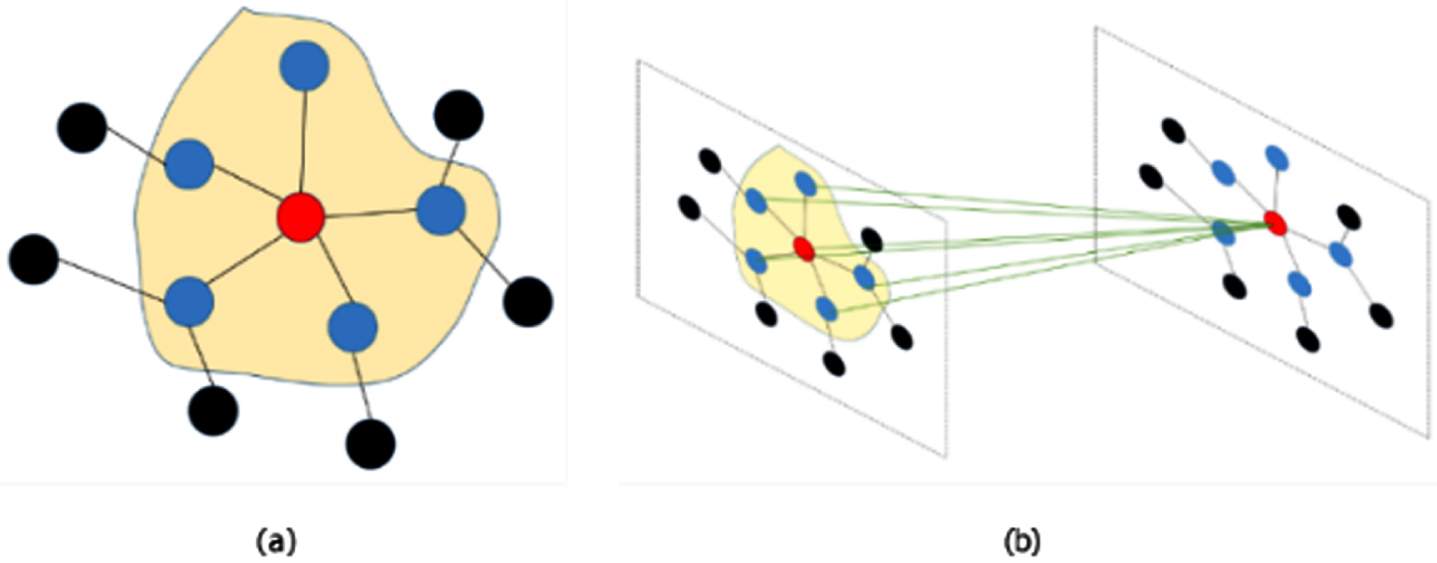
The most widely used to capture temporal correlation is RNN. However, because of the problem of gradient explosion and gradient disappearance, more and more researches use RNN’s variant LSTM to capture temporal correlation. Another variant, GRU is similar to the internal principles of LSTM. Compared to the LSTM, which has many parameters and is difficult to train, the GRU has a simpler structure with fewer parameters, is easy to implement, and achieves the same results with less time cost and computational power [42], so we choose the GRU to capture temporal correlation. Its structure is shown in Fig. 3, where rt represents the reset gate, which determines how to combine the new input information with the previous memory. ut represents the update gate, which is used to control the extent of and the current traffic state
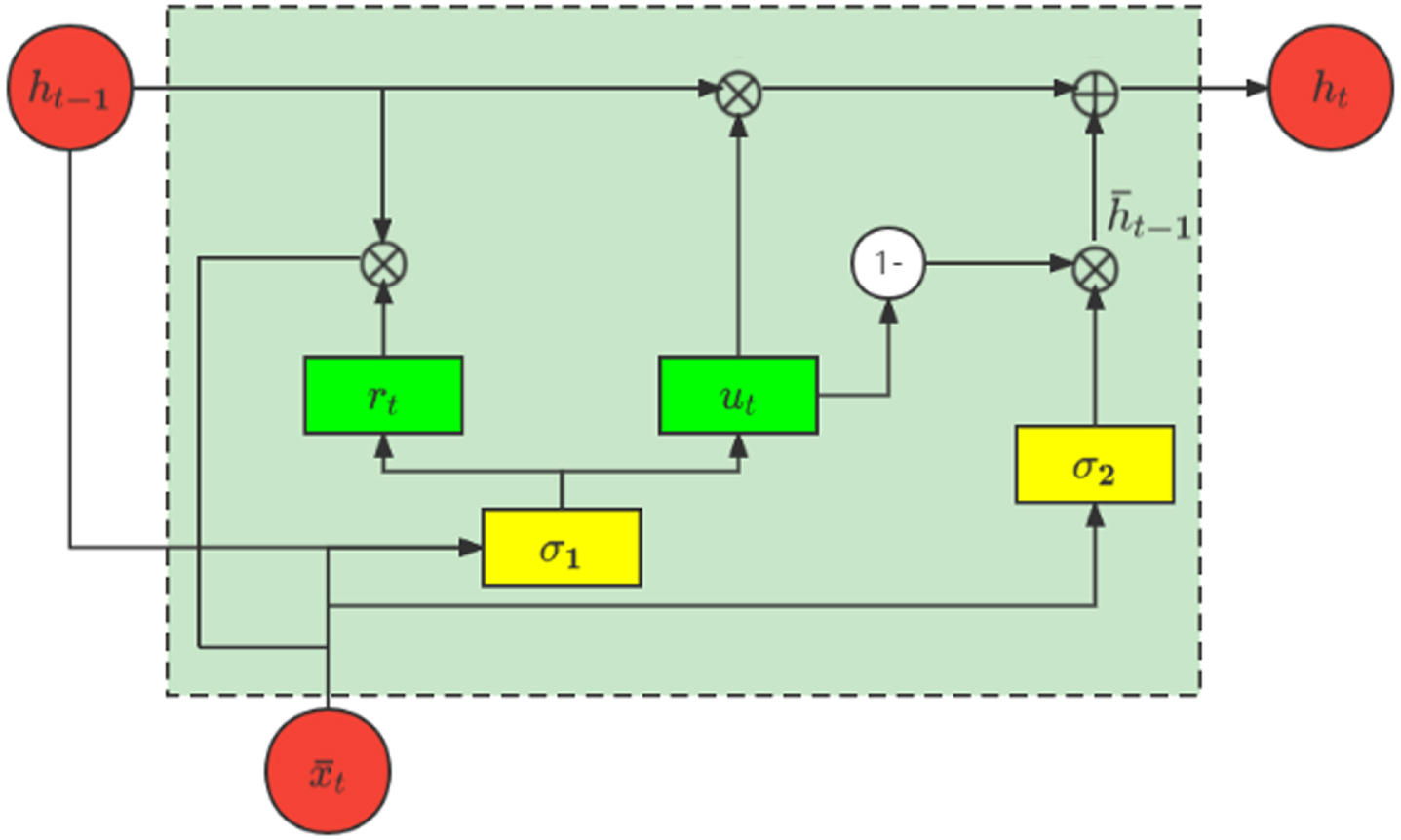
Structure of the gated recurrent unit.
MTA-CN
In this section we describe the structure of MTA-CN. Qin et al. [43] proposed the DARNN model on the time series prediction problem, inspired by the dual stage attention in the model, we propose MTA-CN. Figure 4(a) shows the structure of MTA-CN. Take m historical time series as input, the notation r represents the current time series. Extract the time series χr ∈ RN×(n+1)*T with a historical time step of
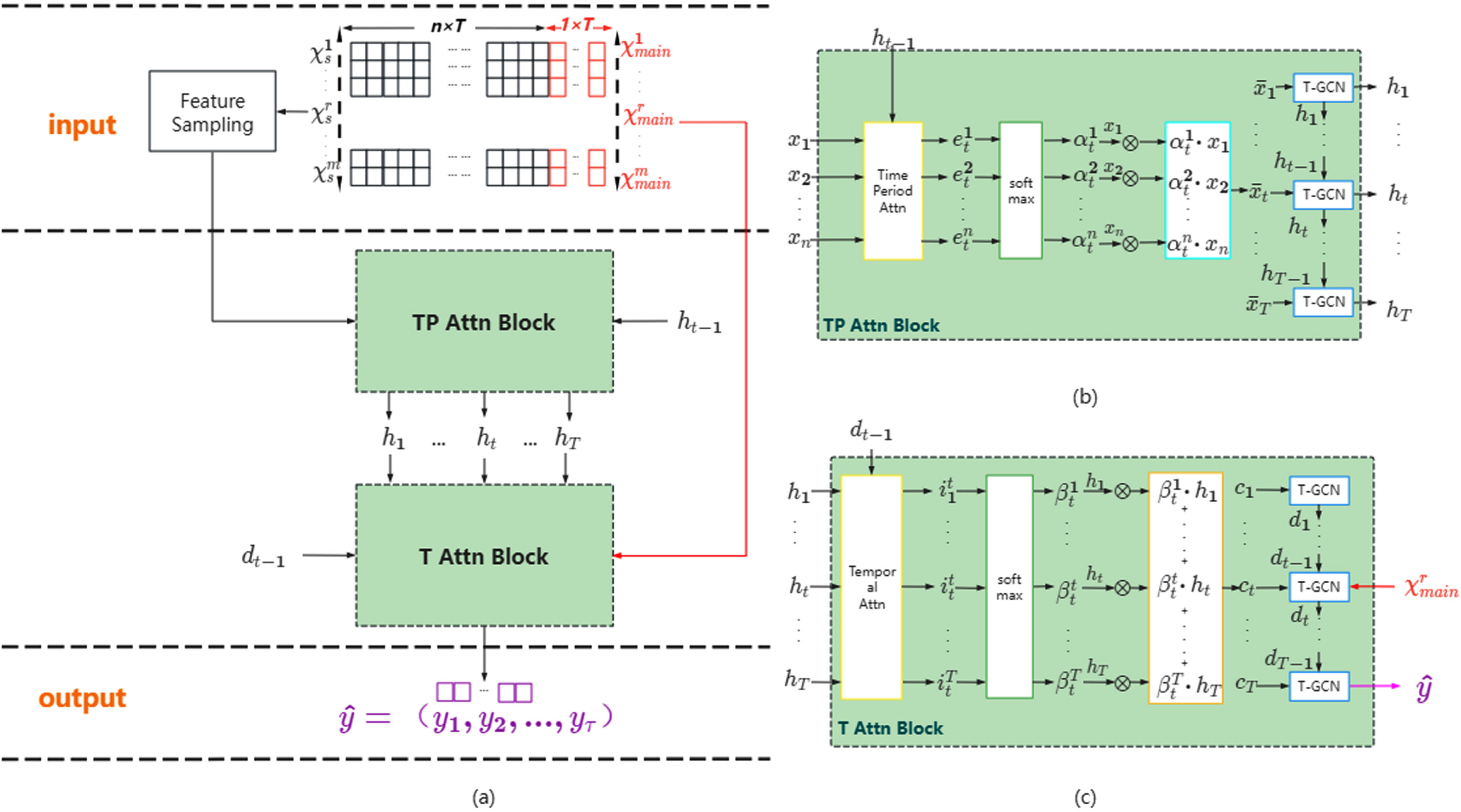
(a) MTA-CN overall architecture. (b) Encoder internal structure. (c) Decoder internal structure.
Before the time series
Time period attention on encoder
As shown in Fig. 4(b), the time series
Through the encoder T-GCN unit, a new hidden state h
t
∈ RN×T×a can be obtained. T-GCN is a combination of GCN and GRU models. Through formulas (2)–(7), it can be obtained as following formulas:
The correlation between the current traffic situation of the node and the previous traffic situation changes nonlinearly with the time step. After passing through the encoder with time period attention, in the decoder part, as shown in Fig. 4(c), in order to adaptively capture Encoder-dependent hidden states, we use temporal attention to capture correlations across different time steps. The temporal attention model is constructed by the hidden state h
i
(1 ⩽ i ⩽ T) obtained in the encoder and the previous hidden state dt-1 of the decoder, the formulas are shown as follows:
Get (each time step has an independent context vector) and then combine it with the main feature
where through linear transformation to get the input y* ∈ RN×T×1. Wcx ∈ R(a+1)×1 is the training parameter in the linear transformation process.
In order to predict the final output
With temporal attention, the decoder can adaptively capture more important time steps. The context vector ct ∈ RN×a and the current hidden state d
t
∈ RN×b are obtained by the decoder. The [ct ; d
t
] ∈ RN×(a+b) formed by combining the two sets of sequences is a time series that simultaneously captures the time period features and the importance of time steps. We get the final output
The pseudo-code of MTA-CN is summarized as follows:
Dataset
To assess the performance of our model, we conducted experiments on two real-world datasets: Los Angeles Expressway (Los-loop) and Shenzhen Luohu District Taxi (Sz-taxi). Los-loop: Traffic speed collected by 207 sensors on the Los Angeles Freeway from March 1st to March 7th, 2012. The sensors record the traffic speed every five minutes. The total number of time slices is 2016. Sz-taxi: The trajectory data of taxis in Luohu District, Shenzhen, from January 1st to January 31st, 2015. It includes 156 main roads in the area, and the traffic speed is recorded every 15 minutes. The total number of time slices is 2976.
For the above two datasets, we divide the first 80% as the training set, 10% as the validation set, and the last 10% as the test set.
Hyperparameters
The hardware environment of this experiment is CPU: 11th Gen Intel(R) Core(TM) i7-11800H @ 2.30 GHz, GPU:NVDIA GeForce RTX 3060 6G.
The software environment is: windows10, python 3.9.12, torch version 1.12.0.
In terms of hyperparameters, we set the learning rate to 0.001, the batch size to 16, the number of iterations to 500, the hidden layer size of the encoder and decoder to a=b=128, and the number of time period features n= 23. In order to improve the convergence speed of the model, we normalize the samples in the interval [0,1]. Because the recording intervals of the two data sets are different, we set the historical time step T l of the data set Los-loop to (n+1)*12, and the historical time step T s of the data set Sz-taxi to (n+1)*4, to predict the traffic speed in the next 15 minutes, 30 minutes, 45 minutes and 60 minutes. Therefore, the prediction steps τ l of the data set Los-loop are (3,6,9,12), and the prediction steps τ s of the data set Sz-taxi are (1,2,3,4). Finally, we use adam optimizer to train our model.
Evaluation metrics
We use four evaluation metrics to evaluate the performance of MTA-CN. Mean Absolute Error (MAE): MAE can well reflect the actual situation of the predicted value error, and the smaller the MAE, the better the model performance.
Root Mean Squared Error (RMSE): RMSE is used to measure the deviation between the true value and the predicted value. The closer the predicted value is to the actual value, the smaller the root mean square error between the two. The smaller the RMSE, the better the model performance.
Coefficient of Determination (R2): R2 is a measure of the goodness of fit of the estimated regression equation. The closer R2 is to 1, the better the fit and the better the performance of the model.
Explained Variance Score (var): var is used to measure the degree to which the model can explain the fluctuation of the data set. When the result is closer to 1, the model performance is better.
In this paper, the following baseline models are selected for comparison with MTA-CN. Support Vector Regression (SVR) [16]: SVR are suitable for small sample data and can solve high-dimensional problems. Autoregressive Integrated Moving Average model (ARIMA) [14]: ARIMA can make dynamic prediction by using the dependencies and correlations between time series observations Gated Recurrent Unit model (GRU) [21]: GRU is a variant of RNN that can capture dependencies with large intervals in time series data. Graph Convolutional Network model (GCN) [33]: GCN extends the convolution operation to the graph structure, considering the spatial structure. A Temporal Graph Convolutional Network (T-GCN) [32]: A hybrid model that uses GCN to extract spatial structure features and GRU to extract temporal features. Attention Temporal Graph Convolutional Network (A3T-GCN) [44]: On the basis of T-GCN, an attention mechanism is added to extract the weight of the time step.
Table 2 shows the performance results of the MTA-CN model and other baseline models predicting the next 15 minutes, 30 minutes, 45 minutes, and 60 minutes on the Los-loop dataset and the Sz-taxi dataset. (*) indicates values too small to be statistically significant. Our proposed model outperforms most of the baseline models in both datasets. Based on the results, we draw the following conclusions.
Comparison of prediction results between MTA-CN and other baseline models
Comparison of prediction results between MTA-CN and other baseline models
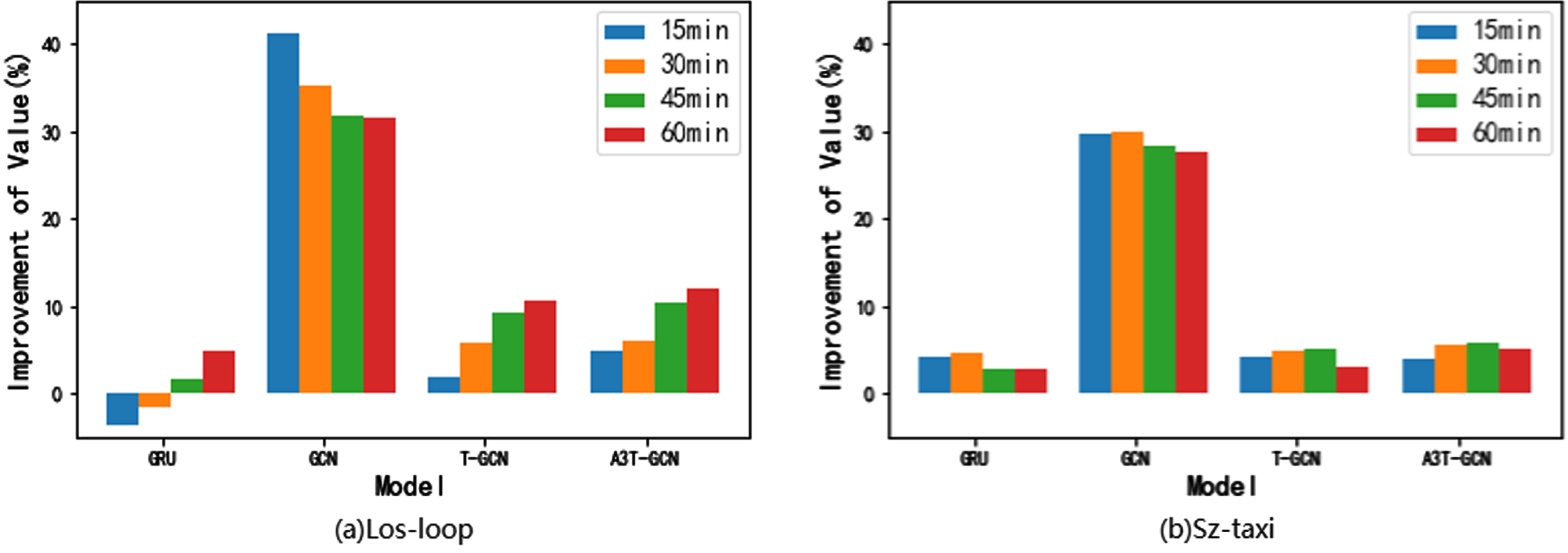
Deep learning-based methods are more effective than traditional machine learning methods on the two datasets. Traditional methods have limited ability to model non-linear and complex traffic data. For example, the ARIMA model requires stable data, but due to the complexity of real-life traffic situations and the many influencing factors, ARIMA performs poorly compared to other baseline models. Due to the ever-increasing amount of data, traditional machine learning approaches are increasingly challenged to outperform data-driven deep learning models in terms of performance. In contrast, deep learning-based methods can model nonlinear data and consider the topology of the traffic network, leading to higher accuracy. Among them, MTA-CN has more advanced performance than other models. In order to prove that MTA-CN can not only consider temporal and spatial correlations, but also learn temporal patterns from long-term time series, we compare the MTA-CN model with GRU, GCN, T-GCN, and A3T-GCN, as shown in Figs. 5 and 6, they represent the improvement percentage of our model compared to some other deep learning baseline models on the two evaluation indicators RMSE and MAE, the calculation formula is as follows:
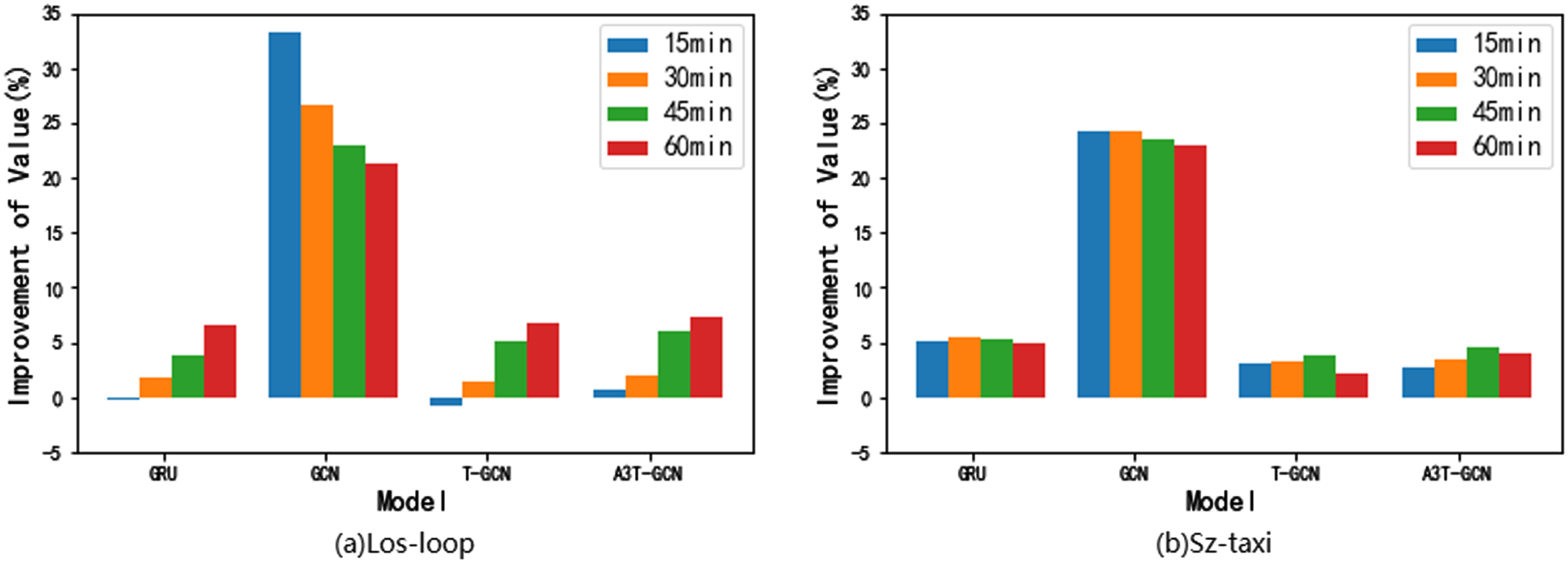
Percentage improvement of MTA-CN compared to other deep learning baseline models on RMSE metric for different prediction steps.
Percentage improvement of MTA-CN compared to other deep learning baseline models on MAE metric for different prediction steps.
In the 60-minute prediction of the two datasets, MTA-CN outperformed several models in terms of the improvement percentage of RMSE and MAE indicators. Compared to the GRU, MTA-CN achieved approximately 6.54% and 5.02% improvement in the RMSE metric, and approximately 4.8% and 2.9% improvement in the MAE metric. This is because the GRU model only aggregates temporal features without considering spatial features. Compared to the GCN, MTA-CN achieved approximately 21.37% and 23.02% improvement in the RMSE metric, and approximately 31.54% and 27.54% improvement in the MAE metric. The significant difference in performance is due to the fact that GCN only aggregates spatial features without considering temporal features. As a model based on spatiotemporal features, MTA-CN exhibits better predictive accuracy than GRU and GCN, which only consider single factors.
Compared to T-GCN, which is based on spatiotemporal features, MTA-CN has achieved an improvement of approximately 6.82% and 2.17% in terms of RMSE, and approximately 10.64% and 3.04% in terms of MAE. Compared to T-GCN, MTA-CN not only considers spatio-temporal features, but also utilizes an attention mechanism to select more important temporal features for prediction. As a consequence, MTA-CN achieves better prediction performance.
A3T-GCN not only considers spatio-temporal features but also captures the correlation of temporal features, assigning higher weights to more important temporal features. Compared to A3T-GCN, MTA-CN achieves improvements of approximately 7.34% and 4.09% in RMSE, and approximately 12% and 5.11% in MAE, respectively. This is because MTA-CN takes into account longer-term temporal features and aggregates them into a special sequence, resulting in higher accuracy.
However, for some lower prediction steps, MTA-CN’s prediction accuracy was slightly inferior to some baseline models. For example, in the 15-minute prediction and 30-minute prediction on the Los-loop dataset, the prediction accuracy of MTA-CN was not as good as GRU and T-GCN. Nevertheless, at high prediction steps, MTA-CN achieved better accuracy than other baseline models, indicating that our model is more suitable for long-term prediction.
In order to test the long-term prediction ability of the model, we plotted the trend of two evaluation indices as the prediction step size increases for each model. Although some models that only consider time correlation can achieve better results in short-term prediction, the prediction difficulty increases as the prediction interval increases, resulting in a decrease in accuracy. This is because errors stack up with each prediction and become larger as the interval increases. As shown in Fig. 7, SVR, GRU, T-GCN, and A3T-GCN perform well in short-term prediction on the Los-loop dataset, but their accuracy sharply declines as the interval increases. The accuracy of MTA-CN declined relatively slowly. In the Sz-taxi dataset (Fig. 8), the accuracy decline trend of these models is relatively stable due to the different measurement intervals of the two datasets. This is due to the different measurement intervals between the two data sets, the measurement interval of Sz-taxi is 15 minutes, and the measurement interval of Los-loop is 5 minutes, so the prediction steps corresponding to Los-loop are 3, 6, 9, 12 respectively, while the prediction steps corresponding to the SZ-taxi data set are only 1, 2, 3, 4. In conclusion, our model MTA-CN demonstrates excellent long-term prediction ability with minimal change in prediction results as the prediction step size varies. Therefore, it can be used for both short-term and long-term prediction.
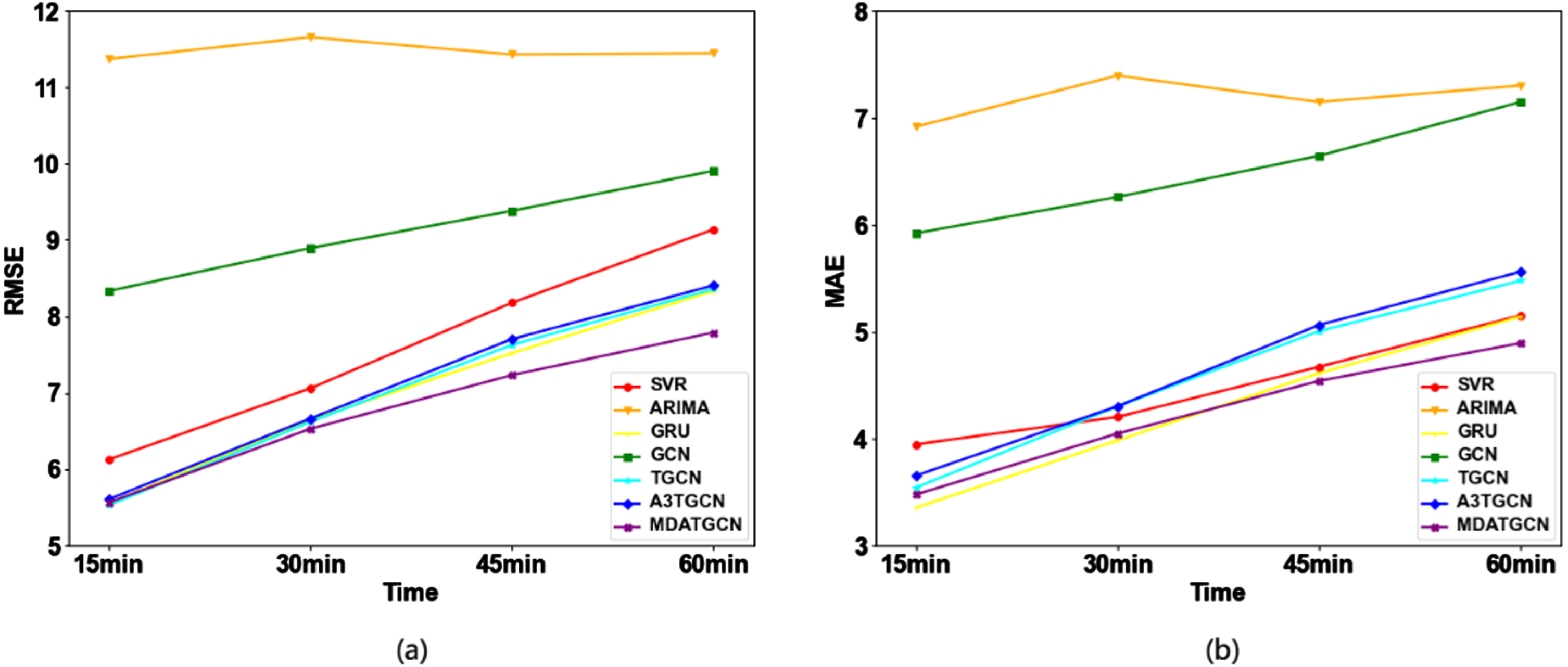
Under different prediction steps. (a) Changes in the evaluation index RMSE on the Los-loop dataset. (b) Changes in the evaluation index MAE on the Los-loop dataset.

Under different prediction steps. (a) Changes in the evaluation index RMSE on the Sz-taxi dataset. (b) Changes in the evaluation index MAE on the Sz-taxi dataset.
To assess whether MTA-CN captures long-term temporal features, we introduce additional noise sequences to the dataset. Specifically, we add a noise sequence of equal length to the time period feature in the Los-loop dataset and the Sz-taxi dataset. Then we input these sequences into the MTA-CN model. In this paper, the historical time step is denoted as (n+1)T, where n=23 represents the 23 time period features in the encoder. We add 23 additional time series of length T to the input time series, which are randomly distributed between [0,1]. Figure 9(a) and (b) show the weight distributions of 46 sequences, where the first 23 represent the original sequence, and the last 23 represent the noise sequence. We use all 46 sequences as input and apply the attention network to scale these weights. Our results demonstrate that the attention mechanism assigns larger weights to the original sequence and smaller weights to the noisy sequence, indicating that MTA-CN adaptively selects more relevant time period features and captures longer temporal correlations. Therefore, our model not only exhibits excellent predictive performance, but also demonstrates interpretability advantages.
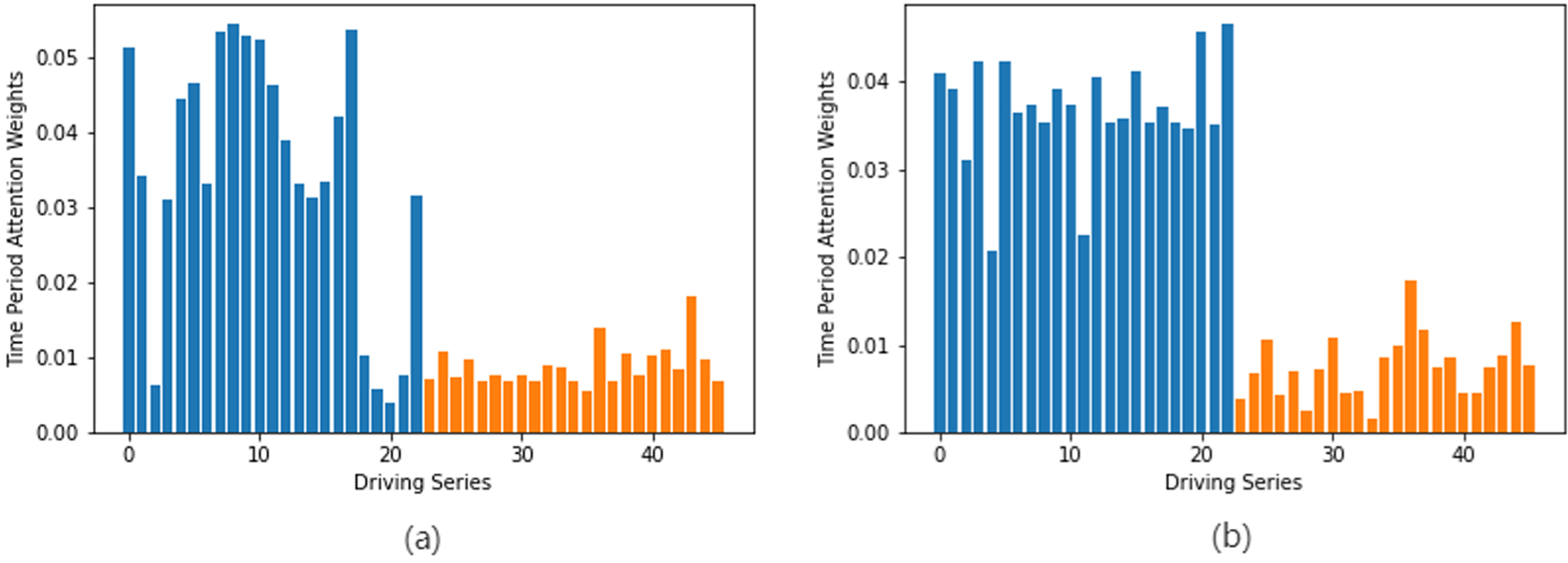
Time period feature attention weight map, the first twenty-three represent real time period features, and the last twenty-three represent added noise sequences. (a) Los-loop. (b) Sz-taxi.
To gain a better understanding of MTA-CN, we selected a road from the Los-loop dataset and the Sz-taxi dataset respectively and visualized the prediction results of the test set. In Fig. 10(a)–(d) illustrate the prediction results of 15 minutes, 30 minutes, 45 minutes, and 60 minutes on the Los-loop test set, respectively. In Fig. 11(a)–(d), we find the prediction results of 15 minutes, 30 minutes, 45 minutes, and 60 minutes on the Sz-taxi test set, respectively.
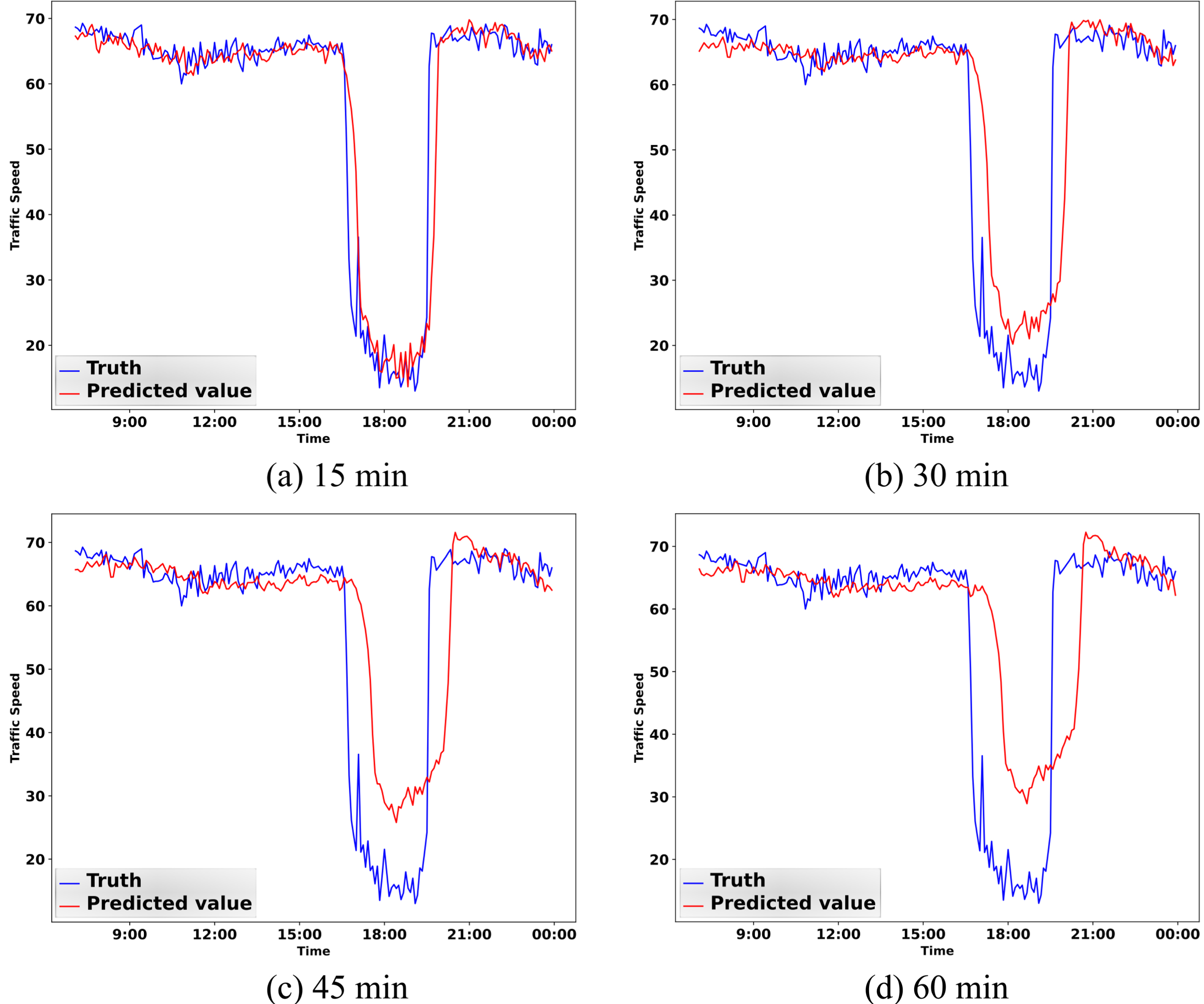
Visualization of different prediction steps on the Los-loop test set.
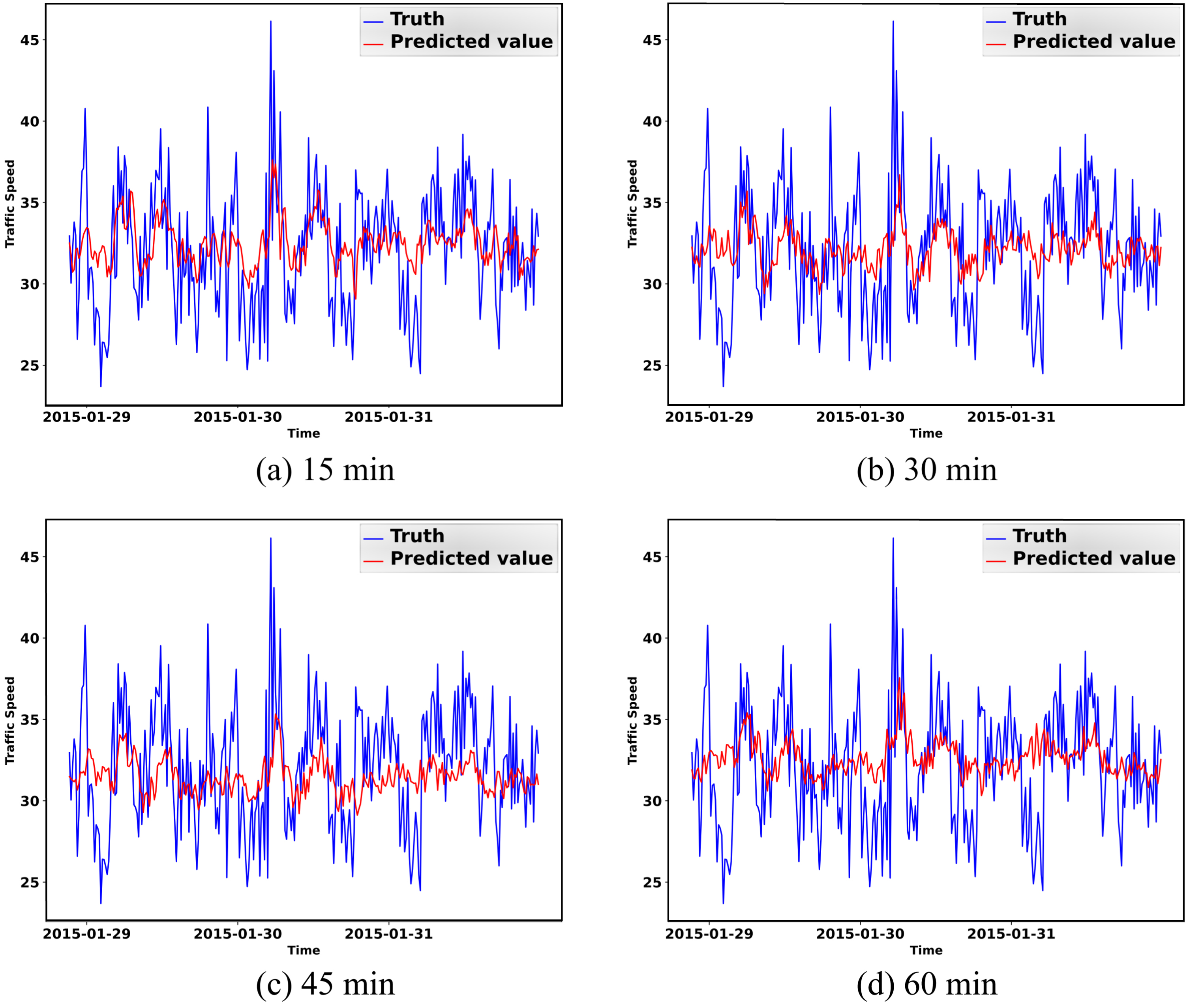
Visualization of different prediction steps on the Sz-taxi test set.
We observed that short-term predictions on the same dataset were better than long-term predictions. In the Los-loop dataset, the prediction accuracy for the 15-minute interval was high, but as the prediction interval increased, the accuracy of the model in some time periods with significant changes in actual values decreased, such as 15 : 00–21 : 00. However, in relatively stable periods, such as 9 : 00-15 : 00, the prediction accuracy was not significantly affected despite the accumulation of errors. In periods with more significant changes, errors accumulated more, leading to decreased prediction accuracy. Moreover, analysis of the prediction results in the Sz-taxi dataset showed that the model’s prediction accuracy for local maximum and minimum values was poor, which was attributed to the over-smoothing problem of GCN during training.
Despite these limitations, the MTA-CN model was able to capture the temporal and spatial variation trends of the road and produce relatively good prediction results, indicating its effectiveness in traffic speed prediction.
We proposed a MTA-CN for traffic speed prediction, which network comprises an encoder with time period feature attention and a decoder with temporal attention. The time period feature attention mechanism enables the encoder to selectively identify relevant time period features, while the temporal attention mechanism allows the decoder to adaptively capture correlations at different time steps. Instead of the traditional recurrent neural network, we used a Temporal Graph Convolutional Network (T-GCN), which integrates Graph Convolutional Neural Network (GCN) and Gated Recurrent Unit (GRU) to capture the topology of non-Euclidean space and the dynamic changes of node traffic information. The spatio-temporal correlation of traffic road networks can be fully considered by T-GCN, and based on two attention mechanisms, MTA-CN can learn the correlation from long-term time series. MTA-CN performs better in almost all of the different prediction ranges when using it to compare with other baseline models on two real world datasets. The model we proposed successfully extracts spatial features and long-term temporal features from the traffic information.
In the future works, the model proposed in this paper could be improved in the several directions, such as contribute to the progress of efficiently predicting the peak hours or road accidents in the studied traffic network. We only use GCN to extract spatial features. Building on the foundation of this study, replacing GCN with other advanced graph neural networks may lead to improved research outcomes.
Footnotes
Acknowledgments
This work was supported in part by Fujian Provincial Department of Science and Technology under Grant No. 2021J011070, and Fujian University of Technology under Grant No. GY-Z18148.