
Abstract
The study addresses the challenges of human action recognition and analysis in computer vision, with a focus on classifying Indian dance forms. The complexity of these dance styles, including variations in body postures and hand gestures, makes classification difficult. Deep learning models require large datasets for good performance, so standard data augmentation techniques are used to increase model generalizability. The study proposes the Indian Classical Dance Generative Adversarial Network (ICD-GAN) for augmentation and the quantum-based Convolutional Neural Network (QCNN) for classification. The research consists of three phases: traditional augmentation, GAN-based augmentation, and a combination of both. The proposed QCNN is introduced to reduce computational time. Different GAN variants DC-GAN, CGAN, MFCGAN are employed for augmentation, while transfer learning-based CNN models VGG-16, VGG-19, MobileNet-v2, ResNet-50, and new QCNN are implemented for classification. The study demonstrates that GAN-based augmentation outperforms traditional methods, and QCNN reduces computational complexity while improving prediction accuracy. The proposed method achieves a precision rate of 98.7% as validated through qualitative and quantitative analysis. It provides a more effective and efficient approach compared to existing methods for Indian dance form classification.
Keywords
Introduction
In current era, deep learning has become most significant approach for solving problems and is extensively utilized in numerous fields speech recognition, object detection, visual object detection [1], medical health care systems [3] and various domains [2]. This approach has been made infinite growth in computer vision domain for the fine-grained recognition of objects [4], place recognition [5] and detection of objects [6] for instance traffic signs detection [7], and also has been explored in other domains such as classification tasks like face pose estimation [8], face and non-face speckle classification [9], recommendation systems [10], and natural language processing (NLP) [11]. To achieve particular task, Deep neural networks learn different levels of features of a dataset through complex network architectures. Classification tasks in deep learning are challenging, and appropriate deep learning methods even outperform human recognition capabilities in this area. The quantity of training datasets has a significant impact on learning success when using this data-driven training strategy. Iterative training with huge datasets can produce superior outcomes for some challenging problems [12]. The datasets needed for model training, however, are not always adequate, particularly for the valuable and complex datasets that are incomplete or redundant and contain even less useful information after data cleaning. While utilizing shallow networks does not excerpt the rich depth information and the model’s generalizability is relatively poor, adding more deep network layers to classification tasks with small-scale datasets is prone to overfitting.
Earlier researchers are trying to overwhelmed this issue by utilizing data augmentation. Most popular methods of data augmentation comprise simple transformations applied on images such as translation, rotating, mirroring and scaling. In order to progress the training process of networks is a common method in computer vision problems [13] are employ traditional data augmentation. However, only little amount of extra information can be extracted from small changes to the images. Synthetic data augmentation of high-quality samples is novel and advanced method of data augmentation. In order to advance the training of the model, synthetic data samples learned using a generative model enable greater changeability and improve the dataset.
Generative Adversarial Networks are one such effective method inspired by game theory for training a model that synthesises images (GANs) [14]. This model comprises of two networks, the first network produces fake images called generator and the second network distinguishes amongst real and fake images repeatedly called discriminator which were trained in an adversarial process. GANs have been gained great wide popularity in the field of computer vision and various variants of GANs such as GAN [14], Deep convolution GAN [15], GAN using Laplacian pyramid [16], Conditional GAN [17], Auxiliary GAN [18] were newly been proposed to produce excellent quality of realistic images. Other fascinating applications of GAN comprise producing one style of images from another style images (image-to-image translation) [19], inpainting of images by utilizing GAN [20]. Limited data in the ICD dataset poses a significant challenge when it comes to classifying various dance forms. With a smaller dataset, there is a higher risk of overfitting, where the model becomes too specialized to the training data and fails to generalize well to new, unseen data. Overfitting can lead to poor performance and inaccurate classification results. As the data size increases, training deep learning models, such as CNNs, can indeed become challenging due to the increased computational requirements and memory constraints.
To address these challenges, in this work we proffered a GAN based augmentation named as ICD-GAN and quantum-based convolution neural network (QCNN) to progress the model classification performance results and decrease the computational time for classification task. The Proposed GAN model uses GAN variants like Deep convolution (DC-GAN), Conditional (CGAN) and Multiple Fake Class (MFC-GAN) for generating high quality of synthesized images. The key contributions of this paper are Produce new images by traditional augmentation. Synthesis of high-quality dance images by GAN based augmentation with different GAN variants like DCGAN, CGAN, and MFC-GAN. Build various CNN architectures like VGG16, VGG19, ResNet-50, MobileNet-v2 and QCNN for performing classification task by the concept of transfer learning. Compare the classification accuracy results with and without augmentation, CNN models with QCNN. For quantitative analysis ANOVA test has been conducted to compare the classification results with and without augmentation-based training data. Run time analysis is performed by comparing the execution time for different CNN architectures. Lastly compare the performance results of proffered method with state of art results.
The remaining paper is systematized in the following manner. Section-2 we survey some essential concepts of GAN, and some variants of GANs and training issues, various classification models applied on ICD. Section-3 we demonstrate traditional and GAN based augmentation methods applied in image synthesis process and QCNN for classification Section-4, we present the experiment results of augmentation and classification Section-5 discussions on the work by comparative analysis, performance analysis, quantitative analysis and runtime analysis. Finally, conclusion and future enhancement are given in Section-6
Related work
Indian classical dance, known as Natya Sastra, is a significant art form that reflects Indian culture and traditions. It encompasses eight categories of dance forms, highlighting the diversity of Indian heritage. These dance styles effectively convey human emotions. However, classifying these styles poses a challenge due to their variations. A study by [21] explores the use of traditional Indian dance, specifically Bharatanatyam, as a teaching tool for geometry and mathematics. The study introduces a categorical content analysis methodology that helps Indian children comprehend mathematical shapes through dance, providing a unique approach to integrate mathematics and dance education while promoting the understanding of geometric patterns. [22] found a historical relationship between kathak and geometry, showcasing the connection between ICD and mathematics. Researchers of paper [23] suggest, a novel framework for categorising ICD styles from films. Through the use of optical flow and deep convolutional neural network (DCNN) [24], the representations are retrieved. Additionally, a multi-class linear support vector machine was used to train these representations (SVM). This model results an accuracy of 75.83% [25]. Nrityantar [26] introduced a pose-oblivious classification method for Indian classical dance sequences. [27] utilized sparse representations of HOOF characteristics and achieved a precision rate of 86.67% using SVM. [28] developed a segmentation model using DWT and LBP, classified with [29] Ada Boost. [30] recognized dance forms and mudras using HOG and SVM. [31] proposed a three-step pipeline with RNN for Indian dance style classification. [32] developed an AI tool using CNN, achieving a recognition rate of 93.33%. [33] introduced a DCNN model using ResNet50 with an accuracy of 0.911. [34] improved CNN for ICD classification using Transfer Learning with an accuracy of 85.4%. [35] proposed a pose-estimation based LSTM model with an accuracy of 98.53%. [36] optimized CNN with Hybrid PSO and GWO algorithms, achieving an accuracy of 97.3%.
Earlier researchers have utilized deep learning-based transfer learning methods for ICD classification. However, it suffers from classification challenges. To address these, in this proposed work, a GAN-based augmentation technique is implemented to generate high-quality synthetic images. This approach aims to increase the dataset size, overcome overfitting, and reduce computational time. Additionally, the classification accuracy is improved by employing a QCNN.
Proposed methodology
This section describes the methodologies proffered in this work. In the proposed method we describe various augmentation techniques for generating new images and various CNN and QCNN architectures to classify the dance forms.
Work flow of proposed work
This research proffered a new methodology for classification of Indian classical dance by using traditional and GAN data augmentation methods to increase the data set size that automatically enhance the classification accuracy. Figure 1 depicts the process of proffered method. Initially the classical data set was collected from Kaggle which consists of 540 images if various dance forms like Kuchipudi, bhartnatyam, kathak, kathakali, mohiniyattam, Odissi, satriya and Kuchipudi. Consequently, the dance dataset was pre-processed using various image pre-processing techniques. Next apply traditional image augmentation for generating new images and those images, and real images were trained with CNN model to perform dance classification. Later GAN model was used to generate fake images, those fake, real and images were used for training QCNN model for classification. At last, all the real, traditional data augmentation generated images and GAN generated images were used to build the QCNN model for the classification of various dance forms.

Workflow diagram.
The main problem with training model is the limitation of large labelled training ICD dataset. It results overfitting of data. We enhanced the data in two different ways: 1) Traditional augmentation, which consists of various well-known image manipulations on provided data samples, and 2) Synthesis of new examples, which are learned from the data examples using generative models. This allowed us to increase the training dataset and improve the classification results in the dance classification task. We begin with traditional data augmentation techniques and then describe proffered method illustrated in Fig. 2 of generating high quality of synthetic dance images using GANs.

ICD GAN model.
Data Augmentation is one of the most efficient technique of generating new images from existing dataset. The dataset is increased by using this method. There are several approaches used to augment the given dataset. The traditional method to do this is by flipping, rotating, cropping, padding, scaling, blurring, lightening, sharpening etc. However, the dataset produced using this conventional method can still be too tiny for a deep learning model. To overcome this, the GAN deep learning model was developed.
ICD-GAN based augmentation
The classification model used in this work is based on the GANs based augmentation [14]. They have gained popularity recently because of their superior synthetic data generation capabilities. GANs are part of the class of models known as generative, and they are frequently used to either learn (explicitly) or sample from complex probability distributions of picture data. The objective of generative model to generate new samples by indirectly learn the data distribution p data from the set of samples x(1) x(2), . . . x(n). We explore three GAN variants for producing new images of dance forms, as depicted in Fig. 3: (a) that produces labelled examples for each dance class distinctly (b) that integrates class conditioning to produce all labelled examples at once (c) generates multiple labelled examples.
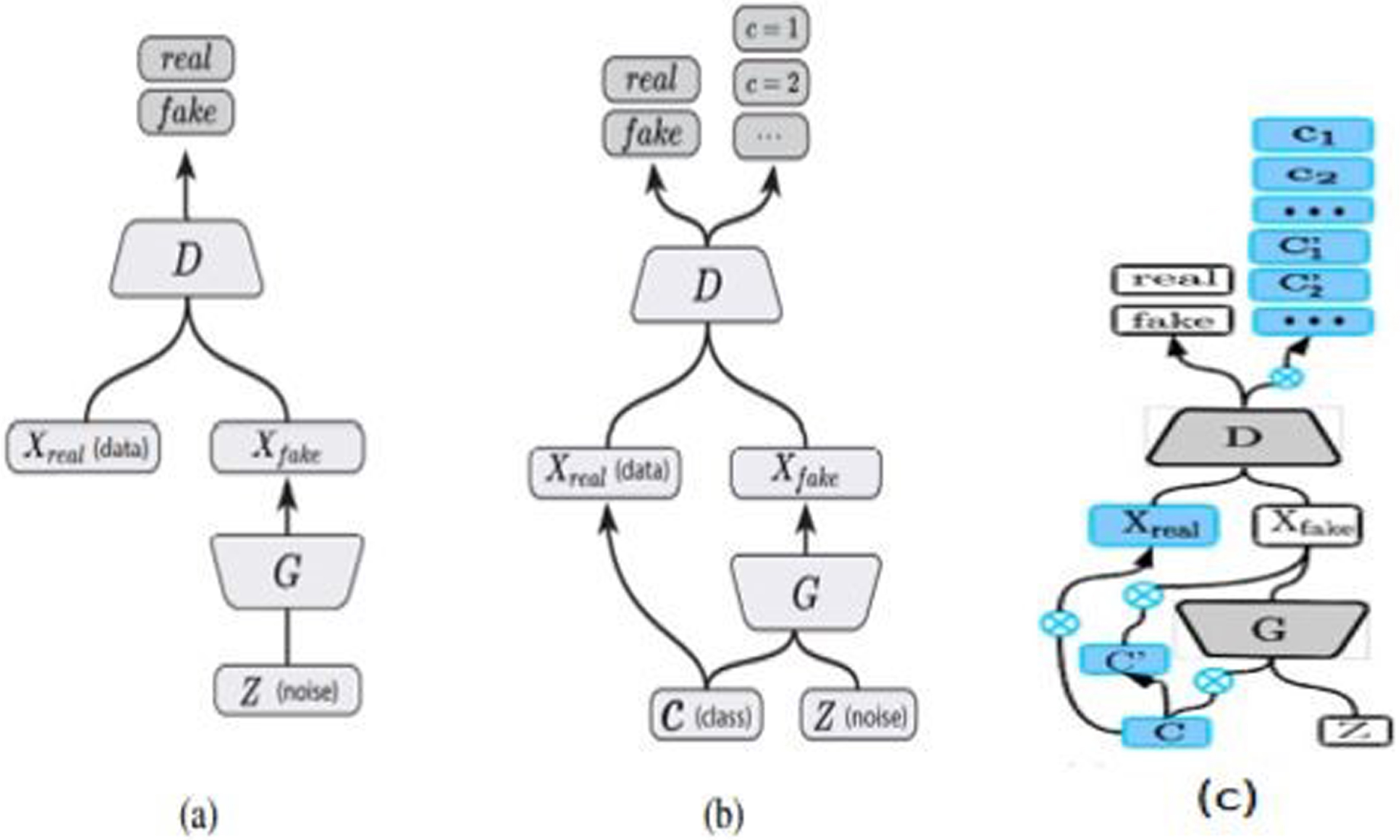
GAN Variants (a) DCGAN (b) Conditional GAN (c) MFC GAN.
The Deep Convolutional GAN was the first GAN variation we used (DCGAN). We adopted the [15] architecture, in which the G and D networks are both deep CNNs. They recommended adjustments to the original GAN introduced by [14], which serves as the foundation model for all other types of GAN models, as well as architectural recommendations for stable GAN training. Here, two neural networks were being trained simultaneously to make up the model. The first network is designated D is known as discriminator. The job of the discriminator is to distinguish between the fake and real samples. It takes sample x as input and returns output D (x), which is the probability that the sample is real. The second network is designated G is known as Generator. The generator produces fake samples that D would consider to be real samples with high likelihood. G maps G (z) to the image space of distribution p g by taking input samples z(1)..., z(n) from a known simple distribution p z typically a uniform distribution. The objective of G is to achieve p g = p data . GAN networks are trained by optimizing the two-player minimax game loss function as defined in Equation 1.
In Equation (1) p z (z) represents the random noise distribution, p data denotes the true data distribution. During this process, D can reject the samples from G along with confidence score near to 1, and therefore the loss log(1 –D(G(z))) saturates and G doesn’t learn whatsoever from zero gradient when discriminator D is being trained considerable better than the generator G. To avoid this, we have to train G to maximize log D(G(z)) rather than to minimize log (1 –D(G(z))). Though the updated loss function for G results a dissimilar scale of gradient than the original one, but it still delivers the same gradient direction and it does not saturate.
3.2.3.1. Generator Architecture of ICD As shown in Fig. 4, the generator network creates dance images that have been downsized to be 64×64×3. It accepts as input a vector of 100 randomly generated numbers that were selected from a uniform distribution. The network architecture comprises four fractionally-stride convolutional layers, fully connected layer restructured to size 4×4×1024 and 5×5 kernel is used to up sample the image. An interpretation of a fractionally-strided convolution, commonly referred to as a “deconvolution,” is to enlarge the pixels by interspersing zeros. A larger output image will be produced after convolution over the expanded image. Except for the output layer, each layer of the network is subjected to batch-normalization. The GAN learning process is stabilized by normalizing responses to have mean value as zero and unit variance throughout the whole mini-batch, which stops the generator from condensing all samples into a single point. All layers of the network except the last output layer, which employs tanh activation function, are activated using ReLU activation functions.
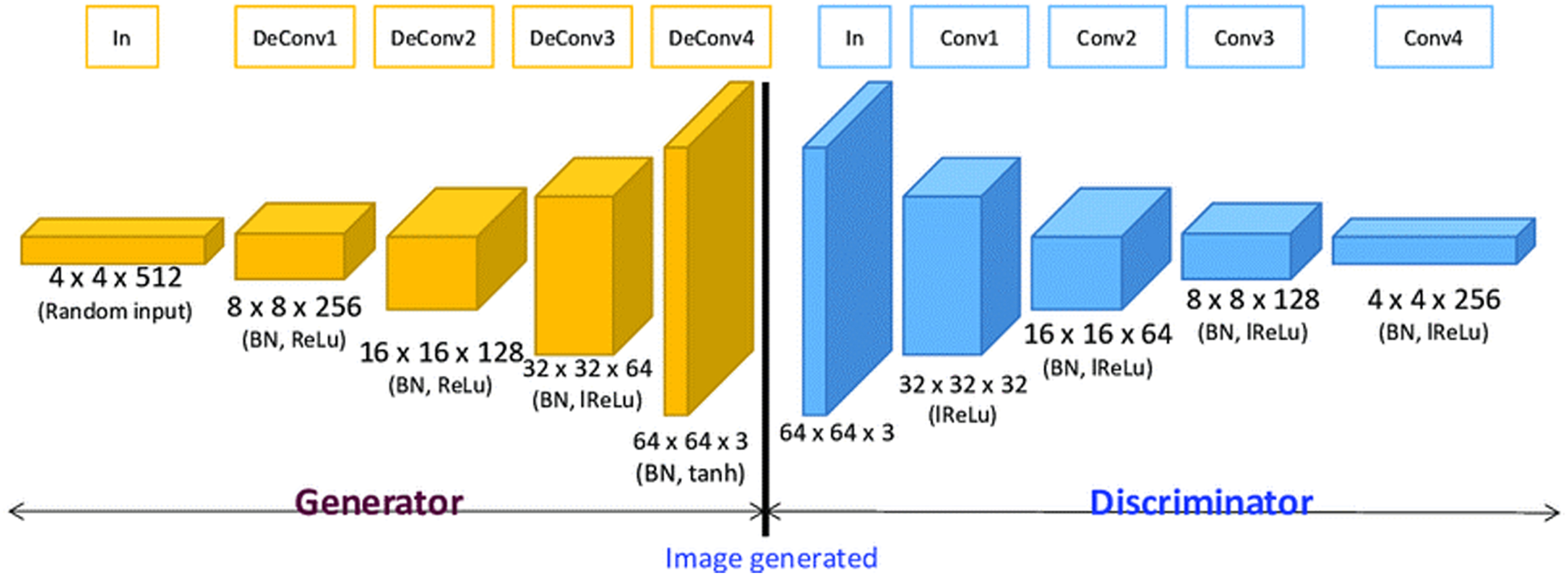
DC GAN Layered architecture.
3.2.3.2. Discriminator architecture of ICD. The discriminator network seen in Fig. 4 has a normal CNN design and outputs one conclusion, “Is this image real or fake?” from an input image with the dimensions 64×64×3. The network comprises of 4 convolution layers with filter size of 5×5 and a fully connected layer. Instead of employing pooling layers, 5 strided convolutions are applied to each convolution layer to reduce spatial dimensionality. Every layer of the network is subjected to batch-normalization, with the exception of the input and output layers. All the layers uses Leaky ReLU activation functions and Sigmoid function in the output layer which calculates the likelihood probability score of the image which lies between 0 and 1.
3.2.3.3. Training DCGAN Model. We trained the DCGAN model to produce dance individually for each dance style. The training process was performed repeatedly for both generator and discriminator. For each dance style type l ∈ (Kuchipudi, kathakali, bhartnatyam, odissi, Manipuri, sattriya, mohiniyattam, kathak) we employed mini-batches of with 35 samples x(1) x(2), . . . x(n)and 35 noise samples z(1) z(2), . . . z(n) that were drawn randomly from uniform distribution and those values are between [–1, 1]. Scaling the training images to the range of the tanh activation function (–1, 1). The slope of the leak in the Leaky ReLU was set as 0.2. Initialized weights had a zero-centered normal distribution with 0.02 standard deviation. Stochastic gradient descent(SGD) was applied in conjunction with the Adam optimizer [38], an adaptive moment estimator that incorporates the first and second moments of the gradients, regulated by parameters β1 = 0.5 and β2 = 0.999, respectively. We used a learning rate of 0.0002 over 50 epochs.
In this work we consider another variant of GAN is CGAN [17]. Which allows images to generated based on conditions. It also consists of two components such as generator and discriminator. The generator and discriminator both receive some additional conditional input information. The additional information is the class label for each image. Let y be the supplementary information such as class labels. By adding y to the generator and discriminator in addition to the input image, we can do conditioning.
The adversarial training framework allows for considerable flexibility in how this hidden representation is composed. In the generator the previous input noise p z (z), and y are combined in joint hidden representation. x and y are used as inputs to discriminative function in discriminator. The objective function of a two-player minimax game would be as Equation (2)
The architecture of CGAN generator is same as the DCGAN but discriminator architecture is changed to that have kernel size 3×3 with stride convolutions each odd layer and includes the dropout of 0.5 in each layer except for the last layer. The discriminator classifies the images into 8 categories. The architecture of conditional GAN is shown in Fig. 5
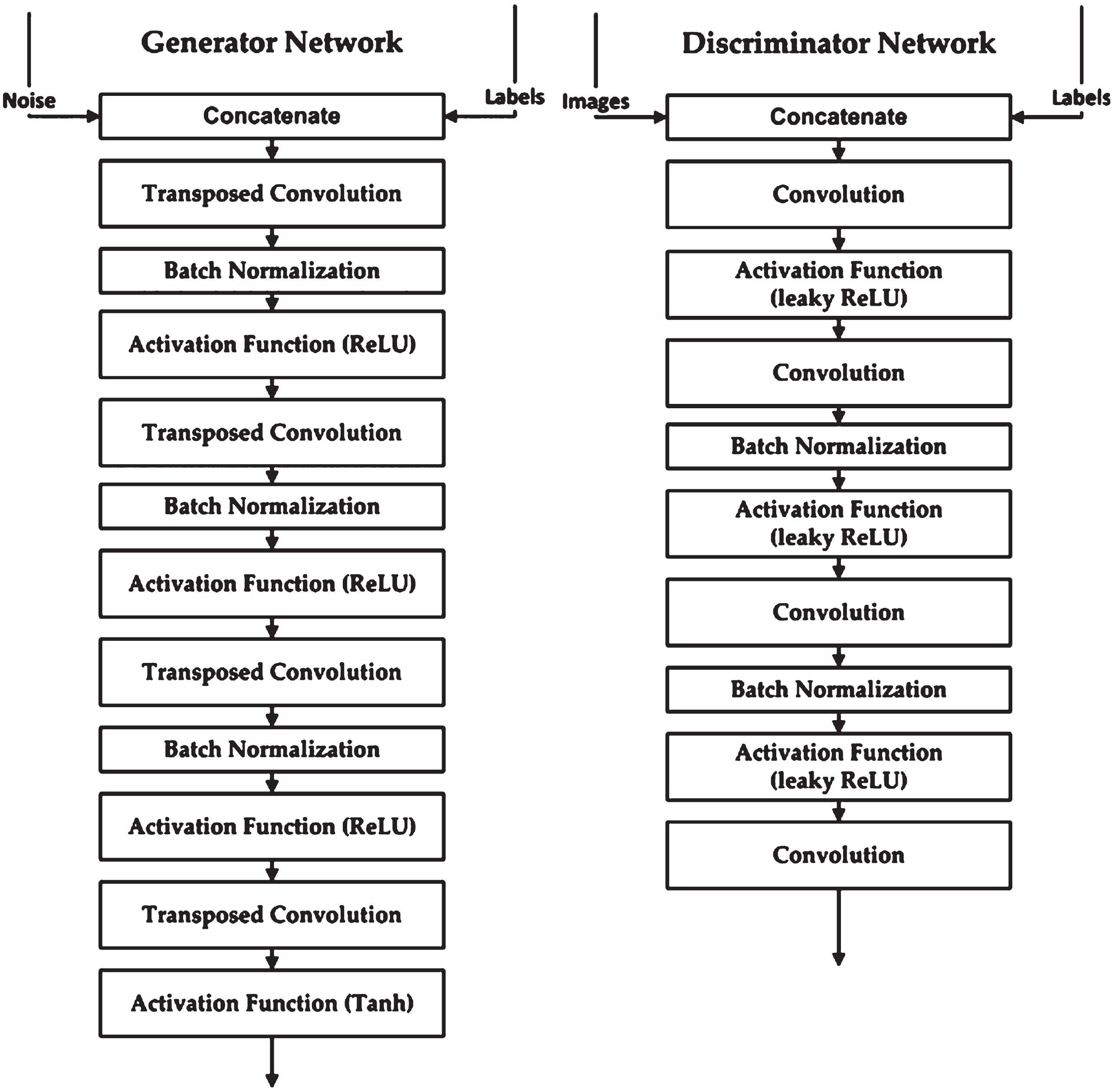
CGAN layered architecture.
MFC-GAN [53] is used to produce plausible images that were utilized to augment trained data. The architecture is shown in Fig. 3(c). Generally, DCGAN is used to generate fake images without labelling. Conditional GAN is used to generated fake images with labels by providing additional label information to the generator and the discriminator checks whether it is fake or real label. Where as in MFC GAN each class labels have been converted into n-bit one-hot -encoding vector. n denotes the no. of classes. We have been padding ‘n’ zeros to the right of the label encoding to create a new representation for actual labels in order to handle fake classes. Thus, by padding n zeros to the left of the original label encoding, a fake class label c′ is created for each real label c. For instance, if class 0 is encoded as 1000000000 for real label, we would now denote this class label by way of 10000000000000000000 and its corresponding fake label by way of 00000000001000000000. To produce class specific samples, we trained MFC-GAN generator utilizing real labels particularly. In ICD dataset there are 8 categories of dances so 8 class labels were generated. Label conditioning directs the development of class-specific samples and motivates the generator to create realistic samples [40]. MFC-GAN divides generated images into distinct false classes while classifying real images into real classes throughout the training process. MFC-GAN is trained with a adapted C-GAN. The fundamental objective is maximizing the log-likelihood of categorizing real examples into real classes C and fake examples into fake classes C′ as defined in Equations (3)-(5).
In which
The architecture of CNN was depicted in Fig. 6 Generally, CNN are widely used for solving image classification and computer vision tasks.
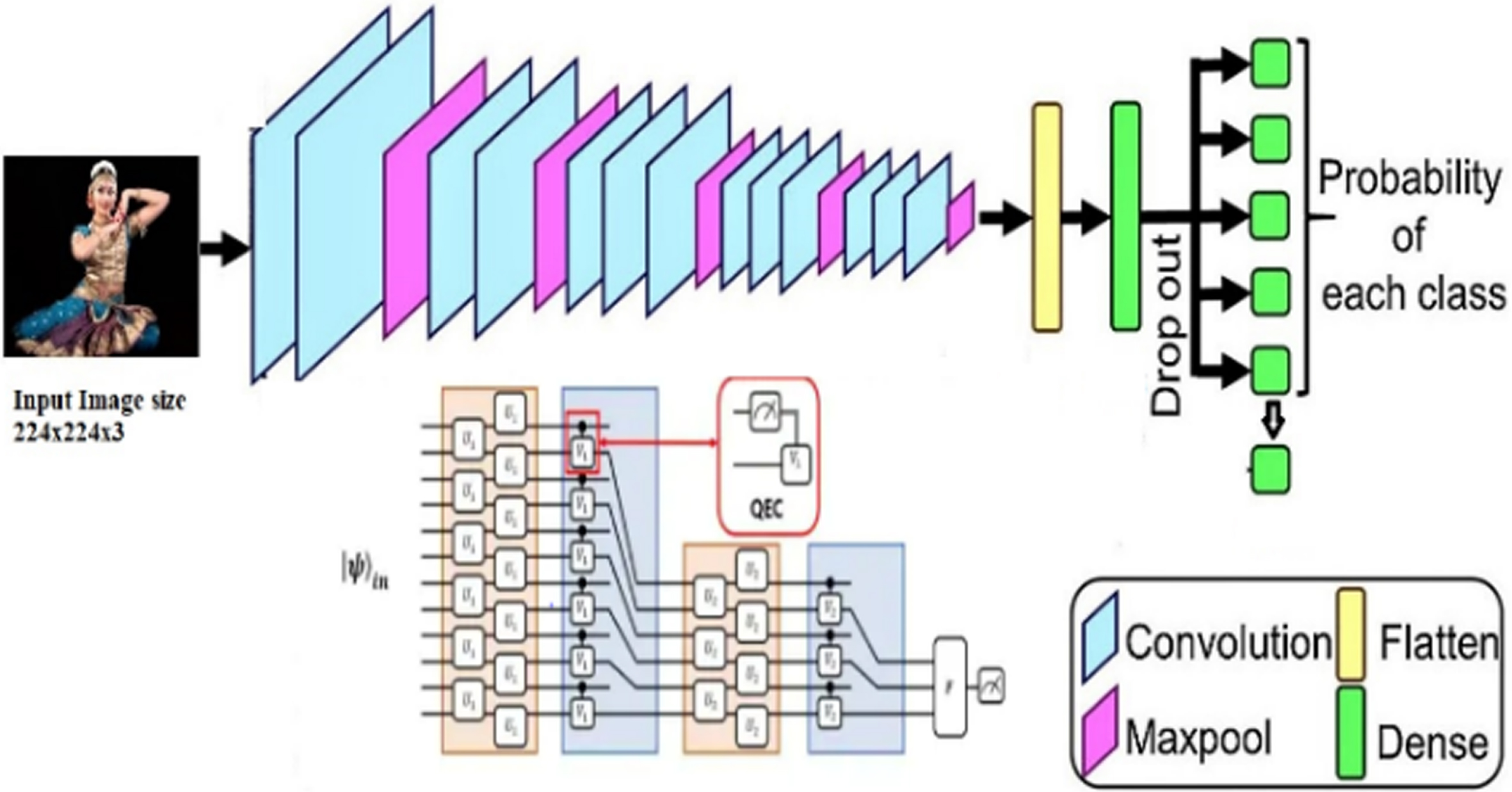
Architecture of ICD-CNN.
In our classification model initially all the images are resized to 224×224×3 with an intensity value rescaled to [0,1]. This architecture comprises of 5 batches of layers. Batch1 consists of 2 convolution layers followed by 1 pooling layer which decreases the size of input into 112×112×64. Batch2 consists of 2 convolutions layers followed by one pooling layer the image size becomes 56×56×256. Batch3 contains 3 convolution layers followed by 1 pooling layer which results an image size 28×28×512. Batch 4 contains 3 convolution layers with 1 pooling layer which results 14×14×512. Batch5 with 3 convolution layers with 1 pooling layer the output size is 7×7×512. A global pooling layer reduces the size into 1×1×512. At the end 2 Fully connected layers, dropout layer with dropout rate 0.5 and at the end SoftMax layer which classifies the image into 8 classes. ReLU remains as activation function in this network.
Cong suggests QCNN model by adding Quantum Error Correction (QEC) to the Multi scale Entanglement Renormalization Ansatz (MERA) model [55] to improvise the performance. For each label in MERA has a representative state |ψ. Since QCNN employs MERA’s reverse direction. The definitive solution can be obtained as a label, if the input data is |ψ. On the other hand, QCNN is unable to produce definitive solution, if |ψ′ that cannot be produced in MERA is provided as input data. To overwhelmed and solved this problem by employing QEC to give extra degrees of freedom. The result obtained in the pooling layer must be |0 which is similar to the newly given state in MERA when the data given to QCNN is |ψ. On the other hand, if |ψ′ which MERA cannot generate is given as input data, there is a possibility that it will be |1 in the measured result. Using these, an extra gate is given to the adjacent qubits to rectify the result, if |1is measured. This approach can give improved performance through supplementary deterministic extent results.
In QCNN the quantum convolution layer (QCL) describes a layer behave similar a convolution layer in the quantum system. The QCL applies a filter to the input feature map to obtain feature maps composed of new data. However, the quantum convolution layer uses a quantum computing environment for filter operation, unlike the convolution layer. Quantum computers have the advantages of superposition and parallel computation that do not exist in classical computing, which can reduce the learning time and evaluation time. However, existing quantum computers are still limited to small quantum systems. The quantum convolution layer does not apply the entire image map to a quantum system at once, but processes it as much as the filter size at a time, so small quantum computers can construct the quantum convolution layer.
The quantum convolution layer of QCNN as shown in Fig. 7. The process is as follows:
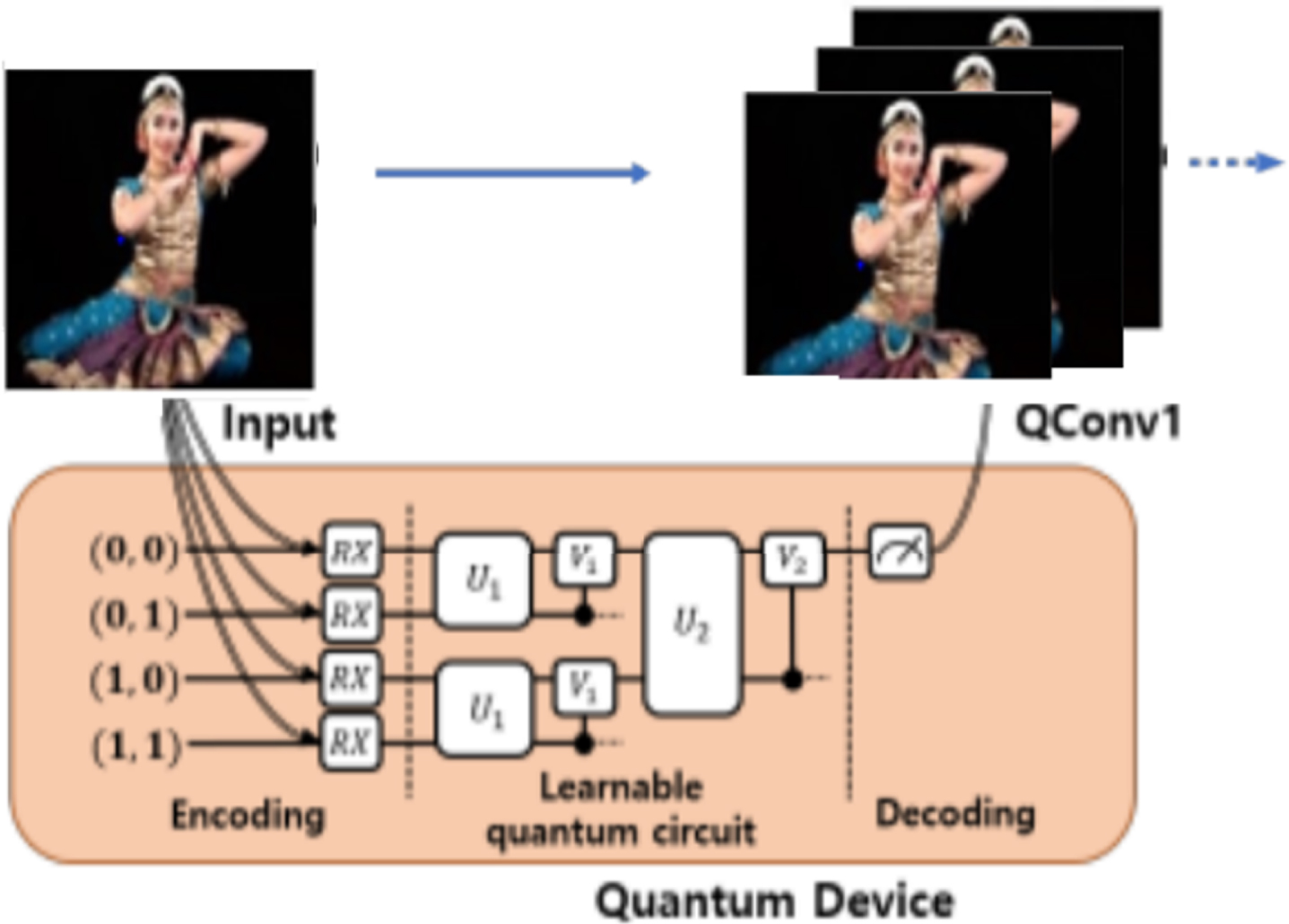
Quantum convolution layer for image classification.
All pixel data corresponding to the filter size is encoded and stored in qubits. The filters that can extract the hidden state from the input state are applied by the learnable quantum circuits. New classical data are obtained through measurement during the decoding process. Create the new feature map by repeating steps 1 through 3.
During the encoding process of 1) converts the classical information into quantum information by employing a rotation gate corresponding to a pixel data to qubits. There are various encoding methods that can be used, and the one chosen can alter the quantity of qubits needed and the effectiveness of learning. One or more quantum states may be measured in order to establish the decoding procedure for step 3). It is possible to determine classical facts by measuring quantum states.
The random quantum circuit in 2) can be made from a combination of multiple gates. By including variable gates, the circuit can also do optimization using the gradient descent approach. This circuit can be designed in various ways that can affect learning performance depending on the design method. MERA typically needs O(n2) operations in n 2-sized filter, but in a quantum system, the parallelism of qubits allows for the creation of filters with O(log(n)) depths.
This section depicts a set of experiments and results. CNN architecture discussed in Section 3.3.6 are used to test the classification findings. We then analysed the effects of GAN based data augmentation for classical dance forms, as compared to traditional data augmentation methodology. For synthetic classical dance forms, we put the two techniques into practice as explained in Section 3. In our experimentations we found that the MFCGAN method performed better for generating images with class labels. Next the performance was evaluated by implanting 5 different deep convolution networks such as VGG16, VGG19, MobileNet-v2, ResNet50, QCNN to classify the dance forms by Transfer Learning.
Data set description
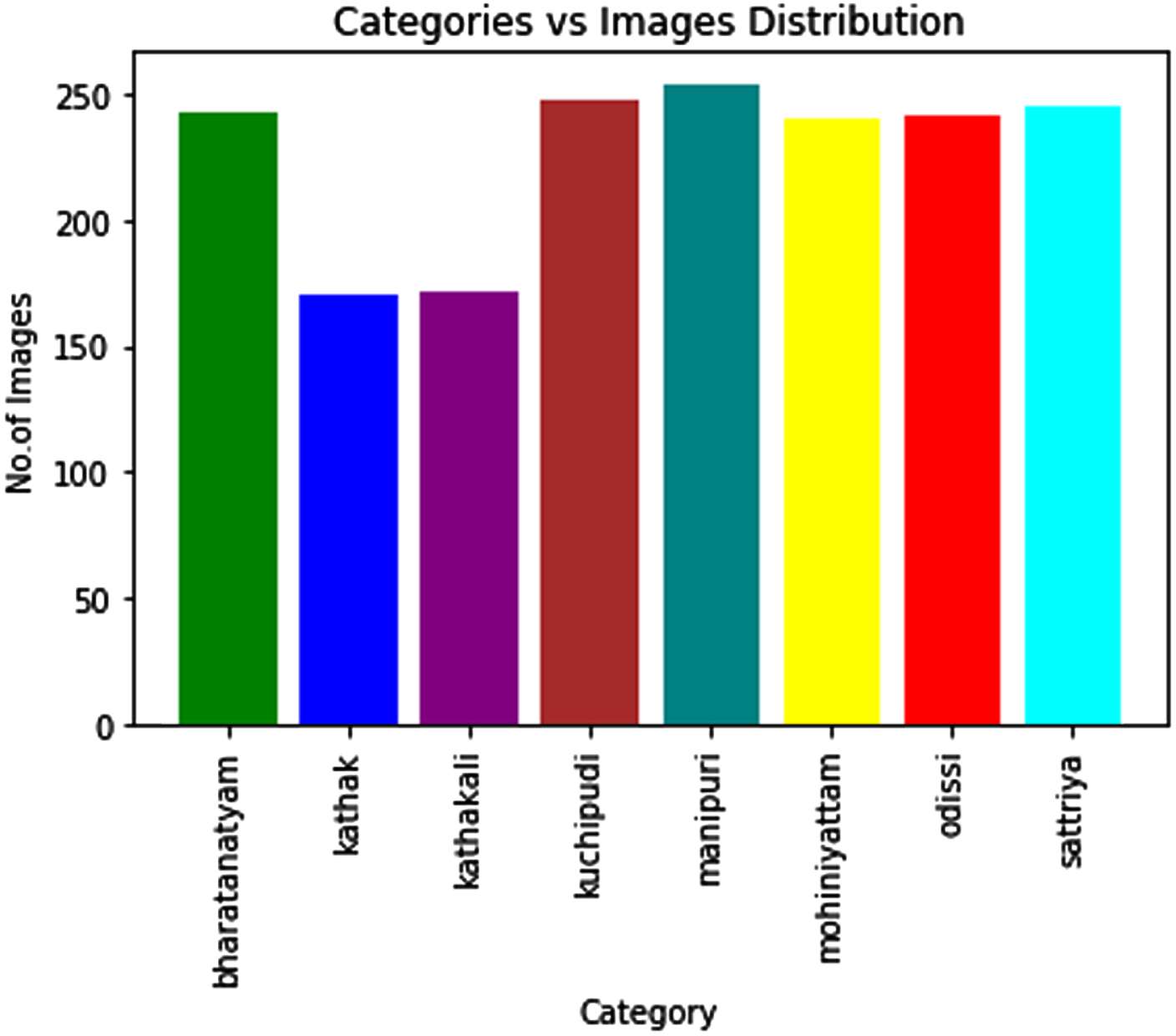
In this proffered work we use ICD data set which is collected from Kaggle.com. This data base consists of 560 images with various dance forms like Bharatnatyam, Kuchipudi, kathakali, kathak, Odissi, Sattriya, Mohiniyattam, and Manipuri. This data set organized into two sub folders training and testing and each subfolder contain 8 categories of dance images with separate folders.
Experimental set up
All the training and testing procedures were done in Windows 10 OS environment, with Intel Core i7-7700 CPU and Nvidia RTX 2080 GPU. The models were built and trained using TensorFlow v1.13.0 and Kera’s deep learning framework.
Image augmentation results
In this experiment images are generated in two ways classical augmentation and GAN based augmentation. During traditional augmentation it generates 1048 new images were generated for various dance forms. Subsequently, we use GAN models like DCGAN, ACGAN and MFCGAN to generate fake images. During this process GAN models produce 1812 new images. Figure 8 shows the original images of the data set Fig. 9. shows some experiment results that generates fake images on ICD dataset. The distribution of images in the ICD dataset are shown in the Fig. 10.

Sample images of ICD dataset.

Real verses fake images.
ICD Image Dataset with augmentation.
To visualize high dimensional data set an advanced tool called T-distributed Stochastic Neighbour Embedding (TSNE) [54] is used. It is a popular dimensionality reduction technique for data exploration and visualization that means the initial stage of data preparation. Figure 11 depicts the data exploration analysis on ICD dataset with and without data augmentation.

TNS Distribution on ICD Dataset.
In this experiment, to build various CNN architectures the hyperparameters used are No. of layers, batch size, Relu is the activation function it is a non-linear function, softmax function for multi class classification, adam optimizer is the learning function, batch size and no. of epochs. Table 2 presents each model and its hyper parameters; Table 3 presents the parameters of both generator and discriminator of various GAN architectures.
Performance evaluation
To address the quantitative performance of proffered model we use the performance metrics. Precision, recall, f1-score, accuracy, sensitivity, specificity, Cohen/Kappa Score and Matthew Score.
During this experimentation, initially the GAN network model was implemented. Generator and Discriminator two network were constructed. Generator generates fake images whereas discriminator differentiate the real and fake images. Figure 12 shows the generator and discriminator loss graph. The model was trained with 50 iterations. Generator maximizes the loss whereas discriminators reduce the loss. Next, ICD classification is done with different CNN model and QCNN architectures. Figure 13 and Fig. 14 depicts the QCNN model accuracy graph and loss graph. QCNN model was trained with 70 epochs. During the experimentation 75% data was used for training and 25% data for testing. It results 98.7% accuracy. On experimentation we interpret that ICD classification with VGG16, VGG19, ResNet50, MobileNet-v2, QCNN gives performance accuracy of 92.4%,97.9%,95.4%,97.2%,98.7%.

DC-GAN loss graph.

QCNN training graph.
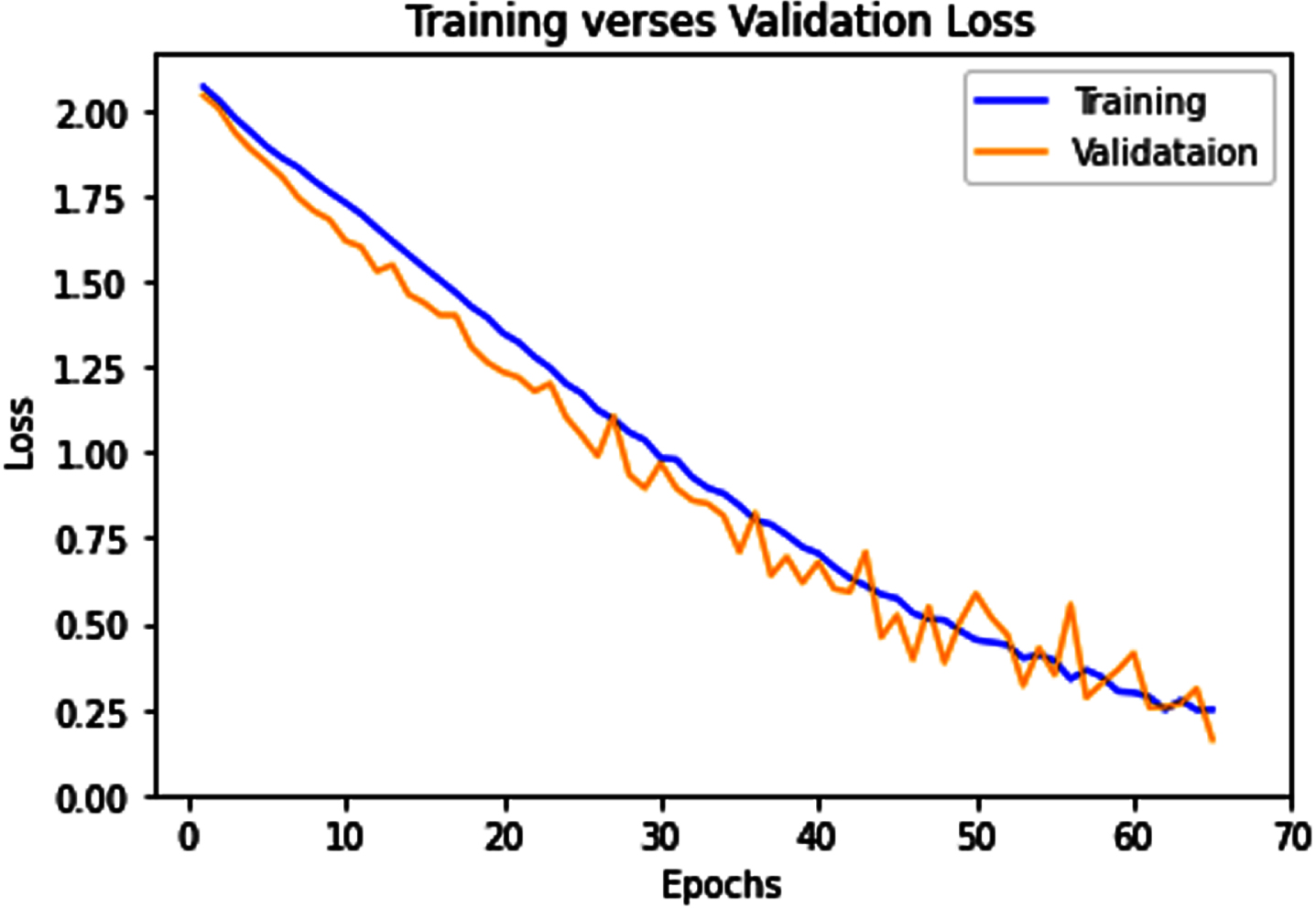
QCNN Model Loss graph.
Various GAN Models
CNN Model Parameters
GAN Model Parameters
The proferred QCNN model was tested with validation data. Figure 15 depicts the dance style classification of QCNN model.

QCNN validation results on ICD.
In this segment we conducted qualitative and quantitative analysis of the proffered method. Not only that compare our model with state-of-art results. And also calculated each model time in terms of seconds.
Performance analysis
The experimental outcome has been performed by assessing the model performance in terms of accuracy, precision, recall, f1-score, specificity, sensitivity kappa score and Mathew score. Figure 16(a)–(d) exhibits the performance of each CNN Model with and without augmented data. In correlation with all models QCNN Network model illustrates the best performance with reduced computational cost. The QCNN with augment dataset portrays an accuracy-98.7%, sensitivity-98.3%, specificity-99.9%, precision-99.5%, recall-96.9%, fi-score-98.3%, Cohen/kappa score-97.3% and Mathew Score-88.5%. Figure 17 shows that augmentation-based classification shows better performance than without augmentation-based classification.
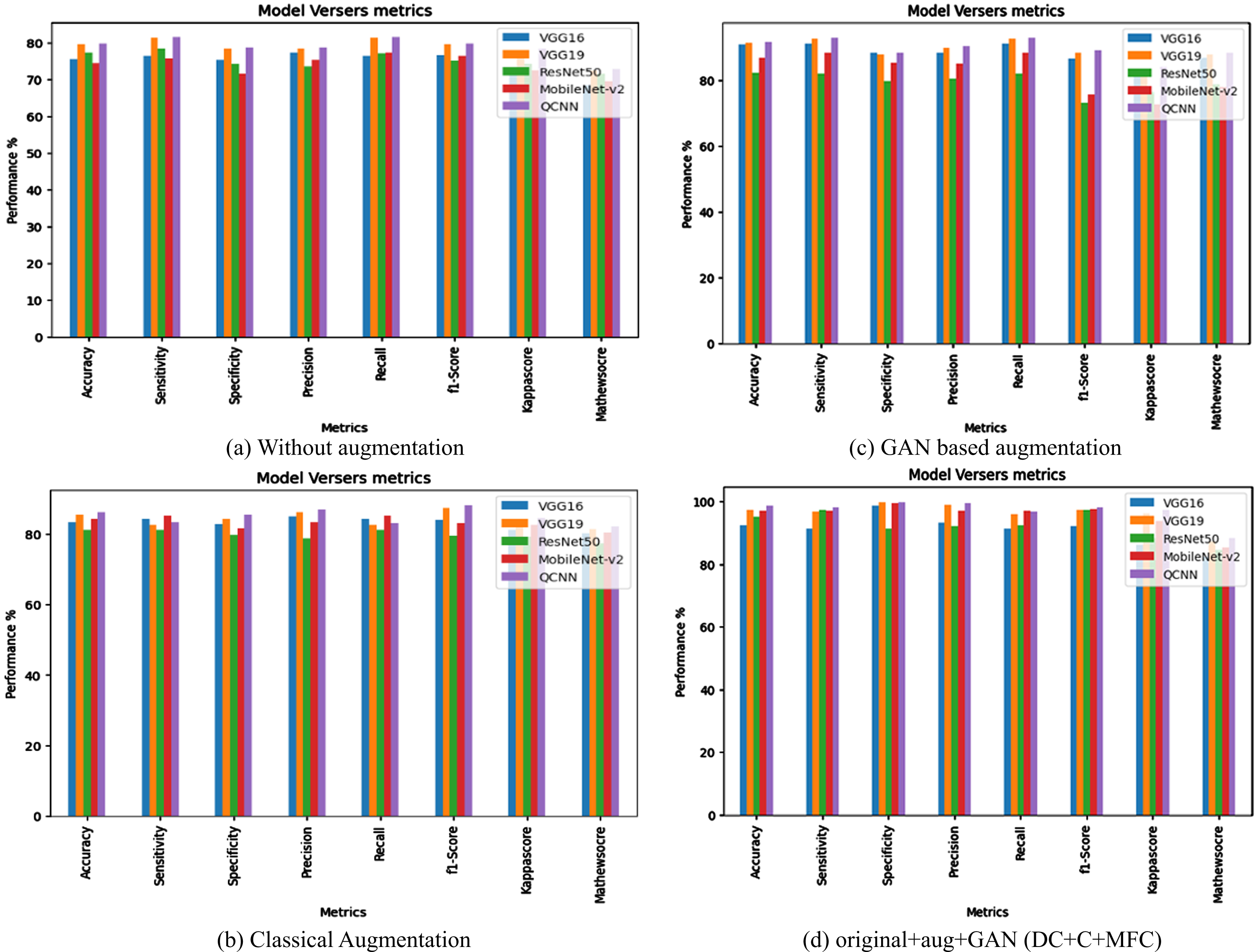
Performance analysis with/without augmentation.

ICD performance graph.
In this study the run time analysis of the proffered model can be performed by taking the running time of each classification model. Here we have implemented VGG16, VGG19, ResNet50 and MobileNet-v2 CNN architectures with transfer learning approach and QCNN for the ICD classification with and without augmented data. All the models were trained with 50 epochs. At each 10 epochs the time was taken in seconds. Figure 18 depicts the training time for each model. Compared to all QCNN takes O(log(n)) time and CNN takes O(n2) time.
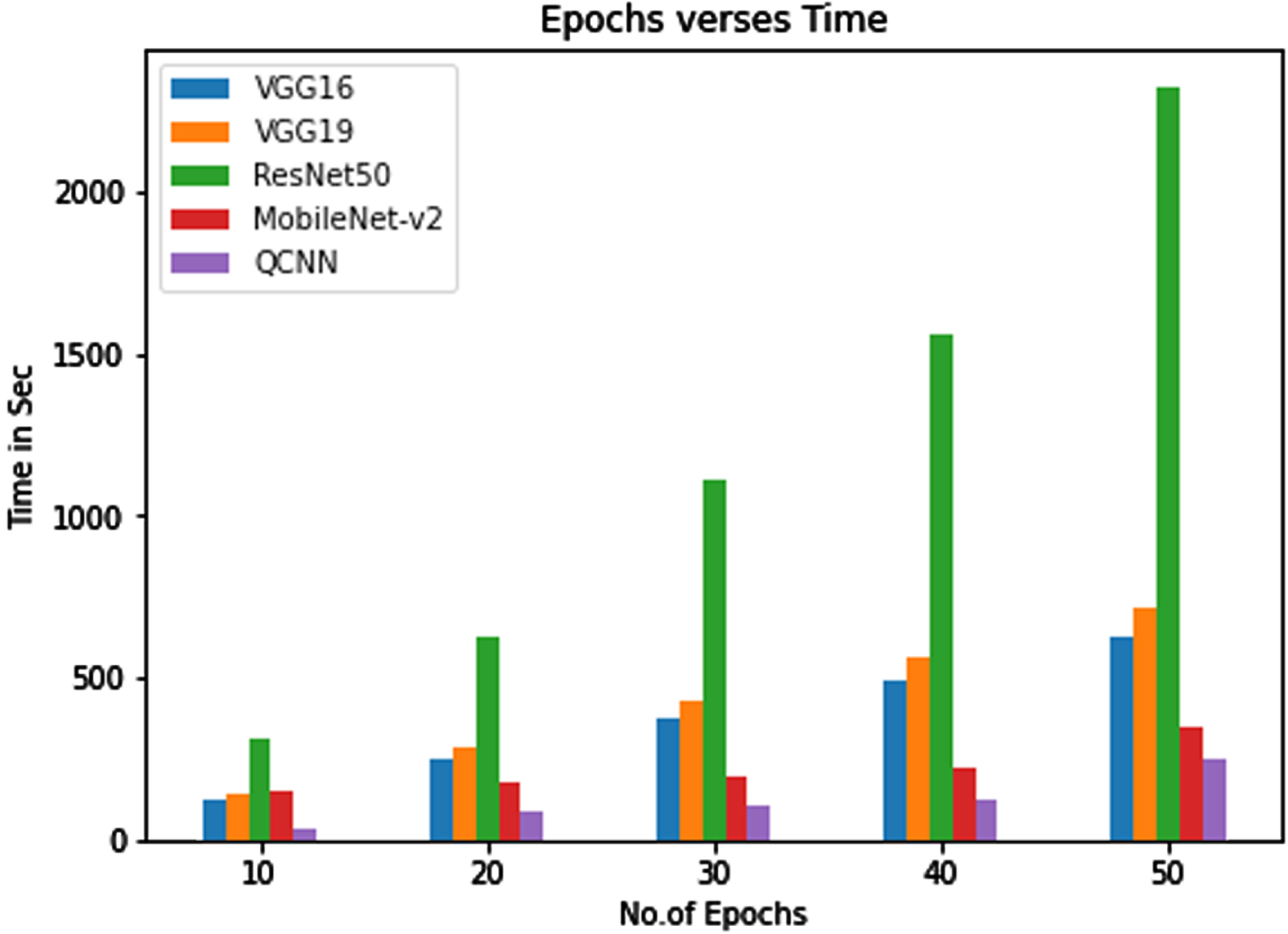
Time complexity graph.
In this experiment we conducted analysis of variance(ANOVA) test for finding the statistical difference between the without, traditional and GAN based augmentation. To determine the level of significance between more than two independent variables ANOVA test is used. In this experiment we have been taken the results of without augmentation, classical augmentation and GAN(DC+C+MFC) models accuracy values. The ANOVA test can be done through following steps
Set up the null hypothesis H0 and alternative hypothesis H1 to find the level of significance. Let H0 : μ1 = μ2 = μ3 and H1 : All means are not equal and consider the Level of significance α= 0.05
Select the suitable test statistic. Here the test Statistic is F statistic for ANOVA where
Define the rule
To find the critical value of F we consider the degrees of freedom.
Let df1 = k - 1 and df2 = N - k here k is the no. of variables and N is no. of samples. In our study k = 3 and N = 18. So, the critical value is 3.68. rule is that if F> = 3.68 then reject the Null Hypothesis (H0).
During this analysis we computed the test statistic F we get the value as 4.174. so, F> = 3.68 so we reject the null hypothesis and finally concluded that with and without augmentation does not yields the same performance. The GAN based augmentation results best classification accuracy than without augmentation.
State of art comparison
In this study we compare the proffered method with state-of-art methods. Table 4 shows the ICD Classification with state of art methods. Compared to earlier methods our model results 98.7% of classification accuracy.
Conclusion and future enhancement
This research specifically tackles the obstacles related to human action recognition and analysis in computer vision, with a primary emphasis on classifying Indian dance forms. The intricate nature of these dance styles, characterized by variations in body postures and hand gestures, presents challenges in achieving accurate classification. To overcome the limitations imposed by deep learning models that typically rely on extensive datasets, we employ standard data augmentation techniques to enhance the model’s ability to generalize beyond the constraints of limited data availability. In this work, implemented traditional data augmentations along with GAN(DC+C+MFC) for overfitting problem and QCNN classification to reduce computational time. Additionally, few deep transfer learning models (VGGNet16, VGGNet19, MobileNet-v2, ResNet50) and proposed QCNN were implemented in this paper for investigation. A comparison was conducted between traditional and GAN based augmentation with deep transfer learning and QCNN with performance metrics such as sensitivity, specificity, precision, accuracy, and F1 score, Kappa score and Mathew score. The results shows that QCNN with augmented data performed well to classify ICD dance forms with an accuracy of 98.7% and also reduces the computational time. By statistical analysis it was concluded that augmentation-based classification and without augmentation-based classification does not yields the same results. When compare to state of art results our proffered method shows the best accuracy and also reduced the computational cost.
The study’s findings are based on a specific dataset of Indian classical dance forms. The generalizability of the results to other datasets or dance forms may be limited. The accuracy of the classification results relies on the accuracy of the ground truth labeling of the dataset. Human subjectivity in labeling dance forms could introduce errors or inconsistencies in the dataset. The study focused on classification accuracy and computational time reduction within a controlled experimental setting. However, the real-world application of the proposed methods may introduce additional challenges such as variations in lighting conditions, background clutter, or occlusions.
ICD classification accuracy with state of art comparison
ICD classification accuracy with state of art comparison
The study suggests future work involving the generation of quality synthesis images using human pose estimation-based images. Researchers can explore the potential of incorporating human pose estimation techniques to generate synthetic dance images. This approach can further enhance the diversity and quantity of training data, potentially improving the accuracy and robustness of the classification model. And also, the research should consider evaluating the proposed methods in real-world scenarios to assess their practical feasibility and effectiveness.
The findings of this study have several important managerial implications for the field of Indian classical dance classification. Researchers and practitioners involved in deep learning and dance classification can benefit from considering the following implications.
Enhancing the classification accuracy
The study highlights the effectiveness of employing the proposed QCNN model for accurate classification of Indian classical dance forms. Managers can consider implementing QCNN in their classification systems to improve the accuracy of dance form identification. By achieving a high accuracy rate of 98.7%, organizations and researchers can have more confidence in the classification results and make better-informed decisions based on the output.
Reducing computational time
The utilization of QCNN not only improved classification accuracy but also reduced computational time. Managers can adopt this model to reduce the time required for classifying Indian classical dance forms, thus increasing efficiency and scalability. By implementing QCNN, organizations can process a larger volume of data within a shorter timeframe, enabling faster analysis and decision-making processes.
Comparing traditional and GAN-based augmentation
The study conducted a comparison between traditional data augmentation techniques and GAN-based augmentation. Managers can consider using GAN-based augmentation methods for data preprocessing in dance classification tasks. This approach can address overfitting problems and improve the robustness of the classification model. By incorporating GAN-based augmentation, organizations can enhance the quality and diversity of training data, leading to better classification performance.
Transfer learning model selection
The study explored the performance of various transfer learning models, including VGGNet16, VGGNet19, MobileNet-v2, and ResNet50. Managers can leverage these findings to select appropriate pre-trained models for Indian classical dance classification tasks. This decision should be based on factors such as the available dataset size, computational resources, and specific performance requirements. By utilizing the appropriate transfer learning model, organizations can benefit from pre-trained features, reducing the need for extensive training and accelerating model development.
Performance metrics consideration
The study evaluated the classification performance using various metrics, including sensitivity, specificity, precision, accuracy, F1 score, Kappa score, and Mathew score. Managers should consider incorporating these metrics into their evaluation framework for assessing the performance of dance classification systems. By utilizing a comprehensive set of performance metrics, organizations can gain a holistic understanding of the model’s strengths and weaknesses, enabling them to identify areas for improvement and make data-driven decisions.
By considering these managerial implications, organizations and practitioners can enhance their Indian classical dance classification systems, leading to more accurate and efficient dance form identification. The implementation of the proposed methods and techniques can drive advancements in deep learning-based classification systems and contribute to the field of dance research and preservation.