
Abstract
Dense passage retrieval is a popular method in information retrieval recently, especially in open domain question answering. It aims to retrieve related articles from massive passages to answer the question. Retriever can increase retrieval speed with less loss of accuracy compared to other methods. However, the pretrained language models used in recent research are often ineffective in semantic embedding, which will reduce accuracy. In addition, we find that contrastive learning will diverge the representation space, and Siamese models with independent parameters on both sides will decrease generalization performance. Therefore, we propose span prompt dense passage retrieval (SPDPR) based on span mask prompt tuning and parameter sharing in Chinese open-domain dense retrieval. This model can generate more efficient representation embeddings and effectively counteract the separation tendency between positive samples. We evaluate the effectiveness of SPDPR in DYKzh, as well as two Chinese datasets. SPDPR surpasses all SOTAs implemented in DYKzh and achieves a competitive result in other datasets.
Introduction
Open-domain dense retrieval (DR) uses vector similarity to retrieve relevant passages, making it an essential component of open-domain question answering systems, as well as search engines and voice assistants. Table 1 provides an example of the DR system, which searches numerous passages to retrieve those that may contain the answer to a given question. For example, the answer "dodo" can be found in the first passage.
A sample of open-domain dense retrieval
A sample of open-domain dense retrieval
Currently, DRs are being trained using the contrastive learning strategy [1]. This approach uses a specially designed loss function to increase the distance between positive samples and decrease the distance between negative samples, achieved by dividing the vectors into a spherical unit space [2]. In the DR task, the questions and the corresponding passages are positive examples, and the questions with the others are negative. Therefore, semantic representation and sample selection are two main topics in dense retrieval. On semantic representation, Li et al. [3] and Su et al. [4] pointed out that the hidden embedding dimension of the [CLS] token may collapse in pretrained language models (PLMs) like BERT [5], usually used as the representation of the sentence in downstream tasks such as semantic similarity and dense retrieval.
To solve this problem, some researchers modified the structure of PLMs and retrained them for better semantic representation [6]. Some designed targeted pretraining tasks to enhance the representation of the [CLS] token [7]. However, these approaches do not fully exploit the potential of PLMs and require high computation costs. In addition, existing models typically used independent representers on both sides of the model, which are different from most contrastive learning models in other tasks. Independent representer may gradually separate the representation space in the training process. It will increase the distance between untrained positive samples and reduce retrieval accuracy.
To address the aforementioned issues and advance the research progress in the Chinese dense passage retrieval, this paper presents the following contributions. Firstly, a Chinese open domain retrieval dataset, DYKzh, is constructed to solve the problems of low retrieval difficulty and unnatural question format in existing datasets. Secondly, to overcome the disadvantages of existing methods that rely heavily on pre-trained language model [CLS] token, this paper proposes a span prompt dense passage retrieval (SPDPR) model.
SPDPR introduces discrete prompt tuning for the first time in dense passage retrieval [9], eliminating the shortcomings of using [CLS] token and significantly reducing training costs. Given that Chinese vocabulary typically consists of multiple terms, this model also proposes a span mask prompt template that uses multiple consecutive [MASK] prompts instead of a single [MASK] prompt. Furthermore, to improve the generalization of the model by mitigating the independent training risk of the two representers parameters, a weight sharing strategy is proposed.
The contributions of this paper can be summarized as follows: We design a Chinese open domain passage retrieval model SPDPR. We propose span masking prompt tuning methods and adopt the representer parameter sharing strategy to reduce the distance between the representation spaces of questions and passages. We validate SPDPR’s performance on a standard Chinese open-domain dense retrieval dataset DYKzh and 2 ordinary retrieval datasets. For comparison, we reproduce multiple baseline models in Chinese. Results show that span masking prompt template and parameter sharing strategy increase the accuracy of Chinese dense retrieval. From the experimental results, we analyze the change process of the representation space with the training in the Siamese model. We conclude that the parameter sharing strategy can help improve the generalization of the model.
Open-domain dense retrieval
Open-domain Dense Retrieval is an effective approach when compared to both sparse retrieval methods and re-ranking retrieval methods [10]. Sparse retrieval methods, such as TF-IDF and BM25, are commonly utilized to query relevant articles in search engines; while TF-IDF [11] examines the relevance of passages based on word frequency and co-occurrence between queries and passages, BM25 [12] considers the impact of passage length. However, since both methods rely on exact word matching, they are unable to handle synonyms. Re-ranking retrieval techniques utilize a correlation calculation approach to retrieve relevant passages based on neural network models’ capabilities using input from both questions and passages. For instance, Nie et al. [13] devised a multi-granularity model for large-scale reading comprehension, where the retrieval part inputs the question and passage into the model together and obtain the vector at the [CLS] position. The ranking model computes all the passages for each input question, resulting in a substantial reduction in inference speed, given the large number of sets of passages, which fails to meet the demand [10].
Dense Retrieval, on the other hand, is capable of handling synonyms and substantially enhances the inference’s running speed by caching passage embeddings, with only a minor loss of accuracy. DR models employ the Siamese structure to obtain semantic representations of questions and passages. DPR [1] and ORQA [14] leverage pre-trained language models (e.g., BERT [5] and RoBERTa [15]) to generate semantic representations. These representations are trained with unsupervised inverse close task (ICT) or supervised in-batch negative contrastive learning. However, Reimers and Gurevych [16] propose that some PLMs have not been prepared for semantic representation at the [CLS] position. Li et al. [3] and Su et al. [4] argue that the outputs of these PLMs undergo dimensional collapse. Xiong et al. [17] points out that the ICT task and in-batch negative strategy are too simple to train models. Therefore, research on DR focuses on improving the model structure and designing training tasks.
Improving the model structure focuses on enhancing the semantic representation of PLMs. SEED-Encoder [7] trains the model to improve the representation at the [CLS] by introducing a bottleneck between the backbone and the prediction head. Condenser [6] adds shortcuts from the middle of the backbone model to the prediction head, in addition to the bottleneck. These models redesign the structure of PLMs and retrain them to avoid the shortcomings of [CLS]. Others concentrate on the selection of training samples. ANCE [17] dynamically acquires negative samples using the model being trained. RocketQA [18], on the other hand, selects negative samples using a ranking model. LaPraDoR [19] and DANCE [20] improve the representation by enhancing the self contrasts.
The Table 2 illustrates that current approaches primarily utilize the Siamese model structure, with variations mainly in the training approach. Some models aim to enhance the model structure with retraining and address the shortcomings of the pre-trained language model’s [CLS] token.
Some prior works in Dense Passage Retrieval
Some prior works in Dense Passage Retrieval
However, there are two issues with existing methods that reduce the prediction accuracy of the model. Firstly, when Siamese models are employed, the parameters of both representers are independent. Although parameter independence may seem logically sound, it causes the representation space of the two representers to gradually diverge during the training phase, reducing the generalization performance of the model. Secondly, existing methods rely on the representation performance of the [CLS] token of the pre-trained language model. However, the semantic representation capability of this token is inadequate and unsuitable for dense passage retrieval tasks. Moreover, retraining the model to overcome this shortcoming incurs high computational costs, making it impractical to respond quickly to rapid changes in the collection of articles in actual scenarios.
Contrastive learning (CL) is a representation learning method commonly used to solve classification tasks. It needs to design the loss function to pull relevant samples closer and push irrelevant samples farther in the representation space. Therefore, these samples can be classified by a simple linear classifier [21]. Contrastive learning is suitable for unsupervised tasks where the input sample and its perturbations are positive to each other. This strategy has recently been widely used in sentence textual similarity (STS) [22, 23]. Contrastive learning can also be applied to supervised tasks. Khosla et al. [24] proposed a supervised contrastive learning loss function in computer vision. In contrast, although dense retrieval is a supervised task, unsupervised loss functions are usually used because there is no category concept like classification problems [1].
Contrastive learning in dense retrieval usually uses the in-batch negative strategy in training. Tsai et al. [25] show that the classification error rate decreases with the increasing size of negative samples, which is also an empirical consensus in dense retrieval. Qu et al.[18] expands the overall batch of negative samples by obtaining negative samples from other GPUs during multi-GPU training. Xin et al. [20], on the other hand, use a momentum queue and incrementally update negative samples. Some recent studies have focused on unsupervised dense retrieval tasks, which focus on constructing suitable positive samples. Xu et al. [19] uses ICT and Dropout to create positive samples, and Gao et al. [26] use the same passage strategy to achieve this.
Tasks using contrastive learning usually use the Siamese model structure, i.e., the two inputs feed into two PLMs with shared parameters to obtain the corresponding semantic embeddings for downstream tasks. However, in the field of dense retrieval, most models have independent parameters on both sides. This is probably due to the large semantic gap between question and passage, but it may also lead to an increase in the representation gap between the two models as the training proceeds.
Prompt tuning
Prompt tuning is a machine learning paradigm that fully exploits the capabilities of pretrained language models. It requires a prompt template that resembles the pretrained task for specific tasks with a few shot samples. Prompt tuning has been mainly used in classification tasks. For example, Schick et al. [27] designed the “{text} It was [MASK].” to determine the probability of “great” or “bad” at [MASK] for classifying sentiment. Ding et al. [28] constructed the “{text} {entity} is a [MASK].” template for fine-grained category annotation of named entities. In addition to discrete templates, prompt tuning contains continuous templates [29–31]. They use vectors directly in the word embedding layer space and only adjust the vectors to achieve the expected performance. Prompt tuning has also been applied in semantic representation. Jiang et al. [32] successfully investigated prompt tuning for the STS task and experimented with manually written discrete and automatic templates. Jiang et al. [33] experimented with continuous templates and also achieved a competitive result. However, these techniques are tailored to English language usage. Given the distinct lexical structures in Chinese, these approaches may encounter certain limitations.
Method
Task definition
The user’s input question is Q and the set of all passages is D = d1, d2, ⋯ , d n . The corresponding vectors h q , h d 1 , h d 2 , ⋯ , h d n are obtained by passing the question and the passages through the representation model M, respectively. The goal of the task is to estimate the probability that a passage can answer the input question using similarity between vectors. Ranking all passages in descending order of probability, the higher the ranking of the golden passage d q . The higher the retrieval accuracy of the model. The final model parameters θ are in Eq (1).
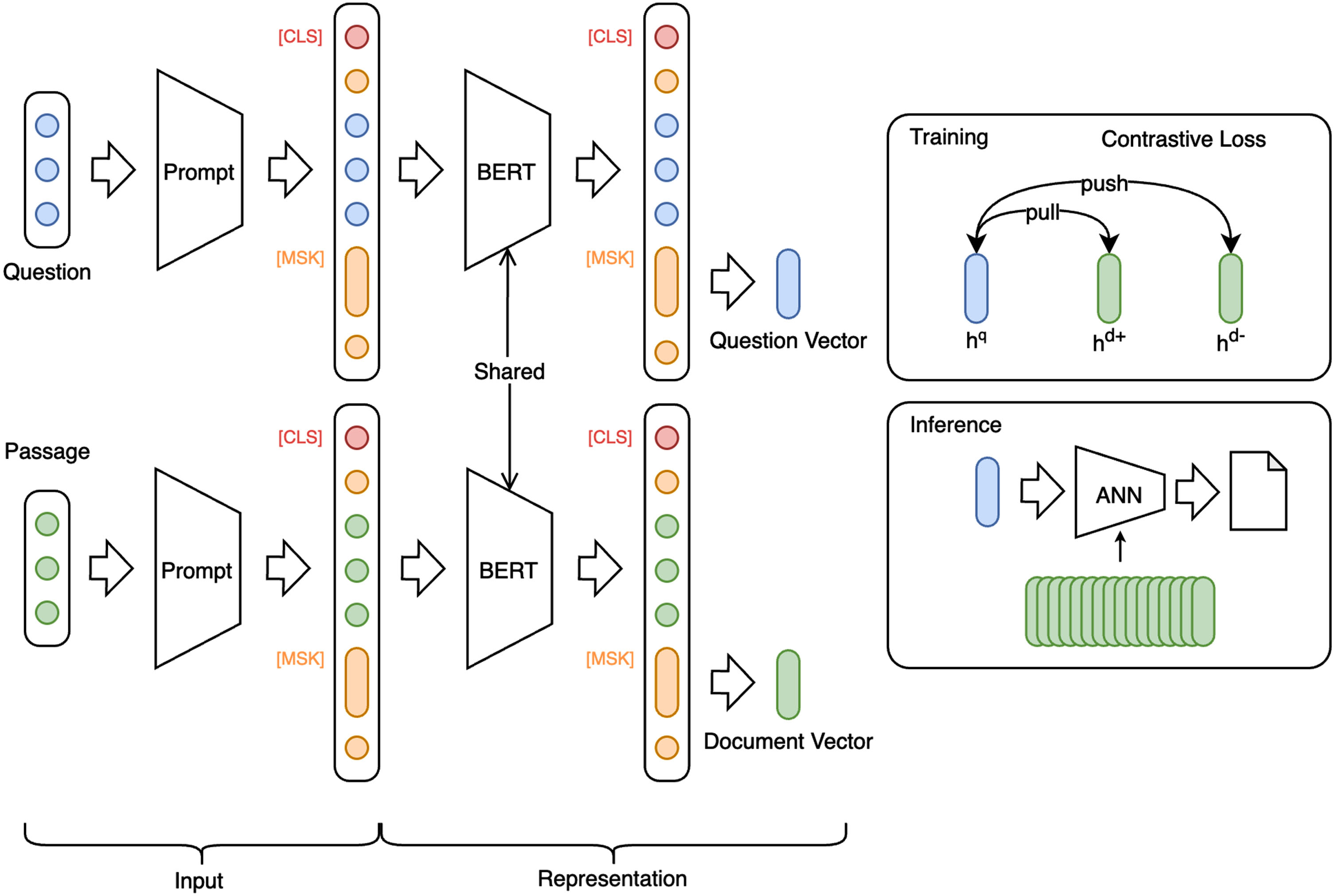
SPDPR model. The circles stand for the term or the corresponding hidden vectors. The blue one and green one is the question and passage term. The red one stand for the [CLS] of PLM, and the yellow one is the prompt template. The question vector and the passage vector are obtained from the [MASK] after the prompt template.
To address the limitations of the current open domain dense passage retrieval model, we propose the Span Masking Prompt Tuning Dense Passage Retrieval model (SPDPR). The structure of the model, depicted in Fig. 1, follows the DPR model and represents questions and passages as vectors through a Siamese model. However, it employs two pre-trained language models with shared parameters as its backbone. The input section then applies the span masking prompt template to both sides, with the hidden vector at the [MASK] position serving as the semantic embeddings of the question or passage.
The Siamese model, also referred to as the two towers model, is a popular machine learning approach utilized to align two feature spaces. Specifically, the Siamese model consists of two identical representation models. Each model transforms input sentences into feature embeddings, and subsequently uses contrastive learning to match the outputs of both models. This process trains the representation models to align features in a comprehensive and effective manner.
Input
To avoid using embeddings at [CLS] of PLMs with dimensional collapse, SPDPR adopted prompt tuning to obtain representation from embedding at [MASK] instead. However, existing discrete templates are generally not applicable to Chinese and face generalization challenges in multiple datasets.
Most Chinese words are divided into multiple terms in the vocabulary of PLMs instead of the single one in English. Inspired by this, we proposed the Span Mask Prompt Template (SMPT) to obtain semantic representation of questions and passages. SPMT uses multiple consecutive [MASK]s to fully represent a Chinese word, bringing downstream tasks closer to pretrained tasks. Several examples of SMPT compliance are shown in Table 3. In SPDPR, given the difference in the form of questions and passages, different SMPTs are usually used on both sides.
Samples of SMPT and Normal prompt template
Samples of SMPT and Normal prompt template

Let the index of each character r in question q in PLMs vocabulary be i r 1 , i r 2 , ⋯ , i r ||q|| , and the index of each character e in passage d be i e 1 , i e 2 , ⋯ , i e ||d|| . If the SMPT is ’{text}[MASK][MASK]’, the question and passages input sequence of the PLM are in Eq (2)(3).
where i[C], i[S], i[M], i[P] stand for the index of [CLS], [SEP], [MASK] and [PAD] in PLMs vocabulary.
The representation layer incorporates pre-trained language models (PLMs) to derive semantically contextual embeddings. In current models, the PLMs on both sides typically use separate parameters due to the presumed significant semantic gap between the question and the passage. This approach poses a risk of deviations in the representational space of the two PLMs during the training process, particularly for untrained passages.
Therefore, this model proposes a parameter sharing approach among representers. Accordingly, the above potential separation hazard in the representation space is circumvented.
Let
Where the PLM (·) means the pretrained language model. The question representation and the passage representation are the hidden states at the first [MASK] in the span.
When dense retrieval uses a Siamese model, it is usually trained using contrastive learning. If the passage can answer the question, they are mutually positive samples and vice versa. SPDPR mainly followed the DPR[1] approach, using negative samples obtained by BM25 and other negative samples in the batch.
The contrastive loss function is the logarithm likelihood function of positive samples. For the training sample
Where h q is the semantic representation of the question, h d + , h d i- are the ones of positive and negative passages. Similarity function sim (·) usually use the dot product function as Eq (6).
Since handicraft prompts are sensitive to downstream datasets, SPDPR uses multiple prompt templates for training. During the training process, templates are randomly selected to form the input, thus improving generality in different datasets.
The representations of passages are fixed at each inference. These vectors can be calculated and stored before deployment to increase speed. The inference process generates the corresponding vectors of the questions with the best prompt by the SPDPR model above. Approximate Nearest Neighbors (ANN) tools such as FAISS [34] obtain the associated passage vectors as retrieval results.
Experiments
Setup
Because there are limited studies on Chinese dense passage retrieval, we established the DYKzh Chinese open domain question answering dataset using the XQA method proposed by [8] and evaluated SPDPR with various reimplemented models using this dataset.
Dataset
The DYKzh dataset comes from Wikipedia’s section called Did You Know, which consists of manually written article recommendation questions and hyperlinks to the corresponding articles. Nowadays, the form of the recommendation question is mainly a wh-question, but some old recommendations are yes-no questions. Therefore, the dataset only retained the wh-question and organized them into the form of the question, article title, and article content, which were used as the question, answer, and passage in the dataset, respectively. Table 1 above is an example of the DYKzh dataset.
In addition, the passage collection was from archived files of all Chinese Wikipedia articles. And we used WikiExtractor to get all the passages filtered out of meta articles like redirects and disambiguation. DYKzh contained a total of 557,754 passages and 39,331 questions. Since there are some variants of Chinese, some vocabulary in some regions has a gap with simplified Chinese. Therefore, all the words of Chinese variants were processed using OpenCC and regular expressions. Finally, the passages in the DYKzh dataset were aligned to complete the construction of the article collection.
In addition to the DYKzh dataset, the paper validates DuReaderretrieval and MultiCPR. But their questions are made up of scattered words. MultiCPR passages are even not fluent sentences. Therefore, these two datasets are not satisfactory for evaluating retrieval models in open domain question-answering systems, but they can also be reasonable references.
Model
Compared to the SPDPR model, we used BM25 for sparse retrieval and some dense retrieval models on the DYKzh. The retrieval test uses only the method of traversing all passages to obtain accurate similarity ranking results, in order to more precisely evaluate the effectiveness of feature embedding for each model. BM25 is a sparse retrieval method considering the length of documents. We used the default implementation of Pyserini [35] for Chinese with parameters k1 = 0.9, b = 0.4. DPR[1] is a dense retrieval model training on the English corpus. For comparison, the PLM in the model was changed to Chinese-BERT-wwm fully trained in Chinese and optimized for Chinese vocabulary in the masking language task. Due to the shortage of Chinese corpus, we trained models with 6 epochs on the DYKzh dataset with a batch size of 16. DPR-ANCE[17] is another DPR trained with ANCE’s strategy. ANCE dynamically updates training data from the previous version of the model. Since the time difference between the trainer and the inferencer is too large, we manually executed the ANCE pipeline and trained for 6 epochs. RocketQA[18] is the first dense retrieval model trained on millions of Chinese documents, which has achieved competitive results in both English and Chinese corpus. The model uses a two-step strategy by concatenating the dual model and cross-model retriever based on the Chinese pretrained language model, ERNIE. For comparability, we train its dual model for 6 epochs with a batch size of 16. SPDPR used the SMPT and parameter sharing strategy, and other hyperparameters and optimizer settings were consistent with the original DPR model.
Metrics
This task metric is top-k accuracy. All the questions from the test set were fed to the model for prediction, and the top-k accuracy is the percentage of correct articles ranked in the top-k results. The formal representation is in Eq (7)
where D is the dataset, r (q, d) means the ranking function of the DRs, which is the rank of the passage d in all documents according to the question q, and I (·) stands for indicator function, which the output is 1 when the proposition is true, vice versa.
According to the experiments of DPR, we used top-1, top-5, top-20 and top-100.
The hardware environment is a computing server equipped with 4 Nvidia A40 graphics cards, the CPU is Intel Xeon Silver 4210R, the memory is 128GB, and it works under good heat dissipation conditions.
The software environment is Ubuntu 18.04 operating system, and CUDA version is 11.6. The above model is implemented using PyTorch 1.12.1 machine learning framework written based on Python 3.9.12 programming language.
Contrast experiment
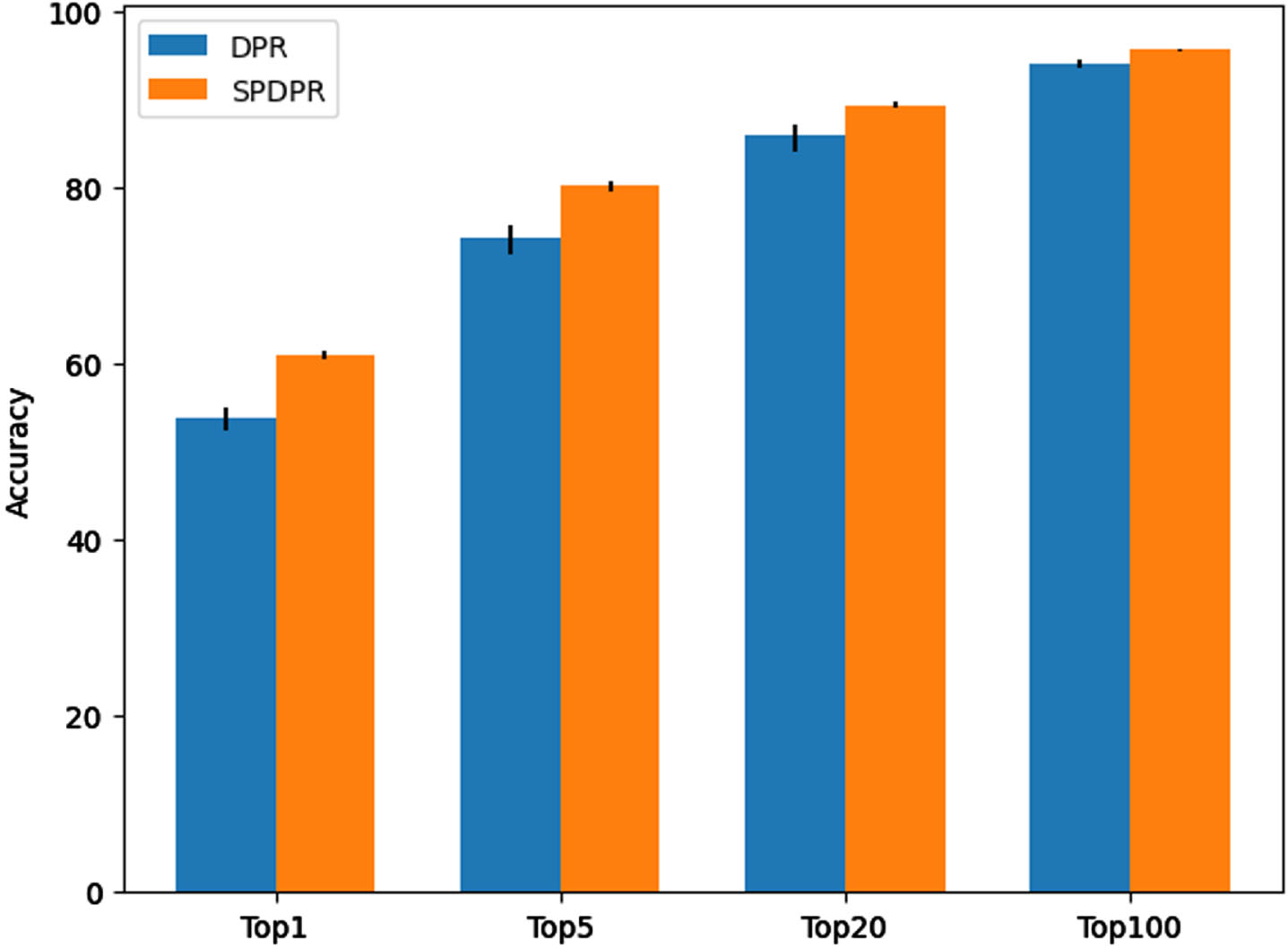
The results are in Table 4. On the DYKzh dataset, each dense retrieval model exceeds BM25, indicating that the reproduction results are correct. The accuracy of SPDPR on DYKzh is higher than that of other models, showing that SMPT and parameter sharing strategy improve retrieval accuracy. RocketQA achieved the best results on the DuReader dataset but performed significantly worse on the other datasets. It shows that RocketQA’s generalization performance is poor.
The result of models on dense retrieval
The result of models on dense retrieval
We analyzed the training process of the Siamese model to further investigate the contribution of parameter sharing strategy. We captured the representation spaces in the DPR’s and SPDPR’s training process by calculating the mean similarity between positive and negative samples.
To reduce the effect of model training on representation space, we filter out the passages that appear in the DYKzh training set from the development set. The total dispersion of the representation space is defined as the average similarity between the question and the negative sample passage Sbase. For comparison, we observe changes in the average similarity between the question and its positive sample passages Spos. Formalized as Eq (8)(9).
We separately analyze the variation of the representation space during training for DPR, SPDPR, and a variant of DPR using only the parameter sharing strategy. The results of the experiment are shown in Table 5. First, we observe that question and passage representation spaces become increasingly separated during training. However, both the parameter sharing strategy and the prompt learning method reduce the separation between positive samples. They will effectively improve the generalization capability of the model.
The representation spaces status during training
Sensitivity to random seeds
Random seeds can significantly affect the optimization outcomes of a model, particularly in neural network-based models. Consequently, this study employs 6 different random seeds at random to train the model, and evaluates the corresponding accuracy fluctuations.
The results are shown in Fig. 2. It has been observed that SPDPR exhibits significantly greater stability than DPR when subjected to various random seed values. This demonstrates the reliability of SPDPR’s approach.
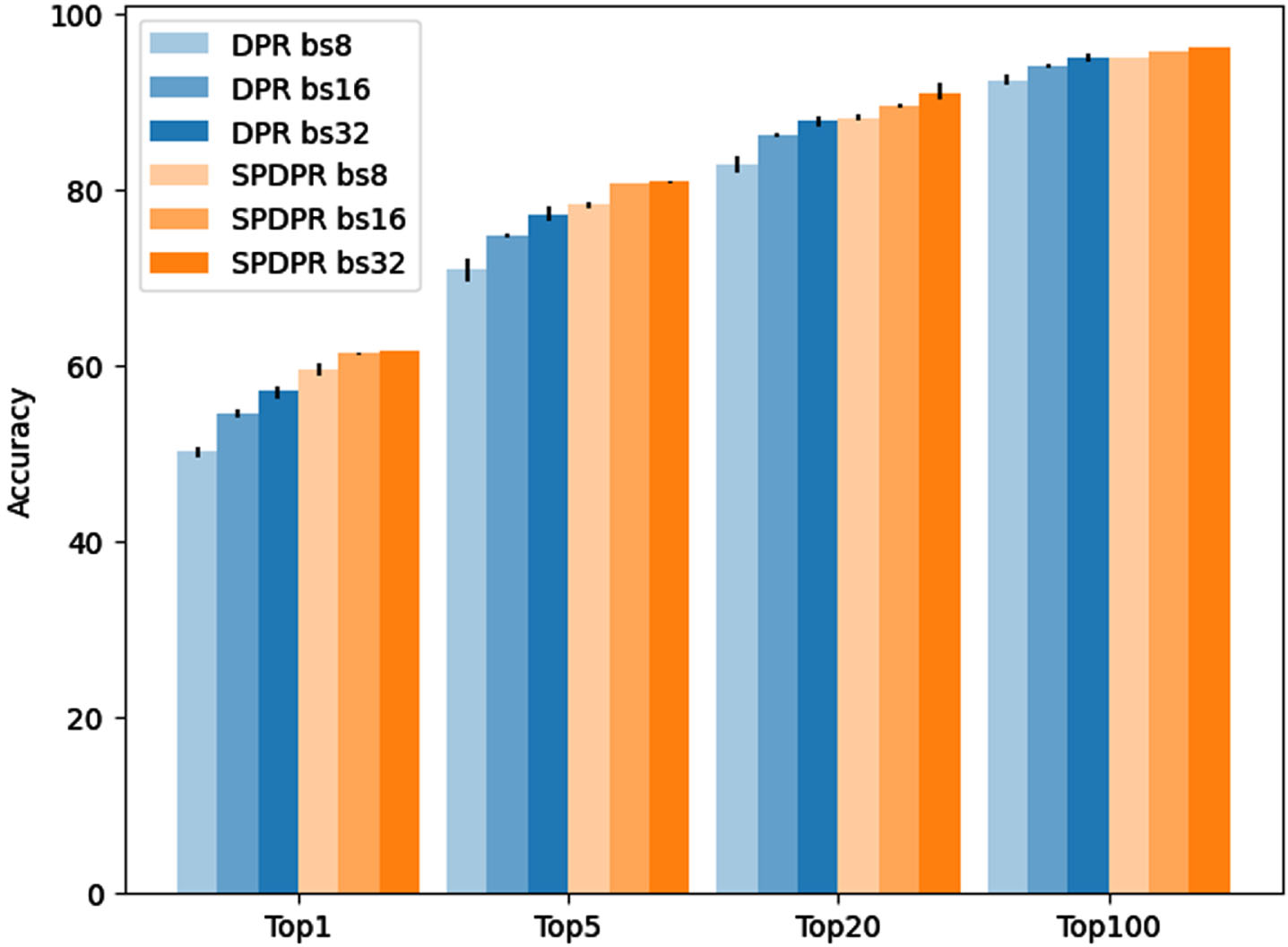
Sensitivity to batch sizes
Sensitivity to random seeds.
Sensitivity to batch sizes.
When training Siamese models through contrastive learning, it is widely acknowledged that higher batch sizes lead to improved model training. This paper provides an experimental analysis of the sensitivity of SPDPR and DPR models to batch size changes. In this study, the batch sizes of 8, 16, and 32 were selected and the model was trained with 3 random seeds. The accuracy of the model in the test set was meticulously recorded.
The results are illustrated in Fig. 3. Results indicate that batch size impacts both models, with SPDPR being relatively less susceptible. This could be attributed to the SPDPR model’s multi-template approach, which enhances the model’s overall stability.
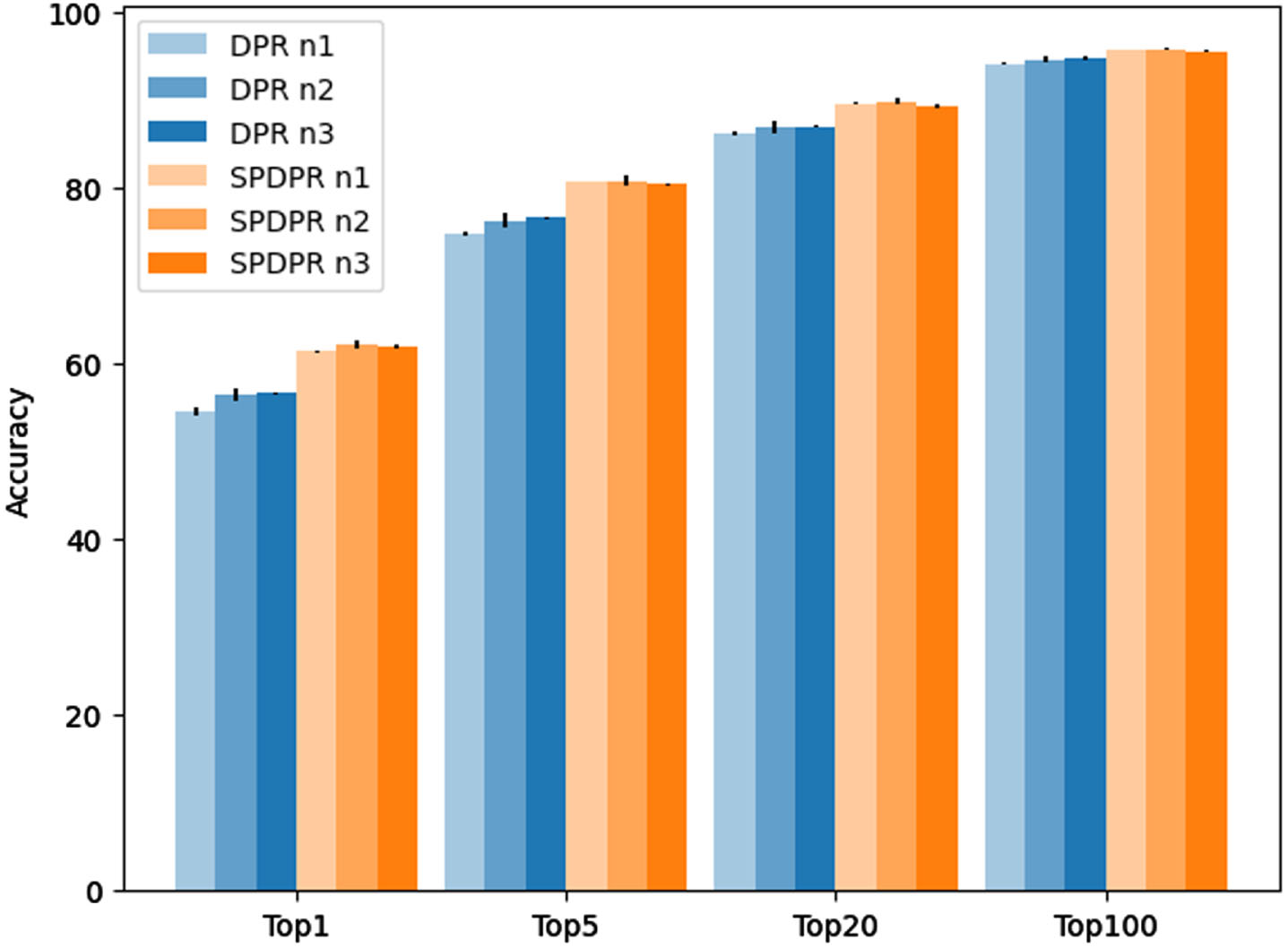
Sensitivity to number of negative samples.
Similar to batch size, the quantity of negative samples also has an impact on the ultimate accuracy of the model in contrastive learning training. It is widely accepted that a larger number of negative samples leads to higher accuracy in the trained model. Consequently, this research paper designated the number of negative samples to be 1 (the default setting), 2, and 3, utilizing 3 distinct random seeds for experimentation.
The results are presented in Fig. 4. It is evident that increasing the number of negative samples results in only marginal improvement in the accuracy of the two models. The results indicate that neither model exhibits sensitivity to the hyperparameter for the number of negative samples used.
This paper focused on the open domain dense retrieval in Chinese and found that some existing models still had room for further improvement. At present, semantic representation models still focused on the hidden vector at [CLS] in PLM, but the vector is still unsuitable as a full sentence representation. In addition, the existing models use separate parameters for question and passage representers. This paper experimentally confirms that this leads to a decrease in the generalization performance of the model.
In this paper, we proposed SPDPR to solve the above problems. SPDPR reduced the semantic gap between Chinese questions and passages by using span masking prompt templates. In addition, we constructed DYKzh, a Chinese Wikipedia-based open domain question answer dataset based on the XQA method, and evaluated the retrieval accuracy of several models on this dataset. Experiments have shown that SPDPR has a significant improvement over DPR in several metrics, and also achieves competitive results on several datasets.
Through further experiments, we found that the Siamese model has a tendency to gradually separate the representation space during the training process, and experimentally confirmed that the parameter sharing strategy helps to reduce the separation between positive samples, thus improving the retrieval accuracy of the model. Sensitivity analysis also confirmed that the SPDPR model has better stability on multiple parameters.
In future research, primary consideration should be given to the feasibility of implementing continuous prompt templates. This approach has the potential to reduce the need for manual prompt template design, while simultaneously training more robust and effective templates from the dataset. Moreover, as computational power increases, unsupervised contrastive learning can be explored to further enhance the practical applicability of the dense passage retrieval task.
Footnotes
Acknowledgments
The work was supported by the National Natural Science Foundation of China (No. 62071060), and the Beijing Key Laboratory of Work Safety Intelligent Monitoring.