
Abstract
Deep-learning (DL) is a new paradigm in the artificial intelligence field associated with learning structures able to connect directly numeric data with high-level patterns or categories. DL seems to be a suitable technique to deal with computationally challenging Brain Computer Interface (BCI) problems. Following DL strategy, a new modular and self-organized architecture to solve BCI problems is proposed. A pattern recognition system to translate the measured signals in order to establish categories representing thoughts, without previous pre-processing, is developed. To achieve an easy interpretability of the system internal functioning, a neuro-fuzzy module and a learning methodology are carried out. The whole learning process is based on machine learning.
The architecture and the learning method are tested on a representative BCI application to detect and classify motor imagery thoughts. Data is gathered with a low-cost device. Results prove the efficiency and adaptability of the proposed DL architecture where the used classification module (S-dFasArt) exhibits a better behaviour compared with the usual classifiers. Additionally, it employs neuro-fuzzy modules which allow to offer results in a rules format. This improves the interpretability with respect to the black-box description. A DL architecture, going from the raw data to the labels, is proposed.
The proposed architecture, based on Adaptive Resonance Theory (ART) and Fuzzy ART modules, performs data processing in a self-organized way. It follows the DL paradigm, but at the same time, it allows an interpretation of the operation stages. Therefore this approach could be called Transparent Deep Learning.
Keywords
Introduction
Deep Learning (DL) paradigm has become one of the most cited terms in artificial intelligence in the recent years. It contains a set of techniques historically used to represent and store knowledge in artificial devices and with the ability of learning new information. They have joined and transformed to a more automatic way of implementing the learning process. DL expression was coined in 2006, as Schmidhuber mentioned in [37] and goes beyond the classical neural networks to get closer to the human learning process where an abstract concept can be identified directly from the data sensors (human senses). The common features of the algorithms identified as DL could be [3]: They are composed of several levels or layers of non-linear operations. From particular to more abstract They must discover abstractions with as little human effort as possible. They can transfer human knowledge to machine-interpretable form. Categories of higher level learn from lower level features. This is the way to learn from sensory data. Depth of architecture refers to the number of levels.
The Fig. 1 shows, in schematic form, the comparison between Deep Learning algorithms and classical pattern classification algorithms.
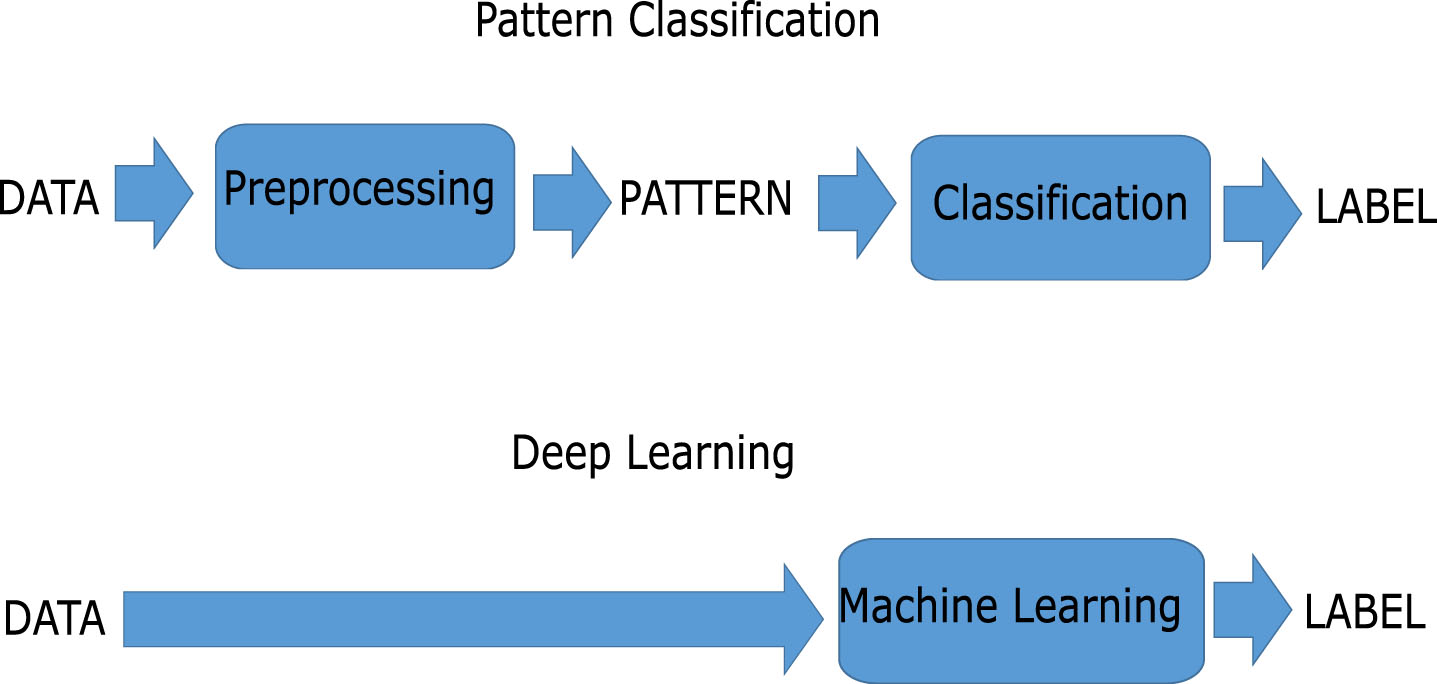
Classical Pattern Recognition versus Deep Learning paradigm.
Applications in image processing, speech recognition and other pattern recognition systems have been developed using Support Vector Machines, Deep Long Short-Term Memory, etc. Great acceptance has had the Deep Belief Networks where a stack of Restricted Boltzmann Machines is disposed to improve learning capability.
BCI systems capture brain signals and decode them with the purpose of interacting with certain devices without any muscular intervention [30]. Most of the BCI mechanisms used for this purpose are based on electroencephalogram (EEG) techniques, where the electrodes detecting the electric potentials caused by the neurons inside the brain are placed on the scalp of the user [25]. This technology has fundamentally been applied to medical and psychological brain research, rehabilitation treatment of motor dysfunction [44]. However, the decrease in the cost of the headsets is closing the gap between the research or medical environment and the households, where applications such as video gaming are starting to pave the way for the adoption of BCI devices by the marketplace. One of the most difficult problems faced by BCIs is called motor imagery and it consist in properly classifying three mental tasks: left hand movement, right hand movement and generation of words beginning with the same random letter. Solving this problem only with non-invasive EEG data involves processing signals that are highly variable, not only between users, but also within a single user depending on daytime or the fatigue level. Artifacts and outliers usually arise increasing the difficulty of this problem.
Some pattern recognition problems can be directly validated by a human being. A typical example is shown in Fig. 2.

Handwritten characters recognition application.
However, it must be noted that the EEG signals cannot be read and decoded straightaway by nobody, even the most experienced neurologist Fig. 3.
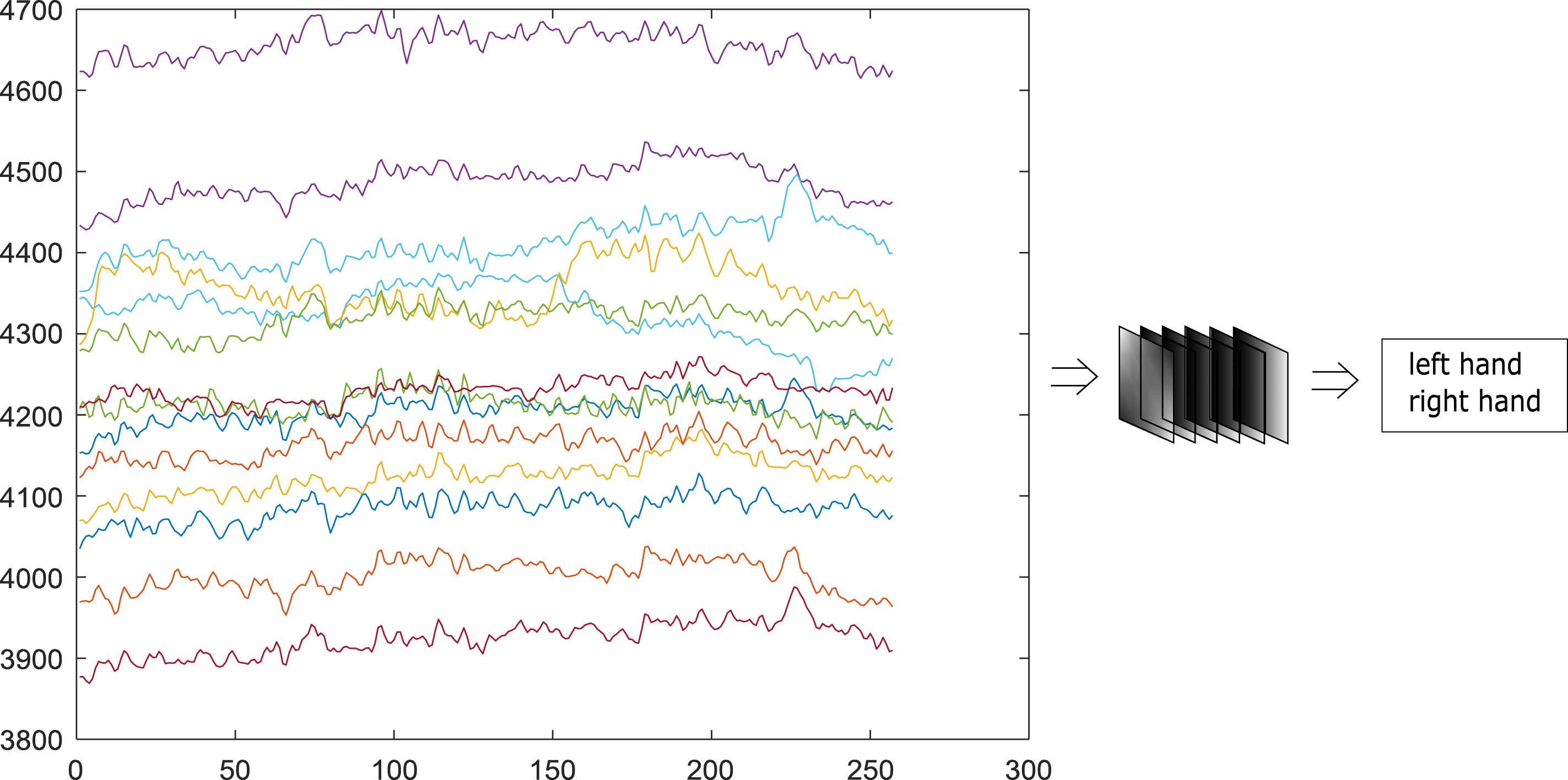
EEG signals recognition for BCI application.
It is an emerging area, which fits very well with artificial intelligence and more specifically to the DL way of doing. It is able to extract the underlying information in those difficult problems. The BCI problem is solved following several steps and all of them can be carried out by mean of AI methods, increasing the abstract level of representation. DL must avoid the presence of noise or the high dimensional EEG data that characterized the motor imagery problem, as mentioned in [13]: “the successful implementation of deep learning methods for the classification of EEG signals is quite an achievement”. In that paper, recordings from three electrodes (C3, Cz, and C4) and five electrodes (C3 C1, Cz, C2, and C4) are included, and only two states are taken into account.
DL process is applied in [41] to BCI problems using Convolutional Neural Networks and Recurrent Neural Networks with Long Short-Term Memory architecture. It is applied to a non- motor imagery problem (The stimuli are non-overlapping flickering lights from five magenta boxes with frequencies 6.66 Hz, 7.5 Hz, 8.5 Hz, 10 Hz, and 12 Hz. The objective is to distinguish between the different stimuli frequencies by analysing the Steady State Visually Evoked Potential.
In [45] also Convolutional Neural Networks are used to deal with a motor imagery problem using BCI Competition IV dataset [40] for the experimental work.
A Deep Belief Network of three layers of Restricted Boltzmann Machine is used in [25] to compare Power Spectrum Density extraction methods and classifiers to improve the recognition accuracy in different motor imagery tasks (left hand, right hand and foot movements). A survey of DL technology applications to BCI problems, can be found in [1, 33, 47]. The BCI motor imagery case with EEG signals is examined in this paper.
The motor imagery problem is one of the hardest issues in BCI technology. Here, the mental categories are imaging moving some body part, foot, hand, tongue, etc. The brain activation of this task is linked with the activation of the real movement. Therefore, this kind of problem is suitable to implement rehabilitation systems, exoskeleton control, prosthetic limbs [30], etc. BCI Competition [6, 40] is a forum where researchers can discuss the advance of knowledge in this field. To this aim, a challenge problem is proposed for each edition. Nowadays the databases provided in this competition are still used as testbeds in new researches, i.e. in [14] DL is proposed to deal with Motor Imagery problems using BCI Competition Data. Specifically, BCI Competition III Set V [6] dealt with the prediction of the following tasks: “movement intention of the left hand”, “movement intention of the right hand” and “thinking of a word”.
This Competition provided data from three users with three sessions for each one, to be used to build the prediction model. Data from a fourth session was also provided in order to validate the predictions. Data was gathered with a professional EEG (Biosemi) Fig. 4(a) hardware following a protocol: Experiments were carried out with the user seated and still. Experiments lasted 4 minutes and each 15 seconds a new mental category was presented in a random way. The user was asked to think in the mental task presented and then labelled. A break time of 5 minutes between two sessions was mandatory. The sampled frequency of EEG signals was 512 Hz.
A criterion was established to allow a fair comparison among the methods presented. A window of only the last second registered data can be used to compute the next prediction value. The model must give a prediction value every half a second. The quality of the proposed model is determined with the comparison of the global success rate.
Several works have been proposed at this Competition using Neural Networks, Common Spatial Patterns, Support Vector Machines, Linear Fisher Discriminant, Gaussian Classifiers [4, 5, 16, 22, 26, 36, 43].
Adaptive resonance theory
Deep learning implementations typically use multilayer networks. In this paper we propose an alternative based on Adaptive Resonance Theory (ART) because one of the fundamental characteristics of the ART is its modular nature. It provides a series of building blocks with specific functionality that can be used to build complex architectures [19]. The functioning of the brain is based on basic elements (neurons) that interact generating complex structures. The flexibility that the ART architecture provides to define complex structures from basic elements, and even incorporate elements such as fuzzy logic, has made it possible to apply it to multiple problems [12]. In many cases, this type of architecture aims to process data to reach categories of abstract thought [18] specifically its relationship with thought and the generation of motor commands [20].
To deal with the contribution of different outputs in different time instants, a multidimensional Sustained Temporal Order REcurrent (STORE) [27] type module is proposed. It works as a buffer storing the last model predictions. At first it has a flat characteristic meaning that the unit activations, which represent the predictions, do not depend on the memorized sequence. The units activations of the STORE module are connected to the input by an on-center off-surround multiplicative competitive net [24] through an instar module [17]. The labels associated to the mental tasks are the net outputs.
S-dFasArt model [42] is a supervised version of a dynamical Fuzzy Adaptive System ART based (FasArt) model [7] allowing classifying time signals with some characteristics that make it suitable to BCI applications. The model is able to deal with temporal data, so not only the instantaneous value is taken into account, but also when the data is registered (time order reception). The model can be interpreted as a fuzzy-logic system, therefore as a rule set among fuzzy sets. This is very efficient way to manage data with uncertainty because fuzzy logic is introduced as a tool to make decisions under uncertainty conditions. It has an incremental way of learning where the set size is not preselected. The number of rules can grow depending on the learning process. It can handle very large learning sets (big data) and it can update the model with new learning data without affecting the already stored information (stability-plasticity dilemma). There are no constraints for the number of rule antecedents, so the input dimension is not a problem. The dynamical feature of S-dFasArt model allows it to filter outliers in data coming from artifacts usually found in biological signals. The rules are defined from the learning examples, so there is no problem in generating contradictory ones (same antecedents lead to different labels). In this case the output will activate two labels with the same volume without involving the right-labelled rules that are generated from the close data.
The S-dFastArt performance in BCI applications has been compared against other classification methods using the BCI Competition III Set V Database showing the best success rate [8, 28].
Low cost platforms
To increase the number of BCI systems applications, there must be a price drop in hardware and an improvement in comfort use. With this goal in mind, some devices that could be named as “low cost”, have appeared to expand the scope of people that could use BCI technologies [11, 32]. These are classified as follows: End-use devices: they are addressed to a final user, usually with a particular objective, for instance helping a user to relax or helping one to concentrate, as Neurosky [23]. Devices of development: they are designed for research and development purposes, as Open BCI [39]. General use devices: they link features of the previous groups. They can be used with closed software given by the manufacturer, but also tools for research and development are supplied. Emotiv EPOC, Fig. 4(b), and Emotiv Insight can be considered in this group.

Headset comparison (a) Biosemi. (b) Emotiv EPOC.
In this last set of devices of general use, some features must be highlighted:
Easy to use: It is important that they are easy to place, especially with inexperienced users or with little knowledge of it. The flexible structures seem to be better than the scalp helmets.
Adaptability: It has to be adaptable to cope with the different user’s morphologies, different length and density hair ….
Sensor technology: Sensors that need driver gel are non-friendly, the time of the setup increases and it is not comfortable when they are removed. Better are those, which only need saline, and the best are the dry sensors, both flexible and rigid ones.
Data communication: wireless transmission between the measure device and the process equipment is the ideal way for the user.
Sensor position: it is relevant to be able to locate sensors in different places, that is, depending on the problem that is being addressed.
Emotiv EPOC is one of the main low-cost devices, taking into account the previous ideas. It has a fixed structure with diadem shape and plastic arms allowing some flexibility and achieves scalp contact for most users. Primarily it uses dry sensors, but sometimes saline is used to improve conductivity. This does not have any effect on the user’s hair which remains unaffected. This hardware can be bought both with the manufacturer’s software in a closed version, or with a version for developers. This last one permits access to the raw data coming from the sensors.
The mentioned features and the low cost of the Emotiv EPOC system, has led to researchers to consider it for dealing with engineering problems that need EEG signals acquisition. Some papers have been published making comparisons of data quality between Emotiv and professional equipment [2, 15, 21, 34]. Also papers for BCI applications with this device have appeared [10, 29, 31, 46].
Figure 4 shows a Biosemi and an Emotiv team. The advantages in terms of ease of use and preparation time provided by the Emotiv equipment are evident, especially when considering its use by a user not accustomed to this type of technology.
In the 1 section, the areas of interest considered in the work have been shown: BCI, Motor Imagery, ART Theory and low-cost platforms. Based on this, an architecture to be applicable to different BCI problems and that shares the Deep Learning methodology is proposed. It allows a straightforward application from the raw data to the results without previous steps. On the one hand, the proposed architecture is made up of modules developed in the ART and Fuzzy-ART theory and attempt to be self-organizing and therefore does not require an external expert to determine its topological characteristics or parameters. On the other hand, the use of ART and Fuzzy-ART modules allows an interpretation of the functioning of the architecture, which eliminates the black-box characteristic of many Deep Learning proposals. The presented architecture could be named as: Transparent Deep Learning, because it is self-organizing, learns directly from the data and allows an interpretation of how the processing is performed.
Paper organization
The 2 section shows the proposed architecture as well as the learning methodology following the Deep Learning philosophy. In the 3 section, the capabilities of the proposed architecture are explored showing its self-organization capacity: in the self-adjustment of the parameters, in the determination of the structure and in the automatic selection of the most relevant characteristics of the learning data. Objective results of the performance of the architecture with a set of original data are also provided. Finally, the most relevant conclusions of the work carried out are collected in the 4 section.
Deep-learning architecture for BCI challenges
In this Section, a generic architecture is proposed to deal with problems associated to the BCI paradigm. It will allow to connect EEG sensors measures with mental categories, following the Deep Learning spirit shown in the Fig. 1. Working with BCI application and EEG signals, some drawbacks could be stressed: Spatial variability: Sensor placement is always imprecise and it is not possible to place them again in the same locations in a new experiment. Variability among users: The anatomical differences of each user due to hair length, head size, and so on, leads to a great level of variability Variability in the same user: The characteristics of raw data collected in one experiment followed by a second experiment in the same user could be quite different. Wrong data due to artifacts and high noise level. Difficulty to label the categories: The learning process data cannot be labelled even by expert people. High dimensionality of data: EEG devices work with several channels of sensors and with high sample frequencies. This produces large amount of data to be processed in the learning task.
In order to deal with these challenges, a new architecture is presented as shown in Fig. 5. It is a global approach to the problem that, starting from raw data gathered with sensors, leads to high level mental categories. In this figure, an example with three categories associated to three mental categories are considered: “movement intention of right hand”, “movement intention of left hand”, “thinking of a word”. Obviously, there are a lot of mental activities that could be considered: “thinking singing a song”, “mentally rotating an object”, “movement intention of the left-right foot”,…, where the architecture is also appropriated because it is independent from the categories chosen. Some stages are proposed to process the information in a self-organizing way.
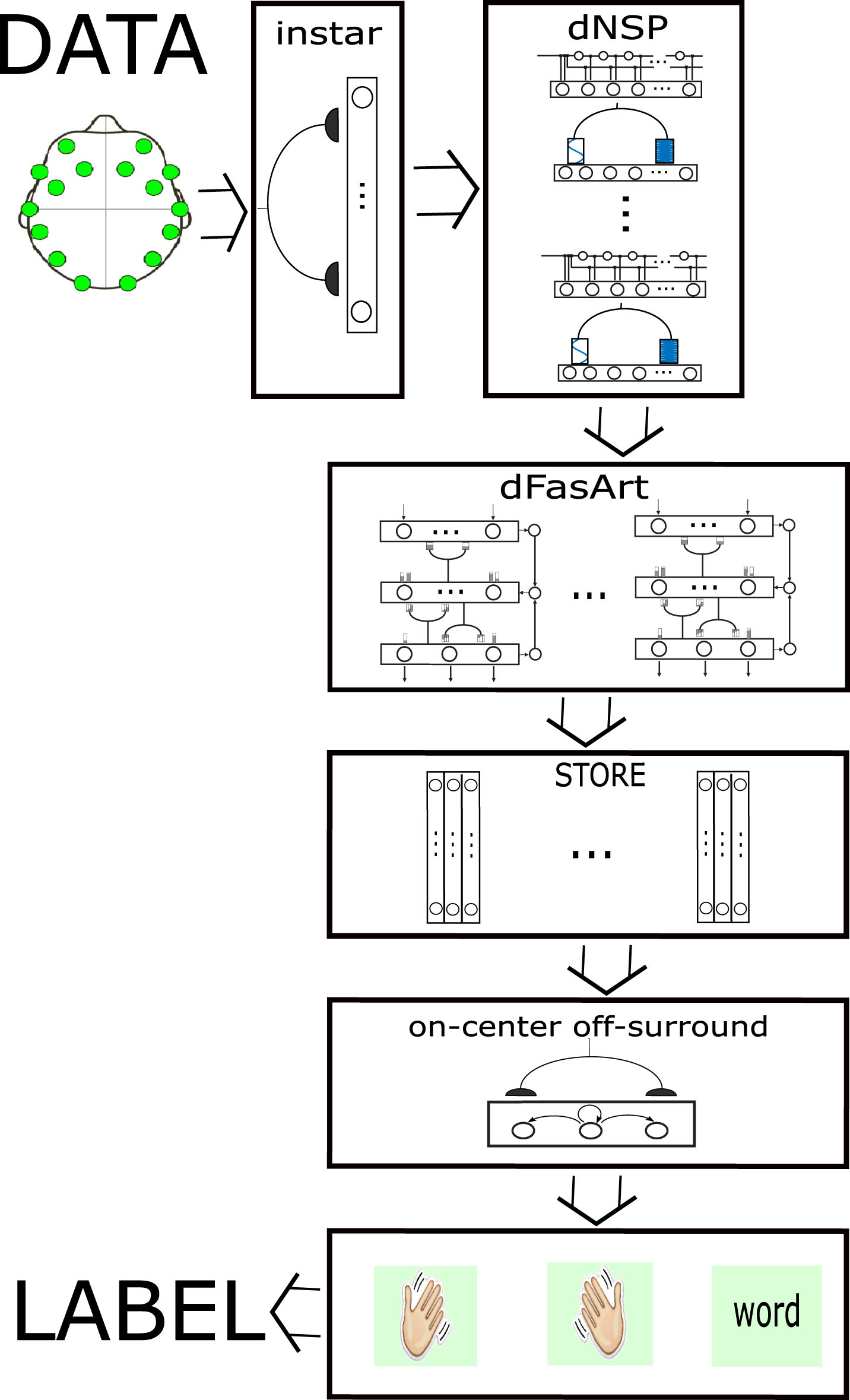
Proposed Architecture.
The proposed architecture uses different modules proposed in the framework of the Adaptive Resonance Theory and Fuzzy Logic Systems. The architecture takes advantage of the different functionality of the modules to process the data directly, in accordance with the Deep Learning paradigm, but at the same time allows an interpretability of its different stages in a model that could be named as Transparent Deep Learning.
The raw data is collected from the sensors on the scalp. These have a poor spatial resolution, so it is not possible to locate them always in the same position and the regularity in the measurement is not assured. To avoid this difficulty, a first processing stage is proposed mapping from a two-dimensional space, where sensors are located, to an input vector of entries by an instar module [17].
To study biological signals (e.g. cochlear implants) a frequency decomposition is a basic tool. So, a second stage is proposed based on dNSP model [9]. It allows making a frequency representation of time signals while maintaining the timing character. This stage increases the problem dimensionality because the number of frequency bands considered will multiply the number of time signals.
The proposed architecture has a multi-model scheme to facilitate the definition (learning) of different models coming from different sessions data, taking into account the intra-user variability. It is also useful to handle inter-user variability. The multi-model scheme has a drawback because it gives several output alternatives that could be valid.
The S-dFasArt stage in the architecture proposed in Fig. 5 requires a learning process to build the rule base for the S-dFasArt model. To this aim, the learning sessions collected from each user are used. The structure is different for each user to manage the inter-user’s variability. Four mechanisms are selected to define the multi-model system, as shown in Fig. 6. Rule generation: S-dFasArt learning algorithm is used to build the rules set from the data coming from each of the considered sessions. The N rules appear as: IF x1 IS Where:
Parameter adjustment: The parameters (σ y At) associated with the fuzzy character and with the activation speed of the categories that must be adjusted, Fig. 6(b). A learning algorithm is designed for this task. The adjustment of the parameter σ implies the modification of the fuzzy sets that define the rules, which become the fuzzy sets (in red in Fig. 6(b)). Rule pruning: Inefficient rules are pruned from the models, Fig. 6(c). The red crosses in the figure mean the rules that are discarded. Dimensionality reduction: Data dimensionality is adjusted, Fig. 6(d). In the figure the fuzzy sets associated with the dimensions that are selected as relevant for the model are framed.
Note that the last three mechanisms (adjustment, pruning and reduction) allow the model to enhance information coming from other sessions, different to the session used to generate the model. This seeks to improve the model’s generalization ability to handle the intra-user variability.
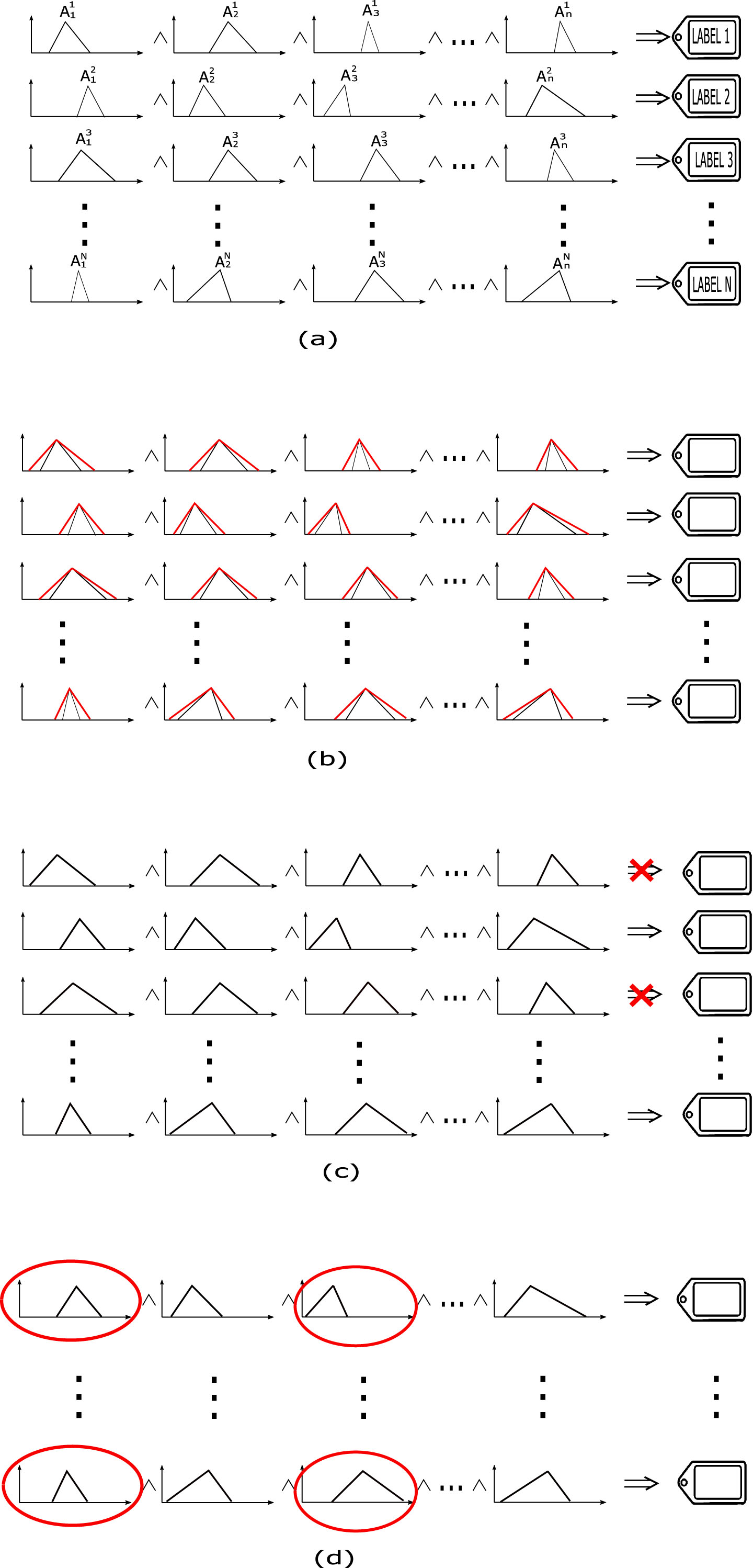
Learning methodology for S-FasArt models. (a) Rules generation. (b) Parameter adjustment. (c) Rule pruning. (d) Dimensionality reduction.
In this paper, the behaviour of the proposed architecture is tested strictly following the constraints, rules, time specifications, sessions and mental categories of the BCI Competition III (Set V). This is well established and formally described in the literature [6]. For that purpose, a new data set has been collected from four healthy male users with ages between 25 and 50 years old. All of them had no experience with BCI system and they were right-handed. The hardware used was Emotiv EPOC and the sampled frequency was 127 Hz. As the Competition determined, a weight matrix based in Laplacian distribution is used to make the first spatial projection. To compute the Power Spectrum Density for the frequency treatment, the Welch method has been applied.
The problem faced includes two mental categories associated with motor imagery (“movement intention of the left hand”, “movement intention of the right hand”), and a third one without motor significance (“thinking in a word”). So, the proposed model can be employed for two purposes: to detect motor intention in a synchronous way (with no prior knowledge of the event time) and to detect the laterality of the motor intention.
An experimental study is carried out to show the solutions that this learning architecture offers, in order to select the right configuration according to the problem faced. To study the architecture performance and to select the learning methodology, only three data sessions (S1,S2,S3) have been used. The fourth one (S4) has been reserved for the validation task.
In reference [8] a S-dFasArt module is used for the classification of the BCI Competition III (Data set V). There, S-dFasArt method obtained the best results with a success rate of 76.07%, which improves significantly the average of 68.75% of the competition winner. In the rules of BCI Competition III (Data set V) a classical methodology with a data pre-processing stage was used.
Learning and adjustment method
As mentioned above, three data sessions are used for the learning task. Initially, three different models will be generated, one for each learning session, using S-dFasArt [42] architecture. This architecture generates fuzzy rules set which exhibits the data structure used in the learning process 5.
The activation/membership functions are triangular and are determined from three weights. In the j antecedent of the i rule, these weights are (w ij , c ij , v ij ).
The units activation and the weight learning are computed with differential equations according to the assumptions of Adaptive Resonance Theory [17]. Once the learning task has been done, the number of the model parameters will be: P = 3 * N * M + N, where N is the number of rules created and M is the input vector dimension, that is to say, the number of antecedents of each rule.
The prediction of S-dFasArt architecture depends on two design parameters: σ y A t . The first one modifies the support of the fuzzy sets for the rules antecedents that have triangular activation functions. This support is the interval [w ij - σ, v ij + σ] for the j-th antecedent of the i-th rule. It regulates the level of the rule fuzziness [7]. The second parameter, A t , governs the speed of unit’s activation, and therefore the speed the model responds to input changes [7]. Low values of A t leads to a slow change in system activation state and so, the input value must be persistent in order to produce a change in network weights.
In the other way, high values of A
t
carries to quick activation variations when the input changes. Initially, these parameters must be adjusted in an external way, which would make the model not fully self-organized. To avoid this, an algorithm to parameter adjustment using learning techniques with neuronal inspiration, is proposed. It is a variation of the known Perceptron learning rule [35]. In an incremental way it is given by the algorithm described in equation 1
where f (x) =1 if x > 0 and f (x) =0 in another case. J (A t , σ) value is related with the model success for a selected test set. This algorithm is executed until there are no variations in parameters. ΔAt and Δσ will be alternated between positives and negatives values, and they are chosen among a discrete set of possible candidates. In a first step, the same session will be used to do the rule learning and the parameter adjustment. This implies that three different models can be generated.
The activation sequence in the upper layer of units in S-dFasArt is connected with a STORE module set. This set, through an Instar module, also feeds an on-center off-surround net. So, the most activated category results as the unique activated category. Then, the label associated to that one is proposed as the prediction output.
Data collected in Table 1 show the large deviation between the success rate when the session is the same used for the learning task and adjustments, from other sessions. The average of the results obtained for the four users that make up the database are collected.
A single session for learning and adjustment. Mean values for the four users
This indicates the intra-user variability. To fix this problem, an information mix coming from different sessions is proposed. At first, a session will be used for model generation and a different one will be used for the adjustment task. The goal is that the built rules acquire enough generality to represent two learning sessions. Now, each model will be created starting from two different learning sessions (Sa,Sb) so that: Session Sa for the learning task Session Sb for the adjustment task. Session Sc is not used to generate the model.
With this method, the three learning sessions collected can create six different models. The third session (Sc) is not employed at all to the model’s development, so the success rate for that session will suggest the model generalization ability.
The results shown in Table 2 have been compared with those obtained using the same session for the learning and adjustment task (Table 1). It can be seen that: The rate of success of the adjustment session is higher when this session has not previously been used for learning than when the same session was used for both learning and adjustment. The success rate for a session used neither for learning nor for adjustment, increases when different sessions have previously been used for those tasks.
Learning and cross adjustment sessions. Mean values for the four users
The improvement of using different sessions for learning and adjustment has been maintained. The increase in the success rate for the adjustment session shows that part of the understood information has been incorporated into the model, so that the model learns and adapts to include information from the new evidence (data).
On the other hand, the increase in the success rate of the session that has not been used neither for the learning task nor for the adjustment, manifest that the model generated with the two sessions presents a better generalization character than the one obtained from a single session. Rule variations coming from the adjustment phase make the model suitable to represent a data set with high variability and so, suitable to respond better to the intra-user variability problem.
One of the problems we usually face presents wrong labelled data. These generate rules whose predictions can be inconsistent. Examples where the same situation generates different conclusions, have been presented to the system. This is a handicap to learn properly and produce a non-defined output. To solve this, the S-dFasArt architecture incorporates a match-tracking mechanism that incorporates rules that consider the different outputs even if they come from the same antecedents. The problem could persist because there is not an objective way to choose among all of these rules. The solution proposed is to add a rule pruning stage. Here, the rules are evaluated according to their performance and the ones with the best marks are selected. For the assessment task efficiency criteria have been proposed:
It consists of three phases: To learn, to adjust and to prune. Each of them uses one of the available sessions to make the learning task as follows: Sa session is used for the S-dFasArt learning phase to generate the model. Sb session is used for the model parameter adjusting phase. Sc session is used for the pruning phase of the model rules.
Efficiency criteria for the rule pruning: This method gets one of the learning sessions and computes the predictions of each one of the previously defined models. The rule that has driven to each prediction and if it has been right or wrong, is stored.
At the end, a global calculation of the number of times that each rule has led to a right or a to a wrong prediction is carried out. The model will be composed by the rules set with a positive balance in this evaluation.
The results using the efficiency criteria for the rule pruning task are shown in Table 3
Efficiency pruning
Efficiency pruning
Some outcomes can be obtained from Table 3: The success rate for the session used both for the adjustment and pruning tasks increases. The success rate for the session used for the pruning task but not for the adjustment increases
Therefore, the effect of the pruning task is to include information from the session used, in the same model that was generated with data coming from another session.
This method uses a Group Method Data Handling (GMDH) [38] algorithm to select the rules that will constitute the model. A Regularity Criterium (RC) [28] based in the success rate is defined:
Initially the model consists of a single variable. With this assumption, RC value is computed for all the possible models that can be generated with a single variable. The model with the highest score is chosen. In the following steps, the number of variables is enlarged adding a new one. Again, RC value is computed for all the possible models and the model with the highest score is chosen. If this mark is better than the previous one, the new variable that has produced it is incorporated into the model. Now, we will try adding a new variable in a new interaction.
The GMDH algorithm is used to reduce the vector dimensionality associated with the antecedent’s space of S-dFasArt model. So, the number of rules antecedents (at first are 168) is decreased.
From Table 4 the conclusions that can be highlighted for the effect of dimensionality reduction are: The success rate for the session used both for the adjustment and reduction tasks increases. The success rate for the session used for the reduction task but not for the adjustment increases. The success rate for the session used both for the adjustment and reduction-pruning tasks increases. The success rate for the session used for the reduction-pruning task but not for the adjustment increases.
Dimensionality reduction
The model ability to predict properly a data session increases if the dimensionality reduction has been done with the same session. Therefore, the information contained in the session used for the reduction task is added to the model. Also, but with a lower degree of certainty, it can be deduced: The success rate of the session not used, neither for the adjustment nor for the reduction task, increases. The success rate of the session not used, neither for the adjustment nor for the reduction-pruning task, increases. The success rate of the session used only in the adjustment task, increases.
These leads to think that from a generic point of view, the dimensionality reduction has improved the model’s generalization ability, and so the capacity to predict different situations from those that have been used for the learning stage.
It must be noted that, in relation to the number of architecture parameters, for each model the initial number was P i = 3 * N i * M + N i where N i =number of model rules of i-th model and M = dimension of input vector, 168 for this issue. For instance, using the values of Table 2 we can compute:
For rule pruning and parameter reduction model using the values of Table 4 and with 6 models, the number of parameters are:
In the same way with 12 models:
It can be seen that in this last case, the number of parameters is 30 times lower with double of the models. The reduction in computational burden is obvious because the lower parameters used, the lower rules activations and belonging values must be computed. This is remarkable in an application with limited hardware.
As it was described in Section 1.2 the BCI Competition III Set V deal with a problem with three mental categories. This allows us to propose several problems to be solved with our architecture.
The problem faced includes two mental categories associated to motor imagery (“movement intention of left hand”, “movement intention of right hand”), and a third one without motor significance (“thinking of a word”). So, the proposed model can be employing for two purposes: to detect motor intention in a synchronous way (with no prior knowledge of the event time) and to detect the laterality of the motor intention.
The first one is to distinguish between motor and none motor thoughts. With this aim, a success rate can be defined as the number of times that a motor category is predicted properly A
M
versus the number of motor categories (N
I
+ N
D
), Motor success=
The results for this rate with the 4 users (in %) are stored in Table 5. Confusion matrices are shown in Table 6.
Dimensionality reduction influence in success rate for each user
Dimensionality reduction influence in success rate for each user
Confusion matrices. In brackets the data for 12 models
The well-known performance Cohen’s Kappa index is computed in Table 7 for all the users with the validation session using 6 and 12 models.
Cohen kappa value for each user using 6 or 12 models
The results collected in Table 5 indicate that the success rate in the prediction of MOTOR patterns is almost the same using 6 models (77.59%) or 12 models (77.59%). Also, the difference in the success rate for the WORD category is not significant: 75.78% for 6 models and 75.88% for 12 models. This behavior is maintained in the global rate: 56.17 % for 6 models compared to 57.90 % using 12 models. It can be inferred that the architecture can extract the most relevant information from data using only 6 models, which simplifies the necessary calculations and clearly reduces the computational cost.
Likewise, the obtained results reflect the ability of the system to discern between data associated with a motor activity and data associated with a non-motor activity. All this, using low-cost, non-invasive capture equipment, and using a generic and self-organizing architecture that does not require specific previous knowledge of the problem.
In this paper, a self-organized DL architecture, going from the raw data to the labels, is presented. It has a neurofuzzy scheme and a learning methodology allowing it to deal with different kinds of issues. One of them is the BCI-EEG paradigm, which has some characteristics that make it especially difficult to manage. The proposed system is suitable to face the EEG challenges. On the one hand, the fuzzy character of the showed architecture provides a natural way to processing data with great uncertainty, because the model is able to decode the prediction models as a rule set that joins fuzzy sets with labels associated to mental states. On the other hand, the high dimensionality and the presence of noise are avoided pruning the inefficient rules and adjusting the problem dimensionality.
The proposed learning methodology is arranged in several stages. Firstly, the signals are processed with a dNSP architecture to obtain an initial frequency composition. Secondly, neurofuzzy dFastArt algorithms with a mechanism of parameters adjustment are used to generate multiple models from several learning sets in an autonomous way. Thirdly, a learning method that prunes existing rules is used to erase the relationships generated from incoherent learning data. At last, there is a STORE module and an on-center off-surround network, which constitute a method to gather the evidences and to make the final decisions.
The architecture shares the paradigms of multilayer modularity and self-organization that characterizes the DL. It allows to predict high level mental categories directly from EEG sensor measurements. The modular attribute of the proposed architecture allows to understand how it works, solving the dark “black-box” nature of the DL systems. The activation of the output units of dNSP module fits with the frequency composition of the EEG signals. The work of the neurofuzzy S-dFasArt unit can be interpreted from the If THEM rules applied on fuzzy sets. This feature is even relevant to the rule generation because for each decision the module makes it is possible to determine which rule is using and which examples, taken from the learning set, have carried to the generation of each rule.
To test the proposed DL architecture, a particular BCI problem has been tested. It is the motor imagery issue. Some processing alternatives have been studied. The results prove the efficiency to detect the movement intention thoughts. Although the sensor’s positions on the scalp have not been the most appropriate to predict the laterality problem, and the difficulty of the problem faced, the success rates are very acceptable: Motor 77.59%, Word 75.78%.
A relevant contribution of the proposed architecture is that it allows an interpretation of the data processing, called Transparent-Deep Learning (T-DL). Which means, that it maintains the principles of DL but adding the possibility to interpretate the intermediate steps. Therefore, the results can be seen as the application of a set of rules which are easy to understand.
Footnotes
Acknowledgments
The authors belong to the Neuro-Technology, Control and Robotics (NEUROCOR) research group placed in the Technical University of Cartagena. They want to thank Dr. Juan Antonio Martínez León’s work. We would also like to thank the reviewers for their comments.