
Abstract
Chinese medical named entity recognition (CMNER) aims to extract entities from Chinese unstructured medical texts. Existing character-based NER models do not comprehensively consider character’s characteristics from different perspectives, which limits their performance in applying to CMNER. In this paper, we propose a local and global character representation enhanced model for CMNER. For the input sentence, the model fuses the spacial and sequential character representation using autoencoder to get the local character representation; extracts the global character representation according to the corresponding domain words; integrates the local and global representation through gating mechanism to obtain the enhanced character representation, which has better ability to perceive medical entities. Finally, the model sent the enhanced character representation to the Bi-LSTM and CRF layers for context encoding and tags decoding respectively. The experimental results demonstrate that our model achieves a significant improvement over the best baseline, increasing the F1 values by 1.04% and 0.62% on the IMCS21 and CMeEE datasets, respectively. In addition, we verify the effectiveness of each component of our model by ablation experiments.
Introduction
Chinese medical named entity recognition (CMNER) aims to extract specific entities from unstructured medical texts and identify their types, such as symptoms, drug names, body parts, etc. This task is the basis of downstream tasks such as information retrieval and intelligent question-answering in the medical domain. In the past researches, named entity recognition(NER) is usually formalized as a sequence labeling problem, in which a sentence is divided into multiple tokens as the input, and the model outputs the corresponding entity tags of tokens. For Chinese NER, tokens commonly have two forms, i.e. character granularity and word granularity [1, 2]. The sequence model based on word granularity may encounter the problem of improper word segmentation, resulting in wrong entity boundaries. Therefore, most Chinese NER models are based on character granularity. However, Chinese characters do not contain independent semantics, and character-based models may result in the incomplete entity or wrong categories. To solve this problem, researchers mainly consider how to introduce much more word information for the character-based model. For example, Zhang et al. [3] proposed Lattice model, integrating the embedding of matched words with character embedding in a unique way to enhance character representation. Ma et al. [4] proposed SoftLexicon, which classifies the matched words into four sets and integrates the word embedding of the four sets with character embedding. Liu and Xiao et al. [5] proposed a model that injects lexical features into the bottom layer of BERT, and character information and word information can fully interact in BERT.
The above methods show that character feature enhancement can make up for the ability deficiency of Chinese characters to independently perceive entities. However, these character enhancement methods do not comprehensively consider the character’s characteristics from different perspectives, which limits their performance in applying to CMNER. In fact, Chinese characters in medical domain have useful characteristics for identifying domain entities, which is mainly manifested in two aspects:
1) The local characteristic. A Chinese character has a kind of glyph structure commonly composed of radicals and other components, and we call it the local characteristic. A character containing some specific radical usually belongs to a medical entity, and Chinese characters with the same medical radical component have similar medical entity categories. For example, Chinese characters constructed by the medical radical component "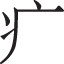 " are usually the characters of medical entities and mostly related to disease entities, such as "
" are usually the characters of medical entities and mostly related to disease entities, such as " cancer", "
cancer", " Scar", "
Scar", " plague" and "
plague" and " epidemic". Characters composed of the medical radical "
epidemic". Characters composed of the medical radical "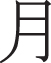 " are related to body parts, such as "
" are related to body parts, such as " brain", "
brain", " liver", "
liver", " kidney", "
kidney", " lung", etc. This local characteristic can be obtained by the spacial and sequential ways. As shown in Fig. 1, for the spacial way, a Chinese character can be regarded as a two-dimensional image with specific radical. On the other hand, from the perspective of sequence, a character can be disassembled into sequences of the radical and the other components. Spatial and sequential representation can highlight the radical from different aspects to enhance the ability of Chinese characters indicating medical entities.
lung", etc. This local characteristic can be obtained by the spacial and sequential ways. As shown in Fig. 1, for the spacial way, a Chinese character can be regarded as a two-dimensional image with specific radical. On the other hand, from the perspective of sequence, a character can be disassembled into sequences of the radical and the other components. Spatial and sequential representation can highlight the radical from different aspects to enhance the ability of Chinese characters indicating medical entities.

Local and global characteristic of characters.
2) The global characteristic. Medical words constituted by specific Chinese characters also indicate a specific entity. For example, the character " brain" in Figure 1 constitutes medical words such as "
brain" in Figure 1 constitutes medical words such as " meningitis" and "
meningitis" and " cerebral infarction", while those domain words belong to medical entities. Medical words responding to a character need to be obtained from the entire medical dataset, so we call it the global characteristic. Using these medical words to obtain the global representation can further improve the entity-representing ability of Chinese characters.
cerebral infarction", while those domain words belong to medical entities. Medical words responding to a character need to be obtained from the entire medical dataset, so we call it the global characteristic. Using these medical words to obtain the global representation can further improve the entity-representing ability of Chinese characters.
Drawing on the aforementioned analysis, we introduce a novel approach to address the limitations of existing CMNER models. Our proposed method integrates both local and global information of Chinese characters, aiming to enhance the model’s ability to accurately perceive potential entity boundaries and categories. By leveraging this comprehensive information, we expect to improve the overall performance of CMNER and provide more precise and reliable results in identifying medical entities. Comparing with previous works, the major contributions of our paper are three-fold:
1) We propose a local and global character representation enhanced model for CMNER. To the best of our knowledge, it is the first attempt to integrate the local and global information of Chinese characters to enhance their ability of perceiving the potential entity boundaries and categories, and thereby to improve the performance of NER.
(2) We use the autoencoding mechanism to fuse the spatial local representation and the sequential local representation, and use the interaction gating mechanism to control the contribution of local and global representation, so as to obtain the comprehensive character representation from different perspectives.
(3) Extensive experiments on two benchmark datasets show that our proposed method significantly outperforms the other baseline methods, and the in-depth analysis shows the effectiveness of local and global representation, as well as fusing and gating mechanism.
Before the emergence of deep learning, researchers mainly adopted traditional machine learning methods for NER. Lafferty [6] first proposed CRF, and McCallum [7] first successfully applied it to NER. Settles [8] proposed the method of combining CRF with feature set for biomedical NER task. Ju [9] uses SVM to identify the names of the specified type from the biomedical text, and Tang [10] developed a NER system based on SVM to identify the clinical entities in the hospital charging summary. In addition, they extracted two different types of word features and integrated them with the clinical NER system based on SVM. Liu [11] first established a medical dictionary, and then studied the role of different types of features in the Chinese clinical text NER task based on CRF. Although the research has made great progress, they have to spend a lot of energy on feature engineering [12] to obtain better recognition results. In addition, there are still many problems such as high-dimensional sparse data, poor scalability, cold start and difficulties of user preference modeling, which makes medical NER based on traditional machine learning unsatisfactory.
For medical NER, Yao et al. [13] used neural networks to train a large number of medical texts to generate word vectors, and then build multi-layer CNNs for NER. Li et al. [14] used Bi-LSTM as the basic NER structure, and Zeng et al. [15] combined BiLSTM and CRF to achieve good results in the drug name recognition task. After that, the attention mechanism was introduced to highlight the important information in the input sequence. Luo et al. [16] constructed a model combining BiLSTM-CRF and the attention mechanism in document-level compound named entity recognition, and obtained global information by introducing attention mechanism to ensure the consistency of the same entity labeling in document-level data. Medical texts contained intricate information, including a large number of domain words and professional knowledge, which requires more efficient ways to solve the task of medical NER.
For Chinese NER, the comparison between word-based method and character-based method indicated that the latter was a better choice empirically [17, 18]. In order to compensate for the lack of semantic expression by characters alone, researchers integrated lexical information into character-based models. The typical method was Lattice-LSTM [3] which can automatically find more useful words from the context and pass to each character to enhance the character representation for NER. On this basis, many methods tried to improve Lattice method. Gui et al. [19] proposed the LR-CNN model to solve the problem that Lattice structures cannot effectively handle lexical information conflicts or parallelized computing. SoftLexicon [4] introduced lexical information through label and probability methods at the character representation layer. Yan et al. [20] took full advantage of these models in enhancing the ability of capturing remote context dependencies. Besides, there were also many methods exploiting external knowledge for Chinese NER [21, 22]. He et al. [23] used knowledge-graph to enhance word representation. Yin et al. [24] introduced the radical-level features to obtain more structural information, and used the self-attention mechanism to capture the dependencies between characters. Meng et al. [25] used Chinese character images to extract features such as strokes and structure of Chinese characters, achieving promising performance. In the above works, it has been proved that the feature extension and enhancement of Chinese character can result in better NER performance.
Methodology
In this section, we will introduce our proposed approach. Formally, we denote a Chinese sentence
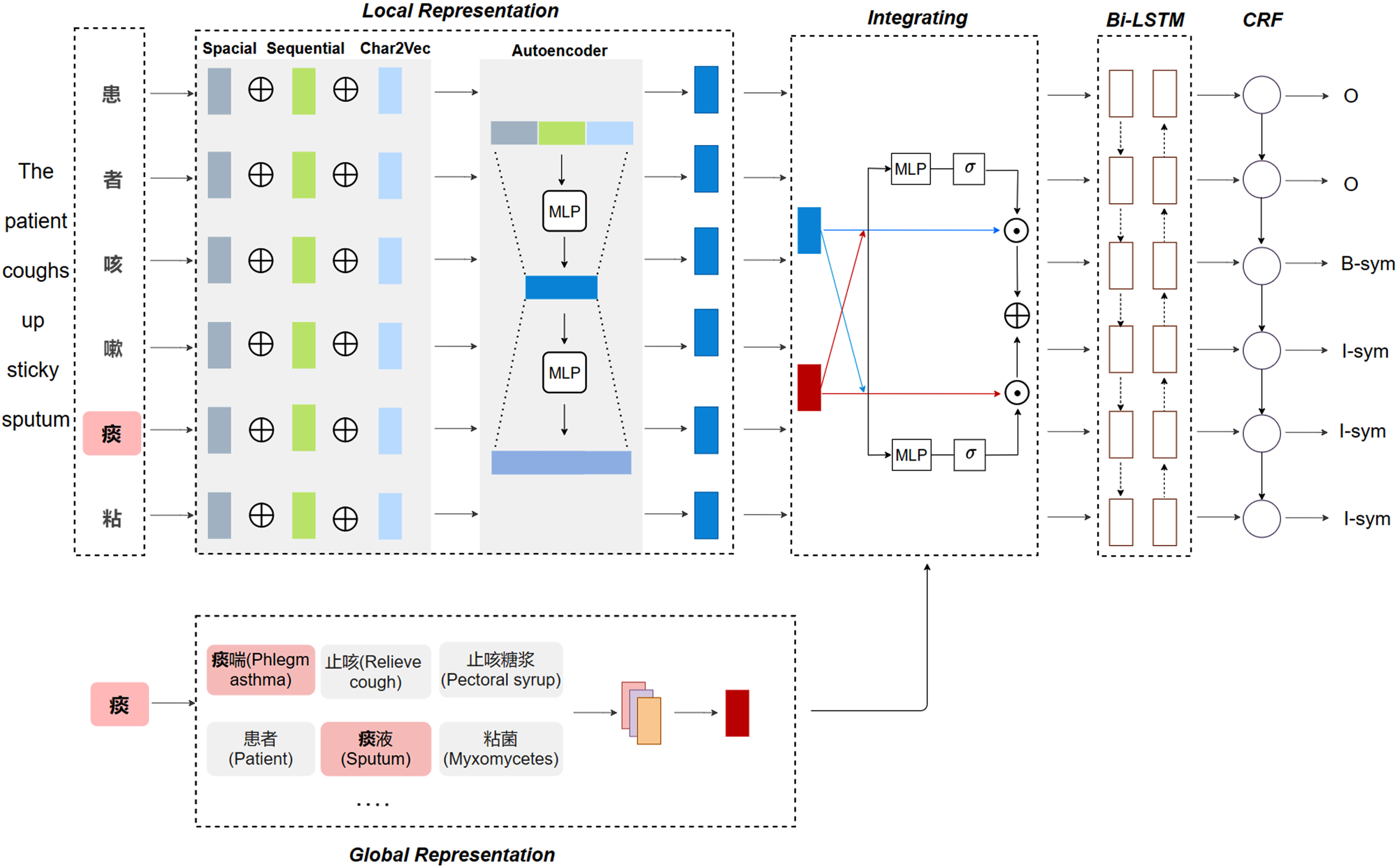
The architecture of our model.
For each character c
i
, We obtain the spacial representation
Spacial representation
First, we regard a character c
i
as a two-dimensional image. From the perspective of spatial processing, we can obtain its spacial representation by the image feature encoder. Referring to the practice of the model proposed by Meng et al.[25], we converted c
i
character into six 8-bit gray images corresponding to six different fonts
Then, we used a convolution operation Conv1 with 5×5 convolution kernel size and 384 output channels to obtain hidden vector
We put
As mentioned in the introduction, radical components in a character have strong function to indicate entity, which may not be fully reflected only by the spacial representation. Therefore, we need to further emphasize the role of the radicals as independent components in a character. We divide a character into radicals and the other components, and then use the sequence feature encoder to extract the sequential representation of the character.
First, we split the character c
i
into K parts
Character-based Chinese NER models usually use Char2-Vec vector trained on large-scale corpus as the initial embedding of characters [26], which contains the context local information of characters. In our model, we also use the pre-trained character embedding lookup table E
c
to get Char2Vec vectors, which is trained by Word2Vec model on a massive Chinese corpus Gigaword
1
. We map the character c
i
to its Char2Vec representation
After obtaining the three local vectors of a character, it is necessary to fuse them to obtain the comprehensive local representation. Because of the great differences in the three representations, we use the autoencoding mechanism to fuse them. Specifically, we concatenate
In this module, we obtain the global representation of characters by utilizing the domain word vectors which commonly contains entity information. The global representation of a character is decided by four situations that the character appears in domain words. We perform the following steps:
Firstly, we use the medical segmentation tool pkuseg 2 , an open source segmentation Toolkit, to segment the collected medical corpuses 3 , and train word embedding on the segmented corpuses by skipgram model [27]. We set the window size of skipgram to 4, and remove the words less than 5 times. Then we get a medical domain dictionary D and a word embedding lookup table E d for each domain word.
Next, we make the character c i as a query to search domain words in dictionary D. If a word w in D contains the character c i . we assign w to one of the four sets B (c i ),M (c i ),E (c i ),S (c i ) according to the different positions of c i in w, Specifically, according to c i appears at the beginning, middle, or end of the domain word, the word w is classified into the set B (c i ),M (c i ),E (c i ) respectively, if c i is same as w (that is, the character is an independent word),the word w is classified into the word set S (c i ).
Then we count the weight
After obtaining the local and global representation of a character, we use gating-mechanism to control their contributions to the comprehensive representation, since one of the representations may have information redundancy compared to the other. The calculation formula is as follows:
Finally, the local and global representation is multiplied by its corresponding gating and concatenated to be the comprehensive representation
Character-based NER is a continuous tokenization task with strong constraint relations between neighboring characters. Therefore, the contextual information of the characters in the sentence sequence should also be considered. We feed the sequence of comprehensive character representations into the Bi-LSTM network to extract the context representation
In the tags output stage, we use CRF as the decoder. CRF will affect the results of the current tag based on the results of the previous tag. Specifically, CRF is composed of an emission matrix and a transition matrix. The emission matrix
We first introduce the datasets, experimental parameters setting and evaluation metrics. Then we present the experimental results of the proposed method and comparison model on the two public datasets, we conduct ablation and parameters experiments on the dataset, Finally, the results and analysis are given. Our model is implemented using PyTorch and requires a minimum 8GB of graphics memory for model training. With a relatively small parameter count of 11.4 million, our model is more compact compared to other existing models. For training, we utilize a GTX 3090 GPU with 24GB of memory on a Linux platform. It takes approximately 1025 seconds to complete one epoch and around 23 hours to finish the entire training process. During the training process, we continuously evaluate the model’s F1 score on the validation set after each epoch. The model parameters achieving the highest F1 score on the validation set are saved, and this saved model is further evaluated on the test set. Once the model is trained and saved, it can efficiently extract specific entities from input sentences and provide corresponding labels. It is important to note that if the sentence length exceeds 512 characters, proper segmentation is required to ensure the model’s optimal performance.
Datasets
To evaluate the performance of our model, we conduct experiments on two medical datasets. One is IMCS21 provided by the Chinese Conference on Computational Linguistics (CCL), which includes more than 60K sentences, and contains five entity types, including symptom, drug name, drug type, examination and operation. Another is CMeEE from the Chinese Biomedical Language Understanding Evaluation, which contains more than 20K sentences. The dataset contains nine categories of medical entities such as common pediatric diseases, body parts, clinical manifestations, medical procedures and so on. The IMCS21 dataset contains a significant number of short sentences with sparse entity distributions, while the CMeEE datasets mostly consist of longer sentences with denser entity distributions, where entities tend to be longer than those in the former dataset. This presents a greater challenge for entity recognition in the latter dataset. These two datasets are publicly available 4 , and details are shown in Table 1.
Statistics of datasets
Statistics of datasets
To evaluate the performance of the model, the evaluation metrics adopted in this paper is the precision rate (P), the recall rate (R) and f1-score (F1):
In our model, we adopt Adam optimizer with the learning rate of 0.0015 and the decay step of 0.05. The hyper-parameter λ is set to 0.1 by experimental comparison. Details of parameters settings are shown in Table 2:
Experimental parameter settings
Experimental parameter settings
BiLSTM-CRF [28]: The model uses Bi-LSTM to encode character sequences and input hidden vectors to CRF layer for decoding to obtain sequence labels.
Lattice [3]: The model encodes all the characters in the sentence and words recognized by the dictionary, so as to integrate potential word information into the character-based LSTM model.
WC-LSTM [29]: The model is an improved Lattice-based method. The dimension of word embedding is fixed and word embedding is only fused into the last character in the word.
IDCNN [30]: It is iterated dilated convolutional neural networks, which adds a division width to the convolution kernel of CNN to increase the receptive field, so that each convolutional output contains a larger range of information. It can alleviate the disadvantage of CNN with weak feature extraction ability on the input of long sequences.
LR-CNN [19]: The model continuously extracts n-gram information through multi-level CNN, weights different words weights through hierarchical attention, and finally extracts features by fusing attention.
LGN [31]: The model adopts the lexicon-based graph neural network. Each character is taken as a node, and the edge is formed by the matched words. Based on the interaction of multiple graphs between characters, potential words, and the whole sentence, the problem of word ambiguity in NER can be effectively solved.
SoftLexicon [4]: The model improves the way of introducing word information based on Lattice. By integrating lexical information into character representation, it can be transferred to different sequence annotation frameworks, and it is easy to merge with the pretraining model.
FLAT [32]: The model flattens the Lattice structure from a directed acyclic graph to a flat Transformer structure, which takes advantage of long-distance dependencies of Transformer and designs the clever position code to improve the performance of NER.
MECT [26]: The model exploits multiple data embedding, integrates radical, character and word information through cross transformer network, and uses random attention to further improve performance.
Result analysis
Overall results
Experimental results of the different models on CmeEE and IMCS21 are given in Table 3. We can observe that: 1) Our model achieves the best performance on the two datasets. Compared with MECT, which has the best performance among the baselines, the F1 value of our model improves by 1.04% in CMeEE and 0.62% in IMCS21. Our model achieved the highest F1 score on both the text-long and entity-dense CMeEE dataset as well as the text-short and entity-sparse IMCS21 dataset. This indicates that our model has the capability to effectively process texts of varying lengths and densities of entities. Based on this observation, we can speculate that our model exhibits a certain degree of generalization capability. 2) On the whole, the performance of BiLSTM-CRF and WC-LSTM are the lowest. It maybe owing to that BiLSTM-CRF uses only the contextual information of characters, omitting important semantic of words. WC-LSTM has a low performance because its shortest word-first strategy is not suitable for these medical datasets with long entities. CNN-based models such as IDCNN and LR-CNN achieve lower F1 values than MECT and FLAT because they are limited in learning global semantic features. 3) Our model, MECT and Lattice+Glyce outperformed LGN, SoftLexicon, and FLAT on the whole, which shows that the external glyph or radical information is helpful for CMNER. 4) All the models have better results on IMCS21 than CMeEE. While our model can enhance the accuracy of entity boundaries and categories, it struggles to process complex, lengthy texts and entity-dense medical datasets. In the case of CMeEE datasets with longer sentence and entity-dense, the model identifies multiple continuous entities as a single entity, leading to a lower recall rate and fewer predicted positive entities.
Experimental results of different models on CMeEE and IMCS21
Experimental results of different models on CMeEE and IMCS21
We performed the following ablation experiments to verify the effect of the local and global character representation.
Experimental results are shown in Table 4. It can be seen that the removal of local or global representation leads to a huge decrease of the F1 value by 8.44% and 5.06%, respectively, which verifies that both local and global representation plays an important role in guaranteeing the performance of our model. What’s more, the spacial and sequential ways are helpful to represent the local information of characters completely, and support the model to gain the best performance.
Ablation results of the local and global representation
Ablation results of the local and global representation
Comparison of fusion methods
In order to verify the effectiveness of the proposed local fusion method, we conducted experiments on CMeEE with the other local feature fusion methods.
The experimental results are shown in Table 5. It can be seen that the autoencoding fusion of our model gets the best result, and the F1 value is 0.51% and 1.67% higher than other methods.
Experiment results of different fusion methods
Experiment results of different fusion methods
We further explored the effect of the hidden vector dimension in the autoencoder. We perform experiments with the dimension of the hidden vector
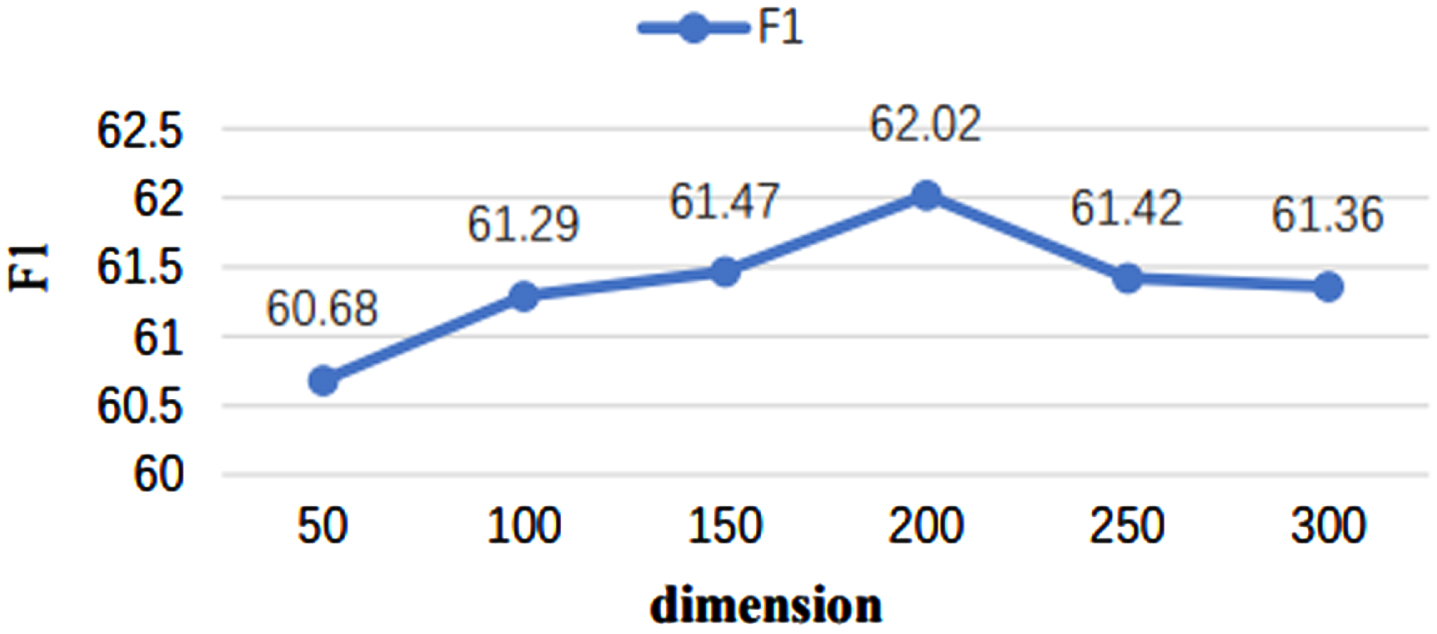
The effect of fusion vector dimension.
In order to verify the effectiveness of the local and global representation gating methods on our model, we also conducted experiments on the CMeEE dataset with three other methods.
The experimental results are shown in Table 6. We can see that Integration ADD is not as effective as Integration CAT , due to the latter method may save local and global information more completely. Our model uses the gating mechanism to process the local and global representations, and then concatenate them together, which can select the most important information, so as to obtain the optimal performance.
Experiment results of different integration methods
Experiment results of different integration methods
Table 7 shows the number of recognizing errors of different models on the two datasets, including the beginning boundary error (BE), the end boundary error (EE), and the entity type error (TE). Compared with the other models, the number of BE, EE and TE of our model are reduced obviously. It shows that the model in this paper significantly improves the performance of medical entity boundary and entity type recognition.
Analysis of entity recognition errors
Analysis of entity recognition errors

Case analysis.
Figure 4 lists several instances from CMeEE. We can see from the first sentence that LR-CNN and SoftLexicon are unable to recognize the second entity that follows the first, demonstrating the limitations of their recognition capabilities for numerous consecutive entities. For the second sentence, the type of the entity " RNA
RNA ” (viral RNA protein complex)" is predicted incorrectly by LR-CNN, which may owe to that the model uses CNN to obtain the context representation, while CNN cannot extract the remote information of characters sufficiently. The boundary of this entity is recognized incorrectly by SoftLexicon. The reason may be that the model introduces too much word information to harm judging the character boundary. Our model can effectively recognize the boundaries and types of medical entities owing to its reasonable utilization of the local character information and the global word information. Furthermore, in this particular case, the longer entity includes the two characters present in the shorter entity. If both entities have been labeled correctly in the training corpus, some high-performing models can accurately recognize them. However, if a model is trained solely on the entity "
” (viral RNA protein complex)" is predicted incorrectly by LR-CNN, which may owe to that the model uses CNN to obtain the context representation, while CNN cannot extract the remote information of characters sufficiently. The boundary of this entity is recognized incorrectly by SoftLexicon. The reason may be that the model introduces too much word information to harm judging the character boundary. Our model can effectively recognize the boundaries and types of medical entities owing to its reasonable utilization of the local character information and the global word information. Furthermore, in this particular case, the longer entity includes the two characters present in the shorter entity. If both entities have been labeled correctly in the training corpus, some high-performing models can accurately recognize them. However, if a model is trained solely on the entity " (virus)," the characters "
(virus)," the characters " (virus)" in the longer entity "
(virus)" in the longer entity " RNA
RNA (viral RNA protein complex)" may be erroneously identified as a separate entity.
(viral RNA protein complex)" may be erroneously identified as a separate entity.
Conclusion
In this paper, we propose a novel character representation enhanced model to improve the performance of NER in medical Chinese text. According to the observation that both certain radicals inside the character and certain domain words containing the character imply medical entity meaning, we propose to combine these local and global representations by autoencoding and gating mechanism, therefore to improve the medical entity-aware ability of characters. The proposed model demonstrates satisfactory results for medical named entity recognition, as confirmed by the ablation study, which highlights the usefulness and rationalization of the proposed modules. However, real industrial settings often face challenges such as high labeling costs and insufficient generalization. To address this, hybrid systems combining the rules-based model with our model are typically used. We’ll investigate this further in the future.