
Abstract
This paper defines an improved similarity degree based on inclusion degree as well as advanced information system based on interval coverage and credibility, and thus an attribute reduction framework embodying 4×2 = 8 reduct algorithms is systematically constructed for application and optimization in interval-valued decision systems. Firstly, a harmonic similarity degree is constructed by introducing interval inclusion degree and harmonic average mechanism, which has better semantic interpretation and robustness. Secondly, interval credibility degree and coverage degree are defined for information fusion, and they are combined to propose a δ-fusion condition entropy. The improved condition entropy achieves the information reinforcement and integrity by dual quantization fusion of credibility and coverage, and it obtains measure development from granularity monotonicity to non-monotonicity. In addition, information and joint entropies are also constructed to obtain system equations. Furthermore, 8 reduct algorithms are designed by using attribute significance for heuristic searches. Finally, data experiments show that our five novel reduct algorithms are superior to the three contrast algorithms on classification performance, which also further verify the effectiveness of proposed similarity degree, information measures and attribute reductions.
Keywords
Introduction
Attribute reductions (ARs) play an important role in data pre-processing, which have become a key research direction, such as on data mining [1, 2], information processing [3, 4] and machine learning [5, 6]. Specifically, knowledge granularity and information measurement underlie ARs, thus they become the main driving forces for ARs improvement [7, 8].
ARs come from rough set theory, which can effectively deal with uncertain information [9]. Classical rough set theory mainly involves single-valued systems. Due to the complexity of practical problems, single-valued systems have been extended to interval-valued information systems (IVISs) and interval-valued decision systems (IVDSs).
In IVISs/IVDSs, knowledge granularity and information measurement are two important factors for ARs. Therefore, this paper begins by elaborating the existing research status and improvement space from the following three aspects of knowledge granularity, information measurement and ARs. (1) Similarity degree between intervals is the foundation for building knowledge granularity, which is concerned by many researchers. The classical similarity degree (recorded as SD) in Equations (2)(3) is proposed by [10], which mainly considers integrated maximum and minimum of intervals’ endpoints. By [11], α-weak similarity degree is put forward by combining the maximum and minimum similarity degrees. Ma et al. [12] utilize kernel function and the distance to define kernel similarity degree. Liu et al. [13] put forward new distance to define a similarity degree. In [14], intersection-union similarity degree (recorded as IUSD) is defined by ratio of the intersection lengths to union lengths. Dai et al. [15] define the relative bound difference similarity degree (recorded as RBD) by using the distance between the endpoints. Generally speaking, these SDs essentially mainly consider the endpoint or distance and may lack sufficient semantic analysis. Specifically, we focus on SD and IUSD which are related to inclusion degrees. IUSD between
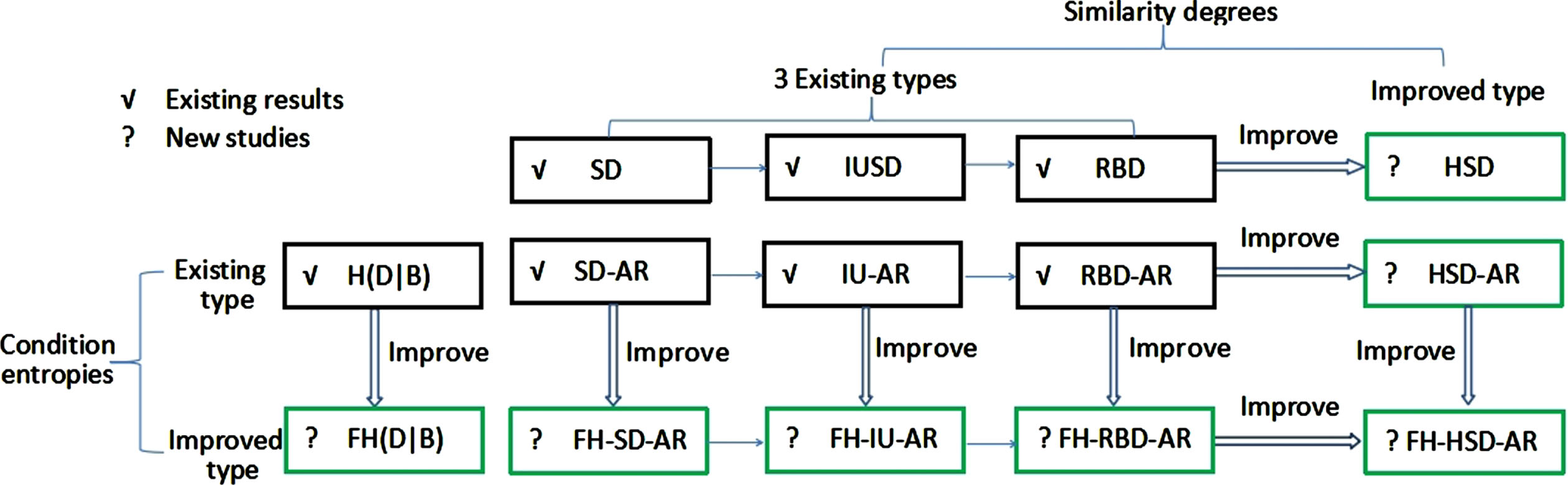
Research framework and development thoughts of similarity degrees, information measures and attribute reductions.
Through the above background, there is improvement room in the existing knowledge granularity, information measures and ARs. More specifically, Dai et al. [15] utilize 3 SDs (i.e., SD, IUSD, RBD) and a CE H δ (D|B) to establish a monotonic ARs framework. This paper puts forward a non-monotonic CE FH δ (D|B) and a harmonic similarity degree (recorded as HSD) to reconstruct the uncertainty measures, and thus constructs a non-monotonic ARs framework. These two innovations lead to the systematic comparison and optimal selection in the horizontal-vertical framework, meanwhile our research framework and development thoughts of SDs, information measures and ARs are shown in Fig. 1. (1) Horizontally, the proposed harmonic similarity degree HSD improves the existing SD, IUSD and RBD in [10, 15]. HSD is defined by using harmonic average of inclusion degrees that indicates the degree of one interval included by another one. Inclusion degrees have good semantics, and they have many practical applications [20, 27]. In addition, the value of HSD is between SD and IUSD, i.e., IUSD ≤ HSD ≤ SD (See Theorem 1), the fact shows that HSD can better depict the similarity degree because SD is often too large while IUSD is too small. Based on HSD, interval similarity relations and similarity classes are naturally established to further improve the subsequent measurements. (2) Vertically, a non-monotonic δ-fusion CE FH δ (D|B) in Equation (13) is proposed to improve the monotonic CE H δ (D|B) in [15]. H δ (D|B) only depends on the cardinality of similarity classes and their intersection with decision classes, while the proposed FH δ (D|B) can objectively reflect the classification decision-making ability because of deeply considering the interval credibility and coverage. Therefore, improved FH δ (D|B) can maintain the information integrity and systematization. In addition, information entropy and joint entropy are systematically constructed. (3) By Fig. 1, 8 ARs are compared based on four SDs and two CEs, for example, FH-HSD-AR and HSD-AR represent two combinations of (HSD, FH δ (D|B)) and (HSD, H δ (D|B)). It is worth noting that our focus is HSD, FH δ (D|B) (recorded as FH(D|B)) and 5 improved ARs, these major contributions are marked with green border. Our proposed 5 ARs (i.e., HSD-AR, FH-SD-AR, FH-IU-AR, FH-RBD-AR, FH-HSD-AR) outperform the existing 3 methods (i.e., SD-AR, IU-AR, RBD-AR) by classification performance. Therefore, these horizontal-vertical comprehensive comparisons can lead to optimized choices of ARs on SDs and CEs.
The rest is organized as follows. Section 2 reviews some basic concepts in IVDSs. Section 3 proposes a novel harmonic similarity degree which induces similarity relation and similarity class, and their basic properties are further studied. Section 4 first defines the interval credibility degree and coverage degree, then comprehensively utilizes them to construct a non-monotonic CE. Furthermore, the responding information and joint entropies are systematically constructed, and their relationships and properties are verified. Section 5 constructs an ARs framework for heuristic search based on 4 SDs and 2 CEs, and designs the corresponding 4×2=8 reduct algorithms. In Section 6, datasets experiments verify our methods by SDs, CEs and classification accuracies of ARs. Finally, Section 7 summarizes this paper.
This section will review some basic concepts in IVDSs, such as similarity degree, similarity relation and similarity class. Next, a possibility degree between two interval values is reviewed first.
Considering an interval-valued decision system IVDS = (U, AT = C ∪ D, V, f), where U = {x1, x2, ⋯ , x n } is a non-empty finite set of objects, C = {c k |k = 1, 2, ⋯ , r} represents a non-empty finite set of condition attributes while the set D = {d} is composed of a decision attribute d, f is a mapping function: U × C → V a , V a is an interval, and the value range is V = ⋃ a∈CV a .
If x
i
, x
j
∈ U,
An interval-valued decision table
Granulation
Further, the δ interval similarity class of x
i
and the similarity granulation with respect to B are
If B1 ⊆ B2 ⊆ C, then If 0 ≤ δ1 ≤ δ2 ≤ 1, then
Next, a useful example is offered to explain relevant concepts mentioned above in an IVDS.
For similarity granulation, the condition attribute addition chain and δ increase sequence are set as
In IVDSs, similarity degrees (SDs) deduce similarity relations and condition granularities, so they are the foundation of subsequent uncertainty measurements and ARs. An improved similarity degree is proposed by means of inclusion degree and harmonic average, so as to promote later uncertainty measurements (especially CE) and ARs.
By Equation (1) in Introduction, the relationships of two inclusion degrees and two SDs (SD and IUSD) seem to be unreasonable. Specifically, if two inclusion degrees have different values
By Equations (9) (10), 3 SDs are concretized in IVDS, thus IUSD-based and HSD-based granularity structures can be obtained by analogy with Definition 2.
(1) IUSD B (x i , x j ) ≤ HSD B (x i , x j ) ≤ SD B (x i , x j ).
(2)
In general, the proposed HSD has following three advantages, compared with the existing SD and IUSD. According to Equation (8), HSD is defined from the perspective of inclusion degrees’ harmonic mean, which has clearer semantics and richer information than SD and IUSD. The idea is inspired by a case on arithmetic average of inclusion degrees [20], i.e., By Theorem 1, the advanced HSD achieves a compromise from the perspective of size relationship. In fact, SD is too large and IUSD is too small, while HSD becomes a better case between them. In addition, Through Theorem 1, HSD-based similarity class
Therefore, HSD enriches the research of SDs, and it can obtain the mechanism improvement and development. Furthermore, HSD will be used for subsequent uncertainty measures and ARs to show its improvement effects. Before that, an example is utilized to illustrate the effectiveness of the proposed HSD.
Focus on all objects on attribute c1, we have
As for similarity granulation, the granularity relationship
So far, three SDs (i.e., SD, IUSD, HSD) can obtain three granulation coverings (such as in Table 2), which are the foundations of information measures. For convenience, we mainly utilize the representative similarity class
In interval-valued systems, many information measures pursue granularity monotonicity [12, 19]. However, monotonic attribute reduction methods may not get ideal classification effects [28], because these measurement values may be low when the original data has poor classification performance. For this reason, robuster measures with great values and granularity non-monotonicity are worth further exploration. In this section, two concepts of interval credibility degree and coverage degree are first introduced into IVDSs, then they are comprehensively utilized for improved information measures including CE, information entropy and joint entropy. First of all, the existing CE is reviewed as follows.
Next, the interval credibility degree and coverage degree are generalized in IVDSs to establish improved information measures.
FH
δ
(D|B) ≥ H
δ
(D|B).
If If
If ∅ ⊂ B1 ⊆ B2 ⊆ C, then neither FH
δ
(D|B1) ≤ FH
δ
(D|B2) nor FH
δ
(D|B1) ≥ FH
δ
(D|B2) always holds. If 0 ≤ δ1 ≤ δ2 ≤ 1, then neither FH
δ
1
(D|B) ≤ FH
δ
2
(D|B) nor FH
δ
1
(D|B) ≥ FH
δ
2
(D|B) always holds.
Base on these properties mentioned above, the relevant construction mechanism and rationality of improved FH
δ
(D|B) are described as follows. In fact, credibility degree and coverage degree have been applied in other systems, such as dual quantization fusion of In contrast, the existing H
δ
(D|B) is mainly related to α
ij
, while the advanced FH
δ
(D|B) is concerned with α
ij
and β
ij
. In other words, H
δ
(D|B) mainly emphasizes condition-oriented interval credibility degree α
ij
with relative information, but ignores decision-oriented coverage degree β
ij
with absolute information. Therefore, improved FH
δ
(D|B) can contain more information by comprehensively fusing interval credibility degree and coverage degree, and thus it can strengthen subsequent ARs of IVDSs. H
δ
(D|B) impels monotonic ARs, while non-monotonic ARs may achieve better classification learning effect, and the latter is becoming a development direction of ARs, such as applications in incomplete interval-valued decision systems [21], neighborhood decision systems [24] and fuzzy neighborhood decision systems [7, 26]. In contrast, FH
δ
(D|B) obtain granularity non-monotonicity in Theorem 2, thus it stimulates non-monotonic ARs to improve classification learning performance.
In general, the advanced FH
δ
(D|B) fusing interval credibility degree with coverage degree can effectively reflect the classification ability from dual quantitative perspective of condition-oriented relative information and decision-oriented absolute information, and it obtains a larger value and measurement development from granularity monotonicity to non-monotonicity.
Furthermore, information entropy and joint entropy are successively constructed based on proposed CE, and their relationship are further studied as follows.
By Equations (13) (14) (16), we have
Next, all the proposed uncertainty measurements are calculated in Algorithm 1. Steps 1-9 calculate similarity class
1:
2:
3:
4: Compute
5:
6: By Equation (10), compute
7:
8: By Definition 2, similarity class
9:
10: Let FH δ (D|B) = FH δ (B) = FH δ (B, D) =0.
11:
12: By Equation (14), information entropy is FH δ (B)←
13: for D j ∈ U/D
14: Condition entropy and joint entropy are obtained by Equations (13) (14), FH δ (D|B) ← FH δ (D|B)-
FH δ (B, D) ← FH δ (B, D)-
Furthermore, we will illustrate the proposed uncertainty measures and their properties by an example below.
Focus on attribute subset B1 = {c1} and threshold δ1 = 0.1 based on HSD, by Algorithm 1, we have
In order to justify the non-monotonicity of FH
δ
(D|B) in Theorem 2, we offer two counterexamples,
This section will utilize two CEs and four SDs to construct ARs and corresponding algorithms. Thus, ARs based on H δ (D|B) in [15] will be reviewed first to extend new ARs based on improved HSD and FH δ (D|B).
H
δ
(D|R) = H
δ
(D|C). ∀a ∈ R, H
δ
(D|R - {a}) ≠ H
δ
(D|R).
FH
δ
(D|R) = FH
δ
(D|C). ∀a ∈ R, FH
δ
(D|R - {a}) ≠ FH
δ
(D|R).
In addition, the significance of attribute a ∈ C - R with respect to R is defined as
According to Definitions 10 and 11, reduct R satisfies joint sufficient condition (1) and individual necessary condition (2). Regarding reduction policy, Dai et al. [15] use the minimum entropy H δ (D|R ∪ {a}) (i.e., maximum significance Sig H (a, R, D) = H δ (D|R) - H δ (D|R ∪ {a})) to add attribute a for heuristic search. The attribute subset R obtained by this policy contains few redundant attributes, so the steps of deleting redundant attributes can be omitted to reduce the complexity of the algorithm. Following the same strategy, our AR algorithms based on ♡ δ (D|B) (♡ ∈ {H, FH}) are designed in Algorithm 2. Step 1 calculates ♡ δ (D|C), then initializes R =∅ and ♡ δ (D|R) = -1. Steps 2-8 constitute a while loop to add attributes. In Step 5, the most important attribute is added by using maximum significance for heuristic search. Step 7 obtains incremental subset R and calculates ♡ δ (D|R). Finally, Step 9 outputs reduct R.
1: Compute the entropy ♡ δ (D|C) by Algorithm 1, initialize R =∅ and ♡ δ (D|R) = -1.
2:
3: R★ = C - R.
4:
5: Compute Sig♡ (c j , R, D) by Equation (18), then sequentially select c j that satisfies maximum.
6:
7: Let R = R ∪ {c j }, then compute ♡ δ (D|R).
8:
9:
By Algorithm 2, two CEs H δ (D|C) , FH δ (D|C) can be used to construct reduction algorithms by the same reduction strategy. In addition, 3 reduction algorithms are given in [15] based on 3 different SDs IUSD, SD, RBD and the same CE H δ (D|C). In order to comprehensively compare with 3 algorithms in [15], 4 SDs IUSD, SD, RBD, HSD and 2 CEs H δ (D|C) , FH δ (D|C) are considered from two dimensions of knowledge granularity and information measurement. Thus, we establish a reduct framework involving 4×2 = 8 AR algorithms, i.e., SD - AR, IU - AR, RBD - AR, HSD - AR, FH - SD - AR, FH - IU
-AR, FH - RBD - AR, FH - HSD - AR, where the three existing algorithms SD-AR, IU-AR, RBD-AR become comparative algorithms here which respectively correspond to marks PD, IU, RBD in [15]. For example, H δ (D|C) and FH δ (D|C) (or simply FH) can inspire algorithms HSD-AR and FH-HSD-AR based on HSD. Next, the detailed process of representative ARs is revealed by an example.
The detailed process of algorithm FH-HSD-AR on δ = 0.5
Details of the 8 datasets
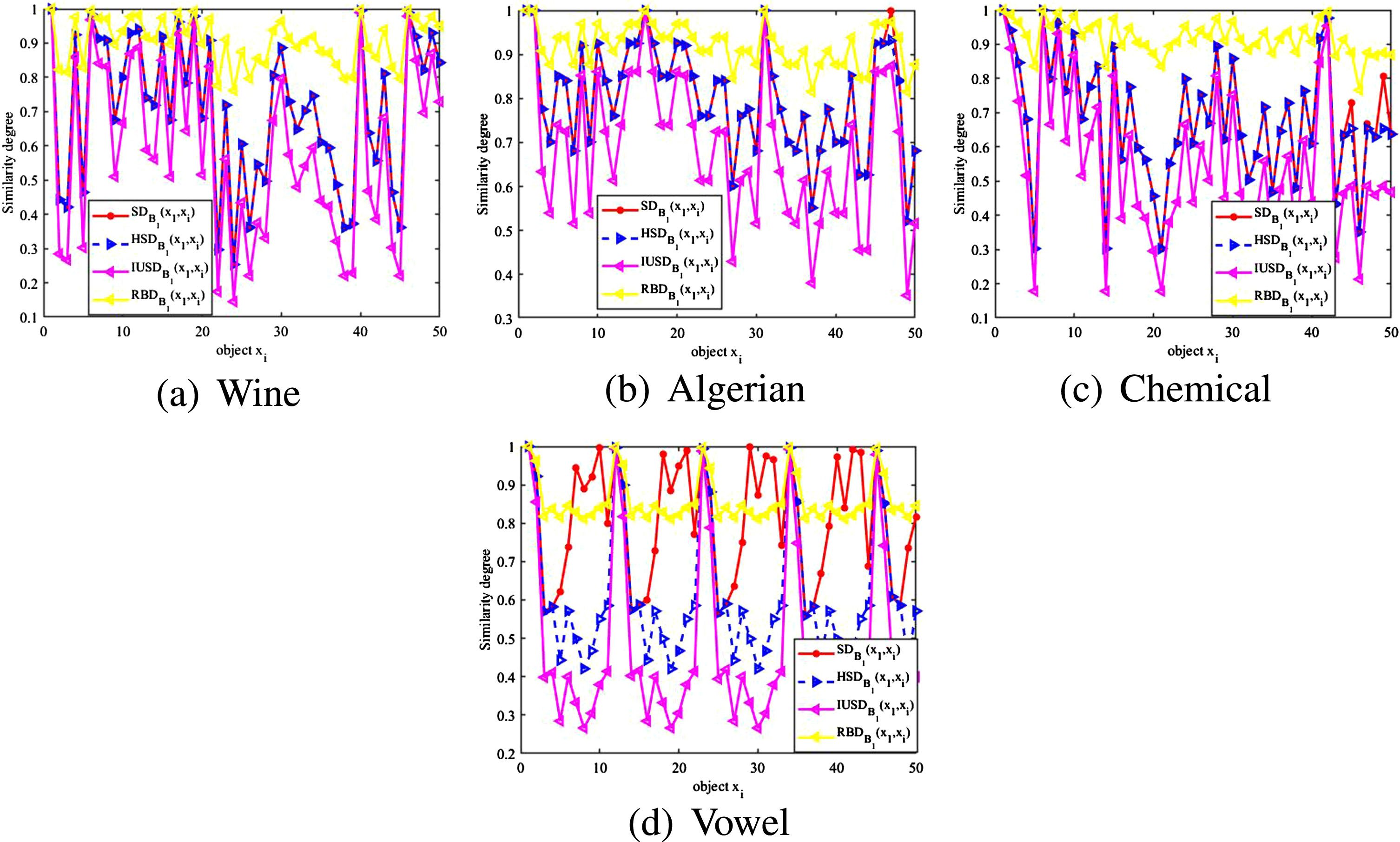
Comparison of four SDs between x i and x1 on B1.
In this section, data experiments will show the advantages of our proposed methods. In simulation experiments, 8 classification datasets from UCI machine learning repository [30] are used, whose details are described in Table 4. In dataset (e) Facebook, five objects with missing values are deleted. In dataset (h) Leaf, the number attribute is also deleted because of independence with classification. Since these datasets are real types, real value r can be converted to interval I r = [r - 2σ, r + 2σ], where σ is the standard deviation of equivalence class [x i ] D on attribute c j [13, 32].
Regarding SDs, we mainly focus on four ones SD c 1 (x1, x i ), IUSD c 1 (x1, x i ), RBD c 1 (x1, x i ) and HSD c 1 (x1, x i ) (i = 1, 2, ⋯ , 50) of 4 representative datasets (a)-(d) for overall observation. Thus, a family of two-dimensional graphs are shown in Fig. 2 for comparison of four SDs, where the horizontal and vertical axes represent x i and SDs. By comparison in Fig. 2, RBD is too big and much close to 1 in most cases, IUSD is always too small and very close to 0, while HSD always locates between SD and IUSD. Therefore, the fact validates Theorem 1, and the proposed HSD is effective.

Comparison of two CEs on fixed δ = 0.5 and B i -chain.
As for CEs, H δ (D|B) and FH δ (D|B) are calculated based on HSD. Thus, CEs based on fixed δ = 0.5 and Bi-chain (B1 = {c1}⊆ ⋯ ⊆ {c1, ⋯ , c r } = B r = C) are depicted in Fig. 3. By Fig. 3, we can verify non-monotonicity of FH δ (D|B) in Theorem 2 and FH δ (D|B) ≥ H δ (D|B) in item (3) of Proposition 2.
The classification accuracies and reduction lengths of 8 ARs
Next, 8 algorithms in Equation (19) are mainly implemented for comprehensive comparison,
Table 5 records the specific reduct lengths and classification accuracies of 8 ARs on eight datasets, where the bold represent the maximum accuracies while the numbers in parentheses represent reduct lengths. As shown in Table 5, all 8 algorithms can effectively remove redundant attributes. Specifically, 8 datasets have average length 12.4 of whole attribute sets, IU-AR obtains minimum average length 3.3, while FH-RBD-AR reaches maximum average length 9.7. Thus, 8 ARs are reasonable. By Table 5, our method FH-HSD-AR can achieve optimal accuracy in most cases. In the last 2 lines of Table 5, average accuracies and maximum frequencies on all the datasets are used for final evaluation, so the final ranking is
In general, our methods (especially suboptimal FH-RBD-AR and optimal FH-HSD-AR) outperform the existing methods, in term of classification performance. These ranking results in Equation (20) can adequately reflect the advantages of the proposed algorithms from the perspective of robustness and optimization.
The final results in Equation (20) are rearranged into Table 6, where the symbols ← and ↑ respectively indicate the horizontal and longitudinal maximums, while the italic and bold styles respectively indicate the suboptimal and optimal accuracies. Table 6 provides accuracies comparisons to show 2-dimensional (i.e., CEs-longitudinal and SDs-horizontal) improvements. Firstly, 4 SDs can be compared on all CEs. As for H, HSD-AR (0.9597) and RBD-AR (0.9611) are superior to IU-AR (0.9542) and SD-AR (0.8171). Regarding FH, FH-HSD-AR (0.9779) is significantly better than FH-RBD-AR (0.9614), FH-IU-AR (0.9527) and FH-SD-AR (0.8311). The ranking results can deduce the sorting
Secondly, two CEs can be contrasted on all SDs. As for IUSD, IU-AR (0.9542) and FH-IU-AR (0.9527) have almost equal accuracies. Regarding HSD, FH-HSD-AR (0.9779) with more accuracy outperforms HSD-AR (0.9597). The same conclusions are hold for SD and RBD. The ranking results can deduce the sorting of CEs as follows,
Finally, the improvements of SDs and CEs are further compared by the increment of accuracies. As for SDs improvement, FH-RBD-AR (0.9614)⟶ FH-HSD-AR (0.9779) gets the increments 0.9779 - 0.9614 = 0.0165. As for CEs improvement, HSD-AR (0.9597)⟶ FH-HSD-AR (0.9779) reaches the increments 0.9779 - 0.9597 = 0.0182. Therefore, two dimensional improvements are comprehensively verified, and CEs improvement is slightly more than SDs improvement.
Average accuracies of 8 ARs on 4 SDs and 2 CEs
Through the above results and analyses, our methods (especially FH-RBD-AR and FH-HSD-AR) bring about obvious improvements over the existing methods, in terms of SDs, CEs and ARs.
In this paper, an ARs framework of 4×2 = 8 algorithms is established by using improved similarity degree HSD and improved condition entropy FH, from knowledge granulation and information representation of IVDSs. The improvement of HSD is based on the harmonic average of inclusion degrees, and it can obtain intermediate value. The improvement of FH benefits from the fusion of comprehensive interval coverage and credibility which are richer and more robust than separate credibility. In addition, information entropy and joint entropy are correspondingly constructed to obtain an information system. Furthermore, 5 improved ARs (especially FH-HSD-AR) can achieve better classification performance than 3 contrastive algorithms in [15]. In general, HSD and FH jointly promote uncertainty measurements from two dimensions, thus their combined ARs provide strong robustness and applicability. Therefore, our studies can promote the uncertainty measurement and ARs of IVDSs.
The following three aspects will be worthy of further study. (1) SDs based on inclusion degrees are reasonable for strong application. (2) Our measurements and ARs can be applied to other systems, such as interval-set systems and neighborhood systems. (3) The study of incremental uncertainty measurements and ARs are valuable for dynamic interval-valued systems.