
Abstract
3D point cloud has irregularity and disorder, which pose challenges for point cloud analysis. In the past, the projection or point cloud voxelization methods often used were insufficient in accuracy and speed. In recent years, the methods using Transformer in the NLP field or ResNet in the deep learning field have shown promising results. This article expands these ideas and introduces a novel approach. This paper designs a model AaDR-PointCloud that combines self-attention blocks and deep residual point blocks and operates iteratively to extract point cloud information. The self-attention blocks used in the model are particularly suitable for point cloud processing because of their order independence. The deep residual point blocks used provide the expression of depth features. The model performs point cloud classification and segmentation tests on two shape classification datasets and an object part segmentation dataset, achieving higher accuracy on these benchmarks.
Introduction
3D data addresses the spatial information gap in 2D images and is in urgent need in various applications, including robotics, autonomous vehicles, and augmented reality. In contrast to photographs, which are organized on standard pixel grids, 3D point clouds are collections immersed in continuous space [1]. Owing to the disordered and unstructured nature of point clouds, it is not feasible to directly apply image processing methods to point cloud processing. Furthermore, the performance is further constrained by the inherent sparsity and the presence of noise.
Point cloud analysis has significantly improved in recent years thanks to the addition of neural networks. This advancement is evident across various applications, including 3D shape categorization [2], semantic segmentation [3], and so on. As a result of convolutional neural networks’ (CNNs) success in the field of image processing, new ideas have emerged. For example, [4–6] suggest developing convolution operators for point cloud that can aggregate local data. In order to obtain the normalized feature domain for convolution, they reorder the input point sequence. These studies primarily build upon the concepts introduced by PointNet [2], but real-time performance remains a significant challenge. At the same time, the Transformer series [7–9] are also favored by practitioners in point cloud processing. The self-attention operator used in this series is invariant to the arrangement and cardinality of the input elements, considering that point cloud are essentially sets embedded in 3D space [1], its central location inside the Transformer network renders it highly suitable for processing 3D point cloud. [10] aims at processing set data and also decreases the algorithm complexity of Transformer, but the use of multi-head attention still demands significant computational resources. Inspired by these, this paper developes a self-attention module for 3D point cloud processing. The module investigates how self-attention is applied to the immediate areas surrounding each point, and how positional information is encoded in the network. The networks that are produced employ pointwise operations and self-attention. In addition, inspired by the classical network of image analysis [11, 12], this paper considers the memory consumption problem that may be caused by using only a loop of attention blocks to extract point cloud features. Therefore, a simple deep residual MLPs is designed to extract deep aggregation features.
Referring to the above methods, this paper designs a new point cloud processing combined network model. By doing so, the model benefits from the inherent order invariance of Transformer, does not need to specify the order of the point cloud data, completes feature learning through the attention mechanism, and take advantage of the efficiency benefits of the highly optimized MLPs. This new network architecture is called AaDR-PointCloud, and its logical design is shown in Fig. 1.
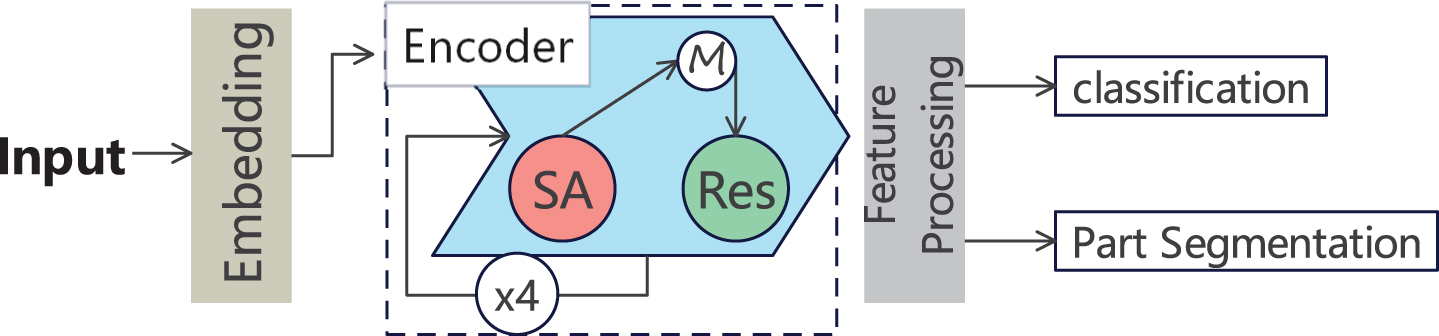
Our network, AaDR-PointCloud, takes the original point cloud as input and projects it onto an embedding layer using a simple MLP layer. The processed features are then obtained through an internally looped encoder, which is outlined by the dotted frame and operates once as indicated by the blue arrow. This series of processing leads to the final output results for classification and partial segmentation.
This paper demonstrates the significant effect of AaDR-PointCloud in 3D point cloud learning tasks and compares it with previous work. Among them, AaDR-PointCloud performs shape classification tests on the dataset ModelNet40 [13] (overall accuracy 93.2%) as well as ScanObjectNN [14] (overall accuracy 83.6%), and object part segmentation tests on ShapeNetPart [15] (85.5% instance mIoU). In addition, the results of ablation experiments also prove that the design of each module is meaningful.
In summary, our main contributions can be summarized as follows: This paper designs a new point cloud processing combination network. The order independence of the attention module used in the network is well-suited for point cloud tasks, and the deep residual point blocks used express the depth features brought by the cyclic structure. Our model provides a point cloud processing idea of circularly combining deep residual MLP and attention methods. This paper tests the model on data sets in multiple fields and conducts ablation studies to explain the necessity and rationality of module design. Experimental data show that the model has achieved good performance in shape classification and partial segmentation.
Pixels in a 2D image are arranged in regular grids and may be analyzed using classical convolution, while the point cloud is disorganized and dispersed in 3D space, essentially a set. Learning-based methods for processing 3D point clouds can be divided into the following types: voxel-based, projection-based, point-based, and networks using Transformer and self-attention.
Graph-based networks can learn spatial attributes by treating each point in the point cloud as a vertex of the graph and creating directed edges for the graph based on the neighbors of each vertex [28]. The Edge Conditioned Convolution (ECC) approach, which was devised by Simonovsky [29] et al., treats each point as a vertex of the graph and connects all of its neighbors by a directed edge. The point cloud is then represented by a filter generation network (such as MLP). DGCNN [30] performs graph convolution on kNN graphs. LDGCNN [31] removes the transformation network of DGCNN and links different levels of hierarchical features to improve its performance. In order to utilize the local geometric structure, KCNet [32] learns features using kernel correlation and graph pooling.
Without quantization, the network built on continuous convolution is applied directly to the set of points in three dimensions. Compared with the convolution kernel defined on the 2D grid structure, the convolution kernel of the 3D point cloud poses challenges in designing due to the irregularity of the point cloud [28]. Convolution is described by PointConv [26] as a continuous, 3D Monte Carlo estimation of convolution. Under the same parameter settings, its convolution kernel further streamlines 3D convolution into two operations: matrix multiplication and 2D convolution. This increases memory and computational efficiency. The RIConv operator proposed by Zhang [33] et al.transforms convolution into 1D with low-level rotation invariant geometric features as input. In SFCNN [34], convolving the projection of a point cloud on an icosahedron, the features connected to the vertices of the polyhedron and their adjacent nodes through a convolution-maximum pooling-convolution structure. PointCNN [5] standardizes the potential order of input points through MLP, and then convolves the converted features. The interpolation convolution operator InterpConv proposed by Mao [35] et al. can measure the geometric relationship between the input point cloud and the kernel weight coordinates.
The above point-based methods are extensively influenced by residual networks. Reference [11] is one of the earliest papers on ResNet, introducing the concept of residual blocks with skip connections that allow information to propagate by adding input and output. He et al. 36 introduce the concept of identity mapping, further simplifying the design of residual blocks, making the network easier to train. They also explore variations of residual blocks, some of which incorporated batch normalization, thus offering greater design flexibility. Together, they lay the foundation for ResNet, enabling it to effectively handle and address the training challenges of deep networks, even when this process may not be well-suited for resource-constrained environments.
So, inspired by the above methods, our method combines the advantages of the self-attention (SA) module and the deep resiual MLP module, and arranges them to work in a sequential sequence to obtain better results. Previous work applied global attention to point cloud, which leads to complex computation and rapid memory growth, while our self-attention (SA) in local applications can avoid this problem and broaden the applicability of application of point cloud models.
Methods
This section first reviews the general formulas of Transformer and self-attention (SA) operator, as well as the source of ideas for deep residual MLP module design. Next, this paper proposes the AaDR-PointCloud framework for point cloud learning, explaining the outline and detailed design of the encoder and the hierarchical aggregation module in turn. It shows how to apply the point cloud representation learned by the model to various tasks of point cloud processing, including point cloud classification and segmentation.
Background
Transformer has achieved great success in the field of natural language processing, and the attention mechanism proposed in [7] is increasingly being used. An encoder-decoder structure was originally used to develop the attention mechanism during neural machine translation (NMT), which was then rapidly applied to tasks of a similar nature. The attention mechanism is now widely used in deep learning models, not just those that use an encoder-decoder hierarchy. It is worth mentioning that the attention mechanism can be applied only on the encoder to solve tasks such as text classification or representation learning. The application of this attention mechanism is called self-focusing or internal focusing mechanism, and the most common is the application of Self-Attention mechanism.
[7] use the QKV model to explain the Self-Attention mechanism. In this model, the input is represented as
In addition, the residual network [11] proposed by He Kaiming is a creative work. Its idea is to transform the mapping of network learning from X to Y into learning the difference from X to Y - X, and then add the learned residual information to the original output. This solution solves problems that arise with increasing depth in deep learning, such as gradient vanishing, gradient explosion, and training saturation. The SE-Net [12] proposed by Hu Jie et al. can learn to use global information to selectively emphasize information features and suppress less useful features, bringing significant performance improvements to the existing state-of-the-art networks.
According to the above design concept, this article designs a new effective combination of network to deal with point cloud tasks. The detailed framework of our method is shown in Fig. 2.
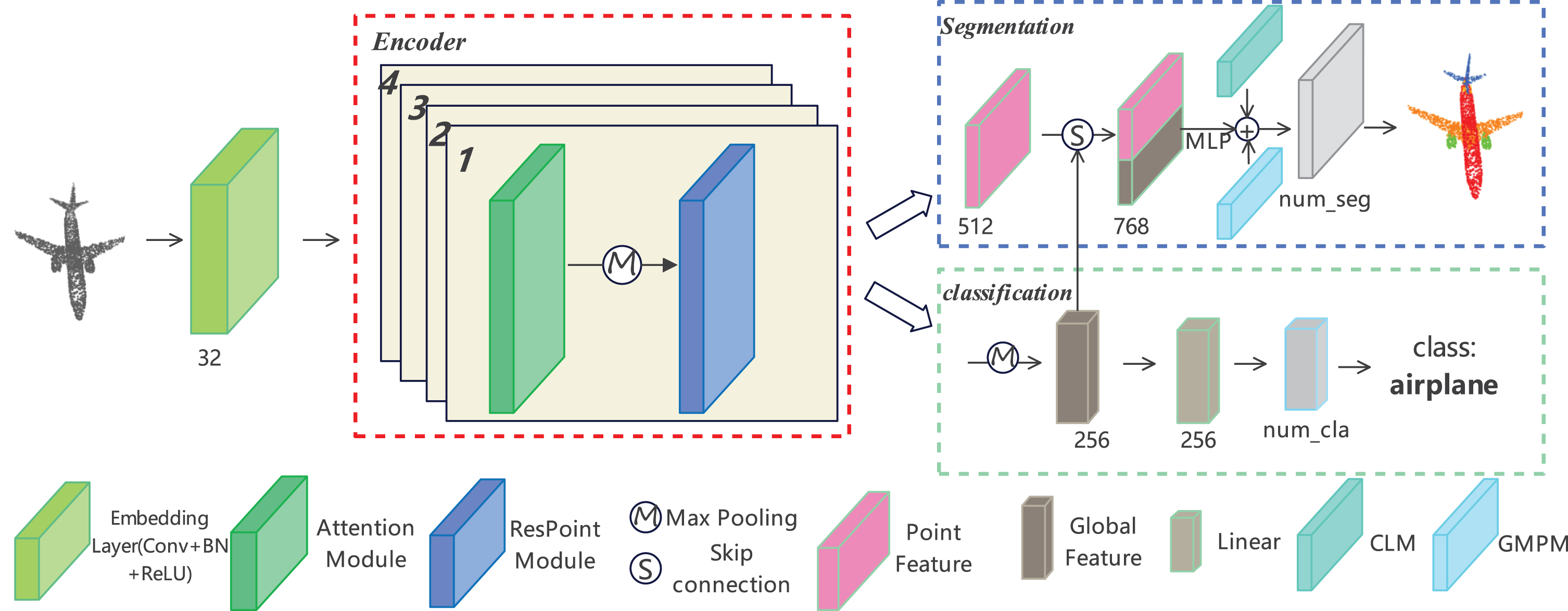
The network structure of AaDR-PointCloud consists of an input embedding module followed by a cyclic stacked attention-residual combination module. The resulting feature map is used for classification or segmentation tasks, which are performed through multiple linear or convolutional layers. The number below each layer indicates the number of output channels. In segmentation tasks, ’CLM’ stands for class label mapping, and ’GMPM’ represents global max pooling mapping, each comprising two convolutional layers. The red dotted box signifies the combination module design.
Specifically, the attention module of AaDR-Point Cloud has almost the same design concept as the original Transformer, the design details and formulas of the module and the deep residual feature extraction module are as follows: given an input point cloud
Using the above model, this paper perform shape classification and object segmentation tasks on the input point cloud.
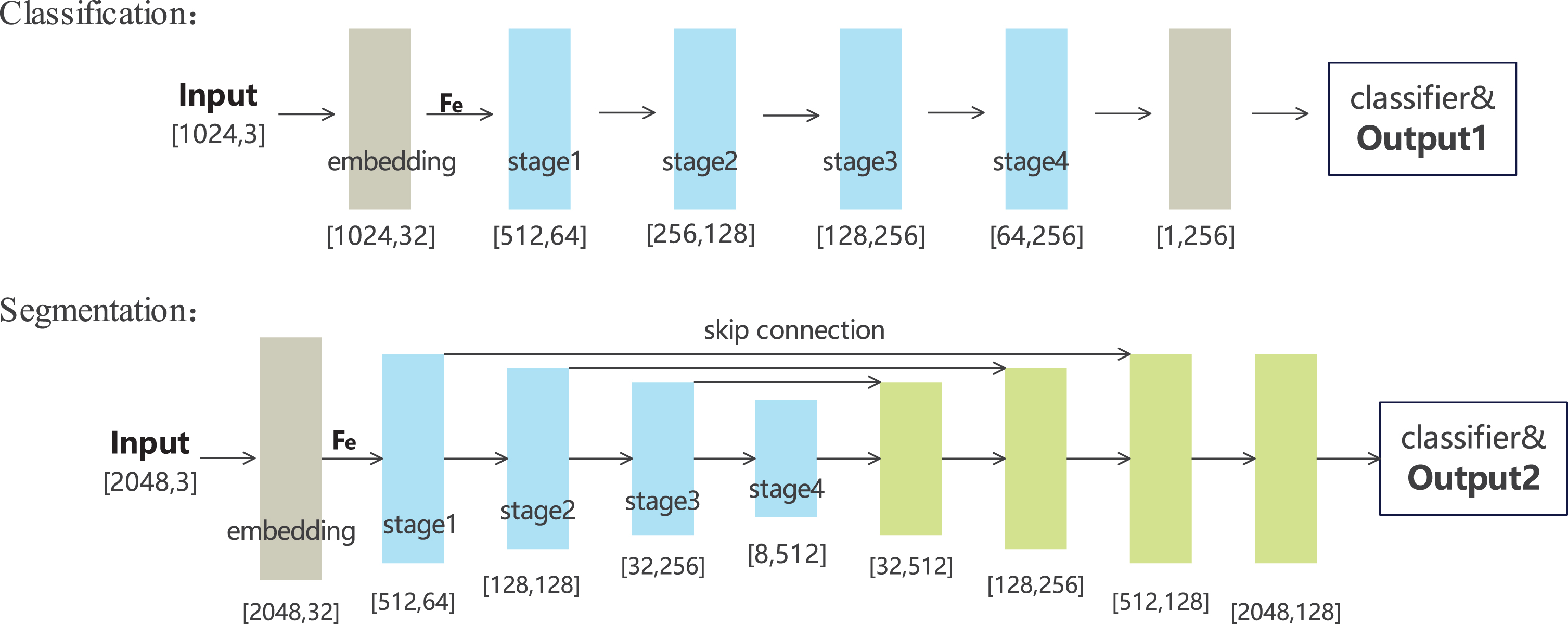
The process of
For the simple implementation of AaDR-PointCloud, this article redesigns the self-attention in the original Transformer into a process with the input data stream as a ’point’, and its architecture is shown in Fig. 4. According to Sections [7] and 3.1, the
Firstly, according to formula (2), the matrix dot product method is used to infer the attention weight formula and normalize it:
Then, the self-attention output feature
In the above formula,
Finally, another layer of MLP provides the output feature
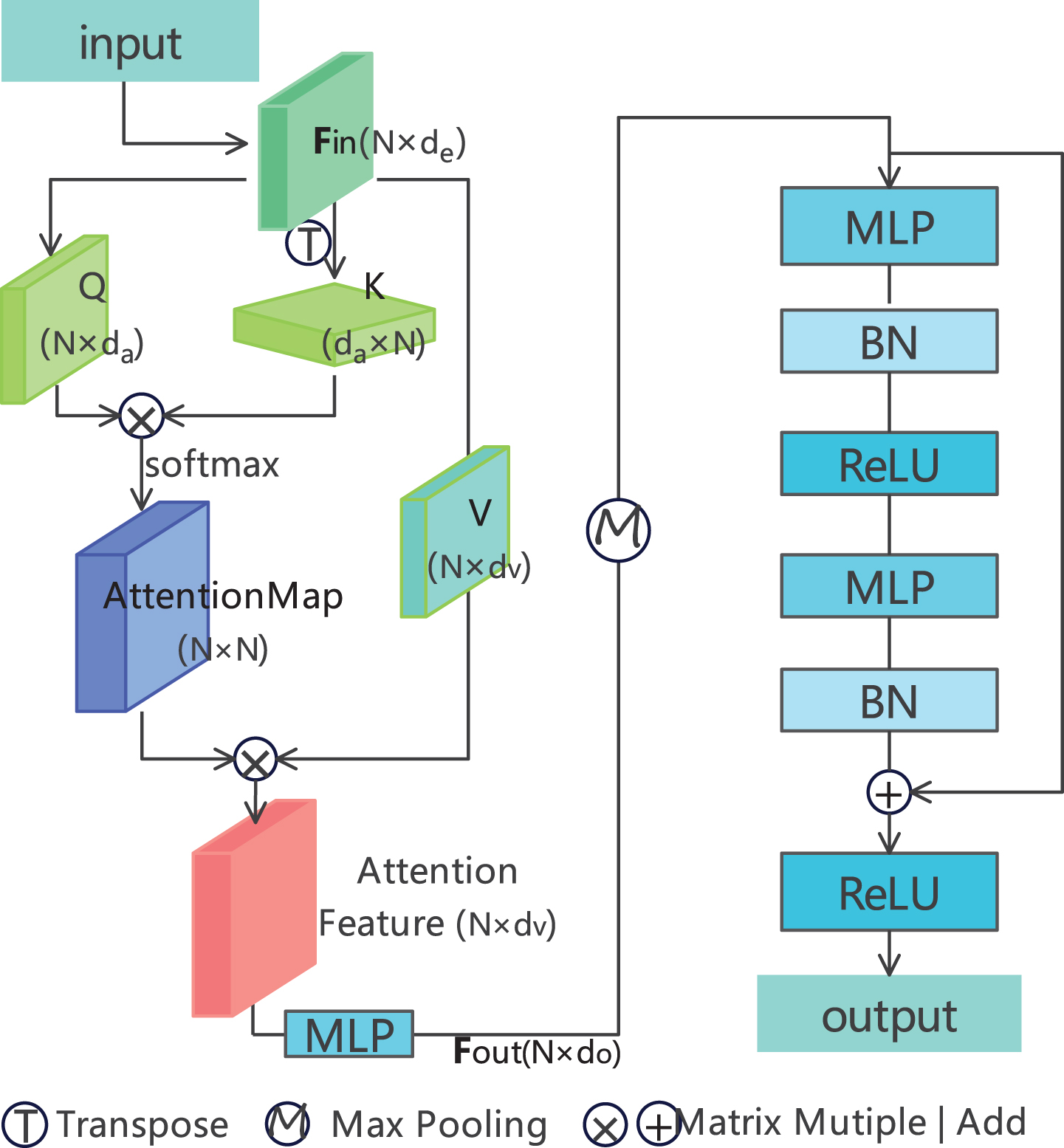
Detailed design of combination module. Left: Self-Attention(SA) block; M: Maximum Pooling operation; Right: Deep Residual Point MLP block.
In this paper, our AaDR-PointCloud is trained and tested on public shape classification datasets and partial segmentation datasets. The implementation details will be displayed in each part. For the former, this paper utilizes two datasets: the ModelNet40 dataset and the ScanObjectNN dataset. As for the latter, the ShapeNet dataset is selected. In addition, this paper also carried out ablation studies to prove the actual effect of the model.
Shape classification
Datasets
The ModelNet40 dataset is one of the most commonly used datasets for point cloud classification. The dataset comprises 12,311 CAD models distributed across 40 object categories, with 9,843 models allocated for training and 2,468 for testing, maintaining a ratio of approximately 4: 1. The sampling strategy is to uniformly sample each object to 1024 points for comparison with previous work. Compared with the point cloud processing dataset ModelNet40 released in 2015, the ScanObjectNN dataset is an updated point cloud benchmark. This dataset introduces real-world data interferences like background, noise, and occlusion, which present a more significant challenge for point cloud analysis and bolster the credibility of test results. It contains 15000 objects, divided into 15 classes and 2902 unique object instances.
Setup
For ModelNet40 and ScanObjectNN data sets, this paper sets the batch size to 8, and the initial learning rate is 0.001. The cosine annealing plan is used to adjust the learning rate of each period. The only difference is that the former dataset is trained for 300 cycles, while the latter dataset is trained for 200 cycles. All training processes are implemented on NVIDIA Corporation GP104 [GeForce GTX 1070] GPU. For other comparison methods, this paper takes the best results from the original paper, which ensures that the model in this paper is still competitive in most cases.
Evaluation metrics
On the evaluation metrics, this paper uses the class average accuracy (mAcc) and the overall accuracy (OA) on the test set.
The mean classification accuracy is the average of the classification accuracy for each shape category. It can be mathematically represented as:
The overall accuracy refers to the ratio of the number of correctly classified samples to the total number of samples. It can be mathematically represented as:
These two metrics can be used to evaluate the performance of 3D shape classification models. The mAcc measures the average classification accuracy among different categories, while OA measures the overall classification accuracy.
The experimental results are shown in Table 1 and Table 2. After training with the model, the overall accuracy on ModelNet40 is 93.2%, which is 4.0%, 3.1% and 1.3% higher than the voxel-based model Subvolume [42], the multi-view-based model MVCNN, and the point-based model PointNet++ respectively. And, the model have achieved an overall accuracy of 83.6% on ScanObjectNN, 5.7% and 0.8% higher than PointNet++ and MVTN [50] respectively.
Classification results on the ModelNet40 dataset
Classification results on the ModelNet40 dataset
Classification results on the ScanObjectNN dataset
Additionally, Table 1 provides partial comparisons of model parameters, training speed, and testing speed. It can be observed that the classical PointNet model, despite its lower accuracy, has a small number of parameters and achieves an inference speed of 217 samples per second. From this perspective, it indeed represents a milestone achievement in the field of point cloud processing. PointConv delivers strong results, but it comes with a large number of parameters and high inference cost (7.2 samples per second). In comparison, our model reduces the number of parameters while maintaining a lower inference cost (78.8 samples per second), resulting in competitive performance.
Datasets
Our model uses ShapeNet as the test data set for partial object segmentation. The ShapeNet dataset is a shape repository represented by a 3D CAD model of an object. It contains 16881 object part instances of 16 shape categories and 50 part labels, each instance includes 2–6 parts. Taking the classic PointNet as an example, our model randomly selects 2048 points as sampling points to compare with other work.
Setup
Except for a training period of 350 rounds, all other settings are the same as those in Section 4.1.2 for the shape classification dataset.
Evaluation metrics
In terms of evaluation metrics, this paper employs Intersection over Union (IoU) on the test set to assess segmentation performance, including Class mIoU and Instance mIoU.
Class mIoU represents the average IoU across all classes. Assuming there are N classes, for each class i, its IoU (IoU i ) can be computed, and then the average IoU across all classes is taken. The formula is represented as:
Similarly, Instance mIoU is the average IoU across all instances. In point cloud segmentation tasks, each point can be assigned to a specific instance of a class. For each instance, its IoU (IoU inst j ) can be calculated, and then the average IoU across all instances is computed. The formula is represented as:
The results of segmentation are shown in Table 3. Our model has achieved competitive results. Compared with PointNet and DGCNN, AaDR-PointCloud increased by 3.4% and 1.5% on Cls.mIoU (class mIoU) respectively, and increased by 1.8% and 0.3% on Inst.mIoU (instance mIoU).
Segmentation results on ShapeNet dataset
Segmentation results on ShapeNet dataset
In addition, this paper also visualizes the ground truth and our part segmentation prediction results in Fig. 5, which shows that our results are basically close to the ground truth.
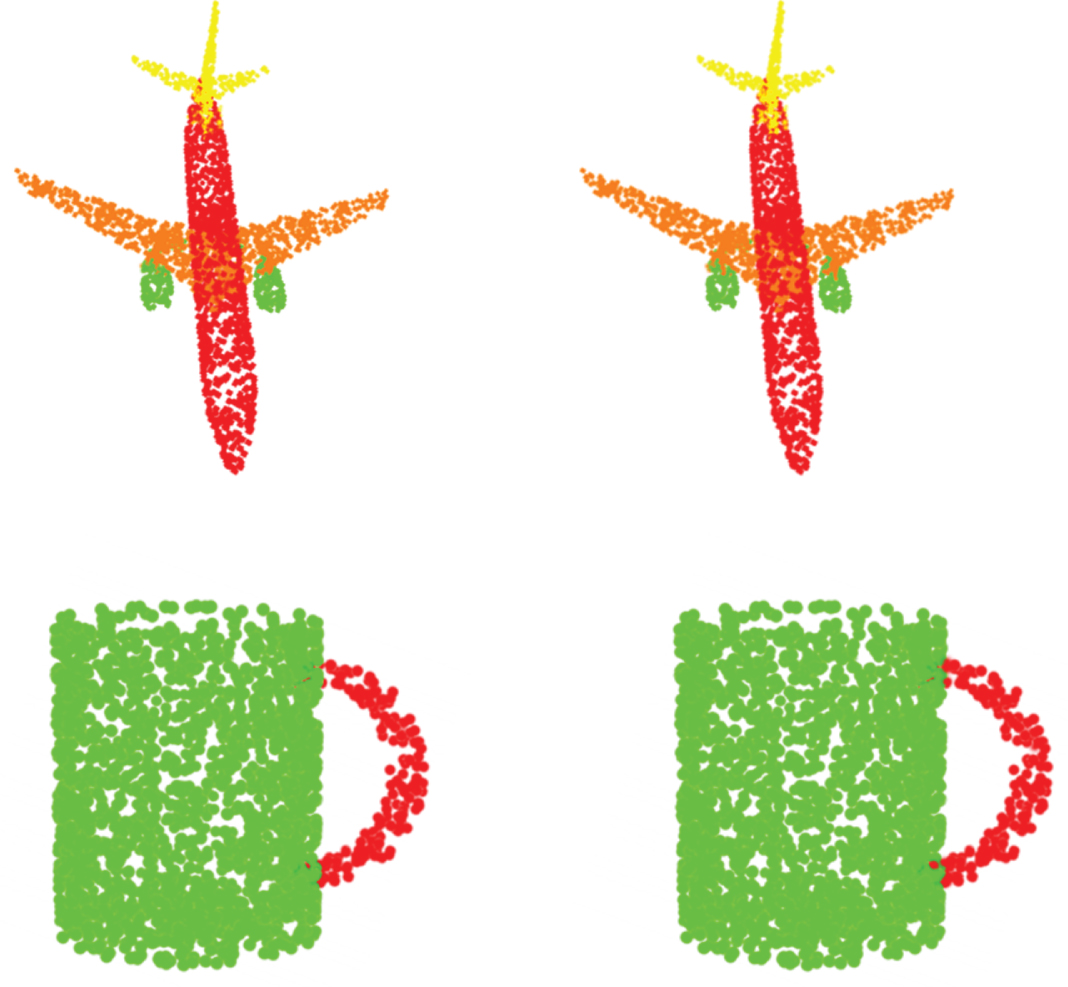
Part segmentation results on ShapeNetPart. The left is ground truth and the right is our prediction.
In the model presented in this paper, the introduction of Transformer is a necessary prerequisite for achieving high-precision point cloud recognition. However, it comes at the cost of increasing the model’s parameter count, resulting in longer training and testing times. Therefore, the challenge addressed in this paper is how to reduce model complexity while simultaneously ensuring higher accuracy. Compared to state-of-the-art methods, the advantage of this approach is that it extends the idea of “introducing Transformers or Residual Networks into the point cloud domain” by cleverly designing a combined model of both. Through ablation experiments, the rationale and necessity of the module design are explained, ultimately achieving competitive results on multiple datasets.
Ablation study
Ablation experiment: classification results when the number of neighbors k on the shape classification data set ScanObjectNN is different
Ablation experiment: classification results when the number of neighbors k on the shape classification data set ScanObjectNN is different
but the time cost of training model increases significantly, resulting in waste of resources.
Research on component ablation on the ScanObjectNN test set
Inspired by the successful application of Transformer and ResNet in the field of NLP and 2D image, this paper introduces the self-attention (SA) module and deep residual network into point cloud analysis, and design a combined model to extract point cloud information. This paper takes into account the effectiveness of feature extraction and the simplicity of network design. The model has achieved good results in tasks such as point cloud shape classification and point cloud object part segmentation, which shows that our model has good point cloud processing performance.
However, Transformer is more suitable for processing large-scale data input in the design concept. In the field of point cloud where data sets are scarce, there are still some limitations in its application. Our future work is to use more training data to optimize our model, and to inspire thinking about Transformer’s work in other point cloud areas, such as point cloud target detection.
Footnotes
Acknowledgement
The authors would like to thank all the people who have contributed to this paper for their selfless work. This work is supported by the 14th Graduate Education Innovation Fund of Wuhan Institute of Technology (CX2022352), the Hubei Technology Innovation Project (2019AAA045), the National Natural Science Foundation of China (62171327, 62171328, 62072350).