
Abstract
Crowd counting aims to estimate the number, density, and distribution of crowds in an image. The current mainstream approach, based on CNN, has been highly successful. However, CNN is not without its flaws. Its limited receptive field hampers the modeling of global contextual information, and it struggles to effectively handle scale variation and background complexity. In this paper, we propose a Multi-scale Hybrid Attention Network called MHANet to solve crowd counting challenges more effectively. To address the issue of scale variation, we have developed a Multi-scale Aware Module (MAM) that incorporates multiple sets of dilated convolutions with varying dilation rates. The MAM significantly improves the network’s ability to extract information at multiple scales. To tackle the problem of background complexity, we have introduced a Hybrid Attention Module (HAM) that combines spatial attention and channel attention. The HAM effectively directs attention to the crowd region while suppressing background interference, resulting in more accurate counting. MHANet has been extensively experimented on four benchmark datasets and compared against state-of-the-art algorithms. It consistently achieves superior performance in terms of the MAE evaluation metric. MHANet outperforms the current state-of-the-art methods by margins of 1.9%, 5.4%, 0.4%, and 0.8% on the ShanghaiTech Part_A, ShanghaiTech Part_B, UCF-QNRF, and UCF_CC_50 datasets, respectively. Furthermore, a series of ablation experiments targeting MAM and HAM were conducted in this paper, and the experimental results fully demonstrate that MAM and HAM can effectively address the challenges of scale variation and background complexity, ultimately enhancing the accuracy and robustness of the network.
Introduction
Crowd counting aims to estimate the number, density, and distribution of a crowd in an image. In recent years, large-scale gatherings of people have posed a huge challenge to public health and safety. Examples include the prevention and control of COVID-19 and stampede [1]. Moreover, crowd counting plays an irreplaceable role in traffic control [2] and smart city construction [3].
Early researchers utilized detection-based [4–6] and regression based [7, 8] methods for crowd counting. Detection-based methods were effective in low-density crowd areas but vulnerable to target occlusion. Later, researchers proposed several regression-based methods that could partially address the occlusion problem, but are still ineffective in obtaining the location information of the crowd and counting in extremely dense crowds. With the development of deep learning, Convolutional Neural Networks (CNNs) have become popular among researchers due to their powerful local feature extraction ability and flexible network structure. CNNs have shown remarkable results in the field of computer vision, including crowd counting. However, CNNs have limitations, such as their limited receptive field, which makes it difficult to model global contextual information. Additionally, crowd counting datasets commonly have a large number of target scale variations and complex background issues, which pose significant challenges for accurate counting. Due to the prevalence of wide-angle lenses in datasets, the crowd close to the camera appears larger in the picture, while the crowd far away appears smaller, as shown in Fig. 1(a). The continuous change in target scale can lead to the omission of maximum or minimum scale targets, affecting the accuracy of the counting. Moreover, complicated background cases where people are distributed under different lighting conditions, as shown in Fig. 1(b), can cause misjudgment between foreground and background, leading to differential counting errors.

The two major challenges in crowd counting. (a) The problem of scale variation. (b) The problem of background complexity.
Therefore, researchers have attempted to get out of this dilemma by enhancing the global context modeling capability of CNNs. One such approach is to use a multi-column structure to enhance the multi-scale feature extraction capability of the network. For example, Zhang et al. [9] proposed a three-branch multi-column convolutional neural network consisting of convolutional kernels of different sizes, called MCNN. The method extracts information at three different scales and then fuses them to enhance the multi-scale information extraction capability of the network. Another type of approach is to add an attention module to the network, which aims to generate an attention feature map to guide the network to better locate the crowd regions. For example, Jiang et al. [10] used the first 13 layers of VGG-16 to construct attention branches, but this significantly increased the computational burden of the model. Although these methods can achieve some results, there is still a huge room for improvement.
In this paper, we propose a Multi-scale Hybrid Attention Network called MHANet to address the problem of scale variation and background complexity in crowd counting. For the scale variation problem, a Multi-scale Aware Module (MAM) is proposed inspired by dilated convolution [11], which delicately employ combinations of different dilated rates to prevent the network from gridding effect [12]. For the background complexity problem, we propose an innovative Hybrid Attention Module (HAM), which perfectly hybrids spatial attention and channel attention, to enhance the global context modeling ability of the MHANet.
Our contribution can be summarized in the following fourfold: We propose a Multi-scale Hybrid Attention Network (MHANet) for Crowd Counting, which can better deal with the crowd counting challenges. We designed a Multi-scale Aware Module (MAM) that uses dilated convolutions with different dilated rates to obtain different sizes of receptive fields. The MAM generates higher accurate count results. We designed a Hybrid Attention Module (HAM) that combines channel attention and spatial attention, and enhances the global modeling capabilities of the MHANet. MHANet has been experimented on several challenging datasets and achieved surprisingly competitive results.
Traditional crowd counting methods
Detection-based methods [4–6] achieve some results for low-density crowd, while the counting effect is considerably reduced in dense scenes. Thus, some researchers have proposed local feature extraction methods, where the object to be detected according to localised areas of the body. Compared to the former method, the local detection is more robust, but the results are still not particularly efficient in high-density scenarios.
Researchers have attempted to address the limitations of the detection method by exploring regression methods [7, 13]. Regression methods offer improved accuracy compared to detection methods, which are constrained by high-density scenarios. However, regression methods involve complex computational procedures. Furthermore, most conventional counting methods rely on global count regressions, disregarding spatial information. Traditional crowd counting methods heavily rely on manual feature extraction and exhibit bias towards sparse scenes. Consequently, their performance suffers in complex situations involving crowd occlusion, foreground perspective, multi-scale variations, and cross-scene scenarios.
Deep learning-based crowd counting methods
CNN-based methods have been studied and fruitful progress has been achieved. Three related works are temporarily described here, namely the image-pyramid-based approach [14, 15], multi-column approach [9, 16–19], and the multi-level approach [10, 20–23]. However, they are imperfect because of CNN’s limited receptive field, which leads to poor global context modeling capabilities, with the result that counting is ineffective in the face of drastic changes in head size and extremely complex backgrounds.
In recent years, the Vision Transformer (ViT) has emerged as a prominent technique in computer vision tasks. An example of its successful application in crowd counting is TransCrowd [24], which utilizes weakly supervised training to achieve excellent results. Despite these impressive advancements, ViT currently cannot entirely replace the dominant position of CNN. First, ViT divides images into patches, and each patch in the image lacks the original spatial structure, resulting in information loss. This breaks down the inherent spatial relationships present in the image. Second, since the patches have a fixed size, it becomes challenging for the ViT to accurately extract multi-scale features, which are crucial for handling objects of different sizes. Third, the computation becomes significantly expensive when the ViT performs multi-head attention, leading to a performance gap compared to CNN, especially when the computational resources are similar. Considering the aforementioned reasons, CNN currently holds certain advantages in terms of efficiency and computational economy over ViT.
Dilated convolution
Dilated convolution [12] was initially proposed to address the challenge of image segmentation. Traditional methods for image segmentation commonly utilized pooling layers and convolutional layers to expand the network’s receptive field and reduce the resolution of feature maps. Subsequently, upsampling techniques were employed to restore the original size of the feature maps. However, this conventional approach inevitably resulted in a decrease in accuracy. In contrast, dilated convolution introduces gaps within the kernel, allowing for an expanded receptive field without altering the dimensions of the feature map. The spacing between kernel elements is controlled by the dilation rate. The effect of dilated convolution can be visualized as if the kernel expands and covers a larger area without increasing its size. Specifically, the size of the convolution kernel after dilation rate scaling can be viewed as D
k
:
MHANet as a whole employs an encoder-decoder architecture as shown in Fig. 2. Firstly, the images are passed through the first 13 layers of VGG-16 to extract features at different scale levels, and after passing through the MAM and the HAM, it incorporates the features map into the decoder. The decoder uses multiple convolution operations and upsampling to output the final density map. This section describes the encoder, decoder, multi-scale aware module, hybrid attention module, and loss function of MHANet, respectively.
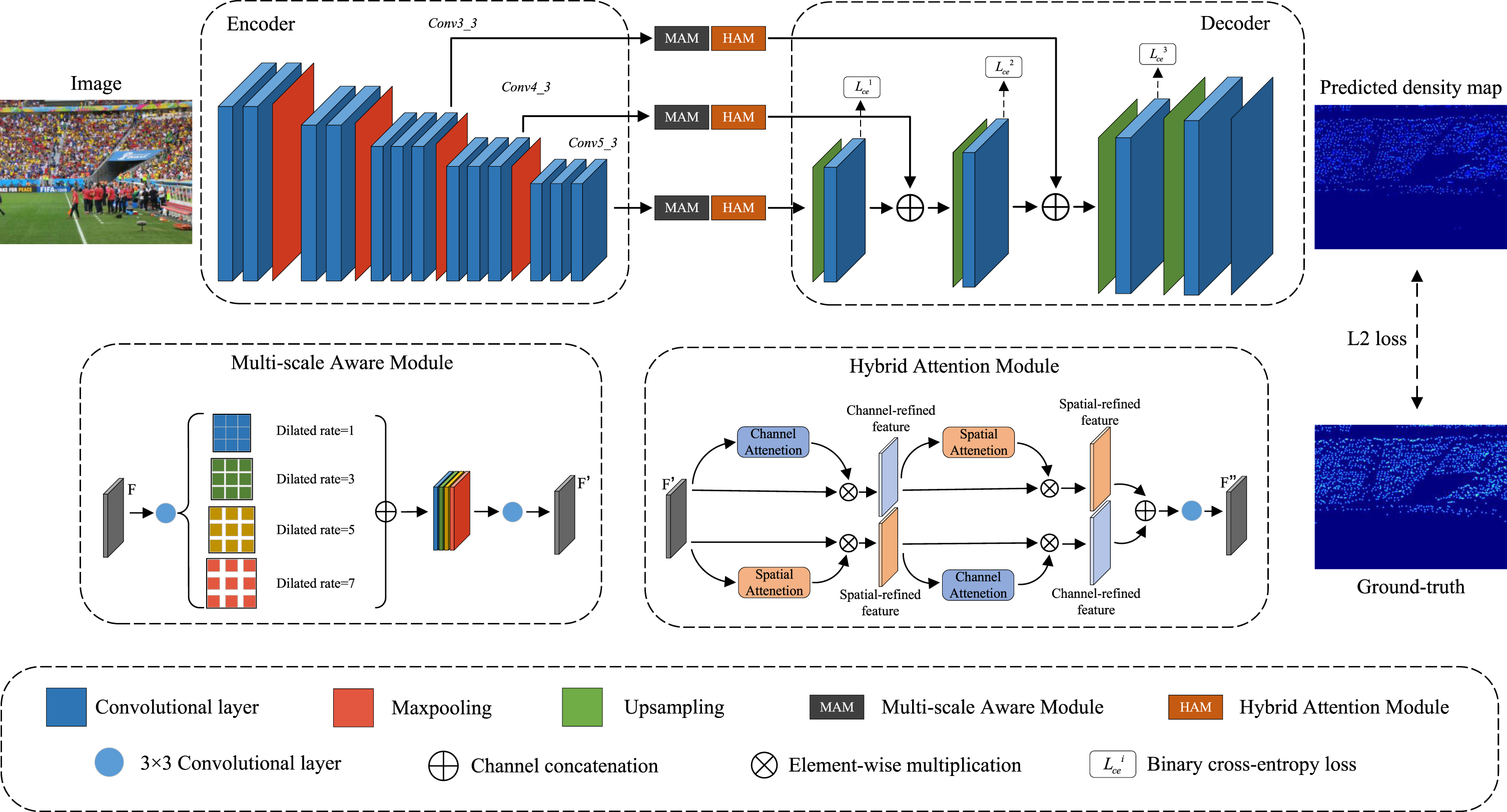
The overall structure of MHANet. Firstly, the images are passed through the first 13 layers of VGG-16 to extract features at different scale levels, and after passing through the MAM and the HAM, it incorporates the features map into the decoder. The decoder uses multiple convolution operations and upsampling to output the final density map.
The encoder phase utilizes the first five stacks of VGG-16. Originally designed for classification tasks, VGG-16 networks quickly found application in various computer vision tasks due to their exceptional representational capacity and simple network structure. To alleviate overfitting, pre-trained networks are commonly employed.
In the encoder, the input image is fed to extract shallow features initially. This is because the shallow stage of the network has smaller receptive fields, enabling the capture of fine details such as color, texture, edges, and angles. As the network depth increases, the feature maps undergo multiple convolution operations and subsampling, resulting in larger receptive fields. At this stage, each pixel represents feature information for a region or neighboring regions, providing semantic context for comparison.
Three representative features, namely Conv3 _ 3, Conv4 _ 3, and Conv5 _ 3, are extracted at different scale levels. Specifically, for an RGB image of size H × W, their resolutions are
Decoder
The decoding process is a sequential procedure aimed at restoring the size of the feature map. Due to the adoption of four 2× downsampling during the encoding stage, in the decoding stage, four 2× upsampling is used to gradually restore the size of the feature maps.
To address the limitation of acquiring deep semantic information directly through upsampling shallow detail information, we introduce two skip links, integrating the preserved features Conv3 _ 3 and Conv4 _ 3 from the encoding phase into the decoding process. Specifically, the feature maps of Conv3 _ 3 and Conv4 _ 3, each with their respective sizes, are individually concatenated. Consequently, MHANet can access more comprehensive semantic and detailed information, resulting in improved accuracy in localizing crowd areas.
Multi-scale aware module
Due to the wide-angle view prevalent in the crowd counting dataset, the scale of the crowd close to the lens is larger, while the scale of the crowd farther from the lens is smaller. This drastic scale variation presents challenges to the counting. Therefore, this paper proposes a Multi-scale Aware Module (MAM), as shown in Fig. 2, to address the scale variation problem more effectively.
The MAM employs dilated convolutions as filters to capture richer multi-scale information. However, a specific dilation rate can only capture information at a particular scale, and overlapping of the same dilation rate can result in a gridding effect [12]. Therefore, we carefully choose the strategy of concatenating four sets of dilated convolutions with dilation rates of 1, 3, 5, and 7 to handle continuous scale variations more effectively. The whole procedure can be described as:
Spatial attention transforms the spatial information of an input feature into another space while retaining its key information. Channel attention allows the input feature map to learn dependencies in the channel dimensions and then adaptively rescale the features for each channel, allowing the network to focus on the more available channels while enhancing the learning ability.
Inspired by the work of Park et al. [25], a novel Hybrid Attention Module (HAM) is proposed that combines spatial attention and channel attention, as shown in Fig. 2, to address the problem of background complexity more effectively. Specifically, HAM is composed of an upper and lower branch connected in parallel. For the upper branch, the feature map F′ first undergoes channel attention for channel-domain refinement, resulting in . It is then passed through spatial attention for spatial-domain refinement, resulting in . For the lower branch, the feature map F′ goes through spatial attention to obtain , followed by channel attention to obtain . Finally, a 3 × 3 convolution is used to fuse the outputs, resulting in F″. The entire process can be formalized as follows:
The loss function of MHANet is split into two parts, and we adopt the MSE to calculate the loss L
density
for the final prediction result:
Experimental environment
The experimental procedure utilized the Windows 10 operating system and an NVIDIA-3060 GPU. Additionally, a series of data augmentation operations were conducted on the images in the dataset to acquire a more diverse training sample. For images with an edge length of less than 400, bilinear interpolation was applied to increase the edge length to 400. Subsequently, local image patches were randomly flipped, and contrast and grayscale were adjusted to expand the data volume and enrich the training data. In the case of images with extremely large resolutions, the bilinear interpolation method was employed to uniformly resize them to 1024×768 before data enhancement.
Evaluation metrics
We used the MAE and the MSE as the evaluation metrics of the experiment. They are defined by:
We evaluate our method across four benchmarks, including ShanghaiTech Part A (ST Part_A) [9], ShanghaiTech Part B (ST Part_B) [9], UCF-QNRF [34], and UCF_CC_50 [35]. The experimental results are presented in Table 1, while some visualization results are shown in Fig. 3.
Experimental results on ST Part_A, ST Part_B, UCF-QNRF and UCF_CC_50
Experimental results on ST Part_A, ST Part_B, UCF-QNRF and UCF_CC_50
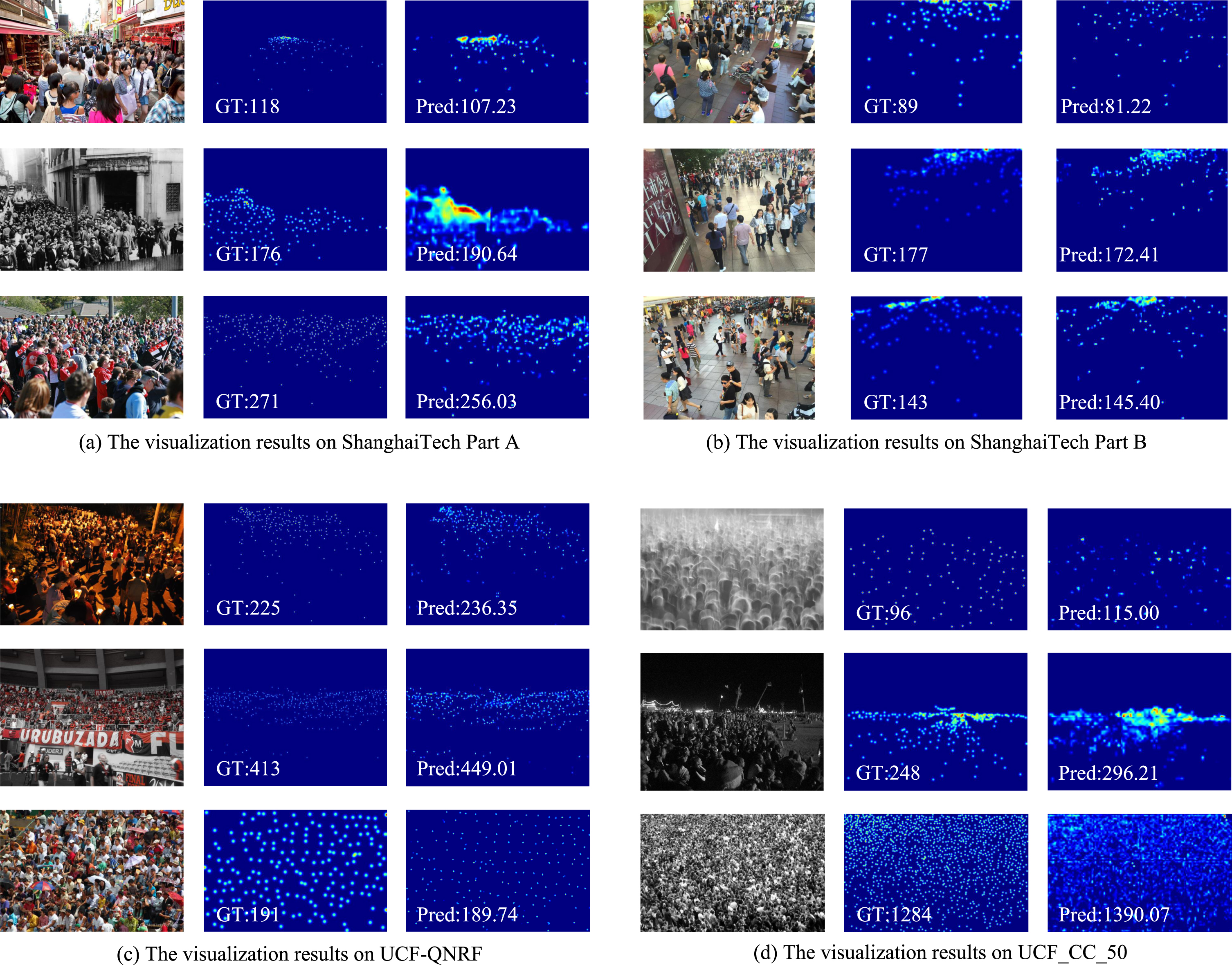
Visualization results on different datasets, where the three columns of pictures from left to right are the true image, the ground-truth and the predicted density map.
The ShanghaiTech dataset is divided into ST Part_A and ST Part_B. ST Part_A contains a total of 241, 677 head annotations, with an average of 501 annotations per image. Most of the images are sourced from the Internet and have varying scene information.
Table 1 demonstrates that MHANet achieves an MAE of 57.4 and an MSE of 94.2 for ST Part_A. Our MAE outperforms the first-place DMCNet [33] by 1.9%, indicating the effective focus of our network on crowd areas and its ability to suppress complex background interference.
ST Part_B
All images in ST Part_B were taken from surveillance cameras in Shanghai. This dataset has a single source, a relatively small average number of people, and a relatively sparse crowd scene, with an average of 124 people per image.
Table 1 shows the counting results of MHANet on ST Part_B, which demonstrate excellent performance with an MAE of 7.0 and MSE of 10.8. Our MAE outperforms the first-place SFCN [27] by 5.4%. For MSE, our method also outperforms the state-of-the-art AMRNet [30] by 1.8%. These results indicate that our method achieves high accuracy even in low-density regions. Our network incorporates a multi-scale aware module, allowing it to capture head information at different sizes. This capability enables accurate counting even when there is significant variation in head size, maintaining minimal counting errors.
UCF-QNRF
The UCF-QNRF dataset is an extremely challenging crowd counting dataset with rich scenes and diverse viewpoints, densities, and lighting conditions. 1, 535 images were annotated with a total of 1, 251, 642 head-annotated points.
Table 1 demonstrates the strong adaptability of MHANet to extremely complex scenarios, surpassing even newer methods such as TransCrowd [24] and DMCNet [33]. Our proposed method achieves excellent results in terms of both MAE and MSE evaluation metrics. However, it is worth noting that our MSE value is 13% higher than the state-of-the-art AMRNet [30], indicating the potential for further improvements in the robustness of our network. This difference may be attributed to the limited receptive field of the CNN, which poses a disadvantage.
UCF_CC_50
UCF_CC_50 are collected from the Internet, and the scenes include concerts, demonstrations, and other highly crowded occasions, with a total of 50 extremely dense images taken at different resolutions and from different perspectives. The average number of headcounts per image is 1,280, which exceeds that of other crowd counting datasets. Considering the limited number of UCF_CC_50 images, the publisher of this dataset defined a cross-validation protocol to augment the sample size.
As shown in Table 1, the results indicate that our method achieves an MAE of 182.5 and an MSE of 240.4. Comparing our method to AMRNet [30], we observe a 0.8% improvement in MAE, and when compared to CAN [26], there is a 1.3% improvement in MSE. These findings demonstrate that MHANet exhibits remarkable accuracy and robustness, even when dealing with limited RGB information.
Ablation study
We conduct a series of ablation studies on the ST Part_A. In the implementation, the basic backbone network structure is used as a baseline and the corresponding modules are added step by step to verify their effectiveness.
Ablation study for multi-scale aware module
The experimental comparison results show that the backbone network baseline already has a decent counting effect, but when MAM is added, the counting performance of the network is further improved, as shown in Table 2 and visualized in Fig. 4(a).
Ablation study for multi-scale aware module
Ablation study for multi-scale aware module
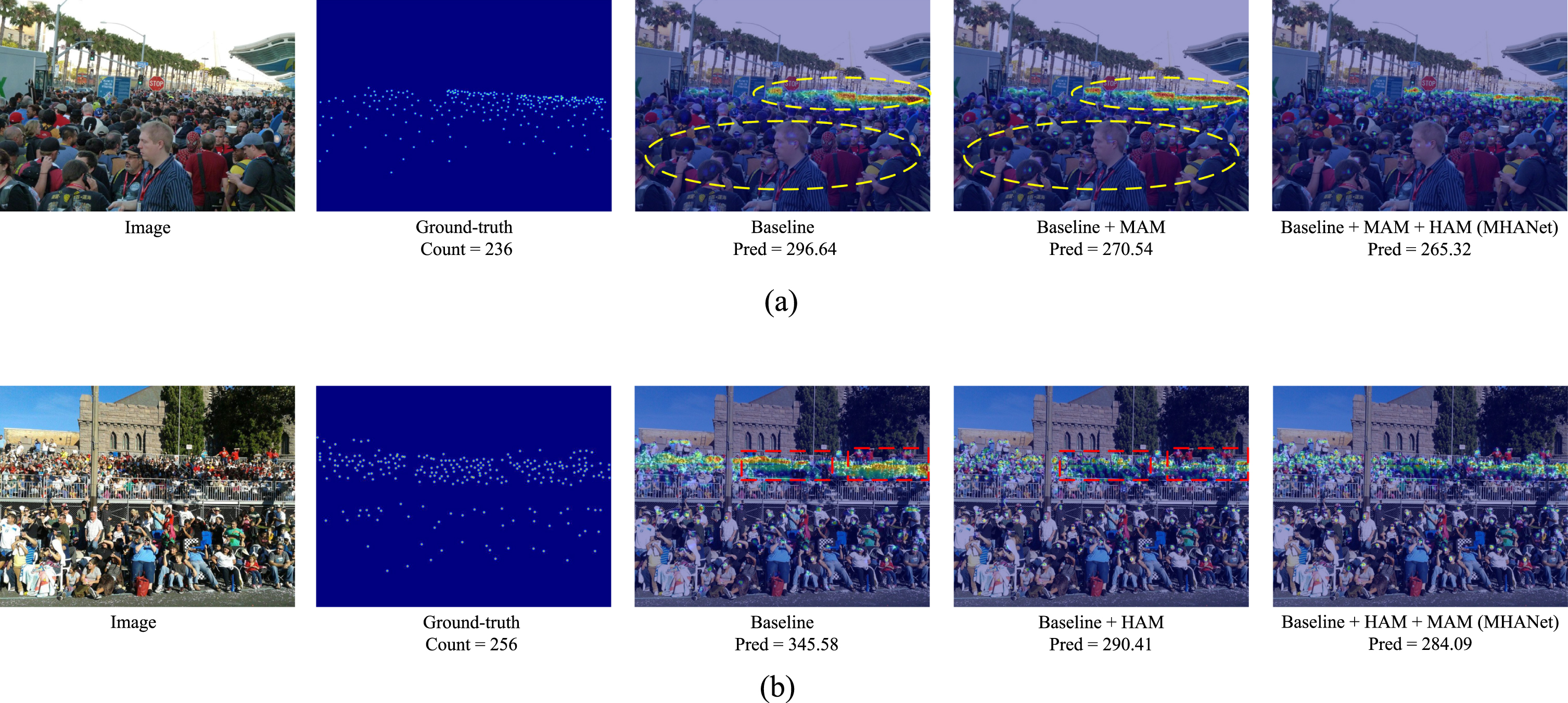
Visualization results of ablation study. (a) The visualization results of the ablation study of MAM. (b) The visualization results of the ablation study of HAM.
According to the experimental results, the accuracy of the count is significantly improved when the MAM is added to the backbone network, indicating that the MAM plays a key role in dealing with the rapid change of the human head scale.
To validate the effectiveness of dilated convolutions in MAM, we extract multi-scale features using dilated convolutions with different dilation rates to compare their performance. For the setting of the dilation rate, four schemes "1, 1, 1, 1", "1, 2, 3, 4", "2, 4, 6, 8", and "1, 3, 5, 7" are tried as shown in Table 3.
Ablation study for multi-scale aware module
According to the experimental results, when dilated convolutions are used in MAM, the counting accuracy of the network is relatively improved, and the best counting performance is achieved with dilated rates of 1, 3, 5, and 7, respectively.
The comparison results of the experiments show that the counting effect of the network is significantly improved after the addition of the HAM, as shown in Table 4 and visualized in Fig. 4(b).
Ablation study for hybrid attention module
Ablation study for hybrid attention module
From the ablation studies, we can see that the backbone network is already able to obtain relatively accurate density maps, but the foreground information is further enhanced after incorporating the attention module. At the same time, the background noise interference is suppressed so that the foreground part of the density map is more significant and the background error is relatively smaller, further improving the counting accuracy.
We design two types of total loss schemes, L density loss function alone and L density plus weighted L i loss. Moreover, for the coefficient λ, we design three schemes such that λ is 1e-2, 1e-3, and 1e-4, and the results are given in Table 5.
Ablation study of the loss function
Ablation study of the loss function
We can see the second type of scheme can get better experimental results, and in addition, when the value of λ is 1e-4, the ideal result close to 1e-3 is achieved, which also indicates that our loss function has some robustness for the value of λ.
In this paper, a Multi-scale Hybrid Attention Network is proposed to address the problem of scale variation and background complexity more effectively in crowd counting. The proposed MHANet incorporates MAM and HAM. The MAM consists of four sets of dilated convolutions with different dilation rates, effectively enhancing the network’s multi-scale information extraction capability. The HAM consists of two sets of spatial attention and channel attention in parallel, effectively increasing the network’s attention to the crowd region and suppressing background interference. Additionally, in the decoding phase, a multi-level supervised loss function is used to obtain more accurate counting results. Compared to other existing methods, the proposed MHANet achieves MAE evaluation scores of 57.4, 7.0, 86.2, and 182.5 on ST Part_A, ST Part_B, UCF-QNRF, and UCF_CC_50 datasets, respectively, surpassing the current state-of-the-art methods by 1.9%, 5.4%, 0.4%, and 0.8%, respectively. However, the MHANet still has some limitations compared to other excellent methods. For instance, when dealing with uneven crowd density distribution, the counting accuracy would decrease due to CNN’s limitation in modeling global contextual information. Furthermore, the complex design structure of MAM and HAM leads to increased computational complexity and longer training time for the network.
There are still many tasks awaiting further exploration by researchers, such as the application of ViT in crowd counting and the study of cross-modal issues in crowd counting. In the future, we plan to explore a lightweight algorithm to achieve crowd counting and extend our approach to other counting domains to make further contributions.
Footnotes
Acknowledgment
This work was supported by the National Natural Science Foundation of China (No. 62163016, 62066014), the Natural Science Foundation of Jiangxi Province (20212ACB202001, 20224BAB202016).