
Abstract
With the continuous development of knowledge graph completion (KGC) technology, the problem of few-shot knowledge graph completion (FKGC) is becoming increasingly prominent. Traditional methods for KGC are not effective in addressing this problem due to the lack of sufficient data samples. Therefore, completing the task of knowledge graph with few-shot data has become an urgent issue that needs to be addressed and solved. This paper first presents a concise introduction to FKGC, which covers relevant definitions and highlights the advantages of FKGC techniques. We then categorize FKGC methods into meta-learning-based, metric-based, and graph neural network-based methods, and analyze the unique characteristics of each model. We also introduced the research on FKGC in a specific domain - Temporal Knowledge Graph Completion (TKGC). Subsequently, we summarized the commonly used datasets and evaluation metrics in existing methods and evaluated the completion performance of different models in TKGC. Finally, we presented the challenges faced by FKGC and provided directions for future research.
Keywords
Introduction
With the continuous advancement of artificial intelligence, knowledge graph technology has also been continuously advancing. As a pivotal technology in the realm of artificial intelligence, knowledge graph plays an indispensable role in areas such as intelligent search and intelligent question answering. Knowledge graphs(KGs) are composed of many different datasets, such as YAGO [1], DBpedia [2], Freebase [3], and NELL [4], etc., domestic large-scale knowledge graphs such as CN-DBpedia, RORKG, Chinese Wikipedia Encyclopedia knowledge graphs, Oracle cloud knowledge graphs, etc. all contain rich semantic information. These KGs, which encompass copious structured information, facilitate machine comprehension and application of human knowledge. These KGs have been extensively utilized in do-mains including natural language processing, machine learning, and artificial intelligence. Google launched a search engine product based on KGs in 2012, and first proposed the concept of knowledge graph, introducing the benefits of using knowledge graphs to enhance search. Google believes that “things, not strings”, that is to say, in the search engine, all kinds of things in the world should not be just strings, but things with actual meaning [5]. KG plays their unique role in search engines [6], question and answer systems [7, 8], dialogue systems [9], recommender systems [10, 11], knowledge inference [12, 13], entity alignment [14], and event prediction [15, 16].
Nonetheless, the drawbacks of knowledge graphs surface as the scope of knowledge graphs continues to expand. Owing to the inadequacy of knowledge sources and the imperfectness of data integration, there is often a dearth of information in knowledge graphs. Knowledge Graph Completion Technology utilizes machine learning and deep learning approaches to learn from the existing triples in knowledge graph, predict the missing triples, and ultimately accomplish the objective of completing knowledge graph and enhancing its usability.
For KGC, scholars have done a lot of research work. Experiments show that the method of knowledge graph embedding is a more effective method for KGC [17], which predicts missing entities, relations, or attributes by mapping entities and relations into a low-dimensional vector space and calculating the similarity or distance between them, for example, TransE based on vector space embedding [18], which is one of the most representative models. Knowledge graph embedding has shown good performance and robustness in the task of KGC. Current completion methods require a significant number of entity and relational data triples for training to obtain a better representation of knowledge graph embeddings, but in few-shot knowledge graphs, the available training data is often limited. For example, in the medical field, the contents of knowledge graph are usually constructed manually by experts, however, due to the limited time and energy of experts, the constructed knowledge graph is usually incomplete, and there are few triples available for training, which greatly affects the effect of KGC.
In recent years, numerous domestic and foreign scholars have conducted extensive research on few-shot knowledge learning, particularly on solving the issue of few-shot knowledge graph completion. This paper comprehensively summarizes the field of few-shot knowledge graph completion in recent years, allowing future scholars to gain a comprehensive understanding of the subject. Furthermore, this paper elucidates and explains the various FKGC methods. The primary contributions of this paper are: In this paper, we classify recent research on FKGC into three categories based on the methods used: meta-learning-based methods, metric-based methods, and graph neural network-based methods. At the same time, we also analyze the model ideas of existing FKGC models and their model characteristics. In this article, we summarize and analyze the application of FKGC in a specific domain – Few-shot Temporal Knowledge Graph Completion. In addition, we present the existing models and investigate their model structures and characteristics. We summarize the commonly used datasets and evaluation metrics in the domain of FKGC, and also compare the effects of different models in experiments to analyze the differences in performance of the models under the same conditions. We analyze the current challenges in the domain of FKGC research and provide references for future research directions in this domain.
Concept and features of few-shot knowledge graph completion
Before delving into the main methods, datasets, and challenges of FKGC, it is important to provide a brief introduction to the field. This includes defining few-shot knowledge graphs and highlighting the benefits of using FKGC techniques.
Definition of few-shot knowledge graph
Few-shot learning
Li et al. [19] proposed the Few-Shot Learning (FSL) method to improve the generalization of deep learning classification models in small sample sizes and learn from limited supervised information. FSL involves learning from a few labeled samples, a concept known as FSL. Traditional feature extraction methods in FSL are limited in expressing the complexity and variability of the data due to the limited number of training samples available. One-shot learning, first proposed in literature [20], used learned classes to predict new classes when only one training sample was available.
The most basic idea of FSL is to learn a similarity function: sim (e, e′) to compare the similarity between two samples e and e’. The larger the value, the higher the similarity, vice versa. The specific steps are: (1) learning the similarity function from the large-scale training set; (2) comparing the similarity between the query and support set, and selecting the sample with the highest similarity as the final result of the prediction.
In the development of FSL, a number of methods based on deep learning have emerged, such as protomorphic networks [21], twin networks [22], and relational networks [23], which achieve the high performance of improving learning efficiency and accuracy by automatically learning features in the data. In summary, FSL is the extraction of abstract concepts in data with a limited number of samples to generalize to unseen datasets.
Few-shot knowledge graph completion
A knowledge graph is a collection of a vast number of triples that are usually represented in the form of (subject, relation, object). In this form, the subject represents an entity, the object can either be another entity or a value and the relation indicate the connection between the subject and object. By arranging these triples in graph format, knowledge graphs can offer comprehensive information about the associations between entities, enabling machines to have a better understanding and utilization of these relationships. Additionally, knowledge graphs can be continually modified and enhanced by adding and updating triples to accommodate new application scenarios and requirements.
However, large-scale knowledge graphs are often incomplete, and a large number of triads have missing problems. Numerous studies have focused on completing knowledge graphs by predicting missing triples [24], which involves determining the likelihood of unknown triples being valid. Knowledge graph completion task can be represented as follows: in knowledge graph G = { (s, r, o) } ⊆ E × R × E, E and R are the set of entities and the set of relations. KGC task is typically divided into two subtasks: entity prediction and relationship prediction. In entity prediction, the objective is to predict the missing entity o in a triple given the other known entities (s, r, ?). In relationship prediction, given two known entities (s, ? , o), the objective is to infer the missing relationship r between them. However, in real scenarios, many knowledge graphs lack sufficient relational data. For instance, in Wikidata, approximately 10% of relation triples contain fewer than 10 instances [25]. FKGC applies knowledge graph completion tasks in FSL scenarios. Given a few-shot relation r and a few-shot reference entity pair (s k , o k ) ⊆ R r of r to complement knowledge graph. As shown in Fig. 1, a 3-shot KGC task is demonstrated. For the relation capital_of, the missing entity part of the query set is predicted by learning given of 3-shot relations in support set.
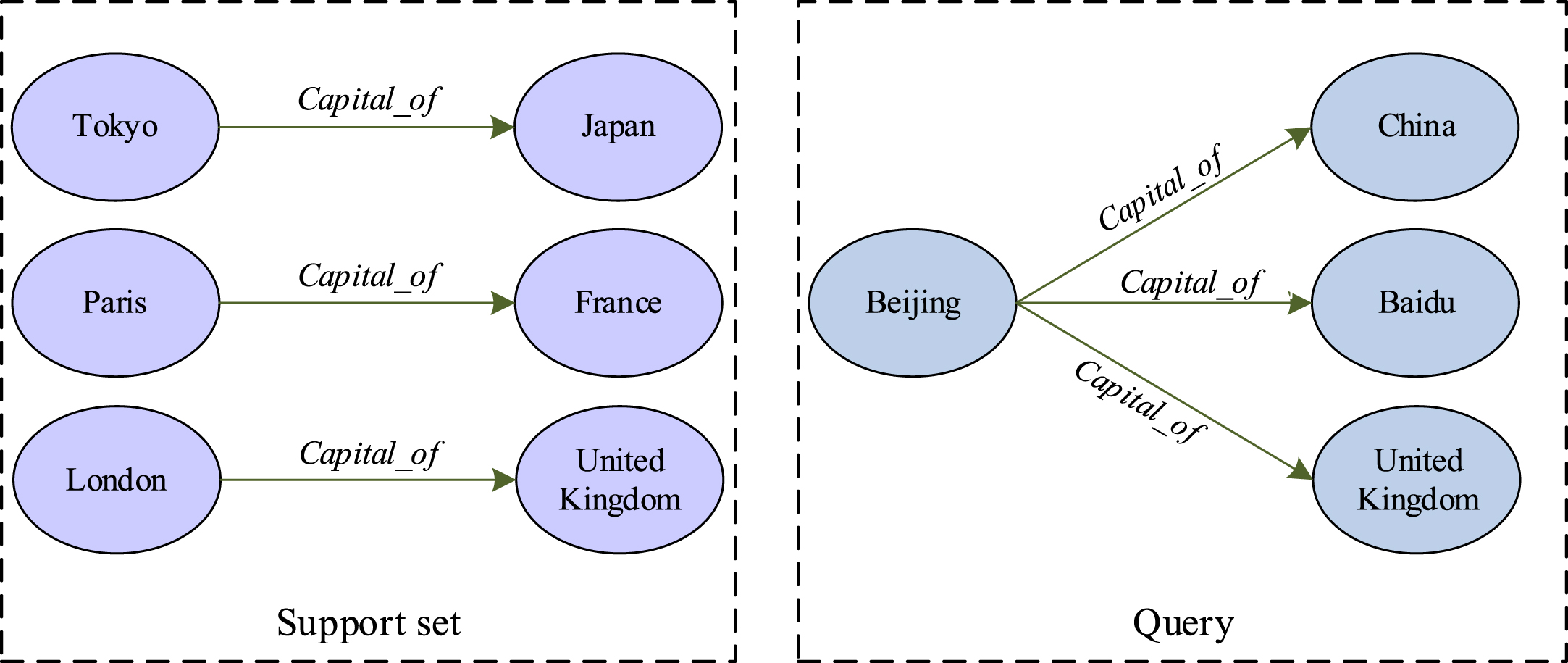
3-shot Knowledge graph complementation task.
There are two concepts that often appear in few-shot completion, namely N-way and K-shot. N-way indicates that extraction of N categories data from the dataset, such as 5-way indicates that extraction of data from 5 categories. K-shot means that there are only K samples for model training, such as 5-shot means that there are only five samples to predict the relationship between unknown entities.
Faster training speed: FKGC can complete the training task in a shorter time because it only requires a small amount of data for model training. Therefore, FKGC techniques are more suitable for large-scale knowledge graph applications that require efficient algorithms and techniques. Better generalization ability: Few-shot knowledge graphs lack sample data. However, the ability of a model to generalize plays a crucial role in predicting new entities and relations. FKGC usually adopts more flexible models and algorithms that can improve the prediction accuracy to learn the laws of knowledge graphs. Better interpretability: FKGC models and algorithms are often more intuitive and therefore easier to interpret and understand. Because these models can better explain the laws between entity relationships in knowledge graph, FKGC has more advantages in knowledge graph reasoning.
Few-shot knowledge graph completion methods
In recent years, due to the developing research on knowledge graph completion and inference, there has been increasing interest in improving the performance and efficiency of KGC using few-shot data. Literature [26] proposed a few-shot relationship classification dataset and Few-shot learning-based approach. This literature provides a reliable evaluation criterion to compare the performance of different few-shot learning methods on KGC task. Subsequently, Xiong et al. [27] proposed the matching network-based model Gmatching for predicting the missing parts of long-tail relationships in knowledge graph to perform the FKGC. In this section, we outline the existing FKGC tasks as meta-learning-based approaches, metric-based approaches, and graph neural network-based approaches
Meta-learning-based approach
In FSL, meta-learning methods concentrate on acquiring transferable knowledge from numerous auxiliary FSL tasks to facilitate swift generalization to new tasks. Meta-learning is an approach that enables machines to learn how to learn [28], employing previous knowledge and experience to direct new learning tasks and empowering the acquired models with the capacity to learn across tasks. According to the literature [29], meta-learning can be defined as the reduction of a network’s loss function across the entire dataset through parameters.
In FKGC tasks, it is challenging to train models using large-scale knowledge graph completion techniques due to the scarcity of available training data. As a result, the idea of meta-learning is employed to enhance the accuracy of FKGC by learning generic knowledge and utilizing the acquired models in few-shot tasks. In 2018, Xiang et al. [30] adapted Model-Agnostic Meta-Learning (MAML) to the NLP domain and introduced an Attention-Enhanced Meta-Learning (A-MAML) method, which incorporates the attention mechanism to improve the few-shot text classification task, within the MAML framework. The attention mechanism is utilized to capture correlations between various tasks, and it has the capability to rapidly adjust to the features of new tasks. Chen et al. [31] introduced a method MetaR, a meta-learning approach that reduces the learning time and adapts to a limited number of triples for new relations, making it suitable for few-shot tasks. MetaR consists of two main modules Relation-Meta Learner (RML), which generates the relational elements of head and tail entity embeddings from the support set. Embedding Learner, a fast-updating relational element, uses the idea of TransE to design scoring functions to evaluate the truth value of entities in specific relational cases, such as Equation (1).
Finally, the loss function of the model is defined as Equation (2), and the model is updated based on this loss. Although MetaR has better results in terms of accuracy, it ignores the relevant semantic information of the entities. Meta-KGR [32] is a meta-learning-based multi-hop inference algorithm for the few-shot multi-hop inference problem. For query triples with the same relations, Meta-KGR is based on the on-policy RL method proposed by Lin et al. [33], which uses reinforcement learning to train agents to search for target entities and inference paths. This approach is similar to MAML in that it uses the task of high-frequency relations to capture information about relation types and entity types, and generates an adapter module for each few-shot relation to enable representation and generalization capabilities. In the design of the model, Meta-KGR is divided into two phases: relation-specific learning and meta-learning. In relation-specific learning, knowledge graph search process is analogized to Markov Decision Process (MDP), and the Equation (3) is used to encode.
The loss function Equation (4) is defined as the total loss of the relationship-specific network when searching for paths.
Meta-KGR aims to learn the initial parameters, allowing it to dynamically adapt to each few-shot relational task. It is experimentally concluded that Meta-KGR is robust to the threshold K of the few-shot task while achieving high experimental results, and can obtain better completion effect.
Existing few-shot completion methods rely more on the background knowledge graph to provide context and shared knowledge. To address this problem, Jiang et al. [34] proposed MetaP, which extracts the patterns of a triad directly through a convolutional filter-based pattern learner while introducing a Residual Update Mechanism (RUM) to preserve the original features while fine-tuning the entity embedding, using an effective balance mechanism to compute the validity of the triad. The model consists of a pattern learner and a pattern matcher, which extracts the model directly from the triad by learning the mapping of entities to pairs of relations, thus reducing the dependence on the background graph. The MetaP approach is not influenced by the background knowledge graph, which means that its completion performance is not affected by the characteristics of the knowledge graph used.
Zheng et al. [35] proposed Meta-iKG, a subgraph-aware link prediction model with few-shot via meta-learning to convert the link prediction task to subgraph modeling. The model consists of a relationship-specific learning module and a meta-learning module. The meta-learner is constructed by the task of high-frequency relations, and the subgraph scoring function specific to the relations is trained by providing good initial points. To address the poor performance results of Meta-iKG in large-sample relations, the model applies Meta-SGD [36] to update the meta-learner and introduces a large-sample relation update procedure to eliminate the bias introduced by few-shot relation meta-updates and obtain generalizability across different size knowledge graphs.
Sparse neighborhoods and complex relations in knowledge graphs are also challenges to be faced by the few-shot completion problem. Existing methods such as TransH [37] and TransR [38] can handle the more complex scenarios that occur in knowledge graphs, but these models require the use of a significant number of samples for learning, which is difficult to achieve the learning requirements in few-shot knowledge graphs. Niu et al. [39] used a gated network and graph attention mechanism to encode few-shot relational neighborhoods and proposed the GANA model to derive a general representation of few-shot relations. Using the MAML-based method MTransH is adapted in the local phase to transfer the updated relational representation and hyperplane parameters from the reference set to the query set to learn all parameters. The model experimented for 1-N, N-1, and N-N relation complexities, all with improved performance compared to MetaR. This suggests that it is more efficient to capture semantics in the adjacent entities and relations of few-shot relation to represent such relations. However, the model does not achieve similar results in handling N-N complexity compared to 1-N and N-1 complexity, and the possible reason is that the completion effect is related to the complexity of the few-shot completion task.
Due to the FKGC limitations in harnessing the potential of pairwise triplet-level interaction and context-level relational information, Wu et al. [40] proposed the Hierarchical Relational learning framework (HiRe) to acquire more three-dimensional and generalizable representation space. FKGC is divided into three sub-tasks: aggregating adjacency information to enhance entity representation, learning the meta-representation of given relation and computes similarity between the query and reference sets in three subtasks, hierarchically for the three levels of relations. Context-level relationship learning using contrast learning, which incorporates the target triad and context-level relevance in entity embedding to improve entity embedding. In relationship learning, a transformer-based Meta-Relationship Learner (MRL) [41] is proposed to improve the generalizable meta-representation of the learned target relationships by using mutual modeling between triads. Entity-level relationship learning based on meta-representation, influenced by TransD [42], proposed an embedding learner based on meta-representation MtransD that dynamically constructs the mapping matrix between entity-relationship pairs. After these three levels of relationship learning, HiRe employs a MAML-based training strategy [43] to optimize for each meta-task within a unified framework. HiRe is capable of effectively learning the meta-representation of relationships and can have better generalization ability in new relationships.
Yao et al. [44] suggested incorporating a priori type information into two-module learning framework Few-shot KGC (PiTI-Fs). The model is composed of two main modules: priori knowledge-learning module and meta-learning module. In priori knowledge module, the meta-graph is extracted through entity clustering to obtain a priori type information. Additionally, the background graphs and meta-graph are pre-trained to acquire entity embeddings and type embeddings. Since the identical cluster entities share the same category of attributes, the embeddings of the background graphs and meta-graph are aggregated using an aggregation function to use to rep-resent entity embeddings. In the module of meta-learning, the difference in importance between different entities is taken care of by introducing Transformer-based encoders to obtain the few-shot relational representation and predicting the missing triples in an optimization-based meta-learning framework, which is driven by MetaR. The model exploits a priori type information ignored by previous approaches to optimize FKGC task.
In few-shot knowledge graph completion tasks, the dynamic characteristics between entities play a special role. DARL [83] is a new meta-learning based dynamic adaptive relationship learning model that incorporates neighbor relationships into entity embeddings using a dynamic neighbor encoder to capture better meta-knowledge semantic information. To further enhance its meta-learning capability, DARL constructs an attention-based fusion strategy for different attributes of the same relationship.
Metric-based methods evaluate triplets by embedding entities and relations into a vector space and learn a metric function by computing the distance or similarity between vectors in the space, and obtain the highest-scoring triple representation. This is completed for the FKGC task, which represents the general flow of the metric learning approach. Current knowledge graph completion techniques based on metric methods solve the knowledge graph completion problem by converting the knowledge graph into a vectorized space for modeling, such as TransE, RESCAL [45], ComplEX [46], and ConvE [47].
However, existing models require a substantial number of entities and relations for training in order to derive the model, which makes the existing models ineffective in specific few-shot knowledge graphs. To address the above problem, Xiong et al. [27] introduced Gmatching model, which was the first approach to address one-shot KGC in the context of link prediction. In contrast to previous approaches, Gmatching relies only on entity embedding and local graph structure to match entity pairs by learning matching metrics. Because it can perform the prediction task for any relationship without any adjustment after training, while previous metric-based methods require fine-tuning to adapt to new relationships, training on two one-shot datasets, NELL-One and Wiki-One, has achieved better results than various previous embedding models.
Due to its earlier proposal, Gmatching ignores the influence of heterogeneous neighbors on entity embedding. while it mainly focuses on the one-shot completion problem, which tends to ignore the interaction between few-shot reference instances in multi-sample relationship modeling leading to the under-expression of reference instances. To solve this problem, Zhang et al. [48] proposed Few-Shot Relation Learning model (FSRL) to improve the influence of neighboring nodes on entity embedding by using graph structure and heterogeneous types. First, a heterogeneous neighbor encoder is used, which learns the feature encoding of the output nodes by considering the varying impacts of their relational neighbors. Then, the reference set Rr corresponding to each relation r is efficiently utilized by a recurrent autoencoder aggregation network. Finally, the similarity score between query pairs and the reference set is calculated using a matching network to obtain entity pairs with high similarity, and a gradient descent method based on meta-training is used to optimize the model parameters. FSRL efficiently captures knowledge from the heterogeneous graph structure, aggregates the representations of few-shot references, and matches for each relationship matches similar entity pairs of the reference set, but the entity and relationship weights are still assigned statically, ignoring the dynamic characteristics of entities and relationships.
Considering the dynamic properties of entities and relations in KGs, the representations of entities and relations may vary depending on the specific task, entities may be polysemous and relations may be polysemous. Sheng et al. [49] proposed an adaptive attention network [50] FAAN to solve the FKGC task by contrasting input queries with a given reference to learn the predictable metric functions. FAAN model is divided into: using adaptive neighbor encoders in the entity representation to demonstrate different role information of entities in different task relations, determining the role information represented by entities due to the correlation based on task relations and proximity relations, modeling task relation embeddings as transitions between head and tail entity embeddings under the influence of TransE to obtain pre-trained entity embeddings, using bilinear dot product to calculate the correlation scores of task relations and entity neighbors, and subsequently combine the pre-trained entity embeddings and role-aware neighbor embeddings to obtain the final representation of entities; the Transformer encoder is used for learning in the entity pair relationship representation, and the entity embeddings obtained by the adaptive neighbor encoder are used to form entity pair embeddings with the relationship embeddings, and the entity pairs are represented by the L Transformer block to encode the entity pair representation. Using the entity pair Transformer encoder helps to discriminate the fine-grained meaning of task relations associated with different entity pairs; finally, the query is compared with the given reference using an adaptive matching processor to score the semantic similarity between the query and the reference by means of a metric function.
However, FAAN does not take into account the effect of the rate on the contextual semantics of the reference set on the relationship representation when dealing with complex relationships and cannot distinguish the importance of neighbors well. In subsequent studies, some scholars have improved the FAAN model, and Pu et al. [51] proposed a type-aware attention network for FKGC, which is mainly divided into type-aware neighbor encoder, Transformer encoder, and joint matching prototype network. In the existing task relations and reference and query triples, the dynamic properties of entities are considered, and the type-aware attention is obtained by a type-aware neighbor encoder, which learns the type information implicitly in neighboring entities and obtains the importance differences of different entity neighbors to achieve the effect of enhanced entity embedding representation. In the reference set aggregation process, aggregating entity-level prototypes and relationship-level proto-types jointly help query pairs to select reference sets that are more similar to them, thus solving the problem that previous methods cannot distinguish the importance of neighbors well when they encounter 1-N and N-N complex situations during learning one-hop neighbor features. Ran et al. [52] use relationship-based learning by fusing path discovery with a contextual semantics network for FKGC and proposed FRLN (Few-shot Relational Learning Network), which mainly includes a neighborhood aggregation encoder, a relational representation encoder, and a matching computational unit. Influenced by the literature [27], which proposed that the relationship prediction can be improved by explicitly encoding the one-hop neighborhood of the KG, the output embedding vector not only retains the features of the vector itself but also incorporates its attribute features in different neighborhood relationships after the neighborhood aggregation encoder. In the relational representation encoder, a simplified R-TLM [53] (Recurrence-Transformer Language Model) is used to optimize the Transformer encoder by adding an LSTM unit to each Transformer encoder output and summing the outputs of all LSTMs to derive the final output obtained by summing all LSTM outputs and learning the contextual semantic representation between entity pairs by concatenating LSTM units. Finally, the final matching score of the triads is calculated using the matching computation unit, and the triad with the highest score is the prediction result. In the model training speed, FRLN demonstrates excellent performance by rapidly reducing the difference between predicted output and expected output.
Unlike the approach of using entity embeddings to represent relations in the model, to reduce the overdependence of relations on entities, Xu et al. [54] proposed the hierarchical attention aggregator and recoding verifier HARV for FRL. HARV consists of a hierarchical attention aggregator, few-shot relation encoder, relation-recoding verifier, and a matching network. Since heterogeneous neighbors contribute differently to the central entity, HARV first introduces a unique hierarchical neighbor aggregator to represent the central entity while extending FSRL to obtain the representation of head and tail entities. Subsequently, the representations of supporting entity pairs and their neighbor relationships are encoded separately to improve the effectiveness of the relational aggregation network. After the above process, the entities in the query set are embedded in the matching network as well as the relationship embedding computation loss to derive the similarity between the query set and the support set. HARV improves the performance of the model by focusing on the valuable information interactions between the relationships and demonstrates its uniqueness in FKGC task.
There may be multiple different relationships between the same pair of entities in knowledge graph. While only modeling the semantic information of head and tail entities cannot accurately derive the specific relationships between entities under a particular relationship. Literature [55] proposed a relation-specific context learning (RSCL) framework to learn a metric function to solve the FKGC task. RSCL uses a subgraph extractor to extract a graph context representation in the background KG, generating a subgraph consisting of head and tail entities and their direct and distant neighbors. Subsequently, the representation information is learned through a hierarchical attention network, which comprises a global context encoder and a local neighbor encoder that encodes the subgraph triples. Finally, a hybrid attention aggregator is proposed, which uses attention mechanism to achieve the effect of assigning different weights to the triples in order to make the model more focused on query-related references, aggregating global and local relationship-specific representations to measure the reasonableness of the query triples. Unlike previous models, RSCL obtains richer relational dependencies than existing models without losing valuable local information of entities by modeling the context of the triad graph.
Liang et al. [84] proposed a method called Transformer Appending Matcher (TransAM) to address the few-shot knowledge graph completion problem. TransAM performs entity sequence matching to leverage entity interactions both within and between triplets. It splits the self-attention module into local and global views to capture more fine-grained entity-level semantic meanings.
Graph neural network-based approach
A number of studies in recent years have attempted to apply graph neural network (GNN) [56] to the FKGC task. GNN enhances node representation by recursively aggregating and transforming neighboring nodes through structured data modeling [57–59], which can capture the information of neighboring nodes and achieve better results in FKGC. For example, literature [60] used GNN-based neighbor aggregation method to address the dynamic KGC problem when counting the representation of entities.
Baek et al. [61] proposed a graph inference network framework called GEN for solving the off-graph link prediction task. GEN learns the node embeddings of unseen entities through a meta-learning approach and can predict the links between visible and invisible entities simultaneously. By meta-training GEN, the model is able to generalize the existing graph knowledge to any invisible entity, thus enabling the off-graph link prediction task. The experimental results demonstrate the superior performance of the proposed model and suggest novel ideas and approaches in the area of graph-based learning and link prediction. GEN is a general framework dedicated to extra-graph link prediction rather than a specific GNN architecture. Therefore, it is compatible with any GNN implementation of multi-relational graphs.
In domain-specific knowledge graphs, technical terms are usually ambiguous, which increases the difficulty of processing word syntactic structure information in a few-shot learning environment. Ling et al. [62] advanced a deep representation learning model to address the problem of insufficient data by fusing triadic information of technical terms (including lexical phrases, text and graph information) to learn semantic representations of subjects and objects. The model utilizes word representation learning methods and GNN networks modeling sentence information, and introduces long short-term memory networks to learn contextual information of different sentences to achieve sentence semantic modeling. The citation of this method has achieved better results in solving the problem of learning unstructured medical professional vocabulary with multiple meanings, and also helps to solve the problem of difficult learning of medical professional samples.
The literature [63] advanced the Connected Subgraph Reasoner (CSR), which employs Hunter’s [64] method of elimination induction to perform a few-shot prediction task directly by connecting two entities of a triad in a subgraph of knowledge graph without the need for processes such as meta-learning. Explicitly modeling shared connectivity subgraphs between support and query triads, the model first contextualizes the triads in KG, finds the shared hypotheses through the connectivity subgraphs, and finally uses the evidence suggestion module to test whether there is evidence close enough to the hypotheses.
As the GNN model is learned further, the Over-Smoothing [65, 66] problem of excessive similarity of neighboring nodes arises. GAT can extend the feature representation by multi-headed attention, but does not consider the relationship between neighbors at the same level. To adapt to the few-shot learning scenario, the RGCN-based relational prediction model is modified by using attention mechanism. The attention mechanism can dynamically adjust the model’s focus on different inputs, allowing for better utilization of limited training samples.
Wang et al. [67] advanced an RGCN model based on relational graph convolutional networks. The model includes an intra-layer neighborhood attention module that focuses on the most relevant neighborhood entity nodes. The inter-layer memory attention module is also used to maintain the memory of the original RGCN layers. Both modules serve to enhance the effect of the model in FKGC and eventually achieve the effect of weakening the transition smoothing phenomenon.
Summary
This chapter introduces three aspects of meta-learning-based, metric-based and graph neural network-based knowledge graph completion methods for few-shot. The meta-learning-based approach can empower the model to learn and there is also ample scope for further development. The metric-based approach can learn to calculate the metric function and facilitate the formulaic representation. However, the model’s accuracy may be reduced when faced with few-shot scenarios, which are characterized by limited training samples. The graphical neural network-based approach uses graphical neural networks to improve the expressiveness of the model, but it will have higher computational complexity. In Table 1, we summarize the above models from different methods and compare different methods of existing FKGC from model partitioning and model features to show the unique characteristics of each model.
Classification of FKGC methods
Classification of FKGC methods
In this section, we introduce a development direction of FKGC technique, i.e., its application in the field of temporal knowledge graphs. Temporal knowledge graphs (TKGs) [68–71] describes the change of facts in temporal order. Unlike static knowledge graphs, TKGs represents the graph information at that time by adding timestamped extended triples to quadruples [72], e.g., (Joseph Biden, President, United States, January 20, 2021), which is a temporal knowledge graph quadruple that represents the relationship between the entity “Biden” and “United States” with “President” on January 20, 2021. HyTE [73] and DE-SimplE [74] are two models for TKGC. HyTE embeds temporal information into the entity-relation space and utilizes the TransE model as an interaction model to calculate the credibility scores of facts. DE-SimplE extends SimplE by exploring ephemeral functions to model entity embeddings at different timestamps. Both approaches explore how to improve the performance of TKGC by embedding temporal information into knowledge graph representation. However, obtaining large-scale TKGs is difficult due to the cost of labeling and the time-varying nature of labels. Therefore, methods for automatic prediction and inference of missing facts in few-shot temporal knowledge graphs are gradually becoming the direction of more researchers’ attention [75–78].
Several FKGC models are only applicable to static KGs, and cannot be effectively used for TKGs due to the lack of consideration for the temporal dimension of entities and relations. These models employ encoders that fail to embed temporal relation-ships between entities and disregard the sharing of information among few-shot entities, resulting in negative effects from misinformation. To address these challenges, Bai et al. [79] have advanced a novel model named FTMF. The model utilizes a self-attentive mechanism to combine temporal information within a neighborhood for entity representation, a recurrent automatic aggregation network to improve interaction among reference entities, and an error-tolerance mechanism to mitigate the impact of erroneous information in the dataset. Finally, a similarity network is used to score the similarity between entities. Therefore, FTMF model can accomplish KGC in the few-shot temporal knowledge graph context and enhance the completion performance of the FKGC.
Wang et al. [80] advanced the Meta-Temporal Knowledge Graph inference (MetaTKGR) framework. MetaTKGR is divided into a temporal-aware representation for representing new entities, which uses a temporal encoder to represent the new entities, and model training using meta-temporal inference. The temporal encoder uses a time-constrained width-first search algorithm to sample multi-hop neighbors and then aggregates information directly from the sampled neighbors in a focused manner to obtain a temporal-aware representation of the new entity. Meta-Temporal inference uses a two-layer optimization (internal and external) to learn the optimal sampling and aggregation parameters, and the learned parameters are able to adapt to the new entity and maintain temporal robustness.
Lin et al. [81] proposed MetaRT method for the task of linkage prediction of few-shot TKGs. MetaRT method operates by extracting meta-information of specific relations and conducting fast updates, enabling the model to swiftly acquire the most critical information in the TKG and achieve autonomous learning. MetaRT consists of three modules: a relation meta-learner, relationship meta-acquisition in entities and temporal information acquisition in the support set. The TKG embedding learner computes the truth values of the quartets generated by the subject entity, object entity, temporal and relationship meta-learner and uses the score function for embedding learning. The gradient meta-learner, which acquires the gradient meta from the scores computed by the TKG embedding learner and uses the loss function for learning. The relational elements are updated quickly by gradient elements before they are transferred to the query set.
Previous methods of temporal knowledge graph completion do not take into consideration the gain effect of temporal information in knowledge graph. For this rea-son, a model named FS-Path is proposed in the literature [82]. FS-Path is a model applicable to inference of temporal knowledge graph based on few-shot relations, which combines the features of temporal information and relations with few training samples and proposes TKG inference strategy based on few-shot relations. The strategy explicitly completes the inference task by multi-hop path inference, which enhances the interpretability of the inference process. Meanwhile, introduces temporal information to extend the traditional ternary representation to a quadratic representation with temporal information, which gains inference from high-dimensional in-formation and improves the accuracy of inference results. This model utilizes meta-learning to learn meta-parameters from high-frequency relations, allowing it to adapt to few-shot relations and significantly improve its generalization ability. FS-Path can infer in few-shot knowledge graphs to perform relational inference efficiently, thus achieving better results.
Experimental comparison
As FKGC techniques continue to evolve, researchers have developed different evaluation benchmarks, which are typically created using commonly used FKGC datasets. NELL-One and Wiki-One are two new datasets that have been proposed for use in few-shot knowledge graph completion tasks in recent studies. In addition to public datasets, there are some existing models designed for specific few-shot KG datasets. In this section, we will introduce several datasets and evaluation metrics commonly used for FKGC.
Dataset parameters
Dataset parameters
NELL-One: The dataset is based on the NELL dataset, a large-scale knowledge graph construction system developed by Carnegie Mellon University. It is a system that continuously collects structured knowledge by reading web pages. By taking the latest dumps and removing those reverse relations. Also, relations with less than 500 but more than 50 triples are selected as a few-shot task. In sample partitioning, 51/5/11 relations are used for training/validation/testing division.
Wiki-One: The dataset is based on the Wiki dataset, a large-scale corpus constructed by Wikipedia, which contains various types of data such as article text, links, categories, images, and citations from Wikipedia. Similar to the construction method of the NELL-One dataset, the training/validation/testing partitioning ratio is set as 133 : 16 : 34 in the sample partitioning.
FB15K-237: The dataset published by Facebook AI Research, is a subset of the FB15K dataset. The dataset, covers 237 relationship types. the goal of FB15K-237 is to improve the difficulty of knowledge graph inference tasks.
NELL-995: It is a knowledge graph dataset obtained by automatic learning. This dataset covers many types of entities and relationships such as people, organizations, places, and things, and can be used for research and applications in the fields of natural language processing and knowledge graph construction. Since NELL-995 is knowledge obtained by automatic learning, its data quality and completeness may not be as good as manually constructed knowledge graphs. However, since the data volume of NELL-995 is relatively small, it can be used for some small-scale knowledge graph construction and relationship extraction tasks, or as a completion dataset to other knowledge graphs.
Evaluation metrics
1) MRR (Mean reciprocal rank)
This indicator is the average inverse ranking of the forecast results, the larger the indicator, the higher the final ranking. Meanwhile, the larger the MRR value, the better the forecast results. The calculation of this indicator is shown in the Equation (5):
where |T| is the sum of the number of all triples, and rankn denotes the predicted ranking of the links in triples.
2) Hits@n
Hits@n measures the proportion of correct entities that the model contains in the first n returned results, so a larger value indicates that the greater the number of correct entities in the first n results, the better the predicted result. In general, Hits@n is generally taken as Hits@1, Hits@3, Hits@5, and Hits@10 as the metric. The calculation of this indicator is shown in the Equation (6):
Where II is indicator function, holds a true value if the function takes on a value of 1, and a false value otherwise, represented as 0.
After describing the datasets and evaluation metrics commonly used for the FKGC, we compare the experimental results for the existing FKGC models described in Section 2 to summarize and evaluate the model effects. For a fair comparison, the results of the models using experiments conducted in the same dataset NELL-One, while ensuring a fixed embedding dimension of 100, were chosen for the comparison of the four-evaluation metrics MRR, Hits@10, Hits@5, and Hits@1 in the 5-shot and 1-shot scenarios. Table 3 reports the performance of the above models in the NELL-One dataset, where the experimental data of the models are mainly from the literature [39, 55].
Comparison of effectiveness of FKGC
Comparison of effectiveness of FKGC
As shown in the table, it is clear that in the NELL-One dataset, the majority of current FKGC models exhibit superior performance compared to the original KGC model indicating that FKGC method can effectively predict few-shot relationships. Although TransH is the best-performing model in traditional KGC, it is not suitable for FKGC tasks since it requires a significant number of examples for training. Among all the models compared in the table, Figs. 2 and 3 demonstrate that the GANA model has achieved the most favorable outcomes in almost all evaluation metrics, owing to its utilization of valuable neighborhood information and the filtration of neighbor noise information. The few-shot relational representation is updated through MtransH, and the model can be generalized to complex relational situations.
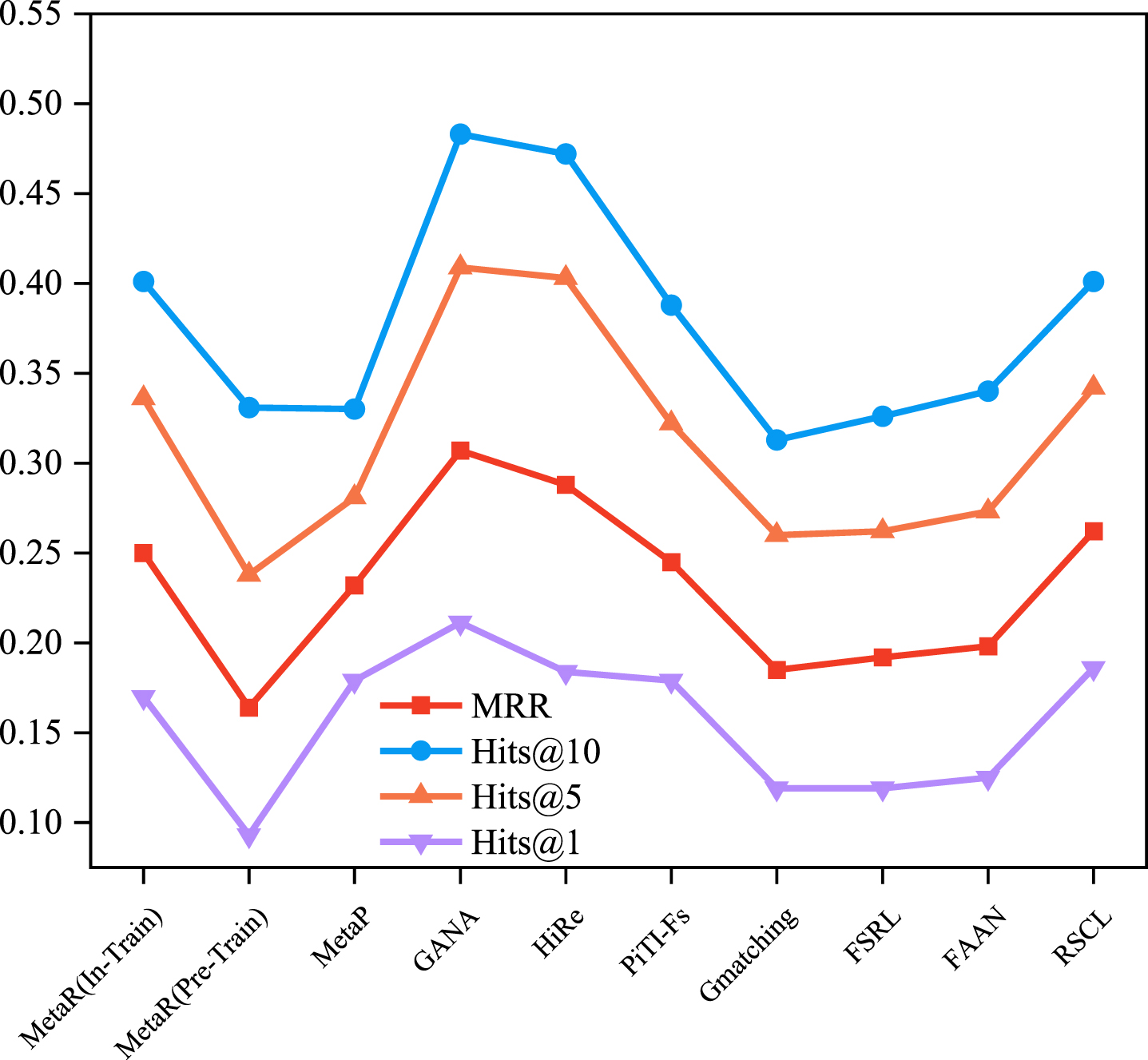
Experimental comparison of few-shot models under 1-shot.
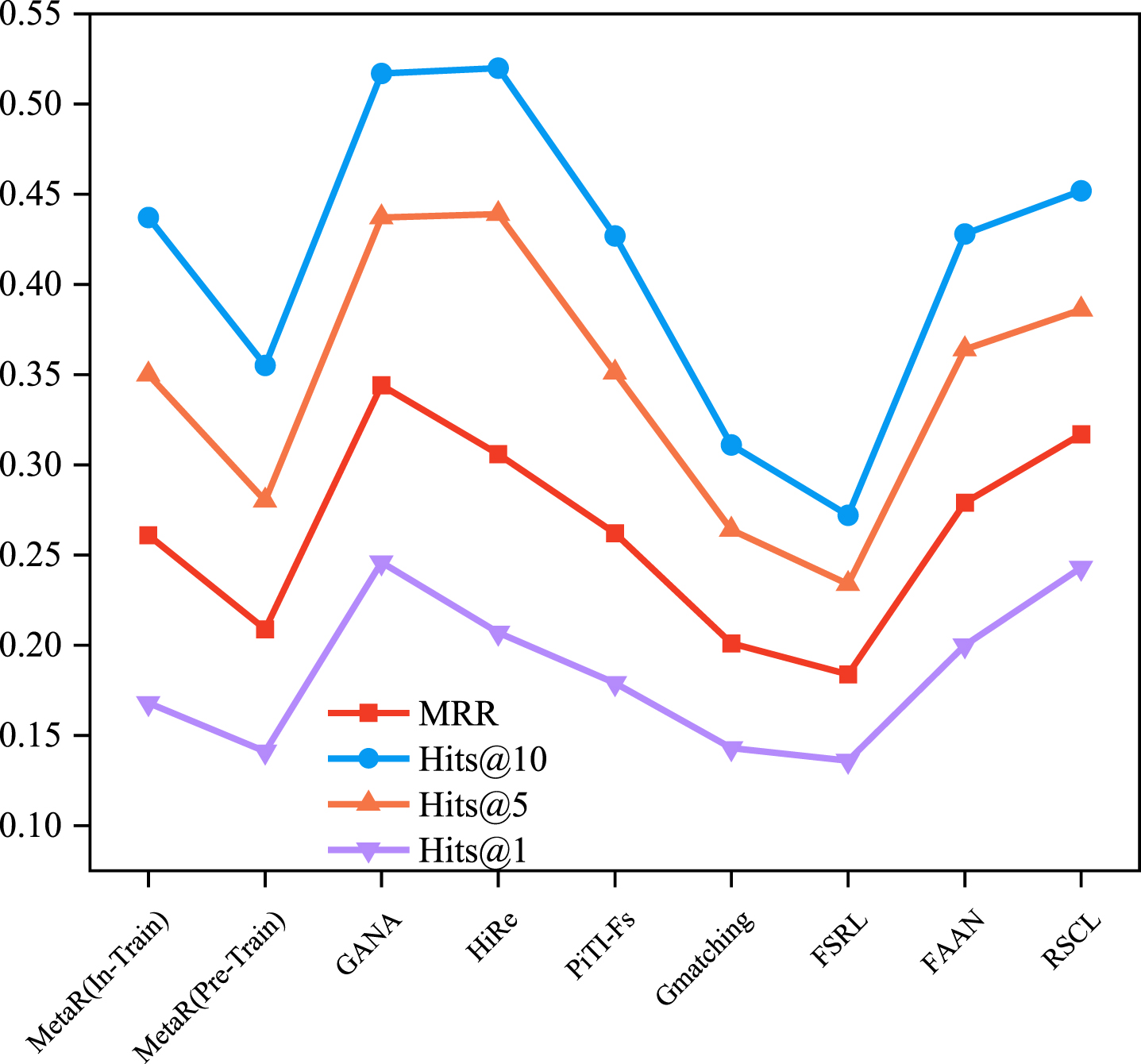
Experimental comparison of few-shot models under 5-shot.
With the development of FKGC, researchers have proposed different completion methods from various aspects, but a number of challenges in FKGC still need to be addressed and coped with. The following discusses of the specific problems for FKGC are as follows: Graph sparsity problem: In the real world, KGs are usually very sparse, making it difficult to collect enough positive and negative samples to train models. Therefore, how to perform efficient FKGC in sparse KGs is still a problem to be explored. Weak relationship problem: Some entities have very weak relationships with each other, which may be only one few-shot. In this case, it is difficult to work effectively with few-shot knowledge graph completion. Therefore, how to deal with such weak relationships and integrate them into the model still needs more in-depth research. Cross-modal relationship problem: In KGs, there are not only relationships between entities and entities, but also relationships between entities and other modal data such as text and images may exist. How to effectively combine these data of different modalities for FKGC is a problem to be studied in depth. Adversarial attack problem: In real world, KGs may be subject to adversarial attacks, such as corrupting the correctness of KGs by adding wrong knowledge or using wrong inference mechanisms, leading to misleading completion results. There-fore, how to prevent adversarial attacks with few-shot and improve the robustness of the model is also a direction to be explored. Interpretability problem: The few-shot knowledge graph completion model usually requires inference on small amount of data; therefore, the interpretability of the model is very important to help users understand the inference process and results of the model. Therefore, further research is still needed on how to improve the interpretability of the model.
To overcome the challenges in FKGC, an effective method is to introduce a hybrid model, which can address the limitations of using a single model for completion. In future studies, attempts can be made to improve the performance of FKGC by exploiting the advantages of different methods and techniques through hybrid models.
Conclusion
The progress of artificial intelligence has contributed to the development of KG. However, the phenomenon of few-shot learning is becoming more and more apparent in KG. When it comes to acquiring difficult data in specific domains, the FKGC approach is less efficient. Therefore, exploring the FKGC task holds great practical significance.
In this paper, we start by addressing the problem of FKGC and introduce the concept and characteristics of FKGC. We classify the existing FKGC models into three categories: Meta-learning-based, Metric-based, and Graph Neural Network-based completion methods, according to their usage methods. We also analyze the structural information of their usage models and their advantages in detail. Additionally, we introduce a specific domain of FKGC, the few-shot temporal knowledge graph completion. Finally, we summarize the experimental results of different models and point out the challenges of FKGC. By summarizing the current representative research work and development trend, we hope to provide valuable reference information for future scholars engaged in the field of few-shot knowledge graph complementation and promote the future development of the field of few-shot knowledge graph complementation.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China (U1804263, 62272163), the Science and Technology Project of Henan Province (222102210096, 222102210027), the Doctoral research foundation of Zhengzhou University of Light Industry (2020BSJJ067), the Natural Science Foundation of Henan Province of China (202300410508, 222300420371), the Key Research Project of Higher Education of Henan Province (22A520047), the key foundation of Science and Technology Development of Henan Province (142102210081), the Songshan Laboratory Pre-research Project (YYJC012022023), the Henan Province Science Foundation (232300420150, 222300420230), and the Open Foundation of Henan Key Laboratory of Cyberspace Situation Awareness (HNTS2022005).