
Abstract
Disease diagnosis is very important in the medical field. It is essential to diagnose chronic diseases such as diabetes, heart disease, cancer, and kidney diseases in the early stage. In recent times, ensembled-based approaches giving effective predictive performance than individual classifiers and gained attention in assisting doctors with early diagnosis. But one of the challenges in these approaches is dealing with class-imbalanced data and improper configuration of ensemble classifiers with optimized parameters. In this paper, a novel 3-level stacking approach with ADASYN oversampling technique with PSO Optimized SVM meta-model (Stacked-ADASYN-PSO) is proposed. Our proposed Stacked-ADASYN-PSO model uses base models such as Logistic regression(LR), K-Nearest neighbor (KNN), Support Vector Machine (SVM), Decision Tree (DT), and Multi-Layer Perceptron (MLP) in layer-0. In layer-1 three meta classifiers namely LR, KNN, and Bagging DT are used. In layer-2 PSO optimized SVM used as the final meta-model to combine the previous layer predictions. To evaluate the robustness of the proposed model It is tested on five benchmark disease datasets from the UCI machine learning repository. These results are compared with state-of-the-art ensemble models and non-ensemble models. Results demonstrated that the proposed model performance is superior in terms of AUC, accuracy, specificity, and precision. We have performed statistical analysis using paired T-tests with a 95% confidence level and our proposed stacking model is significantly differs when compared to base classifiers.
Introduction
Disease diagnosis is a process by which a doctor determines whether a patient has a disease based on the patient’s health condition and to determine the type of disease the patient has. In an actual disease diagnosis environment especially when there is a huge number of patients and the amount of data to be processed is too large, it may be troublesome for doctors to handle in a short period. In disease diagnosis to improve the predictive performance, we ensure that data should be preprocessed and processed with outliers, missing values, and data scaling. Various preprocessing techniques such as Inter Quartile Range (IQR) are used to assess the variability where most of your values lie. Most of the disease datasets are class-imbalanced, and classification results are biased towards the majority class. There is much attention to dealing with class imbalanced data for effective disease diagnosis. In the literature, there are various oversampling techniques are already used in disease diagnosis such as Synthetic Minority Over-Sampling Technique (SMOTE), Borderline Synthetic Minority Over-Sampling Technique (BSMOTE), Adaptive Synthetic Minority Over-Sampling Technique (ADASYN), Random Over-sampling Technique (ROS) [1]. SMOTE creates new artificial instances utilizing knowledge about the neighbors that surround each sample of the minority class [2]. Whereas in other approaches oversampled instances are arbitrarily chosen through duplication. To determine the k closest neighbors of a given minority data instance from the neighborhood, SMOTE uses the K-Nearest Neighbour (K-NN) technique. BSMOTE steps are similar to SMOTE to produce artificial data [3]. In order to solve the issue of minority instance misclassification (and to improve the detection rate of minority instances), it also reinforces the border by taking borderline minority class instances into account while producing synthetic data.ADASYN creates more minority samples near the decision border, helping to develop the classification boundary [4]. Based on the percentage of majority samples in the KNN sets of the minority class, this technique will calculate the number of synthesized minority samples.ROS replicates minority class instances and inserts them into the same class to provide a balanced training dataset, which is the oldest oversampling technique [5].
Various ensembled-based approaches have already been used to improve the predictive performance of models such as bagging [6], boosting, and stacking [7]. In bagging [6] bootstrapped approach is used for homogeneous classifiers to maintain diversity and reduce bias. Boosting [8] is an ensemble modeling technique that attempts to build a strong classifier from the pool of weak classifiers. It is done by building a model by using weak models in series. While bagging and boosting used homogeneous weak learners for ensemble, stacking often considers heterogeneous weak learners, learns them in parallel, and combines them by training a meta-learner to output a prediction based on the different weak learner’s predictions [9].
Hyper-parameter optimization will improve the predictive performance of the individual classifier [10]. In the literature, various search techniques are used for hyperparameter optimization such as grid search, random search, etc [11]. In the stacked ensemble parameter optimization of the base model as well as the meta-model is also important otherwise, it may impact the performance of the ensemble model [10]. Various meta-heuristic algorithms such as evolutionary-based, nature-inspired algorithms are used for hyperparameter optimization [12]. Particle swarm optimization (PSO) is an algorithm for swarm intelligence based on stochastic and population-based adaptive optimization inspired by the social behavior of bird flocks and fish swarms [13].
The best configuration of the stacking model will give an effective predictive performance. so selecting optimal base models and meta-models are important in the stacking approach [14].
Following is the arrangement of the remaining sections. A literature review is in the second section, and the Background of the proposed work is in the third section. The proposed work is covered in Section 4, results are covered in Section 5, and the Discussion is in Section 5 followed by a conclusion.
Motivation
In disease diagnosis, most of the datasets are class imbalanced. ML models are biased toward the majority of samples in class imbalanced data. To address this problem various oversampling approaches are used. Directly applying oversampling techniques does not guarantee the improvement of performance due to noise while generating synthetic data. To overcome this we combined oversampling and ensemble learning to improve the predictive performance. But in the ensemble approach, most of the researchers attempted the optimization of base classifiers with limited research on the optimization of meta-classifiers.In the stacking approach if we are increasing the number of layers there should be an effective meta-model that can combine the predictions of the previous layers. we have optimized base classifiers with grid search and the last level meta-model with Particle swarm optimization(PSO) with a novel fitness function. Research questions are to be addressed with the proposed approach.
RQ 1. Can we improve predictive performance with oversampling and ensemble approach?
RQ 2. Extended stacking approach(Multi-level) is better in prediction than the basic stacking approach?
RQ 3. Does final Meta-model parameter optimization make any improvement in overall performance?
RQ 4. How does the proposed model have more significance than other base-level models statistically?
Contributions
The following contributions are made to improve the performance. Various oversampling techniques such as SMOTE, BSMOTE, ADASYN, and ROS used for class imbalance and chosen suitable oversampling techniques for the proposed model. Optimized parameters of base classifiers and level 1 meta-model parameters with grid search and level-2 meta-model parameters with Particle swarm Optimization(PSO). Proposed hybrid model consists of ADASYN oversampling and a 3-level stacking approach with a PSO-optimized SVM meta-model. Finally, statistical analysis with paired T-test was performed to test the significance of the proposed model with base-level classifiers.
Literature review
Kalagotla et al. proposed a novel stacking technique on PID and compared the AdaBoost and stacking revealing that the accuracy of stacking a heterogeneous ensemble 78.2% outperforms the AdaBoost a homogeneous ensemble 76.54% [15]. D. Joshi et al. used the R tool on the PID dataset to predict T2DM. They applied DT and LR classifiers on PID and reported 78.26% and 74.48% accuracies respectively [16].
S. Arukonda et al. [17] proposed a disease diagnosis ensemble model. This study used four diversity-based classifiers on five data bags and optimized classifiers from a pool of 20 diverse learners using GA. This study used PID, SHD, CKD, and WBC disease datasets used to test the robustness of the models. Accuracies are 90.91%, 96.05%, 97.56%, and 98.08% respective to PID, CKD, SHD, and WBC datasets.
Singh et al.proposed a stacking approach on PID and evaluated the predictive performance of various ensemble approaches such as Bagging (L-SVM), Bagging (RBF-SVM), Bagging (Poly-SVM), Bagging (REP), Bagging (4.5), Ada boost(DS), Ada boost (C4.5), Random Subspace Method (RSM), Random Forest, Majority Voting (MV), Stacking, Stacking (LR), Stacking (NSGA-II) the proposed system achieve the highest accuracy of 83.8%, the sensitivity of 96.1%, specificity of 79.9%, f-measure of 88.5% and area under ROC curve of 85.9% [18].
S.Arkonda et al. proposed a model for Lung cancer is one of the most common cancer-related disorders with a high mortality rate, which is mostly owing to the late detection of malignancy [19].
Mohapatra et al. proposed a two-level stacking approach for detecting heart irregularities and predicting Cardiovascular disease and pre-processed with outlier detection and the stacking of classifiers for predicting heart diseases [20]. In this study, various classifiers were used to take advantage of their differences in strengths. Using MLP as the meta-learner, Obtained results with 92% accuracy. The proposed stacked classifier outperformed the traditional machine learning classifiers better in terms of overall parameter comparison with a precision of 92.6%, a sensitivity of 92.6%, and a specificity of 91%.
Sampath et al. proposed a model for cancer disease. Cancer is still a fatal illness with numerous subtypes, posing numerous hurdles in biomedical research [21].
Tiwari et al. proposed an Ensemble framework for cardiovascular disease prediction proposed framework consist of Stacking Based Ensemble learning which adds diversity to the classifier experimented on IEEE Data Port proposed stacked ensemble attained an accuracy of 92.34% [9]. Obaidat et al. proposed a stacking ensemble model for predicting heart attacks and combines a group of three base-level classifiers such as Naive Bayes, Random Forest, and Extreme Gradient Boosting (XGBoost) in the predictive model [22].
Background
Classifier combination for ensembles
The selection of classifiers and a combination of those for the best ensemble is a very tedious task [23]. Researchers and data analysts use various machine learning algorithms and choose the best algorithm according to the performance measures [24]. To make the best predictions, a single algorithm may be unable to capture the entire underlying structure of the data [25]. This is where the successful integration of numerous models gathered into a single meta-model has been discovered [25]. Bagging creates numerous versions of predictors and aggregates them by voting on each version and taking the average of them [6]. Bagging meta-estimator and random forest are two algorithms that use the bagging approach [6]. Boosting works similarly to bagging in that it combines numerous low-performing base learners in an adaptive manner [8]. Bagging is beneficial for data sets with noisy values, according to experimental results. Stacking is the third approach. It uses the output of selected classifiers on the training data to predict response values using another learning algorithm. The stacking generalization architecture typically consists of two layers. First, in layer 0, there is base classification, which uses basic classifiers to build the ensemble by training the dataset. It generates the second layer’s input. Second, in layer 1, the meta-classification integrates the outputs of layer 3 using a meta-classifier to build the final predictive model.
Hyperparameter optimization of classifiers
Best hyperparameters will give a better performance so optimization of hyperparameters is a very crucial step in machine learning [26]. Hyperparameter optimization is the process of selecting the right parameter values for classifiers in order to build the best prediction model. For optimizing hyperparameters, there are numerous methods available [10], including (1) grid search, (2) random search, (3) simulated annealing algorithm, (4) bayesian optimization, (5) genetic algorithm, and (6) particle swarm optimization. Grid search, random research, and Bayesian optimization are the most prevalent hyperparameter optimization methodologies [26].
The Grid search is the most basic way. For each possible combination of all hyperparameter settings, a prediction model will be built, and each model will be assessed to see which architecture produces the best results. Random search provides better models than grid search because it searches a larger, less promising configuration space. The following method, also known as the surrogate method, keeps track of previous assessment outcomes that are utilized to form a probabilistic model and converts the hyperparameters to a probability of a score on the objective function that it employs. Because they investigate the best set of hyperparameters to evaluate based on previous trials, it may be able to find a better set of hyperparameters in less time [27].
A genetic algorithm is a meta heuristic algorithm that is based on the evolutionary concept [28]. It looks for individuals that have the best chance of survival. The abilities of one generation are passed on to the next. The next generation inherits that trait from their parents and matures into better people as a result. The worst of humanity will gradually fade away. This concept will be utilized to optimize classifier hyperparameters. The population, chromosomes, and genes will be programmed to look for space, hyperparameters, and values. The fitness value will calculate and evaluate performance. On chromosomes, selection, cross-over, and mutation will be utilized to create a new generation and assess performance. These steps will be repeated until the best hyperparameters are found. Particle swarm optimization is another evolutionary optimization technique. Particle swarm optimization is less difficult to implement than the Genetic approach. It works by allowing a group of particles to move semi-randomly around the search space [13].
Outlier Removal using IQR
IQR is a data prepossessing used to remove outliers. By dividing a rank-ordered dataset into four equal portions, or quartiles, it calculates dispersion [29]. The middle values in the first and second halves of the rank-ordered dataset, respectively, are designated by the letters Q1, Q2, and Q3, while the median value for the entire set is denoted by Q2. Then, Q3-Q1 is equal to IQR. Here, data instances outside of the normal range (Q1-(1.5*IQR) or Q3+(1.5*IQR) are considered outliers.
Particle Swarm Optimization (PSO)
PSO was developed from the study of bird migration and foraging behavior by Eberhart and Kennedy near the end of the twentieth century [30]. Each member of the group has a unique perceptual capacity, which allows them to recognize the best local and global individual locations and change their next behavior accordingly. Individuals are treated as particles in a multi-dimensional search space in the method, with each particle representing a potential solution to the optimization issue. The particle characteristics are described using three factors: location, velocity, and fitness value. The fitness function determines the fitness value. The particle modifies its traveling direction and distance independently based on the ideal global fitness value, iterative arriving at the best option. we are using velocity and position updates for every iteration based on that it computes the personal best and global best and up to termination condition met or no of iterations. It takes a group of candidate solutions and uses a position-velocity updating approach to try to select the optimal one. Uses a star topology, in which each particle is drawn to the best-performing particle. The position update can be defined as:
Here, c1 and c2 are the cognitive and social parameters respectively. They choose between two options for particle behavior: (1) pursue its own best or (2) follow the swarm’s global best position. Overall, this determines whether the swarm is explorative or exploitative. In addition, the swarm’s inertia is controlled by the parameter w.
SVM is a popular statistical-based supervised machine learning technique. It is used for regression and classification tasks [31]. It was developed in 1995 by Cortes and Vapnik to improve class separation and reduce prediction error. SVM is well known for working with both linear and non-linear data and is highly good at overcoming dimensionality-related problems [32]. It works well with short datasets and high-dimensional feature spaces in particular. SVM divides training samples into distinct classes when dealing with linear data by locating a hyperplane with the greatest margin. Additionally, it establishes the maximum separation between the support vectors or nearest points to the margin edge, and the hyperplane with n-1 dimensions [33]. The mathematical formula for maximizing the margin is represented by equation (1), which signifies the weight vector, the input vector, and the bias [34]. Using some kernel functions and the kernel trick, SVM uses a kernel-based approach to cope with non-linear data, locating the optimum hyperplane to linearly segregate data [35]. The list of Kernel functions that were looked through in this study to identify the best is shown below [33]. The linear kernel function is shown in equation (2), where c is a constant.
K-Nearest Neighbor (K-NN)
KNN is a non-parametric supervised machine learning technique. It was created in the early 1950s and later expanded by Thomas Cover [36]. As it uses the entire dataset to categorize the unlabeled data points by assigning them to the closest class based on the distance measurement, K-NN is regarded as a lazy learner technique. The distances that were looked for in this study to determine the best outcomes are listed below. The formulas for computing the Euclidean distance, Minkowski distance, and Manhattan distance, respectively, are represented by equations (6), (7), and (8), where k stands for the total number of neighbors and p is any real value [37]. Euclidean distance: K-NN begins by scouring the whole training dataset in search of (K) neighbors that have the shortest path between the target point and the data points. The new data is then classified using the neighborhood’s data points’ majority voting results.
Decision Tree (DT)
DT is a popular supervised machine learning approach for both classification and regression problems. Although the concept of a DT has been around since the late 1950s, it only really gained traction in 1986 when Quinlan put up the idea of trees with numerous responses [38]. It is renowned for having a structure like a tree that is simple to understand when visualized as a tree. Leaf nodes and internal nodes make up DT. The leaf nodes denote the resultant class, but the internal nodes signify a test over an attribute and have numerous branches reflecting the test outcome. The best quality features are selected using a hierarchical or statistical approach, and DT is built using a recursive divide-and-conquer strategy [39].
Multi-layer perceptron
MLP is a feed-forward network with gradient descent as a backpropagation algorithm. It reduces loss function and maximizes performance. Unlike perceptron, MLP has more than one layer. The input layer just translates the input whereas the hidden and output layer computes the weighted sum of inputs and their associated weights plus the bias of that neuron [40].
Bagging is an ensemble approach that is introduced by Breiman in 1996 [6]. It employs a bootstrapping technique to create a diverse subset of training datasets as it lessens the variance. Then, these subsets are trained parallel through multiple weak learners. Afterward, the outcome of each learner is aggregated using soft or hard voting depending on the task type.
Stacking
Stacking is another ensemble framework, where a new classifier combines a number of distinct predictions from base learners to classify the unseen sample. It was first presented by Wolpert in 1992 to completely minimize bias and variance, which increases predictive accuracy [7]. There are two layers in the stacking structure [41]. The first layer consists of many base learners, while the second layer acts like a combiner and meta-learner. Basic stacking in Fig. 1 and extended (3-level) stacking in Fig. 3 are shown.

stacking ensemble model.
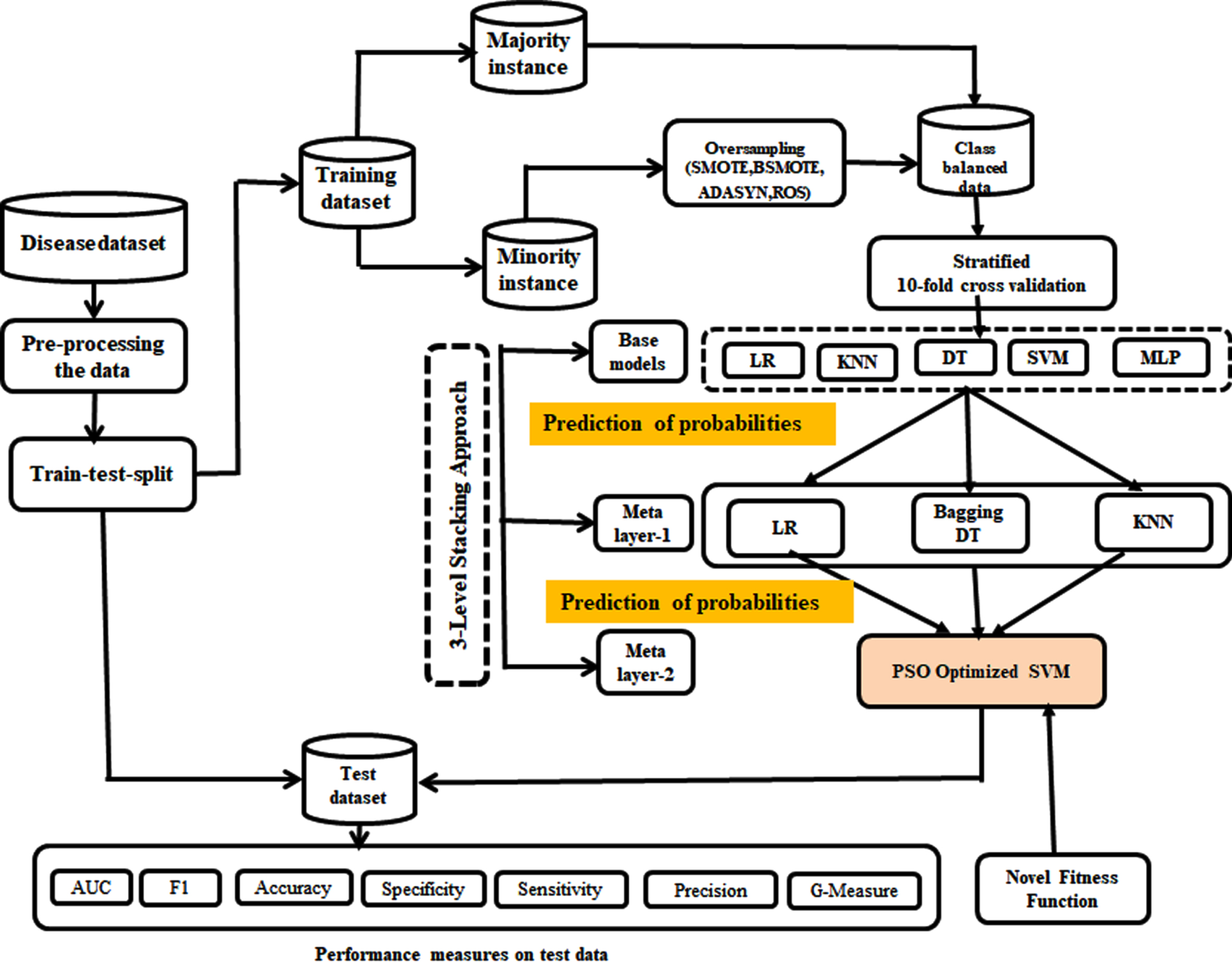
proposed model.

3-level stacking ensemble.
In our proposed work we have performed preprocessing of the dataset and removed outliers, missing values, and scaled the data. model selection using 10-FCV. Proposed hybrid model consists of ADASYN oversampling and a 3-level stacking approach with a PSO-optimized SVM meta-model. designed a three-layer stacking framework with KNN, DT, SVM, MLP, and LR in layer-0, Bagged DT, KNN, and LR in layer-1, and optimized SVM in layer-2. optimized SVM hyperparameters using PSO with novel fitness function. Finally, statistical analysis with paired T-test was performed to test the significance of the proposed model with base-level classifiers.
In proposed model is shown in Fig. 2. The 3-level proposed model is described in the section.
Initially data set will be pre-processed using IQR. Then, the dataset further experiments for best oversampling technique for class balance.
Architecture of the proposed Ensemble
An extended version of the two-layer stacking ensemble has been proposed to investigate whether stacking increases prediction model accuracy. The proposed stacked generalization is made up of three layers: (1) base classification, (2) meta classification 1, and (3) meta classification 2. To obtain the layer 2 meta-models, the proposed stacking classifier utilized five (5) base classifiers, all of which were trained using three (3) selected meta-classifiers. The three (3) meta-models formed by each meta-classifier were transmitted to the next layer, which produced the final prediction model with a single meta-classifier.
For layer 0 base classification, the proposed extended stacking classifier employs the LR, KNN, DT, SVM, and MLP algorithms. Because these ML models were chosen using 10-FCV.
Individual classifiers create prediction models with varying degrees of accuracy. Layer 0’s output prediction models were used as layer 1’s inputs.
Layer 1 meta-classifiers include LR, KNN, and bagged DT classifiers. The choice of a meta-classifier should be based on the prediction job, and as of this writing, the meta-learners have opted to produce the layer 1 output [42]. SVM was used as the proposed procedure’s layer 2 meta-classifier. The selection of distinct algorithms is motivated by the fact that they take fundamentally varied approaches to model generation and focus on data in different ways to make a meaningful contribution to ensemble implementation. On a single dataset S, different learning algorithms L1, L2,..., L N are applied to examples s k =(x k , y k ), i.e., pairs of feature vectors (x k ) and their classifications. (y k ). The first layer generates the basis classifiers C1, C2,..., and C N , where C k = L k . Meta-level classifiers are trained in the second layer to aggregate the outputs of base-level classifiers.
Stacking framework
A novel three-level stacking framework is proposed. In the proposed framework there are three levels. In Level 0, LR, KNN, DT, SVM, and MLP classifiers are used. In level 1, Bagging DT, KNN, and LR classifiers are used. In level 2, an optimized SVM is used. Here, the SVM parameters are optimized using PSO with a novel fitness function.
Multi-level stacking appraoch
To enhance the performance of the level 2 stacking approach (level-0 base models and level-1 meta models) extended the number of levels. In our proposed model total of 3 levels (level-0 base models,level-1 meta classifiers,level-2 meta classifiers).In our proposed approach we have selected the best-performing models from a pool of ML algorithms such as LR, KNN, DT, MLP, SVM, NB, and RC. From the pool NB and RC are not selected because the cross-validation score is less. The selected models are considered base models and have undergone for stacking approach. Stacking performance may degrade if we will not do a proper configuration of ensemble classifiers. To avoid overfitting we have used 10-FCV to generate predictions of base models. All base models’ probabilistic outcomes and original class labels become auxiliary datasets for training the meta-classifiers of layer 1. In a similar way meta classifiers layer-1 will use 10-FCV and generates probabilistic outcomes here one more auxiliary dataset will generate and used for training of level-2 meta classifier. Here level-1 and level-2 depending on previous layers will predict in similar ways but level-1 and level-2 classifiers are completely different. Here selected meta classifiers used in level-1 are LR, KNN, and bagging DT. Meta classifiers in level-1 will train with all base classifiers. Meta classifiers in level-2 will train based on the meta classifier’s level-1 predictions. so the last level meta classifier is used as SVM.SVM is so efficient non-linear algorithm that can classify samples so efficiently. Through evolutionary search, SVM parameters are optimized using particle swarm optimization.PSO is a bio-inspired optimal search algorithm. Unlike other optimization algorithms, it required only an objective function and few hyperparameters compared to GA.it is not dependent on the gradient or any differential form of the objective.
1: T ← Termination
2: P ← Position
3: V ← Velocity
4: f c ← fitness of the candidate
5: p best ← Personal best
6: g best ← global best
7: V new ← new velocity
8:
9: t ← 1
10: N p ← Swarmsize
11:
12: Intialize P and V randomly
13:
14: Evaluate fitness f using eq 5
15: Compute fitness of candidate
16:
17: p best = f c
18: p best = ppv
19:
20: if g best < f c
21: g best = f c
22:
23: update V using eq 1
24: update P using eq 2
25:
26: j <number of particles
27:
28: V new = V max
29:
30: V new = V min
31:
32:
SVM hyperparameter tuning using PSO
SVM is used as a binary classifier that is used to determine classes from diseased data. SVM with a kernel function is used to improve classification performance whenever data is not linearly separable. The proposed model uses non-linear SVM with Radial Basis Function (RBF) as kernel function which is given in Equation 3.
||y - y i || is the L2-norm.
There are two hyperparameters in Equations 3 and 4. To achieve enhanced SVM performance, we have to fine-tune kernel function parameters (γ) as well as a soft margin (c). We are proposing PSO for this purpose as PSO converges very fastly and quickly moves from exploration to exploitation than other bio-inspired approaches. The Algorithm 1 will describe how PSO is used for SVM hyperparameters tuning.
We have proposed a novel fitness function that optimizes SVM hyperparameters. The function is devised for imbalanced data by considering AUC, F1-score, and G-measure. For better SVM performance on imbalanced data, the fitness function needs to be maximized.
Experimental setup
The HP Compaq Intel(R) Core(TM) i7-1065G7 CPU and 8 GB RAM were used in this experiment. All the modules in the proposed methodology and results analysis is carried out using Python and the sklearn library. The HP Compaq Intel(R) Core(TM) i7-1065G7 CPU and 8 GB RAM were used in this experiment. All the modules in the proposed methodology and results analysis is carried out using Python and the sklearn library.
Datasets
Various bench-marked disease data sets are used to evaluate the performance of the proposed model from the UCI repository [43]. Those are Pima Indian Diabetes dataset (PID) Statlog Heart Data (SHD) Cleveland Heart Disease Data (CHD) Chronic Kidney Disease (CKD) Wisconsin Breast cancer (WBC)
and the description of datasets shown in Table 1.
Datasets used in this study
Datasets used in this study
All the disease datasets are processed before the construction of the proposed ensemble model. In the pre-processing following steps are carried replaced zero values with a median. checked numerical columns, binary columns with 2 values, and columns with more than 2 values. label encoding of binary columns. multi-value columns are duplicated. scaling numerical columns with a standard scalar. dropping original values merging scaled values for numerical columns. outlier removal with IQR
Outliers removal with IQR
Finally, IQR is applied to remove the outliers from the disease dataset. IQR is applied with two thresholds namely Q1 = 0.25 and Q3 = 0.90 where Q1 is a threshold used in quartile1 and Q3 is a threshold used in quartile3. Data samples whose values are below Q1 and above Q3 are considered as outliers. Once the outliers are identified these outliers are replaced by low - limt if sample value < Q1 else replaced with up - limt if sample value > Q3. The low - limt and up - limt are calculated using Equation 6.
To evaluate the performance of the proposed model various performance measures such as accuracy, sensitivity, specificity, G-measure, Precision, Recall, and F1-score are chosen. These measures are obtained from the confusion matrix which is given in Table 2. These measures are defined as follows:
Confusion matrix
Confusion matrix
Where, TP represents the disease positive class that the classifier has classified as disease positive, TN represents the disease negative class that the classifier has observed as disease negative, FP represents the disease negative class that the classifier has categorized as disease positive and FN represents the disease positive class that the classifier has classified as disease negative. The Receiver Operating Characteristic curve (ROC) is a graph that depicts the relationship between the TPR and FPR, indicating the TPR that we can expect for a certain trade-off with FPR. The Area Under the ROC curve (AUC) score, which means that the resulting score measures the model’s ability to properly predict the disease classes.
Further, to evaluate the performance of the proposed model Area Under ROC Curve (AUC). AUC is a proper measure when the dataset is imbalanced. A Receiver Operating Characteristic (ROC) curve is a graph showing the performance of a classification model at all classification thresholds. It plots TPR on the x-axis and FPR on the y-axis at different classification thresholds.
The above-pre-processed disease datasets Table 1 are partitioned into training datasets and test datasets and the confusion matrix for evaluation is shown in Table 2. There is plenty of ML-based classifiers but all the classifiers may not give a better predictive performance so for selecting classifiers we have used 10-FCV of LR, KNN, DT, SVM, MLP, NB, and RC.Out of those NB and RC classifiers are giving poor predictive performance and are not selected in most of the datasets. So we have removed NB and RC classifiers for further processing. Model selection is shown in Table 3. Class-imbalanced disease datasets will affect the classifier performance the training dataset is undergo various oversampling techniques such as SMOTE, BSMOTE, ADASYN, and ROS. This over-sampled training dataset is applied to various hyperparameters tuned classifiers. Tuned hyperparameters are shown in Table 4. These results of various oversampling techniques are shown in Table 5 and the best results are highlighted. From the table, it is observed that ADASYN outperforms the majority of the classifiers in the majority of disease datasets in terms of AUC measure which is the right measure for imbalanced datasets. Hence, we have considered ADASYN oversampling technique for further process.
Model selection with 10-FCV
Model selection with 10-FCV
Optimized hyperparameters values of selected classifiers
Performance comparison of various oversampling techniques over disease datasets w.r.t. AUC
After applying ADASYN oversampling technique on the disease dataset class labels are balanced. This balanced data set is partitioned into 10-Fold Cross Validation (10-FCV). Next, this balanced dataset is used for training of proposed stacking framework.
The proposed stacking framework consists of three layers. Using 10-FCV in each fold level one learner are trained with 9 folds and validated with the remaining one fold this process will repeat to all base models. Probabilistic predictions of the 10-fold cross-validation along with a true class label will form meta-features in the auxiliary dataset. All the base models LR, KNN, SVM, DT, and MLP in level 0 along with three meta-models LR, KNN, and bagged DT in level-1 trained using generated meta-features from the auxiliary dataset. similar to the base models meta-models will also generate probabilistic predictions using 10-fold cross-validation from a new auxiliary dataset generated in the previous layer. All the probabilistic features along with the original class label form a new auxiliary dataset for final meta-model training. using with new auxiliary dataset final meta-model will be trained. Once the meta-model training, all the base classifiers will undergo training with the entire training data. Final predictionS with text data. The last level meta-model combines the predictions and it will give the final outcome of diseased or not diseased. Here level-0 and level-1 parameters are optimized with grid search and level-2 optimized with SVM.
The PSO itself has some hyperparameters and these parameters are chosen per the construction coefficient method discussed in PSO Parameter Selection. Next, this fine-tuned PSO is applied to optimize the SVM parameters with a novel fitness function in Equation 5. The fine-tuned hyperparameters of both SVM and PSO are given in Table 12. The optimization of SVM parameters C and γ using PSO is given in algorithm 1.
The PSO has a cognitive constant (c1), social constant (c2), inertia weight (ω), swarm size, and maximum iterations for termination control parameters. The c1, c2, and w are fine-tuned as per the construction coefficient method [57]. This method helps to prevent explosion and also aids particles to converge to an optimal solution. The following formula and inequalities are used to fine-tune c1, c2, and ω values.
The testing dataset experiments on the proposed model and all base-level classifiers with respect to PID, SHD, CHD, CKD, and WBC are compared and the best results are highlighted it is shown in Table 6. Next, the proposed model is compared with meta models in layer 1 and layer 2, and results are shown in Table 8, and the best values are highlighted. The table shows that the proposed model performs better in terms of accuracy, AUC, F-Score, and precision. The proposed model with respect to five disease datasets is shown and the best results are highlighted in Table 7.
Performance of various classifiers on various data sets before applying the proposed model
Performance of various classifiers on various data sets before applying the proposed model
Proposed model performance on PID, SHD, Cleveland CKD and WBC datasets
Performance of with meta classifiers in layer-1 and layer-2 on various data sets
Optimized SVM parameters of various disease datasets shown in Table 9. Proposed model comparison of individual and stacking model analysis is shown in Table 12. Further, the proposed model is compared with the state-of-the-art ensemble models in the literature. These results are shown in Table 13 and the best results are highlighted. The table shows that the proposed model performs better than other state-of-the-art ensemble models in terms of Accuracy, AUC, and Specificity.
SVM parameter tuning using PSO
Statistical analysis of the performance of base class and proposed stacking model (p<0.05)
Statistical analysis of layer1 and layer2 stacking with base models (p<0.05)
Comparison of the proposed model with individual models
Comparison between SOTA ensemble models and proposed model on various datasets
Further, the proposed model is compared with the state-of-the-art no-ensemble models in the literature. These results are shown in Table 14 and the best results are highlighted. The table shows that the proposed model performs better than other state-of-the-art models in terms of Accuracy, AUC, and precision.
Comparison between SOTA non-models and proposed model on various datasets
Using 10-fold cross-validation, the statistical significance of the difference between individual base classifiers and the ensemble’s final prediction model is evaluated using a paired t-test technique with a significance level of 95Because the training and testing data sets do not overlap, the 1x10 t-test is used. Other procedures, such as ten repeats of ten-fold cross-validation (10x10) and five two-fold cross-validations (5x2), have numerous flaws. The test and training sets overlap in the 10x10 t-test, resulting in an underestimation of the algorithm’s true variance. Although the 5x2 t-test does not overlap the training and testing datasets, it is not sensitive to algorithm modifications. As a result, hypotheses testing is used to evaluate the stacking ensemble with the individual machine learning algorithms and the stacking ensemble final prediction with the intermediate prediction at level 2. By generating a null and alternative hypothesis, the statistical significance of the difference in prediction accuracy between the proposed staking ensemble and the individual algorithms is determined. The null hypothesis (H0) assumed that both models performed equally well, whereas the alternative hypothesis (H1) assumed that the models performed differently. The following are the hypotheses developed for comparing the proposed stacking ensemble and the LR algorithm: H0: There is no difference between the proposed stacking ensemble and the LR classifier in terms of performance.
In this manner, the null and alternative hypotheses for all algorithms for whole datasets were created, and they were tested using the Python-supported paired t-test module. Table 10 shows that data sets all had p-values less than 0.05. This suggests that the null hypothesis may be rejected, and statistically convincing evidence has been provided that LR and the proposed stacking ensemble perform differently.
The hypothesis test is repeated for the remaining pairs. The KNN and the proposed stacking model are then selected for the paired t-test. The results reveal that there is a substantial difference between the performance of the KNN algorithm and the novel stack with a 95% confidence level. When a single dataset does not match the criterion and the other’s p-values are less than the significant threshold value, the DT and stack pair work in the same way. As a result, this demonstrates that there is a discernible difference between the selected algorithm pair in terms of prediction accuracy. The p-values for SVM and the suggested stacking ensemble were examined, and all datasets were found to be significant at the 0.05 level. As a result, it is possible to deduce that the SVM and the stacking ensemble perform differently. To begin the t-test, the DT and stacking ensemble are coupled. The null hypothesis was rejected with 95% certainty, implying that these algorithms performed differently in prediction tasks. Finally, the p-value analysis was performed on the last two algorithm pairs. The null hypothesis was rejected with 95% confidence based on the findings of the paired t-test, and the alternative hypothesis was accepted by demonstrating that there is a substantial difference between their performances. Table 11 shows the statistical significance levels of the variations in prediction accuracy of meta-models produced in layers 1 and 2.
The primary goal of this study is to determine whether there is any utility in adding an additional layer to the proposed stacking ensemble. The significance level of accuracy between the layer 1 output and the layer 2 stack is obviously below the threshold (0.05) for all datasets. This indicates that there is a discernible difference between them, and hence the null hypothesis was rejected.
As a result, it may be stated that there is a difference in their forecast accuracies. The null hypothesis was rejected again, whereas the alternative hypothesis was accepted. The paired t-test significant values were less than the cutoff (0.05). As a result, the null hypothesis was rejected and the alternative hypothesis was accepted due to a significant difference between them.
Finally, the last two pairs were applied to the paired t-test, and the null hypothesis was rejected while the alternative hypothesis was accepted because the significant values for all of the test datasets were less than 0.05. These statistical numbers demonstrate that dividing the stack generalization into three layers can result in significant and obvious accurate prediction results for any machine learning application.
Discussion
The following research questions are addressed with the proposed stacking approach.
RQ1. Can we improve predictive performance with oversampling and ensemble approach?
In our approach, we have used a hybrid model with ADASYN oversampling and a stacked ensemble. It gives a significant performance with respect to various performance measures such as AUC, F1 score, sensitivity, and specificity balancing with ADASYN, and improving the model performance with 3-level stacking will significantly improve in the overall performance of the model.
RQ2. Extended stacking approach(Multi-level) is better in prediction than the basic stacking approach?
In the basic stacking approach base models and one meta-model are. Plenty of research has already been done. In stacking choosing the best configuration of base models as well as meta-models is very crucial otherwise the model will degrade the performance of the individual classifier. The extended stacking approach will always improve performance than basic stacking unless the best configuration and hyperparameters of the classifiers are. RQ 3. Does the final Meta-model parameter.
optimization make any improvement in overall performance?
In 3-level stacking, final meta-model selection and parameter optimization are very important. Many parameter optimization techniques are there but meta-heuristic optimization such as PSO will optimize efficient way.
RQ 4. How does the proposed model have more significance than other base-level models?
we can evaluate our proposed model performance with the statistical analysis we have done in the statistically paired T-test majority of the classifiers on various datasets significantly differ with p-value (<0.05) with a 95% confidence level.
Carefully choosing base classifiers and parameter optimization with evolutionary algorithms will significantly improve stacking model performance. Large datasets will take a lot of computation time so we need high-power computing resources to deal with multilevel stacking.
Oversampling sample techniques may reduce performance due to noise while generating synthetic data we can be cautious about borderline samples to improve the predictive model performance.
Conclusion
In order to improve the disease diagnosis performance, a three level stacking framework is proposed in this paper. The proposed model is feeded with pre-processed dataset. During pre-processing step IQR was used for outlier removal and ADASYN for class imbalance. This pre-processed dataset is used to train the proposed 3-level stacking framework. In this stacking framework, level 0 learners (LR, KNN, SVM, DT, KNN, and MLP) and level 1 learners (Bagged DT, KNN, and LR) are optimized using grid search. The level 2 learner i.e., SVM is optimized with PSO. For better optimization process a novel fitness function is proposed. The proposed model experimented on PID, SHD, CHD, CKD, and WBC datasets. The proposed model is compared with different combinations of base laerners and outperformed in terms of all the performance measures. Further, the proposed model is compared with SOTA ensemble and non-ensemble methods in terms of accuracy, AUC, specificity, and precision and it outperformed all the models in terms of AUC and accuracy on all the datasets. Finally, to prove the robustness of proposed model a paired statistical t-test is performed. The statistical test proved that proposed model significantly differs from all the base-level models.