
Abstract
Multi-source online transfer learning uses the tagged data from multiple source domains to enhance the classification performance of the target domain. For unbalanced data sets, a multi-source online transfer learning algorithm that can oversample in the feature spaces of the source domain and the target domain is proposed. The algorithm consists of two parts: oversampling multiple source domains and oversampling online target domains. In the oversampling phase of the source domain, oversampling is performed in the feature space of the support vector machine (SVM) to generate minority samples. New samples are obtained by amplifying the original Gram matrix through neighborhood information in the source domain feature space. In the oversampling phase of the online target domain, minority samples from the current batch search for k-nearest neighbors in the feature space from multiple batches that have already arrived, and use the generated new samples and the original samples in the current batch to train the target domain function together. The samples from the source domain and the target domain are mapped to the same feature space through the kernel function for oversampling, and the corresponding decision function is trained using the data from the source domain and the target domain with relatively balanced class distribution, so as to improve the overall performance of the algorithm. Comprehensive experiments were conducted on four real datasets, and compared to other baseline algorithms on the Office Home dataset, the accuracy improved by 0.0311 and the G-mean value improved by 0.0702.
Introduction
In the field of machine learning, transfer learning is an important technology, it has been extensively studied [1, 2]. Many models in applications are constructed based on a large amount of training data, but collecting and labeling sufficient data can be difficult and expensive [3,4]. The main purpose of transfer learning is to use the useful information extracted from one or more source domains to improve the learning performance of the target domain. A typical example is that it is difficult to collect enough tiger data, but cat data is abundant. Transfer learning can be used to build a tiger classification model using cat data. Therefore, the obvious advantage of transfer learning is to use the useful knowledge in the source domain to improve the overall function prediction performance and reduce the expensive number of markings needed. Therefore, transfer learning has been applied to various fields. The application of different transfer learning methods is described in the consciousness recognition task of human-computer dialogue systems [5]. Tthe application of transfer learning is introduced in cross domain recommendation algorithms [6].
At the start of research into transfer learning, knowledge was only transferred from a single source domain to the target domain [7, 8]. However, in certain practical applications, knowledge learned from multiple source domains can be easily transferred to the target domain [9]. For instance, in the case of document classification in five languages, to classify documents in English, one can learn from documents translated from French, German, Spanish, and Italian to English. Each translated document can serve as a source domain [10]. However, different source domains have varying contributions to the target domain. To overcome this limitation, a boosting-based method can be utilized to design more complex multi-source transfer learning algorithms [11].
Most multi-source transfer learning is conducted in an offline environment [12–14]. In some practical applications, the training data of the target domain is not provided in advance, but received sequentially in the process of learning the function of the target domain; this is called online transfer learning [15]. In the era of big data, online learning can handle a large and rapidly growing amount of data tasks that traditional batch processing algorithms cannot handle. In online learning, the objective domain function receives one sample and its corresponding label in each round; it then uses the objective function to predict the current sample and obtain the prediction result. It then updates the objective function based on the loss information between the actual labels of the current sample and the predicted results. Online learning is applied to large-scale planning in model service computing [16], which improves the time efficiency of prediction while also meeting the real-time requirements of computation. For multi-source online transfer learning, the final prediction result of each round of arriving samples is obtained by combining the prediction results of multiple source classifiers and target classifiers.
Imbalanced dataset refers to a dataset where the number of examples in each class is not equal. This can also pose a challenge for machine learning algorithms, as they may tend to predict the majority class more often and have poor performance on the minority class. Most transfer learning algorithms do not address unbalanced datasets, assuming that the distribution of data categories is balanced. However, unbalanced data is common in many real-world classification problems. Traditional classifiers assume equal misclassification costs for different categories, which can result in poor performance when dealing with imbalanced datasets. Misclassifying a minority class sample as a majority class sample can be extremely costly. Previous studies have proposed various methods to handle imbalanced datasets, which can be classified into data-based sampling methods, cost-sensitive methods, and algorithmic level methods [17]. Data-driven sampling methods balance the dataset before training the classifier. Cost-sensitive methods impose higher penalties on decision functions for misclassifying minority class samples. Algorithmic approaches modify classifiers such as support vector machines to address class imbalance [18, 19].
Multi-source domain refers to the situation where data is collected from multiple sources or domains, which may have different distributions, features, or labels. This can pose a challenge for machine learning algorithms that are trained on one domain and tested on another, as the model may not generalize well to new data. In multi-source online transfer learning, the target domain extracts useful knowledge from multiple source domains to help with target function classification. An online transfer learning algorithm is proposed, it could use multiple source domains related to the target domain [20]. A multi-class classification algorithm is proposed based on multi-source online transfer learning, which classifies multiple classes through a two-stage integration strategy [21]. A multi-source online transfer learning method is proposed [22]. In the process of online training, a small number of samples in the target domain were amplified to improve the overall classification performance. However, in the real world, the data in most classification tasks usually has an imbalanced category distribution. Unbalanced data classification is an important research topic in the field of machine learning and is also important in multi-source online transfer learning. In multi-source online transfer learning, the data categories of the source and target domains may be unbalanced. When the target domain data is imbalanced, the prediction results of the target domain function tend to lean towards the majority class; when the source domain data is imbalanced, the results of combining multiple source and target classifiers are highly likely to lean towards the majority class; when the data in both the source and target domains is unbalanced, more complex situations can arise. Obviously, multi-source online transfer learning for unbalanced data sets is an important and challenging topic that deserves extensive research. A multi-source information fusion method based on information sets (MSIF) is proposed [23]. The main goal of most information quality (IQ)-based measures is to combine data provided by multiple information sources to enhance the quality of information essential for decision makers to perform their tasks. However, there is few work to fuse multi-source information from the perspective of possibility distribution (PD) and use IQ as the evaluation criteria for feature selection. A novel representation model of possibility distributions is proposed based on fuzzy multisets [24]. Dempster-Shafer theory (DST), as a generalization of Bayesian probability theory, is a useful technique for achieving multi-source information fusion under uncertain environments. Nevertheless, when a high degree of conflict exists between pieces of evidence, unreasonable results are often generated using Dempster’s combination rule. How to fuse highly conflicting information is still an open problem. An improved belief Hellinger divergence measure is proposed [25], which can fully consider the uncertainty in basic probability assignments, to quantify the conflict level between evidence.
In this paper, a multi-source online migration learning algorithm called OTLMS_STO (multi-source online migration learning based on oversampling in source and target domain feature space) is proposed. This algorithm mainly studies the binary classification problem of unbalanced data. The existing method dynamically combines the source domain and target domain functions through the weight vector in the process of online learning, but does not consider the unbalanced distribution of source domain data and target domain data categories at the same time, and the OTLMS_STO algorithm proposed in this paper The minority class samples are oversampled in the feature space of the source domain and the target domain respectively, the source function is trained using balanced data, and the target function is improved in the process of online prediction, which effectively solves the problem of unbalanced category distribution. In the oversampling phase of the source domain, each source domain uses SVM as a classifier, synthesizes minority samples in the feature space of the source domain, and trains the SVM classifiers of each source domain by balancing the Gram matrix generated by the data. SVM is chosed as their model of choice because it has been shown to perform well on unbalanced datasets. SVM is known for its ability to handle high-dimensional data and to find non-linear decision boundaries. Additionally, SVM has a regularization parameter that helps to prevent overfitting, which is important when working with unbalanced data. If another model was used instead of SVM, the results may be affected depending on the characteristics of the dataset and the performance of the alternative model. For example, decision trees and random forests are also commonly used for unbalanced datasets, but they may not perform as well as SVM when dealing with high-dimensional data. On the other hand, deep learning models such as neural networks and convolutional neural networks may outperform SVM in certain cases, but they require more data and processing power to train effectively. Ultimately, the choice of model depends on the specific characteristics of the dataset and the goals of the analysis.
In the online oversampling phase of the target domain, passive aggressive (PA) algorithm is used to build the decision function of the target domain [26]. The target domain reaches a batch of data in each round, and searches for k-nearest neighbors from the minority samples that have already reached the batch in the previous round. Then, a few new classes of samples are synthesized on the line segment between the seed and neighboring sample pairs, and the generated new samples and the original samples in the current batch are used to train the decision function of the target domain. Finally, the improved source and objective functions are combined through weight vectors. The samples generated in the source and target domains are linearly separable, which can overcome the limitations of SMOTE (synthetic minority oversampling technique) method for nonlinear problems in the process of oversampling [27]. Experiments on several text and image datasets show that the proposed algorithm has better performance than the baseline algorithm of online transfer learning.
Materials and methods
Multi-source online transfer learning
In this chapter, we mainly introduce the multi-source online transfer learning algorithm HomeOTLMS [20]. HomeOTLMS combines classifiers built on multiple source and target domains to achieve effective ensemble segmentation Classer. By utilizing useful information from multiple source domains, the problem of insufficient sample data in the target domain is solved, ultimately improving the performance of the target domain.
HomOTLMS first constructs their decision functions in the offline batch learning paradigm based on the pre provided training data of m source domains (gs1 (x) , gs2 (x) … , g
s
m
(x)). For the target domain, an online passive attack algorithm is used to construct a decision that is updated onlineFunction g
t
(x). The target domain receives one sample per round. In the i-th round, the target domain receives instances (x
i
, y
i
) , , and then uses a function to predict the given instance x
i
, and calculates the hinge loss of the target domain decision function based on the real label y
i
:
If the decision function suffers a non-zero loss on instance xj, then it is added as a support vector to the support vector set to update the decision function in the target domain:
Where T i = min{ c, L i /k (x i , x i ) }, k (· , ·) is a kernel function. The kernel function plays a crucial role in the performance of many machine learning algorithms, particularly in kernel methods. It is a function that measures the similarity between two data points in the feature space. By computing the dot product between the transformed feature vectors, the kernel function implicitly maps the data points to a higher-dimensional space, allowing for the separation of non-linearly separable data. The choice of kernel function depends on the problem domain and the characteristics of the data. Some commonly used kernel functions include linear, polynomial, radial basis function (RBF), and sigmoid. Linear kernel functions are commonly used for linearly separable data, while polynomial kernels are used for data that are not linearly separable in the original feature space. RBF kernels are used for non-linearly separable data and are effective in capturing complex patterns in the data. Sigmoid kernels are used in neural networks and logistic regression.
After obtaining decision functions for multiple source and target domains, HomOTLMS combines them with weights to achieve effective integrated decision functions. By constructing a weight vector
Normalize the weights before each decision function prediction to ensure that the sum of the weights in front of all decision functions is 1:
When the i-th sample arrives,
HomOTLMS trains the target domain decision function through each round of target domain samples, and simultaneously adjusts the weight of each classifier to update the final integrated decision function, so as to carry out effective multi-source online transfer learning. However, the HomeOTLMS algorithm cannot effectively cope with the uneven distribution of data categories in the source or target domains. The following introduces a new multi-source online transfer learning method, which can reduce the overall classification error by manually balancing the distribution of source domain and target domain categories.
This section formally introduces the problem of uneven distribution of data categories in multi-source online transfer learning. For a given m source domains, D s ={ D s 1 , D s 2 . . . . D s m } is used to represent them, and D T is used to represent the target domains. Using X S j × Y S j represents the data space of the j-th source domain D S j where the feature space of the source domain is X S j = R d j . For the target domain, its data space uses X×Y represents, where the feature space is X = R d . And here, the source and target domains share the same label space y s j = y ={ + 1, - 1 } and also share the same feature space, that is, for ∀ j = 1, 2, 3, m, R dj = R d .
Unlike HomeOTLMS, the proposed algorithm is mainly applied to the problem of the target domain arriving at a batch of data online each time. For the target domain
The source domain uses SVM to train the classifier, and the target domain uses online passive attack algorithm (PA) to train the classifier. Both the source domain and the target domain use training in the feature space to obtain an optimal separation hyperplane to predict samples. When the categories are unbalanced, the hyperplane may be more sensitive to most class samples, and the prediction results are biased towards most classes. For the data in both the source and target domains, their category distribution may be uneven. Assuming that the sample with category +1 is a minority class, and the sample with category – 1 is a majority class. Using imbalanced source domain data to train multiple source classifiers, knowledge transferred from the target domain to the source domain may bias towards the majority class, which can have a negative impact on the data in the target domain. If the target domain data itself is imbalanced, there is a great possibility of skewing the target decision function towards the majority class, thereby affecting the final outcome of the integrated decision function. More complex situations often arise when the data in the source and target domains are unbalanced. The proposed OTLMS_STO algorithm in this article improves the overall classification performance of the integrated decision function by oversampling in the sample feature space of the source domain and the target domain, and better realizes knowledge transfer.
Oversampling in the feature space of the source domain
Proposed OTLMS_STO algorithm first oversampling in the feature space of the source domain, and improves the classifier of the source domain by using the balanced data set after sampling. Using basic classifiers such as SVM in multiple source domains, SVM classifies samples by identifying separation hyperplane in high-dimensional implicit feature space. For imbalanced datasets, SMOTE is an excellent sampling method that utilizes domain information to comprehensively generate minority sample points. It generates new samples on the line segment between two adjacent samples. However, for high-dimensional text and image data, SMOTE is limited to the problem of nonlinear separability.
Due to the fact that SVM classifiers from multiple source domains operate in the feature space, composite samples can be generated in the same feature space to address class imbalance issues. Figure 1 shows the proposed TLMS_ STO The structure of the algorithm in improving multiple source domain stages is mainly divided into two key steps: the first step is to generate a synthesized minority class of new samples in the feature space of the source domain, making the dataset of the source domain more balanced; The second step is to train classifiers from multiple source domains using the modified balanced dataset. The following describes each step in detail.

Structure of OTLMS_STO algorithm in process of source domain.
Use
Where, k (· , ·) is a kernel function, Calculate the distance between seeds and neighbors through kernel functions without needing to know φ (x) The specific form of the function.
After obtaining the K-nearest neighbors of all minority class samples in the source domain, many sets of seeds and neighbor pairs are obtained. From them, an appropriate number of sample pairs are selected and a new sample is generated on the line segment between them. Number of new minority class samples generated Lt-new to make the current source domain’s class.
Distribute relatively evenly and assign a label to each new sample. Synthesize new samples in the feature space according to the following Equation (6).
Where, αmn is a random number between 0 and 1, randomly generated during the equation use process, as set in the reference literature [28].
Note, that when the+1 labeled samples in the target domain are minority classes, it is not certain that the+1 labeled samples in each source domain are also minority classes. Therefore, when balancing source domain data, it is necessary to determine the number of classes based on the specific number of samples in the two categories.
The SVM classifier in the source domain can be trained through the Gram matrix K1, which is composed of the inner product of each pair of samples in the source domain:
The generated Lt-new new samples are added to the Gram matrix K1 to train the SVM classifier of the source domain. The new Gram matrix representation is expressed in Equation (8):
Where, each element
According to Equations (9) and (10), it can be seen that the augmented kernel matrix K is only composed of training samples in the source domain and the kernel function k (·, ·), without the need to know the mapping function φ (x) The specific form of. Therefore, any effective kernel function can be used to train source domain SVM, while the proposed OTLMS_STO algorithm uses Gaussian kernel functions to train SVM.
This section mainly introduces the processing steps of the proposed OTLMS_STO algorithm for imbalanced target domains. The target domain is trained using the PA algorithm, which also has an optimization problem similar to SVM. The prediction mechanism is based on a hyperplane, which divides the instance space into two half spaces. In the stage of improving the objective domain function, the objective decision function can utilize the same kernel techniques as SVM classifiers to synthesize samples using dot products in the feature space without the need to know the feature mapping function φ (x). Therefore, the new samples generated in the source and target domains can be controlled to be in the same feature space through the same kernel function and bandwidth. The data points generated in the target domain have better linear separability in high-dimensional space and can be used to improve the target decision function.
Figure 2 shows the proposed OTLMS_STO algorithm improves the structure of the target domain stage. The samples in the target domain arrive in multiple batches. When the target domain arrives at a batch of data, the processing process is divided into three steps: the first step is to oversampling a small number of samples in the current batch, so that the class distribution is relatively balanced. In Fig. 2,

Structure of OTLMS_STO algorithm in process of target domain.
When the sample
Before conducting multi-source online transfer learning on the current batch of samples, the objective decision function g T (x) is improved with the new samples generated. However, the new minority class samples generated according to Equation (6) utilize commonly unknown feature mapping functions φ (x) Therefore, the new synthesized sample φ (xmn) cannot be obtained specifically. The objective decision function adopts the PA algorithm, which calculates the inner product of two samples through the kernel function each time to add support vectors, thereby improving the objective function. Therefore, when the objective function receives new samples generated in the feature space, the inner product of the ordinary sample and the composite sample can be calculated according to Equation (9), and the inner product of the composite sample and the composite sample can be calculated according to Equation (10), thereby using the new samples to train the objective decision function. And modification.
The stage of entering the source domain is similar, where only the training samples and kernel function k (·, ·) need to be known, without the need to know the mapping function φ (x) The specific form of.
Using composite instances to improve the target domain decision function, when the hinge loss is greater than 0, the composite instance is added as a support vector to the support vector set, while also maintaining the separability of the feature space, i.e.
Prove that the objective domain function consists of support vectors, which can be expressed in Equation (12):
Assume that the current batch of samples
Substituting the minority class sample φ (x
pq
) generated by Equation (6) into the objective function to get Equation (14):
Where, g T (x m ) ⩾ 0, g T (x n ) ⩾ 0, x m , x n belong to the minority class, α mn ∈ [0, 1].
Therefore, the samples generated in the feature space of the target domain can also ensure that the categories are separable. Each batch of new samples generated will optimize the hyperplane of the objective function in the feature space to improve the performance of the objective function.
Then conduct multi-source online transfer learning on all samples in the current batch to get the final results of this batch.
Proposed OTLMS_STO algorithm is divided into two stages: (1) improving classifiers in multiple source domains; (2) The target domain classifier is improved, and the improved source classifier is used for multi-source online transfer learning.
Algorithm description and complexity analysis in the first stage:
Find the k-nearest neighbors of each minority class sample, forming seed pairs of k samples x m and neighbor x n
In the above algorithm, Step 2.1 finds all minority class samples with a time complexity of O(N), where N is the total number of samples in the current source domain. The time complexity of finding k-nearest neighbors for all minority class samples in step 2.2 is O(n_min2), n_ Num is the number of minority class samples in the current source domain. The time complexity of calculating the Gram matrix in step 2.4 is O((N + n_num)2d), where d is the dimension of the sample. Therefore, the total time complexity is O(n(N + n_min2+(N + n_num)2d)), where n is the number of source domains and can be approximated as O(nd (N + n_num) 2).
Algorithm description and complexity analysis in the second stage:
Calculate parameters before loss L and support vector
When the loss is greater than 0, update the objective decision function according to Equation (2), where the kernel function is obtained from Equations (9) and (10).
In the above algorithm, the time complexity of finding k-nearest neighbors in step 1.1 is O(3m1m2d), where m1 and m2 are the minority and majority classes in the current and previous batches, respectively, and d is the dimension of the sample. Step 1.3 Improve the time complexity of the objective decision function using synthesized samples with O(4svd), where s is the total number of new samples and v is the number of support vectors.
Step 1.4 Train the current batch of raw samples with a time complexity of O(2nvd), totaling n samples. There are a total of N batches in the entire target domain, with a total time complexity of O(N(3m1m2d+4svd+2nvd)), which can be approximated as O(N (m1m2d+4svd+2nvd)).
Experiment and performance analysis
The OTLMS_STO proposed in this chapter algorithm was compared with multiple baseline algorithms for online learning, and experiments were conducted on real-world datasets: the 20 Newsgroups dataset, Office Home dataset, Modern Office-31 dataset, and DomainNet dataset. In order to obtain reliable results, with the same parameter settings, data from multiple source domains is used as training data, and data from the target domain is used as test data. Each experiment is repeated 10 times by changing the arrival order of test instances. The results show that the proposed algorithm achieves better performance than the baseline algorithm.
Dataset introduction
The source domain dataset is the original dataset used to train the model, usually collected from the same domain. For example, in image classification tasks, the source domain dataset can be a set of well labeled photos taken from the same camera, location, and lighting conditions. The target domain dataset is a dataset used for testing models, typically collected from different domains. For example, in the same image classification task, the target domain dataset can be photos taken from different cameras, locations, and lighting conditions. In domain adaptation and Transfer learning, the goal of the target domain dataset is to evaluate the generalization ability of the model, that is, the performance ability of the model in the new domain. The purpose of the source domain dataset is to train the model to adapt to the target domain dataset and improve its performance.
•20Newsgroups
20Newsgroup Datasets (http://qwone.com/ Jason/20Newsgroups/) is a popular dataset for text applications in machine learning technology, which collects approximately 20000 newsgroup documents and is divided into an average of 20 newsgroups with different themes. Among them, each newsgroup corresponds to a different topic, some newsgroups have very close connections with each other, while others are highly unrelated. Highly relevant news groups consisting of five major themes, such as OS, IBM, Mac, and X, are comp themed news groups, while crypt, electronics, med, and space are sci themed news groups. In the experiment, the news groups in the comp topic were marked as positive examples, while the news groups in the sci topic were marked as negative examples. Thus, four related learning domains can be constructed: os_ vs_ crypt, ibm_ vs_ electronics, mac_ vs_ Med and x_ vs_ space. Select one domain randomly as the target domain and the other three domains as the source domain to generate four transfer learning tasks. The imbalance rate for each group of tasks is 0.3.
•Office-Home
The Office Home dataset contains approximately 15500 images from four different neighborhoods, including Art, Clipart, Product, and Real World images [29]. Each domain contains a graph of 65 categories
Like. In the experimental setup, images from the Real World domain are used as the target domain, and the Art, Clipart, and Product domains are used as the source domain. In 65 categories of the Real World domain, select one target domain with less samples and one target domain with more samples to form a secondary task, and select the same category for the three source domains to form a transfer learning task. Before the experiment, perform simple preprocessing on the original images in the task, processing each image into a 1×A vector of 10 000. Experiment total 33 sets of transfer learning tasks were generated. Among the 33 sets of tasks, there is 1 set of tasks in the RealWorld domain with an imbalance rate between [0.1, 0.2), 14 sets of tasks with an imbalance rate between 0.2, 0.3), and 18 sets of tasks with an imbalance rate between 0.3, 0.4).
•DomainNet
The DomainNet dataset is the largest domain adaptation dataset to date, consisting of 6 different domains, 345 categories, and approximately 600000 images. The six domains are Clipart, Infograph, Painting, Quickdraw, Real, and Sketch, while the categories range from furniture, fabric, electronics to mammals, architecture, and more. In the experiment, one class with fewer samples and one class with more samples is selected from Real photos and real world images to form a target domain, and the other five domains are used as source domains to form a transfer learning task. A total of 45 groups of transfer learning tasks were generated in the experiment. Among the 45 groups of tasks, there are 5 groups of tasks in the Real domain with imbalanced rates between 0, 0.1), 7 groups of tasks with imbalanced rates between 0.1, 0.2), and 33 groups of tasks with imbalanced rates between 0.2, 0.3).
•Modern Office-31
The Modern Office-31 dataset is a transfer learning dataset for image classification 30]. It contains subsets of four fields: Amazon (A), Webcam (W), Synthetic, and Dslr (D), divided into 31 categories, with a total of 7210 images. In Modern Office-31 data
Centralized, not only the total number of samples in each field is different, but also the distribution of categories within each field is unbalanced. Modern Office-31 data sets can be processed through unbalanced methods to improve the effect of transfer learning. In the experiment, each image in the preprocessed dataset was 1×A vector of 10 000. Use Webcam as the target domain and the other three domains as the source domain. Then select a category with more samples and a category with less samples in Webcam to form a group of transfer learning tasks, and a total of 20 groups of tasks are generated. Among the 20 tasks, 5 tasks in the Webcam domain have an imbalance rate between [0.2 0.3), 9 tasks have an imbalance rate between 0.3 0.4) rand 6 tasks have an imbalance rate between 0.4 0.5).
Baseline algorithm and evaluation indicators
To evaluate the performance of the proposed OTLMS_STO algorithm, it was compared with several latest online learning methods through experiments. The PA algorithm is a classic online learning algorithm [26], and using PA as a comparison algorithm does not require knowledge transfer. Using data from various source domains to initialize PA first, a variant of the PA algorithm called “PAIO” is implemented. At the same time, it is also compared with HomOTLMS [20], a famous multi-source online transfer learning algorithm, which can use the useful knowledge of multiple source domains to improve the classification performance of the target domain. In addition, the proposed algorithm will be combined with OTLMS_IO [22] and OTLMS_FO [26] is compared. Both algorithms improve performance by oversampling the unbalanced target domain. The former samples in the input space, and the latter samples in the feature space. All algorithms are implemented in Python language.
Dataset introduction evaluates the performance of classifiers on imbalanced datasets, but using a single evaluation criterion such as accuracy or error rate is usually ineffective. This experiment uses accuracy and G-mean to evaluate the performance of the dataset, which can evaluate the model performance of imbalanced data. When the samples are all divided into the same class, the value of G-mean is 0. Table 1 shows the binary confusion matrix. The calculation equation of G-mean is Equation (15):
Two-classification confusion matrix
Two-classification confusion matrix
Parameter settings
On the 20Newsgroups, Office Home, DomainNet, and Mo dern Office-31 datasets, the proposed OTLMS_STO algorithm is compared with four baseline algorithms of transfer learning. In order to make the comparison more fair, all algorithms have adopted experimental settings that are as similar as possible. For k-nearest neighbors of minority samples in each batch, OTLMS_ STO will automatically set a k value to ensure that the generated few new samples of the same class can achieve a relatively balanced distribution of the current batch’s categories. Due to the widespread application of Gaussian kernel functions, this article uses Gaussian kernel training functions. The algorithm proposed in this article can also use other kernel functions and search for the optimal bandwidth σ in the range of [10-2, 102].
In the experiment in section 3.3.7, the impact of different compromise parameter C values on experimental performance was analyzed, and the compromise parameter C of all algorithms on all datasets was set to 5. According to the analysis of the algorithm error bound in reference [20], the weight discount parameter can be obtained β=M/(m + ln (n + 1)), where m is calculated as The number of errors made by the method, n is the number of source classifiers.
Experimental results on the 20Newsgroups dataset
Table 2 lists the performance of various comparison algorithms on the 20Newsgroups dataset, with evaluation metrics including accuracy and G-mean. From the experimental results, it can be observed that the proposed OTLMS_STO algorithm achieved better performance than all baseline algorithms in four sets of learning tasks. The performance of OTLMS_STO algorithm is superior to PA and PAIO, indicating that the proposed algorithm can effectively extract knowledge from multiple source domains. The proposed OTLMS_STO algorithm in 4 sets of tasks performs better than HomeOTLMS because it ignores the issue of imbalanced data categories between the source and target domains. The performance of algorithm OTLMS_IO and OTLMS_FO are superior to HomeOTLMS, but both comparison algorithms only consider expanding samples in the target domain, while the proposed OTLMS_STO algorithm amplifies minority class samples in the feature space of the source and target domains. Figure 3 shows a line chart showing the error rates of different algorithms in four groups of tasks changing with the increase of the number of samples. From Fig. 3, it can be seen that as the number of training samples increases, the error rates of the six algorithms also significantly decrease. And OTLMS_STO algorithm in os_vs_crypt, mac_vs_med and x_vs_space task of is always better than that of comparison methods.

Error rate of each algorithm on 20Newsgroups dataset with increase of the number of samples.
Results of different learning algorithms on 20 Newsgrops dataset (mean±standard deviations) unit: %
Low error rate. Among them, HomeOTLMS, OTLMS_IO, OTLMS_FO and OTLMS_STO algorithm has better results when the initial sample size is small, which proves that the above algorithms can effectively extract knowledge from multiple source domains. The error rate of the OTLMS_STO algorithm proposed in this article is lower than other algorithms on most tasks, proving that the proposed algorithm can effectively improve the imbalanced source and target domains.
33 sets of experimental tasks were conducted on the image dataset Office Home, and Table 3 shows the numerical results of all comparative algorithms on two indicators. Among them, HomeOTLMS, OTLMS_IO, OTLMS_FO and OTLMS_STO algorithm has better performance than ordinary online learning algorithms, indicating that transferring knowledge from multiple source domains helps predict the target domain. The evaluation of OTLMS_STO, OTLMS_IO and OTLMS_FO is better than that of HomeOTLMS, as the first three algorithms consider the imbalance of target domain categories.
Results of different learning algorithms on Office-Home dataset(mean±standard deviations) unit: %
Results of different learning algorithms on Office-Home dataset(mean±standard deviations) unit: %
But OTLMS_STO algorithm has better performance. It can simultaneously expand a few samples from the core space of the source domain and the target domain, effectively modify the hyperplane in the feature space, and clearly see the changes of the classifier from the G-mean index. Figure 4 shows the histogram of the accuracy rate of the three main algorithms on 33 groups of tasks, and Fig. 5 shows the line chart chart of G-mean indicators of 33 groups of tasks. On the vast majority of tasks, OTLMS_STO algorithm should have better performance and better performance for a few classes. This indicates that the proposed algorithm can not only transfer knowledge from multiple source domains, but also effectively cope with imbalanced datasets.
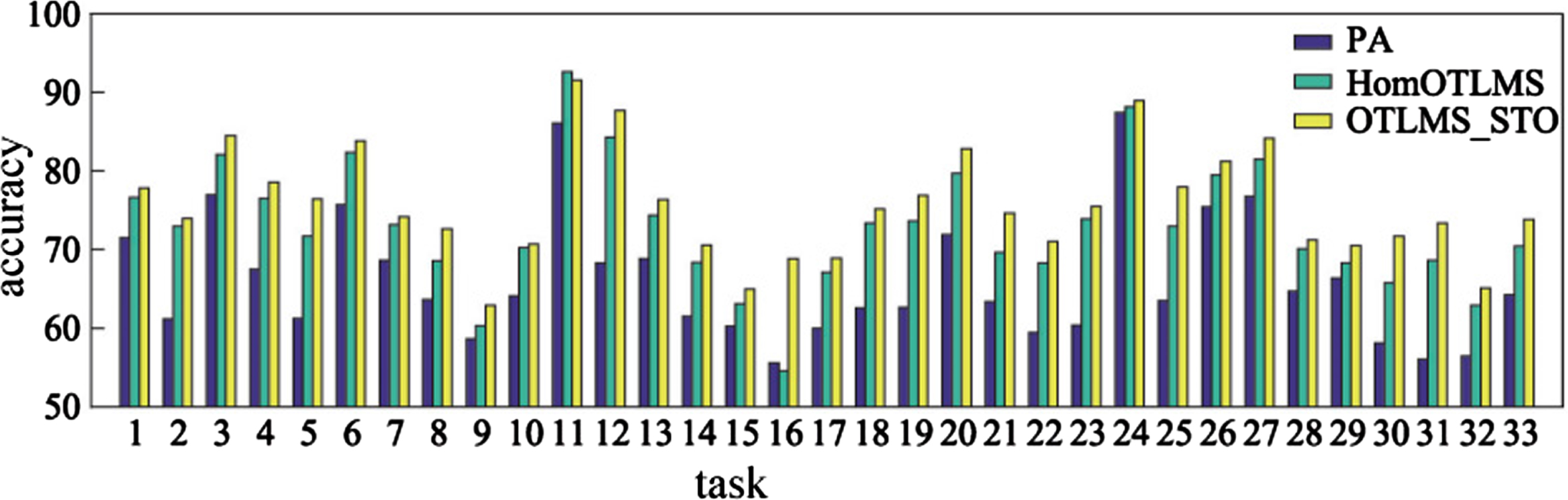
Accuracy of 33 groups of tasks on Office-Home dataset.
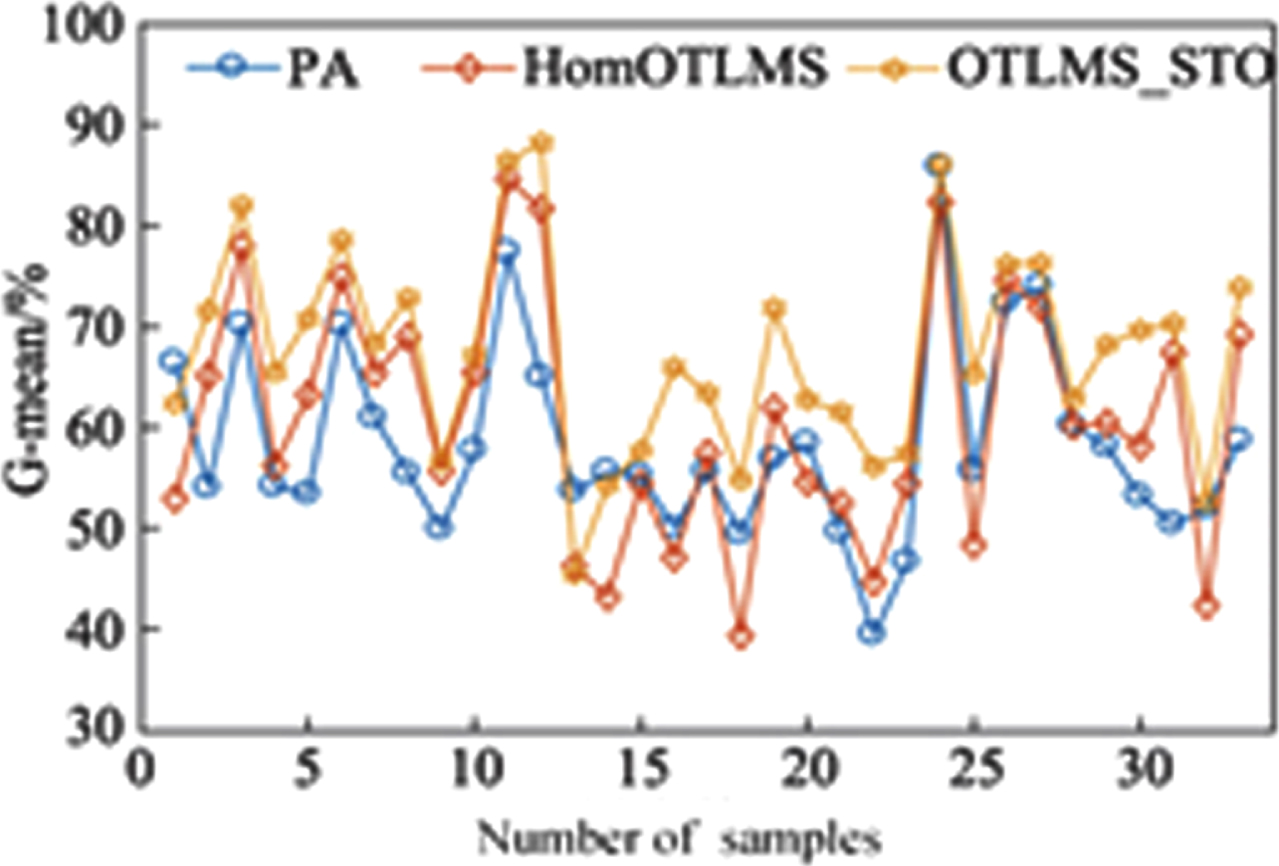
G-mean of each group of tasks on Office-Home.
To better validate the performance of the OTLMS_STO algorithm, a total of 60 experimental tasks were conducted on the image dataset DomainNet. Table 4 presents the numerical results of four sets of tasks, and the data in the experimental results clearly support the proposed method, achieving optimal performance beyond the comparison algorithm in all tasks. This indicates that the proposed OTLMS_STO algorithm can extract effective knowledge from multiple source domains and has good results in cases of imbalance between the source and target domains. The DomainNet dataset contains a total of 5 source domains. When combining source and target domains, the proportion of target domains is only 1/6, so OTLMS_FO improves the performance of the objective decision function by amplifying samples in the target domain. And the proposed OTLMS_STO algorithm can synthesize minority class samples in the kernel space of the source domain, and then train the source domain classifier using an augmented kernel matrix. By combining multiple source classifiers and target classifiers, better performance can be achieved. Affected by spatiality and observability, Fig. 6 shows PA, HomeOTLMS, and OTLMS_STO algorithm achieved results in 45 sets of tasks, while ignoring the results of other algorithms. In most tasks, the proposed algorithm outperforms the two comparison algorithms. Figure 7 shows the G-mean values of three main algorithms, and the results indicate that the proposed OTLMS_STO algorithm can handle imbalanced data, especially with better performance for datasets with a large number of source domains.

Accuracy of 45 groups of tasks on DomainNet dataset.
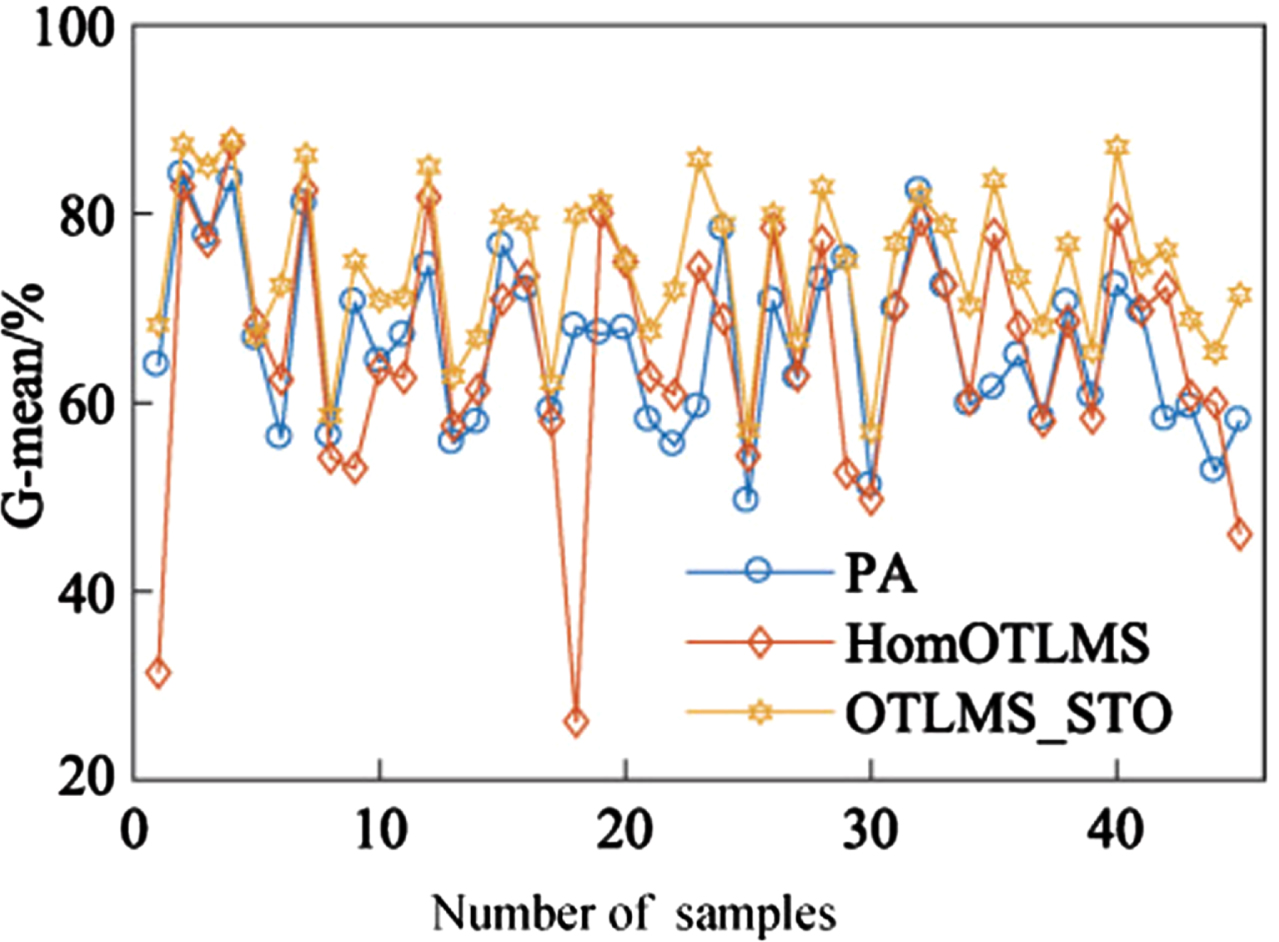
G-mean of each group of tasks on DomainNet dataset.
Results of different learning algorithms on DomainNet dataset (mean±standard deviations) unit: %
A total of 20 experimental tasks were conducted on the Modern Office-31 image dataset. Table 5 presents the accuracy and G-mean numerical results of using all algorithms on several randomly selected tasks. Book
Results of different learning algorithms on Modern Office-31 dataset (mean±standard deviations) unit: %
Results of different learning algorithms on Modern Office-31 dataset (mean±standard deviations) unit: %
The OTLMS_STO algorithm proposed in the article enhances the classification performance of the target domain by utilizing useful information from multiple source domains. Therefore, in terms of accuracy indicators, OTLMS_STO achieves competitive performance. Meanwhile, OTLMS_STO amplifies minority class samples in the feature space of the source and target domains, while improving the functions of the source and target domains to avoid the final integrated decision function leaning towards the majority class. From Table 5, it can be observed that OTLMS_STO algorithm on G-mean metric Achieved optimal performance.
Figure 8 shows the average accuracy results of 20 experimental tasks on the Modern Office-31 dataset in PA, HomeOTLMS, and OTLMS_STO algorithms. From the figure, it can be seen that the proposed OTLMS_STO algorithm has optimal performance in the vast majority of tasks, which proves that the proposed algorithm can effectively utilize knowledge from the source domain to improve performance, and proves the effectiveness of expanding samples in both the feature spaces of the source and target domains on functional performance. Figure 9 shows the G-mean results of 20 experimental tasks on PA, HomOTLMS, and OTLMS STO algorithms, demonstrating the effectiveness of OTLMS STO in dealing with imbalanced data.
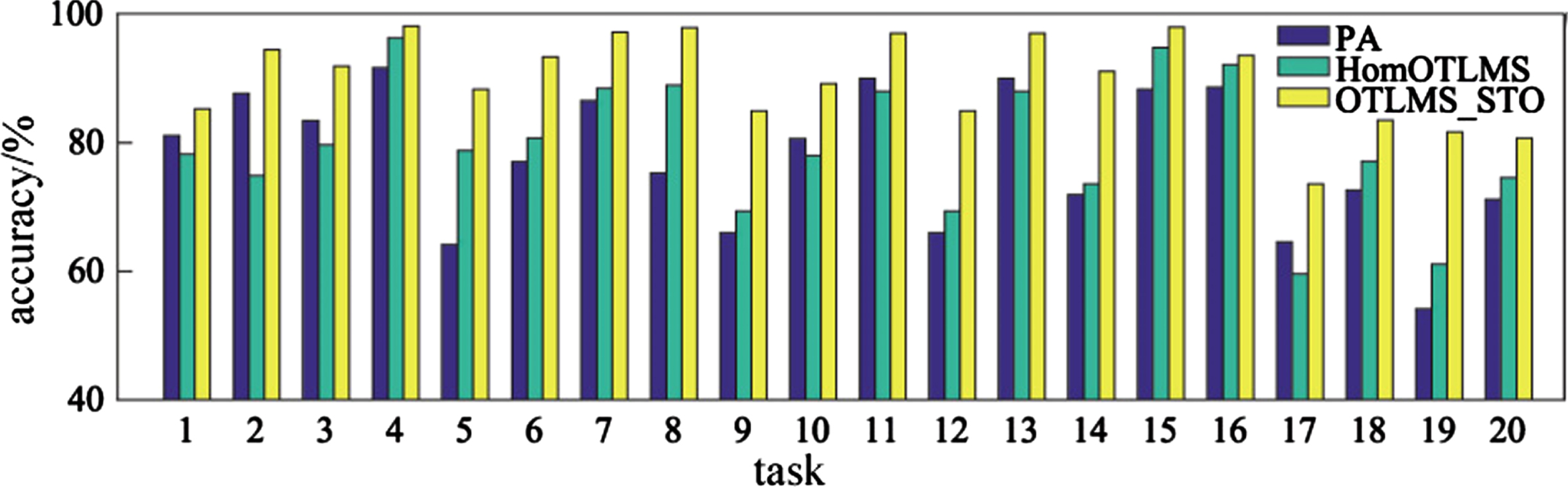
Accuracy of 20 groups of tasks on Modern Office-31 dataset.
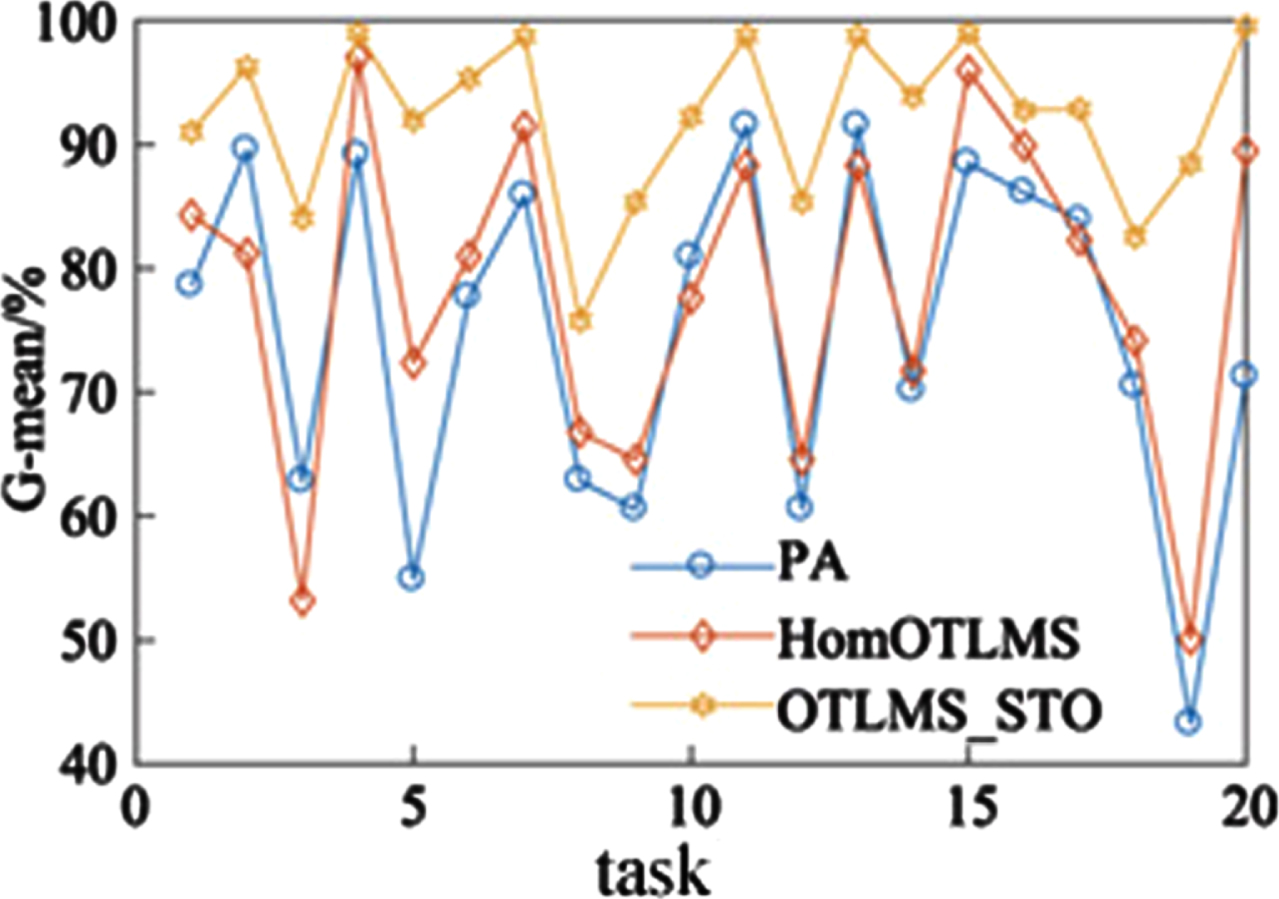
G-mean of each group of tasks on Modern Office-31 dataset.
Table 6 presents the rank values of accuracy for a total of 102 experimental tasks on all three datasets, as well as the average rank values for each dataset. In the accuracy ranking of the five algorithms, the first rank value is 1, the second rank value is 2, and so on. For the 20 Newsgroups dataset, task1–4 represents tasks 1, 2, and Task 3 and Task 4, followed by 1–11, are the rank values of tasks 1–4. From the table, it can be seen that in the vast majority of tasks, the experimental results of the proposed OTLMS_STO algorithm rank first, and the average rank value also performs well.
Rank value average rank value of task accuracy in each group
Rank value average rank value of task accuracy in each group
The method proposed in this article involves some adjustable parameters, including the compromise parameter C. Figure 10 shows the potential impact of different C values on the 20Newsgroups dataset. From the graph, it can be observed that the accuracy of OTLMS_STO and other methods varies significantly with different C. For the same task, different algorithms achieve the best performance at different C values. From Fig. 10, it can be concluded that under different C values, OTLMS_STO algorithm is more accurate and stable than other transfer learning algorithms, which verifies the effectiveness of the proposed algorithm. In the experiment, set the C value of all algorithms to 5.

Evaluation of all algorithms with different C values on 20Newsgroups dataset.
Quantitative analysis is an essential tool for evaluating the performance of algorithms and systems. In this article, Python is used to implement their algorithm and tested it on multiple tasks. They recorded the average running time of the algorithm and summarized it in Fig. 11. From the graph, it can be observed that as the number of samples increases, the average running time of OTLMS_STO algorithm is more expensive than other algorithms.

Time cost each algorithm with increase of the number of samples.
A Windows machine with a 6×2.6 GHz CPU processor and 16 GB of memory are used to run their experiments. The machine specifications are important to consider because they can affect the performance and running time of the algorithm.
Multi-source information fusion is a sophisticated estimating technique that enables users to analyze more precisely complex situations by successfully merging key evidence in the vast, varied, and occasionally contradictory data obtained from various sources. Restricted by the data collection technology and incomplete data of information sources, it may lead to large uncertainty in the fusion process and affect the quality of fusion. Reducing uncertainty in the fusion process is one of the most important challenges for information fusion. This paper considers the online transfer learning problem of unbalanced data, where the data in the target domain arrives in batches and knowledge is migrated from multiple offline source domains. For imbalanced source domains, this algorithm applies.
Expand minority class samples in the feature space to balance the source domain categories, and then use the augmented kernel matrix to train the source domain to form multiple improved offline source domain classifiers. For the imbalanced target domain, this algorithm searches for k-nearest neighbors of the minority classes in the current batch sample from the minority class samples in the previous arrival batch, and then improves the objective function using the synthesized new sample. Finally, several improved source classifiers and target classifiers are combined for multi-source online transfer learning, and extensive experiments are carried out on text and image data sets. The experimental results show that the proposed algorithm can not only effectively transfer knowledge from multiple source domains, but also effectively cope with the uneven distribution of data categories in the source and target domains. This article investigates the binary classification problem of imbalanced source and target domains. Multi class classification problems are more challenging, and offline and online objective functions need to consider multiple classes and the situation of imbalanced classes within them simultaneously Condition. In the future, we will continue to study the multi classification and multi source online transfer learning problem of unbalanced source domain and target domain.
Footnotes
Acknowledgments
This work was supported by 2023 Social Science Achievements Evaluation Committee of Hunan Province General funding project: Research on the Construction of Mainstream Ideological identity mechanism of Higher vocational students under the background of “Intelligent communication” (Project No: XSP2023FXZ036).