
Abstract
The contemporary development of cloud is a next generation federated cloud technology envisioned by virtualization to enable cost-efficient usage of computing resources. The resources are intended on scalability as data grows enormously with on demand services. Federated cloud is an efficient networked computing environment that can adopt infrastructure which aims for virtual unlimited pool during on demand services. The challenging task for federated cloud includes managing workloads of individual cloud, progressing virtual machine volumes, cost utilization, fair load distribution. In order to addresses these challenges, this approach uses “Optimized Bit Matrix based Node Acquisition for Federated cloud (BMNF)”. The framework process two different approaches: managing bit matrix and fulfilling load distribution in federated cloud based on cost aware workloads. The formation of bit matrix designed by each member in cloud services that validates load availability status. Load distribution factor concentrates on fair allocation with cost aware policy at individual level. BMNF policy segregates the request among various clouds by analyzing bits patterns. In addition to load distribution using bit matrix, it also focuses on improving cost utilization and targets with better quality of load distribution. The proposed working model is highly efficient with computation and communication overhead for federated cloud.
Keywords
Introduction
In recent years, the deployment of virtualized resources on demand has helped cloud computing establish itself as a consolidated paradigm for the delivery of services [1]. By the evolution of this paradigm, Cloud computing has become the next-generation flexible architecture for enterprises. The resources for networking and computing that support virtualization need to considered and enhanced together. In addition to the traditional data-center oriented models, federated cloud deployment was widely used for the administration of various internal and external cloud computing services to suit corporate requirements, offering improved computing and communication capabilities to meet end customers’ Quality of Service (QoS) demands. The Virtual machines (VMs) is utilized as infrastructure to consumers in which the computing infrastructure is hosted, and controlled by cloud providers. They are managed by Virtual Instances (VIs) in several flavors. Cloud users should load Virtual Machine Images (VMI) in Virtual Integrated Systems (VIs) in order to deploy their applications, where VMI is a combination of the operating system and the necessary software packages to run the applications. The virtual machines (VMs) that are pre-installed with operating systems and application software must be maintained by the cloud consumer. Depending on the instance type, use, and data centre, they are charged differently. In the vast cloud market, it is difficult for consumers to choose the finest resources from providers and allocate resources according to their demands. One of the way to deliver cloud services, and enabling cloud providers to manage clients application in the terms of virtual machines (VMs) is provided by Infrastructure as a Service (IaaS).
The significant motivation There is the potential for IaaS providers to make profit through disseminating data centre resources at their disposal to allocate millions of users. Regardless of the technology used by cloud providers, they offer a consistent interface for accessing, managing, monitoring, and evaluating various cloud provider services. A comparison to commercial clouds shows that multi-cloud distribution of VMs improves functionality and lowers costs when compared with a single cloud deployment. Although a cloud provider is utilized to have limitless resources, there will always be a maximum cost due to limitations on the hardware and network bandwidth available [2].
Federated cloud
For completing the task of cloud providers, more resource management techniques needed. The QoS becomes conservative factor in such a way that providers delay in resource management strategies by reducing the number of resources allocated to requirements. The providers must be in the position to dynamically increase the virtual resources based on the server request to enable QoS by accepting the workload [3]. To enhance such scenario, establishment of cloud federation can be done for developing coordination between providers.
A cloud federation follows regulations for providers to allot resources which aims for reducing resource that available in the local infrastructure. This leads to rejection of client requests due to acceptance of requests to other members in the federation. More specifically, for cloud computing to properly deliver on its promise, there needs to be the technological means to federate various data centers, including those controlled by other companies. Infrastructure providers can only use their combined capacities to offer a seemingly limitless service computing utility through federation. When a request for a virtual machine (VM) is made on demand and non-availability of idle resources in the data centers, the federated cloud may decide to raise the spot price and stop providing the VM.
For resource provisioning, Openstack software platform [26] is utilized through data center in order to manage hardware pools of computing, storage, and networking resources. It is a cloud operating system that manages sizable computing pools and gives customers the ability to add resources.
The main objective is to allocate virtual resources to fulfil as many on-demand requests as feasible with respect to profit for providers. The proposed algorithm uses different strategies that facilitate decision-making choices hold by providers regarding user’s demand through federated cloud.
The rest of this paper is organized as follows. section 2, summarize the literature review. The system model with Cloud federation using bit matrix concept is described in Section 3. In Section 4, the policies for resource provisioning and bit matrix techniques are explained. Evaluation of proposed algorithm is explained in section 5. In section 6, experiments, implementation, evaluation and inference of the proposed model is given in section 7.
Literature review
Several studies have been conducted for allocating virtual resources by considering different perspectives from cloud providers.
Fair resource allocation
Based on fair load distribution, the following works has been adopted in cloud environment for sharing resources under contract method in federated cloud. Jinlai Xu et al. [4] produces the method that depends on the resource allocation. cloud service providers are both buyers and sellers. The fair allocation of resources done through contract allocation auction that emphasize on maximizing revenue for a specific provider. The beginning of resource fair allocation is finalized with contract duration at the agreed-upon cost. The vendor is required to share the contractual resources within the allotted time frame. Experimental results proposed that job distribution is effective over the established contract period.
A.B.M Alam et al. [5] describes trust assessment in multi-cloud environments for improving QoS with resource allocation model. The main aim of the proposed approach is to allocate resource in a reasonable amount of time effectively with trust evaluation using genetic algorithm. The proposed service broker policy outlines the user’s SLA expectations. The broker then finds a suitable datacenter that offers the best performance and lowest cost for supporting specified user applications in the cloud. The primary goal of the proposed framework is to allocate requested user applications in the cloud at a lower cost. Evaluated outcome presents in large rise in user duties servicing at cheaper prices.
Jie Wei et al. [6] produces a creative strategy for allocating resources that selects datacenters based on latency. The approach classifies datacenters based on the K-Means for identifying delay using algorithm. The proposed approach measures datacenter latency and then selects appropriate datacenters based on latency. Once chosen, the federated cloud’s VMs are placed there using the Binary Quadratic Programming approach and made available to real-time application providers. This technique has been tested using real latency between datacenters, the price for spending virtual machines, and the expenditure of data transfer, and it has demonstrated a reduction in overall latency as well as financial advantage.
The approach of resource allocation done for IaaS that reduces delay and focused on resource elasticity [13]. The approach ensures system stability by periodical processing of overclocking. The servers balanced with delay dependent optimization that takes over the admission control for overclocking. The resource utilization from data center is occurred from cloud edge even in the demand of high server and volumes. The methodology for requesting routing and resource allocation is systematically made and simulation environment is verified by overclocking at maximum rate.
Energy and cost consumption
In the current environment’s polluted surroundings, awareness of energy consumption is quite important. Thus, a method that took into account both internal and external datacenter physical resources, as well as the associated power utilization, is described in Fagui Liu et al. [7]. The method that is being presented consolidates smart software by transferring virtual machines between non-green and green datacenters using energy-conscious operations in a federated cloud. The proposed method creates a matrix of destination and granularity to evaluate energy usage. Later it finds a path that is a collection of components, each of which the optimum green location at the time in a given period is identified.
The two metrics i) quickest method to analyze path for selecting a datacenter based on bandwidth availability ii) A bioinspired method for work scheduling and server selection within a datacenter is explained in Siqian et al. [8]. The major objective of the suggested methods aims to lower network costs for a virtual machine allocation on demand. The algorithm does two different types of sorting: a local sort that yields a list of servers that are ranked by their cost derived with an average computation. Second worldwide list of individuals, arranged by level of fitness. If the following server is not a better candidate for allocation, starting with the first server of the first chromosome, virtual machines are allocated.
In Divya et al. [10], a method for smart clouds and framework for parking predictions are suggested. The combination of IoVT based kernel and smart cloud is designed which is economically advantageous in terms of energy and the environment. It is supported to dynamically scale both up and down computer funds to manage a spike in demand. The proposed approach, which i) reduces the datacenter deployment per provider ratio and share, enables numerous providers to make the most use of compute resources. ii) Using aggregators to distribute the available energy. iii) Finally, choose more environmentally friendly, carbon-free engines when appropriate. A relevant issue about the energy consumption and cost utilization are dealt in Savita et al. [18]. In this approach, provider demands a minimum prize per VM and proves minimum utilization of power. The mechanism attempts to turning off idle nodes to save power ensures the providers to increase their profit over the prices to compete in the Cloud market [20].
Provisioning in intercloud environment
In Rashid et al. [9], describes a method for securing IoT medical data in Health Care Systems in terms of its storage on public cloud systems. proposed system will greatly help in efficient storage of IoT application medical data. The method uses Enhanced Role Based Access Control (ERBAC) provide secure storage of medical data in the cloud systems based on these role based access policies.
The inter cloud service execution requires integrated version of monitoring and verification. In Pooja et al. [11], the strategy of analysis done for minimal metric monitoring service that increases reliability in variety of private cloud infrastructure. The scheduled tasks estimate responsiveness with varying in time and load conditions. The presented results evaluated hardware characteristics, overall load and utilization of actual cloud providers that is in line with SLAs. In such cases, CPUS were under provisioned and it is reflected in the pattern of infrastructure.
InterCloud’s goals, and architectural components are detailed in [16]. The architecture that is being shown allows for application scaling across many cloud providers. There are three modules in architecture. Cloud Broker, Cloud Coordinator, and Exchange. Several cloud service providers and users are linked by Cloud Exchange. It utilizes the resource data that is currently available and supplied by cloud coordinators, it evaluates infrastructure requests received from brokers. Most of the algorithm focuses on maximizing IaaS provider’s profit that analyzes through service composition. In this model, optimal allocation strategy for decision making was proposed. This model includes parameters such as workload, Cost of outsourcing, the quantity of resources outsourced, and server maintenance costs.
Federated cloud based on SLA
Hariharan et al. [12] show the effects of federated cloud computing on SLA. A precise model for federated cloud SLA assessment has been developed, and this will be compared to non-federation systems. Two models are used to calculate the evaluation: first focuses on deterministic and second evaluation based on probabilistic. In Rejin et al. [17], data integrity for federated cloud architecture is implemented for ensuring benefits of SLA to meet user needs, problems with the federated cloud environment, as well as possible solutions, are examined. It has been argued that the development of federated clouds, which enable a variety of services to be offered and free organizations from uncertainty, is the greatest solution for all organizations. Previously, outsourcing issue with a data centre termination option for spot VMs are provided. Under such circumstances, comparison of two attempts can be identified [21].
Load balancing
A model that partitions the public cloud to balance the load has been developed [14]. Servers, balancers, and the primary controller are all included in the design. Each cloud’s status is indicated as overload, normal, or idle. The primary controller contacts all of the partition balancers when a task is added, and the work is then scheduled for a partition that is not overcrowded. Each partition’s balancer further determines the load on each server, and tasks are then scheduled on the server with the least load. This architecture increased resource availability, performance, and resource consumption by dynamically allocating work to the server that was least busy.
A new efficient VM load balancing algorithm [15] determines the anticipated response time for each VM. When a request is made, the algorithm notifies the data centre controller for VM with the fastest anticipated response time and schedules the request to that VM. The allocation count for the chosen VM is then increased by the algorithm. The data centre controller [19] reports the algorithm for VM deallocation when the service request is complete. The assessed outcome demonstrates that selecting VMs wisely can decrease average response times while also boosting cloud performance as a whole.
System model
Cloud federation is the interconnection of cloud computing environments of two or more service providers which built for the load balancing and emphasizing providers for in demand. The Model adopts a heuristic approach to solve the resource allocation by provisioning. In this section, cloud federation including various types of services was described. Later, the resource provisioning and requirements for Cloud federation are discussed.
Cloud federation
Functional diagram of cloud federation processing framework in this work is shown in Fig. 1. The cloud federation is depending on provider who acts autonomously. Federation can help providers to envision overload and balance them with specific focus in on demand services. At the center of this model, there is a single pool supporting three interoperability techniques such as resource provisioning, data storage and combination of complementary resources.
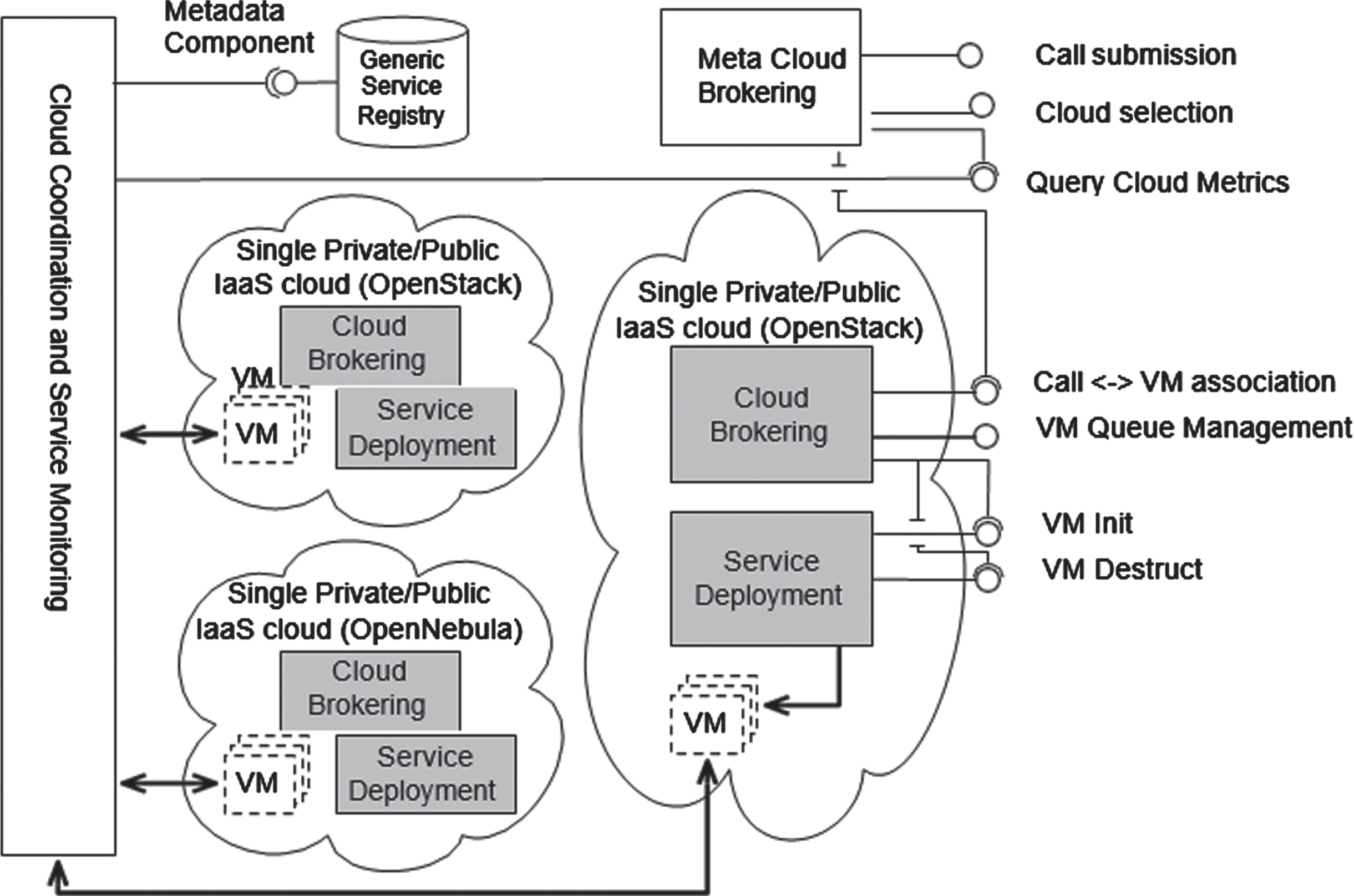
Federated cloud management.
Cloud coordinator can decide allocation of resources from different cloud service providers (CSP). The cloud coordinator is the component who estimates the amount and range of idling capacity for every supplier who exchanges with other members. The cost estimation done by providers based on demand basis. Federated cloud takes care of distributed data and workflow management. The federation of cloud resources enables a client to select the best cloud services provider to address a unique technological or business necessity inside their organization, taking into account flexibility, cost, and service availability. The agreements between federated members and providers are connected with profit to all its members. The cloud federation allows agreements as Federation Level Agreement (FLA) for allocation of resources. The mechanism deals with private information pertaining to the provider with regards of actual resources used by the providers. Considering the above scenario and predictions, resource allocation policy is proposed in the next section that identifies how various service providers decisions have an impact on revenue among the clients.
The main challenging task when providers allocate resources of their capacity in the form of spot VMs. A federated cloud provider must choose between raising the spot price and terminating spot VMs or outsourcing the request to another federation member. This would be done when it receives an on demand request for VMs when there are no available resources in the data center.
Federated cloud shares the workload between the CSP and determines interoperability between the two clients. Some of the major issues and challenges in processing federated cloud are as follows:
Performance and networking cost
Networking being a key aspect of handling cloud-based services, it is suggested to have a reliable routine that would cost and optimize the workflows. This enhances raw infrastructure, elasticity through web interface and pay-per-use.
Security and privacy
Cloud environment Protects the outsourced data through delegates installation. Data security incorporates scrambling the data by ensuring that legitimate systems are executed for data sharing. It majorly concerns with managing security mechanism to the provider and assured increasing level of trust.
Interoperability and portability
User’s data requires portability for components that can be moved to the cloud. It depends on interoperability with other components that remain on in-house systems. This approach needs managing interfaces for data elements and virtual workloads.
The major contribution of the work is to optimize computational costs of executed instances and dynamic provisioning of VM allocation with fair load allocation. To evaluate this, consolidation of utilized VMs and execution performance will be taken in to account for the global perspective.
Resource provisioning
In a cloud management, when all the nodes are operative, provider demands a minimum price per VM and a minimum utilization. The proposed policy focuses on profitable utilization of local resources which is extremely preferred to external resources. However, if the workload cannot be supported locally, later it increases the provider’s profitability. Regarding the resource provision in cloud federation, most of the algorithm focuses on maximizing IaaS provider’s profit that analyzes through service composition. This system model refers a thorough analysis of a problem with practical advantages. The proposed policy is based on VM provisioning to improve the allocation of resources which aids in selecting the most practical choice based on the services that are available. The outsourcings to other providers are implemented for renting free resources or power-saving node shutdowns to idle nodes. This method won’t result in a decrease in the price of buying and hosting IT equipment. This envisions remain profitable when the providers had to raise their pricing, which reduced their ability to compete in the cloud market.
Optimal allocation of cloud resources
Using Virtualization, resources for networking and computing must be managed and optimized together. Since the data is dynamically stored and within networked clouds, to real substrate resources, this necessitates the provisioning of collections of virtual resources driven by users. The impact of creating need for virtual machines (VMs) that are preloaded with operating systems and application software must be maintained by the cloud consumer.
In this work, allocation of cloud resources is estimated the following aspects
a) This work proposes the idea of bit matrix, which is representation of the environment and current resource availability status generated by each individual cloud member when processing a user request.
b) Design an optimal allocation policy BMNF for load distribution reduced response times for requests, improved energy efficiency among various cloud members, and improved quality.
c) Analysis of BMNF policy’s performance and comparison of another existing algorithm.
Proposed model
Despite of involving resource management in the cloud federation, everyone focuses on maximizing IaaS providers to gain profit. In this section, the model for optimal allocation strategy for decision making was proposed.
User demands are inputted into a resource allocation process, which then outputs the result of the allocation. Previously, outsourcing issue with a data centre termination option for spot VMs are provided. The first one gives VMs resources so that the cloud service provider may make more money. The second one distributes VMs throughout the several data centers to balance the load in a federated cloud system. The parameters include workload, cost of outsourcing, free resources sold, the quantity of resources outsourced, and server maintenance costs. For promoting an integrated management in resource allocation for delivering efficient cloud implementation through IaaS, Openstack will be utilized.
VM allocation algorithm
In this part, the algorithm based on virtual machine allocation is maintained by controller components for optimal allocation. This will support various resource pool and group entities to aim to find hosts with a lot of workloads to boost utilization. Less hosts will be implemented, which will result in higher utilization. OpenStack compute is the element that makes it possible for users to create and control virtual servers using machine images. Large networks of virtual computers are configured and managed by OpenStack computing. In the first stage, based on the request of consumer, initialization of Host and VM was furnished then based on RAM and CPU utilization cost, the VM allocation is done.
In the second stage, when we request for allocation, it checks for reserved request and based on that utilization threshold values were compared. The comparison will result the minimum value which leads to allocation of VM to the reserved request. Either case if request is on demand, then resource provisioning will compare the neighbor cost as well as compute cost to allocate the VM. The general method followed in proposed algorithm has been shown in Fig. 2.

VM allocation based on request.
In general, the necessary characteristics should be offered by an allocation method included in Section 4. The algorithm was done for each type of virtual machine that can scale without bounds. The providers are working as on-demand type who will process the allocation of Virtual Machine. If the allocation is not reserved then the operation will be handled till it reaches the first provider after they transmit it to the next request. since the allocation will be worked on their own benefits.
The proposed algorithm is an algorithm which aims for an ideal virtual resource distribution in a federated cloud. The algorithm produces cost estimation, load balancing, and enables high availability with higher profit.
Globalvariable requestutilization, thresholdvalue;
// optimal resource allocation algorithm Start VM based on RAM, CPU, cost
begin vmallotProcess(thresholdvalue); begin rejectallotment;
begin allocateVMneighbor begin stopallotVM
//preemptive scheduling algorithm Dequeue a content request; lookup corresponding content; schedule the content; update statistics and repeat;
begin store thresholdvalue; allocateVM; end Output the VM allocation using Thresholdvalue
For the proposed algorithm, the rules that have been suggested, each of which differs in how it addresses fresh on-demand demands that can’t be met by nearby resources.
Federation-aware resource allocation (FARA)
In this policy, the service for cloud exchange by other participants is pre checked and then provides the utilization. The procedure next followed as allotment for request who provides in cheapest price. The decision for spot VMs while outsourcing is not possible, then new on-demand request will be executed. The decision concludes whether outsourcing is profitable with on demand request and spot termination.
Given a sequence of allocation task AT = <T1, T2, . . . , Tm>, utilize the allotment of the use virtual machines fair allocation process in AT. A federation aware route P can be used to represent a resource allocation plan. There are sets of virtual machines in each row that need to be allocated for federated cloud in the allocated task:
The resource allocation plan P represents the federation aware process and uses the sequence that available in AT. The plan is approximately equivalent to,
The exclusive virtual machines are handled as an allocation division by resource allocation methods. The virtual machines VM1 = V1, V2, V3, V4, V5 in each task Ti will be considered for allocation. The virtual machine cannot be used by another allotted Task Tj. Then another allotment for next set of virtual machines VM2 = {V6, V7, V8, V9, V10} need to be allotted for task Tj.
Federation oriented utilization (FOU)
In this policy, the use of outsourcing is contrasted with the removal of spot VMs. The emphasis is on identifying spot VM terminations that result in profit loss and spot VM replacements that boost profit. Additionally, terminating spot VMs could result in a rise in the spot price.
Federated Cloud Manager (FCM) serves as the administrator of the “M” clouds (c1, c2, . . . , cM) that make up the suggested federated cloud architecture. Every cloud provider dedicates ‘m’ hosts with various hardware setups (h1,h2, . . . hm) on ‘m’ hosts to the federated environment. Consequently, the federated cloud’s Total Infrastructure Load (TIL) might be determined by
FCM dynamically distributes “n” virtual machines (VMs) across “M” FC clouds that are available to it. Requests with dynamic lengths must be planned among the various cloud members in the best possible way to meet performance requirements like equitable Optimal resource utilization, lower power consumption at each cloud, sharing of workloads within federated cloud members, and faster improvement in response times while maintaining SLA.
The total utilization of outsourced VMs and request of spot VMs are derived as federation-oriented utilization. The FOU policy compares them using fair allocation at each cloud as active with ‘p’ to m-p hosts (HT) and hosts operating (HA) in spot terminating VMS mode can be expressed as
The main goal of the proposed model is to Equitable load distribution across different cloud members in federated cloud
Optimize the cost assurance at each cloud individually with overall cost consumed in FC
Bit Matrix Pattern [1 1] [1 0] [0 1] [0 0] is used in the proposed model, where each pattern denotes the degree of resource availability across the FC’s cloud members as requests which is being planned.
The Load Dispersal Aspect (LDA) is calculated by FCM based on the overall resource volume committed by the cloud. This workload distribution in a federated cloud is managed by utilization of those volumes. LDA (CSortedLDA) is used to order clouds in ascending order. An incoming queue is generated when multiple request joins, FCM publishes the request’s needs to all cloud members. In the federated cloud architecture, each cloud member creates a bit matrix that represents the importance and effect of VM deployment on the execution of those requests and it is delivered to the manager. In addition to the sorted cloud list CSortedLDA, FCM analyses the bit matrix acknowledged from each cloud member taking into account host utilization, request completion time, and cloud power consumption. Manager chooses and schedules the request to the best cloud based on analysis.
Functionality and analysis of Bit Matrix
A distinct web hosting application service is available on VM hosts, whose workload used a uniform distribution to construct and whose CPU utilization distribution is considered. Every time the creation of an instance to implement web-hosting service required 150000MIPS or it takes 10 min to complete execution with assumption of 100% utilization.
1) Effect of spot request: The experiment intended for assessing alterations in the ratio of on-demand queries may affect performance indicators.
2) Effect of persistent spot requests: This evaluation shows how adjusting the amount of persistent spot VM requests has an impact on the providers.
3) Effect of providers in the federation: with the ratio, it is ideal that the provider can handle the growing number of providers and also have an outsourced option which have less VMs available on demand. These are refused which make use of serving the outsourced request.
The challenges in cloud federation will accept trading idle resources for virtual resources or outsourcing decisions that are profit-driven. The strategy also considers the providers’ ability to turn off any data centre nodes that are not in use in order to conserve energy. However, they failed to take into account various VM types, or prospective measures like terminating low priority leases on-demand and spot [26]. Recently, the goal of utilizing spot VMs has drawn a great deal of focus. To achieve, an optimal allocation can be done with consideration of QoS as a level by approving more service request with respect to maximize cloud provider’s profit.
Methodology for estimating BMNF
FCM is the interface via which users interact with the federated cloud. An FCM has several linked clouds. The manager interacts with each cloud broker in response to a request before deciding which cloud is the best one based on a variety of performance criteria. Cloud Broker monitors a certain cloud, is in charge of placing VMs on the proper host, and gives consumers access to computing resources to fulfil their requirements. Users who require virtual infrastructure to fulfil their needs using FCM are the last segment.
The major three working components of FCM are broadly categorize as: i) examining the LDA of each cloud and dispersing the load over many clouds in an even manner. ii) Determining the best by examining the obtained bit matrix pattern in accordance with certain performance standards. iii) Managing the request scheduling and VM deployment in the chosen cloud.
Fair load adoption
In this context, FCM evenly divides the load between various clouds. Previously Rajeswari et al. [24], proposed estimates load distribution policy in terms of power consumption in federated cloud. In this model, the concept of fairness is defined based on the overall resource capacity of each cloud that has committed to the actual use of capacity in a federated context. This allows the model to calculate LDA. The manager organizes clouds in ascending order according to the estimated LDA with the goal of providing higher priority to the clouds with the lowest resource utilization. The evaluation findings demonstrate “unfairness” between the federated cloud among available cloud system.
Optimal Bit Matrix for cloud selection
The FCM technique requesting each cloud broker’s bit matrix pattern in response to user queries. The table below shows various bit matrix patterns created by different cloud brokers, along with their significances and effects.
Recently, a variety of matrix-based computations for cloud optimization have been proposed, e.g., DMac [25]. None of the current systems make use of some of the unique characteristics of matrix programs to produce effective partitioning methods for matrix data. Both input and intermediate phases, there will be a number of distributed matrix compute processing issues. Considering the situation of its existing resource availability, a bit matrix is created by each cloud broker and sent back to FCM. Then manager evaluates based on a bit matrix for the request completion time, cloud power usage, host utilization, as well as other factors after receiving it. In the sorted cloud list, the manager uses the bit matrix value [1 1] to find the first cloud. It is present in the list C
SortedL
DA
. This is the best cloud since it saves on VM deployment, cost, resources, and power consumption, and because user requests are fulfilled on time and in accordance with SLA.
The FC manager uses the bit matrix, and then value of first cloud identified is [1 0] in the sorted list of cloud if there are no clouds with the bit pattern of value [1 1] in C SortedL DA .
This covers best option since it maximizes the usage of the running host, completes user requests in the allotted time, and satisfies SLA. It also saves electricity by deploying the virtual machine on the running host itself.
The manager then utilizes bit matrix for the first identified cloud with the value [0 1] of sorted list CSortedLDA if there are no clouds with the bit pattern [1 0]. This is a good approach because the user’s request is fulfilled on time and the SLA is met by the deployment of the VM.
Finally, the bit pattern of value [0 1] exist with no selection of cloud, a round-robin method is used to choose a cloud with [0 0] as a bit pattern from the generated matrix.
Here, two levels of analysis are performed: 1) At FCM level 2) At cloud broker level. Each cloud broker evaluates whether a request can be fulfilled promptly, the evaluation using BMNF model are as follows: VMs can be launched and requests can be carried out on hosts that are now running; VMs can be deployed on running VMs. On a new host, VMs can be launched and requests can be carried out by switching from sleep to active mode.
This analysis is used by the cloud broker to construct a Bit Matrix, which is then sent to the FCM.
The Manager does analysis that was received from all the cloud brokers, C
SortedL
DA
at the opposite end utilizing the Bit matrix and cloud allotment, choosing the ideal cloud with the following goals: The virtualization must complete the request execution in a timely manner. The cloud must use the least amount of energy. The load must be distributed fairly among the cloud members.
The suggested strategy allows for the achievement of performance evaluation like: equitable load sharing, faster response times, and shorter waiting time, adherence to SLA, total cost spent and optimized power consumption. The goal of the presented architecture is to decrease the number of hosts and VMs in an individual cloud while maintaining fair load distribution and QoS standards.
Considering facts on optimal allocation, analyze the suggested federated cloud model’s performance and viability, Optimized Bit Matrix based Node Acquisition for Federated cloud (BMNF), an ecosystem of federated clouds is created by distributing a set of computational resources among several clouds. Here five clouds are set up with varied capacity for the examination. Table 2 below displays multiple cloud formation will be tracked with setup inside each cloud created for the assessment in the suggested approach. Each cloud has a specified weight as WC1 = 1, WC2 = 2, WC3 = 4, WC4 = 8, WC5 = 16 depends on the number of resources committed to the federated cloud environment.
Federated cloud configuration with workload estimation
Federated cloud configuration with workload estimation
The experiment was carried out by creating more than 1500 jobs of varying lengths, which were continually delivered to the FCM every 5 seconds, ranging from [5–50] requests. At each data centre, VMs are dynamically constructed during the simulation process to handle the incoming requests.
The application prototypes employ a federated cloud architecture, which is representative of a practical deployment configuration. The architecture consists of (i) the Cassandra-X [29] deployment arrangement, which includes two nodes of the Apache Cassandra cluster (stable version 3.11.1), one of which is active and operational, whilst the other node is inert (i.e., dormant). the standby mode; and (ii) the MongoDB-X deployment configuration contains a single node Service MongoDB (stable version) 3.4.9); (iii) the Cassandra-Y deployment configuration includes only one node Apache Cassandra (stable version) service 3.11.1); and (iv) a single node MongoDB service (stable version 3.4.9) is included in the MongoDB-Y deployment scenario.
CloudSim report toolkit [27], which consists of Netbeans IDE 12.5 [28] and CloudSim 3.0.3, has been utilized as the platform for the simulation experiment. To resemble the suggested algorithms, the classes of the CloudSim simulator have been expanded. This working model is developed in Java. A 64-bit Windows 10 computer with an Intel® CoreTMi7-3770 processor and for the test, 8GB of DDR3 SD RAM was used. Results from Round Robin and Distance Based load distribution are compared with those from the proposed BMNF model to show its efficacy and fairness.
In Fig. 3, the proposed BMNF estimates the percentage of load distribution among various cloud members at various time periods. It has been compared with round robin, and distance-based load distribution methodologies. Notably, the suggested BMNF model shows compared to the fair load allocation among all cloud members, avoiding unfair load distribution caused by the other two existing solutions for each time slot. The suggested BMNF model nevertheless upholds equity among various cloud members when load increases over time, according to a general trend that may be observed here. This is because, while choosing the cloud and allocating requests to it, FCM takes into account both the Bit Matrix status that it receives from the cloud members as well as the LDA at each cloud.

Effect of load distribution at different time slots.
Figure 4 shows the average response times derived by three approaches for requests served at various clouds. The average response time for all three clouds in the proposed BMNF model is decreased by 9.4 seconds when compared to the Round Robin technique and by 9.6 seconds when compared to the Distance Based approach. Here broker works allotment of virtual machine with load balancing based on request and results in Predicted Completion Time (PCT). Figure 4 shows that, as compared to current methods, each cloud’s average response time to queries is considerably low. This is so that managers may choose the best cloud. Every cloud broker creates a Bit Matrix to show if requests can be fulfilled within a specified time frame either by launching a new VM or using an already-existing VM. Additionally, the broker chooses VMs within each cloud that offer the bare minimum PCT.

Response time of requests.
The average request waiting time is illustrated in Fig. 5. Compared to the other two methods that are currently in use, the proposed BMNF model has a shorter waiting time. Due to bit matrix, FCM can find a cloud that fulfills the request on time. Additionally, a cloud’s broker assigns requests to virtual machines (VMs) with the lowest PCT.

Waiting time of requests.
A random matrix with the same dimensions to study the effectiveness of the dynamic cost-based optimization strategy has incurred. The skew values illustrate different plan with similar executions. The extensive computation costs and its waiting time will be generated using random matrix computation.
In comparison to the other two load distribution approaches, the suggested model’s reduced rate of SLA violation is shown in Fig. 6. Because each request is processed immediately after receipt, there are fewer SLA violations now. FCM determines a cloud that focuses and fulfil the workload on an active VM by the deadline given or alternatively builds a VM on an ideal cloud. As a result, the majority of requests are fulfilled on time and in accordance with SLA.
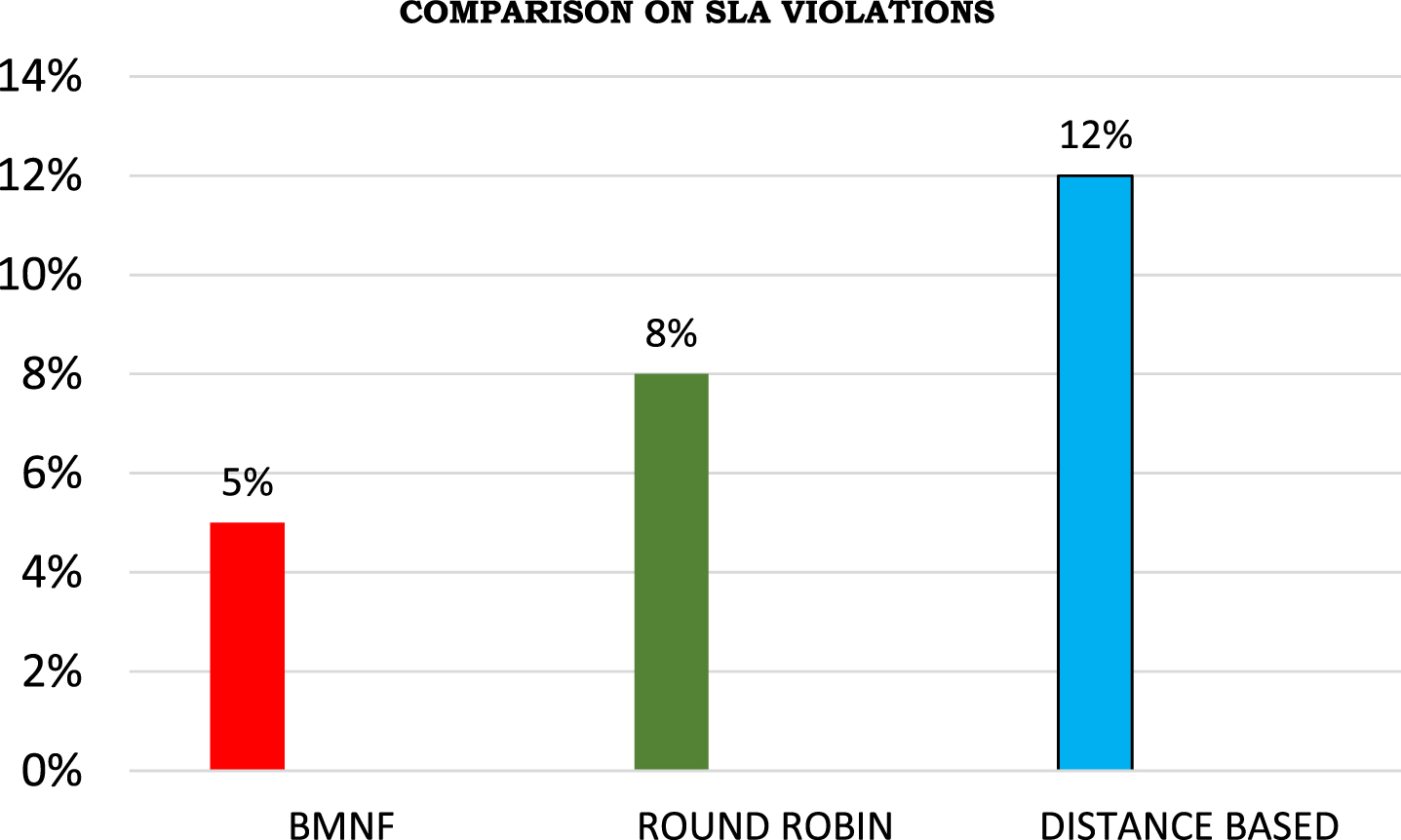
Percentage of SLA violaitions.
Overall, the distance-based strategy not consider each cloud load and the Round Robin technique ignores the transmission lag as a result of its frequent selection of clouds that based on a cyclical process. Both strategies involve the deployment of more virtual machines, which results in an inefficient load distribution and higher power usage. Both strategies do not address the requests’ finish times, either. This lengthens waiting and response times. However, the suggested BMNF model considers the contribution of various clouds’ resources to the federation as well as their present consumption, estimated completion time, and host in live or inactive mode state when deploying a new allocation of VM. As a result, reaction times are enhanced, waiting times and energy consumption are reduced, and the load is distributed fairly across cloud members.
In a federated cloud setting, proposed model incurs a novel technique to allocate load across various cloud members. Each cloud’s LDA is determined using FCM, and the clouds are sorted as a result. When a request is received, the manager broadcasts the request specifications to each cloud brokers. When completing the request, different cloud brokers create a Bit Matrix based on the circumstances. The FCM chooses the best cloud by analyzing LDA, cloud duration of active mode, and bit matrix received from the cloud. The execution of a series of dynamically produced requests on an ideal cloud is used to assess the algorithms and federated cloud architecture. The scheduling algorithm’s assessment of the performance parameters response time, waiting time, SLA violation, as well as the model for energy use and fair load distribution across various members, which benefits over cloud providers, is an important factor to take into account. Overall evaluation of the proposed policy’s performance reveals fair load adoption, with an average of 45.3%, 46.4%, 49.5% of the load allotted to Cloud 1 to 3, compared to Round Robin’s 56.6%, 29%, 18.34% of the load, and distance-based approach 63%, 28%, 22.6% of the load, respectively. In addition, the proposed policy reduces power usage by around 37% to 40% and response times by an average of 48.7% to 52% when compared to the current approach.
Conclusion and future work
Here we compared the policies of optimal case allocation that based on the capacity of memory resources allotted according to user-configured resource allocation policies (such as reservation, shares, and limit), and compared it to the presumption that each virtual machine in the cluster uses all of the resources allotted to it.
The ratio of executing on-demand service with a high percentage of spot VMs, locally is more profitable. The customers decision over terminating spot VMs could result in fewer service interruptions. Furthermore, contracting with cloud is more gainful when spot VMs are hard to come by because doing so might cause customers to stop using the services. Additionally, federation assists under-utilized providers in generating income by allowing them to sell idle resources to other members. Strategies for considering as a continuation of this work, forecasting future resource availability to guide decisions of cloud selection will be explored.