
Abstract
The semantic segmentation of high-resolution remote sensing images has broad application prospects in land cover classification, road extraction, urban planning and other fields. To alleviate the influence of the large data volume and complex background of high-resolution remote sensing images, the usual approach is to downsample them or cut them into small pieces for separate processing. Even if combining the two methods can improve the segmentation efficiency, it ignores the differences between the middle and the edge regions. Therefore, we consider the characteristics of large and irregular region in high-resolution remote sensing images, and then propose an irregular adaptive refinement network to locate the irregular edge region, which will be refined adaptively. Specifically, on the basis of effectively preserving the global and local information, the prediction confidence is calculated to locate pixel points that are poorly segmented, so as to form irregular regions requiring further refinement, avoiding to ‘over-refine’ intermediate region with good segmentation. At the same time, considering the difference in the refinement degree of different pixels, we propose to adaptively integrate the local segmentation results to refine the coarse segmentation results. In addition, in order to bridge the gap between the two extreme ends of the scale space, we introduce a multi-scale framework. Finally, we conducted experiments on the Deepglobe dataset showing that the proposed method performed 0.37% to 0.87% better than the previous state-of-the-art methods in terms of mean Intersection over Union (mIoU).
Introduction
The essence of image semantic segmentation is to classify images pixel by pixel. With the continuous development of remote sensing technology, the high-resolution characteristics of remote sensing images provide rich spatial structure and texture information, and the semantic segmentation of high-resolution remote sensing images has received widespread attention and plays an important role in land cover classification [1], road extraction [2], urban planning [3] and other applications. However, semantic segmentation of high-resolution remote sensing images still faces significant challenges. Compared with traditional images, remote sensing images are usually taken from high altitude and overhead, which leads to poor differences between classes. For example, it is difficult to distinguish agricultural and barren, rangeland and forest only by simple texture features. In addition, high-resolution remote sensing images exhibit class imbalance. Specifically, the proportion of different classes varies. Some classes span the whole image, such as water, while some classes become minority classes compared to these majority classes above, such as architecture. This means that high-resolution remote sensing images require both global feature and local detail feature to describe them together. However, for semantic segmentation of high-resolution images, there are two mainstream processing methods: one is to input the model after downsampling the input image, obtain the segmentation results, and then upsampling. This method retains the global information, but continuously downsampling loses the rich detail information. The other method is to cut the image into patches, and independently perform semantic segmentation on each patch, and finally ensemble the local segmentation results into high-resolution segmentation map. This method retains local information, but the small receptive field leads to the lack of context information.
Therefore, a common way to solve the limitations of the above methods is to combine them and learn from each other’s strengths to offset their own weaknesses. Global-Local Network (GLNet) [4] has demonstrated the effectiveness of this method by deeply integrating feature maps from global and local branches, capturing not only context dependencies from downsampling inputs, but also high-resolution fine structures from amplified local patches. However, this method does not take into account the characteristic of large connected areas in high-resolution remote sensing images, and the middle part of these large areas does not need to be refined with detailed information. In order to save running time and memory, an effective method is to calculate the prediction uncertainty of the coarse segmentation results of each cropped patch corresponding to the regular areas, then select the patches with high uncertainty to refine. However, this method does not take into account the irregular region of remote sensing image. For example, a water area will span several local patches, and regular cropped will destroy the integrity of the area belonging to the same class. There are still intermediate areas that do not need to be refined in the selected refined regular patches. Therefore, we consider hierarchical localization of irregular regions requiring refinement based on prediction uncertainty of coarse segmentation. In addition, GLNet [4] also treats all pixels in each local image equally, but for the different pixels, the contribution of segmentation results with different sizes is different, and the degree of refinement is also different. Moreover, for HSR images, there is a huge gap between the scale of the whole image and the scale of the local patch, so the direct fusion effect is not very ideal. In order to effectively integrate the global contexts and local details, we adaptively integrate the local segmentation results based on the coarse segmentation results after taking into account the different refinement degrees of different pixels. Meanwhile, in order to bridge the huge gap between the global image and the local image, we propose to consider multiple scales in between.
In this paper, we propose an Irregularity Adaptive Refinement Network (IARNet), which consists of two components: pointing irregular regions and adaptive refinement. Our proposed method mainly locates irregular regions with low segmentation certainty based on category stratification, and then adaptively integrates global contextual information and local detail information in multiple stages. Specifically, in the global segmentation stage, the global image is input into the model to obtain coarse segmentation results. In order to further improve the segmentation accuracy, the prediction confidence was calculated to select pixels difficult to be segmented by the model, forming irregular regions requiring further refinement. Then, for the pixels in these irregular regions, the local segmentation results are adaptively fused to refine the coarse segmentation results. In addition, in order to bridge the gap between the two extreme ends of the scale space, we propose a multi-scale framework in which the output segmentation map will be progressively refined during image analysis. To evaluate the effectiveness of the model, we conducted experiments on public datasets. The important contributions of our research are summarized below. We propose a segmentation uncertainty criterion to locate poorly segmented pixels in the global image to form irregular regions, so as to further enhance segmentation. It re-examines the coarse segmentation results from the perspective of probability statistics. This part can be used after any popular semantic segmentation network. We propose an adaptive weight generation mechanism, which refines the coarse segmentation results by adaptively fusing local segmentation results for the located irregular regions at each refinement stage, thus improving the accuracy of semantic segmentation. We demonstrate the effectiveness of our method by achieving state-of-the-art semantic segmentation performance on publicly available remote sensing image datasets with high spatial resolution.
The rest of the paper is organized as follows: Chapter 3 describes the design concept and composition of the proposed IARNet framework in detail. The experimental datasets, model evaluation methods, experimental procedures and analysis of experimental results are given in Chapter 4.
Related work
With the rapid development of deep learning, more and more convolutional neural networks are widely used in image semantic segmentation. As a pioneering work, Full Convolutional Network (FCN) [5] replaces all fully connected DCNN layers used for image classification with full convolutional layers to output two-dimensional feature maps. Subsequently, improved networks based on FCN were proposed successively, such as U-Net [6], SegNet [7], etc., which adopted the encod-decoder structure. DeepLab [8–11] uses dilated convolution to magnify the filter’s field of view and establish connections between distant pixels. In order to improve segmentation speed and reduce memory usage during semantic segmentation, ENet [12] uses an asymmetric codec structure with early downsampling to reduce the number of floating point operations and memory footprint. ICNet [13] performs cascaded feature maps and model compression from multi-resolution branches under appropriate label guidance. With the rapid development of Transformer, many researchers have extended Transformer to semantic segmentation tasks. The appearance of VIT [14] introduces the pure Transformer structure into the image classification. After the image is divided into patches and embedded, Transformer is used for calculation, and the classification is realized through MLP. AFNet [15] designed a multi-level architecture with Scale Feature Attention Module (SFAM) and used an adaptive fusion network to improve the performance of remote sensing image segmentation. ST-Unet [16] designed the spatial interaction module and the feature compression module, which alleviated semantic ambiguity and reduced the loss of details. Ref. [17] uses self attention instead of partial convolution to improve the feature extraction ability of CNN, thereby improving the classification performance of images. SETR [18] deployed a pure Transformer to encode the image into a series of patches, and enhanced the segmentation by modeling the global context of each layer of Transformer. However, although the network model based on the Transformer has good precision performance, it has a large number of network model parameters. In addition, if the training date is insufficient, it is easy to overfit.
Combining multi-scale feature information can help the network aggregate different perspectives and provide more contextual information for each pixel [19, 20]. Feature Pyramid Network [21] upsamples feature maps of different scales and aggregates them with the output of the lower layers. PSPNet [22] combines different scale feature maps to expand receptive fields, and introduced a pyramid pool module to extract context information and global information from different receptive fields in images. ParseNet [23] aggregates the global context into the local field of view to provide additional information. BiSeNet [24] also includes a global pooling branch that adds the global context to the feature map at the final stage. While these methods are effective, they require a large amount of GPU memory. Ref. [25] proposes a method for semantic segmentation of ultra-high resolution images, which utilizes an independent multi-scale network and adaptive high-resolution weights to combine the network output with corresponding training weights to obtain the final output. However, this method has the disadvantage that there is no information sharing among network branches. CascadePSP [26] refines coarse segmentation results from a pre-trained model to produce high-quality results.
In the field of remote sensing semantic segmentation, HMANet [27] proposed a new attention framework that reduces feature redundancy and improves the efficiency of self attention mechanisms through region representation. FarSeg [28] enhances the recognition of foreground features by learning foreground related contexts related to the foreground scene relationship of remote sensing images. Ref. [29, 30] utilize HRNet to enhance the low to high features extracted from different branches, in order to enhance the embedding of scale related contextual information. GLNet [4] combines global and local information and interacts with deep shared layers, and this network can balance its performance and GPU memory usage. MagNet [32] proposes a new multi-scale framework that solves the problem of local blurring by viewing images at multiple zoom levels and directly outputs high-resolution segmentation. FCtL [33] introduces a segmentation model based on a novel locality-aware contextual correlation to process local image patches, and proposed a contextual semantic refinement network, which is endowed with the ability of reducing boundary artifacts and refining mask contours during the generation of final high-resolution mask. Ref. [34] proposed a Hierarchical Context Aggregation Network (HCANet) for semantic segmentation of high-resolution remote sensing images, which is designed with two compact hollow space pyramid modules (CASPP and CASPP+). The CASPP module replaces the copy and crop operations in U-Net to extract multi-scale context information of multi-semantic features of ResNet. The CASPP+ module is embedded in the middle layer of the HCANet decoder to provide a powerful aggregation path for contextual information. In the decoder of HCANet, the multi-scale context information obtained by CASPP module is integrated layer by layer and used for semantic segmentation of high-resolution remote sensing images. However, these models fuse contextual information equally for each pixel, and fuse it through a “black box” neural network. Different from previous work, our model only locates local irregular regions for selective context fusion and “transparently” adaptively fuses context information.
Proposed method
On the basis of the above research status and improvement ideas, we propose a novel segmentation network of high-resolution image, Irregular Adaptive Refinement Network (IARNet). Next, we first provide the overview of the network and further introduce its composition, including the Irregular Area Positioning Module (IAPM) and the Adaptive Refinement Module (ARM).
Overview of network architecture
As shown in Fig. 1, the core of IARNet framework consists of Irregular Area Positioning Module and Adaptive Refinement Module. At each stage, semantic segmentation is performed on the cropped image patches to obtain several segmentation image patches, which are then concatenated back to the original size segmentation image. Then, IAPM is used to locate pixels with unsatisfactory segmentation results, and ARM is combined with the local segmentation results of the next stage for refinement to improve the global segmentation effect. In our framework, the segmentation network can be any segmentation backbone consisting of a combination of IAPM and ARM relationships.
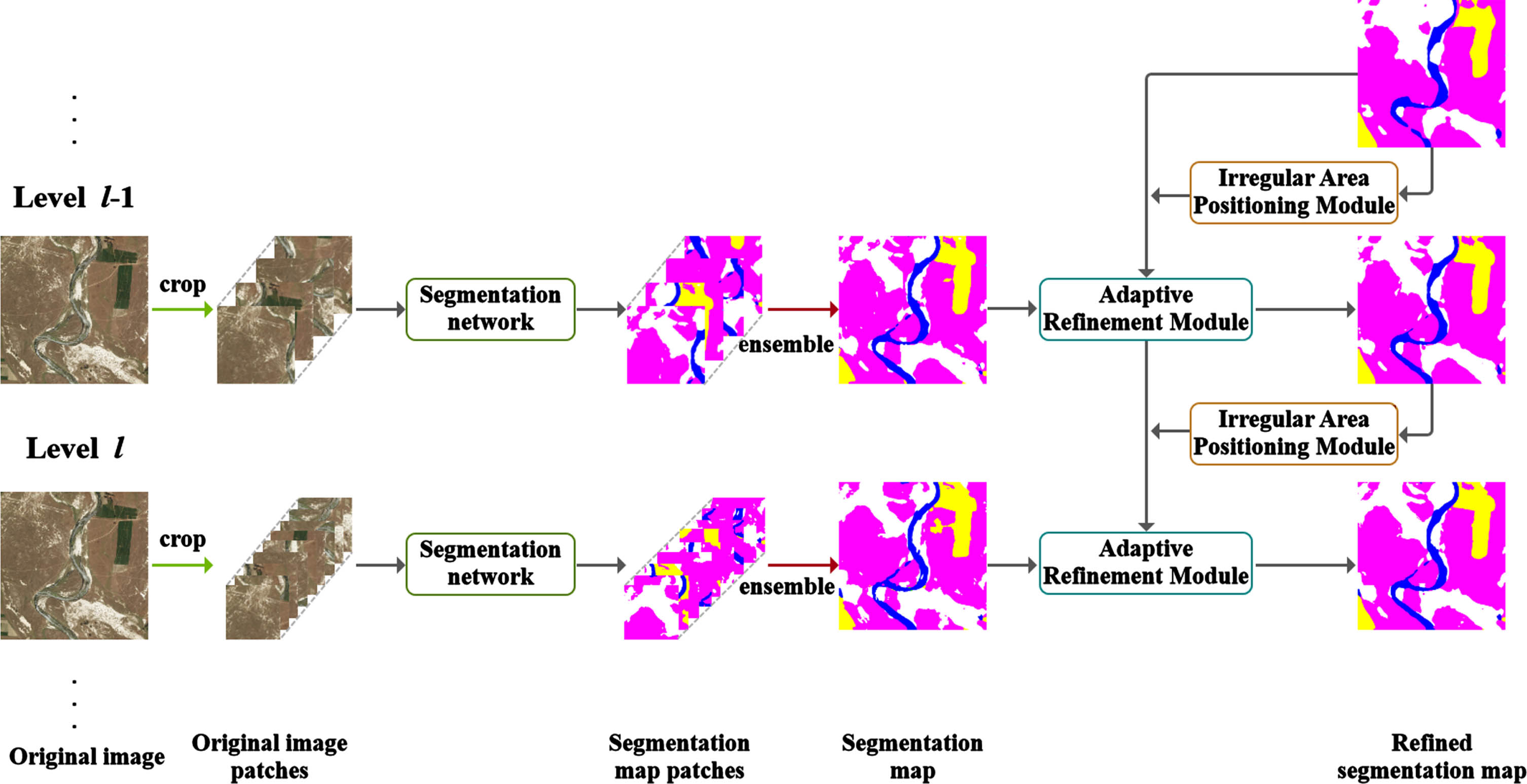
Overview of our proposed IARNet.
The Irregular Area Positioning Module is the fundamental component of our framework, which is used to screen out pixels with low segmentation accuracy at each stage. The input to this module is a scale cumulative segmentation map of size H×W×C from all previous scales. The output of this module is an irregular region composed of pixels with low segmentation accuracy. Figure 2 depicts the process of IAPM, which consists of the following steps. Firstly, the input segmentation map is layered according to the classification to obtain the C-layer segmentation result map {s1, s2, ⋯ , s C }. Then calculate the overall segmentation confidence of each category {u1, u2, ⋯ , u C }. Subsequently, by comparing the confidence of each pixel and its class, the points with high segmentation uncertainty are selected to obtain irregular areas with relatively inaccurate segmentation for each class. Finally, these irregular areas are combined to obtain the irregular area of the whole map.

The structure of the IAPM.
The confidence degree reflects the prediction certainty. For the semantic segmentation of remote sensing images, the prediction accuracy of the points with high prediction uncertainty is usually low. Inspired by this, we design the IAPM module and propose a criterion of pixel prediction uncertainty based on confidence. For each high-resolution image, it is downsampled and fed into the backbone of IARNet to extract the depth features M
global
∈ RH×W×C. Then, apply softmax function to the channel dimension and take the maximum value of each pixel on the channel dimension, denoted as u
ij
∈ (0, 1). Therefore, the confidence matrix of the global image is U
global
RH×W×1, and the calculation formula is given in Equation (1).
Subsequently, based on the confidence level of the global image, the classification results can be divided into classes to obtain the overall confidence level of C classes {u1, u2, ⋯ , u
C
}, where
where n
c
is the number of pixels belonging to class c,
For each class, when the score of the pixel point
Finally, irregular regions of different categories {A1, A2, ⋯ , A C } are combined to get the final irregular region of the whole map.
The adaptive refinement module, which is the core component of our framework, is used to refine the irregular regions that IAPM locates at each processing stage. For irregular regions with high segmentation uncertainty, combined with the segmentation results from smaller field of view, the detailed information is used to refine the remote sensing image to overcome the inter-class similarity and intra-class difference. For processing stage l, the input to this module is two segmentation maps of size H×W×C: (1) the scale cumulative segmentation map Sl-1, from all previous scales. (2) the segmentation map of a specific scale S p , the segmentation graph of a specific scale. The output of this module is the updated scale cumulative segmentation map S l . According to the irregular regions located by IAPM that need to be refined, the coarse segmentation result of pixels in the irregular region is replaced by the prediction result, which is adaptively fused the context information of the larger-field image and the local detail information of the smaller-field image, in order to realize the enhanced segmentation feature. The structural diagram of ARM is shown in Fig. 3.
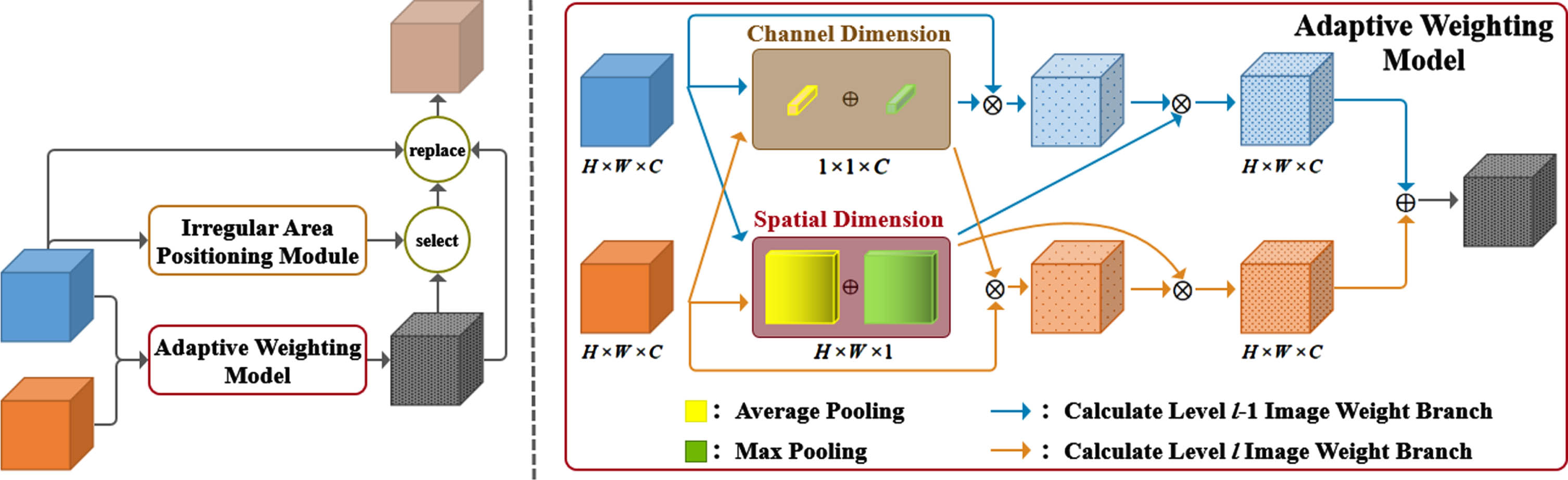
The structure of ARM.
According to the results of IAPM localization, we get the irregular regions which need further refinement after coarse segmentation. For the irregular region, the segmentation results of two different scales are taken as input. In order to effectively utilize the context information and local details, considering that the fusion weights of different pixels should be different for the segmentation results of different scales, we design a combination of channel domain and spatial domain to adaptively allocate weights to the prediction results of each pixel. The specific method is described below.
In order to guide the network to focus on the local feature information of images from different field of view, we adaptively assign weights to the cumulative refinement results of the previous stage Sl-1 and the segmentation results of the current stage S p along the channel dimension and spatial dimension respectively from the average and maximum values. As for the channel dimension, each layer of channels in the prediction results represent the probability value of the pixel belonging to different classes, and their contributions to the segmentation results is different. We use the abstract attribute of pooling operation to reconstruct the pixel prediction result into the description of 1×1×C channel. In terms of spatial dimension, the use of spatial relationship features enhances the model’s ability to distinguish image content. We allocate weights at the spatial level and compresse along the channel axis to obtain H×W×1 spatial description to determine the spatial location of key information aggregation. The above process can be expressed as Formula (4):
For each stage l, the segmentation results of different scales after weight allocation are fused, and the formula is
Then the module receives the positioning results of the irregular region from IAPM, selects pixels that need to be refined, replaces the predicted results of these pixels with the above adaptive fusion results, and obtains the final segmentation results of adaptive refinement.
In this section, we conduct comprehensive experiments on our proposed model on Deepglobe [35], a classical high-resolution remote sensing image dataset, compare and present it with Baseline and other advanced methods in terms of both evaluation indicators and visualization results, to demonstrate the improvement of segmentation quality of our proposed model. Finally, we demonstrate the benefits of multi-scale stages.
Dataset
The DeepGlobe Land Cover Classification Challenge is the first public dataset offering high-resolution sub-meter satellite imagery focusing on rural areas. Due to the variety of land cover types and to the density of annotations, this dataset is more challenging than existing counterparts described above. DeepGlobe Land Cover Classification Challenge dataset contains 1146 satellite images of size 2448×2448 pixels in total, split into training/ validation/test sets, each with 803/171/172 images (corresponding to a split of 70% /15% /15%). All images contain RGB data, with a pixel resolution of 50 cm, collected from the DigitalGlobe Vivid+dataset. The total area size of the dataset is equivalent to 1716.9km2.
Each satellite image is paired with a mask image for land cover annotation. The mask is an RGB image with 7 classes following the Anderson Classification. The class distributions are available in Table 1. Some example labeled areas are demonstrated in Fig. 4 as examples of farm, forest, and urban dominant tiles, and a mixed tile.
Class distributions in the DeepGlobe land cover classification
Class distributions in the DeepGlobe land cover classification

Some example land cover class label (right) and corresponding original image (left) pairs from interesting areas.
Urban land: Man-made, built up areas with human artifacts.
Agriculture land: Farms, any planned (i.e. regular) plantation, cropland, orchards, vineyards, nurseries, and ornamental horticultural areas; confined feeding operations.
Rangeland: Any non-forest, non-farm, green land, grass.
Forest land: Any land with at least 20% tree crown density plus clear cuts.
Water: Rivers, oceans, lakes, wetland, ponds.
Barren land: Mountain, rock, dessert, beach, land with no vegetation.
Unknown: Clouds and others.
We divided the 803 high-resolution images into train, validation and test sets, which contained 455, 207 and 142 images respectively. The dense notes contain seven classes of landscape areas, including cyan for “Urban”, yellow for “Agricultural”, purple for “Rangeland”, green for “Forest”, blue for “Water”, and white for “Barren”, of which the seventh category, called “unknown”, is not considered.
In this paper, the Feature Pyramid Network (FPN) [21] with a Resnet50 backbone was used as the segmentation network. In addition, the input size is 508×508px. When training our module, we randomly cropped the image patch and applied the following data enhancements: rotation, horizontal and vertical flipping. We used SGD optimizer with momentum of 0.9, decayed weight of 5×10–4, and initial learning rate of 1×10–3. We used cross-entropy as the loss function for training segmentation. We implemented IARNet using PyTorch to start from the public implementation of FPN with ResNet50, and used a batch size of 8 for training on a workstation with a signal NVIDIA GeForce RTX 3080.
Evaluation metrics
Mean Intersection over Union(mIoU), Precision, Recall and mean Pixel Accuracy(mPA) are four commonly used evaluation indexes for semantic segmentation tasks. Among them, mIoU is one of the most commonly used standards for all kinds of bench-mark data sets. Most of the model evaluation and comparison in image semantic segmentation papers take it as the main evaluation index. Suppose there are N classes in total. Denote P
ii
(i = 1, 2, ⋯ , C) as the number of pixels of class i predicted to belong to class i, and denote P
ij
(i = 1, 2, ⋯ , C) as the number of pixels of class i predicted to belong to class j. Then mathematical formulas of mIoU can be written by
The Feature Pyramid Network (FPN) [21] with Resnet-50 backbone was used as the segmentation network as in the previous work GLNet [4]. We also used the same input size 508×508 as GLNet. We used three refinement stages with three scales 508⟶896⟶1284⟶2448. The results are shown in Table 2. Our experimental results refer to the previous work MagNet [32], and are divided into the classical semantic segmentation network and the network improved for high-resolution images. The classic semantic segmentation networks are then experimented on two paths: downsampling and patch processing. PointRend [31] and MagNet [32] in the network improved for high-resolution images also use the same segmentation backbone as GLNet [4] for training, and their accuracy is higher than GLNet [4]. In addition to comparing mIoU, we also compared mPA and accuracy with baseline and some advanced methods. By comparison, the experimental results of our method are all higher than those of other advanced networks. Among them, the experimental results of MagNet [32] are the results of operating under the same equipment as the method in this paper. According to the results, our method is 3.03% higher than baseline on mIoU, 0.87% higher than GLNet [4], 0.69% higher than PiontRent [31], and 0.37% higher than MagNet [32]. Fig. 5 depicts the segmentation results of IARNet. From Fig. 5, it can be seen that our proposed method improves the segmentation performance of some long lines and large areas compared to the baseline.
Performance of IARNet and other segmentation models on DeepGlobe Dataset
Performance of IARNet and other segmentation models on DeepGlobe Dataset

Visualization results of the IARNet.
We show the segmentation performance of baseline, GLNet [4], and IARNet for all Deepglobe classes in Table 3 and Fig. 6. Among all categories, the “Agriculture” class has the highest classification accuracy at 87.9%, as it accounts for a large proportion in the dataset. In contrast, the “Rangeland” and “Barren” classes are less accurate because “Agricultural”, “Rangeland”, and “Barren” are three classes of objects that are similar in appearance but different in class. Compared to the baseline, IARNet segmentation accuracy improved by 5.3% and 8.6% on Rangeland and Barren respectively. The experimental results show that IARNet has a good ability to identify ambiguous categories such as Agriculture, Water and Forest.
Segmentation performance measured in mIoU(%) on DeepGlobe
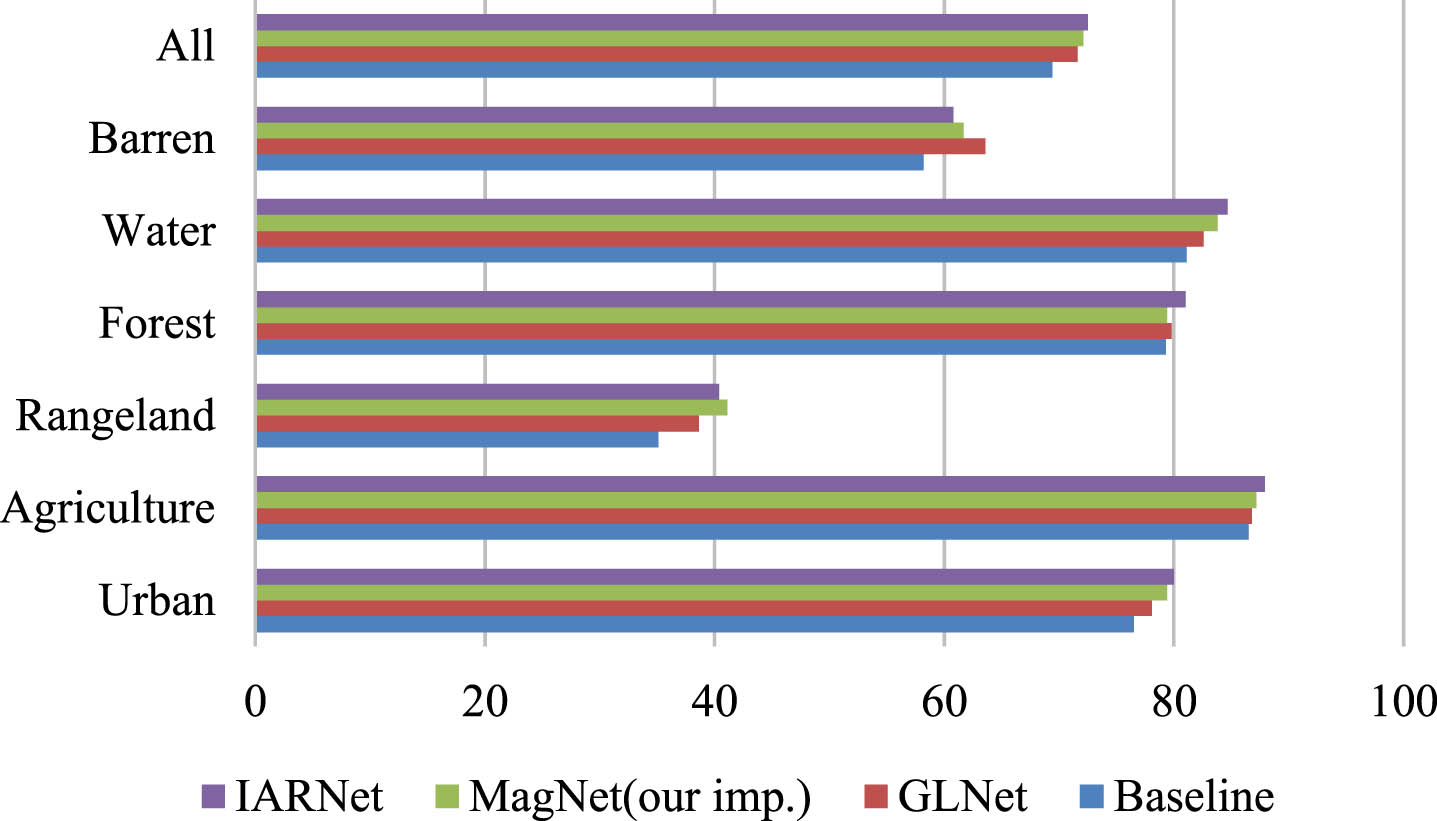
The segmentation performance for all of the classes.
Table 4 shows the results of IARNet for a different number of scales. While the direct refinement from the lowest to highest scale improves about 1.64% mIoU, from 69.88% to 71.52%, adding one intermediate scale between the smallest and largest scales improve the performance by 2.27% and 2.34% mIoU respectively, adding two intermediate scales between the smallest and largest scales improve the performance by 2.59% mIoU. From this, it can be seen that adding multiple scales between global image and local image can effectively bridge the gap between the two scales and improve the segmentation performance.
Performance of IARNet on Deepglobe with and without intermediate scale levels
Performance of IARNet on Deepglobe with and without intermediate scale levels
In this paper, we proposed IARNet, a multi-scale segmentation framework for semantic segmentation of high-resolution remote sensing images. Our network was mainly composed of Irregular Area Positioning Module and Adaptive Refinement Module. Specifically, IAPM located irregular regions with poor segmentation effect in rough segmentation, while ARM performed adaptive refinement on the segmentation results of pixels in these regions. To avoid the problem of being too global or local, patches of multiple scales were considered, from the coarsest to the finest levels. We have demonstrated its advantages on challenging high-resolution remote sensing image datasets, where IARNet performed 0.37% to 0.87% better than previous state-of-the-art methods in terms of mIoU [14, 15].
Footnotes
Acknowledgment
This research was funded by the National Natural Science Foundation of China (no. 62072024 and 41971396), the Projects of Beijing Advanced Innovation Center for Future Urban Design (no. UDC2019033324 and UDC2017033322), R&D Program of Beijing Municipal Education Commission (KM202210016002), and the Fundamental Research Funds for Municipal Universities of Beijing University of Civil Engineering and Architecture (no. X20084 and ZF17061) and the BUCEA Post Graduate Innovation Project (PG2022144 and PG2023143).