
Abstract
Feature selection can remove data noise and redundancy and reduce computational complexity, which is vital for machine learning. Because the difference between nominal attribute values is difficult to measure, feature selection for hybrid information systems faces challenges. In addition, many existing feature selection methods are susceptible to noise, such as Fisher, LASSO, random forest, mutual information, rough-set-based methods, etc. This paper proposes some techniques that consider the above problems from the perspective of fuzzy evidence theory. Firstly, a new distance incorporating decision attributes is defined, and then a relation between fuzzy evidence theory and fuzzy β covering with an anti-noise mechanism is established. Based on fuzzy belief and fuzzy plausibility, two robust feature selection algorithms for hybrid data are proposed in this framework. Experiments on 10 datasets of various types have shown that the proposed algorithms achieved the highest classification accuracy 11 times out of 20 experiments, significantly surpassing the performance of the other 6 state-of-the-art algorithms, achieved dimension reduction of 84.13% on seven UCI datasets and 99.90% on three large-scale gene datasets, and have a noise tolerance that is at least 6% higher than the other 6 state-of-the-art algorithms. Therefore, it can be concluded that the proposed algorithms have excellent anti-noise ability while maintaining good feature selection ability.
Introduction
Research background and related works
Feature selection is an essential means to enhance the performance of learning algorithms, and also a crucial data preprocessing step in pattern recognition. Feature selection methods can be divided into two categories: filtering and packaging techniques, depending on their independence from subsequent learning algorithms. Filtering techniques are independent of subsequent learning algorithms and directly utilize the statistical properties of all training data to evaluate features, such as Fisher, mutual information, rough-set-based approaches, etc. Their advantage is fast speed, but they are highly susceptible to noise. Wrapper techniques use the training accuracy of subsequent learning algorithms to evaluate subsets of features, such as random forest, recursive feature elimination, etc. Their advantage is that the error is low, but they are not suitable for large datasets due to the high amount of computation involved.
An important application of rough set theory is feature selection in data analysis. Due to the presence of numerous redundant features and noise in many datasets, feature selection is necessary prior to data mining. Feature selection is an important “data preprocessing” step. It can not only reduce the size of the dataset but also enhance the accuracy of knowledge discovery. Currently, research focus on how to develop a better heuristic function to evaluate the importance of features in a dataset [1].
Rough set theory can be used for processing imprecise, inconsistent, and incomplete information [2]. It is widely used for feature selection without any prior knowledge [3]. Due to strict equivalence requirements, traditional rough set theory is only suitable for discrete data. Most real data are continuous, such as gene expression data and sensor data. If continuous data is transformed into categories through discretization, some information loss may occur.
To solve the above problem, Lynn et al. [4] built a neighborhood rough set model by substituting a neighborhood relation for an equivalence relation. They defined a neighborhood operator by using a mapping
Al-shami [17] introduced several new types of neighborhoods called containment neighborhoods to improve rough sets’ accuracy measure. Al-shami [18] introduced a topological method to produce new rough set models with more accurate measures and approximations. Al-shami [19] used new types of maximal neighborhoods to establish a rough set model for the best approximations and accuracy measures. Al-shami [20] proposed a topological concept called “somewhere dense” to improve approximation and accuracy measures in rough set theory. Al-shami et al. [21] established some generalized rough-set models based on the topological structures generated by subset neighborhoods and ideals.
The rough set model based on fuzzy covering extends the classical rough set model. A variety of rough set models based on fuzzy covering are proposed [22–33]. Among these models, the models based on the fuzzy covering are particularly valued for their excellent information fusion ability. By changing 1 into a variable parameter β, Ma [29] extended the fuzzy covering to fuzzy β covering. Zhang et al. [30] designed a rough set model based on the fuzzy β covering and applied it to the decision-making. Huang et al. [31, 32] proposed a robust rough set model and a noise-tolerant discrimination index based on fuzzy β covering.
The evidence theory describes the uncertainty of evidence using the uncertain interval composed of a belief function and a plausibility function. [34]. The belief and the plausibility of a set are the quantitative descriptions of the uncertainty. The upper and lower approximations of a set are qualitative descriptions of the information. Therefore, there is a close relation between the evidence theory and rough set theory [35]. Some scholars applied the evidence theory to feature selection by combining it and the rough set theory. Chen et al. [36] established a bridge between the fuzzy covering and evidence theory, and then reduced the attributes of the decision information system based on the evidence theory. Peng et al. [37] studied feature selection in an interval-valued information system based on the Dempster-Shafer evidence theory.
Evidence theory based on the crisp sets is difficult to deal with the fuzzy phenomenon. Fuzzy set theory is good at dealing with this kind of phenomenon and is widely used in various fields [38–41]. Therefore, the fuzzy evidence theory is proposed to deal with fuzzy information. Wu et al. [42] extended the evidence theory to the fuzzy evidence theory and defined a pair of fuzzy belief and plausibility functions. Yao et al. [43] proposed two reduction methods based on fuzzy belief and fuzzy plausibility in fuzzy decision systems. Feng et al. [44] studied the relative reduction of a fuzzy covering system using fuzzy evidence theory.
Motivation and inspiration
In real-life situations, data are often collected through measurement processes, resulting in missing values and noise that are unavoidable. Unfortunately, many existing feature selection methods are susceptible to noise contamination. Therefore, the fundamental driver behind this paper is to address the issue of the poor robustness to noise of existing feature selection algorithms.
There are few research findings on feature selection based on the fuzzy evidence theory, and no studies in this field have been conducted in recent years. Yao et al. [43] and Feng et al. [44] developed a theory of feature selection based on fuzzy evidence theory but did not provide corresponding algorithms. Yao et al. [43] only conducted experiments on an artificial dataset containing nine samples, while Feng et al. [44] only studied coverings reduction in an artificial fuzzy coverings system containing three samples. Their feature selection methods based on fuzzy evidence theory are not noise-resistant. The reflective fuzzy β covering has good noise tolerance abilities [31, 32]. Additionally, Euclidean distance is difficult to accurately measure the difference between nominal attribute values.
Given the aforementioned issues, this paper proposes two robust feature selection algorithms based on fuzzy evidence theory, reflective fuzzy β covering, a novel distance metric, and an anti-noise mechanism. The primary objectives of the study are summarized as follows: Develop a new distance metric that can more accurately quantify the differences between nominal attribute values. Introduce an effective anti-noise mechanism to enhance the noise tolerance of the algorithms. Establish a bridge between fuzzy β covering theory and fuzzy evidence theory to facilitate the calculation of fuzzy belief and fuzzy plausibility. Design an anti-noise feature selection algorithm that can improve the noise tolerance by at least 5%.
The contributions of this paper are summarized as follows: A new distance metric has been defined to replace Euclidean distance, aiming to address the difficulty of accurately measuring the similarity between nominal attribute values for more accurate feature selection. The corresponding relationship between fuzzy β covering with an anti-noise mechanism and fuzzy evidence theory has been established. Therefore, fuzzy belief and plausibility can be calculated based on fuzzy β covering, and the computational difficulties have been overcome. Two robust feature selection algorithms for hybrid data have been proposed based on fuzzy belief and plausibility with good noise tolerance capabilities.
Organization
The rest of the paper is organized as follows. Section 2 reviews the relevant concepts and theories of fuzzy relation, fuzzy rough set, and fuzzy evidence theory. Section 3 defines the fuzzy β covering decision information system and gives some properties. Section 4 defines a new distance function for hybrid information systems. Section 5 establishes a connection between fuzzy evidence theory and fuzzy β covering and designs two feature selection algorithms using fuzzy belief and plausibility. Section 6 conducts some experiments to verify the performances of our algorithms. Section 7 sums up the paper.
Preliminaries
The section is a review of fuzzy relations and fuzzy evidence theory.
The meanings of some symbols used in this article are as follows.
Ω: a finite set of objects.
I: [0, 1].
2 Ω : all subsets of Ω.
I Ω : all fuzzy sets of Ω.
Let
A fuzzy set F on Ω is a map F : Ω → I, where F (ω) (ω ∈ Ω) is called the membership degree of ω to F.
∀a ∈ I,
∀F ∈ I
Ω
, then F is expressed as
R is called a fuzzy relation on Ω when R is a fuzzy set on Ω × Ω. R can be expressed as M (R) = (R (ω i , ω j )) nn , where R (ω i , ω j ) ∈ I is the similarity between ω i and ω j .
IΩ×Ω denotes the set of all fuzzy relations on Ω.
∀ ω, ω′ ∈ Ω, define
Obviously,
Let (Ω, R) (R ∈ IΩ×Ω) denote a fuzzy approximation space.
∀ϒ ∈ I
Ω
, define
The above fuzzy rough set model can be counted as the extension of the classical rough set model.
Robust fuzzy relations can be defined using fuzzy β covering [32]. Therefore, next, we introduce fuzzy β covering and its related theories.
Let
Let
Obviously,
(1) If
(2) If
Then
If
Let (Ω, Δ) be a fuzzy β CIS with
Obviously,
The parameterized fuzzy β neighborhood is designed as follows:
This design makes the fuzzy β covering noise-resistant because too small value is likely to be noise.
Clearly,
Denote
(1) If β1 ≤ β2, then
(2) If
(3) If λ1 ≤ λ2, then
Huang et al. [33] pointed out that Definition 2.4 has a shortcoming, i.e.,
Then
(4) If β1 ≤ β2, then
(5) If
(6) If λ1 ≤ λ2, then
(7)
Then
Fuzzy evidence theory can deal with fuzzy phenomena, but evidence theory can’t. Fuzzy evidence theory uses the membership function to construct the fuzzy belief and plausibility functions.
The difference between objects is effectively captured by the distance between the information values of attributes. HISs have various types of attribute values. To measure the difference between two objects with different types of attribute values more accurately, a new distance metric is proposed using decision attributes.
Let
Let
An HIS (Ω, Θ, d)
An HIS (Ω, Θ, d)
Obviously,
(1) ρ c (θ (ω) , θ (ω)) =0 ;
(2) 0 ≤ ρ c (θ (ω) , θ (ω′)) ≤1 .
If M = 0, let ρ r (θ (ω) , θ (ω′)) =0.
Obviously, we have
According to the above analysis, we define a new distance function between information values of HIS.
The difference between nominal attribute values is measured by a probability distribution, which is more consistent with reality. Definition 3.9 can effectively handle incomplete hybrid information systems.
According to Definitions 3.6, 3.8 and 3.9, we have
(1) ρ (θ1 (ω1) , θ1 (ω3)) =0, (2)
Let
Fuzzy belief function and fuzzy plausibility function
Firstly, establish a link between fuzzy evidence theory and fuzzy rough set theory, enabling the calculation of fuzzy belief and fuzzy plausibility using fuzzy rough set theory, thereby addressing the computational difficulty encountered when calculating fuzzy belief and fuzzy plausibility. Subsequently, explore some fundamental properties of the fuzzy belief function and fuzzy plausibility function.
∀ ω ∈ Ω, pick
Thus
Note that F1 ≠ F2,
This follows that
By Definition 2.12,
(2) Let ϒ ∈ I
Ω
. Then
Thus
Note that
Thus,
(3) Let ϒ ∈ I
Ω
. Then
Thus
Note that
Thus,
(1) Fuzzy belief monotonically increases concerning the attribute subset, while fuzzy plausibility monotonically decreases concerning the attribute subset, namely
if B1 ⊂ B2 ⊆ Θ, then ∀ ϒ ∈ I
Ω
, ∀ β ∈ (0, 1] ,
(2) Fuzzy belief and fuzzy plausibility monotonically increase concerning the fuzzy set, namely
if ϒ1 ⊆ ϒ2 ϒ1, ϒ2 ∈ I
Ω
, then ∀ B ⊆ Θ, ∀ β ∈ (0, 1]
(3) Fuzzy belief monotonically decreases concerning the neighborhood radius, while fuzzy plausibility monotonically increases concerning the neighborhood radius, namely
if 0 ≤ λ1 < λ2 ≤ 1, then ∀ B ⊆ Θ, ∀ ϒ ∈ I
Ω
By Theorem 2.8(2), we have
Then
So
Since B1 ⊂ B2 ⊆ Θ, by Theorem 2.8(4), we have
Then
So
Thus
(2) Let B ⊆ Θ and β ∈ (0, 1].
Since ϒ1 ⊆ ϒ2, by Theorem 2.8(3), we have
Then
So
(3) Let B ⊆ Θ and ϒ ∈ I Ω .
Since 0 ≤ λ1 < λ2 ≤ 1, by Theorem 2.8(5), we have
Then
Thus
In this paper, ∀ B ⊆ Θ, let
(1) If B1 ⊂ B2 ⊆ Θ, then ∀ β, λ ∈ [0, 1],
(2) If 0 ≤ λ1 < λ2 ≤ 1, then ∀ B ⊆ Θ,
Taking β = 0.8 and λ = 0.2 as an example, the fuzzy belief and fuzzy plausibility of different attribute subsets of data in Table 1 are calculated as follows.
λ-belief reduction and λ-plausibility reduction in an HIS
In this section, the definitions of attribute reduction based on fuzzy belief and fuzzy plausibility are first provided. Attributes are also referred to as features. Subsequently, two feature selection algorithms are developed based on the definition of reduction.
(1) B is called a fuzzy λ-belief coordinated subset of Θ concerning d, if
(2) B is called a fuzzy λ-plausibility coordinated subset of Θ concerning d, if
Let
(1) B is called a fuzzy λ-belief reduction of Θ concerning d, if
(2) B is called a fuzzy λ-plausibility reduction of Θ concerning d, if
(1)
(2) ∀ i,
(3)
(1)
(2)
(3)
(1)
(2)
(3)
(1)
(2)
(3)
(1) The significance of θ based on fuzzy λ-belief is defined as
(2) The significance of θ based on fuzzy λ-plausibilty is defined as
We specify
Two feature selection algorithms based on fuzzy belief and fuzzy plausibility are given below.


Algorithm 1 uses
Taking β = 0.8 and λ = 0.2 as an example, the FSFB’s feature selection process for the data in Table 1 is demonstrated as follows.
Therefore, {θ3, θ1} is a feature selection result of {θ1, θ2, θ3}.
Experimental analysis and results
To evaluate the performance of FSFB, its classification performance and noise tolerance are compared with eight advanced feature selection algorithms on ten datasets. These datasets are downloaded from UCI Machine Learning Repository 1 , KRBM Dataset Repository 2 , and ASU feature selection repository 3 , and their details are listed in Table 2.
10 datasets
10 datasets
In this part, the anti-noise performance of fuzzy belief and fuzzy plausibility is verified.
The method of adding noise to data is as follows: For real-valued attributes, first, transform the data to the interval [0,1], and then randomly select x% of the data to be randomly assigned a number between 0 and 1. x is taken as 0, 5, 10, 15, 20, and 25 respectively. For categorical attributes, x% of randomly selected data are randomly assigned to the categorical attribute values. Similarly, x is taken as 0, 5, 10, 15, 20, and 25 respectively.
Parameters setting: β = 0.8, λ = 0.2.
Figures 1 and 2 show the fuzzy belief and fuzzy plausibility of 10 original data sets and their fuzzy belief and fuzzy plausibility after adding noise as the number of attributes in the data gradually increases. As the added noise continues to increase, the fuzzy belief and fuzzy plausibility do not change much, indicating that they are not sensitive to noise.
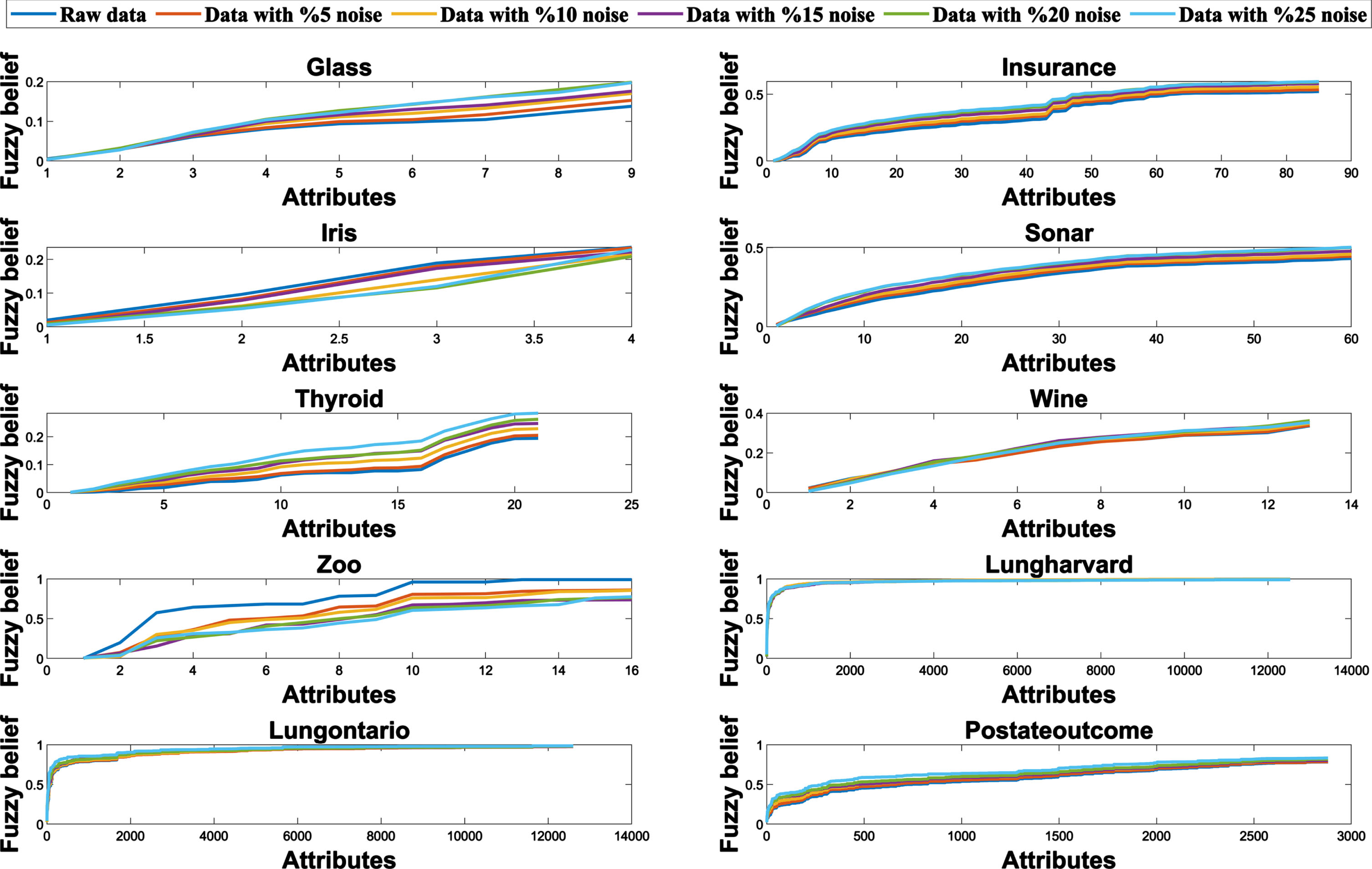
Fuzzy belief of different noise levels with the increase of attributes
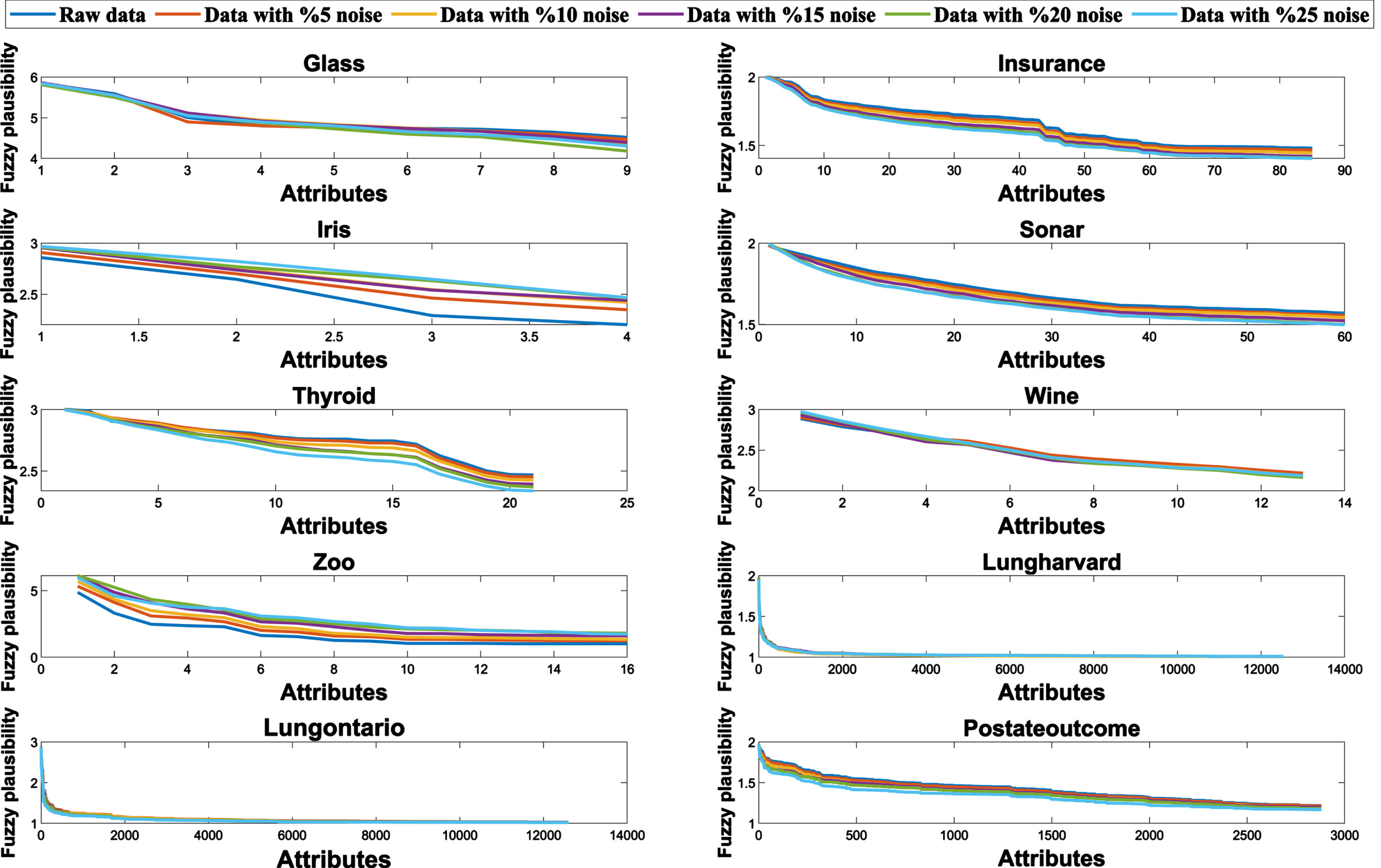
Fuzzy Plausibility of different noise levels with the increase of attributes
Figure 3 shows the mean and variance of fuzzy belief and fuzzy plausibility at different noise levels. When the noise level changes, the mean and variance of 9 data sets in 10 data sets almost remain unchanged, and those of Zoo have little change, as shown in Fig. 3. This indicates that noise has little effect on fuzzy belief and fuzzy plausibility.
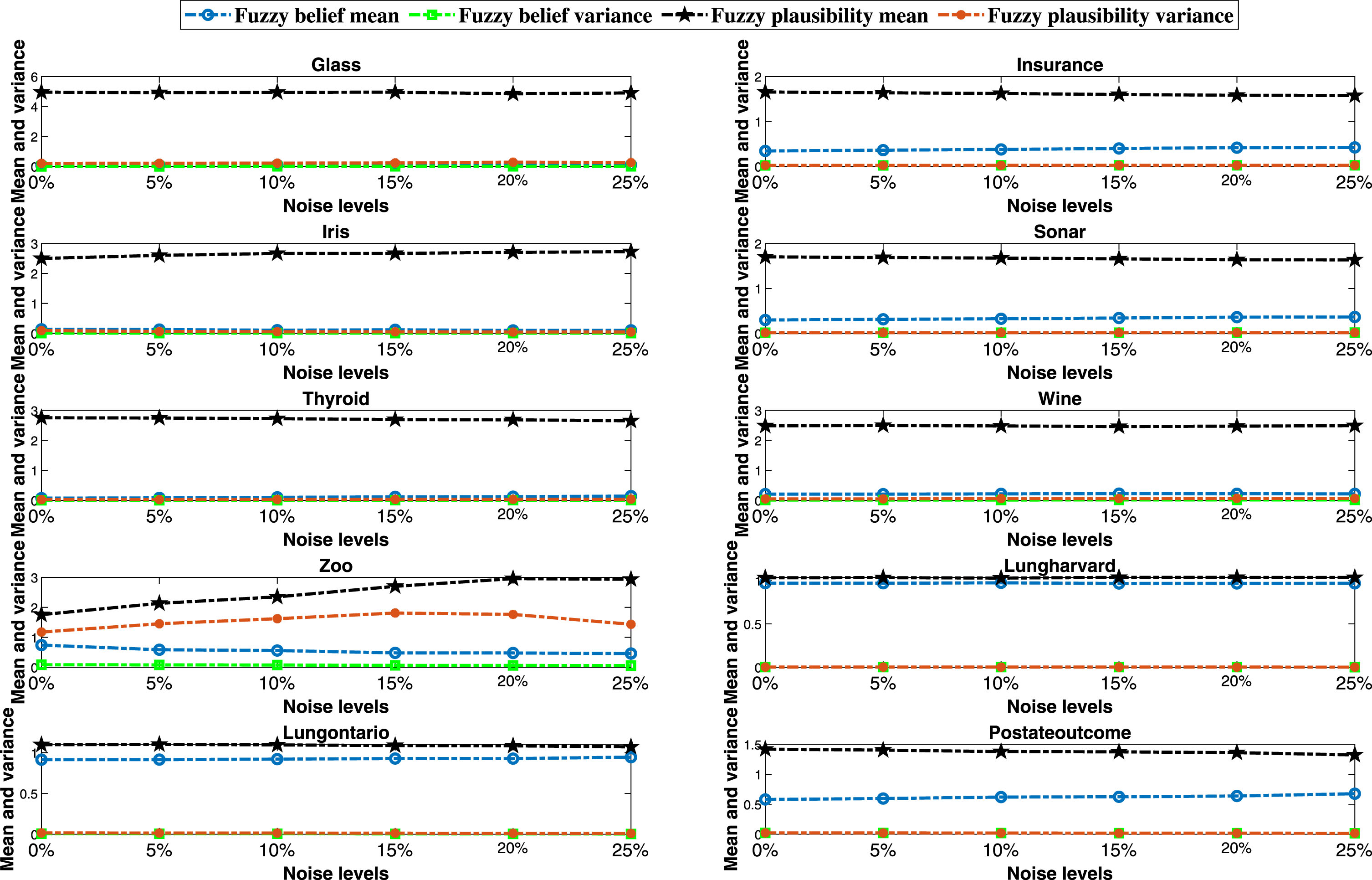
Mean and variance of fuzzy belief and fuzzy plausibility at different noise levels
Figure 4 shows that fuzzy belief and fuzzy plausibility are highly negatively correlated at various noise levels. Noise has little influence on the correlation between fuzzy belief and fuzzy plausibility. Therefore, only the performance of FSFB is shown below.
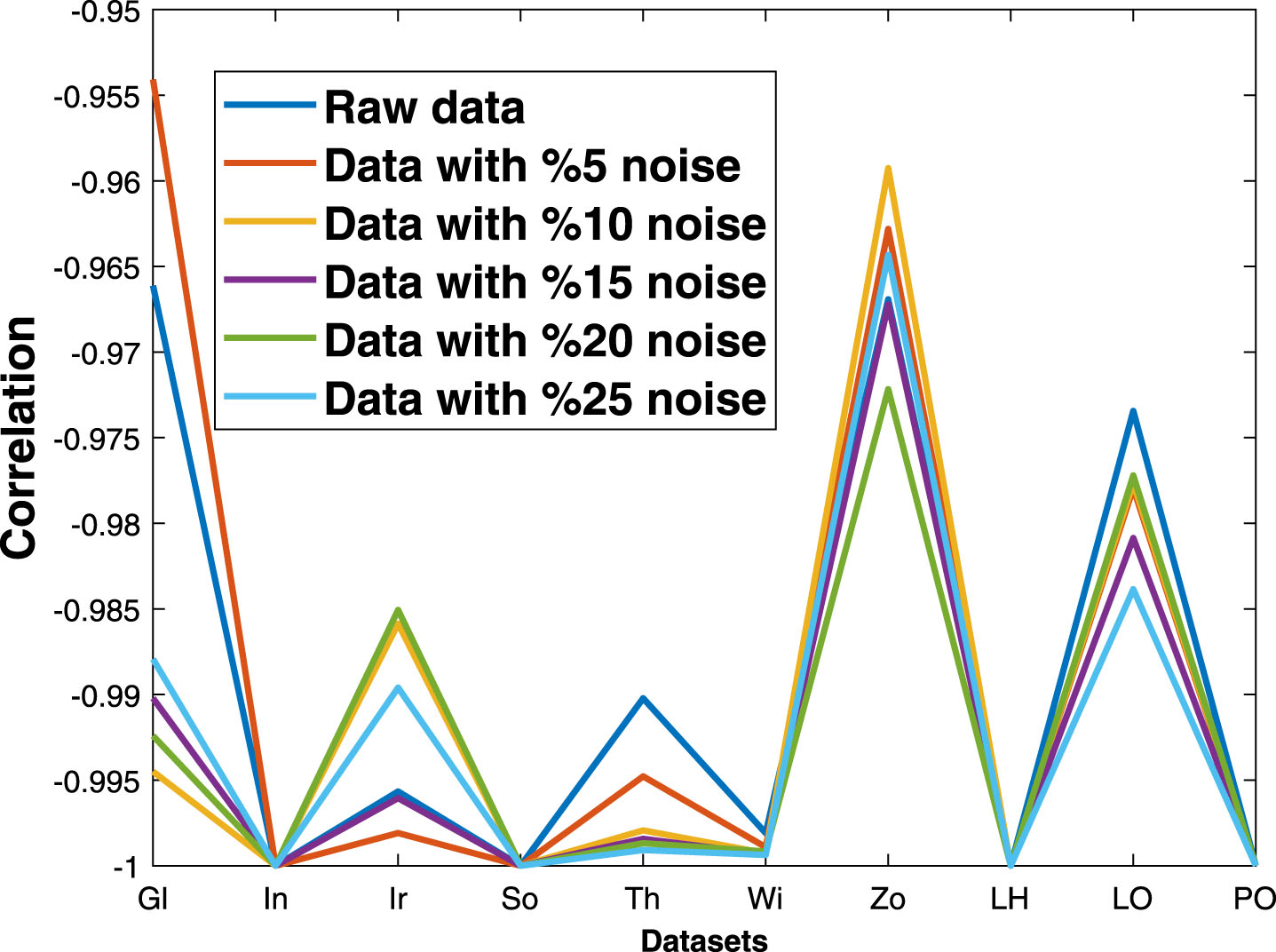
Correlation between fuzzy belief and fuzzy plausibility at different noise levels
Parameter values affect feature selection results. Let β and λ take values of {0.5, 0.6, 0.7, 0.8, 0.9} and {0.1, 0.2, 0.3, 0.4, 0.5}, respectively. Thus,β and λ have a total of 25 combinations. Each combination may correspond to a feature selection result of FSFB. The classification accuracy of all feature selection results on ten datasets is shown in Fig. 5 using the CART classifier.
Table 3 shows a pair of optimal parameter values for each dataset according to CART classifier.
The experimental results obtained by KNN are approximately consistent with CART.
Figure 5 shows that different values of parameters have a great impact on classification accuracy. Different values of parameter β mean different granularity. The larger the value of β, the more accurate the granularity is. The value of β can also be regarded as the threshold of information fusion. The larger the threshold is, the more accurate the information involved in the fusion is. Different values of parameter λ mean different anti-noise capabilities. The larger the value of λ is, the stronger the anti-noise capability is, but it also means that the risk of filtering out useful information will increase.
The following conclusions can be summarized from Fig. 5 and Table 3. Within the value range of the two parameters, FSFB has achieved relatively high classification accuracy on most datasets, which shows that it has good stability. For those datasets with a small number of samples, the value of λ is small, which means that if it is too large, key information may be filtered out. For those datasets with a small number of features, the value of β is small, which means that they have low threshold requirements for information fusion because of few features. For three large gene datasets, the value of β is large, which means that they have high threshold requirements for information fusion because of a large number of features. The fusion information needs to have a high degree of membership and thus characterizes the knowledge more accurately.
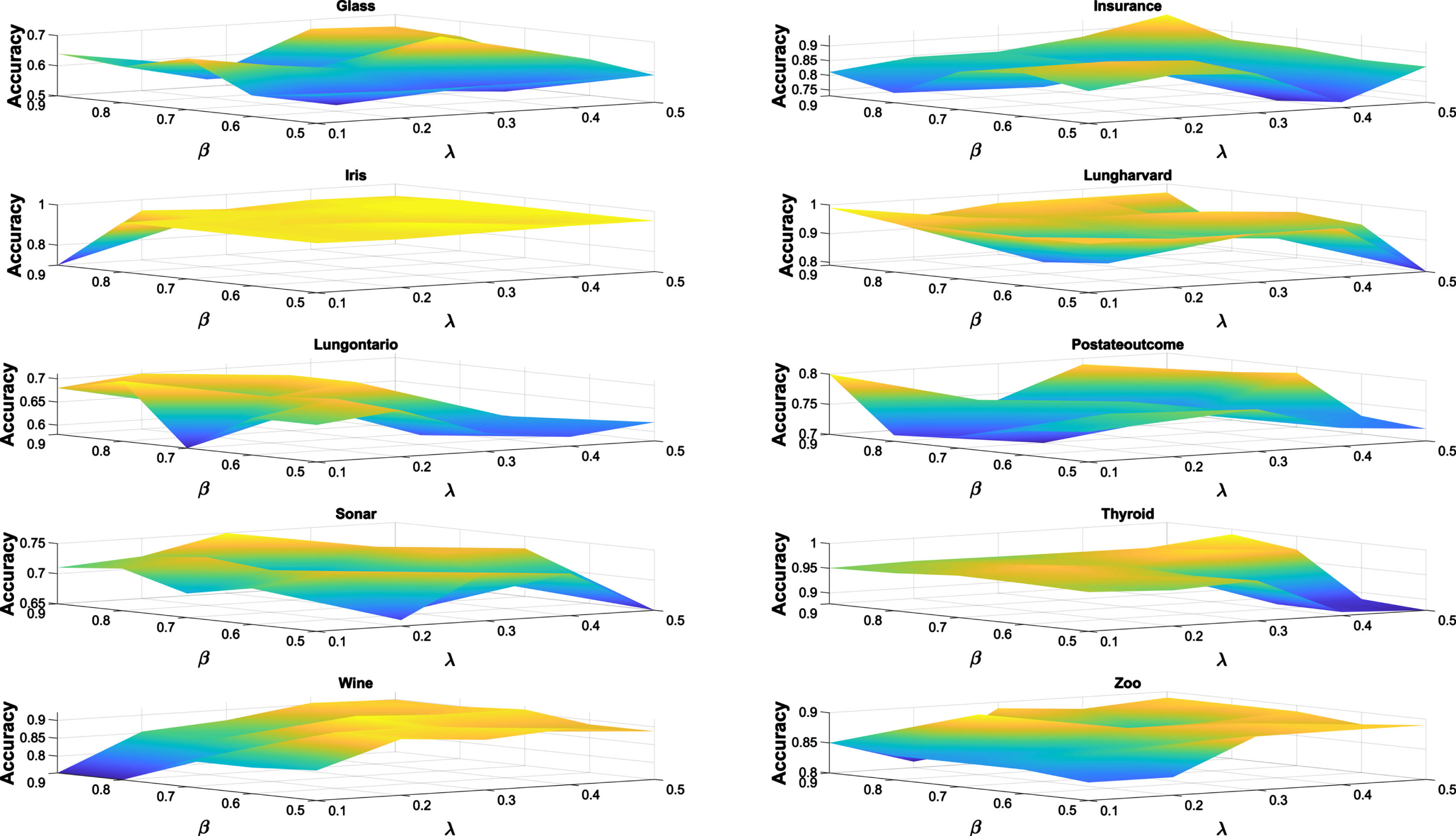
Classification accuracy of 10 datasets in the case of different parameter values by using CART classifier
Optimal parameter values of ten datasets
In this part, FSFB is compared with 7 state-of-the-art feature selection algorithms in classification performance and the size of selected feature subsets on 10 datasets. They are FBC [33], FSI [47], MFBC [31], NDI [46], NSI [48], VPDI [32], and QCISA-FS [55], respectively.
FBC is based on the fuzzy β-covering, and its fuzzy relation does not meet the reflexivity. FSI is based on fuzzy rough self-information, and its fuzzy relation meets the reflexivity. MFBC is based on the multi-granulation fuzzy rough sets, and its fuzzy relation does not meet the reflexivity. NDI is based on the neighborhood discrimination index, and its neighborhood relation meets the reflexivity. NSI is based on neighborhood self-information, and its neighborhood relation meets the reflexivity. VPDI is based on the variable precision discrimination index, and its fuzzy relation meets the reflexivity. FSFB is based on the fuzzy evidence theory and fuzzy β-covering, and its fuzzy relation meets the reflexivity. QCISA-FS is a quantum-inspired cooperative swarm intelligence algorithm based on the rough sets.
KNN (K-nearest neighbor,K=5) and CART (Classification And Regression Tree) are used to estimate the classification accuracy with the ten-fold cross-validation. All experimental results are the average of 100 repeated experiments. For those algorithms with parameters, their parameter values all take the optimal values. The final experimental data are shown in Tables 4–6.
The number of selected features
The number of selected features
Classification accuracy of the feature sets selected by KNN (%)
Classification accuracy of the feature subsets selected by CART (%)
Table 4 indicates that all seven algorithms effectively reduce redundant features, especially for three large-scale gene datasets. The average size of the selected feature subsets is far smaller than that of the original datasets. FSFB achieved a dimension reduction of 84.13% for seven UCI datasets and 99.90% for three large-scale gene datasets. The average of features selected by FSFB is only slightly greater than NSI, but FSFB has the highest classification accuracy. Therefore, FSFB is not easy to overfit and underfit. The average of features selected by MFBC is the largest, but MFBC’s average classification accuracy is not high, which indicates that MFBC is overfitting.
Tables 5 and 6 show that FSFB is superior to the other six algorithms and the original datasets in terms of average classification accuracy. In a total of 20 experiments, FSFB achieved the highest classification accuracy 11 times and is far more than other algorithms. These results show that the proposed algorithm is effective. Table 7 shows the feature subsets obtained by FSFB. The bold data represent the maximum classification accuracy.
Feature subsets selected by FSFB
Each raw dataset is regarded as an algorithm and FSFB is regarded as the control algorithm. Friedman [50] and Bonferroni-Dunn tests [51] are used for analyzing the statistical differences between the control algorithm and other comparison algorithms.
The Friedman test is defined as follows:
F0.1 (8, 72) =1.7571 according to F-distribution table when α = 0.1, a = 9 and d = 10. According to Formula (5.1), Tables 8 and 9, the value of F F is equal to 2.7596 and 3.391 respectively. Obviously, they are both greater than 1.7571. Therefore, the performance of 8 algorithms is statistically different for the two classifiers.
Classification accuracy ranking of eight algorithms according to KNN
Classification accuracy ranking of eight algorithms according to CART
Next, the Bonferroni-Dunn test [52] is used as a post hoc test to analyze the performance difference between the control algorithm and the comparison algorithms. Its critical value is defined as follows:
q0.1 = 2.498 when α = 0.1 and a = 9 [52]. Therefore, CD0.1 = 3 according to Formula (5.2) when α = 0.1, a = 9 and d = 10. The CD diagrams of the KNN classifier and CART classifier are shown in Figs. 6 and 7, respectively. Figure 6 shows that FSFB is statistically superior to VPDI, QCISA-FS, NSI, FSI, and the raw dataset at a confidence level of α = 0.1. Figure 7 shows that FSFB is statistically superior to MFBC, FBC, FSI, NDI, VPDI, and the raw dataset at a confidence level of α = 0.1.

CD diagram of Bonferroni-Dunn test using KNN classifier

CD diagram of Bonferroni-Dunn test using CART classifier
In this section, the noise tolerance performance of seven feature selection algorithms is evaluated.
In many practical applications, it is required for the feature selection algorithm to be robust, i.e., it can obtain a stable feature subset when exposed to data noise. If the selected feature subset varies significantly when exposed to data noise, this algorithm is said to be conditionally sensitive.
The robustness (stability) of the feature selection algorithm can be evaluated based on its ability to repeatedly select features when different batches of data with the same distribution are provided. As the true distribution of data is usually unknown, data from different batches are generated by adding different levels of noise.
Let Θ j and Θ0 denote the feature subsets selected by the jth batch of noisy data and the raw data, respectively. Then, the similarity between Θ j and Θ0 can be defined by Jaccard Index [54] as follows:
T j can provide an evaluation of the robustness and reflect the anti-noise ability of a feature selection algorithm. The greater the similarity, the stronger the anti-noise ability.
According to the method mentioned in section 6.1, 5%, 10%, 15%, 20% and 25% noises are added to the original data respectively. The experimental result is the average value of 10 times of noise added randomly.
Figure 8 and Table 10 show the average similarity of different algorithms and data sets. Compared with the UCI datasets, the large-scale gene datasets are more affected by noise because of too few samples. FSFB achieves the maximum similarity on six data sets in ten data sets, far more than other algorithms. While the proportion of noise increases, both the distribution of data and the importance of features will change. This leads to obvious differences in the best feature subset selected by the algorithm. Even so, the average similarity of FSFB still reaches 65%, at least 6% higher than other algorithms. Therefore, FSFB is more robust than the other six algorithms.

Average similarity between feature subset obtained from original data and feature subsets obtained from noisy data
Average similarity between feature subset obtained from original data and feature subsets obtained from noisy data
This paper presents a novel distance metric that is guided by decision attributes and is more accurate than Euclidean distance for measuring the difference between nominal feature values. We establish a connection between fuzzy evidence theory and fuzzy β covering with an anti-noise mechanism, which addresses the computational challenges of fuzzy belief and fuzzy plausibility calculations. We propose two feature selection algorithms that are based on this new distance metric, fuzzy β covering, fuzzy evidence theory, and the anti-noise mechanism. Experimental results demonstrate that the proposed algorithms outperform six state-of-the-art algorithms in terms of classification performance and noise tolerance. Therefore, the algorithms proposed in this study are robust and effective. However, it should be noted that the computational complexity of the proposed algorithms is high, and grid optimization of parameters is required. This can result in long computational times when applied to large-scale gene datasets. In the future, we plan to investigate means of reducing computational complexity and automating parameter optimization of the proposed algorithms.
Acknowledgements
The authors would like to thank the editors and the anonymous reviewers for their valuable comments and suggestions, which have helped immensely in improving the quality of the paper. This work is supported by Excellent Scientific Research and Innovation Team of Anhui Colleges (2022AH010098), Doctoral Research Start Project of Chizhou University (CZ2021YJRC01), Provincial Quality Engineering Project of Higher Education Institutions (2022zybj068), Outstanding Engineer in Data Science and Big Data Technology, “Six Excellence and One Top” Project and Major Scientific Research Project of Higher Education Institutions in Anhui Province.
Appendix
(2) 1)“
2) In order to prove that “
Let λ ≤ β, ϒ (ω) ≥1 - β . Put
Since λ ≤ β, we have
Note that ϒ (ω) ≥1 - β. Then
3) In order to prove that “
Note that ϒ (ω) ≤ β. Then
(3) Let ϒ ⊆ Ξ. Then ∀ ω ∈ Ω, ϒ (ω) ≤ Ξ (ω).
In order to prove that
Suppose ϒ (ω) ≥1 - β. Then
Suppose Ξ (ω) ≤ β. Then
(4) It follows from Proposition 2.6(1).
(5) It can be proved by Proposition 2.6(2).
(6) It can be proved by Proposition 2.6(2).
(7) It is sufficient to show that
Suppose (ϒ ∩ Ξ) (ω) ≥1 - β. Then ϒ (ω) , Ξ (ω) ≥1 - β. Thus
Hence
Suppose ϒ (ω) , Ξ (ω) ≤ β. Then (ϒ ∪ Ξ) (ω) ≤ β. Thus
Thus
Hence
(8) Obviously,
Suppose
Suppose
Thus
Similarly, it can be proved that
So
Since B ⊆ Θ, by Theorem 2.8(3),
By Lemma 4.7, we have
(2) ⇒ (3). Suppose ∀ i,
This implies that
Thus
(3) ⇒ (1). Suppose
Thus
Since B ⊆ Θ, by Theorem 2.8(3), we have
Then
This implies that
By Lemma 4.7, we have
Thus
So
Since B ⊆ Θ, by Theorem 2.8(3),
By Lemma 4.7, we have
(2) ⇒ (3). Suppose ∀ i,
This implies that
Thus
(3) ⇒ (1). Suppose
Thus
Since B ⊆ Θ, by Theorem 2.8(3), we have
Then
This implies that
By Lemma 4.7, we have
Thus
Footnotes
http://archive.ics.uci.edu/ml/index.php
http://leo.ugr.es/elvira/DBCRepository/
http://featureselection.asu.edu/datasets.php