
Abstract
The Flexible Job Shop Scheduling Problem (FJSP) is an extension of the classical Job Shop Scheduling Problem (JSP). The research objective of the traditional FJSP mainly considers the completion time, but ignores the energy consumption of the manufacturing system. In this paper, a mathematical model of the energy-efficient flexible job shop scheduling problem is constructed. The optimization objectives are completion time, delay time, and total equipment energy consumption. To solve the model, an improved non-dominated sorting genetic algorithm (CT-NSGA-II) is proposed to obtain the optimal scheduling solution. First, the heuristic rules of GLR were used to generate the initial population with good quality and diversity. Second, different crossover and variation operators are designed for the process sequencing and equipment selection parts to enhance the diversity of the evolutionary population. The sparsity theory is introduced to find sparse solutions and three neighborhood structures are designed to perform local search on sparse solutions to improve the uniformity of the optimal solution set distribution. Finally, a competitive selection strategy based on the bidding mechanism is proposed for the Pareto optimal solution set to obtain a better scheduling scheme. The experimental results show that the proposed improved algorithm is feasible and effective in the FJSP problem considering energy consumption, and the algorithm has some application value in improving the efficiency of smart shop operation.
Keywords
Introduction
The JSP (Job Shop Scheduling Problem) is an important part of the development process of the manufacturing industry, and the traditional JSP problem can no longer meet the scheduling needs of complex job shops. FJSP (Flexible Job Shop Scheduling Problem) is an extension of JSP, and FJSP can be defined as: the workpiece to be processed is in the set of optional processing machines, and the appropriate processing machine is selected to accomplish the set processing goal. Compared with traditional job shop scheduling, flexible job shop scheduling relaxes the constraints on processing machines and is more in line with the real production situation. The optional processing machines for each process become multiple, and the scheduling task is not only to determine the processing sequence of the process, but also to determine the machine allocation for each process. In the past decades of research on FJSP scheduling problems, from the perspective of scheduling optimization objectives, most of the literature focuses on optimization scheduling with the objectives of minimizing completion time and production cost. With the intensification of energy consumption, the optimization indexes mainly considered in traditional FJSP (such as completion time, product quality, etc.) are no longer comprehensive, and multi-objective optimal scheduling that integrates the objectives of time and energy consumption has been increasingly emphasized. The purpose of this paper is to solve the FJSP problem considering completion time, delay time, and energy consumption by improving the non-dominated sorting genetic algorithm.
In recent years, scholars at home and abroad have made certain achievements in solving the research of FJSP. Suhaimi et al. [1] studied the Lagrangian relaxation algorithm with the optimization objective of minimizing the weighted time and considering the auxiliary processing time constraint of the equipment; Shu [2] established a scheduling model to minimize the total delay and modeled the FJSP as a MDP (Markov decision process) without losing generality, making it feasible to solve the DFJSP (Double Flexible Job-shop Scheduling Problem) through RL (Reinforcement Learning). Singh et al. [3] proposed a multi-objective algorithm based on an improved particle swarm algorithm to generate a rescheduling scheme, which shortens the completion time and improves the stability at the same time; Li et al. [4] proposed an improved two-population hybrid genetic algorithm to solve FJSP, in which one population focuses on global search and the other population is responsible for local search, by exchanging The effectiveness of the algorithm was verified by comparing the simulation results; Xing et al. [5] proposed a novel heuristic algorithm to solve the MOFJSP(multi-objective flexible job-shop scheduling problem), which takes the initial solution as the base and simultaneously uses two different search algorithms to iteratively update it for population evolution; Li et al. [6] proposed a new taboo search algorithm, which designed different neighborhood structures to search for solutions to the device selection and process ordering problems in MOFJSP, respectively.
In the actual production process, equipment energy consumption is also a problem that needs to be considered in a comprehensive manner, and many scholars have proposed different solutions to the energy saving FJSP problem. Wang et al. [7] proposed a multi-objective parallel variable neighborhood search algorithm to optimize the maximum completion time and energy consumption for the characteristics of BFSP (blocking flow shop scheduling problem); Luan et al. [8] proposed a discrete whale optimization algorithm to optimize the FJSP with processing time cost and energy cost as the objectives. Zhang et al. [9] established a scheduling model with the maximum completion time of the workpiece and machine energy consumption as the optimization objectives. and proposed a wolf pack algorithm with improved coding and verified the effectiveness of the algorithm in two workshop scheduling examples. Wang et al. [10] proposed a hybrid genetic algorithm based on process translation. Different process neighborhood shift operations are defined in the algorithm, and then an active energy-saving scheduling strategy for machine tools is proposed. Zhang et al. [11] designed a three-stage decoding non-dominated sorting genetic algorithm to solve the FJSP problem considering energy consumption and obtained better-distributed populations by improving the dynamic adaptive crossover operator in the algorithm. Li et al. [12] proposed an energy-saving strategy from semi-active decoding to active decoding to fully active decoding for the goal of total energy consumption, designed a hybrid modal algorithm to improve the crossover approach, and finally verified the feasibility of the algorithm in saving energy consumption in the workshop through extensive experiments. Meng et al. [13] constructed a mixed-integer linear programming model based on energy consumption, and proposed a frog-hopping algorithm with added neighborhood search to solve the model, and finally verified the reliability of the model and algorithm through experiments. Li et al. [14] proposed an efficient optimization algorithm IGSA (iterated greedy and simulated annealing) to solve CFJSP (flexible job shop problem with crane transportation) by minimizing the fabrication time and energy consumption. An Y et al. In order to reduce the total energy consumption in the manufacturing workshop with degradation effects and imperfect maintenance, an integrated multi-objective optimization model is formulated to simultaneously minimize the makespan, total tardiness, total production cost and total energy consumption [15]. And a HMOEA/P (hybrid multi-objective evolutionary algorithm with Pareto elite storage strategy) is proposed to address the model. a hybrid initialization method is designed to obtain a high-quality initial population, and the LS (Local Search) mechanism based on the critical path is constructed to accelerate the convergence of the algorithm [16]. Yildirim and Mouzon [17] developed a multi-objective genetic algorithm to minimize the energy consumption and the completion time of a single machine system.
For the highly complex characteristics that FJSP has, the existing mainstream multi-objective optimization algorithm methods are ICA (Imperial Competition Algorithm), MOEA/D (multiobjective evolutionary algorithm based on decomposition), MOPSO (Multiple Objective Particle Swarm Optimization), and Non-Dominated Sorting Genetic Algorithm-II (NSGA-II). NSGA-II, MOEA/D, ICA, and MOPSO perform similarly on two objectives, and NSGA-III has better performance on three objectives and above. So, in this paper, NSGA-II is selected to solve the multi-objective optimization problem.
NSGA-II (Non-dominated Sorting Genetic Algorithm-II) is a non-dominated ranking genetic algorithm with elite strategy proposed by Deb based on genetic algorithm [18]. The evolutionary selection mechanism of this algorithm enables a full range of comparisons between individuals in a multi-objective optimization environment, and thus has been widely used in the field of multi-objective optimization. Liu et al. [19] proposed an optimization method for stamping plant scheduling based on the dynamic congestion NSGA-II algorithm with the objectives of energy consumption and completion time and used dynamic calculation methods in the process of congestion calculation to obtain a better Pareto solution set.; Gu et al. [20] proposed an improved algorithm based on loser group and hybrid coding strategy for the shortcomings of the congestion coefficient operator in which good individuals are not retained, and verified it using the ZDT (Zero-Ductility Transition) series of problems, which effectively improved the robustness and convergence of the algorithm; Han et al. [21] designed an improved NSGA-II algorithm to solve the hybrid flow shop scheduling problem to optimize the delay time cost and load imbalance cost; Guo et al. [22] developed a Pareto optimization model and proposed a scheduling method based on the NSGA-II optimization process combined with an efficient production process simulator. Du et al. [23] improved the individual selection process of the traditional elite selection strategy by optimizing the neighborhood search approach to avoid the algorithm from falling into local convergence due to reduced population diversity, and verified the effectiveness of the algorithm through experimental simulations. Dong et al. [24] proposed a multi-objective optimization algorithm solution model for worker flexibility, machine flexibility and parallel process flexibility in multi-objective flexible job shop scheduling by combining the algorithm structure of the invasive tumor growth optimization algorithm and the screening mechanism of the solution in NSGA-II. Xie et al. [25] proposed an improved NSGA-II algorithm with differential local search, which exploits the directional bootstrap role of the variational operator in differential evolution to extract the differential vectors in it, and combined this strategy with the NSGA-II algorithm to improve the uniformity of the distribution of the Pareto optimal solution set.
Although the NSGA-II algorithm has been used to some extent in the field of shop floor scheduling, the following problems still exist in its implementation process and application effects: Most of the existing studies focus on the optimization of traditional objectives such as completion time and cost by applying NSGA-II, and the research on multi-objective FJSP scheduling considering energy consumption is not sufficient. The traditional NSGA-II algorithm in the process of solving multi-objective problems in the actual solution process shows poor diversity of populations, low solution accuracy, early maturity and other problems that still need further improvement.
This paper takes the actual situation of flexible shop production as the entry point, and on this basis focuses on the model of energy-saving scheduling problem of flexible job shop with maximum completion time, total delay time and total equipment energy consumption as the optimization objectives. The novelty of this paper is to propose an improved NSGA-II algorithm (CT-NSGA-II) for solving the model based on the selection mechanism of sparsity and competition. Generate initial populations using GLR (global selection, local selection and random selection) heuristic rules to improve the quality and diversity of initial populations. The improved crossover operator and dynamic mutation operator are designed for the process sequencing and equipment selection part to improve the diversity of the evolutionary population. The sparsity theory is introduced to find sparse solutions, and three neighborhood search structures are introduced to perform neighborhood search on sparse solutions to obtain the updated children, which improves the uniformity of the optimal solution set distribution. A competitive selection strategy based on the bidding mechanism is proposed to introduce the concept of competitive intensity to competitively select the Pareto optimal solution set to obtain a better scheduling solution.
The rest of this paper is organized as follows: Section 2 describes the FJSP problem considering energy consumption and constructs the scheduling model. Section 3 describes the CT-NSGA-II algorithm and its solving steps. Section 4 conducts simulation experiments and analysis of the algorithm. Section 5 concludes the whole paper.
Problem description and model construction
Under the limit of maximum load capacity of the flexible shop production cell, there are n workpieces to be processed, where i ={ 1, 2, 3, . . . , n }, and the set of workpieces is denoted as J ={ j1, j2, j3, . . . , j n }. where workpiece j i contains O i processes, O ij is the ith workpiece that is the jth process of workpiece j i , and the processing order of each process is certain. There are m processing machines in the production plant, k ={ 1, 2, 3, . . . , m }, and each process can be processed by any one of the optional processing machines in the set M ={ M1, M2, M3, . . . , M k , . . . , M m }. Each processing machine has different processing time and energy consumption, that is, the processing time and energy consumption of the same process vary according to the selection of different processing machines, and the best processing machine for each process is determined through reasonable scheduling methods.
This paper makes the following assumptions: One equipment can only process one workpiece at a time. No interruptions are allowed while the equipment is processing. All processes of the workpiece follow a predefined sequence to complete the machining sequentially, without advancement or postponement. There are no advantages or disadvantages between workpieces. Does not stop running when the equipment is idle. Does not take into account the preparation time of the equipment before machining, as well as the time of loading and unloading of the workpiece during the machining process. Does not take into account unforeseen circumstances such as equipment failure.
We all know that the sub-objectives of a multi-objective optimization problem are indeed contradictory to each other, and the improvement of one sub-objective may cause the performance of another sub-objective or several sub-objectives to be reduced, that is to say, it is difficult to make several sub-objectives reach the optimal value together at the same time. In reality, even in the case of single-objective, the effect of a certain aspect is difficult to reach the optimum, so in the multi-objective optimization can only be coordinated in the middle of them and compromise processing, so that the various sub-objectives are as far as possible to achieve optimization. The scheduling model constructed in this paper includes three optimization objectives, which are: minimizing the maximum completion time, minimizing the total delay time, and minimizing the total energy consumption of the system. Table 1 predefines the notation in the mathematical model.
Symbol definition
Symbol definition
The decision variables in the model are:
x ijk : 0-1 variable, if O ij is processed on machine k, x ijk = 1; otherwise, x ijk = 0;
ziji′j′k: 0-1 variable, if O
ij
is processed on machine k prior to Oi′j′, ziji′j′k = 1; otherwise, ziji′j′k = 0.
Equation (4) and Equation (5) determine the calculation of partial energy consumption. Equation (6) indicates that all processes of a workpiece are completed sequentially in a predetermined order; Equation (7) indicates that once a process is started, it cannot be interrupted until it is completed; Equation (8) indicates that only one job can be processed on one machine at a time. Equations (9)–(11) represent positive constraints; Equations (12) and (13) specify the range of values of 0-1 variables.
Compared with the existing scheduling model, this paper constructs a multi-objective FJSP model with maximum completion time, total extension time and total system energy consumption as the optimization objectives according to the actual production of flexible job shop. The total energy consumption of the system includes four parts: fixed energy consumption of the workshop, energy consumption of workpiece transfer, energy consumption of equipment processing and unload energy consumption. More comprehensive consideration of various factors in the workshop, on the one hand, fully considered a variety of energy consumption of the flexible workshop, on the other hand, also considered the processing time and delivery date indicators, the model optimization of energy consumption indicators comprehensive, and at the same time can effectively improve the production efficiency, so that the results of the scheduling can be more objective and comprehensive reflection of the workshop managers on the various aspects of the requirements of the overall coordination and balance of the management decision-making is more accurate, better meet the customer delivery time requirements.
A. ALGORITHM OVERVIEW AND IMPLEMENTATION STEPS
NSGA-II algorithm is a mainstream algorithm for solving multi-objective optimization problems [26]. The principle of NSGA-II algorithm is to construct non-dominated solution sets with different ranks by using the dominance relationship between individuals of the population, and to compare the individuals of the same rank with each other by the crowding comparison operator, and to combine with the genetic crossover mutation operation to generate the offspring population to complete the population update, and finally to select the solution set with the highest non-dominated rank as the optimal solution set of the problem [27].
Although NSGA-II has been widely used in solving multi-objective optimization problems in various fields, in the actual solving process, its results are affected by the initial population, which may cause the algorithm to fall into local optimum if the initial population is not good enough. Based on the fact that it exhibits deficiencies such as poor population diversity and early maturity. In this paper, based on the characteristics of the multi-objective flexible job shop energy saving scheduling problem, the CT-NSGA-II algorithm is adopted and two neighborhood structures are designed for sparse solutions. By executing two neighborhood search operations with equal probability for sparse solutions, the diversity of the population is improved to expand the population size, and then the algorithm’s ability to find the best is effectively improved. Finally, the satisfactory solution is selected from the optimal solution set as the final solution by drawing on the competitive selection strategy based on the bidding mechanism. The implementation process of CT-NSGA-II is shown in Fig. 1, and the detailed steps are as follows:
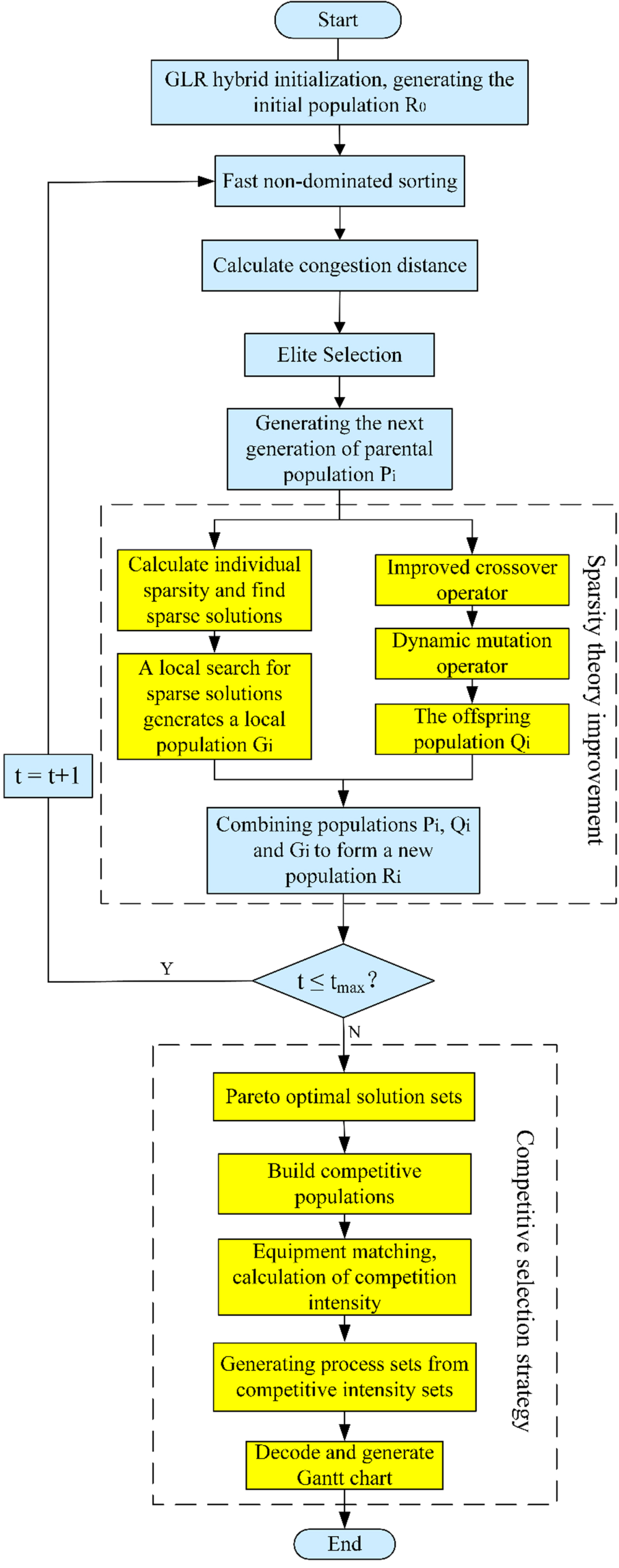
CT-NSGA-II flow chart
Generate an initial population
By fast non-dominated sorting, all individuals of the population are ranked to obtain the set of non-dominated solutions at each level
Perform crossover and mutation operations on the individuals in
calculate the sparsity for all individuals in
Combine
Perform the same operation as step 2 for the new population
Determine whether
B. ALGORITHM IMPLEMENTATION PROCESS
Encoding and decoding
According to the characteristics of the multi-objective intelligent scheduling problem in the flexible workshop, the coding method adopts an extended process-based two-segment coding method, with the first segment being the process code for determining the processing order and the second segment being the machine code for determining the processing machine of the corresponding process, and the coding process is shown in Fig. 2.

Process-based coding
In Fig. 2, the gene strings [1, 1] encoded based on processes in order indicate the processes as ( Population initialization
In the NSGA-II algorithm, the quality of the initial population greatly affects the convergence speed and solution quality of the algorithm. The population initialization method in this paper refers to the GLR initialization method in the literature [27], i.e., a combination of global selection (GS), local selection (LS), and random selection (RS) are used to generate the initial population.
In this paper, we first execute the GLR initialization principle (the ratio of GS, LS, and RS is 0.6, 0.3 and 0.1) to generate two populations P1, P2 of size N, respectively, and then merge the two populations. If the number of remaining individuals in the population is greater than N, the top N individuals are selected as the initial parent population P. Otherwise, the remaining individuals are filled by the random initialization principle. Fast non-dominated sorting
For multi-objective optimization problems, the fast-sorting method can effectively reduce the computational complexity and improve the efficiency of operations, so this paper uses the fast-sorting method to Pareto sort the individuals and grade the non-dominated solutions in the population. First, the population is set to P, the symbol n p represents the number of dominated individuals p in the population, and the symbol S p represents the set of dominated solutions of individual p. The description of fast non-dominated sorting is presented in Procedure 1.
Crowdedness ranking
Crowding indicates the distance between genes in the same non-dominated layer. The greater the distance between genes, the better the gene diversity. The smaller the distance between genes, the poorer the diversity. The selection of genes is based on the above idea. The gene crowding at the two endpoints of each level is defined as infinity. The crowding degree of the remaining individuals y(i) is:
In Equation (14), Select
The selection operation is to achieve the superiority of individuals in the population, where the individuals with higher fitness are selected with higher probability and the individuals with lower fitness are selected with lower probability. In this paper, the tournament method is used to select individuals, and two individuals are selected from the population at a time for fitness comparison, and the individual with high fitness value is put into the crossover pool. At the same time, the elite retention strategy is used to select and retain the best individuals to improve the global convergence of the algorithm. Crossover
The crossover operation of the algorithm is performed separately for the part of workpiece sorting and the part of device selection. The workpiece sorting part uses the precedence preserving order-based crossover (POX) operation. The equipment selection part uses order-based crossover (OBX). The process is as follows:
(1) Cross-operation of work process
The work order crossover is performed using a sequence-based priority-preserving crossover operation, as shown in Fig. 3. In Fig. 3, P1 and P2 denote parent individuals, and C1 and C2 denote child individuals. First, all the workpieces are randomly divided into two subsets S1 and S2, and then the workpieces belonging to S1 in P1 are copied to C1 and the workpieces belonging to S2 in P2 are copied to C2, keeping the workpiece positions unchanged; the workpieces belonging to S2 in P2 are copied to C1 and the workpieces belonging to S1 in P1 are copied to C2, keeping the workpiece order unchanged.
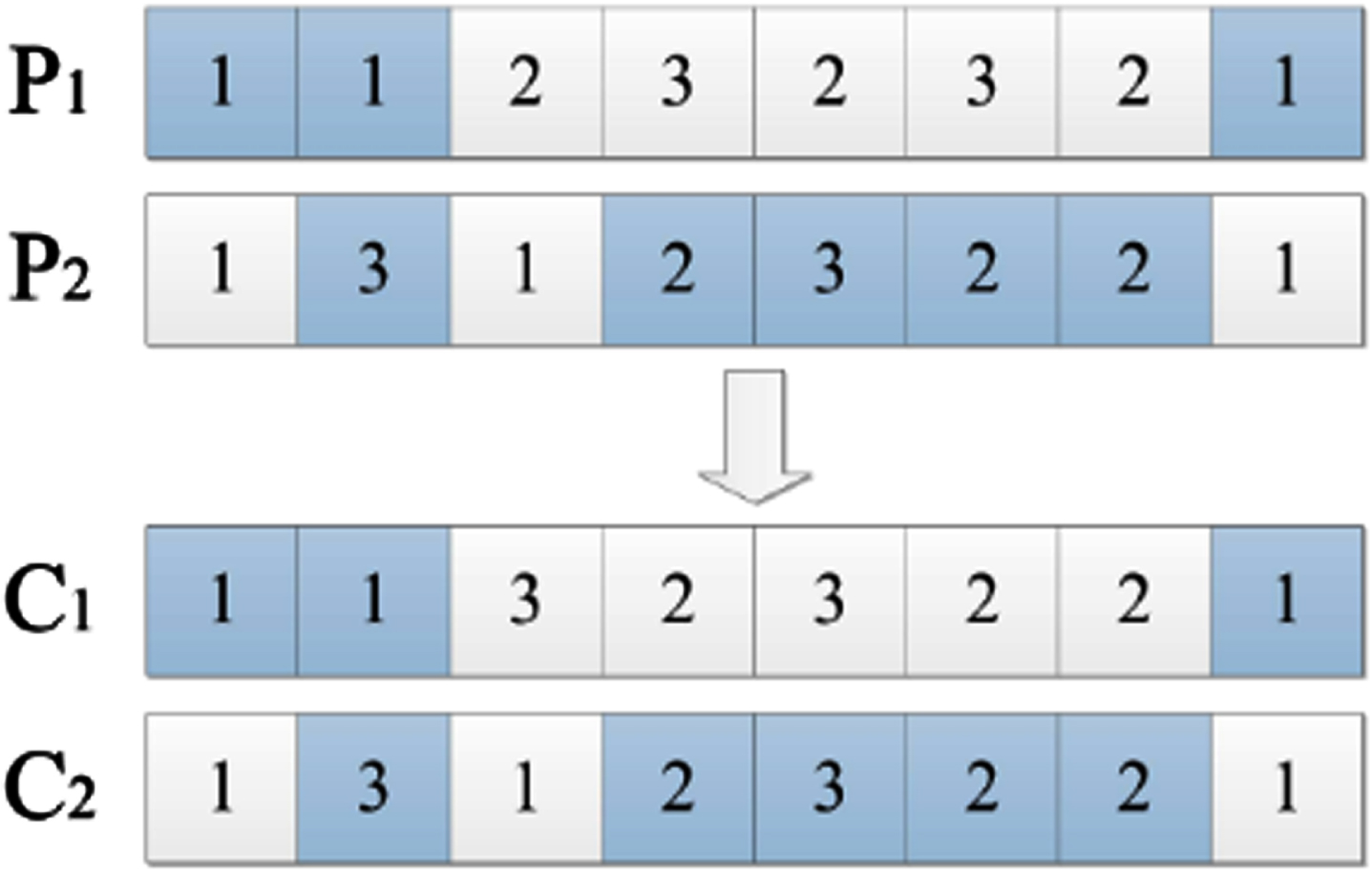
POX crossover operation
(2) Equipment cross-operation
As shown in Fig. 4, equipment crossover is performed using the sequence-based crossover (OBX) operation. Here P1, P2, C1, C2 represent the same meaning as the process crossover operation and K1, K2, K3, K4 represent the subset of locations. Where
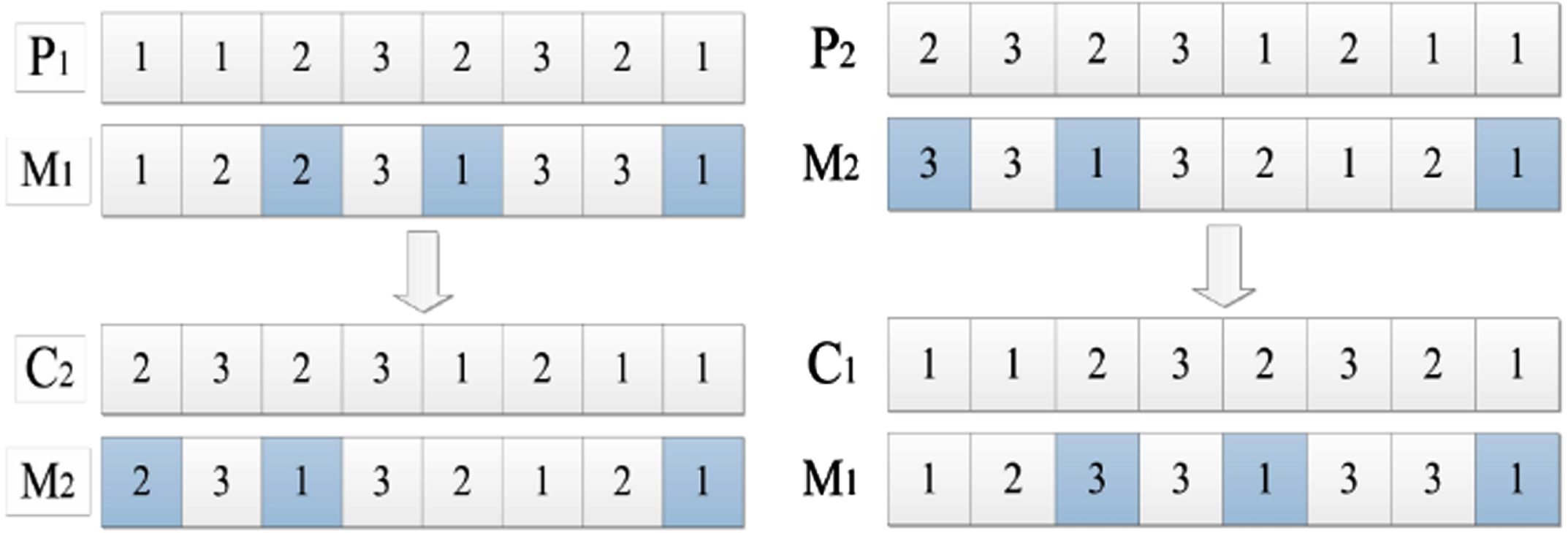
OBX crossover operation
Step 1: Create four subsets K1, K2, K3, K4.
Step 2: Randomly select a few position numbers from the device code and put them into K1, and put the remaining position numbers into K2;
Step 3: Copy the values belonging to K2 in parent P1 to child C1, and copy the values belonging to K1 in parent P2 to child C2, keeping the positions unchanged;
Step 4: Find the process code corresponding to K1 in P1 in the process code of P2 and put its corresponding position sequence, and then put the rest of the position sequence in P2 in K4;
Step 5: Copy the value corresponding to K3 in P2 to the value corresponding to K1 in C1, and copy the value corresponding to K1 in P1 to the value corresponding to K3 in C2, keeping the order unchanged. MUTATION
The mutation process of the algorithm is carried out separately for the process sequencing part and the equipment selection part.
(1) Mutation operations in the sorting part of the work order
A dynamic mutation operator is proposed for the process sorting part: there are three types of mutation operations: permutation, insertion and inverse order, and one of them is selected with equal probability for each iteration. The three mutation operations are as follows:
Swap mutation: two different positions e1 and e2 are randomly selected in the process code, and the elements corresponding to these two positions are exchanged.
Insert mutation: randomly select two different positions e1 and e2 in the process code, and insert the element corresponding to e2 in front of e1.
Reverse order mutation: Two different positions e1 and e2 are randomly selected in the process code, and the elements between these two positions are arranged in reverse order.
(2) Variant operation of the device selection section.
The mutation operation in the machine selection section performs a random replacement mutation. Two gene positions are randomly selected to replace the selected machine with any other machine from the set of its corresponding machines. NSGA-II ALGORITHM COMBINING SPARSITY THEORY
To address the shortcomings that the crowding comparison operator in the traditional NSGA-II algorithm cannot effectively guarantee the diversity of evolving populations, and that the resulting optimal solution set is not uniformly distributed and appears premature. In this paper, we improve the diversity of the evolving population and the uniformity of the optimal solution set distribution by introducing sparsity theory [28] to find sparse solutions and performing local search on sparse solutions to obtain local search children.
(1) Calculating sparsity
The steps to obtain the sparse solution are as follows.
Step 1: In order to eliminate the differences between the objective functions of different magnitudes, the objective functions of all individuals in the population were normalized.
Let the population size be n and the number of optimization objectives be m. i is the index of individuals in the population and j is the index of the objective function. Let the objective function corresponding to individual i be (
Step 2: Calculate the Euclidean distance ρ of each individual from other individuals based on Equation (16):
Step 3: Calculate the sparsity of each individual according to Equation (17):
(2) Neighborhood Search
After the sparse solution is determined, the local search children are generated by performing a neighborhood search around the sparse solution. There are two general approaches to neighborhood search, one is to use the traditional neighborhood search structure. The other is to construct a new neighborhood structure by combining the problem characteristics and optimization objectives.
In this paper, a neighborhood search combining three neighborhood structures N1, N2, and N3 is designed after considering the characteristics of the addressed problem and the encoding structure of the chromatic special. The first two neighborhood structures are related to the process code and the latter one is related to the machine code. One of N1 ∪ N3 and N2 ∪ N3 is selected with equal probability at each iteration to perform the neighborhood search operation. The specific structure is as follows.
Neighborhood structure N1: in the process sequencing section, two processes are randomly selected and their positions in the process code are exchanged. As shown in Fig. 5(a).
Neighborhood structure N2: select two processes at random in the process sorting code segment and insert the next process to the first position of the previous process. As shown in Fig. 5(b).
Neighborhood structure N3: Find the machine with the highest load M
max
, select a random process among all the processes on M
max
, and select a random replacement machine among the backup machines for that process. As shown in Fig. 5(c).
COMPETITIVE SELECTION STRATEGY BASED ON THE STATE OF THE PROCESSING MACHINE
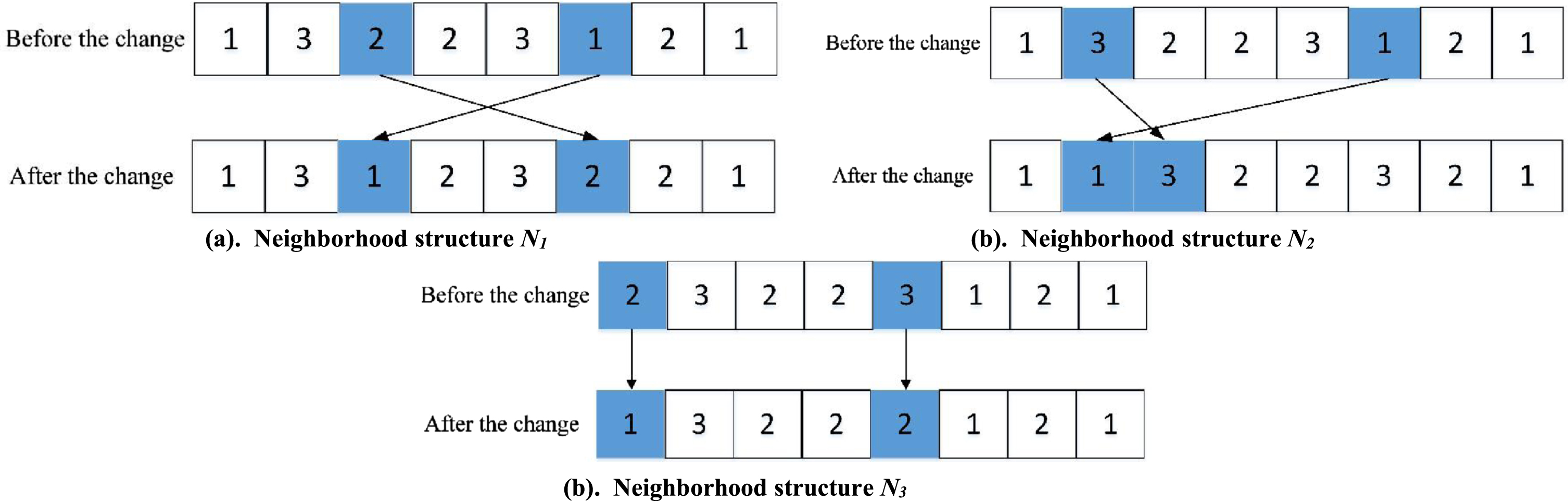
Neighborhood transform structure
The result obtained at the end of the iteration of the algorithm is a Pareto optimal solution set containing multiple individuals, and all individuals in the solution set are mutually non-dominated optimal solutions. In recent years, some scholars have also made extensive applications and explorations in the allocation, selection and scheduling of network resources by drawing on the idea of bidding mechanism [29–31].
This paper draws on the competitive selection method of the bidding mechanism. By introducing the concept of competitive intensity, the problem of local optimum caused by information asymmetry between processing machine information and the process to be processed is reduced. Thus, the actual maximization of the set target is achieved, which is conducive to the processing machine resources to meet the objective requirements of the law of value, competition mechanism and supply-demand relationship. The sequence of processing machines and the sequence of processes to be processed can be configured more rationally. The improvement is to consider the factors such as the process energy consumption of each processing machine, the total working hours of the machine to be processed, and the idle time of the machine between the previous and subsequent processes, and use it as the basis for the process to select the optimal scheduling scheme of the appropriate processing machine.
The definition criterion The criterion The criterion The criterion R3 is the idle time L
ijk
of the processing machine M
k
under the process O
ij
.
Based on the criterion R1, criterion R2, and criterion R3, the competitive intensity
After determining the criteria, the steps to specify the competitive selection strategy are: first, construct the competitive population based on the Pareto optimal solution set; then, calculate the competitive strength of each processing machine based on the process O ij information in each competitive population, and generate the competitive strength set of processing machines; second, the optimal combination of solutions in the Pareto optimal solution set is determined based on the magnitude of the competitive intensity, and the larger the value of competitive intensity, the better the solution; finally, the optimal solution in the optimal combination of solutions is determined based on the Dephi survey method, and the scheduling Gantt chart is output based on the resulting optimal solution. The Gantt chart shows the processing information of the process on the optimal processing machine and the ranking information between different processes on the same processing machine.
Comparing CT-NSGA-II, which introduces sparsity theory and improved operators, with the traditional NSGA-II algorithm. The processing energy rates of all equipment in the standard algorithm are randomly generated on [5, 18] and the no-load energy rates of all equipment are randomly generated on [1, 3] based on the method of literature [32]. The fixed energy consumption rate of the workshop and the transfer energy consumption of all workpieces were 30kw/h and 1.8kw/time, respectively. The data of energy consumption rate per unit time for all equipment are shown in Table 2.
Data table of standard arithmetic energy consumption rate (kw/h)
Using the machine processing time as well as the processing cost information, minimizing the completion time and the production energy consumption as the optimization objectives for the experiments, the standard algorithms are solved separately. Taking MK04 as an example, the experimental results are shown in Fig. 6. It can be seen that the solution quality and distribution of the CT-NSGA-II algorithm are better than the original algorithm.
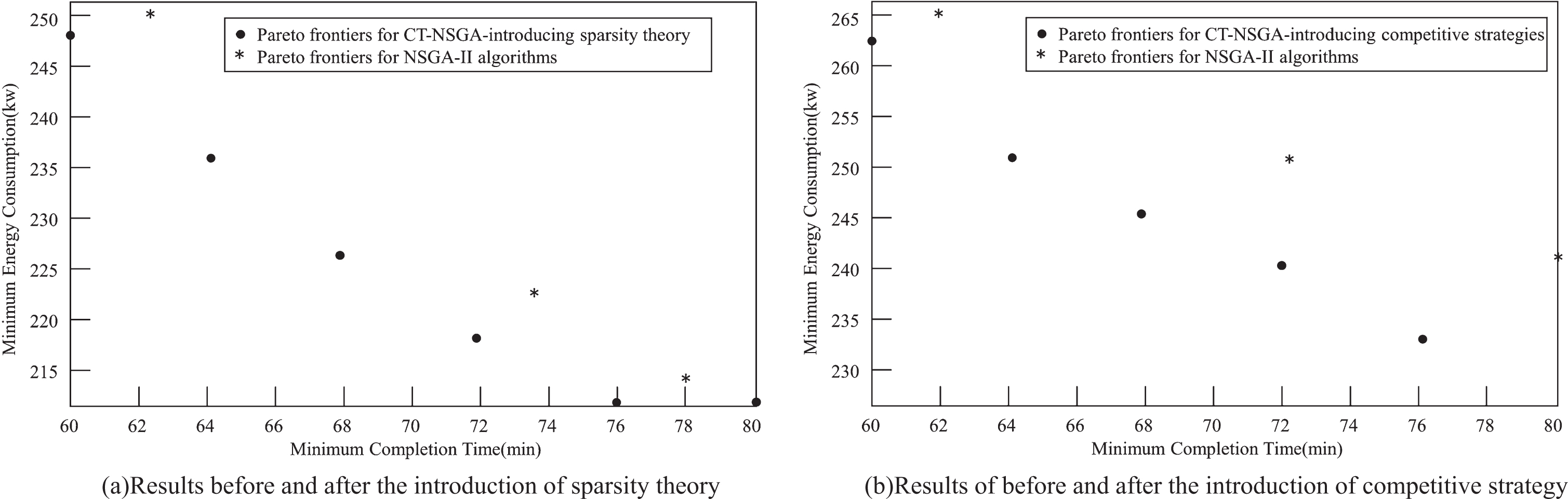
Comparison of experimental results between the CT-NSGA-II and the NSGA-II.
In this section, we first set the tuning parameters for the operation of the algorithms. Next, the standard algorithms are solved and verified using each of the three algorithms. Finally, the CT-NSGA-II algorithm is applied to the engineering cases to verify its effectiveness.
A. ALGORITHM PARAMETER TUNING
The algorithm parameters of CT-NSGA-II are set to include: population size N, crossover probability P c , mutation probability P m , maximum evolutionary generation t max , and individual sparsity discriminant threshold k in sparsity theory.
The method of parameter tuning is to analyze the effect of different settings of five parameters on the optimization results by using the Taguchi method with MK01 as the test example, so as to find out the better parameter setting scheme.
Four reasonable level values for the five parameters are given in Table 3, and the corresponding 16 parameter combination schemes are given in Table 4. For each parameter combination setting method, the CT-NSGA-II algorithm was run 10 times independently.
The values of the five parameters
The values of the five parameters
The way the five parameters are combined and their response values
Since it is a multi-objective optimization problem, the average value of the inverse generation distance (IGD) is chosen as the response value [33]. The resulting average response values of each parameter are shown in Table 5. From Table 5, it can be seen that the different values of the five parameters lead to a large difference in the variation of the corresponding average response values. The maximum number of iterations was 0.0196 at the four levels, followed by a discriminant threshold of 0.0183 for individual sparsity, 0.0183 for crossover probability, 0.0150 for population size, and 0.0147 for variance probability.
Average response values for the five parameters
The trend graphs of the response values of the five parameters are shown in Fig. 7. Analysis of Fig. 7 shows that t max has the greatest effect on the optimization results, and the other four parameters have a smaller effect. Therefore, the CT-NSGA-II algorithm is optimized best with the parameter values N = 200, P c = 0.8, P m = 0.15, t max = 1200, and k = 0.2. Therefore, this setting scheme is uniformly adopted for the parameters of the CT-NSGA-II algorithm and NSGA-II algorithm in the experiments of this chapter.
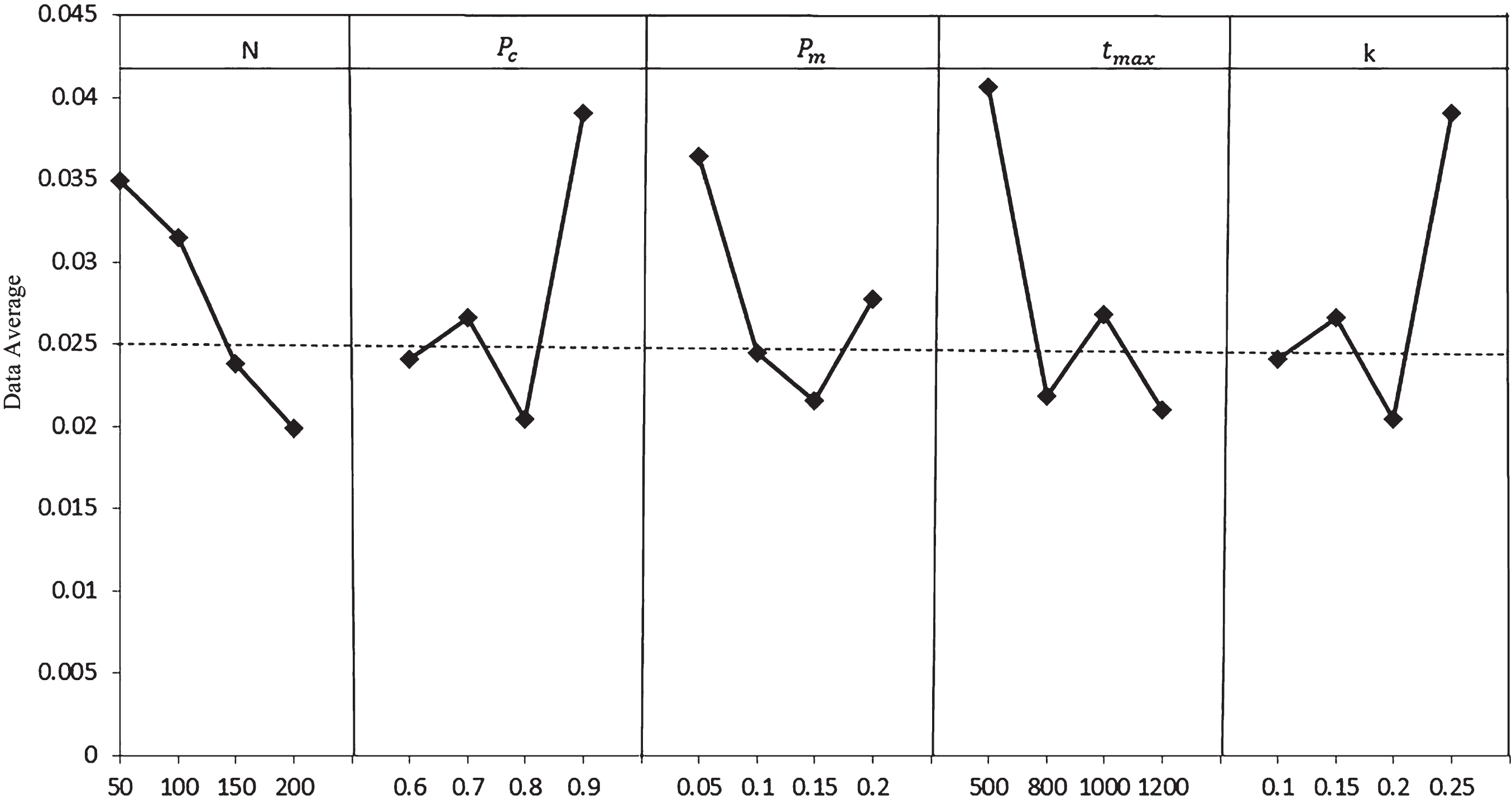
Graph of response trend of parameters
B. SIMULATION ANALYSIS OF STANDARD ALGORITHMS
In this section, CT-NSGA-II, the conventional NSGA-II algorithm [18], and the MOEA/D algorithm [34], which aims to minimize the total energy consumption and cost, are used to solve the standard examples, respectively. We choose 10 BRdata FJSP benchmarks (Mk01-Mk10) to test the performance of the algorithm. The solution method used in this paper was implemented using C# language, and the computational program was run on MATLAB 2016b platform and visual studio 2013 with computer configuration of Intel(R) Core (TM) i7-7700HQ CPU @2.80 GHz, 8.00 GB RAM.
To effectively apply the above algorithm for the solution, Based on the literature [35], the delivery date data for all workpieces are generated according to Equation (21).
In Equation (21), d j represents the delivery time of the jth workpiece, r j represents the placement time of the jth workpiece, t j represents the looseness of the jth workpiece, s j represents the total number of processes of the workpiece, and pl,j represents the processing time of the workpiece Ol,j. The values of t j can be taken as 2,1.5,1, which represent time lax, moderate, and tight, respectively. Based on the literature [36], the different time laxity (tight, moderate, loose) are set to 34%,33%,33% in each case.
The parameters of the CT-NSGA-II algorithm and NSGA-II algorithm were set according to the parameters after tuning in the previous section. The corresponding weights of f1, f2, and f3 are obtained by Delphi survey method as 0.3,0.3,0.4.
The parameter settings of the MOEA/D algorithm are referred to the literature [34]. Its aggregation function uses Chebyshev aggregation method. The population size is set to 62, the probability of mutation is set to 1.0, the number of splits is set to 10, the size of the weight vector neighborhood is set to 20, the maximum number of replaceable solutions per child is set to 1, and the maximum number of iterations is set to 1200. the above three cases are run 10 times to take the average value, and the simulation results are shown in Table 6 below. In Table 6, “best” represents the best value and “avg” represents the average value.
Simulation results of standard algorithm
Analyzing Table 6, we can see that for the index of maximum completion time, the CT-NSGA-II algorithm obtains the optimal average value for 5 cases of MK01, MK04, MK06, MK07, MK09. The NSGA-II algorithm obtains the optimal average value for 4 cases of MK02, MK03, MK05, and MK08. The MOEA/D algorithm obtained the optimal average of 2 cases, MK10, MK02, MK03, MK05 and MK08. The CT-NSGA-II algorithm obtains the optimal average value for 7 cases of MK02-MK07, MK09, and 2 cases of MK01, MK06, and the MOEA/D algorithm obtains the optimal average value for 4 cases of MK02, MK06, MK08, and MK10. For the total energy consumption objective: CT-NSGA-II algorithm obtained the optimal average value for 5 cases of MK01-MK03, MK08, MK09. NSGA-II algorithm obtained the optimal average value for 4 cases of MK04-MK07. MOEA/D algorithm obtained the optimal average value for 1 case of MK10.
Taking MK04 as an example, the corresponding Gantt charts after solving the three algorithms are shown in Figs. 8, 9, and 10. From the scheduling results of the Gantt charts, it can be seen that the scheduling solution generated by CT-NSGA-II can effectively shorten the completion time and delay time and reduce the processing energy consumption. Therefore, the CT-NSGA-II algorithm outperforms the NSGA-II algorithm and the MOEA/D algorithm in solving the flexible job shop scheduling under the standard cases in terms of solution accuracy.
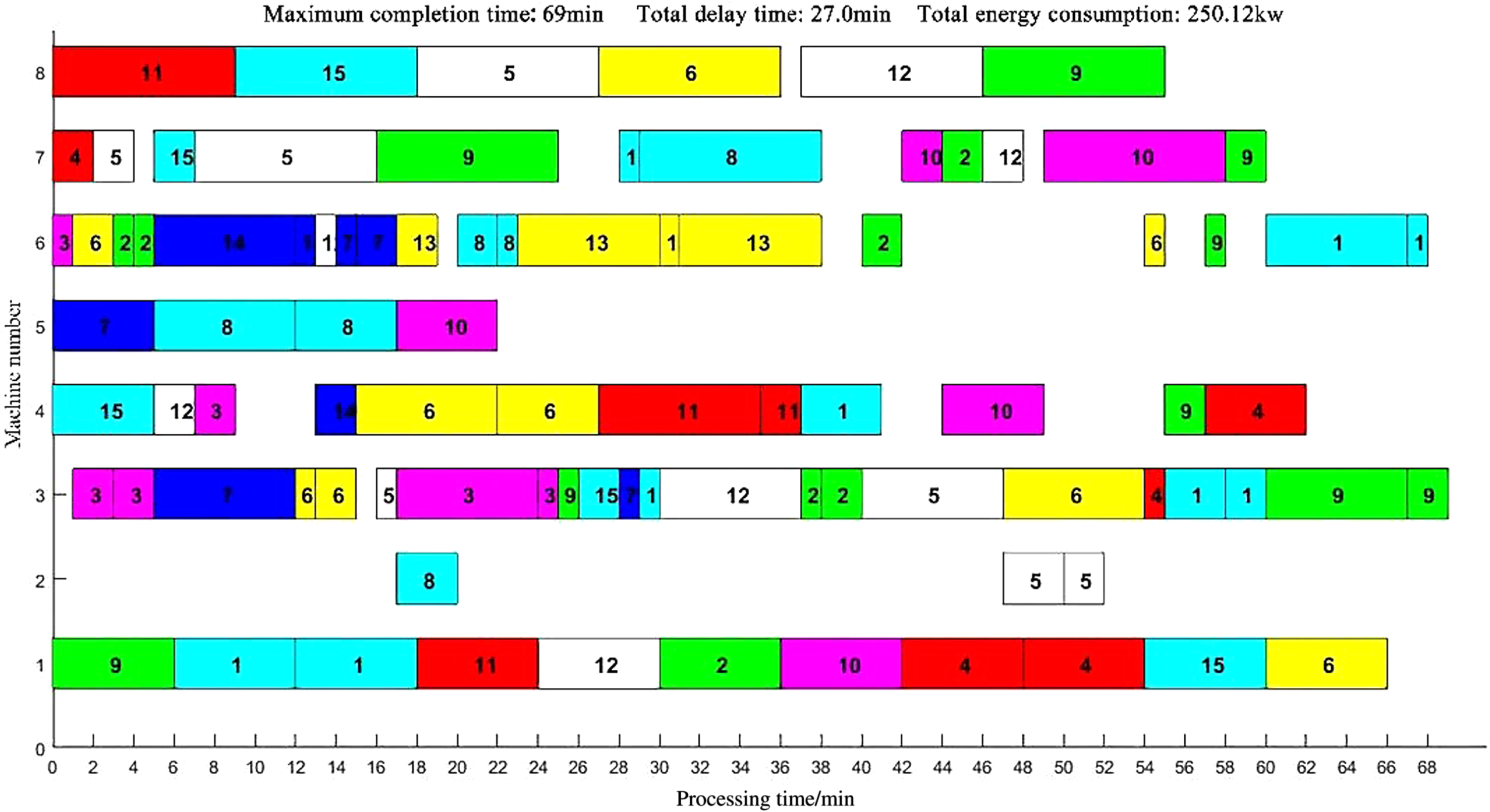
NSGA-II Solving Gantt Chart for MK04 Scheduling Results
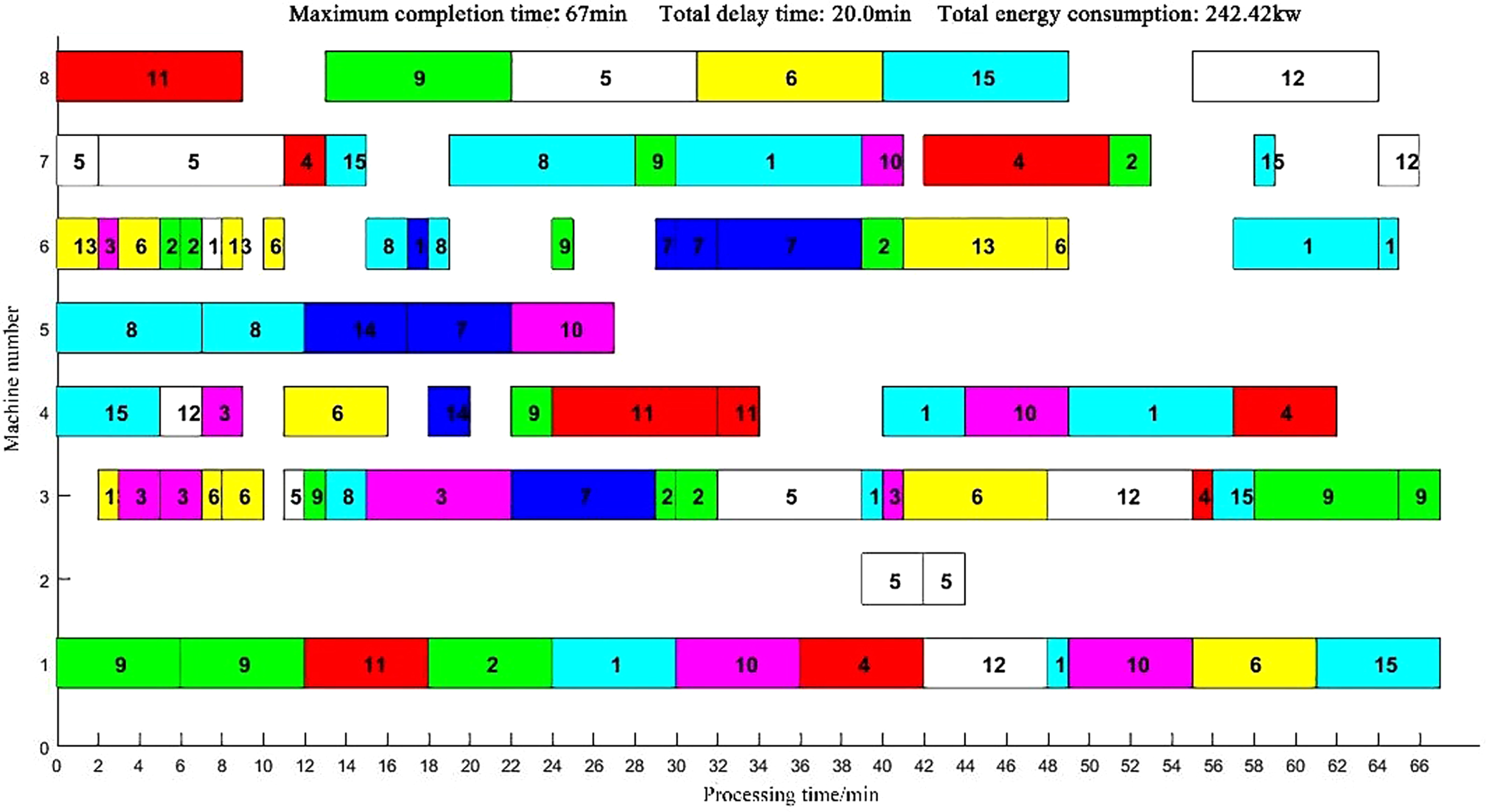
CT-NSGA-II Solving Gantt Chart for MK04 Scheduling Results
MOEA/D solving Gantt chart for MK04 scheduling results
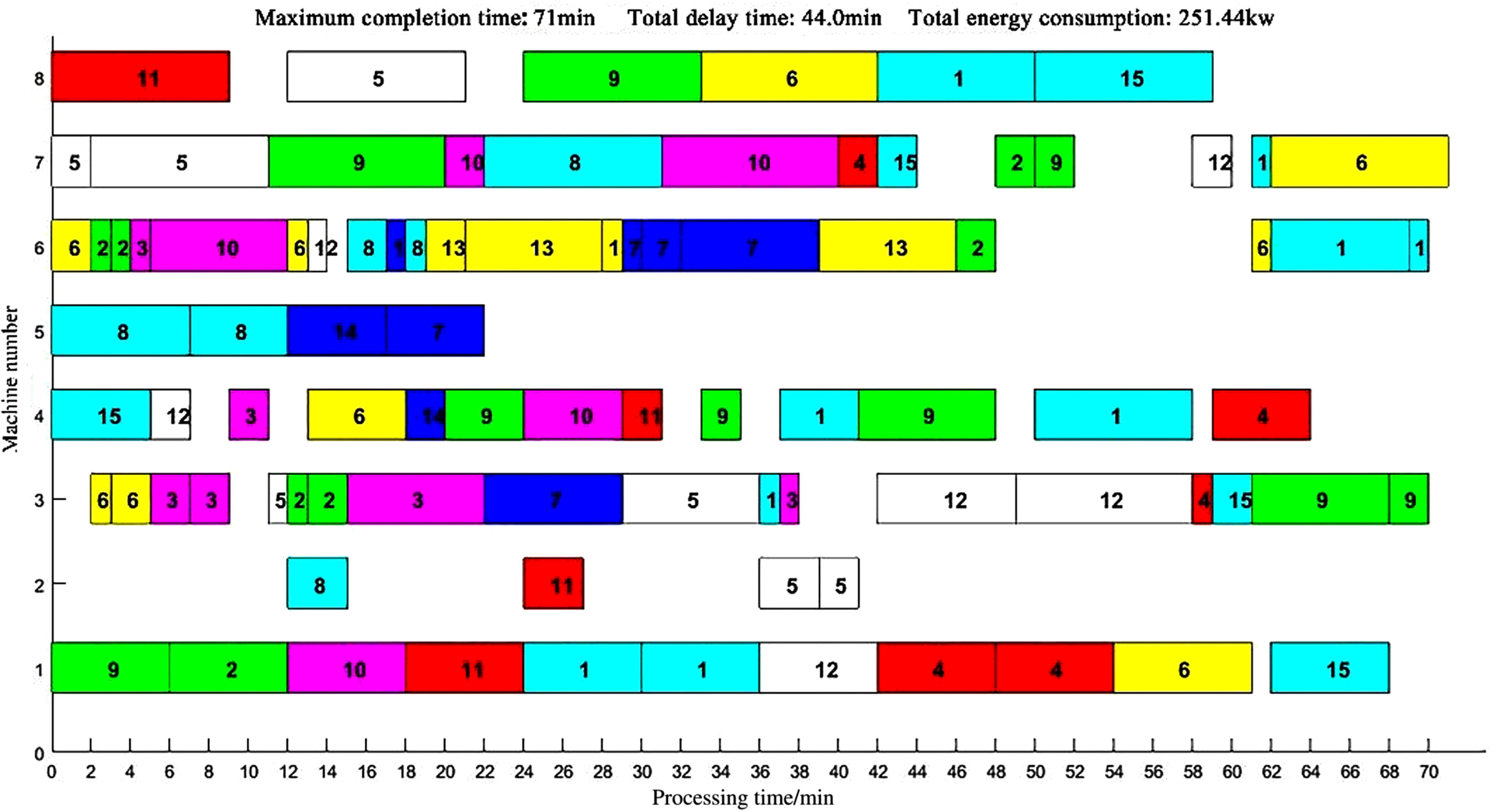
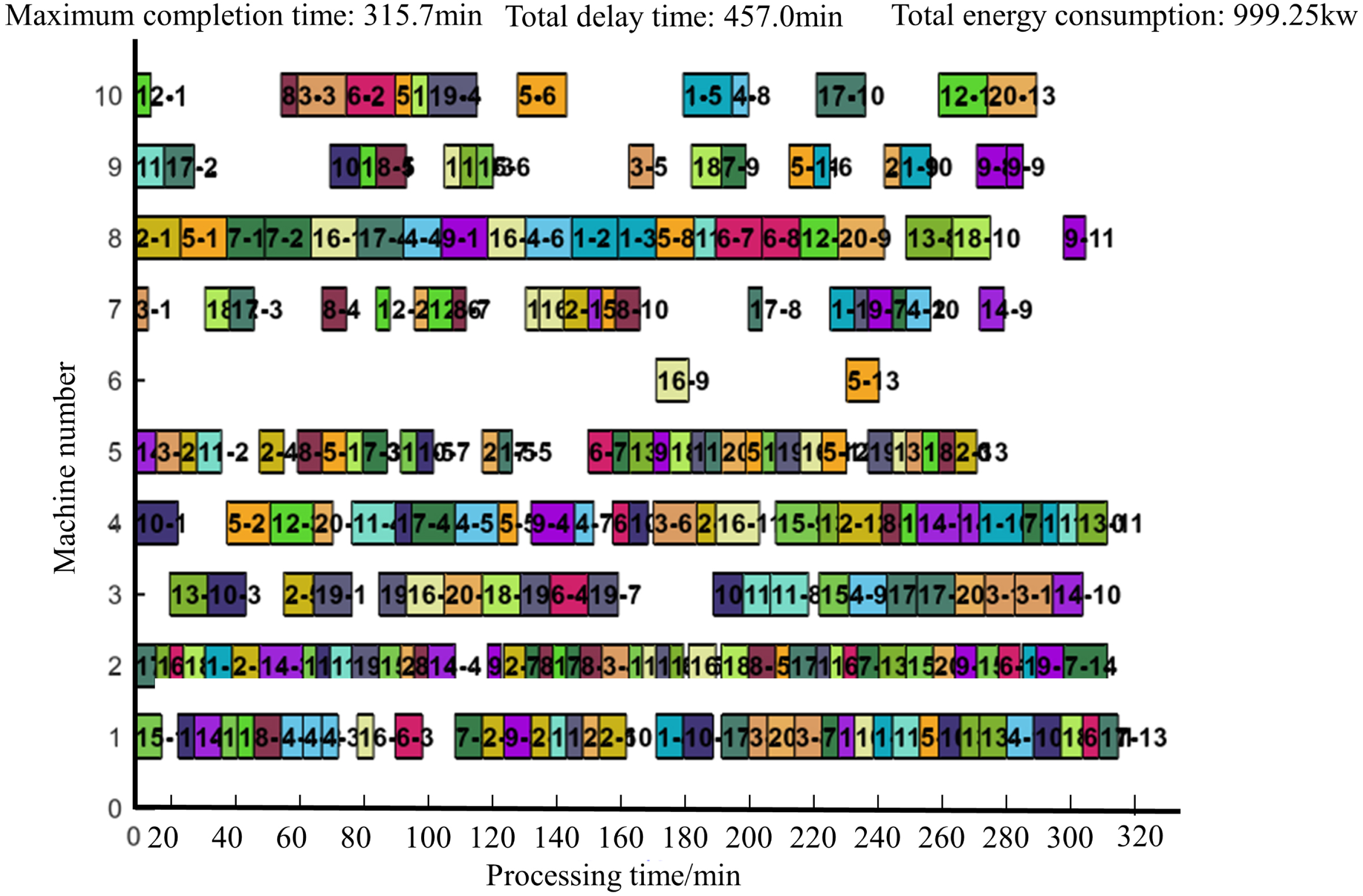
CT-NSGA-II does not get the optimal solution every time in large-scale instances, but the scheduling of the CT-NSGA-II algorithm is able to achieve more optimal values in terms of the combined effect. Taking MK09 as an example, CT-NSGA-II achieves the optimal solution in all three optimization objectives: maximum completion time, total extension time, and total energy consumption. The Gantt charts corresponding to the three algorithms after solving are shown in Figs. 11–13.
NSGA-II Solving Gantt Chart for MK09 Scheduling Results
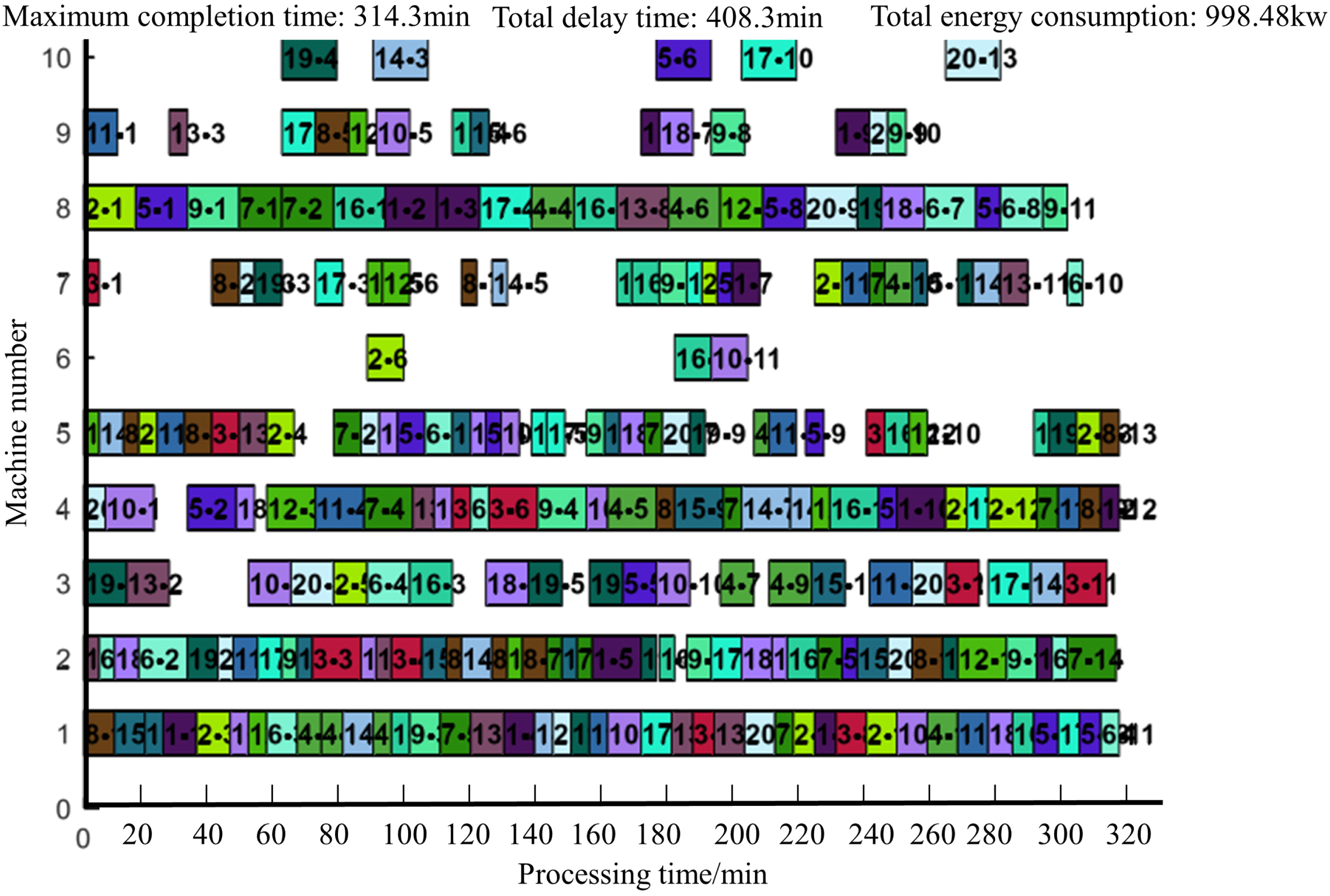
CT-NSGA-II solving Gantt chart forMK09 scheduling results
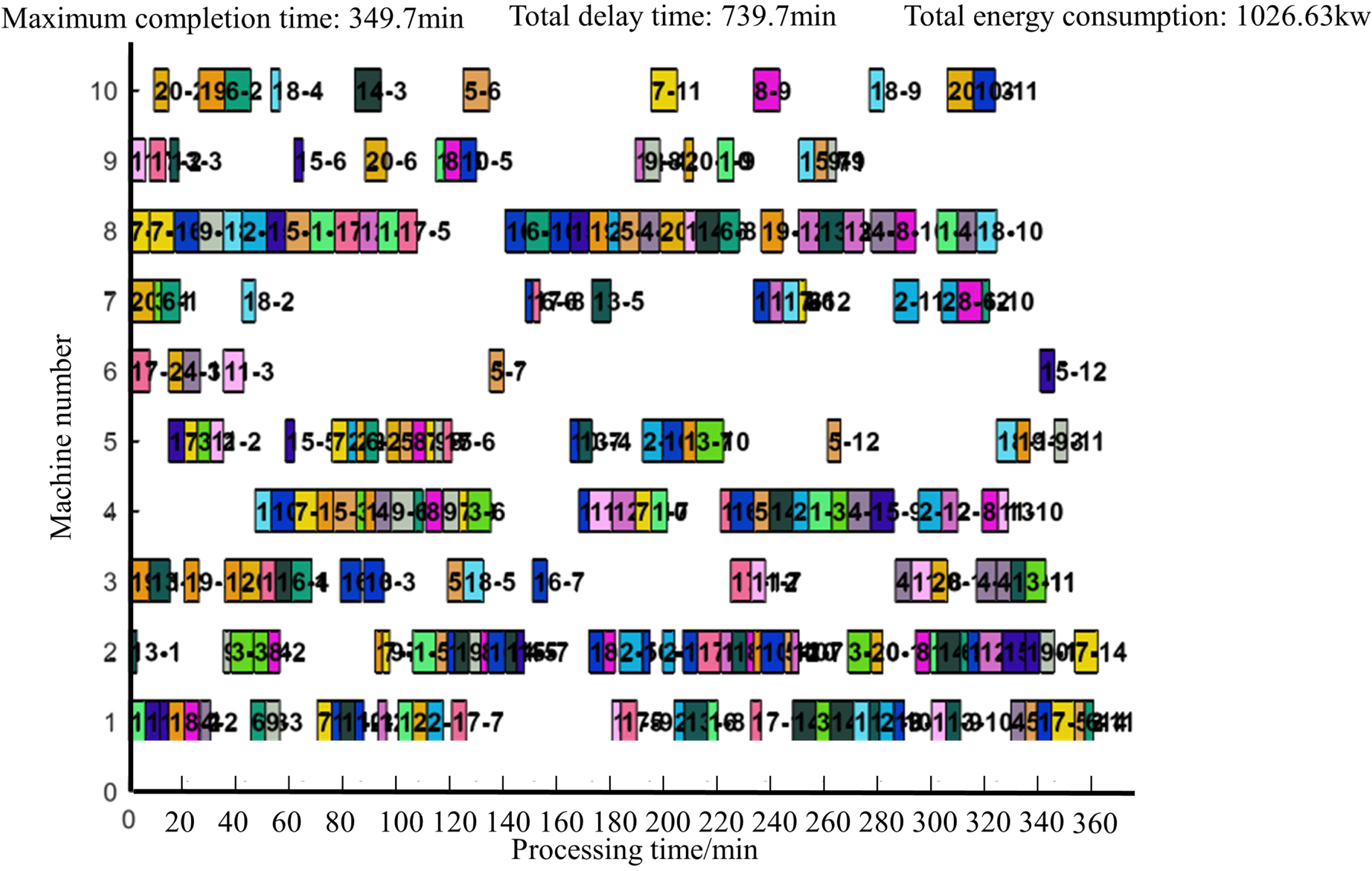
MOEA/D solving Gantt chart for MK09 scheduling results
C. ALGORITHM PERFORMANCE ANALYSIS
In order to verify the effectiveness of the algorithm proposed in this paper more comprehensively, this section uses the super volume and the inverse generation distance, which are common evaluation metrics for the performance of multi-objective optimization algorithms, as evaluation metrics. The validity of the proposed neighborhood structure is first verified under the same algorithm, and then the standard cases are solved using different algorithms to verify the superiority of the algorithm in this paper.
1) Performance evaluation index
The inverse generation distance (IGD) [33] is used as a comprehensive metric to evaluate both the convergence and the distribution performance of the solution set. To calculate the IGD, a set of reference points uniformly distributed over the real Pareto fronts is required. The smaller the IGD value, the better the fit of the solution set to the Pareto frontier. The ideal Pareto front surface is generated as an approximate combination of the optimal set of solutions obtained by the algorithm over many solutions. The real Pareto frontier in this case is the approximate frontier obtained by aggregating the solution sets obtained from all the tested algorithms run 10 times each. The IGD calculation formula is as follows.
In Equation (22), PF is the true Pareto front of the multi-objective optimization problem; |PF| is the scale of the true Pareto front of the problem; cr is the point on the approximate Pareto front created by the multi-objective optimization algorithm; p is the point on the true Pareto front; the function distance() is used to calculate PF and the shortest distance from a point p on PF to the approximate Pareto front distance(p,cr).
Convergence and diversity are also generally considered when evaluating the performance of an algorithm. the HV measure (supervolume measure) [32], a classical one-dimensional measure in multi-objective optimization, can accurately visualize the diversity and convergence of the Pareto solution set. The larger the HV value, the better the overall performance of the algorithm. In calculating the HV value, a reference point needs to be given in advance. In this paper, the reference point is set to the true optimal boundary, which is 1.1 times the maximum value of each target dimension. The HV measure is calculated as in equation (23), where vol(a) denotes the volume of the hypercube enclosed by some non-dominated solution a of algorithm A and the reference point.
2) Model Correctness Verification
In order to verify the correctness of the constructed model, this section solves the model with the single objectives of completion time, delay time, and energy consumption, respectively, by referring to the multi-objective algorithm in the literature [38] compared with CPLEX. The deviation amounts of the three objectives obtained by solving CPLEX with the CT-NSGA-II algorithm are compared, and the CPU running times of the two methods are recorded. Considering the limitation of the scale of the CPLEX solving problem, the small-scale cases of MK01-MK05 are selected for solving based on the parameter setting in the previous section. In this paper, in order to speed up the solution of CPLEX and reduce the solution time, the gap is set not to be 0, multiple feasible solutions are pursued, and the optimal solution is selected among the output multiple feasible solutions. Although Gap is not 0, the solver output is close to the optimal solution and can be used to verify the correctness of the model. The comparison results are shown in Table 7.
Comparison results of CT-NSGA-II and CPLEX
As can be seen from Table 7, the solutions obtained by the CT-NSGA-II algorithm solution are very close to the CPLEX solution results under the small-scale arithmetic example, which verifies the correctness of the model in this paper. In the five sets of cases, the maximum deviation of completion time between CT-NSGA-II and CPLEX is 2.5%, the maximum deviation of delay time is 5.2%, and the maximum deviation of energy consumption is 1.2%, which are all within the acceptable range. In addition, the CT-NSGA-II algorithm can save more solution time than CPLEX when the case size gradually increases.
3) Neighborhood structure validation
In order to explore the effectiveness of the proposed neighborhood search strategy, this section compares CT-NSGA-II with itself after removing the neighborhood search, and the algorithm after removing the neighborhood search is called CNINNS (CT-NSGA-II with no neighborhood search) here. The parameters of both algorithms were set as in the previous section. To overcome the random error, both algorithms were run 10 times independently for each test problem and the statistical results were taken for comparison. The results of CT-NSGA-II and CNINNS runs on the 10 test problems regarding IGD and HV are given in Table 8.
Solution results of CT-NSGA-II and CNINNS arithmetic cases
As can be seen in Table 8, for the IGD and HV measurement values, the difference between CT-NSGA-II and CNINNS is small on a few instances (MK03/MK06). However, CT-NSGA-II significantly outperforms CNINNS on the remaining test instances. As a whole, CNINNS did not outperform CT-NSGA-II in any of the measured cases. Therefore, it can be concluded that the proposed novel neighborhood structure can improve the convergence of the algorithm to some extent.
4) Analysis of algorithm operation results
The solution results of CT-NSGA-II algorithm, NSGA-II algorithm and MOEA/D algorithm for the above ten standard cases are compared and analyzed. Here the parameters of the three algorithms are set as in the previous section. In order to overcome the random error, all three comparison algorithms are run independently for 10 times and the average results are taken. The results are shown in Table 9, and the key data have been bolded.
Statistical results of IGD
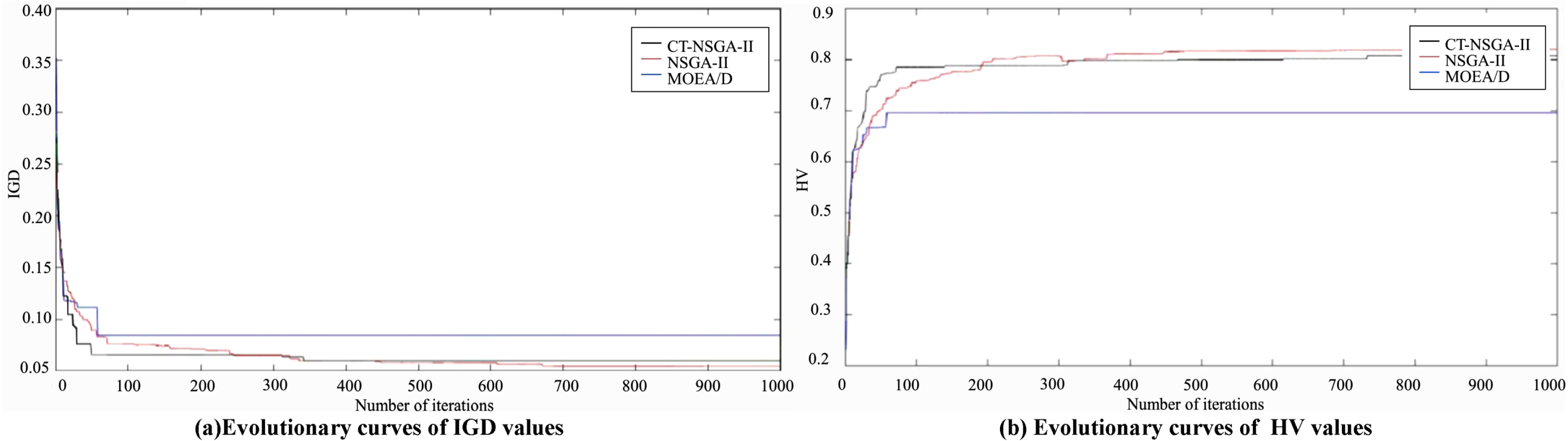
Compared with the other two algorithms, the CT-NSGA-II algorithm achieves optimal IGD values for all seven cases except MK03, MK06 and MK10. It also achieves the second best IGD value for solving MK03 and MK10, the best HV value for solving all 8 cases from MK03 to MK10, and the second best HV value for solving MK02. NSGA-II achieves optimal IGD values for solving MK06 cases, suboptimal IGD values for solving MK04-MK05, MK07-MK09, and suboptimal HV values for solving MK01, MK03-MK10 cases. MOEA/D achieves optimal IGD values for solving a total of 2 cases, MK03 and MK10, and optimal HV values for solving the MK01-MK02 cases.
Figures 14–17 show the evolutionary convergence plots of HV and IGD values obtained when solving examples MK04, MK05, and MK06 for CT-NSGA-II, NSGA-II, and MOEA/D algorithms, respectively. Analysis of the curves shows that: during the evolutionary process, the IGD values of all three algorithms are decreasing and the HV values are increasing. Moreover, the IGD and HV values decreased and increased significantly between 0 and 100 iterations, and the decrease and increase of IGD and HV values slowed down after 100 iterations. Finally, all three algorithms converge after 100 iterations. However, the IGD evolution curve of CT-NSGA-II is always below the other two algorithms between 100 and 1000 iterations, and its HV evolution curve is always above the other two algorithms between 100 and 1000 iterations. The above analysis shows that the CT-NSGA-II algorithm can achieve better HV and IGD values than the MOEA/D algorithm and NSGA-II algorithm, and its comprehensive performance of multi-objective optimization is better.
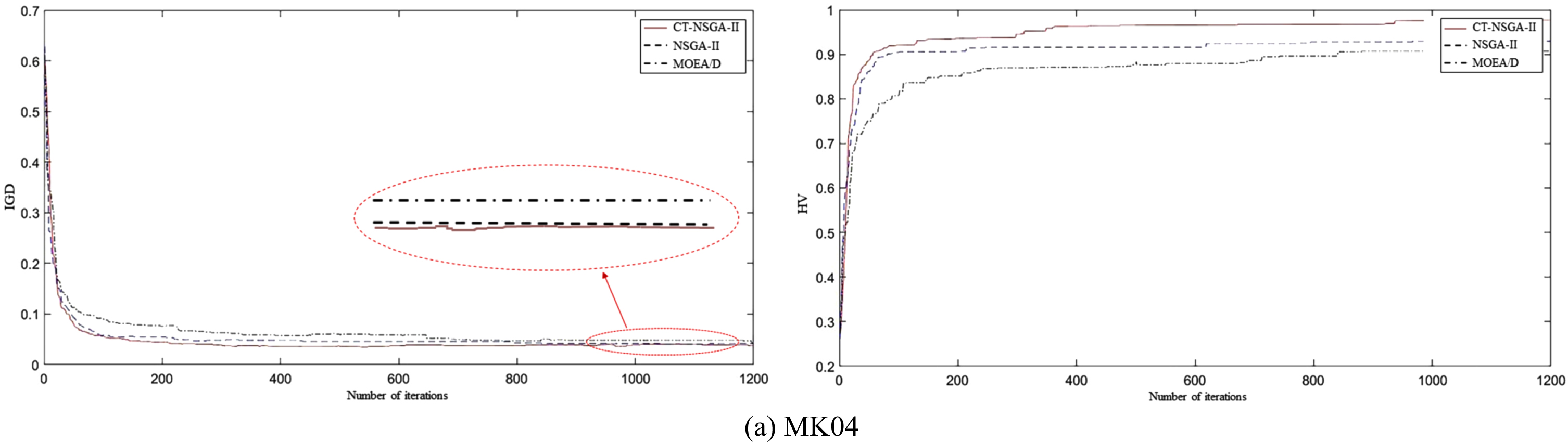
Evolutionary curves of IGD values and HV values obtained from three algorithms solving MK04

Evolutionary curves of IGD values and HV values obtained from three algorithms solving MK05

Evolutionary curves of IGD values and HV values obtained from three algorithms solving MK06
Evolutionary curves of HV values obtained from three algorithms solving different cases
D. ENGINEERING CASE ANALYSIS
In order to further verify the effectiveness of the model and algorithm, the actual production data of the manufacturing production plant of Company A is used as a case, and two algorithms, NSGA-II and CT-NSGA-II, are used to simulate and solve it. The processing information is shown in Table 10 and Table 11, which shows that the case belongs to the 10×6 FJSP problem. The simulation environment and the parameter settings of the two algorithms are the same as in the previous section.
10*6 FJSP problem
10*6 FJSP energy consumption data
In the energy consumption data in Table 11 the fixed energy consumption is 35kw/h and the transfer energy consumption is 2kw per time.
The simulation solution of the above example can be obtained as shown in Figs. 18–20, and the analysis shows that:
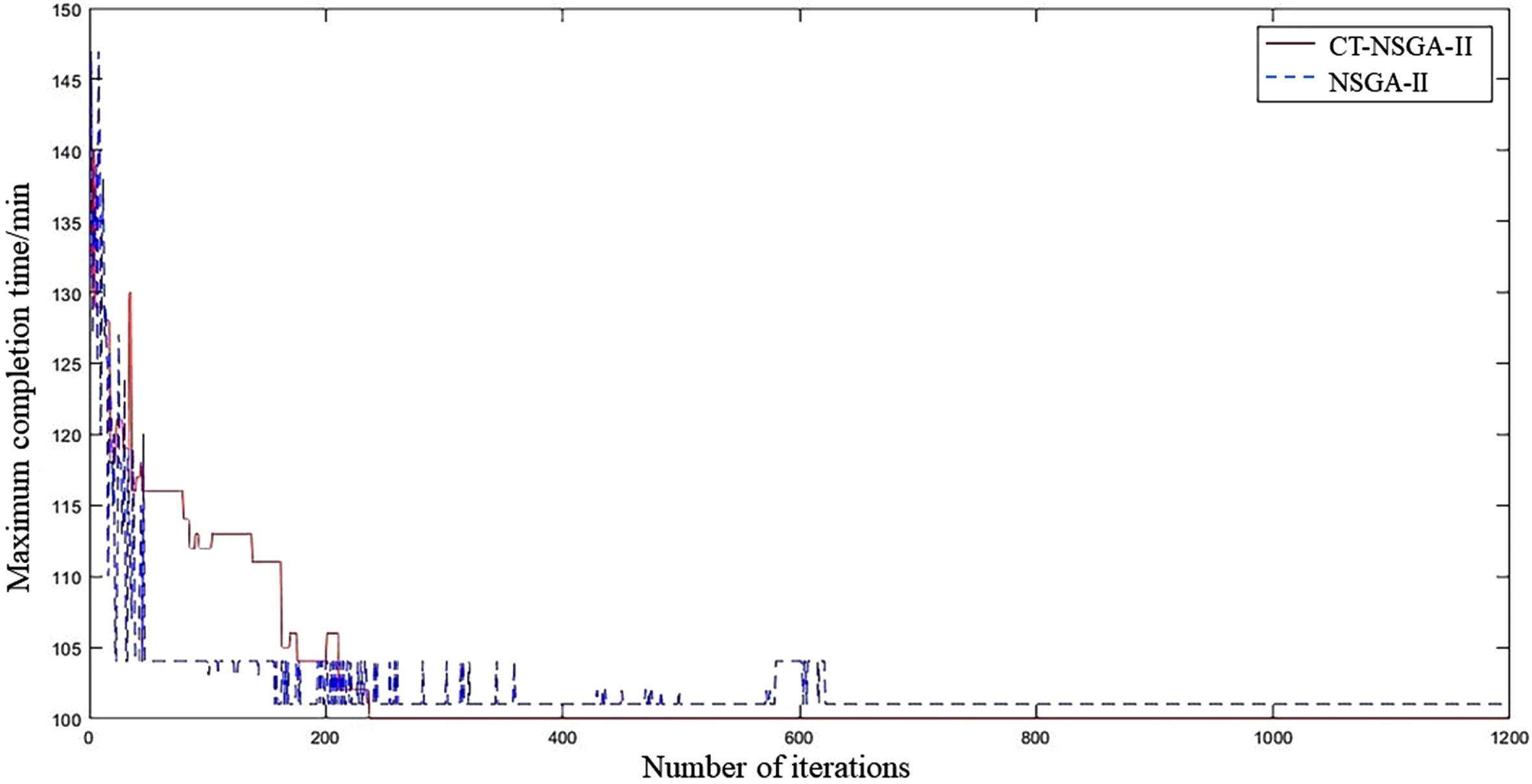
Maximum completion time convergence curves obtained by two algorithms for solving the 10*6 FJSP problem
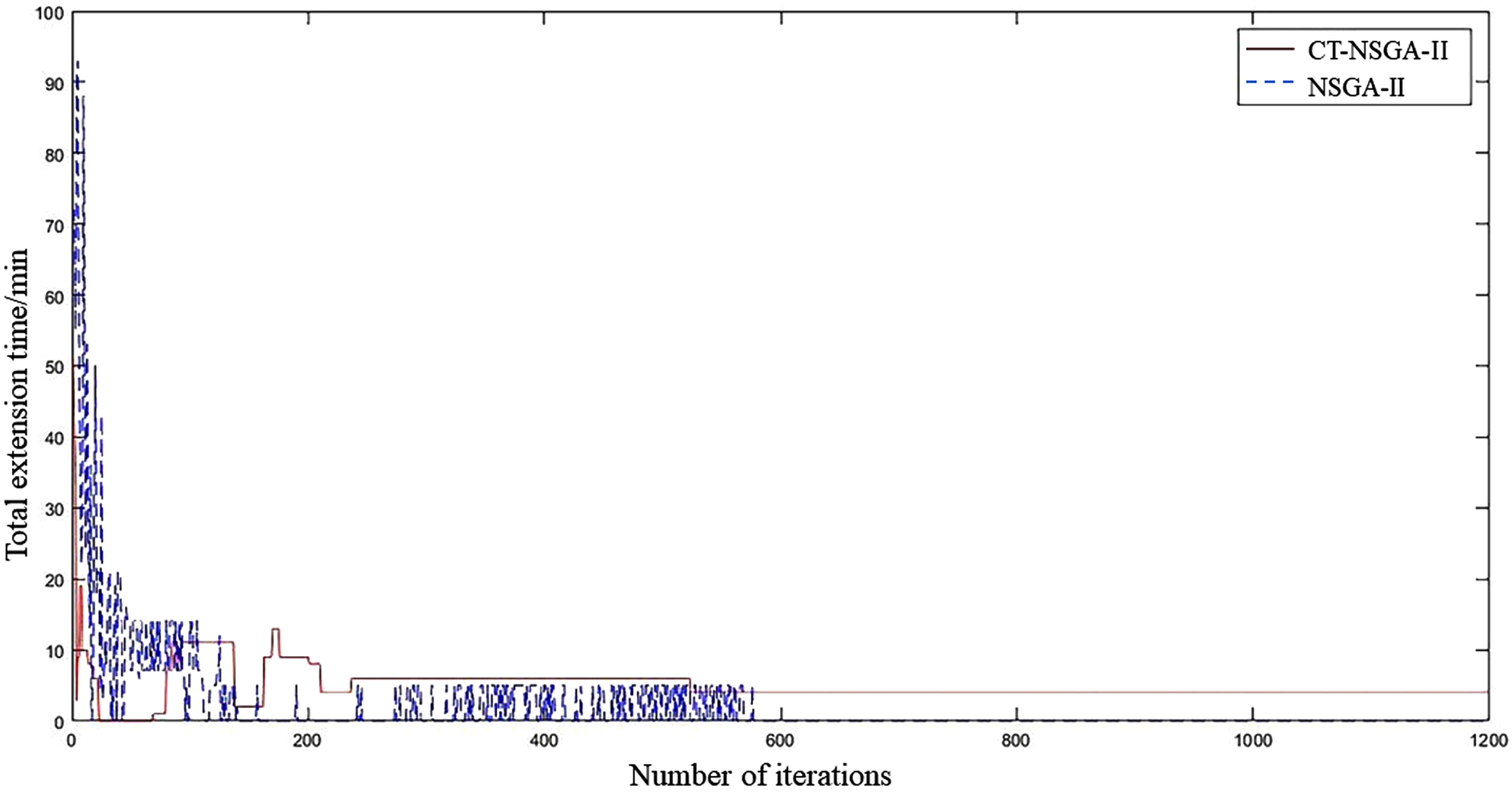
Convergence curves of the total extension time obtained by two algorithms for solving the 10*6 FJSP problem
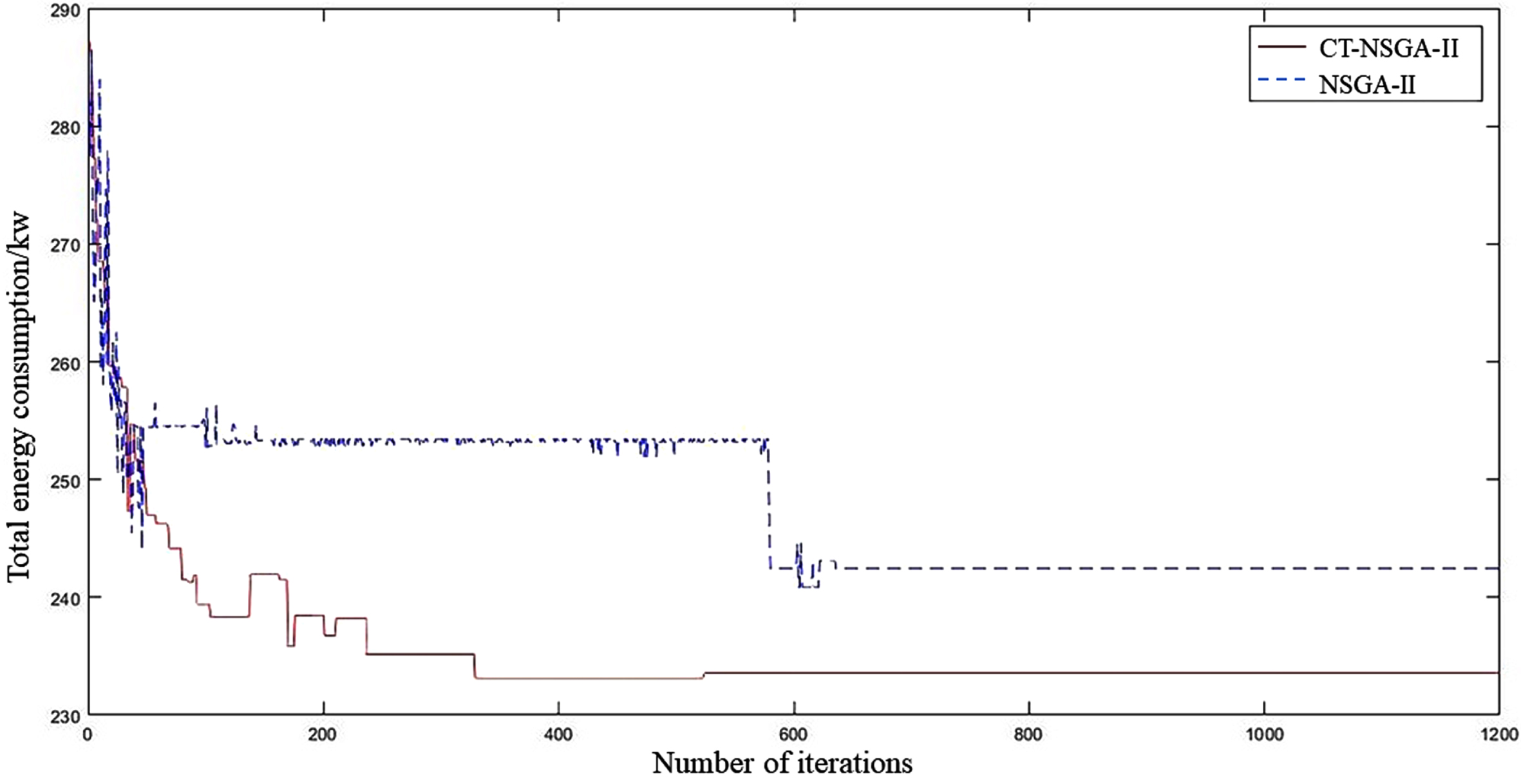
Convergence curves of the total energy consumption obtained by two algorithms for solving the 10*6 FJSP problem
1) The CT-NSGA-II algorithm outperforms the NSGA-II algorithm in both total energy consumption and maximum completion time, but the NSGA-II algorithm slightly outperforms the CT-NSGA-II algorithm in total extension time. The main reason is that the energy consumption of the equipment generally decreases as the total load of the equipment increases. As a result, the increased equipment load, reduced energy consumption and completion time may result in longer delivery dates for some orders.
2) NSGA-II algorithm curve is more volatile, CT-NSGA-II algorithm curve is smoother. The reason is that when the NSGA-II algorithm solves the low-dimensional MOP problem, the number of solutions in the Pareto solution set is largely due to the poor population diversity, which leads to a large difference in the optimal compromise solution selected each time and makes the optimal solution uncertain.
The Gantt charts of the scheduling results of the two algorithms are shown in Figs. 21–22. In terms of energy saving effect, the energy consumption of the scheduling solution obtained by CT-NSGA-II algorithm is 233.56kw, and that of NSGA-II algorithm is 242.42kw. The current scheduling method used by enterprise A is first-come-first-processed, and the energy consumption of this method is 275.8kw. The CT-NSGA-II algorithm can effectively reduce energy consumption compared with the existing scheduling method of the enterprise.
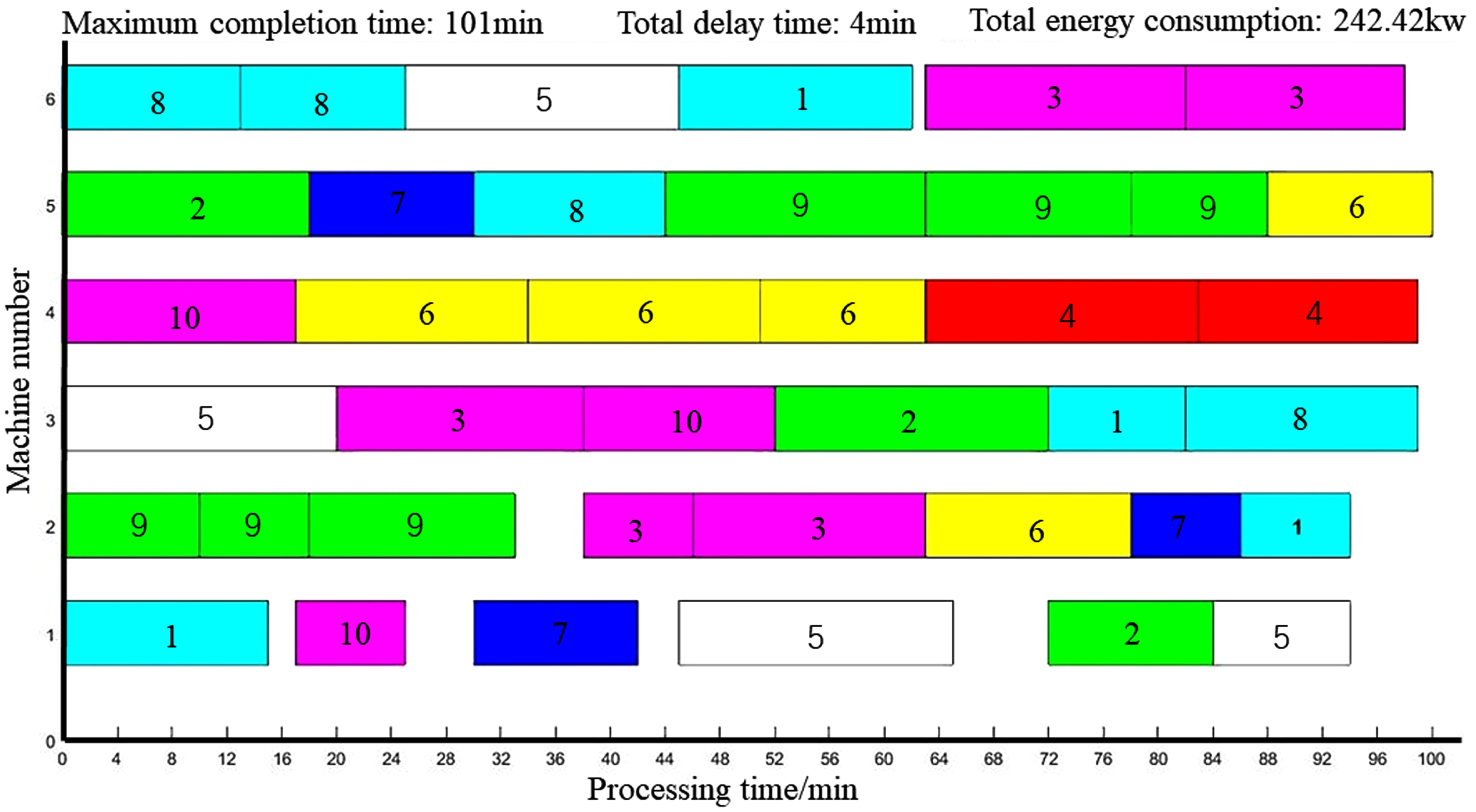
CT-NSGA-II Solving 10*6 FJSP Problem Scheduling Results Gantt Chart
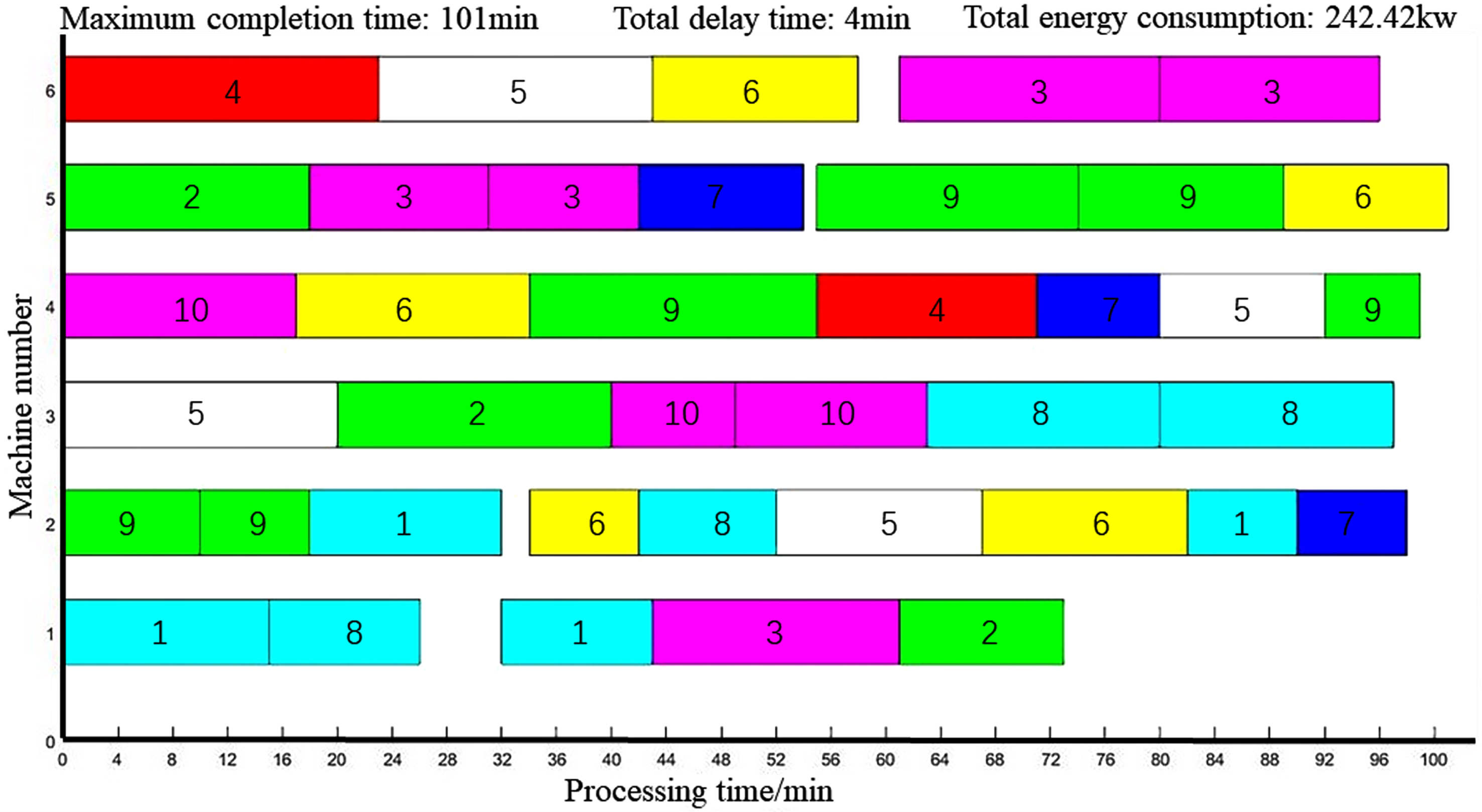
NSGA-II solving 10*6 FJSP problem scheduling results Gantt chart
Considering the limitations of the comparison effect when solving cases with the same type of algorithms and the chance of the solution results in a single run, we added three algorithms, BDCSO [39], IBA [40], and ICA [41], to further validate the case solution based on the comparison of CT-NSGA-II and traditional NSGA-II algorithms. These three algorithms were selected because the optimization objectives of energy consumption and completion time are considered in all of them and are typical algorithms for solving the MOFJSP problem. The Taguchi method described in Section 4-A is used to calibrate the parameters of all algorithms. The final configuration of the parameters for the newly added algorithms is given in Table 12. Each algorithm was run 10 times randomly. The mean values of the corresponding performance parameters are recorded in Table 13.
Algorithm parameters after calibration
Comparison of CT-NSGA-II with other algorithms
From Table 13, we can see that CT-NSGA-II outperforms the other algorithms in terms of completion time, delay time, and energy consumption index. And CT-NSGA-II can obtain a larger number of non-dominated solutions. the running time of CT-NSGA-II is slightly longer than that of NSGA-II, which is due to the added neighborhood search strategy that increases the running time by a small amount. The Pareto fronts obtained by the five algorithms are shown in Fig. 23. the Pareto fronts of CT-NSGA-II outperform the other four algorithms in terms of convergence and diversity, and are closer to the ideal Pareto fronts.
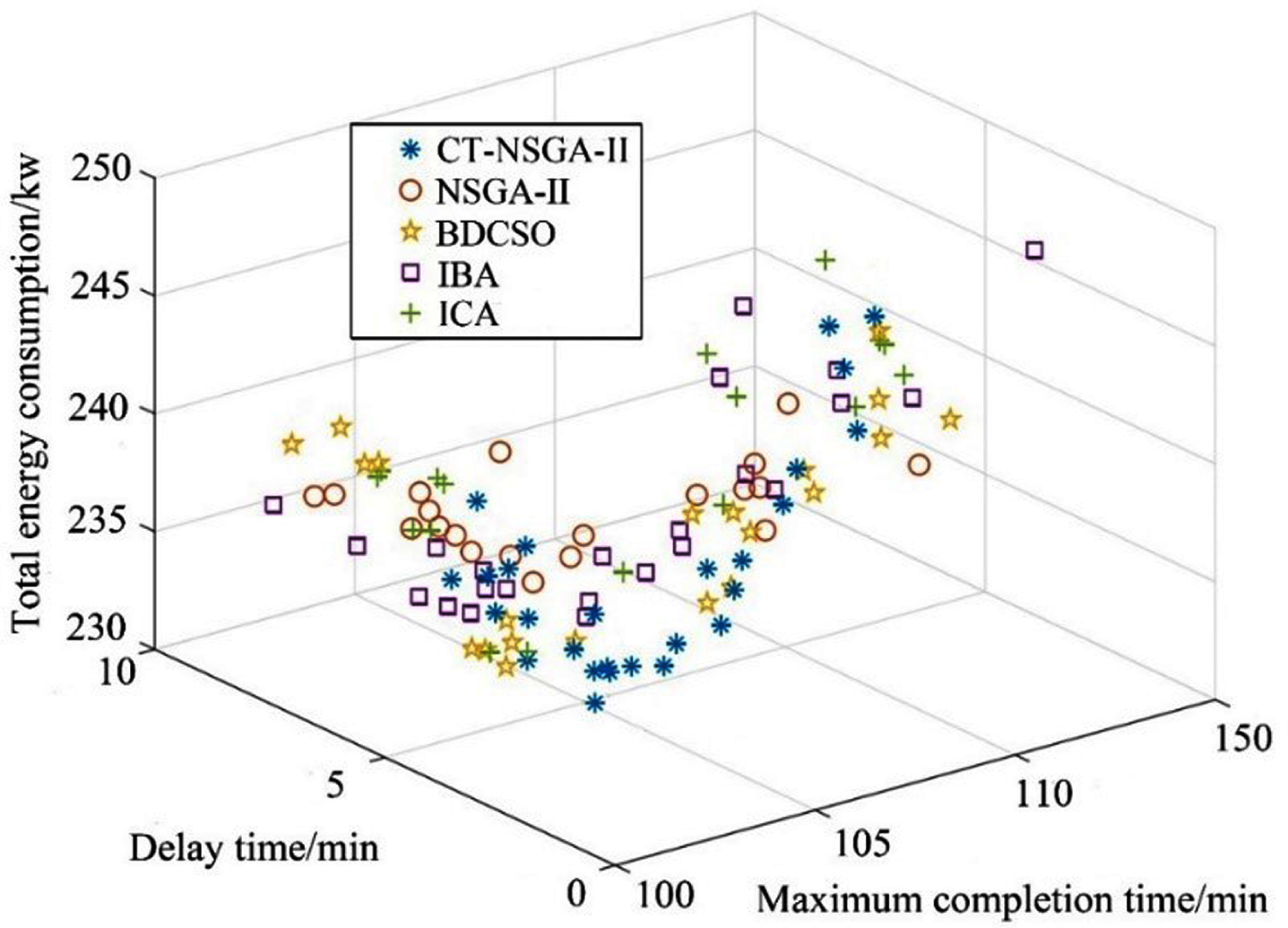
The Pareto front obtained by the five algorithms
To further compare the quality of the obtained solutions, the algorithm performance was further evaluated using the IGD and HV metrics mentioned in Section 4-C. Each algorithm is run 10 times randomly and the corresponding parameter metrics are recorded in Table 14. Where “Avg” denotes the mean value of the ten corresponding data sets.
Performance metrics of the five algorithms
As can be seen in Table 14, the mean values of IGD, HV of CT-NSGA-II are the best among the five groups of algorithms, and there are nine sets of reference values that can be chosen among the ten sets of run results of IGD. The results show that the solution set obtained by CT-NSGA-II has better convergence compared to the remaining four algorithms. The combined results of Table 13, Table 14, and Fig. 23 are sufficient to prove the superiority of CT-NSGA-II among the five algorithms. This algorithm enhances the balance between convergence and diversity and improves the quality of the Pareto solution set
In this paper, a multi-objective flexible job shop scheduling model with maximum completion time, total delay time, and total energy consumption of the system as optimization objectives is constructed according to the actual production of flexible job shop. The model fully considers various energy consumptions of the flexible job shop on the one hand, and processing time and lead time targets on the other. A CT-NSGA-II solution algorithm is proposed for the constructed model, which generates a higher quality initial population by a GLR hybrid initialization method. The sparsity theory is introduced to perform two different neighborhood search operations on sparse solutions, which increases the diversity of the new generation population and improves the ability of the algorithm to jump out of the local optimum, and then a more comprehensive set of Pareto optimal solutions can be obtained. Finally, the competitive selection strategy is applied to select the optimal compromise solution from the Pareto optimal solution set. The correctness of the constructed model and the effectiveness of the proposed algorithm are verified through the simulation solutions of the standard and enterprise cases. In future work, the following directions deserve further research:
In the next research, the parameter selection and implementation steps of the algorithm can be further improved to achieve better optimization results, while the time and space complexity of the algorithm should also be considered.
The application of sparsity theory needs to be improved for the case of high-dimensional targets to improve the reliability of the algorithm.
Footnotes
Acknowledgments
This work was partially supported by the Natural Science Foundation of Hebei Province under Grant No. E2022202136.
Funding
This work was supported by the Natural Science Foundation of Hebei Province under Grant E2022202136.
Competing interests
The authors have no relevant financial or non-financial interests to disclose.
Author contributions
All authors contributed to the study conception and design. All authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Ethical and informed consent for data used & data availability and access
The datasets generated during the current study are available from the corresponding author on reasonable request.