
Abstract
Reservoir structure optimization of echo state networks (ESN) is an important enabler for improving network performance. In this regard, pruning provides an effective means to optimize reservoir structure by removing redundant components in the network. Existing studies achieve reservoir pruning by removing insignificant neuronal connections. However, such processing causes the optimized neurons to still remain in the reservoir and thus hinder network inference by participating in computations, leading to suboptimal utilization of pruning benefits by the network. To solve this problem, this paper proposes an adaptive pruning algorithm for ESN within the detrended multiple cross-correlation (DMC2) framework, i.e., DMAP. On the whole, it contains two main functional parts: DMC2 measure of reservoir neurons and reservoir pruning. Specifically, the former is used to quantify the correlation among neurons. Based on this, the latter can remove neurons with high correlation from the reservoir completely, and finally obtain the optimal network structure by retraining the output weights. Experiment results show that DMAP-ESN outperforms its competitors in nonlinear approximation capability and reservoir stability.
Keywords
Introduction
Echo state networks (ESN) proposed by Jaeger [1, 2] is considered as an effective bio-inspired method for dealing with temporal trend data. The reservoir is the typical structure of an ESN, a large-scale internal recurrent topology. It can project the input signal into a high-dimensional state space, and then perform a nonlinear transformation on a time-dependent signal. In fact, this can be considered as a typical feature-learning process. In a classical ESN, the output weights are the only structure that needs to be trained and can be obtained by solving simple least squares problems. It avoids the problems of sluggish convergence and high computing costs that occur in traditional recurrent neural networks (RNN). Nowadays, thanks to its simple topology and powerful nonlinear feature characterization ability, ESN is widely used in many fields, such as time series prediction [3], anomaly detection [4], and language modeling [5].
However, the structural optimization of ESN remains a challenging problem. On the one hand, it is difficult to satisfy the accuracy requirements of complex nonlinear time series prediction in most situations since the reservoir of classical ESN is randomly generated. On the other hand, it always requires a lot of trials and even luck to choose a suitable reservoir size. Obviously, the reservoir cannot learn enough knowledge from the input data to satisfy the inference requirements if the neurons are too few, while too many neurons may lead to the potential overfitting problem [6]. For these reasons, ESN is severely limited in its promotion.
To this end, it is highly necessary to design efficient structural optimization methods for such an ESN, especially in the optimization of reservoir size.
Related work
RelatedWork Currently, a large number of researchers have made some attempts at the structural optimization of ESN. For example, Rodan and Tino et al. [7] developed a simple cycle reservoir network (SCRN) with deterministic parameters, which can perform comparably to a standard random ESN on widely used time-series benchmarks. Xue et al. [8] proposed an ESN model with both ring topology and leakage-integrated units, which produced richer reservoir dynamics and lower reservoir state correlation. Kawai et al. [9] introduced the small-world network topology into the design of the reservoir structure. Such a clustering structure can extend the range of echo state properties and contribute to the extension study of ESN topology. Xue et al. [10] proposed an ESN structure optimization algorithm based on particle swarm optimization, which allowed the adjusted network to have better adaptability, stronger prediction and stability. However, these solutions maintain the pursuit of high estimation accuracy without considering the applicability in real deployments. For example, the size of these networks can easily surge to converge to the best possible performance, which is inefficient and impractical. In addition, these networks can easily fall into the trap of overfitting problem with increasing network size. Hence, it is imperative to explore an efficient ESN with small size.
To tackle the above problem, network pruning can be considered as an effective structural optimization method for ESN, which can significantly reduce the model size, runtime memory, and computational operations at a low network training overhead. Particularly, designers generally tend to design reservoirs large enough to ensure that the extracted features are comprehensive enough. Nevertheless, not every neuron in the reservoir is able to detect the key features of the network input, leading to the existence of redundant neurons. In other words, a good reservoir should be high cohesion and low coupling with sufficient feature mapping capability [11]. For such a reservoir structure, it can easily be obtained by network pruning. On the one hand, pruning can remove unimportant network parameters, so that the pruned network has a smaller size. On the other hand, the reservoir does not focus on unimportant features since only important neurons are retained after pruning, which avoids potential overfitting problems. In some recent work, various methods have been proposed to remove redundant parameters in ESN. Scardapane et al. [12] proposed an online pruning algorithm for redundant connections of reservoirs, which allowed to obtain optimal sparse reservoirs in a robust approach. Liu et al. [13, 14] proposed a method to remove redundant connections based on the correlation between reservoir nodes, which solved the redundancy problem of reservoir information. In addition, there are also some studies focused on pruning redundant connections from the reservoir to the output layer [15–18]. These studies made contributions to reservoir structure optimization by reducing redundant parameters in the network. However, it is worth noting that the neurons optimized by the above methods are still existing in the reservoir, which may perturb the reservoir dynamics directly or indirectly and even negatively affect the network inference by participating in the computation. As a result, the network is unable to fully exploit the benefits provided by the optimized neurons, thereby resulting in a sub-optimal performance improvement for the pruned network. Hence, our interest lies in finding an efficient pruning algorithm to remove the entire redundant neurons from the reservoir, aiming to completely eliminate their negative impact on the ESN. Specifically, in order to optimize the topology of an ESN from a pruning perspective, it is particularly critical to accurately assess the correlation between reservoir neurons. Such a correlation can provide important a priori knowledge for the pruning procedure, enabling it to accurately identify neurons that should be removed from the reservoir. For this reason, it is crucial to seek an effective method for analyzing correlations between reservoir neurons. It is well known that the traditional Pearson correlation coefficient (PCC) is commonly used to measure the association relationship between two neurons [18, 19]. However, such an analytical tool heavily relies on the linear assumption of the data, and exhibits significant inapplicability when dealing with non-stationary data [20]. Unfortunately, the assessment of correlation between reservoir neurons is often achieved by analyzing the dependencies between their state series, but these state series frequently exhibit significant non-linear and non-stationary behavior [21]. Hence, PCC is not well-suited for the analysis of correlation between reservoir neurons.
The detrended multiple cross-correlation (DMC2) coefficient is a powerful tool for modeling the dependencies among multiple variables [22]. Unlike PCC, it not only overcomes the limitations of the linearity assumption of the original data, but also does not have strict requirements on the stationarity of the data. So far, it has been widely used in many fields [22, 23]. For example, Wang et al. accurately identified PM2.5 as the main factor affecting air quality of Beijing using DMC2 and demonstrated that their analysis results have statistical significance [20]. Da et al. defined a method for assessing the statistical significance of DMC2 based on a probability distribution function and accurately quantified the interactions between stock data from different financial markets [24]. Moreover, some researchers have also applied DMC2 to the modeling of ecological data and have shown that it can provide better statistical results than traditional methods [25]. In view of the aforementioned advantages, this paper considers employing DMC2 to assess the correlation among reservoir neurons, with the aim of providing accurate and reliable prior knowledge for the subsequent pruning procedure.
Contributions
In this paper, we propose an adaptive pruning algorithm for ESN structure optimization within the DMC2 framework, i.e., DMAP. The DMC2 measure of reservoir neurons and reservoir pruning are its two main functional parts. Specifically, the former can evaluate the correlation of reservoir neurons to provide guidance for reservoir pruning. Subsequently, the latter can completely remove the neurons with high correlation from the reservoir, and finally, the optimal reservoir topology can be obtained by retraining the output weights of the network. Extensive experiments show that DMAP algorithm greatly reduces the size of the ESN network, while the nonlinear approximation performance and stability are improved. The contributions of this study are outlined below. We propose a novel adaptive pruning algorithm (DMAP) for removing unimportant neurons from the reservoir, which enhances the network’s prediction capability and stability. We quantify the correlation among multiple reservoir neurons by DMC2. We prove the DMAP’s effectiveness through extensive simulation experiments. We measure the reservoir richness after each pruning using the average state entropy (ASE).
The remainder of this paper is structured as follows. Section 2 provides an overview of the ESN. Section 3 gives a general overview of DMAP algorithm. Section 4 performs a large number of simulations to prove the effectiveness of our strategy. The pruning process of DMAP is discussed in detail in Section 5. Finally, Section 6 provides a summary of our work.
Echo state network
A standard ESN consists of a reservoir with N nodes characterized by a nonlinear transfer function f (·). At moment t, this network is driven by the input signal
Specifically, as a discrete-time nonlinear system, the ESN reads
where
As mentioned above,
where i = 1, 2, … , N, represents the number of the corresponding reservoir neuron.
The corresponding network readouts are then collected into the target matrix Y, denoted as
Specifically, in order to mitigate the effects of reservoir initialization, the certain washout time tmin should be discarded. In fact, it can be viewed as a regression problem to determine a suitable
where
·
denotes a 2-norm operator. The optimal solution for
where
Notably, the three main hyperparameters of an ESN need to be initialized before the training procedure, i.e., α, β, and r. α is an input-scaling parameter, and the elements in β is the sparsity parameter, defined as the proportion of non-zero elements to the total elements in the reservoir weight matrix r is the spectral radius parameter, defined as the maximum of the absolute values of all the eigenvalues of the reservoir weight matrix where the elements of
This section describes the general framework for optimizing the reservoir structure by DMAP, as shown in Fig. 1 overview. In this framework, two main parts are involved: DMC2 measure of reservoir neurons and reservoir pruning. Functionally, the former can estimate the correlation between neurons in the reservoir based on quantitative DMC2 measure. Taking this as a basis, the latter allows to obtain a compact reservoir by removing highly correlated neurons from the reservoir. Next, the relevant algorithms involved in modules DMC2 measure of reservoir neurons and reservoir pruning are described in detail, respectively.

Schematic diagram of optimizing reservoir structure by DMAP.
In this subsection, we provide a detailed construction procedure for the DMC2. Firstly, obtain the state vectors of all neurons in the reservoir. Subsequently, the detrended cross-correlation analysis (DCCA) coefficient (defined as the ratio between the detrended covariance function
Assuming that
where m
i
and m
j
represent the mean values of
where υ = 1, 2, 3, ⋯ , ϒ. Furthermore, we can obtain the corresponding detrended variance functions FDFA i and FDFA j as well as the detrended covariance function FDCCA by Equation (10), denoted as follows
Next, the DCCA coefficient of the i-th neuron versus the j-th neuron can be evaluated, which is computed by a function ρi, j (n) about the window length n, that is
For any given scenario, 0 ≤ δ i (n) ≤1, with a rigorous derivation in [20]. Specifically, δ i (n) =0 indicates no multiple cross-correlation, while δ i (n) =1 indicates perfect multiple cross-correlation [23]. In our scenario, δ i is used to measure the correlation between the reservoir neurons, aiming to provide guidance for the subsequent pruning procedure to identify redundant neurons.
In this subsection, we provide a detailed description of reservoir pruning in the DMAP framework. Unlike these methods that only set the weights to zero [12–18], DMAP can completely remove these selected redundant neurons from the reservoir under the guidance of DMC2 criteria. The advantage of such processing is that any potential perturbations caused by the optimized neurons can be eliminated because they no longer exist in the network. It results in a more efficient and simplified network structure.
Algorithm algorithmic gives the pseudocode for optimizing ESN structures using DMAP. Specifically, create an ESN with large enough size and drive the reservoir by sample data, recording the states of the neurons, and storing them into X. Then, we can calculate the output weight matrix
1: ♯
2: Randomly generate
3: Set r∈(0, 1);
4: Configure an ESN;
5:
6: ♯
7:
8: Update reservoir states using Equation (1);
9: Collect network state
10:
11: Calculate
12: N← Obtain reservoir size by
13: ♯
14:
15: Calculate ♯ i of i-th reservoir neuron by Equation (13);
16: Save δ i to Γ (i);
17:
18: ♯
19:
20: i←Obtain the index of the largest value in Γ
21:
22:
23:
24: Γ (i) = null;
25:
26:
27: break;
28:
29:
Simulations
In this section, we verify the effectiveness of the proposed DMAP method, considering three different datasets: the chaotic mapping system Mackey-Glass (MG), the Multiple Superimposed Oscillator (MSO) problem, and the daily mean temperature (Temp) of Beijing. In our scenario, each dataset is divided into two parts for training and testing, respectively. Moreover, to emphasize the advantages of our method, we also evaluate some ESN-based models, unoptimized ESN (U-ESN), ESN based on Pearson correlation pruning (named P-ESN in this paper) [14], and C-ESN based on contribution pruning [17]. In the following experiments, each evaluated model under consideration has no output feedback. To ensure fairness, the same hyperparameter settings are used for each model in the same prediction task, and Tables 1 lists the detailed parameter settings.
Hyperparameter settings of the evaluated models in three time series prediction tasks
Hyperparameter settings of the evaluated models in three time series prediction tasks
In this part, we provide comprehensive explanations for the considered datasets, including the MG, the Temp, and the MSO. In this study, each dataset is split into two subgroups: the training set and the testing set, and their lengths are set to 300 and 300, respectively. Specifically, 100 time steps are discarded with the aim of washing out the initial transient. The description of the considered dataset is given below.
It is well known that the MG system [26, 27] is a typical benchmark with chaotic attractors for time series modeling. It has been extensively utilized for performance assessment of predictive models in many literatures. A time-delay differential equation with the following form can be used to derive the MG time series
Additionally, the real-world dataset of daily mean temperature in Beijing is used for our experimental evaluation. The data collection period spanned from December 9, 2021, to July 31, 2023, comprising a total of 600 records.
Finally, the analyzed MSO time series is created by adding up a number of straightforward sinusoidal functions, given by
In our scenario, the Root Mean Square Error (RMSE) and the maximum local Lyapunov exponent (λ) are considered to measure the nonlinear approximation performance and stability of the evaluated models, respectively.
The RMSE reflects the deviation degree of the actual and predicted values, and the smaller the RMSE, the better the model prediction performance. The formula of the RMSE can be expressed as
On the other hand, we explore the Jacobi matrix of the reservoir state update (1) and produce a derived metric, i.e., the maximum local Lyapunov exponent, λ. Such a quantity is used to approximate the separation rate in phase space for trajectories with very similar initial conditions. λ is considered to characterize reservoirs, and is widely used as a measure of reservoir stability in much of the literature [29, 30]. λ can be calculated by considering the Jacobi matrix at moment t, and denoted as follows when the neuron uses a hyperbolic tangent activation function
where
Fig. 2shows the fitting results of each model to the original signal in the three time series prediction tasks. Specifically, the partial fitting results in each subfigure are given as a picture-in-picture (PIP) for better visualization. From the trend-change details in these PIPs, the prediction curves of the proposed DMAP-ESN are more similar to the trends of the desired curves compared to the other alternatives, especially in the MG and MSO prediction tasks, implying the optimal nonlinear approximation capability.

Prediction results of the evaluated models when the minimum RMSE test can be obtained (initialized reservoir size N = 100).
Figure. 3 shows the violin plots of the prediction errors after taking the absolute values of the evaluated models in three prediction tasks. Each violin plot consists of a box plot and density traces located on its left and right sides. The symmetric density traces can visualize the distribution of the absolute values of the prediction errors, and its width reflects the frequency of occurrence of data points. The built-in box plots give information about the basic distribution of data. On the one hand, the boxes of DMAP-ESN are the flattest and closer to zero overall, especially in Fig. 3(a), meaning smaller deviations in predicting the data. On the other hand, the minimum mean values also imply its advantage in prediction performance. Tables 2 shows the performance comparison results of each model when N = 50, 100. Once again, the minimum RMSE test suggests that DMAP-ESN is the optimal architecture to handle these prediction tasks.
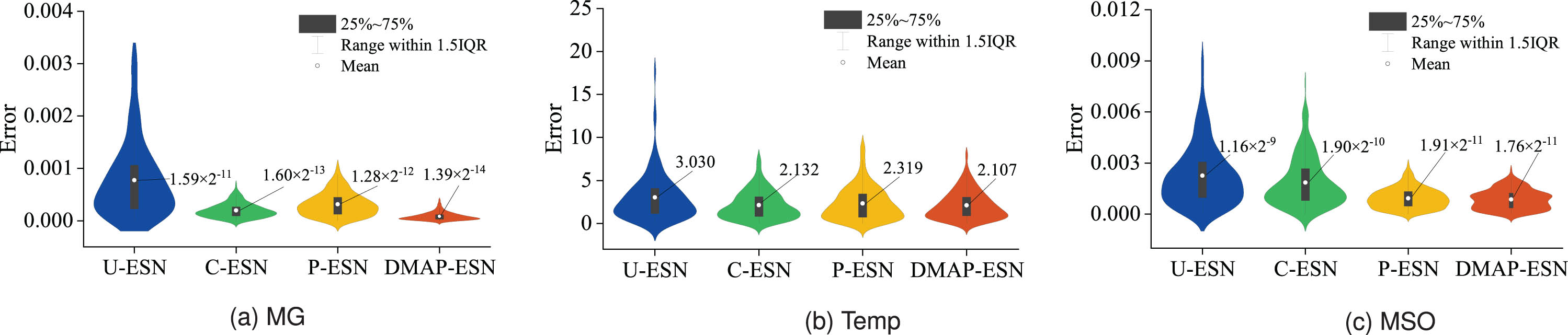
Violin plots of the prediction errors after taking the absolute values of the evaluated models in three time series prediction tasks (initialized reservoir size N = 100).
Minimum RMSE test (×10-3) condition of each experiment group
Bold values indicate the best test performance for the current task.
Tables 3 lists the number of reservoir neurons removed by DMAP when the minimum RMSEtest can be obtained. Obviously, the number of removable neurons is task-dependent. For example, only 30 neurons can be removed from the reservoir in the MSO task, whereas up to 90 neurons can be removed from the reservoir in the Temp task when the initial N = 100. Therefore, this implies that we should analyze the characteristics of the input data in more depth in order to reasonably choose the appropriate initial reservoir size for that data, which helps reduce the time consumed by pruning.
Number of removed reservoir neurons by DMAP
Fig. 4shows the obtained λ of the evaluated model reservoirs by varying r. As expected, it is seen from this figure that λ of DMAP-ESN is the minimum and reaches zero at the latest compared to its competitors, especially in Fig. 4(a). It indicates that the reservoir topology optimized by DMAP suppresses the chaos of neural dynamics to a greater extent, which possesses optimal stability compared with the considered alternatives. As a result, it is reasonable to believe that the processing of removing the neurons with high DMC2 completely from the reservoir can maximally eliminate the perturbation components of the network and contribute to enhancing reservoir stability.

Lyapunov exponent versus spectral radius.
In fact, the nonlinear approximation capability of ESN is closely related to reservoir stability, as shown in Fig. 5. For each task, it can be noticed that the RMSE test of each model is at a small value when the λ < 0 (refer to the relevant panels in Fig. 4). However, once λ > 0 (beyond the stability edge), the RMSE test increases significantly and fluctuates drastically with the growth of r. Combined with the discussion of reservoir stability in Fig. 4, it can be proven that DMAP-ESN allows the use of larger r to obtain satisfactory prediction performance and has stable dynamics.

RMSE test versus spectral radius.
In this subsection, the process of ESN optimization by DMAP is discussed in detail when the initial N = 100, and our interest focuses on clarifying the effects caused by pruning on the network, such as reservoir richness, memory capacity, etc., aiming to give sufficient understanding to the question of how the proposed method affects the dynamic behaviors of the network.
DMC2 Visualization
Fig. 6 shows DMC2 coefficients of the removed neurons in the pruning process. It is worth noting that only one neuron is removed in each pruning. From this figure, it is seen that the DMC2 coefficients of the removed neurons hold significantly high values at the early stage of pruning, implying a high coupling of the reservoir at this time. However, DMC2 declined gradually as pruning continued, the reason for this being that high-similarity neurons are selectively removed by the proposed discard strategy. Hence, this proves that DMAP algorithm possesses a remarkable de-redundancy ability. In fact, it also suggests that our method may have the potential to solve the problem of reservoir collinearity [31], although this is beyond the scope of this paper.

Heat map of the removed neurons δ during the pruning process, where the data are normalized for better visualization.
Fig. 7 shows the RMSE test of the models evaluated at different reservoir sizes. Specifically, in each subfigure, the red curve is drawn according to the RMSE test obtained by the DMAP-ESN after each pruning operation while processing the current task, where the initialized reservoir size is 100. The blue curve is drawn according to the RMSE test obtained by the unoptimized U-ESN at different reservoir sizes while processing the current task.

RMSE test curves of DMAP-ESN during the pruning process.
On the one hand, from the red curves in Fig. 7(a)-(c), it can be seen that the RMSE test of DMAP-ESN shows a significant decreasing trend after each pruning operation in the early stage of structure optimization, implying the improvement of the model’s nonlinear approximation performance. This is due to the fact that pruning the appropriate number of reservoir neurons is equivalent to the feature selection process of the model [32]. This process effectively removes redundant and irrelevant features from the reservoir, mitigating their detrimental effect on the network readout, and thus improves the nonlinear approximation capability of DMAP-ESN. However, the performance of DMAP-ESN decreased significantly with further compression of the reservoir size after pruning, such as in Fig. 7(a) when N < 55, in Fig. 7(b) when N < 4, and in Fig. 7(c) when N < 67. This is because excessive pruning results in the removal of important reservoir neurons, with the network failing to detect key features related to the input signal, leading to a degradation in the prediction ability of the DMAP-ESN. Additionally, this also appears to be related to the loss of reservoir richness [33].
On the other hand, from the blue curves in Figs. 7(a)-(c), it is seen that these curves have significant fluctuations, meaning that U-ESN of different sizes produces unreliable results, despite the fact that it may have better performance than DMAP-ESN when the reservoir size is equal in some cases. As discussed at the beginning of this paper, that is why it is a difficult task to choose the appropriate reservoir size to obtain satisfactory performance for an ESN with significant stochastic properties. For this challenge, our method can solve it effectively. At the beginning of the network design, engineers do not need to bother about the size of the reservoir, but just set the size of the reservoir at random, then DMAP can optimize the initialized ESN to a reasonable size and with excellent performance.
To investigate the effect of the removed neurons on the information content of the reservoir, we calculate the average state entropy (ASE) of the reservoir after each pruning operation, and it is a good metric for quantifying dynamical richness [34]. In this paper, the ASE of the reservoir is given by
Fig. 8 shows the ASE of the DMAP-ESN reservoir after each pruning. From this figure, it is observed that the ASE changes only weakly and remains at a high level when pruning the appropriate number of neurons. It indicates that the contribution of the removed neurons in enriching reservoir information content is weak. However, the curves decline rapidly with further increases in the number of the removed neurons, such as in the MSO task and when m > 36. There is no doubt that too much pruning increases the risk of important neurons being removed, which leads to a significant decrease in reservoir information content. As a result, it can confirm the inference we make in Fig. 7. That is, excessive pruning operations can negatively affect the reservoir richness, thereby leading to a loss of network performance.

ASE curves of DMAP-ESN reservoir during the pruning process, where m denotes the number of removed neurons.
To investigate the difference in the ability of DMAP-ESN to encode past input information, we evaluate its memory capacity (MC). As described by jaeger in [35], the ability to reconstruct the input signal from a previous time t can be measured by MC. For a given time delay k, the well-fitting characteristic is measured based on the squared correlation coefficient between the desired output (i.e., input signal delayed by k time steps) and the observed network output y(t)
Fig. 9 shows the forgetting curves of DMAP-ESN in three prediction tasks when k = 1, 2, . . . , 40, where detCoeff is the square correlation coefficient (e.g., MC k in Equation (23)). It is seen that DMAP-ESN shows weaker memory capacity than U-ESN in most situations as k increases. Furthermore, Tables 4 lists the STM capacity of DMAP-ESN in three prediction tasks when T = 40. As we observed, DMAP-ESN is beaten without suspense by the competition in three prediction tasks. It is obvious that a smaller reservoir means a weaker memory capacity [36]. Therefore, the number of removed neurons should be limited if we expect the pruned network to retain its STM capacity as much as possible.

The forgetting curves of DMAP-ESN.
STM capacity of DMAP-ESN in three time series prediction tasks
In this paper, we investigate the problem of structural optimization in ESN modeling for nonlinear regression tasks. Distinguishing from other existing studies, this paper proposes a novel pruning algorithm in the framework of DMC2 for optimizing the reservoir structure, namely DMAP. It can completely remove the neurons with high correlation from the reservoir, thereby eliminating their negative impact on the network. This approach makes the optimized network structure more suitable for nonlinear regression tasks. Extensive simulation results show that DMAP-ESN outperforms the comparative models in nonlinear approximation capability and reservoir stability.
So far, our study has only considered the simple situation of using DMAP-ESN for predicting time series with noise-free data, whereas the interference of random noise may lead to degradation of the model performance. In recent work [37], Chen et al. proposed a probabilistic regularization method to optimize the output weights of an ESN by taking into account the distributional information of the modeling error, and it improves the ability of the model to handle noisy data. Inspired by this, we will strive to investigate similar methods to optimize the output weights of DMAP-ESN in the future, aiming to enhance its resistance to noise interference. One potential solution is to optimize the output weights of the network by removing the connections from reservoir neurons with high DMC2 to the output layer, and we firmly believe that such an optimization is expected to enhance the robustness of DMCP-ESN to noise interference.
Footnotes
Acknowledgements
This work was supported in part by the Science and Technology Project of Hebei Education Department, Grant ZD2021088, and in part by this work was supported in part by the open fund project from Marine Ecological Restoration and Smart Ocean Engineering Research Center of Hebei Province, Grant HBMESO2315.