
Abstract
Recently, actor-critic architectures such as deep deterministic policy gradient (DDPG) are able to understand higher-level concepts for searching rich reward, and generate complex actions in continuous action space, and widely used in practical applications. However, when action space is limited and has dynamic hard margins, training DDPG can be problematic and inefficiency. Since real-world actuators always have margins and interferences, after initialization, the actor network is likely to be stuck at a local optimal point on action space margin: actor gradient orients to the outside of action space but actuators stop at the margin. If the hard margins are complex, dynamic and unknown to the DDPG agent, it is unable to use penalty functions to recover from local optimum. If we enlarge the random process for local exploration, the training could be in potential risk of failure. Therefore, simply relying on gradient of critic network to train the actor network is not a robust method in real environment. To solve this problem, in this paper we modify DDPG to deep comparative policy (DCP). Rather than leveraging critic-to-actor gradient, the core training process of DCP is regulated by a T-fold compare among random proposed adjacent actions. The performance of DDPG, DCP and related algorithms are tested and compared in two experiments. Our results show that, DCP is effective, efficient and qualified to perform all tasks that DDPG can perform. More importantly, DCP is less likely to be influenced by the action space margins, DCP can provide more safety in avoiding training failure and local optimum, and gain more robustness in applications with dynamic hard margins in the action space. Another advantage is that, complex penalty for margin touching detection is not required, the reward function can always be brief and short.
Introduction
Highly developed in the last decade, reinforcement learning (RL) shows outstanding progress in artificial intelligence [1, 2], as well as nearby areas such as advanced robot [3–5], game agent [6–9], word translation [10], dialogue [11–13] and advertisement [14]. The fundamental concept of RL is to optimize the overall reward within an episode, observing and interacting the outside environment by a state-to-action close loop, which belongs to a problem of Markov decision process (MDP). From 2016, DeepMind [15] technology begins to design and implement powerful deep neural networks on RL tasks, namely as deep reinforcement learning (DRL). Compared with previous RL based on models, DRL is able to perform a model-free approach to arbitrary nonlinear systems, but also it is efficient to derive and store complex action-value function. Besides, DRL directly leverages neural networks to analyse the state space, reducing the ambiguity induced by man-made definition of state patterns. The DRL intelligence enables machines to learn, summarize, predict and act automatically in unknown environment.
To solve a MDP problem, model-based RL, such as AlphaZero [16], tries to learn an environment model describing the possible transition from previous state and action to the reward and next state. When the RL model is closed enough to the real system, without any further actions to attempt, we can use greedy dynamic planning algorithms to find the optimal policy. However, model-free RL shows a comprehensive system model is not necessary for the MDP problem. Instead, the sum of future reward can be estimated by an expectation of action-value function defined by Bellman equation. The action-value function can be updated by temporal difference methods literately or Monte Carlo methods periodically. If we can estimate the action-value function accurately, the policy to reward optimum can be determined. Although model-free RL is unable to predict the state transition, they are adaptive and robust to be implemented. Hence, model-free RL, such as DDPG [17], DQN [15], PPO [18], and A3 C [19], has a wider development than model-based RL.
Classified by the form of agent output, there are two types of RL: value-based RL and policy-based RL. Value-based RL, such as DQN [15, 20–23], aims to find a distribution of reward in state-value space, approached by a neural network. The output of the network lists out the probable reward after different actions in current state. Policy-based RL, such as DPG [24] and PPO [18], aims to build a direct state-to-action policy with a neural network. The network can generate appropriate actions to gain optimal reward when a state is fed into the agent. Value-based DRL shows excellent performance in playing most games, but it also has limitations when comparing with policy-based RL: (i) It is difficult to implement value-based DRL to tasks with continuous action space. For instance, in mechanical robot control, the joint angles are not convenient to be described in a discrete form. (ii) It is difficult to implement probabilistic policy on value-based RL, in which the action space is fixed and limited, and not convenient to be explored. However, policy-based RL is also challenged by issues such as local optimal converge. Therefore, a new series of method namely actor-critic methods, such as DDPG [17], and its expanded version A3 C [19], are proposed by combining advantages of value-based RL and policy-based RL. Inside actor-critic methods, the output of the actor network is also the input of critic network. The critic network works as an approximator of the action-value function, and the actor network is trained to optimize the reward. The two networks collaborate together, forming a complete agent for model-free learning, which is able to handle most of continuous tasks.
Demonstrated by lots of real-world practical applications, continuous DRL shows promising performance in recent tasks such as robot behavior generation [25, 26], dynamics control [27] and navigation [28]. DRL agent becomes appealing because researchers begin to pay more attention to the intelligence, autonomous performance and the adaptation ability to complex environment. In robot behavior generation tasks, DRL architectures are used to help the robot to respond appropriately at correct timing [29]. Movement can be generated together with coordinate matching, transformation and redundancy reduction optimized, which is believed to have the potential to overcome the challenge of a higher dimensionality in robotics [30]. DRL enables every parameter to be customized for individuals [26] and avoid repetitive offset calibration such as installation errors, friction and centre of gravity. In mechanical dynamics control, DRL improves the property in optimization of gain values for model-based controllers [31] by deeply exploring the prior knowledge. Gain values for force feedback or flight dynamics can be modified context-dependently by the internal neural network, the result has a more vibrationless performance and can provide adequate stability [32]. Without DRL, the partial derivatives coefficients in dynamics would be hard to measure because they depend on the cross effects of many factors and some deflects that have not been considered during design. In navigation and path planning tasks, since model-free RL learns outside environment as a black-box test, navigation problems can also be addressed more efficiently than online trajectory planning [33]. The parameters can slightly adjust and constantly compensate for changing of known and unknown factors while optimizing the movement output.
However, some issues are found during the practical implementation of continuous actor-critic DRL. In real-world applications such as DDPG, the action space of an actuator is often limited, and could has hard margins when the actuator reaches its maximum length, angle, speed, etc. Although we can use reward function to punish the margin to avoid reaching its limitation, when the actor dimension is high, the margin can be dynamic and hard to measure by a simple function, e.g., assembling interference. In this condition, penalty functions are too complicated to be used. Besides, the margins can be unknown in some tasks, whether touching the obstacles is unknown to the DRL agent. In this condition, even using random process for local exploration, the actuator cannot exceed the margin and the exploration could not get rid of local optimum. Since DDPG uses local gradient to update parameters, in the initial training, the training is likely to be stuck at a point on the action space margin to come to a local optimum converge: The gradient forces the action output to move towards the outside of the action space but the actuators stop at the margin, while the error is unknown to the DRL agent. If we use a too large random process for local exploration, the training could be in potential risk of failure. Therefore, DDPG lacks robustness and discussions in dealing with complex, dynamic and unknown margin.
Therefore, to solve this problem and obtain a more robust and normalized DRL architecture, in this paper, we modify DDPG to DCP. We retain the overall duel-network architecture, but the core parameter update process is changed: Rather than leveraging critic-to-actor gradient, the training of DCP is regulated by a T-fold compare among random proposed actions around the actor network. Because of the modification, DCP shows notable novelties in three aspects:
More safety and robustness in training: DCP is less likely to be influenced by action space margin or converge to local optimum, the accuracy and success rate is demonstrated to be robust and stable.
Larger range of random process: To avoid local optimum, the variance of the local random exploration is robust and can be extremely as large as the whole action space, while the training of DCP is less likely to be failed.
Convenient reward function: Even in complex tasks, the reward function for DCP can always be brief and short, since penalty function for margin touching detection is not necessary.
To valid DCP and compare to related algorithms, we have design two experiments to demonstrate its performance to function on different models. The former task is a blind navigation task to avoid barrier walls, which is suitable for rescue inside buildings. The map is unknown to the DRL agents and the agents should reach the goal with high accuracy and low time consumption. The results show that, the DCP has higher accuracy than DDPG and less influenced by the action space margin, but also DCP has an improved robustness in using large random process and different reward functions. The latter experiment is a game of badminton singles with hard margins in the field. Each player is modeled by a collaboration of three DRL agents, controlling ball catching, ball serving and location reset. Rules and environment of the game are similar to the reality. The final scores show that DCP has an obvious advantage from DDPG especially in ball serving. The game also demonstrates the collaborative performance of combining multiple DCP agents.
Methods
Deep deterministic policy gradient (DDPG)
Developed from family of policy gradient (PG), DDPG [17] is able to solve DRL problems with continuous state and action space. Discrete problem can also be solved by adding a softmax layer after the network output. In the training of DDPG, a replay buffer saves the transition from a state to the next state, recording the action history and reward on each time step. Each action is added with a small random process to prevent local optimum. The critic network is trained by the reward expectation from Bellman equation: the current reward with a discounted future reward, shown in Equation (1).
The actor network is trained by firstly taking the action gradient ∇ a of the critic network Q, shown in Equation (2). The gradient propagates back to the input of critic network, and then become the output gradient ∇ θ P of the actor network P by the chain rule.
Hence, the parameters in actor network can optimize the output of critic network by gradient ascent. But a small difference is, the gradient of actor network ∇
θ
P
is derived by the action without the random a = P (si), while the gradient of critic network ∇aQ is derived by the action with the random
Figure 1 shows a complete training sequence within a time step:<1 > Action a
i
is generated by the actor network P after a state s
i
is received.<2 > The action a
i
is added with a random process, then comes to
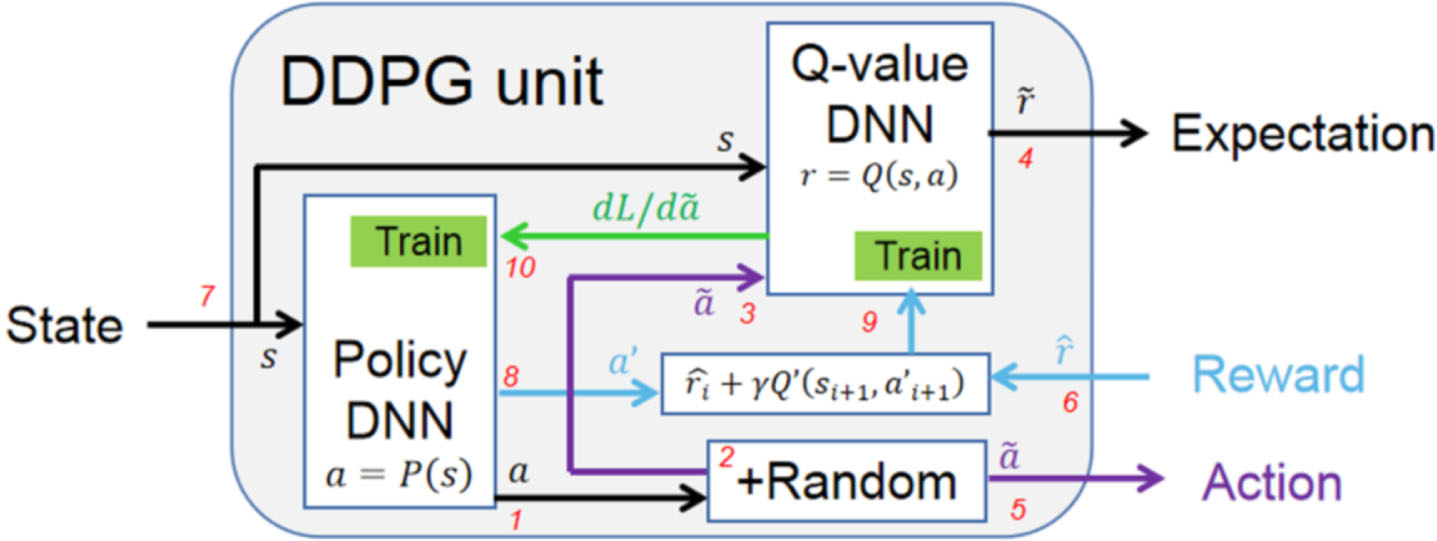
Function diagram of the DDPG in training mode. The index 1 to 10 is correspond to the sequence of training within a time step. Train, collecting training data points.
Based on DDPG, we modify DDPG to DCP. Briefly shown in Fig. 2, state s and action
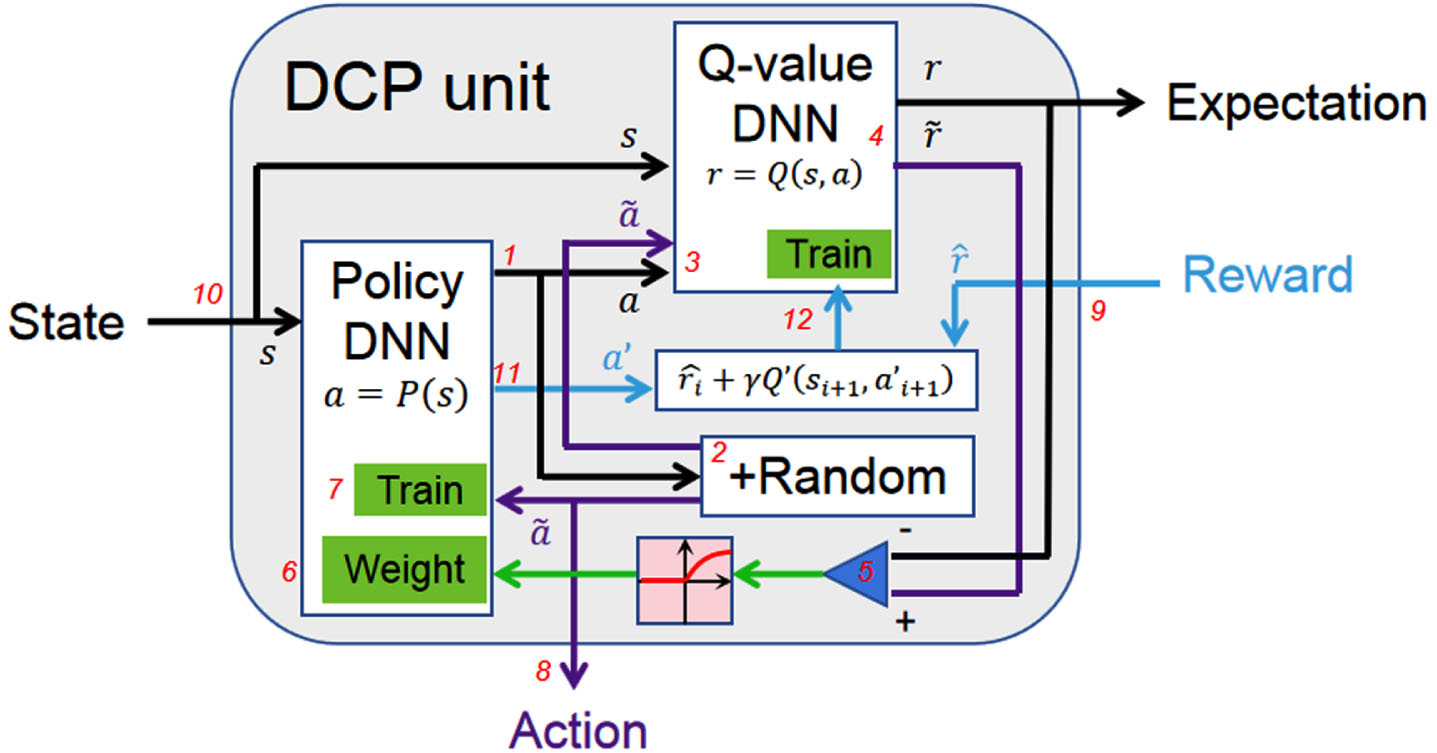
Function diagram of the DCP in training mode. The index 1 to 12 is correspond to pseudo code of the algorithm steps from 1 to 12. Weight, weighted factor for each data point. Train, collecting training data points.
However, the update of the actor network P is based on a T-fold compare of the expectation: After an action a
i
is generated by the actor network, the random action
Depending on the value that
Therefore, the training of the actor network does not rely on the gradient ascent from the critic network. Instead, the parameter update of the actor network is substantially driven by the advantage
In the training of DDPG, the actor network is updated by the gradient ∇ a Qoriginated from the output layer of the critic network. The gradient passes back through the whole network to the input layer of the critic network. Then the gradient comes to the output layer of the actor network ∇ θ P P, and passes back through the whole actor network. However, in tasks with very deep layers, the training has more risk of divergence, vanishing gradient and time consuming. In comparison, the training of DCP actor network does not rely on the gradient from the critic network, the two networks can be trained separately. Hence, DCP has smaller risk and more robustness in large-scale network training.
To implement DCP, there are five steps: (i) Depending on the requirement of the task, the structures of online networks P and Q should be selected. The layer width and depth should be able to handle the complexity of the task, but should not be too large, otherwise it would be under-fitting. The neural networks can be initialized to random following an uniform distribution of
Experimental configurations
Task environment
The following two experiments demonstrate the DCP and make comparison with related algorithms. In the first experiment, we design a simple case of path planing task. Path planing is important and often used in applications of robot navigation to avoid obstacles. Similar to rescue inside buildings, the task is to perform a blind navigation between labyrinthine walls to get to the center. We have tested the performance of our DCP with DDPG, PPO and DQN. The shape of the wall is shown in Fig. 3, which is unknown to the DRL agents. The DRL agent should pass through the gaps between walls and move onto the center. Since this is a blind navigation task, the agents can only know the coordinates on the map by inertial measurement units or position system like GPS. In each task, the origin is randomly selected on the stage boundary of 6 units. The thickness of the walls is 0 unit. When the agent moves toward the walls, the walls can create dynamic hard margins in the agent’s action space: We assume that only the movement component paralleled to the wall is allowed, the vertical movement component is blocked. Besides, whether touching the wall is unknown to the agent.
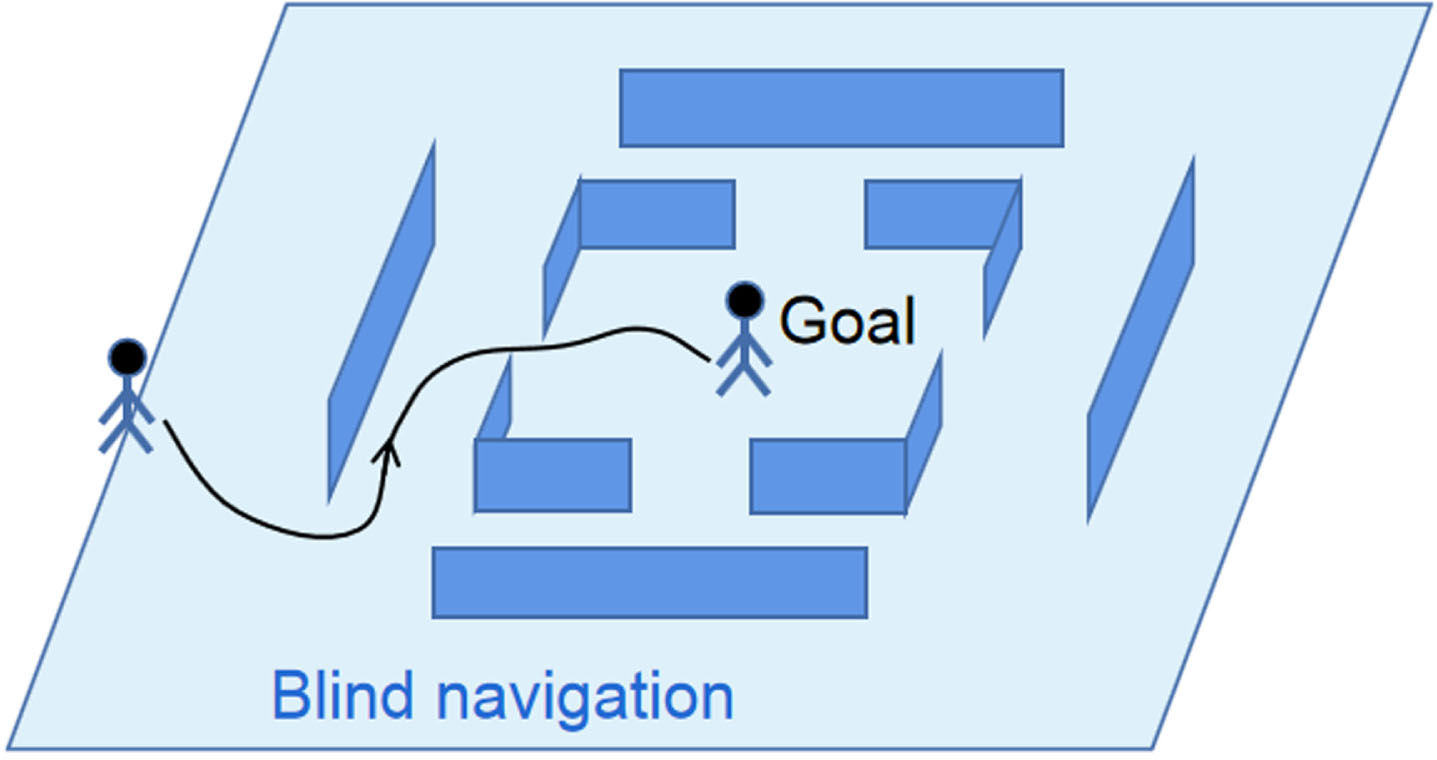
Path planning task. The shape of the barrier walls is unknown to the DRL agents. The walls can create hard boundaries in the agent’s action space, and the boundaries vary in different locations.
Both DDPG agent and DCP agent has a duel-networks architecture. The PPO agent and DQN agent only contains the actor network. Their actor network and critic network are the same but trained in different ways. The input of the actor networks includes the location coordinates x, the network output includes the movement on each coordinate Δx, described by an increment vector, shown in Equation (9).
The input of the critic network in Equation (10) is formulated in a form of the action-value function.
All the networks use the same depth with the same hidden layer length. We test the scale from 2 hidden layers by 32 layer length to 6 hidden layers by 64 layer length, which is sufficient for the function requirement of the task. The reward for the DRL agent is given by three ways. Equation (11) is the local reward (LR), which estimates the advantage in a single step action. LR will become negative if the agent moves away from the center, vice versa. Equation (12) is the global reward (GR), which estimates the overall progress after a single action step. GR measures the negative distance to the center. Equation (13) combines LR and GR, balanced by weight factors. C, C1 and C2 are constants which can perform normalization. αL and αR are weight factors. All these reward functions contain no punishment from touching walls.
Since the DQN agent is a discrete actor, we use an 8-options softmax layer on its network output, containing 8 movements of 0.25 unit length in directions of n times 45 degrees, n = 0 to 7. A training episode is ended once the DRL agent crosses the boundary or reaches the center (<0.1 unit) and keeping stable 10 steps, then a new episode begins. The network learning rate for all agents are the same 1/4096, trained for sufficient 3,000 episodes. The L2 regulator rate is 1e-4. Dropout 0.5 is also used.
The accuracy of DCP is less influenced by the margins
The performance of the four agents is estimated by the error to goal, success rate and time consumption. The error is defined by Equation (14), which is distance from the goal to the location that DRL agent converges.
Especially, if the DRL agent converges within a loop around the goal, the error is the averaged distance to the goal. We test each agent for 100 times. Figure 4 shows some trajectories of the four DRL agents. All agents can stop at a stable ending but the DQN agent. DCP and PPO can converge at a location closer to the center than DDPG and DQN. All the agents can roughly find the shortest path towards the goal. Figure 6 upper chart shows the error of all trajectories that successfully reach the goal, stable < 2 units, among the 100 tests. DCP has a smaller error than DDPG. We also test the performance of four agents without the barrier wall in a contrast experiment. Figure 5 shows some trajectories tested without the barrier walls, and again we summarize its error among 100 tests in Fig. 6 lower chart. We find the barrier walls lead to a large error increment in DDPG and DQN. The influence on DCP and PPO is relatively smaller. Hence, the training mechanism of DCP and PPO is better than that of DDPG and DQN, in solving continuous problems with hard action space margins.
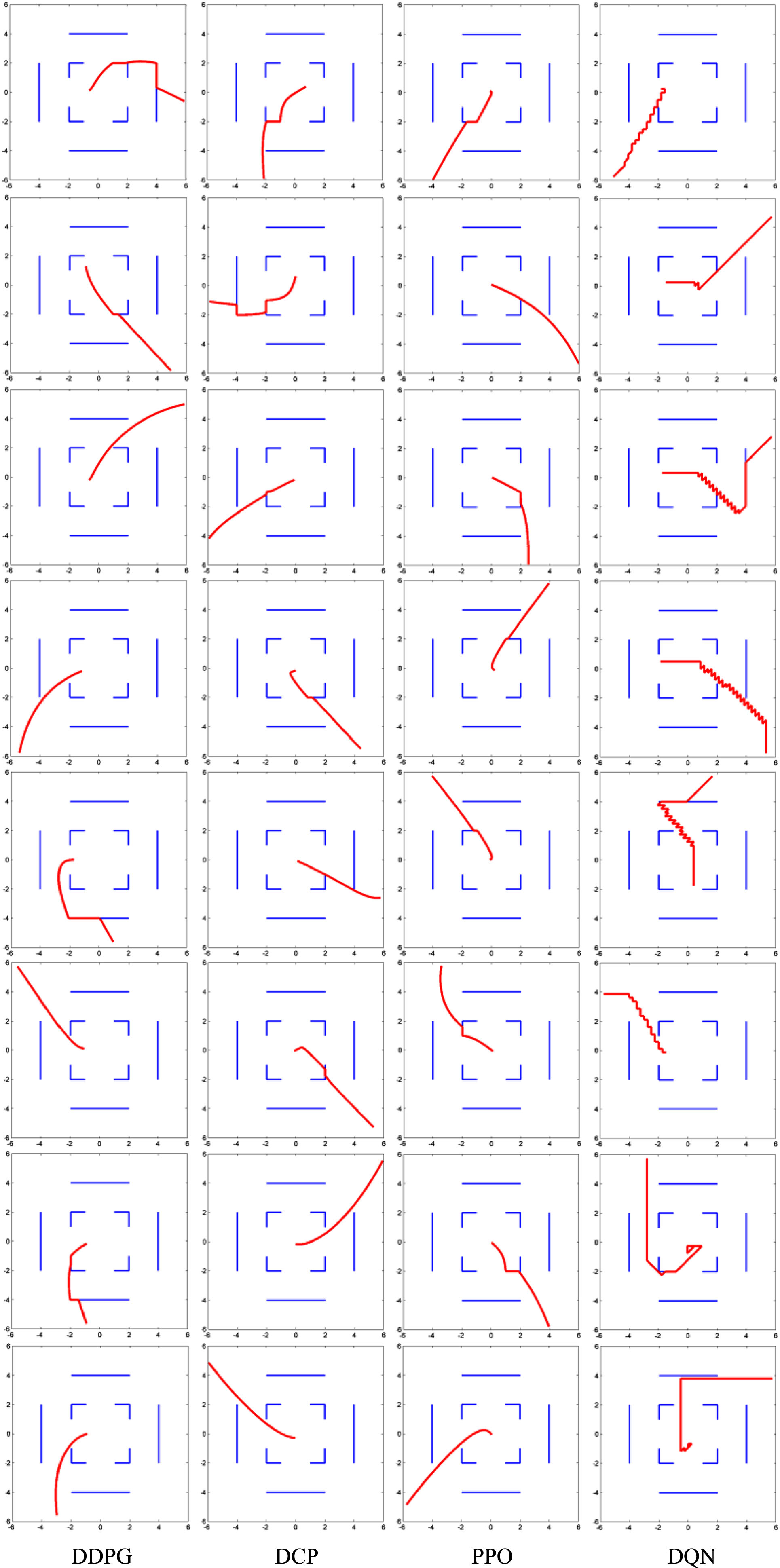
Some trajectories of the four DRL agents.
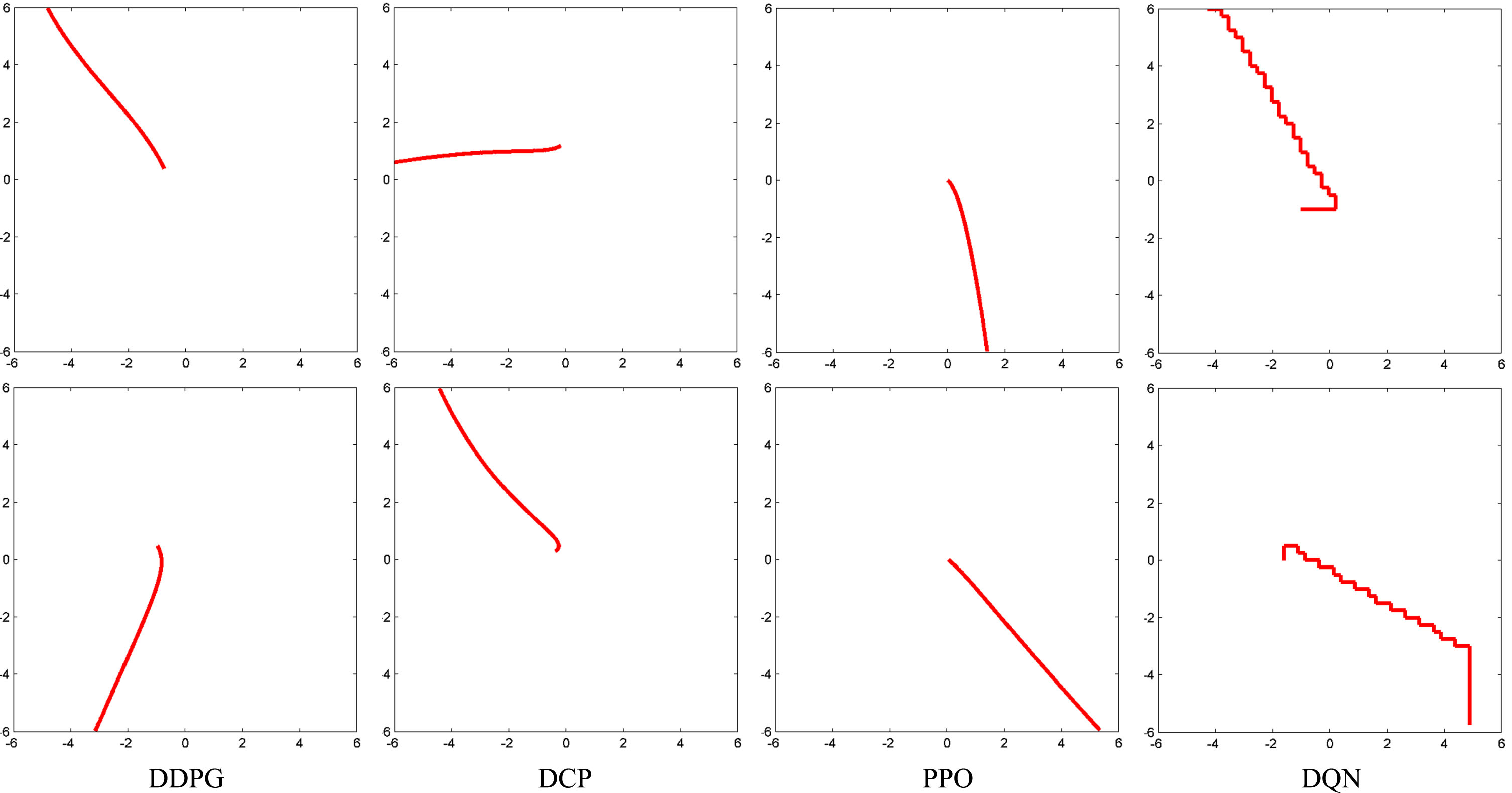
Comparison test. Some trajectories of the four DRL agents, tested without barrier walls.
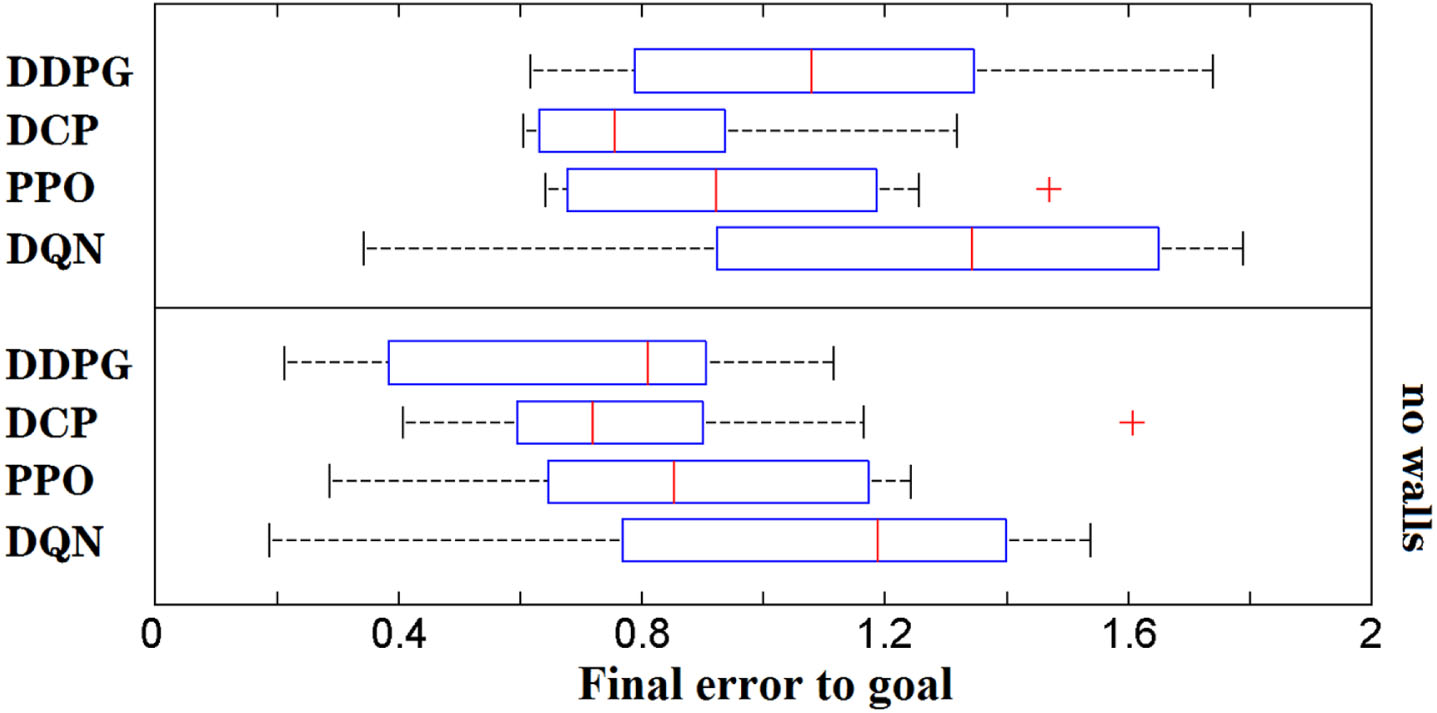
Accuracy of the path planning task. The final error among 100 tests with barrier walls is shown in the upper chart. In comparison, the lower chart shows the final error among 100 tests without barrier walls.
We summarize the steps which the four agents use to reach the goal among the 100 tests in Fig. 7. The DDPG has the lowest time consumption but the difference between DDPG and DCP is small. Although DCP does not use gradient, to find the shortest way, the efficiency of using T-fold compare to find the steepest ascent way is basically similar to DDPG, which can achieve similar effect of critic-to actor gradient.
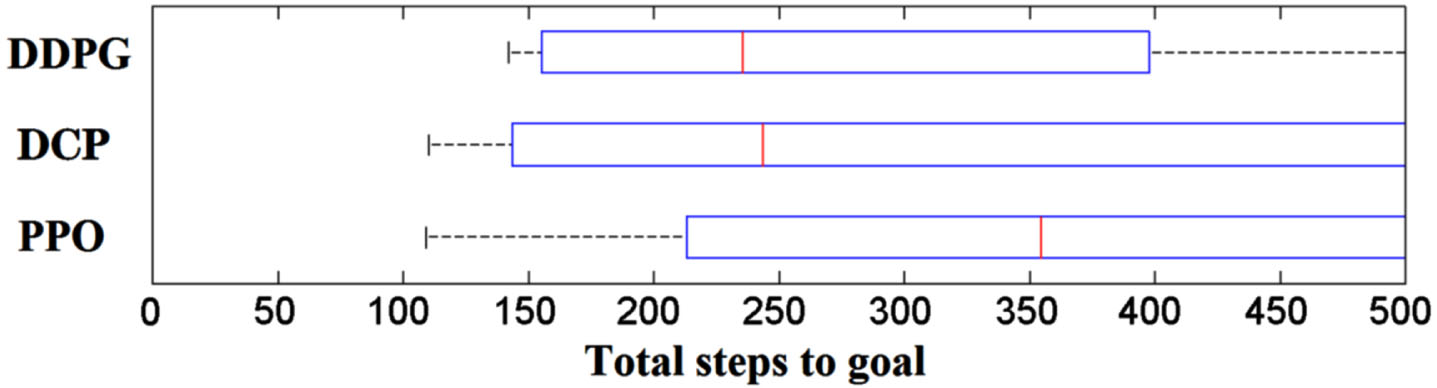
Time consumption of the path planning task. The total time steps among 100 tests are compared between DDPG, DCP and PPO. Since DQN belongs to discrete methods, the comparison may not be reasonable.
Due to the parameters initialization and insufficient training, there are still some cases that DRL agents fail to reach the goal. Table 1 lists out the success rate of the four agents, under different network sizes. The DCP has the highest success rate and surpasses DDPG obviously. Among all four agents, the network size over 4×48 is sufficient for the path planning task.
Success rate of the DRL agents (using different network sizes)
Success rate of the DRL agents (using different network sizes)
(Total 100 tests).
We also test how reward function influences the four agents. We train the four agents three times by reward functions Equation (11) to Equation (13), then repeat the test again. The success rate of using the three reward functions is shown in Table 2. The DDPG agent is influenced by reward functions, and its rate decreases when using LR. It indicates that the training is slow and insufficient. In comparison, DCP shows a wider adaptability of different form of reward functions.
Success rate of the DRL agents (using different reward functions)
Success rate of the DRL agents (using different reward functions)
(Total 100 tests, using 4×48).
In DDPG and DCP, the variance of the random exploration process is a hyperparameter that control the efficiency of learning. A large random process can speed up the exploration of the action space. But in DDPG, the random cannot be too large since DDPG assumes
Rate of training failure (using large random)
Rate of training failure (using large random)
(Total 100 tests, using 4×48 GR).
Experimental configurations
Game environment
The second experiment is a complex RL application in competitive ball sports. We have tested the performance of the three continuous DRL agents: DDPG, DCP and PPO in playing singles badminton games. Discrete RL methods such as DQN are problematic and hard to implement since a continuous and precise coordinates is required to guide the players to reposition on field, but also an accurate angle is required to make the ball bypass the other player. This experiment builds a virtual coliseum to test the performance of DRL agents. We use standard field of badminton singles, the field has a 3D hard margin of 13.4 meters length and 5.18 meters width. The height of the barrier net between players is 1.55 meters. The trajectory of the ball on air is calculated by numerical simulation considering gravity and squared-speed drag in time step of 0.001 second. A player wins marks while the other player makes a mistake. For instance: failed to catch a ball, serve a ball to the outside or hit the net. A game is ended when either of the players gets more than 10 marks while has 2 marks superior to the other, or either of the players gets 20 marks. Overall, the rules of the game are mostly similar to the reality, but some complicated and professional details are simplified and removed, such as service line and left-right half field switching. Besides, here we assume the maximum ball speed that a player can serve is 77 meters per second. The maximum moving speed of a player is 4.5 meters per second. The maximum radius that a player can catch a ball is 1.3 meters. These simplifications and settings may be slightly different from the real conditions but would not influence our model demonstration.
Multi-agent collaboration
In the second experiment, multiple DRL agents collaborate together to perform the task. Shown in Fig. 8, a complete player is built by three individuals agents, namely the “catch” agent, the “serve” agent and the “reset” agent. The “catch” agent aims to estimate a location on self field to move to after the other player serves a ball, where the player itself can best capture the ball, shown is Equation (15).
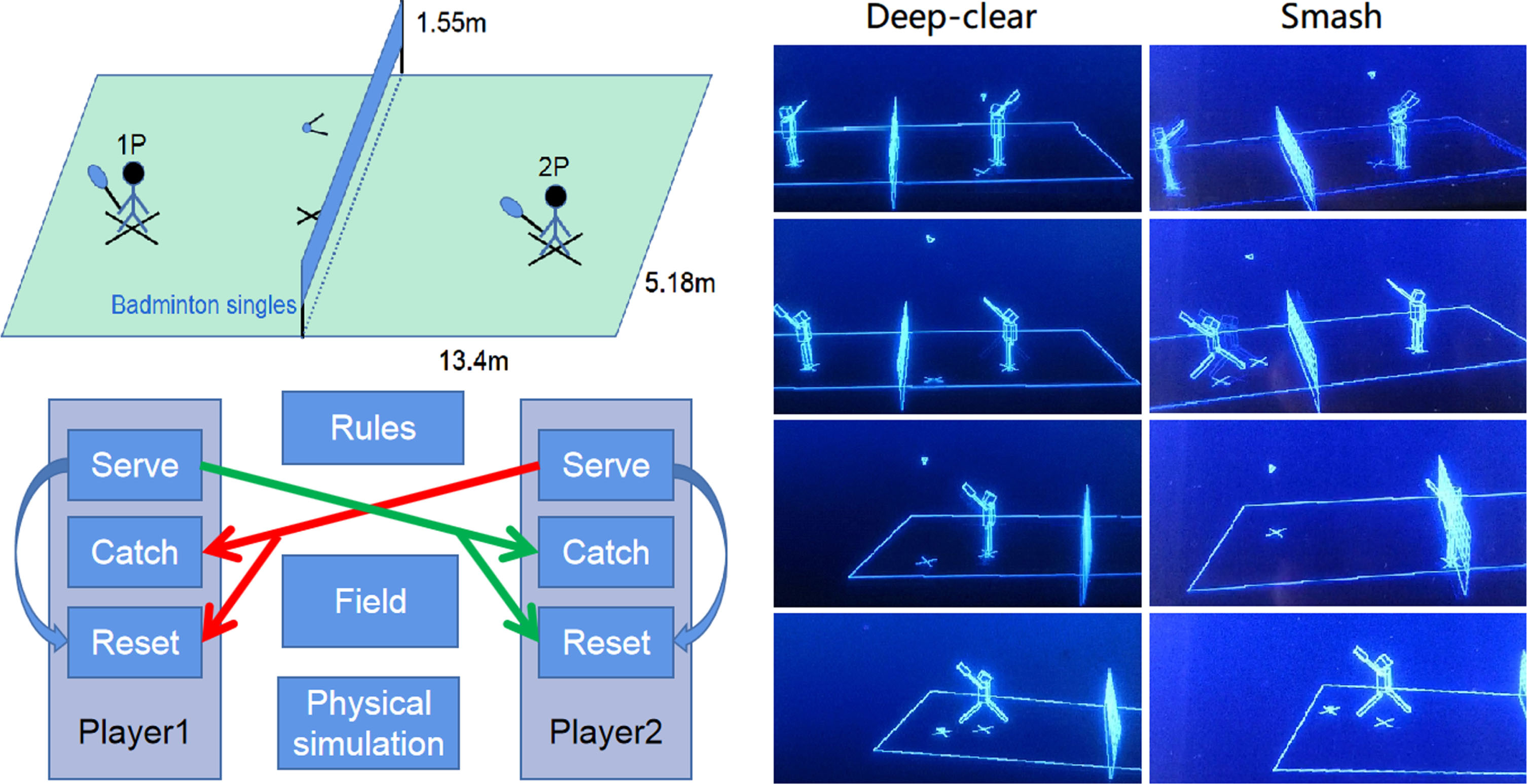
Singles badminton games. The physical environment is simulated by a neural-computing pad. Each player is modeled by the collaboration of three RL agents. Three teams of players trained by DDPG, DCP and PPO participate in the competition.
l
k
is the current location of player k. x and
Hence, the “catch” agent and the “serve” agent are hostile between players. The “reset” agent helps to predict a location on self field where the player itself are likely to catch next ball after a ball has just served to the other player, shown in Equation (17).
Since the ball has not been captured and served by the other player yet, the “reset” agent operates before the “catch” agent. All input of the three DRL agents contains necessary global information of current game, they are position and velocity of the ball and location of both players. The outputs of the agents control the location of player and ball serving, respectively. The three agents cooperate together but perform different functions at different timings. Compared with the first experiment, the second experiment can test the collaboration performance in solving complex tasks.
The reward function for the “catch” agent is shown in Equation (18), which is a reward plus a Gaussian radial basis function d. C is a constant.
The reward would become a negative punishment if the ball is failed to be captured. The radial basis function measures the distance from the player to the ball. The reward function for the “serve” agent is shown in Equation (20), which is separated into four conditions.
Both the first and second condition are punishment since they are self mistakes. If a serving ball is captured by the other player, there is no punishment or reward. Only the last condition will have a positive reward. The reward function for the “reset” agent is also the same value of the “catch” agent, since both of them are aimed at catching ball. All reward functions are simple and contain no punishment about whether the agent touches the action space margin. Figure 9 show the sequence chart of the three agents.
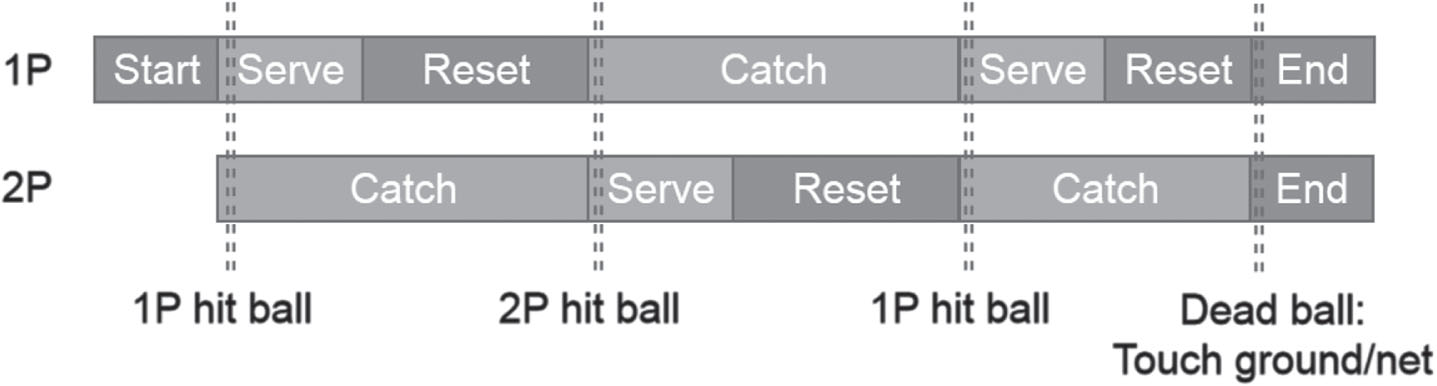
Sequence chart of the three agents.
The game is started by a ball serving by either of players, following by a reset movement. Meanwhile, the other player enters the catching phase. Once captured, two players switch its phases. The game is ended when a dead ball occurs. Then the marks are updated and reward functions are activated.
In each agent, there is an actor network and may have a critic network. Hence, total 12 neural networks are activated during a game. The parameter initialization is similar to the first experiment. All networks use an architecture of 4 hidden layers with 48 layer length. Each training episode is corresponded to a mark, which is from the first ball serving until the ball drops on the ground or net. The network learning rate for all agents are the same 1/4096, trained for sufficient 20,000 episodes. The L2 regulator rate is 1e-4. Dynamic input normalization is updated on every minibatch of 64. Dropout 0.5 is also used.
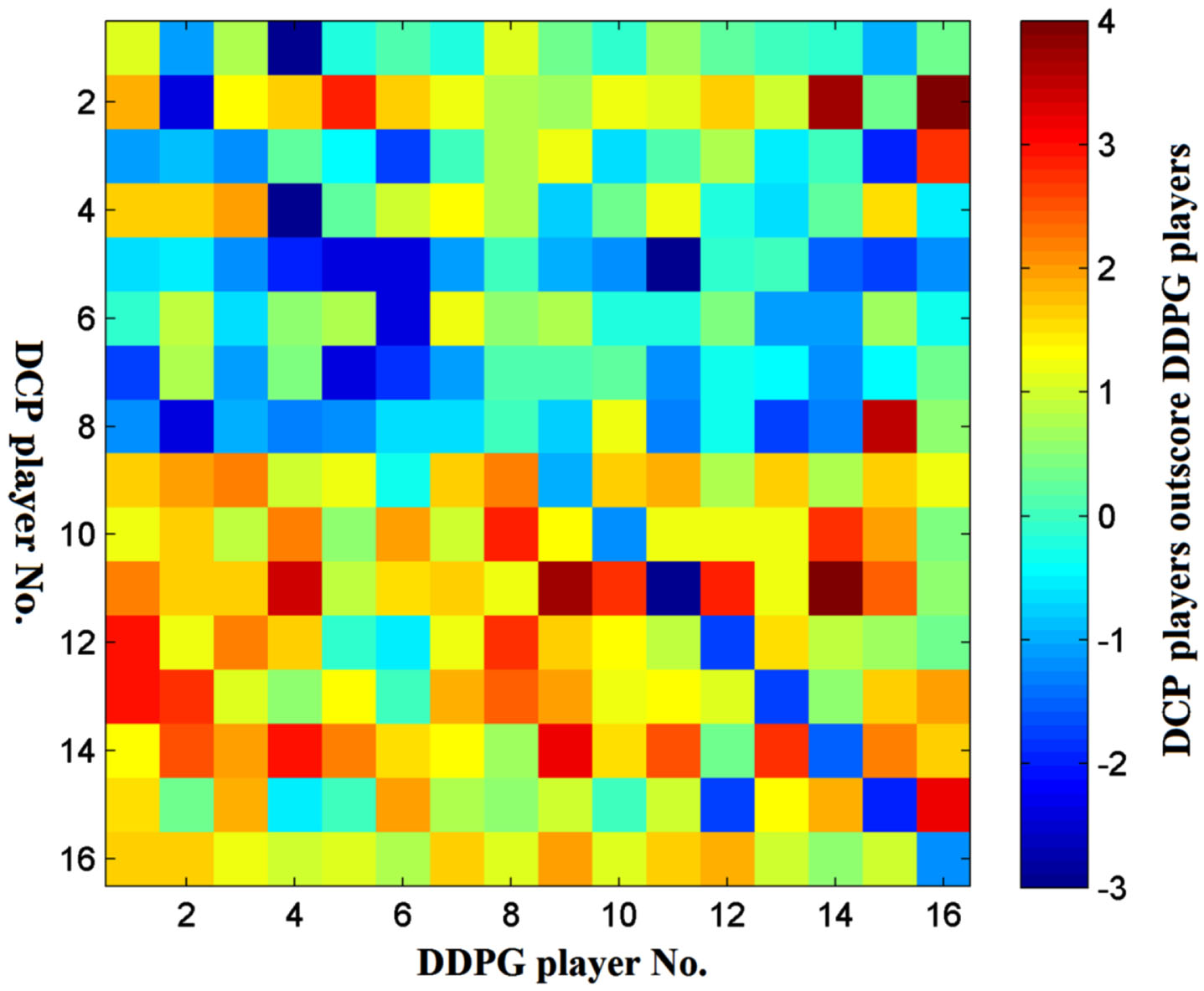
We have trained three teams: DDPG team, DCP teams and PPO teams. Within each team, 16 players randomly take competitions with each other. The standard deviation of the random exploring process of every DRL agents are changed randomly from 0.02 to 0.2 in every games. The performance of each team is estimated by the average score, the success rate of “catch” and the error rate of “serve”.
Overall scores of DCP increase as T increases
Overall scores of the three teams
Overall scores of the three teams
(The DCP team is trained three times by T = 1, T = 4, and T = 16, based on the same parameter initialization.).
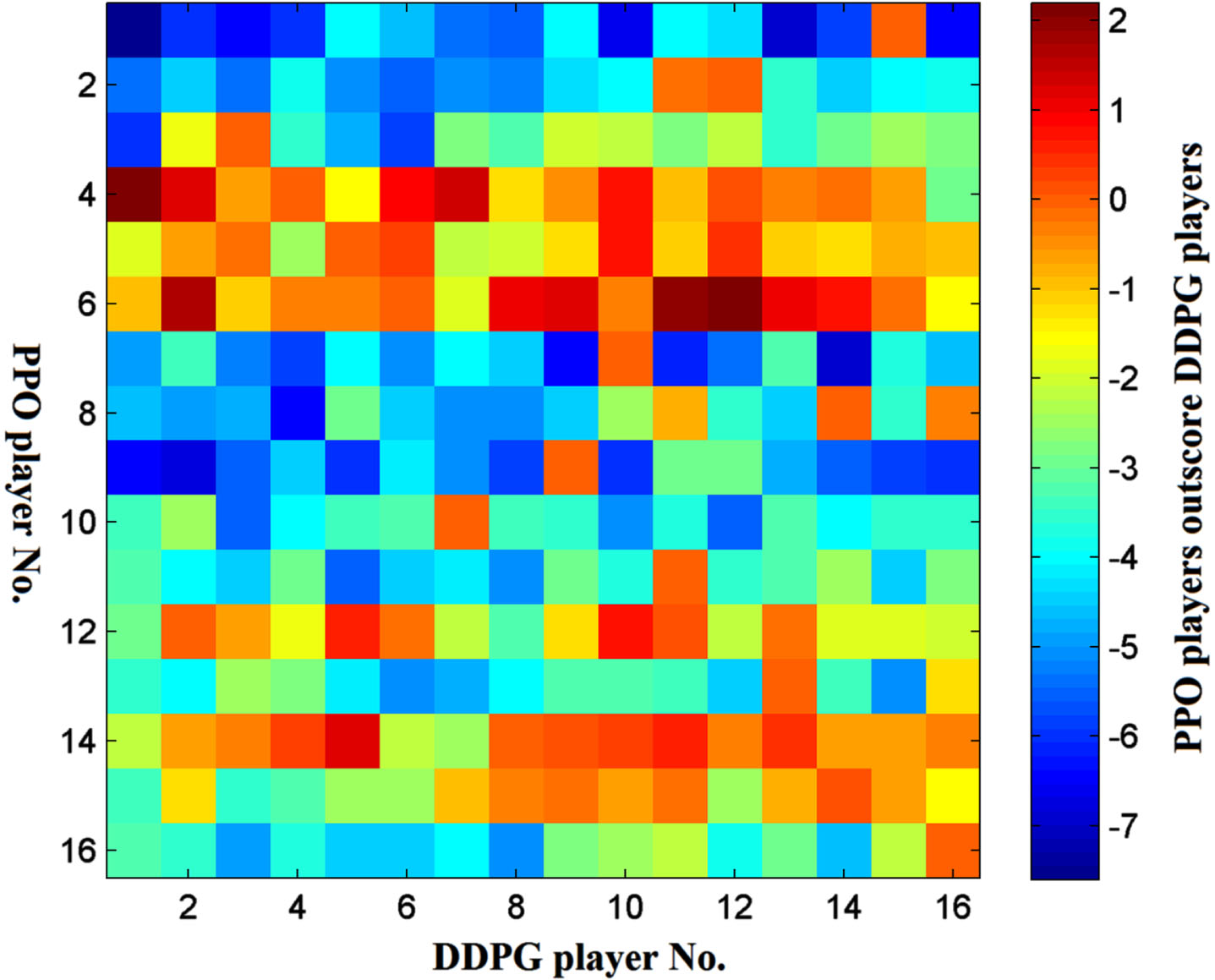
Scores contribution of each player. (P1 = DDPG, P2 = PPO).
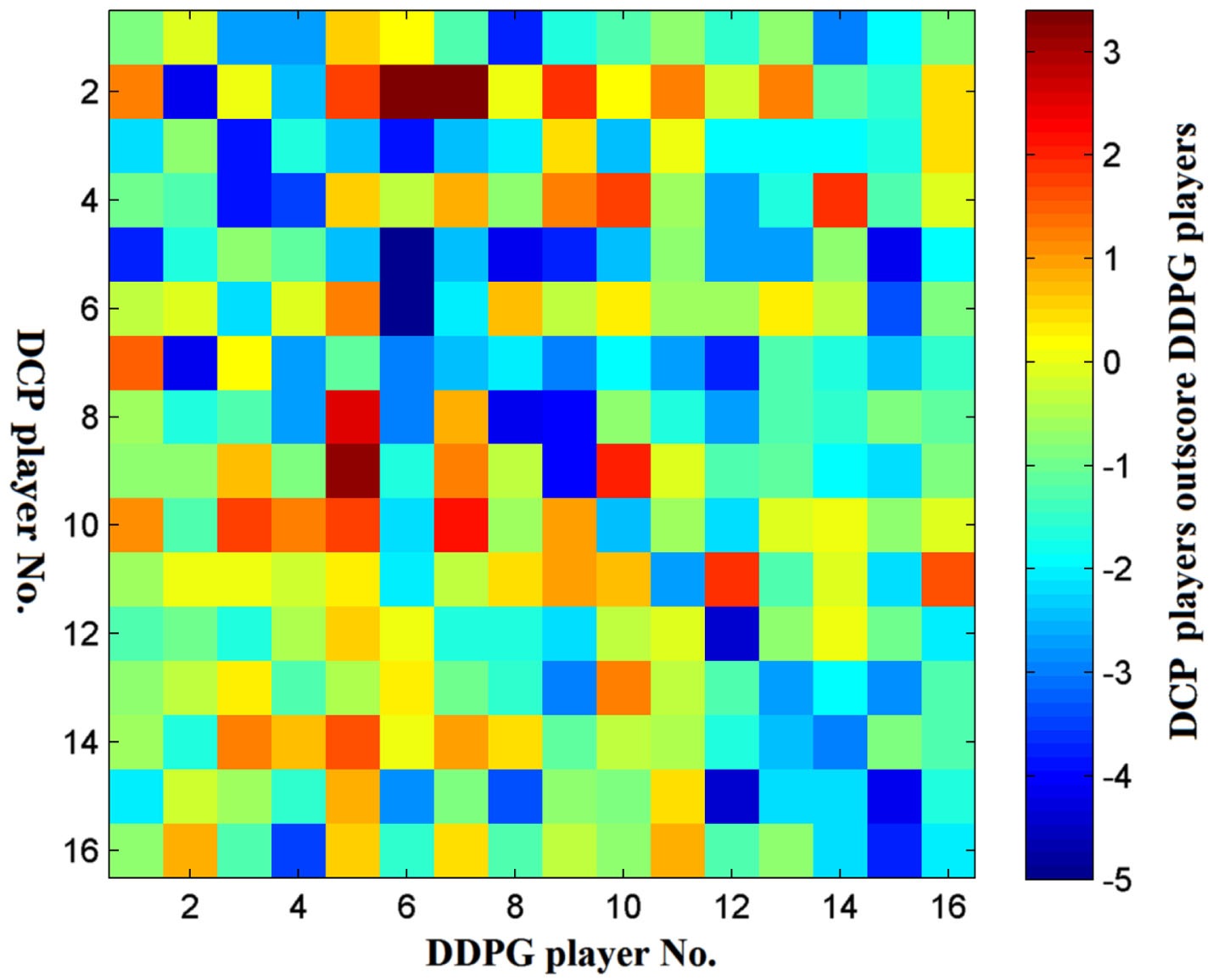
Scores contribution of each player. (P1 = DCP16, P2 = PPO).
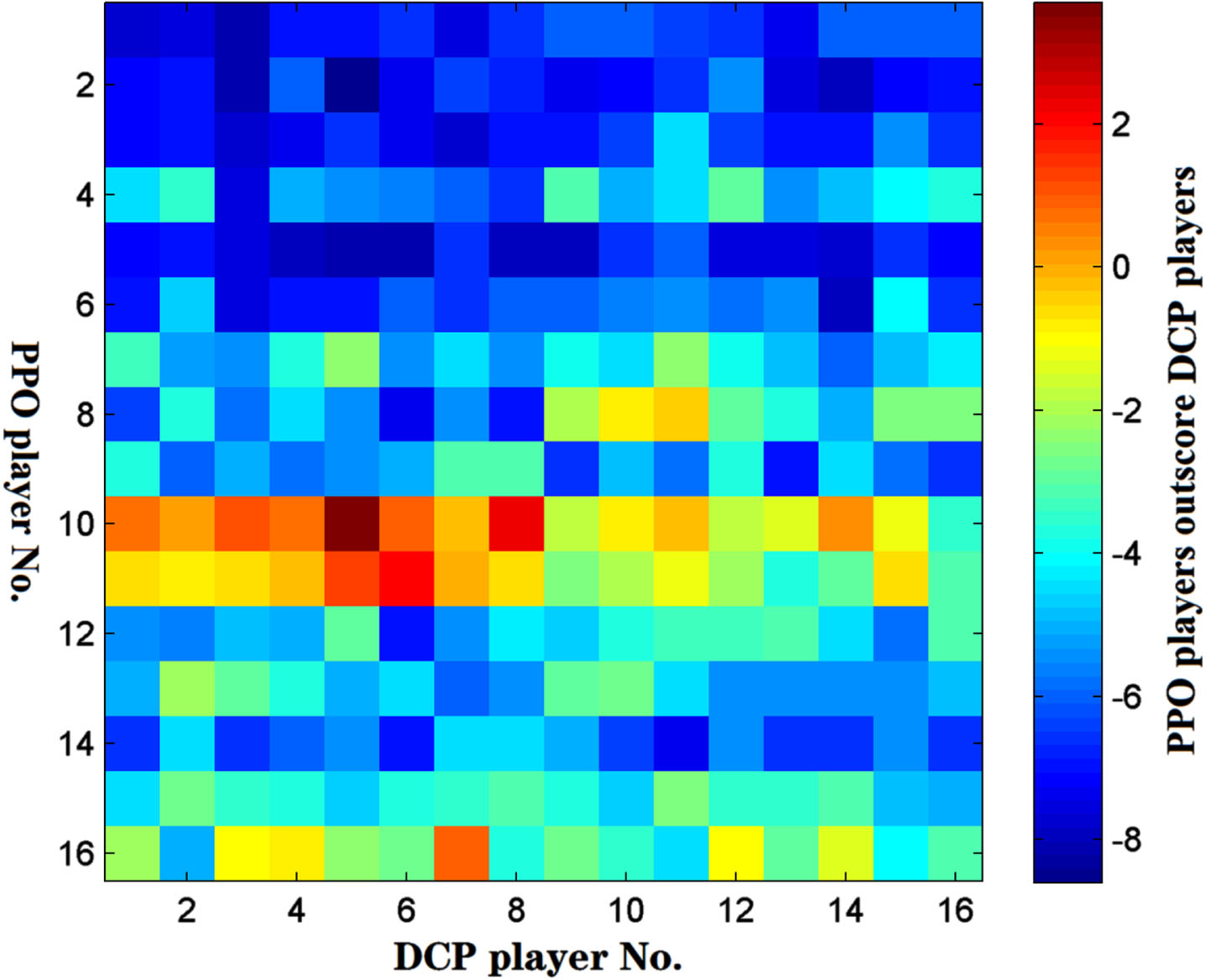
Scores contribution of each player. (P1 = DDPG, P2 = DCP (T = 1)).
Scores contribution of each player. (P1 = DDPG, P2 = DCP (T = 16)).
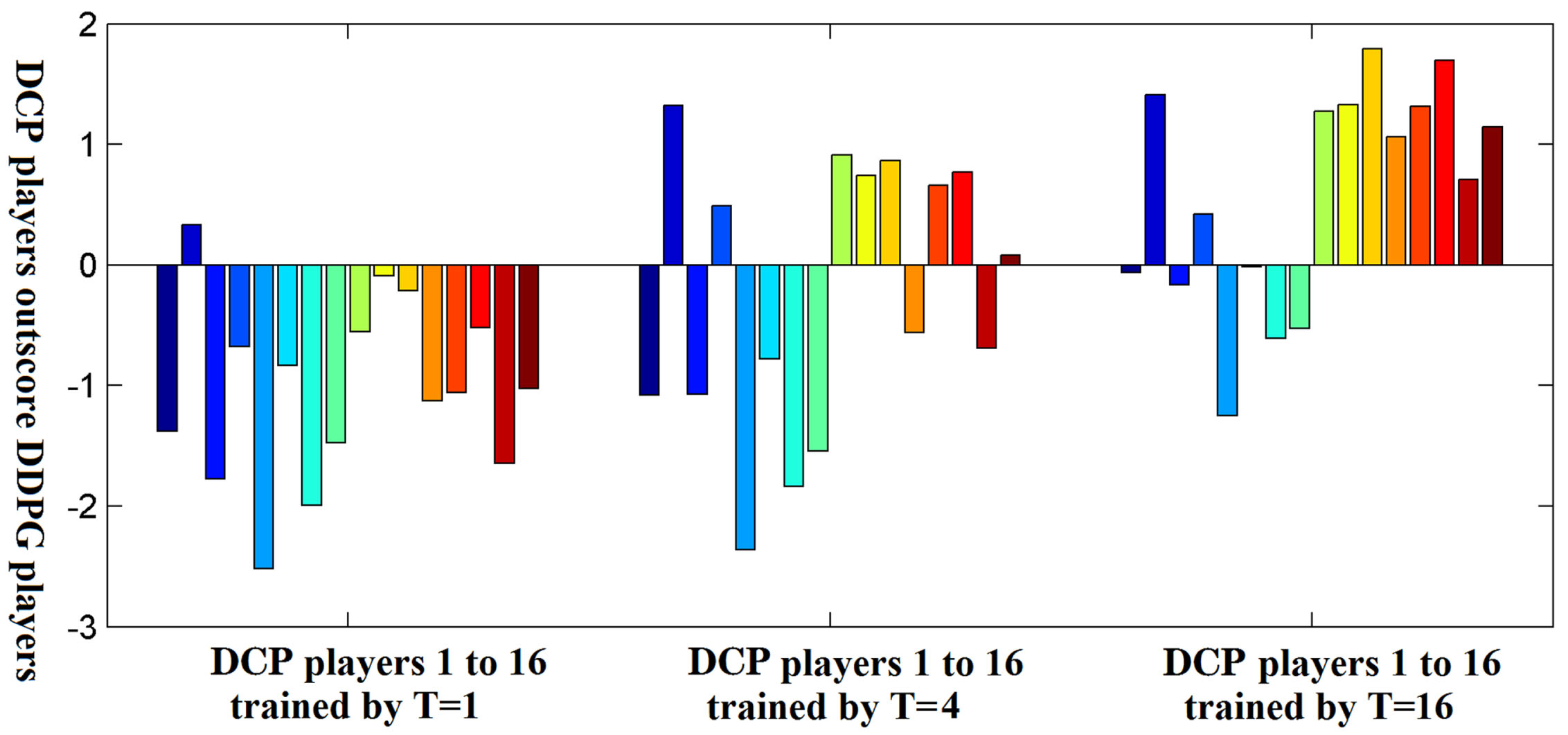
The influence of the hyperparameter T. When T is larger than 4, DCP can gradually surpass DDPG.
The overall scores may not be an accurate estimation since the final performance can only demonstrate the cooperation of the “catch” agent, the “serve” agent and the “reset” agent. A fault can be risen from any of them. Hence, we firstly analyze the performance of the “catch” agent by the success rate by Equation (23). Ball served outside or hitting net is ignored.
After the badminton competition, we test the “catch” agent by an additional ball catching test: one player catching a ball served by the other player. In Fig. 15, the heat map shows the action-value function (Q-value network) in different conditions of players locations and ball position. The hot areas indicate the best locations to capture the ball, learned by DDPG and DCP players. We find the overall shapes are quite similar. Both of them are also consistent to real human decisions. Table 5 lists out the success rate of DDPG players, DCP players and PPO players, respectively. The rate of DDPG and DCP are basically similar and superior to PPO by 5% to 10%.
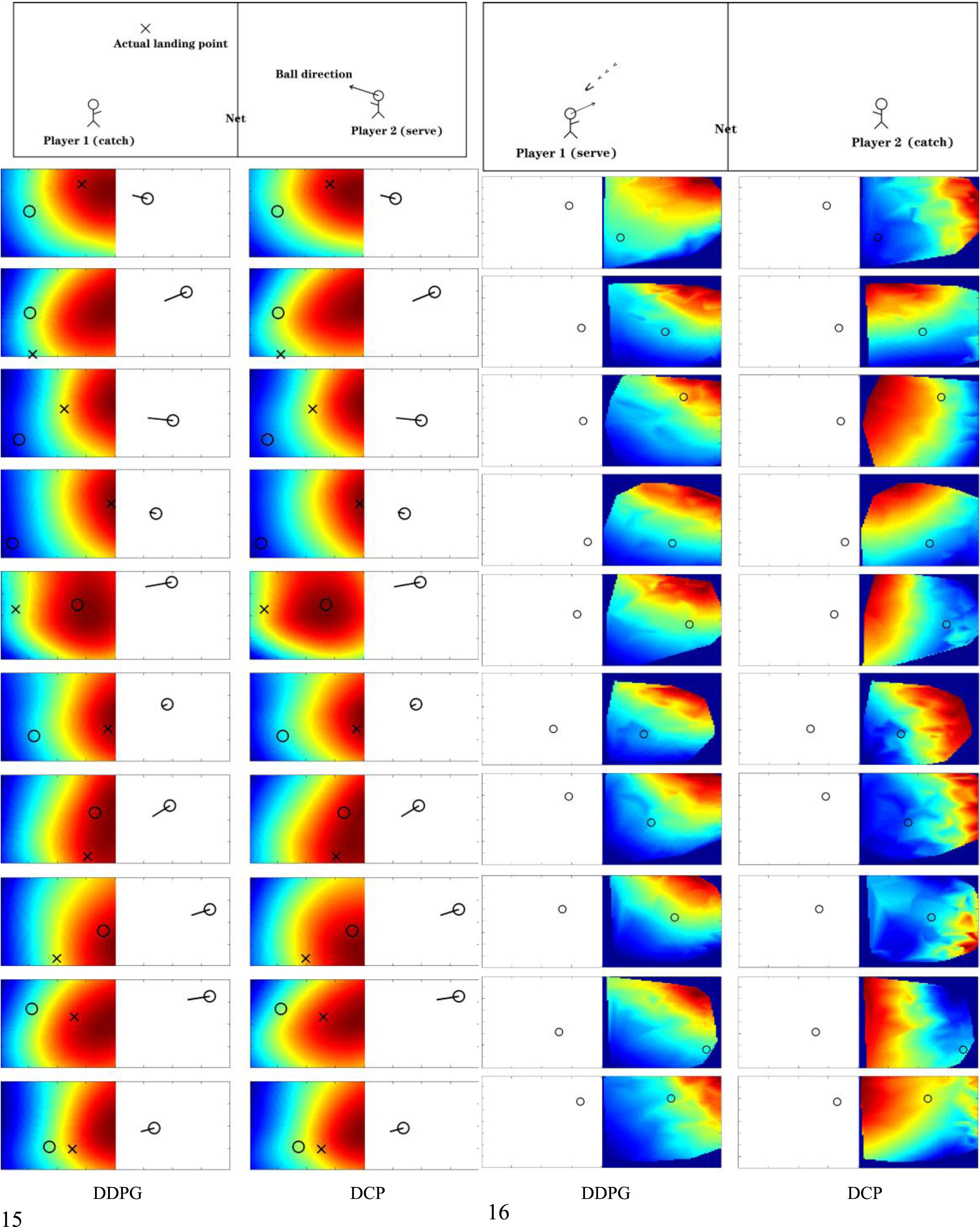
(left). Action-value function learned by the “catch” agent. The hot areas indicate the best locations to capture the ball, comparing DDPG and DCP. Fig. 16(right). Action-value function learned by the “serve” agent. The hot areas indicate the best location to serve the ball to, where the other player is unlikely to capture the ball, comparing DDPG and DCP.
Ball catching test of the “catch” agent
(Total 1,000 tests).
We test the performance of the “serve” agent by the error rate defined by Equation (24), only dead ball is considered. Ball captured by the other player or touching within field is not regarded as a fault.
Similar to the “catch test”, we visualize the action-value function of the “serve” agent, shown in Fig. 16. A player is serving a ball which has just been captured, in different conditions of players locations. The hot areas indicate the best location to serve the ball to, where the other player is unlikely to capture the ball. We find in some conditions, DDPG and DCP could make different decisions. The difference in action-value function leads to preferences of DDPG and DCP players in behavior stage. For examples, the DCP player in Fig. 8 (left) often serve deep-clear balls, the DDPG player in Fig. 8 (right) often serve smash balls. These preferences happen in both DDPG and DCP players and may result from parameters Initialization. Table 6 lists out the error rate of DDPG players, DCP players and PPO players, respectively. The DCP has the smallest error rate, which is 10% lower than DDPG. Compared with the “catch test”, the “serve test” shows larger difference between DDPG and DCP.
Ball serving test of the “serve” agent
(Total 1,000 tests).
Since the “reset” agent works a supplementary “catch” agent, we test its performance by a contrast “catch test”: to estimate the success rate of “catch” between enabling the “reset” agent and disabling the “reset” agent. Table 7 shows the incremental success rate as the result from enabling the “reset” agent. A roughly 10% improvement occurs on all DDPG and DCP players. However, the improvement is basically equal, the “reset” agent is not the primary factor for the score difference between the DDPG and DCP teams.
Ball catching test of the “catch” and the “reset” agent
Ball catching test of the “catch” and the “reset” agent
(Total 1,000 tests).
As DDPG is implemented to real-world applications, we find some limitations of DDPG in solving practical problems. The influence of limited action space margin is less discussed in DDPG, which would undermine the training mechanism facilitated by action space margin. Besides, the robustness of DDPG cannot be guaranteed when the random exploration process is large. In this paper, we modified DDPG to DCP by modifying the core updating process of the actor network (policy network): the training is regulated by a T-fold compare among random proposed adjacent actions rather than the partial derivatives from the input layer of the critic network (Q-value network). In comparison, DCP can better deal with applications with complex, dynamic and unknown hard margins in action space. The performance of the first experiment demonstrates that, the accuracy of DDPG is decreased after we adding barrier walls in the path planning task (Fig. 6), while the accuracy of DCP is not influenced by the barrier walls. Besides, the DCP also has an improved robustness in large random process (Table 3) and various reward functions (Table 2). To validate in complex applications, in the second experiment we use a badminton game to examine the collaborative performance of DCP. The total scores show that DCP is able to surpass the DDPG when T is larger than 4 (Table 4) (Fig. 14). To find out the difference, we estimate the individual performance of the three subsystem: the “catch” agent, the “serve” agent and the “reset” agent. Both DDPG and DCP can learn a similar action-value function in ball catching (Fig. 15), but the success rate of DCP is slightly higher (Table 5), though reinforced by the “reset” agent (Table 7). The main difference occurs on the “serve” agent, the action-value functions of ball serving can be different in DDPG and DCP (Fig. 16). Meanwhile, DCP has the lowest error rate in ball serving (Table 6).
Overall, DCP has an obvious improvement from DDPG, and we believe it is effective, efficient and qualified for all DDPG applications. Limited by the paper length, our demonstration may not cover every details and there could be more case studies about DCP. In the future work, we will validate DCP and DDPG to various tasks to obtain a more universal and practical DRL framework.
Data availability
Data and programs in this study are available from the corresponding author upon reasonable request.
Conflicts of interest
All authors declare no conflict of interest.
Funding statement
This study was funded by National Natural Science Foundation of China (grant number 12172287).
Footnotes
Acknowledgments
The authors would like to show gratitude to our colleague, Dr. Zhongyun Fan for providing technical assistance.