
Abstract
Although facial expression recognition (FER) has a wide range of applications, it may be difficult to achieve under local occlusion conditions which may result in the loss of valuable expression features. This issue has motivated the present study, as a part of which an effective multi-feature cross-attention network (MFCA-Net) is proposed. The MFCA-Net consists of a two-branch network comprising a multi-feature convolution module and a local cross-attention module. Thus, it enables decomposition of facial features into multiple sub-features by the multi-feature convolution module to reduce the impact of local occlusion on facial expression feature extraction. In the next step, the local cross-attention module distinguishes between occluded and unoccluded sub-features and focuses on the latter to facilitate FER. When the MFCA-Net performance is evaluated by applying it to three public large-scale datasets (RAF-DB, FERPlus, and AffectNet), the experimental results confirm its good robustness. Further validation is performed on a real FER dataset with local occlusion of the face.
Keywords
Introduction
Facial expressions are the most direct form of communication and expression of human emotions and emotional states (e.g., sadness, fear, anger, surprise, disgust, joy, contempt, neutral, etc.). Thus, extensive research has been conducted in the field of facial expression recognition (FER) with the aim of its adoption in a variety of domains, such as artificial intelligence (AI), human-computer interaction [1], driving fatigue monitoring [2], and knowledge acquisition detection [3]. However, local occlusion during the recognition process can induce noticeable changes in the facial appearance in space, compromising the FER effectiveness. Thus, extensive research effort has been dedicated to overcoming this shortcoming.
Most currently available facial expression feature extraction strategies are based on traditional machine learning (ML) and deep learning (DL) methods. The approaches in the former category mainly rely on hand-crafted features or shallow learning, such as local binary patterns (LBP) [4], LBP on three orthogonal planes (LBP-TOP) [5], sparse learning [6], and histogram of gradient (HOG) [7]. However, these hand-crafted features are often insufficiently robust and accurate under local occlusion conditions. Consequently, to capitalize on the advances in the DL field, various DL network models have been proposed [8–12] as this strategy facilitates focus on the more meaningful areas of expression [13, 19]. In the more recent studies, the occlusion problem was addressed by reconstructing the occluded face regions through the application of deep models. For example, Lu et al. [15] reconstructed the occluded facial regions based on the Wasserstein generative adversarial network model to highlight enough expression features. However, due to the wide variety of occlusion positions and types, most facial images cannot be reconstructed accurately based on this approach. To overcome this challenge and more accurately restore local occlusion images, Liu et al. [16] proposed an end-to-end network model for local occlusion in low-quality images featuring human face. On the other hand, Poux et al. [17] proposed a new auto-encoding method with hop links and applied it in the reconstruction of occlusion sections in optical funnels. While these methods effectively address occlusion in controlled settings and specific image types, they are difficult to generalize and thus lave limited utility in real-world scenarios. Therefore, to alleviate the adverse influence of occlusion on the facial expression features, Li et al. [18] proposed the PG-CNN attention model based on the facial landmark point selection aided by the local region block input attention network. Several authors have also adopted patch-based analysis to solve the occlusion issues, and have shown that it is capable of capturing the importance of each relevant facial feature. For this purpose, Wang et al. [19] performed random, fixed position, and landmark-based cropping on relatively large regions, and used the relational attention module and the region bias loss function to refine the weights initially assigned to the facial features. However, as the aforementioned methods rely on facial landmark points for region block selection, their performance is compromised when applied to occluded face images. Thus, to improve the FER performance, researchers are increasingly drawing upon the findings yielded by human psychology studies, which indicate that the facial perception mechanism in the human brain extracts both global and local key information when interpreting emotions. Specifically, in the MA-Net proposed by Zhao et al. [20], the multi-scale module and CBAM module [21] are utilized to extract global and local facial feature information, thus effectively eliminating the interference of occlusion. In this context, attention mechanism is also studied with the goal of obtaining detailed local information. For example, to enhance the discrimination ability, Farzaneh et al. [22] proposed Deep Attention Center Loss (DACL) which adaptively selects some important feature elements. On the other hand, in the mask-based attention parallel network developed by Ju et al. [23], the binary mask extracted from key landmark detection is employed to construct a mask-based attention module. This method locates the region related to expression and embeds it into the parallel network to extract features. The extracted parallel features are subsequently segmented into multiple independent blocks from the spatial dimension, allowing facial expressions to be independently predicted, thus addressing the region occlusion problem. However, these methods only focus on a single regional feature of the face, which may be difficult to obtain enough recognitionfeatures.
Therefore, Although the methods discussed above alleviate many of the occlusion issues, in practice, FER is still affected by several problems, as the loss of expression feature information due to local occlusion undermines the discrimination ability of deep convolutional models, due to which FER may require multiple regional features for expression recognition under local occlusion. As the existing methods can use a single regional feature only, this shortcoming has motivated us to propose an effective Multi-Feature Cross-Attention Network (MFCA-Net). This method benefits from a multi-feature convolution module and thus reduces the influence of deep occlusion on deep convolution. Moreover, the proposed strategy can decompose deep features into multiple sub-features, as well as extract rich and robust multi-scale expression recognition features from each sub-feature. As local occlusion may require multiple regional features for expression recognition, a local cross-attention module is developed to allow the model to focus on multiple salient features simultaneously.
As shown in Figure 1, the MFCA-Net consists of a multi-feature convolution module branch and local-cross attention module branch. To alleviate the issues of missing expression information features, multi-feature convolution module learns multi-scale features of a single basic block, while the local cross-attention module enables simultaneous focus on multiple salient features. The main contributions of this work are summarized below:
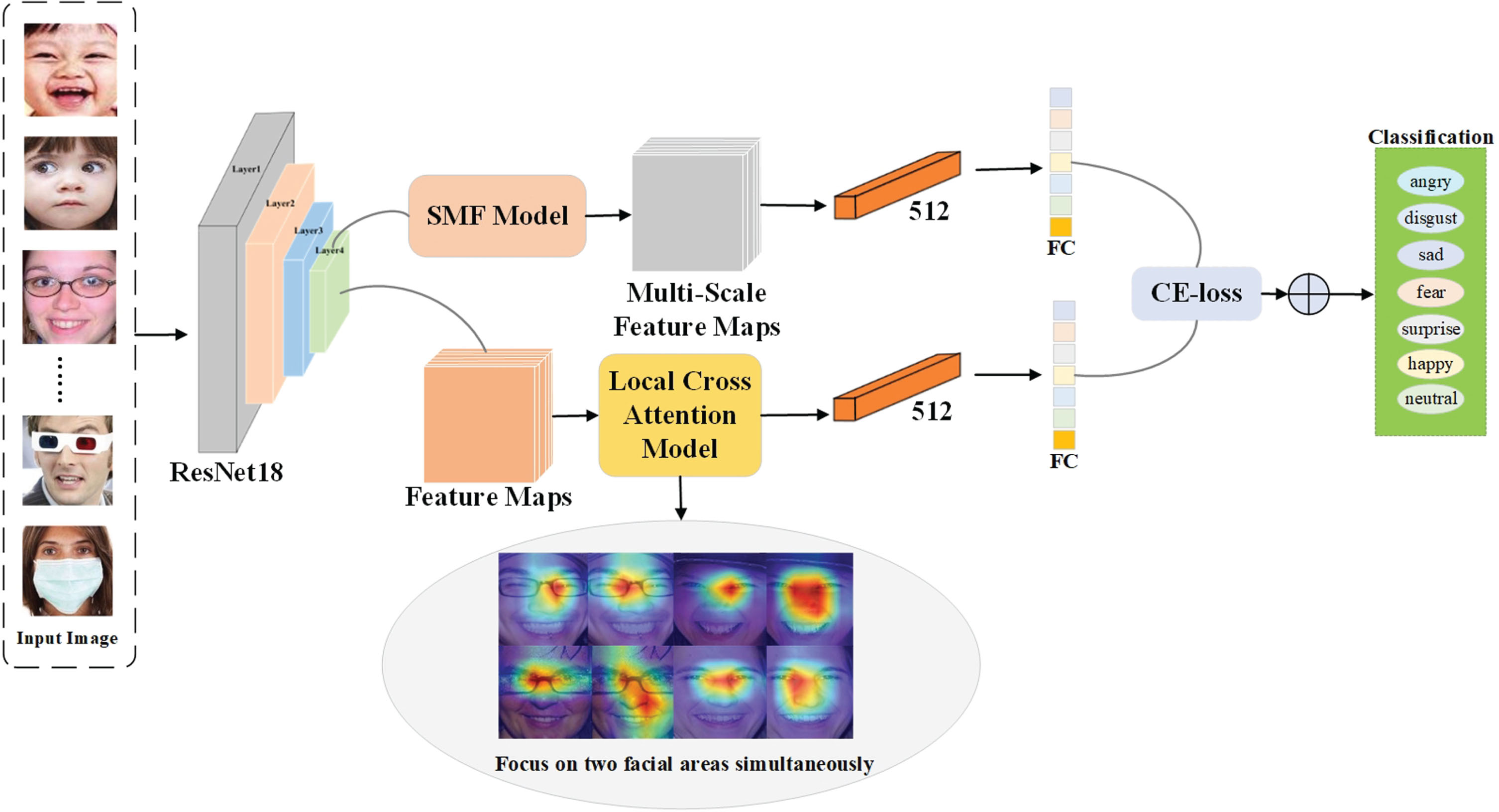
The pipeline of MFCA-Net.
1) The proposed MFCA-Net employs multi-feature convolution and local cross-attention to effectively address the face occlusion issue in real-world scenarios.
2) As the multi-feature convolution module decomposes the features within a single basic block, it can reduce the impact of occlusion on deep convolution. The channel salient features of SENet attention are introduced to highlight the overall features, obtain rich and robust multi-scale expression recognition features, and alleviate the problem of expression information feature loss.
3) The local cross-attention module is used to attend to the prominent features of multiple local, unoccluded face regions.
4) MFCA-Net outperforms the state-of-the-art methods not only on the FER datasets including RAF-DB, FERPlus, AffectNet-7, and AffectNet-8, but also on the occlusion subsets including Occlusion-RAF-DB, Occlusion-FERPlus, Occlusion-AffectNet, and FED-RO.
As the main aim of this work is improving the FER performance under occlusion conditions, in the sections below, focus is given to the extant FER research, the attention mechanism under occlusion in real-world scenarios in particular.
Occlusion FER
In real-world scenarios, the face can easily be occluded by different objects (such as masks, glasses, hands, scarfs, etc.) which can be present simultaneously and may appear in random positions. Thus, while the occlusion caused by glasses and hats can be roughly predicted, temporary occlusion due to occasionally placing hands in front of one’s face is difficult to model. Currently, facial occlusion is mostly addressed via holistic-based or region-based approaches.
In the holistic-based methods, the face is treated as a whole and relevant features are extracted through deep learning. In this context, to mitigate the impact of occlusion on feature extraction, Zhao et al. [18] proposed the MA-Net network, which relies on the extraction of both global and local facial features. As a part of their work, Lu et al. [15] reconstructed the occluded facial regions based on the Wasserstein generative adversarial network model to highlight enough expression features. However due to the large number of locations and types of occlusion, this method cannot accurately reconstruct facial images, leading to unsatisfactory de-occlusion results. To overcome these challenges, Zhao et al. [24] proposed a robust FER network denoted as EfficientFace, which relies on local feature extractors and channel spatial modulators that can perceive both local and global facial features. According to their test results based on wild datasets, this strategy exhibits strong robustness under occlusion conditions.
The authors that opted for region-based methods explicitly divide the face into several overlapping or non-overlapping segments. For example, Zhong et al. [25] developed a graph structure representation method where each node on the graph represents the appearance information around a facial landmark, and the edges represent the geometric information encoded by the distance between two nodes. On the other hand, Gong et al. [26] proposed a multi-feature fusion network (MFNet) based on a shallow Gabor convolutional network designed to enhance the adaptability of learning features for orientation and scale changes, and to improve the capacity to capture detailed local features. As a part of their investigation, Ruan et al. [27] constructed a path selection multiple network model to achieve FER under local facial occlusion scenarios.
Attention
According to the extant research on human visual perception, the visual gaze can be quickly shifted by the attention mechanism to focus on the target of interest. When presented with occluded facial features, humans typically only focus on the unoccluded local features, and this strategy is increasingly being explored in FER research.
For example, Albanie et al. [28] proposed the Squeeze and Excitation Networks (SENet) to perform channel-wise feature reconstruction, thereby enhancing the expression feature learning potential. Similarly, Woo et al. [21] proposed the Convolution Block Attention Module (CBAM), which sequentially connects channel and spatial attention to obtain rich attention features. As a part of their work, Li et al. [18] addressed the issues of local facial occlusion in real-world FER by adopting robust global-local attention (gA-CNN and PG-CNN) networks. Their approach was shown to improve the overall recognition accuracy by selecting the most relevant 24 points and reconstructing the weight in each partition using attention. On the other hand, to enhance the recognition of facial expressions in occluded images, Wang et al. [19] proposed the Region Attention Network (RAN) to capture the key regions in images containing human faces affected by different degrees and types of occlusion and featuring pose variation. To address the fact that different facial classes have intrinsic similarities in facial features, and the difference between facial expressions may be subtle, Wen et al. [29] developed an attention network which recognizes that facial expressions are simultaneously expressed in multiple facial regions, achieving good results.
However, most of the attention methods discussed above focus on a single facial region to enhance the facial feature recognition ability. In contrast, the local cross-attention module proposed in this work simultaneously focuses on the most informative channel features and the most meaningful spatial expression regions, thereby capturing features with strong discriminative power and handling the problem of local occlusion more effectively. Compared with the strategy proposed by other authors [29], the local cross-attention method proposed here is more parsimonious, as the total number of model parameters is 14.38M, and the GFLOPs is 1.95G.
Method
Overview
To address the fact that local occlusion of the face leads to the loss of expression features, the MFCA-Net network is developed to obtain robust facial features even under occlusion conditions. MFCA-Net comprises the backbone network ResNet18 [30], the multi-feature convolution module, and the local cross-attention module. As can be seen from Figure 2a depicting the basic structure of ResNet18, it is used for feature extraction, while considering the number of parameters in the model. It also benefits from a shortcut method to solve the problems of network degradation, gradient disappearance, and explosion. Next, the multi-feature convolution module obtains multi-scale features from multiple directions of the face, which can effectively reduce the impact of occlusion on deep convolution. In the next step, the local cross-attention module captures and integrates the attention features of different facial expression regions to decrease the influence of non-expressive regions, thereby enhancing the significant expression features situated in the unoccluded local regions of the face. Finally, 512 feature vectors are obtained for each of the two modules, and the recognition result is obtained through decision fusion by fully-connected layers.
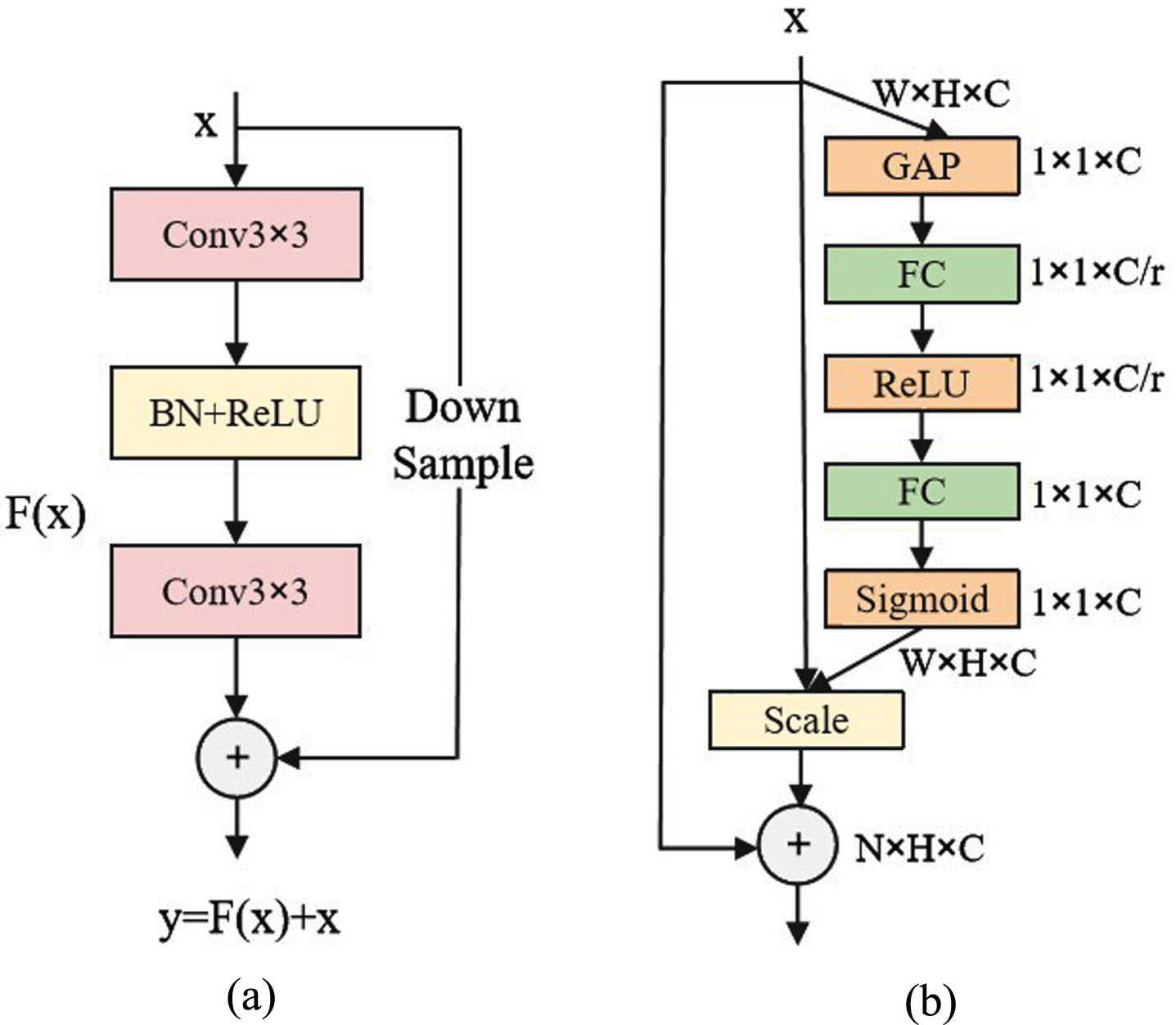
(a) ResNet18 Basic Block. (b) SENet Block.
In computer vision tasks, multi-scale features are established on the fine-grained feature descriptions of visual images by uniformly dividing the feature map into several independent subsets and extracting and combining these independent features. The currently available networks incorporate multi-scale modules, such as DCN, PyConv, etc., as this improves network performance, given that multi-scale features are utilized in image classification, facial analysis, and many other domains. In essence, these methods represent multi-scale features in a hierarchical manner.
In this work, the multi-feature convolution module designed in this paper extracts multi-scale features within a single basic block. In the convolutional neural network, the convolution operation of each layer will extract the feature of the input feature map in the local receptive field. The deeper convolution usually has a wider receptive field for extracting high-level semantic features. However, shallower convolutions have narrower receptive fields and are used to extract rich geometric features. A wide receptive field is easily affected by occlusion, and adding shallow geometric features can effectively reduce the impact of occlusion on depth convolution.

Symmetric multi-feature convolution module.
As shown in Figure 3, depicting the structure of the multi-feature convolution module adopted in this work,a symmetric multi-feature convolution module is incorporated in the last convolution layer of ResNet18, which consists of a regular 3×3 and 1×1 convolution, a 3×3 convolution with a dilation rate of 2, and SENet. The dilated convolution can can assist the regular convolution in obtaining a larger receptive field without adding any parameters, which allows features to be extracted from a larger range of images. SENet is mainly used to enhance the significant channel features after the aggregation of sub-features. As can be seen from Figure 2b, SENet is a lightweight attention mechanism that only focuses on channels. The Squeeze operation applies global pooling to compress the W×H×C feature map to 1×1×C, thereby obtaining global receptive field information. This is followed by an excitation process that assigns relevance weights to each part. In the multi-feature convolution module,a feature map X is first obtained by performing a 3×3 convolution. The feature map X is evenly divided into S mapping subsets denoted by X
i
, where i ∈ {1, 2, …, S}, due to which each subset of feature mapping X
i
has a spatial size of 1/S, which is the same for all subsets. Next, each X
i
is processed by a regular 3×3 convolution and a dilated convolution with a dilation rate of 2. The S and X
i
are concatenated before applying SENet to enhance the channel-wise significant multi-scale features. the two symmetrical modules are subjected to concatenation and a 1×1 convolution layer. The output of multi-feature convolution module can be expressed as:
Where p1 ∈ {up}, p2 ∈ {down}, f1(·) denotes the normal 3×3 convolution, f2(·) represents the 3×3 convolution with a dilation rate of 2,
From Eq. (4,5,6), W×H is the spatial dimension, F sq (·) is the Squeeze operation, F ex (·) is the Excitation operation, W1 and W2 are the weights of the two fully-connected layers used for reducing and increasing dimensionality, δ is the ReLU activation function, and σ is the Sigmoid activation function.
In the multi-feature convolution module, S is searched only in the range 1 to 10 with a step size of 1. For our setting S=4 was found to perform best. A larger S may lose more information and also increase the computational overhead. A small S results in insufficient information to be obtained. In order to obtain richer features, all
The multi-feature convolution module is consisted of four multi-scale convolution blocks and an SENet module. Thus, a larger number (S) of mapping subsets facilitates learning based on significantly richer receptive field sizes, but it may increase the number of model parameters which would render it computationally expensive. On the other hand, since multi-feature convolution can simultaneously learn deeper semantic features and shallower geometric features, it increases the diversity of facial expression features and can reduce the sensitivity of deep convolution to occlusion. It is inspired by [31, 32], that occlusion noise affects the judgment of deep convolution on the target task, and the analysis considering sensitivity will be combined with the target task in the future. To demonstrate the effectiveness of the multi-feature convolution module proposed in this work, class activation maps were visualized through Grad-CAM++ [33] whereby darker color indicates greater focus of the multi-feature convolution module on the prominent facial region. As shown in Figure 4, compared with the ResNet18 residual structure, the convex region is larger, indicating that the multi-feature convolution module can extract more diverse features than ResNet18, allowing the model to obtain sufficient number of features for effective FER.

The proposed method was applied to the RAF-DB validation set, and the results were visualized using Grad CAM++ for baseline, multi-feature convolution module, and local cross-attention.
For FER under occlusion conditions, most existing methods rely on the unoccluded parts of the face. However, in practice, FER under local occlusion may require multiple regional features for expression recognition, whereas the existing methods can only use a single regional feature. To overcome this shortcoming, a local cross-attention module is developed that allows simultaneous focus on multiple local unoccluded facial regions, whereby FER is achieved by enhancing the subtle features that are present in multiple local regions.
As shown in Figure 5, the local cross-attention module is composed of spatial attention unit and channel attention unit. The spatial attention unit consists of a 1×1 convolution, a 3×3 convolution, and a ReLU activation function, the main role of which is to extract local features. The channel attention unit is composed of a global Max pooling (GMP), two linear layers, and a Sigmoid activation function. The GMP takes the maximum operation for each feature channel from the spatial unit to aggregate the spatial information of the feature map, while the two linear layers are used to achieve a mini autoencoder which is applied to encode channel information.
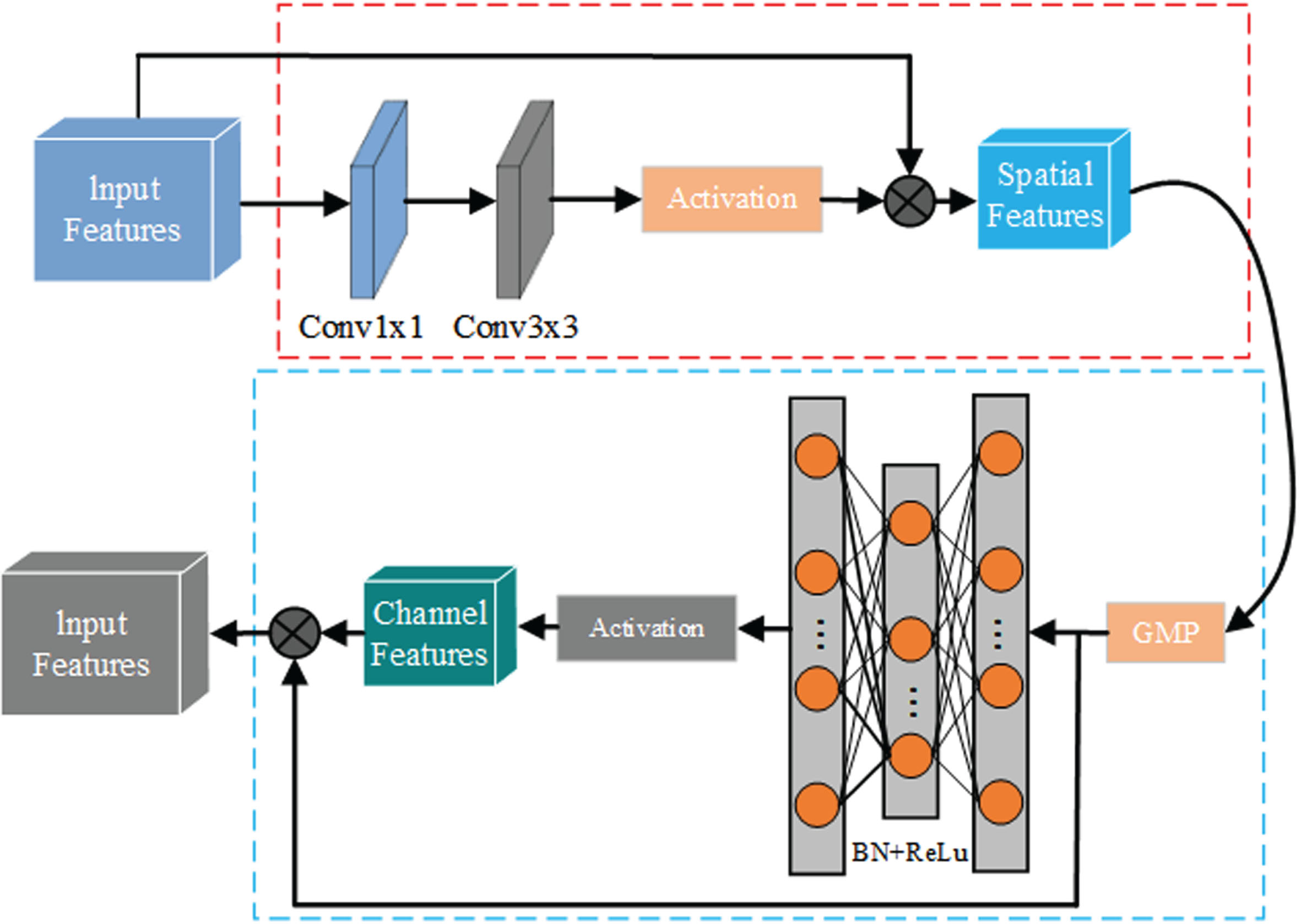
Local cross-attention module.
The spatial attention unit receives the feature map S extracted from ResNet18, S ∈ R7×7×512, where 7 denotes the spatial size and 512 is the channel size. Accordingly, the extracted feature map is subsequently reduced to 256 through a 1×1 convolution and the spatial features are extracted via a 3×3 convolution. The channel unit receives the spatial features as input and outputs the extracted channel features. Finally, a feature vector with a local cross-attention size of 512 is obtained. These processes are described in more detail below.
Let N r be the ResNet18 backbone network, where p r denotes its parameter, and x i is the input feature vector. Then, the following expression holds:
Suppose H j is the spatial attention number and F sj is the output spatial attention feature, where j is the number of cross heads, then the spatial attention of the output can be expressed as follows:
Where w s is the network parameter for H j .
Similarly, suppose
Where w
c
is the network parameter for
To demonstrate the effectiveness of the local cross-attention module, the Grad-CAM++ was applied and the findings are shown in Figure 4. It is evident that, compared with the traditional ResNet18, the CAM based on local cross-attention enhances the model’s ability to extract facial expression features under occlusion conditions. For example, when applied to a masked face, the module can focus solely on the multiple regions of the face that are not occluded, whereas in the image showing a frontal face, the module can focus on the multiple prominent regions of the facial components.
(1) Cross-attention fusion loss
As cross-attention can capture multiple facial regions and form multiple attention maps, to avoid overlaps, the attention maps are first scaled using the Log-softmax function to emphasize the most relevant regions. Next, partition loss [29] is used to guide the attention to different regions. Finally, the attention maps are normalized through a BN layer, as described below.
Assuming that Z=a i ∈ Rn×c, the Log-softmax function can be expressed as follows:
Where Z i is the i-th vector of the attention map, while Z j represents its j-th element. Accordingly, the partition loss can be represented as:
Where C represents the attention map channel size and
(2) Cross-entropy Loss
Due to the poor complementarity of MFCA-Net on the two branches, decision-level fusion is adopted. Specifically, after global average pooling, the multi-scale aggregation module obtains a 512-dimensional feature vector, while the cross-attention module normalizes features through a BN layer, which also results in a 512-dimensional feature vector. These two branches make predictions through a fully-connected layer, using the Cross-entropy Loss as the loss function. Therefore, inspired by [34], in our work, Cross-entropy Loss is used to quantify MFCA-Net, and the input is the probability distribution of the model output, which represents the predicted probability for each target task category. The output is to compute the cross-entropy between the predicted probability distribution and the true probability distribution, which outputs a scalar value as the loss. A smaller loss means that the model’s prediction is closer to the true distribution, while a larger loss means that the model’s prediction is more different from the true distribution. The Cross-Entropy Loss can be formulated as:
Where N is the number of samples, C represents the number of expression categories,
(3) Combined loss function
The overall loss function is attained by combining the cross-entropy loss and the partition loss to optimize our MFCA-Net, expressed as:
The effectiveness of MFCA-Net presented in the preceding sections was validated by applying it to three public datasets, namely RAF-DB [35], AffectNet [36], and FERPlus [37]. Further tests were performed on four real occlusion datasets, namely Occlusion-RAF-DB, Occlusion-FERPlus, Occlusion-AffectNet, and FED-RO [38]. In addition, ablation experiments were carried out to assess the effectiveness of each module, using benchmark data exemplified in Figure 6.

Sample images extracted from the RAF-DB (the first row), FERPlus (the second row), and AffectNet (the third row) databases.
When applying it to the RAF-DB, AffectNet, and FERPlus datasets, the MFCA-Net model was directly trained using the officially aligned images. For this purpose, all input images were resized to 224×224 pixels before performing random cropping, horizontal flipping, and erasing as these data augmentation methods prevent over-fitting. As the ResNet18 model served as the baseline network, to achieve fair evaluation, a pretrained ResNet-18 model from the MSCeleb-1M [39] face recognition dataset was used in all experiments. The MFCA-Net model was implemented in Pytorch code on a Windows 10 operating system and was trained on a workstation with a TESLA T4 16GB GPU. MFCA-Net model had 20.87M parameters with the GFLOPs of 2.42G. In the stage of model inference, the recognition time of MFCA-Net on a single image is 0.0767s.
During the model training process, the SGD optimizer with a momentum parameter of 0.9 and a weight decay of 1e-4 was utilized. Model training was conducted on the RAF-DB and FERPlus datasets for 50 epochs, with the batch sizes of 256 and 128, and the initial learning rates of 0.1 and 0.04, respectively. After the completion of each set of 10 epochs, the learning rate was decayed by a factor of 0.1. For the AffectNet-7 and AffectNet-8 datasets, model training was conducted for 20 epochs, whereby the learning rate decayed by a factor of 0.1 every 4 epochs, while the batch size was set to 256 and the initial learning rate to 0.04. To achieve class balance, during the training phase for the AffectNet dataset, a dataset sampling strategy was introduced, whereby the low volume categories were upsampled and the high volume categories were downsampled.
RAF-DB [35] is a facial image dataset that contains 29,672 real-world scene images, labeled with seven basic expressions (anger, disgust, fear, joy, neutral, sadness, surprise) and eleven compound expressions. In the experiments, the focus was on identifying the seven basic expressions using a training set of 12,271 images and a test set of 3,068 images. For this purpose, each image was aligned and cropped to the same size (100×100 pixels).
AffectNet [36] is currently the largest wild facial expression database, containing 450,000 manually annotated facial images collected from the internet through three major search engines. It includes both AffectNet-7 and AffectNet-8 classification, as AffectNet-8 also includes the “contempt” class in addition to the aforementioned seven emotion categories. This dataset is comprehensive, as it includes not only images of people from different races, but also features background changes, lighting variations, and different postures and types of obstruction, among other factors that can affect FER. In our experiments, AffectNet-7 and AffectNet-8 were evaluated separately, whereby AffectNet-8 was assessed using 287,651 images as the training set for imbalanced classes, with 500 images for each class, and 4,000 images as the test data. For AffectNet-7, 283,901 images served as the training set for imbalanced classes, with 500 images for each class, and 3,500 images as the test data.
FERPlus [37] is a dataset of human facial expressions captured in real-world scenarios, obtained by relabeling the FER2013 dataset. It contains 28,709 training images, 3,589 validation images, and 3,589 testing images of 48×48 pixel size, each belonging to one of ten classes of extremely imbalanced expressions. To evaluate the model, in addition to anger, disgust, fear, joy, neutral, sadness, and surprise, the "contempt" class was also considered.
FED-RO is a dataset of 400 real-world facial expression images with variations in facial occlusion that are collected through Bing and Google search engines from which any overlaps with the RAF-DB and AffectNet datasets have been removed by Li et al. [38]. Each image in this dataset contains genuine and unique occlusion. In the experiments, the model was first trained on the AffectNet and RAF-DB training datasets and was subsequently tested by applying it to FED-RO.
Evaluation indicators
The proposed model is subjected to ablation experiments and comparisons with state-of-the-art methods on the publicly available datasets RAF-DB and, FERPlus and AffectNet. The evaluation indicators used is Accuracy (%), which is commonly used to measure the performance of a classification model and represents the ratio of the number of samples correctly predicted by the model to the total number of samples. It can be expressed as follows:
Where TP denotes the number of samples correctly categorized for positive samples, TN denotes the number of samples correctly categorized for negative samples, FP denotes the number of samples incorrectly categorized for positive samples, and FN denotes the number of samples incorrectly categorized for negative samples.
An ablation analysis was conducted on public datasets RAF-DB, AffectNet-8, and FERPlus to demonstrate the effectiveness of the proposed method when applied to real-world scenarios. In the experiments, the performance of multi-feature convolution module and cross-attention module was evaluated, as well as the addition of SENet in the multi-feature convolution module and cross-attention module while varying the M value.
To verify the effectiveness of each module, a pre-trained backbone network was used in the ablation analysis. As shown in Table 1, the recognition rate of a single multi-feature convolution module on RAF-DB, AffectNet-8 and FERPlus is increased by 0.02%, 0.07% and 0.03%, respectively. When symmetric multi-feature convolution module applied to RAF-DB, AffectNet-8, and FERPlus, the recognition rate by 0.10%, 0.48%, and 0.07%, respectively, indicating that it can extract rich facial expression features for each sub-feature. Furthermore, when the SENet attention mechanism is added to the symmetric multi-feature convolution module, the recognition rates on RAF-DB, AffectNet- 8, and FERPlus are improved by 0.36%, 0.56%, and 0.35%, respectively. These results demonstrate that the module can obtain robust FER features for the overall sub-feature as well as alleviate the problem of missing expression information features. Moreover, the cross-attention module improves the recognition rate by 0.36%, 0.50%, and 0.61% on RAF-DB, AffectNet-8, and FERPlus, respectively, indicating that this module can obtain features from multiple regions to improve FER. Finally, when all these modules are combined into the algorithm, the recognition rates on RAF-DB, AffectNet-8, and FERPlus are improved by 1.37%, 0.96%, and 1.53%, respectively.
Analysis of each module when applied to RAF-DB, AffectNet-8, and FERPlus (%)
Analysis of each module when applied to RAF-DB, AffectNet-8, and FERPlus (%)
Therefore, the decomposition of deep features and the decomposition of SENet in the proposed symmetric multi-feature convolution module can significantly reduce the sensitivity of deep convolution to occlusion, obtain rich and robust salient expression recognition features for each sub-feature, and alleviate the problem of missing facial expression information features. Additionally, the cross-attention module can simultaneously focus on multiple salient facial regions that have not been occluded, as well as mitigate interference from occlusion and enhance the model’s recognition ability. In sum, superior performance in real-world scenarios was achieved due to these enhancements in our method.
Given that the cross-attention module size (M) affects the model performance, its impact was assessed using the RAF-DB dataset and the findings are shown in Figure 7. As the cross-attention model is superior to the single attention model, in further experiments, two cross-attention modules were employed to enhance the recognition performance of the model.
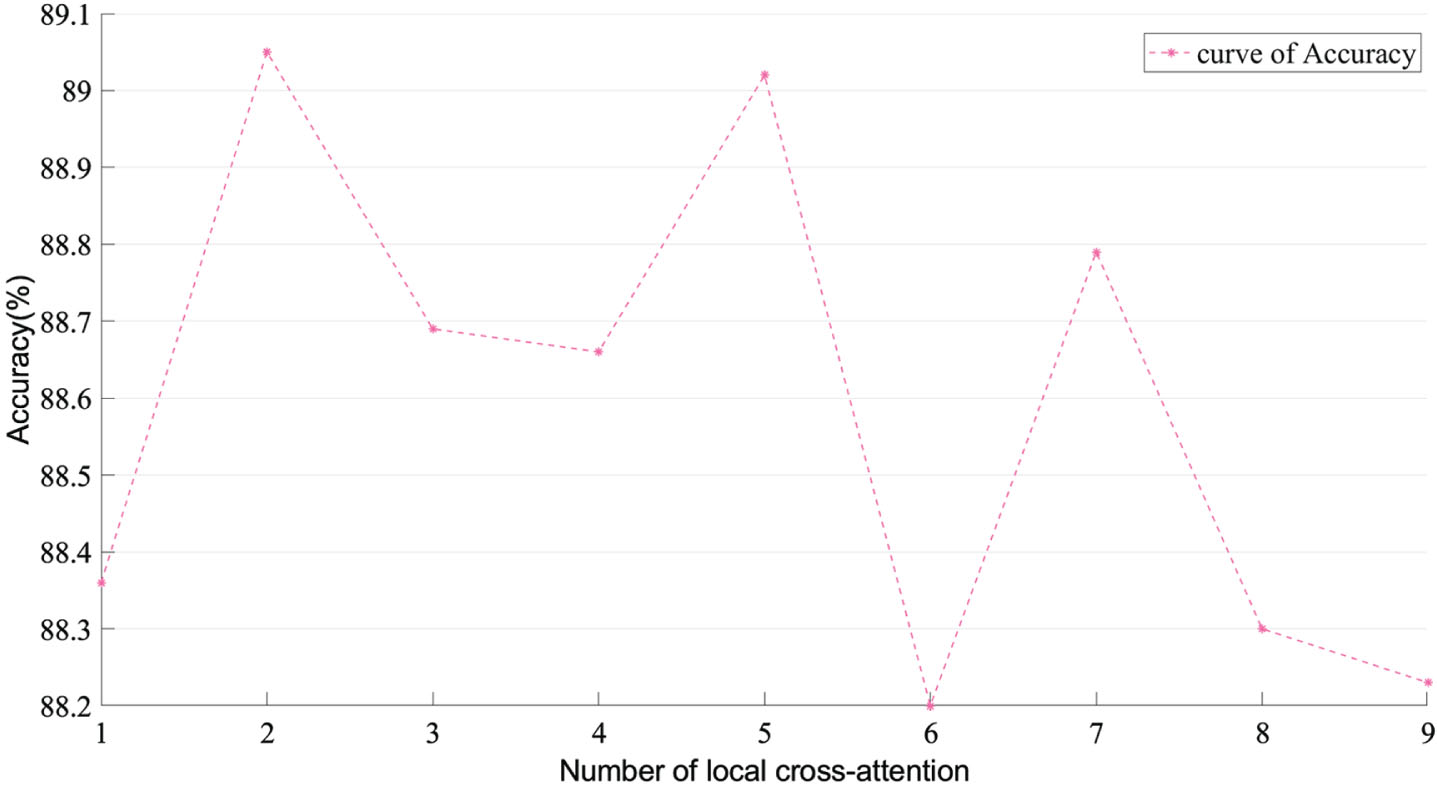
The results of ablation analysis of the local cross-attention module applied to RAF-DB.
Two traditional fusion strategies are compared: feature-level fusion and decision-level fusion. Feature-level fusion directly combines the feature vectors obtained from the two branches into a single feature vector for comprehensive analysis and processing, and trains the FER classifier to obtain the final recognition result. However, decision-level fusion fuses the recognition results of the two branches, and the final decision result is the global optimal decision. Table 2 indicates that decision-level fusion is clearly due to feature-level fusion.
The two fusion strategies are compared on RAF-DB
In this section, the proposed method is compared with state-of-the-art approaches by applying each to the RAF-DB, AffectNet-7, AffectNet-8, and FERPlus datasets.
1) Results on RAF-DB: The results shown in Table 3 indicate that the MFCA-Net method outperforms many state-of-the-art alternatives, achieving 90.06% accuracy. Compared to the attention-based methods such as RAN [19], LANet [40], LAViT [41], and DAN [29], the MFCA-Net outperforms the best-performing DAN method by 0.36%. Compared to the loss-based methods, i.e., DACL [22] and EAFR loss [42], the MFCA-Net method also outperforms the best-performing EAFR loss method by 0.26%. Likewise, our network outperforms the MA-Net [20] and MFNet [26] by 1.53%. At the same time, a confusion matrix is used to further illustrate the results, as shown in Figure 8(a), Disgust expression is easily confused with Sadness expression, possibly because these two expressions have similar facial features. The proposed MFCA-Net model achieves high accuracy on other categories of expressions.
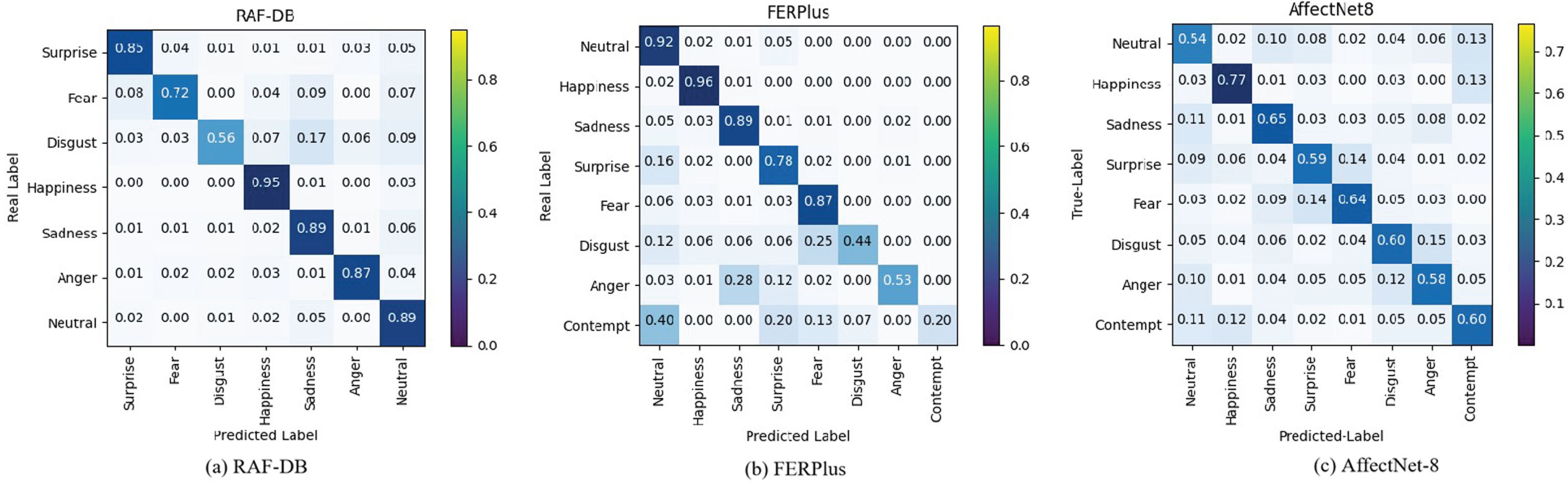
Confusion matrix of RAF-DB (a), FERPlus (b) and AffectNet-8(c).
The results obtained by applying state-of-the-art approaches to the RAF-DB dataset
2) Results on FERPlus: The results reported in Table 4 indicate that the MFCA-Net method achieves an accuracy of 89.19%, which is a 0.64% improvement relative to the attention-based method RAN [19] as well as 1.59% enhancement relative to the loss-constructed RW Loss [43]. Moreover, the MFCA-Net method outperforms other feature extraction network models. At the same time, a confusion matrix is used to further illustrate the results, as shown in Figure 8(b), Disgust expression, Anger expression and contempt expression are easily confused with other expressions, but the proposed MFCA-Net model performs well on other categories of expressions.
Comparison of the proposed method with state-of-the-art alternatives when applied to the FERPlus dataset
3) Results on AffectNet: As the AffectNet dataset has been manually annotated with eleven facial expression classes, it was used along with AffectNet-8 to evaluate the effectiveness of the MFCA-Net method. However, given that the AffectNet dataset contains an imbalanced training set, a data sampling strategy was adopted during the training process. The aim was to rebalance the interclass distribution and automatically estimate the weight of the samples when sampling from the imbalanced dataset, while undersampling the majority class samples and oversampling the minority class samples. As can be seen from the results reported in Table 5, an accuracy of 65.74% and 61.12% is achieved by our method when applied to AffectNet-7 and AffectNet-8, respectively, thus outperforming most existing methods. Specifically, when compared to the attention-based methods DAN [29] and LAViT [41], the MFCA-Net method shows a slight superiority to DAN when applied to AffectNet-7. When tested on AffectNet-8, the MFCA-Net method’s performance is also superior to the other methods, with the exception of the attention-based methods DAN [29] and RAN [19]. At the same time, the confusion matrix is used to further illustrate the results on the AffectNet-8 dataset, as shown in Figure 8(c). The dataset itself is difficult to recognize due to various noises, but the MFCA-Net model proposed in this paper shows good performance on various types of expressions.
Comparison of the AffectNet-7 and AffectNet-8 results with those obtained by the state-of-the-art methods
4) MFCA-Net features: As shown in Figure 9, the feature extraction capability of MFCA-Net is demonstrated, that is, the highlighted area represents the feature extraction capability of MFCA-Net. When performing feature selection, MFCA-Net can select more useful features on images without occlusion. On the local occlusion image, useful features can be extracted from the local unoccluded regions. Through visual data analysis, MFCA-Net shows good feature extraction ability on both images without occlusion and occlusion.
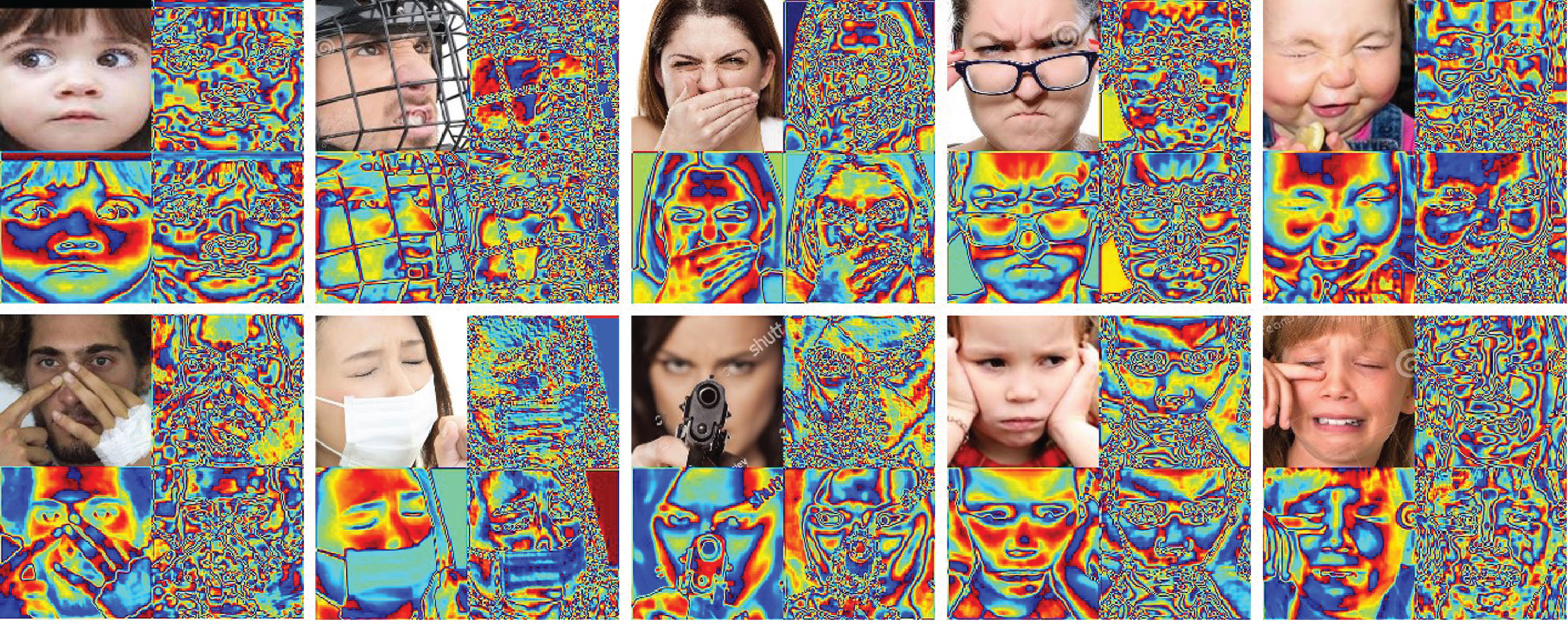
Feature extraction capability of MFCA-Net.
In order to evaluate the performance of the MFCA-Net model in real-world scenarios, it was applied to several datasets featuring realistic occlusion, including Occlusie-RAF-DB, Occlusie-FERPlus, Occlusion-AffectNet, and FED-RO. While the same experimental settings for the Occlusie-RAF-DB, Occlusie-FERPlus, and Occlusion-AffectNet datasets were adopted as reported in pertinent literature. For the FED-RO dataset, all training images from RAF-DB and AffectNet datasets were merged for fair comparison, and testing was conducted on FED-RO. Several examples of images from the real occlusion datasets are shown in Figure 10.

Realistic occlusion sample images sourced from the RAF-DB (the first row), AffectNet (the second row), FERPlus (the third row), and FED-RO (the fourth row) databases.
As can be seen from Table 6 providing a comparison of the MFCA-Net method with state-of-the-art approaches, it achieves significantly higher performance on the Occlusie-RAF-DB, Occlusie-FERPlus, Occlusion-Aff-ectNet, and FED-RO datasets, with the accuracy rates of 87.74%, 86.28%, 62.66% and 71.25%, respectively. Thus, MFCA-Net demonstrates strong generalization ability as well as the potential for practical applications in real-world scenarios. It also effectively solves the significant challenge of local occlusion in FER.
Comparison of the proposed method with state-of-the-art alternatives when applied to the Occlusie-RAF-DB, Occlusie-FERPlus, Occlusion-AffectNet, and FED-RO datasets with real occlusion
In this work, a multi-feature cross-attention network (MFCA-Net) was presented and applied to solve FER under local occlusion conditions. The findings yielded by the extensive analyses and experiments confirm that the proposed method can obtain robust multi-scale and local features. Specifically, MFCA-Net consists of multi-feature convolution and local cross-attention modules. The multi-feature convolution module decomposes deep features into multiple sub-features, extracts multi-scale features, and reduces the loss of expression information caused by deep convolution networks being affected by local occlusion. The local cross-attention module can simultaneously focus on multiple facial regions that have not been occluded, extract features from these regions, and alleviate the interference caused by local occlusion.
The experiments conducted on the public datasets RAF-DB, AffectNet, and FERPlus demonstrate the robustness and effectiveness of MFCA-Net. The feature extraction ability of MFCA-Net is demonstrated by dataset visualization. Compared to other state-of-the-art methods, MFCA-Net achieves optimal performance and performs equally well on datasets with real occlusion.
However, in a specific environment, the proposed method has limitations, as shown in Figure 11, blurred images, low quality and excessive occlusion area can lead to erroneous labeling of expressions. In the future work, will try to address these noise problems.

The first row is the true label and the second row is the false label.
Footnotes
Acknowledgments
This research was supported by the National Natural Science Foundation of China (62241206) and the Science and Technology Projects of Guizhou Province (QKHJCZK2022YB195, QKHJCZK2023YB143, QKHPTRCZCKJ2021007, QKHJCZK2022YB550, ZCKJ2021007), the Youth Science and Technology Talent Growth Project of Guizhou Province (QJHKY2021104), the Natural Science Research Project of Education Department of Guizhou Province (QJJ2023061, QJJ2023012), the Education Evaluation Reform Pilot Project of Guizhou Province “Quality Evaluation of Teaching Process”.