
Abstract
This paper introduces an innovative approach, the LS-SLM (Local Search with Smart Local Moving) technique, for enhancing the efficiency of article recommendation systems based on community detection and topic modeling. The methodology undergoes rigorous evaluation using a comprehensive dataset extracted from the “dblp. v12.json” citation network. Experimental results presented herein provide a clear depiction of the superior performance of the LS-SLM technique when compared to established algorithms, namely the Louvain Algorithm (LA), Stochastic Block Model (SBM), Fast Greedy Algorithm (FGA), and Smart Local Moving (SLM). The evaluation metrics include accuracy, precision, specificity, recall, F-Score, modularity, Normalized Mutual Information (NMI), betweenness centrality (BTC), and community detection time. Notably, the LS-SLM technique outperforms existing solutions across all metrics. For instance, the proposed methodology achieves an accuracy of 96.32%, surpassing LA by 16% and demonstrating a 10.6% improvement over SBM. Precision, a critical measure of relevance, stands at 96.32%, showcasing a significant advancement over GCR-GAN (61.7%) and CR-HBNE (45.9%). Additionally, sensitivity analysis reveals that the LS-SLM technique achieves the highest sensitivity value of 96.5487%, outperforming LA by 14.2%. The LS-SLM also demonstrates superior specificity and recall, with values of 96.5478% and 96.5487%, respectively. The modularity performance is exceptional, with LS-SLM obtaining 95.6119%, significantly outpacing SLM, FGA, SBM, and LA. Furthermore, the LS-SLM technique excels in community detection time, completing the process in 38,652 ms, showcasing efficiency gains over existing techniques. The BTC analysis indicates that LS-SLM achieves a value of 94.6650%, demonstrating its proficiency in controlling information flow within the network.
Keywords
Introduction
There is a formation of a fresh generation of services, namely wikis, blogs, Google+, Facebook, YouTube, Wikipedia, Twitter, Amazon, along with Flickr due to the development in technology. These services are provided with numerous information, which causes information overload problems owing to various formats and thereby limits their usage [1]. Also, the Archival materials are also digitized and made available online to people for free or by paying a fee. Despite conveying a significant improvement, such circumstances also create the information overload problem specifically in the academic world, which allows people to easily access more knowledge [2]. Thus, to address this problem, an RS is developed by removing the relevant data together with providing items that are nearer to the user’s interest [3]. For several sorts of items like newspapers, research papers, and emails, various RS has been designed and implemented; also, they are wielded in several fields, namely economics, education, and scientific research [4]. For dealing with the information overload issue of the modern era, the information retrieval community is regarded as an alternative technique to retrieve information grounded on a community of users RS [5].
Usually, a few mostly deployed digital libraries by researchers are Google Scholar, IEEE Digital Library, along with Science Direct [6]. Accessing details as of digital sources is also augmenting gradually with the increased number of digital libraries and their support of universities to deploy digital resources. However, the development in science has made researchers struggle to detect the articles they search for from a vast number of articles [7].
The different types of recommendation techniques utilized are categorized into ‘4’ key divisions: (A) Content-Based Filtering (CBF), (B) Collaborative Filtering (CF), (C) Graph-Based method (GB), along with (D) Hybrid recommended method. The other techniques of RS are the latent factor together with the topic regression matrix factorization system [8]. Nevertheless, owing to the nature of the data being used, it undergoes more weaknesses including (A) cold start, (B) sparsity of data, and (C) overspecialized recommendation. Thus, community detection-centric RS is deployed. Currently, in the academic field, paper RS have become an indispensable tool [9]. In the scientific community, recommending similar scientific articles for researchers is termed a scientific paper recommendation. Concerning the latent interests in the researchers’ publication profiles, the community detection-based RS provides relevant information to the researchers; also, it aids them to get a better idea in a particular research area. Further, the recommendation algorithms are updated constantly, thus, the accuracy is also enhanced over time [10]. However, the major disadvantage is recommending the same articles to all researchers. Thus, an efficient article RS based on community detection with topic modelling using LS-SLM and PCC-LDA is proposed.
Contributions of the Proposed Algorithm:
Addressing the crucial aspect of relevance in scientific article recommendations by leveraging domain-specificity. Achieved through the strategic partitioning of the citation graph into communities, ensuring that selected articles align with user interests.
Tackling scalability challenges prevalent in existing algorithms for community detection. The proposed Linear Scale-Local Smart Moving (LS-SLM) algorithm focuses on enhancing scalability by optimizing computational time while maintaining a high degree of accuracy, modularity, Normalized Mutual Information (NMI), and betweenness centrality.
Introducing advanced preprocessing strategies to mitigate network size and complexity issues without compromising essential information. Techniques such as graph coarsening and node sampling are employed to streamline the citation graph, paving the way for more efficient community detection.
Demonstrating the superior performance of the proposed algorithm compared to existing counterparts. Notable improvements are observed in terms of relevance, as the algorithm excels in providing communities that yield meaningful and pertinent topics, influencing the quality of recommended articles.
Integrating the PCC-LDA (Pearson Co-Correlation Coefficient) algorithm for effective topic modelling. PCC-LDA contributes by offering an explicit measure of association between terms and topics, particularly through Pearson’s Correlation Coefficient. This strategic choice enhances the algorithm’s capability to identify and rank strongly associated terms under each topic.
Prioritizing computational time as a key contribution. The proposed algorithm significantly improves computational efficiency, addressing a critical concern in scientific article recommendation systems. This efficiency gain is essential for user satisfaction and system responsiveness.
Offering a holistic enhancement approach before the actual recommendation of scientific articles. The algorithm achieves a balance between computational efficiency and result quality, ensuring that the recommended articles are not only timely but also strongly associated with relevant topics.
Unveiling a noteworthy contribution in the identification of strongly associated terms under each topic. This outcome is critical for enhancing the depth and specificity of the recommendations, contributing to a more refined and personalized user experience.
Problem definition
In the quest to improve article recommendation systems, the paper identifies the need for advanced methodologies that effectively leverage community detection and topic modelling. Although the existing research methodologies provide various advantages in the field of article RS, existing solutions lack the desired accuracy and efficiency, prompting the formulation of the LS-SLM technique. There exist certain drawbacks, which are enlisted as follows, In the RS field, the most successful technique is CF. Grounded on the neighbor’s preferences, suggestions were created by CF. However, it suffers from poor accuracy, scalability, along with cold start problems. CF suffers as of ‘sparsity’ and ‘new user’ problems. The item’s feature representation is hand-engineered to a few extents in CBF; this methodology necessitates a huge domain knowledge. CBF recommendation system doesn’t consider what others think of the item, thus, lower-quality item recommendations may occur. Existing Unigram, and Bigram-centric citations are only based on the count of words. It does not concentrate on the articles’ content similarity.
To alleviate the aforementioned issues, this paper proposes an efficient LS-SLM and PCC-LDA-based article RS.
The remaining part is arranged as: relevant related works are elucidated in Section 2; the details and fundamental concepts of the proposed methodology are delineated in Section 3; the efficiency of the proposed work compared to some of the existing methods are given in Section 4; the paper is wrapped up with the future work in Section 5.
Literature survey
Jelodar et al., 2021 presented a semantic mining system grounded on topic modelling for constructing a recommendation system to extract scholars-interested research fields as of conference publications. The natural language processing-based Latent Dirichlet Allocation (NLP-based LDA)’s outcomes were more distinctive for elucidating the topics when analogized to describing the single words for a semantic description of a set of papers. For professional recommendation systems, deploying the fusion of machine learning along with topic modelling approaches might be effectual. Nevertheless, the system did not use it [11].
Chaudhuri et al., 2021 explored a hidden feature identification scheme to design an effectual research article recommendation system. For depicting a research article, ‘4’ indirect features like (A) keyword diversification, (B) text complexity, (C) citation analysis over time, along with (D) scientific quality measurement were conducted. As per the outcomes, a research article was defined by the technique’s indirect features when contrasted with the direct features. But, it was performed by a few hidden features only [12].
Dai et al., 2020 recommended a neural network system for context-aware citation recommendation by fusing Stacked De-noising Auto Encoders (SDAE) and Bi-directional Long Short-Term Memory (Bi-LSTM). By employing the attentive information from the citation context, SDAE was extended into Attentive SDAE (ASDAE) for acquiring an effectual embedding for cited papers, which enhanced the actual SDAE’s learning ability. Citations were suggested; also, suitable citation contexts were extracted for the long term. However, just a few effectual link functions were wielded [13].
Wang et al., 2019 introduced an automatic title generation methodology, which fuses personalized recommendations along with topic trend analysis techniques. For detecting the users’ interests in a topic structure together with its representative keywords in the prevailing study, hierarchical latent tree analysis was deployed. As per the experimental outcomes, the topic recommendations’ performance was augmented by adding Google Trend indicators along with personal factors. The research scope was narrowed within the journal papers; thus, every word and phrase was wielded prevailingly. Yet, attaining the maximal degree of novelty and innovation was not possible [14].
Habib & Afzal, 2019, explored a system for a paper recommendation, which extended the prevailing bibliographic coupling by integrating in-text citation analysis and their availability in the research paper’s logical sections. As per the experimental outcomes, this system had a considerable augmentation over the prevailing bibliographic coupling and content-centric research paper suggestion. But, the weights were not allocated automatically [15].
Z. Ali et al., 2022, presented a heterogeneous network embedding system, which jointly learns node representations by exploiting semantics equivalent to the (A) author, (B) time, (C) context, (D) field of study, (E) citations, along with (F) topics. This system depicted enhancements over the DBLP datasets of 10% for Mean Average Precision (MAP) along with 12% for normalized discounted cumulative gain metrics. Nevertheless, this system performed with just a few factors along with contextual information by presenting attention mechanisms [16].
Liu et al., 2020, developed a keyword-driven and popularity-aware paper recommendation grounded on an undirected paper citation graph called PRkeyword +pop. An undirected paper citation graph was constructed; also, the users’ keyword query was considered as the Steiner tree problem. In searching for a set of satisfactory papers, this system’s advantages were proved when analogized to the other competitive techniques. When contrasted with the prevailing techniques, this methodology acquired desirable outcomes. However, the system faced the sparsity issue of the prevailing paper citation graph [17].
Nassar et al., 2020 recommended a multi-criteria CF grounded on 15 deep learning. ‘2’ parts were available in this system: the user’s and items’ features were acquired; also, it was inputted into the criteria ratings of a deep neural network that detected the criteria ratings. This system was general, easy to implement, as well as model-independent. A few deep learning techniques were deployed; also, they didn’t employ more complex deep networks or else other representation techniques [18].
Sharma et al., 2022 explored a hybrid system-centric book recommendation system, which anticipates recommendations. This system was a fusion of CF and CBF that was elucidated in the ‘3’ phases. In building successful e-commerce businesses, developers and other stakeholders were aided by this system. It was performed on offline data sets. However, this system performed just in offline data sets, where it didn’t permit monitoring the real user acceptance level for the given recommendations [19].
S. Ali et al., 2022 introduced an architecture, which designs semantic recommendations with the assistance of virtual agents grounded on user requirements along with preferences; thus, helping in seeking suitable courses in a real-world setting. The E-learning Recommendation Architecture (ELRA) augmented the skills and accomplishments, and learning success (by more than 90%). But, in an online learning environment, this system had low course quality [20].
Pradhan & Pal, 2020b developed Content and Network-centric Academic VEnue Recommender system (CNAVER). By deploying rank-centric mixture of the Paper-Paper Peer Network (PPPN) along with the Venue-Venue Peer Network (VVPN) systems, an incorporated network was offered. When analogized to other best-in-class methodologies, this system exhibited higher scores of precision, accuracy, Mean Reciprocal Rank (MRR), and diversity. When weighed against cutting-edge methodologies, top-notch venues were displayed by CNAVER as far as the H5-index. Only a few machine learning methodologies were deployed that enforced the random walker not to go too far as of interest primary venue [21].
Pradhan et al., 2020 recommended a unified architecture, which included Bi-LSTM and Hierarchical Attention Network (HAN). This system, which only necessitates the abstract, title, keywords, field of study, along with author of a fresh paper for recommending scholarly venues, is also called the modularized Hierarchical Attention-centric Scholarly Venue Recommender system (HASVRec). For making venues’ precise predictions, modularized structure information and attention were useful. Just a few meta-path features were deployed; also, for combining the embedding of multiple paths, a few deep-learning techniques were deployed [22].
Jain et al., 2018 explored a Journal Recommendation System (JRS) that resolved the publication issue for several authors. Here, CBF was deployed. As per the outcomes, the system assisted the authors in detecting suitable journals; also, fasten their submission process; then, augment user experience. For the dimensionality reduction, LDA was wielded; also, semantic analysis was done. However, to construct a recommendation system, only a few basic similarity measuring methodologies were deployed [23].
Pradhan & Pal, 2020a developed a Diversified yet Integrated Social network analysis and Contextual similarity-centric scholarly Venue Recommender (DISCOVER). (A) Centrality measure calculation, (B) citation and co-citation analysis, (C) topic modeling-centric contextual similarity, and (D) key-route identification cantered key path analysis of a bibliographic citation network were included in the suggested system. When analogized to the prevailing methodologies, higher-quality venues were recommended by DISCOVER. Here, a few disciplines were only deployed; also, it is performed with the specified dataset [24].
Yu et al., 2018 recommended a Personalized Academic Venue Recommendation Exploiting (PAVE) co-publication networks. With a restart system on a co-publication network, this system ran a random walk that encompasses ‘2’ sorts of associations, namely coauthor, and author-venue relations. In suggesting academic venues for researchers with rarer publications, that is junior researchers, this system performed better. In co-publication networks, just ‘3’ academic factors were exploited. The features like citation relations could be encompassed [25].
Z. Ali et al., 2021 elucidated a network embedding system called Global Citation Recommendation by deploying a Generative Adversarial Network (GCR-GAN). For generating personalized citation recommendations, the Heterogeneous Bibliographic Network (HBN) was exploited. By attaining 11% Mean Average Precision (MAP) along with 12% normalized Discounted Cumulative Gain (nDCG) metrics enhancements, it surpasses the prevailing methodologies. For relevant labels, this system didn’t perform well [26].
[30] Abdelrazek et al. (2023): Abdelrazek et al.’s comprehensive survey on topic modeling algorithms and applications provides valuable insights into various techniques and their effectiveness in different contexts. This survey particularly enriches our understanding of topic modeling approaches, aiding in the refinement of our PCC-LDA method. Their review of diverse topic modeling algorithms has enabled us to draw parallels and highlight the strengths of our approach in handling the intricacies of article recommendation systems.
[31] Jiang et al. (2022): In their study, Jiang et al. explore user interest community detection on social media using collaborative filtering. This work is particularly relevant to our LS-SLM method as it shares the underlying principle of detecting communities based on user interests, albeit in a different application domain. The collaborative filtering approach they discuss provides us with additional perspectives on community detection, allowing us to further validate the effectiveness of our method in identifying and recommending relevant academic articles.
[32] Vanchinathan et al. (2022): Although Vanchinathan et al.’s work on numerical simulation and experimental verification of a fractional-order controller using a whale optimization algorithm is in a different technical domain, their methodological rigor and the use of optimization algorithms offer valuable insights. Their application of advanced optimization techniques in engineering systems has parallels in our use of the LS-SLM method for optimizing community detection in large datasets. This connection enriches our discussion on the methodological advancements we bring to the field of recommender systems.
Critical analysis of literature review
The references cover a wide range of recommendation techniques, including collaborative filtering, content-based filtering, hybrid methods, and novel algorithms like Fuzzy Routing-Forwarding (FCNS) and Fuzzy Reasoning Routing-Forwarding (FRRF). Hybrid models, such as those presented in [1, 6], and [24], leverage multiple recommendation strategies for improved accuracy. Some references, like [2, 24], and [27], delve into context-aware personalized recommendation systems, acknowledging the importance of considering user context and preferences. References [4, 26], and [25] explore community-based and network embedding approaches, recognizing the influence of social networks and community structures in article recommendations. The papers [13] and [9] introduce advanced technologies like stacked denoising autoencoders and knowledge-guided article embedding refinement, showcasing the integration of cutting-edge technologies in recommendation systems. Some references, like [3, 11], and [21], propose domain-specific solutions, tailoring recommendation algorithms for specific fields such as research articles, academic venues, and e-learning. Several papers, including [6, 22], and [26], present comprehensive evaluations using various metrics such as accuracy, precision, and F-score, emphasizing the importance of thorough validation. Some references, like [15] and [5], acknowledge challenges in citation recommendation and propose novel methods to overcome these challenges.
Proposed article recommender system
Usually, researchers have to read certain scientific articles that are associated with their interests more intensively for the generation of a novel study idea and to write a good article. Nevertheless, analysing the various number of articles and selecting the one among them is complicated and time-consuming work. Thus, this paper proposes an efficient article RS, and the structure are displayed in Fig. 1.

Block diagram of the proposed methodology.
Initially, the input sources are collected from the DBLPv12 dataset. Generally, the DBLPv12 dataset is provided with numerous files in JSON format (J s ). Details regarding the Id, title, authors, venue, year, keywords, references, Date of Issue (DoI), Abstract, volume, issue, and n_citation are encompassed in the DBLPv12 dataset. Since the processing of JSON files consumes more time, it is converted into CSV format (ς s ) for further processing.
Attribute extraction
Then, the essential attributes are extracted to aid in a better recommendation process. The process of extracting significant information as of a huge amount of available data from the document is termed attribute extraction. The id, title, references, year, and Abstract are some of the handcrafted attributes extracted from the CSV file.
Construction of citation graph
Here, the extracted attributes are graphically represented. Certain attributes such as ID, title, reference, and year are represented graphically into nodes and edges. Let g (n, e) represents the graph with n nodes and e edges.
Abstract filtering
Now, standard abstracts (
Where, α a implies the abstract filtering process, and c signifies the word extracted from the filtered abstract.
Here, the obtained standard abstracts are pre-processed. The process of the effective transformation of the raw data into an understandable format for further analysis is termed pre-processing. Steps like (A) Tokenization, (B) Stop word removal, (C) Stemming, along with (D) Lemmatization are performed. Such pre-processing steps are discussed for the pre-processing of the filtered abstract.
a. Tokenization
Effective processing of complex data is quite difficult since the filtered abstract is in the form of a paragraph. Thus, Tokenization is utilized. Breaking a stream of text into words, phrases, symbols, or else other meaningful elements termed tokens are involved in tokenization. Hence, for further processing purposes, the list of tokens becomes the input, which is depicted as (
b. Stop word Removal
Then, stop word removal takes place. Stop word removal is carried out to remove the most frequently occurring meaningless words. And, are, this, etc. are some of the most commonly occurring stop words in the context or textual documents. The presence of such stop words acts as an obstacle to the effective article recommendation system and affects the proposed technique’s performance. Thus, the output obtained after the stop word removal process is explicated as (
c. Stemming and Lemmatization
Next, to remove numerous suffixes and condense them under the same root word, the stemming process is carried out. For instance, the words like “continue”, “continuously” and “continued” to one word “continue”. Hence, the document size is minimized by the stemming process; thus, improving the computation efficiency. Hence, the output obtained after stemming and the Lemmatization process is denoted as (
Feature extraction with TF-IDF
Then, features are extracted from the pre-processed output. The process of extracting crucial features as of the pre-processed data is termed feature extraction. Here, by employing TF-IDF technique, feature extraction is carried out. By evaluating the importance of a word to the whole corpus, TF-IDF extracts the crucial features from the document. The TF-IDF operation is detailed below. The probability of occurrence of a term in the document is defined in Term Frequency (TF) in the TF-IDF algorithm. Here, the bias in the lengthy document is usually reduced by normalizing the term in the range [0, 1]. TF(t) = (Number of times term t appears in a document) / (Total number of terms in the document). Moreover, by using Inverse Document Frequency (IDF), the specificity of a particular term or a word in the document is computed. The most frequently occurring words are not considered for analysis in IDF because those words that occur more frequently act as stop words. Thus, uncommon words are only considered. The IDF (ℑ (ρ, φ)) process is explained as [14],
Here, φ implies the document corpus, and |φ| signifies the total number of documents. Thus, the set of features (X I ) extracted is X I = X1, X2, …… , X N . Here, N detects the number of features extracted.
Word2Vector is the next step. The features extracted are fed as input to the Word2Vector process and produce a corresponding vector representation for each unique word. It is the process of transforming words into vectors by considering the syntax and semantic features of words and is mainly used as an effective prediction model for learning word embedding. For effective Word2Vector representation, BoW is the most commonly used approach. The BoW is nothing but the representation of textual information (histogram representation) retrieved from the visual scenes. The working procedure of BoW is described below, Vocabulary generation: It is the primary step in BoW methodology. Here, the extracted features are quantized or clustered in the form of a visual term. These terms are nothing but the codes in the codebook. Defining terms: Here, by employing the Nearest Neighbour (NN) technique, features or vectors are assigned to the terms generated in the previous step. Generating term vector: Finally, by utilizing the appearance (number) of times each term appears in the image, the term vector is represented in the form of a histogram. Thus, the output obtained using the BoW method, which is defined as H (F
e
).
Similarity score via LSE
Thus, for the vector representation obtained, the similarity score is determined. The Levenshtein Similarity Evaluation (LSE) approach is used in the proposed work for the similarity score measurement. By performing certain operations like Insertion, Deletion, and Substitution, LSE measures the similarity between the two strings in different abstracts. Thus, LSE is otherwise called edit distance. The process involved in LSE-based similarity score measurement is detailed further down,
Step: 1 Let M and N be the two strings of length u and v. Initially, the edit distance between the two strings is calculated through the creation of a matrix ℓ [u, v] using the forthcoming Equation (3) [29].
Here, min implies the minimum distance computed using the formula given below [29]
Where, F (u, v) implies the similarity parameter, which is obtained as follows [29],
Where, M(u) is the u th word of M, and N(ν) refers to the v th word of N.
Step 2: Then, the similarity between the two strings M and N is evaluated and is expressed as follows [29],
Here, (S (M, N)) implies the similarity between two strings. As the Levenshtein distance (ℓ d ) increases, the similarity becomes smaller. Thus, the similarity score measured using LSE is modelled as χ s .
For effective detection of community, the graph constructed (g (n, e)) and the similarity score evaluated (χ
s
) is fed into LS-SLM. The most widely used technique for the effective detection of optimal communities based on the merging of community and movement of individual nodes is termed the Smart Local Moving (SLM) algorithm. Moreover, the adapted local moving heuristic technique increased the modularity through the community splitting process. But, the SLM fails to detect the hidden relations among the nodes in the network. Thus, in the conventional SLM, the Linear Scaling (LS) technique is employed. This alteration in traditional SLM is termed LS-SLM and the process is described below. Primarily, an improved community structure is obtained by moving every node to its neighbouring community through the execution of the modularity function (ℵ), which is expressed in (7).
Here, pq implies the vertices, E
pq
signifies the number of edges lying between p and q, W
pq
denotes the number of expected edges, β (·) depicts the hidden relations among the nodes in the network, and ς
p
, ς
q
elucidates the community with vertex p and q. Hence, the node will be moved back to its previous community or maintained in its own community depending on the quality of the modularity function obtained. Next, the local moving heuristic step is applied to the community structure. Here, each node in the subnetwork is assigned to its own singleton community. The network is reduced by detecting the nodes (communities) in the subnetwork after the community structure construction process. Thus, the detected communities are placed in the corresponding subnetworks. The reduced network thus obtained is applied as input to the recursive call and the process continues until a final network structure that cannot be reduced further is obtained. Hence, the optimal community detected is denoted as ζ(d). Finally, all the detected communities can be visualized and topic modelled using PCC-LDA. The pseudocode for the proposed PCC-LDA is displayed further,
Also, by employing PCC-LDA, the topics are recognized or extracted from the detected communities. One among the famous topic modelling methodologies, which represents each document as a random mixture over a set of latent topics, is termed Latent Dirichlet Allocation (LDA); also, each topic is depicted as a distribution over a vocabulary. Topics are modelled through word probabilities in LDA. The words with greater probabilities provide a better idea about the particular topic. Moreover, each topic is represented in the form of a probabilistic distribution function of words in LDA. It functions by looking at the word co-occurrences within documents, which might affect the modeling accuracy. Thus, to alleviate the above-mentioned issues, by employing Pearson Correlation Coefficient (PCC), the correlation between the words in the topic is determined, and the steps in PCC-LDA are described below. Primarily, a multinomial distribution η(τ) is selected with parameters φ from the Dirichlet distribution for the topic τ (τ ∈ { 1, 2, 3, . . . , t }). Then, select a multinomial distribution η(δ) for the document δ (δ ∈ { 1, 2, 3, . . . , T }) with a parameter φ. Next, the multinomial distribution η(ω
a
) for selecting a word is ω
a
(a ∈ { 1, 2, 3, . . . , A
δ
}). From the first document, select the topic x
a
from η(δ) and then select a word ω
a
from η
x
a
. Thus, the probability of the corpus is modelled in the upcoming formula [11],
Where, s, t implies the corpus-level parameters, v signifies the variables in the document, and the term inside the bracket signifies the correlation determined using PCC. Hence, the topics are efficiently modelled and the pseudocode for PCC-LDA is elucidated below.
Standard pseudo code for LS-SLM
Here, the proposed technique’s performance analysis is done. In the working platform of PYTHON, the proposed methodology is employed. In Figs. 2 and 3, the simulation graph for the whole community detection analysis for the proposed methodology is shown.

Citation or direct graph.
Simulation output of the community detection for various methods (a) SLM (b) SBM (c) FGA (d) LA and (e) the proposed method.
The output of the citation graph or direct graph for the proposed article recommender system is depicted in Fig. 2. A directed graph, which describes the citations within a collection of documents, is termed a citation graph. By employing id, title, reference, and year, the citation graph was constructed. From all abstracts, the standard abstracts are filtered by the number of characters less than 1500 and greater than 900.
In Fig. 3 (e), the community detection output for the proposed LS-SLM method is shown. The input for the community detection is the presented citation or direct graph and similarity score. For revealing the hidden relations among the nodes in the network, community detection was done by using the LS-SLM technique.
“dblp. v12.json”, which is a citation network dataset, is deployed. From (A) DataBase systems and Logic Programming (DBLP), (B) Association for Computing Machinery (ACM), (C) Microsoft Academic Graph (MAG), along with (D) other sources, the citation data is extracted. 629,814 papers along with 632,752 citations are encompassed in the 1st version. Every paper is related to (A) abstract, (B) authors, (C) year, (D) venue, and (E) title. This data set can be used for clustering of network side information, and studying the influence of citation networks. It is also utilized for detecting the utmost influential papers and analysing the topic modeling, etcetera.
Performance analysis
Concerning a few performance metrics, the proposed LS-SLM technique’s performance is analogized to the available Louvain Algorithm (LA), Stochastic Block Model (SBM), Fast Greedy Algorithm (FGA), and Smart Local Moving (SLM).
The proposed LS-SLM’s performance analysis cantered on accuracy and precision metrics are depicted in Fig. 4. For accuracy, the LS-SLM obtained 96.083%, which is 3.26% higher than the existing SLM and 16% higher than the existing LA. The existing LA shows a low accuracy value and the proposed LS-SLM technique shows the highest accuracy value. For precision, the LS-SLM attained 6.3265%, which is 8.6% higher than the existing FGA. Thus, for accuracy and precision, the LS-SLM attains superior results.
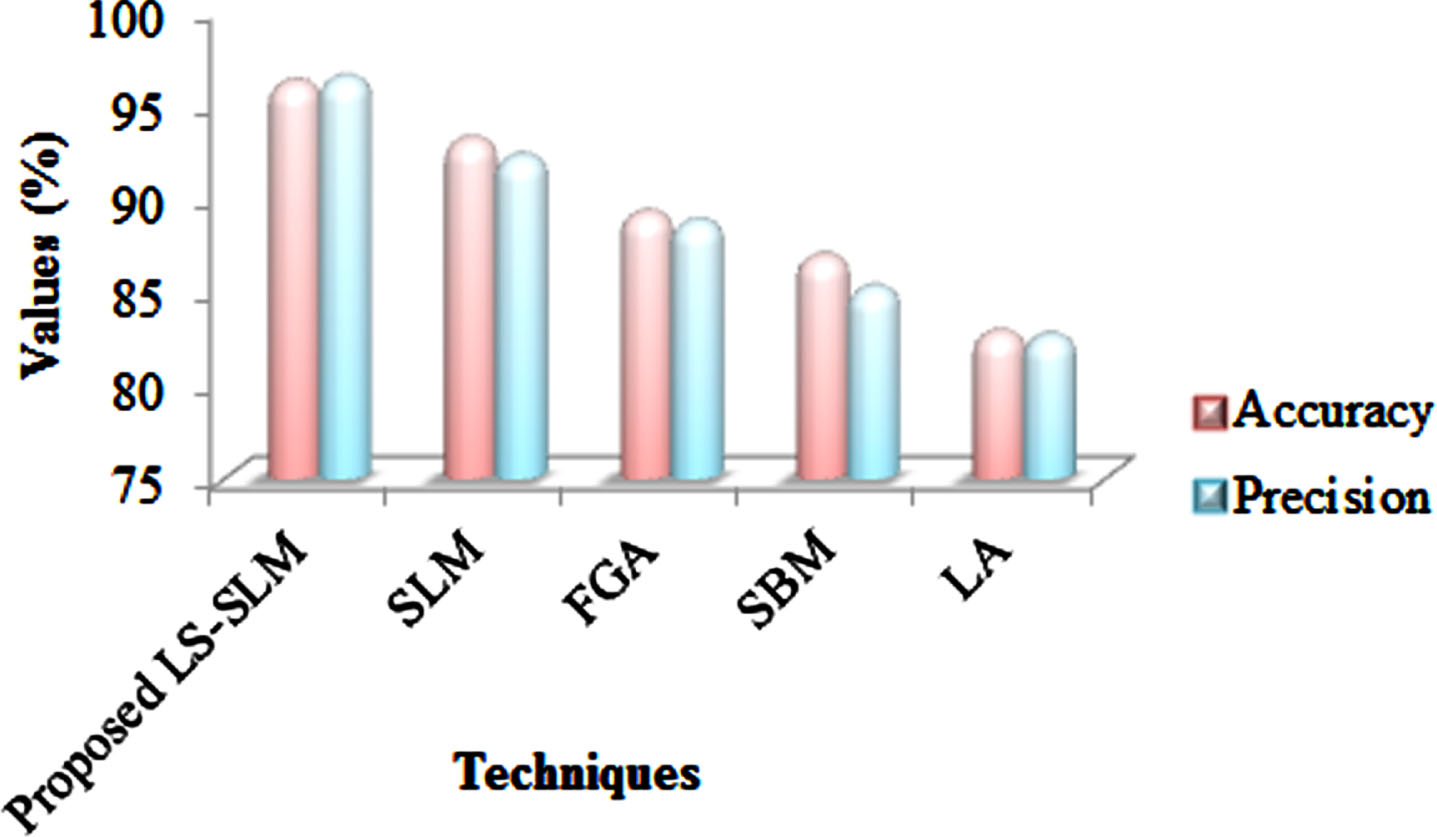
Performance analysis based on accuracy and precision.
In Table 1, the proposed LS-SLM technique’s modularity performance is shown. For modularity, the LS-SLM acquires 95.6119%; while the prevailing SLM, FGA, SBM, and LA attain values of 92.7733%, 87.2515%, 85.9740%, and 81.5393%, respectively. Thus, when compared to the other existing methods, the LS-SLM technique attains better modularity value.
Modularity (MOD) analysis for the proposed technique with the existing techniques
In Fig. 5, the proposed LS-SLM’s sensitivity analysis is shown. The proposed LS-SLM technique obtains the highest sensitivity value of 96.5487% and the existing LA technique obtains the lowest sensitivity value of 82.3256%. Thus, the proposed LS-SLM technique achieves a good sensitivity value.

Sensitivity analysis for the proposed LS-SLM technique with the existing techniques.
In Fig. 6, the graphical representation of the proposed LS-SLM technique based on specificity and recall is shown. For specificity, the LS-SLM acquired 96.5478%, which are 7.6% higher than the existing FGA technique and 16% higher than the existing LA technique. For recall, the LS-SLM attained 96.5487%, which is 13% superior to the existing SBM technique. Hence, the proposed LS-SLM technique attains a better result for both the specificity and recall metrics.
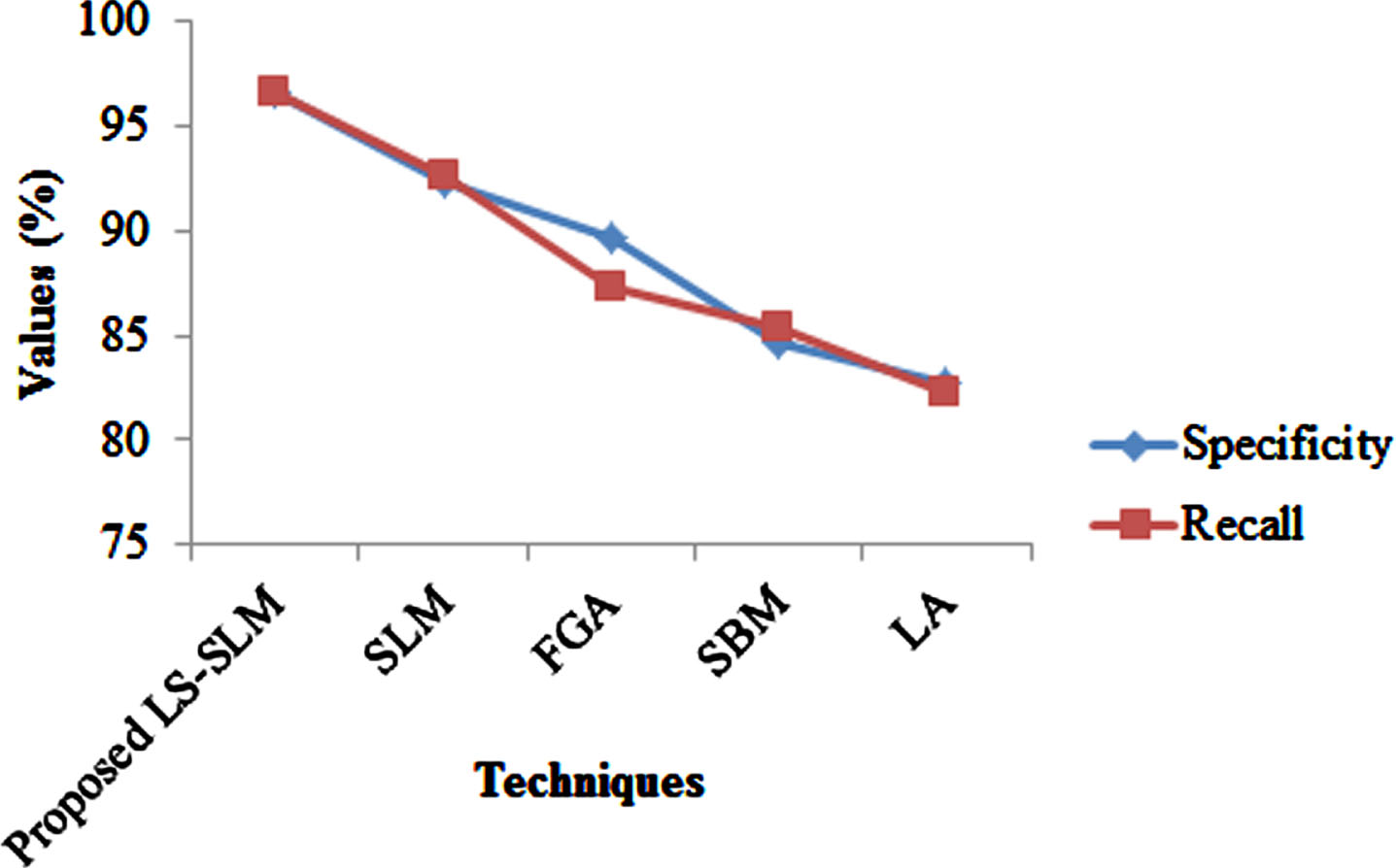
Demonstration of the proposed technique with the existing techniques based on specificity and recall.
The normalized mutual information analysis for the proposed LS-SLM technique is depicted in Table 2. The normalized mutual information value for the proposed LS-SLM is 96.6365% and the value for the existing technique SLM is 93.5668%, which is 6% higher than the existing FGA technique, but it is 3% lower than the proposed LS-SLM technique. Thus, when analogized to the prevailing methodologies, the LS-SLM achieves superior results.
Analysis of the proposed technique with existing techniques based on Normalized Mutual Information (NMI)
In Fig. 7, the performance analysis for the proposed LS-SLM technique based on F-Score is displayed. For f-score, the LS-SLM acquired 95.4512%; while, the prevailing SLM, FGA, SBM, and LA attained 91.3769%, 88.4143%, 84.5976%, and 83.2021%, respectively. Thus, the LS-SLM achieves better results for the f-score performance metrics.

Performance analysis based on F-Score.
The graphical representation of community detection time analysis for the proposed LS-SLM technique is depicted in Fig. 8. For community detection, the LS-SLM attained 38652 ms, which is 14895 ms lower than the existing SBM, 19995 ms lower than the existing LA technique, 8562 ms lower than the existing FGA, and 3504 ms lower than the existing SLM technique. Thus, the proposed technique achieves lower community detection time.
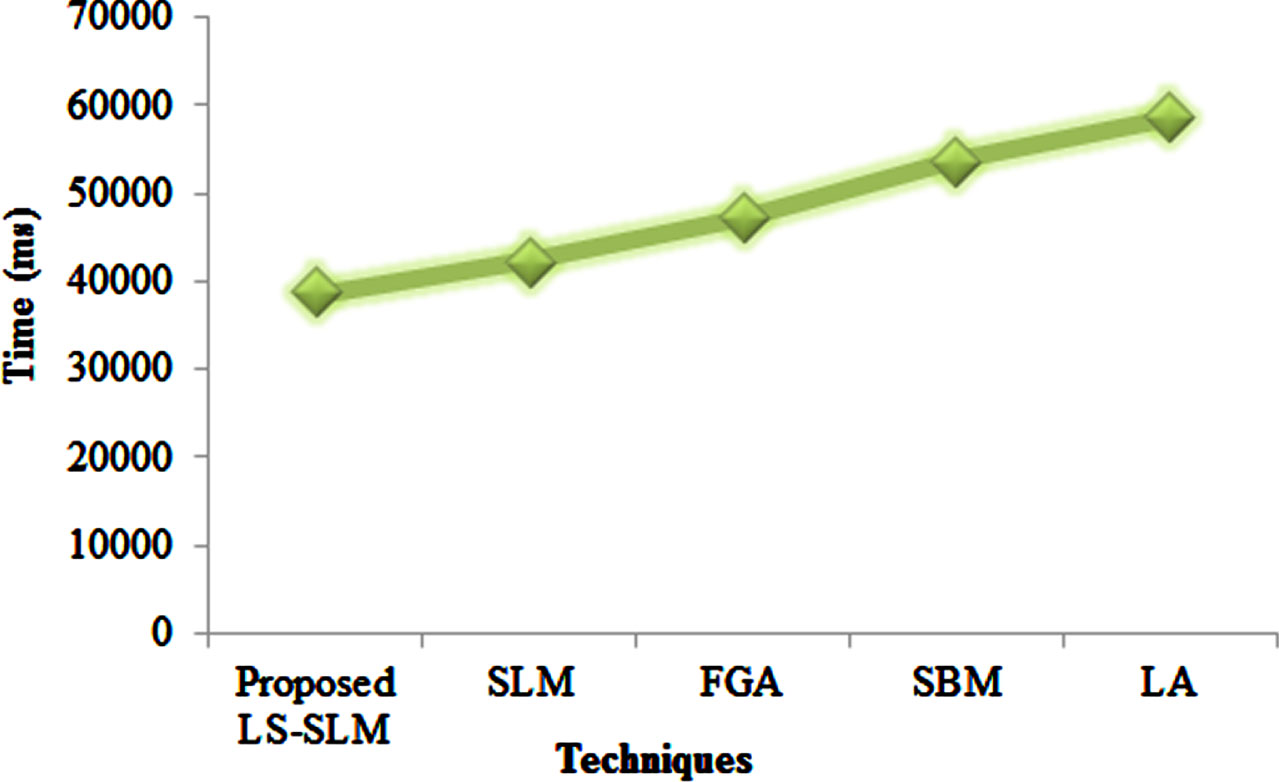
Graphical representation of the proposed LS-SLM technique with existing techniques based on community detection time.
In Table 3, the BTC analysis for the proposed LS-SLM technique is shown. Regarding BTC, the proposed LS-SLM obtains a value of 94.6650%, which are 5.74% higher than the existing FGA technique and 15.1% higher than the existing LA technique. Thus, the LS-SLM attains a good BTC value.
Betweenness Centrality (BTC) analysis
The communities detected along with the topics generated with corresponding article IDs are depicted in Fig. 9. Various topics like “context-dependent automatic textile image annotation employing networked knowledge” are generated with ID number 24270 under the image processing community. Likewise, various other topics are also covered under various communities. The detected communities are then ranked in which the high-ranked communities are preferred for topic modeling which in turn is utilized for future reference.

Performance measurement based on the communities detected.
The proposed LSSLM’s performance is weighed against the prevailing Global Citation Recommendation employing Generative Adversarial Network (GCR-GAN) [26], and Citation Recommendation wielding Heterogeneous Bibliographic Network Embedding (CR-HBNE) [16] are done, which is taken from the literature papers.
In Table 4, the proposed LS-SLM technique is compared with the existing techniques with respect to literature papers based on precision. For precision, the LS-SLM acquires 96.32%, which is 56.11% higher than the existing GAN-HBN. Thus, the LS-SLM achieves a better result for precision.
A comparative analysis of the proposed LS-SLM technique based on precision
A comparative analysis of the proposed LS-SLM technique based on precision
LS-SLM incorporates linear scale optimization, ensuring computational efficiency in large-scale citation networks.
Introduces LSM for uncovering hidden relationships, enhancing accuracy and precision in community detection.
Prioritizes modularity for robust community structures in scientific citation networks.
LS-SLM tailors its approach to the unique characteristics of scientific citation graphs, addressing the limitations of generic similarity computation methods.
Linear scale optimization in LS-SLM adapts to the challenges posed by large-scale citation networks.
LSM in LS-SLM captures local dynamics, addressing the limitation of generic similarity measures in uncovering hidden relationships.
The LS-SLM algorithm’s innovations make it a powerful tool for community detection, addressing limitations observed in existing strategies applied to opportunistic social networks and mobile edge computing-based networks, as evidenced by the advancements introduced in FRRF and FCNS.
This enhanced analysis is crucial for demonstrating the effectiveness and superiority of LS-SLM in the realm of community detection and topic modelling.
This comprehensive and enhanced comparative analysis underscores the LS-SLM technique’s potential and efficiency. It not only affirms the effectiveness of our proposed method but also contributes significantly to advancing the field of community detection and topic modelling, providing a reliable benchmark for future research.
This paper proposes an efficient article RS based on community detection with topic modelling using LS-SLM and PCC-LDA. Hence, the performance is evaluated for the proposed method. Regarding accuracy, precision, specificity, recall, F-Score, Community Detection time, Modularity, Normalized Mutual Information, and Betweenness Centrality, the performance of the proposed LS-SLM technique is analysed with the prevailing SLM, FGA, SBM, and LA. The paper focuses on the challenge of recommending scientific articles to users based on the relevance of articles within domain-specific communities. The proposed algorithm aims to improve upon existing methods by addressing scalability issues and providing better results in terms of modularity, accuracy, NMI, and betweenness centrality.