
Abstract
Convolutional neural networks (CNNs) have received significant attention for change detection (CD) on multimodal remote sensing images, but they struggle to capture global cues due to the locality of convolution operations. In contrast, the transformer can learn global semantic information by dividing the input image into patches, adding position encodings, and utilizing the self-attention mechanism. Motivated by this, we propose mSwinUNet, a novel end-to-end multi-modal model with swin-transformer-based and U-shaped siamese network architectures for supervised CD using Sentinel-1 Synthetic Aperture Radar (SAR) and Sentinel-2 Multispectral Imager (MSI) data. mSwinUNet contains multi-modal encoder with difference module, bottleneck, and fused decoder, and all of them are based on swin transformer. Firstly, tokenized multi-modal bitemporal image patches are fed into multiple Siamese encoder branches to extract multi-level multi-modal difference feature maps in parallel. Subsequently, the last level multi-modal difference maps are fused to generate the smallest scale change map in the bottleneck. Then, the hierarchical decoder incorporates patch expansion and fusion operations to fuse multi-scale difference and change maps, effectively recuperating the details of the change information. Finally, the last patch expansion and a linear projection are applied to output the final change map, which preserves the identical spatial resolution as the input image. Extensive experiments have shown that mSwinUNet outperforms several the state-of-the-art multi-modal CD methods on OSCD dataset and the corresponding Sentinel-1 SAR data.
Introduction
Change detection (CD) is universally recognized as a critical research topic in the field of intelligent interpretation of remote sensing images [15, 21]. It aims to identify the changed areas between bi-temporal remotely sensed images in earth observation. Such changed areas are important cues for various remote sensing applications, such as land use investigation [6], ecological environment monitoring [13], resource management [20], and nature disaster assessment [2], etc. However, changed area extraction from bi-temporal images still mainly relies on manual digitization by GIS technology [24]. Accordingly, how to automatically and accurately identify the changed areas has attracted increasing attention [17, 31].
Nowadays, deep learning from computer vision has become increasingly applied in remote sensing image analysis. The supervised CD can be formulated as a problem of image classification or segmentation. Thus, deep convolutional neural networks (ConvNet) have also adopted for CD task. For optical image CD, Zhan et al. [28] have proposed a deep siamese convolutional network and got good performance. Unfortunately, the network generates a large number of parameters and it is also difficult to be trained end-to-end, because the size of the feature maps from each convolutional layer is the same as that of the input image and a k-nearest neighbor (k-NN) approach [25] was introduced. Daudt et al. [7] have presented fully convolutional siamese networks (FCNNs) to perform CD. This network which is constructed by encoder-decoder architecture can reduce the network parameters and can be trained end-to-end from scratch. Lots of follow-up work [5, 22] is devoted to stacking convolutional layers, dilated convolutions, and channel/spatial attention in the network architecture to capture global details. In order to further enhance the semantic feature representation extracted from remote sensing image, a advanced transformer [4] has been introduced into a ConvNet encoder. However, this encoder is not suitable for multispectral (including more than three bands) remote sensing images because its backbone was ResNet which is applied pre-trained weight obtained by training on large RGB-image-based dataset. Bandara et al. [1] have tried to bring pure Transformer into the CD domain and proposed a hierarchical transformer encoder with a lightweight MLP decoder, which can be trained on multispectral remote sensing image dataset. Furthermore, zhang et al. [29] have introduced the swin transformer block [19] as the basic unit and designed SwinSUNet with Siamese U-shaped structure, which can better extract change information. Since then, the family of transformer variants [14, 27] has been widely introduced for change detection tasks.
However, above-mentioned work do not consider the fusion of multi-modal remote sensing images collected from multiple sensors, thus missing the opportunity to utilize the variety of remote sensing images available to provide supplementary information. Ebel et al. [9] have proposed multi-modal siamese architecture that ingests both Optical and SAR data and processes the multi-modal information. Compared to the optical baseline, the improvement in CD accuracy is still very small. To further promote the fusion of SAR and Optical data at decision level with deep learning, Hafner et al. [11, 12] have proposed dual stream U-Net (DS_UNet) to process the SAR and Optical image pair in parallel and then fuse extracted change maps from both sensors at the final decision stage. It is regrettable that the above method still stacks convolutional layers in the network architecture. Nowadays, no research has been done on advanced transformers for multi-modal CD.
Motivated by multi-modal fusion [9, 12] and advanced transformer technology [3], we propose a novel end-to-end
mSwinUNet is composed of multi-modal encoder with difference module, bottleneck, and decoder used for multi-modal fusion. They are all built using the Swin Transformer block. The multi-modal encoder is specifically designed to process multi-modal bitemporal input images by utilizing multiple Siamese encoder branches. These branches split the input bitemporal images into non-overlapping image patches using both patch partition and linear embedding methods. The image patches are treated as tokens and fed into the hierarchical Swin transformer, which comprises patch merging and Swin transformer blocks for learning multiscale bitemporal features. Then, the difference maps between these bitemporal features are computed via difference module. The last level multi-modal difference maps are fused through concatenation and linear projection in the bottleneck. Nextly, the decoder performs up-sampling on the extracted change map using patch expanding. The upsampled features are fused with the multi-scale and multi-modal difference maps at each stage of the hierarchical Swin transformer. Finally, the decoder applies the last patch expanding and a linear projection to restore the change map to its original spatial resolution as the input images, and further performs CD prediction. We train and validate our proposed mSwinUNet on multi-modal satellite observations including Onera Satellite CD (OSCD) dataset and the corresponding Sentinel-1 SAR data, whereby multi-modal bitemporal remote sensing images is labeled with one actual binary change map. Extensive experiments demonstrate that our proposed mSwinUNet can further improve capability of extracting spatio-temporal change map and integrate the rich complementary information from disparate sensors, thereby obtaining the superior multi-modal CD performance than previous counterparts.
The main contributions are summarized as follows:
(1) we propose mSwinUNet, a novel end-to-end multi-modal siamese network that utilizes the U-shaped architecture and swin transformer. To our best knowledge, mSwinUNet is the first transformer network designed purely for supervised multi-modal CD. Therefore, it has both the ability to can leverage supplementary information from multi-modal remote sensing images and the capability to extract better their long-term global spatiotemporal features.
(2) Instead of concatenating both bitemporal features with different scale from the encoder branches, we utilized the absolute value of the element-wise subtraction process to generate the difference maps. The results of our experimentation indicate that this approach yields better results.
(3) The effectiveness and efficiency of the proposed mSwinUNet have been extensively validated through experiments conducted on real-world multi-modal satellite observations, including the OSCD dataset and corresponding Sentinel-1 SAR data. Our method outperforms several recent multi-modal CD methods in terms of accuracy and efficiency, as demonstrated by the experimental results.
The remainder of this paper is organized as follows. Section II describes in detail our proposed mSwinUNet architecture for multi-modal CD task. The dataset, evaluation metrics, baselines, experimental settings and performance comparison are reported in Section III. Finally, conclusion is drawn in Section IV.
Proposed mSwinUNet network architecture
Architecture overview
The overall network architecture of our proposed mSwinUNet is depicted in Fig. 1. From this figure, we can observe that mSwinUNet follows the similar structure as SiamUNet [9], utilizing the Siamese network architecture. It comprises of two encoder branches, each focusing on a distinct modal type, and a decoder that fuses the multi-modal and multi-scale features. The main difference between the two models is that the basic element and difference module of SiamUNet [9] respectively are convolution and concatenation operation, while the ones of mSwinUNet respectively are Swin transformer block [29] and element-wise absolute of the subtraction (Sub&Abs), so mSwinUNet has stronger ability to extract global information and change maps in space-time.
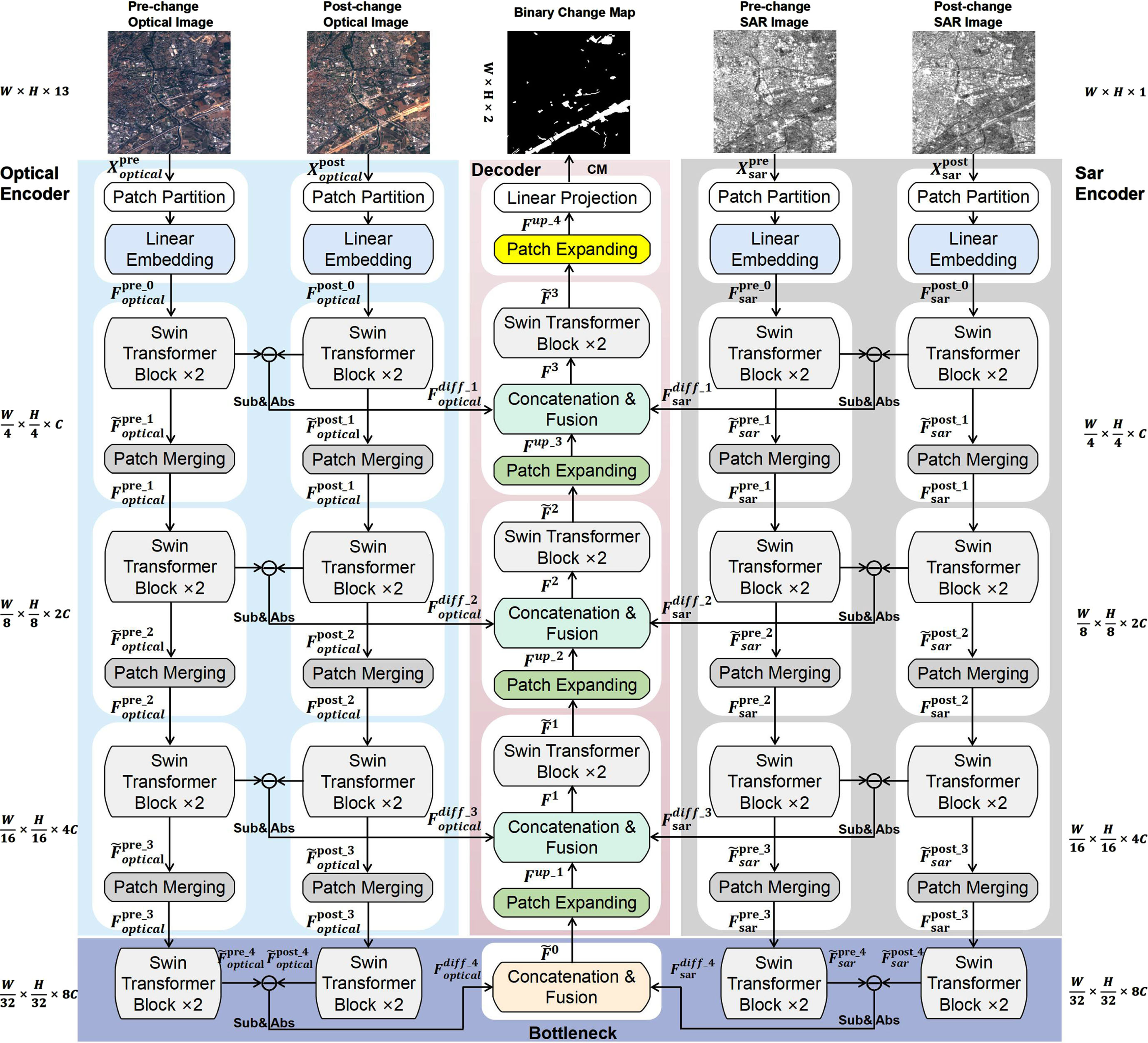
The multi-modal network architecture of our proposed mSwinUNet for supervised CD. The network consists of two encoder branches with difference module for Optical and SAR modalities, bottleneck, decoder, and all of them are based on swin transformer block. Pre-change and post-change optical images are bi-temporal images obtained from Sentinel-2 Multispectral Imager data, whereas pre-change and post-change SAR images are bi-temporal images derived from Sentinel-1 Synthetic Aperture Radar data. Binary change map is the label.
mSwinUNet consists of two encoder branches with difference module, bottleneck, and decoder. The two branches composed of Swin transformer blocks of different levels are used to simultaneously process optical and SAR bi-temporal images in parallel and generate hierarchical multi-scale features, which are both high-resolution coarse-grained and low-resolution fine-grained. The difference maps of hierarchical and multi-scale features from multi-modal bi-temporal images are computed by the difference modules. The bottleneck module predominantly utilizes concatenation and linear projection to fuse difference maps at the final stage of the multi-modal encoder branches. The decoder is mainly responsible for fusing the difference maps computed via difference modules from the multi-modal encoder branches. This helps to offset the loss of spatial information that occurs due to down-sampling. Ultimately, the decoder uses the last patch expanding layer to carry out 4× up-sampling to restore the resolution of the change maps to the input resolution (W×H). A linear projection is then applied to these up-sampled change maps to produce pixel-level change detection predictions. Each part is introduced detailedly as follows.
The main building block of our proposed mSwinUNet with swin transformer [19] is built on the shifted window partitioning strategy. The basis block comprises two consecutive swin transformer blocks as illustrated in Fig. 2. In each swin transformer block, a LayerNorm (LN) layer, a multilayer perceptron (MLP) with GELU non-linearity, a residual connection, and two multi-head self-attention modules (W-MSA and SW-MSA) are included. These modules are distinct from window partition approaches employed to minimize the effect of window locality. The two successive swin transformer blocks of the l-th layer in mSwinUNet network can be formulated as:

Two Successive swin transformer blocks of the l-th layer in mSwinUNet.
where
where Conv2D is a 2-d convolution operation, k is kernel size, m denotes Optical or SAR modality of remote sensing image,
where
where
The multi-modal swin transformer blocks are used to constructed the bottleneck to relearn the feature down-sampled by previous patch merging. In the bottleneck, the main work is to fuse and up-sample the multi-modal difference maps from the last layers of two encoder branches. This procedure is implemented through a concatenation operation and a linear projection layer as follows:
where
where
and
are the difference feature maps generated by the encoder of (last-l)-th layer corresponding to the decoder of l-th layer;
where
DataSet and evaluation metrics
To validate the proposed mSwinUNet, we performed experiments on the publicly available Sentinel-2 Onera Satellite CD (OSCD) dataset introduced by Daudt et al. [8], along with the corresponding Sentinel-1 SAR image data published in [12]. The OSCD dataset comprises 24 pairs of bitemporal multispectral images captured by Sentinel-2 satellites from different cities across the world. Each of the Sentinel-2 images in the bitemporal image pair has 13 bands. The corresponding sentinel-1 SAR images are collected from different orbits, and maintain the same resolution as OSCD dataset by preprocessed means of removing speckle noise, pixel-wise mean and normalization, and image resampling. The sentinel-1 SAR image has only 1 band. Each multi-modal bitemporal image pair is labeled with one pixel-wise groundtruth change map. We split officially it into two parts: 14 training sites of the multi-modal dataset for training and 10 ones for evaluating.
Meanwhile, Overall Accuracy (OA), Precision, Recall, and F1-score (F1) were utilized to evaluate the performance of the proposed mSwinUNet in multi-modal change detection tasks, in comparison to state-of-the-art methods from different perspectives. In the change detection task, OA represents the proportion of correctly predicted changed and unchanged pixels to the total number of pixels, Precision indicates the proportion of accurately predicted changed pixels out of all predicted changed pixels, Recall quantifies the fraction of correctly predicted changed pixels out of the actual changed pixels, and F1 score provides a balanced measurement of recall and precision, offering a comprehensive evaluation of the model’s performance. Their values range from 0 to 1, with higher precision values indicating fewer false detections and larger recall values indicating fewer missed predictions. The F1 score and OA serve as overall evaluation metrics for the prediction results, with larger values indicating better prediction outcomes. Their formulas can be expressed as follows:
To demonstrate the effectiveness of our proposed mSwinUNet model, we make a comparison to the following several existing state-of-the-art baselines:
UNet [23] is a mono-modal network model, we integrate Sentinel-1 (S1) and Sentinel-2 (S2) observations into a single input tensor and processed them jointly.
SiamUNet [9] is the first multi-modal Siamese network that ingests both optical and SAR data, and processes the multi-modal information using a convolutional encoder-decoder architecture.
DS_UNet [12] is a dual-stream UNet model that can extract informative change features from both optical and SAR image pairs simultaneously. These change features are then fused in the final decision stage.
Experimental settings
All the experiments were conducted using Pytorch 1.11.0, on a 64-bit CentOS 7.9.200 Server equipped with an AMD EPYC 7702 64-Core Processor CPU, 128GB RAM, and NVIDIA GA100 GPU support. In order to improve the quality of the dataset, the technique of data augmentation utilizes random strategies, including random flipping, random cropping, and random 90 degree rotation. All the trainable parameters of the baselines and our model were initialized randomly. To facilitate the training, we chose AdamW as the optimizer with a weight decay of 0.01 and beta values of (0.9, 0.999). Cross-Entropy (CE) Loss was applied for training. With a batch size of 2, we experimented with the learning rate decay values of [0.25, 0.3, 0.5], while keeping the learning rate fixed at 0.001. We set the learning rate to 0.001 and explored the learning rate decay in the range of [0.25, 0.3, 0.5]. The training process was terminated if no improvement was observed after 500 epochs. Each experiment was conducted ten times to reduce any random fluctuations and recorded their average results.
Performance comparison on difference module
To verify the effectiveness and superiority of the element-wise absolute of the subtraction (Sub&Abs) of the two feature maps as the difference module in each encoder branch of mSwinUNet, we have compared our results with mainstream difference modules of Convolution [1] and Concatenation [9, 29]. The numerical results are summarized in Table 1. From this table, we can see that the performance of Sub&Abs is much better than Convolution and Concatenation. This shows our introduced Sub&Abs has more powerful ability to compute difference feature maps in multi-modal CD task.
Performance comparison on difference module
Performance comparison on difference module
We verify the performance of our proposed mSwinUNet under different modality combinations. In Table 2, we have summarized the quantitative results and drawn the following findings: (1) In the case of mono-modality, the Optical modality achieves much better performance than SAR modality. This is because Sentinel-2 multispectral image has 13 bands, enabling more feature information. (2) Under modality combination situations, the combination of Optical and SAR modalities outperforms either mono-modality alone. This is because mSwinUNet is able to makes full use of the complementary information between Optical and SAR modalities.
Performance comparison with modality combination
Performance comparison with modality combination
We summarized the performance comparison conducted between our model and the baselines in Table 3. (1) Compared to other models, the UNet [23] model achieves an Overall Accuracy of 0.948, F1-score of 0.304, Precision of 0.366, Recall of 0.260, exhibiting the worst performance. This is attributed to the fact that the Optical and SAR modalities are simply combined together as a single input into standard UNet. (2) SiamUNet [9] is better than UNet [23]. This is because it is a first multi-modal Siamese architecture based on UNet to process Optical and SAR data separately by multi-modal encoders and fuse the extracted features at multiple decoder depths. (3) DS_UNet [12] outperforms SiamUNet [9]. This is due to the fact that DS_UNet further fuses SAR and optical features at decision level. (4) In comparison, our proposed mSwinUNet achieves the best result. This justifies the effectiveness of our mSwinUNet for multi-modal remote sensing CD, because swin transformer block can extract more descriptive features and our network architecture has a stronger ability to fuse these Optical and SAR features.
Performance comparison between our proposed method and several state-of-the-art baselines
Performance comparison between our proposed method and several state-of-the-art baselines
Figure 3 depicts a comparison between the visual results of an intuitive and qualitative evaluation of the performance of both baselines and our proposed mSwinUNet on the test images. The rows 1-2 demonstrate respectively Sentinel-2 Optical images captured at time t1 and t2, while the rows 3-4 showcase the Sentinel-1 SAR images captured at the same times. The fifth row displays the corresponding groundtruth change maps. From row 6 to 9, it can be observed that the visual result from baselines and mSwinUNet and the performance is gradually improving. These qualitative results were consistent with the quantitative results in Table 3. The fact shows the superiority of our proposed mSwinUNet model over the baselines.

Visualization results from UNet [23], SiamUNet [9], DS_UNet [12] and our proposed mSwinUNet model on the OSCD test dataset and the corresponding SAR image test dataset. For the convenience of viewing, different colors are used to express different meanings; white indicates true positive, green indicates false negative, magenta means false positive, and black denote true negatives, respectively.
This paper presented mSwinUNet, a novel multi-modal siamese network architecture that uses the Swin Transformer to further improve change detection performance using multi-modal bi-temporal remote sensing imagery. It comprises three key components: a multi-modal encoder, a decoder, and a bottleneck for fusing the multi-modal difference information. mSwinUNet has both the ability to extract better their long-term global spatiotemporal features and leverage supplementary information from multi-modal remote sensing images, leading to improved accuracy in multi-modal CD tasks. Extensive experiments have indicated that mSwinUNet outperforms several state-of-the-art baselines on the Sentinel-2 optical and the corresponding Sentinel-1 SAR image dataset.
Inevitably, there are some limitations in our work that can provide direction for our future work: (1) Currently, the input images for the mSwinUNet model are the Optical and SAR bi-temporal images. As future work, we will plan to incorporate more modalities of remote sensing images to evaluate the performance of the multi-modal siamese network (mSwinUNet) for CD tasks, as the encoder’s number can increase with the number of available modalities. (2) mSwinUNet is applied for supervised multi-modal change detection tasks. Next, our future plan is to develop multi-modal deep learning model with swin-transformer-based and U-shaped siamese network architecture for unsupervised and weakly supervised CD tasks, with the goal of reducing the labeling burden of remote sensing images.
Footnotes
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China under Grants 62271361 and 52271366, and the Department of Science and Technology, Hubei Provincial People’s Government under Grant 2021CFB513.