
Abstract
Detecting behavioral changes associated with suicidal ideation on social media is essential yet complex. While machine learning and deep learning hold promise in this regard, current studies often lack generalizability due to single dataset reliance. Traditional embedding techniques struggle with semantic analysis,leading to challenges in achieving high accuracy models and conventional validation methods have data drift limitations. To address these challenges, this study proposes a novel evaluation approach using natural language processing across diverse platforms like Twitter and Reddit. By integrating BERT embedding, adept at handling semantic nuances, with an optimized Stacked Classifier combining different base classifiers and XGBoost as the meta-classifier, the model excels in swiftly detecting signs of suicidal ideation compared to the Voting Classifier, i.e., the combination of Decision Tree, Random Forest, Gradient Boost and XGBoost and several machine learning models. Additionally, the study explores advanced embedding techniques like MUSE and LLM, and deep learning models including Bi-LSTM, Bi-GRU, and Text-CNN for comparison.This ensemble approach aims to create a model that is not only interpretable but also robust, reducing computational complexity and enhancing resilience against noisy data—common challenges faced in text classification tasks. Through K-fold validation, which involves partitioning the dataset into k equal-sized subsets or "folds" and training the model k times, using k-1 folds for training and one-fold for testing each time, the proposed model achieves impressive accuracy rates of 97% on Reddit and 96% on Twitter datasets, underscoring its effectiveness in identifying suicidal ideation across social media platforms.
Introduction
Nowadays, the prevalence of health issues like anxiety and depression is increasing, particularly in developed countries [25]. If it may leave untreated, then these disorders can lead to behavioural changes and severe illness, potentially resulting in suicide attempts [22, 26]. Identifying the reasons and people at risk of suicide is a complex task. People experiencing feelings of depression are more prone to suicide attempts. The factors contributing to suicide can be categorized into health, environment, and personal history, as stated by the American Foundation for Suicide Prevention. Mental health concerns are often associated with a higher risk of suicide [32, 33]. In-depth studies on the psychology of suicide have revealed that personality, cognitive factors, social influences, and negative life experiences play significant roles [30, 31]. Understanding the daily routines of individuals is crucial for predicting behavioural changes and illness. Changes in their life patterns may act as triggers for suicidal thoughts [34].
Suicidal ideation, which arise from feelings of depression and despair, involves contemplating self-destruction. Recognized risk factors like depression, behavioral shifts, and negative emotions are vital signs for potential suicides. Early identification of suicidal thoughts is a global priority, with WHO aiming for a 10% reduction in rates by 2030. Detection involves analyzing writing style or tabular data, utilizing online platforms to monitor and prevent suicide. This pressing issue highlights the need for diagnosing behavioral changes for prevention. Early intervention, alongside advancements in social media and computational linguistics, holds promise for reducing suicide rates[27]. The application of artificial intelligence and machine learning methods enables a better understanding of public intentions, facilitating early intervention [20, 21]. Analyzing social content, including feature engineering, sentiment analysis, and deep learning efforts, plays a vital role in detecting suicidal ideation and advancing current research trends [35, 36]. Prior studies often assessed models using singular datasets, potentially limiting their ability to generalize. Despite the prevalence of embedding techniques like count vectorizer, TFIDF, word2vec, and GloVe, they face limitations such as disregarding semantic meaning, word order, and syntax, and struggling with fixed-size representations and out-of-vocabulary words. The conventional practice of splitting datasets into training, testing, and validation sets aims to evaluate model over-fitting but is flawed due to risks like overfitting or under-fitting with limited data, variability from random set selection, biases from imbalanced datasets, and challenges in addressing data drift over time. This research explores creating an interpretable and robust text classification model by leveraging the benefits of stacking, which mitigates overfitting, combines diverse model strengths, and adapts to various feature spaces. It aims to address challenges like computational complexity and noise resilience, common in text classification tasks. By leveraging BERT’s contextual bidirectional embedding and subword tokenization, the Stacked Classifier, integrating Decision Trees, Random Forests, and Gradient Boosting, along with XGBoost as the meta-classifier, shows improved performance in detecting suicidal ideation, assessed through k-fold cross-validation. Furthermore, it is compared against a Voting Classifier, Bi-LSTM, Bi-GRU, and TEXT-CNN, incorporating various feature extraction techniques like MUSE andLLM.
The significant contributions are summarized as follows: BERT embedding, leveraging contextual bidirectional modeling and subword tokenization, excels in extracting features for robust semantic representation in sequential patterns. The Proposed Stacked classifier, surpasses the Voting Classifier and other models, providing interpretability, robustness, reduced computational complexity, and resilience to noisy data, while uncovering long-distance relationships within suicidal posts. K-fold cross-validation provides a more robust evaluation of the model’s generalization across diverse social media platforms, such as Reddit and Twitter datasets.
The document is structured as follows: Section 2 provides an overview of previous studies on suicide detection on social media. Section 3 describes the methodology, including the proposed ensemble stacked classifier technique and specific approaches used in the model. Section 4 focuses on experimental results, covering data and categorization analysis, along with discussions and study limitations. Lastly, Section 5 concludes the report, outlining limitations and offering recommendations for future research in this field.
Related work
Researchers have taken notice of the alarming increase in suicide rates and have introduced various clinical practices, including questionnaire surveys and automated post-detection methods, to identify suicide attempts. Previously, detection relied solely on clinical methods like face-to-face interviews and questionnaires, emphasizing the importance of understanding the psychology and behaviour associated with suicidal ideation through direct interactions [10, 28]. Surveys and interviews with individuals who have attempted suicide have been conducted on platforms such as Weibo and other social media sites [29]. In a notable study, Katchapakirin et al. conducted an experiment on Facebook in 2018 to detect depression within the Thai community [1]. J. Gao et al. developed a model using SVM, Random Forest, and LSTM to detect suicide risk by manually annotating comment datasets on YouTube [2, 19]. Their LSTM model achieved an accuracy of 84.5%. Valeriano et al. were engrossed in detecting suicidal ideation in Spanish-language posts and utilized the Twitter API to extract the dataset [3]. Through human annotations and pre-processing techniques to remove unwanted materials, they converted the dataset into vectors using TF-IDF and Word2Vec. They then applied algorithms such as SVM and Logistic Regression, achieving accuracy rates of 74% and 79%, respectively. These studies demonstrate the potential of leveraging social media data and machine learning algorithms to address the complex issue of suicide detection. A limitation of these study lies in the dataset’s bias, and potential improvement in results may be achieved by using a more balanced distribution of data.
Studies from 2018 to 2023 have delved into suicidal ideation detection employing a range of methodologies [11, 15]. In 2018, Aladag et al. leveraged RF, LR, and SVM on Reddit data, noting a limitation in reliance on a single dataset [4]. Coppersmith et al. combined datasets to predict behavior changes and suicide risks, utilizing Bi-directional LSTM with Self-Attention for a 94% accuracy, though limited by a focus on females aged 18 to 24 [5]. Sawhney et al. explored deep learning with RNN, LSTM, and CNN-LSTM, achieving varying accuracies for suicidal ideation detection [6]. Shing et al. and introduced CNN for this purpose, while S. Ji et al. provided a comprehensive review of diverse methods for predicting suicidal ideation, including clinical practices and deep learning techniques[7–9]. In subsequent years, Tadesse et al. achieved a superior result of 93% with the LSTM-CNN model[13], Ning et al. proposed a deep learning method with C attention for an 84.3% accuracy [14] and Zepeng et al. utilized FastText and TextCNN models with accuracies of 84.87% and 87.15%, respectively[16]. Akshma et al. achieved a high recall of 94.94% by applying attention over CNN and LSTM to a Reddit dataset[38], while Bhavini et al. utilized a Twitter dataset and a stacked CNN-LSTM model for a 93.92% accuracy[37]. Liu et al. introduced an ensemble model emphasizing feature combination and proposed integrating models like BERT for enhanced multi-classification [17]. Meanwhile, Li Z and Zhou implemented a unique approach involving balanced subset training of base classifiers for improved model refinement[16]. In 2023, Ghosal et al. developed a framework effectively discerning depression-related content and suicidal risk using FastText embeddings, TF-IDF vectorization, and XGBoost, showcasing remarkable results on a Reddit dataset, outperforming baseline models with a 0.78 AUC and a 0.71 weighted F-score [33].
In prior studies, researchers mainly focused on monitoring social media posts to identify changes in people’s behavior and signs of mental health issues. Although past research has made progress with machine learning and deep learning techniques. However, there are still limitations such as reliance on single datasets, biases, overfitting concerns, and the need for better feature extraction to enhance accuracy and minimize classification errors. Furthermore, there is a necessity to develop a model that is both easy to understand and strong, thereby reducing computational complexity and improving its ability to handle noisy data—common challenges encountered in text classification tasks. Thus, to overcome these limitations and introduce novelty into the research, the study used two diverse datasets, Reddit and Twitter, ensuring a nearly balanced distribution. It applied hyperparameter tuning through grid search optimization, addressed overfitting via K-fold cross-validation, and enhanced feature extraction using pre-trained models like BERT which is further compared with MUSE and LLM GPT. The proposed novel ensemble stack classifier model combines Decision Tree, Random Forest, and Gradient Boost as base classifiers, with XGBoost as the meta-classifier with less computation time and perform well in noisy data. These findings highlight significant contributions, providing a potential solution to previous limitations.
Methodology
The proposed method for detecting changes in behaviour or signs of suicidal thoughts involves a few steps. It consists of several steps like Data gathering, Data pre-processing, Feature Engineering and prediction of suicidal or non-suicidal posts. The following subsections and Fig. 1 provide a concise overview of each step involved in the present work.
Work flow.
The data for this study was collected from Kaggle [39], focusing on posts from Reddit to distinguish between suicidal and non-suicidal content. The posts were extracted from two subreddit threads, "Suicide Watch" (Dec 16, 2008, to Jan 2, 2021), and "Depression" (Jan 1, 2009, to Jan 2, 2021), using the Push Shift API. A total of 38,016 posts were gathered. The training dataset constitutes 80% of the total, encompassing 30,412 posts, with 15,164 labeled as related to suicide and 15,248 as non-suicide-related. The remaining 20%, designated as the testing data, is considered authentic and real data directly input into the trained model. The Twitter dataset, sourced from GitHub [40], was curated for identifying suicidal behavior on social media and comprised approximately 9,118 tweets. This dataset was divided into training and testing datasets at an 80:20 ratio, employing a specific random state number. Within the training Twitter dataset, there are 7,295 tweets, of which 3,913 were labeled as indicative of suicidal ideation, while the remaining 4,102 were classified as non-suicidal. Both the Reddit and Twitter datasets showed a balanced distribution, with roughly equal numbers of suicidal and non-suicidal tweets.
Data preprocessing
Text pre-processing is a crucial step in preparing the dataset for the model. This involves several phases, including text tokenization, removal of stop words, elimination of URLs, punctuation removal, lowercase conversion, lemmatization, and removal of non-English words [17, 24]. By applying these pre-processing steps [9, 23], the text data is transformed accordingly. The quality of the data plays a vital role in determining the performance of the model. Inconsistent data can significantly impact the model’s performance, underscoring the importance of proper data pre-processing or cleaning.
Feature extraction
Feature extraction involves converting raw data into numerical format while retaining essential information, crucial for machine learning or deep learning tasks. Count Vectorizer is commonly used to transform text documents into numerical vectors, resulting in a sparse matrix representation. TF-IDF Vectorizer evaluates word importance by assigning higher weights to terms that appear less frequently in the document compared to the entire corpus. N-grams, such as bi-grams (n=2) and tri-grams (n=3), capture sequential text sequences. While increasing the value of n expands feature variety, optimal results were obtained with n=2, generating 717,046 attributes compared to 234,558 with n=3.
BERT is a language representation model that went through pre-training using a large collection of unlabeled text. This dataset covered a range of pre-training tasks. The introduction of BERT was outlined in the paper titled "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" authored by Devlin et al. in 2018. BERT’s notable characteristic is its strong bidirectionality [12]. It creates thorough bidirectional textual representations during the pre-training phase, successfully integrating context from both preceding and following segments [41, 43]. The study made use of the "bert-base-cased" model, a pretrained model tailored for English text with case sensitivity preserved. This model comprises 12 transformer encoder modules, which process input data in a thorough and hierarchical manner. It features hidden layers of size 768, allowing it to transform each input token into a 768-dimensional vector during computation. With 12 multi-head attention mechanisms, the model comprehensively captures various aspects of information within the input text. In total, the model encompasses 110 million trainable parameters. BERT models are esteemed for their ability to condense text into concise vectors that encapsulate the text’s semantic meaning. This model can accommodate sequences of up to 512 tokens in length. Specifically, when applied to the Reddit dataset, it generated 30,412 sequences, each comprising 512 attributes, and for the Twitter dataset, it produced 7,295 sequences, each with 512 attributes through the BERT extraction process.
Multilingual Unsupervised and Supervised Embeddings (MUSE) stands as an advanced solution within the realm of natural language processing, specifically tailored to overcome the intricate challenges posed by cross-lingual word embeddings [42, 44]. MUSE’s primary objective revolves around the creation of a cohesive vector space, wherein words originating from a multitude of languages find representation, thereby granting the capacity for streamlined language-related tasks and seamless translation processes. The innovation of MUSE lies in its adept amalgamation of unsupervised and supervised learning methodologies. By expertly fusing these approaches, MUSE orchestrates the alignment of words and phrases across disparate languages, forging meaningful semantic connections even when the direct equivalents might be absent. This revolutionary technique serves to not only bolster comprehension across languages but also to propel the efficacy of essential undertakings like machine translation, cross-lingual information retrieval, and sentiment analysis. In entirety, MUSE’s impact resonates profoundly in the sphere of language technology, elevating its potential to new heights amidst the intricacies of diverse linguistic landscapes. The Multilingual Universal Sentence Encoder (MUSE) is a pretrained neural network designed for converting sentences into meaningful vectors. MUSE features a model structure comprising 6 layers, including a hidden layer with 512 units and incorporates 12 heads for multi-headed attention, contributing to its ability to understand diverse sentence contexts. Additionally, it includes a dropout rate of 0.1 to enhance its robustness. This model is composed of approximately 50 million parameters and accommodates sequences of up to 512 tokens in length. Applying the MUSE approach, it derived 30,412 sequences, each consisting of 512 attributes, from the Reddit dataset, and 7,295 sequences with the same attribute length from the Twitter dataset.
The Large Language Model (LLM) stands as a remarkable milestone in the fields of artificial intelligence and natural language processing[45]. Built upon the transformative architecture of Generative Pre-trained Transformer, this model embodies the forefront of technological innovation. Its exceptional ability to comprehend context, generate coherent text, and provide insights across a wide array of subjects positions it as an invaluable asset for various applications, ranging from content synthesis and summarization to language translation and contextual comprehension. The LLM model is essentially a pre-trained GPT-2 model tailored for the English language. Its primary objective is causal language modeling (CLM), predicting what words come next in a sentence. The model is characterized by 768-dimensional embeddings, a Transformer architecture with 12 layers for both encoding and decoding, 12 attention heads for capturing different aspects of context, and GELU activation for nonlinear transformations. This compact GPT-2 variant comprises 124 million parameters and can handle sequences up to 512 tokens in length. When applied to the Reddit dataset, it extracts 30,412 segments, each comprising 512 tokens, and for the Twitter dataset, it extracts 7,925 segments with the same token length.
Classification model
The decision tree is a well-known machine-learning algorithm utilized for classification and regression purposes [3]. It takes the form of a tree-like model, with internal nodes symbolizing features or attributes, branches representing decision rules based on those features, and leaf nodes denoting the final outcomes or predictions. Data classification is carried out by utilizing the entropy technique, which is represented as shown in equation 1, which denotes pi as the probability of the occurrence.
Gradient Boosting is a popular machine learning algorithm that combines multiple weak predictive models (often decision trees) to create a strong predictive model [9]. It is based on the principle of iteratively improving the model’s performance by minimizing a loss function.
Extreme Gradient Boosting (XGBoost) is a powerful machine learning algorithm that is known for its exceptional performance and flexibility in solving various regression and classification problems [13]. XGBoost is an advanced implementation of Gradient boosting that incorporates additional enhancements to improve model accuracy and efficiency. By employing a combination of boosting and parallel processing techniques, XGBoost iteratively builds an ensemble of weak prediction models, typically decision trees, to form a robust and accurate final prediction model. XGBoost is an ensemble model that combines multiple classification and regression trees (CART).
The Ensemble Voting Classifier is a machine-learning model that aggregates predictions from multiple individual classifiers to generate a final prediction. Each classifier within the ensemble is trained independently on the same dataset using different algorithms or configurations. The voting classifier then combines the predictions of its constituent classifiers, selecting the final prediction based on either a majority or weighted vote. In a majority vote, the class with the highest number of votes from the classifiers is chosen as the final prediction, while in a weighted vote, each classifier’s vote is weighted based on its performance or confidence level. In this approach, the Ensemble Voting classifier combines predictions from Decision Tree, Random Forest, Gradient Boosting, and XGBoost classifiers. Each classifier predicts a class label, and the final prediction is determined by the majority class among all the classifiers.
The proposed Stacked Classifier combines predictions from various classifiers using a meta-classifier for the final prediction. It operates in two levels: first, individual classifiers are trained independently, and their predictions are collected. Then, these predictions, along with original features, are used to train the meta-classifier, enhancing accuracy as shown in Fig. 2. Stacking classfier achieves robustness against overfitting by training all base models on the same dataset, minimizing the risk of fitting noise. It capitalizes on the unique strengths of each base model, minimizing bias and variance for better generalization, and offers adaptability to diverse feature spaces, facilitating tailored model selection and flexibility. By leveraging different classifiers like Decision Tree, Random Forest, and Gradient Boosting as base classifiers, and XGBoost as the meta-classifier, the model enhances prediction performance and versatility. Each base classifier is trained independently, and their predictions, along with original features, are used to train the meta-classifier XGBoost as illustrated in Algorithm 1. This approach optimally combines the strengths of various classifiers to improve prediction accuracy and overall model performance.

Proposed Stacked Classifier.
Grid optimization, also known as grid search, is a technique used to find the optimal hyperparameters for a machine learning or deep learning model by exhaustively searching through a predefined grid of hyperparameter values. Here is the grid optimization done for the models used in stacked classsifier. The base classifier has been designed by the Decision Tree, Random Forest, Gradient Boosting and the meta clasifier as XGBoost classifiers. For each Classifier, a grid of possible values for the respective hyperparameters is defined. The grid search algorithm will then evaluate the performance of the model using different combinations of hyperparameters from the grid. The finest parameter chosen is given in Table 1.
Parameter tunned with the grid search
Parameter tunned with the grid search
The study evaluates the proposed method’s efficacy in identifying suicide-related posts, employing metrics like false positive, false negative, true positive, and true negative. Precision is the ratio of true positives to the total positive predictions, while Recall assesses the method’s ability to correctly identify genuine positives. The F1-score, as harmonic mean of Precision and Recall, offers a comprehensive evaluation. Adopting a macro-average approach assigns equal importance to both classes i.e. suicidal and non-suicidal posts. Precision_macro, Recall_macro, and F1-Score_macro are calculated by averaging values for both classes, providing a balanced assessment of the model’s performance across categories. This collective evaluation includes Precision, Recall, F1-score, and Accuracy.
Experiment to examined the stacked classifier against voting classifier and other machine learning models
The main objective is to identify alterations in behaviour indicative of suicidal tendencies by analyzing social media posts. This section discusses the use of natural language processing (NLP) for predicting suicidal thoughts, as well as the evaluation of different machine learning techniques to assess their performance. The pre-processed datasets of Twitter and Reddit are used for further process. The feature extracted as vectors are than fed into the several machine learning models like Decision Tree as DT, Random Forest with n-estimator=120 as RF, Bernoulli Naïve Bayes as NB, Gradient Boosting n-estimator=800 as GB, XGBoost with n-estimator=500 XGB, Ensemble Voting Classifier (combination of DT+RF+GB+XGB) and the proposed Stacking Classifier (base classifier: DT, RF, GB and meta Classifier as XGB).
First, the study proceeds by establishing a pipeline structure that integrates Count Vectorizer with N-gram analysis, transformed into TF-IDF representation, enhancing feature engineering. Thus, these features are fed to Decision Tree, Random Forest, Naïve Bayes, Gradient Boosting, Ensemble Voting Classifier, and Stacking Classifier, resulting in accuracies of 87%, 88%, 75%, 89%, 91%, and 93% for the Twitter dataset, and 84%, 89%, 77%, 90%, 91%, and 94% for the Reddit dataset, as shown in Table 2. This experiment concludes that the ensemble Stacking Classifier not only demonstrates superior performance but also offers efficient computation time, making it the best choice in terms of both aspects.
Count Vectorizer + Ngram + TFIDF Feature Extraction
Count Vectorizer + Ngram + TFIDF Feature Extraction
A comprehensive evaluation of advanced and contemporary embedding techniques has been conducted, alongside a diverse array of machine learning models. Various advanced word embedding techniques such as BERT, MUSE, and LLM GPT have been employed to enhance word representations. Additionally, these state-of-the-art embeddings have been integrated into diverse machine learning models including Decision Tree Random Forest (with n-estimators set to 120), Bernoulli Naïve Bayes, Gradient Boosting (with n-estimators set to 800), XGBoost (with n-estimators set to 500), Ensemble Voting Classifier, and Stacking Classifier. Table 3 presents a comparative analysis of the performance of these advanced embedding models like BERT, MUSE, and LLM (GPT), when used in conjunction with various machine learning algorithms. The experimentation was carried out on two consistent datasets: Twitter and Reddit. Among the evaluated models, the Stacking Classifier demonstrated the most remarkable results. Specifically, when combined with BERT embedding, it achieved accuracy rates of 96% and 97% on the Twitter and Reddit datasets respectively. MUSE embedding yielded accuracies of 95% and 96%, while LLM GPT embedding attained 94% and 95% accuracy on the respective datasets. Figures 3, 4, and 5 illustrate the ROC curve of BERT, MUSE, and LLM embeddings with several machine learning models.
Embedding BERT, MUSE and LLM with Machine Learning Method
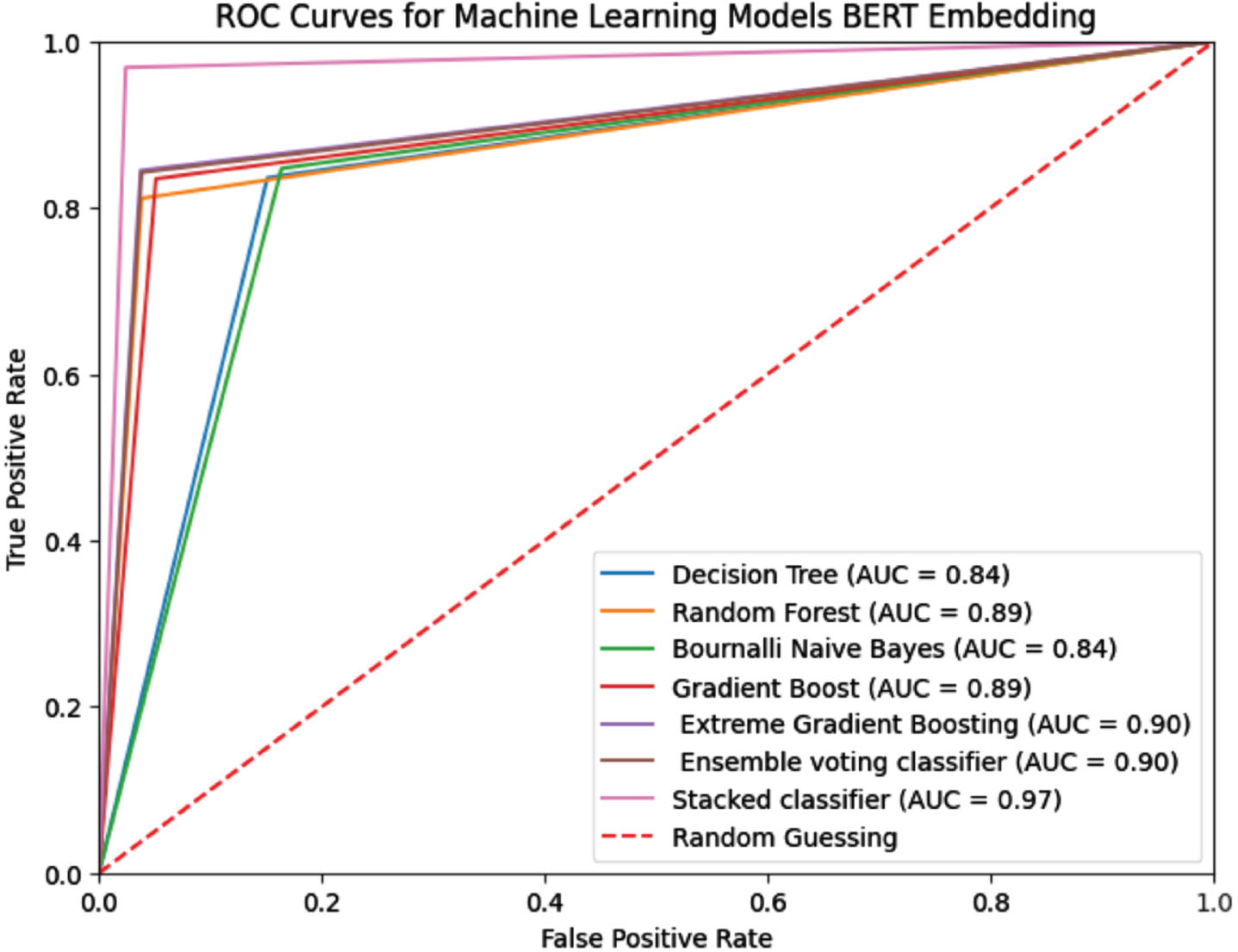
Comparision ROC curves with BERT Embedding.
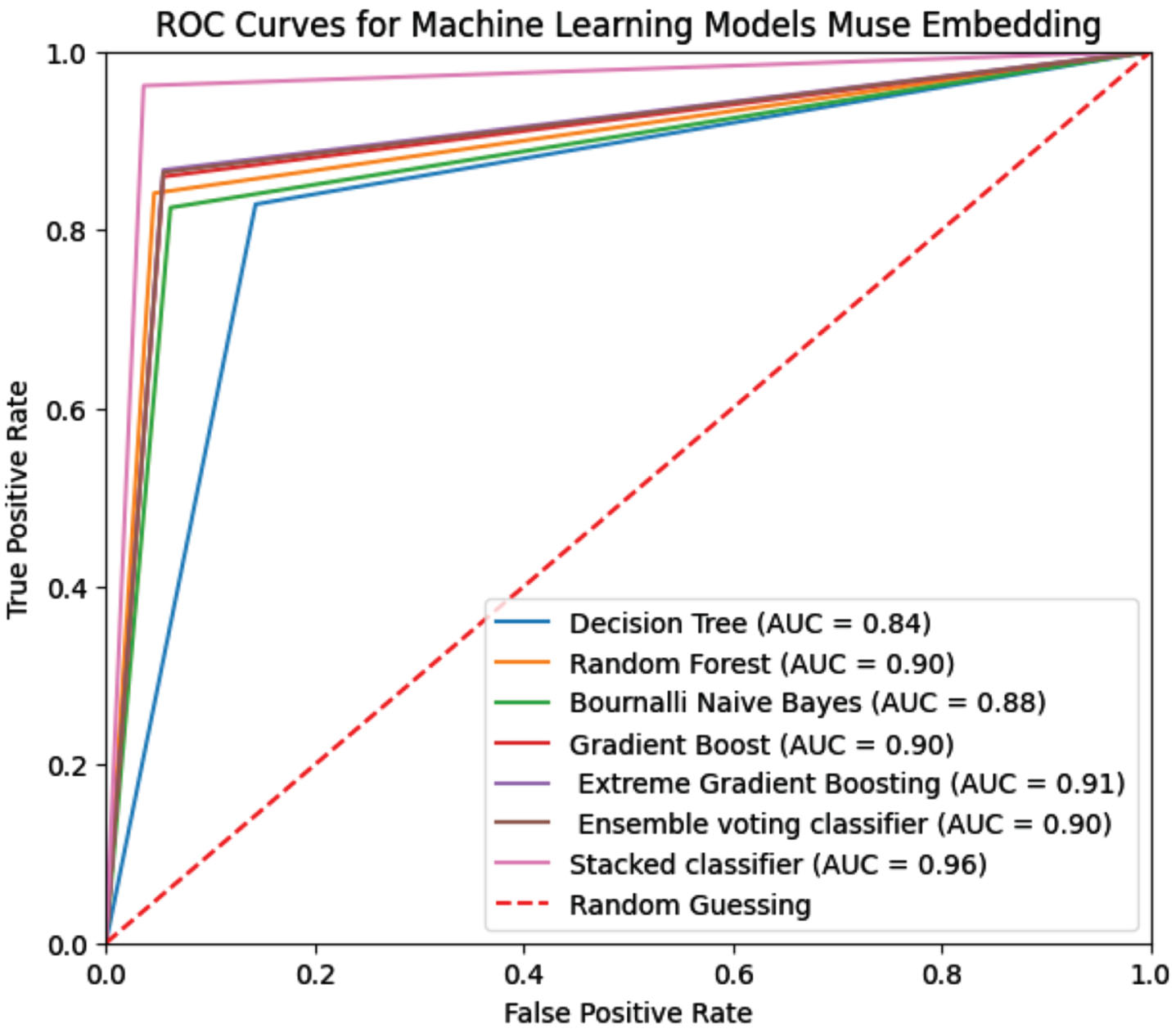
Comparision ROC curves with MUSE Embedding.
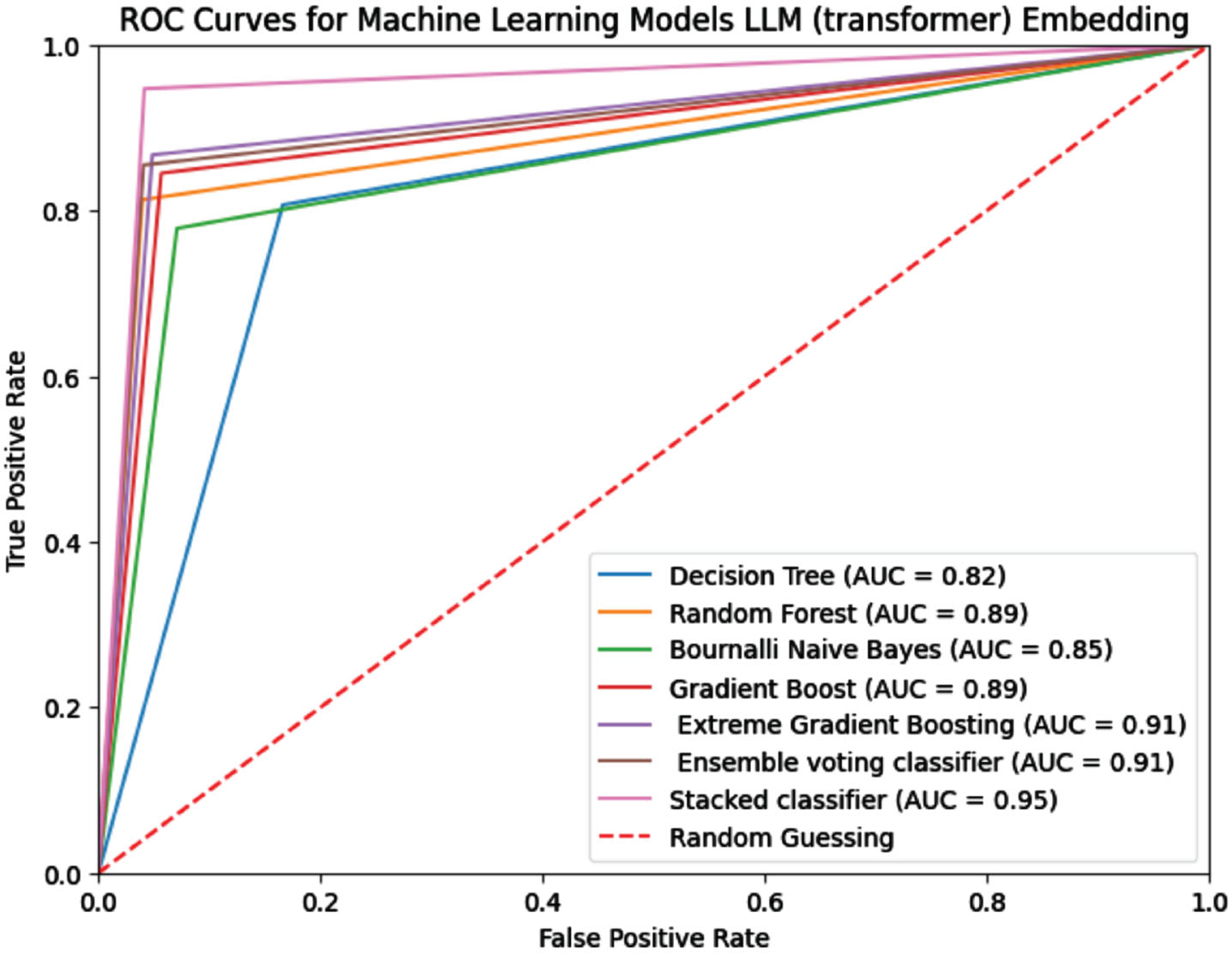
Comparision ROC curves with LLM Embedding.
Furthermore, the study was expanded to incorporate additional advanced deep learning models, namely Bi-LSTM, Bi-GRU, and Text-CNN, coupled with the advanced embedding techniques BERT, MUSE, and LLM GPT. The comparative results of these advanced deep learning approaches are illustrated in Table 4. According to the Table 4, it is evident that the Stacking classifier requires less computational time than the advanced deep learning model. Consequently, upon evaluating the advanced deep learning models, it can be inferred that the stacking classifier yielded the most favorable outcomes across all methodologies. The grid search optimization technique was utilized to refine the hyperparameters of three distinct deep learning architectures: Bidirectional Long Short-Term Memory (BI-LSTM), Bidirectional Gated Recurrent Unit (Bi-GRU), and Text Convolutional Neural Network (Text-CNN) as shown in Table 5. Each architecture underwent a methodical exploration of various hyperparameter configurations to ascertain the most effective settings for enhancing model performance.For the BI-LSTM model, a range of epochs from 10 to 40 was considered, alongside learning rates spanning 0.001 to 0.1. Diverse batch sizes, units (64 within the LSTM layer), optimizers (Adam, RMSprop, SGD), and dropout rates (including 0.18) were investigated. Similarly, the Bi-GRU architecture underwent a parallel hyperparameter search, encompassing epochs from 10 to 40, learning rates spanning 0.001 to 0.1, and an assortment of batch sizes, units (64 within the GRU layer), optimizers (including Adam), and dropout rates (including 0.18). Conversely, optimization of the Text-CNN model involved epochs spanning 10 to 40, learning rates ranging from 0.001 to 0.1, diverse batch sizes, units (64 within Convolutional and Fully Connected layers), dropout rates (including 0.18), optimizers (with Adam as the chosen option), kernel sizes of 2, 3, and 5, as well as Conv1D filters (including 128).
Embedding BERT, MUSE and LLM with Deep Learning Method
Embedding BERT, MUSE and LLM with Deep Learning Method
Parameter tunning of Deep Learning Technique
The experimental study aimed to compare the proposed Stacked Classifier against Voting Classifier and several other machine learning model’s performance. Furthermore, the study also compared the proposed model against deep learning methods for detecting suicidal ideation in social media posts. Various word embedding techniques were employed, including the pipeline of Count Vectorizer, TFIDF, and N-gram and the pretrained model as BERT, MUSE, and LLM GPT, for comparision. The proposed BERT integrated Stacking Classifier model yielded impressive results 96% on Twitter and 97% on the Reddit dataset. MUSE and LLM GPT embeddings also performed well but didnt able to achieve the remarkable result. Overall, the study highlights the effectiveness of Stacking Classifier, particularly when using BERT as feature extraction.
Cross-validation is a highly reliable technique for assessing model performance. It is particularly useful when working with limited input data. By dividing the data into k folds, the model can be trained and tested on different subsets of the data. The cross-validation score is then calculated to evaluate the model’s effectiveness. This process ensures a thorough and unbiased assessment of the model’s performance without relying on a single training-test split. The Table 6 shows the result of Stacked or Stacking Classifier. The 5-fold cross-validation mean average of the Twitter and Reddit datasets illustrates the Stacked Classifier has given the best performance in the study.
K-Fold Cross Validation of Stacking Classifier
K-Fold Cross Validation of Stacking Classifier
The time complexity of the stacking Classifier, where the base classifiers are Decision Tree, Random Forest, and Gradient Boosting, and the meta-classifier is XGBoost, depends on factors such as the number of training instances (n), the number of features (d), the number of base classifiers (m), and the respective time complexities of training each base classifier (Tbase), training the meta-classifier (Tmeta), making predictions using a base classifier (Tpredbase), and making predictions using the meta-classifier (Tpredmeta). The overall time complexity for training the stacking Classifier can be approximated as (m * Tbase) + Tmeta, while the time complexity for making predictions using the trained stacking Classifier can be approximated as (m * Tpredbase) + Tpredmeta.
Comparision with related work
The study’s performance is influenced by various factors, including hardware considerations and external disturbances, which can hinder direct comparisons with other research findings. When evaluating the proposed model against existing ones, it’s crucial to consider factors such as hardware variations and external noise, which can complicate comparisons. However, the study seeks to create a benchmark for comparison by adopting a comparable dataset and methodology. In a previous study by Bhavini et al. [37], the same Twitter dataset [40] was used with word embeddings as input to a Stacked CNN-LSTM model, achieving an impressive 93.92% accuracy. Akshma et al. utilized the same Reddit dataset, consisting of 20,000 posts, and employed GloVe embeddings as input for an Attention over CNN and LSTM model, reaching an accuracy of 88.48% [38]. In 2023, Ghosal et al. introduced a framework that effectively distinguishes between depression and suicidal risk content. They used a combination of FastText embeddings, TF-IDF vectorization, and the XGBoost classifier, achieving outstanding results with a 0.78 AUC and a 0.71 weighted F-score on a Reddit dataset, surpassing baseline models [33]. In 2019, Tadesse et al. utilized word embeddings as input for the LSTM-CNN model and outperformed, achieving a notable 93% accuracy in the Reddit dataset [19]. In 2021, Ning et al. used word and document embeddings in a deep learning approach with C attention, securing an accuracy rate of 84.3% for subtask 2 on the Twitter dataset [14]. Considering the analysis of related work, the proposed Stacked Classifier, which combines Decision Tree, Random Forest, and Random Forest as base classifiers, with XGBOOST as the meta-classifier, with BERT embedded method achieved an impressive 96% accuracy in the Twitter dataset and 97% on the Reddit dataset, as depicted in Fig. 6. This study can be seen as an extension and advancement of the related work, primarily building upon [37] and [38].
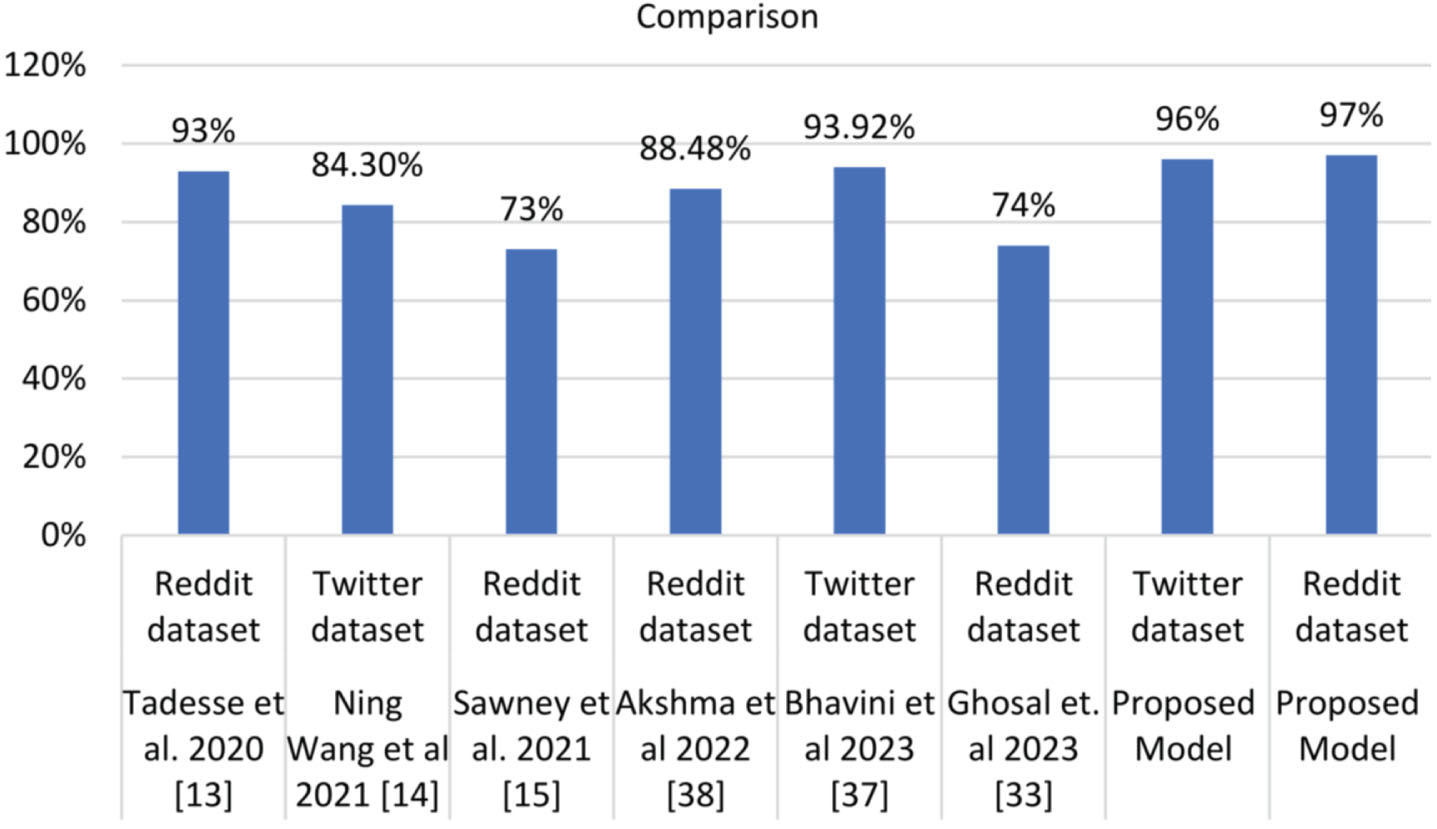
Comparision of related work.
Suicidal ideation, a critical global health concern, demands early detection and intervention. Key indicators like persistent depression and behavioral changes help identify at-risk individuals. Researchers use techniques such as feature engineering and sentiment analysis to progress in this area. However, prior studies on identifying suicidal posts faces limitations like reliance on single datasets, biased data, requiring improved feature extraction additionally, there’s a need for a model balancing simplicity and strength, reducing computational complexity and handling noisy data effectively. This study aims to tackle these challenges to advance understanding and prevention of suicidal ideation. The model’s ability to generalize across diverse social media platforms was a significant finding. Two distinct datasets were used, representing Reddit and Twitter, each with its unique writing styles and linguistic traits. Despite the differences, the model performed consistently well across both datasets, showcasing its generalization capabilities. The Reddit dataset contained 15,164 posts related to suicide and 15,248 non-suicidal posts, while the Twitter dataset included 3,913 tweets indicating suicidal ideation and 4,102 non-suicidal tweets for training. This ensured a balanced distribution for fair training and minimized the risk of biased predictions.
Previous studies commonly utilized embedding techniques like count vectorizer, TFIDF, and word vectorizer, each with limitations. Count vectorizer overlooks semantic meaning, TFIDF disregards word order and syntax, and word embedding methods like word2vec or GloVe face challenges with fixed-size representations and out-of-vocabulary words. This study emphasizes the use of the pre-trained model BERT to overcome these limitations. BERT’s bidirectional contextual analysis and subword tokenization effectively handle out-of-vocabulary words and capture nuanced word meanings and semantic relationships. Sections 4.1 and 4.2 compare BERT with embedding techniques like MUSE and LLM, demonstrating BERT’s superior performance in feature extraction.
Detecting suicidal ideation in text faces challenges like sparse datasets and significant noise. Previous research often relies on deep learning, leading to lengthy computations, high complexity, and may cause potential overfitting on some dataset due to limited data. This ensemble method aims to combat these issues by crafting a model that is both interpretable and resilient. It aims to streamline computations and bolster the model’s ability to handle noisy data, effectively addressing inherent challenges in text classification tasks and to create the robust ensemble model. In section 4.1, the study compares voting and stacking classifiers, showing that stacking, using Decision Tree, Random Forest, and Gradient Boost as base classifiers and XGBoost as the meta-classifier, generally outperforms voting classifiers in capturing complex relationships. Stacking uses a meta-learner to optimize predictions, enhancing adaptability and performance. Voting relies on predetermined rules like majority voting for prediction aggregation. Stacking’s flexibility and optimization distinguish it from the fixed methods of voting classifiers. Additionally, stacking tends to have shorter training times compared to voting classifiers.
The literature often discusses evaluating model overfitting through traditional train-test splits but acknowledges limitations such as data scarcity, random set selection variability, biases from imbalanced datasets, and challenges in addressing data drift. To overcome these limitations, this research employs K-fold cross-validation, dividing the dataset into k subsets for training and testing iteratively. This approach mitigates overfitting or underfitting, maximizes data usage, and ensures consistent model performance. Section 4.3 confirms the model’s effectiveness and absence of overfitting with a mean average of 96.1% on the Twitter dataset and 97.3% on the Reddit dataset, demonstrating its robustness across diverse datasets.
The current study emphasizes minimizing classification errors, building on prior research achievements. Notably, Bhavini et al. (2023) and Akshma et al. (2022) achieved accuracies of 93.92% on Twitter and 88.48% on Reddit datasets, respectively. Ghosal et al. (2023) introduced a framework surpassing baseline models with 78% accuracy on Reddit. Tadesse et al. and Ning et al. also reached noteworthy accuracies of 93% and 84% on Reddit and Twitter datasets, respectively. Utilizing BERT feature extraction, this study achieved remarkable accuracies of 96% on Twitter and 97% on Reddit datasets, as detailed in Section 4.5.
The study’s limitation lies in its exclusive focus on text, overlooking behavioral cues from other formats like images, videos, audio clips, or emojis. Non-verbal cues and visual or auditory elements often convey emotions or behavioral changes not captured through text alone. User engagement frequency, posting patterns, and social interactions could provide valuable insights into behavior shifts and emotional well-being. Sole reliance on text analysis restricts findings, potentially missing subtle nuances in human interaction. Future research should integrate diverse data types and external contextual information to better understand behavior changes, disease markers, and mental health indicators on social media platforms.
Conclusion
The proposed model’s goal is to reduce the suicide rate in society by accurately detecting signs of suicidal intent in social media conversations. By analyzing behaviour changes and disease symptoms through social media data, this model aims to identify individuals at risk and provide timely medical care or assistance, which is crucial for effective suicide prevention. Unfortunately, ordinary life events and hardships can now have devastating consequences for individuals, their families, and their friends. Therefore, there is an urgent need for a reliable model that can effectively recognize and address posts related to suicide on social media. The proposed model, called the Stacked Classifier, combines several algorithms (Decision Tree, Random Forest, Gradient Boost) as base classifiers and employs XGBoost as the meta classifier to extract relevant information, achieving impressive accuracy rates of 97% for the Reddit dataset and 96% for the Twitter dataset.
The study’s limitation lies in its exclusive focus on text-based analysis, overlooking valuable cues from alternative formats such as images, videos, audio clips, or emojis. This hampers the understanding of non-verbal and contextual information crucial for discerning behavior and mental health indicators on social media. To address this, future research should integrate diverse data types and employ feature selection techniques to classify individuals with suicidal tendencies better. Investigating correlations between suicidal behavior and factors like family environment is essential, alongside leveraging advanced methodologies like FastText word embedding and diverse machine learning models for improved classification across datasets.