
Abstract
This paper presents an in-depth study and analysis of oil painting classification and simulation using an improved embedded learning fusion vision perception algorithm. This paper analyzes and models the image quality evaluation problem by simulating the human visual system and extracting quality perception features as the main entry point to improve the prediction accuracy of the overall algorithm. This paper proposes a multi-classification method of CCNN, which uses the similarity measure based on information first to achieve multi-classification of artwork styles and artists, and this part is the main part of this paper. This paper uses the wiki art repository to construct a dataset of oil paintings, including over 2000 works by 20 artists in 13 styles. CNN achieves an accuracy of 85.75% on the artist classification task, which is far more effective than traditional deep learning networks such as Resnet. Finally, we use the network model of this paper and other network models to train the classification of 3, 4, and 6 categories of art images. The accuracy of art image classification by this paper’s algorithm is higher than that of the current mainstream convolutional neural network models, and the extracted features are more comprehensive and more accurate than traditional art image feature extraction methods, which do not rely on researchers to extract image features. Experiments show that the proposed method can achieve excellent prediction accuracy for both synthetic distorted images and distorted images.
Introduction
Since ancient times, both domestic and foreign art painting has been a symbol of people’s spiritual support. It is an art form in that people use their painting style to abstract and summarize objective things and show them to the world with their rich emotional expression [1]. Before the development of Internet technology, people’s understanding, appreciation, and learning of art images were mainly concentrated in a small art circle around the artist, and the diversity of art forms and art creation methods were relatively single. With the popularity of the Internet, the digital display of images based on the Internet has become increasingly mainstream, allowing people to understand relevant art information faster and more comprehensively, and allowing Chinese and Western art painting to collide with new art creation styles in terms of painting forms, creative techniques, and expression of emotions, promoting the exchange and sharing of Chinese and Western cultures [2]. Increased people can understand various art creation styles through the Internet, which prompts art lovers to devote themselves to art creation or make more people understand, appreciate, and collect art images, promoting the development and dissemination of art creation.
It is not easy to describe the thought process of making choices for a particular genre. Because of this, the task of classifying artworks has traditionally been left to human experts [3]. The main research directions for classifying work styles using machine learning methods are as follows: calligraphy, music, and painting. Among them, music style classification in this thesis can be regarded as the style classification of one-dimensional signals. In contrast, image classification, such as calligraphy and painting, can be regarded as two-dimensional signal classification. Since their practical application scenarios do not require the introduction of reference information to assist in the calculation of image quality scores, this class of methods has a very important research significance [4]. It is also because blind image quality evaluation methods do not need reference information to assist in calculating quality scores, and the images contain rich content scene information and complex distortion information, leading to such methods still facing many difficulties and challenges.
Related works
In terms of feature extraction, calligraphic feature extraction techniques are generally divided into two categories: stroke extraction methods and global feature extraction methods [5]. Global features, on the other hand, focus on the statistical patterns in character images. To better address the distortion in stroke extraction, Gong et al. proposed a stroke extraction method based on matching feature points and line segments with reference strokes [6]. Farooq et al. extracted stroke segments based on the directional filtering technique to refine the stroke shape by iteratively minimizing the reconstruction error [7]. However, too much stroke detail in style recognition may lead to misclassification and loss of performance [8]. The colour feature is a commonly used image feature. Still, it is not applicable in calligraphy analysis because calligraphic works are composed of grayscale images or binary images with very limited colour levels. Researchers have achieved good classification accuracy by extracting texture features based on strokes to distinguish calligraphy styles [9].
Both tasks are very challenging because even the works of the same painter vary greatly in style. Image processing techniques have been used to provide art historians with quantitative tools, such as pigmentation analysis, statistical quantification of brush strokes, etc. A review of the subject in the “literature” covers several studies on painting classification using low-level features encoding colour, shading, texture, and edges [10]. In contrast, Gómez-Silva et al. proposed using colour-based statistical computation to extract global features and composition-based local features by segmenting painting objects to classify painting styles [11]. Based on the extracted features, using SOM for style classification and visual analysis of paintings provides a new way for art quantification.
In this section, we describe the methods and classification of oil painting style feature extraction in detail and analyze and compare several common similarity measure learning methods. Since traditional deep learning networks require many dataset samples, compared with the large sample data in the Image-Net task, the number of samples of artists’ works in the art style classification task is often small, and how to learn more features on a small dataset and use the model for automatic classification is a key problem [12]. In response to the shortcomings of traditional networks, this paper improves the classification of traditional models. It proposes a cross-contrast neural network model (CCNN) to explain the principles of cross-contrast networks. This paper introduces an oil painting dataset for style classification, for which the traditional deep network model and the CCNN model are trained, followed by experiments and results analysis to demonstrate the superiority of the CCNN model proposed in this paper. Finally, the CCNN model is migrated and used, and the internal mechanism of style feature extraction is further explored by visualizing the trained network model.
Analysis of improved embedded learning algorithms for visual perceptual fusion
Feature integration theory is one of the most influential theories of visual perception today, not only because of its role in explaining early visual perception but also because the theory fits well with the properties of artificial intelligence and computers in processing visual information. In this paper, we develop a system that includes a computational model of topological perception theory and apply it to the saliency detection task [13]. Then a topological complexity calculation method based on image topological features is proposed and statistically analyzed to reveal a positive correlation between image saliency and topological features. In addition, inspired by guided search theory, the work develops a topological saliency prior-guided global-local saliency fusion framework for combining topological and local contrast saliency maps [14]. To implement a general blind image quality evaluation method, this paper proposes a content-aware and distortion inference-based quality evaluation method to effectively predict the quality scores of synthetic distorted images and distorted images, as shown in Fig. 1. The quality evaluation method based on content awareness and distortion inference proposed in this paper consists of four components.

Quality evaluation network framework based on content perception and distortion inference.
Directly fusing such content features and distortion features with different characteristics will reduce the learning ability of the network [15]. Therefore, the adaptive fusion block proposed in this chapter aims to adaptively fuse the extracted content features and distortion features based on the weight values, and it consists of four attention-based fusion blocks, which describe spatial relations, temporal relations, and causal relations between topological and local geometric properties. The possibility of integrating local saliency cues by using topological properties as saliency priors has been discussed in the previous section. Along the non-selective pathway, the topological complexity-only saliency map designed in this paper is computed by the following equation.
Where the enhancement function is:
The first part of the weight term Equation (3) uses the inverse of the topological saliency before reducing the saliency of the background region and thus increasing the saliency of the object region. The work in this chapter argues that contrasts from background pixels can enhance the saliency of foreground pixels. In contrast, contrasts from foreground pixels can similarly reduce the saliency of background pixels. Meanwhile, the second part of the weight term equation emphasizes the effect of the spatial distance between superpixels, i.e., assigning larger weights to superpixels close to s
k
and smaller weights to superpixels far from s
k
. This model then multiplies S
ots
and S
d
to obtain S
td
to model the bootstrap of topological complexity on selective pathways.
In this chapter, two and three 3×3 convolutional layers are used instead of one 5×5 and one 7×7 convolutional layer, respectively, to reduce the computational complexity and achieve the same perceptual field. Next, the output features of different receptive fields are fused by a splicing operation. Again, the channels are compressed using a 1×1 convolution operation.
After obtaining the multi-scale content features and distorted features adjusted by the adaptive fusion block, the quality prediction block aims to learn the mapping relationship between the extracted features and the quality scores, which is performed as quality regression through the fully connected layer. Given the fused feature maps
Entropy was originally used to represent the disorder of molecules in thermodynamics. In image processing, it is called image entropy, which is used to indicate the amount of information in an image. The larger the image entropy value is, the richer the information content is, and vice versa, the smaller the information content is. The formula for calculating entropy is shown below:
Where K represents the number of intervals to which the pixels are mapped, the value of K affects the entropy and p n represents the ratio of the number of pixels falling in the nth interval [n, n + 1] to the total number of pixels.
After getting the correct model structure by editing and adjusting, we continue to test the correctness of the weights. Only when both the model structure and the weights are correct, we can guarantee the correctness of the final inference results. If the weights are converted wrongly, then the inference process may fail to load the model, the inference result is incorrect, etc., and usually, a lot of comparison tests are needed to locate the error. Finally, the successfully converted model is inferred and tested on the test set to ensure the results’ correctness and the accuracy’s stability, and the model conversion is completed, as shown in Fig. 2.

Partial visualization of the model structure.
In the importance-based channel pruning process, the channel output after the activation layer is used as the input of Equation (7) to calculate the image entropy of each channel, which is used to characterize the information size of the channel, and rank the channel importance of each layer, and to prune the channels with small information content and keep the channels with large information content in the pruning process to achieve model pruning [16].
Each new channel combination structure generated during the structure search pruning process requires fine-tuning training of the network on the training set and testing the model’s accuracy on the test set to obtain the accuracy of the pruning model. Since the objective function is to obtain the minimum value, the accuracy is obtained by subtracting 1 from the model’s error.
During the deployment of the embedded platform model, image data can be transferred from the camera to the application platform through RTSP protocol, MIPI interface, and USB interface, where RTSP is used for long-distance transmission or network camera devices, characterized by limited transmission speed but fast application. In contrast, the MIPI interface is mainly used for short-distance and fast transmission, common cell phone and computer cameras, characterized fast transmission but requires driver support.
Once the image data is transferred to the embedded computing module through the MIPI interface, it is decoded and pre-processed before being fed into the model for inference [17]. After that, we need to pre-process the BGR format image according to how the SSD model processes the image during the training process to ensure the correctness of the input data. Simple pre-processing can be done with the framework’s pre-processing module, while complex pre-processing operations can be done with the OpenCV library or other image-processing libraries.
The images are pre-processed and input to the SSD network for inference, and the output of the inference needs to be post-processed. The output of the general model framework is in the form of a matrix, and only after parsing can we obtain information about the detected targets, categories, and probabilities, and further logical processing, such as target display labelling and information statistics, can be performed with the acquired information. Most of the model deployment work is done after the model conversion, data acquisition, and post-processing are completed. Finally, the model needs to be coded and protected for practical application. It is important to consider the security issue when deploying the model, especially when it is deployed in the actual environment. The coding protection of the model is very important.
Before proceeding with the modelling, this thesis first specifies the target task. The ILSVRC dataset is ImageNet, and this classification task is to determine 1000 different categories, i.e., the classification result is 1000 categories [18]. And in the task of this thesis, this thesis classifies the artworks of 20 painters. Since ImageNet is a 10 million image database and the maximum number of works of each painter in this thesis is not more than 400, it is more complicated to retrain a new network in this case, and the parameters are also more difficult.
The initialization parameters of the model are based on the parameters trained in the ImageNet 1000 class classification and are fine-tuned according to the style classification task of this thesis. The initialization parameters of the model are based on the parameters trained in ImageNet 1000 class classification and fine-tuned according to the style classification task of this thesis. The parameters are as follows. The network has a total of 22210197 parameters and 401269 parameters to be trained.
Part of the overfitting problem during network training is due to the insufficient number of training samples. Data enhancement is mainly the process of increasing image data by using specific methods to create distorted images that belong to the same class as the original image, as shown in Fig. 3. The implementation of the deep learning style classification model in this thesis is based on Keras. There are two ways to build model instances using Keras in general, one is built by the Input class, and the other is built by the model class. The specific forms are different [19]. The default input image size is (224, 224, 3). To load the model’s parameters, we need to download the h5 file to the local area. For some layers that do not need to be trained in this thesis, we set trainable = False to ensure that the corresponding part will not be modified during the training process. This thesis uses Keras’ ReduceLROnPlateau function to set the iterative strategy for the learning rate. When the evaluation metric (validation set accuracy) is no longer improved, the learning rate is reduced to 0.8 times the original one; the best classification results are found when the learning rates are 10e - 3 for Inception and Resnet and 10e-5 for VGG.
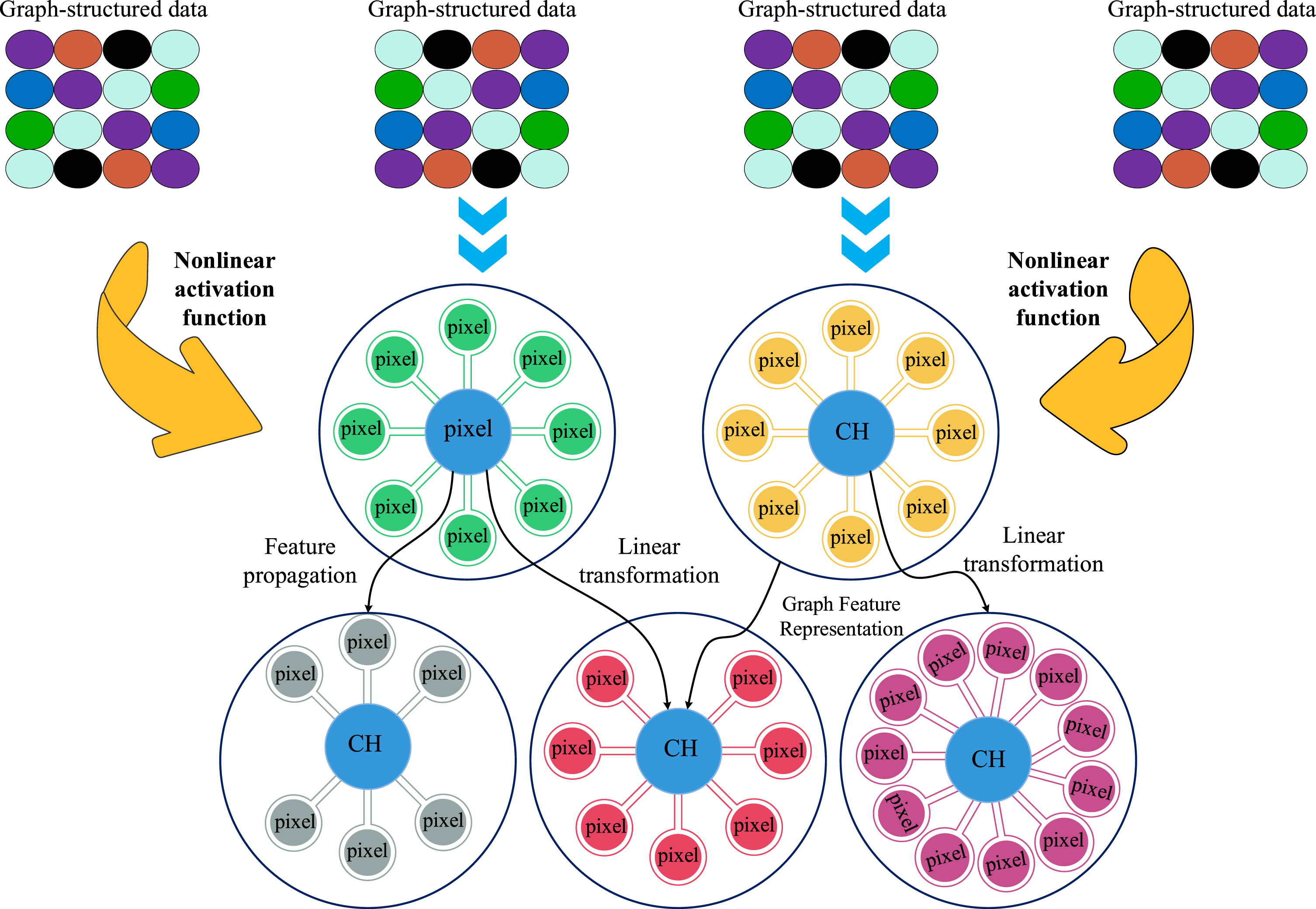
Steps of oil painting classification.
Target detection is now a fundamental research direction in many artificial intelligence fields, and target detection has made great progress with the rapid development of image deep learning technology and its derivative applications, such as text recognition, face recognition, graphic retrieval, and a series of other applications. Multi-target detection technology has two mainstream techniques in this research area, namely one-stage and two-stage target detection, where the main difference between the two is whether the target region proposal and the classification of the target region are divided into two different stages. These two types of algorithms have their advantages and disadvantages. For example, two-stage is more accurate for small target recognition and more accurate for border prediction compared to one-stage. In contrast, the one-stage method has a model simpler, faster computation and smaller model parameters.
Since its introduction, the plain Bayesian model has been widely used because of its simple logic, stable algorithm, and insensitivity to missing data. However, the conditional independence assumption proposed in this model is more difficult to be realized in practical applications, where there are often large or small correlational links between the feature attributes of the targets to be classified.
Data features have both discrete and continuous data features in terms of presentation. The two are very different in terms of the values that can be taken, and the values that can be taken care of are uncountable if no constraints are placed on the continuous type features [20]. When time is introduced into the field of probability identification, it is not difficult to find that the change of situation and the development of things are inseparable from time, so some people call the sequence of events over time a random process. But for the continuity of time, the inference model must make a partition to ensure the time complexity of the model. Events and time are interdependent; events developed by the passage of time may be in a state now at a certain moment because of historical factors, so it is not difficult to find that events and time are inseparable. But time also has a large and small influence on things, and as time goes on, the mutual influence between events becomes smaller and smaller. Therefore, some scholars based on this phenomenon proposed the Markov property. Markov property defined in the current event is only related to the event at a time in the past rather than the event in all the past time, as shown in Fig. 4.
Embedded learning oil painting simulation design framework.
Within the scope of machine vision research, image classification is the most fundamental and widely used research direction, which has undergone a long research process with a history of more than 50 years so far and has undergone several development stages, during which many new and effective methods have been born, which have also yielded good results and improved classification performance in the face of problems with different degrees of difficulty [21]. The gradual development of deep neural networks has brought a new research direction to image classification and has become the main method to solve image classification problems.
Performance analysis of improved embedded learning algorithm for visual perceptual fusion
In this paper, the CCNN model implementation is based on the TensorFlow framework, and the model’s training includes image pre-processing, model initialization and training, parameter tuning, and other steps. The fully connected layer is located at a later position in the convolutional neural network, and its final output is a probability value that can achieve the classification function, which is located before the classification function of the image. The network structure mentioned earlier is a mapping operation that transforms the image from data to information representation space. At the same time, the fully connected layer aims to preserve the information while achieving dimensional transformation. The common convolution operation for processing images is treating the information in each image position with the same weight without differentiating between different information. In other words, the convolution process is not biased towards the elements in the feature space that need attention. In practice, each element in the feature space reflects the background and foreground salient objects differently. This lack of focus and uniform convolution of all features affects the accuracy of the results to some extent. If the convolutional network processes all elements of the input signal similarly, the results may be largely disturbed by the elements in the non-significant regions, and the results will be inaccurate. As shown in Fig. 5, it can be obtained that the average loss decreases steadily as the number of training increases, which indicates that the model training is converging towards the expected direction.
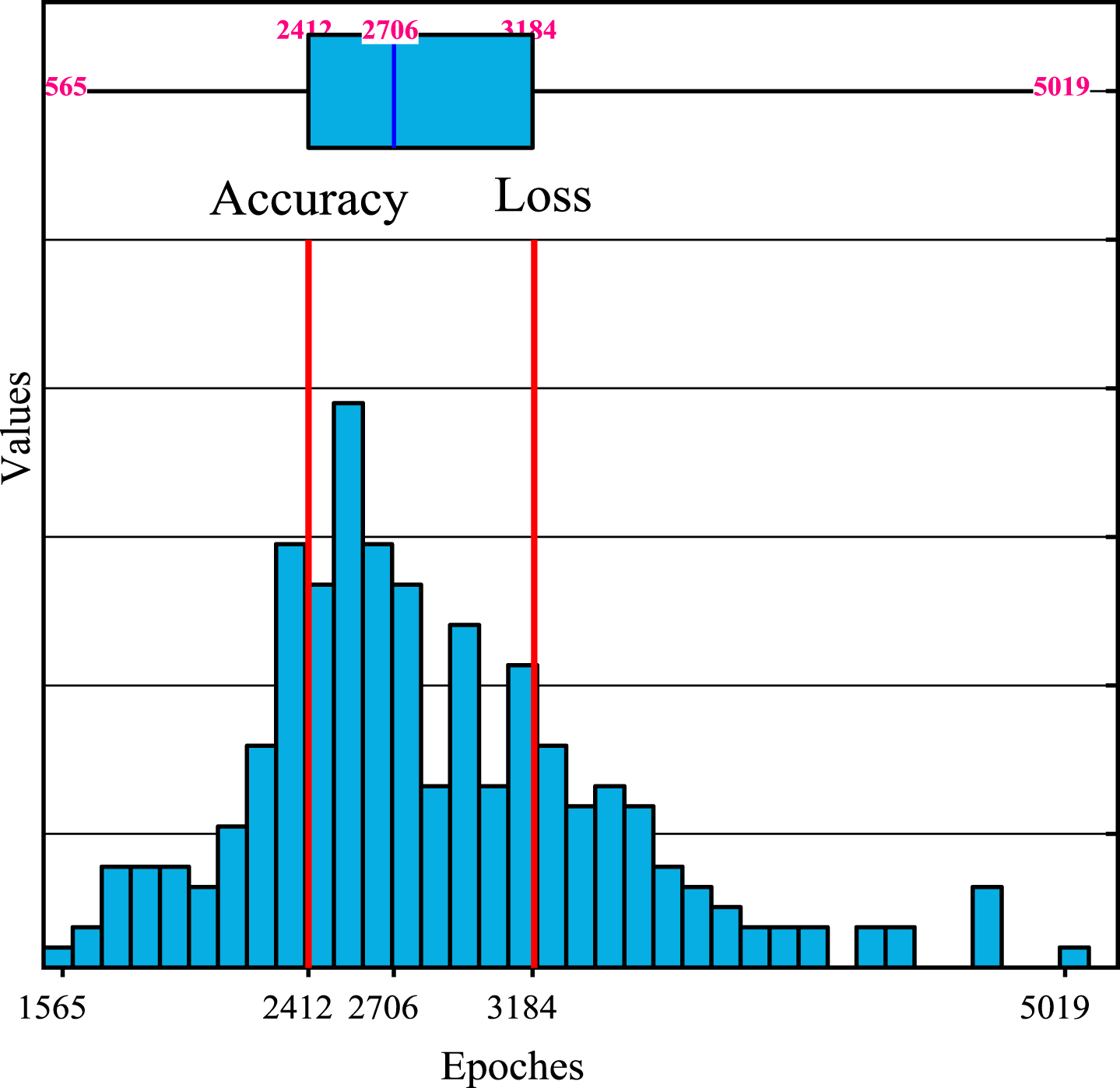
Training set accuracy and loss variation.
The CMKR algorithm mainly includes two core arithmetic sub-modules, namely, the acquisition of spatial relationship features in target detection and cross-modal contextual knowledge fusion and migration, which means that the image features and spatial features of each instance in the image are extracted using the target detection system, and the relationship features between the instances are acquired using the above features. Then the contextual information and relationship features are used for fusion inference to improve the accuracy of the edge computing nodes’ target detection model. Before training, the image size is adjusted to 256*256 to speed up the learning rate, and batch saliency detection is performed on the image to obtain the mask graph. The mask graph is operated with the input data samples to obtain the subject image samples with the background filtered out. The model decay is 0.9, which is used to control the update rate of the model and is trained for a total of 100,000 iterations. For training, one of the 256 categories is randomly selected as the target category for model training. For testing, data from the remaining 255 categories are selected as anomalous data plus the target data together and sent to the single classifier for classification testing, as shown in Fig. 6.
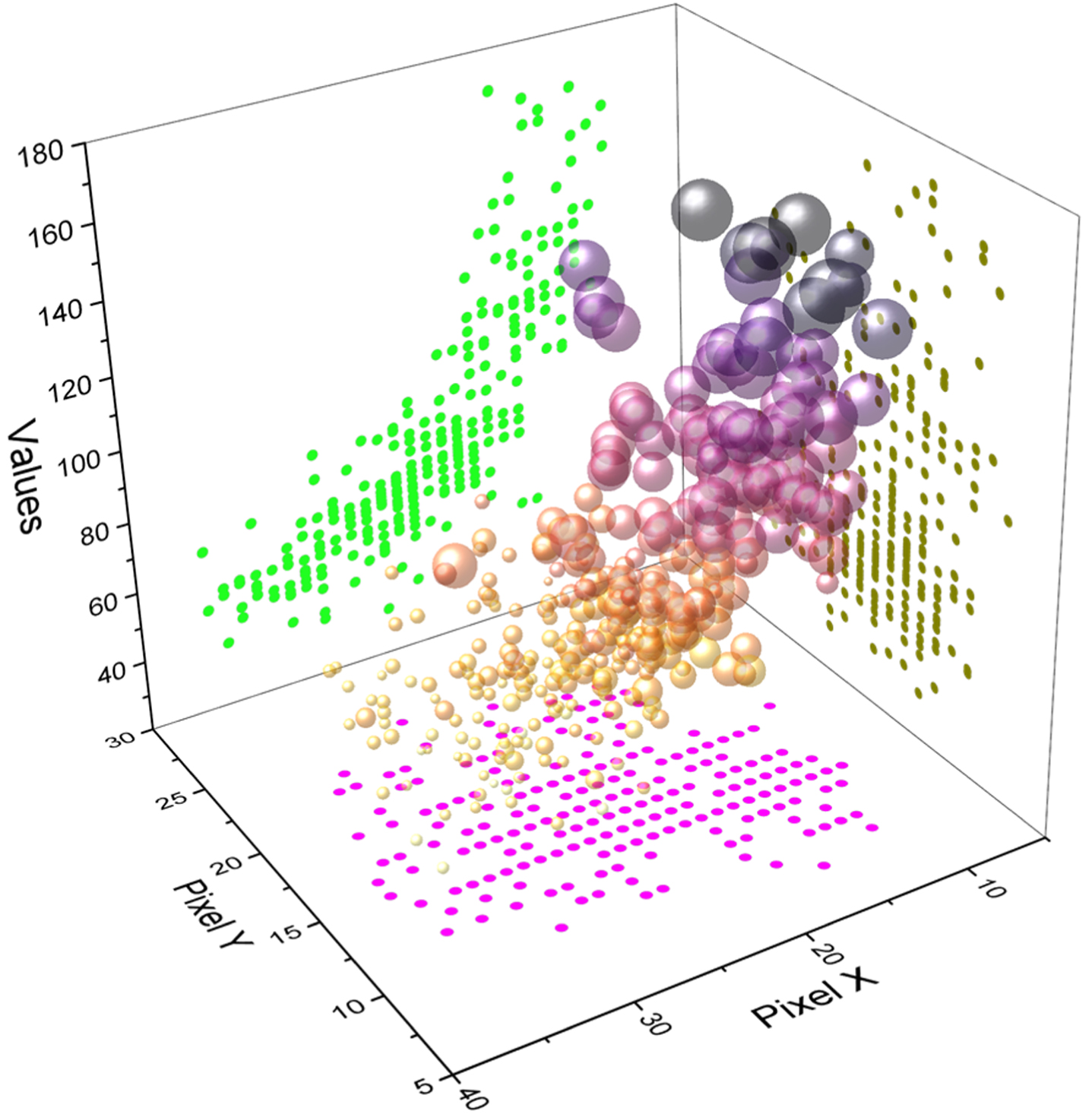
Probability distribution of different images.
The test starts from the feature that the training and validation sets have large differences, which is consistent with the problem faced in intelligent transportation edge computing-based deep learning mentioned in the paper, i.e., the problem of differences in the distribution of sample features due to the model’s training samples in the cloud service and those encountered in the edge computing nodes. Therefore, experiments are used to simulate the occurrence of the above problem, i.e., in this chapter, the model is trained on daytime data samples and validated in nighttime test samples, and finally, the target detection performance of the model is compared in the nighttime test samples.
Traditional deep learning using cloud servers can train a large number of samples due to more computing resources. However, edge computing servers cannot train a large number of models. Still, facing the difference between the samples encountered by the edge nodes and the samples trained by the servers, migration learning can be used to fine-tune the model, which is also mentioned as the knowledge sharing of intelligent transportation edge computing important component under the framework, so this section also evaluates the performance of the knowledge migration capability of the model in less sample training. The model training scheme is adopted as follows: firstly, many daytime data samples are used for model training, in which a small amount of nighttime data is used for model migration learning, and finally, the test results of the model at night are evaluated.
To explore the effectiveness of CCNN for the style classification task, images of artists with different styles were selected for visualization and analysis in this thesis. The method is as follows: 50 images, each of different styles of artists, are selected from the Selected-Likebaiting dataset, and the image size is cropped to 224 x 224 x 3. For the original images, the PCA dimensionality reduction is performed directly on the original images, and the 200-dimensional features obtained are used as the feature representation of the original images. For the CCNN-trained image, the convolution result of 4-1 layers of the CCNN model is taken as the image representation, and the number of dimensions is reduced to 200 features by PCA. In this way, two-dimensional representations of the original and trained images are found. Finally, the t-SNE method was used to map it into a two-dimensional vector. The following figure shows the two-dimensional embedding of the selected painting image. In Fig. 7, it can be observed that for Monet and Renoir, who are also impressionists, the t-SNE distributions of the original images have a very large overlap. In contrast, their distributions can be better separated after CCNN, which indicates that the CCNN of this thesis has a good degree of differentiation between artists within the same genre.

Expressionism and t-SNE tingling visualization of Baroque images.
In addition, the number of activations of the feature maps of the filter trained on the face dataset and the filter trained on the painting dataset is counted for both images. It is found that the number of activated feature maps in the Conv4_1 layer is 277, and the number of suppressed ones is 235 in the oil painting, while the number of activated feature maps in the Conv4_1 layer is 358 and the number of suppressed ones is 154 in the photo. The number of activated feature maps in the Conv4_1 layer is 358, and the number of suppressed ones is 154. The output of the corresponding face photo in the filter is more activated.
The output of the oil painting Vermeer and the digital photo differs in the same set of filters. The number of features is reduced in the process of evolving a digital photo into an oil painting. The number of features output is the same for the oil painting Vermeer input oil painting and face filter. From this result, it can be inferred that: The feature dimensions extracted by the CCNN model are the same when a picture is recognized as a face and as a painting. The number of features is determined by the painting itself, independent of the filter. In the CCNN model, the input image itself determines the number of features activated in the convolutional output of the last layer. In contrast, the filter sets obtained by training according to different data sets determine the specific performance of different features, as shown in Fig. 8.

Simulation results.
Image enhancement enhances the feature areas that the human eye focuses on and suppresses other feature areas. The effectiveness of image enhancement is usually derived from the visual observation of the human eye, and the process is subjective. The reason is that the ImageNet dataset used to pre-train the content feature extractor contains rich distorted images. Finally, the validation and evaluation of the model are carried out on the BDD100K traffic scene target detection dataset according to the problems faced in the knowledge-sharing framework of intelligent transportation edge computing. By dividing the daytime data as the training set and the nighttime data as the test set, the model evaluation of the cross-modal knowledge inference network on the two tasks of target detection performance enhancement and less-sample knowledge migration is completed by simulating the feature distribution of the training data from the cloud server and the mobile edge server with different feature distribution.
The style of artwork is an important part of the meaning of the work, and oil painting is the main painting style in the history of Western painting. With the development of digital technology, many museums are constructing digital oil painting databases, which enable famous artworks to go from the world of museums to the big world, accomplishing a new era of art sharing given by digitalization. For artworks, their art styles are a relatively complex description, so how correctly identifying the art styles of paintings is the key to building a large art database. Recognizing the style of a picture in a fully automated manner is a challenging problem. For standard classification tasks such as facial recognition, which can rely on clearly identifiable features such as eyes or nose, classifying art styles cannot rely on any figurative features and is especially difficult for artworks that are not representative. Secondly, a CCNN multiclassification method is proposed, which can measure the similarity and multi-classify the styles of artworks and the corresponding artists. This part is the main part of this paper. In this paper, the oil painting dataset is constructed using the wiki art library because the image styles such as academy, baroque, and cubism are well defined in the art classification. The dataset includes more than 2000 works from 20 artists in 13 styles. CCNN achieves 85.75% accuracy on the artist classification task, which is much better than traditional deep learning networks such as Resnet.