
Abstract
Task-oriented collaborative dialogues have become an indispensable form of communication in our daily work and learning, in which participants exchange ideas and share information to advance goals. It is crucial to automatically analyze participants’ contributions and understand these dialogues relative to individuals with limited attention spans. In this paper, seven Discourse Role (DR) labels are designed to describe discourse’s different roles in collaborative dialogues for goal achievement. We collected about 11K discourses from a publicly available dialogue corpus and annotated them with DR tags to construct a dataset named MRDR (Meeting Recorder Discourse Role). In addition, this paper proposes a novel hierarchical model, STTAHM (Speaker Turn and Topic-Aware Hierarchical Model), for Discourse Role classification. The model is equipped to perceive speaker turn and dialogue topic and can effectively capture the discourse’s local and global semantic information. Experimental results show that our proposed method is effective on the constructed dataset, and the accuracy of Discourse Role classification reaches 86.99%.
Introduction
With the proliferation of automatic speech recognition systems, the recordings of task-oriented collaborative dialogues are increasing, which creates an excellent opportunity to improve transparency and productivity. However, in the face of such an unprecedented number of conversations, how can we quickly analyze participants’ contributions and understand these dialogues relative to the limited attention span of individuals? Merce et al. [1] proposed three dialogue modes: argumentative, cumulative, and exploratory dialogues. They categorized the discourse mainly on the linguistic and psychological levels. They focused on how people use language to think together when solving problems. Goodman et al. [2] researched the roles that speakers played during collaborative dialogues and categorized them into 12 speaker roles, such as initiator, evaluator, and suggestor. They are mainly designed to identify problems arising in the discussion and give appropriate guidance. Stone et al. [3] provide predefined relationships between discourses in a collaborative dialogue, such as question and answer, contrast, continuation, etc., which explicitly show the flow of information and interactions between the discourses. However, current analysis of collaborative dialogues mainly focuses on the micro level, where the research focuses on the discourse itself or the relationship between the discourses and the discourse, while there are relatively few studies on the macro level. This paper focuses on the role that discourse plays in collaborative dialogues for goal achievement and puts the research focus on the representation of macro dialogue structure.
In task-oriented collaborative dialogues, each discourse plays a specific Discourse Role while expressing a particular content. The following features characterize the discourse of this type of dialogue: (1) Goal-oriented: the discourse usually revolves around a task or a problem. The communication between the participants is oriented to the realization of common goals. (2) Information sharing: discourse involves the sharing and exchanging of information. Participants express themselves through discourse to facilitate information sharing and shared understanding. (3) Cooperation and coordination: discourse is cooperative and coordinated. Participants cooperate and coordinate with each other to achieve common goals. (4) Feedback and evaluation: discourse includes feedback and evaluation. Participants give feedback on the views of others to facilitate consensus and decision-making. (5) Context-sensitive: Discourse is context-sensitive. Participants need to consider the content of previous conversations to understand better and respond to questions or requests. Therefore, based on the above discourse characteristics, this paper designs seven Discourse Role labels for describing discourse’s different roles in collaborative dialogues for goal achievement. The categories and definitions of Discourse Roles are detailed in Section 3.2. For example, a sample task-oriented collaborative dialogue is illustrated in Table 1. For each discourse in Table 1, the corresponding label defines its Discourse Role. These Discourse Roles are related to the facilitation and coordination of the task in which the group is involved. Accurately identifying Discourse Roles provides an objective basis for analyzing the specific contribution of each participant in the conversation. The three main challenges of this paper are:
Example of task-oriented collaborative dialogue
Example of task-oriented collaborative dialogue
First, the datasets with annotations are limited. Although task-oriented collaborative dialogues have become an indispensable form of communication in our daily work and study, almost no annotated corpora are dedicated to detecting discourse roles in such dialogues.
Second, most existing approaches treat oral dialogues as analogous to written texts, ignoring explicit modeling of speaker turns and dialogue topics. In a dialogue, a change in speaker turn causes a shift in Discourse Role. For example, in Table 1, given that the Discourse Role of speaker mn015 is Interpretive Inference, if the next speaker turn changes, i.e., the discourse comes from me012, then the corresponding Discourse Role is likely to be Evaluation; however, if there is no change in the speaker turn, i.e., the speaker remains mn015, then the next discourse role is still likely to be Interpretive Inference. In addition, different topics of dialogue may lead to different distribution of discourse roles, for example, in the topic of "Technical Support," the discourse roles tend to Seeking Clarification and Provide Information, while in the topic of "Problem-Solving", the discourse roles tend to Interpretive Inference and Evaluation. Therefore, it is essential to model speaker turn and dialogue topic in dialogues. Therefore, this paper hypothesizes that modeling speaker turn and dialogue topic as additional contextual information can effectively support discourse role categorization. However, unlike well-structured texts, speaker turn and dialogue topic change as the dialogue progresses, which poses a challenge for discourse role recognition.
Third, unlike text categorization tasks that deal with each discourse individually, discourse role recognition relies on contextual information between discourses. For example, Initiating New Topic may appear as declarative or interrogative sentences, whose discourse features are less obvious. To accurately recognize an Initiating New Topic, it is necessary to determine whether its semantics are related to the previous dialogue. This means that when performing discourse role recognition, the characteristics of individual discourse should be considered, and the context and dynamics of the whole dialogue need to be understood.
To address these challenges, we collect task-oriented dialogue data from an existing corpus of dialogues and annotate it. In this paper, the problem of discourse role classification is treated as a sequence labeling task. Based on [5], a large pre-trained language model RoBERTa [6] is first utilized to obtain discourse embeddings. To equip the model with the ability to perceive speaker turn and dialogue topic, two additional embedding layers were introduced to encode speaker turn and dialogue topic information, respectively. These additional embedding layers generate embedding vectors of the same size as the discourse embeddings, and then they are subjected to a summation operation with the discourse embeddings. Next, the augmented discourse embeddings are fed into a bidirectional long short-term memory network (BiLSTM) to capture the contextual information of the discourse better.The discourse representations output from the BiLSTM are used for discourse role recognition. The main contributions of this paper’s work are as follows:
1) A dataset called MRDR (Meeting Recorder Discourse Role) was constructed. About 11K discourses were collected from the dialogue corpus and annotated with DR tags. This dataset provides a powerful resource for the task of discourse role classification.
2) A novel hierarchical model, STTAHM (Speaker Turn and Topic-Aware Hierarchical Model), is proposed for discourse role classification. The model is equipped with the ability to perceive speaker turn and dialogue topic and effectively capture both local and global semantic information of discourse.
3) Comparative analysis shows that STTATM achieves state-of-the-art performance on MRDR. Furthermore, exhaustive ablation experimental studies determine the effectiveness of each module of the STTATM.
Dialogue mode
The dialogue mode was first proposed in the field of education. In general, informal learning cannot be thoroughly compared to collaborative learning in an educational environment. However, there are similarities in how meaning is formed and recognized, especially when people engage in task-oriented collaborative dialogue. Mercer et al. [1] considered how speakers are currently talking and thinking and proposed three modes of social thinking: argumentative dialogue, cumulative dialogue, and exploratory dialogue. Ferguson et al. [7] explored a method for detecting exploratory dialogue in online synchronous text chat. They manually identified a list of cue phrases indicating the presence of exploratory dialogue. Ferguson et al. [8] used exploratory dialogue to indicate ongoing learning. They developed a self-training framework based on previous work that uses discourse and topic features for classification by integrating cue phrase matching and k-nearest neighbor classification. Ekman et al. [9] developed a framework for encoding exploratory dialogue based on Mercer’s research, including five categories: challenge, evaluation, extension, reasoning, providing information, and community work. The exploratory elements of the whole dialogue were analyzed through qualitative content analysis, focusing on how people use language to think together when solving problems. Based on a coding framework for dialogue modes, this paper defines categories of discourse roles. The focus is on discourse’s role in collaborative dialogues for goal achievement to analyze the participant’s contributions to the dialogue. In addition, discourse roles can reflect changes in the way information is conveyed and the way speakers interact with each other in a dialogue, thus contributing to the understanding of the conversation.
Speaker role
Most of the existing work enhances the ability of language models to understand dialogues mainly by encoding speaker roles. Chi et al. [4] proposed a role-based contextual model that can independently consider the roles of different speakers based on various speaking patterns in multi-person dialogues. Similarly, Chen et al. [10] proposed an attention-based network that utilizes temporal information and speaker roles to improve spoken comprehension. Zhu et al. [11] trained a vector for each speaker role and represented it as a fixed-length append to the embedding of speaker turns to improve the performance of the summary model. Song et al. [12] Used a single-layer neural network to convert speaker roles into vector representations. They attached them to a word encoder, which helps to recognize patient and doctor discourse better. Unlike methods based on speaker roles, the method proposed in this paper focuses on speaker turn and is independent of the speaker’s identity information. Thus, it is still valid when the speakers in a dialogue do not have formal roles. This allows the model to better adapt to different types of dialogue scenarios.
Dialogue act
Dialogue Act (DA) is a semantic label associated with each discourse in a dialogue that indicates the speaker’s intention, e.g., question, backchannel, stated opinion, etc. Recently, many studies have approached DA classification as a sequence labeling task to fully use contextual information between discourses. Chen et al. [13] posed the problem of Dialogue Act recognition in terms of capturing hierarchically rich discourse representations and generalized richer structural dependencies of the CRF attentional graphs without giving up end-to-end training. Li et al. [14] proposed a dual-attention hierarchical recurrent neural network for DA classification. Their model can capture information about DAs and topics in response to discourse and information about their interactions. Raheja and Tetreault [15] utilize a context-aware self-attention mechanism and a hierarchical RNN. Shang et al. [16] use a BiLSTM-CRF architecture that considers speaker information for a DA classification task. Colombo et al. [17] introduced a seq2seq model customized for DA classification using a hierarchical encoder, a novel guided attention mechanism, and beam search applied to training and inference. Malhotra et al. [18] proposed a Transformer-based architecture with novel speaker- and time-aware contextual learning for classifying dialogue behavior in mental health counseling dialogues. Similar to the above work, this paper treats the discourse role categorization task as a sequence labeling task. The difference is that the above approaches assist in discourse category identification by proposing more complex and specialized models to model speaker interaction or conversation topic information, which inevitably introduces many parameters for training. In this paper, speaker turn information and dialogue topic information are encoded through two additional embedding layers. This approach requires only negligible modifications to the recurrent model and introduces O(1) space complexity.
Corpora construction
The Discourse Role dataset, called MRDR, is presented in this section. Overall, 11K utterances are annotated with seven well-designed Discourse Role labels. The rest of the section provides detailed information on data collection, annotation schemes, annotation process, data preprocessing, and data statistics.
Data collection
Since the object of study in this paper is task-oriented collaborative dialogue, a large corpus of dialogues about meetings is consulted to construct a Discourse Role dataset. Ultimately, the MRDA corpus [19] is chosen as the original dialogue data. This is because MRDA is a multi-party, task-oriented, collaborative conversation corpus with a large number of discussions on a wide range of topics. At the same time, the dataset is tagged with dialogue act, which can be used as auxiliary information for annotating the Discourse Role labels. The MRDA dataset is constructed by annotating the dialogue act on the ICSI Conference Corpus [20]. The ICSI Conference Corpus is captured from real face-to-face conferences covering various specialized areas, such as computer science, linguistics, and so on. This gives authenticity and diversity to the conversations in the corpus. It consists of 75 meetings of approximately one hour each. There are 53 unique speakers in the corpus, with an average of about six speakers per session. In ICSI, there are, on average, 10,189 words and 464 turns in the conference transcripts. Since the ASR system generates the transcripts, the textual error rate of ICSI is 37% respectively [21]. This paper selects eight meetings to be annotated with Discourse Role labels.
Dataset annotation scheme
Seven discourse role labels were designed by analyzing data from real collaborative dialogues. These labels aim to describe the different roles of discourse for goal achievement. The specific descriptions are as follows:
Annotation process
The ICSI meeting corpus contains dialogue summaries, topic descriptions, and dialogue act information. Therefore, to improve the annotation quality of the dataset, before annotation, the annotator reads the summaries of the annotated dialogues to understand the content of the dialogues. During the annotation process, the Discourse Role annotation work will be done with the help of conversation topic descriptions and conversation act labels. The annotators are five graduate students from the computer technology major.
At first, the basic unit of Discourse Role annotation was set as turn (i.e., the speaker did not change the words spoken). However, during the annotation process, it was found that some conference speakers spoke too long, and their Discourse Roles changed during the long speech. For example, in the early part of the speech, the Discourse Role is Interpretive Inference(II), and in the later part, the Discourse Role is changed to Seeking Clarification(SC). Therefore, the annotator segments the speaker’s speech according to the semantics of the discourse and takes the speaker’s complete expression as the annotation unit.
To ensure an understanding of the task and the annotation scheme, the dataset was sampled, and each annotator was asked to annotate it according to a prepared set of guidelines. After this, all annotators engaged in a discussion to ensure consistency. After several rounds of annotation and discussion, the entire dataset was available for annotation. After the data annotation, a Kappa score for MRDR was calculated to measure inter-annotator agreement. An inter-annotator consistency score of 0.643 was obtained.
Data pre-processing
To ensure the dataset’s quality and eliminate interfering factors in the discourse role identification task, the following processing measures were taken: (1) Discourses that were not fully transcribed in the dialogue were deleted. (2) All the discourses of one complete formulation of each speaker were concatenated as the unit of the sample, i.e., discourse. (3) Unique numerical codes were assigned to each discourse role in increasing order, and then unique discourse role labels, i.e., DR, were assigned to each discourse. (4) To facilitate the chunking of dialogues, each meeting is considered a complete dialogue segment, and the dialogues are coded with a numerical serial number in increasing order, i.e., dialogue_id. The dataset is processed accurately and orderly through these steps, providing a reliable basis for subsequent analysis and modeling.
Statistics
In total, there are 11064 discourses in MRDR. A total of 6021 data were annotated with one complete expression of the speaker as the annotation unit. Compared to other dialogues, the dialogues in MRDR are usually long, with an average dialogue length of about 1500 times. Since we used one complete expression of the speaker as the annotation unit, the average dialogue length was about 660 times, and the average length of the discourse was 15 words.
Table 2 shows the distribution of Discourse Role labels in the MRDR dataset. It can be observed that Interpretive Inference (II) occupies the most significant proportion, followed by Passively Accepting (PA). In contrast, Non-Exploration (NE) had the smallest percentage. This distribution pattern may be because the process of interpretation and inference is crucial for problem-solving and consensus-building in task-oriented dialogue. At the same time, acceptance of others’ viewpoints and information helps to establish an effective communication and cooperative atmosphere. Non-Exploration (NE) is relatively less frequent because Non-Exploratory discussions may reduce the engagement and depth of the whole dialogue. It is worth noting that the distribution pattern of Discourse Roles included in the MRDR dataset is uneven, with specific Discourse Roles being used more frequently than others in task-oriented collaborative conversations. This distribution pattern reflects the natural variation in participants’ use of the Discourse Role in collaborative dialog. At the same time, the skewed nature of this data presents a challenge for Discourse Role identification.
Distribution of Discourse Role labels in MRDR
Distribution of Discourse Role labels in MRDR
The general structure of the STTATM model proposed in this paper is shown in Fig. 1. In this example, the dialogue consists of five discourses containing two different topics, and the topic changes in the fourth discourse. The STTATM model is a hierarchical encoder tagger. Given a dialogue containing a series of discourses, (1) Discourse-level encoding: discourse embeddings are obtained using a sizeable pre-trained language model RoBERTa, integrating speaker turn information and dialogue topic information to the discourse embeddings. (2) Dialogue-level encoding: The enhanced discourse embeddings are fed into BiLSTM to capture the contextual information of the discourse. Finally, the obtained discourse representations are used for Discourse Role recognition. In this section, each component of the model is described in detail.

General structure of the STTATM model.
Given corpus
Hierarchical dialogue encoder
This paper uses a hierarchical structure to model the relationships between discourses in a dialogue. Each discourse is first encoded independently, and then the encoded discourse sequence is fed into a recurrent neural network to generate a context-aware discourse representation.
Discourse-level coding
In this paper, a pre-trained language model is used to encode each discourse independently. This is because the encoded representations of pre-trained language models have been shown to improve the performance of several NLP tasks. Specifically, RoBERTa is used as the discourse encoder, which is based on the popular BERT [22] with an enhanced training mechanism. RoBERTa has been shown to have better performance than BERT. The RoBERTa tokenizer lowercases and tokenizes each discourse, and then inserts a special [CLS] token at the beginning of the tokenized sequence. The token sequence [[CLS] , Wk,1, Wk,2, …, Wk,Nk] is fed into the Transformer [23] encoder, which is initialized using RoBERTa pre-training weights. The RoBERTa model is further fine-tuned on the Discourse Role classification task.
We are inspired by the study of Transformers [23], who summed positional embeddings with token embeddings in sequence representations. Therefore, this paper sums the speaker turn embedding with the discourse embedding r(u).
Such a design enables speaker turn information and topic information to be integrated with the discourse, which helps to enhance the model’s ability to perceive speaker turn and dialogue topic. In this paper, we also try the tandem operation of discourse embedding with speaker turn embedding and topic embedding, which performs poorly compared to summation.
Since a dialogue text is a continuous sequence of discourse, there is often a strong correlation between the preceding and following discourses, which is crucial for Discourse Role recognition. Therefore, we use BiLSTM to capture the contextual information of each discourse. Given the enhanced discourse embeddings
Finally, using a linear layer to predict the Discourse Role y k of each discourse.
This layer is optimized using cross-entropy loss.
Implementation details
This paper implements the proposed model using the PyTorch framework, and the classification cross-entropy loss is optimized using the Adam optimizer. The complete list of hyperparameters is given in Table 3.
Training hyperparameters
Training hyperparameters
Since the dialogues in MRDR are much longer (up to 1053 times), dialogues are partitioned into fixed-length dialogue blocks to evade overflowing memory during training. As shown in Fig. 2, a dialogue of length 10 is sliced into three dialogue blocks of length 4, where each block denotes a data spot. The chunking operation is not required for validation or testing, as maintaining the computational graph during training consumes more GPU memory.

Example of dialogue blocking.
Keeping the other hyperparameters constant, Table 4 shows the results using different block sizes on MRDR. As the block size increases from small values, the performance improves, and the RNN can utilize more contextual information. Nevertheless, once a threshold is exceeded, a further increase in the block size leads to a performance reduction. In this case, the RNN suffers from gradient disappearance and explosion problems and forgets about long-term dependencies. Therefore, it can be argued that partitioning long dialogue into smaller blocks as input improves performance in the Discourse Role classification task. Therefore, the block_size parameter is set to 16.
Accuracy of using different block sizes on MRDA
Experimental results
In the experiments, the dataset was divided into the ratio of 70:20:10 as training, validation, and test sets, respectively. To measure the performance of the STTATM model and other baseline models, the experiments in this paper use Precision(P), Recall(R), F1-measure(F1), and Accuracy(ACC) as the evaluation metrics of model performance. The speaker turn embedding, and topic embedding proposed in this paper can be used in other embedding-based discourse classification methods. Since these two embeddings are not used in the code of the baseline model, the proposed speaker turn embedding, and dialog topic embedding are not implemented on the baseline. To effectively validate the performance of the STTATM model, this paper uses speaker turn and topic embeddings on the RoBERTa model.
Table 5 shows the results of the comparison experiments. It can be observed that the STTATM model achieved state-of-the-art results on MRDR with an accuracy of 86.99%. Except for the RoBERTa model, none of the other baseline models reached 80% accuracy. The possible reason for this gap is that RoBERTa learns rich contextual information on large-scale textual data through pre-training and can capture the rich semantic representation of discourse. Second, RoBERTa performs well on a small amount of labeled data relative to traditional models because it can migrate pre-trained knowledge. Meanwhile, RoBERTa model’s performance improves significantly with the addition of speaker turn and dialogue topic information, demonstrating the effectiveness of modeling speaker turn and dialogue topic in discourse role recognition task. It is worth noting that the accuracy of the RoBERTa speaker+topic model is still lower than that of the STTATM model. Discourse role recognition relies on remote contextual information.RoBERTa is a Transformer-based model that uses a self-attention mechanism that captures semantic relationships between words. Although it can consider a certain amount of context during pre-training, its self-attention mechanism may be limited when dealing with long sequences. In contrast, BiLSTM is a recurrent neural network that processes sequences in a time-step-by-time-step manner, gradually accumulating and transferring information in the sequences, and thus has advantages in dealing with long-distance dependencies. Thus, the model can understand and model the context at different levels by combining the two, improving the overall understanding of the sequence.
Experimental results of the comparison model
Experimental results of the comparison model
Table 6 shows the performance of the STTATM model in terms of discourse role labels. It can be observed that II, E, SC, PA, and NE are better recognized with accuracies of 89.30%, 71.74%, 89.77%, 93.47%, and 92.86%, respectively. These discourse roles appear more frequently in the dataset, their discourse features are apparent, and the model can capture their discourse features effectively. However, the accuracy rates of PI and INT are 51.52% and 48.94%, respectively. These two types of discourse roles appear less frequently in the dataset, and their discourse forms are diverse, which may lead to difficulties for the model to learn their discourse features thoroughly. In summary, the STTATM model performs well in most discourse roles. However, there is still space to improve the performance of the model for the rare roles with less distinctive discourse features, and more training data or more complex model structures are needed to improve the recognition of these discourse roles.
Labels classification results for STTATM
Figure 3 reports the confusion matrix of STTATM. Two pairs with significant error rates (≥ 40%) can be observed - INT: II (44.7%) and PI: II (42.4%). The STTATM model tends to predict INT and PI as II incorrectly. This error can be attributed to the diversity of discourse, i.e., INT and PI are often presented in different discourse forms. For example, "I think we should......" and "because someone already has...... For example, "I think we should " and "because someone already has " belong to INT and PI, respectively, but they are easily confused with II because of the presence of "I think" and "because," which are keywords of II’s discourse role. Another possible reason is that II is a more significant part of the dataset, and the model may be more inclined to predict the more frequent categories and less effective in predicting the rare categories. For the remaining cases, the error rate can be considered nominal. Therefore, this paper clarifies that STTATM can be further improved with a more balanced dataset.
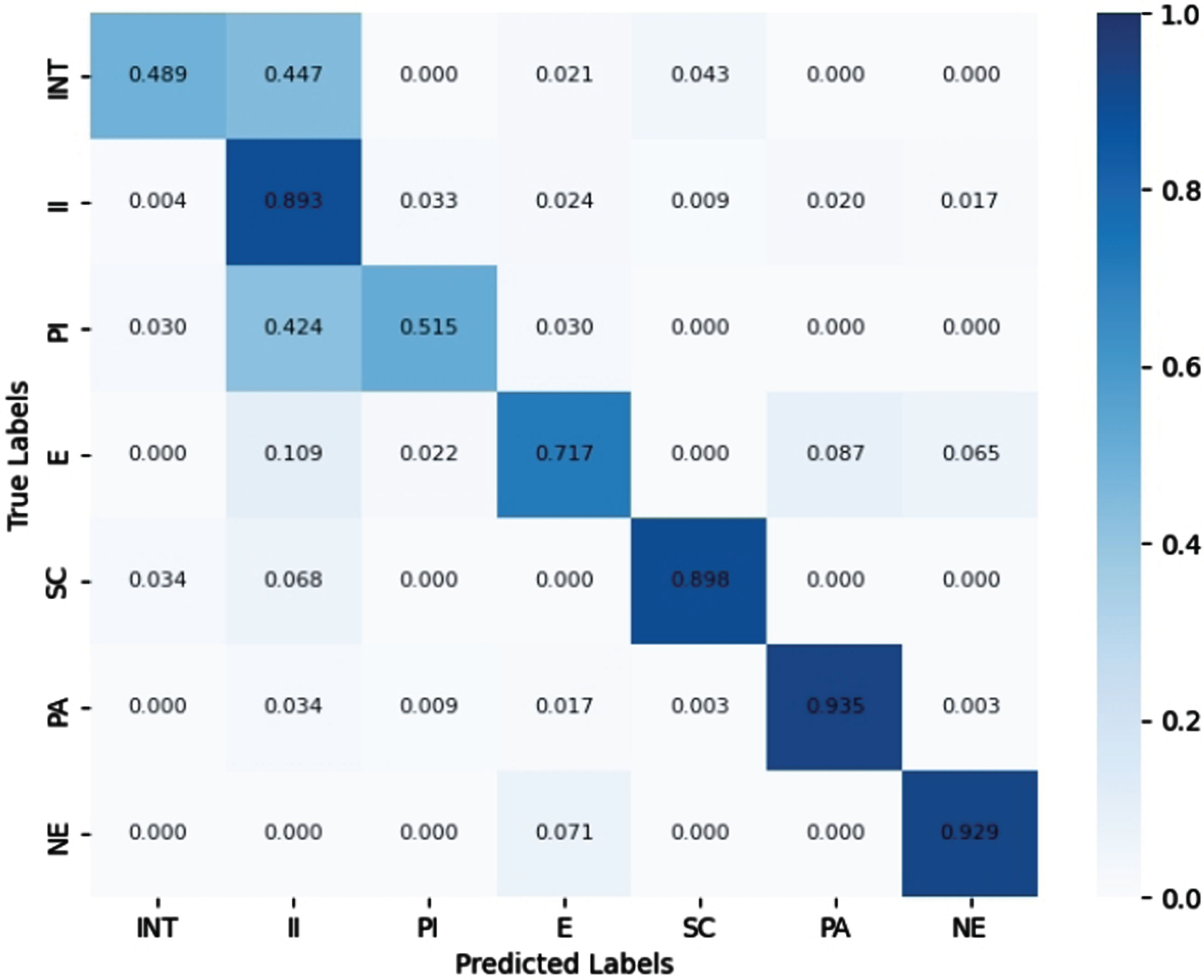
Confusion matrix for STTATM.
Ablation experiments are conducted to verify the effectiveness of speaker turn embedding and dialogue topic embedding in the STTATM model. The experimental results are shown in Table 7. “¬speaker” indicates that no speaker turn embedding is added; “¬topic” indicates that no topic embedding is added. It can be observed that there is a significant improvement in the performance of the STTATM model compared to the STTATM¬speaker +¬topic model, indicating the effectiveness of modeling speaker turn and dialogue topic in the discourse role classification task. In multi-round dialogues, discourse roles usually change dynamically, and speaker turn embedding can help the model capture this dynamism. In addition, there is a correlation between dialogue topics and discourse roles, and dialogue topic embedding can help the model capture this correlation. Meanwhile, it is noted that the STTATM¬speaker model outperforms the STTATM¬topic model in all metrics. Therefore, it can be concluded that dialogue topic information is more effective for discourse role modeling than speaker turn information. Dialogue topics provide a broader context that helps the model understand the overall context of the current dialogue. Although speaker turn information is essential for understanding the alternation between speakers, it provides only local information that limits the model’s understanding of the entire dialogue. Therefore, the speaker turn provides limited auxiliary information.
Comparison results of ablation experiments
Comparison results of ablation experiments
In this work, a new dataset called MRDR is developed to provide a platform for Discourse Role classification in task-oriented collaborative dialogues. In addition, this paper proposes the STTATM model, a hierarchical model for Discourse Role classification. The model encodes discourse from the discourse level and dialogue level, which simulates the relationship between discourses in dialogue and can effectively capture the discourse’s local and global semantic information. Meanwhile, the two global additive embedding vectors introduced provide an effective means for the model to have the ability to perceive speaker turn and dialogue topic. Moreover, this technique only requires negligible modifications to the recurrent model and introduces O(1) space complexity. The approach proposed in this paper focuses on speaker turn being independent of the speaker’s identity information, which allows the model to be better adapted to different types of dialogue. For future work, the dataset used in this experiment has some impact on the final performance of the model due to the small size and uneven distribution of samples across the discourse role categories. Therefore, the following work will be centered on expanding the corpus of different categories of discourse roles to build a larger and more evenly distributed high-quality dataset. At the same time, attempts to try and optimize the model will be explored further to improve the performance of the discourse role recognition model.
Discourse role identification has a variety of practical application scenarios. By identifying discourse roles, it is possible to understand the contributions of individual participants in task-oriented meetings, which helps leaders to manage conversations and optimize collaboration efficiently. In addition, categorizing discourse roles helps to analyze the speaker’s characteristics. For example, participants who tend to be "Interpretive Inference" have higher analytical and reasoning abilities, and those who tend to be "Initiating New Topic" have organizational and guiding abilities. Participants who preferred "Initiating New Topic" could organize and lead. The characteristics of the participants allow for better coordination of cooperation and task assignment, thus increasing teamwork efficiency.
Funding acknowledgment
National Natural Science Foundation of China(621 66041).