
Abstract
As more people express their thoughts on products on various online shopping platforms, the feelings expressed in these opinions are becoming a significant source of information for marketers and buyers. These opinions have a big impact on consumers’ decision to buy the best quality product. When there are too many features or a small number of records to analyze, the decision-making process gets difficult. A recent stream of study has used the conventional quantitative star score ratings and textual content reviews in this context. In this research, a decision-making framework is proposed that relies on feature-based opinions to analyze the textual content of reviews and classify buyer’s opinions, thereby assisting consumers in making long-term purchases. The framework is proposed in this paper for product purchase decision making based on feature-based opinions and deep learning. Framework consists of four components: i) Pre-processing, ii) Feature extraction, iii) Feature-based opinion classification, and iv) Decision-making. Web scraping is used to obtain the dataset of Smartphone reviews, which is subsequently clean and pre-processed using tokenization and POS tagging. From the tagged dataset, noun labeled words are retrieved, and then the probable product’s features are extracted. These feature-based sentences or reviews are processed using a word embedding to generate review vectors that identify contextual information. These word vectors are used to construct hidden vectors at the word and sentence levels using a hierarchical attention method. With respect to each feature, reviews are divided into five classes: extremely positive, positive, extremely negative, negative, and neutral. The proposed method may readily detect a customer’s opinion on the quality of a product based on a certain attribute, which is beneficial in making a purchase choice.
Keywords
Introduction
People are becoming more interested in consumer opinions as the online business develops at a rapid pace. Consumers contribute a large volume of product-related information as a review on e-commerce websites, which has a significant potential business value for marketers and buyers. This data has grown in importance as a source of data that can meet the needs of consumers. Companies, for example, may strive to use this data to improve the quality of their products, while consumers may select the best product for their needs. As a result, these businesses and individuals want a system that can assist them in making decisions based on information provided by customers on relevant online purchasing platforms. The act of selecting, synthesizing, and evaluating many perspectives or options to obtain one that best fulfils the decision maker’s goals is known as decision making.
A recent stream of study has used the conventional quantitative star score ratings and textual content reviews in this context. Rating can be sorted but reviews are often considered more informative and helpful than simple ratings because reviews can help users compare products more effectively. They might highlight specific features, benefits, or drawbacks in comparison to other similar products. Reviews offer a more in-depth and qualitative analysis. This can give potential buyers a more nuanced understanding of the product’s strengths and weaknesses. In this research, a decision-making framework is proposed that relies on feature-based opinions to analyze the textual content of reviews and classify buyer’s opinions, thereby assisting consumers in making long-term purchases. However, because the customers may have different opinions on each feature of the product, a review (document) can contain more than one statement with distinct polarities. Buyers and marketers may be interested in determining the polarity of each feature.
Motivation
As e-commerce sites have grown in popularity, so too much amount of product information that can be found there. People give reviews on e-commerce website and these reviews contain opinions about the product. If we know how to use these opinions, they can be extremely beneficial. In order to make better decisions, organizations must analyze all available data in order to transform it into usable knowledge. Opinion extraction is a common natural language processing application that focuses on identifying terms that indicate users’ opinion-based emotions regarding products [12]. It can be used to aid decision-making by extracting, assessing, and forecasting people’s opinions.
In general, OE refers to a three-level classification of a text’s polarity: document, phrase, and aspect [3]. Some techniques divide the comments into two categories, such as negative and positive, whereas others include many sentiment classes [4].
Consumer opinions must be analyzed at the sentence level to get a more detailed picture. Consumers regularly review products with numerous features or traits, and they typically have differing opinions on each of these features or attributes. As a result, labeling a single review as positive or negative may lose out on important information contained within it when a consumer reviews a product’s multiple features. Figure 1 illustrates how some aspects can be rated positively while others are rated negatively. A feature-based OE may provide a more thorough picture of how customers rate a product, which will ultimately influence future behavior. Using this feature-based analysis, marketing managers can learn a lot about distinct features of the product that would otherwise go unnoticed if the opinion was merely categorized in terms of the entire review [5, 6]. Specifically, [7] focused on the phone category, which is a fascinating case study because of its environmental impact.

Example of feature based opinions.
In previous research [8, 9] authors had discovered that using opinion scores and looking for positive and negative product attributes can help you make better judgments. However, there is a limited number of researches available to undertake decision-making approaches, and we have yet to find studies that have an algorithm for purchasing the best product based on dashboard features. Opinion extraction and text data mining techniques are used to improve the marketing decision-making process by extracting and analyzing the polarity of reviewed products due to the complexity of online reviews.
Firstly, we must understand the concept of opinion and how to extract it from product feature-based reviews. A product feature is a small portion or specialized attribute of a product that has been mentioned by users. Users’ feelings, attitudes, and emotions concerning a specific feature of a product can be used to understand opinions. For example, consider the opinion “I have a Samsung phone. Its battery is poor, but its camera is fantastic,” there are two features, “battery” and “camera,” about which the consumer has a negative and positive opinion, respectively. Although the opinion of a product feature has a big impact, the overall opinion of a Samsung phone creates confusion regarding the product’s quality. As a result, the proposed approach plays a vital part in overcoming the problem of confusion and making the correct decision to purchase the product.
Our contribution
The research makes a significant addition by presenting a clear and efficient framework that is divided into stages. The stages consist of 4 components which are well defined to accomplish the tasks to take decisions for product purchase. These tasks are as follows- Compute the overall opinion score of the entire review as a document level which shows whether the product was liked by people or not. Identification and extraction of product features from Amazon’s Smartphone’s reviews and also collect the features based review sentences. Compute the opinion score of each feature based review sentence as a sentence level to find out what purchasers liked and disliked about a product. Extraction of extremely positive, positive, neutral, negative and extremely negative product features as an aspect level and also evaluate those features. Design an algorithm for Decision making approach.
Article organization
Listed below is the rest of the paper’s structure. A brief literature review of the various methods used to extract product features, generate feature-based opinions, and make purchasing decisions is presented in Section II of this article. The proposed framework, method, and algorithm are described in detail in Section III. Section IV contains information on the experimental design, analysis, and discussion of the results.
Related work
To examine opinions offered by users on E-commerce sites, several methods for feature-based opinion extraction have been presented. To facilitate decision-making, a variety of studies are available for data gathering, feature extraction, and opinion classification. Recent studies [10–15, 47–51] have demonstrated the use of existing approaches for accurately extracting product features and classifying customer opinions about the product, allowing buyers to make a purchasing decision based on their preferences. Here, a study of the literature is conducted using feature-based opinion extraction, which is used to make better purchasing decisions.
Feature-based opinion extraction
The identification of product features and the classification of semantically related words to those features are the two most important aspects of feature extraction [16]. To address these problems, typical frequent-string techniques extract frequent nouns and phrases as product features, then extract opinions about those features.
In [17] the authors proposed a technique using a language model to extract product features and opinions from a collection of customer reviews. The methodology is based on language modeling and can be applied to reviews in any area or language that has semi-structured information on product descriptions. Product reviews can be easily extracted from any E-commerce website, and the seed set of aspects or features can then be easily collected. The method combines a model for extracting opinions and a statistical model for extracting product features. Two new semi-supervised models are proposed [18] for extracting product aspects. Essentially, the proposed methodology gathers relevant product phrases as a seed list of aspects from reviews. Then, based on the seed list, product reviews are regrouped to create more effective textual contexts for topic modeling. Finally, two novel semi-supervised topic models for extracting human-understandable product attributes are being built. In the first recommended topic model, the fine-grained labelled LDA, seeding aspects are employed to aid the model in discovering concepts that are associated with these seeding aspects (FL-LDA). They include unlabeled documents into the second model, the unified fine-grained labeled LDA (UFL-LDA), to expand the FL-LDA model and extract words associated with seeding aspects in customer reviews [18]. Authors [19] proposed the unsupervised rule-based techniques ‘RubE’ to extract subjective and objective information from online consumer evaluations. They extracted subjective aspects by expanding double propagation with indirect dependency and comparative construction after identifying objective features by integrating part–whole relationships with review-specific patterns. Domain-independent rules and pruning algorithms can be used to improve the generality of rule-based feature extraction approaches.
Authors [20] suggested a practical method for analyzing large-scale unlabeled user reviews, which they tested on a genuine Amazon dataset. The suggested method combines a frequency-based and a syntactic-relation-based approach, and it is further advanced by a semantic similarity-based approach. The approach is made up of four different jobs, the first of which is extracting the most important parts from reviews. The essential terms for each main aspect were then extracted using a semantic similarity-based technique. The second task is applying a modified version of TF-IDF to calculate a weight for each feature, and the third task entails assigning a rating to the extracted aspect using a domain-specific lexicon. The final job feeds the aspects and their weights into an algorithm that uses the domain lexicon to produce the overall review sentiment score based on the aspects. Using TF-idf, they were able to achieve an accuracy of 83.453%. Authors [21] proposed a method for extracting aspects and associating opinion terms with the appropriate aspects, then efficiently grouping and summarizing aspect-opinion pairs. The key contribution of this research is the extraction of aspects or features from raw reviews using created rules and a Word2Vec model without the need for domain knowledge about the product. The establishment of rules based on English language syntax for evaluating opinions related to the aspect and finally summarizing opinions on a rating scale is another contribution of this work [21]. Using double word embedding approaches, [22] suggested a text sentiment classification model (DWE). This model combined two independent word vector models, Word2vec and GloVe, to produce a combinatory input of dual convolution neural network channels to represent text (CNN). The initial word vector is continuously trained and updated using the word vector fine-tuning technique to develop a CNN sentiment classification model that performs better than a single vector representation [22]. Opinion mining and sentiment analysis are used to examine product reviews to assist sellers and buyers in making purchasing decisions. The type of online reviews, on the other hand, has an impact on the success of the opinion mining process since they may contain negative phrases or features of the product that are unrelated to it. To address these challenges, [23] propose a semantic-based aspect level opinion mining (SALOM) methodology. The SALOM classifies the opinions and retrieves product features based on semantic similarity. To increase classification accuracy, the proposed model is used to analyze negation terms as well as other types of product features such as synonyms, hypernyms and hyponyms. In [24] author put forth a Hierarchical LSTM approach for autonomous learning, aimed at categorizing instances of hate speech and trolling within social media data that includes a mix of different languages. [25] compared various multilevel ensemble learning model with the existing classifier model. [26] different data mining algorithms performed on the specific dataset by employing several feature selection techniques. In conclusion, it can be stated that utilizing feature selection methods along with any classification algorithm leads to improved performance.
Decision making
For customer satisfaction research, author in [27] developed a decision support model using independent domains. This model was created using a detailed examination of natural language consumer reviews found on the internet. AI (Artificial intelligence) based techniques such as online data extraction, opinion extraction, feature extraction, feature-based opinion extraction and data mining were used to analyze customer reviews. Customer satisfaction was measured qualitatively and quantitatively using these methods. The approach’s effectiveness was tested using two datasets relating to hotels and banks. The results demonstrated the effectiveness of this method for conducting quantitative customer satisfaction research. Authors in [28] proposed an opinion mining methodology based on modern natural language processing and machine learning approaches. Decision making based on weighted description logics is used to select and rank the relevant opinions. As a result, they created the OMA (Opinion Mining Architecture) architecture, which combines different methods to their technique into a single framework. The first results of a study on opinion mining using OMA are given in the financial sector [28]. In [29] author suggested a machine learning-based opinion mining technique to aid in stock investment decision-making. In the context of decision assistance, this study looks into false information filtering for accurate foresight, credit risk assessment, and prediction based on important signal recognition. Investors can modify investment proportions and decide whether stock should be invested or sold at the appropriate moment based on risk signals.
By merging sentiment analysis for items with data mining on a binary decision tree, [30] a method for assisting decision-making. There are three primary steps in the proposed technique. In each tweet, the objects and sentiments associated with those objects are first recognized. Second, translating the emotion of items in tweets into boolean values. Finally, they create and mine a binary decision tree. The experimental results show that the proposed strategy is effective in terms of error ratio and received information. However, in some circumstances, the performance is poor, due to an imbalance in the data labels. Existing opinion extraction systems provide capabilities like feature rating and feature level visualizations, but organizations need to make decisions based on user feedback. An opinion mining system [31] that uses novel ranking schemes and innovative opinion-strength-based feature-level visualization to rank reviews and extract features, all of which are tightly coupled to allow users to spot critical product features and their ranking from massive reviews. Business analysts and customers who want to investigate consumer comments to measure business strategies and purchasing decisions are the target user groups for the proposed system. The finding shows that the review and feature ranking in the decision-making process is improved.
Previous studies on Product feature-based opinion extraction for decision making
Previous studies on Product feature-based opinion extraction for decision making
In this paper, a framework for the decision making process is proposed with regards to buying the best product based on the analysis of feature-wise opinions extracted from previous customer’s comments. The framework is shown in Fig. 2. The framework is divided into four sequential components, where the first component presents the process of fetching the product reviews, the second component shows the process of product’s feature extraction, the third component shows the process of opinion classification and fourth component presents the process of decision making of the best product based on opinions extracted. The dataset of Smartphone reviews are collected from Amazon.in through web scraping, then clean and pre-processing the dataset using tokenization and POS tagging. Noun tagged words are extracted from the tagged dataset and then extract the potential product’s features. After this, remove the irrelevant features using a seed list of smartphone features. These feature based sentences or reviews are processed from word embedding and generate the vectors of reviews that identify contextual information of words. These word vectors are applied to hierarchical attention mechanism and generate the hidden vectors at word level and sentence level. Reviews are classified into five classes such as extremely positive, positive, extremely negative, negative and neutral with respect to each feature. The opinion on the quality of any product with respect to their particular feature can easily be identified by using the proposed method, which is helpful in taking decision to buy the best product. Every component is also presented in detail in further sections with algorithm.
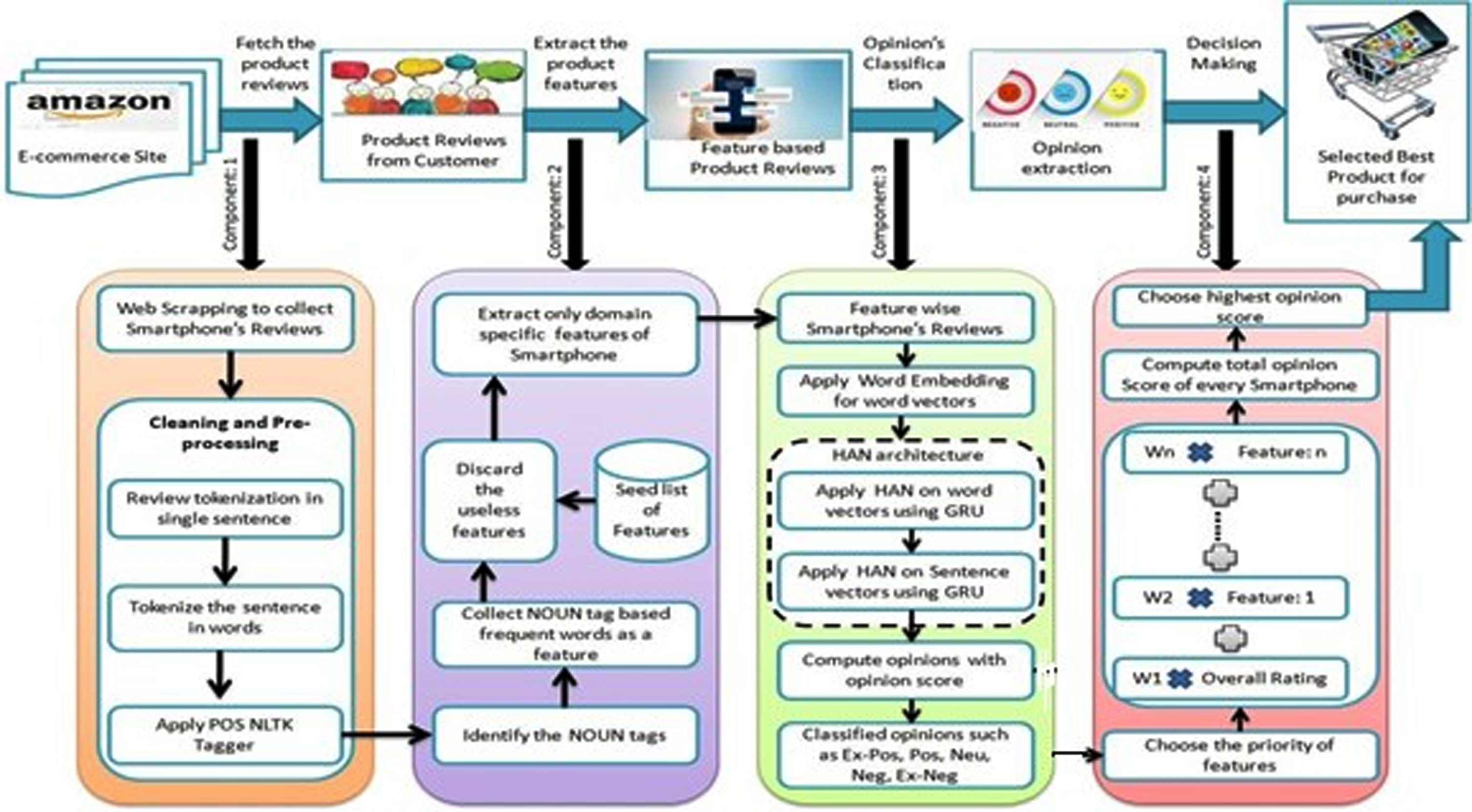
Overall framework for decision making.
Web scraping is performed for extracting data from amazon.in where the result page is “smartphone”. For web scraping the required URL is stored in a text file then extracts the relevant information from the given URL. The extracted results are converted in columns and saved into CSV (comma separated) format. The extracted list of items is mentioned as ‘mobile name’, ‘asin number’, ‘title review’, ‘user review’ and ‘star rating score’. Here, approximately 56,000 review documents are collected. Online reviews are expressed in a casual tone and are treated as raw data. Raw data is typically incomplete, noisy, and inconsistent, with missing values, inaccuracies, and conflicts, among other things. The dataset quality is critical for processing the data. As a result, raw data must be cleaned and pre-processed in the steps below to improve data quality and system efficiency- Clean the data by removing any fake reviews. False reviews are those written by persons who no longer own the product. Convert the entire dataset to lowercase letters. Remove any hyperlinks, missing values, special characters, or spaces between words. In a sentence, tokenize the Product’s reviews. Break the sentence down into words. Eliminate all stopwords and punctuation marks.
Use POS Tagging to categorize words in a phrase into nouns, pronouns, adjectives, adverbs, verbs, prepositions, interjections, and conjunctions [38]. In this case, NLP is utilized to apply pos tagging on the dataset. After tokenization, the reviews are tagged so that the product’s feature may be easily identified as a noun. The review is first tagged to determine the part of speech of the words. The review sentences are tagged using natural language processing (NLP). For example, the part-of-speech tagging for the above reviews are; “The/DT camera/NNP is/VBZ awesome/JJ, but/CC the/DT battery/NN is/VBZpoor/JJ”.
Component II: Product’s features extraction
Feature extraction is the most important task for opinion extraction of particular product in terms of their features presented in reviews. At present, in online portals, numerous reviews are available. These reviews consist of opinions about the product in terms of their product feature. Hence, to perceive the quality of any product with respect to their feature terms, extraction of product features is essential. Here, NLTK based POS tagging is used to tag the product reviews and Word with noun tags (NN) are considered as a feature then extract the potential and domain specific features. Features are extracted from a set of tagged reviews (Tr), from which at a time a single review(R) is processed in an iterative manner. If review (R) exists in a set of reviews (Tr), then it processes every tagged sentence (Sr) of a particular review(R). If (Tr) does not contain any review, then the process is terminated. Processing of every sentence of a single review is done with the analysis of every tagged word (Wr). If the tagged word (Wr) exist in the tagged sentence (Sr), then identify the noun tagged words and if not exists then proceed for another sentence from the same review (R). If the tagged word match with noun tag then maintain the noun based list of features and if not found then other tag based words are discarded. From noun based word feature list, potential and domain specific features are identified. Potential features are those features that have more than 30 frequency counts. Domain specific features are extracted through a seed list of Smartphone features. Now, to extract the domain specific features, create a set of frequently occurring nouns of Amazon’s Smartphone product reviews such as camera, battery, display etc.
Component III: Opinion extraction and classification
In component 3, collect the review sentences according to domain specific features which are obtained in component 2. The detailed process of component 3 can be understood by sub sections.
1) Product feature extraction:
In component 3, identify the sentences of reviews according to domain specific features which are obtained in component 2. Here, again collect the raw dataset of Amazon’s smartphone product reviews and apply the pattern matching with specific feature ‘f’ from extracted domain specific product features ‘Pf’. If a specific feature (f) exists in the product feature list (Pf), then identify the feature specific review and apply word embedding and Bi-GRU for opinion classification which is mentioned in further sections. If (f) not found in (Pf) then terminate the process.
2) Word Embedding using GLOVE:
Word embedding is a form of word representation technique aiming at mapping semantic meaning into a geometric space. It associated a numeric vector to every word in a dictionary, such that the distance (cosine distance) between any two vectors would capture part of the semantic relationship between the two associated words. To perform word embedding in the proposed method, Glove is used to create the vectors of words. In [39] GloVe is an unsupervised learning algorithm for obtaining vector representations for words. It has a pre-trained dataset of 1 billion words with the vocabulary of 4,00,000 words and also has different embedding vector sizes with the dimension of 50, 100, 200 and 300. Here, 100 dimensions are selected for embedding purpose and 50 dimension is selected for the forward direction and another 50 is selected for the backward direction due to its bi-directional nature. In the proposed work, product reviews are treated as a document ‘D’ with the sentences ‘U’ no. of sentences such as {S1, S2, S3,......SX........SU} a and the length of SX sentence is Mi which means Xth sentence consists Mi words. Here, pre-trained Glove model creates word vector as WEWij which shows in below (1).
3) Hierarchical attention mechanism:
In the proposed work, a hierarchical attention mechanism is used for product feature based opinion extraction. This mechanism follows the sequence of hierarchy like document → sentence → words, where document means a complete product review. The mechanism is associated with the attention layer, which is used to extract the information about the contextually related words and sentences in a document. Initially feature based sentences are processed from word level encoder using Bi-GRU and then again processed from sentence level encoding. After the sentence level attention mechanism, the obtained vector is processed from the softmax layer to generate the final vector. The final vector is used to predict the opinion score of that particular feature presented on review. Opinions are classified into five classes such as extremely positive, positive, negative, extremely negative and neutral. Here, a Bidirectional gated recurrent unit (Bi-GRU) is used for the encoding purpose. Bi-GRU is one of the approaches of recurrent neural network (RNN) model, which is used to perform the mapping between the sequences of word vectors to the sentiment classes. Bi-GRU can handle the problem of gradient vanishing; therefore it can predict the correct context of long sequences of words and obtain meaningful information.
Feature wise opinions with its score of products are extracted from component 3. These results are used for selecting the best product from available products. The mathematical equation for calculating the normalized score of a particular product is shown in (5), which is driven from (2), (3), (4). The best product decision equation is shown in (6). Mi is the product for ith number and m is the number of products for i = 1 to m; fik is the features for the corresponding ith product, where k = 1, 2, 3 ... ... .n are the number of features; wj is the weight assigned based on the priority for j = 2, 3 ... ... ... .n features with the following condition and w1 is assigned to the overall rating for every product.
Px = Priority wise features fik according to users input, for x = 1,2,3 ... ... n.
Based on the Priority assigned to a particular feature (if P1 is assigned to fi1 for k = 1), then w2 will be multiplied with fi1. Overall rating of the product is represented by ‘Or’ which is directly added with other scores.
The generalized (5) and (6) can be interpreted as: If there are ‘m’ number of products with ‘n’ number of features, Product normalized score and best product are calculated as
Step 1: maximum weight w1 is multiplied with the overall rating
Step 2: next weight w2 is multiplied with first priority feature p1
Step 3: w3 is multiplied with first priority feature p2, repeat for all features
Step 4: Summation of all feature scores with weight
Step 5: Perform summation of step 4 with step 1 and add product’s normalized score in a list.
Step 6: Repeat step 1 to 5 for all products
Step 7: Find the best product from the list of product score by selecting maximum value.
The algorithm starts from a collection of tagged reviews according to features, then proceeds for feature wise opinion extraction followed by decision making for the best product. The detailed procedure is already mentioned in Section 3.3 and 3.4.
Experiments and result discussion
This section is divided into sub-sections such as data description, evaluation, experimentation and results and discussion.
Data description
Through online scraping, 56,000 Smartphone reviews were obtained, with 80% of the data (44,800 reviews) being utilized for training, 10% (5600 reviews) for validation, and the remaining 10% (5600 reviews) for testing purposes for overall opinion extraction. The maximum number of word features used in experiments is 200000. The proposed method is intended for extracting opinions based on product features. As a result, a collection of reviews and sentences with feature-based attitudes is required. This type of dataset is not publicly available; hence it is constructed manually in the proposed study using the findings of earlier research [40]. From 56,000 reviews, 27,500 sentences are manually annotated, and only five feature-based sentences (camera, battery, pricing, quality, and display) are chosen for testing.
Feature-based sentence sentiments are manually annotated as well. Table 2 shows the statistics for feature-wise sentences.
Product feature based number of sentences
Product feature based number of sentences
The performance of the proposed model is evaluated using accuracy, precision, recall and F-Score measures [41]. Recall represents the ratio of the number of correct predicted opinion with the cumulative number of reference opinion. Precision represents like the ratio of number of correct predicted opinion with all predicted opinion. F1 score is calculated as the harmonic of recall and precision. The recall, precision and F score are mentioned in Equations (7)–(9). accordingly, where Sreference is represented as reference opinion, Spredicted as system generated opinion. It is the finest way to calculate both precision and recall before computing the F-Measure
The proposed approach is implemented in python 3.8 using high level neural network APIs such as Keras for deep learning functions, NLTK for pre-processing and BeautifulSoup for web scraping. Keras conforming form is used to perform a fast and efficient process. The proposed algorithm is applied on one review from the dataset to understand the process. Each review included a star score in the range [1 to 5] and a comment given by the customer. Review R is divided into sub reviews mentioned in Table 3. In this table, few reviews show direct comment on features of a product like R1, R2 etc but few reviews such as R6, R7 show indirect comment which are not able to be identified. Now, these sub reviews are converted into words using the word tokenization method of NLTK and applied to POS tagger for identification of tagged words. Noun tagged words are collected and others are discarded, to identify the product features list. From this list, domain specific features are extracted which are applied on Amazon reviews to segregate feature-wise reviews. For testing the algorithm, only five features of the Smartphone are focused such as camera, battery, display, pricing and quality. On these feature wise reviews, glove is applied for word embedding and these embedded vectors are applied in Bi-GRU for identifying opinions. The categories of opinions are extremely positive, positive, extremely negative, negative and neutral. Features and feature wise opinions of mentioned example are presented in Table 4, which are identified using glove and Bi-GRU method which is explained in detail in Section 3.
Set of sub-reviews of Review R
Set of sub-reviews of Review R
Sub-review with its feature and feature wise opinion
Feature-wise opinion and overall rating of different smartphones
Decision making process is applied on feature wise opinions of every smartphone to identify the best product. Table 5 shows the feature wise opinion and overall rating of different smartphones which were identified after experimentation on amazon’s smartphone dataset. In this table, only initial 3 rows are shown for understanding of feature wise opinions. Suppose feature’s priority given by the user is:
Px = (price: 1, display:2, camera:3, battery:4, quality:5)
Best product is identified according to algorithm:
Suppose, weight ‘wj’ is randomly assigned values according to their priorities such as: w1 = 5, w2 = 1.5, w3 = 1.0, w4 = 0.5, w5 = 0.2, w6 = 0.1
step 1: score = 5* overall opinion
step 2: score = score+1.5*price
step 3: score = score+1.0*display
step 4: score = score+0.5*camera
step 5: score = score+0.2*battery
step 6: normalized score = score+0.1*quality
step 7: step 1 to step 6 apply for all smart phones
step 8: best product = max(normalized score) of all smart phones.
Table 6 shows the proposed method’s performance by product feature, with precision, recall, and f-score for each feature determined using a manually annotated dataset. In this study, feature-based opinion scores are computed and compared to a manually annotated dataset, with the camera feature having the highest recall and precision and the display feature having the lowest recall and accuracy. Glove embedding was used in the approach, which resulted in higher recall values for each feature. Complete and improperly written words, multilingual words, and orthographic terms all diminish memory value in reviews.
Product feature-wise performance of the proposed method on Amazon smartphone review dataset
Product feature-wise performance of the proposed method on Amazon smartphone review dataset
Because of co-referencing between words of reviews, the suggested method is unable to recognize authentic smartphone features in a few situations, lowering the recall score. Few evaluations provide many categories of product features, each with its own polarity, in a single line, which are overlooked and have an impact on recall value. However, because such reviews are uncommon in the Amazon dataset, performance is unaffected. Because the model also detected a few terms as the polarity of smartphone features that are contextually irrelevant in sentences, the precision value drops. The proposed strategy for enhancing performance must also include grammar and spelling checks. In addition, no comparative opinions were found in this work.
The suggested method’s accuracy is compared to current baseline research, which was conducted on an Amazon smartphone review dataset and generated review opinions (Table 7). Although much research has been done in the field of feature-based opinion extraction, this work focuses on a comparison of a few algorithms that were tested on a smartphone dataset and produced superior results. It was discovered that the proposed strategy, which combined hierarchical attention with Bi-GRU and glove-based word embedding, outperformed state-of-the-art methods. Figure 3 shows that the acquired accuracy is 94 percent, which is higher than previous methods. On the smartphone dataset, a few algorithms such as SVM, cascaded CNN (C-CNN), multitask CNN (M-CNN), C-CNN with word2vec, and M-CNN with word2vec were tested, with M-CNN with word2vec achieving the best result. Based on accuracy, the proposed approach is compared to all of these ways, with the hierarchical attention based Bi-GRU with glove embedding achieving the best result. The proposed method is 9.9% more accurate than the M-CNN method. On the smartphone review dataset, it was also discovered that glove embedding outperformed word2vec embedding. The proposed strategy increased GRU performance by combining the attention mechanism with a hierarchical approach. The review is analyzed first at the word level, then at the sentence level, with contextual information correctly identified at both levels. In capturing contextual information of previous and next words, the Bi-GRU model with attention is better able to establish a long-term reliance between explicit words.
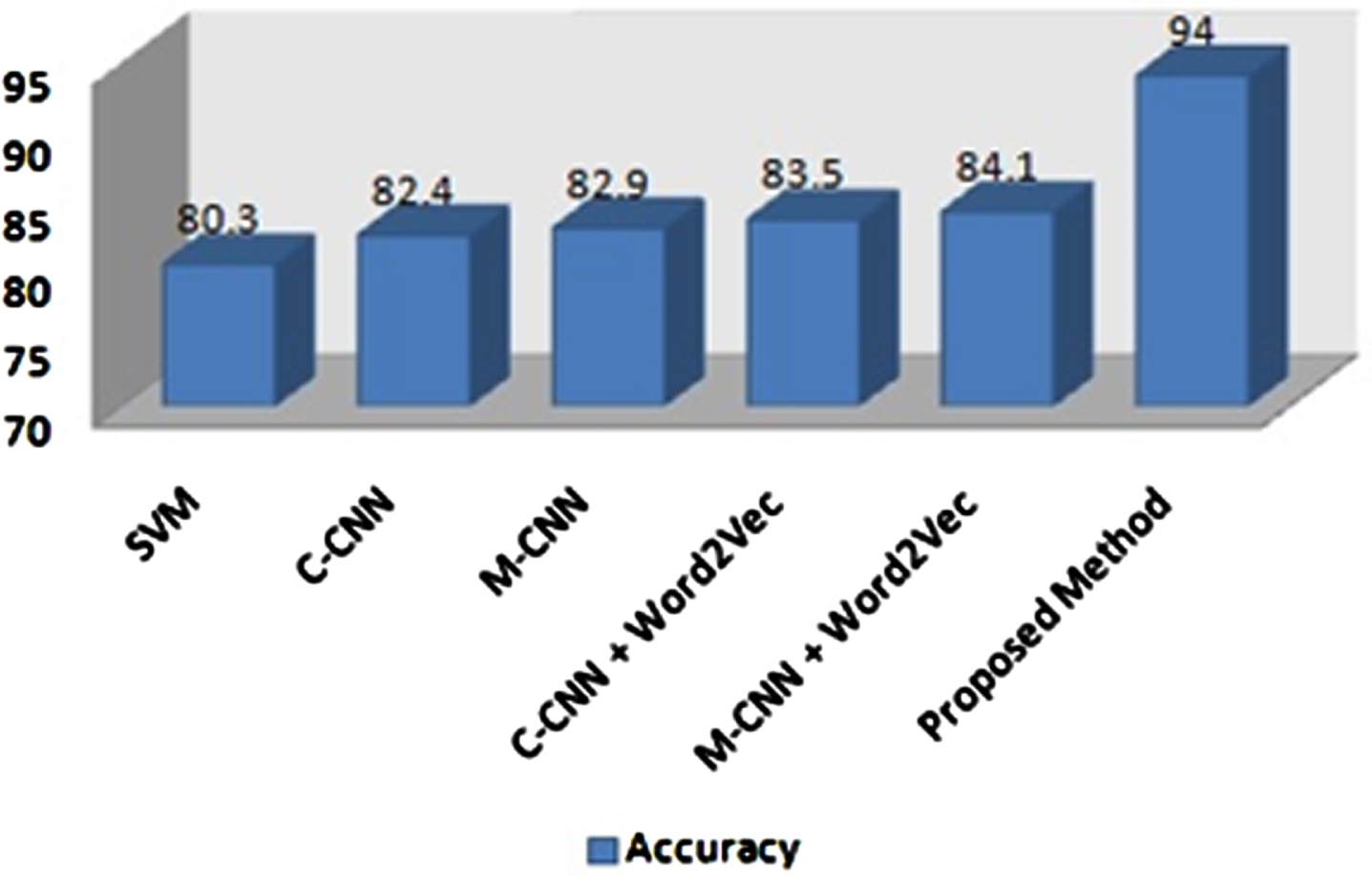
Performance comparison.
Performance comparison of product feature based sentiment classification against existing methods on Amazon smartphone review dataset
In this paper, a framework is presented for making smartphone purchasing decisions based on feature-based opinion extraction and deep learning approaches. The proposed algorithm can help marketers and consumers in making better decisions for analyzing their products and purchases by collecting the text of user generated online reviews and enhancing the granularity of the analysis at the sentence level. Web scraping is used in the proposed framework to collect Amazon reviews of smartphone goods, and NLP pre-processing methods are then applied to the review corpus. Pre-processed data is used to recover product features for opinion extraction based on a certain feature that he or she liked or hated. In addition, opinions regarding the product are gathered from the full review. Glove and hierarchical attention mechanisms are used to extract and classify opinions. Then, feature-based opinions about the product are applied to the decision-making algorithm and identify the best product. It’s important to remember that a customer’s preferences for a product are influenced by various product qualities and the value he or she places on these features. Future research can use the same technique to test the suggested algorithm on various corpus.
Footnotes
Appendix Code for Decision making and Feature Extraction