
Abstract
With the development of artificial intelligence, deep-learning-based log anomaly detection proves to be an important research topic. In this paper, we propose LogCSS, a novel log anomaly detection framework based on the Context-Semantics-Statistics Convolutional Neural Network (CSSCNN). It is the first model that uses BERT (Bidirectional Encoder Representation from Transformers) and CNN (Convolutional Neural Network) to extract the semantic, temporal, and correlational features of the logs. We combine the features with the statistic information of log templates for the classification model to improve the accuracy. We also propose a technique, DOOT (Deals with the Out-Of-Templates), for online template matching. The experimental research shows that our framework improves the average F1 score of the six best algorithms in the industry by more than 5% on the open-source dataset HDFS, and improves the average F1 score of the six best algorithms in the industry by more than 8% on the BGL dataset, LogCSS also performs better than other similar methods on our own constructed dataset.
Keywords
Introduction
Nowadays, with the development of 5G and cloud computing, the modern distributed systems based on microservices are not only widely used in the Internet industry, but also in key fields such as government, finance, IOT [30, 31], etc., This kind of software system services and applications usually have hundreds of millions of massive users. Any service terminal or service quality degradation caused by small software failure will bring huge losses. International Data Corporation (IDC) evaluation report on 1000 enterprises [36] shows that an hour of service downtime will cause an average of $100000 in huge losses. Therefore, large-scale distributed software systems need to ensure uninterrupted service, with high availability and high reliability.
With the increasingly complex operation logic of distributed software system based on micro services, the management cost of operation and maintenance is becoming higher and higher, which brings unprecedented challenges to the traditional network operation and maintenance. First, modern systems are producing logs of around 50 GB (120 million –200 million lines) per hour [1]. The huge number of logs makes it difficult to manually identify key information from noise data for anomaly detection. Even if rule-based matching tools are used, it is still difficult to achieve real-time detection and ensure the accuracy of detection. Second, the traditional operation and maintenance techniques have a high probability of false positives on large-scale logs, which greatly affects the efficiency of operation and maintenance. Last but not least, the large scale and parallelism of modern systems make the system behavior too complex. Each developer is only responsible for a sub-component. Once the system has a problem, it is difficult for the developers to quickly identify the anomaly from the system perspective.
With the development of artificial intelligence (AI), the concept of artificial intelligence for IT operations (AIOps) was first proposed by Gartner in 2016. AIOps is a technology that improves the operation and maintenance ability and automation degree with the help of machine learning algorithm. It can analyze the system operation and maintenance data, automatically find and respond to the problems of the system in real time [6]. The concept of aiops makes the intelligent fault discovery technology based on machine learning and other algorithms attract extensive attention. Multi source operation and maintenance data includes the dynamic data produced in the run of system and historical data (such as forms, system update documents and etc.). Compared with historical data, the system runtime data can reflect the dynamic characteristics of the system and the context information when the system fails, and has better detection and expression ability for unknown faults [36–40]. Data during system operation mainly includes log data and monitoring data. Log data is the text data generated by the printout code embedded in the program by the program developer to assist debugging, which is used to record the variable information and program execution status when the program is running. Monitoring data refers to the resource utilization of the system in the running state, such as the utilization rate of central processing unit (CPU), memory utilization rate, network traffic, number of processes and process resource utilization rate.
The system usually generates a large number of operation and maintenance logs, which record detailed information during the operation of the system. These logs are usually used as the main data source for system anomaly detection. Log-based anomaly detection has become an important research topic in both academics and industries.
With the development of artificial intelligence technology, Deep Learning has been widely used in Computer Vision, NLP, IOT, AIOps etc., and achieved good effect [32–35], In recent years, academia starts to use Deep Learning methods for log anomaly detection [29, 42–45].
There are many proposed methods, such as DeepLog [2], which extracts temporal features based on log templates, has achieved good results in HDFS and BGL open-source datasets. LogRobust enhances the robustness of the model by adding instability and noise to training and testing data, and this method can also solve some OOT problems to a certain extent. Both of the literature [46] and the literature [47] used BERT pre training models to improve the model’s representation ability of log semantic features, and also achieved good experimental results. Currently, most of these learning-based methods have the following problems: they do not adequately extract the temporal and correlational features between logs and do not make full use of the semantic features and statistical features of the log text. They all lack an effective mechanism to solve OOT problems. As a result, they cannot ensure the accuracy of log anomaly detection. For online prediction, the accuracy gradually decreases as the number of new log templates grows.
To solve these problems, we propose LogCSS, a log anomaly detection framework based on a pre-trained model, the Context-Semantics-Statistics Convolutional Neural Network (CSSCNN) based on the semantic and temporal and statistic features of the logs. The CSSCNN first encodes the semantic information with BERT [3], a widely used pre-trained language model. Then it uses a convolutional neural network (CNN) [4] to extract the semantic and temporal features of the log series. To improve the accuracy, it combines these features with the statistic feature of log templates, as the input of a classification model for anomaly detection. The LogCSS framework is also the first to use the novel technique for log template extraction, DOOT. It deals with the Out-Of-Templates (OOT) problem by computing similarities and adding new log templates continuously. We test our framework with some open-source datasets. Experiments show that it performs better than the state-of-the-art baselines. We summarize our contributions as follows: We propose a deep-learning-based log anomaly detection framework named LogCSS. It uses the CSSCNN model to extract the semantic, temporal, and correlational information of the logs, which improves the accuracy of log anomaly detection. We are the first to use a novel technique, DOOT, for log template extraction. It can solve the OOT problem of template matching. It continuously improves the accuracy of template matching and improves the overall effect of log semantic feature extraction. We are the first to use the semantic, temporal, and counting features of logs to train the classification model, which is more comprehensive for the model to extract the anomalous features of the logs, to improve the accuracy of the model. Based on open-source data, we have conducted a large number of comparative experiments with the best log Anomaly detection algorithm model in the industry. The results show that the performance of our LogCSS method is the best.
We organize this paper as follows: Section 2 introduces the related works of log anomaly detection. Section 3 shows an overview of the proposed framework, LogCSS. Section 4 introduces the key technologies of LogCSS. Section 5 shows the experiment results. Section 6 is a summary of our work.
Related work
Anomaly detection is very helpful to reduce the operation and maintenance cost of the production environment, so it has attracted the attention of many scholars. Learning-based log anomaly detection has been widely studied in the past few years. According to different learning methods, they can be divided into supervised log anomaly detection and unsupervised log anomaly detection.
Unsupervised log anomaly detection
Unsupervised learning algorithms are widely used for feature extraction on log data, which helps to discover the common rules on large amounts of unlabeled data. The training data does not have labels and the target is to classify the data. In the early years, many researchers propose to use unsupervised machine learning algorithms for anomaly detection. Farzad et al. [5] are the first to use autoencoder [6] and isolation forest [7] to detect log anomalies. Lin et al. [8] cluster the system logs based on their similarity. Later, some unsupervised deep learning algorithms are proposed for anomaly detection. Du et al. [2] propose DeepLog, an unsupervised learning framework based on LSTM. They use normal logs for the offline training of the model. For online prediction, they check whether the coming log sequence is consistent with the features learned by the model. If not, they mark the log sequence as an anomaly. Recently, LogAnomaly [9] is proposed to improve DeepLog by considering the influence of synonyms and antonyms on templates. Log2Vec [28] also improves DeepLog. It uses graph embedding to capture the correlation features between logs, and classifies them with a clustering algorithm. A weakness of unsupervised learning algorithms is that they need a large number of labeled normal logs. Another problem is that they cluster the logs simply based on similarity, which fails to capture the time correlation of the logs. As a result, unsupervised log anomaly detection methods generally suffer from low accuracy.
Supervised log anomaly detection
In the early years, the traditional supervised methods usually use models like Logistic Regression [10], Decision Tree [11], or SVM [12]. These models are built with statistical probability analysis method14s. They lack the analysis of the semantics of the logs, so they have low accuracy. With the development of deep learning, many supervised log anomaly detection methods based on deep models are proposed. Lu et al. [13] propose an embedding technique called logkey2vec and use CNN to detect the anomalies in large-scale system logs. They extract the internal association between logs with different sizes of convolution kernels. Kimura et al. [4] and Zhang et al. [14] extract typical features from log sequences based on expert experience and use traditional machine learning models (such as Random Forest [15]) to learn the anomalous log patterns. Zhang et al. [16] propose LogRobust, which combines the attention mechanism with Bi-LSTM to extract the semantic information of logs for anomaly detection, and it solves the OOT problem by adding noise to the event template data to enhance the model’s generalization ability. However, once a new log appears that differs significantly from all existing log templates, it can lead to a decrease in model accuracy. Le et al. [17] propose NeuralLog, which uses Transformer [18] to detect log anomalies. Xia et al. [19] propose to use GAN and attention mechanism, which solves the problems of lacking anomalous samples and feedback delay in large-scale software systems. In order to solve the problem that labels of Log Anomaly Detection are precious and difficult to obtain, Zhang et al. [27] proposed a PU learning based method PUAD, which can achieve high accuracy by only requiring a few labels. Logclass [21] is a partial label-based framework for automatically and robustly identifying and classifying abnormal logs of networks and services. The mentioned methods can still be improved, as their models may not accurately extract the log semantic information, and they ignore some local relationships between logs. They also lack the solution to the OOT problem, which leads to low accuracy for online prediction. Wang et al. proposed Lightlog [41], which uses word2vec and post processing algorithm (PPA) to create a low dimensional semantic vector space, and performs exception detection based on TCN, which meets the real-time processing performance requirements of edge devices. However, it ignores the statistical characteristics of logs, so it cannot achieve optimal log exception classification performance. Literature [46] used the BERT-CNN model to analyze logs, and the results of the analysis were used to predict the probability of virtual machine operation failures on the server. The method lacks statistical feature extraction for log event templates. It also did not solve the OOT problem. Literature [47] propose LAnoBERT, a parser free system log anomaly detection method that uses the BERT model, exhibiting excellent natural language processing performance. However, it ignores the contextual features between logs, as well as the statistical characteristics of log events, and does not propose effective solutions to OOT problems.
To solve the mentioned problems, we propose a supervised deep-learning-based log anomaly detection framework, LogCSS. It contains the CSSCNN model for training and prediction. In CSSCNN, we first use BERT, a pre-trained model, to extract the semantic features of the logs. Then we use a CNN model to extract the local relational features between the logs, and combine them with the count matrix as statistic features. We also propose a solution to the online OOT problem.
Overview of LogCSS
The LogCSS framework employs a novel model named CSSCNN. LogCSS consists of a pre-trained BERT model to encode the semantic information and a CNN model to extract the local relational features between logs, and the statistic features of the logs are added for model training. It greatly improves the accuracy of log anomaly detection. LogCSS also employs the DOOT technique. When new log templates are encountered during online prediction, DOOT employs fuzzy matching based on similarity, and updates the template pool, which ensures the accuracy in the long run.
The target of LogCSS is to detect anomalies from a sequence of log text. LogCSS is separated into an offline training process and an online prediction process. The framework is shown in Fig. 1, which includes three parts: data pre-processing, data feature vectorization, and model design.
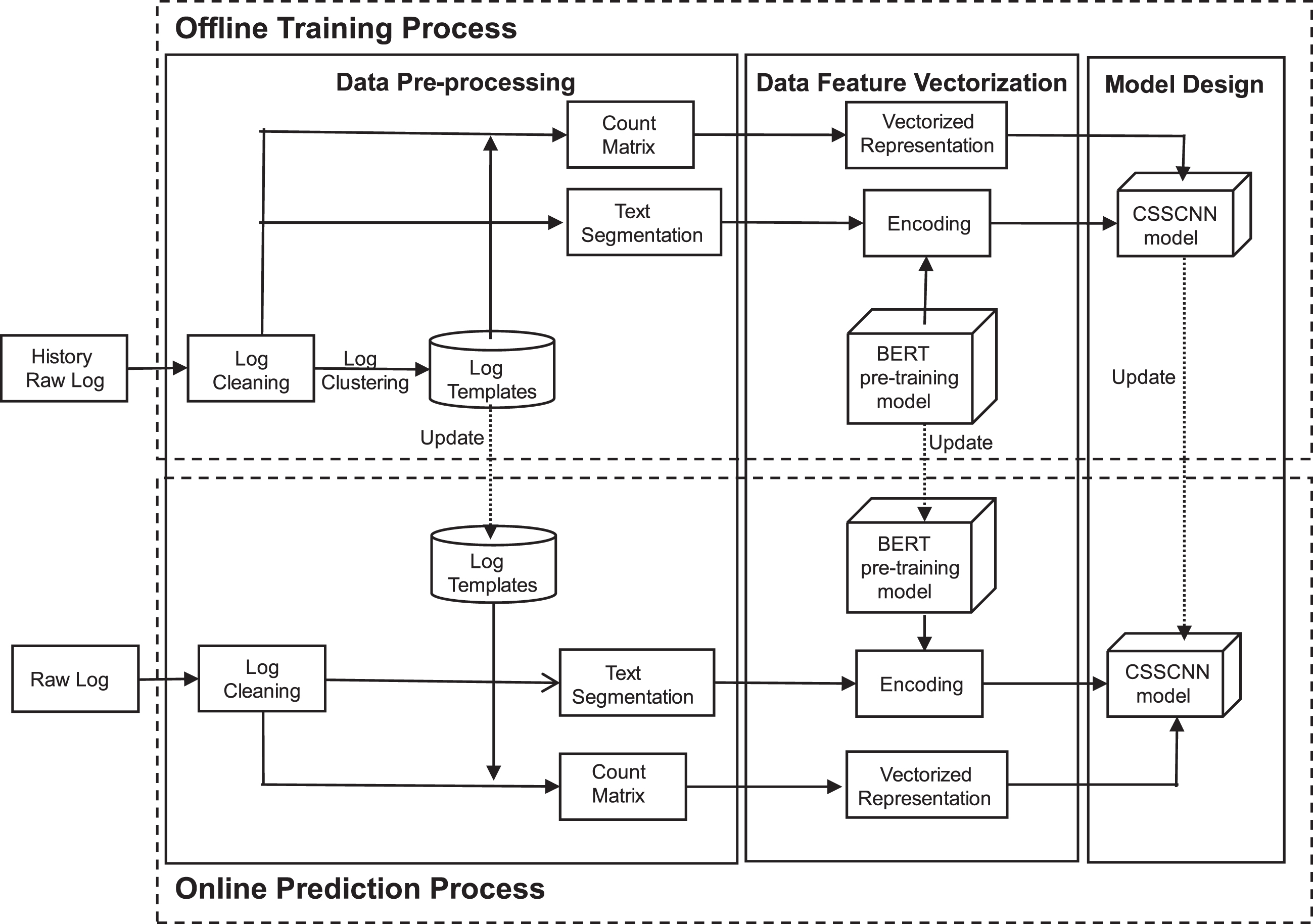
Overview of LogCSS.
There are three steps for data pre-processing: log cleaning, template extraction, and text segmentation.
Log cleaning aims at removing the characters and strings that do not affect the detection of anomalies. We first filter the strings longer than 20 characters and remove the pure digital information, including the time and IP addresses. Then, we use some templates to remove useless punctuations, such as ‘[]’, ‘()’, ‘{}’, ‘> ’, ‘––––’, etc. Afterward, we use identifiers ‘_’ and ‘–’ to find entity strings, such as ‘epn_volte_sip_zte’. Finally, we remove the duplicated text.
Template extraction aims at structuring the log data. Raw log messages are non-structured data containing timestamps and message contents. Each piece of log records a system behavior with the timestamp, the log level, and the content. It is easy to extract the timestamp and log level, but difficult to extract the content. The content consists of fixed strings and variable values. The fixed parts can be extracted as templates because they are always the same when the system encounters the corresponding code. The variable parts are dynamic information that may change with the physical devices and system runtime environments. We use the Drain algorithm [20] to extract the log templates. The main idea of Drain is to build a parsing tree with a fixed depth based on the log data. The tree contains the rules of template extraction. The output of Drain is the template of the input log, such as ‘worker process < *>exited with code < *> ’.
Text segmentation employs the WordPiece algorithm [22], which is widely used in the research of text encoding [3, 24]. WordPiece has a flexible definition of words. For example, ‘loved’, ‘loving’ and ‘loves’ have the same root. If we define such cases as different words, the vocabulary will be very large, which has a bad effect on the model training speed and accuracy. WordPiece can split the words into ‘lov’, ‘ed’, ‘ing’, and ‘es’, which helps reduce the size of the vocabulary. One problem is that, in our case, the log data usually contains combinations of uncommon words. To prevent WordPiece from generating unreasonable sub-words, we segment the words with additional processing, as shown in Table 1.
Word Segmentation Cases
Word Segmentation Cases
As is shown in Table 1, wordpiece may split words like “NameSystem” into ‘names’, ‘##yst’, ‘##em ’, which is obviously not the result we want. We would resplit “NameSystem” into ‘name’ and ‘system’.
LogCSS uses the pre-trained BERT model to extract the semantic features of the logs and encode them into vectors. It also encodes the count matrix as statistic features.To train a Deep Learning model for log anomaly detection, it is necessary to extract the features of the logs, which includes the following aspects: Semantic features. Logs are text statements composed of words, so they contain semantic features. For example, in Fig. 2, the log statement “081109 204525512 info dfs.datanode$packetresponder: packetresponder 2 for block blk_5724928392872299681 terminating” ends up with the word “terminating”, which contains key semantic features. Temporal and correlational features. The logs are printed out by programs and the execution of the program statements follows the program logic, so the adjacent log statements are contextually related, which contains the temporal and correlational features. Statistical features. The log templates, where the variables of the logs are replaced by placeholders, may repeat themselves in a period of time. The statistical characteristics of log templates can also help identify anomalies. Basically, the log templates with a high number of repetitions are not related to exceptions. For example, two logs in Fig. 2, “081109 20465556 info dfs.datanode$packetresponder: received block blk_3587508140051953248 of size 67108864 from /10.251.42.84” and “081109 204722567 info dfs.datanode$packetresponder: received block blk_540203568334525940 of size 67108864 from /10.251.214.112”, have the same log template, “ < *>received block < *>of size < *>from < *> ” [Note: Appendix 1, number 4]. The log template appears twice in the time window, so the two logs are very likely to be normal logs.
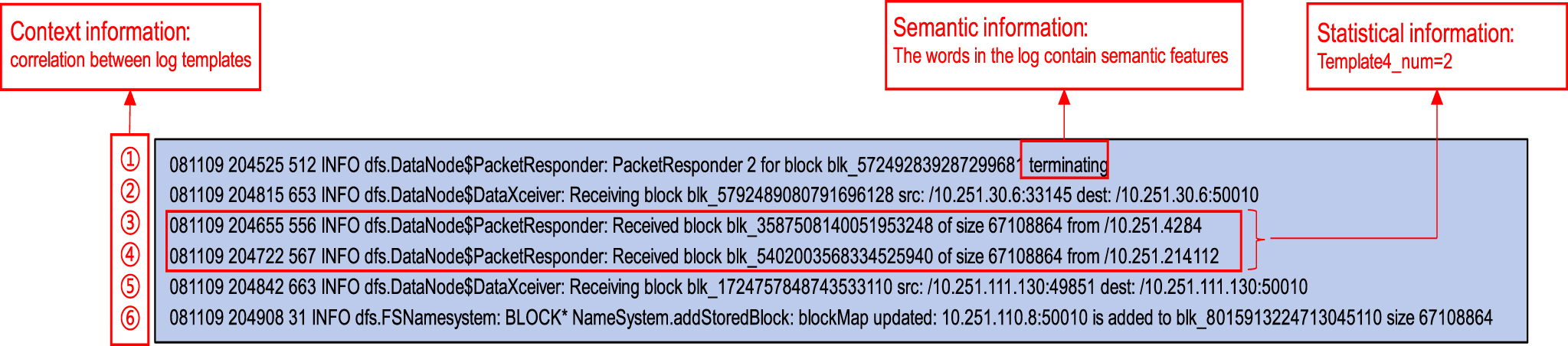
Schematic diagram of three important features of log information.
LogCSS employs a novel CSSCNN model. CSSCNN transfers the semantic features of the logs into a semantic matrix, and encodes it with a CNN model. After a pooling operation for the dimension reduction, the result is concatenated with the statistic features as the input of a fully-connected network. The detection result is outputted by a softmax layer. The detailed process is shown in Section 4.2.
The workflow of LogCSS is separated into an offline training process and an online prediction process. For offline training, we first pre-process the raw log data through log cleaning, template extraction, and text segmentation. Then, we encode the log data with a count matrix and the BERT model. Finally, we use a CNN model to build a classifier for anomaly detection.
For online prediction, we first pre-process the coming log data with a similar procedure. The only difference is that we use DOOT for template matching and updates. Then we use the trained encoder and classifier to predict whether the coming log is an anomaly or not.
In the following subsections, we describe the details of the count matrix, the CSSCNN model, and the DOOT technique.
Key technologies of LogCSS
LogCSS extracts the semantic features of the logs with the pre-trained BERT model, adds the statistic features of the count matrix, and uses CNN for the local relational features between logs. It also solves the problem of online log OOT.Our proposed LogCSS mainly includes three key technologies:Count Matrix,CSSCNN Model,and DOOT.
Count matrix
The count matrix extracts and encodes the counting information of log events. After pre-processing, the raw logs are parsed into a sequence of log templates. Each template corresponds to a type of log event. We count the number of each type of event in a slice of log sequence and encode the information as the input of the classifier model.
We use sliding windows to generate the log sequence slices. We set the window size and the stride according to the dataset. For each slice, we generate a vector with the number of each type of log event. For example, if the vector is [0, 0, 2, 3, 0, 1, 0], then in the slice, log event 3 appears twice, event 4 appears three times, and event 6 appears once. We encode the vector through normalization. Suppose the vector is C = {C1, C2, . . . , Cm}, where Ci is the count of the i-th event in the slice, and n is the number of log templates. We encode C into the count vector VC = {VC1, VC2, . . . , VCm} according to Formula (1).
The count vectors in a log sequence form the count matrix. We concatenate the count vector with the output of the BERT+CNN models, as the input of the classifier.
After pre-processing, each log line is parsed into a word sequence. CSSCNN takes several log lines within a time window as input. It first encodes each line with BERT, then encodes the log sequence with CNN. We concatenate the encoding result with the count vector and input it into a fully connected network as a classifier to predict whether the log sequence is an anomaly. BERT is pre-trained with large-scale unlabeled corpus. It can be used to obtain the representation of the text with rich semantic information, and fine-tuned in specific NLP tasks for the application. In CSSCNN, we use BERT to obtain the semantic representation of the log text, and fine-tune the model during the training process. The output of the BERT model is the log sentence vectors. In recent years, CNN is also used for text classification tasks. In CSSCNN, we use kernels of three sizes to extract the important information between the log sentence vectors from BERT, which extracts the local relational features and improves the accuracy of CSSCNN.
As an example, we take a time window with ws (default ws = 50) log lines LogWindow = {Log1, Log2, . . . . . . , LogWS}. Each log line is segmented into words Log
i
= {Subword1, Subword 2, . . . . . . , Subwordmi}, where mi is the number of words in the i-th log line. To align the sequence lengths for subsequent vector calculations, we implement the following steps: if the number of words in a log is smaller than L, we pad it with 0 to L. If it is larger than L, we remove the words that exceed L. This ensures that the length of each log is L. We consider each log line as a sentence and input it into BERT. The last layer of the BERT encoder generates an embedding vector for each word. After average pooling, we obtain the semantic vector of the i-th log line Si∈Res, where es is the dimension of the embedding vector from the BERT encoder. Thus, we obtain the semantic matrix VSemantic∈Rws ×es of the ws logs in the time window. As shown in Formula (2):
To further extract information from multiple log lines, we input the semantic matrix VSemantic into a CNN model. The structure and hyper-parameters of the CNN model are shown in Table 2. Similar to TEXT-CNN, we set the size of a convolution kernel as h×es, where es is the same as the dimension of a semantic vector, and h is the number of adjacent log lines that involve in a convolution.
Structure and Hyper-parameters of the CSSCNN Model
After computing the convolution and non-linear activation, we obtain (ws-h+1) features, where the i-th feature corresponds to the log lines from the i-th to the (i + h-1)-th. Then we use max-pooling to obtain the maximum feature value, which represents the result of the convolution kernel. In our experiments, we use 3 sizes of convolution kernels, i.e., h = 3, 4, 5. For each size, we have hs = 128 kernels. So, the output of CNN is a vector of (3×hs) dimensions, which contains the semantic and temporal information of the logs in the time window. The output after convolution through each convolution kernel is shown in the following formula 4:
Then we concat the three convolution results, as shown in Formula 5 below:
We concatenate the output of CNN with the count vector, As shown in Formula 6 below:
Then we use VFCInput as the input to the fully connected neural network. The structure of the network is also shown in Table 2, where M is the dimension of the count vector. As shown in Formula (7), we use PReLU as the activation function.
It is a modified version of Leaky ReLU, where ai∈[0,1) is a learnable parameter determined by the data. It shows good performance on the task of ImageNet classification [25] in computer vision. Finally, we use the softmax function to map the output of the fully connected neural network to the abnormal result space, as shown in the following formula.
We also use dropout to avoid overfitting. Dropout and cross entropy are commonly used regularization methods and loss functions in neural networks. They can work together to improve model performance. By using dropout, the risk of overfitting can be reduced, thereby improving the robustness of the model. Cross entropy can measure the difference between the predicted results of a model and the actual results, thereby improving the accuracy of the model. We used the cross entropy loss function to measure the performance of the model. The loss function is shown in Formula (9).
In Formula (3), y(i) is the label of the i-th sample in the batch. 0 as normal and 1 as anomalous.
Table 2 shows the structure and the hyper-parameters of the model. We have hs (hidden size) as the number of the output channels of the CNN kernels, bs (batch size) as the size of a batch for training, ws (window size) as the number of logs in a time window, es (embedding size) as the dimension of the output vector of BERT, L as the number of words in the longest log template, and M as the length of the count matrix. For details of Pseudocode implementation, please refer to algorithm 1, as follows.
From Algorithm 1, it can be seen that our overall processing flow. First, we collect log data from the distributed microservice system, and remove redundant information through data cleaning. Then we select the appropriate log templates through DOOT technology, generate a Count Matrix C based on the statistical information, and encode a Vc matrix. We also generate the word list W from the log templates through the Log Word Segmentation technology, where W = {W1,W2, . . . ,WL} and L is the number of the words. Then we employ the BERT model to encode the word list into a log semantic vector matrix Rws×L×es, where ws is the window size referring to the number of logs in an observation time window, and es is the embedding size of the word generated by BERT. The vector matrix Rws×L×es is further transferred into a feature vector Rws×es i through Feature Pooling to fit the input of the CNN. Then the feature vector Rws×es is convolved and pooled by three convolution kernels (hs is the number of each type of convolution kernel in Fig. 3) to generate three one-dimensional vectors R(hs×1). The three vectors are concat with the statistical matrix Vc to generate a vector V. Finally, the vector V is input into the fully connected neural network and mapped into the result output to the user through sofmax.
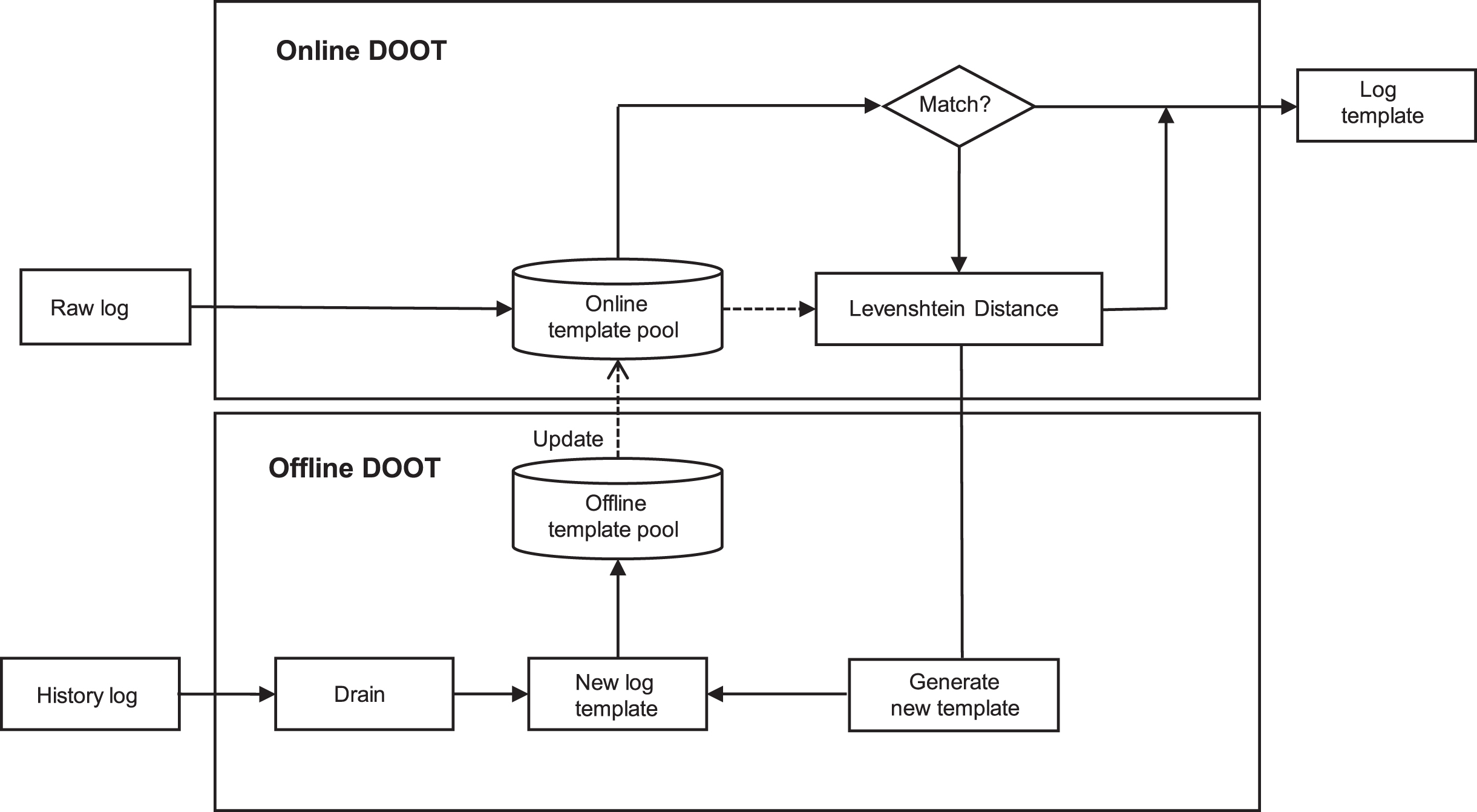
DOOT Log Template Extraction Procedure.
DOOT is designed for log template matching and dynamic updates during online prediction. It continuously updates the log template pool, which increases the precision of log template matching and improves the quality of semantic feature extraction.
We note that OOT (out of template) is almost an inevitable problem for online template matching, where the similarity between the new log and any log template, is larger than the threshold. To solve this problem, DOOT uses Levenshtein Distance [26] for fuzzy matching, which measures the similarity between the strings with their edit distance. DOOT continuously updates the template pool and improves the quality of template extraction.
As shown in Fig. 3, In the offline training process, we extract log templates from training log data with the Drain algorithm, and store them as a template pool. In the online prediction process, we first match the pre-processed log with existing templates. If the similarity is smaller than the threshold, we directly output the matched template. Otherwise, we compute the Levenshtein Distance between the new log and all the existing templates,then output the template with the maximum similarity. We also add the template of the current log into the template pool, and periodically restart the offline training process. DOOT helps increase the rate of successful template matching and improves the accuracy of the anomaly detection model.
Experiments
Experiment setup
We conducted all our experiments on a Linux server with four Tesla M40 24GB GPUs, Intel Xeon CPU E5-2680 v4 @ 3.3GHz, and 256GB memory. The operating system is Ubuntu16.04, and the version of the Nvidia driver is 418.126.02, with CUDA 10.1. We implemented LogCSS with Python 3.8.12, torch 1.8.2, numpy 1.21.2, pandas 1.3.4, and transformers 4.12.5.
The best configuration parameters of our LogCSS on the HDFS dataset are as follows: using the BERT-Mini pre-trained model, learning rate as 1e-4, batch size as 128, window size as 50, stride as 1, the ratio of positive and negative samples as 1 : 1. The settings of LogCSS on the BGL dataset are: using BERT-Tiny pre-trained model, learning rate as 1e-4, batch size as 128, window size as 20, stride as 5, the ratio of positive and negative samples as 0.1 : 1.1.
Evaluation metrics
To measure the effectiveness of LogCSS for anomaly detection, we use precision, recall, and F1-Score as metrics, which are computed as follows.
1) Precision: the ratio of correct predictions in positive predictions.
2) Recall: the ratio of correct predictions in anomaly samples.
3) F1 Score: the harmonic mean of precision and recall.
TP, FP, and FN represent the number of true-positive, false-positive, and false-negative cases.
Datasets
We evaluate our method with other log anomaly detection methods on the open-source datasets HDFS and BGL. The information of the two datasets is shown in Table 3.
Information of HDFS and BGL datasets
Information of HDFS and BGL datasets
HDFS 1 > is a dataset generated by running Amazon EC2 for over 200 days. It is published by Xu et al. [27]. The size of raw log files is 1.55 GB, containing 11,197,954 log lines. The status of each HDFS block is also recorded, and there are 29 unique log keys. The log data is separated into session windows, and each log line is marked with a block ID and its log key. The original training set contains 4,855 normal sessions and 1,638 anomalous sessions. The original test set contains 553,366 normal sessions and 15,200 anomalous sessions.
BGL (Blue Gene/L) 2 is generated by a supercomputer with 128K processes in LLNL. There are 4,747,963 log lines in the dataset, 348,460 of which are labeled as anomalous. An important property of this dataset is that many log keys only appear in a specific period, so it is impossible to have all the normal log keys and normal operation patterns in the training set.
TSLOG (Test environment system log) was generated in our test environment, which ran a large e-commerce shopping transaction business. We intercepted about two months of data, with a total of 131563 rows of logs, of which 2978 rows were marked as exception logs, with a total size of 40.88 MB.
In the following experiments, we use the 80% data in the front as training data and the rest 20% as test data for each dataset.
LogCSS adds the count matrix of the log templates to the features, and uses DOOT technique to solve the OOT problem. We evaluate the effectiveness of the count matrix and DOOT on the HDFS dataset. The experiment results are shown in Table 4.
Ablation Study on Count Matrix and DOOT
Ablation Study on Count Matrix and DOOT
There are 29 recommended event templates in HDFS. We number the 29 templates as is shown in Appendix 1. In the first experiment in Table 4, whenever an event template with serial numbers 1–14 is encountered when training the model, the corresponding log event is replaced by the OOV event template when extracting semantic features. The traditional method does not add count matrix features for training, and the final trained model is used to verify the performance of the algorithm on the test set. The experimental results are shown in Table 4 above. The model trained in this way had greatly reduced the precision rate, recall rate and F1 value. We take similar operations on templates from numbers 15 to 29, and the metrics also become lower. The model trained by our method adopts DOOT technology. When we encounter a new template, we use the similarity calculation to find the template with the closest similarity from the template pool to replace it, and continuously update the template pool. When training the model we add the count matrix to the model for training. The experimental results show that in the case of the above two new templates, the accuracy of our algorithm is not greatly affected, and it still has a very good classification effect. This tables shows that the default OOV template for critical logs harms the accuracy of anomaly detection. The DOOT technique can update the template pool by adding new log event templates, which ensures the accuracy of the anomaly detection algorithm.
We evaluate the configurations of LogCSS with the following experiments, including whether to fine-tune BERT, the log window size, and the method of sentence vector generation.
First, we conduct some experiments to evaluate the effectiveness of fine-tuning BERT in LogCSS. The results in Table 5 show that BERT with fine-tune has better performance. Note that fine-tuning BERT increases the computation cost of training. If the machine has enough resources and processing speed, we suggest to fine-tune the BERT model.
Experiment on BERT Fine-tuning
Experiment on BERT Fine-tuning
Second, we evaluate the influence of the window size on the detection performance. The results are shown in Table 6. The best window size on HDFS is 50. A possible reason is that the HDFS data can be grouped into sessions, and most sessions contain no more than 50 log lines. By setting the window size as 50, the machine learning model can use the session window as input without truncation, which is helpful to the accuracy. The best window size on BGL is 20. The logs in BGL are not grouped into sessions, so it is not easy to find the optimal window size through the dataset.
Influence on Performance from different Window Sizes
Third, we compare different methods of sentence vector generation. The sentence vector is the input of the CNN model, which represents the semantic information of a single log line. It can be generated through pooling or the CLS token. The pooling method takes the average-pooling or max-pooling of the output of the BERT encoder, i.e., the embedding vectors of the words in the log line. The CLS token is generated from the hidden state of the last layer of BERT, with a linear transformation and a Tanh activation. According to the results in Table 7, CLS performs better than the pooling methods.
Experiment on Sentence Vector Generation
Finally, we compare the training time of LogCSS with LR, SVM, and Lightlog. The results are shown in Table 8. LR and SVM use statistical methods to vectorize the data, without extracting the semantic features of the data, so the training time is relatively short. Lightlog uses word2vec algorithm to represent the data semantics in a fixed vector, and uses PPA algorithm to map the problem to a low dimensional semantic vector space, so it also has short training time. Our LogCSS uses the pre-trained model, BERT, for vector representation, which accounts for most of the long training time. For example, the training time on the BGL dataset is (15633 + 7079) seconds, where BERT takes 15633 seconds for forward propagation and CNN takes 7079 seconds for classification. Although Lightlog takes relatively short training time, it has two drawbacks: 1) It uses the word2vec algorithm to represent each word in a fixed manner, which cannot extract word context information. 2) OOT (out of template) is almost an inevitable issue in online template matching, and Lightlog does not have an effective solution. The LogCSS method proposed by us uses BERT to extract Semantic information of logs, which is more effective, and the DOOT method proposed by us can solve the OOT problem.
Experiment on Training time
We evaluate the precision, recall, and F1 score of LogCSS on the HDFS and BGL datasets, and compare them with 6 baselines: Logistic Regression (LR) [10], Support Vector Machine (SVM) [11], CNN [4], LogRobust [16], Log2Vec [28], Lightlog [41] and NeuralLog [17]. We first analyzed and investigated the current best algorithms in principle, and then conducted experimental comparisons on the same data set and the same experimental environment.
Comparison implementation method with baselines
We compared our algorithm with LR, SVM, CNN, Log2Vec, LogRobust, Lightlog and NerualLog in terms of preprocessing technology, feature engineering technology, algorithm model, advantages and disadvantages, as is shown in Table 9.
Comparison of the Implementation Details for Different Methods
Comparison of the Implementation Details for Different Methods
5.6.1.1 Pre-processing. The data preprocessing of log anomaly detection involves log clustering. It generally uses template extraction algorithm to convert log events into log templates. The purpose of this is to reduce the amount of computation and facilitate subsequent log anomaly detection.LR, SVM, CNN, and LogRobust all cluster the logs in the preprocessing stage. The clustered logs form log events or log templates and count the number of log templates within the sliding time window. NerualLog and LogCSS not only cluster logs and count log events, but also vectorization the Semantic information of logs using the BERT pre training model. LightLog has added a PCA-PPA dimensionality reduction method in the preprocessing stage to further reduce computational complexity.Log2Vec does not count log events, but uses two methods: graph creation and graph embedding to extract contextual information from logs.
5.6.1.2 Feature Engineering. In the feature engineering processing stage, LR, SVM, and CNN all use the statistical information of the log template for embedding. Log2Vec considers the location attribute of the network element node where the log is located. This method first constructs the network structure into a graph, and uses the random walk method to embed the graph, and then uses the word2vec algorithm to vectorize the log words. Lightlog uses the word2vec method to obtain the semantic features of the log, instead of using the Bert pre training model for semantic feature extraction, which is different from our method, and it does not obtain the statistical features of the log. LogRobust uses the FastText algorithm to vectorize the log as an N*d-dimensional matrix (N is the number of log lines, d is the embedding size of each word, and the default value is 300). NerualLog is the most similar to our algorithm in feature engineering. Both of them consider the semantic features of the log. First, the words of the log are vectorized through the BERT pre-training model. But our algorithm increases the vectorization of log template statistics, which is different from NerualLog.
5.6.1.3 Algorithmic model. The LR, SVM, and CNN algorithm models are relatively simple, and the LR, SVM, and CNN algorithm models are used to classify the log sequence vector data. Log2Vec uses DBSCAN clustering algorithm and threshold judgment method to classify log vector data. If the feature data similarity of two nodes is lower than a certain threshold, the two nodes are classified into one class. After clustering, the number of nodes in each class is lower than a certain threshold, then the class is regarded as abnormal. LogRobust adopts an attention-based Bi-LSTM model to detect log anomalies. Lightlog uses the TCN algorithm model to detect and classify whether the log is abnormal. NerualLog uses the Transformer algorithm model to classify log sequence data. Ours algorithm first uses the BERT pre-training model to obtain the semantic features of the log, then uses the CNN algorithm to obtain the context features of the log, then counts the number of times the log template appears in the observation window and forms a statistical vector, and finally inputs the three-dimensional feature vector into the full Connect the neural network model and output log anomaly results by softmax function classification.
5.6.1.4 Advantages and limitations. The LR and SVM algorithms are simple, but do not consider the semantic information of the log and the context features. CNN algorithm considers the correlation characteristics between log sequences, but does not consider the semantic characteristics of logs. The Log2Vec algorithm is too computationally intensive and not suitable for large-scale network log anomaly detection scenarios. Lightlog does not consider the statistical characteristics of logs, and the word2vec method cannot better capture the semantic characteristics of logs, so it cannot achieve the best classification effect. LogRobust and NerualLog do not consider the semantic information and statistical information of the log, respectively, and neither can achieve the best classification effect. Our algorithm fully considers the semantic features, statistical features, and context-related features of logs, and uses the CNN algorithm and the BERT algorithm for joint classification, which can achieve better algorithm results.
We compare the performance results of our algorithm with the current state-of-the-art log anomaly detection algorithms under the same experimental environment and conditions. The specific experimental results are shown in Table 10 and Fig. 4 below.
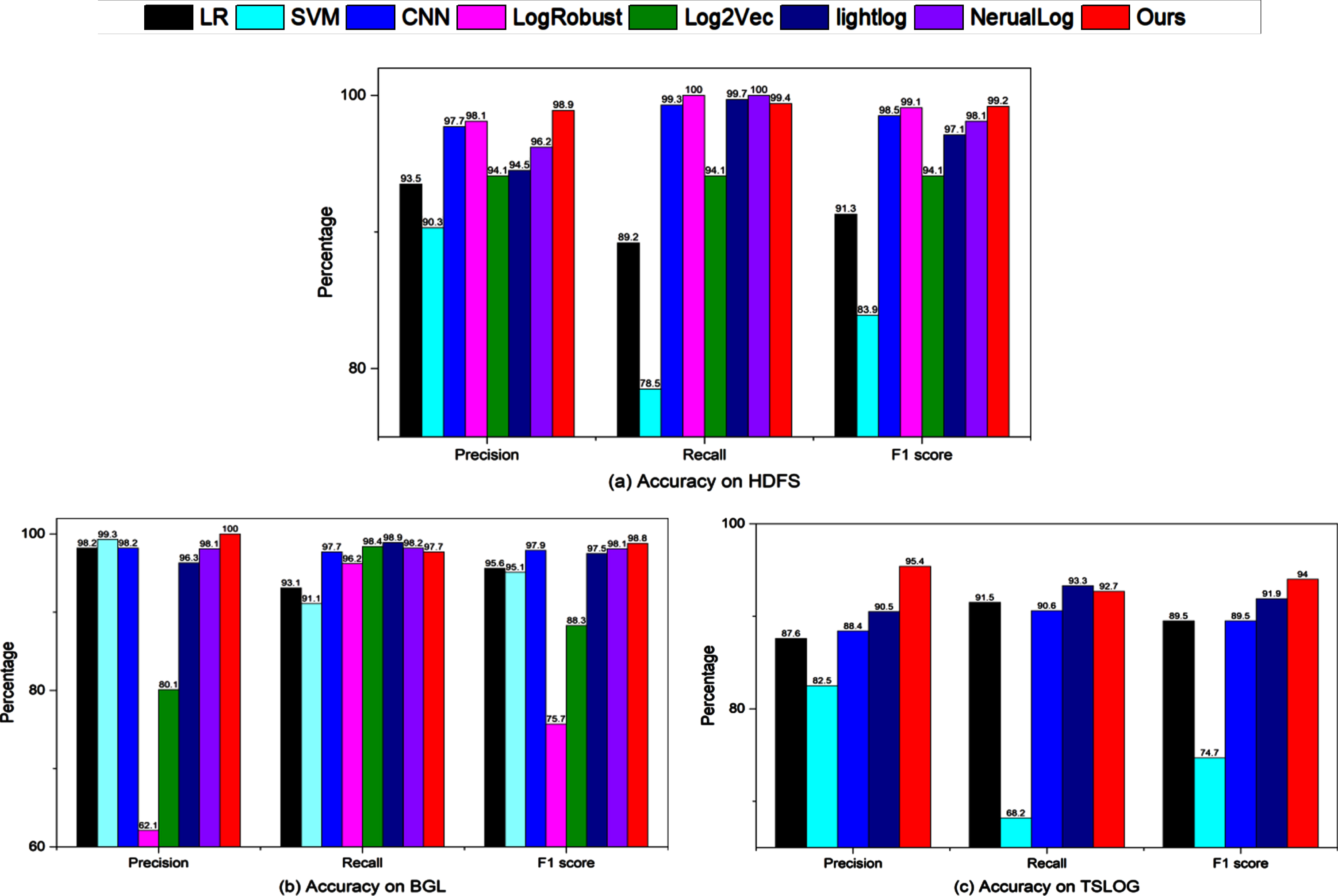
Comparison of Effectiveness between LogCSS and Baselines on HDFS and BGL.
Effectiveness Evaluation on HDFS and BGL
Traditional supervised machine learning algorithms LR and SVM take the count vectors of log templates as input, which is extracted through the Drain algorithm. The experiment data of the other baselines comes from Loghub [29], and they all use slide windows for sampling.
As shown in Table 10 and Fig. 4, our method LogCSS has the best F1-Score on both HDFS and BGL. Traditional machine learning algorithms LR and SVM ignore the semantic information of the logs, so they do not perform well. Figure 4(a) shows that SVM has the lowest recall, and LR also has low precision, recall, and F1-Score. CNN extracts the local relational features between the adjacent logs, but still lacks the extraction of the semantic and statistic features, so it performs worse than LogCSS on HDFS. LogRobust only extracts the semantic information and ignores the local relational information, which leads to the worst performance in Fig. 4(b). Log2Vec, as an unsupervised algorithm that improves DeepLog, requires massive normal data and fails to extract the local correlations within the log series. So, it shows bad performance in Fig. 4(b). Lightlog uses word2vec and post processing algorithm (PPA) to create a low dimensional semantic vector space, and performs exception detection based on TCN, which meets the requirements for real-time processing performance of edge devices. However, it ignores the statistical characteristics of logs and does not use Bert pre training model for semantic feature extraction, so its performance is lower than our proposed LogCSS method in F1-Score. NeuralLog uses the Transformer model to detect log anomalies. It performs worse than CNN in extracting the local relational features between the logs. It also ignores the statistic features, so it has lower F1-Scores than LogCSS on both datasets.
As shown in Fig. 4 (a), although our method LogCSS has a lower Recall rate than RerualLog and LogRobust on the HDFS dataset, LogCSS performs best in terms of accuracy and F1 Score, with an Precision improvement of 0.7% compared to LogRobust and 0.1% compared to NeruaLog on F1 Score; As shown in Fig. 4 (b), although our method LogCSS has a lower Recall rate than Log2Vec, LightLog, and NerualLog on the BGL dataset, it performs the best in Precision, with an Precision improvement of over 1.9% compared to Log2Vec, LightLog, and NerualLog, and an F1 Score improvement of over 0.7% compared to Log2Vec, LightLog, and NerualLog; As shown in Fig. 4 (c), our method has a lower Recall rate than LightLog on the TSLog dataset, but an Precision improvement of 4.9% and an F1-score improvement of 3.1% compared to LightLog.
In conclusion, the experiments show that our LogCSS performs better than all the baselines on HDFS and BGL datasets.
Our algorithm is a supervised algorithm on the premise that a large amount of labeled log data is required. Only under this premise can our algorithm train a better model. However, the labeled data is very scarce and precious in the actual production environment. We will investigate the scenarios lacking labeled data and further improve the effect of log anomaly detection.
Conclusion
Log anomaly detection is very important for the maintenance of large-scale network systems. The accuracy of log anomaly detection directly affects the speed and cost of system operation and maintenance. In this paper, we propose LogCSS for log anomaly detection. We propose a novel model, CSSCNN, for log anomaly detection. It uses the pre-trained BERT model to extract the semantic features of the raw logs, and adds the statistic features for training and prediction. It uses CNN to extract the local relation features between the logs. We also design a log template extraction technique called DOOT to increase the accuracy of log template matching. It solves the problem during online prediction that new log templates can lead to a decrease in the accuracy of the model with time. We evaluate our method on open-source datasets, HDFS and BGL. Experiments show that our method has the best performance compared with other log anomaly detection methods. The method proposed in this paper is mainly applicable to log anomaly detection scenarios with a large amount of labeled data, and we will research the scenarios lacking labeled data and further improve the effect of log anomaly detection in the future.
Conflict of interest statement
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
HDFS Event Templates and Numbers